【MySQL】MySQL索引与事务
目录
前言
1. 索引 (index)
1.1 概念
1.2 作用
1.3 使用场景
1.4 索引的相关操作
查看索引
创建索引
删除索引
2. 索引背后的数据结构
2.1 B+树
2.2 B+树的特点
2.3 B+树的优势
3. 事务
3.1 为什么使用事务
3.2 事务的概念
3.3 使用事务
3.4 事务四大关键特性
4. 事务隔离性解决并发问题
4.1 脏读问题
4.2 不可重复读
4.3 幻读
4.4 隔离级别
前言
数据库使用 select 查询的时候:
- 先遍历表
- 把当前的行给带入到条件中,看条件是否成立
- 条件成立,这样的行就保留。不成立就跳过。
- 如果表非常的小,正常使用没问题。如果表非常大,这样的遍历成本就比较高了。
- 站在时间复杂度角度,至少是O(N)。时间复杂度和空间复杂度都是基于内存的计算的。
- 数据库是把数据存储在硬盘上,每次读取一个数据都需要读取硬盘。
- 读取硬盘这个操作,开销本身就是很大的。读写一次硬盘开销远远大于读1次内存。读1次硬盘相当于读1万次内存。频繁进行读取更是慢上加慢。
- 所以就引出了索引,增加遍历查询速度,减少硬盘的访问次数。
1. 索引 (index)
索引英文是 index。这里的 index 指的是索引,并不是数组下标。
1.1 概念
索引是一种特殊的文件,包含着对数据表里所有记录的引用指针。可以对表中的一列或多列创建索引,并指定索引的类型,各类索引有各自的数据结构实现。(具体细节在后续的数据库原理课程讲解)
1.2 作用
- 索引属于是针对查询操作引入的优化手段。可以通过索引来加快查询的速度,避免针对表进行遍历。
- 数据库中的表、数据、索引之间的关系,类似于书架上的图书、书籍内容和书籍目录的关系。
- 索引所起的作用类似书籍目录,可用于快速定位、检索数据。
缺陷
- 索引会占用额外的磁盘空间,付出额外空间代价来保存索引数据。生成索引,是需要一系列的数据结构,以及一系列的额外的数据,来存储到硬盘空间中的。
- 索引加快了查询速度,但可能会拖慢新增,删除,修改的速度。因为新增、删除、修改数据还需要同步新增、删除、修改索引,产生额外的开销。
整体来说,还是认为索引是利大于弊的, 实际开发中,查询(读)场景一般要比增删改(写)频率高很多。
1.3 使用场景
要考虑对数据库表的某列或某几列创建索引,需要考虑以下几点:
- 数据量较大,且经常对这些列进行条件查询。
- 该数据库表的插入操作,及对这些列的修改操作频率较低。
- 不太在意,索引占用额外的磁盘空间。
满足以上条件时,考虑对表中的这些字段创建索引,以提高查询效率。
反之,如果非条件查询列,或经常做插入、修改操作,或磁盘空间不足时,不考虑创建索引。
1.4 索引的相关操作
创建主键约束(PRIMARY KEY)、唯一约束(UNIQUE)、外键约束(FOREIGN KEY)时,会自动创建对应列的索引。
为什么创建这三个约束,会自动创建对应列的索引:
- primary key 和 uniqe 都是要求对应列的记录不能重复,每次插入/修改被约束列的数据,需要查询判断是否重复。涉及频繁的查询操作。优化查询速度,自动引入索引,查询跟着索引走就不需要一条条记录去遍历了,大大加快了插入/修改的速度。
- foreign key 约束的时候,子表中对应的记录要在父表中存在。往子表中插入/修改对应约束列的数据时,就需要每次查询父表中是否存在。反之,从父表中修改/删除数据时,也需要查询该数据在子表中是否被引用。涉及频繁的查询操作。优化查询速度,自动引入索引。
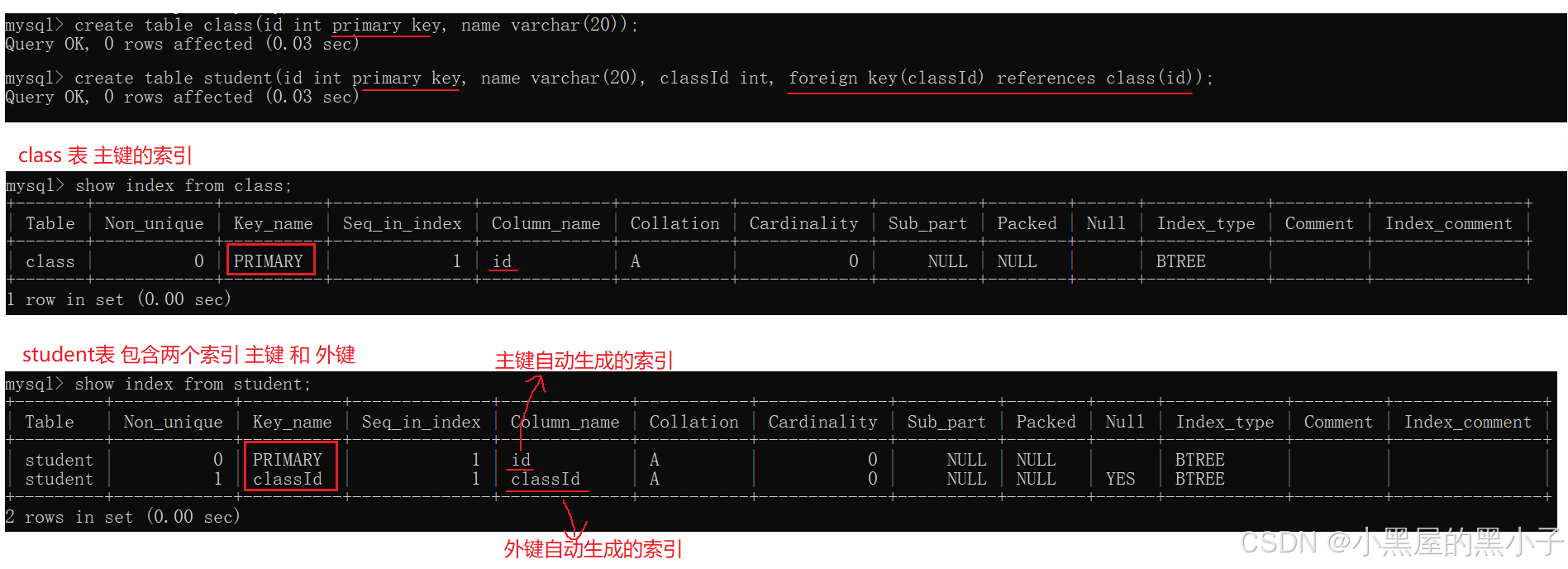
查看索引

 primary key 主键自动生成的索引
primary key 主键自动生成的索引
- 可以理解为:student表中内容,根据id列生成了一份目录;这里自动创建的索引名为primary
- 索引表中的列大概认识一下,不需要全部了解。
- 一个索引是针对一个列来指定的。
- 只有针对这一列进行条件查询的时候,查询速度才能够被索引优化。
例如:
- 此处针对 id 创建索引。使用id进行条件查询,速度是很快。
- select * from student where id = 100; —— 使用索引,不需要一条条记录遍历。
- select * from student where name = '张三'; —— 仍然需要遍历表。
unique 自动生成的索引
foreign key 外键自动生成的索引
- 一本书可以有多个目录。一个表也可以有多个索引。
- 例如:一个字典,目录有多种。拼音目录、笔画目录、部首目录、难检字目录。

创建索引
对于非主键、非唯一约束、非外键的字段,可以创建普通索引。


- 创建索引操作,也是一个危险操作;创建索引的时候,需要针对现有的数据,进行大规模的重新整理。如果当前表是一个空表或者数据不多,创建索引都没有问题。但如果这个表很大,创建索引开销会很大,很容易就把数据库服务器给卡住。
- 例如:有一本很厚的书,现在给这个书手动的写一份目录出来。好的做法,是创建表之初就把索引设定好。
- 一般来说,创建索引,在创建表时已经规划好了。如果表使用了很久,有很多数据,再想创建索引,就要慎重了。
- 如果表很大,坚持要创建索引,使用“移花接木”的技巧方式,尤其是生产环境(线上)的数据库。做法:在另外一台机器部署mysql服务器,创建同样的表,并且把表上的索引创建好,再把之前的机器上的数据给导入到新的mysql服务器上。控制导入数据过程的节奏,多花点时间导数据,不要影响到原来服务器正常的运转。当所有数据都导入完毕,就可以使用新的数据库,替换旧的数据库了。
删除索引

- 手动创建的索引,可以手动删除。自动创建的索引(主键/外键,unique),不可以删除。
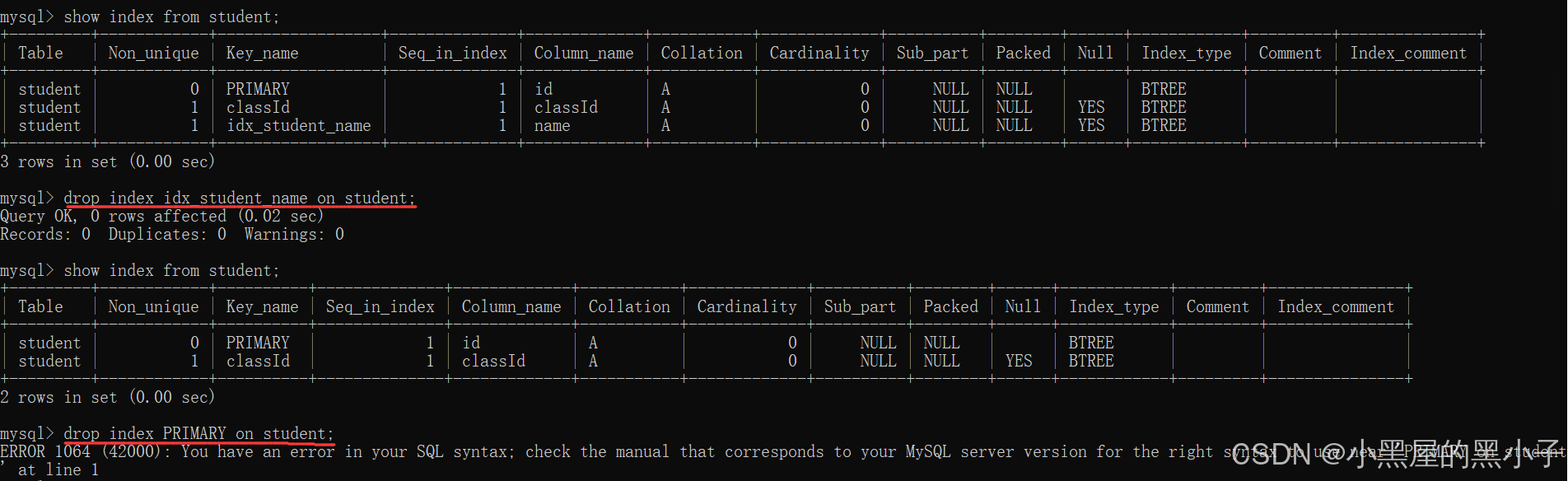
和创建索引类似,删除索引也是一个危险操作。理由同上。
2. 索引背后的数据结构
索引是通过一定的数据结构来实现的。哪些数据结构能加快查询的速度,B+树,为数据库量身定做的数据结构。
mysql的索引的数据结构为什么不能是顺序表,链表,栈,队列,红黑树,哈希表呢?
- 1. 顺序表
在顺序表中间插入或删除元素需要移动大量数据,效率较低。
当容量不足时,需要重新分配更大的存储空间,并拷贝所有数据。
在大规模数据中进行随机查询效率低,尤其是当数据需要排序时。
- 2. 链表
链表不支持随机访问,必须从头开始遍历,查询时间复杂度是 O(n)。
每个节点需要额外的指针存储,内存开销较高。
链表不能快速进行范围查询。
- 3. 栈、队列、堆
栈和队列只适合用于简单的顺序操作,不支持高效的随机查询、范围查询或复杂操作。
栈和队列不支持快速的插入、删除或排序操作。
- 4. 红黑树
里面元素是有序,可以处理精准查询、范围查询、也能一定程度的模糊匹配。
最大的问题, 在于红黑树是二叉树(平衡),每个节点最多两个子树,树的分叉少(结点的度少),表示同样数量的结果集合,树的高度就会更高。意味着查询操作时,比较次数就会变得多,索引这样的结构是存储在硬盘上的,每一次比较就意味着硬盘IO操作。数据库引入的索引是一个改进的树形结构,B+树(N叉搜索树)。
- 5. 哈希表
不适合数据库的查询场景。因为哈希表只能做这种精准查询,无法做到范围查询和模糊查询。
- 红黑树(二叉搜索树)和哈希表都能提高查询速度,但是并不适合数据库的查询场景。

要了解B+树需要先了解下B树,B树有的时候会写作B - 树,不是B减树仍是B树的意思。 '-' 是连接符的意思,不是数学中的减符号。
B树的核心思路和"二叉搜索树"差不多。B树本质上是一个N叉搜索树。
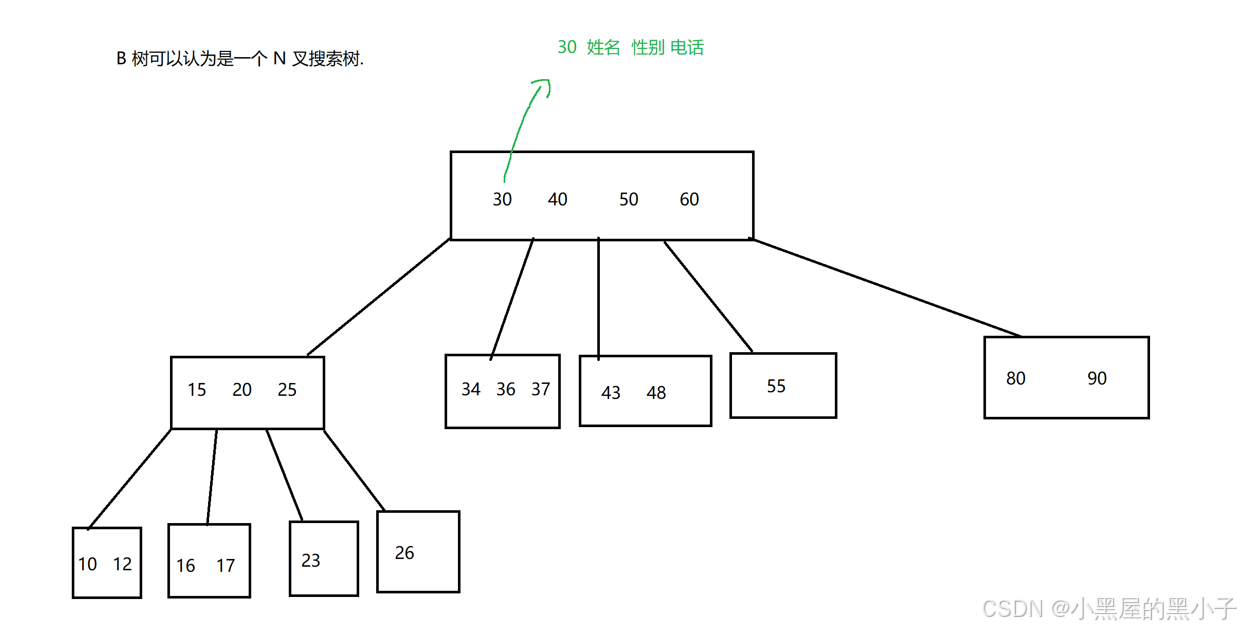
- 每个节点的度都是不确定的。当节点的子树多了以及节点上保存的key多了,意味着在同样key 的个数的前提下,B树的高度就要比二叉搜索树低很多,树的高度越低,进行查询比较的时候访问磁盘的次数就越少,速度就大大提升。
- B树的查询基本思路与二叉搜索树的查询思路是相似的,只不过B树是分了N叉,每个节点需要进行多次比较,确定走哪个区间,从而走哪个子树。
- 一个节点上保存N个key就划分出N+1个区间。每个区间都可以衍生出一系列的子树了。树的高度就大幅度的降低了。
- 由于每个节点是在一个硬盘的区域中,一次读硬盘就读取出了整个节点(多个key )再进行几次比较。(读一次硬盘,相当于内存中1w次比较)
- 一个节点中,虽然是可以保存N个key,也不是无限制的,达到一定的规模,就会触发节点的分裂。当删除元素达到一定的数目,也会触发节点的合并(简化树形结构)。
- 具体什么时候进行拆分,怎么拆分;具体什么时候合并,怎么合并。实际的实现中,不同的场景下可以使用不同的策略。
2.1 B+树
B+树,在B树的基础上又做出改进(也是N叉搜索树),针对数据库量身定做的。
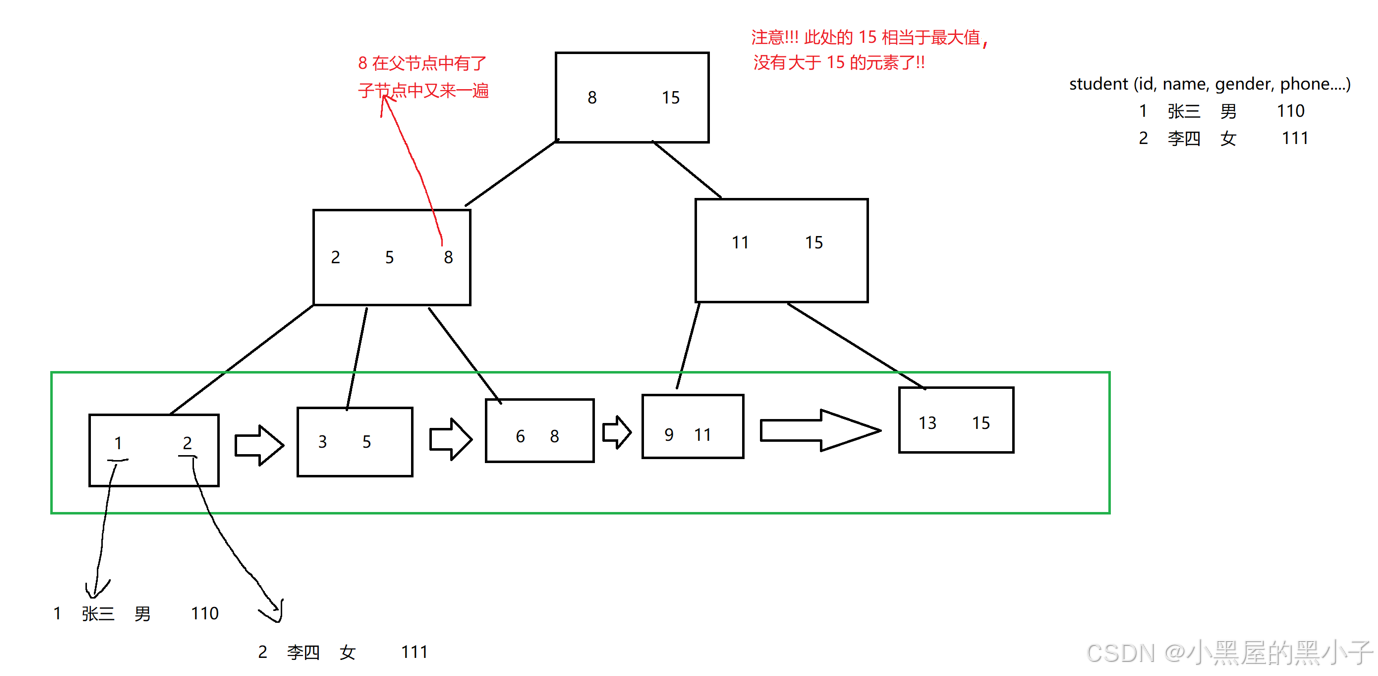
- 整个树的所有数据都是包含在叶子节点中的(所有非叶子节点中的key最终都会出现在叶子节点中)
- 上述这个结构,是默认id是表的主键,如果这个表里有多个索引呢?
- 针对id是主键创建索引,表的数据还是按照 id为主键,构建出B+树通过叶子节点组织所有的数据行。
- 其次,针对 name这一列,则会构建另外一个B+树,但是这个B+树的叶子节点就不再存储这一行的完整数据,而是存主键id是啥,此时,如果你根据name来查询,查到叶子节点得到的只是主键id,还需要再通过主键id去主键的B+树里再查一次(查两次B+树),上述过程称为“回表",这个过程,都是mysql自动完成的,用户感知不到。
- 上面的这个树形结构,是"索引",如果这一列不能比较,就没法建立索引;幸运的是, mysql里的各种类型都能比较,数字、字符串、时间日期。 故mysql中不支持自定义类型
2.2 B+树的特点
- 一个节点,可以存储N 个key,N个key划分出了N个区间(而不是B树中的N+1个区间)
- 每个节点中的key的值,都会在子节点中也存在(同时该key是子节点的最大值,也可以是最小值)
- B+树的叶子节点,是首尾相连,类似于一个链表
- 由于叶子节点是完整的数据集合,所以只在叶子节点这里存储数据表中的每一行的数据,而非叶子节点,只存key值本身即可。
2.3 B+树的优势
1、当前一个节点保存更多的 key,最终树的高度是相对更矮的,查询的时候减少了IO访问次数(和B树是一样的)这里IO特指硬盘的访问

2、所有的查询最终都会落到叶子节点上(查询任何一个数据,经过的IO访问次数,是一样的)
这个相同次数很关键,稳定的能够让程序猿对于程序的执行效率有一个更准确的评估。
3、B+树的所有的叶子节点,构成链表,此时比较方便进行范围查询。
例如:查询学号>5并且<11的同学。只需要先找到5所在的位置,在找到11所在位置从5沿着链表遍历到11,中间结果即为所求,非常方便非常高效。
4、由于数据都在叶子节点上,非叶子节点只存储key,导致非叶子节点占用空间是比较小的,这些非叶子节点就可能在内存中缓存(或者是缓存一部分),又进一步减少了IO的次数。 常量池本质上就是缓存。
例如:假设一个整数按照4个字节算,10亿个这样的整数,占据多大内存空间?(估算即可,不用精确)10亿个这样的 key才不到4G,4G对于计算机内存来说还是非常容易的。
带有索引的数据, mysql 组织数据就是B+树的方式;当你看到一张"表”的时候,实际上这个表不一定就是按照"表格"这样的数据结构在硬盘上组织的,也有可能是按照这种树形结构组织。具体是哪种结构,取决于你的表里有没有索引,以及数据库使用了哪种存储引擎。
3. 事务
3.1 为什么使用事务
开发中经常会涉及到一些场景,需要“一气呵成”的完成一些操作。
【案例】
- 准备测试表:
drop table if exists accout;
create table accout(id int primary key auto_increment, name varchar(20) comment '账户名称', money decimal(11,2) comment '金额');
insert into accout(name, money) values('阿里巴巴', 5000),('四十大盗', 1000);
- 比如说,四十大盗把从阿里巴巴的账户上偷盗了2000元
-- 阿里巴巴账户减少2000
update accout set money = money-2000 where name = '阿里巴巴';
-- 四十大盗账户增加2000
update accout set money = money+2000 where name = '四十大盗';
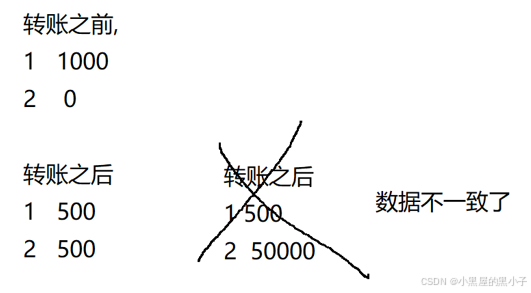
- 假如在执行以上第一句SQL时,出现网络错误,或是数据库挂掉了,阿里巴巴的账户会减少2000,但是四十大盗的账户上就没有了增加的金额。这是比较严重的错误。此时,数据就会出现“不上不下”的中间状态,非常明显的bug!!!
引入事务就是为了避免上述的问题。
解决方案:使用事务来控制,保证以上两句SQL要么全部执行成功,要么全部执行失败。
事务的本质就是把多个sql语句给打包成一个整体,要么全部执行成功,要么全部执行失败。而不会出现"执行一半"这样的中间状态。
3.2 事务的概念
事务指逻辑上的一组操作,组成这组操作的各个单元,要么全部成功,要么全部失败。
在不同的环境中,都可以有事务。对应在数据库中,就是数据库事务。
- 把多个sql语句给打包成一个整体:称为原子性(atom);过去的人们认为原子是事物能够分割的最小单位。现在并非原子是最小分割单位。
- 全部执行失败:不是真的没执行,而是"看起来好像没执行一样",其实是执行了,执行一半出错了,出错之后选择了恢复现场,把数据还原成未执行之前的状态了。
- 这个恢复数据的操作,称为“回滚" (rollback)
【案例】
- 单独执行的每个sql都是自成一个体系,此时这些sql之间是没有原子性的。
- 如果把这俩操作作为一个事务,当第一个 sql执行完之后,数据库崩溃。当下次数据库重新启动完成之后,就会自动的把上次修改一半的数据给进行还原(把1号用户-500再加回来就行了)。

3.3 使用事务
- 开启事务:start transaction;
- 执行多条SQL语句。这个过程中某个环节出现问题,例如程序崩溃/数据库崩溃/机器断电了,就会自动触发回滚机制。
- 提交或主动触发回滚:commit/rollback;
- commit; 提交事物,意思是下面没有sql语句了,该事务结束了。事务结束的标记。
- rollback 是主动触发回滚。出错有很多情况,崩溃/断电只是其中一种(会自发触发回滚),有时候需要主动通过代码方式判断当前是否需要回滚。所以rollback一般是要搭配一些条件判断逻辑来使用的。sql里也能支持条件,循环,变量,函数...,但是日常开发一般不会这么写,更多的是搭配其他的编程语言。例如使用java操作数据库,在java中主动判定某个结果是否符合要求,如果不符合要求进行主动回滚。
- 说明:rollback即是全部失败,commit即是全部成功。

回滚是怎么做到,把数据还原成未执行的状态?
依据日志中的记录,进行回滚操作 。 例如日志里记录的操作是插入,回滚根据记录就删除。记录的操作是删除,回滚根据记录就插入。如果记录的操作是修改,回滚根据记录就改回去。
- 数据库里专门有个用来记录事务关键操作的日志(正因为如此,使用事务的时候,执行sql的开销是更大的,效率是更低)。日志:是打印出来的内容,存放在文件里。
- 日志是存放在文件中的,所以即使是主机掉电,也不影响(回滚用的日志已经在文件中了)。后续一旦重新启动主机,mysql也重新启动,就会发现回滚日志中有一些需要进行回滚的操作。于是就可以完成这里的回滚了。
3.4 事务四大关键特性
数据库的事务,有四个关键的特性:
- 原子性:把多个sql语句给打包成一个整体,要么全部执行成功,要么全部执行失败 ——最核心的特性
- 一致性:事务执行前后,数据要合理。(很多时候是要靠数据库的约束以及一系列的检查机制来完成的)
3. 持久性:事务修改的内容是写到硬盘上持久保存的。重启服务器,数据仍然是存在的。
4. 隔离性:是为了解决"并发"执行多个事务,引起的问题。
并发:
- 一个餐馆(服务器),同一时刻能给多个顾客(客户端)提供服务,这些顾客可能是一个接一个来的,也可能是一起来了一波顾客。
- 此时,服务器同时处理多个客户端的请求,就称为"并发"(齐头并进的感觉)。
- 同时能处理客户端请求越多,并发程度越高,整体的效率就越高。
- 数据库也是服务器,一定会存在多个客户端给服务器提交事务的情况。为了提高效率,就会提高并发程度,但在数据库中提高并发程度之后,可能存在一些问题,会导致数据出现一些“错误”的情况。
- 隔离级别,就是在"数据正确"和"效率"之间做权衡。往往提升了效率,就会牺牲正确性;提升了正确性,就会牺牲效率。
- 事务的隔离性,存在的意义就是为了在数据库并发处理事务的时候不会有问题,即使有问题,问题也不会太大。
4. 事务隔离性解决并发问题
下面介绍,数据库中并发执行事务可能产生的问题,以及数据库的隔离性是怎样解决的。
4.1 脏读问题
问题描述:
- 在我写代码的过程中,同学在我身后经过, 他瞄了一眼我的屏幕,看到了我的代码中写了一些内容,比如他看到了,我的代码里有一个class Student,有一些属性,id, name,gender... 然后他就走了,很可能他走了之后,我的代码又改了。
- 即一个事务A正在对数据进行修改的过程中,还没提交之前;另外一个事务B,对同一个数据进行了读取,此时B的读操作就称为“脏读",读到的数据也称为"脏数据"。
- 脏的意思,是"无效",而不是埋汰。为啥说无效?很可能,A回头又把数据给修改了。即另一个事务读取到的数据不一定是最终的结果,可能是无效数据。
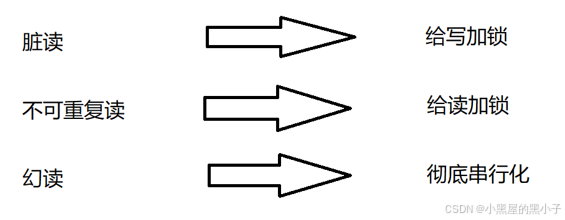
解决方法:写的时候不能读,写操作加锁。
- 为了解决脏读问题,mysql 引入"写操作加锁"这样的机制。
- 即我和同学们商量好,我写代码的过程中你别来看 ,等我改完提交到码云上,你再通过我的码云来看,写的时候不能看(给写操作加锁),写完了才能看。
- 当我写的时候同学没法读,意味着我的“写操作"和同学的"读操作"不能并发了(不同同时执行了)
- 这个给写加锁的操作,就降低了并发程度(降低了效率),提高了隔离性(提高了数据的准确性)
4.2 不可重复读
问题描述:
- 还是我写代码,同学想看,约定好我写的时候不许看,等我提交了,再通过码云来看。当前约定好了写加锁。
- 我写代码提交了版本1,此时就有同学开始读这个代码了;于是我又打开代码继续修改优化代码,然后又提交版本2。这个同学开始读的过程中,读到的是版本1的代码,读着读着我提交了版本2,此时这个同学读的代码,刷的一下变样了。这个问题,叫做“不可重复读"。
- 事务1已经提交了数据,此时事务2开始去读取数据,在读取过程中,事务3修改了数据提交了新的数据,此时意味着同一个事务2之内,多次读数据,读出来的结果是不相同的(预期是一个事务中,多次读取结果得一样)就叫做"不可重复读"。即同一个事务中第二次读取的结果不能复现第一次的结果。
解决方法:读的时候不能写,读操作加锁。
- 解决不可重复读问题,需要给 读操作加锁。
- 同学发现了这个问题之后,知道了是在他读的过程中,我又改代码了,于是来找我和我约定,同学读代码的时候,我也不能修改。
- 脏读问题约定的是,我修改的时侯,提交之前,同学不要读,是给写加锁。而不可重复读问题是在写加锁的基础上约定,同学读的时候,我不能修改,就是给读加锁。
- 通过这个读加锁,又进一步的降低了事务的并发处理能力(处理效率也降低),提高了事务的隔离性(数据的准确性又提高了)
4.3 幻读
问题描述:
- 当前已经约定了读加锁和写加锁,解决了不可重复读和脏读问题。
- 由于约定了读加锁,同学读的时候我不能修改代码,我在这干的等着光摸鱼不干活有点难受,所以我想了办法,同学读Student.java文件,我就创建一个Teacher.java文件,写这个代码; 这样的情况,大多数情况下都没事,少数情况下,个别同学发现了,读代码读着突然冒出个Teacher.java,有的同学就觉得接受不了。
- 在读加锁和写加锁的前提下,一个事务A两次读取同一个数据,发现读取的数据值是一样的,但是结果集不一样(Student.java 代码内容不变,但是第一次看到的是只有Student.java这个文件,第二次看到的是Student,java和Teacher.java ..)这种就称为"幻读"。
解决方法:串行化执行事务。
- 数据库使用"串行化"这样的方式来解决幻读,彻底放弃并发处理事务,一个接一个的串行的处理事务,这样做并发程度是最低的(没并发了,效率最慢的),隔离性是最高的(准确性也是最高的)
- 相当于是同学们要求,在他们读代码的时候,我不要摸电脑,必须强制摸鱼!!!
4.4 隔离级别
上述三个问题,就是并发处理事务的三个典型问题。
mysql提供了4种隔离级别,对应上述三个问题。针对隔离程度进行设置,来应付不同的需求场景情况:
- read uncommitted (读未提交) 没有进行任何锁限制,并发程度最高(效率最高),隔离性最低(准确性最低)
- read committed (读已提交) 给写加锁了,并发程度降低(速度减低了),隔离性提高了(准确性提高了)。
- repeatable read (可重复读) 给写和读都加锁,并发程度又降低(速度减低了),隔离性又提高了(准确性提高了)。
- serializable (串行化) 严格的按照串行的方式,一个一个的执行事务,并发程度最低(没有并发,速度最低),隔离性最高(准确性最高)。
上述隔离级别是mysql内置的机制,可以直接在mysql配置文件中,修改数据库的隔离级别,来设置当前mysql 工作在哪种状态下。

这几个隔离级别,如何选择?
- 根据不同的实际需求/业务场景了,修改配置文件,设置不同的隔离级别。
- 例如:转账的时候,一分钱都不能差,哪怕慢点,也得转对。准确性要拉满,效率不关键。
- 例如:短视频点赞,一个视频有多少赞,要求快,赞的数量差个十个八个都没事。追求的是效率,准确性就不关键。
- 如果没有通过修改mysql配置文件,手动的去设置隔离级别;默认的隔离级别是repeatable read (可重复读)。一般默认的隔离级别,就能很好的应对开发中的绝大部分场景了。
好啦Y(^o^)Y,本节内容到此就结束了。下一篇内容一定会火速更新!!!
后续还会持续更新MySQL方面的内容,还请大家多多关注本博主,第一时间获取新鲜的知识。
如果觉得文章不错,别忘了一键三连哟! 
相关文章:

【MySQL】MySQL索引与事务
目录 前言 1. 索引 (index) 1.1 概念 1.2 作用 1.3 使用场景 1.4 索引的相关操作 查看索引 创建索引 删除索引 2. 索引背后的数据结构 2.1 B树 2.2 B+树的特点 2.3 B+树的优势 3. 事务 3.1 为什么使用事务 3.2 事…...

Apache Spark 源码解析
Apache Spark 是一个开源的分布式计算系统,提供了高效的大规模数据处理能力。下面我将对 Spark 的核心源码结构进行解析。 核心架构 Spark 的主要代码模块包括: Core (核心模块) 包含 Spark 的基本功能,如任务调度、内存管理、错误恢复等 …...

MySQL的日志--Undo Log【学习笔记】
MySQL的日志--Undo Log 知识来源: 《MySQL是怎样运行的》--- 小孩子4919 为了保证事务的原子性,当事务中途遇到各种错误需要将数据回滚(rollback)到原来的样子。为此MySQL提出撤销日志(Undo Log,也称undo日…...

一洽 全力辅助商户平台在线咨询解决方案
在商业数字化转型加速的背景下,客户对高效服务的需求日益增强。商户平台需要通过优化在线咨询服务,提升客户沟通效率与服务质量。一套综合性的在线咨询解决方案,通过整合多维度功能与智能技术,能够有效满足商户与客户的双向需求&a…...

ctfshow-web-新春欢乐杯
这几天做了这个新春欢乐杯,对于我这个小萌新来说有难度,同时也是收获满满,以下是我解题流程和收获 热身 <?php/* # -*- coding: utf-8 -*- # Author: h1xa # Date: 2022-01-16 15:42:02 # Last Modified by: h1xa # Last Modified …...
)
信奥赛之c++基础(初识循环嵌套与ASCII密码本)
🎠 游乐园编程奇遇记——循环嵌套与ASCII密码本 🎡 第一章:摩天轮与旋转木马——循环嵌套 🎪 游乐场里的双重循环 for(int 排数=1; 排数<=3; 排数++){// 外层循环像摩天轮for(int 座位=1; 座位<=5; 座位++){// 内层循环像旋转木马cout << "🎪"…...

同一电脑下使用 python2 和 python3
我本地先安装的2,然后再安装3。在电脑的环境变量 - Path 内,发现3的路径没有被加上,所以在cmd内输入python调用的是python2目录下的python.exe文件。pip.exe则是在Python/Scripts目录下,也就是默认调用的pip也是2的。 解决方案&…...

第十二届蓝桥杯 2021 C/C++组 直线
目录 题目: 题目描述: 题目链接: 思路: 核心思路: 两点确定一条直线: 思路详解: 代码: 第一种方式代码详解: 第二种方式代码详解: 题目:…...

向量数据库实践:存储和检索向量数据
向量数据库是一种专门设计用于存储和检索向量嵌入的数据库系统,能够支持语义搜索、推荐系统、图像识别等 AI 应用场景。 下面将详细介绍向量数据库中向量数据的存储和检索原理及实际应用,希望对各位读者有所帮助。 一. 向量数据的存储与检索流程 在向量…...

Pandas 数据导出:如何将 DataFrame 追加到 Excel 的不同工作表
在数据分析和数据处理过程中,将数据导出到 Excel 文件是一个常见的需求。Pandas 提供了强大的功能来实现这一需求,尤其是将数据追加到同一个 Excel 文件的不同工作表(Sheet)中。本文将详细介绍如何使用 Pandas 实现这一功能&#…...

区块链驱动的供应链金融创新:模型构建与商业化路径研究
区块链驱动的供应链金融创新:模型构建与商业化路径研究 1. 研究背景与意义 1.1 背景介绍 全球供应链金融市场规模预计2025年将达到3.6万亿美元,但传统模式面临四大核心问题:信息孤岛导致信任成本高昂(占交易成本15-20%…...

DAX Studio将PowerBI与EXCEL连接
DAX Studio将PowerBI与EXCEL连接 具体步骤如下: 第一步:先打开一个PowerBI的文件,在外部工具栏里打开DAXStudio,如图: 第二步:DAXStudio界面,点击Advanced选项卡-->Analyze in Excel&#…...

使用springboot+easyexcel实现导出excel并合并指定单元格
1:准备一个单元格合并策略类代码: import com.alibaba.excel.metadata.Head; import com.alibaba.excel.metadata.data.WriteCellData; import com.alibaba.excel.write.handler.CellWriteHandler; import com.alibaba.excel.write.metadata.holder.Writ…...

conformer编码器
abstract 最近,基于Transformer和卷积神经网络(CNN)的模型在自动语音识别(ASR)中显示出有希望的结果,优于递归神经网络(RNN)。Transformer模型擅长捕捉基于内容的全局交互,而CNN则有效地利用了局部特征。在这项工作中,我们通过研究如何将联合收割机卷积神经网络和tr…...
)
每日c/c++题 备战蓝桥杯(P1252洛谷 马拉松接力赛)
洛谷P1060 马拉松接力赛题解:贪心算法在资源分配中的巧妙应用 题目描述 P1060 马拉松接力赛是一道结合贪心策略与动态规划思想的资源分配问题。题目要求将25公里的马拉松接力赛合理分配给5名选手,使得总耗时最短。每位选手可跑1-10公里的整数距离&…...
)
操作指南:vLLM 部署开源大语言模型(LLM)
vLLM 是一个专为高效部署大语言模型(LLM)设计的开源推理框架,其核心优势在于显存优化、高吞吐量及云原生支持。 vLLM 部署开源大模型的详细步骤及优化策略: 一、环境准备与安装 安装 vLLM 基础安装:通过 pip 直接安装…...

目前市面上知名的数据采集器
程序员爱自己动手打造一切,但这样离钱就会比较远。 市面上知名的数据采集工具 数据采集工具(也称为网络爬虫或数据抓取工具)在市场上有很多选择,以下是目前比较知名和广泛使用的工具分类介绍: 一、开源免费工具 Scra…...

BitNet: 微软开源的 1-bit 大模型推理框架
GitHub:https://github.com/microsoft/BitNet 更多AI开源软件:发现分享好用的AI工具、AI开源软件、AI模型、AI变现 - 小众AI 微软专为 CPU 本地推理和极致压缩(低比特)大模型设计的推理框架。它支持对 1-bit/1.58-bit 量化模型进行…...

前端如何获取文件的 Hash 值?多种方式详解、对比与实践指南
文章目录 前言一、Hash 值为何重要?二、Hash 值基础知识2.1 什么是 Hash?2.2 Hash 在前端的应用场景2.3 常见的 Hash 算法(MD5、SHA 系列) 三、前端获取文件 Hash 的常用方式3.1 使用 SparkMD5 计算 MD5 值3.2 使用 Web Crypto AP…...

Java与Kotlin在Android开发中的全面对比分析
趋势很重要 语言发展背景与现状 Android操作系统自2008年正式发布以来,Java长期作为其主要的开发语言。这种选择源于Java语言的跨平台特性、成熟的生态系统以及广泛开发者基础。然而,随着移动开发需求的快速演变,Java在Android开发中逐渐暴…...

Android Kotlin 依赖注入全解:Koin appModule 配置与多 ViewModel 数据共享实战指南
一、基础配置与概念 1. 什么是 appModule appModule 是 Koin 依赖注入框架中的核心配置模块,用于集中管理应用中的所有依赖项。它本质上是一个 Koin 模块(org.koin.core.module.Module),通过 DSL 方式声明各种组件的创建方式和依…...

Flink TaskManager详解
1. TaskManager 概述 Apache Flink 的 TaskManager 是作业执行的核心工作节点,负责实际的数据处理任务。它与 JobManager 协同工作,接受其调度指令,管理本地资源(如 CPU、内存、网络),并执行具体的算子&am…...
)
Docker安装(Ubuntu22版)
前言 你是否还在为Linux上配置Docker而感到烦恼? 你是否还在为docker search,docker pull连接不上,而感到沮丧? 本文将解决以上你的所有烦恼!快速安装好docker! Docker安装 首先,我们得先卸载…...

《深入浅出ProtoBuf:从环境搭建到高效数据序列化》
ProtoBuf详解 1、初识ProtoBuf2、安装ProtoBuf2.1、ProtoBuf在Windows下的安装2.2、ProtoBuf在Linux下的安装 3、快速上手——通讯录V1.03.1、步骤1:创建.proto文件3.2、步骤2:编译contacts.proto文件,生成C文件3.3、步骤3:序列化…...

【含文档+PPT+源码】基于微信小程序连锁药店商城
项目介绍 本课程演示的是一款基于微信小程序连锁药店商城,主要针对计算机相关专业的正在做毕设的学生与需要项目实战练习的 Java 学习者。 1.包含:项目源码、项目文档、数据库脚本、软件工具等所有资料 2.带你从零开始部署运行本套系统 3.该项目附带的…...

再见,物理删除!MyBatis-Plus @TableLogic 优雅实现逻辑删除
在开发应用程序时,我们经常会遇到需要删除数据的场景。但直接从数据库中物理删除(DELETE)数据有时并非最佳选择。为什么呢? 数据恢复: 一旦物理删除,数据通常难以恢复,误操作可能导致灾难性后果。审计追…...

uni-app中获取用户实时位置完整指南:解决权限报错问题
uni-app中获取用户实时位置完整指南:解决权限报错问题 在uni-app开发运行在微信小程序时,获取用户位置信息是一个常见的需求,无论是用于地图导航、附近推荐还是其他基于位置的服务。然而,许多开发者在调用位置相关API时会遇到各种…...

【AI插件开发】Notepad++ AI插件开发1.0发布和使用说明
一、产品简介 AiCoder是一款为Notepad设计的轻量级AI辅助插件,提供以下核心功能: 嵌入式提问:对选中的文本内容进行AI分析,通过侧边栏聊天界面与AI交互,实现多轮对话、问题解答或代码生成。对话式提问:独…...

UnityEditor - 调用编辑器菜单功能
例如: 调用Edit/Frame Selected In Scene EditorApplication.ExecuteMenuItem("Edit/Frame Selected in Scene"); EditorApplication.ExecuteMenuItem("Edit/Lock view to Selected");...
(十),魔法键使用方法,用户态异常信息说明)
OpenHarmony - 小型系统内核(LiteOS-A)(十),魔法键使用方法,用户态异常信息说明
OpenHarmony - 小型系统内核(LiteOS-A)(十) 十四、魔法键使用方法 使用场景 在系统运行出现无响应等情况时,可以通过魔法键功能确定系统是否被锁中断(魔法键也无响应)或者查看系统任务运行状态…...

在 Vue3 中封装的 Axios 实例中,若需要为部分接口提供手动取消请求的功能
核心思路 封装接口时返回 Promise 和 abort 方法: 为需要支持取消的接口返回一个对象,包含 promise 和 abort 方法,用户可通过 abort 主动中断请求。使用 AbortController 或 CancelToken: 推荐 AbortController(浏览…...

QuecPython+audio:实现音频的录制与播放
概述 QuecPython 作为专为物联网设计的开发框架,通过高度封装的 Python 接口为嵌入式设备提供了完整的音频处理能力。本文主要介绍如何利用 QuecPython 快速实现音频功能的开发。 核心优势 极简开发:3行代码完成基础音频录制与播放。快速上手…...

Langchain入门介绍
[声明] 本文参考:Langchain官方文档 什么是LangChain? LangChain 是一个开源的、用于开发由大型语言模型 (LLM) 驱动的应用程序的框架。它的核心目标是将强大的 LLM(如 GPT-4, Claude, Llama 等)与外部数据源、计算资源和工具连接起来,从…...

WebUI可视化:第4章:Streamlit数据可视化实战
学习目标 ✅ 掌握Streamlit的安装与基础配置 ✅ 能够创建数据驱动的交互式界面 ✅ 实现常见图表(折线图、柱状图等)的绘制 ✅ 开发完整的业务数据分析应用 4.1 Streamlit快速入门 4.1.1 环境安装 打开终端执行: bash pip install streamlit 验证安装: bash stream…...

3.4 Spring Boot异常处理
本实战项目通过Spring Boot实现了一个简单的用户信息查询功能,并展示了如何自定义异常处理机制。项目中创建了用户实体类User和用户控制器UserController,在控制器中通过isValidUserId方法校验用户ID是否有效,若无效则抛出自定义异常InvalidU…...

期货有哪些种类?什么是股指、利率和外汇期货?
期货主要可以分成两大类:商品期货和金融期货。商品期货,顾名思义,就是跟实物商品有关的期货,比如农产品、金属、能源这些。金融期货呢,就是跟金融产品有关的期货,比如外汇、利率、股票指数这些。 一、商品…...

Golang | 位运算
位运算比常规运算快,常用于搜索引擎的筛选功能。例如,数字除以二等价于向右移位,位移运算比除法快。...

[论文阅读]ReAct: Synergizing Reasoning and Acting in Language Models
ReAct: Synergizing Reasoning and Acting in Language Models [2210.03629] ReAct: Synergizing Reasoning and Acting in Language Models ICLR 2023 这是一篇在2022年挂出来的论文,不要以现在更加强大且性能综合的LLM来对这篇文章进行批判。 思想来源于作者对…...

拥有600+门店的宠物连锁医院,实现核心业务系统上云
瑞派宠物医院管理股份有限公司(以下简称“瑞派宠物“)从2017年开始数字化转型之路。瑞派宠物在全国有600连锁门店,随着业务量增加,线下部署的财务系统存在设备老旧、机房环境差等问题,部分在公有云上的业务,…...

OceanBase 跻身 Forrester 三大领域代表厂商,全面支撑AI场景
在生成式AI迅猛发展的当下,智能化数据管理已成为企业提升数字化水平、优化运营效率和强化市场竞争优势的战略重点。Forrester 最新发布的《2025年中国数据管理生态系统趋势报告》中,OceanBase凭借原生分布式架构和一体化产品优势,入选 全局数…...

学生管理系统微服务方式实现
//不用这种方式实现也可以,用这种方式是为了房间我们理解微服务的实现方式 微服务的实现方式就是把一个单项目应用的不同功能封装成单独的项目,然后向外暴露一个接口以便调用。如果需要这个功能我们直接调用这个功能对应项目的接口就可以了 服务之间的…...

OpenAI最新的4o图像生成模型 gpt-image-1 深度解析:API KEY 获取、开发代码示例
1. 引言 近期,OpenAI 正式发布了其最新的图像生成 API,模型标识符为 gpt-image-1。这一重要发布,首次将先前在 ChatGPT 中通过 GPT-4o 模型驱动、备受用户欢迎的先进图像生成能力,以编程接口(API)的形式提…...

NAT穿透
NAT是 Net Address Traslation的缩写,即网络地址转换 NAT部署在网络出口的位置。位于内网和公网之间,是连接内挖个主机和公网的桥梁,双向流量都必须经过NAT,装有NAT软件的路由器叫NAT路由器,NAT路由器拥有公网Ip NAT解…...

人工智能与机器学习:Python从零实现性回归模型
🧠 向所有学习者致敬! “学习不是装满一桶水,而是点燃一把火。” —— 叶芝 我的博客主页: https://lizheng.blog.csdn.net 🌐 欢迎点击加入AI人工智能社区! 🚀 让我们一起努力,共创…...

FreeRTOS
FreeRTOS任务调度的三种方式: 抢占式调度 针对优先级不同的任务 时间片调度 针对优先级相同的任务; FreeRTOS中的一个时间片就等于SysTick(滴答定时器)中断周期(1ms); 协程式调度 后续将不再支持。 …...
)
PCI 总线学习笔记(五)
PCI 总线学习系列,参考自 技术大牛博客: PCIe 扫盲系列博文连载目录篇 书籍:王齐老师的《PCI Express 体系结构导读》 下面的文章中加入了自己的一些理解和实际使用中遇到的一些场景,供日后查询和回忆使用 PCI 总线定义了两类配置…...

PyTorch与CUDA的关系
文章目录 前言一、如何查看PyTorch和torchvision的版本1.1 查看PyTorch版本1.2 查看torchvision版本二、如何确认PyTorch和torchvision是否支持CUDA加速2.1 检查PyTorch是否支持CUDA2.2 查看当前可用的GPU设备2.3 检查torchvision是否支持CUDA三、CUDA版本的秘密:为什么PyTorc…...
)
网络中断事件进行根因分析(RCA)
网络中断事件的根因分析(RCA)详解 根因分析(Root Cause Analysis, RCA)是网络运维中用于定位和解决故障的核心方法,目标是找到问题的根本原因,避免重复发生。以下是完整的RCA流程和方法: 1. RC…...

Mac中 “XX”文件已损坏,无法打开 解决方案
前言 Mac中打开软件 出现“XX”文件已损坏,无法打开的提示 怎么处理? 操作总结 1、查看当前 Gatekeeper 是否启用 spctl --status2、完全关闭 Gatekeeper(允许安装任何来源应用) sudo spctl --master-disable3、打开“系统设…...

如何通过python连接hive,并对里面的表进行增删改查操作
要通过Python连接Hive并对其中的表进行增删改查操作,可以使用pyhive库。下面是一个简单的示例代码,演示如何连接Hive并执行一些操作: from pyhive import hive# 建立连接 conn hive.connect(hostyour_hive_host, port10000, authNOSASL)# 创…...