数据结构——二叉树和堆(万字,最详细)
目录
1.树
1.1 树的概念与结构
1.2 树相关的术语
1.3 树的表示法
2.二叉树
2.1 概念与结构
2.2 特殊的二叉树
2.2.1 满二叉树
2.2.2 完全二叉树
2.3 二叉树存储结构
2.3.1 顺序结构
2.3.2 实现顺序结构二叉树
2.3.2.1 堆的概念与结构
2.3.2. 2 堆的插入与删除数据
2.3.2.3 堆排序
2.3.2.4 堆一些杂于实现
2.3.3 实现链式结构二叉树
2.3.3.1 二叉树的遍历:
2.3.3.2 二叉树的几个操作
2.3.3.3 二叉树的性质:
1.树
树大家都见过吧,那么下面是根,上面是分叉。但是咱们今天要讲的树不是你们所想的那种树,而是一种倒过来的树的模型(即下面是分叉,上面是根)。OK,让我们来进入学习。
1.1 树的概念与结构
树是⼀种非线性的数据结构,它是由 n ( n>=0 ) 个有限结点组成⼀个具有层次关系的集合。把它叫做 树是因为它看起来像⼀棵倒挂的树,也就是说它是根朝上,而叶朝下的。
1.有⼀个特殊的结点,称为根结点,根结点没有前驱结点。
2.除根结点外,其余结点被分成 M(M>0) 个互不相交的集合 T1 、 T2 、 …… 、 Tm ,其中每⼀个集合 Ti(1 <= i <= m) ⼜是⼀棵结构与树类似的子树。每棵⼦树的根结点有且只有⼀个前驱,可以 有 0 个或多个后继。因此,树是递归定义的。
如上图就是树。注意:树 形结构中,子树之间不能有交集,否则就不是树形结构 。
看完了树,咱们再来看看非树,
非树形结构:
1. 子树是不相交的(如果存在相交就是上图)。
2.除了根结点外,每个结点有且仅有⼀个父结点 。
3.⼀棵N个结点的树有N-1条边 。
1.2 树相关的术语
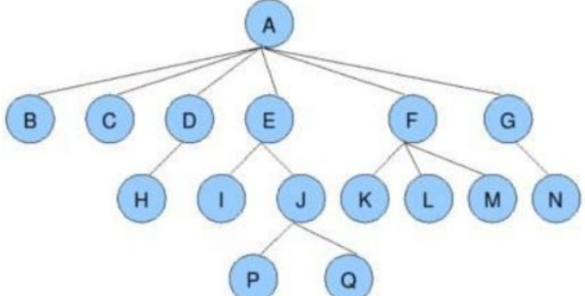
还是以这个图来看:
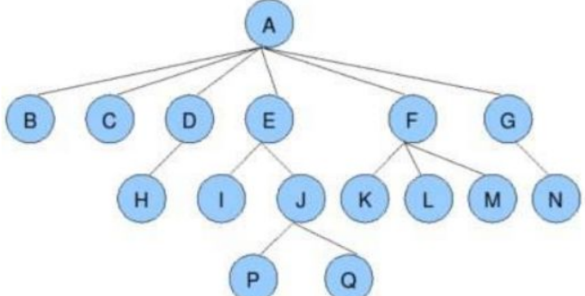
父结点/双亲结点:若⼀个结点含有子结点,则这个结点称为其子结点的父结点;如上图:A是B的父结点
子结点/孩子结点:⼀个结点含有的子树的根结点称为该结点的子结点;如上图:B是A的孩子结点 结点的度:⼀个结点有几个孩子,他的度就是多少;比如A的度为6,F的度为2,K的度为0
树的度:⼀棵树中,最大的结点的度称为树的度;如上图:树的度为 6
叶子结点/终端结点:度为 0 的结点称为叶结点;如上图: B 、 C 、 H 、 I... 等结点为叶子结点
分支结点/非终端结点:度不为 0 的结点;如上图: D 、 E 、 F 、 G... 等结点为分支结点
兄弟结点:具有相同父结点的结点互称为兄弟结点(亲兄弟);如上图: B 、 C 是兄弟结点 结点的层次:从根开始定义起,根为第 1 层,根的子结点为第 2 层,以此类推;
树的高度或深度:树中结点的最大层次;如上图:树的高度为 4
结点的祖先:从根到该结点所经分支上的所有结点;如上图: A 是所有结点的祖先
路径:⼀条从树中任意节点出发,沿父节点-子节点连接,达到任意节点的序列;比如A到Q的路径为: A-E-J-Q;H到Q的路径H-D-A-E-J-Q
子孙:以某结点为根的子树中任⼀结点都称为该结点的子孙。如上图:所有结点都是A的子孙
森林:由 m ( m>0 ) 棵互不相交的树的集合称为森林;
1.3 树的表示法
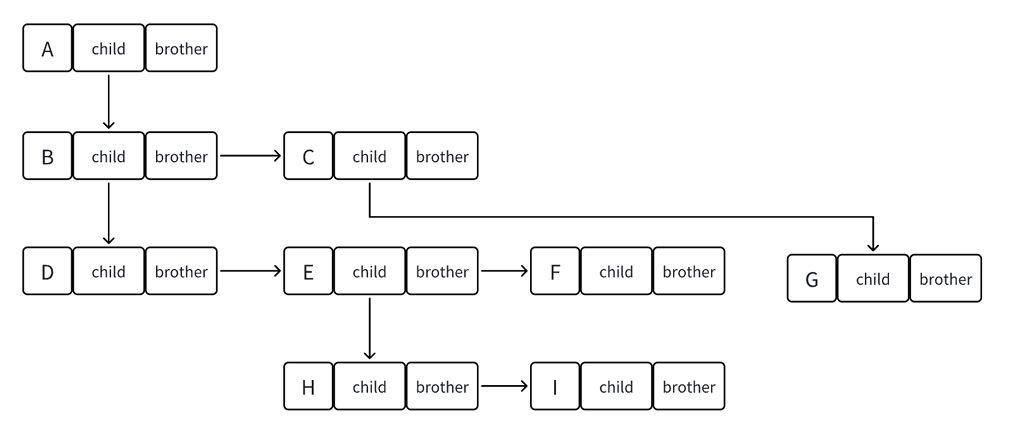
孩子兄弟表示法: 树结构相对线性表就比较复杂了,要存储表示起来就比较麻烦了,既然保存值域,也要保存结点和结 点之间的关系,实际中树有很多种表示方式如:双亲表示法,孩子表示法、孩子双亲表示法以及孩子 兄弟表示法等。我们这⾥就简单的了解其中最常用的孩子兄弟表示法。
struct TreeNode
{
struct Node* child; // 左边开始的第⼀个孩⼦结点struct Node* brother; // 指向其右边的下⼀个兄弟结点int data; // 结点中的数据域
};
2.二叉树
OK,接下来是重头戏,也就是二叉树
2.1 概念与结构
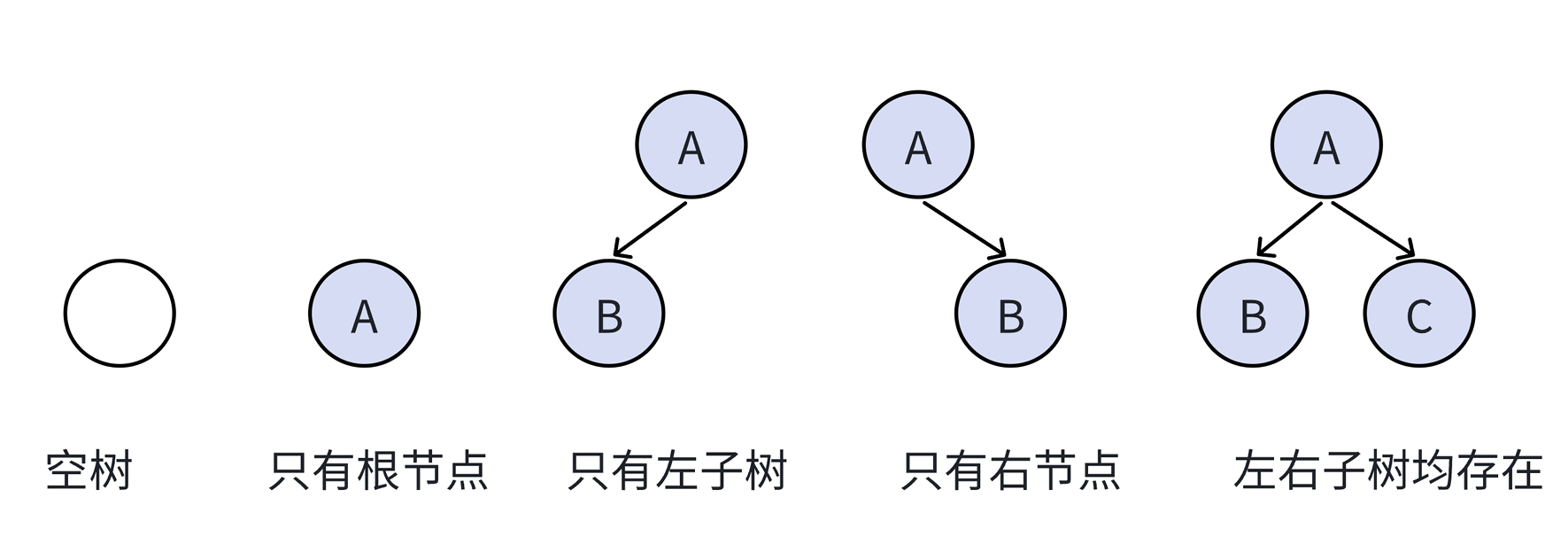
在树形结构中,我们最常用的就是二叉树,⼀棵二叉树是结点的⼀个有限集合,该集合由⼀个根结点 加上两棵别称为左子树和右子树的二叉树组成或者为空。
二叉树的特点:
1. 二叉树不存在度大于 2 的结点
2. 二叉树的子树有左右之分,次序不能颠倒,因此二叉树是有序树。
注意:对于任意的二叉树都是由以下几种情况复合而成的。
2.2 特殊的二叉树
2.2.1 满二叉树
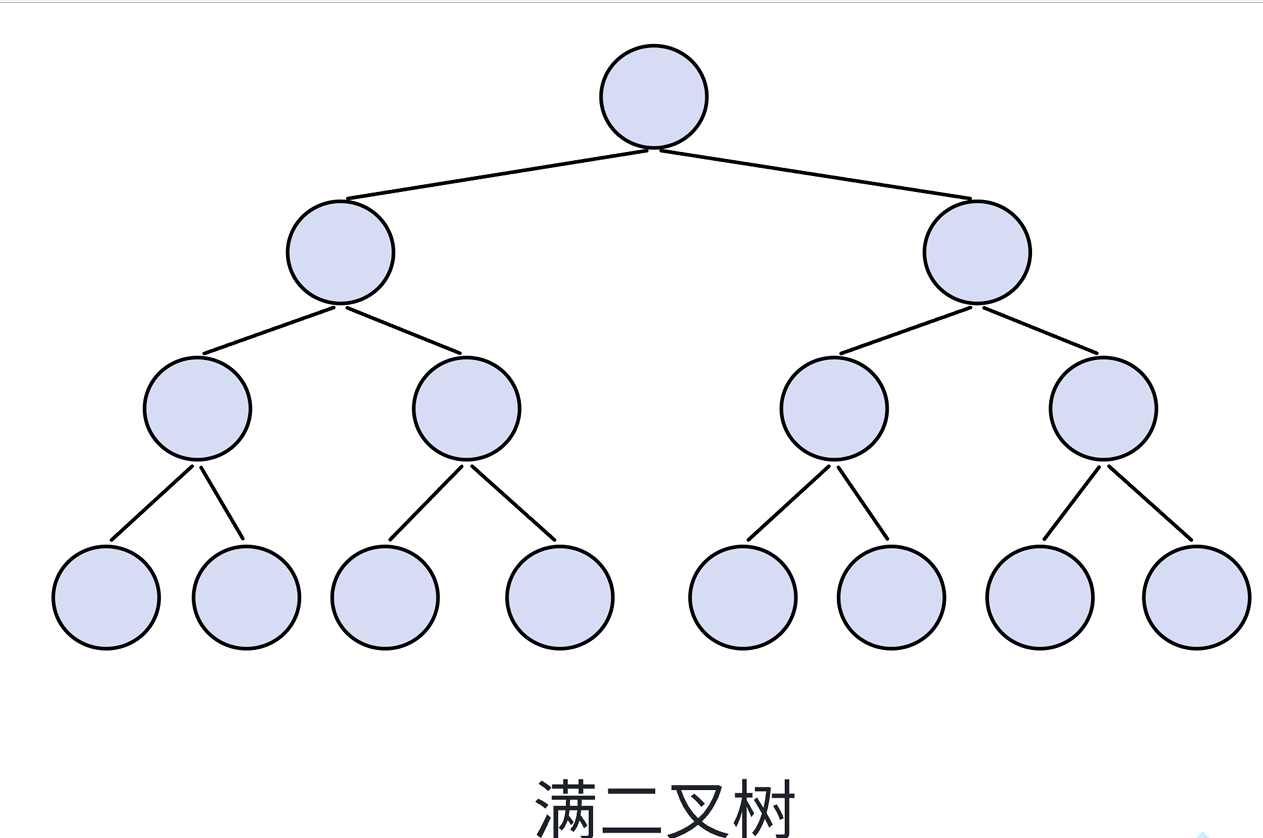
⼀个二叉树,如果每⼀个层的结点数都达到最大值,则这个二叉树就是满⼆叉树。也就是说,如果⼀ 个二叉树的层数为 K ,且结点总数是2^k − 1 ,则它就是满二叉树。
2.2.2 完全二叉树
完全二叉树是效率很高的数据结构,完全二叉树是由满二叉树而引出来的。对于深度为 K 的,有 n 个 结点的二叉树,当且仅当其每⼀个结点都与深度为K的满二叉树中编号从 1 至 n 的结点⼀⼀对应时称 之为完全二叉树。要注意的是满二叉树是⼀种特殊的完全二叉树。 (满二叉树一定是完全二叉树,但是完全二叉树不一定是满二叉树)
二叉树的性质:
咱们由满二叉树推出:
1.若规定根结点的层数为 1 ,则⼀棵非空二叉树的第i层上最多有 2的(i-1)次方个结点。
2.若规定根结点的层数为 1 ,则深度为 h 的二叉树的最大结点数(二叉树的总的节点数)是 (2^h)-1。
3.若规定根结点的层数为 1 ,具有 n 个结点的满二叉树的深度h = log 以2为底,n+1为对数。
推导:因为n=2^h-1;n+1=2^h;h=log以2为底,n+1为对数。
2.3 二叉树存储结构
2.3.1 顺序结构
顺序结构存储就是使用数组来存储,⼀般使用数组只适合表示完全二叉树,因为不是完全二叉树会有 空间的浪费,完全二叉树更适合使用顺序结构存储。
现实中我们通常把堆(⼀种二叉树)使用顺序结构的数组来存储,需要注意的是这里的堆和操作系统 虚拟进程地址空间中的堆是两回事,⼀个是数据结构,⼀个是操作系统中管理内存的⼀块区域分段。
OK,那么咱们现在引入了堆的概念。
2.3.2 实现顺序结构二叉树
2.3.2.1 堆的概念与结构
那么堆是什么呢?那些晦涩难懂的概念咱们就不看了,堆就是一种特殊的二叉树,即用堆来存储这个二叉树。那么堆分为大堆与小堆。大堆或大根堆就是根节点是最大的,而小堆或小根堆就是根节点是最小的。
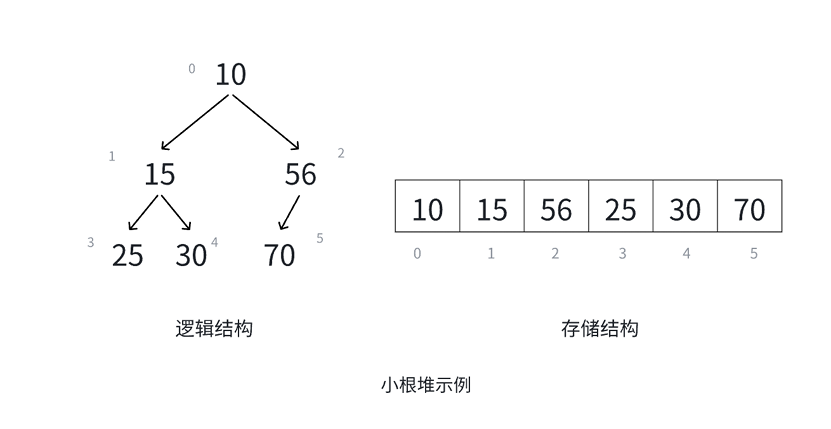
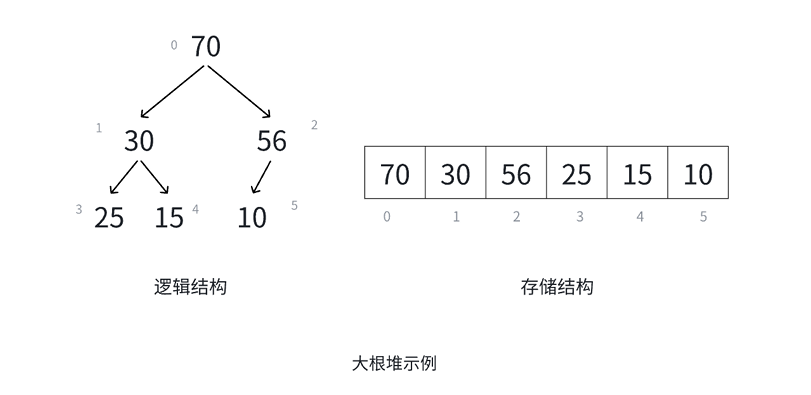
堆 具有以下性质 :
1.堆中某个结点的值总是不大于或不小于其父结点的值;
2. 堆总是⼀棵完全二叉树。(这个很重要)
二叉树性质
对于具有n个结点的完全二叉树,如果按照从上至下从左至右的数组顺序对所有结点从
开始编号,则对于序号为的结点有:这个对于编号,即下标(从0开始,若是i与n的性质一样,都是表示数,那么下面的可以写成i/2.
1.若i>0,i位置结点的双亲序号:
(i-1)/2;i=0,i为根结点编号,无双亲结点
2. 若2i+1<n,左孩子序号:2i+1,2i+1>=n否则无左孩子
3.若2i+2くn,右孩子序号:2i+2,2i+2>=n否则无右孩子
咱们前面说了堆总是一颗完全二叉树,而咱又知道完全二叉树是有顺序的,也就是说,你要是想使用这个堆,你得先确保它是个堆,那么怎么确保呢?就是通过建堆的方法来确定。
下面咱们来介绍两种方法:
1.向上调整法:
//向上调整
void AdjustUp(HPDataType* arr, int child)
{int parent = (child - 1) / 2;while (child > 0){ //小堆: <//大堆: >if (arr[child] > arr[parent]){Swap(&arr[child], &arr[parent]);child = parent;parent = (child - 1) / 2;}else {break;}}
}这个方法是如何调整的呢?它需要传的是孩子结点的位置。因为它是从下面(最后一个孩子节点开始调整)往上调整。那么接下来进行父节点与子节点进行比较,如果说你要建立的是大堆,那么你只需要保证父亲节点始终大于孩子节点即可。(如果孩子节点比父亲节点大了,没关系,swap一下即可)。那么接下来,将此时的父亲节点更新为孩子节点,并且重新更新父节点的位置。最后,重要的是:循环结束的条件是什么呢?是当你这个孩子节点不能到根节点,不然会导致父亲节点越界了,这就很难搞了。
时间复杂度:
为O(logh),h为树的高度,因为不管向上调整还是向下调整,移动的次数,都是树的高度。而时间复杂度,恰好是移动的次数,而树的高度怎么求呢?咱们呢有个公式h=log以2为底,n+1为对数。那么等号后面的这个就是时间复杂度,即logh。
2.向下调整法:
//向下调整
void AdjustDown(HPDataType* arr,int parent,int n)
{int child = parent * 2 + 1;while (child < n){//大堆: <//小堆: >if (child + 1 < n && arr[child] > arr[child + 1]){child++;}//大堆:>//小堆: <if (arr[child] < arr[parent]){Swap(&arr[child], &arr[parent]);parent = child;child = parent * 2 + 1;}else {break;}}
}向上调整法是从最底下往上调整,那么向下调整法就是最根节点开始往下调整。这个地方要传两个重要的参数,即数组中数据的个数,还有就是父亲节点的下标。假如说你要建立大堆,那么你得确保你的孩子节点是最大的(因为一个父亲节点有两个子节点),这里为什么要确保你的孩子节点是最大的呢?因为你下面要swap呀,swap完后就是父亲节点最大了。swap完后,更新此时的孩子节点,让父亲节点移动此时的孩子节点,之后依靠新的父节点的位置更新子节点的位置。因为这是向下调整嘛,所以肯定得向下。那么最后循环结束的条件:你不能让孩子节点越界吧。而且这里在第一个if这得加一个右孩子节点不可以越界(因为会出现,左孩子不越界,但是右孩子越界了,这就很尴尬)。
时间复杂度:
也是logh,h为树的高度。原因同上。
OK,介绍完这两种方法,再来看一下,建堆:
建堆---向下调整
for (int i = (n-1-1)/2; i >= 0; i--)
{AdjustDown(arr, i, n);
}建堆---向上调整
for (int i = 0; i < n; i++)
{AdjustUp(arr, i);
}这里需要注意的是,对于第二种,在一个空数组中循环插入建 堆的,只能用向上建堆法,因为,你后边没有数据,如何进行向下调整呢?只有从插入的最后一个数据开始,向上调整即可。
并且,对于向下调整法建堆,是从最后一个非叶子节点开始的(循环开始的位置)。但是你真正传到向下调整法中,还是从根节点开始(即单趟的向下调整法是从根节点开始)。而建堆是多趟的向下调整(可以想象一下动态图),从最后一个非叶子节点开始调整,一直调整到最上边。
对于向上调整法建堆,直接循环插入数据即可,用向上调整法建堆。这个动图也可以想象出来,即从下标为0开始,一直到最后一个数据结束。
并且,两种方法既可以建立大堆,也可以建立小堆,而具体建立大堆还是小堆,是看你的向下调整法or向上调整法里的具体的实现细节(上面代码有)。
这里比较推荐向下调整法建堆,为什么呢?来看一下数学分析:
向上调整法建堆:
因为堆是完全二叉树,而满二叉树也是完全二叉树,此处为了简化使⽤满⼆叉树来证明(时间复杂度本 来看的就是近似值,多几个结点不影响最终结果)
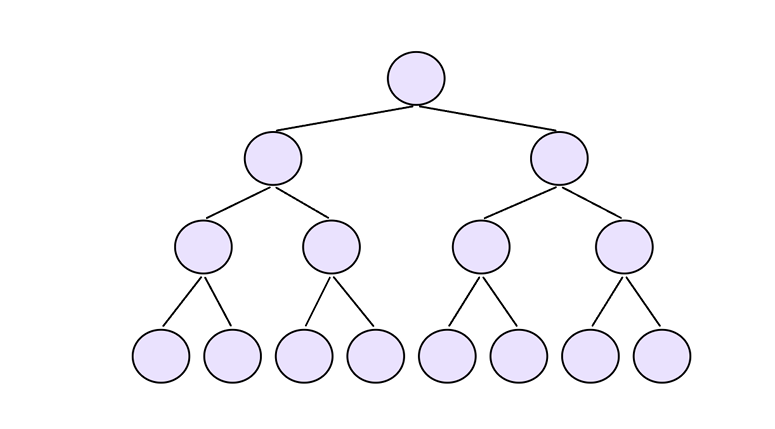
分析: 第1层,个结点,需要向上移动0层
第2层,个结点,需要向上移动1层
第3层,个结点,需要向上移动2层
第4层,个结点,需要向上移动3层
...... 第h层,个结点,需要向上移动h-1层
则需要移动结点总的移动步数为:每层结点个数*向上调整次数(第一层调整次数为0)
①T(h) =2^1 *1+2^2*2+2^3 *3+ . +2^(h-2) *(h-2) +2^(h-1)*(h - 1)
②2*T(h)=2^2*1+2^3 *2+2^4 *3+.+2^(h-1) *(h-2) +2^h *(h-1)
②一①错位相减:
T(h) = -2^1 *1 - (2² +2^3 + .. +2^(h-2) +2^(h-1)) +2^h *(h - 1)
T(h) = -2° -2^1 *1- (2² +2^3 +..+2^(h-2)+2^(h-1)) +2^h *(h - 1)+2^0
T(h) = -(2^0 +2^1 *1+2² +2^3+ . +2^(h-2)+2^(h-1)) +2^h *(h - 1)+2^0
T(h) =-(2^h - 1) +2^h * (h- 1) +2^0
根据二叉树的性质:n=2^h-1和h=log2(n+1)
T(n) =-N+2^h * (h-1) +2^0
F(h) =2^(h-2) +2
F(n) = (n + 1)(log2(n + 1) - 2) +2
由此可得:
向上调整算法建堆时间复杂度为:O(n*log2 n),即n*logn
向下调整法建堆:
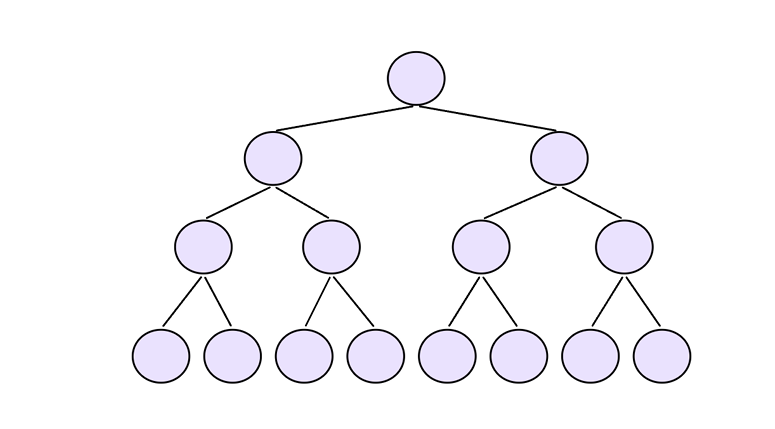
分析:
第1层,2°个结点,需要向下移动h-1层
第2层,2^1个结点,需要向下移动h-2层
第3层,2^2个结点,需要向下移动h-3层
第4层,2^3个结点,需要向下移动h-4层
第h-1层,2^h-2个结点,需要向下移动1层

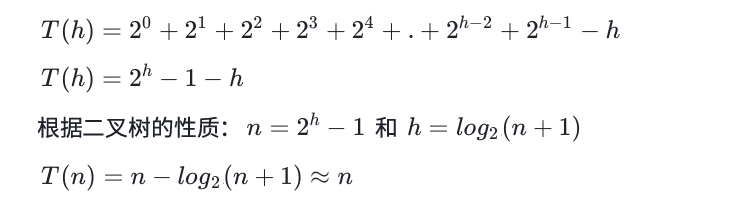
所以,向下调整法建堆的时间复杂度是O(N)。
OK,咱们再来分析一下这段代码:
建堆---向下调整
for (int i = (n-1-1)/2; i >= 0; i--)
{AdjustDown(arr, i, n);
}建堆---向上调整
for (int i = 0; i < n; i++)
{AdjustUp(arr, i);
}第一个时间复杂度是O(N),即((n-2)/2)*logn可能就是n,这涉及到数学问题。
第二个时间复杂度:O(nlogn),即n*logn,完全吻合。
2.3.2. 2 堆的插入与删除数据
咱们一般是把堆的插入与向上调整法一起使用,堆的删除与向下调整法一起使用。原因后面讲。
1.堆的插入:(向上调整法)
1.先将元素插入到堆的末尾,即最后一个孩子之后
2.插入之后如果堆的性质遭到破坏,将新插入结点顺着其双亲往上调整到合适位置即可

//向上调整
void AdjustUp(HPDataType* arr, int child)
{int parent = (child - 1) / 2;while (child > 0){ //小堆: <//大堆: >if (arr[child] > arr[parent]){Swap(&arr[child], &arr[parent]);child = parent;parent = (child - 1) / 2;}else {break;}}
}void HPPush(HP* php, HPDataType x)
{assert(php);//判断空间足够if (php->size == php->capacity){//增容int newCapacity = php->capacity == 0 ? 4 : 2 * php->capacity;HPDataType* tmp = (HPDataType*)realloc(php->arr, newCapacity * sizeof(HPDataType));if (tmp == NULL){perror("realloc fail!");exit(1);}php->arr = tmp;php->capacity = newCapacity;}//直接插入php->arr[php->size] = x;//向上调整AdjustUp(php->arr, php->size);++php->size;
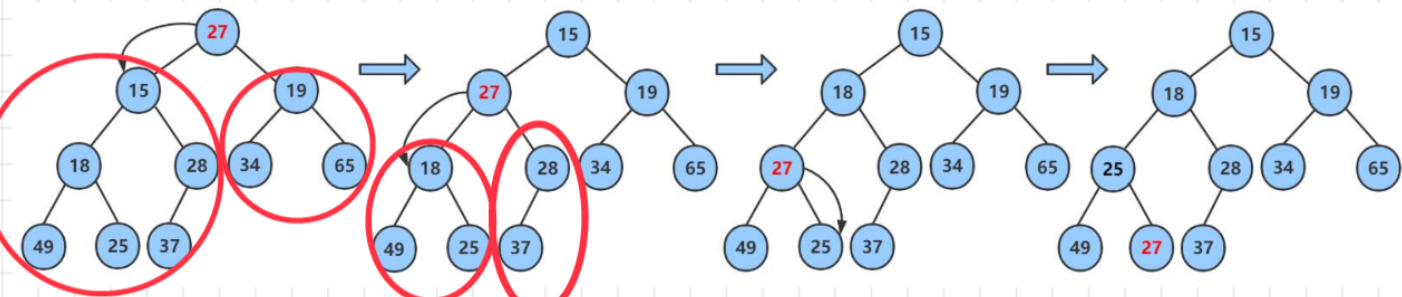
}2.堆的删除(向下调整法)
向下调整算法有一个前提:左右子树必须是一个堆,才能调整。(这个在咱们之前建堆的时候已经保证好了)
1.将堆顶元素与堆中最后一个元素进行交换
果
2.删除堆中最后一个元素
3.将堆顶元素向下调整到满足堆特性为止
//向下调整
void AdjustDown(HPDataType* arr,int parent,int n)
{int child = parent * 2 + 1;while (child < n){//大堆: <//小堆: >if (child + 1 < n && arr[child] > arr[child + 1]){child++;}//大堆:>//小堆: <if (arr[child] < arr[parent]){Swap(&arr[child], &arr[parent]);parent = child;child = parent * 2 + 1;}else {break;}}
}
void HPPop(HP* php)
{assert(!HPEmpty(php));//0 php->size-1Swap(&php->arr[0], &php->arr[php->size - 1]);--php->size;//向下调整AdjustDown(php->arr, 0, php->size);
}OK,咱们来讲一下为什么 堆的插入与向上调整法一起使用,堆的删除与向下调整法一起使用:
你要是插入用向下调整法,不合适,因为会做很多不必要的动作,插入是在末尾插入,那么你要使用向下调整法,向下调整法是从根节点开始,那么你从根节点一直到你要调整的那个数据,是不是都是多余的比较?因为你在插入之前,已经是一个堆了。那还不如直接用向上调整法,从插入的那个数据开始调整。
你要是删除用向上调整法的话,删除后,只有根节点变了,下面的还是一个堆呀(因为咱们之前已经调整过了),所以说用向上调整法,从最后一个节点一直到根节点,都是多余的比较,那为啥不直接用向下调整法,从根节点开始调呢?
OK,明白了吧,其实就是减少冗余的步骤。
2.3.2.3 堆排序
前面咱们已经实现了建堆。那么如果咱们想将一个无序数组排成有序的,必须得两个步骤,先建堆,之后再进行堆排序。来看堆排序的代码:
//堆排序int end = n - 1;while (end > 0){Swap(&arr[0], &arr[end]);AdjustDown(arr, 0, end);end--;}排升序用大堆(因为每次大堆堆顶都是这次的堆的最大值,而将这个最大值取出后放在最后,这个最大值就是整个升序数组中的最大值,压轴的存在)
排降序用小堆。原理同上。即降序的数组最后就是整个的最小的数据。
这个堆排序既可以实现排升序,也可以实现排降序,而具体怎么样,要看前面的是小堆还是大堆。
建堆---向下调整
for (int i = (n-1-1)/2; i >= 0; i--)
{AdjustDown(arr, i, n);
}
堆排序
int end = n - 1;
while (end > 0)
{Swap(&arr[0], &arr[end]);AdjustDown(arr, 0, end);end--;
}建堆---向上调整
for (int i = 0; i < n; i++)
{AdjustUp(arr, i);
}堆排序
int end = n - 1;
while (end > 0)
{Swap(&arr[0], &arr[end]);AdjustDown(arr, 0, end);end--;
}OK,那么再来看看堆排序的时间复杂度呢?
分析:
第1层,2^0个结点,交换到根结点后,需要向下
移动0层
第2层,2^1个结点,交换到根结点后,需要向下
移动1层
第3层,2^2个结点,交换到根结点后,需要向下
移动2层
第4层,2^3个结点,交换到根结点后,需要向下
移动3层
第h层,2^(h-1)个结点,交换到根结点后,需要向
下移动h-1层

这个n哪来的呢?是向下调整法建堆的时间复杂度。再加上第二个循环的时间复杂度,就是堆排序的时间复杂度。
OK,将堆的最主要最重要的部分讲完了。
2.3.2.4 堆一些杂于实现
//堆的结构
typedef int HPDataType;
typedef struct Heap
{HPDataType* arr;int size; //有效数据个数int capacity; //空间大小
}HP;
//堆的初始化
void HPInit(HP* php)
{assert(php);php->arr = NULL;php->size = php->capacity = 0;
}
//堆的销毁
void HPDestroy(HP* php)
{assert(php);if (php->arr)free(php->arr);php->arr = NULL;php->size = php->capacity = 0;
}
//堆的打印
void HPPrint(HP* php)
{for (int i = 0; i < php->size; i++){printf("%d ", php->arr[i]);}printf("\n");
}
//堆的判空
bool HPEmpty(HP* php)
{assert(php);return php->size == 0;
}
//取堆顶元素
HPDataType HPTop(HP* php)
{assert(!HPEmpty(php));return php->arr[0];
}OK,可算是把堆的东西给讲完了。
2.3.3 实现链式结构二叉树
用链表来表示⼀棵二叉树,即⽤链来指示元素的逻辑关系。通常的方法是链表中每个结点由三个域组 成,数据域和左右指针域,左右指针分别用来给出该结点左孩子和右孩子所在的链结点的存储地址, 其结构如下:
typedef char BTDataType;
typedef struct BinaryTreeNode
{struct BinaryTreeNode* left;//
指向当前结点左孩⼦struct BinaryTreeNode* right; //
指向当前结点右孩⼦BTDataType data;//
当前结点值域}BTNode;接下来让咱们手动来实现一颗二叉树吧,实现模型以及代码如下:
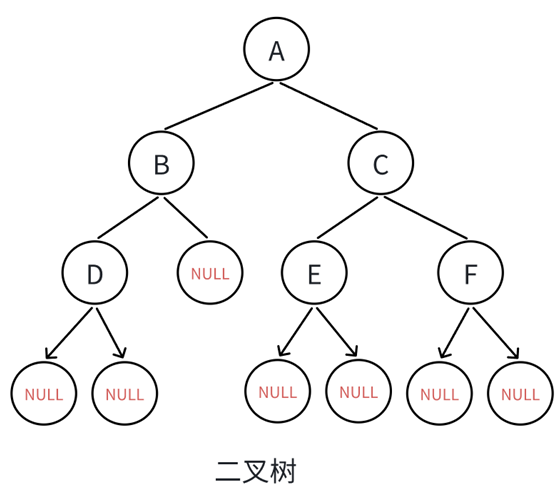
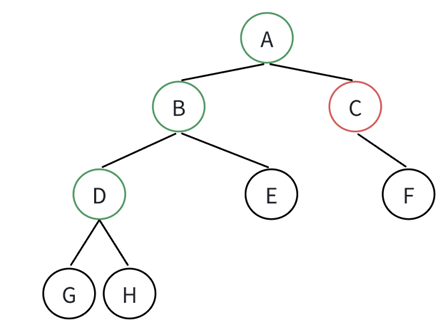
BTNode* buynode(BTDataType x)
{BTNode* newnode = (BTNode*)malloc(sizeof(BTNode));if (newnode == NULL){perror("malloc fail!");exit(1);}newnode->data = x;newnode->left = newnode->right = NULL;return newnode;
}
BTNode* creatBinaryTree()
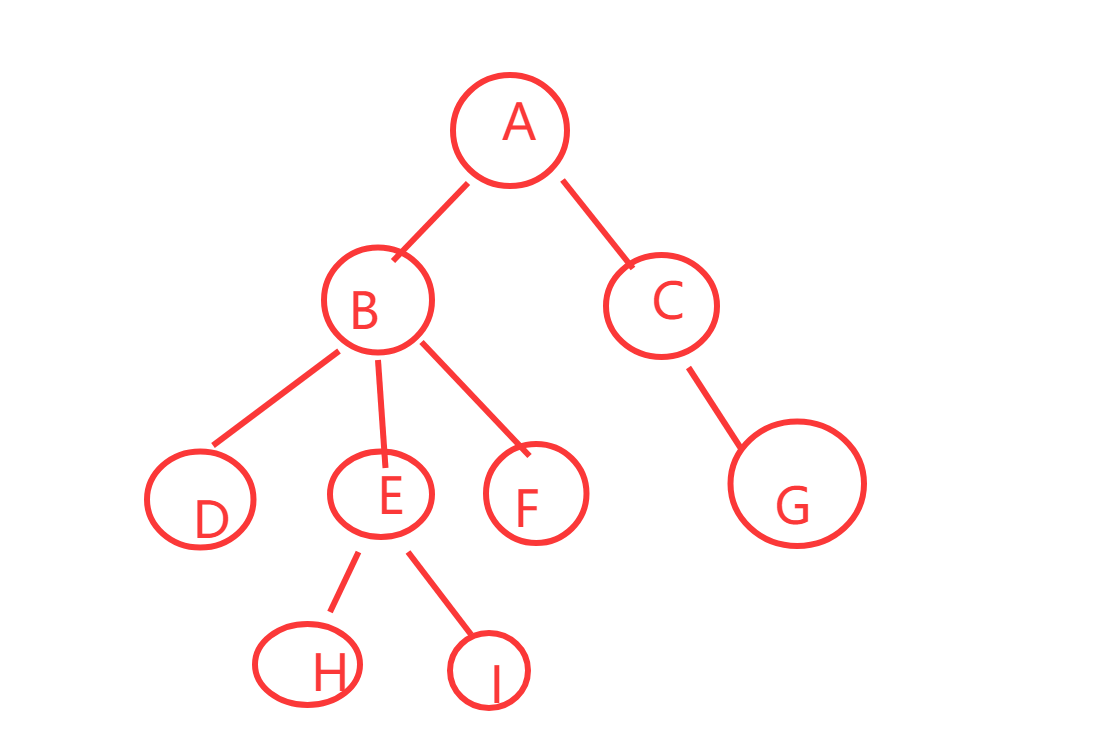
{BTNode* node1 = buynode('A');BTNode* node2 = buynode('B');BTNode* node3 = buynode('C');BTNode* node4 = buynode('D');BTNode* node5 = buynode('E');BTNode* node6 = buynode('F');node1->left = node2;node1->right = node3;node2->left = node4;/*node2->right = node5;*/node3->left = node5;node3->right = node6;return node1;
}2.3.3.1 二叉树的遍历:
按照规则,二叉树的遍历有:前序/中序/后序的递归结构遍历:
1)前序遍历(PreorderTraversal亦称先序遍历):访问根结点的操作发生在遍历其左右子树之前 访 问顺序为:根结点、左子树、右子树
2)中序遍历(InorderTraversal):访问根结点的操作发⽣在遍历其左右子树之中(间) 访 问顺序为:左子树、根结点、右子树
3)后序遍历(PostorderTraversal):访问根结点的操作发⽣在遍历其左右子树之后 访 问顺序为:左子树、右子树、根结点
代码:
//前序遍历
void preOrder(BTNode* root)
{if (root == NULL){printf("NULL");return NULL;}printf("%c", root->data);preOrder(root->left);preOrder(root->right);
}
//中序遍历
void InOrder(BTNode* root)
{if (root == NULL){printf("NULL");return NULL;}InOrder(root->left);printf("%c", root->data);InOrder(root->right);
}
//后序遍历
void PostOrder(BTNode* root)
{if (root == NULL){printf("NULL");return NULL;}PostOrder(root->left);PostOrder(root->right);printf("%c", root->data);
}
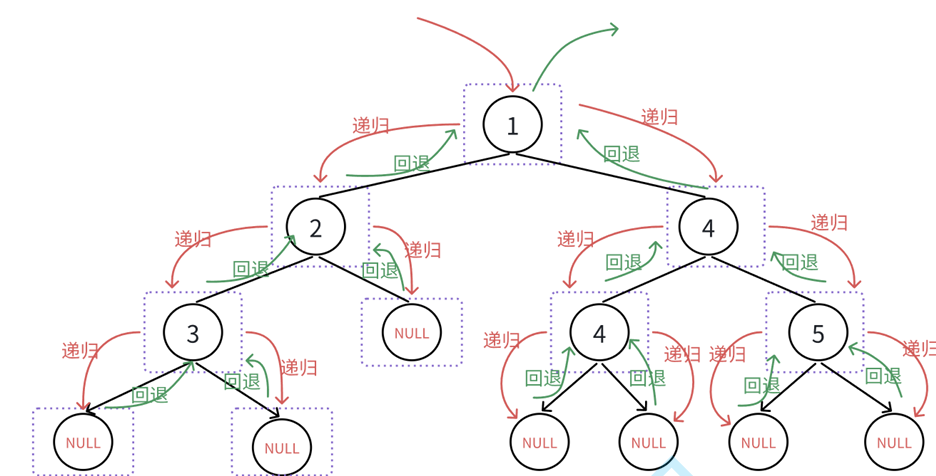
由于涉及到递归,所以咱们来看一个前序遍历的递归图。 是挺复杂的,但也没有很复杂。你只要是搞清他们之间的关系就没什么问题。
注意:递归的时候,这行代码正在递归并不等于这行代码已经递归完了。
2.3.3.2 二叉树的几个操作
那么咱们下面实现另外的几个操作:都是用递归实现的:
以下都是以上面这个为模型。
1.二叉树的节点个数
//二叉树的节点个数
int BinaryTreeSize(BTNode* root)
{if (root == NULL){return 0;}return 1 + BinaryTreeSize(root->left) + BinaryTreeSize(root->right);
}这个也是用递归版本实现的。
 来看本作者画的一个递归的理解的思维导图,也是很好理解的。
来看本作者画的一个递归的理解的思维导图,也是很好理解的。
2.二叉树叶子结点的个数 =左子树叶子节点加上右子树叶子节点
// ⼆叉树叶⼦结点个数
int BinaryTreeLeafSize(BTNode* root)
{if (root == NULL){return 0;}if (root->left == NULL && root->right == NULL){return 1;}return BinaryTreeLeafSize(root->left) + BinaryTreeLeafSize(root->right);
}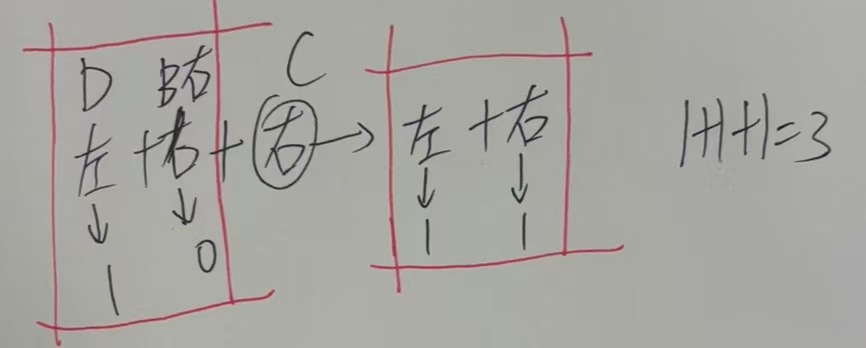 这也是比较好理解的。
这也是比较好理解的。
3.二叉树第k层节点的个数
// ⼆叉树第k层结点个数
int BinaryTreeLevelKSize(BTNode* root, int k)
{if (root == NULL){return 0;}if (k == 1){return 1;}return BinaryTreeLevelKSize(root->left, k - 1) + BinaryTreeLevelKSize(root->right, k - 1);
}
4. 二叉树的深度/高度
int BinaryTreeDepth(BTNode* root)
{if(root == NULL){return 0;}int leftDep = BinaryTreeDepth(root->left);int rightDep = BinaryTreeDepth(root->right);return 1 + (leftDep > rightDep ? leftDep : rightDep);
}
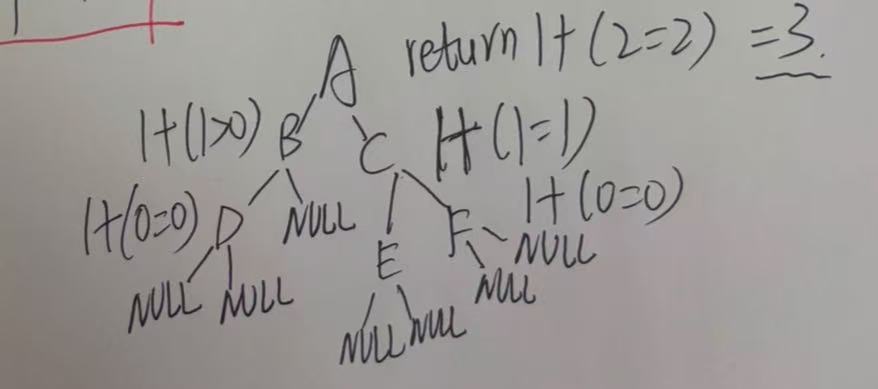 5.二叉树查找值为x的结点
5.二叉树查找值为x的结点
BTNode* BinaryTreeFind(BTNode* root, BTDataType x)
{if (root == NULL){return NULL;}if (root->data == x){return root;}BTNode* leftFind = BinaryTreeFind(root->left, x);if (leftFind){return leftFind;}BTNode* rightFind = BinaryTreeFind(root->right, x);if (rightFind){return rightFind;}return NULL;
}这个也是用的递归写的,即如果当前的根节点不是的,那么就往左右子节点中去找即可。
6.二叉树的销毁
// ⼆叉树销毁
void BinaryTreeDestory(BTNode** root)
{if (*root == NULL){return;}BinaryTreeDestory(&((*root)->left));BinaryTreeDestory(&((*root)->right));free(*root);*root = NULL;
}这里由于要改变二叉树,所以传的是二级指针。
7.层序遍历----队列
void LevelOrder(BTNode* root)
{Queue q;QueueInit(&q);QueuePush(&q, root);while (!QueueEmpty(&q)){//取队头出队头,打印结点值BTNode* top = QueueFront(&q);QueuePop(&q);printf("%c ", top->data);//将队头结点的非空左右孩子结点入队列if (top->left)QueuePush(&q, top->left);if (top->right)QueuePush(&q, top->right);}QueueDestroy(&q);
}首先,函数名为LevelOrder,参数是BTNode指针root,看起来是二叉树的根节点。函数内部创建了一个队列q,并进行了初始化。然后,将根节点入队。接下来进入一个循环,条件是队列不为空。在循环内部,取出队头元素并出队,打印该节点的数据。然后检查该节点的左右子节点,如果有非空的子节点,就将它们入队。最后,销毁队列。
整个的逻辑就是:首先根节点入队,然后循环处理队列中的节点,处理完一个节点后将其子节点入队。这样就能按层次遍历整个二叉树。
8.判断二叉树是否是完全二叉树
bool BinaryTreeComplete(BTNode* root)
{Queue q;QueueInit(&q);QueuePush(&q, root);
//根节点入队,开始层次遍历。while (!QueueEmpty(&q)){//取队头,出队头BTNode* top = QueueFront(&q);QueuePop(&q);if (top == NULL){break;}//队头结点的左右孩子入队列QueuePush(&q, top->left);QueuePush(&q, top->right);}
//入队所有子节点:无论子节点是否为空,均入队,确保后续能检测到结构异常。//终止条件:遇到第一个空节点时跳出循环,后续可能仍有未处理的节点。//队列不为空,继续取队头出队头//1)队头存在非空结点----非完全二叉树//2)队头不存在非空结点----完全二叉树while (!QueueEmpty(&q)){BTNode* top = QueueFront(&q);QueuePop(&q);if (top != NULL){QueueDestroy(&q);return false;}}QueueDestroy(&q);return true;
//剩余节点必须全为空:若存在非空节点,说明在空节点后仍有数据,违反完全二叉树
}这段代码首先通过层次遍历,将节点依次入队,包括NULL节点。当遇到第一个NULL节点时,停止遍历,然后检查队列中剩下的节点是否都是NULL。如果有任何非NULL的节点存在,说明树不是完全二叉树。否则,是完全二叉树。这种方法的时间复杂度是O(n),因为每个节点最多被访问两次。空间复杂度是O(n),因为队列中可能需要存储最多n个节点。
2.3.3.3 二叉树的性质:
对任何一棵二叉树,如果度为0
其叶结点个数为n1,度为2的分支结点个数为n2.,则有
n1 = n2+1

证明上述性质:
假设⼀个二叉树有 2a+b a 个度为2的节点, b 个度为1的节点, c 个叶节点,则这个二叉树的边数是
另⼀方面,由于共有 a+b+c 个节点,所以边数等于 a+b+c-1
结合上面两个公式: 2a+b = a+b+c-1 ,即: a = c-1 。
OK,那么以上就是本篇要讲的全部内容,内容很多很多,本人写也花了很多时间。
希望大家下去可以好好研读。
本篇完....................
相关文章:
)
数据结构——二叉树和堆(万字,最详细)
目录 1.树 1.1 树的概念与结构 1.2 树相关的术语 1.3 树的表示法 2.二叉树 2.1 概念与结构 2.2 特殊的二叉树 2.2.1 满二叉树 2.2.2 完全二叉树 2.3 二叉树存储结构 2.3.1 顺序结构 2.3.2 实现顺序结构二叉树 2.3.2.1 堆的概念与结构 2.3.2. 2 堆的插入与删除数据…...

IdeaVim 配置与使用指南
一、什么是 IdeaVim? IdeaVim 是 JetBrains 系列 IDE(如 IntelliJ IDEA, WebStorm, PyCharm 等)中的一个插件,让你在 IDE 里使用 Vim 的按键习惯,大大提升效率。 安装方法: 在 IDE 中打开 设置(Settings) →…...

前端浏览器窗口交互完全指南:从基础操作到高级控制
浏览器窗口交互是前端开发中构建复杂Web应用的核心能力,本文深入探讨23种关键交互技术,涵盖从传统API到最新的W3C提案,助您掌握跨窗口、跨标签页的完整控制方案。 一、基础窗口操作体系 1.1 窗口创建与控制 // 新窗口创建(现代浏…...

考研系列-计算机组成原理第五章、中央处理器
一、CPU的功能及结构 1.运算器的基本结构 2.控制器结构...

python+flask+flask-sockerio,部署后sockerio通信异常
前言 用python开发了一个flask web服务,前端用html,前后端通过socketio通信,开发环境,windowsminicondavscode,开发完成后本地运行没有问题,然后就开始部署,噩梦就开始了。 问题描述 程序是部…...

深度解析:TextRenderManager——Cocos Creator艺术字体渲染核心类
一、类概述 TextRenderManager 是 Cocos Creator 中实现动态艺术字体渲染的核心单例类。它通过整合资源加载、缓存管理、异步队列和自动布局等功能,支持普通字符模式和图集模式两种渲染方案,适用于游戏中的动态文本(如聊天内容、排行榜&…...

同样开源的自动化工作流工具n8n和Dify对比
n8n和Dify作为两大主流工具,分别专注于通用自动化和AI应用开发领域,选择哪个更“好用”需结合具体需求、团队能力及业务场景综合判断。以下是核心维度的对比分析: 一、核心定位与适用场景 维度n8nDify核心定位开源全场景自动化工具ÿ…...
完整讲解与实战应用)
设计模式每日硬核训练 Day 16:责任链模式(Chain of Responsibility Pattern)完整讲解与实战应用
🔄 回顾 Day 15:享元模式小结 在 Day 15 中,我们学习了享元模式(Flyweight Pattern): 通过共享对象,分离内部状态与外部状态,大量减少内存开销。适用于字符渲染、游戏场景、图标缓…...

基于边缘人工智能的AI无人机-更高效更安全的飞行任务执行
基于边缘人工智能的AI无人机-更高效更安全的飞行任务执行 人工智能有可能改变人们的生活和工作方式。人工智能和无人机是近年来发展迅速的两项技术。当这两种技术结合在一起时,它们会创造出许多以前不可能的应用。基于人工智能的无人机旨在独立执行任务,…...

30、不是说字符串是不可变的吗,string s=“abc“;s=“123“不就是变了吗?
一、核心概念澄清:不可变性的真实含义 1、不可变性的定义 字符串不可变性指对象内容不可修改,而非变量不可修改。 类比: 不可变字符串 装在密封信封里的信纸(内容不可更改)变量赋值 更换信封的指向(从…...

线上查询车辆出险记录:快速掌握事故情况!
在如今汽车成为人们日常不可或缺的交通工具之际,车辆出险记录成为了许多车主关注的焦点之一。为了帮助车主们快速了解车辆出险、理赔、事故记录,现在有了一种便捷的方式,那就是通过API接口在线查询。本文将介绍如何利用API接口,通…...

Python爬虫课程实验指导书
1.1Requests类库的认知 1.1.1 认识请求类库 Requests是用Python语言编写,基于,采用Apache2 Licensed开源协议的。它比urllib更加方便,可以节约我们大量的工作,完全满足HTTP测试需求。urllibHTTP库 Requests官网地址:ht…...

streamlit实现非原生的按钮触发效果 + flask实现带信息的按钮触发
目录 简介不携带信息的触发隐藏指定st.button(label, key)触发button的html代码汇总 携带信息的触发为什么需要携带信息前端JavaScript修改flask处理总代码 简介 由于streamlit可以同时在实现前后端结合,非常方便,但是这也造成了user难以方便的对页面的…...

机器学习基础——Seaborn使用
1.使用tips数据集,创建一个展示不同时间段(午餐/晚餐)账单总额分布的箱线图 import matplotlib.pyplot as plt import numpy as np import pandas as pd import seaborn as snstips pd.read_csv(./tips.csv)sns.boxplot(data tips,x time,y total_bill, )plt.show() 2.使用…...

Godot开发2D冒险游戏——第三节:游戏地图绘制
一、初步构建游戏地图 在游戏场景当中添加一个新的子节点:TileMapLayer 这一层称为瓦片地图层 根据提示,下一步显然是添加资源 为TileMapLayer节点添加一个TileSet 将地板添加进来,然后选择自动分割图集 自定义时要确保大小合适 让Godot自…...

Spark Mllib 机器学习
概述 机器学习是什么 根据百度百科的定义: 机器学习是一种通过算法和模型使计算机从数据中自动学习并进行预测或决策的技术。 定义比较抽象,根据常见的机器学习可以总结出三个关键字: 算法、经验、性能。 机器学习的过程可以抽象成一个pipel…...

在windows使用docker打包springboot项目镜像并上传到阿里云
1、前提:已有spring项目 2、在项目根目录下创建Dockerfile文件 FROM openjdk:11 WORKDIR /ruoyi-admin COPY ruoyi-admin/build/libs/lifecolor-web.jar lifecolor-web.jar CMD ["java", "-jar", "lifecolor-web.jar"] 3、选…...

前端高频面试题day3
JavaScript作用域理解 核心概念 作用域:定义变量/函数的可见范围及生命周期,分为 全局作用域、函数作用域、块级作用域。作用域链:变量查找从当前作用域逐级向上直至全局,遵循词法作用域(静态作用域)。闭…...

时空特征如何融合?LSTM+Resnet有奇效,SOTA方案预测准确率超91%
LSTM有着不错的时序信息提取能力,ResNet有着不错的空间特征信息提取能力。如果现在有时空特征融合的创新需求,我们是否能将LSTM和ResNet两者的优点融合起来呢? 随着这个思路下去,LSTM ResNet混合模型横空出世,在各个…...

蓝桥杯Java全攻略:从零到一掌握竞赛与企业开发实战
蓝桥杯Java软件开发竞赛已成为全国高校学生展示编程能力的重要舞台,本指南将带您从零开始构建完整的Java知识体系,不仅覆盖蓝桥杯高频考点,还延伸至企业级开发实战,助您在竞赛中脱颖而出并为未来职业发展奠定坚实基础。 一、Java基础语法与数据结构 竞赛解题流程图设计 蓝…...

【Nginx】负载均衡配置详解
Nginx作为高性能的HTTP服务器和反向代理服务器,提供了强大的负载均衡功能。本文将详细介绍Nginx负载均衡的配置方法和相关策略。 一、基础负载均衡配置 1.单服务示例配置 配置nginx.conf模块 在Nginx配置文件中定义upstream模块: worker_processes a…...

打造企业级AI文案助手:GPT-J+Flask全栈开发实战
一、智能文案革命的序幕:为什么需要AI文案助手? 在数字化营销时代,内容生产效率成为企业核心竞争力。据统计,营销人员平均每天需要撰写3.2篇文案,而传统人工创作存在三大痛点: 效率瓶颈:创意构…...

【文献速递】snoRNA-SNORD113-3/ADAR2通过对PHKA2的A-to-I编辑影响胶质母细胞瘤糖脂代谢
Cui等人于2025年在Cellular & Molecular Biology Letters上的发表一篇研究论文,题目为“Effect of SNORD113-3/ADAR2 on glycolipid metabolism in glioblastoma via A-to-I editing of PHKA2”。这篇文章的核心内容是研究胶质母细胞瘤(GBMÿ…...

视频HLS分片与关键帧优化深度解析
视频HLS分片与关键帧优化深度解析 🌐 HLS基础架构 #mermaid-svg-OQmrXfradiCv3EGC {font-family:"trebuchet ms",verdana,arial,sans-serif;font-size:16px;fill:#333;}#mermaid-svg-OQmrXfradiCv3EGC .error-icon{fill:#552222;}#mermaid-svg-OQmrXfrad…...

再谈从视频中学习:从给视频打字幕的Humanoid-X、UH-1到首个人形VLA Humanoid-VLA:迈向整合第一人称视角的通用人形控制
前言 本博客内,之前写了比较多的大脑相关的,或者上肢操作,而解读运动控制、规划的虽也有,但相对少 故近期 准备多写写双足人形的运动控制相关 一方面,我们有些客户订单涉及这块二方面,想让双足人形干好活…...

Ubuntu下MySQL的安装
Ubuntu下MySQL的安装 1. 查看当前操作系统版本2. 添加MySQL APT源2.1 访问下载页面,并下载发布包2.2 执行安装指令2.3 安装MySQL 3. 查看MySQL状态4. 设置开机自启动 1. 查看当前操作系统版本 通过命令lsb_release -a查看: 2. 添加MySQL APT源 2.1 访问下…...

DataStreamAPI实践原理——快速上手
引入 通过编程模型,我们知道Flink的编程模型提供了多层级的抽象,越上层的API,其描述性和可阅读性越强,越下层API,其灵活度高、表达力越强,多数时候上层API能做到的事情,下层API也能做到&#x…...

《数据结构初阶》【顺序表 + 单链表 + 双向链表】
《数据结构初阶》【顺序表 单链表 顺序表】 前言:先聊些其他的东西!!!什么是线性表?什么是顺序表?顺序表的种类有哪些? 什么是链表?链表的种类有哪些? ---------------…...

【JS-Leetcode】2621睡眠函数|2629复合函数|2665计数器||
文章目录 2621睡眠函数2629复合函数2665计数器|| 这三个题目涉及setTimeout、promise、数组reduce方法,闭包。 2621睡眠函数 请你编写一个异步函数,它接收一个正整数参数 millis ,并休眠 millis 毫秒。要求此函数可以解析任何值。 原理&am…...

全国各地级城市月度平均房价统计数据2009-2021年
全国各地级城市月度平均房价统计数据2009-2021年.ziphttps://download.csdn.net/download/2401_84585615/90259770 https://download.csdn.net/download/2401_84585615/90259770 来源:安居客,本数据以excel格式展示,列举2.5万多条样本数据。总…...

ElasticSearch从入门到精通-覆盖DSL操作和Java实战
一、ElasticSearch基础概念 1.1 认识elasticSearch ElasticSearch(简称ES)是一款开源的、分布式的搜索引擎,它建立在Apache Lucene之上。简单来说,ElasticSearch就是一个能让你以极快速度进行数据搜索、存储和分析的系统。它不仅…...

SHCTF-REVERSE
前言 之前写的,一直没发,留个记录吧,万一哪天记录掉了起码在csdn有个念想 1.ezapk 反编译 快速定位关键函数 package com.mycheck.ezjv;import adrt.ADRTLogCatReader; import android.app.Activity; import android.content.Context; impo…...

C++学习:六个月从基础到就业——模板编程:模板特化
C学习:六个月从基础到就业——模板编程:模板特化 本文是我C学习之旅系列的第三十四篇技术文章,也是第二阶段"C进阶特性"的第十二篇,主要介绍C中的模板特化技术。查看完整系列目录了解更多内容。 目录 引言模板特化基础…...
)
【中级软件设计师】编译和解释程序的翻译阶段、符号表 (附软考真题)
【中级软件设计师】编译和解释程序的翻译阶段、符号表 (附软考真题) 目录 【中级软件设计师】编译和解释程序的翻译阶段、符号表 (附软考真题)一、历年真题二、考点:编译和解释程序的翻译阶段1、解释2、编译3、解释和编译的异同之处4、符号表 三、真题的答案与解析答…...
垃圾回收器与JVM内存)
G1(Garbage-First)垃圾回收器与JVM内存
G1垃圾回收器简介 G1(Garbage-First)是Java虚拟机(JVM)中的一种垃圾回收器,它是针对服务器端应用设计的,旨在提供高吞吐量和低延迟的垃圾回收性能。G1垃圾回收器的主要目标是高效地管理JVM的堆内存,同时尽量减少垃圾回收(GC)过程对应用程序性能的影响。 特点 分区回收…...

STM32 驱动 INA226 测量电流电压功率
文章目录 一、INA226简介二、引脚功能三、寄存器介绍1.配置寄存器 0x002.分流电压寄存器 0x013.总线电压寄存器 0x024.功率寄存器 0x035.电流寄存器 0x046.基准寄存器 0x05 四、IIC 时序说明1.写时序2.读时序 五、程序六、实验现象1.线路图2.输出数据 一、INA226简介 INA226 是…...

解决新搭建的centos虚拟器,yum下载不了的问题
1. 检查网络连接 确保虚拟机可以访问互联网: ping 8.8.8.8 # 测试基础网络连通性若不通: 检查网卡 IP 配置(参考之前的 IP 恢复步骤)。 确认虚拟机网络模式(如 NAT 或桥接模式)是否允许访问外网。 检查网…...

python连接Elasticsearch并完成增删改查
python库提供了elasticsearch模块,可以通过以下命令进行快速安装,但是有个细节需要注意一下,安装的模块版本要跟es软件版本一致,此处举例:7.8.1 pip install elasticsearch==7.8.1 首先连接elasticsearch,以下是免密示例 from elasticsearch import Elasticsearch# El…...
Python数据存储实战:CSV文件读写与复杂数据处理指南)
Python爬虫(7)Python数据存储实战:CSV文件读写与复杂数据处理指南
目录 一、背景与核心价值二、CSV基础与核心应用场景2.1 CSV文件结构解析2.2 适用场景 三、Python csv模块核心操作3.1 安装与基础读写3.2 高级功能:字典读写与自定义格式 四、处理复杂数据场景4.1 含特殊字符的字段4.2 嵌套数据(如JSO…...

Spring Boot 中的条件注解
Spring Boot条件注解的汇总: 注解作用判断依据使用场景ConditionalOnBean容器中存在指定Bean时,被注解的配置或Bean定义生效指定Bean在容器中存在依赖其他已存在Bean时配置相关功能ConditionalOnCheckpointRestore在特定检查点恢复相关条件满足时生效满…...

Java 字符串分解技术:substring、tokenizing 和 trimming 方法详解
关键点 Java 字符串处理是开发中不可或缺的一部分,广泛用于数据解析和格式化。substring() 方法能够精确提取字符串的子串,需注意索引范围以避免异常。String.split() 是分词的首选方法,支持正则表达式,灵活性高。trim() 和 stri…...

OpenCV进阶操作:图像金字塔
文章目录 前言一、图像金字塔1、什么是图像金字塔2、金字塔类型1) 高斯金字塔 (Gaussian Pyramid)2)拉普拉斯金字塔 (Laplacian Pyramid) 3、图像金字塔的作用 二、图像金字塔中的操作1、向下采样步骤 2、向上采样步骤 3、拉普拉斯金字塔4、结论 三、代码…...

Rust游戏开发全栈指南:从理论到实践的革新之路
一、Rust游戏开发生态全景 1.1 核心引擎框架 Rust游戏生态已形成多层级工具链,覆盖从轻量级2D到3A级项目的开发需求: Bevy:采用ECS架构的模块化引擎,提供优雅的API设计和活跃社区支持,支持实时热重载和跨平台部署Fy…...

[GXYCTF2019]Ping Ping Ping
解题步骤 1、先使用 内敛执行 查看当前的php文件 执行 命令执行 发现空格被过滤 ?ip127.0.0.1$IFS|$IFSwhomi 还有一个点就是这个 执行的命令是不能进行拼接的 可能就是被过滤了 | 所以我们使用 ; 进行绕过一下 空格过滤代替 $IFS ${IFS} ${IFS}$9 //这里$1到$9都可以 $IFS$1…...

马哥教育Linux云计算运维课程
课程大小:19.1G 课程下载:https://download.csdn.net/download/m0_66047725/90640128 更多资源下载:关注我 你是否找了很多资料看了很多视频聊了很多群友,却发现自己技术仍然原地踏步?本教程联合BAT一线导师倾囊相授…...

科技打头阵,创新赢未来——中科视界携千眼狼超高速摄像机亮相第三届科交会
2025年4月26日,合肥,第三届中国(安徽)科技创新成果转化交易会国际合作板块展区,中科视界及其旗下品牌“千眼狼”高速摄像机成为展会焦点。作为国内科学仪器的领军企业,中科视界以“科技打头阵,创…...

【Flutter】Unity 三端封装方案:Android / iOS / Web
关联文档:【方案分享】Flutter Unity 跨平台三维渲染架构设计全解:插件封装、通信机制与热更新机制—— 支持 Android/iOS/Web 的 3D 内容嵌入与远程资源管理,助力 XR 项目落地 —— 支持 Android/iOS/Web 的 3D 内容嵌入与远程资源管理&…...

高能效计算:破解算力增长与能源约束的科技密码
引言 在人工智能和大模型技术迅猛发展的今天,全球算力需求正以每年50%的速度激增[3]。然而,传统计算范式已逼近物理极限——国际能源署预测,到2030年数据中心的全球电力消耗占比可能突破3%[3]。面对这场"算力革命"与"能源危机…...
的工程系统进化法则)
【质量管理】TRIZ(萃智)的工程系统进化法则
在文章【质量管理】现代TRIZ(萃智)理论概述-CSDN博客 我们谈到到现代TRIZ的理论、TRIZ与传统创新的差异等。在文章中我们有说到TRIZ的创始人阿奇舒勒发现其实技术的进化是有规律可循的。 那到底技术进步有什么规律呢? 技术进化发展趋势和路径…...

FastAPI系列07:“请求-响应”过程高阶技巧
“请求-响应”过程高阶技巧 1、自定义 Request自定义 Request的用途如何自定义 Request 2、自定义APIRouteAPIRoute的用途自定义 APIRoute的用途如何自定义 APIRoute 3、使用BackgroundTasks(后台任务)BackgroundTasks的用途如何使用BackgroundTasksBack…...