基于随机变量的自适应螺旋飞行麻雀搜索算法(ASFSSA)优化BP神经网络,附完整完整代码
3. 麻雀搜索算法
麻雀群体分为两个角色,即发现者和跟随者。它们有三个行为:觅食、跟随和侦察。发现者的任务是寻找食物并告知跟随者食物的位置。因此,发现者需要在一个大范围内搜索,而跟随者的觅食范围通常较小。这是更新发现者位置的公式:
X i , j t + 1 = { X i , j t ⋅ exp ( − t α ⋅ M ) , 如果 R 2 < S T , X i , j t + Q ⋅ L , 如果 R 2 ≥ S T . (1) X_{i,j}^{t+1} = \left\{ \begin{array}{ll} X_{i,j}^{t} \cdot \exp\left(\frac{-t}{\alpha \cdot M}\right), & \text{如果 } R_2 < ST, \\ X_{i,j}^{t} + Q \cdot L, & \text{如果 } R_2 \geq ST. \end{array} \right.\tag1 Xi,jt+1={Xi,jt⋅exp(α⋅M−t),Xi,jt+Q⋅L,如果 R2<ST,如果 R2≥ST.(1)
在公式(1)中,(t) 和 (M) 分别表示当前迭代次数和最大迭代次数。(X_{i,j}) 表示第 (i) 只麻雀的位置,(j) 是代表维度。在上述公式中,```markdown
R 2 R_2 R2 和 R i R_i Ri 都是从 0 到 1 的随机数(不为零), R 2 R_2 R2 是一个重要的参数,控制个体的飞行行为。 S T ST ST( S T ∈ [ 0.5 , 1 ] ST \in [0.5, 1] ST∈[0.5,1])是一个安全阈值,是衡量发现者位置是否安全的重要参数。 L L L 是一个 1 × D 1 \times D 1×D 矩阵,所有元素均为 1。如果 R 2 < S T R_2 < ST R2<ST,这意味着当前位置暂时安全,周围环境中没有捕食者,发现者可以在大范围内搜索食物。如果 R 2 ≥ S T R_2 \geq ST R2≥ST,这意味着捕食者的踪迹在当前位置被发现,发现者需要此时去其他安全区域进行觅食活动。
跟随者的位置更新如下:
X i , j t + 1 = { Q ⋅ exp ( ∣ X worst t − X i , j t ∣ r 2 ) , 如果 i ≤ n 2 , ∣ X i , j t − X p t ∣ ⋅ A ∗ ⋅ L , 否则 . (2) X_{i,j}^{t+1} = \left\{ \begin{array}{ll} Q \cdot \exp\left(\frac{|X_{\text{worst}}^t - X_{i,j}^t|}{r^2}\right), & \text{如果 } i \leq \frac{n}{2}, \\ |X_{i,j}^t - X_{\text{p}}^t| \cdot A^* \cdot L, & \text{否则}. \end{array} \right.\tag2 Xi,jt+1={Q⋅exp(r2∣Xworstt−Xi,jt∣),∣Xi,jt−Xpt∣⋅A∗⋅L,如果 i≤2n,否则.(2)
在公式 (2) 中, X p t + 1 X_{\text{p}}^{t+1} Xpt+1 指的是发现者在 t + 1 t+1 t+1 次迭代中所占据的最佳位置( t + 1 t+1 t+1 次迭代尚未结束)和 X worst t X_{\text{worst}}^t Xworstt 代表第 t t t 次迭代中群体所占据的最差位置。 A A A 是一个 1 × D 1 \times D 1×D 矩阵,矩阵中的元素随机分配值为 1 或 -1,且 A ∗ = A T ( A A T ) − 1 A^* = A^T(AA^T)^{-1} A∗=AT(AAT)−1。如果 i > n / 2 i > n/2 i>n/2,这意味着当前跟随者是整个群体的一部分并且没有食物。在这种情况下,跟随者需要去其他地方寻找食物。否则,跟随者将跟随发现者的步伐。
当意识到危险时,麻雀群体将表现出反捕食行为:
X i , j t + 1 = { X best t + β ⋅ ∣ X i , j t − X best t ∣ , 如果 f i ≠ f g , X i , j t + K ⋅ ( ∣ X i , j t − X worst t ∣ ( f i − f worst ) + ϵ ) , 如果 f i = f g . (3) X_{i,j}^{t+1} = \left\{ \begin{array}{ll} X_{\text{best}}^t + \beta \cdot |X_{i,j}^t - X_{\text{best}}^t|, & \text{如果 } f_i \neq f_g, \\ X_{i,j}^t + K \cdot \left(\frac{|X_{i,j}^t - X_{\text{worst}}^t|}{(f_i - f_{\text{worst}}) + \epsilon}\right), & \text{如果 } f_i = f_g. \end{array} \right.\tag3 Xi,jt+1={Xbestt+β⋅∣Xi,jt−Xbestt∣,Xi,jt+K⋅((fi−fworst)+ϵ∣Xi,jt−Xworstt∣),如果 fi=fg,如果 fi=fg.(3)
在公式 (3) 中, X best t X_{\text{best}}^t Xbestt 是在第 t t t 次迭代中获得的全局最优解。上述公式中, β \beta β、 K K K 和 ϵ \epsilon ϵ 是公式中的步长参数。 β \beta β 是一个服从标准正态分布的随机数,用于控制步长大小。 K K K 是从 1 到 1 的任意随机数,表示个体麻雀移动的方向, ϵ \epsilon ϵ 也是一个步长参数,是一个相对较小的常数,其功能是防止分母为零。 f i f_i fi 表示第 i i i 个个体的适应度值, f g f_g fg 和 f worst f_{\text{worst}} fworst 分别表示当前迭代中最佳适应度值和最差适应度值。
如果 f i > f g f_i > f_g fi>fg,则表示个体位于种群的边缘,容易被自然敌人捕食。如果 f i = f g f_i = f_g fi=fg,则表示个体位于种群的中心。此时,麻雀需要靠近其他个体以减少被捕食的概率。
4. 基于随机变量的自适应螺旋飞行麻雀搜索算法
4.1 基于随机变量的帐篷混沌映射
由于 SSA 具有大随机性的缩短问题,因此决定引入有序和均匀的帐篷映射来改进它。许多学者已经应用帐篷映射来解决优化问题 [13]。然而,帐篷映射并不十分稳定。为了减少这种影响,基于随机变量的帐篷映射是一种好方法。因此,在本文中,引入基于随机变量的帐篷映射策略来改进 SSA 的初始化,从而提高种群的初始化更加有序,增强算法的可控性。其具体公式如下:
z i + 1 = { 2 z i + rand ( 0 , 1 ) × 1 N , 0 ≤ z i ≤ 1 2 , 2 ( 1 − z i ) + rand ( 0 , 1 ) × 1 N , 1 2 ≤ z i ≤ 1. (4) z_{i+1} = \left\{ \begin{array}{ll} 2z_i + \text{rand}(0, 1) \times \frac{1}{N}, & 0 \leq z_i \leq \frac{1}{2}, \\ 2(1 - z_i) + \text{rand}(0, 1) \times \frac{1}{N}, & \frac{1}{2} \leq z_i \leq 1. \end{array} \right.\tag4 zi+1={2zi+rand(0,1)×N1,2(1−zi)+rand(0,1)×N1,0≤zi≤21,21≤zi≤1.(4)
帐篷映射后的表达式为:
z i + 1 = ( 2 z i ) mod 1 + rand ( 0 , 1 ) × 1 N . (5) z_{i+1} = (2z_i) \text{mod} 1 + \text{rand}(0, 1) \times \frac{1}{N}.\tag5 zi+1=(2zi)mod1+rand(0,1)×N1.(5)
在公式 (5) 中, N N N 是混沌映射中粒子的数量。
根据帐篷映射的特性,生成混沌序列以生成搜索域中的序列如下:
- 随机生成初始值 z 0 z_0 z0 在 (0, 1) 中,并令 i = 1 i = 1 i=1。
- 使用公式 (5) 执行迭代以生成 z z z 序列,并且 i i i 增加 1。
- 如果迭代次数达到最大值,则停止,并存储生成的 z z z 序列。
4.2 自适应惯性权重
惯性权重策略在粒子群优化算法中很常见 [14]。通常,粒子通过自适应地平衡局部最优和全局最优之间的陷阱来减少算法陷入局部最优的可能性。受此启发,本文增加了惯性权重 ω \omega ω,其随麻雀优化算法中麻雀数量的变化而变化。在算法的初始阶段,它削弱了随机初始化的影响并平衡了莱维飞行机制,从而增强了全局搜索能力,提高了算法的收敛速度。基于麻雀的特性,自适应权重的公式如下:
ω ( t ) = 0.2 cos ( π 1 − t iter max ) (6) \omega(t) = 0.2 \cos\left(\frac{\pi}{1 - \frac{t}{\text{iter}_{\text{max}}}}\right)\tag6 ω(t)=0.2cos(1−itermaxtπ)(6)
公式 (6) 的意义在于, ω \omega ω 在 [0, 1] 之间具有非线性变化的特性。根据余弦函数的特性,算法开始时权重值较小,但优化速度较快,后期权重值较大,但变化速度较慢,因此算法的收敛特性得以平衡。改进后的发现者位置更新如下:
X i , j t + 1 = { w ( t ) ⋅ X i , j t ⋅ exp ( − i α ⋅ iter max ) , 如果 R 2 < S T , w ( t ) ⋅ X i , j t + Q ⋅ L , 如果 R 2 ≥ S T . (7) X_{i,j}^{t+1} = \left\{ \begin{array}{ll} w(t) \cdot X_{i,j}^t \cdot \exp\left(\frac{-i}{\alpha \cdot \text{iter}_{\text{max}}}\right), & \text{如果 } R_2 < ST, \\ w(t) \cdot X_{i,j}^t + Q \cdot L, & \text{如果 } R_2 \geq ST. \end{array} \right.\tag7 Xi,jt+1={w(t)⋅Xi,jt⋅exp(α⋅itermax−i),w(t)⋅Xi,jt+Q⋅L,如果 R2<ST,如果 R2≥ST.(7)
通过引入自适应权重,动态调整麻雀的位置变化,不同指导模式下发现者在不同时间的搜索更加灵活。随着迭代次数的增加,个体麻雀向最优位置收敛,较大的权重使个体移动更快,从而提高了算法的收敛速度。
4.3 莱维飞行机制
在 SSA 中,种群中角色较少,相同的角色更新位置公式相同,这将导致多个个体在相同的最优位置。过高的解重复率将降低算法的效率,这不利于算法的优化。由于发现者具有广泛的搜索范围和全局性,引入自适应权重策略可以有效提高收敛效果。然而,在面对高维复杂问题时,仍有可能陷入局部最优。因此,引入莱维飞行策略以提高算法解的随机性,从而丰富种群位置的多样性。这也可以有效提高算法的搜索效率。
莱维飞行遵循莱维分布。图 1 显示了莱维分布的原理。莱维分布通常用于模拟 [17, 18]。计算步长的公式如下:
s = μ ∣ v ∣ 1 / γ , s = \frac{\mu}{|v|^{1/\gamma}}, s=∣v∣1/γμ,
μ ∼ N ( 0 , σ 2 ) , \mu \sim N(0, \sigma^2), μ∼N(0,σ2),
v ∼ N ( 0 , σ v 2 ) . v \sim N(0, \sigma_v^2). v∼N(0,σv2).
σ μ = { Γ ( 1 + γ ) sin ( π γ / 2 ) Γ [ ( γ + 1 ) / 2 ] ⋅ 2 ( γ + 1 ) / 2 , 如果 γ ≠ 1 , (9) \sigma_\mu = \left\{ \begin{array}{ll} \frac{\Gamma(1 + \gamma)\sin(\pi\gamma/2)}{\Gamma[(\gamma + 1)/2] \cdot 2^{(\gamma + 1)/2}}, & \text{如果 } \gamma \neq 1, \end{array} \right.\tag9 σμ={Γ[(γ+1)/2]⋅2(γ+1)/2Γ(1+γ)sin(πγ/2),如果 γ=1,(9)
其中, σ μ = 1 \sigma_\mu = 1 σμ=1, γ \gamma γ 通常为 1.5。
莱维飞行策略的引入使麻雀在这一阶段更加灵活,也可以使其他个体在不受局部极值约束的情况下找到更好的位置。因此,莱维飞行机制和自适应权重的结合在一定程度上平衡了搜索方法,并且通过莱维飞行机制获得的每个解的质量得到了很大程度的提高,从而大大提高了算法的搜索能力。
4.4 可变螺旋搜索策略
跟随者根据发现者的位置更新动态,这导致它们在搜索过程中出现盲目性和单一性。受鲸鱼算法 [19, 20] 中螺旋操作的启发,引入可变螺旋位置更新策略,使位置更新更加灵活,开发出多种路径以进行位置更新,并平衡算法的全局和局部搜索能力。螺旋搜索图如图 2 所示。
在后续位置更新过程中,螺旋路径不能是固定形状,这导致无序搜索方法和可能陷入局部最优。
提出了一种自适应螺旋飞行麻雀搜索算法。最初,种群通过基于随机变量的帐篷混沌映射初始化,为发现者的优化提供适当的准备。然后,引入自适应权重和莱维飞行策略,使发现者的位置更新方法更加广泛和灵活,然后提出了一种可变螺旋搜索。该策略使跟随者的搜索更加详细,避免了早熟现象,并加快了算法的优化速度。
具体实现步骤如下:
步骤 1:初始化麻雀种群参数,例如,总种群 pop,发现者 pNum,迭代次数 iter,以及解的精度 e。
步骤 2:使用帐篷映射初始化种群个体的位置,并生成 pop 只麻雀个体。
步骤 3:使用相关函数计算每个种群个体的适应度值 f i f_i fi,并找到最大适应度值 f g f_g fg 和最小适应度值 f w f_w fw。
步骤 4:根据适应度值对种群进行排序。
步骤 5:选择适应度值最高的 pNum 个个体作为发现者,其余为跟随者,并使用公式 (7) 和 (8) 并添加策略来更新发现者的位置。
步骤 6:使用公式 (10) 更新 pop 只跟随者的位置。
步骤 7:使用公式 (3) 更新意识到危险的麻雀的位置。
步骤 8:完成一次迭代后,重新计算每个个体的适应度值 f i f_i fi,并更新最大适应度值 f g f_g fg,最小适应度值 f w f_w fw 和相应的位置。
步骤 9:判断算法是否达到最大迭代次数或解的精度。如果达到,优化结果将输出;否则,将返回步骤 4。
图 2 显示了螺旋搜索的示意图。
参数 z z z 根据迭代次数变化,由基于 e e e 的指数函数组成。螺旋的大小和振幅根据余弦函数的性质动态调整。 k k k 是变化系数。根据每个函数的优化特性,为了使算法具有合适的搜索范围, k = 5 k = 5 k=5。 L L L 是一个均匀分布的随机数 [-1, 1]。随着跟随者位置更新范围从大到小,早期阶段发现更多优质位置,后期优化减少了算法的空闲时间,从而提高了算法的全局最优搜索性能。在后期,根据螺旋特性,算法的优化精度在一定程度上得到了提高。
5、ASFSSA优化BP神经网络
BP(反向传播)算法是一种经典的多层前馈神经网络训练算法,由Rumelhart, Hinton和Williams在1986年提出。该算法利用梯度下降法来最小化网络输出与期望输出之间的误差,通过反向传播误差来更新网络中的权重和偏置。以下是BP算法的详细叙述:
5.1 前向传播
在前向传播阶段,输入数据从输入层经过隐藏层传递到输出层,每一层的输出作为下一层的输入。对于每一层的每个神经元,其输出计算如下:
- 输入层:直接输入数据。
- 隐藏层和输出层:
a j ( l ) = f ( ∑ i = 1 n l − 1 w i j ( l ) a i ( l − 1 ) + b j ( l ) ) a_j^{(l)} = f\left(\sum_{i=1}^{n_{l-1}} w_{ij}^{(l)} a_i^{(l-1)} + b_j^{(l)}\right) aj(l)=f(i=1∑nl−1wij(l)ai(l−1)+bj(l))
其中, a j ( l ) a_j^{(l)} aj(l) 是第 l l l 层第 j j j 个神经元的激活值, w i j ( l ) w_{ij}^{(l)} wij(l) 是连接第 l − 1 l-1 l−1 层第 i i i 个神经元和第 l l l 层第 j j j 个神经元的权重, b j ( l ) b_j^{(l)} bj(l) 是第 l l l 层第 j j j 个神经元的偏置, f f f 是激活函数(如sigmoid、tanh或ReLU)。
5.2.计算误差
在输出层,计算网络输出与期望输出之间的误差,通常使用均方误差(MSE)作为损失函数:
E = 1 2 ∑ k = 1 m ( d k − o k ) 2 E = \frac{1}{2} \sum_{k=1}^{m} (d_k - o_k)^2 E=21k=1∑m(dk−ok)2
其中, d k d_k dk 是第 k k k 个样本的期望输出, o k o_k ok 是第 k k k 个样本的实际输出, m m m 是样本总数。
5.3 反向传播
反向传播阶段的目标是通过计算损失函数关于网络参数(权重和偏置)的梯度,并利用这些梯度来更新参数,以减少误差。梯度计算如下:
-
输出层:
δ j ( L ) = ( o j − d j ) f ′ ( z j ( L ) ) \delta_j^{(L)} = (o_j - d_j) f'(z_j^{(L)}) δj(L)=(oj−dj)f′(zj(L))
其中, δ j ( L ) \delta_j^{(L)} δj(L) 是第 L L L 层(输出层)第 j j j 个神经元的误差项, o j o_j oj 是实际输出, d j d_j dj 是期望输出, f ′ f' f′ 是激活函数的导数。 -
隐藏层:
δ j ( l ) = ( ∑ k = 1 n l + 1 w k j ( l + 1 ) δ k ( l + 1 ) ) f ′ ( z j ( l ) ) \delta_j^{(l)} = \left(\sum_{k=1}^{n_{l+1}} w_{kj}^{(l+1)} \delta_k^{(l+1)}\right) f'(z_j^{(l)}) δj(l)=(k=1∑nl+1wkj(l+1)δk(l+1))f′(zj(l))
其中, δ j ( l ) \delta_j^{(l)} δj(l) 是第 l l l 层第 j j j 个神经元的误差项。
5.4 参数更新
利用计算得到的梯度,通过梯度下降法更新网络中的权重和偏置:
w i j ( l ) = w i j ( l ) − η δ j ( l ) a i ( l − 1 ) w_{ij}^{(l)} = w_{ij}^{(l)} - \eta \delta_j^{(l)} a_i^{(l-1)} wij(l)=wij(l)−ηδj(l)ai(l−1)
b j ( l ) = b j ( l ) − η δ j ( l ) b_j^{(l)} = b_j^{(l)} - \eta \delta_j^{(l)} bj(l)=bj(l)−ηδj(l)
其中, η \eta η 是学习率,控制更新步长。
5.5. 迭代训练
重复步骤1到4,直到满足停止条件,如达到最大迭代次数或误差低于某个阈值。
BP算法通过不断调整网络参数,使网络能够学习到输入数据与输出结果之间的映射关系,从而实现对数据的预测或分类。
首先,代码开始时关闭警告信息、关闭所有图窗、清空变量和命令行。接着,导入数据集
在数据分析阶段,设定训练集占数据集的比例为70%,输出维度为1,计算样本总数,并对数据进行打乱处理。然后,计算训练集样本数量和输入特征维度。接着,划分训练集和测试集,并对数据进行归一化处理。
在节点个数设置阶段,定义输入层节点数、隐藏层节点数和输出层节点数。然后,构建一个前馈神经网络,并设置训练参数,包括训练次数、目标误差、学习率和关闭训练窗口。
在参数设置阶段,定义目标函数、优化参数个数、优化参数目标下限和上限、种群数量和最大迭代次数。接着,调用优化算法 ASFSSA 进行参数优化。
在优化算法阶段,将最优初始权值赋予网络预测。然后,重新设置网络训练参数以打开训练窗口,并进行网络训练。接着,使用训练好的网络对训练集和测试集进行预测。
在数据反归一化阶段,将预测结果反归一化,得到最终的预测值。接着,计算训练集和测试集的均方根误差(RMSE)。
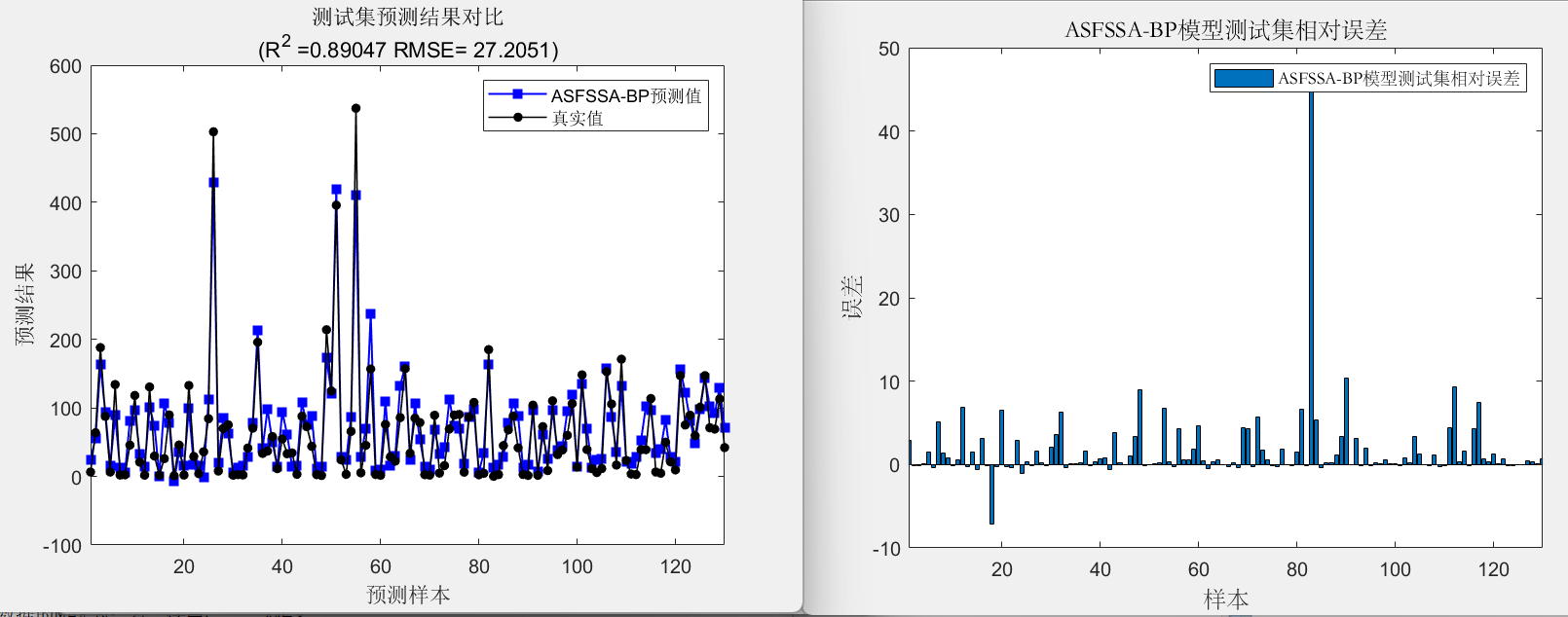
在绘图阶段,计算相关指标,包括 R 2 R^2 R2、平均绝对误差(MAE)和RMSE,并显示结果。然后,绘制优化曲线、训练集和测试集的预测结果对比图、误差图和线性拟合图。
以下是代码中涉及的数学公式:
-
计算训练集样本数量:
num_train_s = round ( num_size × num_samples ) \text{num\_train\_s} = \text{round}(\text{num\_size} \times \text{num\_samples}) num_train_s=round(num_size×num_samples) -
计算输入特征维度:
f _ = size ( res , 2 ) − outdim f\_ = \text{size}(\text{res}, 2) - \text{outdim} f_=size(res,2)−outdim -
计算测试集样本数量:
N = size ( P_test , 2 ) N = \text{size}(\text{P\_test}, 2) N=size(P_test,2) -
计算 R 2 R^2 R2 指标:
R = 1 − norm ( T − T _ s i m ) 2 norm ( T − mean ( T ) ) 2 R = 1 - \frac{\text{norm}(T - T\_sim)^2}{\text{norm}(T - \text{mean}(T))^2} R=1−norm(T−mean(T))2norm(T−T_sim)2 -
计算 MAE 指标:
mae = sum ( abs ( T _ s i m − T ) ) M \text{mae} = \frac{\text{sum}(\text{abs}(T\_sim - T))}{M} mae=Msum(abs(T_sim−T)) -
计算 RMSE 指标:
RMSE = sumsqr ( T _ s i m − T ) M \text{RMSE} = \sqrt{\frac{\text{sumsqr}(T\_sim - T)}{M}} RMSE=Msumsqr(T_sim−T)
最后,代码记录了训练集和测试集的预测结果,并保存了相关数据。
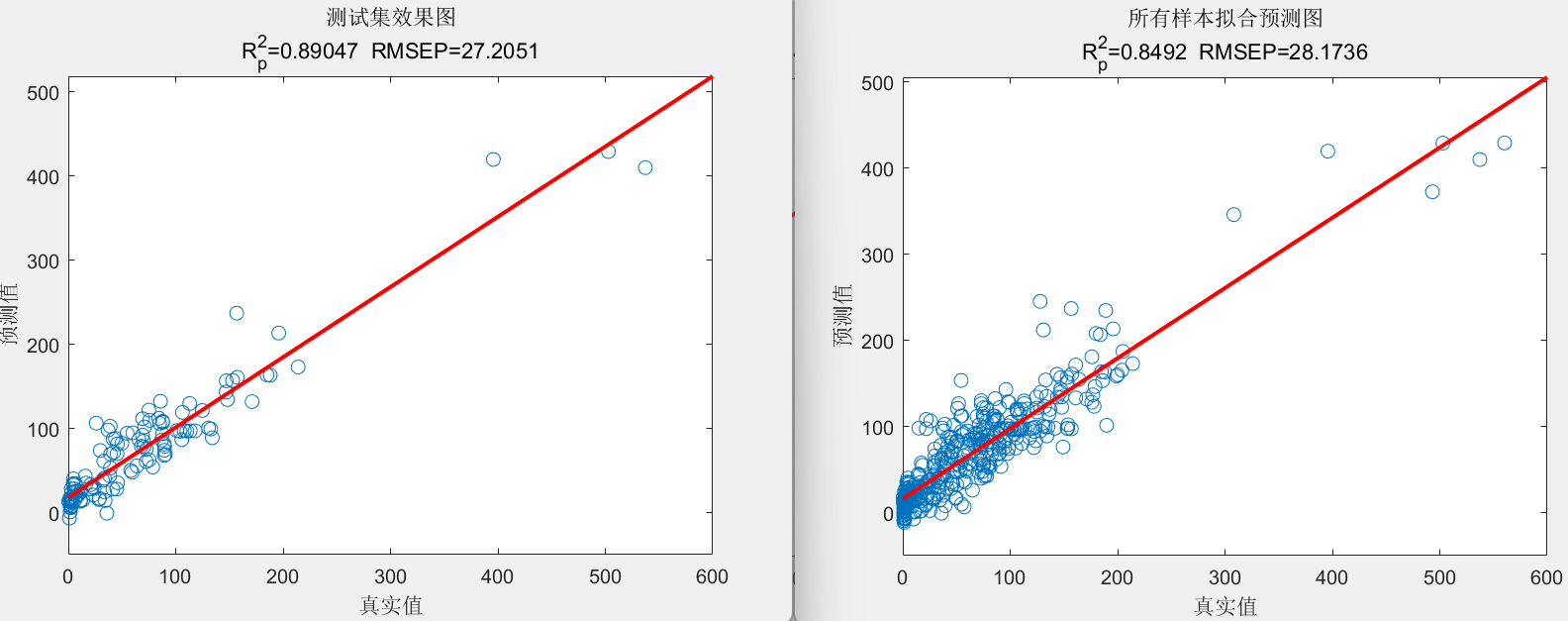
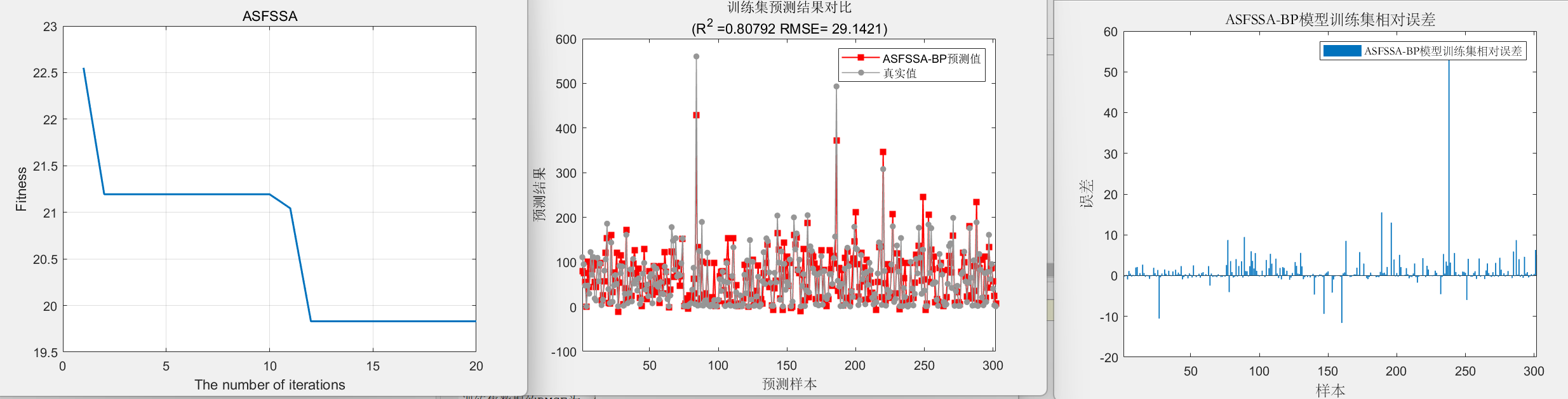
训练集数据的R2为:0.80792
测试集数据的R2为:0.89047
训练集数据的MAE为:20.9069
测试集数据的MAE为:20.211
训练集数据的RMSE为:29.1421
测试集数据的RMSE为:27.2051
相关文章:
优化BP神经网络,附完整完整代码)
基于随机变量的自适应螺旋飞行麻雀搜索算法(ASFSSA)优化BP神经网络,附完整完整代码
3. 麻雀搜索算法 麻雀群体分为两个角色,即发现者和跟随者。它们有三个行为:觅食、跟随和侦察。发现者的任务是寻找食物并告知跟随者食物的位置。因此,发现者需要在一个大范围内搜索,而跟随者的觅食范围通常较小。这是更新发现者位…...

vscode切换Python环境
跑深度学习项目通常需要切换python环境,下面介绍如何在vscode切换python环境: 1.点击vscode界面左上角 2.在弹出框选择对应kernel...

Gradle安装与配置国内镜像源指南
一、Gradle简介与安装准备 Gradle是一款基于JVM的现代化构建工具,广泛应用于Java、Kotlin、Android等项目的构建自动化。相比传统的Maven和Ant,Gradle采用Groovy或Kotlin DSL作为构建脚本语言,具有配置灵活、性能优越等特点。 在开始安装前…...

施工配电箱巡检二维码应用
在过去,施工配电箱的巡检主要依赖于纸质记录方式。巡检人员每次巡检时,都要在纸质表格上详细填写配电箱的各项参数、运行状况以及巡检时间等信息。这种方式在实际操作中暴露出诸多严重问题,信息易出现错误、数据会有造假现象、数据量庞大整理…...

全链路自动化AIGC内容工厂:构建企业级智能内容生产系统
一、工业化AIGC系统架构 1.1 生产流程设计 [需求输入] → [创意生成] → [多模态生产] → [质量审核] → [多平台分发] ↑ ↓ ↑ [用户反馈] ← [效果分析] ← [数据埋点] ← [内容投放] 1.2 技术指标要求 指标 标准值 实现方案 单日产能 1,000,000 分布式推理集群 内容合规率…...

第19章:Multi-Agent多智能体系统介绍
第19章:Multi-Agent多智能体系统介绍 欢迎来到多智能体系统 (Multi-Agent System, MAS) 的世界!在之前的章节中,我们深入探讨了单个 AI Agent 的构建,特别是结合了记忆、上下文和规划能力的 MCP 框架。然而,现实世界中的许多复杂问题往往需要多个智能体协同工作才能有效解…...
)
【C++游戏引擎开发】第25篇:方差阴影贴图(VSM,Variance Shadow Maps)
一、VSM 的核心思想 1.1 VSM 的核心思想 1.1.2 从深度到概率的转变 VSM 的核心创新在于将阴影判定从深度比较转换为概率估算。通过存储深度分布的统计信息(均值和方差),利用概率不等式动态计算阴影强度,从而支持软阴影并减少锯齿。 1.1.3 深度分布的统计表示 VSM 在阴…...
)
代码随想录打卡|Day27(合并区间、单调递增的数字、监控二叉树)
贪心算法 Part05 合并区间 力扣题目链接 代码随想录链接 视频讲解链接 题目描述: 以数组 intervals 表示若干个区间的集合,其中单个区间为 intervals[i] [starti, endi] 。请你合并所有重叠的区间,并返回 一个不重叠的区间数组࿰…...

yum包管理器
1.介绍 yum是一个shell前端软件包管理器,基于RPM包管理,能够从指定的服务器.自动下载RPM包并且安装,可以自动处理依赖关系,并且一次安装所有依赖的安装包。 2.yum基本指令 查询yum服务器是否有需要安装的软件: yum list I grep xx软件列表. 安装指定的yum包&…...

Linux多线程技术
什么是线程 在一个程序里的多执行路线就是线程。线程是进程中的最小执行单元,可理解为 “进程内的一条执行流水线”。 进程和线程的区别 进程是资源分配的基本单位,线程是CPU调度的基本单位。 fork创建出一个新的进程,会创建出一个新的拷贝&…...
)
通过模仿学习实现机器人灵巧操作:综述(上)
25年4月来自天津大学、山东大学、瑞士ETH、南方科技大学、通用 AI 国家重点实验室、爱丁堡大学和中科院自动化所的论文“Dexterous Manipulation through Imitation Learning: A Survey”。 灵巧操作是指机械手或多指末端执行器通过精确、协调的手指运动和自适应力调制&#x…...

LLM数学推导——Transformer问题集——注意力机制——稀疏/高效注意力
Q13 局部窗口注意力的内存占用公式推导(窗口大小 ) 局部窗口注意力:解决长序列内存困境的利器 在注意力机制中,全局注意力需要计算序列中每个元素与其他所有元素的关联,当序列长度 N 较大时,权重矩阵的内…...

Git 入门知识详解
文章目录 一、Git 是什么1、Git 简介2、Git 的诞生3、集中式 vs 分布式3.1 集中式版本控制系统3.2 分布式版本控制系统 二、GitHub 与 Git 安装1、GitHub2、Git 安装 一、Git 是什么 1、Git 简介 Git 是目前世界上最先进的分布式版本控制系统。版本控制系统能帮助我们更好地管…...

系统架构师2025年论文《论软件架构评估》
论软件架构评估 摘要: 我所在的单位是国内某知名医院,2017 年 1 月医院决定开发全新一代某市医院预约挂号系统,我担任本次系统的架构师,主要负责整个系统的架构设计工作。该系统旨在优化医院挂号流程,提高患者就医体验,是医院应对医疗信息化变革和提升服务的重要举措。…...

基于51单片机的超声波液位测量与控制系统
基于51单片机液位控制器 (仿真+程序+原理图PCB+设计报告) 功能介绍 具体功能: 1.使用HC-SR04测量液位,LCD1602显示; 2.当水位高于设定上限的时候,对应声光报警报警&…...

抓包工具Wireshark的应用解析
一、Wireshark简介 Wireshark(前身为Ethereal)是一款开源、跨平台的网络协议分析工具,自1998年诞生以来,已成为网络工程师、安全专家及开发者的核心工具之一。它通过网卡的混杂模式(Promiscuous Mode)捕获…...

在 Java 项目中搭建和部署 Docker 的详细流程
引言 在现代软件开发中,Docker 已成为一种流行的工具,用于简化应用的部署和运行环境的一致性。本文将详细介绍如何在 Java 项目中搭建和部署 Docker,包括配置文件、代码示例以及流程图。 一、整体工作流程 以下是整个流程的概览:…...

15.ArkUI Checkbox的介绍和使用
以下是 ArkUI Checkbox 组件的详细介绍和使用指南: 一、Checkbox 基础介绍 功能特性: 提供二态选择(选中/未选中)支持自定义样式和标签布局支持与数据状态绑定提供状态变化事件回调 适用场景: 表单中的多选操作设置…...

WebUI可视化:第5章:WebUI高级功能开发
学习目标 ✅ 掌握复杂交互逻辑的实现 ✅ 学会自定义界面样式与布局 ✅ 实现安全高效的文件处理 ✅ 优化性能与用户体验 5.1 自定义样式开发 5.1.1 修改主题颜色(以Streamlit为例) 在应用入口处添加全局样式: python import streamlit as st # 自定义主题 st.markdown…...

增加首屏图片
增加首屏图片(bg.jpg) web-mobile类型打包 //index.html脚本 <div id"myDiv_1111"style"background: url(./bg.jpg) 50% 50%/ 100% auto no-repeat ; width:100%;height:100%;position:absolute;"></div> //游戏内脚本…...

联合体和枚举类型
1.联合体类型 1.1:联合体类型变量的创建 与结构体类型一样,联合体类型 (关键字:union) 也是由⼀个或者多个成员变量构成,这些成员变量既可以是不同的类型,也可以是相同的类型。但是编译器只为最⼤的成员变量分配⾜够的内存空间。联合体的特…...

《AI大模型趣味实战》构建基于Flask和Ollama的AI助手聊天网站:分布式架构与ngrok内网穿透实现
构建基于Flask和Ollama的AI助手聊天网站:分布式架构与ngrok内网穿透实现 引言 随着AI技术的快速发展,构建自己的AI助手聊天网站变得越来越流行。本研究报告将详细介绍如何通过两台电脑构建一个完整的AI聊天系统,其中一台作为WEB服务器运行F…...
-超详细)
kubernets集群的安装-node节点安装-(简单可用)-超详细
一、kubernetes 1、简介 kubernetes,简称K8s(库伯内特),是用8代替名字中间的8个字符“ubernete”而成的缩写 云计算的三种主要服务模式——基础设施即服务(IaaS)、平台即服务(PaaS࿰…...

【Linux内核设计与实现】第三章——进程管理04
文章目录 8. exit() 进程退出8.1. exit() 系统调用的定义8.2. do_exit() 函数8.2.0. do_exit() 的参数和返回值8.2.1. 检查和同步线程组退出8.2.2. 清理与调试相关的资源8.2.3. 取消 I/O 和信号处理8.2.4. 检查线程组是否已终止8.2.5. 释放系统资源8.2.6. 释放线程和调度相关资…...

Golang | 迭代器模式
迭代器模式(Iterator Pattern)是一种行为型设计模式,它提供了一种顺序访问聚合对象(如列表、树等集合结构)中元素的方法,而无需暴露其底层实现细节。通过将遍历逻辑与集合本身解耦,迭代器模式使…...

美颜SDK动态贴纸实战教程:从选型、开发到上线的完整流程
在直播、短视频、社交娱乐全面崛起的当下,美颜SDK早已不再局限于“磨皮瘦脸”,而是逐步迈向更智能、更富互动体验的方向发展。动态贴纸功能,作为提升用户参与感和内容趣味性的关键手段,正在被越来越多的平台采纳并深度定制。本文将…...

ArkTS中的空安全:全面解析与实践
# ArkTS中的空安全:全面解析与实践 在ArkTS编程领域,空安全是一个极为关键的特性,它在很大程度上影响着代码的稳定性和可靠性。今天,我们就深入探究一下ArkTS中的空安全机制,看看它是如何保障我们的代码质量的。 ## A…...

C语言基础语法详解:从入门到掌握
C 基础语法 C 语言是一种通用的编程语言,广泛应用于系统编程、嵌入式开发和高性能计算等领域。 C 语言具有高效、灵活、可移植性强等特点,是许多其他编程语言的基础。 在 C 语言中,令牌(Token)是程序的基本组成单位…...

如何把两个视频合并成一个视频?无需视频编辑器即可搞定视频合并
在日常生活中,我们经常需要将多个视频片段合并成一个完整的视频,例如制作旅行记录、剪辑教学视频或拼接短视频素材。简鹿视频格式转换器是一款功能强大的工具,不仅可以进行视频格式转换,还支持视频合并功能。以下是使用简鹿视频格…...

Servlet小结
视频链接:黑马servlet视频全套视频教程,快速入门servlet原理servlet实战 什么是Servlet? 菜鸟教程:Java Servlet servlet: server applet Servlet是一个运行在Web服务器(如Tomcat、Jetty)或应用…...

C语言面试高频题——define 和typedef 的区别?
1. 基本概念 (1) #define 定义:#define 是预处理指令,用于定义宏。作用:在编译之前进行文本替换。语法:#define 宏名 替换内容示例:#define PI 3.14159 #define SQUARE(x) ((x) * (x))(2) typedef 定义:…...

计算机组成原理:指令系统
计算机组成原理:指令集系统 指令集体系结构(ISA)ISA定义ISA包含的内容举个栗子指令的基本组成(操作码+地址码)指令分类:地址码的个数定长操作码变长操作码变长操作码的原则变长操作码的设计指令寻址寻址方式的目的寻址方式分类有效地址直接在指令中给出有效地址间接给出有效地…...

自动清空 maven 项目临时文件,vue 的 node_modules 文件
echo off setlocal enabledelayedexpansion :: vue 的 node_modules 太大 :: maven 打包后的 target 文件也很大, :: 有些项目日志文件也很大,导致磁盘空间不足了, :: 所以写了个脚本,只要配置一下各项目目录, :: 双击…...

服务网格助力云原生后端系统升级:原理、实践与案例剖析
📝个人主页🌹:慌ZHANG-CSDN博客 🌹🌹期待您的关注 🌹🌹 一、引言:微服务的“通信焦虑”与服务网格的出现 云原生架构的兴起推动了微服务的大规模落地,系统拆分为成百上千个小服务,这些服务之间需要频繁通信。然而,通信带来的问题也开始显现: 如何确保服务间…...
)
基于DrissionPage的表情包爬虫实现与解析(含源码)
目录 编辑 一、环境配置与技术选型 1.1 环境要求 1.2 DrissionPage优势 二、爬虫实现代码 三、代码解析 3.1 类结构设计 3.2 目录创建方法 3.3 图片链接获取 3.4 图片下载方法 四、技术升级对比 4.1 代码复杂度对比 4.2 性能测试数据 五、扩展优化建议 5.1 并…...

Spring Cloud Gateway 如何将请求分发到各个服务
前言 在微服务架构中,API 网关(API Gateway)扮演着非常重要的角色。它负责接收客户端请求,并根据预定义的规则将请求路由到对应的后端服务。Spring Cloud Gateway 是 Spring 官方推出的一款高性能网关,支持动态路由、…...

【深度强化学习 DRL 快速实践】Value-based 方法总结
强化学习中的 Value-based 方法总结 在强化学习(Reinforcement Learning, RL)中,Value-based 方法主要是学习一个价值函数(Value Function),然后基于价值函数来决策。常见的 Value-based 方法包括…...

【计算机视觉】CV实战项目 - 基于YOLOv5的人脸检测与关键点定位系统深度解析
基于YOLOv5的人脸检测与关键点定位系统深度解析 1. 技术背景与项目意义传统方案的局限性YOLOv5多任务方案的优势 2. 核心算法原理网络架构改进关键点回归分支损失函数设计 3. 实战指南:从环境搭建到模型应用环境配置数据准备数据格式要求数据目录结构 模型训练配置文…...
)
git版本回退 | 远程仓库的回退 (附实战Demo)
目录 前言1. 基本知识2. Demo3. 彩蛋 前言 🤟 找工作,来万码优才:👉 #小程序://万码优才/r6rqmzDaXpYkJZF 爬虫神器,无代码爬取,就来:bright.cn 本身暂存区有多个文件,但手快了&…...

【KWDB 创作者计划】_深度学习篇---数据获取
文章目录 前言一、公开数据集资源库1. 综合型数据集平台Kaggle Datasets (https://www.kaggle.com/datasets)Google Dataset Search (https://datasetsearch.research.google.com)UCI Machine Learning Repository (https://archive.ics.uci.edu/ml) 2. 计算机视觉专用ImageNet…...

DeepSeek本地部署手册
版本:v1.0 适用对象:零基础开发者 一、部署前准备 1.1 硬件要求 组件最低配置推荐配置说明CPUIntel i5 8代Xeon Gold 6230需支持AVX指令集内存16GB64GB模型越大需求越高GPUNVIDIA GTX 1060 (6GB)RTX 3090 (24GB)需CUDA 11.7+存储50GB可用空间1TB NVMe SSD建议预留2倍模型大小…...

OpenCV中的SIFT特征提取
文章目录 引言一、SIFT算法概述二、OpenCV中的SIFT实现2.1 基本使用2.1.1 导入库2.1.2 图片预处理2.1.3 创建SIFT检测器2.1.4 检测关键点并计算描述符2.1.5 检测关键点并计算描述符并对关键点可视化2.1.6 印关键点和描述符的形状信息 2.2 参数调优 三、SIFT的优缺点分析3.1 优点…...

Kubernetes in action-初相识
初相识Kubernetes 1、构建、运行以及共享镜像1.1 运行镜像1.2 构建镜像1.3 推送镜像 2、Kubernetes初相识2.1 介绍Pod2.2 从构建到运行整体流程2.3 kubectl命令行工具 如有侵权,请联系~ 如有错误,也欢迎批评指正~ 本篇文章大部分是…...
)
九、小白如何用Pygame制作一款跑酷类游戏(添加前进小动物作为动态障碍物)
九、小白如何用Pygame制作一款跑酷类游戏(添加前进小动物作为动态障碍物) 文章目录 九、小白如何用Pygame制作一款跑酷类游戏(添加前进小动物作为动态障碍物)前言一、添加小动物素材1. 在根目录的图片文件夹下新建两个目录分别存放…...

Unity3D IK解算器技术分析
前言 在Unity3D中,逆向运动学(IK Solver)是实现角色动画自然交互的核心技术之一。以下是Unity中常见的IK解算器及其特点的综合分析,结合了原生功能、第三方插件与开源方案的对比: 对惹,这里有一个游戏开发…...

7.11 Python CLI开发实战:API集成与异步处理核心技术解析
Python CLI开发实战:API集成与异步处理核心技术解析 #mermaid-svg-fXGFud0phX2N2iZj {font-family:"trebuchet ms",verdana,arial,sans-serif;font-size:16px;fill:#333;}#mermaid-svg-fXGFud0phX2N2iZj .error-icon{fill:#552222;}#mermaid-svg-fXGFud0phX2N2iZj .…...

百度Create2025 AI开发者大会:模型与应用的未来已来
今日,2025百度AI开发者大会(Create2025)在武汉体育中心盛大开幕。这场以“模型的世界,应用的天下”为主题的盛会,不仅汇聚了李彦宏、王海峰、沈抖等百度高层及行业领袖,更以多项重磅技术发布、前沿议题探讨…...
)
Java实现HTML转PDF(deepSeekAi->html->pdf)
Java实现HTML转PDF,主要为了解决将ai返回的html文本数据转为PDF文件方便用户下载查看。 一、deepSeek-AI提问词 基于以上个人数据。总结个人身体信息,分析个人身体指标信息。再按一个月为维度,详细列举一个月内训练计划,维度详细至每周每天…...

区间和数量统计 之 前缀和+哈希表
文章目录 1512.好数对的数目2845.统计趣味子数组的数目1371.每个元音包含偶数次的最长子字符串 区间和的数量统计是一类十分典型的问题:记录左边,枚举右边策略前置题目:统计nums[j]nums[i]的对数进阶版本:统计子数组和%modulo k的…...

【服务器操作指南】从 Hugging Face 上下载文件 | 从某一个网址上下载文件到 Linux 服务器的指定目录
引言 在服务器操作中,下载和管理文件是常见且重要的任务。从 Hugging Face 平台获取模型资源,或从特定网址下载文件至 Linux 服务器并进行解压,都需要明确的操作步骤。本指南旨在为您提供清晰的操作流程,帮助您快速上手相关任务并…...