[Redis] Redis最佳实践
🌸个人主页:https://blog.csdn.net/2301_80050796?spm=1000.2115.3001.5343
🏵️热门专栏:
🧊 Java基本语法(97平均质量分)https://blog.csdn.net/2301_80050796/category_12615970.html?spm=1001.2014.3001.5482
🍕 Collection与数据结构 (93平均质量分)https://blog.csdn.net/2301_80050796/category_12621348.html?spm=1001.2014.3001.5482
🧀线程与网络(97平均质量分) https://blog.csdn.net/2301_80050796/category_12643370.html?spm=1001.2014.3001.5482
🍭MySql数据库(95平均质量分)https://blog.csdn.net/2301_80050796/category_12629890.html?spm=1001.2014.3001.5482
🍬算法(97平均质量分)https://blog.csdn.net/2301_80050796/category_12676091.html?spm=1001.2014.3001.5482
🍃 Spring(97平均质量分)https://blog.csdn.net/2301_80050796/category_12724152.html?spm=1001.2014.3001.5482
🎃Redis(97平均质量分)https://blog.csdn.net/2301_80050796/category_12777129.html?spm=1001.2014.3001.5482
🐰RabbitMQ(97平均质量分) https://blog.csdn.net/2301_80050796/category_12792900.html?spm=1001.2014.3001.5482
感谢点赞与关注~~~

目录
- 1. Redis键值设计
- 1.1 优雅的key结构
- 1.2 BigKey问题
- 1.2.1 BigKey的危害
- 1.2.2 如何发现BigKey
- 1.2.3 如何删除bigKey
- 1.3 恰当的数据类型
- 1.4 总结
- 2. 批处理优化
- 2.1 Pipeline
- 2.1.1 客户端如何与Redis服务器交互?
- 2.1.2 MSet
- 2.1.3 Pipeline
- 2.2 集群下的批处理
- 3. 持久化配置
- 4. 慢查询优化
- 4.1 什么是慢查询
- 4.2 如何查看慢查询
- 5. Redis内存划分和内存配置
- 5.1 内存碎片与内存划分
- 5.3 缓冲区内存问题分析
- 6. 集群还是主从
- 6.1 问题1: 集群不可用
- 6.2 问题2: 集群带宽问题
- 6.3 问题3: 数据倾斜问题
- 6.4 问题4: 集群的批处理问题(单机命令与集群命令兼容性问题)
- 6.5 问题5: lua和事务的问题
1. Redis键值设计
1.1 优雅的key结构
Redis的key虽然可以自定义,但是最好遵循下面的几个最佳的实践约定:
- 遵循基本的格式: [业务名]:[数据名]:[id]
- 长度不超过44字节
- 不包含特殊字符
例如登录业务,保存用户信息,其key可以设计成如下的格式:
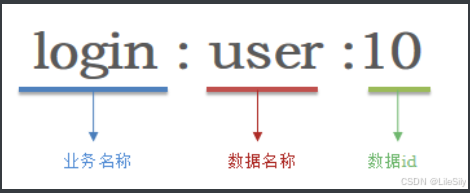
这样设计的好处: - 可读性强
- 避免不同的业务中产生的key发生冲突.
- 方便对不同业务的key进行管理.
1.2 BigKey问题
BigKey通常以Key的大小和Key中的成员的数量综合判定,例如:
- key本身的数据量过大: 一个String类型的key,他的值为5MB
- key中的成员数量过多: 一个Zset类型的key,他的成员数量为10000个.
- key中成员的数据量过大; 一个Hash类型的key,他的成员虽然只有1000个,但是这些成员的value(值)总大小为100MB.
如何判断元素的大小呢?Redis也给我们提供了命令

- 首先可以采用Memery usage命令来查看指定的key以及value占用的大小,但是我们一般不推荐使用Memery指令,因为这个指令对CPU的占用是比较高的.
- 在实际开发中,来衡量一个key是不是大key的时候,我们一般只衡量长度或者是集合中的元素个数就可以.
- 在实际开发中,推荐一个key的value要小于10KB,对于集合类型的key,建议元素数量小于1000.
1.2.1 BigKey的危害
- 网络阻塞
对于BigKey执行读请求时,少量的QPS就可以导致带宽使用率被占满,导致Redis实例,乃至所在的物理机变慢. - 数据倾斜
BigKey所在的Redis实例内存的使用率远超过其他的实例,无法使数据分片的内存资源达到均衡(集群的数据分片在这个实例上分配的插槽比较少). - 数据阻塞
对元素较多的hash,List,zset等做运算会比较好使,导致主线程被阻塞. - CPU压力
对BigKey的数据序列化和返序列化会导致CPU的使用率飙升,影响Redis实例和本机的其他使用.
1.2.2 如何发现BigKey
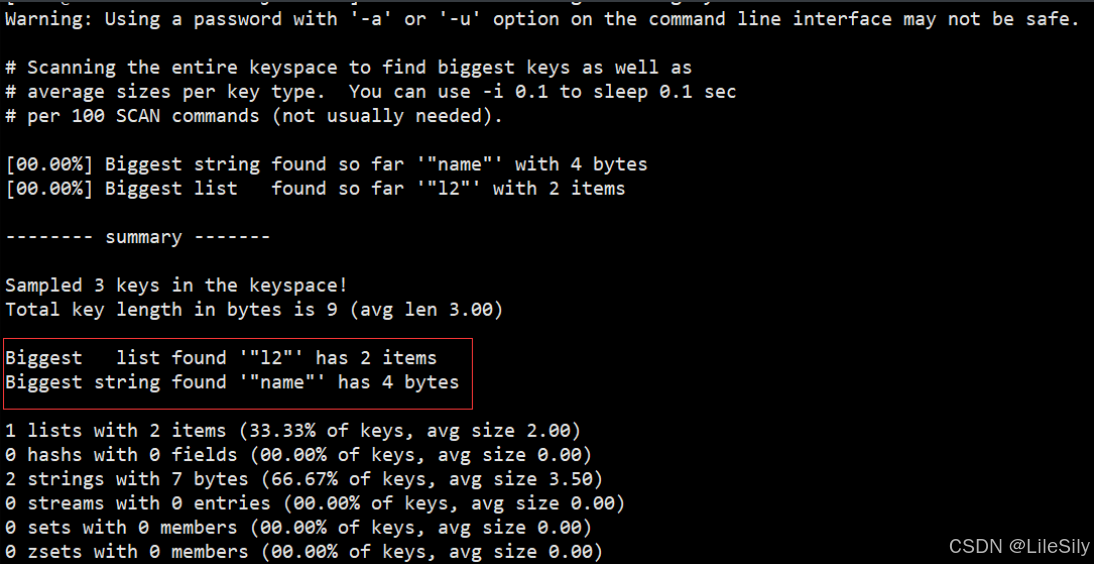
- redis-cli --bigkeys
利用redis-cli提供的–bigkeys参数,可以遍历分析所有的key,并返回key的整体统计信息与每个数据的Top1的bigkey.
命令:redis-cli -a 密码 --bigkeys
 2. scan扫描
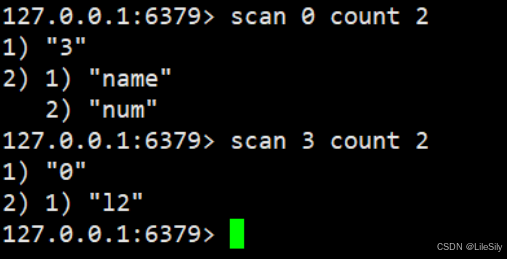
2. scan扫描
自己编程,利用scan(渐进式遍历)扫描redis中的所有key,利用strlen,hlen等命令判断key的长度(不建议使用Memery usage).
- 第三方工具
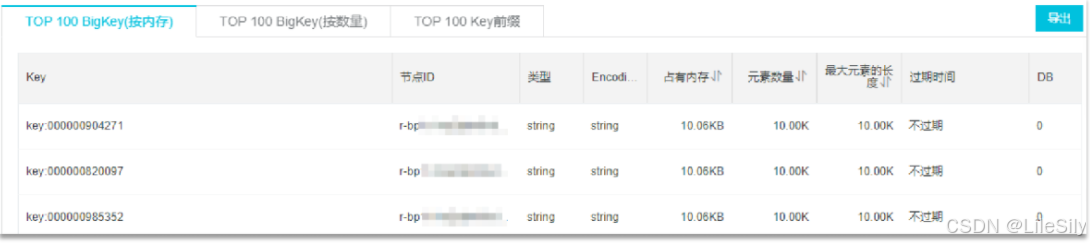
利用第三方工具,如redis-RDB-Tools分析RDB快照文件,全面分析内存的使用情况. - 网络监控
自定义工具,监控进出redis的网络数据,超过预警值的时候主动报警,一般阿里云搭建的云服务器就有相关的监控页面.
1.2.3 如何删除bigKey
如果BigKey占用的内存较多,即便删除了这样的key也需要耗费很长的时间,导致Redis主线程阻塞,引发一系列问题.
- Redis3.0以及一下版本
如果是集合类型,则遍历BigKey的元素,逐个删除子元素,最后删除BigKey - Redis4.0以后
提供了异步删除的命令unlink.
1.3 恰当的数据类型
例1: 比如存储一个User对象,我们有三种存储的方式:
- 方式一: JSON字符串

优点: 实现简单粗暴
缺点: 数据耦合,不够灵活 - 方式二: 字段打散

优点: 可以灵活访问对象的任意字段
缺点: 占用空间大,没办法做统一控制 - 方式三: hash(推荐)

优点: 底层使用ziplist,占用空间小,可以灵活访问对象的任意字段.
缺点: 代码相对复杂
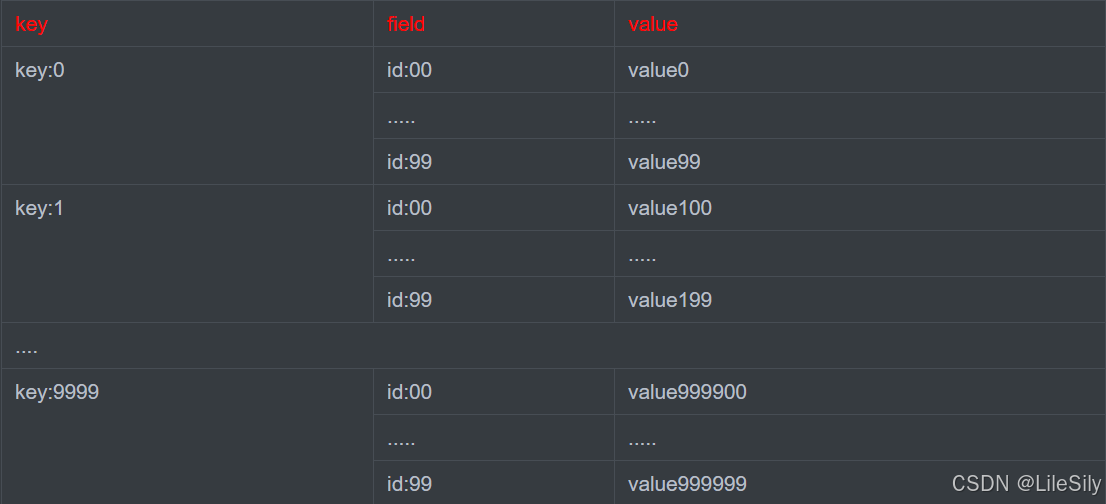
例2: 例如有hash类型的key,其中有100万对Field和value,Field是自增id,这个key存在什么问题,如何优化?

存在的问题:
- hash的Entry数量超过500的时候,会使用Hashtable而不是ziplist,内存占用的内存较多,是一个大key.
- 方案一:
拆分为String类型

存在的问题:
第一String结构底层没有太多的内存优化,内存占用比较多,第二想要批量获取这些数据比较麻烦
- 方案二
拆分为小的hash,将id/100作为key,将id%100作为Field,这样每100个元素为一个hash,这样让每个hash凑采用ziplist存储,存储空间会大大减小.
1.4 总结
- key的最佳实践
- 固定格式: [业务名]:[数据名]:[id]
- 足够简短,一般不超过44字节
- 不包含特殊字符
- value的最佳实践
- 合理的拆分数据,拒绝BigKey
- 选择合理的数据结构
- Hash结构的entry不要超过1000
- 设置合理的超时时间
2. 批处理优化
2.1 Pipeline
2.1.1 客户端如何与Redis服务器交互?
单个命令的执行流程,是一次往返网络传输的耗时+一次Redis执行命令的耗时.

N条命令执行的流程,N次往返的网络传输耗时+N次Redis执行命令的耗时.

Redis处理指令是很快的,其花费的时间主要在网络传输上,于是很容易想到将多条指令批量传输给Redis.批量传输的耗时等于1次往返的网络传输耗时+N次Redis执行命令的耗时.

2.1.2 MSet
Redis提供了很多的MXXX这样的命令,可以实现批量的数据插入,例如:
- mset
- hmset
比如利用mset批量插入10万条数据
@Test
void testMxx() {String[] arr = new String[2000];int j;long b = System.currentTimeMillis();for (int i = 1; i <= 100000; i++) {j = (i % 1000) << 1;arr[j] = "test:key_" + i;arr[j + 1] = "value_" + i;if (j == 0) {jedis.mset(arr);}}long e = System.currentTimeMillis();System.out.println("time: " + (e - b));
}
我我们之前做的OJ刷题系统中,也用到了Redis的批量数据插入.在刷新历史竞赛,未完赛的竞赛,和用户竞赛中,我们使用了批量插入,使用了map把这些数据包装好,之后进行插入即可.
redisService.multiSet(historyExamMap);
redisService.multiSet(unfinishExamMap);
redisService.multiSet(userExamMap);
2.1.3 Pipeline
Mset虽然可以批量处理,但是却只能操作部分的数据类型,比如上面我们只能对set和Hash类型做批量插入,因此如果有对复杂的数据的批量处理需要,比如批量插入字符串类型,建议使用Pipeline.使用jedis.pipelined方法创建一个Pipeline类.之后可以批量把命令放入Pipeline中,使用Pipeline.sync批量执行.
@Test
void testPipeline() {// 创建管道Pipeline pipeline = jedis.pipelined();long b = System.currentTimeMillis();for (int i = 1; i <= 100000; i++) {// 放入命令到管道pipeline.set("test:key_" + i, "value_" + i);if (i % 1000 == 0) {// 每放入1000条命令,批量执行pipeline.sync();}}long e = System.currentTimeMillis();System.out.println("time: " + (e - b));
}
2.2 集群下的批处理
如Mset或者Pipeline这样的处理需要再一次请求中携带多条指令,而此时如果Redis是一个集群,那么批处理命令的多个key必须落在同一个插槽中,但是如果我们在集群模式下进行批处理,这些数据很有可能因为计算出的哈希值不同而落在不同的节点上,如果我们就按照落在一个结点上来写命令的话,就会引起单机结点命令和集群命令不兼容的问题,引起报错.
这个时候,我们有以下的四种解决方案:
- 第一种方案: 串行执行,N次Redis处理+N次网络请求,但这样没有起到优化的效果,一般我们不建议这样干.
- 第二种方案: 串行slot,简单来说,就是执行前,客户端先计算一下对应的key的哈希槽==,一样槽位的key就放到一个组里面,不同的,就放到不同的组里面,然后对每个Pipeline中的数据依次进行批处理==,这种做饭比第一种方法耗时少,但是实现相对复杂一些.
- 第三种方案: 并行slot,相较于第二种方案,在分组完成后串行执行,每个Pipeline依次执行,第三种方案就变成了并行执行各个命令,好几个Pipeline一起执行,所以他的耗时比第二种更短,但是实现起来比第二种更加复杂.
- 第四种方案: hash_tag,Redis计算key的哈希槽的时候,其实是根据key的有效部分来计算的,我们设置key的时候为所有的key设置相同的有效部分,通过这种方式就能一次处理所有的key,这种方式就会导致所有的key都落在一个结点上,产生数据倾斜的问题,所以我们推荐使用第三种方式.
3. 持久化配置
Redis的持久化虽然可以保证数据安全,但是也会带来额外的性能开销,因此持久化请遵循一下原则;
- 单纯用来做缓存的Redis实例尽量不要开启持久化功能.
- 建议关闭RDB持久化功能,使用AOF持久化功能,保证数据的可靠性
- 虽然RDB不可以最大程度保证数据的可靠性,但是可以利用脚本定期在slave结点上做RDB数据备份.
- 合理设置rewrite阈值,避免频繁的bgrewrite.
- 配置
no-appendfsync-on-rewrite = yes,禁止在重写期间做AOF,避免因为AOF引起的阻塞.
4. 慢查询优化
4.1 什么是慢查询
并不是很慢的查询才叫慢查询,而是Redis在执行耗时超过某个阈值的命令,称为慢查询.
慢查询的危害: 由于Redis值单线程的,所以当客户端发出指令之后,他们都会进入到Redis底层的Queue来执行,如果此时有一些慢查询的数据,就会导致大量请求阻塞,从而引起报错,所以我们需要解决慢查询的问题.
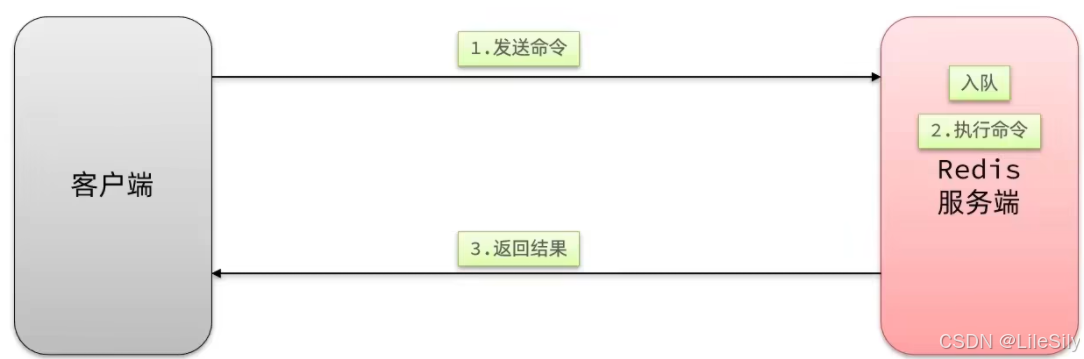
慢查询的阈值可以通过配置指定:
slowlog-log-slower-than: 慢查询阈值,单位值微秒,默认是10000,建议是1000
慢查询会被放入到慢查询日志中,日志的长度有上限,可以通过配置指定:
slowlog-max-len: 慢查询日志的长度(本质上是一个队列的长度),默认是128,建议1000.
修改这两个配置使用config set命令.

4.2 如何查看慢查询
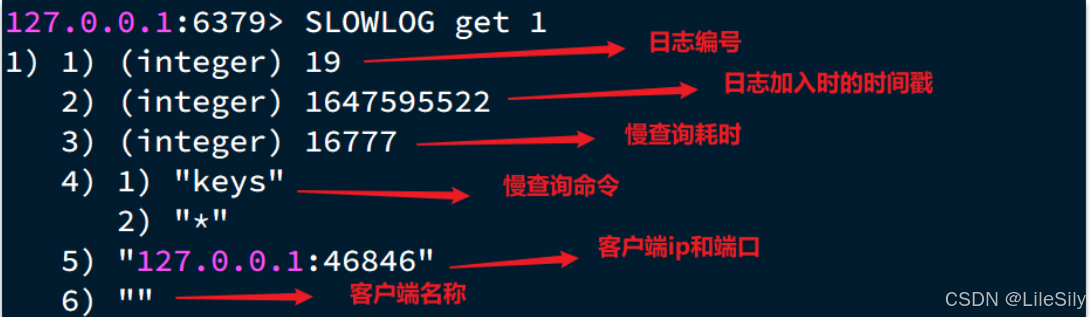
直到了以上内容之后,那么如何去查看慢查询日志列表呢?
slowlog len: 查询慢查询日志的长度slowlog get[n]: 读取n条慢查询日志slowlog reset: 清空慢查询列表
5. Redis内存划分和内存配置
当Redis内存不足的时候,可能会导致key被频繁删除,响应时间变长,QPS不稳定等问题,当内存使用率达到90%以上的时候,就需要我们警惕,并快速定位到内存占用的原因.
5.1 内存碎片与内存划分
Redis底层分配并不是这个key有多大,他就会分配多大,而是有他自己的分配策略,比如有三块内存空间,8,16,20,假定当前的key只需要10个字节,此时分配8坑定不够,那么他就会分配16个字节,多出来的6个字节就不能被使用,这就是我们常说的碎片问题.
内存通常是按照功能去划分的:
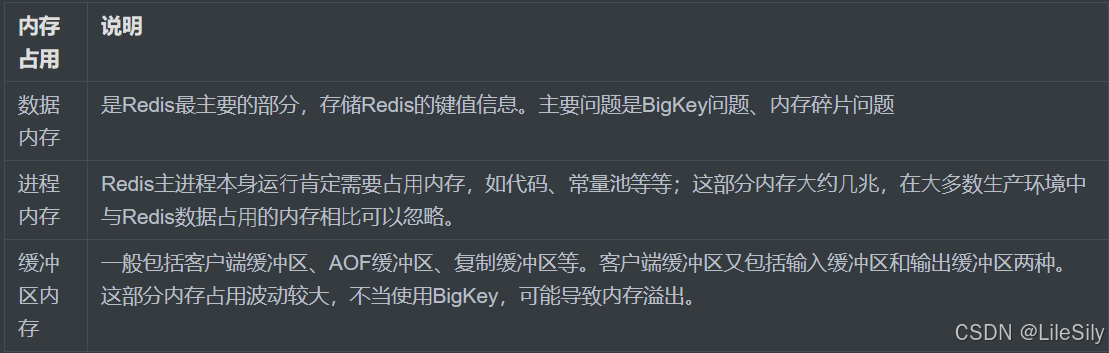
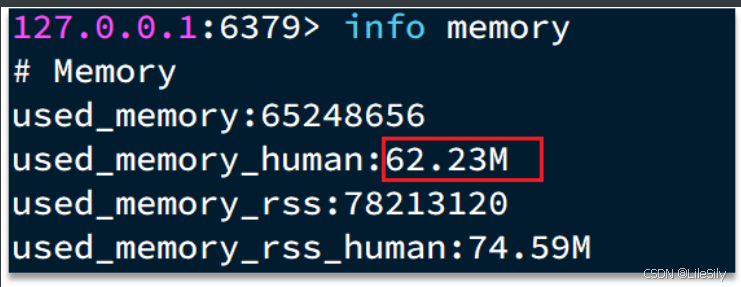
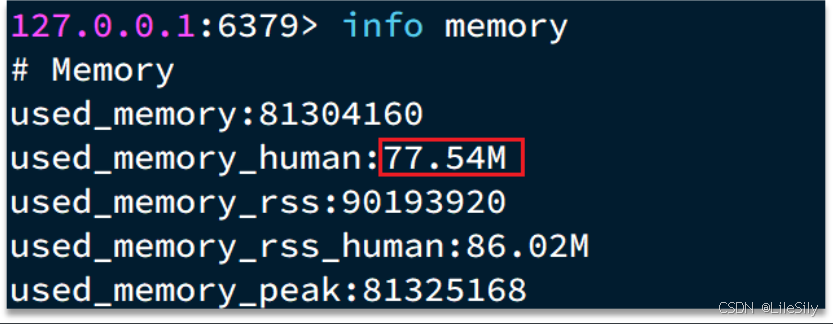
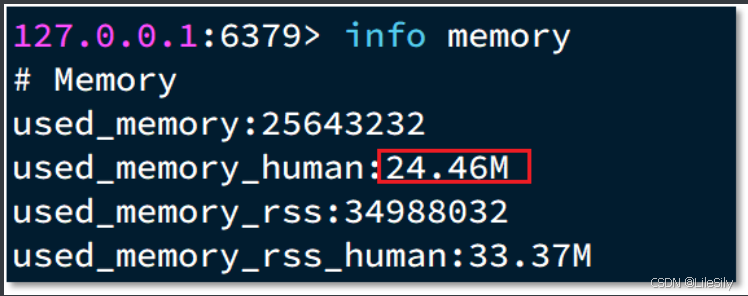
一般通过info memory来查看内存的分配情况
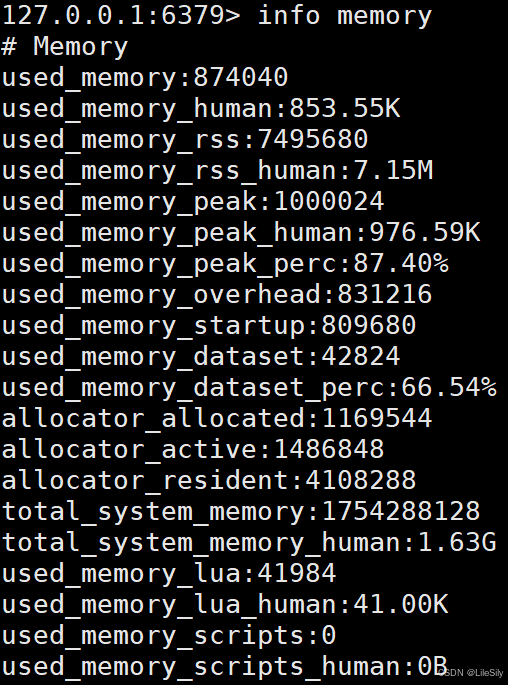
5.3 缓冲区内存问题分析
内存缓冲区常见的有三种:
- 复制缓冲区: 主从复制的repl_backlog_buf,在进行全量复制和部分复制的时候都会用到它,如果太小可能导致频繁的全量复制,影响性能,通过
replbacklog-size来设置.默认1mb. - AOF缓冲区: AOF刷盘之前的缓存区域,AOF执行rewrite的缓冲区,无法设置容量上限.
- 客户端缓冲区: 分为输入缓冲区和输出缓冲区,输入缓冲区最大的1G且不能设置,输出缓冲区可以设置.
以上复制缓冲区和AOF缓冲区不会有问题,最关键的就是客户端缓冲区的问题
客户端缓冲区: 指的就是我们发送命令时,客户端用来缓存命令的一个缓冲区,也就是我们向Redis输入数据的输入端缓冲区和Redis向客户端返回数据的响应缓存区,输入缓冲区最大1G且不能设置,所以这一块我们不用担心,如果超过了这个空间,Redis会直接断开,因为本来此时此刻就代表着Redis处理不过来了,我们需要担心的就是输出端缓冲区.输出缓冲区的配置方法如下:
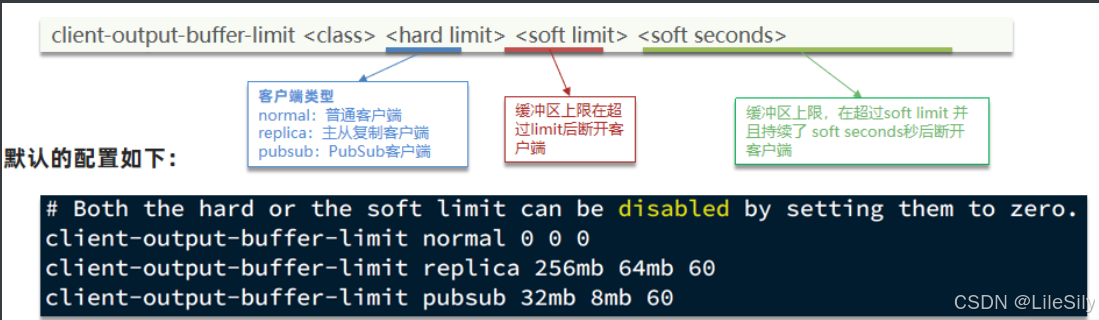
我们在使用Redis的过程中,处理大量的big value,那么会导致我们的输出结果过多,如果输入缓冲区过大,会导致Redis直接断开,而默认配置的情况下,其实他是没有大小的,这就比较坑了,内存可能一下子被占满,会直接导致咱们的Redis客户端断开,所以解决方案有两个.
- 通过我们上面提供的对客户端输出缓冲区的配置方案设置一个缓冲区大小.
- 增加Redis的网络贷款大小,避免我们出现大量的数据从而直接超过了Redis的承受能力.
6. 集群还是主从
先说结论:单体Redis(主从Redis)已经可以达到万级别的QPS,并且也具备很强的高可用性,如果主从能够满足整体业务需求的情况之下**,不是在万不得已的情况下,尽量不要搭建Redis集群**.
集群虽然具备很高的可用性,能实现自动故障回复,但是如果使用不当,会出现一下的问题:
- 可能会导致集群不可用
- 集群带宽问题
- 数据倾斜问题
- 客户端性能问题
- 集群的批处理问题
- lua和事务问题
6.1 问题1: 集群不可用
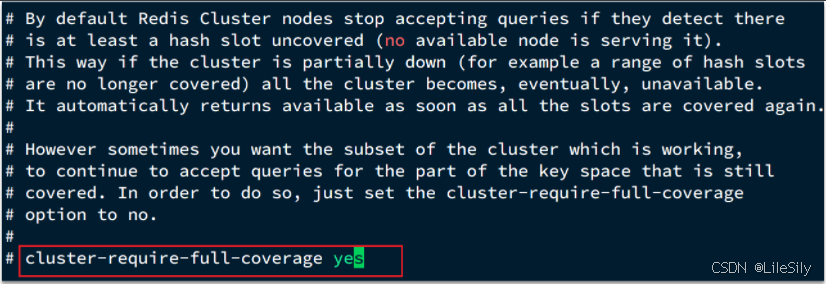
在Redis的默认配置中,如果发现了任意一个插槽不可用,整个集群都会停止对外提供服务.这样服务的可用性不可以保证,所以需要把如下的配置修改为no,即有slot不能用的时候,我们的Redis集群还是可以对外提供服务的.
cluster-require-full-coverage no
6.2 问题2: 集群带宽问题
集群结点之间会不断的互相ping,即发送心跳包来确定其他结点的状态,每次ping携带的信息至少包括:
- 插槽信息
- 集群状态信息
集群中的结点越多,集群状态信息的数据量也越大.这样哦会导致集群中的大量带宽被ping信息所占用,这是一个非常可怕的问题,所以我们需要解决这样的问题:
解决途径:
- 避免大集群,集群结点数最好少于1000,如果业务庞大,则建立多个集群.
- 避免在单个物理机中运行太多的Redis实例
- 配置合适的集群网络请求超时时间
6.3 问题3: 数据倾斜问题
这个问题我们在前面提到过,这里不再赘述
6.4 问题4: 集群的批处理问题(单机命令与集群命令兼容性问题)
有关这个问题咱们已经探讨过了,当我们使用批处理的命令时,redis要求我们的key必须落在相同的slot上,然后大量的key同时操作时,是无法完成的,所以客户端必须要对这样的数据进行处理,这些方案我们之前已经探讨过了,所以不再这个地方赘述了。
6.5 问题5: lua和事务的问题
lua和事务都是要保证原子性的问题,如果你的key不再一个结点上,那么无法保证lua的正常执行和事务的特性的.
相关文章:

[Redis] Redis最佳实践
🌸个人主页:https://blog.csdn.net/2301_80050796?spm1000.2115.3001.5343 🏵️热门专栏: 🧊 Java基本语法(97平均质量分)https://blog.csdn.net/2301_80050796/category_12615970.html?spm1001.2014.3001.5482 🍕 Collection与…...

arm64适配系列文章-第九章-arm64环境上sentinel的部署
ARM64适配系列文章 第一章 arm64环境上kubesphere和k8s的部署 第二章 arm64环境上nfs-subdir-external-provisioner的部署 第三章 arm64环境上mariadb的部署 第四章 arm64环境上nacos的部署 第五章 arm64环境上redis的部署 第六章 arm64环境上rabbitmq-management的部署 第七章…...

3dmax模型怎么处理3dtiles,制作制作B3DM格式文件
1咱们先打3dmax,或su或者其他软件建模型 2记住面一定一定要少,面一定不能多,也不要是VR材质,可以用插件一键处理 3导出fbx 4使用cesium把fbx转换 5这里可以坐标,因为要对地图位置 6转换出来了,3dtiles格式…...

雪花算法生成int64,在前端js的精度问题
1.问题背景 后端对视频生成唯一性id,在发送评论阶段,由于后端接收的json数据格式,设置videoId为int64。前端于是使用js的Number函数,进行字符串转换为数字,由于不清楚js的精度范围,产生了携带的videoId变化…...

软件测试报告包括哪些内容?可出专业软件测试方案的测评机构推荐
随着信息技术的快速发展,软件质量已经成为决定企业竞争力的重要因素之一。软件测试作为保障软件质量的关键环节,其成果汇总形成的“软件测试报告”在项目生命周期中扮演着重要角色。 软件测试报告就是用来反映测试工作全貌的报告。从测试准备、过程、结…...

dockercompose文件仓库
mysql version: 3 # 使用docker-compose的版本,根据需要可以调整# 创建数据目录 # mkdir -p /home/docker/mysql/mysql_data # mkdir -p /home/docker/mysql/mysql_logs # 给予适当的权限(确保MySQL容器可以读写这些目录) # chmod 777 /ho…...

Docker 的基本概念和优势以及在应用程序开发中的实际应用
Docker 是一种开源的容器化平台,可以让开发者将应用程序及其所有依赖项打包成一个独立的容器,从而实现应用程序的快速部署和运行。下面是 Docker 的基本概念和优势: 基本概念: 容器:一个轻量级、独立的运行环境,包含应用程序及其所有依赖项。镜像:一个只读的模板,用于创…...

JavaWeb:HtmlCss
快速入门 <html><head><title>HTML快速入门</title><head><body><h1>Hello HTML</h1><img src"1.png"></img></body> </html>开发工具vscode 常见便签&样式(新闻࿰…...

linux centOS7.9 No package docker-ce available
docker pull apache/apisix:3.2.2-centos Error response from daemon: missing signature key 处理方式如下: 问题:在纯净机里安装docker时报错No package docker-ce available。 解决办法: 1、更新yum,使用yum -y upgrade&#…...
——主成分分析)
机器学习(8)——主成分分析
文章目录 1. 主成分分析介绍2. 核心思想3. 数学基础4. 算法步骤4.1. 数据标准化:4.2. 计算协方差矩阵:4.3. 特征分解:4.4. 选择主成分:4.5 降维: 5. 关键参数6. 优缺点7. 改进变种8. 应用场景9. Python示例10. 数学推导…...

使用深度 Q 学习解决Lunar lander问题
使用深度 Q 学习解决Lunar lander问题 0. 前言1. 使用深度 Q 网络解决 Atari 游戏2. 定义环境3. 解决 Lunar lander 问题相关链接 0. 前言 深度 Q 学习模型只需观察状态作为输入就能够解决经典 Atari 游戏,这是一个重大突破,从那时起,深度强…...

centos7使用yum快速安装最新版本Jenkins-2.462.3
Jenkins支持多种安装方式:yum安装、war包安装、Docker安装等。 官方下载地址:https://www.jenkins.io/zh/download 本次实验使用yum方式安装Jenkins LTS长期支持版,版本为 2.462.3。 一、Jenkins基础环境的安装与配置 1.1:基本…...

Bean的生命周期
1.实例化Bean(通过BeanDefinition反射调用无参构造创建对象,如果没有无参构造,需要指定唯一构造方法) 2.给Bean的属性set()赋值 3.检查Bean是否实现了Aware相关接口,实现的话则执行方法 Aware接口:空接口&…...

【缓存与数据库结合方案】伪从技术 vs 直接同步/MQ方案的深度对比
伪从技术 vs 直接同步/MQ方案的深度对比 直接同步修改或通过MQ消息队列也能实现类似同步功能,但伪从技术(通过消费binlog实现数据同步)在某些场景下具有独特优势。下面我将从多个维度进行详细对比分析: 一、核心差异对比表 方案…...

【前端】【业务场景】【面试】在前端开发中,如何实现文件的上传与下载功能,并且处理可能出现的错误情况?
前端文件上传与下载攻略 本文目标:帮你快速掌握文件上传 & 下载的核心实现方式,并在常见出错场景下保持“优雅不崩溃”。 一、文件上传 1. 基础结构 <input type"file" id"fileInput" /> <button id"uploadBtn&…...

【axios取消请求】如何在token过期后取消未响应的请求
功能背景: 我们在实际项目中通常会遇到登录过期后会跳登录页的情况,回跳过程会根据接口请求的状态码判断是否登陆状态过期,并给出用户提示,如果此时存在多个请求接口同时调用,就会同时报出多个登录过期的提示…...

【高频考点精讲】JavaScript中的组合模式:从树形结构到组件嵌套实战
📚 目录 📦 什么是组合模式?🌲 基础版:用组合模式构建一个简单的树形结构💡 举个更真实的场景:菜单组件🧠 为什么组合模式在前端特别重要?🔨 实战案例:组件嵌套组合 + 权限控制🧩 组合模式的延伸用法:搭建 UI DSL 引擎🧪 面试题时间(欢迎评论区作答)组…...

《仙剑奇侠传二》游戏秘籍
无限冥纸:在丰都城,点击特定的小猫,它会给你五张冥纸,再次点击还会再给五张,可循环获取。无限使用虎煞技能:学会 “虎啸风声” 技能后,将虎煞之力值设置为 16,在战斗中持续使用该技能…...

AWS 中国区 CloudFront SSL 证书到期更换实战指南
适用场景: AWS 中国区(宁夏区域 cn-northwest-1 或北京区域 cn-north-1)CloudFront 分配的 SSL 证书到期后无缝替换,域名主体为 domain.cn。 背景与痛点 当 CloudFront 使用的 SSL 证书即将到期时,需手动替换新证书以避免服务中断。由于 AWS 中国区 不支持 ACM 证书,必须…...
)
【2025A卷】华为OD机试九日集训第3期 - 按算法分类,由易到难,提升编程能力和解题技巧,从而提高机试通过率(Python/JS/C/C++)
目录 一、适合人群二、本期训练时间三、如何参加四、数据结构与算法大纲五、华为OD九日集训第3期第1天、逻辑分析第2天、逻辑分析第3天、双指针第4天、双指针第5天、数据结构map第6天、栈第7天、二叉树第8天、贪心算法第9天、二分查找 六、集训总结国内直接使用最新o3、o4-mini…...

MacOS上如何运行内网穿透详细教程
本文以市面常见、好用的内网穿透为例,一款为开源内网穿透工具Frp;另一款为国产新锐软件ZeroNews。 一、Frp(开源工作、使用自由) 1. 下载 FRP 访问 FRP 的 GitHub 发布页: https://github.com/fatedier/frp/releases 选择适合 …...

第55讲:农业人工智能的跨学科融合与社会影响——构建更加可持续、包容的农业社会
目录 一、农业人工智能的多维融合:科技与社会的桥梁 1. 技术与社会:解决现代农业中的不平等 2. AI与伦理:塑造道德规范与社会责任 3. AI与政策:推动农业政策的科学决策与智能执行 二、AI与农业未来社会的构建:更绿色、更智能、更包容 1. 推动农业可持续发展:绿色农…...

JVM性能优化之老年代参数设置
一、引言 咱们书接上回,上篇文章主要讲解了年轻代参数设置,如果对这一部分还不清楚的建议先去看一下(年轻代参数设置),本文主要为大家介绍老年代参数的设置,掌握好jvm参数的设置是一个高级开发人人员必备的…...

在 Ubuntu 环境为 Elasticsearch 引入 `icu_tokenizer
1. 为什么需要 ICU 分析插件 Elasticsearch 默认的 standard tokenizer 遵循 UAX #29 规则,但在 CJK(中、日、韩)等亚洲语言上仅能按字符切分,无法识别词边界;对包含重音符号、大小写或多脚本混排的文本也缺乏统一归一…...

JMeter 安装及使用 [软件测试工具]
目录 JMeter 1. JMeter 安装 1.1 点击官网下载: JMeter官网下载 1.2 下载后解压即可 1.3 打开 JMeter 1.3.1 方式一: 点击对应程序打开 1.3.2 方式二: 命令行启动 1.4 关闭 JMeter 2. JMeter 基础配置 2.1 修改字体为简体中文 2.2 添加拓展插件 2.2.1 下载其他监听器…...

Unity 资源合理性检测
一:表格过度配置,表格资源是否在工程中存在,并输出不存在的资源 import pandas as pd import glob import osassets [] count 0# 遍历configs文件夹下所有xlsx文件 for file_path in glob.glob(configs/*.xlsx):count 1try:sheets pd.re…...
)
vue-study(1)
黑马智数项目 黑马智数是一个数字化园区管理项目,该项目后台可以在线管理园区内的楼宇、企业、车辆和一体杆等资源,可视化大屏通过园区3D模型实时展示园区概况。通过该项目能学到如何用qiankun搭建微前端架构、用Echarts进行数据可视化、以及前沿的3D模…...

XS5032:高性能3DNR+HDR ISP-TX 2K芯片
爱芯元智 XS5032:高性能3DNRHDR ISP-TX 2K芯片 视频输入 支持MIPI接口,4lane,Max.1.5Gbps/lane 支持Sensor并口(DVP) 视频分辨率 支持多种同轴高清制式和标清制式,包括: 960H25/30fps&…...
:[macOS 64bit App开发]:如何使用NSString类型字符串?)
[原创](现代Delphi 12指南):[macOS 64bit App开发]:如何使用NSString类型字符串?
[作者] 常用网名: 猪头三 出生日期: 1981.XX.XX 企鹅交流: 643439947 个人网站: 80x86汇编小站 编程生涯: 2001年~至今[共24年] 职业生涯: 22年 开发语言: C/C++、80x86ASM、Object Pascal、Objective-C、C#、R、Python、PHP、Perl、 开发工具: Visual Studio、Delphi、XCode、…...

TDengine 流计算引擎设计
流计算架构 TDengine 流计算的架构如下图所示。当用户输入用于创建流的 SQL 后,首先,该 SQL 将在客户端进行解析,并生成流计算执行所需的逻辑执行计划及其相关属性信息。其次,客户端将这些信息发送至 mnode。mnode 利用来自数据源…...

扩展中国剩余定理
中国剩余定理 中国剩余定理 考虑一组模线性同余方程: { x ≡ a 1 ( m o d m 1 ) x ≡ a 2 ( m o d m 2 ) . . . x ≡ a k ( m o d m k ) \begin{cases} x\equiv a_1\pmod{m1} \\ x\equiv a_2\pmod{m2}\\ .\\ .\\ .\\ x\equiv a_k\pmod{mk}\\ \end{cases} ⎩ ⎨ ⎧…...

git检查提交分支和package.json的version版本是否一致
这里写自定义目录标题 一、核心实现步骤1.安装必要依赖2.初始化 Husky3.创建校验脚本4.配置 lint-staged5.更新 Husky 钩子 三、工作流程说明四、注意事项 以下是基于 Git Hooks 的完整解决方案,通过 husky 和自定义脚本实现分支名与版本号一致性校…...
)
Git 详细使用说明文档(适合小白)
Git 详细使用说明文档(适合小白) 1. 什么是 Git? Git 是一个版本控制系统,帮助你管理和跟踪代码的变更。无论是个人项目还是团队协作,Git 都能帮助你记录代码的历史版本,方便回溯和协作。 2. 安装 Git …...
】第二章:嵌入式系统硬件基础知识(2))
【嵌入式系统设计师(软考中级)】第二章:嵌入式系统硬件基础知识(2)
文章目录 3.嵌入式系统的存储体系3.1 存储系统的层次结构3.2 内存管理单元(MMU)3.3 RAM和ROM的种类3.3.1 RAM类型对比3.3.2 ROM类型对比 3.4 高速缓存(Cache)3.5 其他存储设备3.5.1 新型存储技术3.5.2 外存接口技术 3.嵌入式系统的…...
第五章 新字符设备驱动实验)
rk3588 驱动开发(三)第五章 新字符设备驱动实验
register_chrdev 和 unregister_chrdev 这两个函数是老版本驱动使用的函数,现在新的字符设备驱动已经不再使用这两个函数,而是使用 Linux 内核推荐的新字符设备驱动 API 函数。本节我们就来学习一下如何编写新字符设备驱动,并且在驱动模块加载…...

文件上传--WAF绕过干货
本文主要内容 绕过WAF上传文件 -- 安全狗 -- 宝塔 Burp抓包解析 #上传参数名解析:明确哪些东西能修改? Content-Disposition:—般可更改 name:表单参数值,不能更改 filename:文件名ÿ…...

BERT BERT
BERT ***** 2020年3月11日更新:更小的BERT模型 ***** 这是在《深阅读的学生学得更好:预训练紧凑模型的重要性》(arXiv:1908.08962)中提到的24种较小规模的英文未分词BERT模型的发布。 我们已经证明,标准的BERT架构和…...

Kotlin Multiplatform--02:项目结构进阶
Kotlin Multiplatform--02:项目结构进阶 引言正文 引言 在上一章中,我们对 Kotlin Multiplatform 项目有了基本的了解,已经可以进行开发了。但我们只是使用了系统默认的项目结构。本章介绍了如何进行更复杂的项目结构管理。 正文 在上一章中&…...

【ES实战】Elasticsearch中模糊匹配类的查询
Elasticsearch中模糊匹配类的查询 文章目录 Elasticsearch中模糊匹配类的查询通配符查询前缀匹配查询正则匹配查询标准的正则操作特殊运算符操作 模糊化查询Fuzziness text类型同时配置keyword类型 Elasticsearch中模糊类查询主要有以下 Wildcard Query:通配符查询P…...

纯真社区IP库离线版发布更新
纯真社区IP库离线版发布更新 发布者:技术分享 2005年,随着中国互联网的蓬勃发展,纯真IP库诞生了。作为全球网络空间地理测绘技术的领先者,纯真开源项目为中国互联网行业提供了高质量的网络空间IP库数据。纯真IP库目前已经覆盖超…...
:论文与源码解析)
直接偏好优化(Direct Preference Optimization,DPO):论文与源码解析
简介 虽然大规模无监督语言模型(LMs)学习了广泛的世界知识和一些推理技能,但由于它们是基于完全无监督训练,仍很难控制其行为。 微调无监督LM使其对齐偏好,尽管大规模无监督的语言模型(LMs)能…...

uniapp-商城-34-shop 购物车 选好了 进行订单确认
在shop页面选中商品添加到购物车,可选好后,进行确认和支付。具体呈现在shop页面。 1 购物车栏 shop页面代码: 购物车代码: 代码: <template><view><view class"carlayout"><!-- 车里…...
)
Kafka命令行的使用/Spark-Streaming核心编程(二)
Kafka命令行的使用 创建topic kafka-topics.sh --create --zookeeper node01:2181,node02:2181,node03:2181 --topic test1 --partitions 3 --replication-factor 3 分区数量,副本数量,都是必须的。 数据的形式: 主题名称-分区编号。 在…...

虚拟机详解
虚拟机详解 1. 虚拟机(Virtual Machine)的定义 系统虚拟机:通过软件模拟完整计算机系统(CPU、内存、外设等),如 VMware、VirtualBox。进程级虚拟机:为单个应用提供虚拟执行环境,如 …...

NOIP2013 提高组.转圈游戏
目录 题目算法标签: 数论, 模运算思路代码 题目 504. 转圈游戏 算法标签: 数论, 模运算 思路 看题意不难看出, 计算的是 ( x 1 0 k m ) m o d n (x 10 ^ k \times m) \mod n (x10km)modn, 如果直接计算一定会超时, 因此可以使用快速幂进行优化 代码 #include <iost…...

【金仓数据库征文】加速数字化转型:金仓数据库在金融与能源领域强势崛起
目录 一、引言 二、金仓数据库(KingbaseES)概述 1. 发展历程与市场地位 2. 核心技术架构 3. 金仓数据库的特点 三、金仓数据库在金融行业的应用 1. 金融行业的挑战与需求 2. 金仓数据库在金融行业的优势 3. 金仓数据库在金融行业的实际应用案例 …...

济南国网数字化培训班学习笔记-第二组-5节-输电线路设计
输电线路设计 工程设计阶段划分 35kv及以上输变电工程勘测设计全过程 可行性研究(包括规划、工程选站)(包括电力系统一次二次,站址选择及工程设想,线路工程选择及工程设想,节能降耗分析,环境…...

【前端】【业务场景】【面试】在前端开发中,如何实现一个可拖动和可缩放的元素,并且处理好边界限制和性能优化?
问题:在前端开发中,如何实现一个可拖动和可缩放的元素,并且处理好边界限制和性能优化? 一、实现可拖动和可缩放元素 HTML 和 CSS 基础设置: 创建一个 HTML 元素,并为其设置基本样式,使其在页面…...
)
BOM与DOM(解疑document window关系)
BOM(浏览器对象模型) 定义与作用 BOM(Browser Object Model)提供与浏览器窗口交互的接口,用于控制导航、窗口尺寸、历史记录等浏览器行为 window:浏览器窗口的顶层对象,包含全局属性和方法&am…...

504 nginx解决方案
当遇到 504 Gateway Time-out 错误时,通常是因为 Nginx 作为反向代理等待后端服务(如 PHP-FPM、Java 应用等)响应的时间超过了预设的超时阈值。以下是详细的解决方案,结合知识库中的信息整理而成: 一、核心原因分析 后…...