Spark Mllib 机器学习
概述
机器学习是什么
云端机器学习资源
机器学习的种类
Spark MLlib介绍
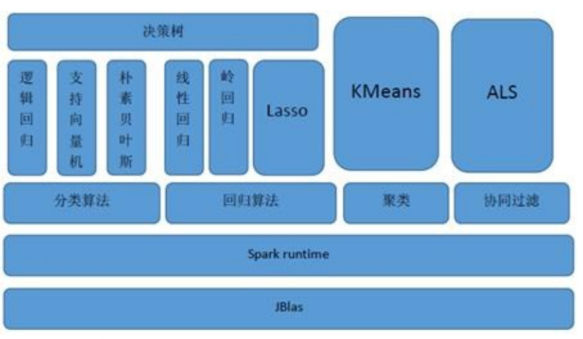
Spark MLlib架构
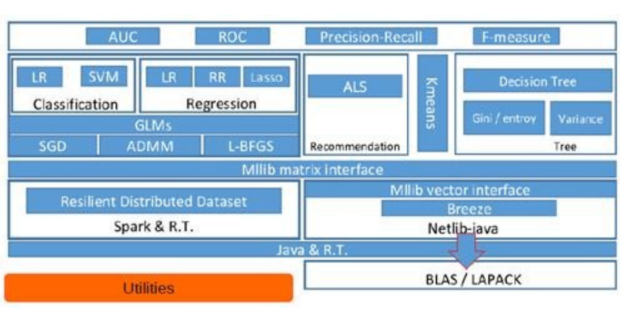
核心组件
数据表示
- Vector/Matrix:本地和分布式向量/矩阵表示
- DataFrame-based API:使用 Spark SQL 的 DataFrame 作为主要数据容器
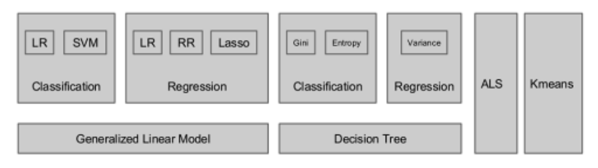
算法分类
- 分类算法:逻辑回归、决策树、随机森林等
- 回归算法:线性回归、广义线性回归等
- 聚类算法:K-means、LDA 等
- 协同过滤:ALS (交替最小二乘法)
- 特征提取与转换:TF-IDF、Word2Vec 等
工作流工具
- Pipeline API:将多个机器学习阶段组合成工作流
- Transformer:将 DataFrame 转换为新 DataFrame
- Estimator:拟合数据生成 Transformer
- 模型评估工具:交叉验证、超参数调优
分类算法
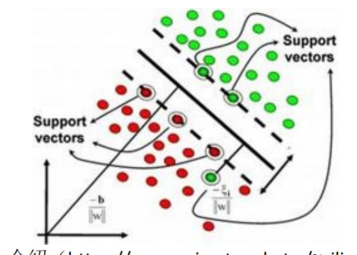
- 输出是离散的类别(如"是/否"、"A/B/C"等)
- 属于监督学习(需要已标注的训练数据)
- 评估指标:准确率、精确率、召回率、F1分数、AUC-ROC等
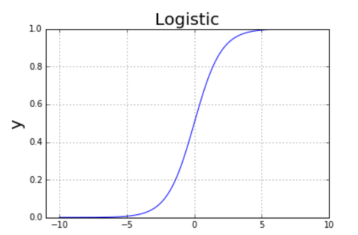
- 逻辑回归(Logistic Regression)
- 决策树(Decision Tree)
- 随机森林(Random Forest)
- 支持向量机(SVM)
- 朴素贝叶斯(Naive Bayes)
- 神经网络(Neural Networks)
- 垃圾邮件检测(垃圾邮件/正常邮件)
- 图像识别(猫/狗/鸟)
- 信用风险评估(通过/拒绝)
- 疾病诊断(患病/健康)
import org.apache.spark.sql.SparkSessionval spark = SparkSession.builder().appName("SparkMLlibDemos").master("local[*]") // 本地模式,使用所有核心.getOrCreate()import spark.implicits._// 1. 准备数据
val trainingData = Seq((1.0, Vectors.dense(0.0, 1.1, 0.1)),(0.0, Vectors.dense(2.0, 1.0, -1.0)),(0.0, Vectors.dense(2.0, 1.3, 1.0)),(1.0, Vectors.dense(0.0, 1.2, -0.5))
).toDF("label", "features")// 2. 创建逻辑回归模型
val lr = new LogisticRegression().setMaxIter(10).setRegParam(0.01)// 3. 训练模型
val lrModel = lr.fit(trainingData)// 4. 打印模型参数
println(s"Coefficients: ${lrModel.coefficients} Intercept: ${lrModel.intercept}")// 5. 预测新数据
val testData = Seq((1.0, Vectors.dense(-1.0, 1.5, 1.3)),(0.0, Vectors.dense(3.0, 2.0, -0.1)),(1.0, Vectors.dense(0.0, 2.2, -1.5))
).toDF("label", "features")val predictions = lrModel.transform(testData)
predictions.show()// 6. 评估模型
import org.apache.spark.ml.evaluation.BinaryClassificationEvaluator
val evaluator = new BinaryClassificationEvaluator().setMetricName("areaUnderROC")val auc = evaluator.evaluate(predictions)
println(s"Area under ROC = $auc")回归算法
- 输出是连续值(如价格、温度、销量等)
- 属于监督学习
- 评估指标:均方误差(MSE)、均方根误差(RMSE)、R²分数等
- 线性回归(Linear Regression)
- 多项式回归(Polynomial Regression)
- 岭回归(Ridge Regression)
- Lasso回归
- 弹性网络(Elastic Net)
- 回归树(Regression Tree)
- 房价预测
- 股票价格预测
- 销售额预测
- 温度预测
import org.apache.spark.sql.SparkSessionval spark = SparkSession.builder().appName("SparkMLlibDemos").master("local[*]") // 本地模式,使用所有核心.getOrCreate()import spark.implicits._// 1. 准备数据
val dataset = Seq((1.0, 1.0, 2.0, 1.0),(2.0, 2.0, 3.0, 2.0),(4.0, 3.0, 5.0, 3.0),(3.0, 4.0, 2.0, 4.0)
).toDF("label", "x1", "x2", "x3")// 2. 特征向量化
val assembler = new VectorAssembler().setInputCols(Array("x1", "x2", "x3")).setOutputCol("features")val assembledData = assembler.transform(dataset)// 3. 划分训练集和测试集
val Array(trainData, testData) = assembledData.randomSplit(Array(0.7, 0.3))// 4. 创建线性回归模型
val lr = new LinearRegression().setMaxIter(10).setRegParam(0.3).setElasticNetParam(0.8)// 5. 训练模型
val lrModel = lr.fit(trainData)// 6. 打印模型摘要
println(s"Coefficients: ${lrModel.coefficients} Intercept: ${lrModel.intercept}")
println(s"RMSE: ${lrModel.summary.rootMeanSquaredError}")
println(s"R2: ${lrModel.summary.r2}")// 7. 预测
val predictions = lrModel.transform(testData)
predictions.select("prediction", "label", "features").show()聚类算法
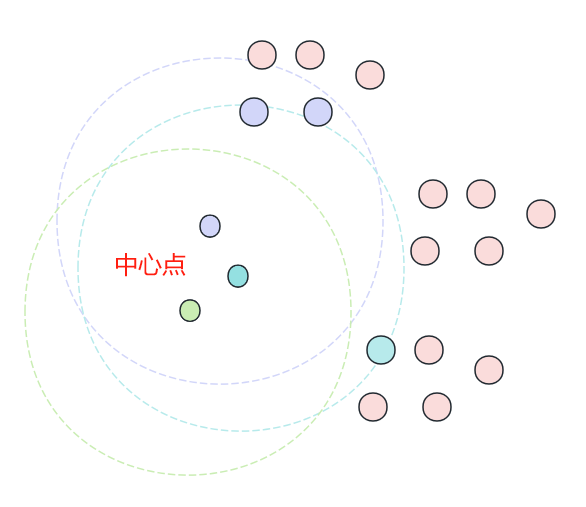
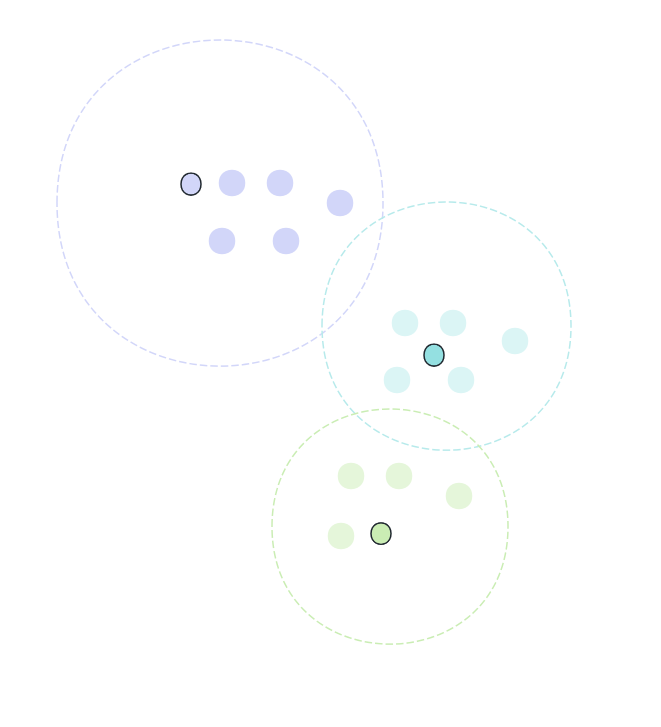
- 无监督学习(不需要已标注数据)
- 没有明确的"正确"答案
- 评估指标:轮廓系数、Davies-Bouldin指数等
- 需要预先指定或自动确定簇的数量
- K均值(K-Means)
- 层次聚类(Hierarchical Clustering)
- DBSCAN(基于密度的聚类)
- 高斯混合模型(GMM)
- 谱聚类(Spectral Clustering)
- 客户细分
- 异常检测
- 图像分割
- 社交网络分析
- 文档聚类
import org.apache.spark.sql.SparkSessionval spark = SparkSession.builder().appName("SparkMLlibDemos").master("local[*]") // 本地模式,使用所有核心.getOrCreate()import spark.implicits._// 1. 准备数据
val dataset = Seq(Vectors.dense(0.0, 0.0),Vectors.dense(1.0, 1.0),Vectors.dense(9.0, 8.0),Vectors.dense(8.0, 9.0),Vectors.dense(0.1, 0.1),Vectors.dense(8.1, 9.1)
).map(Tuple1.apply).toDF("features")// 2. 创建K-means模型
val kmeans = new KMeans().setK(2) // 设置聚类数量.setSeed(1L)// 3. 训练模型
val model = kmeans.fit(dataset)// 4. 预测
val predictions = model.transform(dataset)
predictions.show()// 5. 评估聚类效果
val evaluator = new ClusteringEvaluator()
val silhouette = evaluator.evaluate(predictions)
println(s"Silhouette with squared euclidean distance = $silhouette")// 6. 查看聚类中心
println("Cluster Centers: ")
model.clusterCenters.foreach(println)相关文章:

Spark Mllib 机器学习
概述 机器学习是什么 根据百度百科的定义: 机器学习是一种通过算法和模型使计算机从数据中自动学习并进行预测或决策的技术。 定义比较抽象,根据常见的机器学习可以总结出三个关键字: 算法、经验、性能。 机器学习的过程可以抽象成一个pipel…...

在windows使用docker打包springboot项目镜像并上传到阿里云
1、前提:已有spring项目 2、在项目根目录下创建Dockerfile文件 FROM openjdk:11 WORKDIR /ruoyi-admin COPY ruoyi-admin/build/libs/lifecolor-web.jar lifecolor-web.jar CMD ["java", "-jar", "lifecolor-web.jar"] 3、选…...

前端高频面试题day3
JavaScript作用域理解 核心概念 作用域:定义变量/函数的可见范围及生命周期,分为 全局作用域、函数作用域、块级作用域。作用域链:变量查找从当前作用域逐级向上直至全局,遵循词法作用域(静态作用域)。闭…...

时空特征如何融合?LSTM+Resnet有奇效,SOTA方案预测准确率超91%
LSTM有着不错的时序信息提取能力,ResNet有着不错的空间特征信息提取能力。如果现在有时空特征融合的创新需求,我们是否能将LSTM和ResNet两者的优点融合起来呢? 随着这个思路下去,LSTM ResNet混合模型横空出世,在各个…...

蓝桥杯Java全攻略:从零到一掌握竞赛与企业开发实战
蓝桥杯Java软件开发竞赛已成为全国高校学生展示编程能力的重要舞台,本指南将带您从零开始构建完整的Java知识体系,不仅覆盖蓝桥杯高频考点,还延伸至企业级开发实战,助您在竞赛中脱颖而出并为未来职业发展奠定坚实基础。 一、Java基础语法与数据结构 竞赛解题流程图设计 蓝…...

【Nginx】负载均衡配置详解
Nginx作为高性能的HTTP服务器和反向代理服务器,提供了强大的负载均衡功能。本文将详细介绍Nginx负载均衡的配置方法和相关策略。 一、基础负载均衡配置 1.单服务示例配置 配置nginx.conf模块 在Nginx配置文件中定义upstream模块: worker_processes a…...

打造企业级AI文案助手:GPT-J+Flask全栈开发实战
一、智能文案革命的序幕:为什么需要AI文案助手? 在数字化营销时代,内容生产效率成为企业核心竞争力。据统计,营销人员平均每天需要撰写3.2篇文案,而传统人工创作存在三大痛点: 效率瓶颈:创意构…...

【文献速递】snoRNA-SNORD113-3/ADAR2通过对PHKA2的A-to-I编辑影响胶质母细胞瘤糖脂代谢
Cui等人于2025年在Cellular & Molecular Biology Letters上的发表一篇研究论文,题目为“Effect of SNORD113-3/ADAR2 on glycolipid metabolism in glioblastoma via A-to-I editing of PHKA2”。这篇文章的核心内容是研究胶质母细胞瘤(GBMÿ…...

视频HLS分片与关键帧优化深度解析
视频HLS分片与关键帧优化深度解析 🌐 HLS基础架构 #mermaid-svg-OQmrXfradiCv3EGC {font-family:"trebuchet ms",verdana,arial,sans-serif;font-size:16px;fill:#333;}#mermaid-svg-OQmrXfradiCv3EGC .error-icon{fill:#552222;}#mermaid-svg-OQmrXfrad…...

再谈从视频中学习:从给视频打字幕的Humanoid-X、UH-1到首个人形VLA Humanoid-VLA:迈向整合第一人称视角的通用人形控制
前言 本博客内,之前写了比较多的大脑相关的,或者上肢操作,而解读运动控制、规划的虽也有,但相对少 故近期 准备多写写双足人形的运动控制相关 一方面,我们有些客户订单涉及这块二方面,想让双足人形干好活…...

Ubuntu下MySQL的安装
Ubuntu下MySQL的安装 1. 查看当前操作系统版本2. 添加MySQL APT源2.1 访问下载页面,并下载发布包2.2 执行安装指令2.3 安装MySQL 3. 查看MySQL状态4. 设置开机自启动 1. 查看当前操作系统版本 通过命令lsb_release -a查看: 2. 添加MySQL APT源 2.1 访问下…...

DataStreamAPI实践原理——快速上手
引入 通过编程模型,我们知道Flink的编程模型提供了多层级的抽象,越上层的API,其描述性和可阅读性越强,越下层API,其灵活度高、表达力越强,多数时候上层API能做到的事情,下层API也能做到&#x…...

《数据结构初阶》【顺序表 + 单链表 + 双向链表】
《数据结构初阶》【顺序表 单链表 顺序表】 前言:先聊些其他的东西!!!什么是线性表?什么是顺序表?顺序表的种类有哪些? 什么是链表?链表的种类有哪些? ---------------…...

【JS-Leetcode】2621睡眠函数|2629复合函数|2665计数器||
文章目录 2621睡眠函数2629复合函数2665计数器|| 这三个题目涉及setTimeout、promise、数组reduce方法,闭包。 2621睡眠函数 请你编写一个异步函数,它接收一个正整数参数 millis ,并休眠 millis 毫秒。要求此函数可以解析任何值。 原理&am…...

全国各地级城市月度平均房价统计数据2009-2021年
全国各地级城市月度平均房价统计数据2009-2021年.ziphttps://download.csdn.net/download/2401_84585615/90259770 https://download.csdn.net/download/2401_84585615/90259770 来源:安居客,本数据以excel格式展示,列举2.5万多条样本数据。总…...

ElasticSearch从入门到精通-覆盖DSL操作和Java实战
一、ElasticSearch基础概念 1.1 认识elasticSearch ElasticSearch(简称ES)是一款开源的、分布式的搜索引擎,它建立在Apache Lucene之上。简单来说,ElasticSearch就是一个能让你以极快速度进行数据搜索、存储和分析的系统。它不仅…...

SHCTF-REVERSE
前言 之前写的,一直没发,留个记录吧,万一哪天记录掉了起码在csdn有个念想 1.ezapk 反编译 快速定位关键函数 package com.mycheck.ezjv;import adrt.ADRTLogCatReader; import android.app.Activity; import android.content.Context; impo…...

C++学习:六个月从基础到就业——模板编程:模板特化
C学习:六个月从基础到就业——模板编程:模板特化 本文是我C学习之旅系列的第三十四篇技术文章,也是第二阶段"C进阶特性"的第十二篇,主要介绍C中的模板特化技术。查看完整系列目录了解更多内容。 目录 引言模板特化基础…...
)
【中级软件设计师】编译和解释程序的翻译阶段、符号表 (附软考真题)
【中级软件设计师】编译和解释程序的翻译阶段、符号表 (附软考真题) 目录 【中级软件设计师】编译和解释程序的翻译阶段、符号表 (附软考真题)一、历年真题二、考点:编译和解释程序的翻译阶段1、解释2、编译3、解释和编译的异同之处4、符号表 三、真题的答案与解析答…...
垃圾回收器与JVM内存)
G1(Garbage-First)垃圾回收器与JVM内存
G1垃圾回收器简介 G1(Garbage-First)是Java虚拟机(JVM)中的一种垃圾回收器,它是针对服务器端应用设计的,旨在提供高吞吐量和低延迟的垃圾回收性能。G1垃圾回收器的主要目标是高效地管理JVM的堆内存,同时尽量减少垃圾回收(GC)过程对应用程序性能的影响。 特点 分区回收…...

STM32 驱动 INA226 测量电流电压功率
文章目录 一、INA226简介二、引脚功能三、寄存器介绍1.配置寄存器 0x002.分流电压寄存器 0x013.总线电压寄存器 0x024.功率寄存器 0x035.电流寄存器 0x046.基准寄存器 0x05 四、IIC 时序说明1.写时序2.读时序 五、程序六、实验现象1.线路图2.输出数据 一、INA226简介 INA226 是…...

解决新搭建的centos虚拟器,yum下载不了的问题
1. 检查网络连接 确保虚拟机可以访问互联网: ping 8.8.8.8 # 测试基础网络连通性若不通: 检查网卡 IP 配置(参考之前的 IP 恢复步骤)。 确认虚拟机网络模式(如 NAT 或桥接模式)是否允许访问外网。 检查网…...

python连接Elasticsearch并完成增删改查
python库提供了elasticsearch模块,可以通过以下命令进行快速安装,但是有个细节需要注意一下,安装的模块版本要跟es软件版本一致,此处举例:7.8.1 pip install elasticsearch==7.8.1 首先连接elasticsearch,以下是免密示例 from elasticsearch import Elasticsearch# El…...
Python数据存储实战:CSV文件读写与复杂数据处理指南)
Python爬虫(7)Python数据存储实战:CSV文件读写与复杂数据处理指南
目录 一、背景与核心价值二、CSV基础与核心应用场景2.1 CSV文件结构解析2.2 适用场景 三、Python csv模块核心操作3.1 安装与基础读写3.2 高级功能:字典读写与自定义格式 四、处理复杂数据场景4.1 含特殊字符的字段4.2 嵌套数据(如JSO…...

Spring Boot 中的条件注解
Spring Boot条件注解的汇总: 注解作用判断依据使用场景ConditionalOnBean容器中存在指定Bean时,被注解的配置或Bean定义生效指定Bean在容器中存在依赖其他已存在Bean时配置相关功能ConditionalOnCheckpointRestore在特定检查点恢复相关条件满足时生效满…...

Java 字符串分解技术:substring、tokenizing 和 trimming 方法详解
关键点 Java 字符串处理是开发中不可或缺的一部分,广泛用于数据解析和格式化。substring() 方法能够精确提取字符串的子串,需注意索引范围以避免异常。String.split() 是分词的首选方法,支持正则表达式,灵活性高。trim() 和 stri…...

OpenCV进阶操作:图像金字塔
文章目录 前言一、图像金字塔1、什么是图像金字塔2、金字塔类型1) 高斯金字塔 (Gaussian Pyramid)2)拉普拉斯金字塔 (Laplacian Pyramid) 3、图像金字塔的作用 二、图像金字塔中的操作1、向下采样步骤 2、向上采样步骤 3、拉普拉斯金字塔4、结论 三、代码…...

Rust游戏开发全栈指南:从理论到实践的革新之路
一、Rust游戏开发生态全景 1.1 核心引擎框架 Rust游戏生态已形成多层级工具链,覆盖从轻量级2D到3A级项目的开发需求: Bevy:采用ECS架构的模块化引擎,提供优雅的API设计和活跃社区支持,支持实时热重载和跨平台部署Fy…...

[GXYCTF2019]Ping Ping Ping
解题步骤 1、先使用 内敛执行 查看当前的php文件 执行 命令执行 发现空格被过滤 ?ip127.0.0.1$IFS|$IFSwhomi 还有一个点就是这个 执行的命令是不能进行拼接的 可能就是被过滤了 | 所以我们使用 ; 进行绕过一下 空格过滤代替 $IFS ${IFS} ${IFS}$9 //这里$1到$9都可以 $IFS$1…...

马哥教育Linux云计算运维课程
课程大小:19.1G 课程下载:https://download.csdn.net/download/m0_66047725/90640128 更多资源下载:关注我 你是否找了很多资料看了很多视频聊了很多群友,却发现自己技术仍然原地踏步?本教程联合BAT一线导师倾囊相授…...

科技打头阵,创新赢未来——中科视界携千眼狼超高速摄像机亮相第三届科交会
2025年4月26日,合肥,第三届中国(安徽)科技创新成果转化交易会国际合作板块展区,中科视界及其旗下品牌“千眼狼”高速摄像机成为展会焦点。作为国内科学仪器的领军企业,中科视界以“科技打头阵,创…...

【Flutter】Unity 三端封装方案:Android / iOS / Web
关联文档:【方案分享】Flutter Unity 跨平台三维渲染架构设计全解:插件封装、通信机制与热更新机制—— 支持 Android/iOS/Web 的 3D 内容嵌入与远程资源管理,助力 XR 项目落地 —— 支持 Android/iOS/Web 的 3D 内容嵌入与远程资源管理&…...

高能效计算:破解算力增长与能源约束的科技密码
引言 在人工智能和大模型技术迅猛发展的今天,全球算力需求正以每年50%的速度激增[3]。然而,传统计算范式已逼近物理极限——国际能源署预测,到2030年数据中心的全球电力消耗占比可能突破3%[3]。面对这场"算力革命"与"能源危机…...
的工程系统进化法则)
【质量管理】TRIZ(萃智)的工程系统进化法则
在文章【质量管理】现代TRIZ(萃智)理论概述-CSDN博客 我们谈到到现代TRIZ的理论、TRIZ与传统创新的差异等。在文章中我们有说到TRIZ的创始人阿奇舒勒发现其实技术的进化是有规律可循的。 那到底技术进步有什么规律呢? 技术进化发展趋势和路径…...

FastAPI系列07:“请求-响应”过程高阶技巧
“请求-响应”过程高阶技巧 1、自定义 Request自定义 Request的用途如何自定义 Request 2、自定义APIRouteAPIRoute的用途自定义 APIRoute的用途如何自定义 APIRoute 3、使用BackgroundTasks(后台任务)BackgroundTasks的用途如何使用BackgroundTasksBack…...

游戏服务器不加防护能活多久?
游戏服务器若不加防护,其存活时间受多种因素影响,但通常面临极高的安全风险,可能在数小时至数天内因攻击或漏洞利用而崩溃。以下是具体分析: 1. DDoS攻击与勒索风险 未加防护的服务器极易成为黑客攻击目标,尤其是DDoS…...

Embedding入门概述
概述 Embedding,嵌入,一种将离散的符号数据(如单词、句子、图像等)映射到连续的向量空间中的技术,这些向量能够捕捉数据之间的语义、结构等关系。就是把原本难以直接处理的符号数据,转换成计算机更容易理解…...

革新桌面自动化:微软UFO²操作系统深度解析与未来展望
一、系统架构:多智能体协同的OS级创新 微软UFO(Unified Framework for Operations)是首个深度集成于Windows底层的多智能体操作系统,其核心架构由HostAgent控制中枢与模块化AppAgent执行单元构成。 HostAgent作为系统级调度器…...

【Java】分布式事务解决方案
分布式事务是指在分布式系统中,为了保证多个节点上的操作要么全部成功提交,要么全部失败回滚,所采取的一系列技术手段和协议。 CAP理论 在一个分布式系统中以下三个基本属性无法被同时满足: C(一致性):一致性是指写…...

es数据导出
有大数据量导出的需求 整体思路:分页查询es,一页查询2000条,下一页查询的截止时间取上一页最后一条记录的创建时间(因为分页是按照创建时间逆序排列的),组装最后导出的list,利用EasyExcel导出到…...
)
chrony服务器(2)
安装与配置 [rootserver ~]# systemctl status ntp # 查看ntp状态 安装 # 默认已安装,若需要安装则可执行: [rootserver ~]# yum install chrony -y [rootserver ~]# systemctl start chronyd [rootserver ~]# systemctl enable chronyd Chrony配置文…...

C++入门小馆: STL 之queue和stack
嘿,各位技术潮人!好久不见甚是想念。生活就像一场奇妙冒险,而编程就是那把超酷的万能钥匙。此刻,阳光洒在键盘上,灵感在指尖跳跃,让我们抛开一切束缚,给平淡日子加点料,注入满满的pa…...

从零搭建云原生后端系统 —— 一次真实项目实践分享
一、引言:为什么选择云原生技术打造后端? 在当今数字化加速的时代,业务需求变化频繁,应用需要快速开发、快速上线、快速迭代。传统单体应用后端架构在灵活性、扩展性和稳定性方面越来越难以满足需求。 而云原生(Clou…...

东田数码科技前端面经
东田数码科技有限公司前端面经 一个月三次面试,也是逐渐积攒了许多经验,也有遇到面试官问到的重复的问题,也有一些我不懂的问题,以下是4.27东田前端面经,希望给大家做参考。 1-自我介绍 我是ac鸽,就读与…...

【音视频】SDL窗口显示
SDL视频显示函数简介 SDL_Init(): 初始化SDL系统SDL_CreateWindow():创建窗口SDL_WindowSDL_CreateRenderer():创建渲染器SDL_RendererSDL_CreateTexture():创建纹理SDL_TextureSDL_UpdateTexture(): 设置纹理的数据S…...

小球在摆线上下落的物理过程MATLAB代码
物理建模: 使用摆线参数方程定义轨迹:x r(θ - sinθ), y r(1 - cosθ)通过微分方程求解角度θ随时间变化关系,考虑能量守恒定律计算实时速度分量和切向加速度 可视化特性: 灰色虚线显示完整摆线轨迹红色小球实时显示当…...

【设计模式】享元模式
享元模式属于结构型设计模式 核心思想是通过共享技术,实现相似对象的高效复用。用 1%的资源支撑100%的需求——通过对象状态的分离与共享,用最小内存支持海量对象 内部状态:对象中不变的部分共享 外部状态:对象中变化的部分非共享…...

R中实现数值求导的包numDeriv
介绍 numDeriv 是一个用于数值求导的 R 包,它提供了计算函数导数的简单方法,支持一阶导数和高阶导数的计算。 计算一阶导数 grad(func, x, method"Richardson", sideNULL, eps1e-4, method.argslist(), ...) 参数: func&#x…...

常用的多传感器数据融合方法
1. 概述 根据具体需求(实时性、计算资源、噪声特性)选择合适的方法,实际应用中常结合多种方法(如UKF与神经网络结合)。 传统方法 (KF/EKF/UKF/PF)依赖数学模型,适合动态系统&#…...

[Lc_week] 447 | 155 | Q1 | hash | pair {}调用
447_Q1 题解 class Solution {typedef pair<int,int> PII;// 自定义哈希函数struct HashPII {size_t operator()(const PII& p) const {return hash<int>()(p.first) ^ (hash<int>()(p.second) << 1);}};public:int countCoveredBuildings(int n,…...