深度学习之卷积神经网络入门
一、引言
在深度学习蓬勃发展的今天,卷积神经网络(Convolutional Neural Network,简称 CNN)凭借其在图像识别、计算机视觉等领域的卓越表现,成为了人工智能领域的核心技术之一。从手写数字识别到复杂的医学影像分析,从自动驾驶中的目标检测到智能安防的人脸识别,CNN 无处不在,深刻改变着我们的生活与工作方式。本文将深入剖析 CNN 的原理、结构组成,并通过实际案例展示其强大的应用能力。
二、原理
1、CNN 的核心思想是利用卷积运算来提取图像的特征。与传统的全连接神经网络不同,CNN 通过卷积层、池化层和激活函数等组件,能够自动学习图像中的局部特征和空间层次结构,从而更有效地处理图像数据。
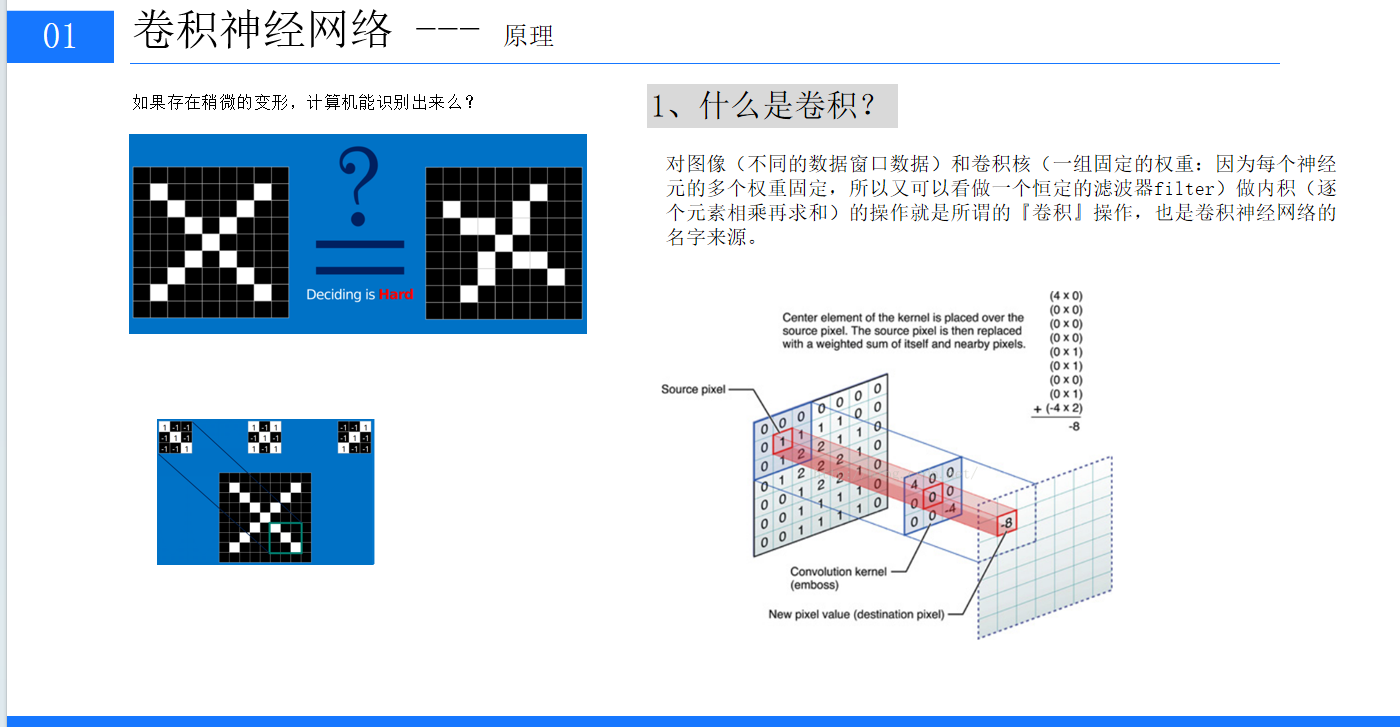
2、卷积层是 CNN 的核心组成部分,负责对输入图像进行特征提取。它通过卷积核与输入图像进行卷积运算,将图像与卷积核对应位置的元素相乘并求和,得到卷积结果。例如,一个 3×3 的卷积核在 6×6 的图像上进行步长为 1 的卷积操作,会生成一个 4×4 的特征图。卷积层中的参数主要包括卷积核的数量、大小、步长和填充方式,这些参数的设置会直接影响特征图的尺寸和提取到的特征类型。

3、激活函数层:为了引入非线性因素,使网络能够学习到复杂的函数关系,在卷积层之后通常会连接激活函数层。常见的激活函数有 ReLU(Rectified Linear Unit)、Sigmoid、Tanh 等。以 ReLU 函数为例,其公式为 f (x) = max (0, x),它能够有效缓解梯度消失问题,加快网络的训练速度,并且计算简单,在现代 CNN 模型中被广泛应用。
4、池化层:池化层的主要作用是对特征图进行下采样,降低数据的维度,减少计算量,同时还能增强模型的鲁棒性。常见的池化操作有最大池化(Max Pooling)和平均池化(Average Pooling)。最大池化会选取池化窗口内的最大值作为输出,能够保留最显著的特征;平均池化则计算池化窗口内的平均值,对特征进行平滑处理。例如,在一个 2×2 的最大池化窗口下,4×4 的特征图会被下采样为 2×2 的特征图。

5、全连接层:经过多层卷积和池化操作后,网络提取到的特征被展平并输入到全连接层。全连接层中的每个神经元都与上一层的所有神经元相连,它将提取到的特征进行整合,并通过激活函数进行非线性变换,最终输出分类结果或回归值。在图像分类任务中,全连接层的输出节点数量通常等于类别数,例如在 MNIST 手写数字识别任务中,全连接层的输出节点数为 10,分别对应 0 - 9 这 10 个数字类别。
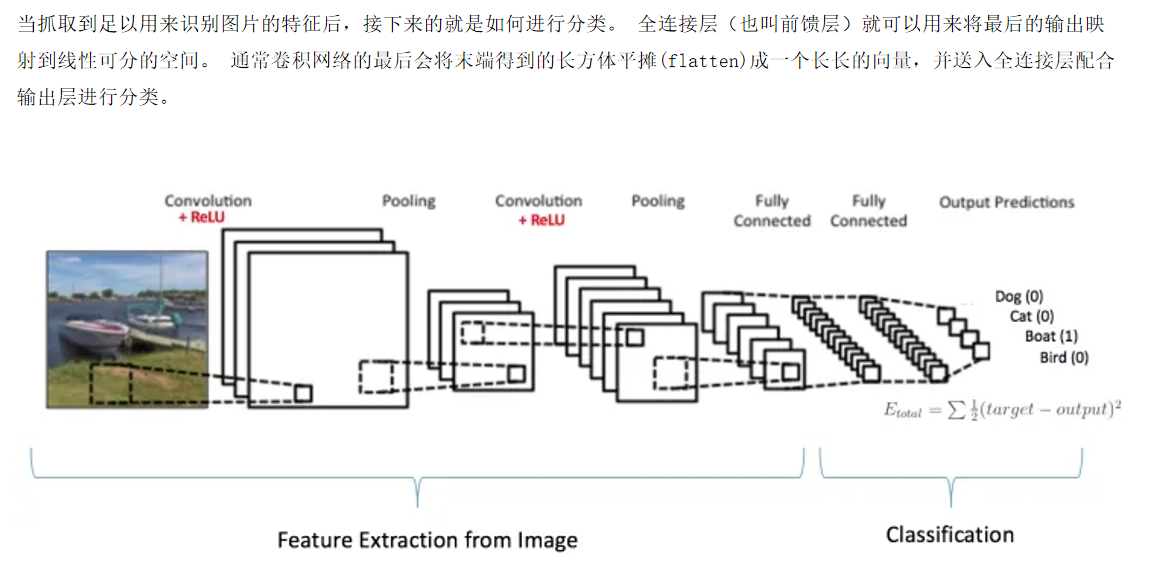
6、输出层:输出层根据具体的任务类型进行设计。在分类任务中,通常使用 Softmax 函数作为激活函数,将全连接层的输出转换为每个类别的概率分布,概率最大的类别即为预测结果;在回归任务中,输出层直接输出连续的数值
三、案例实现
1、环境准备与数据加载
在开始之前,我们需要安装 PyTorch 和 torchvision。PyTorch 是一个强大的深度学习框架,而 torchvision 提供了许多与图像相关的数据集和工具。
import torch
from torch import nn #导入神经网络模块,
from torch.utils.data import DataLoader #数据包管理工具,打包数据,
from torchvision import datasets #封装了很多与图像相关的模型,数据集
from torchvision.transforms import ToTensor #数据转换,张量,将其他类型的数据转换为tensor张量2、下载MNIST数据集
'''下载训练数据集(包含训练图片+标签)'''
training_data=datasets.MNIST(root='data', #表示下载的手写数字 到哪个路径。60000train=True, #读取下载后的数据 中的 训练集download=True, #如果你之前已经下载过了,就不用再下载transform=ToTensor(), #张量,图片是不能直接传入神经网络模型
) #对于pytorch库能够识别的数据一般是tensor张量。'''下载测试数据集(包含训练图片+标签)'''
test_data=datasets.MNIST(root='data', #表示下载的手写数字 到哪个路径。60000train=False, #读取下载后的数据中的训练集download=True, #如果你之前已经下载过了,就不用再下载transform=ToTensor(), #Tensor是在深度学习中提出并广泛应用的数据类型
) #NumPy数组只能在CPU上运行。Tensor可以在GPU上运行,这在深度学习应用中可以显著提高计算速度
print(len(training_data))
3、数据可视化
'''展示手写字图片,把训练数据集中的前59000张图片展示一下'''
from matplotlib import pyplot as plt
figure = plt.figure()
for i in range(9):img,label=training_data[i+59000]#提取第59000张图片figure.add_subplot(3,3,i+1)#图像窗口中创建多个小窗口,小窗口用于显示图片plt.title(label)plt.axis("off") # plt.show(I)#是示矢量,plt.imshow(img.squeeze(),cmap="gray") #plt.imshow()将Numpy数组data中的数据显示为图像,并在图形窗口中显贡a = img.squeeze()# img.squeeze()从张量img中去掉维度为1的。如果该维度的大小不为1则张量不会改变。#cmap="gray
plt.show()4、创建数据加载器和配置设备
"""创建数据DataLoader(数据加载器)
batch_size:将数据集分成多份,每一份为batch_size个数据
优点:可以减少内存的使用,提高训练速度。"""train_dataloader=DataLoader(training_data,batch_size=64)
test_dataloader=DataLoader(test_data,batch_size=64)for X, y in test_dataloader:#X时打包的的每一个数据包print("Shape of X [N, C, H, W]: {X.shape}")print(f"shape of y: {y.shape} {y.dtype}")break'''断当前设备是否支持GPU,其中mps是苹果m系列芯片的GPU。'''
device = "cuda" if torch.cuda.is_available() else "mps" if torch.backends.mps.is_available() else "cpu"
print(f"Using {device} device") #字符串的格式化
5、搭建神经网络模型
'''定义神经网络 类的继承'''
class CNN(nn.Module):#类的名称def __init__ (self): #python基础关于类,self类自已本身super(CNN,self).__init__() #继承的父类初始化self.conv1 = nn.Sequential( #将多个层组合成一起,创建了一个容器,将多个网络合在一起nn.Conv2d( #2d一般用于图像,3d用于视频数据(多一个时间维度),1d一般用于结构化的序列数据in_channels=1, #图像通道个数,1表示灰度图(确定了卷积核 组中的个数)out_channels=16, # 要得到多少个特征图,卷积核的个数kernel_size=5, # 卷积核大小,5*5stride=1, # 步长padding=2, #一般希望卷积核处理后的结果大小与处理前的数据大小相同,效果会比较好。那padding改如何), # 输出的特征图为(16,28,28)nn.ReLU(), # 激活函数,relu层,不会改变特征图的大小(16,28,28)nn.MaxPool2d(kernel_size=2), #池化层,进行池化操作(2x2 区域),输出结果为:(16,14,14))self.conv2 = nn.Sequential( #输入(16, 14, 14)nn.Conv2d(16,32,5,1,2), # 输出(32,14,14)nn.ReLU(), # (32*14*14)#nn.Conv2d(32, 32, 5, 1, 2), # 输出(32,14,14)nn.ReLU(), #(32 14 14)nn.MaxPool2d(2), #输出(32,7,7))self.conv3 = nn.Sequential( #输入(32 7 7)nn.Conv2d(32,64,5,1,2), #(64,7,7)nn.ReLU(),)self.out=nn.Linear(64*7*6,10) #全连接层得到的结果def forward(self,x): #这里必须要写 forward是来自于父类nn里面的函数 要继承父类的功能x=self.conv1(x)x=self.conv2(x)x=self.conv3(x) #输出(64,64,7,7)x=x.view(x.size(0),-1)#把x的数据变成2维的output=self.out(x)return outputmodel = CNN().to(device)#类的初始化完成,就会创建一个对象,model
print(model)
定义了一个继承自nn.Module的CNN类,用于构建卷积神经网络模型。模型包含多个卷积层、激活函数层和池化层:
conv1层:首先通过nn.Conv2d进行卷积操作,将输入的 1 通道图像转换为 16 个特征图;然后使用nn.ReLU激活函数引入非线性;最后通过nn.MaxPool2d进行最大池化操作,降低数据维度。
conv2层:包含两个卷积层和激活函数层,进一步提取图像特征,并通过池化操作降低维度。
conv3层:进行卷积和激活操作,继续提取更高级的特征。
out层:全连接层,将卷积层输出的特征图展平后映射到 10 个类别(对应 0 - 9 这 10 个数字)。
.forward方法定义了数据在模型中的前向传播过程,确保数据按照正确的顺序通过各个层。
6、模型训练与测试
def train(dataloader,model,loss_fn,optimizer):model.train() #告诉模型,现在要进入训练模式,模型中w进行随机化操作,已经更新w。在训练过程中,w会被修改的
#pytorch提供2种方式来切换训练和测试的模式,分别是:model.train()和 model.eval()。
#一般用法是:在训练开始之前写上model.trian(),在测试时写上 model.eval()batch_size_num=1for X,y in dataloader: #其中batch为每一个数据的编号X,y=X.to(device),y.to(device) #把训练数据集和标签传入cpu或GPUpred=model.forward(X) #.forward可以被省略,父类中已经对次功能进行了设置。自动初始化loss=loss_fn(pred,y) #通过交叉熵损失函数计算损失值loss# Backpropagation 进来一个batch的数据,计算一次梯度,更新一次网络optimizer.zero_grad() #梯度值清零loss.backward() #反向传播计算得到每个参数的梯度值woptimizer.step() #根据梯度更新网络w参数loss_value=loss.item() #从tensor数据中提取数据出来,tensor获取损失值if batch_size_num %100 ==0:print(f'loss:{loss_value:>7f} [number:{batch_size_num}]')batch_size_num+=1def test(dataloader,model,loss_fn):size=len(dataloader.dataset)num_batches=len(dataloader) #打包的数量model.eval() #测试,w就不能再更新。test_loss,correct=0,0with torch.no_grad(): #一个上下文管理器,关闭梯度计算。当你确认不会调用Tensor.backward()的时候。for X,y in dataloader:X,y=X.to(device),y.to(device)pred=model.forward(X)test_loss+=loss_fn(pred,y).item() #test_loss是会自动累加每一个批次的损失值correct+=(pred.argmax(1)==y).type(torch.float).sum().item()a=(pred.argmax(1)==y) #dim=1表示每一行中的最大值对应的索引号,dim=0表示每一列中的最大值b=(pred.argmax(1)==y).type(torch.float)test_loss /=num_batchescorrect /=sizeprint(f'Test result: \n Accuracy: {(100*correct)}%, Avg loss: {test_loss}')7、定义损失函数和优化器
loss_fn=nn.CrossEntropyLoss() #创建交叉熵损失函数对象,因为手写字识别中一共有10个数字,输出会有10个结果
optimizer=torch.optim.Adam(model.parameters(),lr=0.01) #创建一个优化器
# #params:要训练的参数,一般我们传入的都是model.parameters()
# lr:learning_rate学习率,也就是步长nn.CrossEntropyLoss是交叉熵损失函数,适用于多分类任务,用于计算模型预测结果与真实标签之间的差距。torch.optim.Adam是一种常用的优化器,用于更新模型的参数,以最小化损失函数。lr=0.01设置学习率,控制参数更新的步长。
6、模型训练与测试流程
epoch=9
for i in range(epoch):print(i+1)train(train_dataloader, model, loss_fn, optimizer)test(test_dataloader,model,loss_fn)通过循环进行多个 epoch 的训练,每个 epoch 都会调用train函数对模型进行训练,训练完成后调用test函数对模型在测试集上的性能进行评估。随着训练的进行,可以观察到损失值逐渐降低,准确率逐渐提高,最终得到一个在 MNIST 数据集上表现良好的手写数字识别模型。
四、总结
本文详细介绍了利用 PyTorch 构建卷积神经网络实现 MNIST 手写数字识别的全过程。从数据集的准备、模型的构建,到训练和测试的各个环节,都进行了深入的代码解析和原理讲解。通过实践,我们可以看到卷积神经网络在图像识别任务中的强大能力,同时也掌握了 PyTorch 框架的基本使用方法。希望本文能够帮助读者更好地理解和应用卷积神经网络,在深度学习领域不断探索前进。
相关文章:

深度学习之卷积神经网络入门
一、引言 在深度学习蓬勃发展的今天,卷积神经网络(Convolutional Neural Network,简称 CNN)凭借其在图像识别、计算机视觉等领域的卓越表现,成为了人工智能领域的核心技术之一。从手写数字识别到复杂的医学影像分析&a…...

【kafka初学】启动执行命令
接上篇,启动:开两个cdm窗口 注意放的文件不要太深或者中文,会报命令行太长的错误 启动zookeeper bin\windows\zookeeper-server-start.bat config\zookeeper.properties2. 启动kafka-serve bin\windows\kafka-server-start.bat config\serv…...

MoE架构解析:如何用“分治”思想打造高效大模型?
在人工智能领域,模型规模的扩大似乎永无止境。从GPT-3的1750亿参数到传闻中的GPT-4万亿级规模,每一次突破都伴随着惊人的算力消耗。但当我们为这些成就欢呼时,一个根本性问题愈发尖锐:如何在提升模型能力的同时控制计算成本&#…...

【Qt】文件
🌈 个人主页:Zfox_ 🔥 系列专栏:Qt 目录 一:🔥 Qt 文件概述 二:🔥 输入输出设备类 三:🔥 文件读写类 四:🔥 文件和目录信息类 五&…...

Linux常见故障:排查思路与错误分析指南
引言 当Linux系统"生病"时,它不会说话但却会通过各种症状"求救"🆘!本文将带你建立系统化的故障排查思维,从磁盘到内存,从网络到服务,全方位掌握Linux系统的"把脉问诊"技巧。…...
优化BP神经网络,附完整完整代码)
基于随机变量的自适应螺旋飞行麻雀搜索算法(ASFSSA)优化BP神经网络,附完整完整代码
3. 麻雀搜索算法 麻雀群体分为两个角色,即发现者和跟随者。它们有三个行为:觅食、跟随和侦察。发现者的任务是寻找食物并告知跟随者食物的位置。因此,发现者需要在一个大范围内搜索,而跟随者的觅食范围通常较小。这是更新发现者位…...

vscode切换Python环境
跑深度学习项目通常需要切换python环境,下面介绍如何在vscode切换python环境: 1.点击vscode界面左上角 2.在弹出框选择对应kernel...

Gradle安装与配置国内镜像源指南
一、Gradle简介与安装准备 Gradle是一款基于JVM的现代化构建工具,广泛应用于Java、Kotlin、Android等项目的构建自动化。相比传统的Maven和Ant,Gradle采用Groovy或Kotlin DSL作为构建脚本语言,具有配置灵活、性能优越等特点。 在开始安装前…...

施工配电箱巡检二维码应用
在过去,施工配电箱的巡检主要依赖于纸质记录方式。巡检人员每次巡检时,都要在纸质表格上详细填写配电箱的各项参数、运行状况以及巡检时间等信息。这种方式在实际操作中暴露出诸多严重问题,信息易出现错误、数据会有造假现象、数据量庞大整理…...

全链路自动化AIGC内容工厂:构建企业级智能内容生产系统
一、工业化AIGC系统架构 1.1 生产流程设计 [需求输入] → [创意生成] → [多模态生产] → [质量审核] → [多平台分发] ↑ ↓ ↑ [用户反馈] ← [效果分析] ← [数据埋点] ← [内容投放] 1.2 技术指标要求 指标 标准值 实现方案 单日产能 1,000,000 分布式推理集群 内容合规率…...

第19章:Multi-Agent多智能体系统介绍
第19章:Multi-Agent多智能体系统介绍 欢迎来到多智能体系统 (Multi-Agent System, MAS) 的世界!在之前的章节中,我们深入探讨了单个 AI Agent 的构建,特别是结合了记忆、上下文和规划能力的 MCP 框架。然而,现实世界中的许多复杂问题往往需要多个智能体协同工作才能有效解…...
)
【C++游戏引擎开发】第25篇:方差阴影贴图(VSM,Variance Shadow Maps)
一、VSM 的核心思想 1.1 VSM 的核心思想 1.1.2 从深度到概率的转变 VSM 的核心创新在于将阴影判定从深度比较转换为概率估算。通过存储深度分布的统计信息(均值和方差),利用概率不等式动态计算阴影强度,从而支持软阴影并减少锯齿。 1.1.3 深度分布的统计表示 VSM 在阴…...
)
代码随想录打卡|Day27(合并区间、单调递增的数字、监控二叉树)
贪心算法 Part05 合并区间 力扣题目链接 代码随想录链接 视频讲解链接 题目描述: 以数组 intervals 表示若干个区间的集合,其中单个区间为 intervals[i] [starti, endi] 。请你合并所有重叠的区间,并返回 一个不重叠的区间数组࿰…...

yum包管理器
1.介绍 yum是一个shell前端软件包管理器,基于RPM包管理,能够从指定的服务器.自动下载RPM包并且安装,可以自动处理依赖关系,并且一次安装所有依赖的安装包。 2.yum基本指令 查询yum服务器是否有需要安装的软件: yum list I grep xx软件列表. 安装指定的yum包&…...

Linux多线程技术
什么是线程 在一个程序里的多执行路线就是线程。线程是进程中的最小执行单元,可理解为 “进程内的一条执行流水线”。 进程和线程的区别 进程是资源分配的基本单位,线程是CPU调度的基本单位。 fork创建出一个新的进程,会创建出一个新的拷贝&…...
)
通过模仿学习实现机器人灵巧操作:综述(上)
25年4月来自天津大学、山东大学、瑞士ETH、南方科技大学、通用 AI 国家重点实验室、爱丁堡大学和中科院自动化所的论文“Dexterous Manipulation through Imitation Learning: A Survey”。 灵巧操作是指机械手或多指末端执行器通过精确、协调的手指运动和自适应力调制&#x…...

LLM数学推导——Transformer问题集——注意力机制——稀疏/高效注意力
Q13 局部窗口注意力的内存占用公式推导(窗口大小 ) 局部窗口注意力:解决长序列内存困境的利器 在注意力机制中,全局注意力需要计算序列中每个元素与其他所有元素的关联,当序列长度 N 较大时,权重矩阵的内…...

Git 入门知识详解
文章目录 一、Git 是什么1、Git 简介2、Git 的诞生3、集中式 vs 分布式3.1 集中式版本控制系统3.2 分布式版本控制系统 二、GitHub 与 Git 安装1、GitHub2、Git 安装 一、Git 是什么 1、Git 简介 Git 是目前世界上最先进的分布式版本控制系统。版本控制系统能帮助我们更好地管…...

系统架构师2025年论文《论软件架构评估》
论软件架构评估 摘要: 我所在的单位是国内某知名医院,2017 年 1 月医院决定开发全新一代某市医院预约挂号系统,我担任本次系统的架构师,主要负责整个系统的架构设计工作。该系统旨在优化医院挂号流程,提高患者就医体验,是医院应对医疗信息化变革和提升服务的重要举措。…...

基于51单片机的超声波液位测量与控制系统
基于51单片机液位控制器 (仿真+程序+原理图PCB+设计报告) 功能介绍 具体功能: 1.使用HC-SR04测量液位,LCD1602显示; 2.当水位高于设定上限的时候,对应声光报警报警&…...

抓包工具Wireshark的应用解析
一、Wireshark简介 Wireshark(前身为Ethereal)是一款开源、跨平台的网络协议分析工具,自1998年诞生以来,已成为网络工程师、安全专家及开发者的核心工具之一。它通过网卡的混杂模式(Promiscuous Mode)捕获…...

在 Java 项目中搭建和部署 Docker 的详细流程
引言 在现代软件开发中,Docker 已成为一种流行的工具,用于简化应用的部署和运行环境的一致性。本文将详细介绍如何在 Java 项目中搭建和部署 Docker,包括配置文件、代码示例以及流程图。 一、整体工作流程 以下是整个流程的概览:…...

15.ArkUI Checkbox的介绍和使用
以下是 ArkUI Checkbox 组件的详细介绍和使用指南: 一、Checkbox 基础介绍 功能特性: 提供二态选择(选中/未选中)支持自定义样式和标签布局支持与数据状态绑定提供状态变化事件回调 适用场景: 表单中的多选操作设置…...

WebUI可视化:第5章:WebUI高级功能开发
学习目标 ✅ 掌握复杂交互逻辑的实现 ✅ 学会自定义界面样式与布局 ✅ 实现安全高效的文件处理 ✅ 优化性能与用户体验 5.1 自定义样式开发 5.1.1 修改主题颜色(以Streamlit为例) 在应用入口处添加全局样式: python import streamlit as st # 自定义主题 st.markdown…...

增加首屏图片
增加首屏图片(bg.jpg) web-mobile类型打包 //index.html脚本 <div id"myDiv_1111"style"background: url(./bg.jpg) 50% 50%/ 100% auto no-repeat ; width:100%;height:100%;position:absolute;"></div> //游戏内脚本…...

联合体和枚举类型
1.联合体类型 1.1:联合体类型变量的创建 与结构体类型一样,联合体类型 (关键字:union) 也是由⼀个或者多个成员变量构成,这些成员变量既可以是不同的类型,也可以是相同的类型。但是编译器只为最⼤的成员变量分配⾜够的内存空间。联合体的特…...

《AI大模型趣味实战》构建基于Flask和Ollama的AI助手聊天网站:分布式架构与ngrok内网穿透实现
构建基于Flask和Ollama的AI助手聊天网站:分布式架构与ngrok内网穿透实现 引言 随着AI技术的快速发展,构建自己的AI助手聊天网站变得越来越流行。本研究报告将详细介绍如何通过两台电脑构建一个完整的AI聊天系统,其中一台作为WEB服务器运行F…...
-超详细)
kubernets集群的安装-node节点安装-(简单可用)-超详细
一、kubernetes 1、简介 kubernetes,简称K8s(库伯内特),是用8代替名字中间的8个字符“ubernete”而成的缩写 云计算的三种主要服务模式——基础设施即服务(IaaS)、平台即服务(PaaS࿰…...

【Linux内核设计与实现】第三章——进程管理04
文章目录 8. exit() 进程退出8.1. exit() 系统调用的定义8.2. do_exit() 函数8.2.0. do_exit() 的参数和返回值8.2.1. 检查和同步线程组退出8.2.2. 清理与调试相关的资源8.2.3. 取消 I/O 和信号处理8.2.4. 检查线程组是否已终止8.2.5. 释放系统资源8.2.6. 释放线程和调度相关资…...

Golang | 迭代器模式
迭代器模式(Iterator Pattern)是一种行为型设计模式,它提供了一种顺序访问聚合对象(如列表、树等集合结构)中元素的方法,而无需暴露其底层实现细节。通过将遍历逻辑与集合本身解耦,迭代器模式使…...

美颜SDK动态贴纸实战教程:从选型、开发到上线的完整流程
在直播、短视频、社交娱乐全面崛起的当下,美颜SDK早已不再局限于“磨皮瘦脸”,而是逐步迈向更智能、更富互动体验的方向发展。动态贴纸功能,作为提升用户参与感和内容趣味性的关键手段,正在被越来越多的平台采纳并深度定制。本文将…...

ArkTS中的空安全:全面解析与实践
# ArkTS中的空安全:全面解析与实践 在ArkTS编程领域,空安全是一个极为关键的特性,它在很大程度上影响着代码的稳定性和可靠性。今天,我们就深入探究一下ArkTS中的空安全机制,看看它是如何保障我们的代码质量的。 ## A…...

C语言基础语法详解:从入门到掌握
C 基础语法 C 语言是一种通用的编程语言,广泛应用于系统编程、嵌入式开发和高性能计算等领域。 C 语言具有高效、灵活、可移植性强等特点,是许多其他编程语言的基础。 在 C 语言中,令牌(Token)是程序的基本组成单位…...

如何把两个视频合并成一个视频?无需视频编辑器即可搞定视频合并
在日常生活中,我们经常需要将多个视频片段合并成一个完整的视频,例如制作旅行记录、剪辑教学视频或拼接短视频素材。简鹿视频格式转换器是一款功能强大的工具,不仅可以进行视频格式转换,还支持视频合并功能。以下是使用简鹿视频格…...

Servlet小结
视频链接:黑马servlet视频全套视频教程,快速入门servlet原理servlet实战 什么是Servlet? 菜鸟教程:Java Servlet servlet: server applet Servlet是一个运行在Web服务器(如Tomcat、Jetty)或应用…...

C语言面试高频题——define 和typedef 的区别?
1. 基本概念 (1) #define 定义:#define 是预处理指令,用于定义宏。作用:在编译之前进行文本替换。语法:#define 宏名 替换内容示例:#define PI 3.14159 #define SQUARE(x) ((x) * (x))(2) typedef 定义:…...

计算机组成原理:指令系统
计算机组成原理:指令集系统 指令集体系结构(ISA)ISA定义ISA包含的内容举个栗子指令的基本组成(操作码+地址码)指令分类:地址码的个数定长操作码变长操作码变长操作码的原则变长操作码的设计指令寻址寻址方式的目的寻址方式分类有效地址直接在指令中给出有效地址间接给出有效地…...

自动清空 maven 项目临时文件,vue 的 node_modules 文件
echo off setlocal enabledelayedexpansion :: vue 的 node_modules 太大 :: maven 打包后的 target 文件也很大, :: 有些项目日志文件也很大,导致磁盘空间不足了, :: 所以写了个脚本,只要配置一下各项目目录, :: 双击…...

服务网格助力云原生后端系统升级:原理、实践与案例剖析
📝个人主页🌹:慌ZHANG-CSDN博客 🌹🌹期待您的关注 🌹🌹 一、引言:微服务的“通信焦虑”与服务网格的出现 云原生架构的兴起推动了微服务的大规模落地,系统拆分为成百上千个小服务,这些服务之间需要频繁通信。然而,通信带来的问题也开始显现: 如何确保服务间…...
)
基于DrissionPage的表情包爬虫实现与解析(含源码)
目录 编辑 一、环境配置与技术选型 1.1 环境要求 1.2 DrissionPage优势 二、爬虫实现代码 三、代码解析 3.1 类结构设计 3.2 目录创建方法 3.3 图片链接获取 3.4 图片下载方法 四、技术升级对比 4.1 代码复杂度对比 4.2 性能测试数据 五、扩展优化建议 5.1 并…...

Spring Cloud Gateway 如何将请求分发到各个服务
前言 在微服务架构中,API 网关(API Gateway)扮演着非常重要的角色。它负责接收客户端请求,并根据预定义的规则将请求路由到对应的后端服务。Spring Cloud Gateway 是 Spring 官方推出的一款高性能网关,支持动态路由、…...

【深度强化学习 DRL 快速实践】Value-based 方法总结
强化学习中的 Value-based 方法总结 在强化学习(Reinforcement Learning, RL)中,Value-based 方法主要是学习一个价值函数(Value Function),然后基于价值函数来决策。常见的 Value-based 方法包括…...

【计算机视觉】CV实战项目 - 基于YOLOv5的人脸检测与关键点定位系统深度解析
基于YOLOv5的人脸检测与关键点定位系统深度解析 1. 技术背景与项目意义传统方案的局限性YOLOv5多任务方案的优势 2. 核心算法原理网络架构改进关键点回归分支损失函数设计 3. 实战指南:从环境搭建到模型应用环境配置数据准备数据格式要求数据目录结构 模型训练配置文…...
)
git版本回退 | 远程仓库的回退 (附实战Demo)
目录 前言1. 基本知识2. Demo3. 彩蛋 前言 🤟 找工作,来万码优才:👉 #小程序://万码优才/r6rqmzDaXpYkJZF 爬虫神器,无代码爬取,就来:bright.cn 本身暂存区有多个文件,但手快了&…...

【KWDB 创作者计划】_深度学习篇---数据获取
文章目录 前言一、公开数据集资源库1. 综合型数据集平台Kaggle Datasets (https://www.kaggle.com/datasets)Google Dataset Search (https://datasetsearch.research.google.com)UCI Machine Learning Repository (https://archive.ics.uci.edu/ml) 2. 计算机视觉专用ImageNet…...

DeepSeek本地部署手册
版本:v1.0 适用对象:零基础开发者 一、部署前准备 1.1 硬件要求 组件最低配置推荐配置说明CPUIntel i5 8代Xeon Gold 6230需支持AVX指令集内存16GB64GB模型越大需求越高GPUNVIDIA GTX 1060 (6GB)RTX 3090 (24GB)需CUDA 11.7+存储50GB可用空间1TB NVMe SSD建议预留2倍模型大小…...

OpenCV中的SIFT特征提取
文章目录 引言一、SIFT算法概述二、OpenCV中的SIFT实现2.1 基本使用2.1.1 导入库2.1.2 图片预处理2.1.3 创建SIFT检测器2.1.4 检测关键点并计算描述符2.1.5 检测关键点并计算描述符并对关键点可视化2.1.6 印关键点和描述符的形状信息 2.2 参数调优 三、SIFT的优缺点分析3.1 优点…...

Kubernetes in action-初相识
初相识Kubernetes 1、构建、运行以及共享镜像1.1 运行镜像1.2 构建镜像1.3 推送镜像 2、Kubernetes初相识2.1 介绍Pod2.2 从构建到运行整体流程2.3 kubectl命令行工具 如有侵权,请联系~ 如有错误,也欢迎批评指正~ 本篇文章大部分是…...
)
九、小白如何用Pygame制作一款跑酷类游戏(添加前进小动物作为动态障碍物)
九、小白如何用Pygame制作一款跑酷类游戏(添加前进小动物作为动态障碍物) 文章目录 九、小白如何用Pygame制作一款跑酷类游戏(添加前进小动物作为动态障碍物)前言一、添加小动物素材1. 在根目录的图片文件夹下新建两个目录分别存放…...

Unity3D IK解算器技术分析
前言 在Unity3D中,逆向运动学(IK Solver)是实现角色动画自然交互的核心技术之一。以下是Unity中常见的IK解算器及其特点的综合分析,结合了原生功能、第三方插件与开源方案的对比: 对惹,这里有一个游戏开发…...