人工智能与机器学习:Python从零实现性回归模型
🧠 向所有学习者致敬!
“学习不是装满一桶水,而是点燃一把火。” —— 叶芝
我的博客主页: https://lizheng.blog.csdn.net
🌐 欢迎点击加入AI人工智能社区!
🚀 让我们一起努力,共创AI未来! 🚀
前言
在 AI 的热潮中,很容易忽视那些让它得以实现的基础数学和技术。作为一名专业人士,通过不使用机器学习库(比如 sklearn、TensorFlow、PyTorch 等)来编写模型,可以显著提升你对这些基础技术的理解。因为有时候,用现成的工具就像吃别人嚼过的糖,没劲!自己动手,那才叫真本事,不仅能搞懂背后的原理,还能在朋友面前炫耀一番:“看我这代码,多牛!”所以,咱们这就开始,一起踏上这个充满挑战和乐趣的旅程吧!🚀
本系列我们会深入探讨各种机器学习模型,并从零搭建它们。在每篇文章结束时,我希望读者能够对这些我们每天作为数据专业人士使用的模型有极其深入和基础的理解。咱们就从多元线性回归开始吧!
多元线性回归
多元线性回归可以用来模拟两个或多个自变量与一个数值型因变量之间的关系。日常用例包括根据房屋的卧室数量、浴室数量、面积等信息预测房价。咱们先来聊聊多元线性回归的一些关键假设。
- 自变量与因变量的线性关系:具体来说,任何一个自变量(或特征)变化 1 个单位时,因变量应该以恒定的速率变化。
- 没有多重共线性:这意味着特征之间需要相互独立。以房价为例,如果卧室数量和浴室数量之间存在某种相关性,这可能会影响模型的性能。确保没有或最小化多重共线性,也能让你更高效地利用给定的数据。
- 同方差性:这意味着在任何自变量水平下,误差都是恒定的。如果咱们的房价预测模型显示,随着预测价格的上升,误差也在增加,那咱们就不能说这个模型满足同方差性了。可能需要对特征数据进行一些变换,以满足这个假设。
数学原理
还记得 (y = mx + b) 吗?大多数人在公立学校的时候都学过这个公式。而多元线性回归则可以用下面的公式表示:
y = B 0 + B 1 x 1 + B 2 x 2 + ⋯ + B n x n + E y = B_0 + B_1x_1 + B_2x_2 + \dots + B_nx_n + E y=B0+B1x1+B2x2+⋯+Bnxn+E
图由作者通过 LaTeX Markdown 提供
- (y):因变量或目标变量,也就是咱们要预测的东西。
- (B_0, B_1, \dots, B_n):“Beta” 或自变量的系数。(B_0) 是截距,类似于 (y = mx + b) 中的 (b)。剩下的系数分别代表剩下的自变量或特征的系数。
- (x_1, x_2, \dots, x_n):自变量或特征。
- (E):“Epsilon”,更实际地说是误差项,也就是咱们的预测值与实际 (y) 之间的差距。
你也可以用矩阵表示法来表示多元线性回归方程。我个人更喜欢这种方法,因为它让我不得不从向量和矩阵的角度去思考,而这些正是几乎所有机器学习模型背后的数学核心。
Y = X B + E \mathbf{Y} = \mathbf{X} \mathbf{B} + \mathbf{E} Y=XB+E
图由作者通过 LaTeX Markdown 提供
咱们来更直观地看看这些变量里都有啥。先从 (\mathbf{X}) 开始,它代表了咱们所有的特征数据,是一个矩阵。注意,这个矩阵的第一列全是 1。为啥呢?这代表了截距项 (B_0) 的占位符。
从数据角度来看,咱们有啥呢?咱们有所有的特征数据、目标变量 (Y),误差项理论上是未知的,但它只是预测值 (y) 与实际值 (y) 之间的差距。换句话说,它只是用来补全方程的。所以,咱们需要求解的是 (\mathbf{B}),也就是权重。
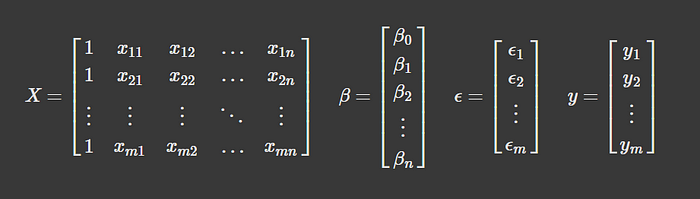
图由作者提供
最小化代价函数
要找到 (\mathbf{B}),请注意,咱们并不是直接求解它。相反,咱们想找到向量 (\mathbf{B}) 中的值,使得预测值与实际值之间的误差最小化。这是通过最小化关于 (\mathbf{B}) 的代价函数来实现的,这个代价函数也被称为均方误差。
MSE = 1 n ∑ i = 1 n ( y i − y ^ i ) 2 \text{MSE} = \frac{1}{n} \sum_{i=1}^{n} (y_i - \hat{y}_i)^2 MSE=n1i=1∑n(yi−y^i)2
图由作者通过 LaTeX Markdown 提供
那怎么找到一个函数的最小值呢?求导并把导数设为 0。在这个例子中,咱们会执行这些步骤,然后求解 (\mathbf{B})。以下是逐步推导:展开代价函数、求导、把导数设为 0 来最小化函数,最后重新排列求解 (\mathbf{B})。
展开代价函数
B = ( X T X ) − 1 X T Y \mathbf{B} = (\mathbf{X}^T \mathbf{X})^{-1} \mathbf{X}^T \mathbf{Y} B=(XTX)−1XTY
图由作者通过 LaTeX Markdown 提供
MSE = 1 n ( Y − X B ) T ( Y − X B ) \text{MSE} = \frac{1}{n} (\mathbf{Y} - \mathbf{X} \mathbf{B})^T (\mathbf{Y} - \mathbf{X} \mathbf{B}) MSE=n1(Y−XB)T(Y−XB)
图由作者通过 LaTeX Markdown 提供
对 (\mathbf{B}) 求导
∂ MSE ∂ B = − 2 n X T ( Y − X B ) \frac{\partial \text{MSE}}{\partial \mathbf{B}} = -\frac{2}{n} \mathbf{X}^T (\mathbf{Y} - \mathbf{X} \mathbf{B}) ∂B∂MSE=−n2XT(Y−XB)
图由作者通过 LaTeX Markdown 提供
最小化函数,即导数设为 0
− 2 n X T ( Y − X B ) = 0 -\frac{2}{n} \mathbf{X}^T (\mathbf{Y} - \mathbf{X} \mathbf{B}) = 0 −n2XT(Y−XB)=0
图由作者通过 LaTeX Markdown 提供
求解 (\mathbf{B})
B = ( X T X ) − 1 X T Y \mathbf{B} = (\mathbf{X}^T \mathbf{X})^{-1} \mathbf{X}^T \mathbf{Y} B=(XTX)−1XTY
图由作者通过 LaTeX Markdown 提供
现在咱们已经搞懂了这个算法背后的数学原理,接下来就用 Python 来实现它吧!
我们的多元线性回归对象
正如前面提到的,咱们会在 Python 中实现它,而且不使用机器学习库。我超喜欢面向对象编程,所以咱们会搭建一个自己的多元线性回归对象。自己动手搭建这个对象的好处是,咱们可以随心所欲地添加功能。比如,我希望咱们的对象能方便地打印出评估指标,还能画出预测值与实际值的散点图。
咱们先从创建对象、导入需要的库(放心,我不会偷偷导入 sklearn 的),还有初始化函数开始。正如我前面提到的,我会搭建一个能自己进行训练集和测试集划分的多元线性回归对象。我希望这个对象能满足涉及这个算法的典型项目的所有需求,除了数据导入。
import pandas as pd
import numpy as np
import random
import matplotlib.pyplot as pltclass MultipleLinearRegression:def __init__(self):# 模型系数,初始值为 None,稍后会计算self.coefficients = None# 训练集特征数据self.X_train = None# 训练集目标数据self.y_train = None# 测试集特征数据self.X_test = None# 测试集目标数据self.y_test = None# 预测值self.y_pred = None
训练集/测试集划分方法
接下来,咱们添加第一个方法。这个方法和 sklearn 中的 train_test_split 长得很像。顾名思义,它会根据训练集的比例,把数据分成训练集和测试集。
def train_test_split(self, X, y, train_size=0.8, random_state=None):"""将数据划分为训练集和测试集。"""if random_state:np.random.seed(random_state)indices = np.arange(len(X))np.random.shuffle(indices)train_size = int(len(X) * train_size)train_indices = indices[:train_size]test_indices = indices[train_size:]self.X_train, self.X_test = X[X.index.isin(train_indices)], X[X.index.isin(test_indices)]self.y_train, self.y_test = y[y.index.isin(train_indices)], y[y.index.isin(test_indices)]
拟合方法
接下来的方法将是咱们对象中最复杂的部分。这里咱们会用训练数据来拟合模型。再次强调,咱们要解的是截距值和系数,这些都由向量 (\mathbf{B}) 表示。
B = ( X T X ) − 1 X T Y \mathbf{B} = (\mathbf{X}^T \mathbf{X})^{-1} \mathbf{X}^T \mathbf{Y} B=(XTX)−1XTY
图由作者通过 LaTeX Markdown 提供
咱们一步步来。准备好学习 numpy 中的一些酷炫函数吧!记得,(\mathbf{X}) 是一个矩阵。目前,矩阵 (\mathbf{X}) 里只有特征数据。回想一下前面的内容,咱们需要一个全为 1 的列,作为截距系数 (B_0) 的占位符。这就是 np.ones() 和 np.hstack() 的用武之地。咱们需要这一列 1 的行数和特征数据的行数一样多。可以用矩阵 (\mathbf{X}) 的 shape() 方法轻松获取行数。第二个参数告诉 np.ones() 需要多少列 1。接下来,用 np.hstack() 把这一列 1 插入到矩阵 (\mathbf{X}) 的第一列。
跟上节奏了吗?现在该讲我认为这个项目中最复杂的代码行了。来看看咱们在解这个方程时必须执行的转置方法(用 (T) 表示)。当你转置一个矩阵时,第一行变成第一列,第二行变成第二列,以此类推。这也意味着一个形状为 2×3 的矩阵会变成一个形状为 3×2 的矩阵。下面是一个代码示例,直观展示这个过程:
import numpy as npa = np.array([[1,2,3],[4,5,6]])print(a,"\n")
print(a.T)

图由作者提供
接下来,咱们讲讲怎么进行矩阵乘法,也就是点积乘法。在 Python 中,特别是在 numpy 中,可以用 "@" 符号进行点积乘法。注意,这个符号经常被用作函数装饰器,但这超出了本文的范围。那两个矩阵怎么相乘呢?简单来说,可以定义为:将第一个矩阵的每一行的元素分别与第二个矩阵的每一列的元素相乘,然后求和。咱们可以用下面的函数来定义它。
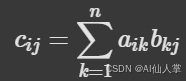
定义只能帮你理解到这儿啦,咱们再看看 Python 里的另一个例子。假设你有两个矩阵,A 和 B,它们都是 2×2 的。如果咱们把这两个矩阵相乘,会得到下面这个矩阵,叫作矩阵 C。
import numpy as npa = np.array([[1,2],[3,4]])b = np.array([[5,6],[7,8]])c = (a @ b)
print(c)
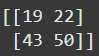
咱们来回顾一下矩阵 C 中的每个值是怎么来的,按行依次来看。第一个值 19 在第一行第一列,计算过程如下:
[
(1 \times 5) + (2 \times 7)
]
更明确地说,咱们取矩阵 A 第一行的第一个元素,乘以矩阵 B 第一列的第一个元素。接着,取矩阵 A 第一行的第二个元素,乘以矩阵 B 第一列的第二个元素,把这两个乘积相加,就得到了 19。接下来,看看 43 是怎么来的:
[
(3 \times 5) + (4 \times 7)
]
花点时间琢磨琢磨这里咱们干了啥。咱们取矩阵 A 第二行的第一个元素,乘以矩阵 B 第二列的第一个元素,然后加上矩阵 A 第二行第二个元素与矩阵 B 第二列第二个元素的乘积。看出规律了吗?简单来说,就是第一个矩阵按行,第二个矩阵按列,这样一对一对地乘,再把结果加起来。记住,结果矩阵的行数应该和第一个矩阵的列数一样,而列数应该和第二个矩阵的行数一样。
别担心,咱们快把这部分拆解完了!接下来,咱们看看怎么用向量 Y 来乘矩阵,这在咱们要解的方程里是必须的。直接上 Python 代码示例。
import numpy as npa = np.array([[1,2,3],[4,5,6]])b = np.array([7,8,9])c = np.dot(a,b)
print(c)
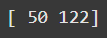
图由作者提供
更明确地说,咱们取第一个矩阵的第一行的元素,分别乘以向量的每个元素,然后求和,就得到了 50。接着,对第二行也做同样的操作。回顾了两个矩阵相乘的过程后,这个就简单多了!
( 1 × 7 ) + ( 2 × 8 ) + ( 3 × 9 ) = 50 (1 \times 7) + (2 \times 8) + (3 \times 9) = 50 (1×7)+(2×8)+(3×9)=50
( 4 × 7 ) + ( 5 × 8 ) + ( 6 × 9 ) = 122 (4 \times 7) + (5 \times 8) + (6 \times 9) = 122 (4×7)+(5×8)+(6×9)=122
最后,咱们得看看怎么计算矩阵的逆。你可能会注意到,这部分咱们用了一个现成的公式。计算矩阵的逆是一个复杂的过程,但别担心,我还会给大伙儿讲讲背后的原理。
更具体地说,矩阵的逆可以用下面这个公式定义,其中 (\text{det}) 是矩阵 A 的行列式,(\text{adj}) 是矩阵 A 的伴随矩阵。伴随矩阵也可以描述为矩阵的余子式矩阵的转置。
A − 1 = 1 det ( A ) × adj ( A ) \mathbf{A}^{-1} = \frac{1}{\text{det}(\mathbf{A})} \times \text{adj}(\mathbf{A}) A−1=det(A)1×adj(A)
先从计算行列式开始。假设下面这个是矩阵 A:
A = [ a b c d e f g h i ] \mathbf{A} = \begin{bmatrix} a & b & c \\ d & e & f \\ g & h & i \end{bmatrix} A= adgbehcfi
行列式可以用下面这个公式计算:
det ( A ) = a ( e i − f h ) − b ( d i − f g ) + c ( d h − e g ) \text{det}(\mathbf{A}) = a(ei - fh) - b(di - fg) + c(dh - eg) det(A)=a(ei−fh)−b(di−fg)+c(dh−eg)
上面的公式可能看起来有点复杂,不过看看你能不能发现其中的规律。变量 (a, b,) 和 (c) 在第一行。注意变量之间的正负号?规律就是正、负、正、负,以此类推(可以认为变量 (a) 是第一个正号)。再看看括号里的内容?注意每组括号里的四个变量,它们在矩阵里既不共行也不共列。这些单独的变量组合代表了余子式矩阵。看看下面这个动图,从更实际的角度看看这个过程。
动图由作者提供
大多数线性回归问题会有超过三个观测值,也就是有很多行。对于更大的矩阵,你可以用的一个方法是拉普拉斯展开,公式如下:
det ( A ) = ∑ j = 1 n ( − 1 ) 1 + j a 1 j × det ( M 1 j ) \text{det}(\mathbf{A}) = \sum_{j=1}^{n} (-1)^{1+j} a_{1j} \times \text{det}(\mathbf{M}_{1j}) det(A)=j=1∑n(−1)1+ja1j×det(M1j)
公式的第一部分代表前面说的正负号规律。变量 a 1 j a_{1j} a1j 是矩阵第一行第 j j j 列的元素,最后的 M 1 j \mathbf{M}_{1j} M1j 是对应变量 a 1 j a_{1j} a1j 的余子式矩阵。要是 M 1 j \mathbf{M}_{1j} M1j也是一个大矩阵呢?那你还得再做一次拉普拉斯展开。如你所见,这个过程很快就会变得计算量很大。
接下来是矩阵 A 的伴随矩阵。矩阵的伴随矩阵就是余子式矩阵的转置。所以,咱们先用下面这个公式计算矩阵 A 中每个变量的余子式。注意, C C C 表示余子式。我还给出了第一行变量的详细计算过程,是不是有点眼熟?
C i j = ( − 1 ) i + j × det ( M i j ) C_{ij} = (-1)^{i+j} \times \text{det}(\mathbf{M}_{ij}) Cij=(−1)i+j×det(Mij)
C 11 = det [ e f h i ] , C 12 = − det [ d f g i ] , C 13 = det [ d e g h ] C_{11} = \text{det} \begin{bmatrix} e & f \\ h & i \end{bmatrix}, \quad C_{12} = -\text{det} \begin{bmatrix} d & f \\ g & i \end{bmatrix}, \quad C_{13} = \text{det} \begin{bmatrix} d & e \\ g & h \end{bmatrix} C11=det[ehfi],C12=−det[dgfi],C13=det[dgeh]
之后,你再取转置,到这里为止,咱们已经讲完了求解向量 B \mathbf{B} B 所需的所有内容!
def fit(self):"""使用训练数据拟合模型。"""# 在 X_train 中添加一列 1,用于截距项X_train_intercept = np.hstack([np.ones((self.X_train.shape[0], 1)), self.X_train])# 使用正规方程求解系数self.coefficients = np.linalg.inv(X_train_intercept.T @ X_train_intercept) @ X_train_intercept.T @ self.y_train
预测方法和预测新数据方法
咱们的模型对象已经具备了预测所需的一切,所以接下来咱们添加一个 predict 方法。这个方法会接收任意一组特征数组,利用咱们的 coefficients 属性来计算预测值。注意,咱们在特征矩阵 X \mathbf{X} X 的第一列额外添加了一列 1。还记得为啥要这么做吗?因为 coefficients 属性中的第一组权重是咱们的 X X X 截距,也就是 B 0 B_0 B0。
咱们还加了一个叫 predict_new 的方法,可以用它来预测一组新的特征值。
def predict(self, X):"""预测给定特征矩阵 X 的目标值。"""# 在 X 中添加一列 1,用于截距项X_intercept = np.hstack([np.ones((X.shape[0], 1)), X])return X_intercept @ self.coefficientsdef predict_new(self, new_features):"""预测一组新特征值的目标值。"""# 确保 new_features 是一个二维数组new_features = np.array(new_features).reshape(1, -1)return self.predict(new_features)[0]
评估方法
最后一步,咱们需要评估咱们的模型。这个方法会在咱们的 train_test_split 方法创建的测试数据上进行预测。有了预测值之后,咱们就可以评估咱们模型的性能了。为了实现这个目标,咱们会计算三种我个人非常喜欢的回归模型评估指标:均方误差、平均绝对误差和决定系数 R 2 R^2 R2。咱们不依赖外部模块来计算这些指标,而是自己动手写代码实现!
均方误差就是预测值与实际值之差的平方的平均值。平均绝对误差就是预测值与实际值之差的绝对值的平均值。 R 2 R^2 R2 可以说是非常独特的,因为它告诉咱们目标变量的变异性有多少是被模型解释的。你也可以把它定义为模型相比每次都直接预测目标变量的平均值要精确多少。我发现对于这两种定义有一些争论,所以咱们还是详细讲讲它到底是怎么计算的吧。这个指标是用 1 减去残差平方和与总平方和的比值来计算的。残差平方和是预测值与实际值之差的平方和。总平方和和它很像,只不过差值是实际值与平均值之间的。现在,如果分子和分母相比平均值来说差距很小的话,你可以推测模型在最小化误差方面做得很好,因为你是在用 1 减去这个值,所以 R 2 R^2 R2 值越接近 1,就说明模型越好。当它接近 0 的时候,你还不如直接用平均值来预测目标变量呢,所以模型可能不太好。也有可能出现负的 R 2 R^2 R2 值,这就意味着你的模型拟合得非常差。
def evaluate(self):"""使用 \(R^2\)、均方误差(MSE)和平均绝对误差(MAE)在测试数据上评估模型。"""y_pred = self.predict(self.X_test)mse = np.mean((self.y_test - y_pred) ** 2)mae = np.mean(np.abs(self.y_test - y_pred))r2 = 1 - np.sum((self.y_test - y_pred) ** 2) / np.sum((self.y_test - np.mean(self.y_test)) ** 2)return {"\(R^2\)": r2, "MSE": mse, "MAE": mae}
把所有内容整合起来
咱们来测试一下咱们的模型类!首先,咱们导入一些数据。咱们会用到 Kaggle 上的 加州房价数据集(CC0)。
df = pd.read_csv('housing.csv')
df.head()

咱们来聊聊这个数据集。housing 数据集大概有 20,000 行,包含了和房屋属性相关的各种特征。咱们会用这个数据来搭建一个多元线性回归模型,用这个数据集中的一些数值特征来预测中位房价。
首先,咱们把数据分成特征和目标变量。
X = df[['housing_median_age','total_rooms','total_bedrooms','median_income']]
y = df['median_house_value']
接下来,咱们用咱们的多元线性回归类,把数据分成训练集和测试集,训练模型,然后评估它。因为咱们的类已经做了大部分的重活儿,所以咱们只需要四行代码就能搞定!
MLR = MultipleLinearRegression()
MLR.train_test_split(X = X,y=y,train_size = 0.8, random_state=42)
MLR.fit()
MLR.evaluate()
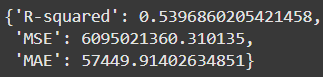
咱们的模型在预测房价方面似乎做得还不错,看看 sklearn 的表现会不会更好。
from sklearn.linear_model import LinearRegression
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LinearRegression
from sklearn.metrics import mean_squared_error,mean_absolute_error, r2_scoreX_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
sklearn_lingreg = LinearRegression()
sklearn_lingreg.fit(X_train, y_train)y_pred = sklearn_lingreg.predict(X_test)mse = mean_squared_error(y_test, y_pred)
mae = mean_absolute_error(y_test, y_pred)
r2 = r2_score(y_test, y_pred)print("\(R^2\):", r2)
print("均方误差(MSE):", mse)
print("平均绝对误差(MAE):", mae)

结果几乎一模一样!希望大家都从这个练习中学到了一些有价值的东西。如今,从 0 到 model.fit() 的过程似乎变得太容易了,这可能会让人忽视了驱动 AI 和机器学习不断发展的模型背后的数学原理。我强烈建议每一位读者自己动手做这个练习,说不定在这个过程中,你还能创造出更适合你用例的模型呢。
哇塞,这一路走过来,咱们不仅从零搭建了一个线性回归模型,还成功地把它跑起来了!从数据预处理、归一化,到实现数学公式,再到用梯度下降找到最优权重,每一步都充满了挑战,但咱们都一一搞定了。最重要的是,咱们还和 sklearn 的大神级模型比了一把,结果发现,咱们的模型一点都不逊色!这感觉,就像自己做的手工汉堡,虽然简单,但吃起来格外香!🎉
相关文章:

人工智能与机器学习:Python从零实现性回归模型
🧠 向所有学习者致敬! “学习不是装满一桶水,而是点燃一把火。” —— 叶芝 我的博客主页: https://lizheng.blog.csdn.net 🌐 欢迎点击加入AI人工智能社区! 🚀 让我们一起努力,共创…...

FreeRTOS
FreeRTOS任务调度的三种方式: 抢占式调度 针对优先级不同的任务 时间片调度 针对优先级相同的任务; FreeRTOS中的一个时间片就等于SysTick(滴答定时器)中断周期(1ms); 协程式调度 后续将不再支持。 …...
)
PCI 总线学习笔记(五)
PCI 总线学习系列,参考自 技术大牛博客: PCIe 扫盲系列博文连载目录篇 书籍:王齐老师的《PCI Express 体系结构导读》 下面的文章中加入了自己的一些理解和实际使用中遇到的一些场景,供日后查询和回忆使用 PCI 总线定义了两类配置…...

PyTorch与CUDA的关系
文章目录 前言一、如何查看PyTorch和torchvision的版本1.1 查看PyTorch版本1.2 查看torchvision版本二、如何确认PyTorch和torchvision是否支持CUDA加速2.1 检查PyTorch是否支持CUDA2.2 查看当前可用的GPU设备2.3 检查torchvision是否支持CUDA三、CUDA版本的秘密:为什么PyTorc…...
)
网络中断事件进行根因分析(RCA)
网络中断事件的根因分析(RCA)详解 根因分析(Root Cause Analysis, RCA)是网络运维中用于定位和解决故障的核心方法,目标是找到问题的根本原因,避免重复发生。以下是完整的RCA流程和方法: 1. RC…...

Mac中 “XX”文件已损坏,无法打开 解决方案
前言 Mac中打开软件 出现“XX”文件已损坏,无法打开的提示 怎么处理? 操作总结 1、查看当前 Gatekeeper 是否启用 spctl --status2、完全关闭 Gatekeeper(允许安装任何来源应用) sudo spctl --master-disable3、打开“系统设…...

如何通过python连接hive,并对里面的表进行增删改查操作
要通过Python连接Hive并对其中的表进行增删改查操作,可以使用pyhive库。下面是一个简单的示例代码,演示如何连接Hive并执行一些操作: from pyhive import hive# 建立连接 conn hive.connect(hostyour_hive_host, port10000, authNOSASL)# 创…...

对Mac文字双击或三击鼠标左键没有任何反应
目录 项目场景: 问题描述 原因分析: 解决方案: 项目场景: 在使用Mac系统的时候,使用Apple无线鼠标,双击左键能够选取某个单词或词语,三击左键能够选取某一行,(百度、…...

【维护窗口内最值+单调队列/优先队列】Leetcode 239. 滑动窗口最大值
题目要求 给定一个整数数组 nums,有一个大小为 k 的滑动窗口从数组的最左侧移动到数组的最右侧。滑动窗口每次只向右移动一位。要求返回滑动窗口中的最大值。 示例 1 输入:nums [1,3,-1,-3,5,3,6,7], k 3 输出:[3,3,5,5,6,7] 解释&#…...

【Leetcode 每日一题】2845. 统计趣味子数组的数目
问题背景 给你一个下标从 0 0 0 开始的整数数组 n u m s nums nums,以及整数 m o d u l o modulo modulo 和整数 k k k。 请你找出并统计数组中 趣味子数组 的数目。 如果 子数组 n u m s [ l . . r ] nums[l..r] nums[l..r] 满足下述条件,则称其为…...

SDC命令详解:使用get_cells命令进行查询
相关阅读 SDC命令详解https://blog.csdn.net/weixin_45791458/category_12931432.html?spm1001.2014.3001.5482 get_cells命令用于创建一个单元对象集合,关于设计对象和集合的更详细介绍,可以参考下面的博客。 Synopsys:设计对象https://c…...

正则表达式及其游戏中应用
一、正则表达式基础知识 ✅ 什么是正则表达式? 正则表达式是一种用来匹配字符串的规则表达式,常用于搜索、验证、替换等文本处理场景。 比如你想找出玩家输入中的邮箱、命令、作弊码……正则就特别好用。 📚 常见语法速查表: …...
 之间共享 DLL)
如何在 MinGW 和 Visual Studio (MSVC) 之间共享 DLL
如何在 MinGW 和 Visual Studio (MSVC) 之间共享 DLL ✅ .dll.a 和 .lib 是什么? 1. .dll.a(MinGW 下的 import library) 作用:链接时告诉编译器如何调用 DLL 中的函数。谁用它:MinGW 编译器(如 g&#x…...

【HTTP/2和HTTP/3的应用现状:看不见的革命】
HTTP/2和HTTP/3的应用现状:看不见的革命 实际上,HTTP/2和HTTP/3已经被众多著名网站广泛采用,只是这场革命对普通用户来说是"无形"的。让我们揭开这个技术变革的真相。 著名网站的HTTP/2和HTTP/3采用情况 #mermaid-svg-MtfrNDo5DG…...

ts中null类型--结合在vue中的使用、tsconfig.json
总结 TypeScript 中的 null 是一个独立的类型,用于明确表示“无值”或“空值”。在实际开发中,常通过联合类型(如 string | null)或与 ref 结合使用,确保代码的类型安全和可读性。 详情解释 在 TypeScript 中,null 是一个独立的类型,表示 null 值本身。以下是一些关于…...

Hadoop生态圈框架部署 - Windows上部署Hadoop
文章目录 前言一、下载Hadoop安装包及bin目录1. 下载Hadoop安装包2. 下载Hadoop的bin目录 二、安装Hadoop1. 解压Hadoop安装包2. 解压Hadoop的Windows工具包 三、配置Hadoop1. 配置Hadoop环境变量1.1 打开系统属性设置1.2 配置环境变量1.3 验证环境变量是否配置成功 2. 修改Had…...
)
深度学习笔记22-RNN心脏病预测(Tensorflow)
🍨 本文为🔗365天深度学习训练营中的学习记录博客🍖 原作者:K同学啊 一、前期准备 1.导入数据 import tensorflow as tf import pandas as pd import numpy as np dfpd.read_csv("E:/heart.csv") df 2.检查数据是否有…...

面试踩过的坑
1、 “”和equals 的区别 “”是运算符,如果是基本数据类型,则比较存储的值;如果是引用数据类型,则比较所指向对象的地址值。equals是Object的方法,比较的是所指向的对象的地址值,一般情况下,重…...

【机器学习速记】面试重点/期末考试
自用,有错误欢迎评论区指出 目录 一、机器学习基础概念 二、机器学习类型分类 三、经典算法与原理 1. 线性模型 2. 决策树 3. SVM(支持向量机) 4. K近邻(KNN) 5. 贝叶斯分类 6. 集成学习 四、模型评价指标 五、模型泛化能力与调参 六、特征工程与数据预处理 七、维…...

Cursor如何手动添加多个大模型?
笔者在前面的文章Cursor接入API: deepseekV3(免费)_cursor api-CSDN博客中介绍了如何添加deepseek到Cursor中,如果要添加其他大模型,比如阿里的通义千问qwen-max-2025-01-25等,方法一样,在官方网站找到模型名称和base_url…...

FerretDB:基于PostgreSQL的MongoDB替代产品
FerretDB 是一种基于NoSQL的分布式数据库,它旨在通过优化存储和查询机制来提供卓越的性能和可靠性。它支持水平扩展和高并发访问,并提供灵活的数据模型,使开发人员能够轻松地存储和检索各种类型的数据。 Stars 数10,057Forks 数439 主要特点…...

JDBC 批处理与事务处理:提升数据操作效率与一致性的密钥
目录 一. JDBC批量添加数据 1. 什么是批量添加数据 2. 实现数据的批量添加 a. 方式一:不分块 二. JDBC事务处理 1. 什么是事务 2. JDBC事务处理实现 三. 总结 前言 本文来讲解JDBC的批处理和事务处理 这对数据的安全性和准确性以及高效率提供很好的办法 话不…...

vue2实现Blod文件流下载
实现思路: 动态创建一个a标签,模拟点击打开链接,实现下载 downLoad() { //调用下载接口Export({Id: id}).then(res > {this.showLoading false;if (res && res.data && res.data.returnCode -1) {this.msgError(res.d…...

js数据结构之栈
JavaScript数据结构 一、什么是数据结构? 数据结构是向相互之间存在一种或者多种特定关系的数据组成的集合, 采用合适的数据结构能给开发者提高开发和储存效率.比如我们在学习Es6中的我们新接触的到的(Set, map), 在合适的时候使用它们能帮助我们更快的的解决问题. 我们每个在…...

[Windows] 卡巴斯基Kaspersky 21.21.7.384 免费版
卡巴斯基免费版从界面到功能和使用体验来说,简洁、高效、严苛、轻巧,可以“弥补”火绒杀毒能力不强,同时也不会像 Microsoft Defender 误报。 链接1:https://pan.xunlei.com/s/VOOhFEeznr_4W6s7-XT8IwN-A1?pwdztn4# 链接2&…...

【HFP】蓝牙HFP协议中音频连接转移与拨号功能的深度解析
目录 一、核心功能矩阵 二、音频连接向 HF 转移 2.1 转移概述 2.2 前提条件 2.3 适用情况 2.4 转移流程 2.5 注意事项 2.6 示例图 三、音频连接向 AG 转移 3.1 转移概述 3.2 前提条件 3.3 特殊情况处理 3.4 转移流程 3.5 注意事项 3.6 示例图 四、通过HF提供号…...
)
Android学习总结之Glide篇(缓存和生命周期)
一、Glide缓存 1. 内存缓存 内存缓存主要包含活动资源缓存与 LRU 内存缓存这两个级别。 活动资源缓存(Active Resources) 作用:用于存放当前正在被显示的图片资源。当某张图片正展示在 ImageView 上时,它会被纳入活动资源缓存…...

Python 快速获取Excel工作表名称
文章目录 前言准备工作Python 获取Excel中所有工作表的名称Python 获取Excel中隐藏工作表的名称 前言 在数据分析与办公自动化领域,通过Python处理Excel文件已成为必备技能。通过获取工作表名称,我们可以: 快速了解文件结构自动化处理多工作…...

基于Docker的Flask项目部署完整指南
基于Docker的Flask项目部署完整指南 项目结构与文件说明 TextWeb/ ├── .dockerignore # Docker构建忽略配置 ├── Dockerfile # Docker镜像构建文件 ├── requirements.txt # Python依赖清单 └── WebServer/└── main.py # Fl…...
)
分布式定时任务(xxl-job)
简介 什么是XXL-JOB 详细的文档类容可以看下面这个链接进入readme xxl-job简介以及下载地址 XXL-JOB是一个分布式任务调度平台,其核心设计目标是开发迅速、学习简单、轻量级、易扩展 在Java Spring Cloud微服务架构中,使用独立的定时任务调度中心&…...

PostgreSQL使用LIKE右模糊没有走索引分析验证
建表&数据初始化可参考PostgreSQL 分区表——范围分区SQL实践 背景: 给t_common_work_order_log的handle_user_name新建索引后,使用LIKE右模糊匹配查询时,发现走的全表扫描 CREATE INDEX order_log_handle_user_name_index ON t_commo…...

Jenkins流水线管理工具
文章目录 前言: DevOps时代的自动化核心 —Jenkins一、Jenkins是什么?二、Linux安装Jenkinswar包方式安装依赖环境下载 Jenkins WAR 包启动 Jenkins 服务启动日志验证配置插件镜像源 docker镜像方式安装依赖环境拉取 Jenkins 镜像运行 Jenkins 容器获取初…...

2025年保安员证考试题库及答案
一、单选题 96、手指出血,为达到止血作用,应该压住()。 A.出血手指的尖端 B.出血手指根部前后两侧 C.出血手指根部左右两侧 D.腕部的桡动脉、尺动脉 答案:C 97、下列选项中对干粉灭火器使用方法叙述错误的是&…...

观测云数据在Grafana展示的最佳实践
背景 在当今的数据驱动世界中,组织越来越依赖于实时数据来做出决策。数据可视化是理解和分析这些数据的关键工具,它帮助用户将复杂的数据集转换成直观的图表和仪表板,从而更容易识别趋势、模式和异常。Grafana,作为一个功能强大的…...

点云从入门到精通技术详解100篇-基于二次误差和高斯混合模型的点云配准算法
目录 知识储备 结合二次误差度量与高斯混合模型的点云配准 算法核心创新点: 关键参数说明: 性能优化建议: 前言 国内外研究现状 全局配准算法的国内外研究 局部配准算法的国内外研究 2 点云配准相关概念与方法 2.1 什么是点云配准 2.2 点云的获取及点云主要数据…...

shell命令一
&> /dev/null yum -y install vsftpd &> /dev/null&> /dev/null &>:将命令的**标准输出(stdout)和标准错误(stderr)**同时重定向。/dev/null:Linux中的“黑洞”设备…...

MySQL性能常用优化技巧总结
1. 索引优化 创建合适的索引 -- 为常用查询条件创建索引 ALTER TABLE users ADD INDEX idx_email (email); ALTER TABLE orders ADD INDEX idx_customer_date (customer_id, order_date);避免索引失效的情况 -- 避免在索引列上使用函数 SELECT * FROM users WHERE DATE(crea…...

在 Spring Boot 中实现 WebSockets
什么是 WebSockets? WebSockets 是一种基于 TCP 的全双工通信协议,允许客户端和服务器之间建立持久的双向连接,用于实时数据交换。相较于传统的 HTTP 请求-响应模型,WebSockets 提供了低延迟、高效率的通信方式,特别适…...

stone 3d v3.3.0版本发布,含时间线和连接器等新功能
1.新加了时间线(timeline)编辑器,可以类似blender一样给对象制作动画 2.新加了度量(metrics)系统,通过scene对象检测器中的useMetrics属性来启用或禁用,启用时所选物体将显示三维度量数据 新加了…...

Parasoft C++Test软件单元测试_对函数打桩的详细介绍
系列文章目录 Parasoft C++Test软件静态分析:操作指南(编码规范、质量度量)、常见问题及处理 Parasoft C++Test软件单元测试:操作指南、实例讲解、常见问题及处理 Parasoft C++Test软件集成测试:操作指南、实例讲解、常见问题及处理 进阶扩展:自动生成静态分析文档、自动…...

Safety Estimands与Efficacy Estimands的差异剖析
1. 研究目标差异 1.1 安全性估计目标 1.1.1 关注潜在风险 安全性估计目标着重于治疗可能引发的不良事件(AE)、严重不良事件(SAE)或实验室指标异常,如化疗药物导致中性粒细胞减少症的发生率,这些指标直接关联到患者治疗过程中的健康风险。 这些潜在风险的评估对于确保治…...

HTML 详解:从基础结构到语义标签
目录 一、HTML 是什么?二、HTML 的基本结构✅ 简要说明: 三、常见 HTML 标签讲解3.1 标题标签 <h1> ~ <h6>3.2 段落和换行3.3 超链接3.4 图像插入3.5 列表无序列表:有序列表: 3.6 表格结构 四、HTML 语义化标签详解五…...

联合索引`ABC`,使用`B=... AND C=... AND A=...`会走索引吗?
在MySQL中,联合索引ABC的查询使用B... AND C... AND A...时,是否使用索引取决于查询条件的顺序和优化器的处理。 一、索引使用原理 最左前缀原则 联合索引的底层存储和查询优化遵循最左前缀匹配原则,即查询条件必须从索引的最左侧列开始连续匹…...

HTML 模板技术与服务端渲染
HTML 模板技术与服务端渲染 引言 在现代前端开发生态中,HTML模板技术与服务端渲染(SSR)构成了连接前后端的重要桥梁。当单页应用(SPA)因其客户端渲染特性而面临首屏加载速度慢、白屏时间长和SEO不友好等问题时,服务端渲染技术提供了一种优雅的解决方案…...

MySQL的MVCC【学习笔记】
MVCC 事务的隔离级别分为四种,其中Read Committed和Repeatable Read隔离级别,部分实现就是通过MVCC(Multi-Version Concurrency Control,多版本并发控制) 版本链 版本链是通过undo日志实现的, 事务每次修改…...
,安装可视化工具kibana)
linux安装单节点Elasticsearch(es),安装可视化工具kibana
真的,我安装个es和kibana,找了好多帖子,问了好几遍ai才安装成功,在这里记录一下,我相信,跟着我的步骤走,99%会成功; 为了让大家直观的看到安装过程,我把我服务器的es和ki…...
上手Go Gin 基于Go语言开发的Web框架,本文介绍了各种路由的配置信息;包含各场景下请求参数的基本传入接收)
(Go Gin)上手Go Gin 基于Go语言开发的Web框架,本文介绍了各种路由的配置信息;包含各场景下请求参数的基本传入接收
1. 路由 gin 框架中采用的路优酷是基于httprouter做的 HttpRouter 是一个高性能的 HTTP 请求路由器,适用于 Go 语言。它的设计目标是提供高效的路由匹配和低内存占用,特别适合需要高性能和简单路由的应用场景。 主要特点 显式匹配:与其他路由…...

纯HTMLCSS静态网站——元神
《原神》主题网页介绍 以对该网页的详细介绍 网页整体结构 头部(header):包含网站的 logo 和导航栏。logo 部分展示了 “原神” 字样,点击可返回首页。导航栏提供了多个页面链接,包括首页、音乐、视频、壁纸、世界、…...

嵌入式开发:基础知识介绍
一、嵌入式系统 1、介绍 以提高对象体系智能性、控制力和人机交互能力为目的,通过相互作用和内在指标评价的,嵌入到对象体系中的专用计算机系统。 2、分类 按其形态的差异,一般可将嵌入式系统分为:芯片级(MCU、SoC&am…...

华为VRP系统简介配置TELNET远程登录!
1.华为 VRP 系统概述 1.1 什么是 VRP VRP(Versatile Routing Platform 华为数通设备操作系统)是华为公司数据通信产品的通用操作系统平台,从低端到核心的全系列路由器、以太网交换机、业务网关等产品的软件核心引擎。 1.2 VRP 的功能 统一…...