OpenAI最新的4o图像生成模型 gpt-image-1 深度解析:API KEY 获取、开发代码示例

1. 引言
近期,OpenAI 正式发布了其最新的图像生成 API,模型标识符为 gpt-image-1。这一重要发布,首次将先前在 ChatGPT 中通过 GPT-4o 模型驱动、备受用户欢迎的先进图像生成能力,以编程接口(API)的形式提供给全球开发者和企业。此举不仅是人工智能领域,尤其是多模态 AI 应用发展的一个关键里程碑,更使得将高保真、高灵活性的图像生成功能直接集成到各类工具、平台和应用程序中成为现实。
gpt-image-1 背后的技术已在 ChatGPT 产品中展现出强大的吸引力。据 OpenAI 透露,该功能上线首周,用户便生成了超过 7 亿张图片,并吸引了数百万新用户,充分印证了市场对此类先进图像生成能力的巨大需求与潜力。
本指南旨在基于 OpenAI 官方公告、技术文档、合作伙伴集成案例及初步社区反馈,对 gpt-image-1 API 进行全面深入的分析。我们将详细探讨其技术特性、核心功能、与先前模型的差异、开发者接入方式(包括 API Key 获取与代码示例)、潜在应用场景、安全措施、市场意义及未来展望,为关注 AI 图像生成领域的技术专家、开发者和决策者提供一份有价值的参考。
2. 揭秘 gpt-image-1:新 API 详解
此次 OpenAI 推出的 API,其核心图像生成模型确认为 gpt-image-1。该模型与备受瞩目的 GPT-4o 模型家族紧密关联,直接利用了驱动 ChatGPT 中 GPT-4o 图像生成功能的底层技术。这意味着,开发者现在能通过 API 调用,获得与 ChatGPT 产品相媲美的图像生成体验。
gpt-image-1 的核心架构被定义为**“原生多模态大型语言模型”** (natively multimodal large language model)。这一架构设计是其与 OpenAI 先前如 DALL·E 系列等专门图像生成模型的根本区别。DALL·E 模型专注于图像生成任务,而 gpt-image-1 将视觉理解和生成能力深度嵌入到一个更广泛的语言模型框架内。这种“原生”集成并非简单的模块拼接,而是在统一架构内处理和理解多模态信息。
这种设计赋予了 gpt-image-1 独特优势:
- 更强的知识整合:能有效利用庞大的世界知识库进行图像创作。
- 更深的视觉理解:能够更深刻地理解视觉信息。
- 更优的指令遵循:能更好地理解融合了文本和视觉元素的复杂指令,生成语义和视觉上更连贯、更符合上下文的输出。
例如,当被要求生成一个包含最受欢迎半宝石的玻璃柜时,gpt-image-1 能利用其内置知识,无需外部参考即可准确选择并逼真呈现紫水晶、玫瑰石英、玉石等。
3. 核心功能与技术规格
gpt-image-1 API 展示了一系列强大的核心功能和明确的技术规格,旨在满足开发者对高质量、高控制度图像生成的需求。
-
高保真生成与风格多样性: 模型能生成细节丰富、画面连贯、视觉效果引人注目的高保真图像,包括照片级真实感。其强大的风格适应能力允许开发者通过提示词描述期望的美学风格(如油画、水彩、像素艺术、3D 渲染、极简线条画等),生成多样化的视觉输出。

-
指令遵循与细节控制: 相较于早期模型,
gpt-image-1在遵循用户指令方面表现显著优越。它能更好地理解和执行包含多个对象(GPT-4o 据称可处理 10-20 个对象)和复杂细节的提示词。其物体数量处理能力及从用户上传图像中学习并融入生成(上下文学习)的能力得到增强,有效解决了以往模型在处理复杂场景、精确控制和个性化定制方面的痛点,显著提升了模型在创意和设计任务中的实用性。 -
文本渲染能力:
gpt-image-1在图像中准确渲染清晰易读、符合语境的文本方面取得了重大突破,克服了以往模型的普遍短板。示例展示了其在海报、邀请函等场景中生成高质量嵌入文本的能力。尽管进步显著,但在极端复杂的布局或字体要求下,文本的精确放置和绝对清晰度有时仍可能面临挑战。 -
世界知识整合: 作为原生多模态模型的一部分,
gpt-image-1能调用底层语言模型的广泛世界知识,生成包含符合现实逻辑和常识性细节的图像。
技术规格 (API 参数)
开发者可通过 API 参数精细控制生成过程。关键参数包括:
model: (必需) 指定使用"gpt-image-1"模型。prompt: (必需) 描述所需图像的文本字符串。n: (可选) 生成图像的数量,默认为 1。size: (可选) 图像尺寸。支持"1024x1024"(方形),"1536x1024"(竖向),"1024x1536"(横向)。另有"auto"选项(默认),模型会根据提示词自动选择最佳尺寸。quality: (可选) 渲染质量。选项包括"low","medium","high", 以及"auto"(默认)。format: (可选) 输出文件格式。支持"png"(默认),"jpeg","webp"。output_compression: (可选) 当format为"jpeg"或"webp"时可用,控制压缩级别(0-100%)。background: (可选) 设置透明背景。仅支持"png"和"webp"格式,建议在quality为"medium"或"high"时使用。设为"transparent"启用。moderation: (可选) 控制内容审核过滤器的严格程度。支持"auto"(默认),"low", 或"strict"。(注意:具体可用值请参考最新官方文档)。
其中,output_compression 和 background (透明度) 的加入,直接满足了平面设计和网页开发等实际工作流中的常见需求,简化了后期处理步骤,使 API 更适用于生产环境。
输入要求 (图像输入)
当使用图像作为输入(例如编辑功能)时:
- 支持格式:PNG, JPEG, WEBP, 以及非动画 GIF。
- 文件大小限制:单个图像文件最大 20MB。
- 分辨率考量:虽然主要针对视觉分析提及,但与视觉输入相关的分辨率限制(低分辨率 512x512,高分辨率短边 768px 长边 2000px)在使用图像进行生成或编辑时也应留意。
4. 高级编辑与多模态交互
gpt-image-1 不仅能从零生成图像,还提供强大的图像编辑和多模态交互能力。
编辑能力
API 提供专门的 /images/edits 端点用于修改现有图像:
- 图像修复 (Inpainting): 允许精确修改图像特定区域。需提供原始图像 (
image参数) 和一个“蒙版”图像 (mask参数)。蒙版是与原图尺寸相同、包含透明通道的 PNG 文件,透明区域指示需要根据prompt修改的部分,不透明区域保持不变。 - 图像到图像生成 / 基于参考图的生成: 可提供一张或多张现有图像作为参考 (
image参数),结合文本提示 (prompt) 指导新图像生成,或对参考图应用风格变换、添加元素等。例如,使用多张产品照片生成包含这些产品的礼品套装组合图。 - 多轮优化 (上下文编辑): GPT-4o 模型本身支持在对话中通过自然语言逐步优化图像。虽然当前
/images/editsAPI 端点可能侧重单次编辑,但这种上下文感知、多轮交互的底层能力预示着未来发展。OpenAI 计划将图像生成/编辑功能整合到其Responses API(即将推出),这将允许通过 API 实现更流畅、基于对话状态的图像创作流程,使图像生成更像持续的创作对话,而非一次性命令。
多模态输入处理
编辑端点能同时接受文本 (prompt) 和图像 (image) 输入,实现真正的多模态操作。模型能分析用户上传的图像,并将其作为视觉灵感或将其细节特征整合到生成结果中(上下文学习)。
角色一致性
尽管 gpt-image-1 在生成连贯图像方面有显著改进,但在跨多张图像、多次生成请求中保持角色(如漫画人物、品牌吉祥物)或特定视觉元素的绝对一致性仍是一个挑战。用户实验和 OpenAI 自身都承认模型可能在这方面遇到困难。对于需要高度视觉身份连续性的应用(如系列漫画、游戏资产),开发者仍需精心设计提示策略或进行迭代优化。
5. gpt-image-1 vs. DALL-E 3/2:关键差异分析
为了解 gpt-image-1 的定位和优势,我们将其与 OpenAI 先前的 DALL-E 3 和 DALL-E 2 API 模型进行比较。
-
gpt-image-1:- 核心优势: 提供最高图像质量、最强指令遵循能力、卓越文本渲染、详细编辑功能(修复、多图参考)、支持透明背景、有效利用世界知识。
- 架构: 原生多模态大型语言模型。
- API 端点:
/images/generations,/images/edits。
-
DALL-E 3 (API):
- 核心优势: 优于 DALL-E 2 的图像质量,支持更大分辨率,擅长处理含较多文本的图像。
- 架构: 专门图像生成模型。
- API 端点: 仅
/images/generations。 - 使用注意: 在 ChatGPT 中表现优异部分归功于内部提示优化。直接使用 API 可能需要开发者自行进行提示工程。
gpt-image-1的原生能力可能使其在 API 调用时更直接达到高质量输出。
-
DALL-E 2 (API):
- 核心优势: 成本相对较低,支持快速并发请求,支持变体生成。
- 架构: 专门图像生成模型。
- API 端点:
/images/generations,/images/edits(修复),/images/variations。 - 局限性: 图像质量和指令遵循能力普遍低于 DALL-E 3 和
gpt-image-1。


关键特性对比表:
| 特性/能力 | gpt-image-1 | DALL-E 3 (API) | DALL-E 2 (API) |
| 模型架构 | 原生多模态大语言模型 | 专门图像生成模型 | 专门图像生成模型 |
| 支持的 API 端点 | Generations, Edits | Generations Only | Generations, Edits, Variations |
| 图像质量 | 最高 | 高 (优于 DALL-E 2) | 较低 |
| 指令遵循能力 | 最强 | 较强 | 一般 |
| 文本渲染 | 优越 | 较好 (擅长文本图像) | 较弱 |
| 编辑能力 (API) | 图像修复 (Inpainting), 多图参考 | 不支持 | 图像修复 (Inpainting) |
| 变体生成 (API) | 不支持 | 不支持 | 支持 |
| 透明背景支持 (API) | 支持 (PNG/WebP) | 未明确 (可能不支持) | 未明确 (可能不支持) |
| 世界知识利用 | 强 | 有限 | 有限 |
| 成本层级 (相对) | 最高 | 中等 | 最低 |
| 关键优势 | 最高质量, 精细指令遵循, 透明背景, 详细编辑 | 更大分辨率 (相对 D2), 文本图像 | 低成本, 快速并发, 支持变体 |
注意: 此表基于现有信息总结,具体细节可能随 OpenAI 更新而变化。
6. 开发者指南:获取、访问、集成与定价
开发者需要了解如何访问和集成 gpt-image-1 API,以及相关的成本结构。
API 访问与端点
gpt-image-1通过 OpenAI 标准 REST API (https://api.openai.com/v1) 提供服务。- 图像生成:向
/images/generations发送 POST 请求。 - 图像编辑:向
/images/edits发送 POST 请求。 - 注意:
/images/variations端点不支持gpt-image-1。 - 未来整合:OpenAI 计划将图像生成能力整合进
Responses API,旨在创建有状态的、类似对话的交互,有望实现更流畅的上下文图像生成与编辑。
认证与 SDK
- API 调用采用标准 API 密钥认证,通过 HTTP 请求头
Authorization: Bearer {YOUR_API_KEY}实现。 - OpenAI 提供多种语言的官方 SDK(如 Python, Node.js)简化集成。
OpenAI API Key 获取与代码示例
获取官方 API Key:
您需要在 OpenAI 官网注册账户,并在账户设置中创建 API Key。请妥善保管您的 Key。
(可选) OpenAI代理兼容接口说明:
开发者优选 uiuiapi 创建 API Key,接口 (https://sg.uiuiapi.com/v1/images/generations) 与 OpenAI 大模型以及接口兼容的服务。使用此类服务需要您在该平台注册并获取其特定的 API Token。本文后续代码示例将主要使用官方 OpenAI 端点和库。

代码示例:使用 OpenAI 官方库
(确保已安装 OpenAI Python/Node.js 库,并设置好 OPENAI_API_KEY 环境变量或在代码中配置)
生成图像
你可以使用 图像生成端点 ,基于文本提示创建图像。了解如何自定义输出(尺寸、质量、格式、透明度)可参见下方的自定义图像输出章节。
你可以设置 n 参数,在一次请求中生成多张图片(默认只返回一张图片)。
import OpenAI from "openai";
import fs from "fs";
const openai = new OpenAI();const prompt = `
A children's book drawing of a veterinarian using a stethoscope to
listen to the heartbeat of a baby otter.
`;const result = await openai.images.generate({model: "gpt-image-1",prompt,
});// 保存图片到文件
const image_base64 = result.data[0].b64_json;
const image_bytes = Buffer.from(image_base64, "base64");
fs.writeFileSync("otter.png", image_bytes);
from openai import OpenAI
import base64
client = OpenAI()prompt = """
A children's book drawing of a veterinarian using a stethoscope to
listen to the heartbeat of a baby otter.
"""result = client.images.generate(model="gpt-image-1",prompt=prompt
)image_base64 = result.data[0].b64_json
image_bytes = base64.b64decode(image_base64)# 保存图片到文件
with open("otter.png", "wb") as f:f.write(image_bytes)
curl -X POST "https://api.openai.com/v1/images/generations" \
# 或是在 uiuiapi.com 获取 api key 以上地址就换成uiuiapi地址-H "Authorization: Bearer $OPENAI_API_KEY" \-H "Content-type: application/json" \-d '{"model": "gpt-image-1","prompt": "A childrens book drawing of a veterinarian using a stethoscope to listen to the heartbeat of a baby otter."}' | jq -r '.data[0].b64_json' | base64 --decode > otter.png
编辑图像
图像编辑端点 可用于:
-
编辑已有图像
-
利用其他图片作为参考生成新图像
-
通过上传图像和掩码,仅替换部分区域(即修补/inpainting)
使用参考图像生成新图
你可以用一张或多张图片作为参考,生成新图片。
本例中我们用 4 张输入图片生成一个包含所有物品的礼品篮新图像。
import base64
from openai import OpenAI
client = OpenAI()prompt = """
Generate a photorealistic image of a gift basket on a white background
labeled 'Relax & Unwind' with a ribbon and handwriting-like font,
containing all the items in the reference pictures.
"""result = client.images.edit(model="gpt-image-1",image=[open("body-lotion.png", "rb"),open("bath-bomb.png", "rb"),open("incense-kit.png", "rb"),open("soap.png", "rb"),],prompt=prompt
)image_base64 = result.data[0].b64_json
image_bytes = base64.b64decode(image_base64)# 保存图片到文件
with open("gift-basket.png", "wb") as f:f.write(image_bytes)
import fs from "fs";
import OpenAI, { toFile } from "openai";const client = new OpenAI();const imageFiles = ["bath-bomb.png","body-lotion.png","incense-kit.png","soap.png",
];const images = await Promise.all(imageFiles.map(async (file) =>await toFile(fs.createReadStream(file), null, {type: "image/png",}),),
);const rsp = await client.images.edit({model: "gpt-image-1",image: images,prompt: "Create a lovely gift basket with these four items in it",
});// 保存图片到文件
const image_base64 = rsp.data[0].b64_json;
const image_bytes = Buffer.from(image_base64, "base64");
fs.writeFileSync("basket.png", image_bytes);
curl -s -D >(grep -i x-request-id >&2) \-o >(jq -r '.data[0].b64_json' | base64 --decode > gift-basket.png) \-X POST "https://api.openai.com/v1/images/edits" \-H "Authorization: Bearer $OPENAI_API_KEY" \-F "model=gpt-image-1" \-F "image[]=@body-lotion.png" \-F "image[]=@bath-bomb.png" \-F "image[]=@incense-kit.png" \-F "image[]=@soap.png" \-F 'prompt=Generate a photorealistic image of a gift basket on a white background labeled "Relax & Unwind" with a ribbon and handwriting-like font, containing all the items in the reference pictures'
使用掩码编辑图片(修补)
你可以提供掩码,指定图片哪些区域需要编辑。掩码的透明区域将被替换,黑色区域则保持不变。
你可以用提示描述整个新图像,不只限于被擦除的区域。如果提供多张输入图像,掩码会应用于第一张图片。
from openai import OpenAI
client = OpenAI()result = client.images.edit(model="gpt-image-1",image=open("sunlit_lounge.png", "rb"),mask=open("mask.png", "rb"),prompt="A sunlit indoor lounge area with a pool containing a flamingo"
)image_base64 = result.data[0].b64_json
image_bytes = base64.b64decode(image_base64)# 保存图片到文件
with open("composition.png", "wb") as f:f.write(image_bytes)
import fs from "fs";
import OpenAI, { toFile } from "openai";const client = new OpenAI();const rsp = await client.images.edit({model: "gpt-image-1",image: await toFile(fs.createReadStream("sunlit_lounge.png"), null, {type: "image/png",}),mask: await toFile(fs.createReadStream("mask.png"), null, {type: "image/png",}),prompt: "A sunlit indoor lounge area with a pool containing a flamingo",
});// 保存图片到文件
const image_base64 = rsp.data[0].b64_json;
const image_bytes = Buffer.from(image_base64, "base64");
fs.writeFileSync("lounge.png", image_bytes);
curl -s -D >(grep -i x-request-id >&2) \-o >(jq -r '.data[0].b64_json' | base64 --decode > lounge.png) \-X POST "https://api.openai.com/v1/images/edits" \-H "Authorization: Bearer $OPENAI_API_KEY" \-F "model=gpt-image-1" \-F "mask=@mask.png" \-F "image[]=@sunlit_lounge.png" \-F 'prompt=A sunlit indoor lounge area with a pool containing a flamingo'
掩码要求
待编辑图片和掩码需为相同格式和尺寸(小于 25MB)。
掩码图片还必须包含 alpha 通道。如果用图片编辑工具创建掩码,请确保保存时包含 alpha 通道。
为黑白掩码添加 alpha 通道
你可以用程序方式给黑白掩码添加 alpha 通道。
为黑白掩码添加 alpha 通道
from PIL import Image
from io import BytesIO# 1. 加载黑白掩码为灰度图
mask = Image.open(img_path_mask).convert("L")# 2. 转为 RGBA,以便有 alpha 通道
mask_rgba = mask.convert("RGBA")# 3. 用掩码本身填充 alpha 通道
mask_rgba.putalpha(mask)# 4. 转换为字节
buf = BytesIO()
mask_rgba.save(buf, format="PNG")
mask_bytes = buf.getvalue()# 5. 保存结果文件
img_path_mask_alpha = "mask_alpha.png"
with open(img_path_mask_alpha, "wb") as f:f.write(mask_bytes)
自定义图像输出
你可以配置如下输出选项:
-
尺寸:图像分辨率(如 1024x1024、1024x1536 等)
-
质量:渲染质量(如 low、medium、high)
-
格式:文件输出格式
-
压缩率:JPEG 和 WebP 格式下的压缩级别(0-100%)
-
背景:透明或不透明
尺寸和质量选项
正方形且标准质量的图片生成速度最快。默认尺寸为 1024x1024 像素。
输出格式
Image API 返回 base64 编码的图像数据。默认格式为 png,也可指定 jpeg 或 webp。
如果使用 jpeg 或 webp,还可通过 output_compression 参数控制压缩级别(0-100%)。比如 output_compression=50 表示压缩 50%。
透明度
gpt-image-1 模型支持透明背景。设置 background 参数为 transparent 即可。
仅 png 和 webp 格式支持透明背景。
透明度建议搭配 medium 或 high 质量使用。
生成透明背景图像示例
import OpenAI from "openai";
import fs from "fs";
const openai = new OpenAI();const result = await openai.images.generate({model: "gpt-image-1",prompt: "Draw a 2D pixel art style sprite sheet of a tabby gray cat",size: "1024x1024",background: "transparent",quality: "high",
});// 保存图片到文件
const image_base64 = result.data[0].b64_json;
const image_bytes = Buffer.from(image_base64, "base64");
fs.writeFileSync("sprite.png", image_bytes);
from openai import OpenAI
import base64
client = OpenAI()result = client.images.generate(model="gpt-image-1",prompt="Draw a 2D pixel art style sprite sheet of a tabby gray cat",size="1024x1024",background="transparent",quality="high",
)image_base64 = result.json()["data"][0]["b64_json"]
image_bytes = base64.b64decode(image_base64)# 保存图片到文件
with open("sprite.png", "wb") as f:f.write(image_bytes)
curl -X POST "https://api.openai.com/v1/images" \-H "Authorization: Bearer $OPENAI_API_KEY" \-H "Content-type: application/json" \-d '{"prompt": "Draw a 2D pixel art style sprite sheet of a tabby gray cat","quality": "high","size": "1024x1024","background": "transparent"}' | jq -r 'data[0].b64_json' | base64 --decode > sprite.png
限制
GPT-4o 图像模型是一款强大且多功能的图像生成模型,但仍需注意以下局限:
-
延迟:复杂提示可能需要最多 2 分钟处理。
-
文本渲染:虽较 DALL·E 系列大幅提升,但在精确文字排版和清晰度方面仍有一定难度。
-
一致性:模型有能力保持图像一致性,但多次生成同一角色或品牌元素时,偶尔仍会出现不一致。
-
构图控制:尽管指令理解已提升,模型在元素精准布局、结构化或版式敏感的图像生成上有时仍有困难。
内容审核
所有提示与生成图像都将根据我们的内容政策进行过滤。
使用 gpt-image-1 生成图像时,可以通过 moderation 参数控制审核严格度。支持以下两种取值:
-
auto(默认):标准过滤,限制生成某些潜在不适宜内容。
-
low:限制更少。
费用与延迟
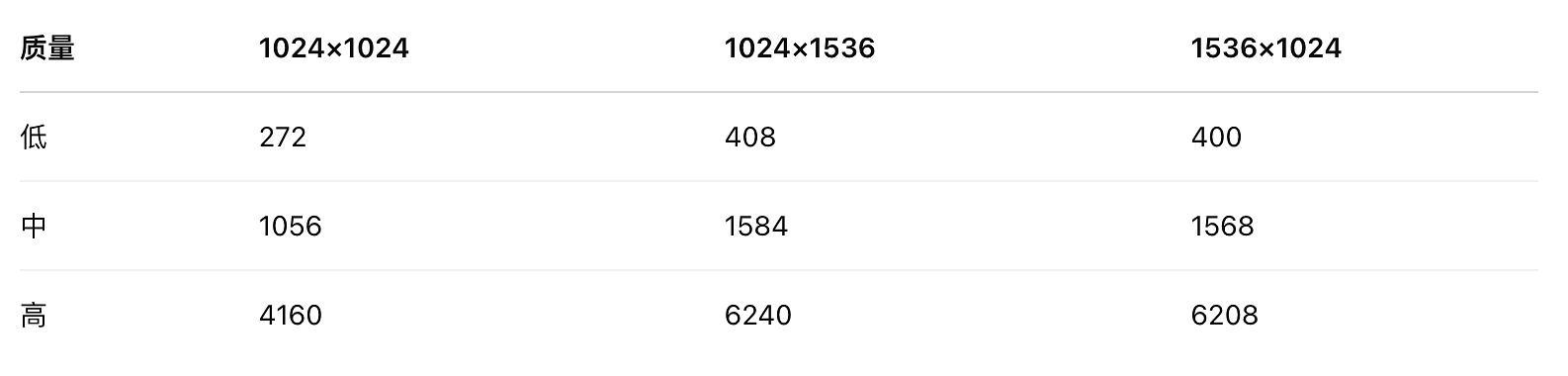
本模型通过先生成专用图像 token 再渲染图片。图片尺寸越大、质量越高,token 数量越多,生成时延与成本也越高。
token 数取决于图像尺寸和质量:
此外还需计算提示文本使用的 输入 token。
详细价格信息可参考 价格页面。
定价结构
gpt-image-1 的使用成本基于token 数量计算,区分不同类型:
- 文本输入 token (提示词): $5 / 百万 token
- 图像输入 token (用于编辑/参考): $10 / 百万 token
- 图像输出 token (生成的图像): $40 / 百万 token
这种结构反映了生成过程是计算资源消耗最大的环节。开发者需考虑成本,尤其对于需要大量生成或高分辨率/高质量图像的应用。
成本估算示例 (基于 OpenAI 信息):
一张 1024x1024 方形图像生成成本大约:
- 低质量 (low): ~$0.02
- 中等质量 (medium): ~$0.07
- 高质量 (high): ~$0.19
(低质量方形图约消耗 272 token,高质量竖向图约消耗 6,240 token)
图像 Token 计算
图像输入的 token 数并非基于像素点,而是根据尺寸计算覆盖图像所需的 32x32 像素“补丁”(patch) 数量。若所需补丁数超 1536 token 预算,图像会被缩小以适应,保持宽高比。最终计费 token 数为调整后的补丁数,单个输入图像上限 1536 token。此计算方式对成本预估带来一定复杂性。
访问要求与潜在问题
- 组织验证: 使用
gpt-image-1API 可能需要完成 OpenAI 的组织验证。 - 初期访问问题: API 发布初期,社区报告了多种访问障碍:
- 组织验证流程卡顿或延迟生效。
- API 密钥缓存问题 (需生成新 Key)。
- 非预期的速率限制错误。
- 模型未在可用列表中显示。
- 地理区域限制 (HTTP 403 错误)。 这些问题给早期采用者带来不便,凸显了新模型推广中的运营挑战。
- 速率限制: API 使用受速率限制 (通常为 TPM - Tokens Per Minute)。
gpt-image-1的具体限制值请查阅最新官方文档或账户后台。
OpenAI gpt-image-1 API 的发布是 AI 图像生成领域的重大进展。它首次将基于 GPT-4o 的领先原生多模态图像生成能力开放给开发者,提供了前所未有的图像质量、指令遵循精度、文本渲染效果和高级编辑功能,相较于 DALL-E 3/2 API 实现了显著飞跃。
该 API 为各行业开发者提供了强大的新工具,有望催生大量创新应用和工作流,从自动化营销素材到交互式设计辅助,再到更智能的多模态 AI 代理。其原生多模态架构预示着视觉内容生成将在未来人机交互中扮演更核心、无缝的角色。
开发者在使用时需考虑其相对较高的成本、关注模型在一致性等方面的局限、并留意潜在的访问稳定性问题。同时,负责任地使用这项技术至关重要。OpenAI 通过安全护栏、可控审核及 C2PA 元数据等措施展现了对安全和溯源的重视。
总而言之,gpt-image-1 API 不仅是 OpenAI 技术实力的展示,更是其推动多模态 AI 平台化、赋能开发者生态战略的关键一步。它的出现,连同 OpenAI 近期发布的一系列先进模型和工具,共同描绘了一个更加智能、交互、多模态的 AI 应用未来。
相关文章:

OpenAI最新的4o图像生成模型 gpt-image-1 深度解析:API KEY 获取、开发代码示例
1. 引言 近期,OpenAI 正式发布了其最新的图像生成 API,模型标识符为 gpt-image-1。这一重要发布,首次将先前在 ChatGPT 中通过 GPT-4o 模型驱动、备受用户欢迎的先进图像生成能力,以编程接口(API)的形式提…...

NAT穿透
NAT是 Net Address Traslation的缩写,即网络地址转换 NAT部署在网络出口的位置。位于内网和公网之间,是连接内挖个主机和公网的桥梁,双向流量都必须经过NAT,装有NAT软件的路由器叫NAT路由器,NAT路由器拥有公网Ip NAT解…...

人工智能与机器学习:Python从零实现性回归模型
🧠 向所有学习者致敬! “学习不是装满一桶水,而是点燃一把火。” —— 叶芝 我的博客主页: https://lizheng.blog.csdn.net 🌐 欢迎点击加入AI人工智能社区! 🚀 让我们一起努力,共创…...

FreeRTOS
FreeRTOS任务调度的三种方式: 抢占式调度 针对优先级不同的任务 时间片调度 针对优先级相同的任务; FreeRTOS中的一个时间片就等于SysTick(滴答定时器)中断周期(1ms); 协程式调度 后续将不再支持。 …...
)
PCI 总线学习笔记(五)
PCI 总线学习系列,参考自 技术大牛博客: PCIe 扫盲系列博文连载目录篇 书籍:王齐老师的《PCI Express 体系结构导读》 下面的文章中加入了自己的一些理解和实际使用中遇到的一些场景,供日后查询和回忆使用 PCI 总线定义了两类配置…...

PyTorch与CUDA的关系
文章目录 前言一、如何查看PyTorch和torchvision的版本1.1 查看PyTorch版本1.2 查看torchvision版本二、如何确认PyTorch和torchvision是否支持CUDA加速2.1 检查PyTorch是否支持CUDA2.2 查看当前可用的GPU设备2.3 检查torchvision是否支持CUDA三、CUDA版本的秘密:为什么PyTorc…...
)
网络中断事件进行根因分析(RCA)
网络中断事件的根因分析(RCA)详解 根因分析(Root Cause Analysis, RCA)是网络运维中用于定位和解决故障的核心方法,目标是找到问题的根本原因,避免重复发生。以下是完整的RCA流程和方法: 1. RC…...

Mac中 “XX”文件已损坏,无法打开 解决方案
前言 Mac中打开软件 出现“XX”文件已损坏,无法打开的提示 怎么处理? 操作总结 1、查看当前 Gatekeeper 是否启用 spctl --status2、完全关闭 Gatekeeper(允许安装任何来源应用) sudo spctl --master-disable3、打开“系统设…...

如何通过python连接hive,并对里面的表进行增删改查操作
要通过Python连接Hive并对其中的表进行增删改查操作,可以使用pyhive库。下面是一个简单的示例代码,演示如何连接Hive并执行一些操作: from pyhive import hive# 建立连接 conn hive.connect(hostyour_hive_host, port10000, authNOSASL)# 创…...

对Mac文字双击或三击鼠标左键没有任何反应
目录 项目场景: 问题描述 原因分析: 解决方案: 项目场景: 在使用Mac系统的时候,使用Apple无线鼠标,双击左键能够选取某个单词或词语,三击左键能够选取某一行,(百度、…...

【维护窗口内最值+单调队列/优先队列】Leetcode 239. 滑动窗口最大值
题目要求 给定一个整数数组 nums,有一个大小为 k 的滑动窗口从数组的最左侧移动到数组的最右侧。滑动窗口每次只向右移动一位。要求返回滑动窗口中的最大值。 示例 1 输入:nums [1,3,-1,-3,5,3,6,7], k 3 输出:[3,3,5,5,6,7] 解释&#…...

【Leetcode 每日一题】2845. 统计趣味子数组的数目
问题背景 给你一个下标从 0 0 0 开始的整数数组 n u m s nums nums,以及整数 m o d u l o modulo modulo 和整数 k k k。 请你找出并统计数组中 趣味子数组 的数目。 如果 子数组 n u m s [ l . . r ] nums[l..r] nums[l..r] 满足下述条件,则称其为…...

SDC命令详解:使用get_cells命令进行查询
相关阅读 SDC命令详解https://blog.csdn.net/weixin_45791458/category_12931432.html?spm1001.2014.3001.5482 get_cells命令用于创建一个单元对象集合,关于设计对象和集合的更详细介绍,可以参考下面的博客。 Synopsys:设计对象https://c…...

正则表达式及其游戏中应用
一、正则表达式基础知识 ✅ 什么是正则表达式? 正则表达式是一种用来匹配字符串的规则表达式,常用于搜索、验证、替换等文本处理场景。 比如你想找出玩家输入中的邮箱、命令、作弊码……正则就特别好用。 📚 常见语法速查表: …...
 之间共享 DLL)
如何在 MinGW 和 Visual Studio (MSVC) 之间共享 DLL
如何在 MinGW 和 Visual Studio (MSVC) 之间共享 DLL ✅ .dll.a 和 .lib 是什么? 1. .dll.a(MinGW 下的 import library) 作用:链接时告诉编译器如何调用 DLL 中的函数。谁用它:MinGW 编译器(如 g&#x…...

【HTTP/2和HTTP/3的应用现状:看不见的革命】
HTTP/2和HTTP/3的应用现状:看不见的革命 实际上,HTTP/2和HTTP/3已经被众多著名网站广泛采用,只是这场革命对普通用户来说是"无形"的。让我们揭开这个技术变革的真相。 著名网站的HTTP/2和HTTP/3采用情况 #mermaid-svg-MtfrNDo5DG…...

ts中null类型--结合在vue中的使用、tsconfig.json
总结 TypeScript 中的 null 是一个独立的类型,用于明确表示“无值”或“空值”。在实际开发中,常通过联合类型(如 string | null)或与 ref 结合使用,确保代码的类型安全和可读性。 详情解释 在 TypeScript 中,null 是一个独立的类型,表示 null 值本身。以下是一些关于…...

Hadoop生态圈框架部署 - Windows上部署Hadoop
文章目录 前言一、下载Hadoop安装包及bin目录1. 下载Hadoop安装包2. 下载Hadoop的bin目录 二、安装Hadoop1. 解压Hadoop安装包2. 解压Hadoop的Windows工具包 三、配置Hadoop1. 配置Hadoop环境变量1.1 打开系统属性设置1.2 配置环境变量1.3 验证环境变量是否配置成功 2. 修改Had…...
)
深度学习笔记22-RNN心脏病预测(Tensorflow)
🍨 本文为🔗365天深度学习训练营中的学习记录博客🍖 原作者:K同学啊 一、前期准备 1.导入数据 import tensorflow as tf import pandas as pd import numpy as np dfpd.read_csv("E:/heart.csv") df 2.检查数据是否有…...

面试踩过的坑
1、 “”和equals 的区别 “”是运算符,如果是基本数据类型,则比较存储的值;如果是引用数据类型,则比较所指向对象的地址值。equals是Object的方法,比较的是所指向的对象的地址值,一般情况下,重…...

【机器学习速记】面试重点/期末考试
自用,有错误欢迎评论区指出 目录 一、机器学习基础概念 二、机器学习类型分类 三、经典算法与原理 1. 线性模型 2. 决策树 3. SVM(支持向量机) 4. K近邻(KNN) 5. 贝叶斯分类 6. 集成学习 四、模型评价指标 五、模型泛化能力与调参 六、特征工程与数据预处理 七、维…...

Cursor如何手动添加多个大模型?
笔者在前面的文章Cursor接入API: deepseekV3(免费)_cursor api-CSDN博客中介绍了如何添加deepseek到Cursor中,如果要添加其他大模型,比如阿里的通义千问qwen-max-2025-01-25等,方法一样,在官方网站找到模型名称和base_url…...

FerretDB:基于PostgreSQL的MongoDB替代产品
FerretDB 是一种基于NoSQL的分布式数据库,它旨在通过优化存储和查询机制来提供卓越的性能和可靠性。它支持水平扩展和高并发访问,并提供灵活的数据模型,使开发人员能够轻松地存储和检索各种类型的数据。 Stars 数10,057Forks 数439 主要特点…...

JDBC 批处理与事务处理:提升数据操作效率与一致性的密钥
目录 一. JDBC批量添加数据 1. 什么是批量添加数据 2. 实现数据的批量添加 a. 方式一:不分块 二. JDBC事务处理 1. 什么是事务 2. JDBC事务处理实现 三. 总结 前言 本文来讲解JDBC的批处理和事务处理 这对数据的安全性和准确性以及高效率提供很好的办法 话不…...

vue2实现Blod文件流下载
实现思路: 动态创建一个a标签,模拟点击打开链接,实现下载 downLoad() { //调用下载接口Export({Id: id}).then(res > {this.showLoading false;if (res && res.data && res.data.returnCode -1) {this.msgError(res.d…...

js数据结构之栈
JavaScript数据结构 一、什么是数据结构? 数据结构是向相互之间存在一种或者多种特定关系的数据组成的集合, 采用合适的数据结构能给开发者提高开发和储存效率.比如我们在学习Es6中的我们新接触的到的(Set, map), 在合适的时候使用它们能帮助我们更快的的解决问题. 我们每个在…...

[Windows] 卡巴斯基Kaspersky 21.21.7.384 免费版
卡巴斯基免费版从界面到功能和使用体验来说,简洁、高效、严苛、轻巧,可以“弥补”火绒杀毒能力不强,同时也不会像 Microsoft Defender 误报。 链接1:https://pan.xunlei.com/s/VOOhFEeznr_4W6s7-XT8IwN-A1?pwdztn4# 链接2&…...

【HFP】蓝牙HFP协议中音频连接转移与拨号功能的深度解析
目录 一、核心功能矩阵 二、音频连接向 HF 转移 2.1 转移概述 2.2 前提条件 2.3 适用情况 2.4 转移流程 2.5 注意事项 2.6 示例图 三、音频连接向 AG 转移 3.1 转移概述 3.2 前提条件 3.3 特殊情况处理 3.4 转移流程 3.5 注意事项 3.6 示例图 四、通过HF提供号…...
)
Android学习总结之Glide篇(缓存和生命周期)
一、Glide缓存 1. 内存缓存 内存缓存主要包含活动资源缓存与 LRU 内存缓存这两个级别。 活动资源缓存(Active Resources) 作用:用于存放当前正在被显示的图片资源。当某张图片正展示在 ImageView 上时,它会被纳入活动资源缓存…...

Python 快速获取Excel工作表名称
文章目录 前言准备工作Python 获取Excel中所有工作表的名称Python 获取Excel中隐藏工作表的名称 前言 在数据分析与办公自动化领域,通过Python处理Excel文件已成为必备技能。通过获取工作表名称,我们可以: 快速了解文件结构自动化处理多工作…...

基于Docker的Flask项目部署完整指南
基于Docker的Flask项目部署完整指南 项目结构与文件说明 TextWeb/ ├── .dockerignore # Docker构建忽略配置 ├── Dockerfile # Docker镜像构建文件 ├── requirements.txt # Python依赖清单 └── WebServer/└── main.py # Fl…...
)
分布式定时任务(xxl-job)
简介 什么是XXL-JOB 详细的文档类容可以看下面这个链接进入readme xxl-job简介以及下载地址 XXL-JOB是一个分布式任务调度平台,其核心设计目标是开发迅速、学习简单、轻量级、易扩展 在Java Spring Cloud微服务架构中,使用独立的定时任务调度中心&…...

PostgreSQL使用LIKE右模糊没有走索引分析验证
建表&数据初始化可参考PostgreSQL 分区表——范围分区SQL实践 背景: 给t_common_work_order_log的handle_user_name新建索引后,使用LIKE右模糊匹配查询时,发现走的全表扫描 CREATE INDEX order_log_handle_user_name_index ON t_commo…...

Jenkins流水线管理工具
文章目录 前言: DevOps时代的自动化核心 —Jenkins一、Jenkins是什么?二、Linux安装Jenkinswar包方式安装依赖环境下载 Jenkins WAR 包启动 Jenkins 服务启动日志验证配置插件镜像源 docker镜像方式安装依赖环境拉取 Jenkins 镜像运行 Jenkins 容器获取初…...

2025年保安员证考试题库及答案
一、单选题 96、手指出血,为达到止血作用,应该压住()。 A.出血手指的尖端 B.出血手指根部前后两侧 C.出血手指根部左右两侧 D.腕部的桡动脉、尺动脉 答案:C 97、下列选项中对干粉灭火器使用方法叙述错误的是&…...

观测云数据在Grafana展示的最佳实践
背景 在当今的数据驱动世界中,组织越来越依赖于实时数据来做出决策。数据可视化是理解和分析这些数据的关键工具,它帮助用户将复杂的数据集转换成直观的图表和仪表板,从而更容易识别趋势、模式和异常。Grafana,作为一个功能强大的…...

点云从入门到精通技术详解100篇-基于二次误差和高斯混合模型的点云配准算法
目录 知识储备 结合二次误差度量与高斯混合模型的点云配准 算法核心创新点: 关键参数说明: 性能优化建议: 前言 国内外研究现状 全局配准算法的国内外研究 局部配准算法的国内外研究 2 点云配准相关概念与方法 2.1 什么是点云配准 2.2 点云的获取及点云主要数据…...

shell命令一
&> /dev/null yum -y install vsftpd &> /dev/null&> /dev/null &>:将命令的**标准输出(stdout)和标准错误(stderr)**同时重定向。/dev/null:Linux中的“黑洞”设备…...

MySQL性能常用优化技巧总结
1. 索引优化 创建合适的索引 -- 为常用查询条件创建索引 ALTER TABLE users ADD INDEX idx_email (email); ALTER TABLE orders ADD INDEX idx_customer_date (customer_id, order_date);避免索引失效的情况 -- 避免在索引列上使用函数 SELECT * FROM users WHERE DATE(crea…...

在 Spring Boot 中实现 WebSockets
什么是 WebSockets? WebSockets 是一种基于 TCP 的全双工通信协议,允许客户端和服务器之间建立持久的双向连接,用于实时数据交换。相较于传统的 HTTP 请求-响应模型,WebSockets 提供了低延迟、高效率的通信方式,特别适…...

stone 3d v3.3.0版本发布,含时间线和连接器等新功能
1.新加了时间线(timeline)编辑器,可以类似blender一样给对象制作动画 2.新加了度量(metrics)系统,通过scene对象检测器中的useMetrics属性来启用或禁用,启用时所选物体将显示三维度量数据 新加了…...

Parasoft C++Test软件单元测试_对函数打桩的详细介绍
系列文章目录 Parasoft C++Test软件静态分析:操作指南(编码规范、质量度量)、常见问题及处理 Parasoft C++Test软件单元测试:操作指南、实例讲解、常见问题及处理 Parasoft C++Test软件集成测试:操作指南、实例讲解、常见问题及处理 进阶扩展:自动生成静态分析文档、自动…...

Safety Estimands与Efficacy Estimands的差异剖析
1. 研究目标差异 1.1 安全性估计目标 1.1.1 关注潜在风险 安全性估计目标着重于治疗可能引发的不良事件(AE)、严重不良事件(SAE)或实验室指标异常,如化疗药物导致中性粒细胞减少症的发生率,这些指标直接关联到患者治疗过程中的健康风险。 这些潜在风险的评估对于确保治…...

HTML 详解:从基础结构到语义标签
目录 一、HTML 是什么?二、HTML 的基本结构✅ 简要说明: 三、常见 HTML 标签讲解3.1 标题标签 <h1> ~ <h6>3.2 段落和换行3.3 超链接3.4 图像插入3.5 列表无序列表:有序列表: 3.6 表格结构 四、HTML 语义化标签详解五…...

联合索引`ABC`,使用`B=... AND C=... AND A=...`会走索引吗?
在MySQL中,联合索引ABC的查询使用B... AND C... AND A...时,是否使用索引取决于查询条件的顺序和优化器的处理。 一、索引使用原理 最左前缀原则 联合索引的底层存储和查询优化遵循最左前缀匹配原则,即查询条件必须从索引的最左侧列开始连续匹…...

HTML 模板技术与服务端渲染
HTML 模板技术与服务端渲染 引言 在现代前端开发生态中,HTML模板技术与服务端渲染(SSR)构成了连接前后端的重要桥梁。当单页应用(SPA)因其客户端渲染特性而面临首屏加载速度慢、白屏时间长和SEO不友好等问题时,服务端渲染技术提供了一种优雅的解决方案…...

MySQL的MVCC【学习笔记】
MVCC 事务的隔离级别分为四种,其中Read Committed和Repeatable Read隔离级别,部分实现就是通过MVCC(Multi-Version Concurrency Control,多版本并发控制) 版本链 版本链是通过undo日志实现的, 事务每次修改…...
,安装可视化工具kibana)
linux安装单节点Elasticsearch(es),安装可视化工具kibana
真的,我安装个es和kibana,找了好多帖子,问了好几遍ai才安装成功,在这里记录一下,我相信,跟着我的步骤走,99%会成功; 为了让大家直观的看到安装过程,我把我服务器的es和ki…...
上手Go Gin 基于Go语言开发的Web框架,本文介绍了各种路由的配置信息;包含各场景下请求参数的基本传入接收)
(Go Gin)上手Go Gin 基于Go语言开发的Web框架,本文介绍了各种路由的配置信息;包含各场景下请求参数的基本传入接收
1. 路由 gin 框架中采用的路优酷是基于httprouter做的 HttpRouter 是一个高性能的 HTTP 请求路由器,适用于 Go 语言。它的设计目标是提供高效的路由匹配和低内存占用,特别适合需要高性能和简单路由的应用场景。 主要特点 显式匹配:与其他路由…...

纯HTMLCSS静态网站——元神
《原神》主题网页介绍 以对该网页的详细介绍 网页整体结构 头部(header):包含网站的 logo 和导航栏。logo 部分展示了 “原神” 字样,点击可返回首页。导航栏提供了多个页面链接,包括首页、音乐、视频、壁纸、世界、…...