Crawl4AI 部署安装及 n8n 调用,实现自动化工作流(保证好使)
Crawl4AI 部署安装及 n8n 调用,实现自动化工作流(保证好使)
简介
Crawl4AI 的介绍
一、Crawl4AI 的核心功能
二、Crawl4AI vs Firecrawl
Crawl4AI 的本地部署
一、前期准备
二、部署步骤
1、检查系统的网络环境
2、下载 Crawl4AI 源码
3、Crawl4AI 环境变量与配置文件的修改
4、启动 Crawl4AI
5、启动 Crawl4AI(不使用 Docker Compose)
n8n 的调用
1、获取网站的 sitemap.xml
2、在 n8n 中创建一个聊天消息触发器,用于传入对应的 sitemap.xml 的 URL
3、在 n8n 中获取 sitemap.xml 并把 XML 格式转化为 JSON 格式
4、对数据进行分割处理并限制 URL 数量
5、循环处理过滤后的每个 URL 并为每个 URL 生成 task_id
6、执行 task_id 指定的任务
7、对执行结果进行判断并执行不同的动作
8、把输出结果生成文件并映射到宿主机指定目录
备份与加载 Crawl4AI 的镜像
一、备份 Crawl4AI 的镜像
二、加载 Crawl4AI 的镜像
简介
在大语言模型(LLM)和生成式 AI 爆发的今天,数据采集的效率与质量直接决定了 AI 应用的落地效果。传统爬虫工具在动态渲染处理、AI 友好输出和大规模部署上的局限性日益凸显,而专为 AI 设计的 Crawl4AI 框架正成为企业级数据管道的首选方案。
Crawl4AI 的介绍
Crawl4AI 是基于 Python 开发的开源智能爬虫框架,其核心设计理念是“为 AI 应用构建专属数据通道”。架构层面采用分层设计:
- 调度层:基于 asyncio 的自适应并发调度器,支持动态调整爬取并发数(单实例可稳定处理 5000 + 并发请求)
- 渲染层:深度集成 Playwright(默认)/Selenium,支持无头 / 有头模式,内置反反爬机制(UA 随机化、请求间隔动态调整)
- 提取层:创新性引入 LLM 驱动的智能提取引擎,支持通过自然语言指令(如 "提取页面中所有产品价格")生成结构化数据
- 输出层:原生支持 Markdown/JSON/CSV 格式输出,特别适配 LLM 的上下文输入要求
一、Crawl4AI 的核心功能
| 功能模块 | 技术实现 | 应用价值 |
|---|---|---|
| 动态渲染支持 | Playwright 内核,支持 JavaScript 完全执行,页面加载超时智能重试(默认 3 次) | 完美处理 SPA 单页应用、动态加载内容(如电商详情页、瀑布流页面) |
| 智能数据提取 | 支持 JSON Schema/CSS 选择器 / LLM 指令三种提取策略,内置正则表达式增强模块 | 非技术人员可通过自然语言指令完成复杂数据提取,降低开发门槛 50% 以上 |
| 分布式部署 | 原生支持 Docker/Kubernetes,提供 Helm Chart 模板,支持分布式任务队列(Redis/RabbitMQ) | 轻松扩展至数百节点集群,满足日均亿级页面爬取需求 |
| 反爬机制 | 随机 UA 池(内置 500 + 真实 UA)、代理 IP 轮换(支持 HTTP/SOCKS5)、请求间隔抖动算法 | 有效绕过 90% 以上的反爬系统,爬取成功率提升至 98% |
二、Crawl4AI vs Firecrawl
Crawl4AI 与 Firecrawl 这两个都是开源的爬虫框架,但是他们之间会存在一些差异,主要体现在核心定位的不同
| 维度 | Crawl4AI | Firecrawl |
|---|---|---|
| 设计目标 | 面向 AI 应用的数据采集管道,深度适配 LLM 输入要求 | 通用型爬虫框架,侧重基础爬取功能 |
| 核心优势 | LLM 智能提取、云原生部署、自适应并发调度 | 轻量级设计、快速原型开发 |
| 技术栈 | Python(asyncio/Playwright) | Python(Scrapy/Selenium) |
| 学习曲线 | 中高(需掌握 AI 提取策略) | 中等(传统爬虫语法) |
Crawl4AI 的本地部署
一、前期准备
环境要求:
| 组件 | 最低配置 | 推荐配置 |
|---|---|---|
| 操作系统 | Windows 10+/macOS 12+/Linux | Ubuntu 22.04+ |
| Python 版本 | 3.9+ | 3.11+ |
| 内存 | 8GB | 16GB+ |
| 存储 | 50GB SSD | 200GB NVMe |
网络环境:
- 本地网络:部署时可以使用 VMware 的 NAT 模式,如果只是本机使用就已经无需调整了,如果是需要内网中为其他设备提供服务,那就需要配置成 bridge(桥接)模式了;如果使用 Docker 部署,可以直接通过使用 Docker Desktop 的默认网络使用即可。
- 外部网络:我们是把 Crawl4AI 部署在 Docker 中,所以构建时需要从网络上拉去镜像,国内虽然有镜像源,但是并没有外面的全,而且通常 github 上的 Dockerfile 都是使用 docker.io 这个官方源去拉取的,所以可能会导致超时导致构建失败,所以提前准备一个靠谱的代理(科学上网)是非常必要的。
docke r 的安装:
关于 Linux 中 do cker 的安装在这里就不进行细说了,可以跟着这篇博客来操作:Ubuntu使用国内源安装Docker,Mysql,Redis_ubuntu docker 国内源-CSDN博客
二、部署步骤
Crawl4AI 可以使用 Python 和 Docker 来部署,推荐使用 Docker 来进行部署,本篇也会基于 Docker 部署的方式来介绍部署步骤。
Python 部署的方式可以看这个链接:Crawl4AI 的 Python 部署方法。
本次演示将会在 Windows 环境下进行安装,Windows 和 Linux 除了 docker 的安装不太一样之外,后面的一系列命令都是一样的。
1、检查系统的网络环境
在装好 Docker Desktop 后开始检查的及时网络问题了,首先我们要把之前提到的“科学上网”打开,并调节到全局模式(拉取镜像的成败关键)

同时即使开了“科学上网”有的还是会失败,这是由于运营商的问题,因为每个运营商对于不同 IP 访问的路由设置都不一样,目前在广东测试发现电信是最好使的。可以根据下面的命令进行 ping 测一下:
ping www.docker.com
ping www.github.com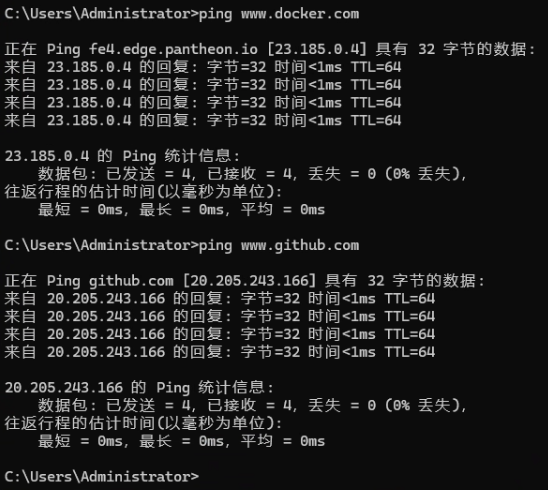
如果到最后实在是没办法了,可以拿我提前安装好的镜像直接导入到 docker 当中来使用,这样就可以避免网络问题了,链接在“备份与加载 Crawl4AI 的镜像”的部分
2、下载 Crawl4AI 源码
Crawl4AI 是一个开源软件,我们可以直接上 Github 上搜索并下载其源码,链接为:https://github.com/unclecode/crawl4ai,可以直接下载 ZIP 压缩或通过 git 命令下载(需要提前安装 git)。
2.1 本次我们使用 git 命令来克隆代码。git 命令安装过程如下:
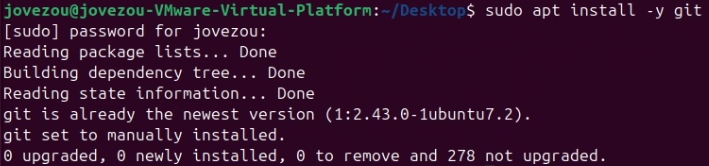
Ubuntu:
sudo apt-get install -y git如果已经安装过会如下图所示
Windows:
直接打开该链接下载:Git - Downloads
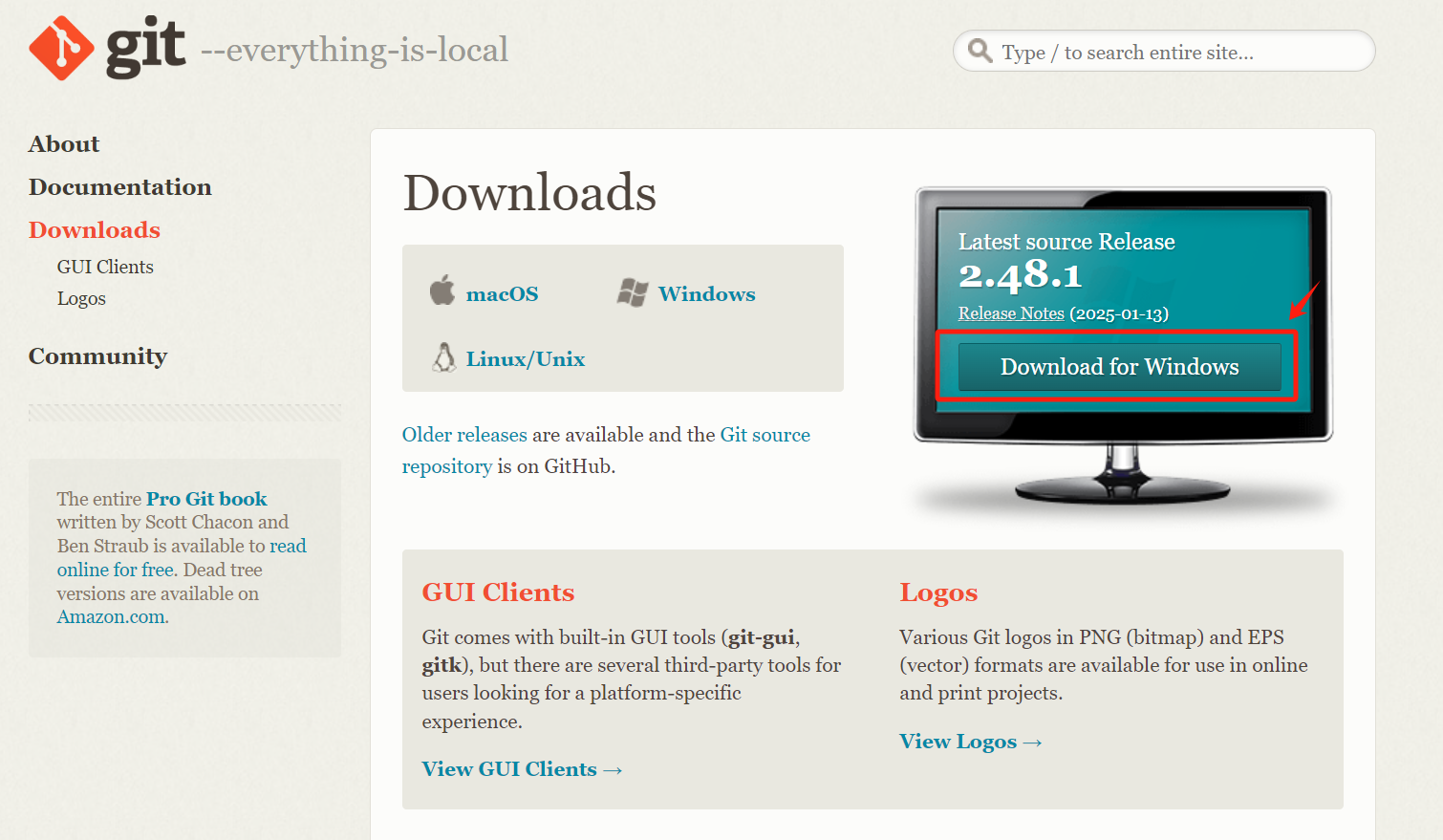
下载完成后双击安装,安装选项默认即可。
2.2 然后我们去 Github 上获取克隆链接,如下图所示
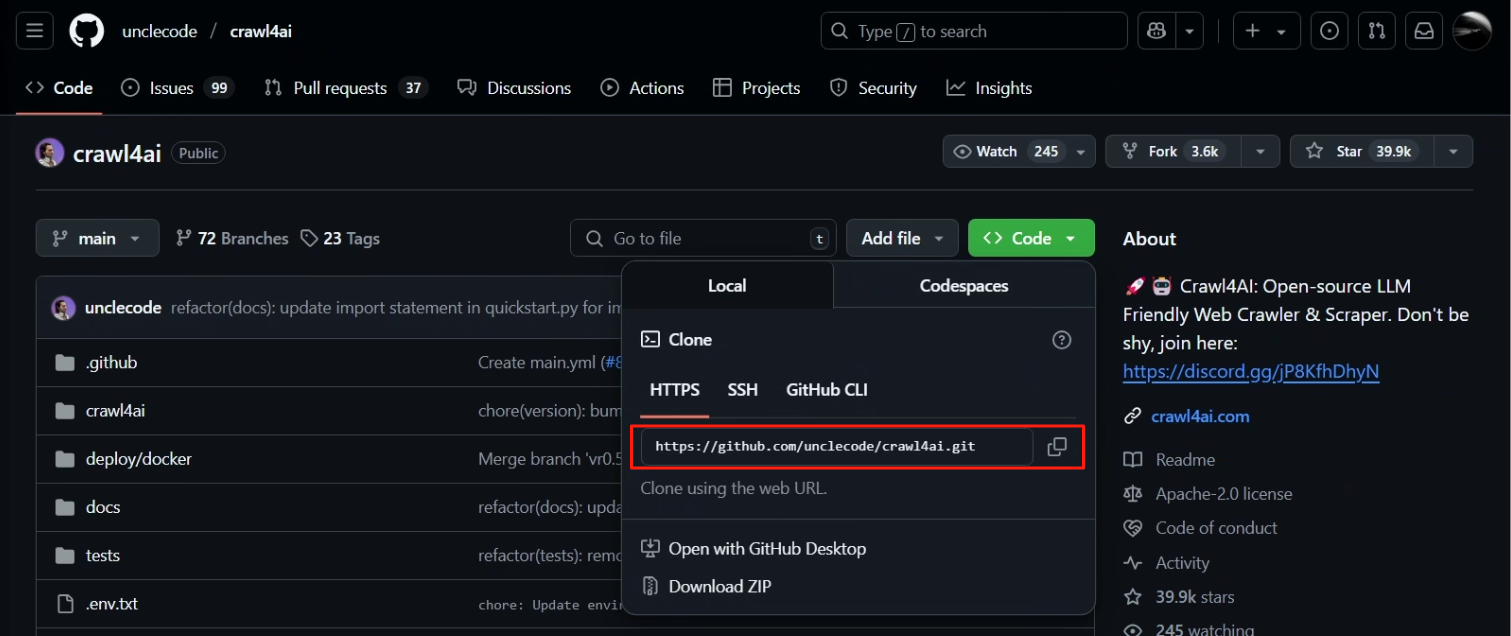
打开目标目录,在地址栏输入 cmd 根据当前目录打开终端,并输入以下命令(该命令会下载到当前所在目录下)
git clone https://github.com/unclecode/crawl4ai.git3、Crawl4AI 环境变量与配置文件的修改
Crawl4AI 源码当中并没有预先准备好的 .env 文件和 docker-compose.yml 文件,如果我们想要使用 Docker Compose 来管理的话那就要自己编写一份了,不过型号官方文档当中有一份参考的可以参考一下:https://docs.crawl4ai.com/core/docker-deployment,我在这里也提供一下经过我改造的 .env 文件和 docker-compose.yml 文件:
.env 文件:
# API Security (optional)
CRAWL4AI_API_TOKEN=12345 # Crawl4AI的API Key# LLM Provider Keys
GROQ_API_KEY = "YOUR_GROQ_API" # GROQ的API Key
OPENAI_API_KEY = "YOUR_OPENAI_API" # OpenAI的API Key
ANTHROPIC_API_KEY = "YOUR_ANTHROPIC_API" # ANTHROPIC的API Key# Other Configuration
MAX_CONCURRENT_TASKS=5 # 最大并发任务数量docker-compose.yml 文件:
name: crawl4ai
version: '3.8'services:crawl4ai:image: unclecode/crawl4ai:all-amd64ports:- "11235:11235"environment:- CRAWL4AI_API_TOKEN=${CRAWL4AI_API_TOKEN:-} # Optional API security- MAX_CONCURRENT_TASKS=${MAX_CONCURRENT_TASKS:-}# LLM Provider Keys- OPENAI_API_KEY=${OPENAI_API_KEY:-}- ANTHROPIC_API_KEY=${ANTHROPIC_API_KEY:-}volumes:- /dev/shm:/dev/shmdeploy:resources:limits:memory: 4Greservations:memory: 1Gnetworks:- backendnetworks:backend:driver: bridgeipam:config:- subnet: 169.254.60.0/24gateway: 169.254.60.14、启动 Crawl4AI
在使用 Docker Compose 启动 Crawl4AI 的容器前,我们需要到 docker-compose.yml 文件所在的目录下打开终端来执行以下第一条命令才行,顺带的我们一起把停止容器和删除容器一起介绍一下
# 通过当前目录下的 docker-compose.yml 文件启动容器,-d 为后台执行的意思
docker compose up -d# 停止当前目录下的 docker-compose.yml 文件管理的容器
docker compose stop# 停止并删除当前目录下的 docker-compose.yml 文件管理的容器,会把相应的容器网络也一并删除掉,但 volume 并不会删除
docker compose down启动时如下图所示

启动完成如下图所示
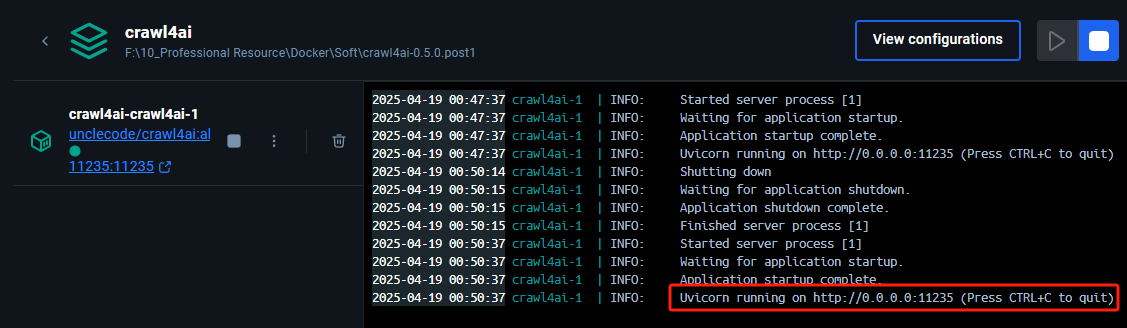
出现 http://0.0.0.0:11235 代表启动成功,但是需要把 0.0.0.0 替换为本机 IP 或 127.0.0.1 才能访问成功。访问成功后会出现 Crawl4AI 的文档,如下图所示
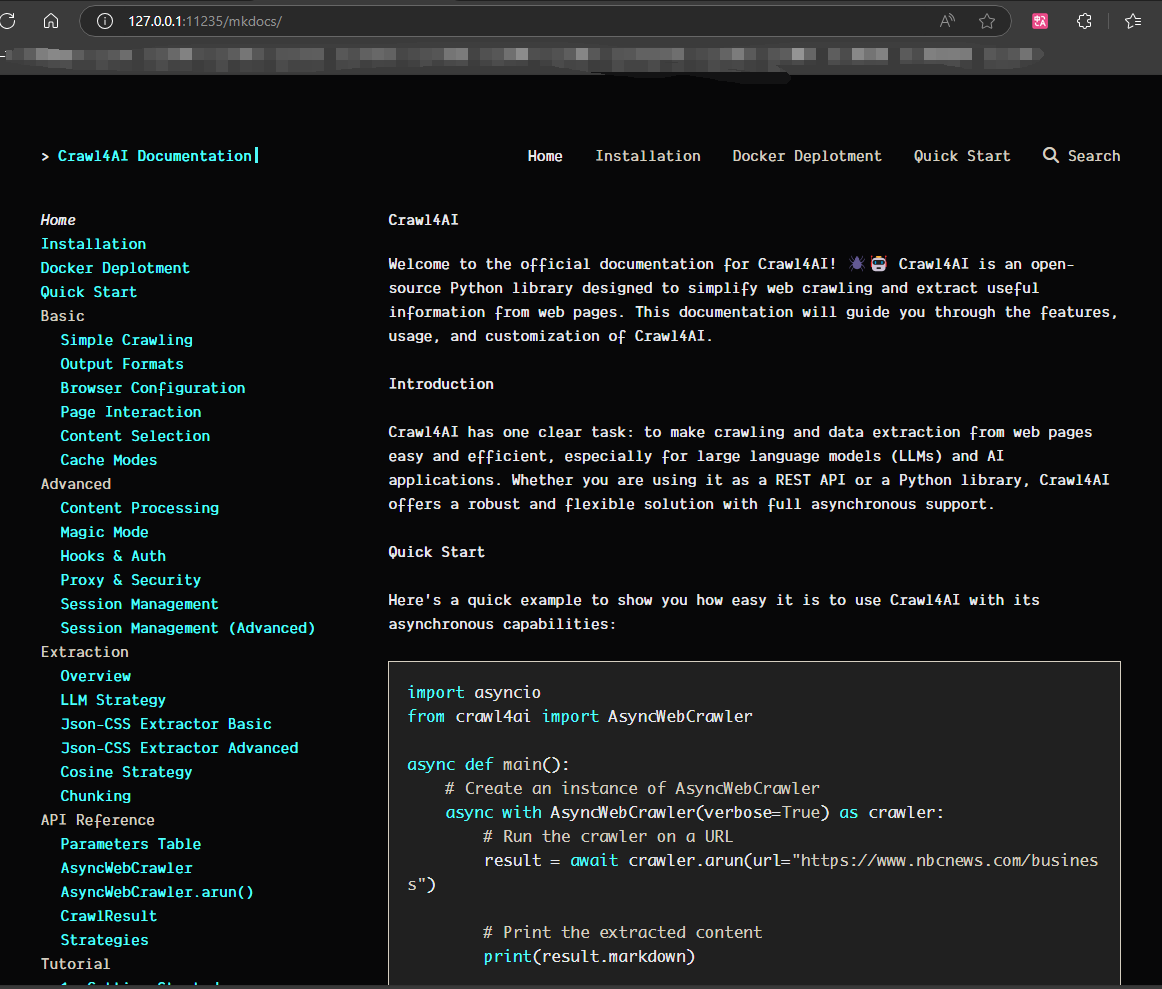
到此 Crawl4AI 就使用 Docker 部署完毕了。
5、启动 Crawl4AI(不使用 Docker Compose)
当然,Crawl4AI 由于只整合成了一个容器,所以并不存在对其他容器的依赖,也就是说它对比起 Firecrawl 来说是比较轻便的,所以我们也可以不使用 Docker Compose 来启动,而是直接使用 docker run 来启动容器也是可以的,只需要执行以下的命令即可
# 拉取镜像,如果前面已经使用 Docker Compose 拉取过了,就不需要执行该命令了
docker pull unclecode/crawl4ai:all-amd64# 直接运行容器,-p 为端口参数(映射到宿主机:容器内部网络),-e 为环境变量 CRAWL4AI_API_TOKEN 是使用 Crawl4AI 的 API Key,最后是镜像名及版本号 unclecode/crawl4ai:all-amd64(版本为 all-amd64)
docker run -p 11235:11235 -e CRAWL4AI_API_TOKEN=12345 unclecode/crawl4ai:all-amd64但是使用 docker run 启动有一个缺点,那就是不能进行统一的管理,例如当你达到“docker compose down”时,需要执行以下一系列的命令
# unclecode/crawl4ai:all-amd64 容器停止运行
docker stop unclecode/crawl4ai:all-amd64
# 删除容器 unclecode/crawl4ai:all-amd64
docker rm unclecode/crawl4ai:all-amd64
# 删除 Crawl4AI 的容器网络,crawl4ai_backend 为网络名,也能使用“网络 ID”来删除
docker network rm crawl4ai_backendn8n 的调用
在使用 n8n 调用 Crawl4AI 前要先确保 n8n 已经成功部署了,具体的部署教程请查看:https://blog.csdn.net/zjw529507929/article/details/147164342
注意:推荐使用 Docker Compose 运行,在 docker-compose.yml 中有对宿主机进行映射的配置
该示例是自动把网页内容生成为 FAQ 格式(RAGFlow 对这种格式支持比较好),并保存文件到宿主机指定目录当中。
1、获取网站的 sitemap.xml
sitemap.xml 是网站地图文件,它是一种遵循特定格式的 XML 文件,用于向搜索引擎等 web 爬虫程序提供有关网站上所有页面的信息,以便它们能够更有效地抓取和索引网站内容。现在很多网站为了能更好的传播自己的网站都会提供 sitemap.xml,例如:
- DeepSeek 的中文 api 文档:https://api-docs.deepseek.com/zh-cn/
- Crawl4AI 的官方文档:https://docs.crawl4ai.com/
当遇到某些网站没有 sitemap.xml 时,我们可以通过一些 sitemap.xml 生成网站来生成,例如:
- 在线生成 sitemap.xml:https://www.xml-sitemaps.com/(免费最多生成500个网站页面链接)
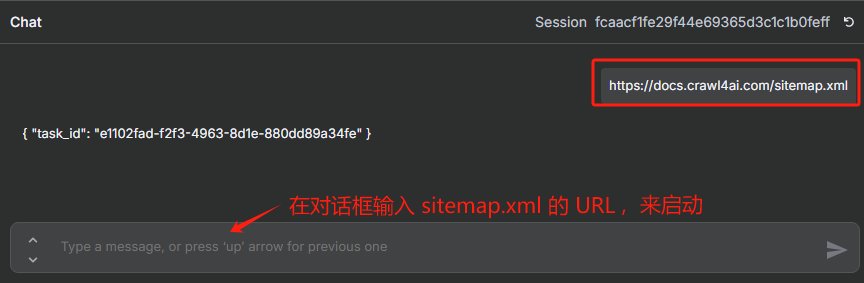
假设我现在要对这个网站:https://www.fsonline.com.cn/(该网站没有自己的 sitemap.xml),在线生成 sitemap.xml,我们打开在线生成 sitemap.xml 的网站,只要直接输入对应的 URL,然后点击 START 就可以开始生成 sitemap.xml 了。
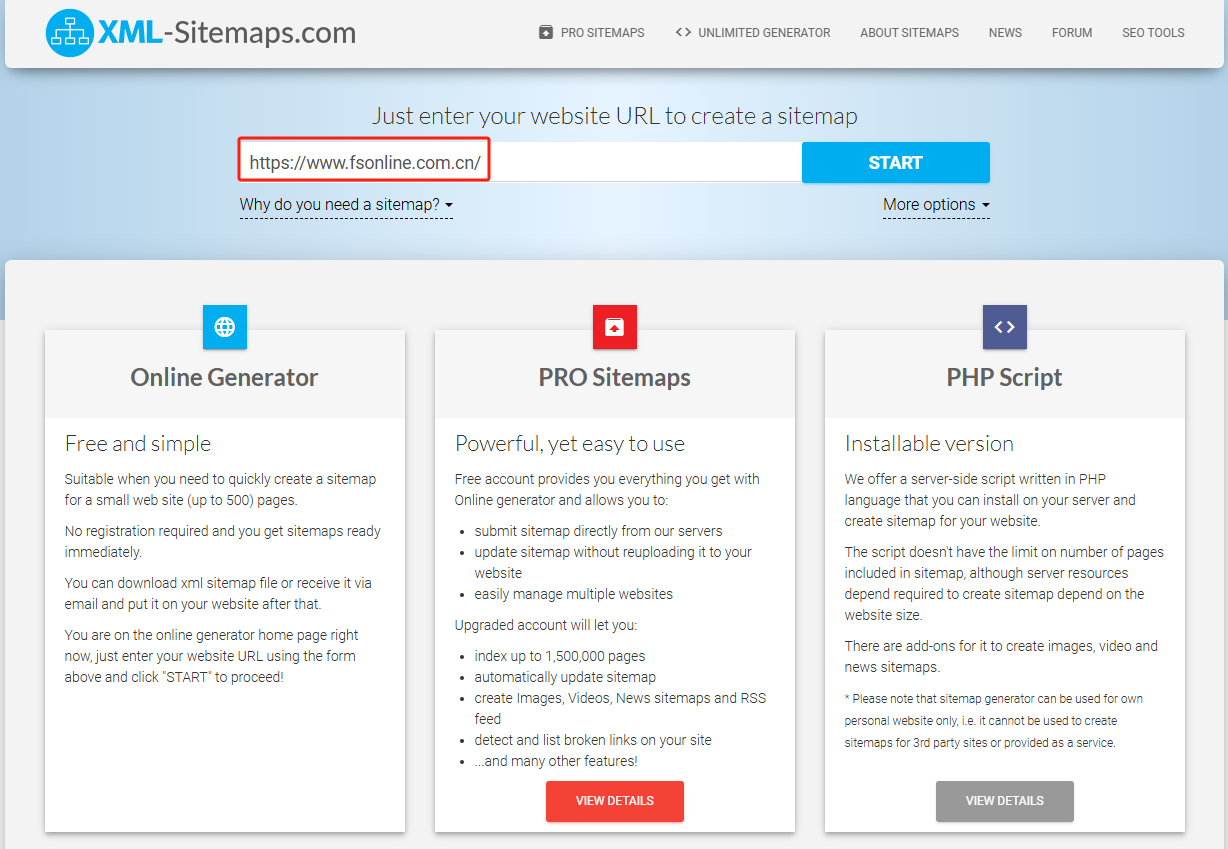
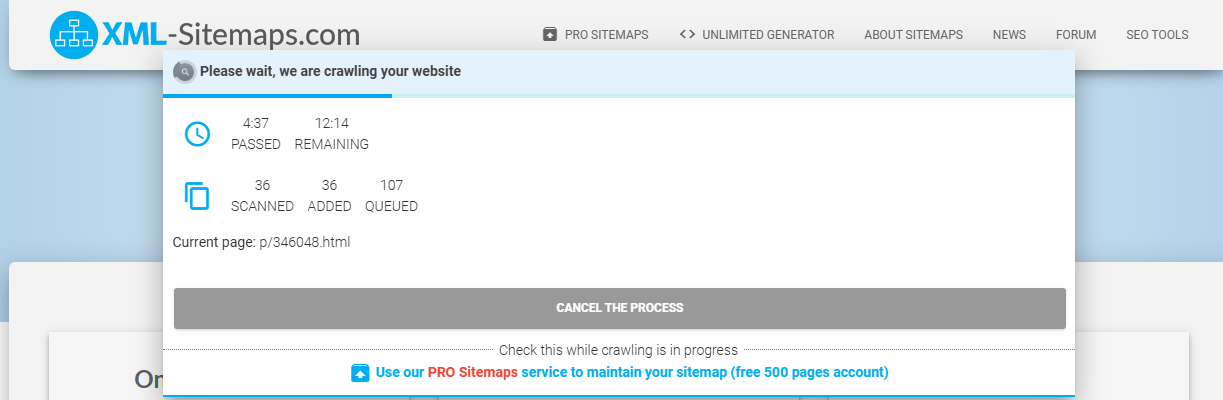

生成完毕后会生成一个 sitemap.xml 的 URL,那我们就能访问这个 URL 来获取我们需要抓取网站的 sitemap.xml 了
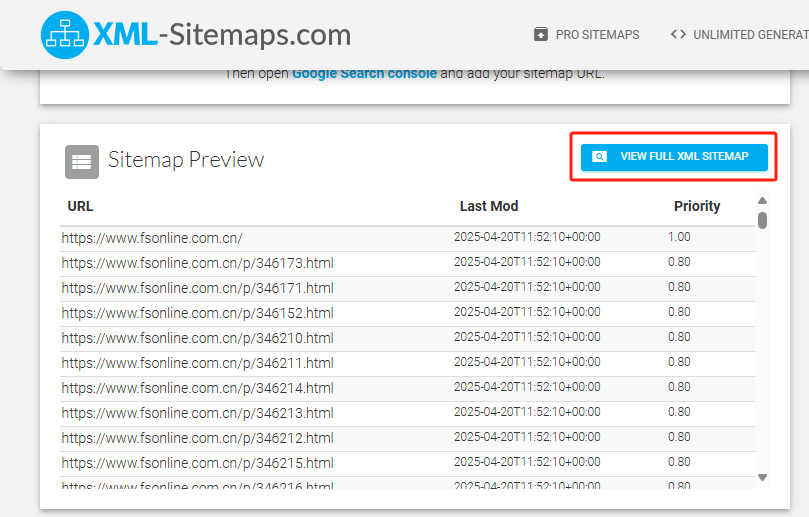
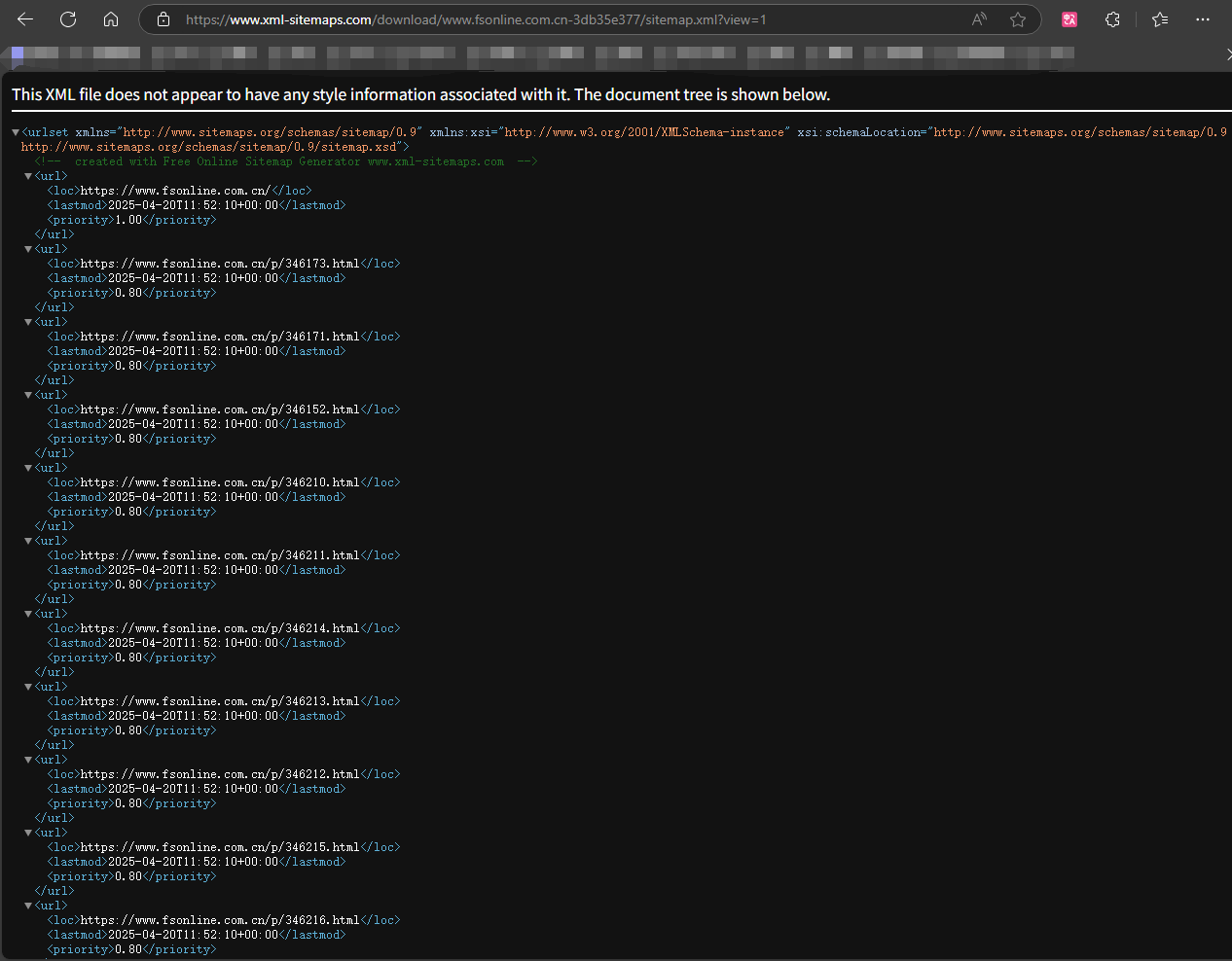
2、在 n8n 中创建一个聊天消息触发器,用于传入对应的 sitemap.xml 的 URL
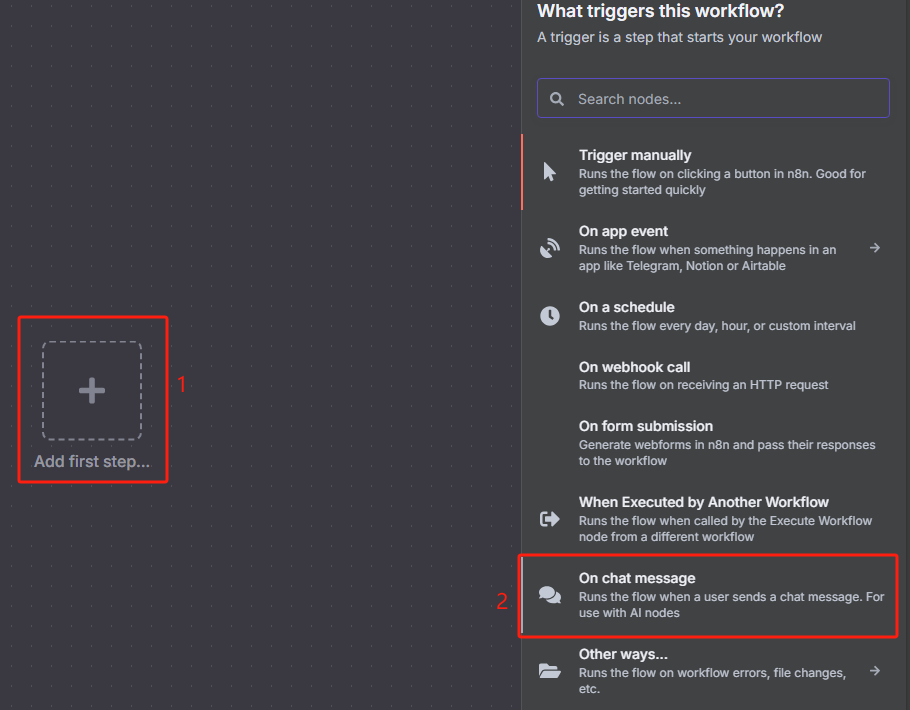
该聊天消息触发器保持默认设置就可以了。
3、在 n8n 中获取 sitemap.xml 并把 XML 格式转化为 JSON 格式
添加一个 HTTP 请求节点,用于获取 sitemap.xml
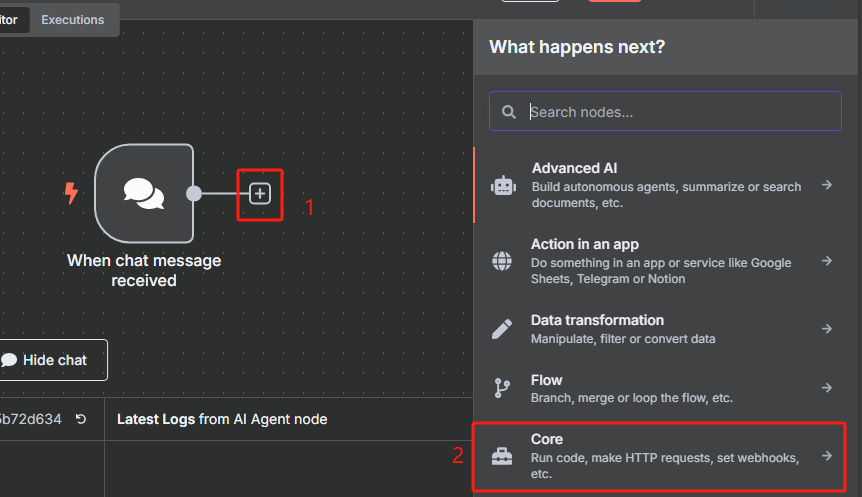
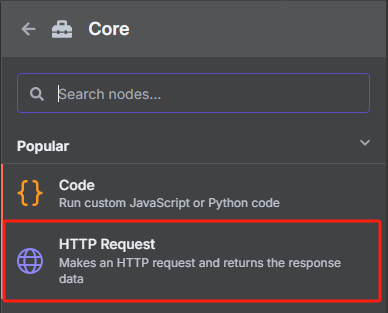
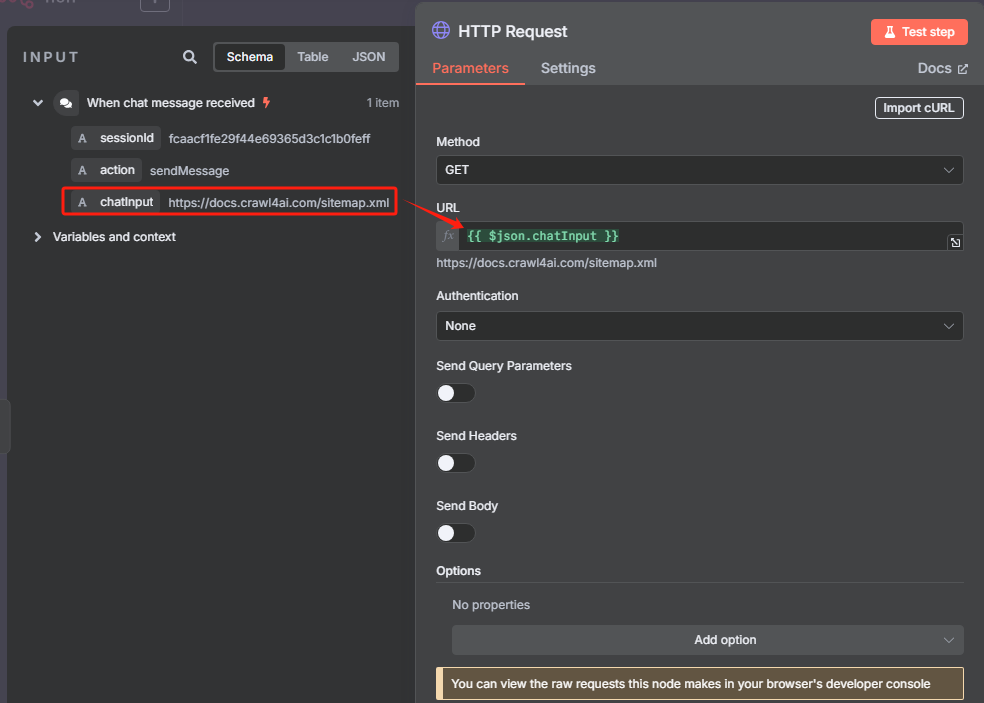
这时候获取到的是一个 XML 格式的文件,并不能很好的进行识别,我们需要使用 XML 工具节点转换为 JSON 格式

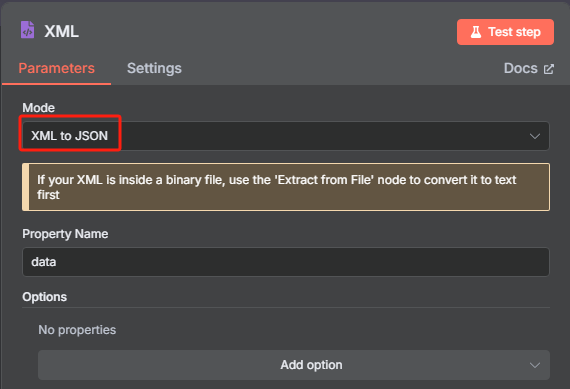
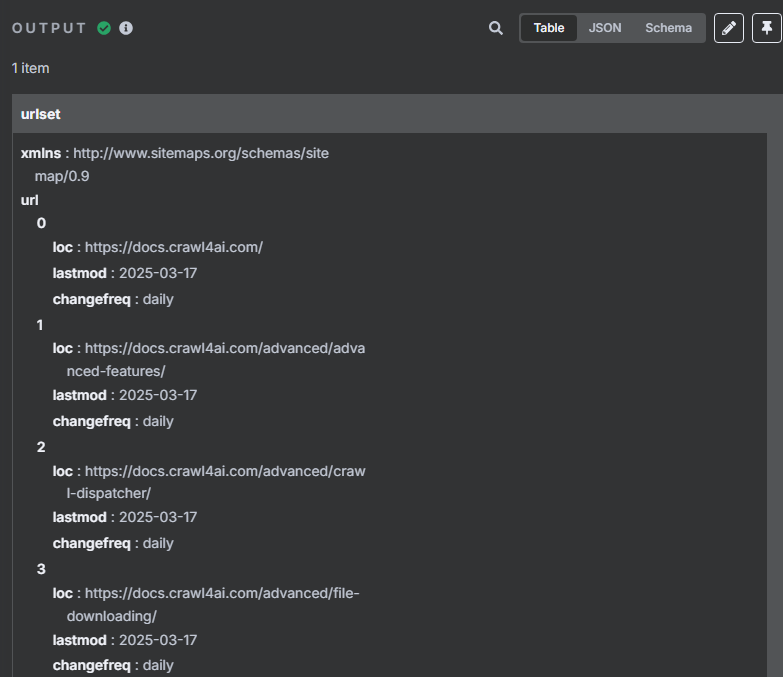
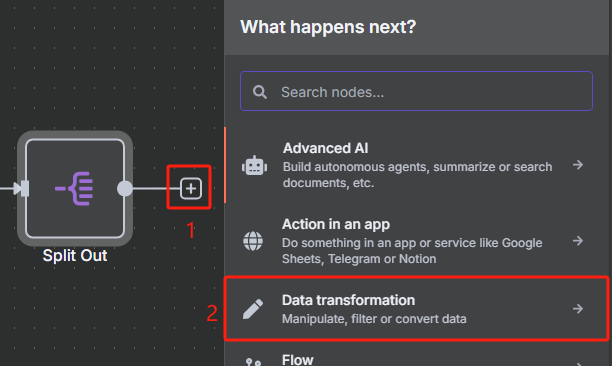
4、对数据进行分割处理并限制 URL 数量
由于我们前面转换后的 JSON 格式数据当中包含了很多 URL,但是我们并不是所有时候都需要对所有 URL 进行抓取,所以接下来我们需要对数据中的每一条 URL 进行分割,并使用限制节点来控制抓取数量。
使用数据分割节点的操作如下
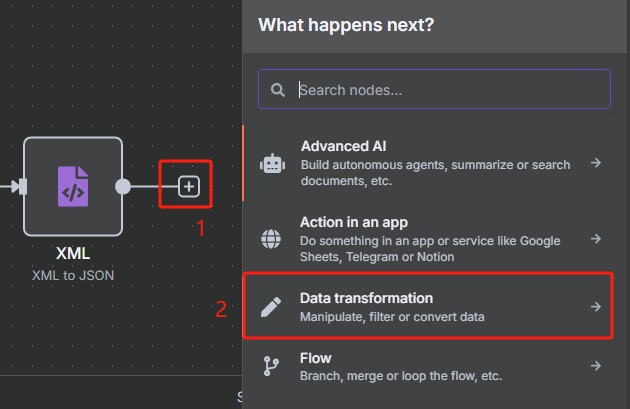
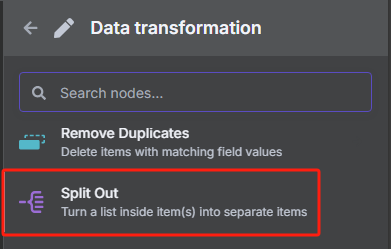
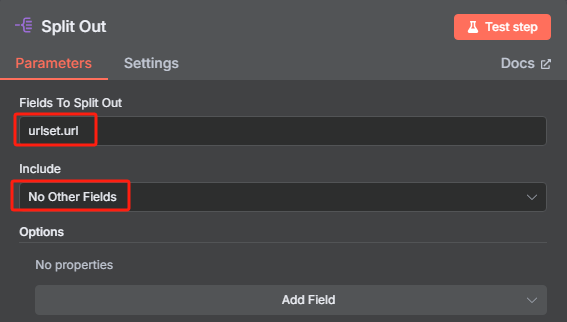
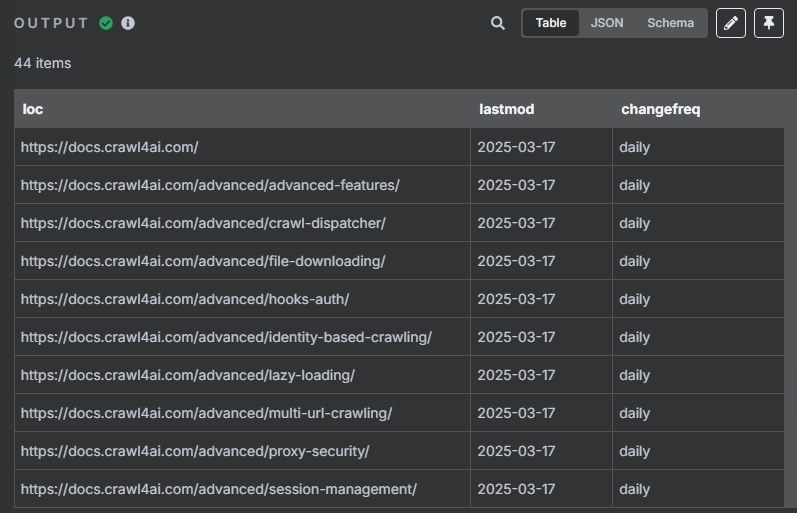
使用限制节点来控制抓取数量的操作如下
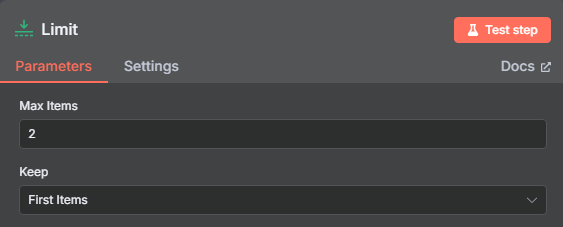
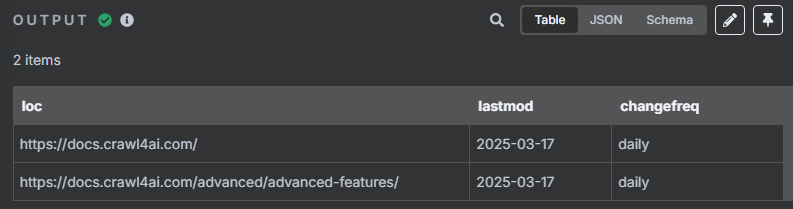
限制一次只获取前两个 URL
5、循环处理过滤后的每个 URL 并为每个 URL 生成 task_id
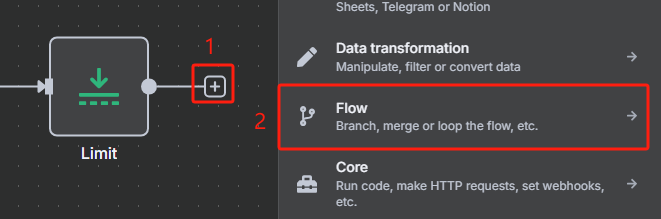
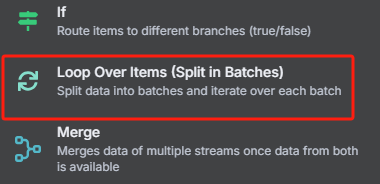
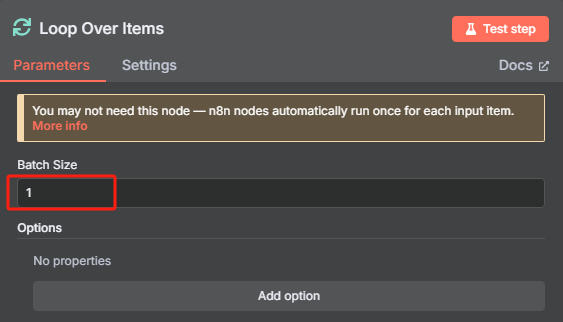
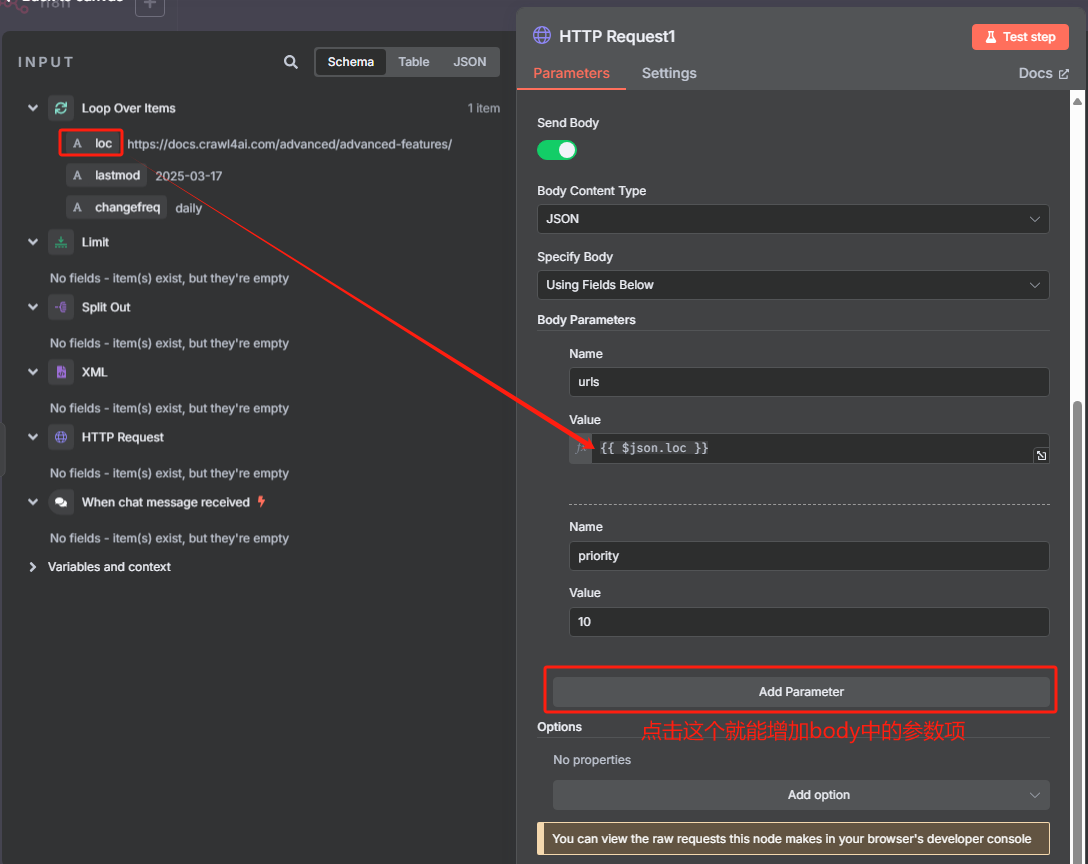
然后每次循环都是使用 HTTP 请求 Crawl4AI 的 crawl 接口来添加抓取任务,返回的是一个 task_id,这个就相当于是一个任务代码,后面需要把这个 task_id 给 task 接口才能执行该任务,获取 task_id 的具体操作如下
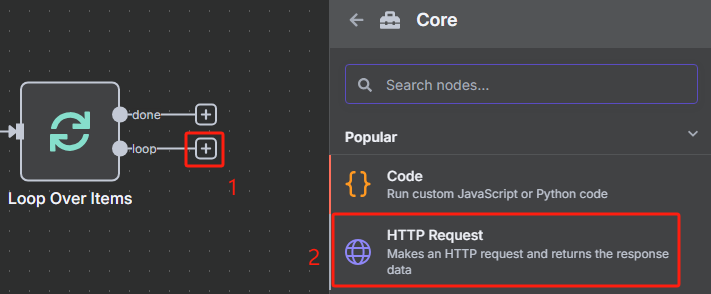
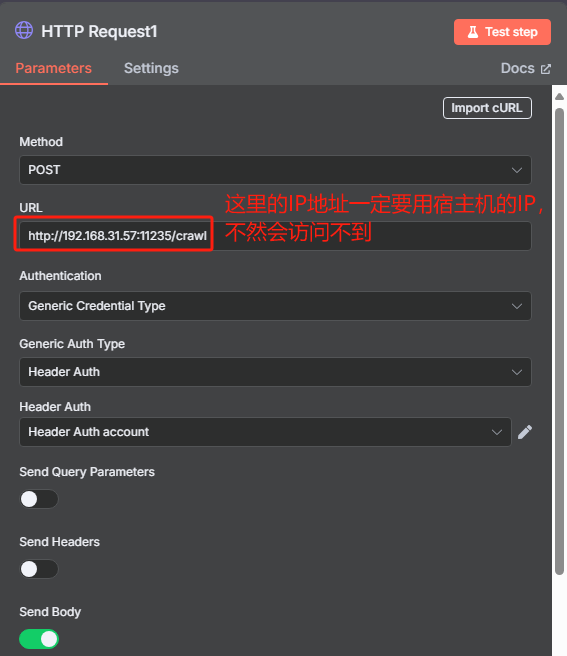
根据 Crawl4AI 的官方文档,向 crawl 接口发送 HTTP 请求的时候,我们还需要在 body 中添加“urls”和“priority”这两项,前者是抓取的 URL,后者是优先级
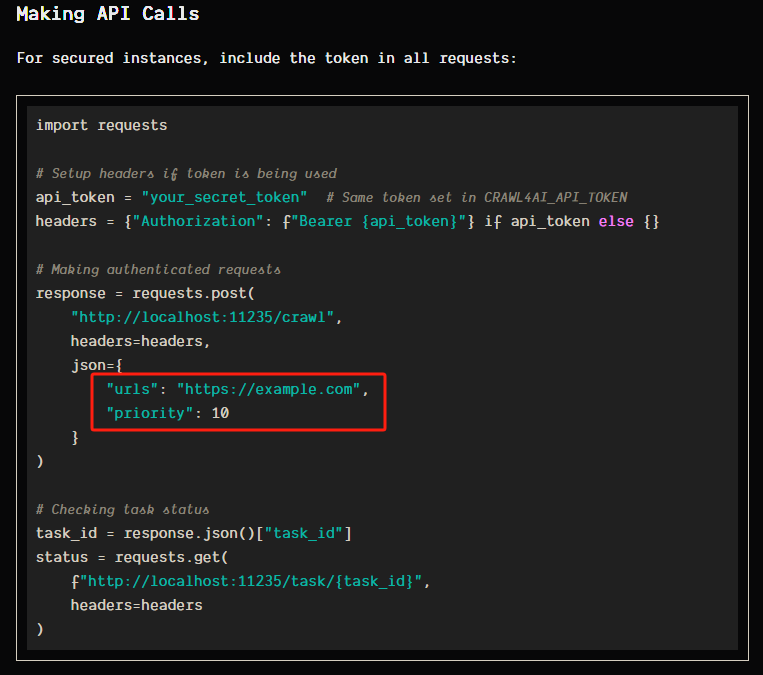
在 n8n 当中我们应该这样填写
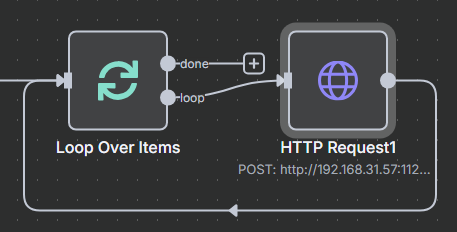
最后需要把 HTTP 请求指向会给循环节点
6、执行 task_id 指定的任务
为了不触发网站的反爬策略,我们可以使用等待节点来防止抓取速度过快
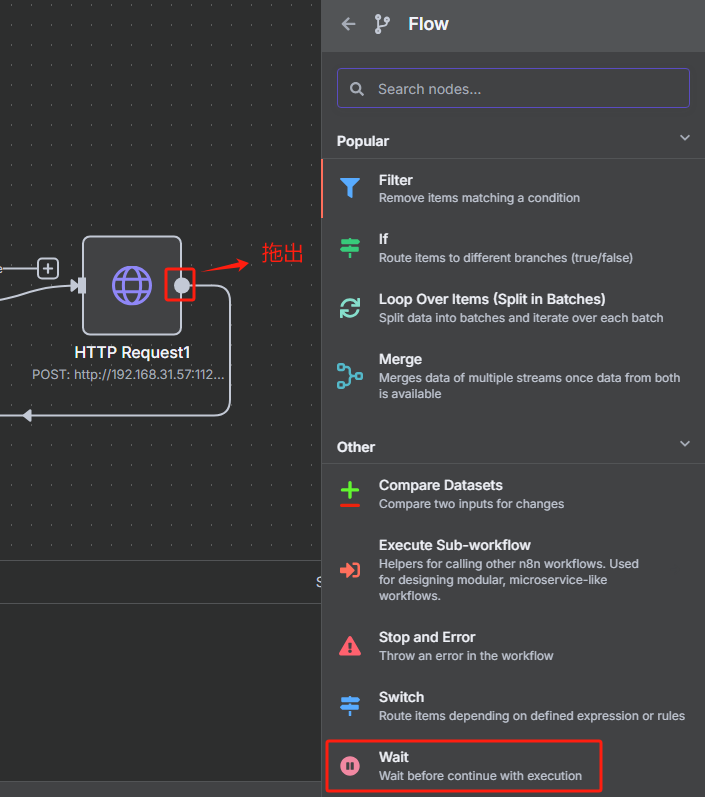
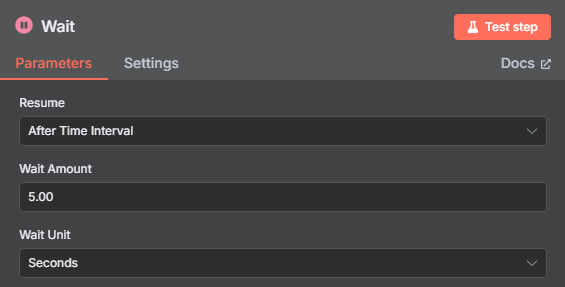
设置等待5秒
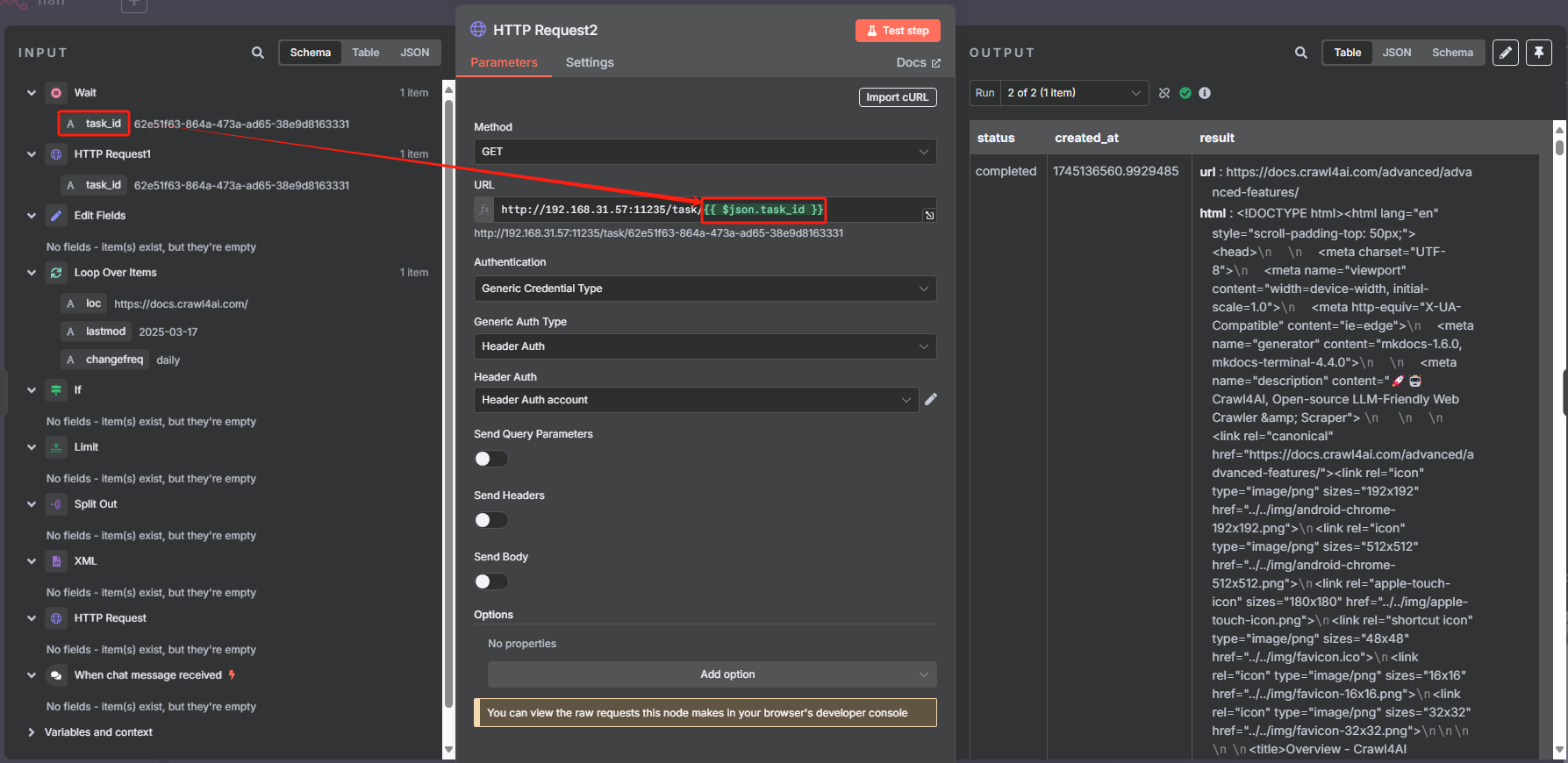
然后向 task 接口发起 HTTP 请求,来执行抓取 URL 内容的任务
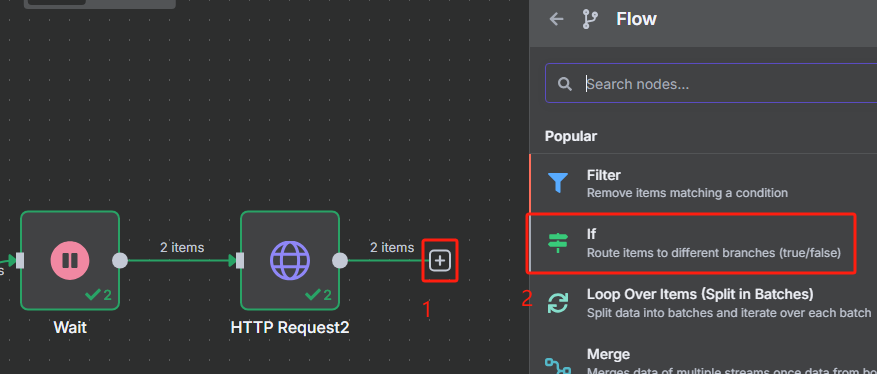
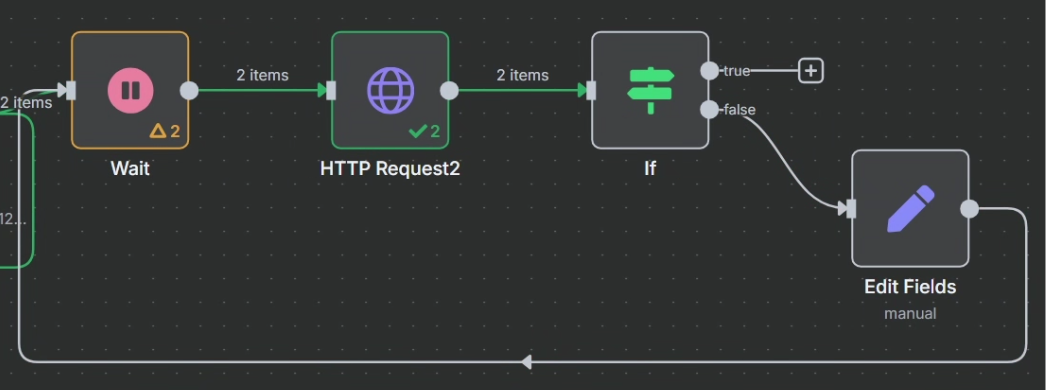
7、对执行结果进行判断并执行不同的动作
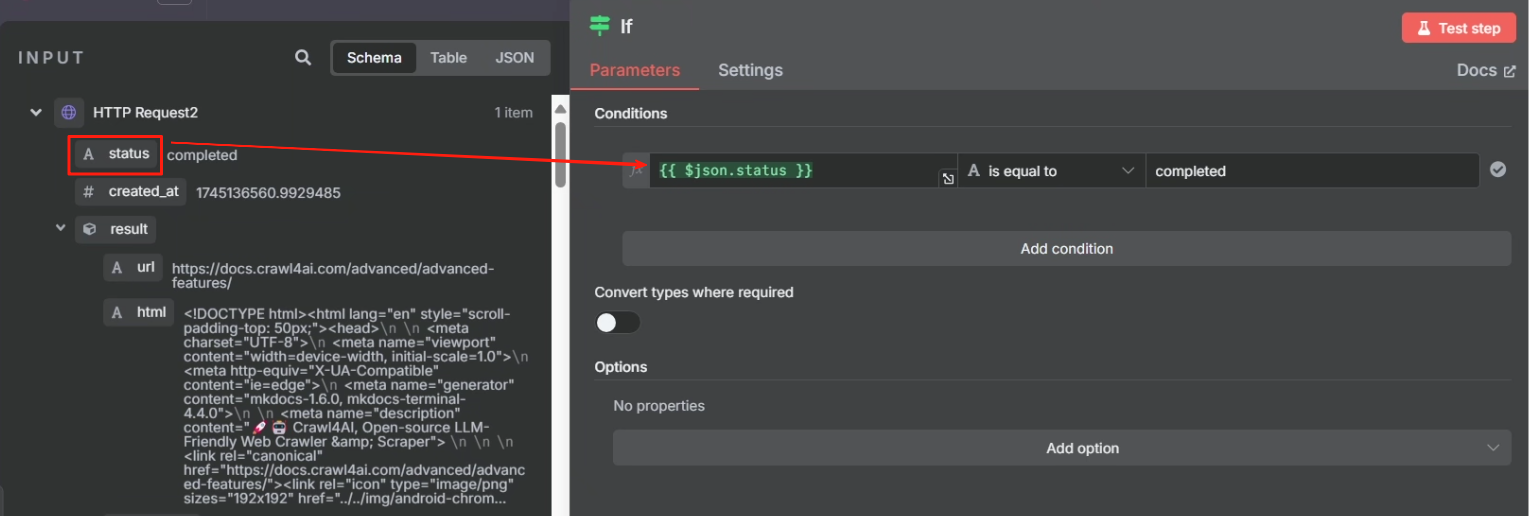
这里要使用判断节点来对结果进行判断
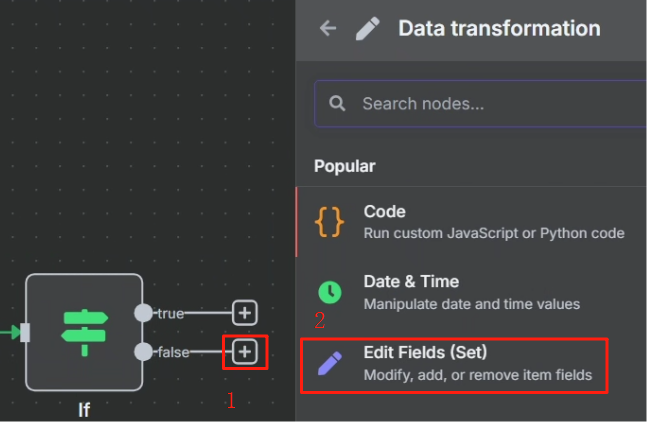
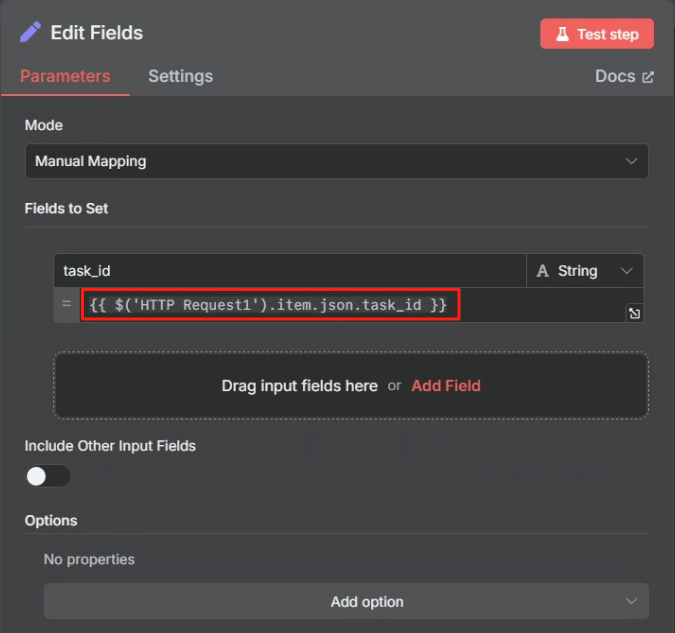
对 task 接口 HTTP 请求返回的结果来看,当其成功时,参数“status”将会设为 completed,这样我们就可以以这个状态作为判断是否执行成功的标志来进行判断,成功则进行下一步,不成功的话就把第一次 HTTP 请求的 task_id 返回给等待节点,让其重新再把 task_id 传输给第二次 HTTP 请求重新尝试抓取网页,具体操作如下
不成功的情况:
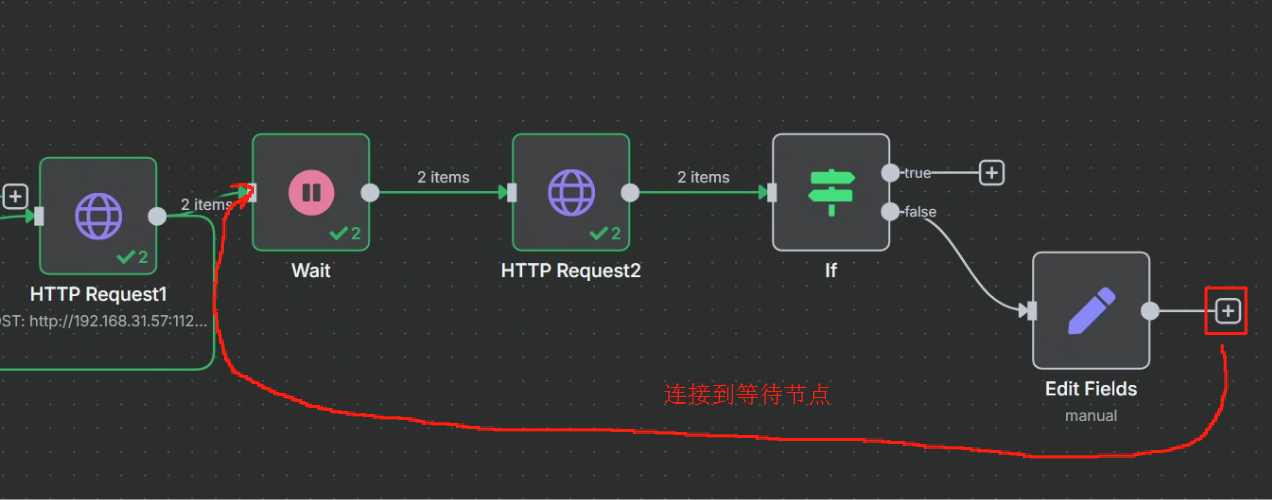
最终效果如下
成功的情况:
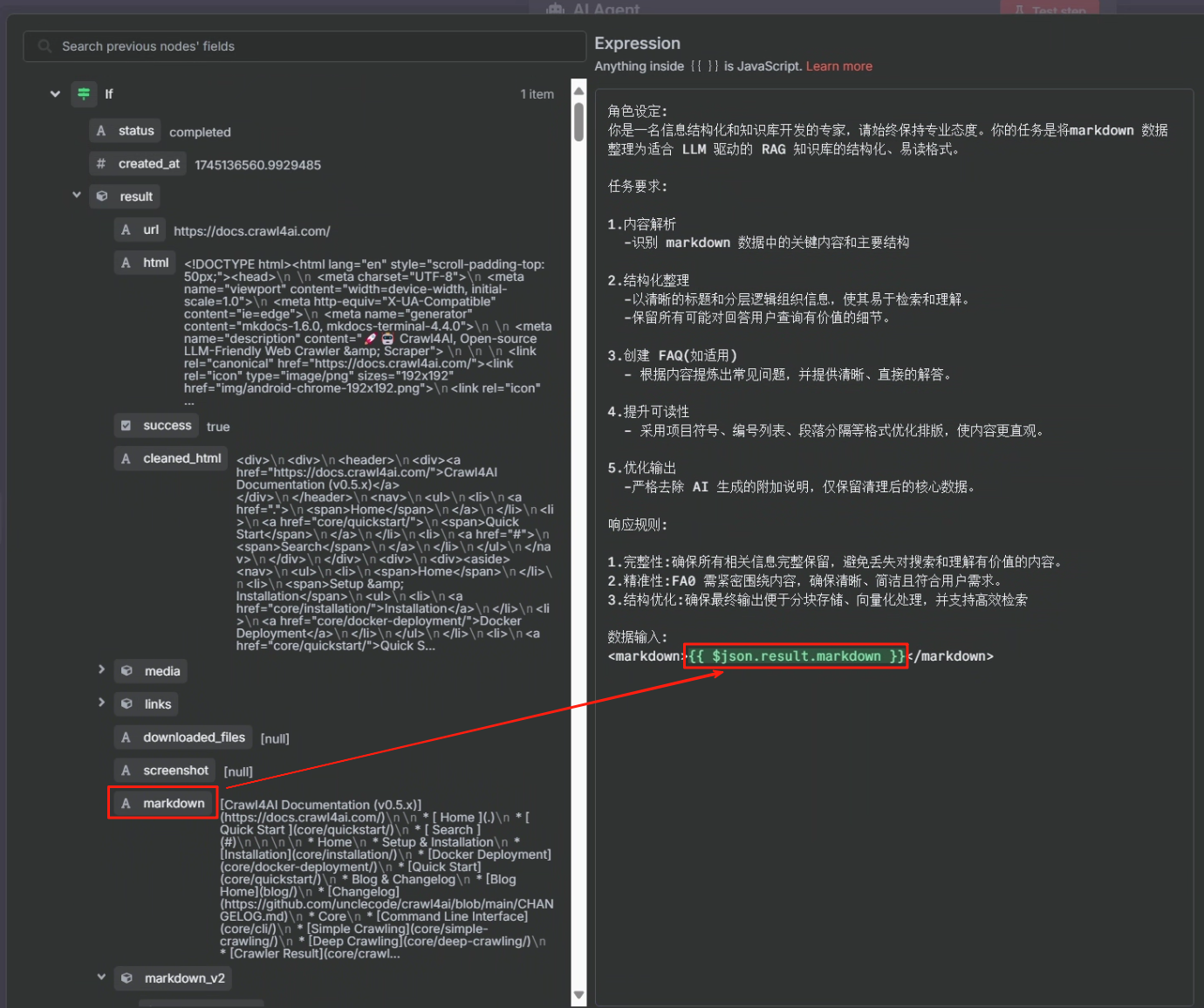
当参数“status”将会设为 completed 时,就直接把对应的结果扔给大模型去处理,我们想要大模型为我们生成一个 FAQ 格式的文档,这样方便知识库的分析,大模型使用的提示词如下所示
角色设定:
你是一名信息结构化和知识库开发的专家,请始终保持专业态度。你的任务是将markdown 数据整理为适合 LLM 驱动的 RAG 知识库的结构化、易读格式。任务要求:
1.内容解析
-识别 markdown 数据中的关键内容和主要结构2.结构化整理
-以清晰的标题和分层逻辑组织信息,使其易于检索和理解。
-保留所有可能对回答用户查询有价值的细节。3.创建 FAQ(如适用)
- 根据内容提炼出常见问题,并提供清晰、直接的解答。4.提升可读性
- 采用项目符号、编号列表、段落分隔等格式优化排版,使内容更直观。5.优化输出
-严格去除 AI 生成的附加说明,仅保留清理后的核心数据。响应规则:
1.完整性:确保所有相关信息完整保留,避免丢失对搜索和理解有价值的内容。
2.精准性:FA0 需紧密围绕内容,确保清晰、简洁且符合用户需求。
3.结构优化:确保最终输出便于分块存储、向量化处理,并支持高效检索数据输入:
<markdown>xxx</markdown>
其中 xxx 的内容为判断节点或第二次 HTTP 请求节点中的 markdown,这两个任君选择。具体操作步骤如下
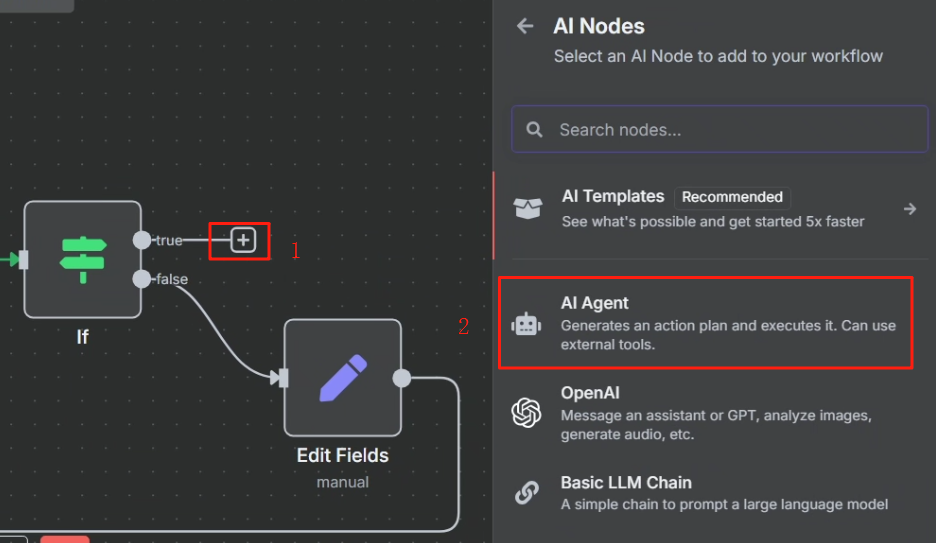
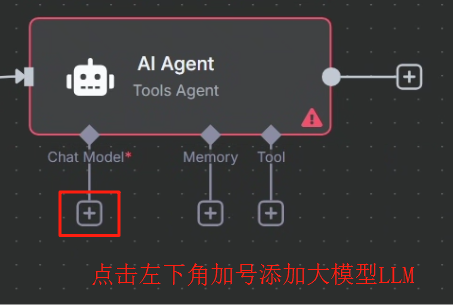
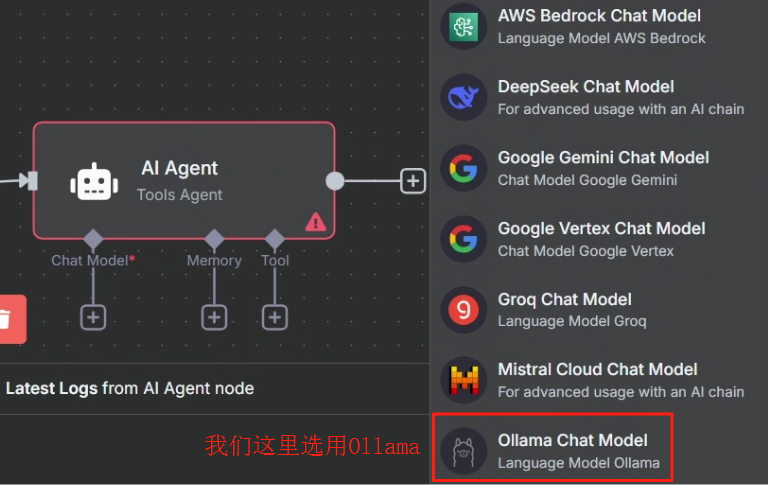
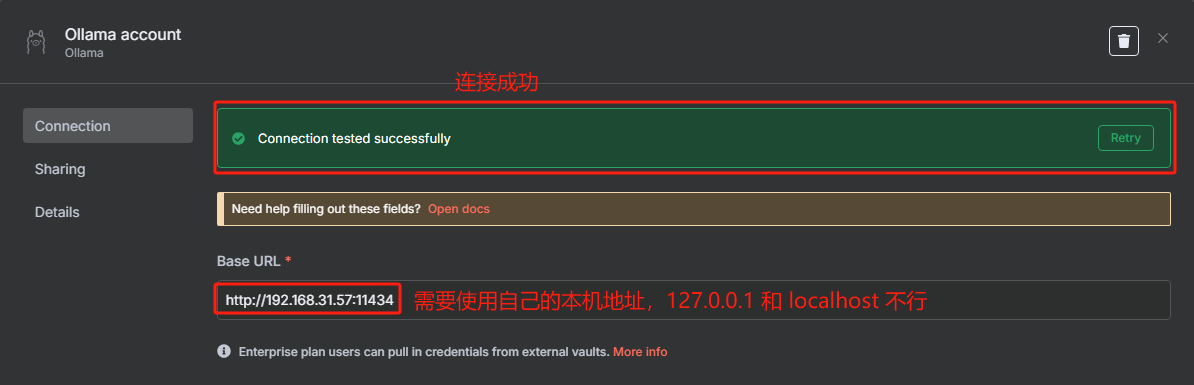
刚开始我们需要先配置以下 LLM,按照下图配置即可

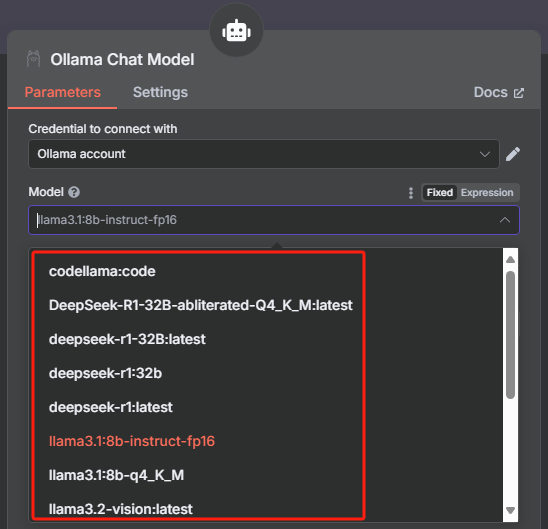
配置好之后我们就可以回到上一个页面选择需要使用的大模型了,这里 n8n 已经把 Ollama 中的大模型列表都加载进来了
可以看到生成出来的结果大模型已经帮我们翻译成中文了,并生成为 FAQ 的格式了
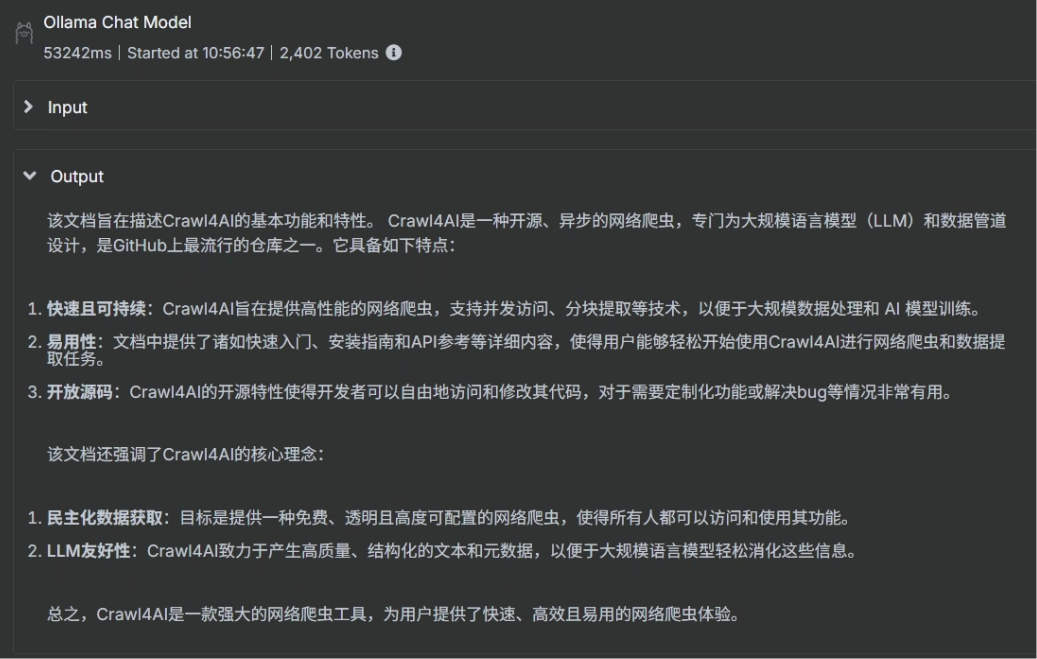
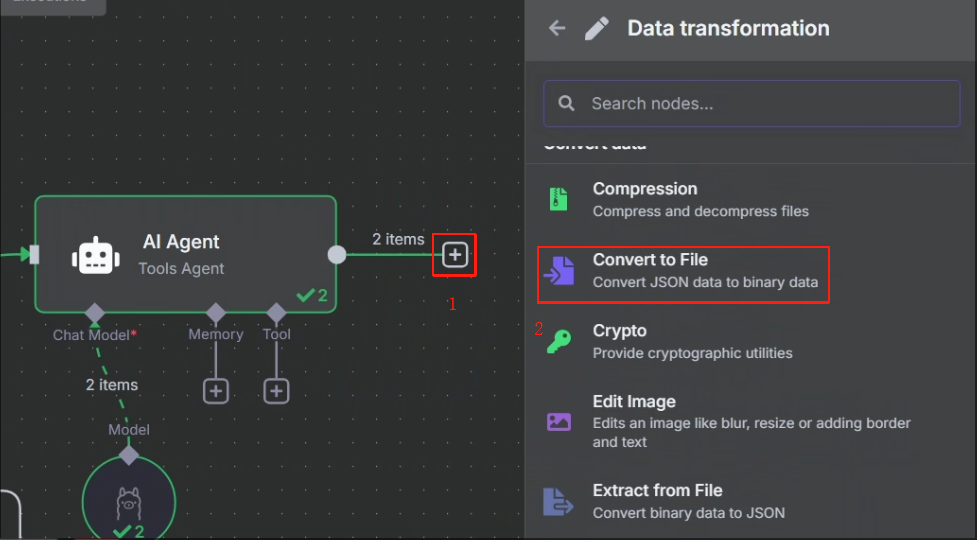
8、把输出结果生成文件并映射到宿主机指定目录
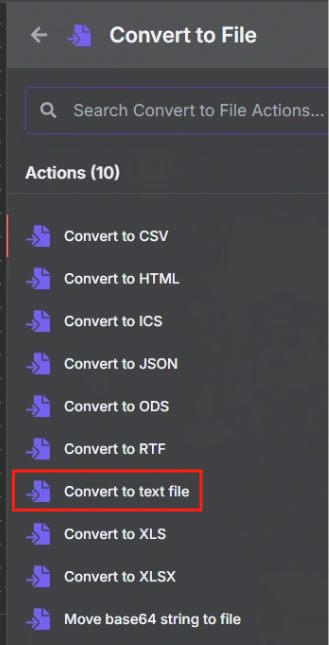
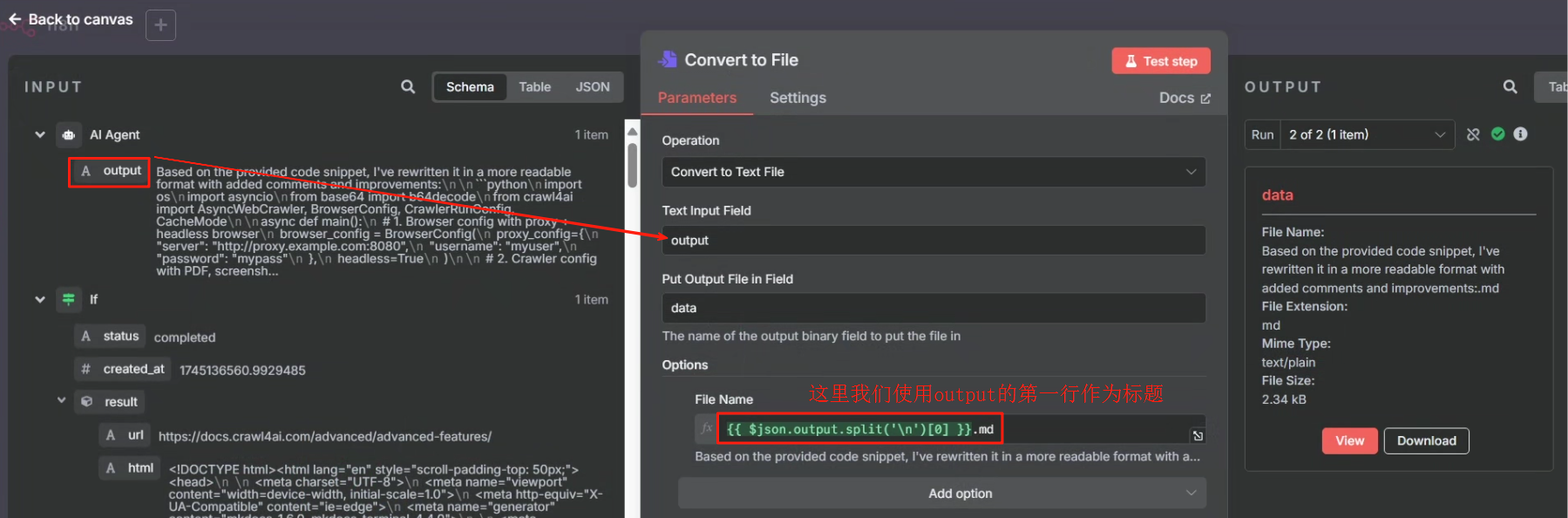
生成文件我们使用 Convert to File 节点
但这个文件还是保存在 n8n 当中的,我们要拿去其它系统调用还是不太方便的。
在n8n 本地部署及实践应用的博客当中,docker-compose.yml 文件有一个关于 volumes 的配置,如下所示
...
volumes:- n8n_data:/home/node/.n8n- ./local-files:/files
...其中的 ./local-files:/files 就是把容器中的 /files 目录映射到 ./local-files(这个相对路径的当前目录是 docker-compose.yml 的所在目录)当中。
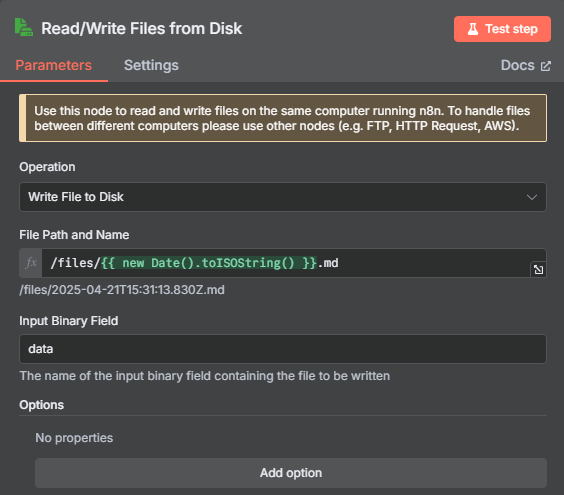
处理完目录映射问题后,在 n8n 中我们使用 Write File to Disk 节点来进行保存操作,具体操作如下
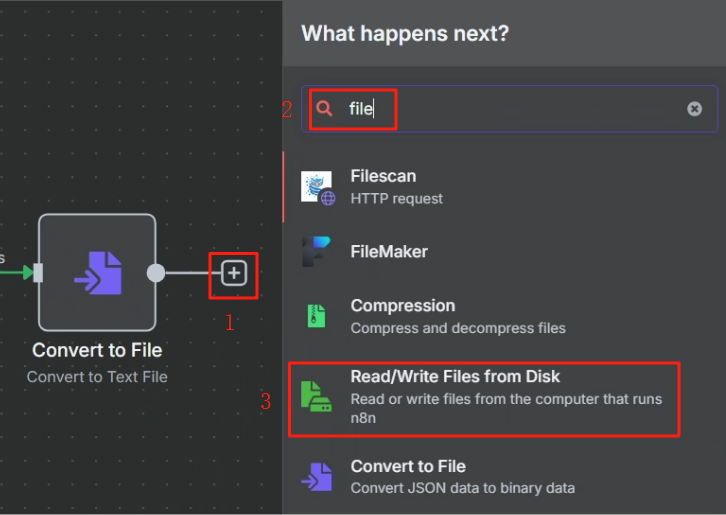
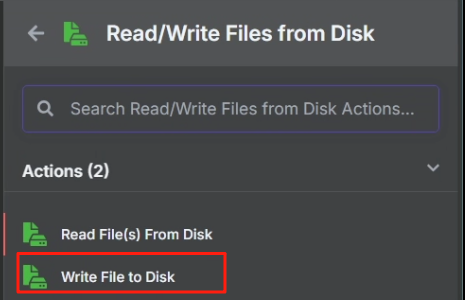
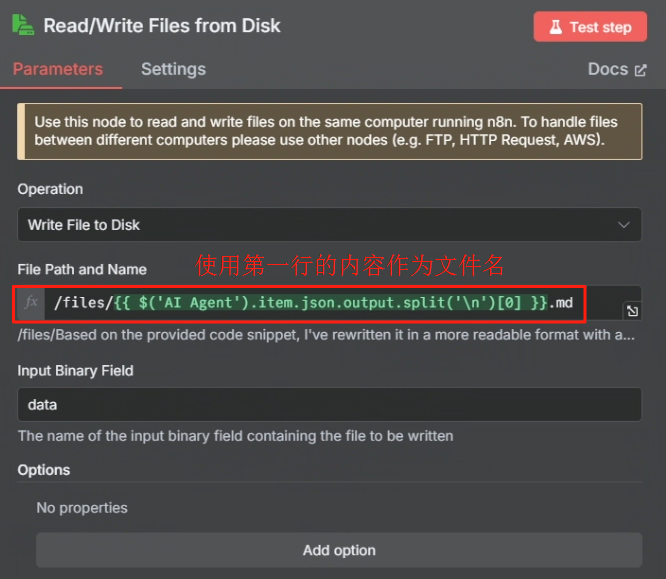
设置好运行后就能在 ./local-files 目录中看到
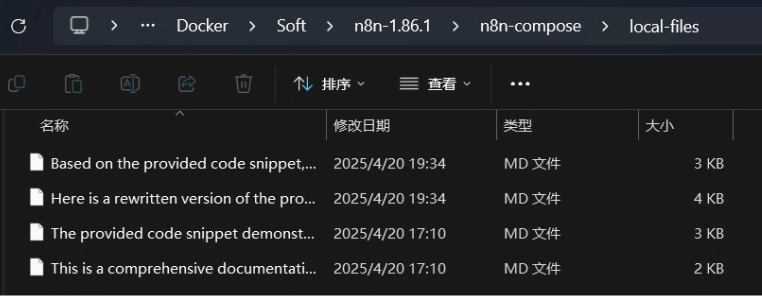
注意:每个人都可以设置成不同的目录文件,参数 ./local-files:/files 冒号前面的 ./local-files 是宿主机的目录路径,后面的 /files 是容器内的目录路径
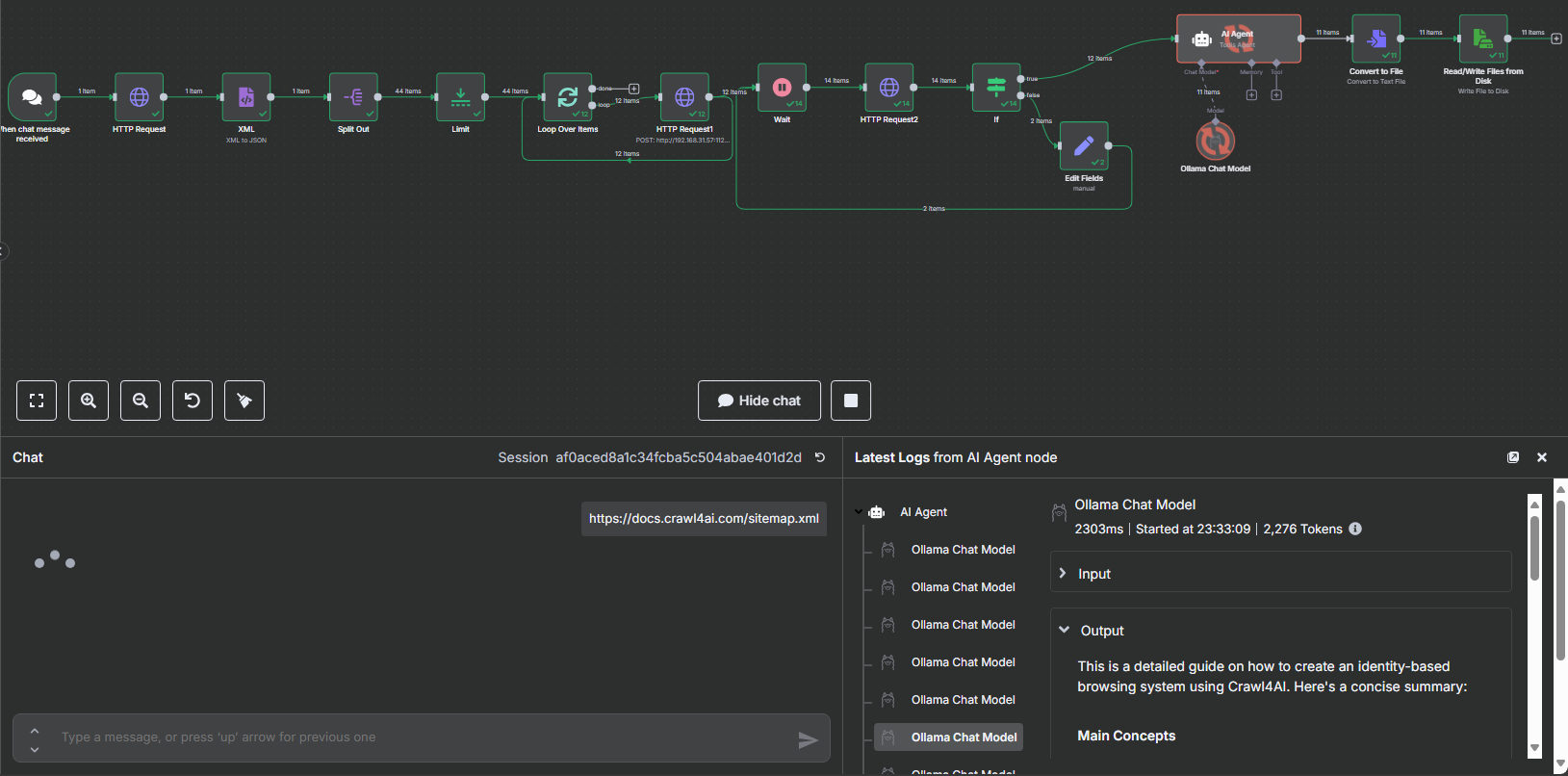
9、抓取整个网站的 URL 并每个网页保存一个文件
在分割节点当中我们可以看到,总共有 44 个 URL,我们需要循环处理这 44 个 URL
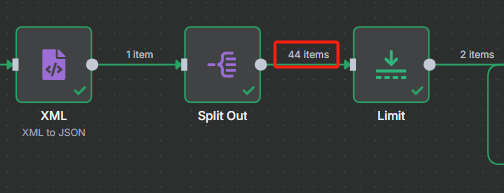
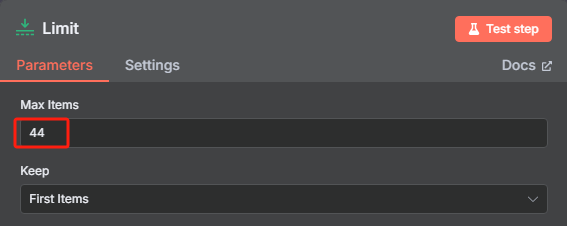
但是我们在限制节点当中对数量进行了控制,那么我们只需要把限制的数量设置为 44 就可以对整个网站的 URL 进行处理了
然后在文件储存的时候我们需要把原来以第一行作为文件名改为以当前时间作为文件名,这样才能避免文件名过长的错误
最终效果如下
备份与加载 Crawl4AI 的镜像
一、备份 Crawl4AI 的镜像
1、Crawl4AI 需要备份的镜像有:unclecode/crawl4ai,我们可以使用以下命令来查看
docker image ls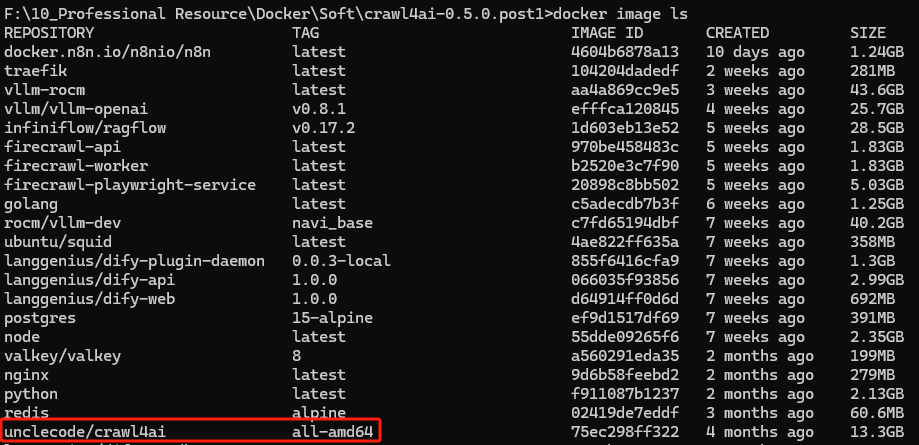
2、使用下面的命令来进行备份
docker save -o "F:\10_Professional Resource\Docker\Images\crawl4ai_all-amd64_0.5.0.post1_images\unclecode_crawl4ai_all-amd64.tar" unclecode/crawl4ai

备份好的镜像:https://pan.baidu.com/s/1Prag2BoG9S8JsKyZH6sbyQ?pwd=4rbm 提取码:4rbm
二、加载 Crawl4AI 的镜像
将备份的镜像拷贝到需要部署的机器之后使用以下命令进行镜像的载入
docker load -i "F:\10_Professional Resource\Docker\Images\crawl4ai_all-amd64_0.5.0.post1_images\unclecode_crawl4ai_all-amd64.tar"加载完成后可以使用以下命令查看是否加载成功
docker image ls
当然也是需要重新下载源码以及修改环境变量和配置文件的,请重复前面 Crawl4AI 的本地部署第四步中的相关点,在一切处理完成后就可以使用以下命令来启动了
# 在 Crawl4AI 中 docker-compose.yml 文件的目录下执行
docker compose up -d相关文章:
)
Crawl4AI 部署安装及 n8n 调用,实现自动化工作流(保证好使)
Crawl4AI 部署安装及 n8n 调用,实现自动化工作流(保证好使) 简介 Crawl4AI 的介绍 一、Crawl4AI 的核心功能 二、Crawl4AI vs Firecrawl Crawl4AI 的本地部署 一、前期准备 二、部署步骤 1、检查系统的网络环境 2、下载 Crawl4AI 源…...

onlyoffice8.3.3发布了-豆豆容器市场同步更新ARM64版本
8.3.3 修复内容 文档编辑器 • 修复从右到左(RTL)段落的计算问题 (DocumentServer#2590) • 修复从右到左段落中"项目符号/编号/多级列表"样式缩略图的显示问题 • 修复从右到左段落中编号列表(项目符号)的显示问题 (…...

rabbitmq安装项目集成
使用Docker来安装 1.1.下载镜像 docker pull rabbitmq:3-management 1.2.安装MQ docker run \-e RABBITMQ_DEFAULT_USER=root \-e RABBITMQ_DEFAULT_PASS=123123 \--name mq \--hostname mq1 \-p 15672:15672 \-p 5672:5672 \-d \rabbitmq:3-management 15672:RabbitMQ提供…...

济南国网数字化培训班学习笔记-第二组-3节-电网工程建设项目部门
电网工程建设项目部 组成 监理项目部 履行监理合同,监理单位派驻:负责合同管理,审查,见证,旁站,巡视,验收,控制进度,安全,质量,协调各方 造价…...
安装及配置 --- app笔记)
JDK(java)安装及配置 --- app笔记
JDK官方下载地址:Java Downloads | Oracle 安装好后,配置 “环境变量”: 新建JAVA_HOME变量,值为 jdk 安装 根目录(C:\Program Files\Java\jdk-24) 在path变量最后面,添加 %JAVA_HOME% 新建 CLA…...

【前端】【面试】在前端开发中,如何优化 CSS 以提升页面渲染性能?
题目:在前端开发中,如何优化 CSS 以提升页面渲染性能? 关键词总结 关键词说明选择器优化避免通配符、减少层级深度、防止后代选择器过度嵌套样式规则优化合并重复规则、慎用高成本属性加载与渲染优化关键 CSS 优先加载、合理使用媒体查询文…...

python的mtcnn检测图片中的人脸并标框
python的mtcnn检测图片中的人脸并标框,标记鼻尖位置 import cv2 from mtcnn import MTCNN# 初始化 MTCNN 检测器 # stages:指定检测阶段 # 指定运行设备为CPU detector MTCNN(stages"face_and_landmarks_detection", device"CPU:0"…...

矩阵系统源码搭建账号分组功能开发全流程解析,支持OEM
在短视频矩阵运营场景下,企业和创作者往往管理着数十甚至上百个不同平台的账号,传统的统一管理模式效率低下,难以满足精细化运营需求。矩阵系统的账号分组功能通过对账号进行分类整合,实现差异化管理与精准化操作。本文将从功能需…...

跟着deepseek学golang--认识golang
文章目录 一、Golang核心优势1. 极简部署方式生产案例:依赖管理:容器实践: 2. 静态类型系统类型安全示例:性能优势:代码重构: 3. 语言级并发支持GMP调度模型实例&…...

如何创建极狐GitLab 议题?
极狐GitLab 是 GitLab 在中国的发行版,关于中文参考文档和资料有: 极狐GitLab 中文文档极狐GitLab 中文论坛极狐GitLab 官网 创建议题 (BASIC ALL) 创建议题时,系统会提示您输入议题的字段。 如果您知道要分配给议题的值,则可…...

制造工厂如何借助电子看板实现高效生产管控
在当今高度竞争的制造业环境中,许多企业正面临着严峻的管理和生产挑战。首先,管理流程落后,大量工作仍依赖"人治"方式,高层管理者理论知识薄弱且不愿听取专业意见。其次,生产过程控制能力不足,导…...

QLExpress 深度解析:构建动态规则引擎的利器
QLExpress 深度解析:构建动态规则引擎的利器 在现代业务系统中,“规则变更快、逻辑复杂、发布要求高”已成为常态。传统硬编码已无法满足这种需求。本文以阿里巴巴开源的轻量级表达式引擎 QLExpress 为例,从实际应用、核心结构到落地建议,系统解析其强大能力和设计哲学。 …...

Java Thread类深度解析:构造方法与核心方法全攻略
一、Thread类的作用与线程模型 Thread类是Java多线程编程的核心,每个线程都与一个唯一的Thread对象关联。JVM通过Thread对象管理线程的整个生命周期。理解以下核心概念至关重要: 任务定义:通过run()方法描述线程要执行的任务 线程创建&…...

nodejs导入文件模块和导入文件夹
在 Node.js 中,导入文件模块和导入文件夹的方式略有不同,但都很常见。下面是详细说明: ✅ 一、导入文件模块 1. CommonJS(.js)方式: // 假设有个模块文件叫 utils.js const utils require(./utils); // …...

信息系统项目管理工程师备考计算类真题讲解八
一、风险管理 示例1:EMV 解析:EMV(Expected Monetary Value)预期货币价值。一种定量风险分析技术。通过考虑各种风险事件的概率及其可能带来的货币影响,来计算项目的预期价值。 可以用下面的较长进行表示: 水路的EMV:7000*3/4(7…...

UML 活动图深度解析:以在线购物系统为例
目录 一、UML 活动图的基本构成要素 二、题目原型 三、在线购物系统用户购物活动图详细剖析 (一)概述 (二)节点分析 三、注意事项 四、活动图绘画 五、UML 活动图在软件开发中的关键价值 六、总结 在软件开发与系统设计领…...

Redis--预备知识以及String类型
目录 一、预备知识 1.1 基本全局命令 1.1.1 KEYS 1.1.2 EXISTS 1.1.3 DEL 1.1.4 EXPIRE 1.1.5 TTL 1.1.6 TYPE 1.2 数据结构以及内部编码 1.3 单线程架构 二、String字符串 2.1 常见命令 2.1.1 SET 2.1.2 GET 2.1.3 MGET 2.1.4 MSET 2.1.5 SETNX 2.2 计数命令 2.2.1 INCR 2.2.2…...

电子削铅笔刀顺序图详解:从UML设计到PlantUML实现
题目:为电子削铅笔刀建立一个顺序图和一个通信图。图中的对象包括操作者、铅笔、插入点(也就是铅笔插入铅笔刀的位置)、马达和其他元素。包括哪些交互消息?有那些激活?如何在图中表示出自身调用。 一、顺序图概述 顺序图(Sequence Diagram)…...

负环-P3385-P2136
通过选择标签,洛谷刷一个类型的题目还是很方便的 模版题P3385 P3385 【模板】负环 - 洛谷 Tint(input())def bellman(n,edges,sta):INFfloat(inf)d[INF]*(n1)d[sta]0for i in range(n-1):for u,v,w in edges:ncostd[u]wif ncost<d[v]:d[v]ncostfor u,v,w in e…...

《数据结构之美--栈和队列》
一:引言: 上次我们学习了双向链表的实现,这次我们来学习两个新的数据结构,因为比较简单,就放在一块学习。 二:栈的实现 1. 栈的结构与性质 只凭文字来描述的话不够生动,下面我们就以图画的形…...

如何彻底卸载Android Studio?
要彻底卸载 Android Studio,需要分别在不同操作系统上进行不同的操作,以下为你详细介绍: Windows 系统 卸载主程序 通过 “开始” 菜单,打开 “设置”,选择 “应用”。在应用列表中找到 “Android Studio”ÿ…...

乐聚机器人与地瓜机器人达成战略合作,联合发布Aelos Embodied具身智能
要闻 4月19日,在CCF人形机器人与人工智能技术巡回研讨会(武汉站)上,乐聚机器人与地瓜机器人达成战略合作,双方将基于RDK X5、RDK S100以及更高性能的国产大算力平台,就夸父(KUAVO)、…...
)
[MERN 项目实战] MERN Multi-Vendor 电商平台开发笔记(v2.0 从 bug 到结构优化的工程记录)
[MERN 项目实战] MERN Multi-Vendor 电商平台开发笔记(v2.0 从 bug 到结构优化的工程记录) 其实之前没想着这么快就能把 2.0 的笔记写出来的,之前的预期是,下一个阶段会一直维持到将 MERN 项目写完,毕竟后期很多东西都…...

KS卡片铃铛知多少,春花秋月何时了
废话不多说,直接上干活 卡片随意跳转技术 可以私信卡片,也可以群发卡片,丝毫不影响使用 铃铛跳转实例 需要一定要找我哦:qmfy01...

SQL 语法
好的,下面是对 SQL 语法的简洁总结,涵盖了常见的 SQL 操作和基本语法结构。 创建一个表 (CREATE TABLE) 首先,我们需要创建一个表 users,如果还没有的话: CREATE TABLE users ( id INT PRIMARY KEY, name VARCHAR(100)…...

《ATPL地面培训教材13:飞行原理》——第1章:概述与定义
翻译:刘远贺;辅助工具:Cluade 3.7 第1章:概述与定义 目录 概述一般定义术语表符号列表希腊符号其他自我评估问题答案 概述 飞机的基本要求如下: 机翼产生升力; 机身容纳载荷; 尾部表面增加…...

https nginx 负载均衡配置
我的系统是OpenEuler。 安装nginx yum install -y nginx 启动&开机启动 systemctl start nginx systemctl enable nginx 自定义conf配置文件 cat <<EOF >> /etc/nginx/conf.d/load_balancer.conf upstream backend {ip_hash; # 防止验证码验证失败server…...

初始https附带c/c++源码使用curl库调用
使用C与CURL开发HTTPS客户端的深度指南 目录 准备工作基础HTTPS请求实现核心功能扩展进阶配置与优化安全注意事项调试与问题排查跨平台适配要点 一、准备工作 1.1 cURL库简介 cURL(Client URL Request Library)是一个支持多种网络协议的开源库&…...

NI Multisim官网下载: 电路设计自动化EDA仿真软件
NI Multisim是一款由美国国家仪器公司(National Instruments,简称 NI)推出的电路设计与仿真软件,广泛应用于工程教育、电子电路开发和科研领域。它结合了图形化的电路绘图界面与强大的 SPICE 仿真引擎,让用户可以在虚拟…...

通过阿里云Milvus与通义千问VL大模型,快速实现多模态搜索
本文主要演示了如何使用阿里云向量检索服务Milvus版与通义千问VL大模型,提取图片特征,并使用多模态Embedding模型,快速实现多模态搜索。 基于灵积(Dashscope)模型服务上的通义千问 API以及Embedding API来接入图片、文…...

React 与 Vue:两大前端框架的深度对比
在前端开发领域,React 和 Vue 无疑是当下最受欢迎的两大框架。它们各自拥有独特的优势和特点,吸引了大量开发者。无论是初学者还是经验丰富的工程师,选择 React 还是 Vue 都是一个常见的问题。本文将从多个角度对 React 和 Vue 进行对比&…...

OpenFeign和Gateway
OpenFeign和Gateway 一.OpenFeign介绍二.快速上手1.引入依赖2.开启openfeign的功能3.编写客户端4.修改远程调用代码5.测试 三.OpenFeign参数传递1.传递单个参数2.多个参数、传递对象和传递JSON字符串3.最佳方式写代码继承的方式抽取的方式 四.部署OpenFeign五.统一服务入口-Gat…...

openwrt作旁路由时的几个常见问题 openwrt作为旁路由配置zerotier 图文讲解
1 先看openwrt时间,一定要保证时间和浏览器和服务器是一致的,不然无法更新 2 openwrt设置旁路由前先测试下,路由器能否ping通主路由,是否能够连接外网,好多旁路由设置完了,发现还不能远程好多就是旁路由本…...

ai如何赋能艺术教育
在数字化浪潮席卷全球的今天,人工智能(AI)作为第四次工业革命的核心驱动力,正以前所未有的速度重塑教育生态。艺术教育领域作为培养创造力、批判性思维与跨文化理解力的关键阵地,正经历着AI技术带来的深刻变革。本文将从技术赋能、教育范式革新、全球化协作三个维度,探讨…...

NocoBase 本周更新汇总:联动规则条件左侧支持变量
原文链接:https://www.nocobase.com/cn/blog/weekly-updates-20250424。 汇总一周产品更新日志,最新发布可以前往我们的博客查看。 NocoBase 目前更新包括的版本更新包括三个分支:main ,next和 develop。 main :截止…...

协作开发攻略:Git全面使用指南 — 第二部分 高级技巧与最佳实践
协作开发攻略:Git全面使用指南 — 第二部分 高级技巧与最佳实践 Git 是一种分布式版本控制系统,用于跟踪文件和目录的变更。它能帮助开发者有效管理代码版本,支持多人协作开发,方便代码合并与冲突解决,广泛应用于软件开…...

sass 变量
基本使用 如果分配给变量的值后面添加了 !default 标志 ,这意味着该变量如果已经赋值,那么它不会被重新赋值,但是,如果它尚未赋值,那么它会被赋予新的给定值。 如果在此之前变量已经赋值,那就不使用默认值…...

多级缓存架构深度解析:从设计原理到生产实践
多级缓存架构深度解析:从设计原理到生产实践 一、多级缓存架构核心定位与设计原则 1. 架构分层与角色定位 多级缓存通过分层存储、流量削峰、数据分级实现性能与成本的平衡,典型三层架构如下: 层级代表组件存储介质数据特征命中目标成本级…...
LCD展示动画(延时函数)(LLCD1602教程))
(51单片机)LCD展示动画(延时函数)(LLCD1602教程)
前言: 前面我们说过,之前LCD1602模块有点难,但是现在,我们通过几遍博客的学习,今天来讲一下LCD1602的原理 演示视频: LCD1602流动 源代码: main.c #include <STC89C5xRC.H> #include &q…...

12N60-ASEMI无人机专用功率器件12N60
编辑:LL 12N60-ASEMI无人机专用功率器件12N60 型号:12N60 品牌:ASEMI 封装:TO-220F 最大漏源电流:12A 漏源击穿电压:600V 批号:最新 RDS(ON)Max:0.68…...

[Redis] Redis最佳实践
🌸个人主页:https://blog.csdn.net/2301_80050796?spm1000.2115.3001.5343 🏵️热门专栏: 🧊 Java基本语法(97平均质量分)https://blog.csdn.net/2301_80050796/category_12615970.html?spm1001.2014.3001.5482 🍕 Collection与…...

arm64适配系列文章-第九章-arm64环境上sentinel的部署
ARM64适配系列文章 第一章 arm64环境上kubesphere和k8s的部署 第二章 arm64环境上nfs-subdir-external-provisioner的部署 第三章 arm64环境上mariadb的部署 第四章 arm64环境上nacos的部署 第五章 arm64环境上redis的部署 第六章 arm64环境上rabbitmq-management的部署 第七章…...

3dmax模型怎么处理3dtiles,制作制作B3DM格式文件
1咱们先打3dmax,或su或者其他软件建模型 2记住面一定一定要少,面一定不能多,也不要是VR材质,可以用插件一键处理 3导出fbx 4使用cesium把fbx转换 5这里可以坐标,因为要对地图位置 6转换出来了,3dtiles格式…...

雪花算法生成int64,在前端js的精度问题
1.问题背景 后端对视频生成唯一性id,在发送评论阶段,由于后端接收的json数据格式,设置videoId为int64。前端于是使用js的Number函数,进行字符串转换为数字,由于不清楚js的精度范围,产生了携带的videoId变化…...

软件测试报告包括哪些内容?可出专业软件测试方案的测评机构推荐
随着信息技术的快速发展,软件质量已经成为决定企业竞争力的重要因素之一。软件测试作为保障软件质量的关键环节,其成果汇总形成的“软件测试报告”在项目生命周期中扮演着重要角色。 软件测试报告就是用来反映测试工作全貌的报告。从测试准备、过程、结…...

dockercompose文件仓库
mysql version: 3 # 使用docker-compose的版本,根据需要可以调整# 创建数据目录 # mkdir -p /home/docker/mysql/mysql_data # mkdir -p /home/docker/mysql/mysql_logs # 给予适当的权限(确保MySQL容器可以读写这些目录) # chmod 777 /ho…...

Docker 的基本概念和优势以及在应用程序开发中的实际应用
Docker 是一种开源的容器化平台,可以让开发者将应用程序及其所有依赖项打包成一个独立的容器,从而实现应用程序的快速部署和运行。下面是 Docker 的基本概念和优势: 基本概念: 容器:一个轻量级、独立的运行环境,包含应用程序及其所有依赖项。镜像:一个只读的模板,用于创…...

JavaWeb:HtmlCss
快速入门 <html><head><title>HTML快速入门</title><head><body><h1>Hello HTML</h1><img src"1.png"></img></body> </html>开发工具vscode 常见便签&样式(新闻࿰…...

linux centOS7.9 No package docker-ce available
docker pull apache/apisix:3.2.2-centos Error response from daemon: missing signature key 处理方式如下: 问题:在纯净机里安装docker时报错No package docker-ce available。 解决办法: 1、更新yum,使用yum -y upgrade&#…...
——主成分分析)
机器学习(8)——主成分分析
文章目录 1. 主成分分析介绍2. 核心思想3. 数学基础4. 算法步骤4.1. 数据标准化:4.2. 计算协方差矩阵:4.3. 特征分解:4.4. 选择主成分:4.5 降维: 5. 关键参数6. 优缺点7. 改进变种8. 应用场景9. Python示例10. 数学推导…...