《深入浅出ProtoBuf:从环境搭建到高效数据序列化》
ProtoBuf详解
- 1、初识ProtoBuf
- 2、安装ProtoBuf
- 2.1、ProtoBuf在Windows下的安装
- 2.2、ProtoBuf在Linux下的安装
- 3、快速上手——通讯录V1.0
- 3.1、步骤1:创建.proto文件
- 3.2、步骤2:编译contacts.proto文件,生成C++文件
- 3.3、步骤3:序列化与反序列化的使用
- 4、proto3语法详解——通讯录V2.x
- 4.1、消息类型的定义与使用
- 4.2、enum类型
- 4.3、Any类型
- 4.4、oneof类型
- 4.5、map类型
- 4.6、默认值
- 4.7、更新消息
- 4.8、option选项
- 5、通讯录网络版
- 6、总结
1、初识ProtoBuf
网络传输数据时,我们需要将结构化的数据序列化成一个大字符串进行传输,然后对端接收后需要反序列化为结构化数据。当我们要把数据写入到磁盘文件中或者数据库中,实现数据的持久化存储时,也是需要进行序列化的。
那么我们当然可以自己实现序列化,不过那样太麻烦了,而且已经有了现成的工具供我们使用了,如:xml、json、protobuf。本篇文章介绍的就是protobuf的安装和使用。
ProtoBuf是什么?
Protocol Buffers是Google的一种语言无关、平台无关、可扩展的序列化结构数据的方法,它可用于(数据)通信协议、数据存储等。
Protocol Buffers 类比于XML,是一种灵活,高效,自动化机制的结构数据序列化方法,但是比XML更小、更快、更为简单。
你可以定义数据的结构,然后使用特殊生成的源代码轻松的在各种数据流中使用各种语言进行编写和读取结构数据。你甚至可以更新数据结构,而不破坏由旧数据结构编译的已部署程序。
简单来讲,ProtoBuf(全称为 Protocol Buffer)是让结构数据序列化的方法,其具有以下特点:
语言无关、平台无关:即ProtoBuf支持Java、C++、Python等多种语言,支持多个平台。
• 高效:即比XML更小、更快、更为简单。
• 扩展性、兼容性好:你可以更新数据结构,而不影响和破坏原有的旧程序。
使用特点:ProtoBuf是需要依赖通过编译生成的头文件和源文件来使用的。
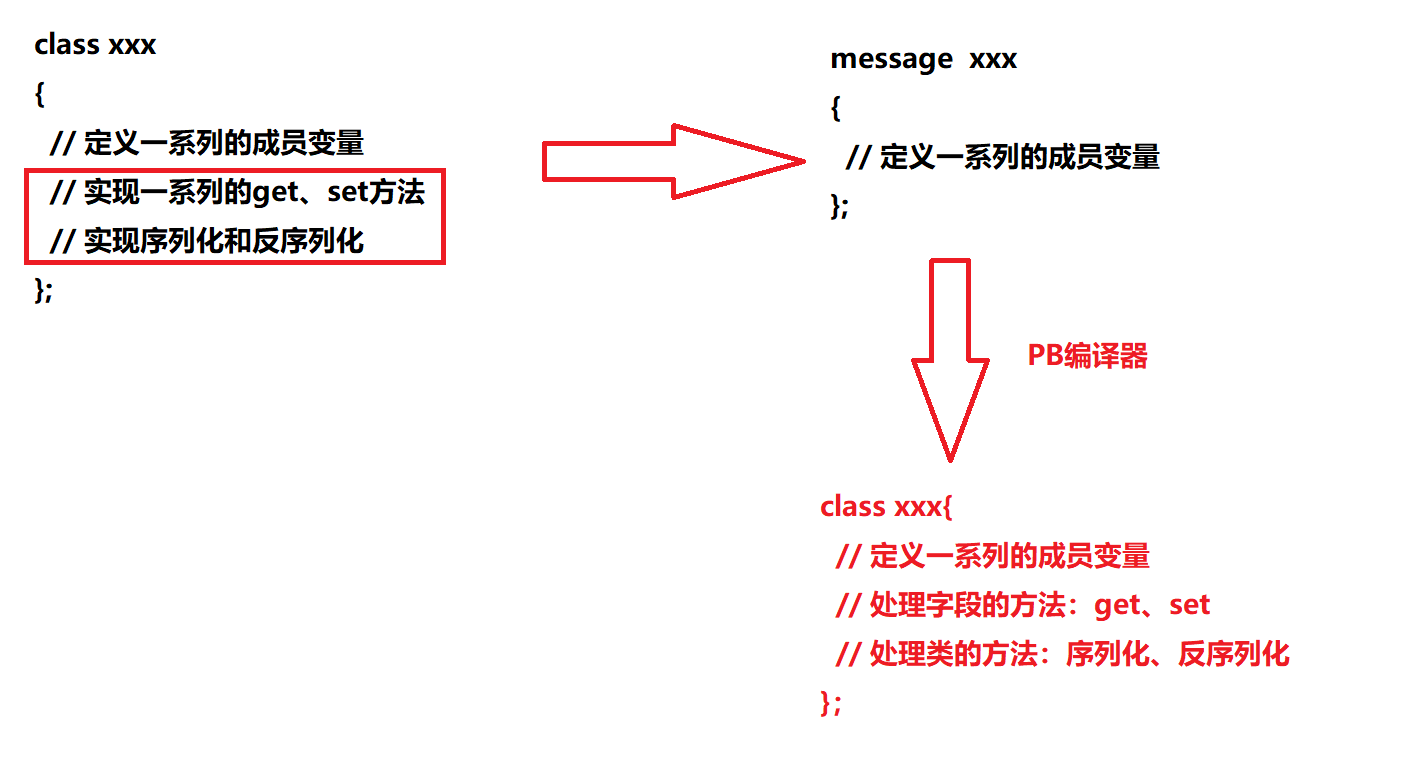
原来我们是需要自己实现一个类,定义一系列成员变量,实现一系列get、set函数和序列化反序列化方法,实现这些方法是比较耗时的。使用了ProtoBuf,我们在.proto文件中定义结构对象message及属性内容,然后通过protoc编译器形成处理字段的get、set和处理类的序列化、反序列化方法,存放在新的头文件和源文件中。
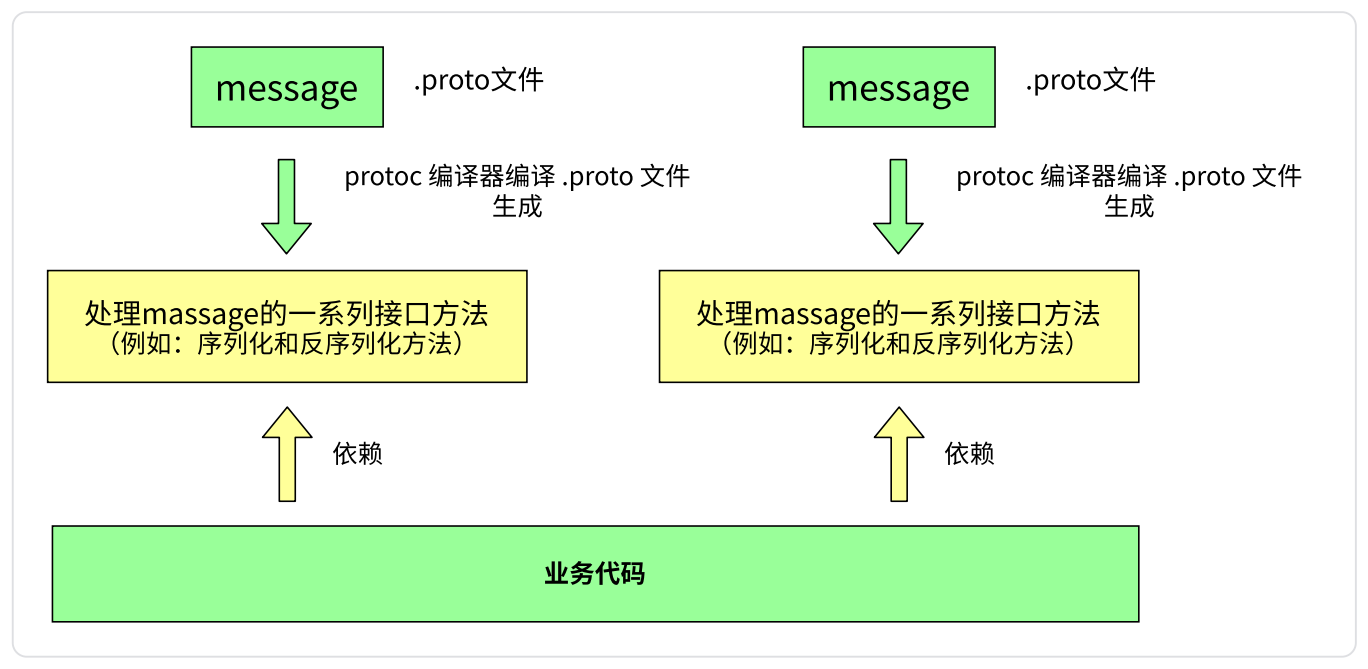
1. 编写.proto文件,目的是为了定义结构对象(message)及属性内容。
2. 使用protoc编译器编译.proto文件,生成一系列接口代码,存放在新生成头文件和源文件中。
3. 依赖生成的接口,将编译生成的头文件包含进我们的代码中,实现对.proto文件中定义的字段进行设置和获取,和对message对象进行序列化和反序列化。
2、安装ProtoBuf
2.1、ProtoBuf在Windows下的安装
下载地址:https://github.com/protocolbuffers/protobuf/releases
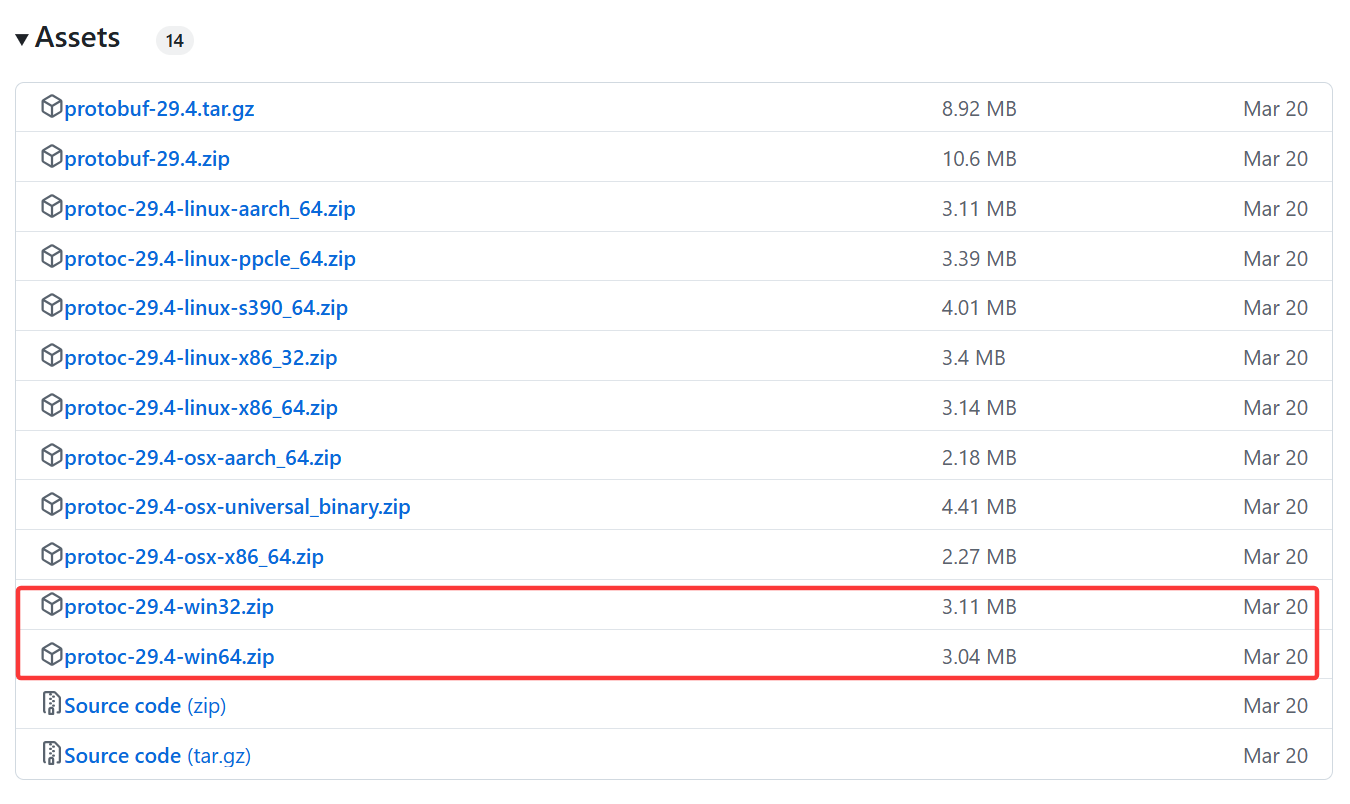
找到你需要的版本,然后找到携带win32/win64的,然后进行下载。
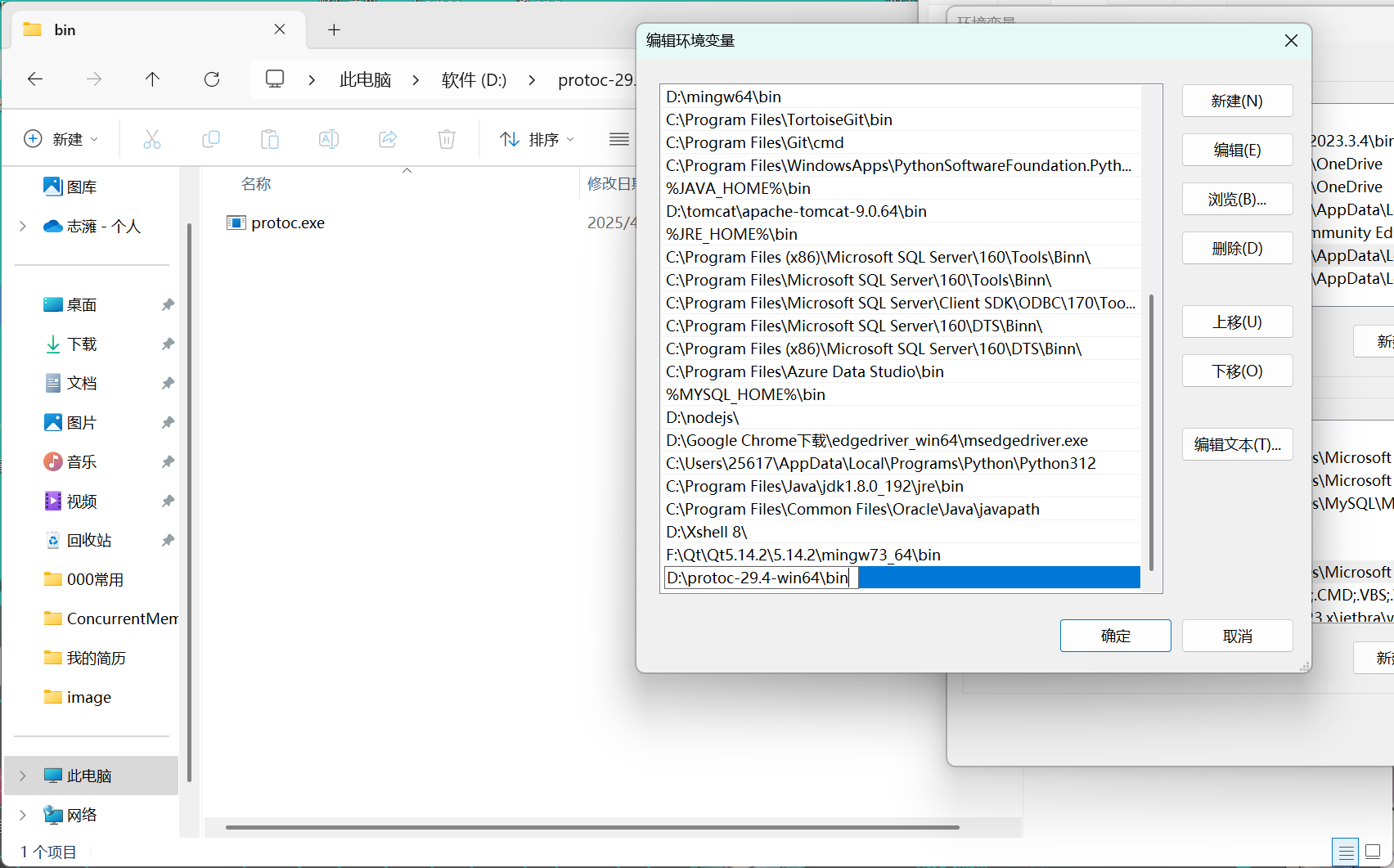
下载后进行解压,选择你要存放的位置。接着在系统变量Path中添加解压后文件的bin路径。
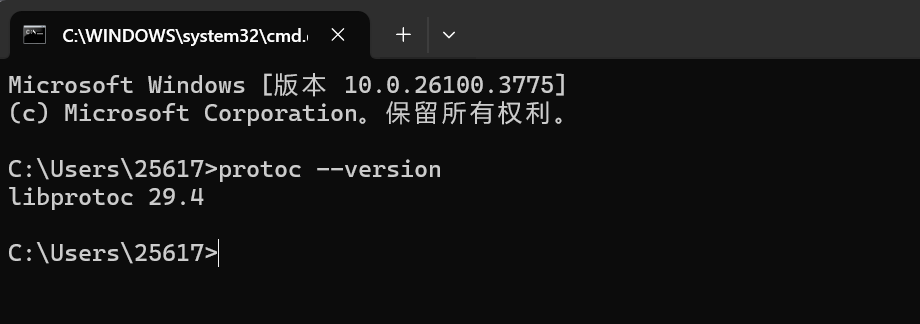
接着我们打开命令行窗口,输入protoc --version,如果显示了版本信息说明安装成功。
2.2、ProtoBuf在Linux下的安装
1、使用CMake构建安装,首先在Linux下安装依赖:
sudo apt install -y cmake
sudo apt install -y cmake make g++ pkg-config unzip
2、然后在下方连接寻找版本和安装包:
下载地址:https://github.com/protocolbuffers/protobuf/releases
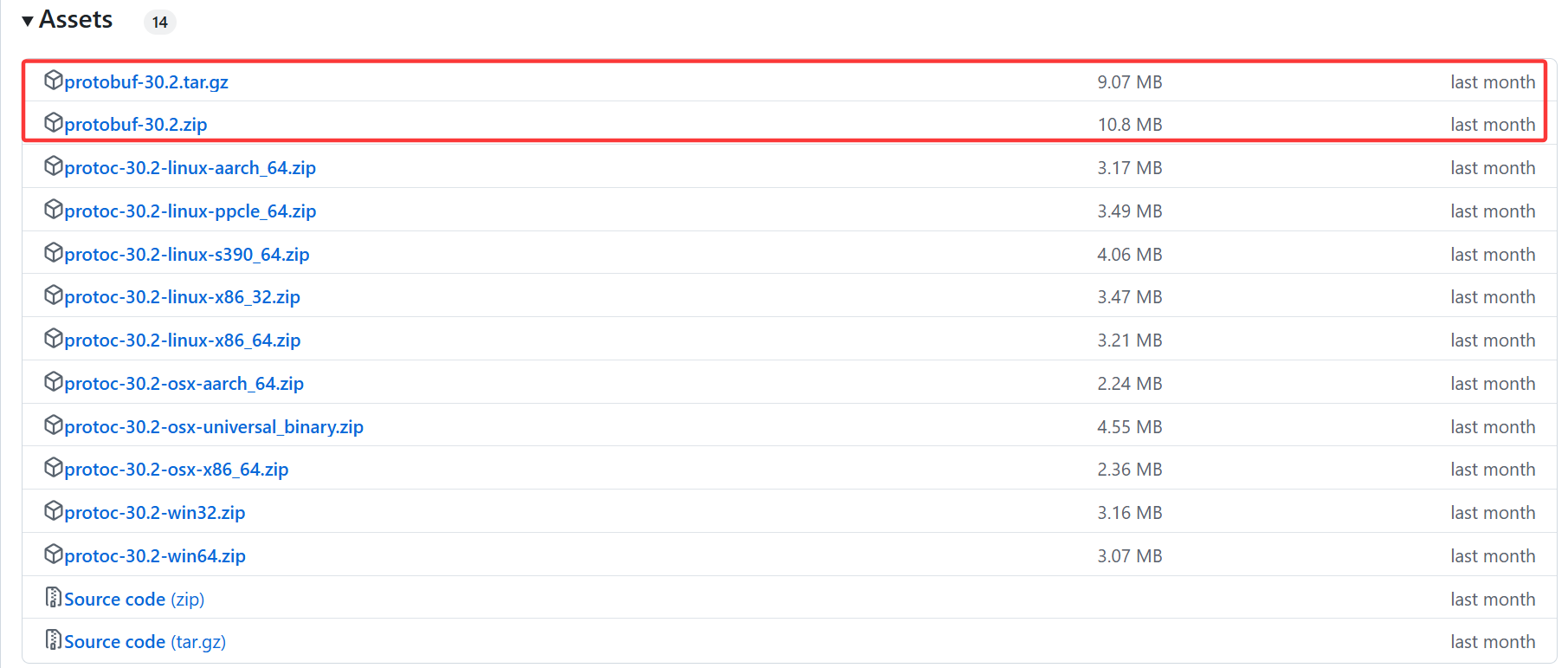

复制连接然后使用wget下载到Linux服务器上。
3、下载后输入以下命令进行解压:
unzip protobuf-30.2.zip
4、解压后进入目录然后执行:
mkdir -p build && cd build
5、生成 Makefile:
cmake .. \-DCMAKE_BUILD_TYPE=Release \-Dprotobuf_BUILD_SHARED_LIBS=ON
6、编译并安装:
make -j$(nproc)
sudo make install
sudo ldconfig
3、快速上手——通讯录V1.0
3.1、步骤1:创建.proto文件
在快速上手中,会编写第一版本的通讯录1.0。在通讯录1.0版本中,将实现:
• 对一个联系人的信息使用PB进行序列化,并将结果打印出来。
• 对序列化后的内容使用PB进行反序列,解析出联系人信息并打印出来。
• 联系人包含以下信息:姓名、年龄。
通过通讯录1.0,我们便能了解使用ProtoBuf初步要掌握的内容,以及体验到ProtoBuf的完整使用流程。
首先创建contacts.proto文件编写message,由于protobuf是依赖编译后的源文件和头文件来使用的,所以我们需要先编写message然后进行编译。
1、文件建议采用小写命名,如果有多个单词就用_连接。

2、第一行指明使用的protobuf语法版本,我们这里选择使用proto3,如果不指定默认就是proto2。
3、package相当于C++的命名空间,给该文件编写的message添加一个命名空间。
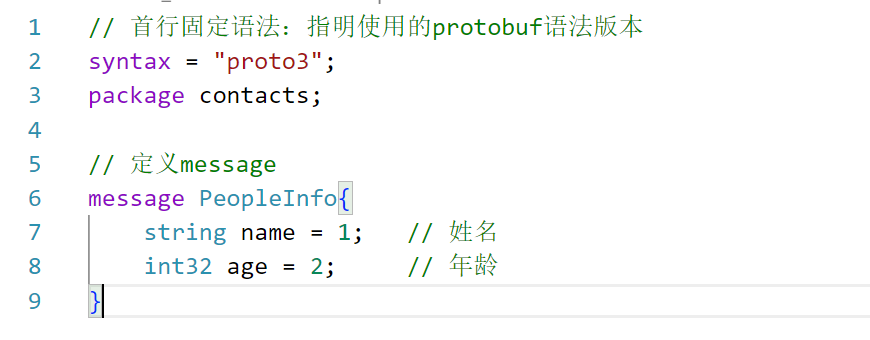
接着定义一个联系人message PeopleInfo。
4、需要给成员变量后面添加=编号,不是给成员变量赋值,而是添加编号,这跟protobuf的原理有关。
5、消息类型命名规范:使用驼峰命名法,首字母大写。
在message中我们可以定义其属性字段,字段定义格式为:字段类型 字段名 = 字段唯一编号;
• 字段名称命名规范:全小写字母,多个字母之间用 _ 连接。
• 字段类型分为:标量数据类型和特殊类型(包括枚举、其他消息类型等)。
• 字段唯一编号:用来标识字段,一旦开始使用就不能够再改变。
该表格展示了定义于消息体中的标量数据类型,以及编译.proto文件之后自动生成的类中与之对应的字段类型。在这里展示了与C++语言对应的类型。
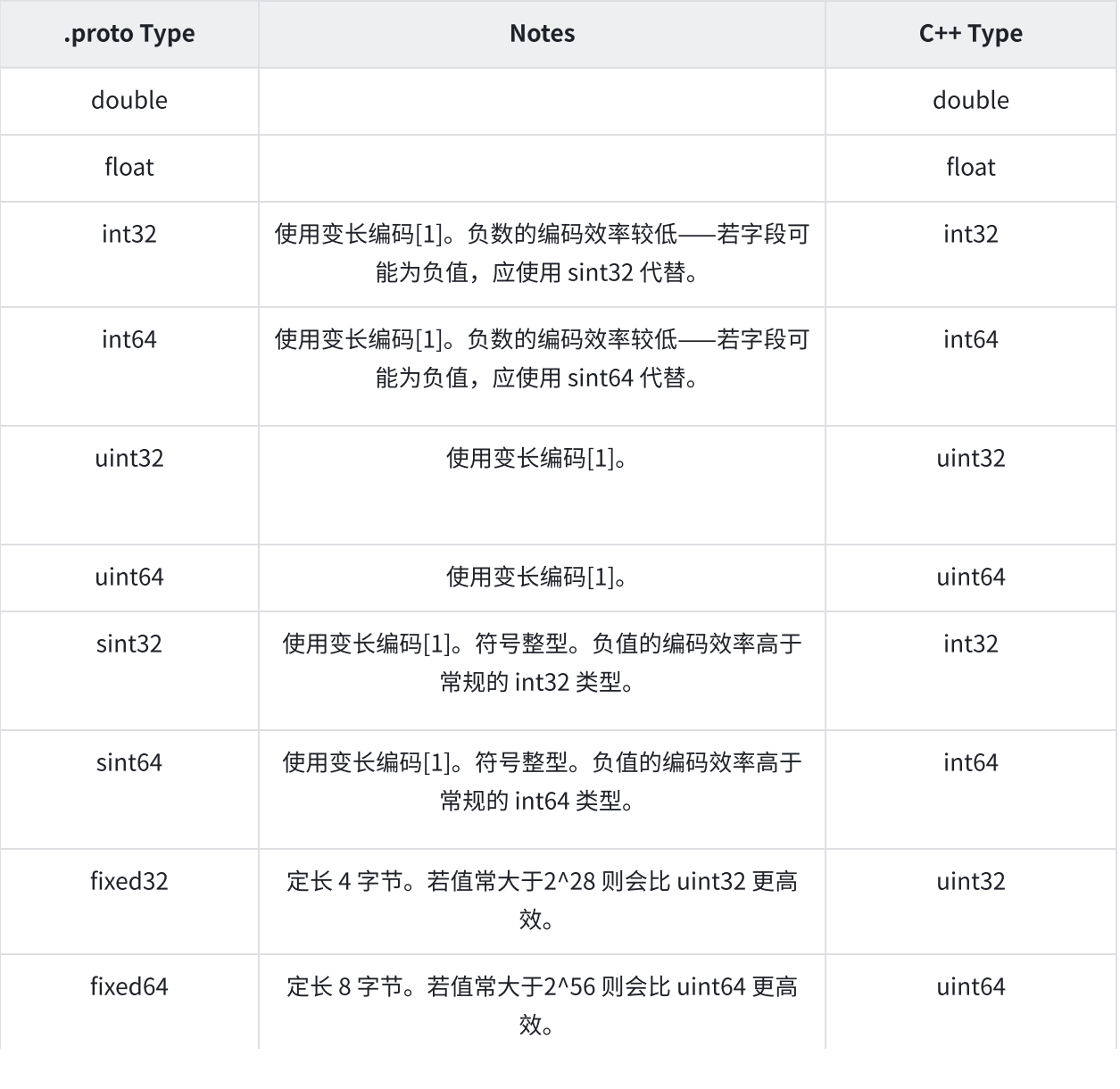
[1] 变长编码是指:经过protobuf 编码后,原本4字节或8字节的数可能会被变为其他字节数。
在这里还要特别讲解一下字段唯一编号的范围:
1 ~ 536,870,911 (2^29 - 1) ,其中 19000 ~ 19999 不可用。
19000 ~ 19999 不可用是因为:在Protobuf协议的实现中,对这些数进行了预留。如果非要在.proto文件中使用这些预留标识号,例如将name字段的编号设置为19000,编译时就会报警。
值得一提的是,范围为 1 ~ 15 的字段编号需要一个字节进行编码, 16 ~ 2047 内的数字需要两个字节进行编码。编码后的字节不仅只包含了编号,还包含了字段类型。所以 1 ~ 15 要用来标记出现非常频繁的字段,要为将来有可能添加的、频繁出现的字段预留一些出来。
3.2、步骤2:编译contacts.proto文件,生成C++文件

使用protoc编译器进行编译,–cpp_out=表明编译后的文件为C++文件,=后面的.表明生成的文件就在当前目录下,然后最后跟要编译的proto文件。编译后可以看到在当前目录下多了两个文件:头文件和源文件。
如果我不在当前路径下编译呢,比如我在上级路径下如何编译?

如图,带-I指明要编译文件所在路径,所以protoc默认是在当前路径下搜索的,如果有多个路径直接在后面跟上即可。同时=后面的路径需要改变。
编译contacts.proto文件后,会生成所选择语言的代码,我们选择的是C++,所以编译后生成了两个文件:contacts.pb.h contacts.pb.cc 。
对于编译生成的C++代码,包含了以下内容:
• 对于每个message,都会生成一个对应的消息类。
• 在消息类中,编译器为每个字段提供了获取和设置方法,以及其他能够操作字段的方法。
• 编辑器会针对于每个.proto文件生成 .h 和 .cc 文件,分别用来存放类的声明与类的实现。
下面我们看一下这两个文件:
在头文件中我们找到了PeopleInfo这个类,并且是在contacts命名空间中的,因为我们上面写了package。
接着继续往下找,我们可以看到对于成员变量都有一个clear_xxx的方法,是用来清空值得。然后get方法就是以变量名为函数名得方法,set方法就是set_xxx。
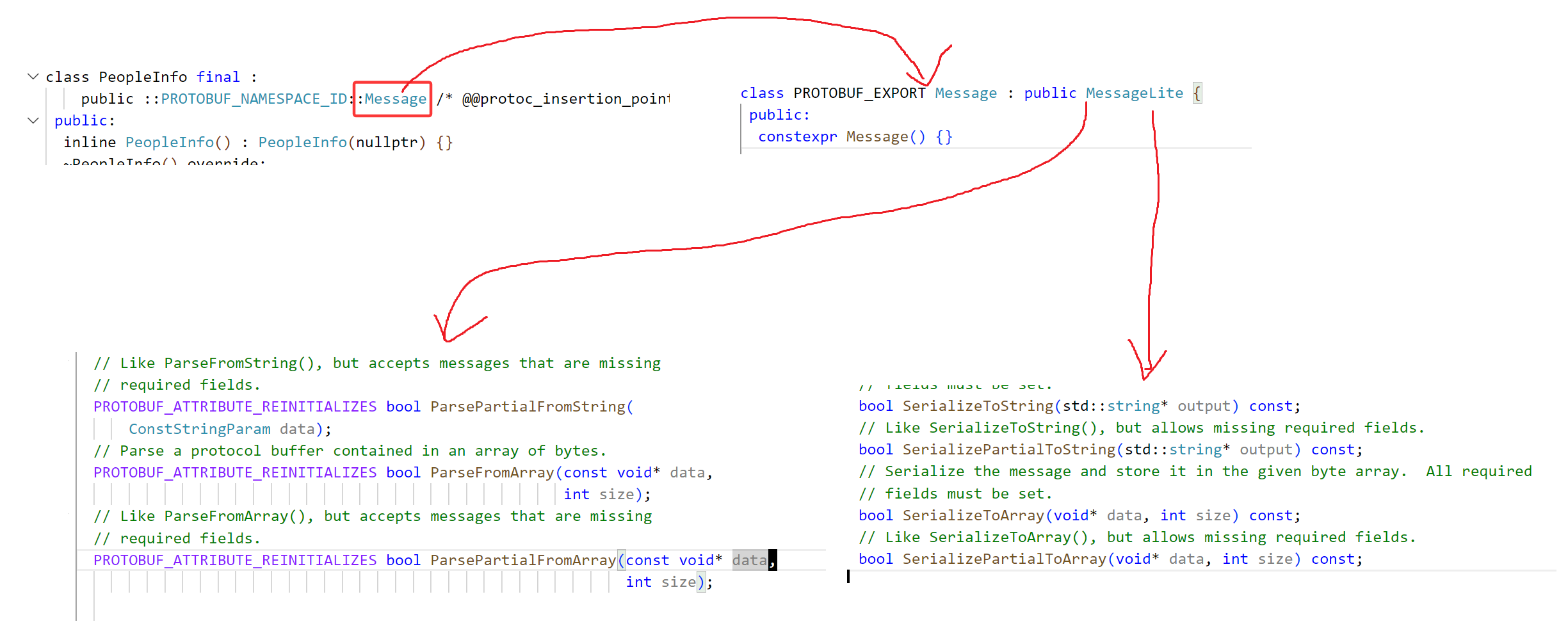
我们得PeopleInfo这个类继承了Meassge,然后Message又继承了MessageLite,在MessageLite中我们可以看到一系列的序列化和反序列化的方法。
• 序列化的结果为二进制字节序列,而非文本格式。
• 以上三种序列化的方法没有本质上的区别,只是序列化后输出的格式不同,可以供不同的应用场景使用。
• 序列化的API函数均为const成员函数,因为序列化不会改变类对象的内容,而是将序列化的结果保存到函数入参指定的地址中。
3.3、步骤3:序列化与反序列化的使用
下面编写main.cc进行测试:
#include <iostream>
#include "contacts.pb.h"int main()
{std::string res;{contacts::PeopleInfo people;people.set_name("张三");people.set_age(20);if (!people.SerializePartialToString(&res)){std::cout << "序列化失败..." << std::endl;return 1;}std::cout << "序列化后的结果: " << res << std::endl;}{contacts::PeopleInfo people;if (!people.ParseFromString(res)){std::cout << "反序列化失败..." << std::endl;return 1;}std::cout << "姓名: " << people.name() << std::endl;std::cout << "年龄: " << people.age() << std::endl; }return 0;
}

编译需要带上两个源文件,由于官方的使用C++11的语法,所以需要加上-std=c++11,同时带-l指明动态库protobuf。
4、proto3语法详解——通讯录V2.x
4.1、消息类型的定义与使用
在语法详解部分,会对通讯录进行多次升级,使使用2.x表示升级的版本,最终将会升级如下内容:
• 不再打印联系人的序列化结果,而是将通讯录序列化后并写入文件中。
• 从文件中将通讯录解析出来,并进行打印。
• 新增联系人属性,共包括:姓名、年龄、电话信息、地址、其他联系方式、备注。
现在我们要实现的是将序列化结果写入文件,然后从文件中读取解析,并添加电话属性。
一个人可能有多个电话,所以我们需要定义一个数组,那么如何定义数组呢?
消息的字段可以用下面几种规则来修饰:
• singular :消息中可以包含该字段零次或一次(不超过一次)。 proto3 语法中,字段默认使用该规则。
• repeated :消息中可以包含该字段任意多次(包括零次),其中重复值的顺序会被保留。可以理解为定义了一个数组。
方式一:定义一个message对象,因为将来可能还要表示电话的类型,比如固定电话还是移动电话等。

方式二:在其他文件中实现message,然后在该.proto文件中导入。
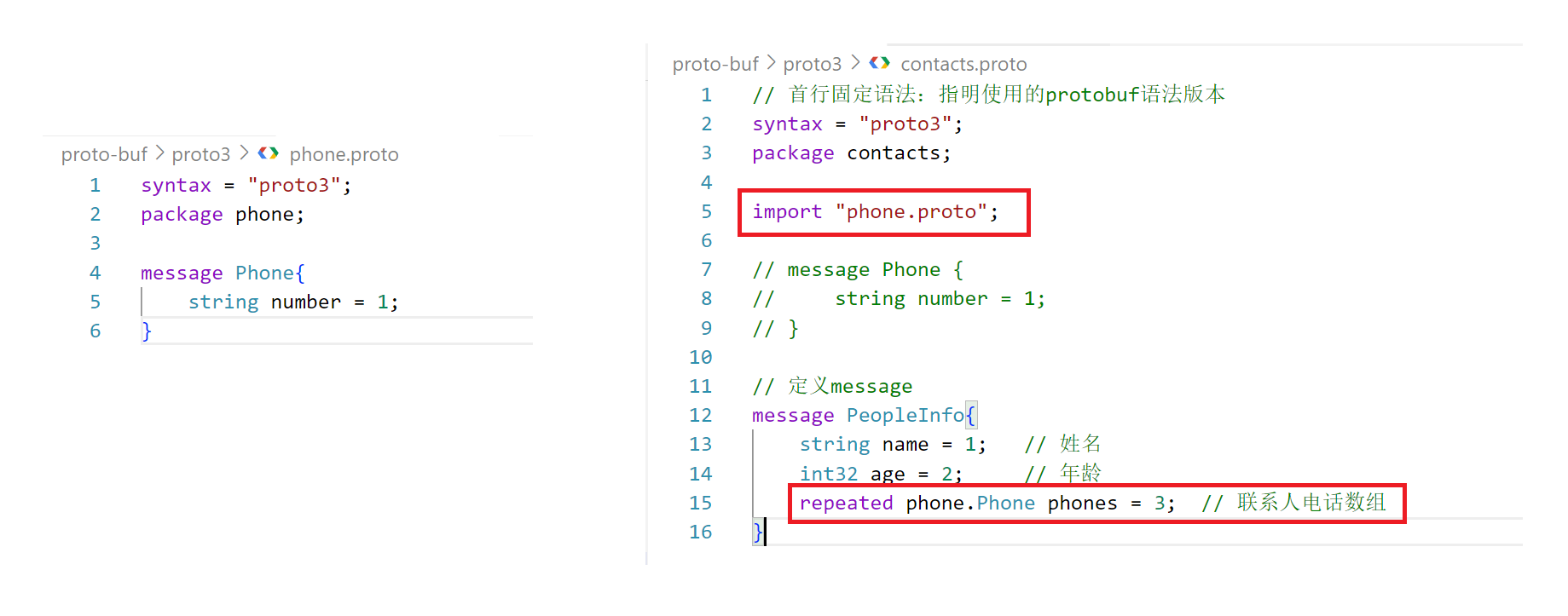
方式三:在message PeopleInfo内部嵌套定义message Phone

我们采用方式三,并定义一个Contacts通讯录对象,进行编译生成源文件和头文件。
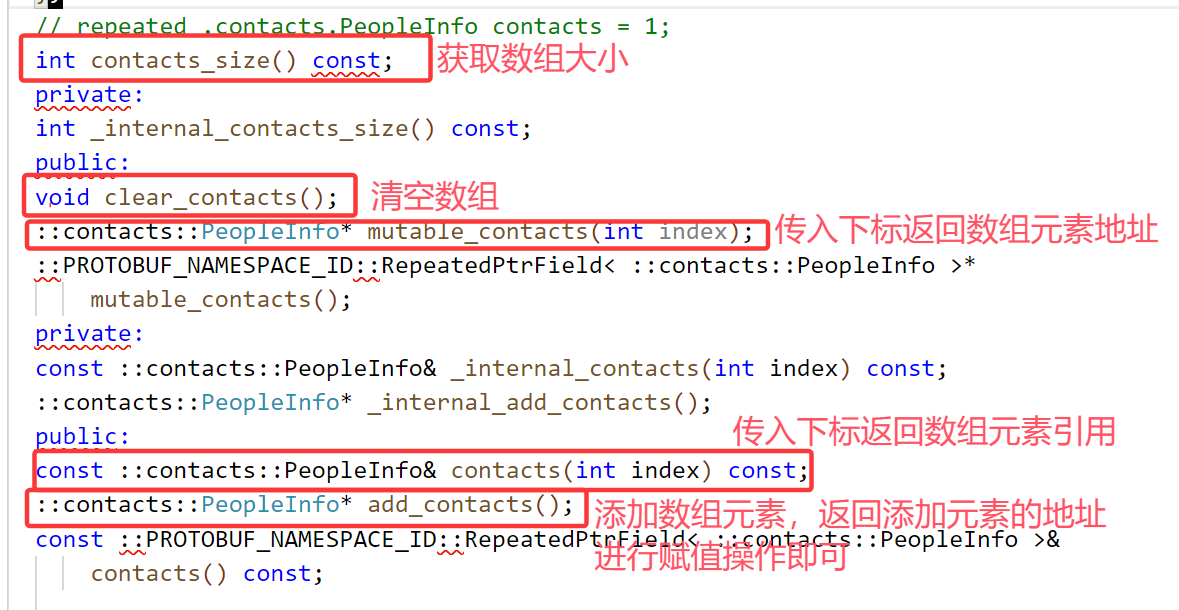
下面看一下对数组操作的方法:
下面编写write.cc:
#include <iostream>
#include <fstream>
#include "contacts.pb.h"const std::string filename = "contacts.bin";void AddPeopleInfo(contacts::PeopleInfo* people)
{std::cout << "请输入联系人姓名:";std::string name;std::getline(std::cin, name);people->set_name(name);std::cout << "请输入联系人年龄:";int age;std::cin >> age;people->set_age(age);std::cin.ignore(256, '\n'); // 清空缓冲区信息for (int i = 0; ; i++){std::cout << "请输入联系人电话" << i + 1 << "(输入回车完成电话新增):";std::string number;std::getline(std::cin, number);if (number.empty())break;contacts::PeopleInfo_Phone* phone = people->add_phones();phone->set_number(number);}std::cout << "添加联系人成功..." << std::endl;
}int main()
{contacts::Contacts contacts;std::fstream input(filename, std::ios::in | std::ios::binary);if (!input){std::cout << filename << " not found, create new file!" << std::endl;}else if (!contacts.ParseFromIstream(&input)){std::cout << "parse error..." << std::endl;input.close();return 2;}AddPeopleInfo(contacts.add_contacts());std::fstream output(filename, std::ios::out | std::ios::trunc | std::ios::binary);if (!contacts.SerializePartialToOstream(&output)){std::cout << "serialize error..." << std::endl;input.close();output.close();return 3;}std::cout << "write success..." << std::endl;input.close();output.close();return 0;
}
write.cc负责从文件中读取通讯录信息出来,如果存在就读取并在原来内容基础上添加联系人,否则就创建文件然后添加联系人写回文件中。

注意点1:input用于打开文件,如果不存在就创建,由于protobuf序列化后都是二进制,所以需要以二进制的方式进行读取或写入。output用于写入文件,由于我们获取了通讯录信息然后添加联系人,所以写入的时候直接覆盖写入即可。
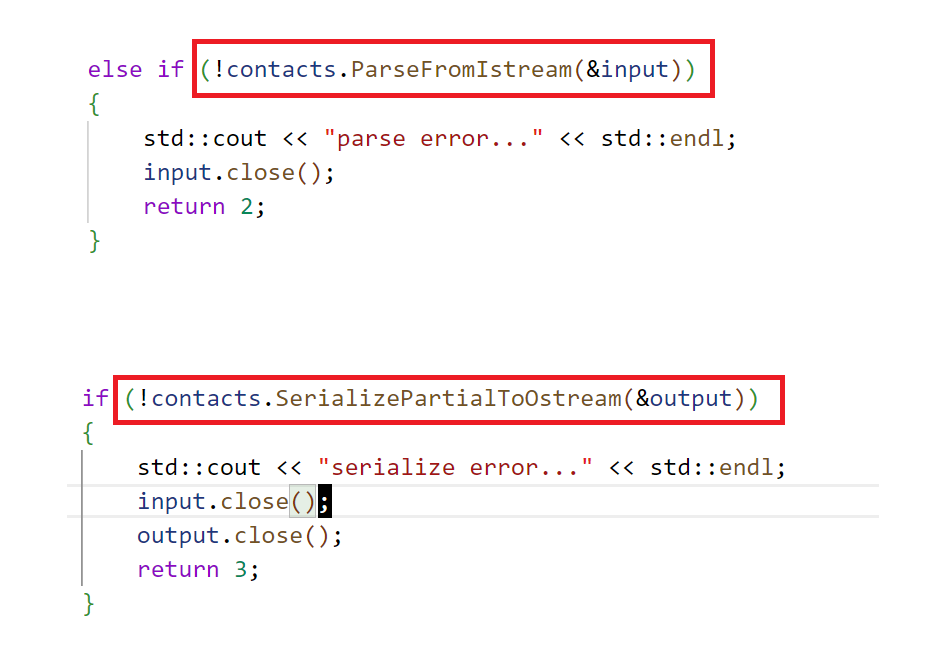
注意点2:ParseFromIstream会从文件中读取数据并进行反序列化到contacts对象中。SerializePartialToOstream会将contacts序列化并写入到文件中。
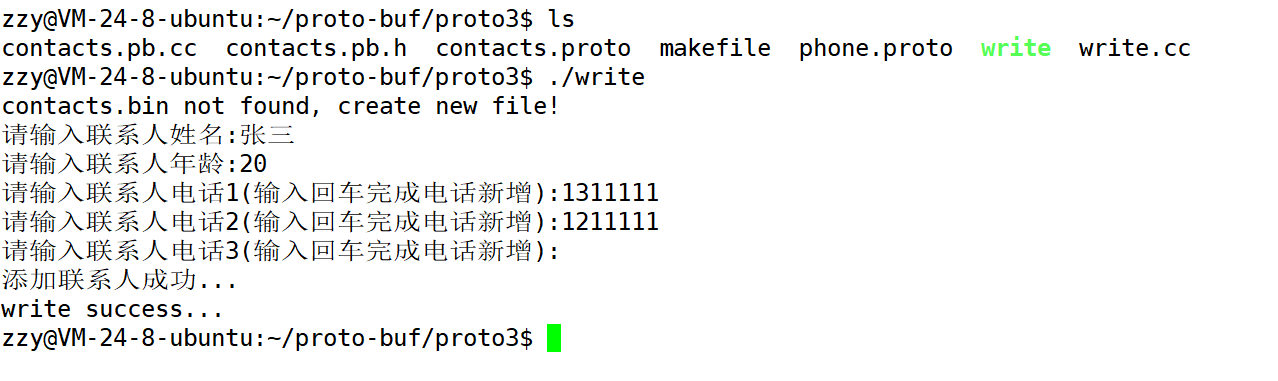
编译后运行程序添加一个联系人信息。
然后实现read.cc从文件中读取联系人信息:
#include <iostream>
#include <fstream>
#include "contacts.pb.h"const std::string filename = "contacts.bin";void PrintContacts(contacts::Contacts& contacts)
{for (int i = 0; i < contacts.contacts_size(); i++){std::cout << "--------------联系人" << i + 1 << "----------------" << std::endl;const contacts::PeopleInfo& people = contacts.contacts(i);std::cout << "联系人姓名:" << people.name() << std::endl;std::cout << "联系人年龄:" << people.age() << std::endl;for (int j = 0; j < people.phones_size(); j++){const contacts::PeopleInfo_Phone& phone = people.phones(j);std::cout << "联系人电话" << j + 1 << ":" << phone.number() << std::endl;}}
}int main()
{contacts::Contacts contacts;std::fstream input(filename, std::ios::in | std::ios::binary);if (!contacts.ParseFromIstream(&input)){std::cout << "parse error..." << std::endl;return 1;}PrintContacts(contacts);return 0;
}

hexdump:是Linux下的⼀个二进制文件查看工具,它可以将二进制文件转换为ASCII、八进制、十进制、十六进制格式进行查看。-C::表示每个字节显示为16进制和相应的ASCII字符

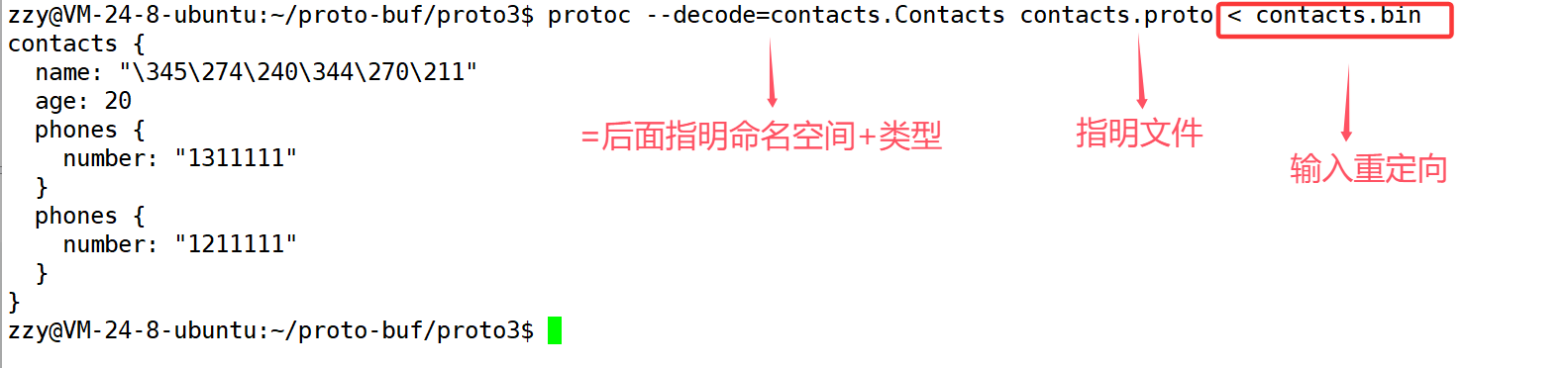
使用protoc -h可以查看protoc可以带的选项。我们看到–decode,表示从标准输入中读取二进制信息然后写入到标准输出中。所以我们也可以通过–decode来读取通讯录文件的信息。

4.2、enum类型

如图我们在文件中定义了枚举类型PhoneType核PhoneTypeCopy。
注意:枚举类型建议全大写,如果多个单词就用_隔开。枚举类型必须从常量0开始,也就是枚举类型的第一个成员必须是从0开始的。枚举的常量值在 32 位整数的范围内。但因负值无效因而不建议使用(与编码规则有关)。枚举类型可以在消息外定义,也可以在消息体内定义(嵌套)。
如图,两个枚举类型在同一个文件下,所以MP核TEL会出现冲突!同级(同层)的枚举类型,各个枚举类型中的常量不能重名。
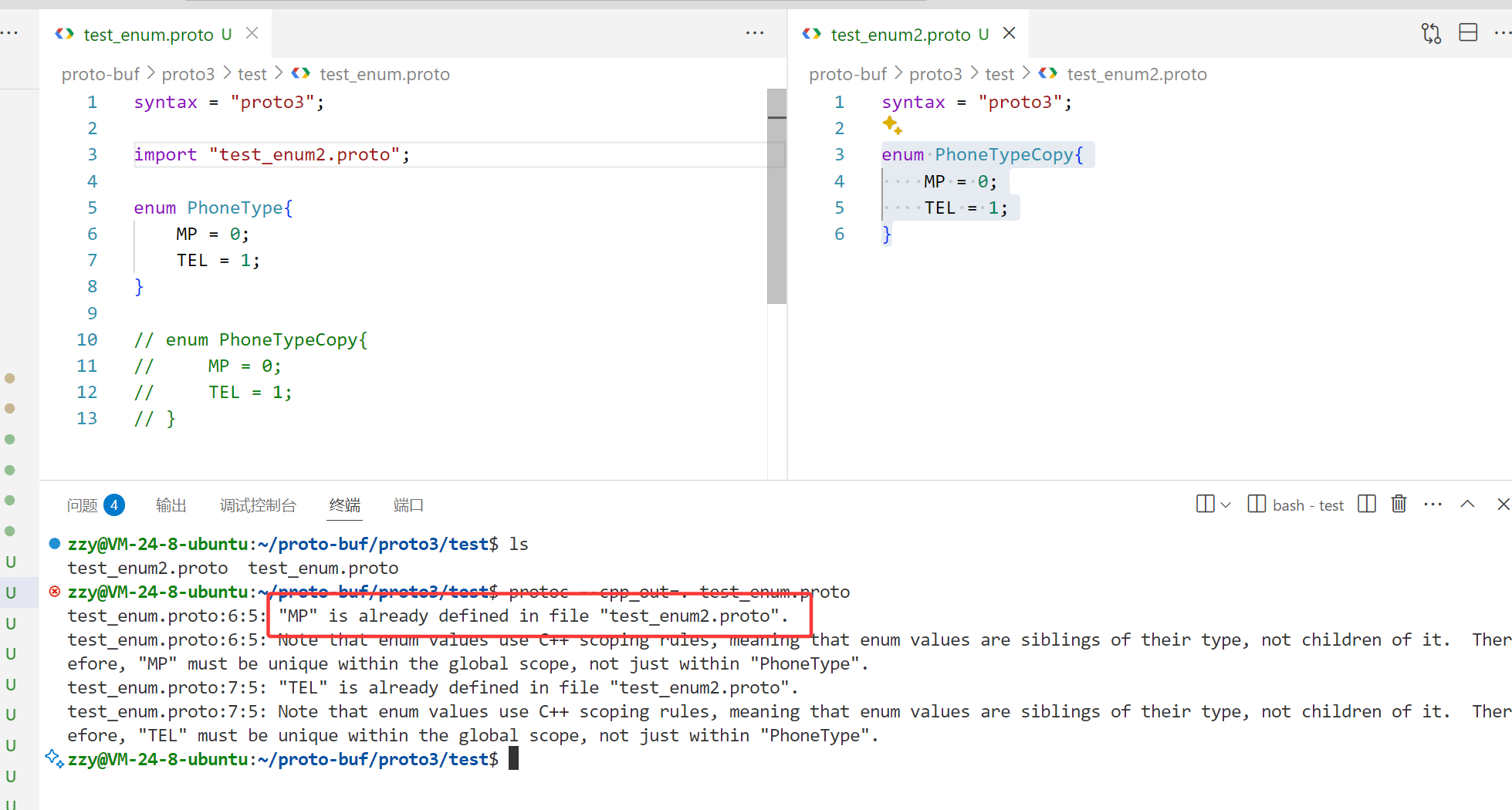
多个 .proto 文件下,若⼀个文件引入了其他文件,且每个文件都未声明package,每个proto文件中的枚举类型都在最外层,算同级。
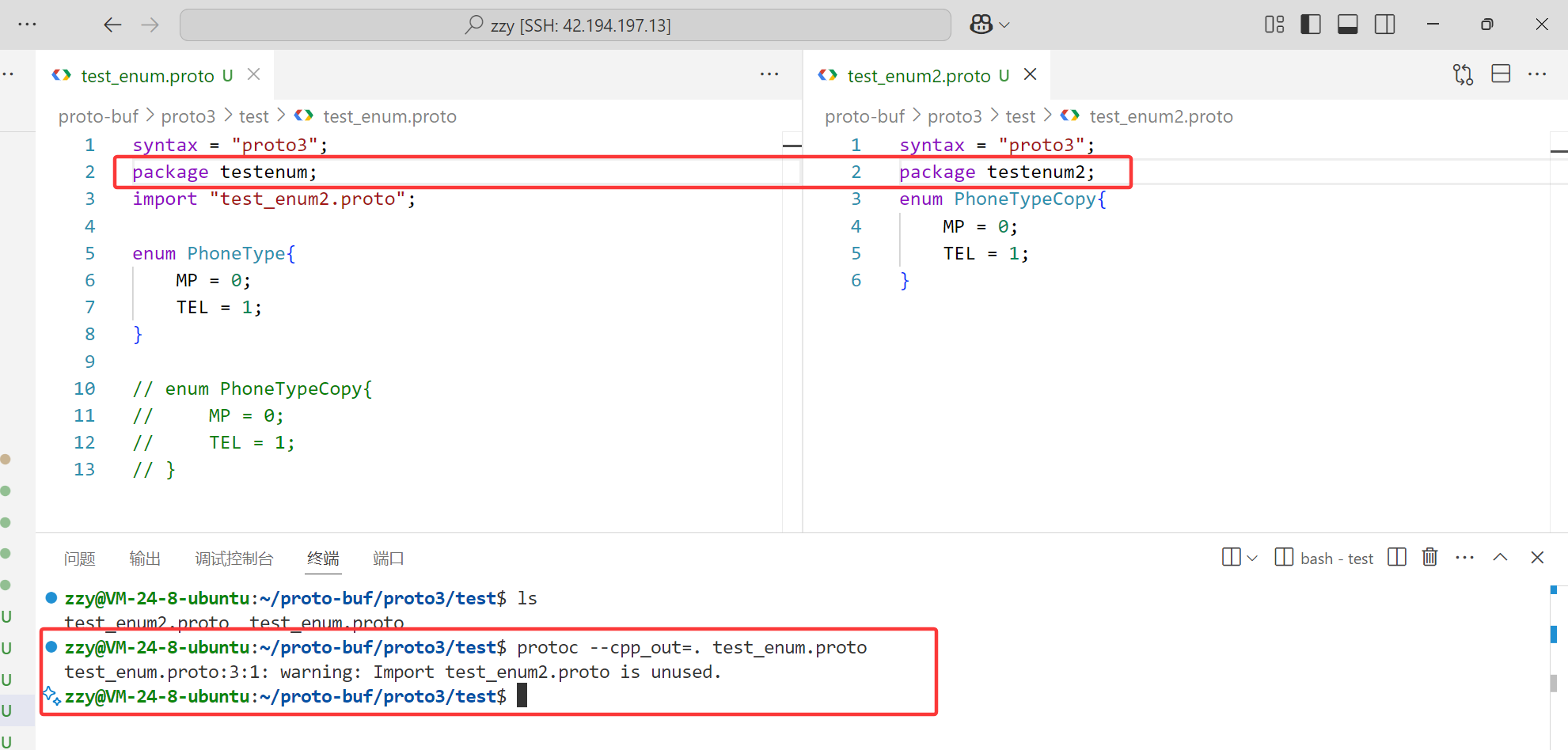
多个 .proto 文件下,若一个文件引入了其他文件,且每个文件都声明了package,不算同级。
另外如果是枚举类型嵌套定义也不算同级。
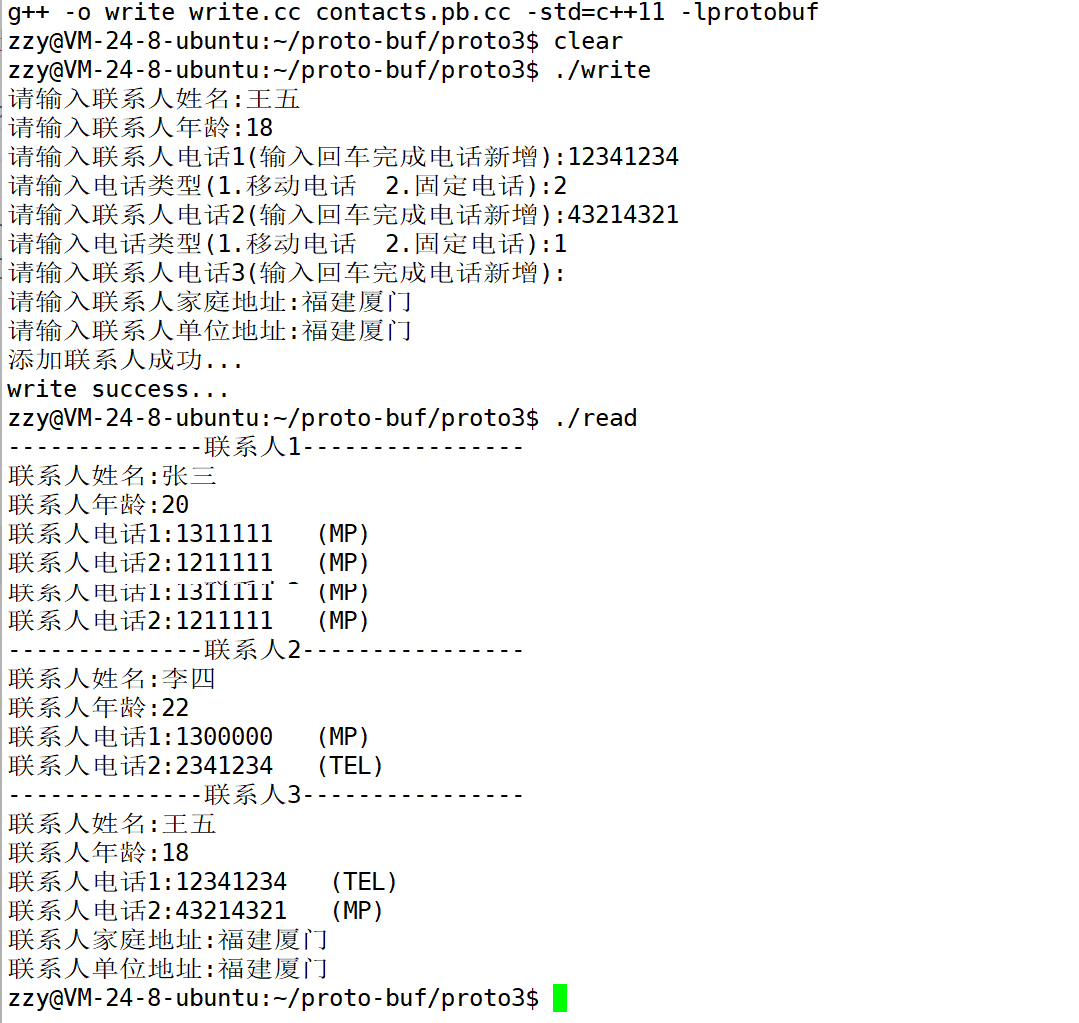
基于上面知识修改contacts.proto添加电话类型枚举字段,并修改write.cc和read.cc。

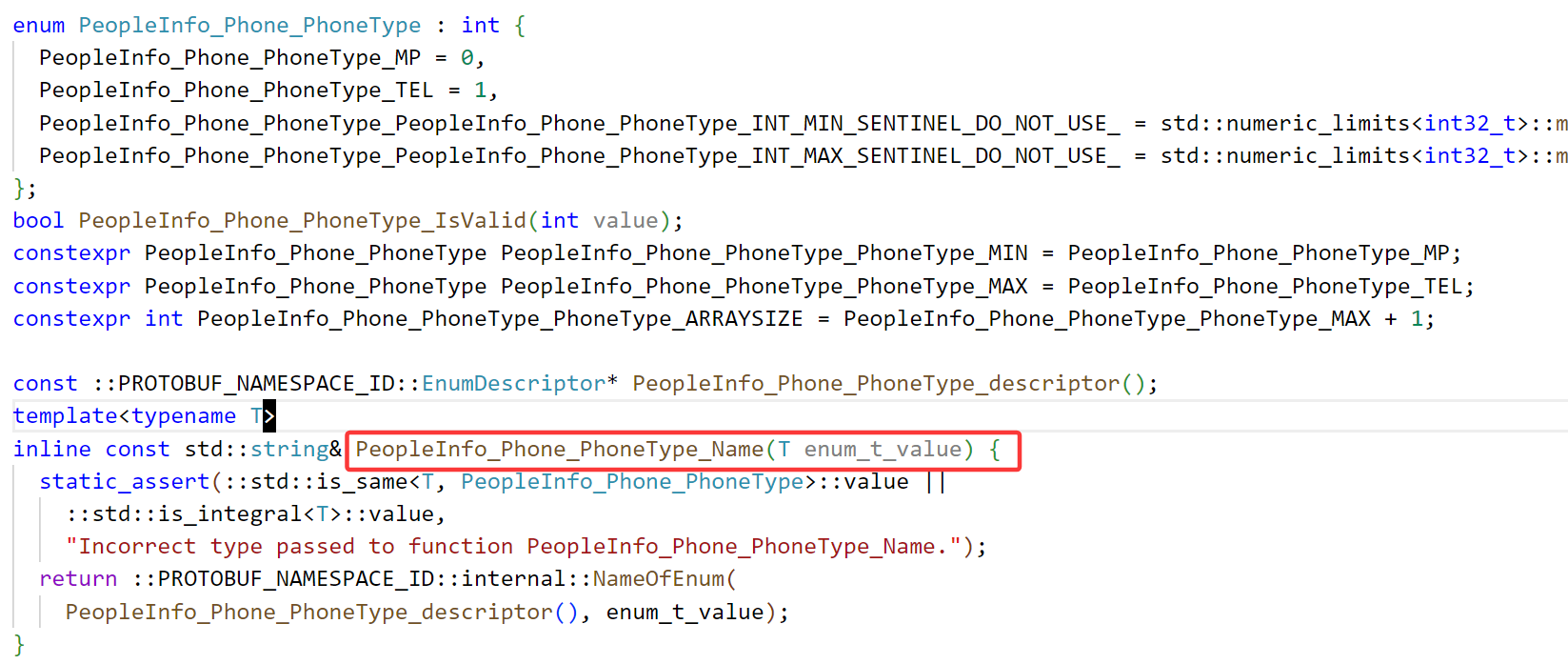
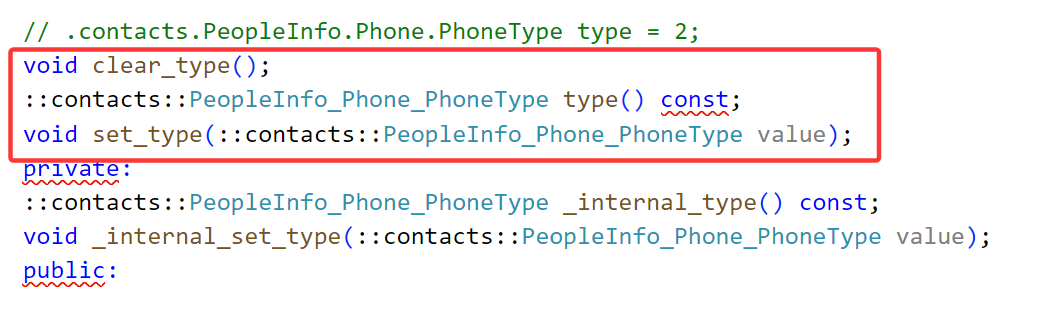
编译后查看头文件,我们发现多了要给类型,这里有个Name的方法,就是通过枚举值获取枚举类型。然后查看Phone中的变量,对于type有清空、获取、设置等方法。
接着添加write.cc和read.cc支持对于电话类型的设置和打印:

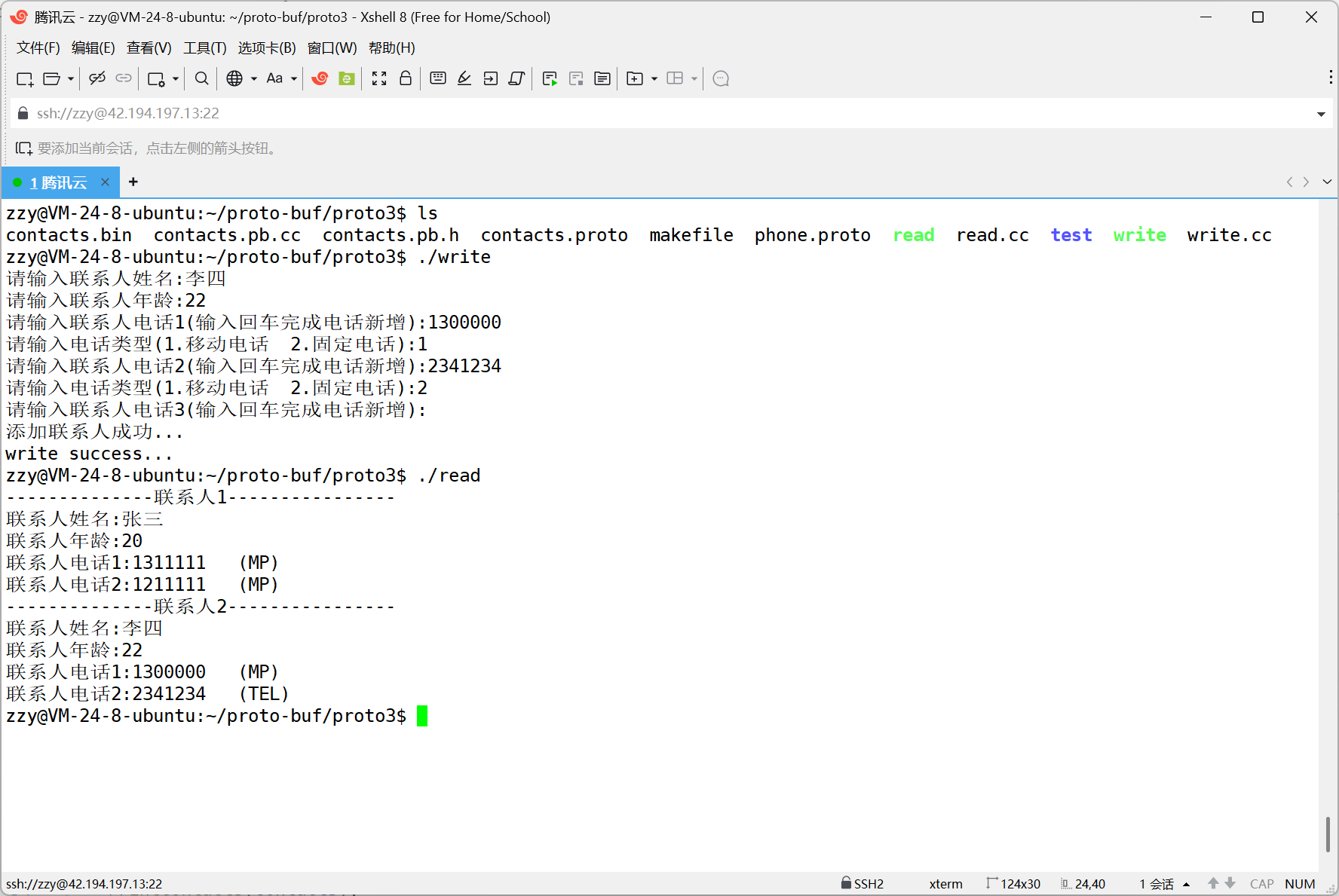
我们之前对于张三的电话是没有设置的,但是这里打印的时候发现是MP,这是因为protobuf在反序列化的时候,如果枚举类型没有设置值的话,就会采用默认值为0的枚举类型。
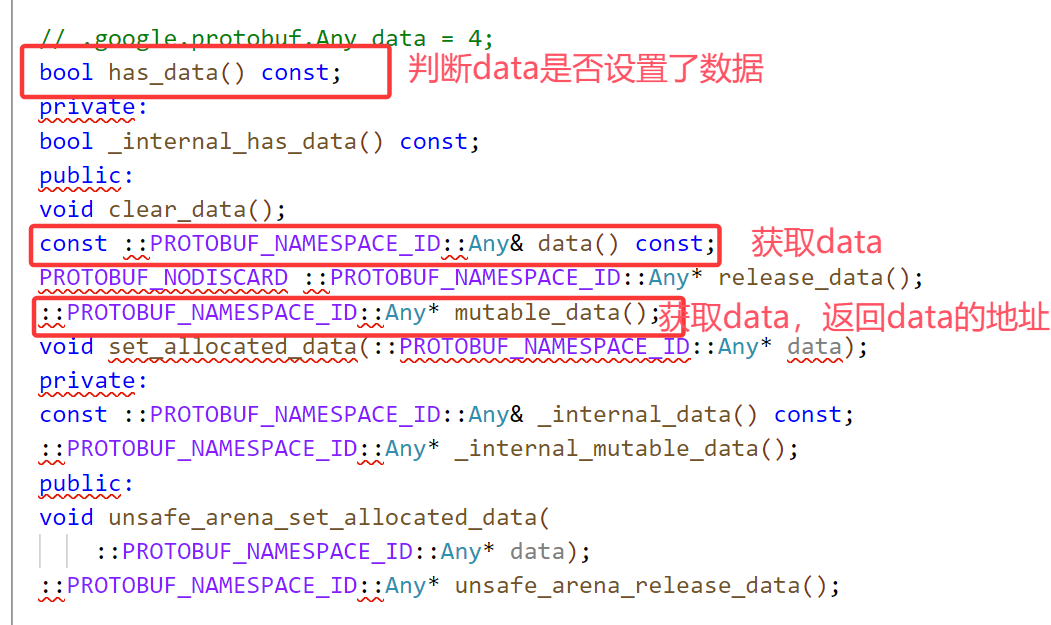
4.3、Any类型
字段还可以声明为Any类型,可以理解为泛型类型。使用时可以在Any中存储任意消息类型。Any类型的字段也用repeated来修饰。
Any类型是google已经帮我们定义好的类型,在安装ProtoBuf时,其中的include目录下查找所有google已经义好的.proto文件。
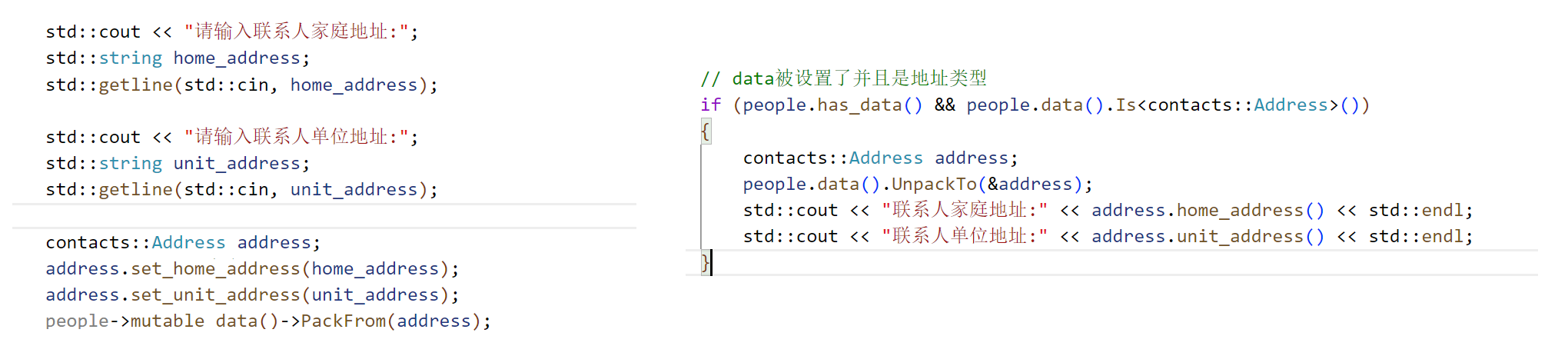
下面我们给通讯录联系人添加地址信息:
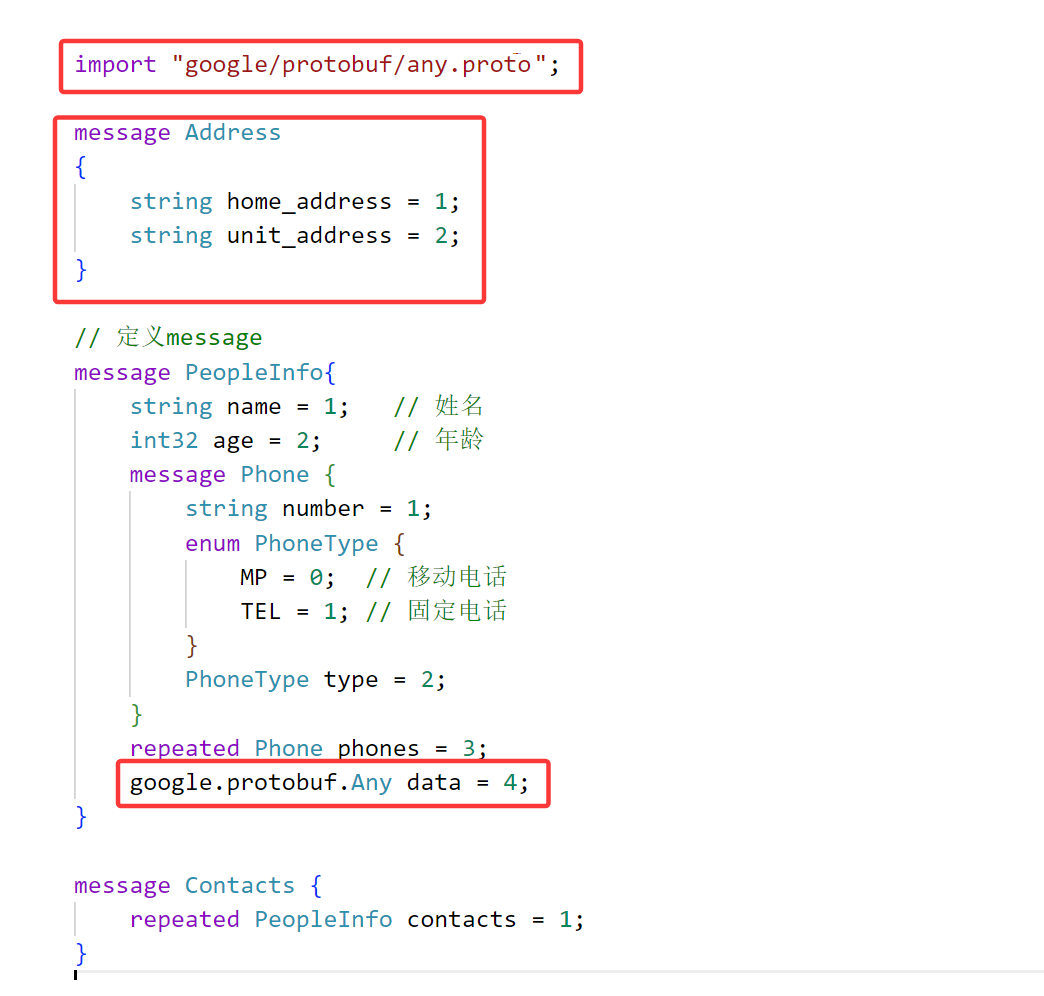
首先定义message Address存放地址信息结构,然后引入谷歌官方定义的.proto文件,由于message Any是有package的,所以在PeopleInfo中定义类型需要指明包名.Any,我们定义了一个data对象,将来就用它存储任意类型也就是地址类型。
编译后查看头文件新增的信息:
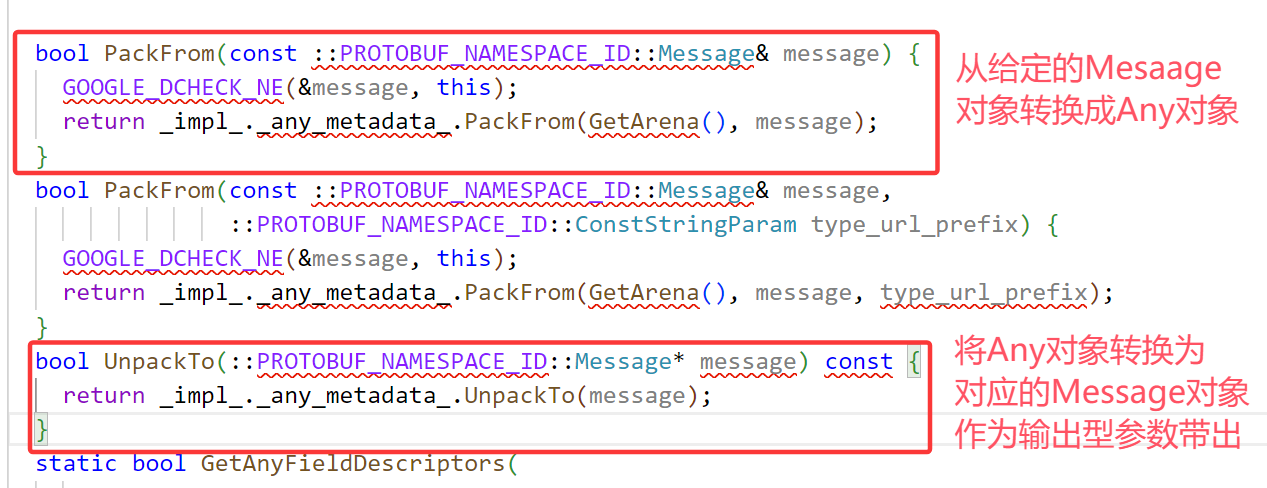

然后补充write.cc和read.cc:
4.4、oneof类型
如果消息中有很多可选字段, 并且将来同时只有一个字段会被设置, 那么就可以使用oneof 加强这个行为,也能有节约内存的效果。
比如联系人有其他联系方式qq和wechat,但是我们只想保留一个。那么就可以使用oneof类型:

不能使用repeated定义数组,如果多次设置只会保留最后一次设置。
编译后查看处理字段方法:
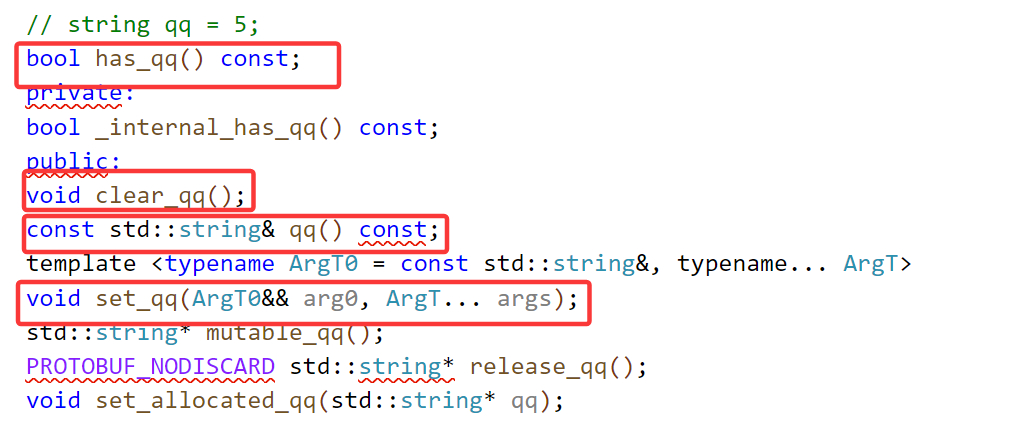
我们发现有clear、get、set方法,并且多了一个has_qq用来判断是否设置了。

other_contact_case返回我们设置了哪个字段,如果没有设置就会返回枚举常量为0。
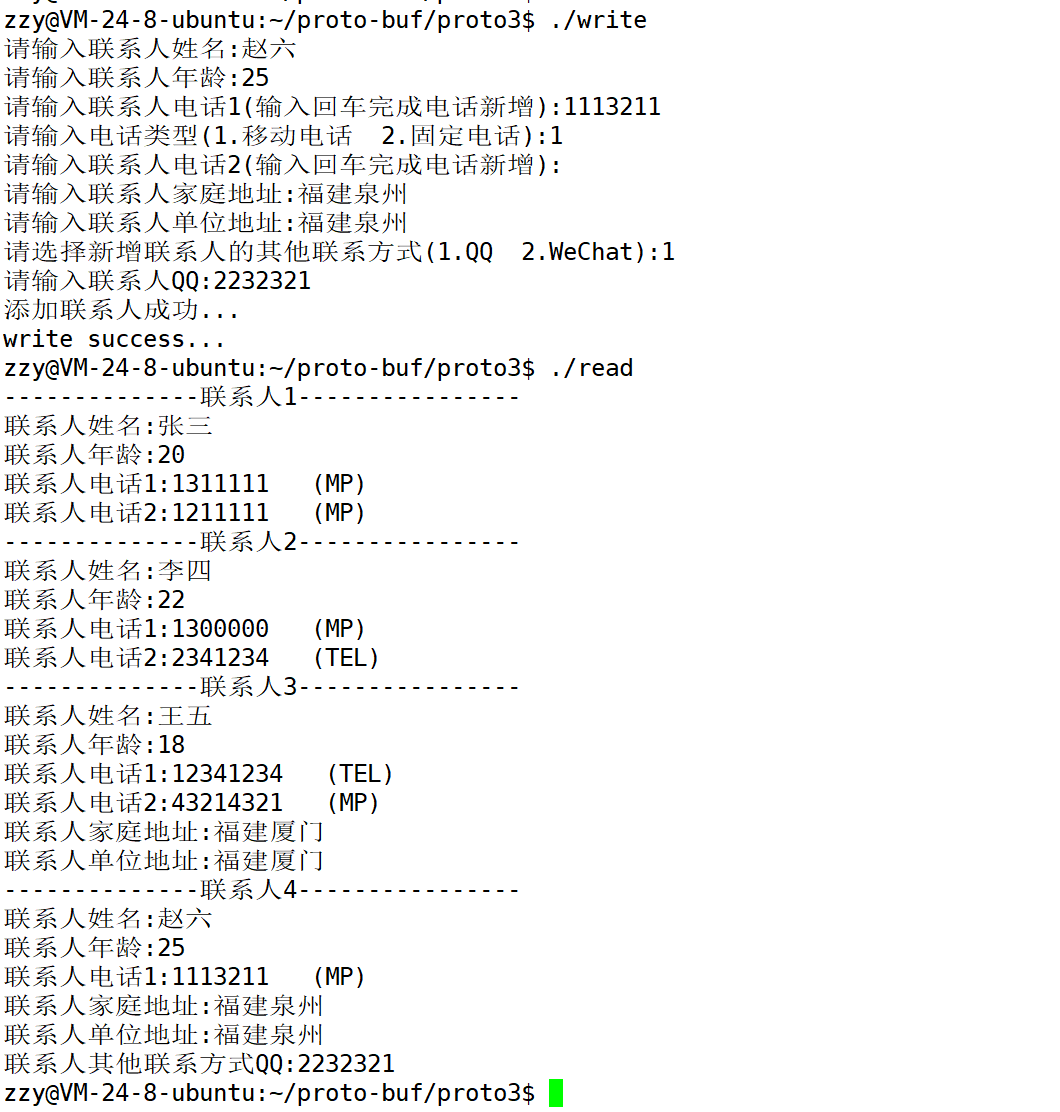
实现write.cc和read.cc
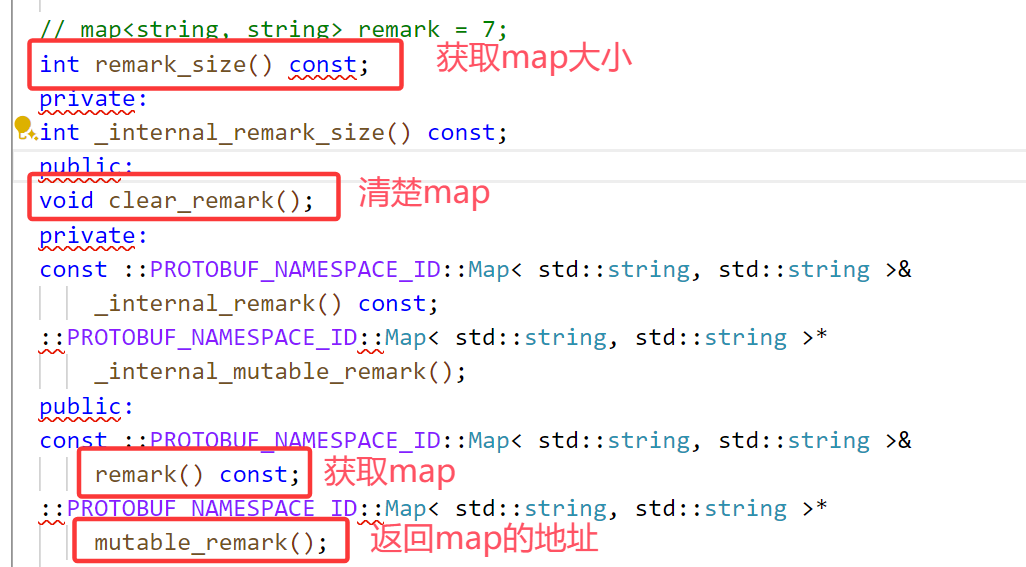
4.5、map类型
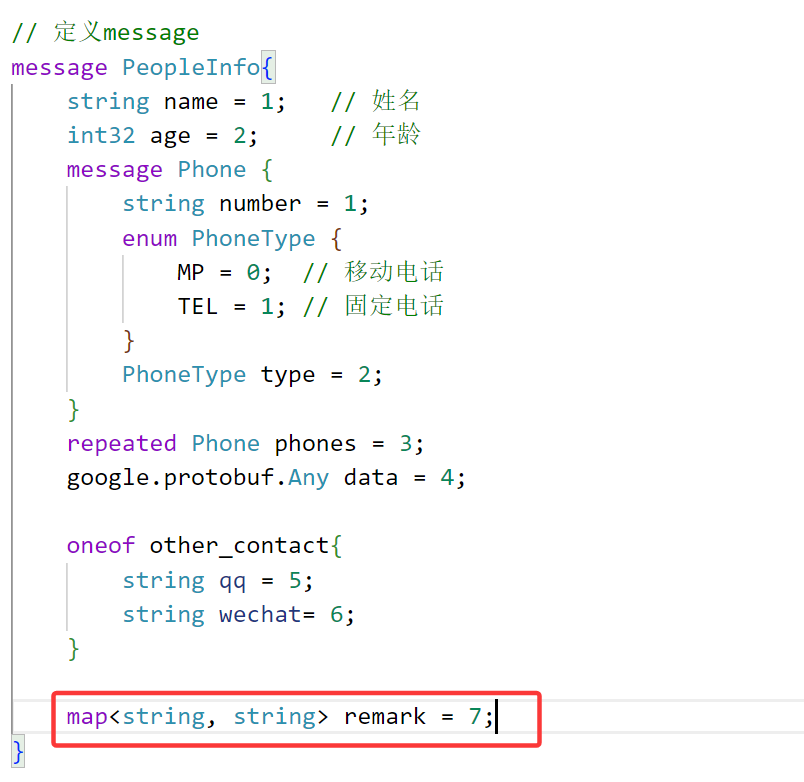
语法支持创建一个关联映射字段,也就是可以使用map类型去声明字段类型,格式为:
map<key_type, value_type> map_field = N;
要注意的是:
• key_type 是除了 float 和 bytes 类型以外的任意标量类型。 value_type 可以是任意类型。
• map 字段不可以用repeated修饰。
• map 中存入的元素是无序的。
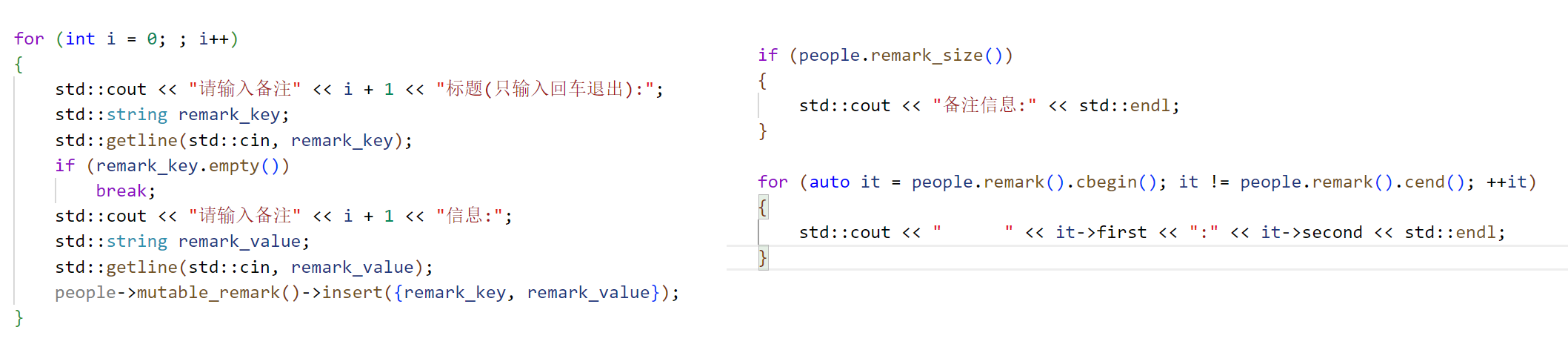
给联系人添加备注信息:
编译后查看字段对应的方法:
实现write.cc和read.cc:
4.6、默认值
反序列化消息时,如果被反序列化的二进制序列中不包含某个字段,反序列化对象中相应字段时,就会设置为该字段的默认值。不同的类型对应的默认值不同:
• 对于字符串,默认值为空字符串。
• 对于字节,默认值为空字节。
• 对于布尔值,默认值为 false。
• 对于数值类型,默认值为 0。
• 对于枚举,默认值是第⼀个定义的枚举值, 必须为 0。
• 对于消息字段,未设置该字段。它的取值是依赖于语言。
• 对于设置了repeated的字段的默认值是空的( 通常是相应语言的一个空列表 )。
• 对于消息字段、oneof字段和any字段,C++和Java语言中都有has_方法来检测当前字段是否被设置。
对于标量数据类型,在proto3语法下,没有生成has_方法。但是在大部分情况下是可以兼容默认值的。
4.7、更新消息
更新消息无非就是三种情况:新增、修改、删除。
对于新增:注意不要和老字段冲突即可。
对于修改:
• 禁止修改任何已有字段的字段编号。
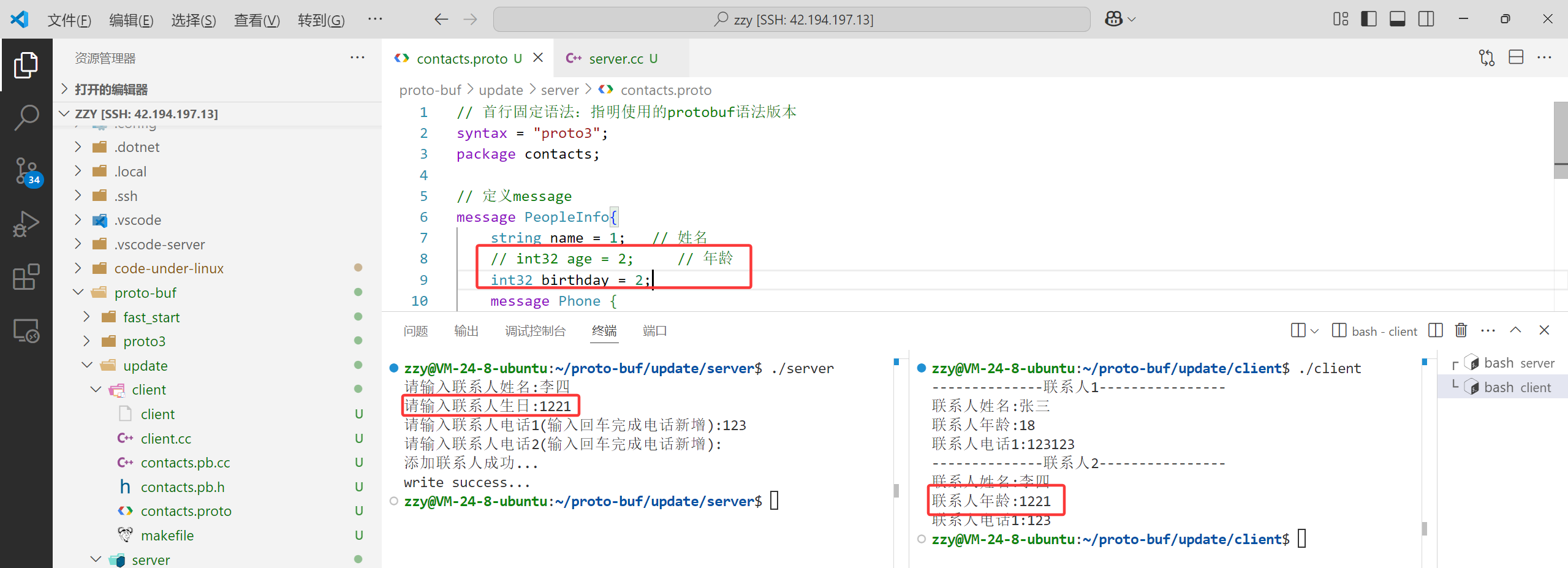
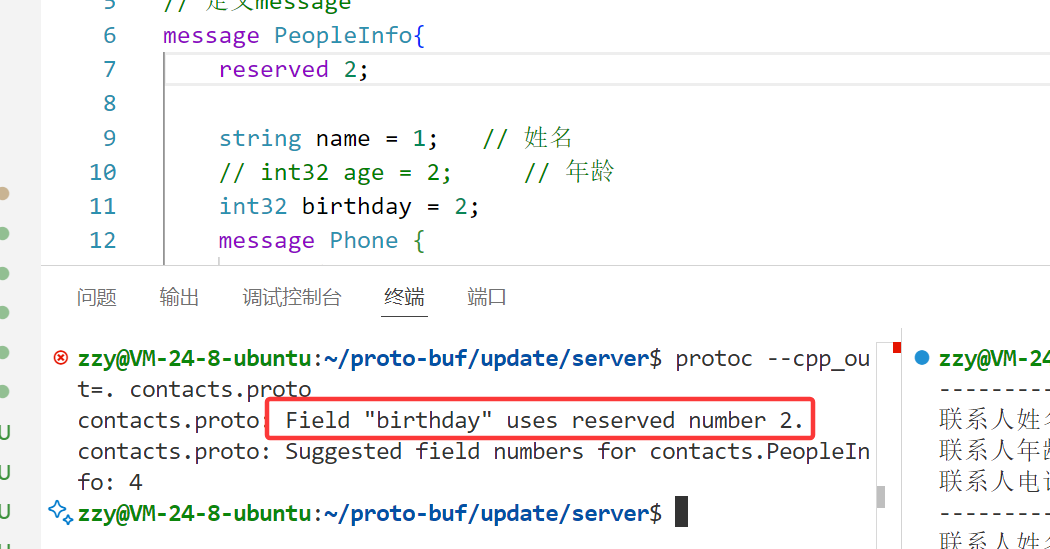
• 若是移除老字段,要保证不再使用移除字段的字段编号。正确的做法是保留字段编号(reserved),以确保该编号将不能被重复使用。不建议直接删除或注释掉字段。
• int32, uint32, int64, uint64 和 bool 是完全兼容的。可以从这些类型中的一个改为另一个,而不破坏前后兼容性。若解析出来的数值与相应的类型不匹配,会采用与C++一致的处理方案(例如,若将64位整数当做32位进行读取,它将被截断为32位)。
• sint32 和 sint64 相互兼容但不与其他的整型兼容。
• string 和 bytes 在合法 UTF-8 字节前提下也是兼容的。
• bytes 包含消息编码版本的情况下,嵌套消息与 bytes 也是兼容的。
• fixed32 与 sfixed32 兼容, fixed64 与 sfixed64兼容。
• enum 与 int32,uint32, int64 和 uint64 兼容(注意若值不匹配会被截断)。但要注意当反序列化消息时会根据语言采用不同的处理方案:例如,未识别的 proto3 枚举类型会被保存在消息中,但是当消息反序列化时如何表⽰是依赖于编程语言的。整型字段总是会保持其的值。
• oneof:
◦ 将一个单独的值更改为新oneof类型成员之一是安全和二进制兼容的。
◦ 若确定没有代码一次性设置多个值那么将多个字段移入一个新oneof类型也是可行的。
◦ 将任何字段移入已存在的oneof类型是不安全的。
对于删除:不能直接删除。如果要删除老字段,必须保证不适用已经被删除的或者已经被注释掉的字段编号。
确保不会发生这种情况的一种方法是:使用reserved将指定字段的编号或名称设置为保留项 。当我们再使用这些编号或名称时,protocol buffer的编译器将会警告这些编号或名称不可用。

复制我们之前写的代码,将write.cc修改为server.cc,read.cc修改为client.cc删除掉message PeopleInfo中的信息,留下一些简单的信息进行测试即可。
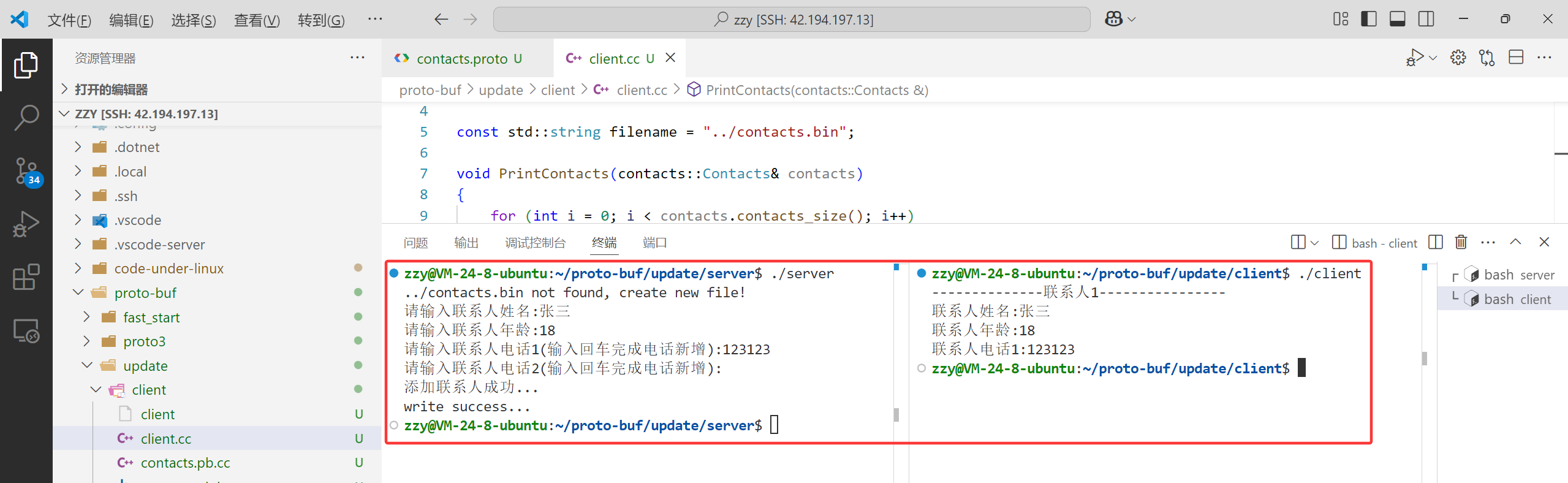
我们先写入一个联系人信息,发现读取没有任何问题,接着我们把服务端的message PeopleInfo中的年龄改了,修改为生日:int birthday = 2;并且使用和之前年龄一样的编号2,但是客户端并不发生变化。接着修改write.cc中的设置年龄改为设置生日,重新编译服务端并且继续写入新联系人的信息,然后客户端再进行读取,我们看看会发生什么:
当服务端添加新的联系人后,添加的联系人生日被客户端当作年龄了,因为它们使用相同的编号2。
下面我们使用reserved保留2,再进行测试:
接着我们将birthday的编号改为4,然后编译运行添加新联系人王五,客户端在进行读取。
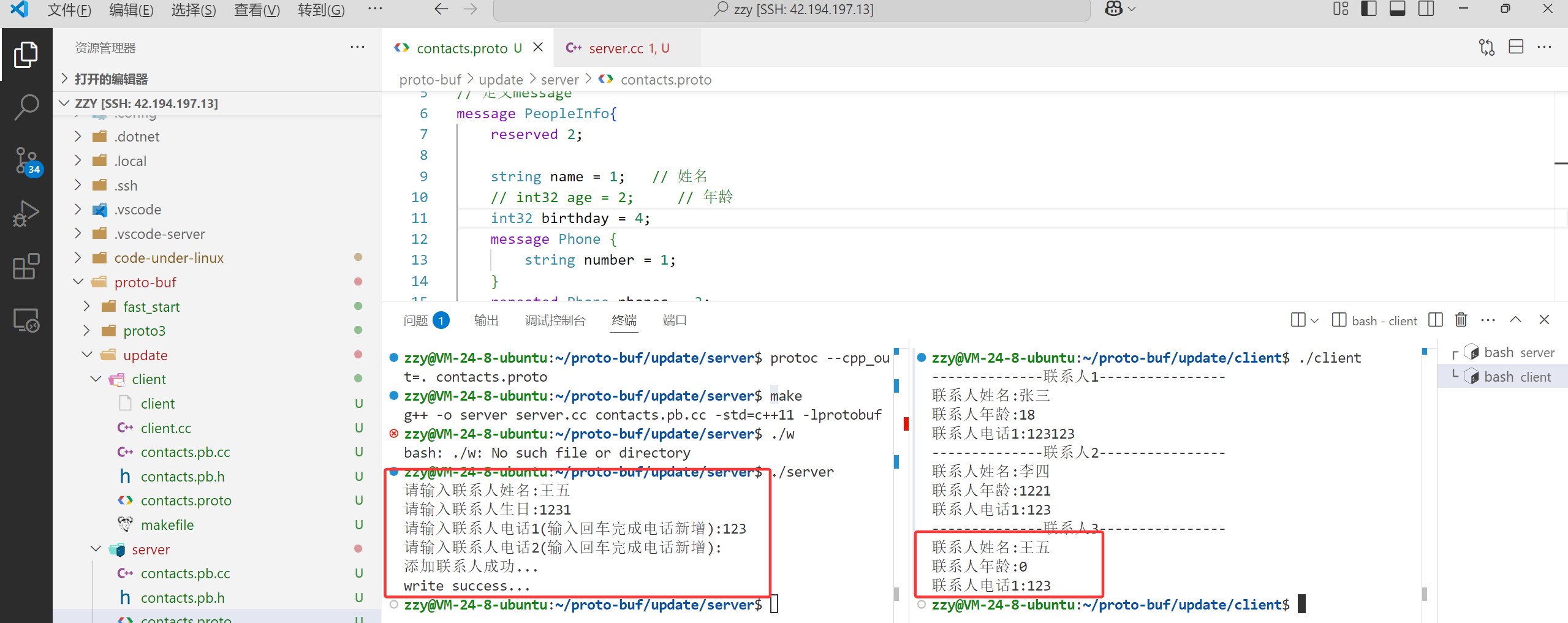
此时客户端王五没有年龄,所以使用了默认值0。
我们向service目录下的contacts.proto新增了生日字段,但对于client相关的代码并没有任何改动。验证后发现新代码序列化的消息(service)也可以被旧代码(client)解析。并且这里要说的是,新增的生日字段在旧程序(client)中其实并没有丢失,而是会作为旧程序的未知字段。
• 未知字段:解析结构良好的protocol buffer已序列化数据中的未识别字段的表示方式。例如,当旧程序解析带有新字段的数据时,这些新字段就会成为旧程序的未知字段。
• 本来,proto3在解析消息时总是会丢弃未知字段,但在3.5版本中重新引入了对未知字段的保留机制。所以在3.5或更高版本中,未知字段在反序列化时会被保留,同时也会包含在序列化的结果中。
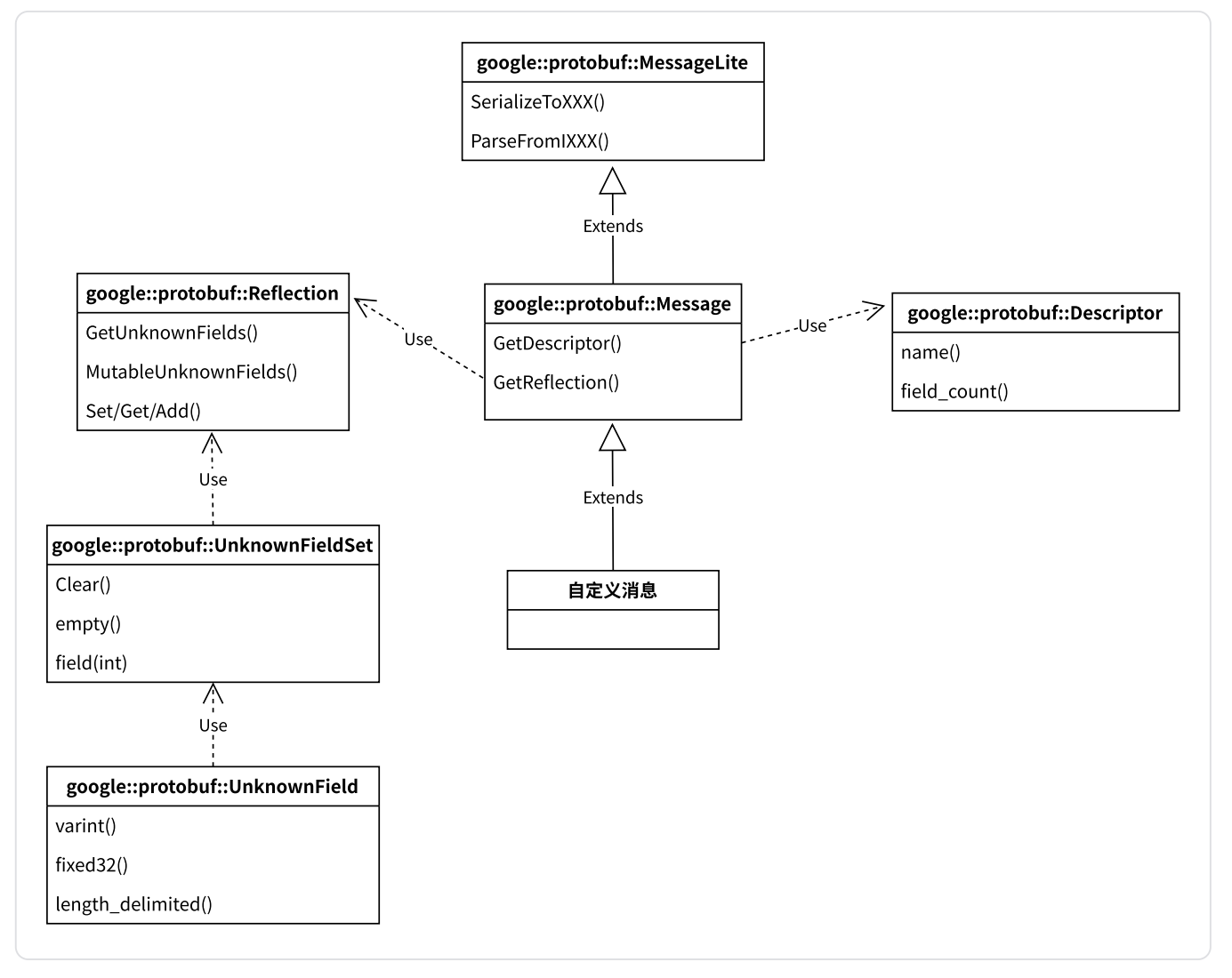
我们自己定义的message,实际上继承了Message,而Message又继承了MessageLite,MessageLite里面实现了message的序列化和反序列化方法。Message中可以通过GetDescriptor获取一个指针,该指针指向了Descriptor对象,该对象描述了message自定相关内容。Message中还可以通过GetReflection方法获取指针指向Reflection对象,该对象里面有自定义消息读写字段的相关方法,并且我们注意到该对象里面还有一个GetUnknownFields方法,可以获取未知字段,该方法又获取了UnknownfieldSet对象,这个set里面保存了未知字段,可以清空,可以判断是否为空,还可以获取UnknownField,这个对象就是具体的未知字段了。
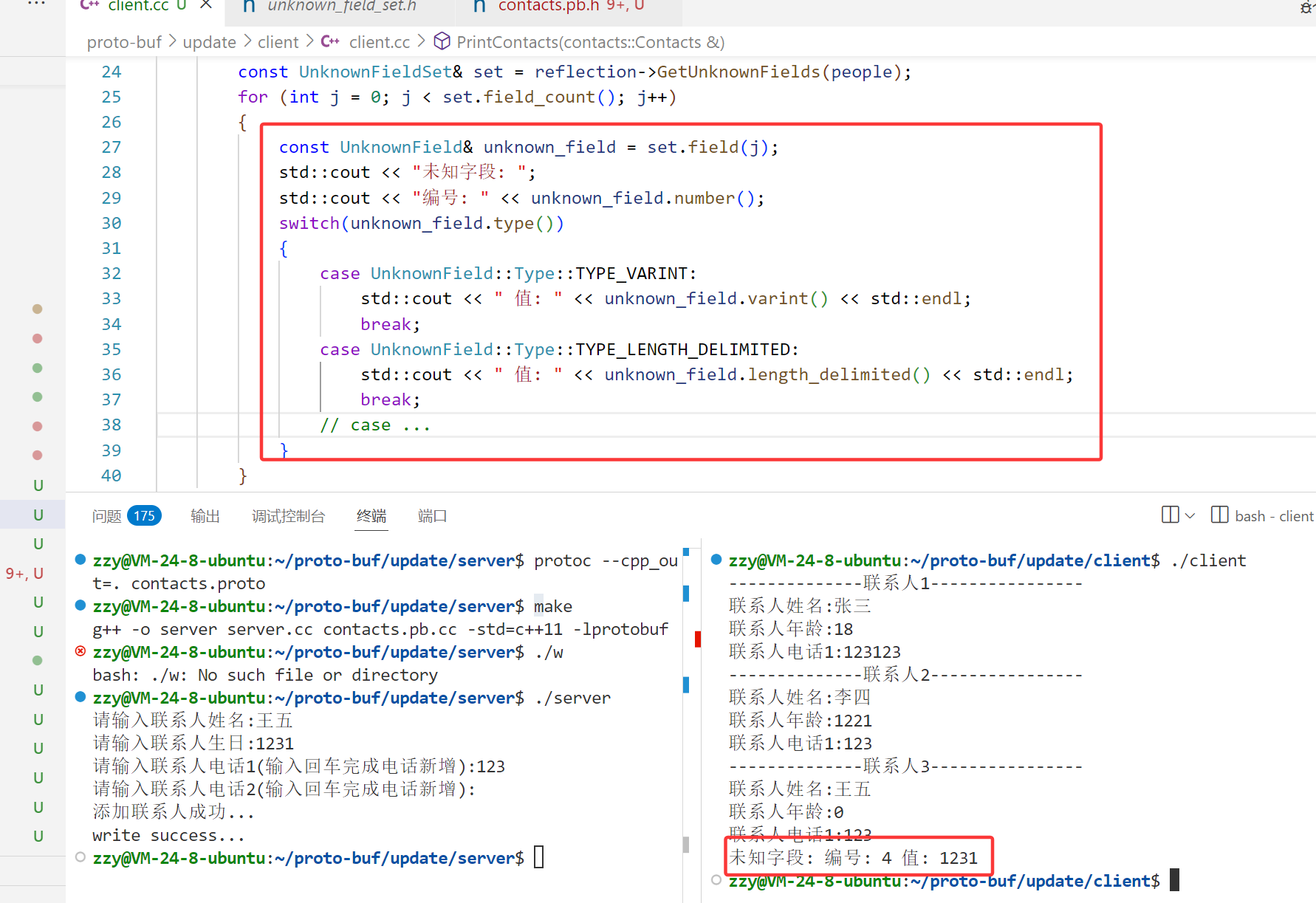
下面我们打印未知字段:需要拿出UnknownField对象
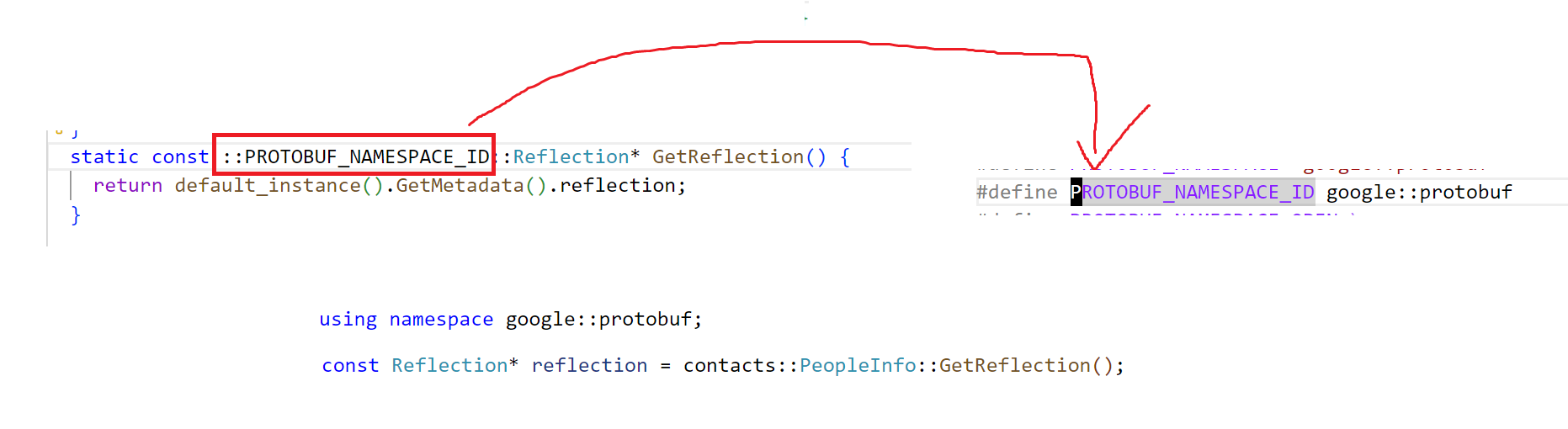
首先我们需要调用GetReflection获取Reflection*指针,这是一个静态成员函数,这个对象命名空间被typedef了一下,实际上就是google.protobuf,为了简写,我们直接展开这个命名空间。
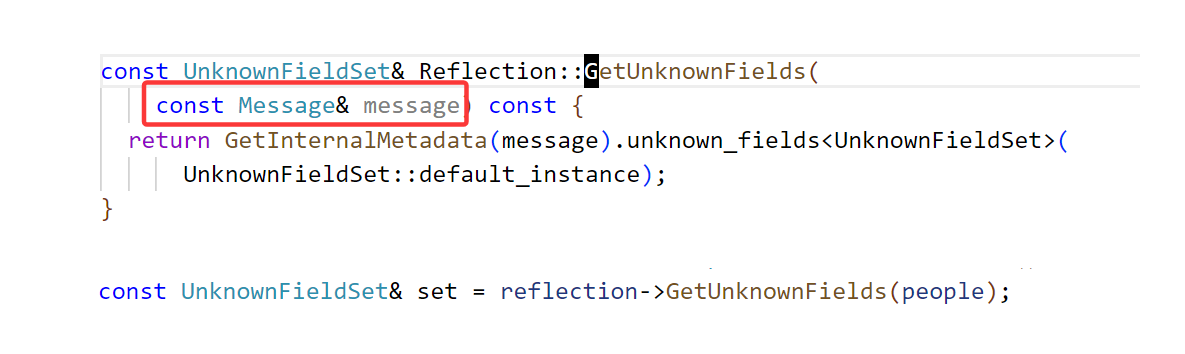
接着调用Reflection对象中的GetUnknownFields获取未知字段的Set集合。注意需要传入message对象,返回值是一个引用。

通过field获取UnknownField对象,我们可以查看一下该对象里面有什么。
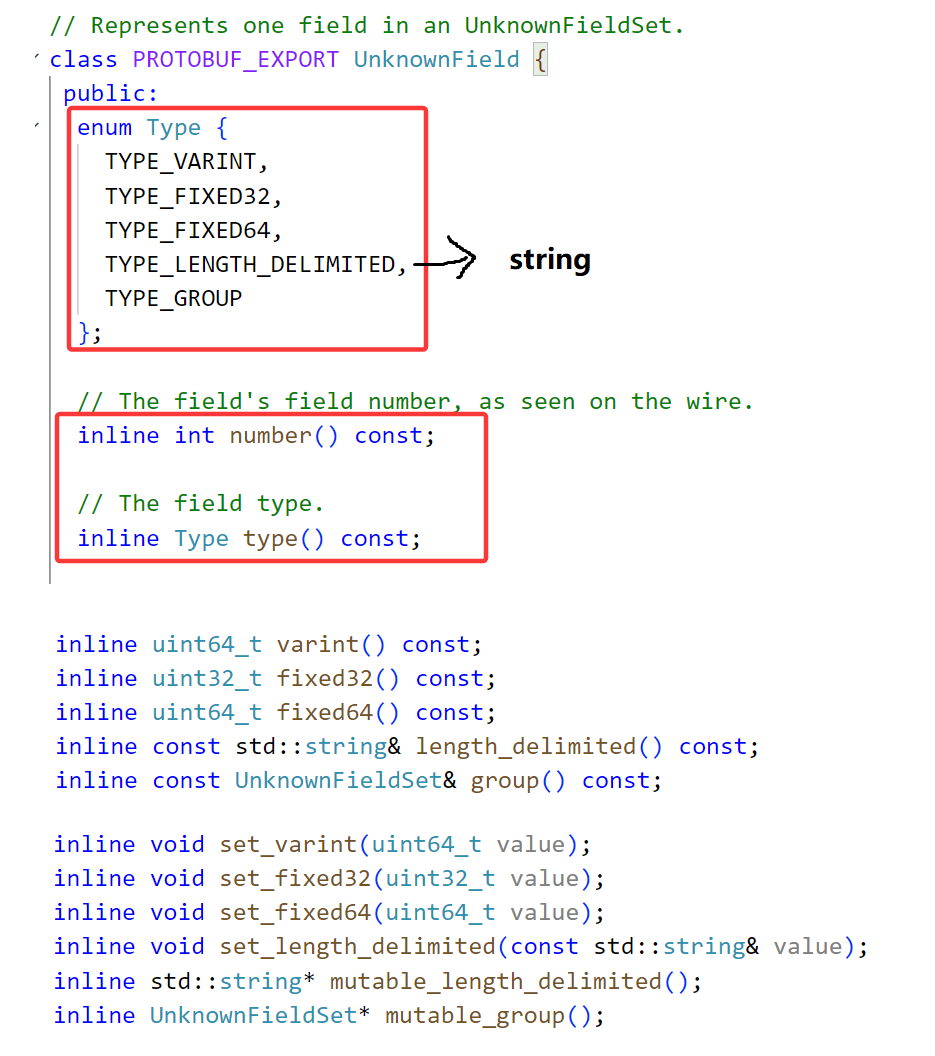
number()方法用于获取该未知字段的编号,比如我们前面服务端的int32生日字段编号为4,那么我们调用该函数获取到的就是4。type返回上面定义的枚举类型,我们生日字段是int32,那么对应的就是TYPE_VARINT,如果是fixed32就是TYPE_FIXED32,如果是string就是TYPE_LENGTH_DELIMITED。
根据type()方法获取枚举常量,我们根据枚举常量来判断要调用下面的varint()、fixed32()等方法获取未知字段。并且还支持我们去设置未知字段。
前后兼容性:
根据上述的例子可以得出,pb是具有向前兼容的。为了叙述方便,把增加了生日属性的service称为新模块。未做变动的client称为老模块。
• 向前兼容:老模块能够正确识别新模块生成或发出的协议。这时新增加的生日属性会被当作未知字段(pb 3.5版本及之后)。
• 向后兼容:新模块也能够正确识别老模块生成或发出的协议。
前后兼容的作用:当我们维护一个很庞大的分布式系统时,由于你无法同时升级所有模块,为了保证在升级过程中,整个系统能够尽可能不受影响,就需要尽量保证通讯协议的“向后兼容”或“向前兼容”。
4.8、option选项
先看现象:
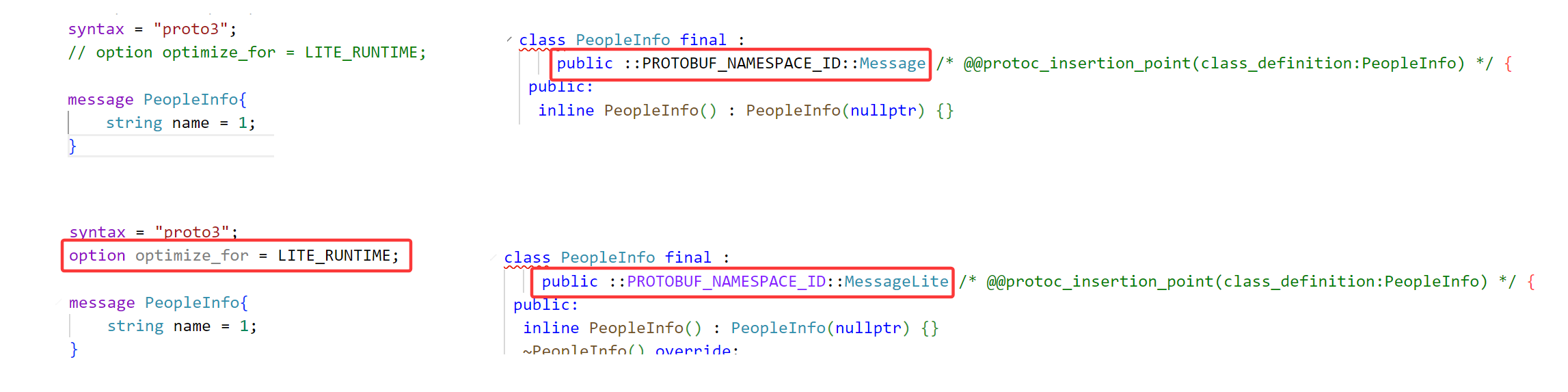
在上方,我们没有添加选项,编译后的头文件中我们查看PeopleInfo这个类是继承于Message的,当我们添加选项后重新编译,PeopleInfo是继承于MessageLite的。这肯定是和我们添加的选项有关。
.proto文件中可以声明许多选项,使用option 标注。选项能影响proto编译器的某些处理方式。
选项的完整列表在google/protobuf/descriptor.proto中定义。

由此可见,选项分为文件级、消息级、字段级等等, 但并没有一种选项能作用于所有的类型。
常用选项列举:
optimize_for : 该选项为文件选项,可以设置protoc编译器的优化级别,分别为SPEED、CODE_SIZE、LITE_RUNTIME。受该选项影响,设置不同的优化级别,编译.proto文件后生成的代码内容不同。
◦ SPEED:protoc编译器将生成的代码是高度优化的,代码运行效率高,但是由此生成的代码编译后会占用更多的空间。SPEED 是默认选项。
◦ CODE_SIZE:proto编译器将生成最少的类,会占用更少的空间,是依赖基于反射的代码来实现序列化、反序列化和各种其他操作。但和SPEED恰恰相反,它的代码运行效率较低。这种方式适合用在包含大量的.proto文件,但并不盲目追求速度的应用中。
◦ LITE_RUNTIME:生成的代码执行效率高,同时生成代码编译后的所占用的空间也是非常少。这是以牺牲Protocol Buffer提供的反射功能为代价的,仅仅提供encoding+序列化功能,所以我们在链接BP库时仅需链接libprotobuf-lite,而非libprotobuf。这种模式通常用于资源有限的平台,例如移动手机平台中。
5、通讯录网络版
Protobuf还常用于通讯协议、服务端数据交换场景。那么在这个示例中,我们将实现一个网络版本的通讯录,模拟实现客户端与服务端的交互,通过Protobuf来实现各端之间的协议序列化。
需求如下:
• 客户端可以选择对通讯录进行以下操作:
◦ 新增一个联系人
◦ 删除一个联系人
◦ 查询通讯录列表
◦ 查询一个联系人的详细信息
• 服务端提供增、删、查能力,并需要持久化通讯录。
• 客户端、服务端间的交互数据使用Protobuf来完成。
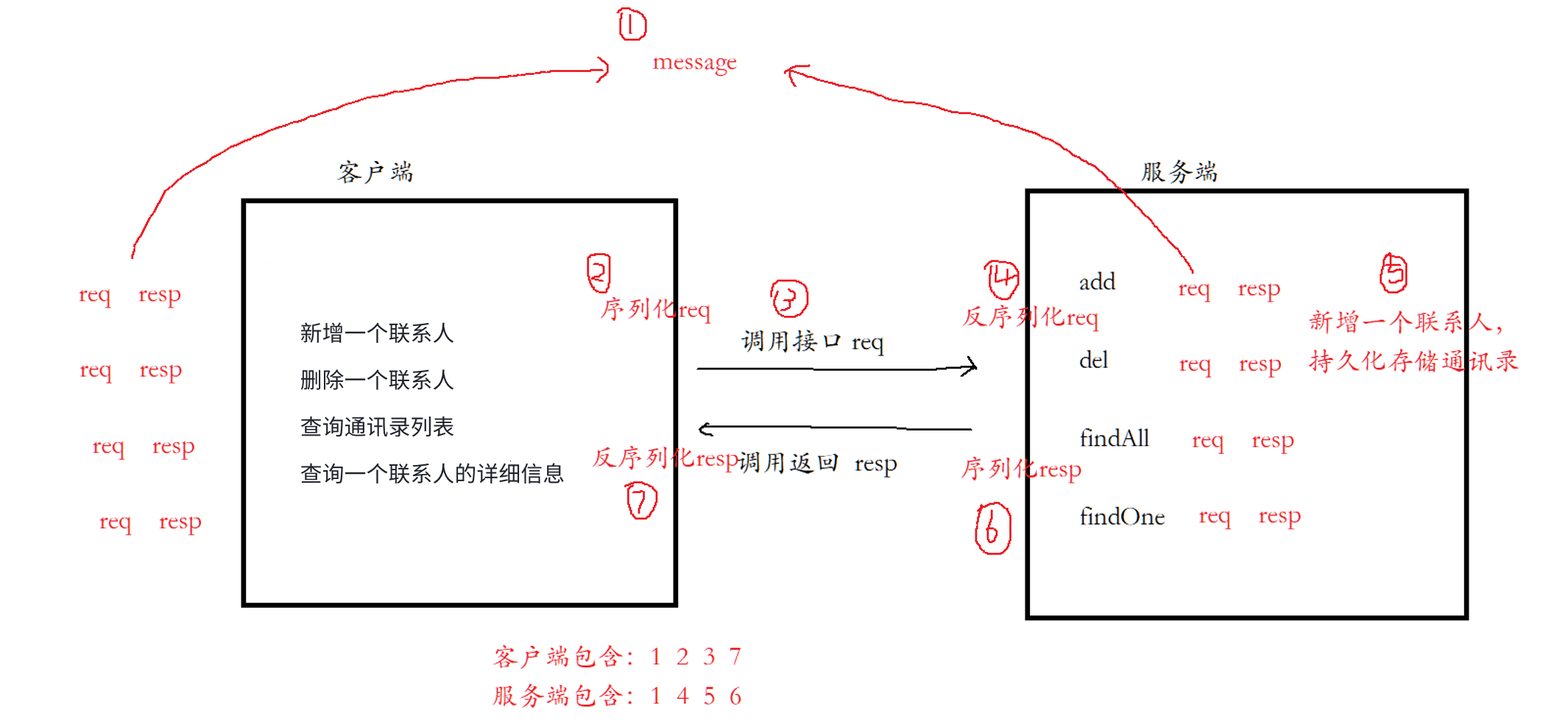
首先来分析一下如何实现,客户端通过调用接口向服务端发起req,然后服务端调用返回req。对于双方来说,不管是何种请求,都需要有req和resp,所以第一步我们要定义message对象。接着客户端将req进行序列化通过网络传输给服务端,服务端接收后进行反序列化然后新增联系人,同时实现数据持久化,然后再构建resp,序列化后发送给客户端,客户端接收后需要进行反序列化。
1、环境搭建
Httplib库:cpp-httplib是个开源的库,是一个c++封装的http库,使用这个库可以在linux、windows平台下完成http客户端、http服务端的搭建。使用起来非常方便,只需要包含头文件httplib.h即可。编译程序时,需要带上-lpthread选项。
源码库地址:https://github.com/yhirose/cpp-httplib
需要先将该库下载到Linux服务器上。可以使用git clone克隆到本地。
服务端代码:
#include <iostream>
#include "httplib.h"using std::cout;
using std::endl;
using std::cerr;
using namespace httplib;int main()
{cout << "----------服务启动-----------" << endl;Server server;server.Post("/test-post", [](const Request& req, Response& resp){cout << "接收到post请求!" << endl;resp.status = 200;});server.Get("/test-get", [](const Request& req, Response& resp){cout << "接收到get请求!" << endl;resp.status = 200;});server.listen("0.0.0.0", 8080);return 0;
}
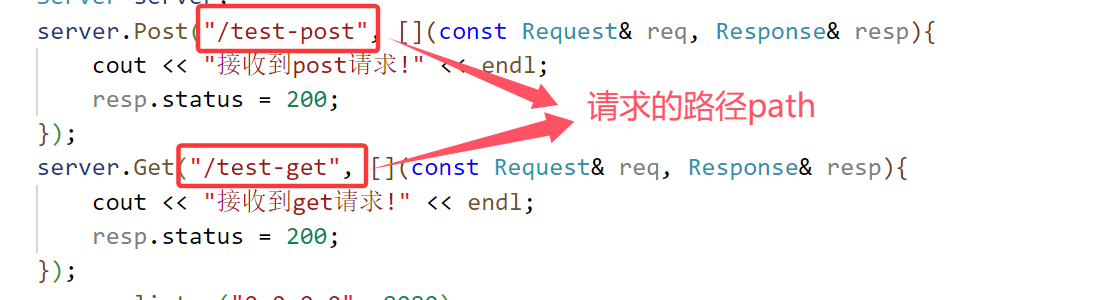
客户端代码:
#include <iostream>
#include "httplib.h"using std::cout;
using std::endl;
using std::cerr;
using namespace httplib;const std::string serverip = "42.194.197.13";
const uint16_t serverport = 8080;int main()
{Client cli(serverip, serverport);Result resp1 = cli.Post("/test-post");if (resp1->status == 200){cout << "调用post成功!" <<endl;}Result resp2 = cli.Get("/test-get");if (resp2->status == 200){cout << "调用get成功!" << endl;}return 0;
}

编译后进行测试,至此项目环境搭建完成。
2、约定双方协议
syntax = "proto3";
package add_contacts;message AddContactsReq
{string name = 1; // 姓名int32 age = 2; // 年龄message Phone {string number = 1;enum PhoneType{MP = 0;TEL = 1;}PhoneType type = 2;}repeated Phone phones = 3; // 电话
}message AddContactsResp
{bool success = 1; // 调用是否成功string error_desc = 2; // 错误描述string uid = 3; // 用户uid
}
3、实现客户端。
实现异常类ContactsException.hpp
#pragma once
#include <iostream>class ContactsException
{
public:ContactsException(std::string str = "A problem") :_message(str){}std::string what() const { return _message;}
private:std::string _message;
};
实现客户端:
#include <iostream>
#include "httplib.h"
#include "ContactsException.h"
#include "add_contacts.pb.h"
using std::cin;
using std::cout;
using std::endl;
using std::cerr;
using namespace httplib;const std::string serverip = "42.194.197.13";
const uint16_t serverport = 8080;enum OPTIONS{QUIT = 0,ADD_,DEL,FIND_ALL,FIND_ONE,
};void menu()
{// 只实现添加联系人的功能cout << "---------------------------------" << endl;cout << "---------- 1.添加联系人 ----------" << endl;cout << "---------- 2.删除联系人 ----------" << endl;cout << "---------- 3.查询所有联系人 -------" << endl;cout << "---------- 4.查询单个联系人 -------" << endl;cout << "------------ 0.退出 ------------" << endl;cout << "---------------------------------" << endl;
}void BuildAddContactsReq(add_contacts::AddContactsReq& req)
{cout << "请输入联系人姓名:";std::string name;std::getline(std::cin, name);req.set_name(name);std::cout << "请输入联系人年龄:";int age;std::cin >> age;std::cin.ignore(256, '\n');req.set_age(age);for (int i = 0; ; i++){std::cout << "请输入联系人电话" << i + 1 << "(仅输入回车表示退出)" << ":";std::string number;std::getline(std::cin, number);if (number.empty()) break;add_contacts::AddContactsReq_Phone* phone = req.add_phones();phone->set_number(number);std::cout << "请输入联系人电话类型(1.移动电话 2.固定电话)" << ":";int op;std::cin >> op;std::cin.ignore(256, '\n');switch(op){case 1:phone->set_type(add_contacts::AddContactsReq_Phone_PhoneType::AddContactsReq_Phone_PhoneType_MP);break;case 2:phone->set_type(add_contacts::AddContactsReq_Phone_PhoneType::AddContactsReq_Phone_PhoneType_TEL);break;default:break;}}
}void AddContacts()
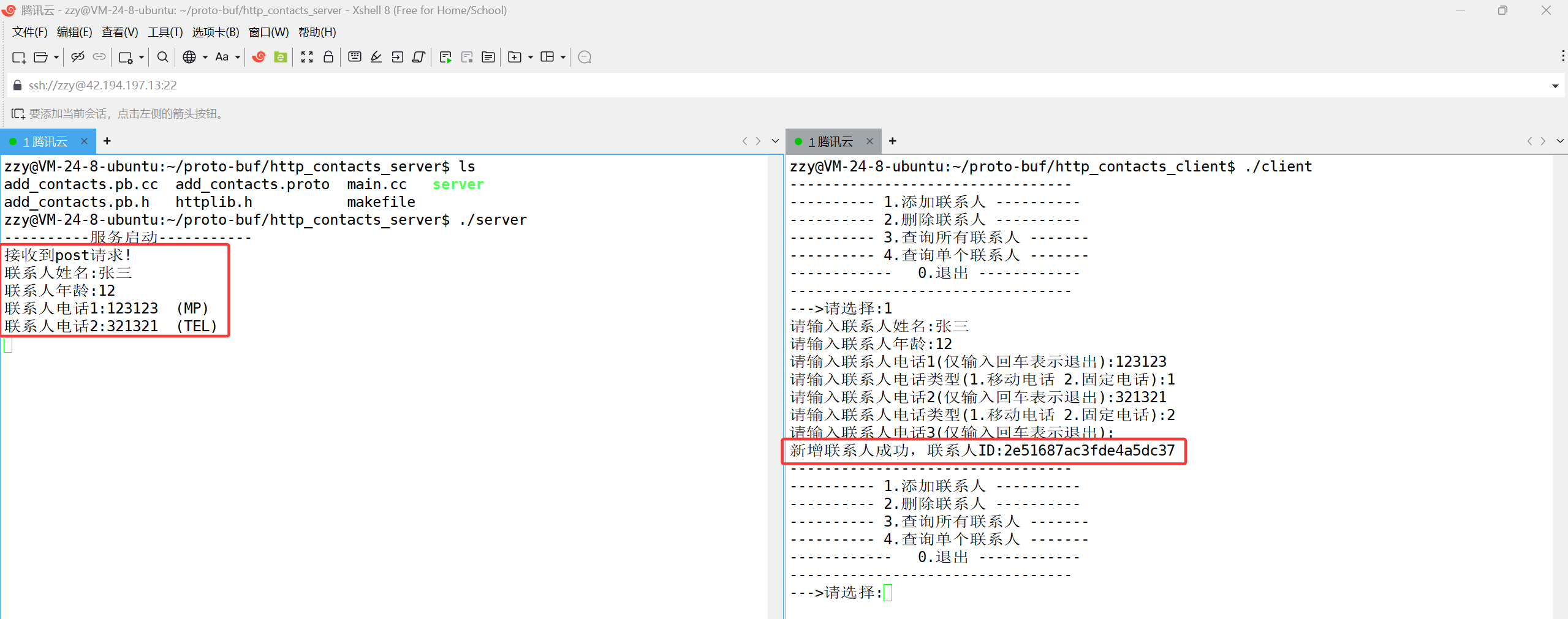
{Client cli(serverip, serverport);// 构造reqadd_contacts::AddContactsReq req;BuildAddContactsReq(req);// 序列化reqstd::string req_str;if (!req.SerializeToString(&req_str)){throw ContactsException("AddContactsReq序列化失败!");}std::string error_desc;// 发起post调用auto res = cli.Post("/contacts/add", req_str, "application/protobuf");if (!res){error_desc.append("/contacts/add 连接异常!错误信息:").append(httplib::to_string(res.error()));throw ContactsException(error_desc);}// 反序列化respadd_contacts::AddContactsResp resp;bool parse = resp.ParseFromString(res->body);if (res->status != 200 && !parse){error_desc.append("/contacts/add 调用失败!").append(std::to_string(res->status)).append("(").append(res->reason).append(")");throw ContactsException(error_desc);}else if (res->status != 200){error_desc.append("/contacts/add 调用失败!").append("(").append(res->reason).append(")").append(resp.error_desc());throw ContactsException(error_desc);}else if (!resp.success()){error_desc.append("/contacts/add 结果异常!").append("异常原因:").append(resp.error_desc());throw ContactsException(error_desc);}// 结果打印cout << "新增联系人成功,联系人ID:" << resp.uid() << endl;
}int main()
{while (true){menu();int op = 0;cout << "--->" << "请选择:";cin >> op;cin.ignore(256, '\n');try{switch(op){case QUIT:cout << "--->退出!" << endl;return 0;case OPTIONS::ADD_:AddContacts();break;case OPTIONS::DEL:case OPTIONS::FIND_ALL:case OPTIONS::FIND_ONE:break;default:cout << "--->选择有误!请重新选择" << endl;break;}}catch(const ContactsException& e){std::cout << "--->操作通讯录时发生异常" << std::endl;std::cout << "--->异常信息: " << e.what() << std::endl;return 1;}}return 0;
}// int main()
// {
// Client cli(serverip, serverport);
// Result resp1 = cli.Post("/test-post");
// if (resp1->status == 200)
// {
// cout << "调用post成功!" <<endl;
// }
// Result resp2 = cli.Get("/test-get");
// if (resp2->status == 200)
// {
// cout << "调用get成功!" << endl;
// }// return 0;
// }
4、实现服务端
#include <iostream>
#include "httplib.h"
#include "add_contacts.pb.h"using std::cout;
using std::endl;
using std::cerr;
using namespace httplib;class ContactsException
{
public:ContactsException(std::string str = "A problem") :_message(str){}std::string what() const { return _message;}
private:std::string _message;
};void PrintContact(add_contacts::AddContactsReq& req)
{std::cout << "联系人姓名:" << req.name() << std::endl;std::cout << "联系人年龄:" << req.age() << std::endl;for (int i = 0; i < req.phones().size(); i++){const add_contacts::AddContactsReq_Phone* phone = req.mutable_phones(i);std::cout << "联系人电话" << i + 1 << ":" << phone->number() << " (" << add_contacts::AddContactsReq_Phone_PhoneType_Name(phone->type()) << ")" << std::endl;}
}static unsigned int random_char() {// ⽤于随机数引擎获得随机种⼦std::random_device rd;// mt19937是c++11新特性,它是⼀种随机数算法,⽤法与rand()函数类似,但是mt19937具有速度快,周期⻓的特点// 作⽤是⽣成伪随机数std::mt19937 gen(rd());// 随机⽣成⼀个整数i 范围[0, 255]std::uniform_int_distribution<> dis(0, 255);return dis(gen);
}// ⽣成 UUID (通⽤唯⼀标识符)
static std::string generate_hex(const unsigned int len) {std::stringstream ss;// ⽣成 len 个16进制随机数,将其拼接⽽成for (auto i = 0; i < len; i++) {const auto rc = random_char();std::stringstream hexstream;hexstream << std::hex << rc;auto hex = hexstream.str();ss << (hex.length() < 2 ? '0' + hex : hex);}return ss.str();
}int main()
{cout << "----------服务启动-----------" << endl;Server server;server.Post("/contacts/add", [](const Request& req, Response& resp){cout << "接收到post请求!" << endl;// 反序列化reqstd::string resp_str = req.body;add_contacts::AddContactsReq request;add_contacts::AddContactsResp response;try{if (!request.ParseFromString(resp_str)){throw ContactsException("反序列化失败!");}// 新增联系人,持久化存储通讯录--->仅打印,有兴趣自行处理PrintContact(request);// 构建respresponse.set_success(true);response.set_uid(generate_hex(10));// 序列化respstd::string resp_str;if (!response.SerializeToString(&resp_str)){throw ContactsException("AddContactsResp序列化失败!");}resp.status = 200;resp.body = resp_str;resp.set_header("Content-Type", "application/protobuf");}catch(const ContactsException& e){resp.status = 500;response.set_success(false);response.set_error_desc(e.what());std::string resp_str;if (response.SerializeToString(&resp_str)){resp.body = resp_str;resp.set_header("Content-Type", "application/protobuf");}std::cout << "/contacts/add 发生异常,异常信息:" << e.what() << std::endl;}});server.listen("0.0.0.0", 8080);return 0;
}// int main()
// {
// cout << "----------服务启动-----------" << endl;// Server server;
// server.Post("/test-post", [](const Request& req, Response& resp){
// cout << "接收到post请求!" << endl;
// resp.status = 200;
// });
// server.Get("/test-get", [](const Request& req, Response& resp){
// cout << "接收到get请求!" << endl;
// resp.status = 200;
// });
// server.listen("0.0.0.0", 8080);
// return 0;
// }
最终效果:
6、总结
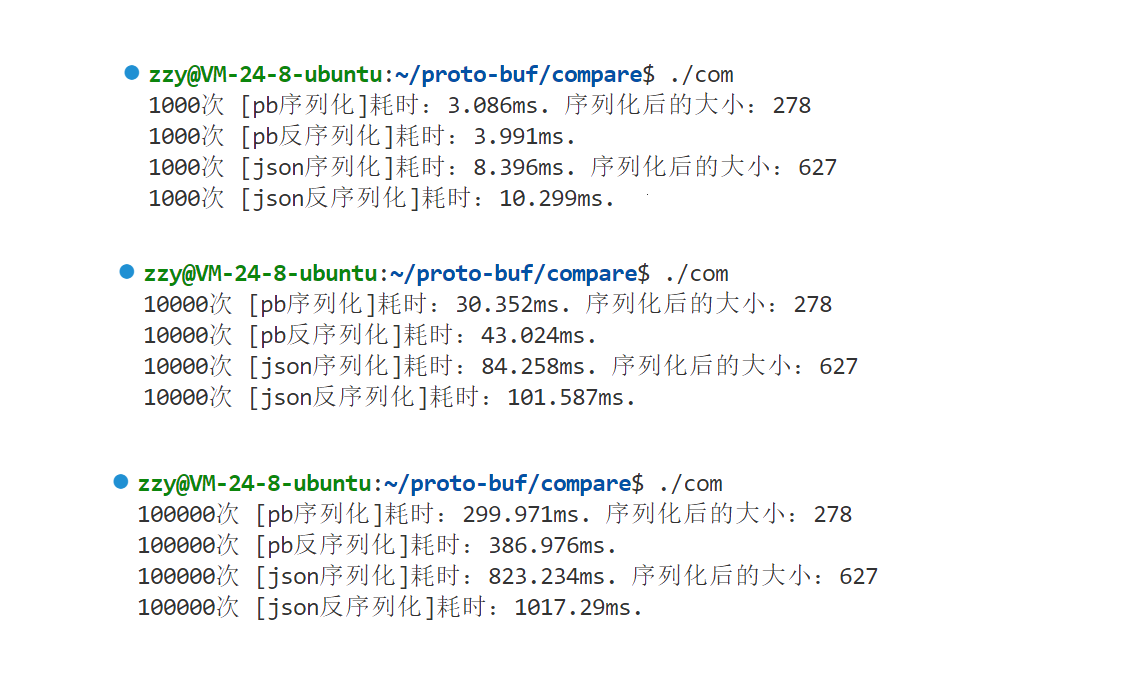
上图是测试了protobuf和json的序列化和反序列化性能,分别进行1000次、10000次、100000次测试对比,结果如图。很明显,protobuf的序列化和反序列化能力要比json来的快,并且序列化后的大小也要比json小。
小结:
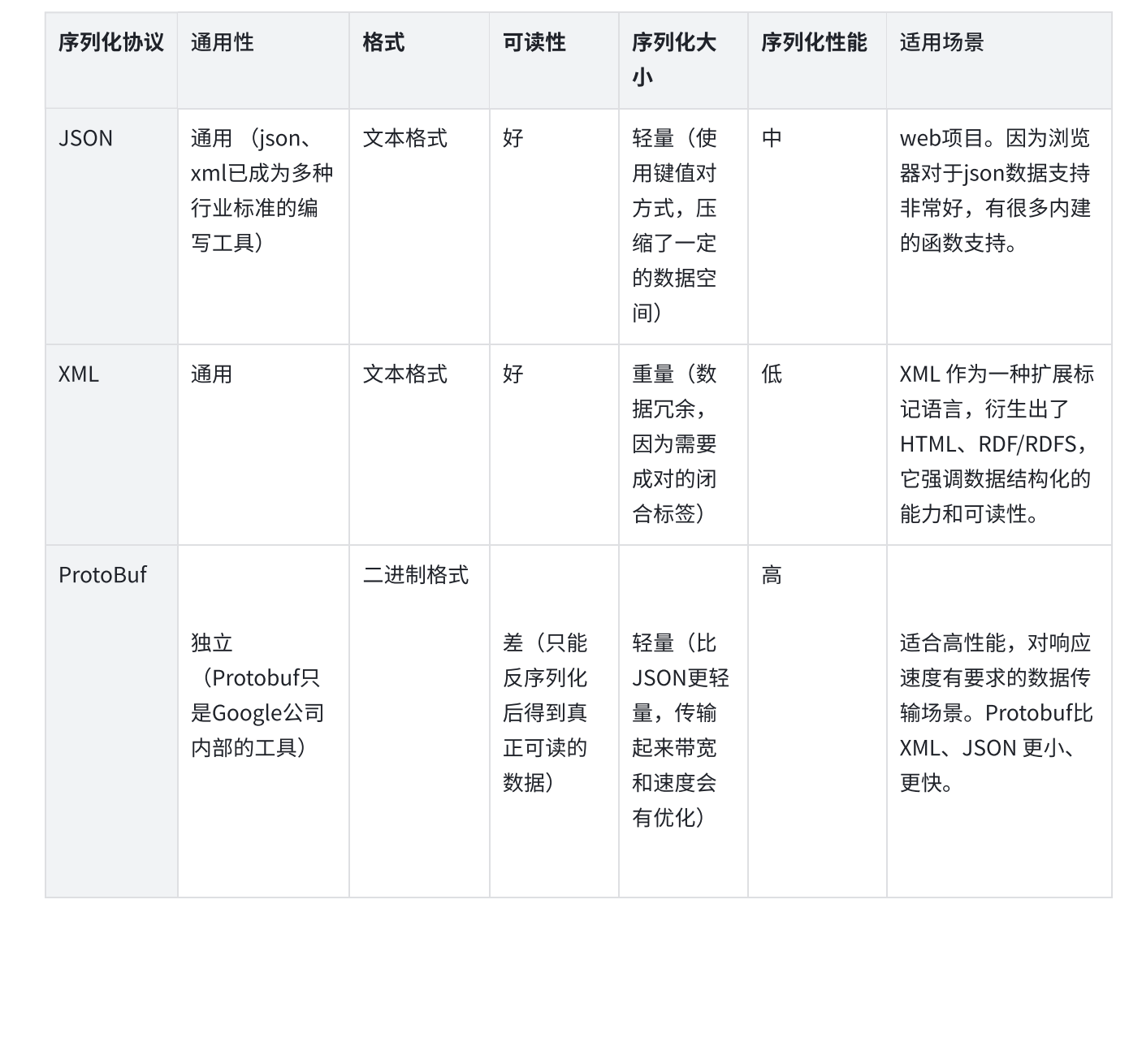
1、XML、JSON、ProtoBuf都具有数据结构化和数据序列化的能力。
2、XML、JSON更注重数据结构化,关注可读性和语义表达能力。ProtoBuf更注重数据序列化,关注效率、空间、速度,可读性差,语义表达能力不足,为保证极致的效率,会舍弃一部分元信息。
3、ProtoBuf的应用场景更为明确,XML、JSON的应用场景更为丰富。
相关文章:

《深入浅出ProtoBuf:从环境搭建到高效数据序列化》
ProtoBuf详解 1、初识ProtoBuf2、安装ProtoBuf2.1、ProtoBuf在Windows下的安装2.2、ProtoBuf在Linux下的安装 3、快速上手——通讯录V1.03.1、步骤1:创建.proto文件3.2、步骤2:编译contacts.proto文件,生成C文件3.3、步骤3:序列化…...

【含文档+PPT+源码】基于微信小程序连锁药店商城
项目介绍 本课程演示的是一款基于微信小程序连锁药店商城,主要针对计算机相关专业的正在做毕设的学生与需要项目实战练习的 Java 学习者。 1.包含:项目源码、项目文档、数据库脚本、软件工具等所有资料 2.带你从零开始部署运行本套系统 3.该项目附带的…...

再见,物理删除!MyBatis-Plus @TableLogic 优雅实现逻辑删除
在开发应用程序时,我们经常会遇到需要删除数据的场景。但直接从数据库中物理删除(DELETE)数据有时并非最佳选择。为什么呢? 数据恢复: 一旦物理删除,数据通常难以恢复,误操作可能导致灾难性后果。审计追…...

uni-app中获取用户实时位置完整指南:解决权限报错问题
uni-app中获取用户实时位置完整指南:解决权限报错问题 在uni-app开发运行在微信小程序时,获取用户位置信息是一个常见的需求,无论是用于地图导航、附近推荐还是其他基于位置的服务。然而,许多开发者在调用位置相关API时会遇到各种…...

【AI插件开发】Notepad++ AI插件开发1.0发布和使用说明
一、产品简介 AiCoder是一款为Notepad设计的轻量级AI辅助插件,提供以下核心功能: 嵌入式提问:对选中的文本内容进行AI分析,通过侧边栏聊天界面与AI交互,实现多轮对话、问题解答或代码生成。对话式提问:独…...

UnityEditor - 调用编辑器菜单功能
例如: 调用Edit/Frame Selected In Scene EditorApplication.ExecuteMenuItem("Edit/Frame Selected in Scene"); EditorApplication.ExecuteMenuItem("Edit/Lock view to Selected");...
(十),魔法键使用方法,用户态异常信息说明)
OpenHarmony - 小型系统内核(LiteOS-A)(十),魔法键使用方法,用户态异常信息说明
OpenHarmony - 小型系统内核(LiteOS-A)(十) 十四、魔法键使用方法 使用场景 在系统运行出现无响应等情况时,可以通过魔法键功能确定系统是否被锁中断(魔法键也无响应)或者查看系统任务运行状态…...

在 Vue3 中封装的 Axios 实例中,若需要为部分接口提供手动取消请求的功能
核心思路 封装接口时返回 Promise 和 abort 方法: 为需要支持取消的接口返回一个对象,包含 promise 和 abort 方法,用户可通过 abort 主动中断请求。使用 AbortController 或 CancelToken: 推荐 AbortController(浏览…...

QuecPython+audio:实现音频的录制与播放
概述 QuecPython 作为专为物联网设计的开发框架,通过高度封装的 Python 接口为嵌入式设备提供了完整的音频处理能力。本文主要介绍如何利用 QuecPython 快速实现音频功能的开发。 核心优势 极简开发:3行代码完成基础音频录制与播放。快速上手…...

Langchain入门介绍
[声明] 本文参考:Langchain官方文档 什么是LangChain? LangChain 是一个开源的、用于开发由大型语言模型 (LLM) 驱动的应用程序的框架。它的核心目标是将强大的 LLM(如 GPT-4, Claude, Llama 等)与外部数据源、计算资源和工具连接起来,从…...

WebUI可视化:第4章:Streamlit数据可视化实战
学习目标 ✅ 掌握Streamlit的安装与基础配置 ✅ 能够创建数据驱动的交互式界面 ✅ 实现常见图表(折线图、柱状图等)的绘制 ✅ 开发完整的业务数据分析应用 4.1 Streamlit快速入门 4.1.1 环境安装 打开终端执行: bash pip install streamlit 验证安装: bash stream…...

3.4 Spring Boot异常处理
本实战项目通过Spring Boot实现了一个简单的用户信息查询功能,并展示了如何自定义异常处理机制。项目中创建了用户实体类User和用户控制器UserController,在控制器中通过isValidUserId方法校验用户ID是否有效,若无效则抛出自定义异常InvalidU…...

期货有哪些种类?什么是股指、利率和外汇期货?
期货主要可以分成两大类:商品期货和金融期货。商品期货,顾名思义,就是跟实物商品有关的期货,比如农产品、金属、能源这些。金融期货呢,就是跟金融产品有关的期货,比如外汇、利率、股票指数这些。 一、商品…...

Golang | 位运算
位运算比常规运算快,常用于搜索引擎的筛选功能。例如,数字除以二等价于向右移位,位移运算比除法快。...

[论文阅读]ReAct: Synergizing Reasoning and Acting in Language Models
ReAct: Synergizing Reasoning and Acting in Language Models [2210.03629] ReAct: Synergizing Reasoning and Acting in Language Models ICLR 2023 这是一篇在2022年挂出来的论文,不要以现在更加强大且性能综合的LLM来对这篇文章进行批判。 思想来源于作者对…...

拥有600+门店的宠物连锁医院,实现核心业务系统上云
瑞派宠物医院管理股份有限公司(以下简称“瑞派宠物“)从2017年开始数字化转型之路。瑞派宠物在全国有600连锁门店,随着业务量增加,线下部署的财务系统存在设备老旧、机房环境差等问题,部分在公有云上的业务,…...

OceanBase 跻身 Forrester 三大领域代表厂商,全面支撑AI场景
在生成式AI迅猛发展的当下,智能化数据管理已成为企业提升数字化水平、优化运营效率和强化市场竞争优势的战略重点。Forrester 最新发布的《2025年中国数据管理生态系统趋势报告》中,OceanBase凭借原生分布式架构和一体化产品优势,入选 全局数…...

学生管理系统微服务方式实现
//不用这种方式实现也可以,用这种方式是为了房间我们理解微服务的实现方式 微服务的实现方式就是把一个单项目应用的不同功能封装成单独的项目,然后向外暴露一个接口以便调用。如果需要这个功能我们直接调用这个功能对应项目的接口就可以了 服务之间的…...

OpenAI最新的4o图像生成模型 gpt-image-1 深度解析:API KEY 获取、开发代码示例
1. 引言 近期,OpenAI 正式发布了其最新的图像生成 API,模型标识符为 gpt-image-1。这一重要发布,首次将先前在 ChatGPT 中通过 GPT-4o 模型驱动、备受用户欢迎的先进图像生成能力,以编程接口(API)的形式提…...

NAT穿透
NAT是 Net Address Traslation的缩写,即网络地址转换 NAT部署在网络出口的位置。位于内网和公网之间,是连接内挖个主机和公网的桥梁,双向流量都必须经过NAT,装有NAT软件的路由器叫NAT路由器,NAT路由器拥有公网Ip NAT解…...

人工智能与机器学习:Python从零实现性回归模型
🧠 向所有学习者致敬! “学习不是装满一桶水,而是点燃一把火。” —— 叶芝 我的博客主页: https://lizheng.blog.csdn.net 🌐 欢迎点击加入AI人工智能社区! 🚀 让我们一起努力,共创…...

FreeRTOS
FreeRTOS任务调度的三种方式: 抢占式调度 针对优先级不同的任务 时间片调度 针对优先级相同的任务; FreeRTOS中的一个时间片就等于SysTick(滴答定时器)中断周期(1ms); 协程式调度 后续将不再支持。 …...
)
PCI 总线学习笔记(五)
PCI 总线学习系列,参考自 技术大牛博客: PCIe 扫盲系列博文连载目录篇 书籍:王齐老师的《PCI Express 体系结构导读》 下面的文章中加入了自己的一些理解和实际使用中遇到的一些场景,供日后查询和回忆使用 PCI 总线定义了两类配置…...

PyTorch与CUDA的关系
文章目录 前言一、如何查看PyTorch和torchvision的版本1.1 查看PyTorch版本1.2 查看torchvision版本二、如何确认PyTorch和torchvision是否支持CUDA加速2.1 检查PyTorch是否支持CUDA2.2 查看当前可用的GPU设备2.3 检查torchvision是否支持CUDA三、CUDA版本的秘密:为什么PyTorc…...
)
网络中断事件进行根因分析(RCA)
网络中断事件的根因分析(RCA)详解 根因分析(Root Cause Analysis, RCA)是网络运维中用于定位和解决故障的核心方法,目标是找到问题的根本原因,避免重复发生。以下是完整的RCA流程和方法: 1. RC…...

Mac中 “XX”文件已损坏,无法打开 解决方案
前言 Mac中打开软件 出现“XX”文件已损坏,无法打开的提示 怎么处理? 操作总结 1、查看当前 Gatekeeper 是否启用 spctl --status2、完全关闭 Gatekeeper(允许安装任何来源应用) sudo spctl --master-disable3、打开“系统设…...

如何通过python连接hive,并对里面的表进行增删改查操作
要通过Python连接Hive并对其中的表进行增删改查操作,可以使用pyhive库。下面是一个简单的示例代码,演示如何连接Hive并执行一些操作: from pyhive import hive# 建立连接 conn hive.connect(hostyour_hive_host, port10000, authNOSASL)# 创…...

对Mac文字双击或三击鼠标左键没有任何反应
目录 项目场景: 问题描述 原因分析: 解决方案: 项目场景: 在使用Mac系统的时候,使用Apple无线鼠标,双击左键能够选取某个单词或词语,三击左键能够选取某一行,(百度、…...

【维护窗口内最值+单调队列/优先队列】Leetcode 239. 滑动窗口最大值
题目要求 给定一个整数数组 nums,有一个大小为 k 的滑动窗口从数组的最左侧移动到数组的最右侧。滑动窗口每次只向右移动一位。要求返回滑动窗口中的最大值。 示例 1 输入:nums [1,3,-1,-3,5,3,6,7], k 3 输出:[3,3,5,5,6,7] 解释&#…...

【Leetcode 每日一题】2845. 统计趣味子数组的数目
问题背景 给你一个下标从 0 0 0 开始的整数数组 n u m s nums nums,以及整数 m o d u l o modulo modulo 和整数 k k k。 请你找出并统计数组中 趣味子数组 的数目。 如果 子数组 n u m s [ l . . r ] nums[l..r] nums[l..r] 满足下述条件,则称其为…...

SDC命令详解:使用get_cells命令进行查询
相关阅读 SDC命令详解https://blog.csdn.net/weixin_45791458/category_12931432.html?spm1001.2014.3001.5482 get_cells命令用于创建一个单元对象集合,关于设计对象和集合的更详细介绍,可以参考下面的博客。 Synopsys:设计对象https://c…...

正则表达式及其游戏中应用
一、正则表达式基础知识 ✅ 什么是正则表达式? 正则表达式是一种用来匹配字符串的规则表达式,常用于搜索、验证、替换等文本处理场景。 比如你想找出玩家输入中的邮箱、命令、作弊码……正则就特别好用。 📚 常见语法速查表: …...
 之间共享 DLL)
如何在 MinGW 和 Visual Studio (MSVC) 之间共享 DLL
如何在 MinGW 和 Visual Studio (MSVC) 之间共享 DLL ✅ .dll.a 和 .lib 是什么? 1. .dll.a(MinGW 下的 import library) 作用:链接时告诉编译器如何调用 DLL 中的函数。谁用它:MinGW 编译器(如 g&#x…...

【HTTP/2和HTTP/3的应用现状:看不见的革命】
HTTP/2和HTTP/3的应用现状:看不见的革命 实际上,HTTP/2和HTTP/3已经被众多著名网站广泛采用,只是这场革命对普通用户来说是"无形"的。让我们揭开这个技术变革的真相。 著名网站的HTTP/2和HTTP/3采用情况 #mermaid-svg-MtfrNDo5DG…...

ts中null类型--结合在vue中的使用、tsconfig.json
总结 TypeScript 中的 null 是一个独立的类型,用于明确表示“无值”或“空值”。在实际开发中,常通过联合类型(如 string | null)或与 ref 结合使用,确保代码的类型安全和可读性。 详情解释 在 TypeScript 中,null 是一个独立的类型,表示 null 值本身。以下是一些关于…...

Hadoop生态圈框架部署 - Windows上部署Hadoop
文章目录 前言一、下载Hadoop安装包及bin目录1. 下载Hadoop安装包2. 下载Hadoop的bin目录 二、安装Hadoop1. 解压Hadoop安装包2. 解压Hadoop的Windows工具包 三、配置Hadoop1. 配置Hadoop环境变量1.1 打开系统属性设置1.2 配置环境变量1.3 验证环境变量是否配置成功 2. 修改Had…...
)
深度学习笔记22-RNN心脏病预测(Tensorflow)
🍨 本文为🔗365天深度学习训练营中的学习记录博客🍖 原作者:K同学啊 一、前期准备 1.导入数据 import tensorflow as tf import pandas as pd import numpy as np dfpd.read_csv("E:/heart.csv") df 2.检查数据是否有…...

面试踩过的坑
1、 “”和equals 的区别 “”是运算符,如果是基本数据类型,则比较存储的值;如果是引用数据类型,则比较所指向对象的地址值。equals是Object的方法,比较的是所指向的对象的地址值,一般情况下,重…...

【机器学习速记】面试重点/期末考试
自用,有错误欢迎评论区指出 目录 一、机器学习基础概念 二、机器学习类型分类 三、经典算法与原理 1. 线性模型 2. 决策树 3. SVM(支持向量机) 4. K近邻(KNN) 5. 贝叶斯分类 6. 集成学习 四、模型评价指标 五、模型泛化能力与调参 六、特征工程与数据预处理 七、维…...

Cursor如何手动添加多个大模型?
笔者在前面的文章Cursor接入API: deepseekV3(免费)_cursor api-CSDN博客中介绍了如何添加deepseek到Cursor中,如果要添加其他大模型,比如阿里的通义千问qwen-max-2025-01-25等,方法一样,在官方网站找到模型名称和base_url…...

FerretDB:基于PostgreSQL的MongoDB替代产品
FerretDB 是一种基于NoSQL的分布式数据库,它旨在通过优化存储和查询机制来提供卓越的性能和可靠性。它支持水平扩展和高并发访问,并提供灵活的数据模型,使开发人员能够轻松地存储和检索各种类型的数据。 Stars 数10,057Forks 数439 主要特点…...

JDBC 批处理与事务处理:提升数据操作效率与一致性的密钥
目录 一. JDBC批量添加数据 1. 什么是批量添加数据 2. 实现数据的批量添加 a. 方式一:不分块 二. JDBC事务处理 1. 什么是事务 2. JDBC事务处理实现 三. 总结 前言 本文来讲解JDBC的批处理和事务处理 这对数据的安全性和准确性以及高效率提供很好的办法 话不…...

vue2实现Blod文件流下载
实现思路: 动态创建一个a标签,模拟点击打开链接,实现下载 downLoad() { //调用下载接口Export({Id: id}).then(res > {this.showLoading false;if (res && res.data && res.data.returnCode -1) {this.msgError(res.d…...

js数据结构之栈
JavaScript数据结构 一、什么是数据结构? 数据结构是向相互之间存在一种或者多种特定关系的数据组成的集合, 采用合适的数据结构能给开发者提高开发和储存效率.比如我们在学习Es6中的我们新接触的到的(Set, map), 在合适的时候使用它们能帮助我们更快的的解决问题. 我们每个在…...

[Windows] 卡巴斯基Kaspersky 21.21.7.384 免费版
卡巴斯基免费版从界面到功能和使用体验来说,简洁、高效、严苛、轻巧,可以“弥补”火绒杀毒能力不强,同时也不会像 Microsoft Defender 误报。 链接1:https://pan.xunlei.com/s/VOOhFEeznr_4W6s7-XT8IwN-A1?pwdztn4# 链接2&…...

【HFP】蓝牙HFP协议中音频连接转移与拨号功能的深度解析
目录 一、核心功能矩阵 二、音频连接向 HF 转移 2.1 转移概述 2.2 前提条件 2.3 适用情况 2.4 转移流程 2.5 注意事项 2.6 示例图 三、音频连接向 AG 转移 3.1 转移概述 3.2 前提条件 3.3 特殊情况处理 3.4 转移流程 3.5 注意事项 3.6 示例图 四、通过HF提供号…...
)
Android学习总结之Glide篇(缓存和生命周期)
一、Glide缓存 1. 内存缓存 内存缓存主要包含活动资源缓存与 LRU 内存缓存这两个级别。 活动资源缓存(Active Resources) 作用:用于存放当前正在被显示的图片资源。当某张图片正展示在 ImageView 上时,它会被纳入活动资源缓存…...

Python 快速获取Excel工作表名称
文章目录 前言准备工作Python 获取Excel中所有工作表的名称Python 获取Excel中隐藏工作表的名称 前言 在数据分析与办公自动化领域,通过Python处理Excel文件已成为必备技能。通过获取工作表名称,我们可以: 快速了解文件结构自动化处理多工作…...

基于Docker的Flask项目部署完整指南
基于Docker的Flask项目部署完整指南 项目结构与文件说明 TextWeb/ ├── .dockerignore # Docker构建忽略配置 ├── Dockerfile # Docker镜像构建文件 ├── requirements.txt # Python依赖清单 └── WebServer/└── main.py # Fl…...
)
分布式定时任务(xxl-job)
简介 什么是XXL-JOB 详细的文档类容可以看下面这个链接进入readme xxl-job简介以及下载地址 XXL-JOB是一个分布式任务调度平台,其核心设计目标是开发迅速、学习简单、轻量级、易扩展 在Java Spring Cloud微服务架构中,使用独立的定时任务调度中心&…...