直接偏好优化(Direct Preference Optimization,DPO):论文与源码解析
简介
虽然大规模无监督语言模型(LMs)学习了广泛的世界知识和一些推理技能,但由于它们是基于完全无监督训练,仍很难控制其行为。
微调无监督LM使其对齐偏好,尽管大规模无监督的语言模型(LMs)能够学习广泛的世界知识和一些推理技能,但由于它们的训练完全是无监督的,要精确控制它们的行为是困难的。
现有方法为了获得这种可操纵性,会收集人类对模型生成内容相对质量的标签,并微调无监督LM,使其与这些偏好一致,通常会使用基于人类反馈的强化学习(RLHF)。然而,RLHF是一个复杂且经常不稳定的过程,首先需要拟合一个反映人类偏好的奖励模型,然后使用强化学习微调大型无监督LM,以最大化这个估计奖励,同时不太偏离原始模型。
在这篇论文中,我们介绍了一个RLHF中新的奖励模型参数化方法,该方法可以在闭式中提取对应的最优策略,使我们仅使用简单的分类损失来解决标准的RLHF问题。最终算法我们称之为直接偏好优化(DPO),该算法稳定、性能良好且计算成本低,无需在微调时从LM中进行抽样或进行显著的超参数调整。
实验表明,DPO可以与现有方面一样或更好地微调LM以对齐人类偏好。值得注意的是,使用DPO微调LMs在控制生成内容的情感方面超过了基于PPO的RLHF,并且在摘要和单轮对话的回复质量上效果相当或有提升,同时大大地简化了实现和训练过程。
1 介绍
在大型数据集上训练的大规模无监督语言模型(LMs)获得了惊人能力。然而,这些模型是在人类生成的具有多样化的目标、优先级和技能的数据集上训练的。
然而,这些模型是基于具有各种目标、优先级和技能集的人类生成的数据进行训练的。其中一些目标和技能集我们可能并不想模仿;例如,我们想要我们的AI编程助手理解常见的编程错误并纠正,但在生成代码时,我们希望我们的模型倾向于它训练数据中存在的(可能很罕见)高质量编程能力。同样地,我们希望我们的语言模型能理解50%的人相信的常见误解,但我们当然不希望模型在关于这个误解的查询中有50%声称它是真的!换句话说,从模型广泛的知识和能力中选择期望的回复和行为,对于构建安全、高效和可控的AI系统来说,是至关重要的。
虽然现有方法通常使用强化学习(RL)引导LMs对齐人类偏好,但我们将证明现有方法使用的基于RL的目标,可以通过简单的二元交叉熵目标精确地优化,大大地简化了偏好学习流程。

图1:DPO不使用强化学习优化人类偏好。现有的使用人类反馈微调语言模型的方法,首先是在一些提示和人类对提示的多个响应的偏好的数据集上拟合一个奖励模型,然后使用RL寻找可以最大化学习奖励的策略。与之相反,DPO使用一个简单的分类目标直接优化最能满足偏好的策略,拟合一个隐式的奖励模型,其对应的最优策略可从闭式中提取。
在高层次上,现有方法使用精心策划的人类偏好集合向语言模型灌输期望行为,这些偏好表示人类认为安全且有用的行为类型。这种偏好学习发生在初始的大型文本数据集上大规模无监督预训练阶段之后。
虽然最直接的偏好学习方法是在高质量的人类示例响应上有监督微调,但最成功的方法类别是基于人类(或AI)反馈的强化学习(RLHF/RLAIF)。RLHF方法对一个人类偏好数据集拟合一个奖励模型,然后使用RL来优化一个语言模型策略,以产生被分配了高奖励的响应,同时不过度偏离原始模型。
虽然RLHF产生了在对话和编码能力上表现不错的模型,但RLHF流程比监督学习复杂的多,涉及多LMs训练以及在训练循环中从LM策略中采样,导致计算成本非常高。
本文中,我们展示了如何直接优化语言模型以遵循人类偏好,无需显式的奖励建模或者强化学习。我们提出了一种直接偏好优化(DPO)算法,它隐式地优化与已有的RLHF算法相同的目标(KL散度约束的奖励最大化),但实现简单,训练直接。直觉上,相对于不偏好响应,DPO更新增加了偏好响应的对数概率,但它包含了一个动态的、每个例子的重要性权重,这可以防止我们发现的使用朴素的概率目标时出现的模型退化。
与现有方法一致,DPO依赖于一个理论偏好模型(例如Bradley-Terry模型);该模型衡量给定奖励函数与经验偏好数据的一致性。然而,尽管现有方法使用偏好模型定义偏好损失来训练奖励模型,然后再训练一个策略优化学好的奖励模型,DPO使用一个变量变体直接将偏好损失定义为策略函数。给定一个模型响应的人类偏好数据集,DPO因此可以使用简单的二元交叉熵目标来优化策略,产生一个对隐式奖励函数的最优策略,以拟合偏好数据。
我们主要的贡献是直接偏好优化(DPO),一种简单从偏好中训练语言模型的非强化学习算法。实验证明,DPO至少与现有方法(包括基于PPO的RLHF)的性能相当,可以使用多达6B参数的语言模型,从情感调节、总结、对话等任务中的偏好中学习。
2 相关工作
规模不断增大的语言模型可以使用零样本或少样本提示完成一些任务。然而,在指令和人工回复的数据集上微调,对于提升这些模型的性能和对齐用户意图至关重要。“指令微调”过程可以使LLMs在指令微调数据集之外的指令上具备泛化性,通常增加了模型的可用性。
尽管指令微调取得了成功,但相对于专家示例来说,人类判别回复质量的数据更容易收集【排序数据比生成数据容易收集】。因此,后续的工作利用人类偏好数据集微调LLM,以提升模型在翻译、总结、故事编写、指令遵循等方面的专业性。
这些方法首先利用偏好数据集优化一个神经网络奖励函数,以兼容偏好数据集下的偏好模型。然后,使用强化学习算法微调一个语言模型,以最大化给定奖励,常见方法有REINFORCE、PPO及其变体。
这项紧密相关的工作是,利用经过人类反馈微调的LLMs来遵循指示,生成针对特定属性(如安全性和无害性)的额外合成偏好数据,以LLM的注释形式为准则,只使用人类提供的弱监督进行文本标注。
这些方法代表了两个领域的融合:一个工作领域是使用强化学习训练语言模型用于各种目标,另一个领域是从人类偏好中学习的通用方法。
尽管使用相对人类偏好的方法具有吸引力,但使用强化学习微调大语言模型仍是一种主要的实践挑战;本文提供了一种合理的方法论,可不使用RL优化相对偏好。
在语言之外的领域,从偏好中学习策略已在赌博机和强化学习环境中进行了研究,并提出了几种方法。
使用偏好或行动排序而非奖励的上下文赌博机制学习,被称为上下文对决赌博机制(CDB)。在缺乏绝对奖励的情况下,CDB的理论分析将最优策略的概念替换为冯·诺依曼赢家,其对其他任何策略的预期胜率至少为50%。然而在CDB场景,偏好标签是在线给出的,而在人类偏好学习中,我们通常是从固定的离线偏好标注的批次中学习。
类似地,基于偏好的RL(PbRL)从未知的“评分”函数中学习二元偏好,而非奖励。目前存在各种PbRL,包括可以重用离线偏好数据的方法,但通常涉及首先明确估计潜在的评分函数(即奖励模型),然后再进行优化。相反,我们提出了一种单阶段策略学习方法,直接优化策略来满足偏好。
3 预备知识
我们回顾一下Ziegler等人提出的RLHF pipeline,其通常包括三个阶段:
- 监督微调(SFT)
- 偏好采样和奖励学习
- RL优化
监督微调(SFT): RLHF的初始模型 π SFT \pi^\text{SFT} πSFT,通常是在高质量的感兴趣的下游任务(如对话、总结等)上使用监督学习微调的预训练的语言模型。
奖励建模阶段(Reward Modeling Phase): 在第二阶段,SFT模型使用提示 x x x,产生答案对 ( y 1 , y 2 ) ∼ π SFT ( y ∣ x ) (y_1, y_2) \sim \pi^\text{SFT}(y|x) (y1,y2)∼πSFT(y∣x)。然后让标注员从这些答案对中标注一个偏好的答案,表示为 y w > y l ∣ x y_w > y_l | x yw>yl∣x,其中 y w y_w yw和 y l y_l yl分别表示偏好回复和不偏好回复。假设这些偏好是由一些潜在的奖励模型生成的,但实际上我们并不能访问这些奖励模型。
存在一些建模偏好的方法,Bradley-Terry (BT) 模型是一个常见的选择(尽管更一般的Plackett-Luce排序模型在我们可以访问的多个排序答案时也与该框架兼容)。BT模型将人类偏好分布 p ∗ p^* p∗定义为以下形式:
p ∗ ( y 1 > y 2 ∣ x ) = exp ( r ∗ ( x 1 , y 1 ) ) exp ( r ∗ ( x , y 1 ) ) + exp ( r ∗ ( x , y 2 ) ) = 1 1 + exp ( r ∗ ( x , y 2 ) − r ∗ ( x , y 1 ) ) = σ ( r ∗ ( x , y 1 ) − r ∗ ( x , y 2 ) ) \begin{align} p^*(y_1>y_2|x) &=\frac{\exp(r^*(x_1, y_1))}{\exp(r^*(x, y_1)) + \exp(r^*(x, y_2))} \\ &=\frac{1}{1+\exp(r^*(x,y_2)-r^*(x,y_1))}=\sigma(r^*(x,y_1)-r^*(x,y_2)) \tag 1 \end{align} p∗(y1>y2∣x)=exp(r∗(x,y1))+exp(r∗(x,y2))exp(r∗(x1,y1))=1+exp(r∗(x,y2)−r∗(x,y1))1=σ(r∗(x,y1)−r∗(x,y2))(1)
假设可以访问从 p ∗ p^* p∗中采样的一个静态数据集 D = { x ( i ) , y w ( i ) , y l ( i ) } i = 1 N \mathcal D = \{x^{(i)}, y_w^{(i)}, y_l^{(i)}\}_{i=1}^N D={x(i),yw(i),yl(i)}i=1N,那么我们可以参数化奖励模型 r ϕ ( x , y ) r_\phi(x,y) rϕ(x,y),并通过最大似然来估计参数。将问题框定为二分类问题,我们有以下负对数似然损失:
L R ( r ϕ , D ) = − E ( x , y w , y l ) [ log σ ( r ϕ ( x , y w ) − r ϕ ( x , y l ) ) ] (2) \mathcal L_R(r_\phi, \mathcal D)=-\mathbb E_{(x,y_w,y_l)} \big[\log \sigma(r_\phi(x,y_w)-r_\phi(x,y_l))\big] \tag 2 LR(rϕ,D)=−E(x,yw,yl)[logσ(rϕ(x,yw)−rϕ(x,yl))](2)
其中, σ \sigma σ为逻辑函数。在LMs的背景下,网络 r ϕ ( x , y ) r_\phi(x,y) rϕ(x,y)通常是从SFT模型 π SFT ( y ∣ x ) \pi^\text{SFT}(y|x) πSFT(y∣x)初始化,并且在transformer的最后一层加上线性层,用于预测奖励标量值。为保证奖励函数低方差,此前工作对奖励做了标准化,例如对于所有的 x x x,使得 E x , y ∼ D [ r ϕ ( x , y ) ] = 0 \mathbb E_{x,y\sim\mathcal D}[r_\phi(x,y)]=0 Ex,y∼D[rϕ(x,y)]=0。
强化学习微调阶段(RL Fine-Tuning Phase): 在强化学习阶段,我们使用学习好的奖励函数为语言模型提供反馈。具体来说,我们用公式表示以下最优问题:
max π θ E x ∼ D , y ∼ π θ ( y ∣ x ) [ r ϕ ( x , y ) ] − β D KL [ π θ ( y ∣ x ) ∣ ∣ π ref ( y ∣ x ) ] (3) \max_{\pi_\theta}\mathbb E_{x\sim\mathcal D, y\sim\pi_\theta(y|x)}\big[r_\phi(x,y)\big]-\beta\mathbb D_\text{KL}\big[\pi_\theta(y|x)\ ||\ \pi_\text{ref}(y|x)\big] \tag 3 πθmaxEx∼D,y∼πθ(y∣x)[rϕ(x,y)]−βDKL[πθ(y∣x) ∣∣ πref(y∣x)](3)
其中, β \beta β是用于控制与基础参考模型 π ref \pi_\text{ref} πref(即初始的SFT模型 π SFT \pi^\text{SFT} πSFT)之间偏差的参数。实际上,语言策略模型也是从 π SFT \pi^\text{SFT} πSFT初始化。这个附加约束非常重要,它可防止模型偏离奖励模型准确度高的分布太远,同时也可以保持生成多样性以及防止模型在某个高奖励答案上出现坍塌。
由于语言生成离散性,该目标函数不可微,因此通常使用强化学习优化。标准方法通常是构建以下形式的奖励函数,并使用PPO优化。
r ( x , y ) = r ϕ ( x , y ) − β ( log π θ ( y ∣ x ) − log π ref ( y ∣ x ) ) r(x,y)=r_\phi(x,y)-\beta(\log\pi_\theta(y|x)-\log\pi_\text{ref}(y|x)) r(x,y)=rϕ(x,y)−β(logπθ(y∣x)−logπref(y∣x))
4 直接偏好优化
受大规模问题(如微调语言模型)上应用强化学习存在挑战的驱动,我们的目标是推演出一种直接使用偏好的简单的策略优化方法。不同于之前的RLHF模型,此类方法先学习奖励模型然后再使用RL优化,我们的方法利用了一种特定的奖励模型参数化选择,使得可以以闭式提取其最优策略,而不需要RL训练循环。
接下来我们详细描述,我们的关键观点是利用从奖励函数到最优策略的分析映射,这使我们能够将奖励函数的损失函数转化为策略的策略损失。这种变量改变的方法避免了拟合显式、独立的奖励模型,而是在现有的人类偏好模型(如Bradley-Terry模型)下进行优化。本质上,策略网络代表语言模型和(隐式)奖励。
推演DPO目标函数
我们从与之前工作相同的RL目标开始,即公式3,针对一个通用的奖励函数 r r r。根据之前工作,很显而易见,在公式3中,KL约束下的奖励最大化目标的最优解具有以下形式:
π r ( y ∣ x ) = 1 Z ( x ) π ref ( y ∣ x ) exp ( 1 β r ( x , y ) ) (4) \pi_r(y|x)=\frac{1}{Z(x)}\pi_\text{ref}(y|x)\exp\Big(\frac{1}{\beta}r(x,y)\Big) \tag 4 πr(y∣x)=Z(x)1πref(y∣x)exp(β1r(x,y))(4)
其中, Z ( x ) = ∑ y π r e f ( y ∣ x ) exp ( 1 β r ( x , y ) ) Z(x)=\sum_y\pi_{ref}(y|x)\exp\Big(\dfrac{1}{\beta}r(x,y)\Big) Z(x)=∑yπref(y∣x)exp(β1r(x,y))为配分函数。
推导过程(详见附录A.1)
max π E x ∼ D , y ∼ π θ ( y ∣ x ) [ r ( x , y ) ] − β D KL [ π ( y ∣ x ) ∣ ∣ π ref ( y ∣ x ) ] = max π E x ∼ D , y ∼ π [ r ( x , y ) ] − E x ∼ D , y ∼ π [ β log π ( y ∣ x ) π ref ( y ∣ x ) ] = min π E x ∼ D , y ∼ π [ log π ( y ∣ x ) π ref ( y ∣ x ) − 1 β r ( x , y ) ] = min π E x ∼ D , y ∼ π [ log π ( y ∣ x ) π ref ( y ∣ x ) exp ( 1 β r ( x , y ) ) 1 Z ( x ) Z ( x ) ] = min π E x ∼ D , y ∼ π [ log π ( y ∣ x ) 1 Z ( x ) π ref ( y ∣ x ) exp ( 1 β r ( x , y ) ) − log Z ( x ) ] \begin{align} & \max_\pi\mathbb E_{x\sim\mathcal D, y\sim\pi_\theta(y|x)}\big[r(x,y)\big]-\beta\mathbb D_\text{KL}\big[\pi(y|x)\ ||\ \pi_\text{ref}(y|x)\big]\\ &=\max_\pi\mathbb E_{x\sim\mathcal D,y\sim\pi}\Big[r(x,y)\Big]- \mathbb E_{x\sim\mathcal D,y\sim\pi}\Big[\beta\log\frac{\pi(y|x)}{\pi_\text{ref}(y|x)}\Big] \\ &=\min_\pi\mathbb E_{x\sim\mathcal D,y\sim\pi}\Big[\log\frac{\pi(y|x)}{\pi_\text{ref}(y|x)}-\frac{1}{\beta}r(x,y)\Big]\\ &=\min_\pi\mathbb E_{x\sim\mathcal D,y\sim\pi}\Big[\log\frac{\pi(y|x)}{\pi_\text{ref}(y|x)\exp\Big(\dfrac{1}{\beta}r(x,y)\Big)\dfrac{1}{Z(x)}Z(x)}\Big]\\ &=\min_\pi\mathbb E_{x\sim\mathcal D,y\sim\pi}\Big[\log\frac{\pi(y|x)}{\frac{1}{Z(x)}\pi_\text{ref}(y|x)\exp\Big(\dfrac{1}{\beta}r(x,y)\Big)}-\log Z(x)\Big] \end{align} πmaxEx∼D,y∼πθ(y∣x)[r(x,y)]−βDKL[π(y∣x) ∣∣ πref(y∣x)]=πmaxEx∼D,y∼π[r(x,y)]−Ex∼D,y∼π[βlogπref(y∣x)π(y∣x)]=πminEx∼D,y∼π[logπref(y∣x)π(y∣x)−β1r(x,y)]=πminEx∼D,y∼π[logπref(y∣x)exp(β1r(x,y))Z(x)1Z(x)π(y∣x)]=πminEx∼D,y∼π[logZ(x)1πref(y∣x)exp(β1r(x,y))π(y∣x)−logZ(x)]令 Z ( x ) = ∑ y π ref ( y ∣ x ) exp ( 1 β r ( x , y ) ) Z(x)=\sum_y\pi_\text{ref}(y|x)\exp\Big(\dfrac{1}{\beta}r(x,y)\Big) Z(x)=∑yπref(y∣x)exp(β1r(x,y)),则上述分母为概率分布,定义为 π ∗ ( y ∣ x ) \pi^*(y|x) π∗(y∣x)。由于 Z ( x ) Z(x) Z(x)不是 π \pi π的函数,最小化时可忽略,因此:
max π E x ∼ D , y ∼ π θ ( y ∣ x ) [ r ( x , y ) ] − β D KL [ π ( y ∣ x ) ∣ ∣ π ref ( y ∣ x ) ] = min π E x ∼ D , y ∼ π [ log π ( y ∣ x ) π ∗ ( y ∣ x ) − log Z ( x ) ] = min π E x ∼ D , y ∼ π [ log π ( y ∣ x ) π ∗ ( y ∣ x ) ] = min π E x ∼ D [ D K L ( π ( y ∣ x ) ∣ ∣ π ∗ ( y ∣ x ) ) ] \begin{align} & \max_\pi\mathbb E_{x\sim\mathcal D, y\sim\pi_\theta(y|x)}\big[r(x,y)\big]-\beta\mathbb D_\text{KL}\big[\pi(y|x)\ ||\ \pi_\text{ref}(y|x)\big]\\ &=\min_\pi\mathbb E_{x\sim\mathcal D,y\sim\pi}\Big[\log\frac{\pi(y|x)}{\pi^*(y|x)}-\log Z(x)\Big]\\ &=\min_\pi\mathbb E_{x\sim\mathcal D,y\sim\pi}\Big[\log\frac{\pi(y|x)}{\pi^*(y|x)}\Big]\\ &=\min_\pi\mathbb E_{x\sim\mathcal D}[\mathbb D_{KL}(\pi(y|x)\ ||\ \pi^*(y|x))] \end{align} πmaxEx∼D,y∼πθ(y∣x)[r(x,y)]−βDKL[π(y∣x) ∣∣ πref(y∣x)]=πminEx∼D,y∼π[logπ∗(y∣x)π(y∣x)−logZ(x)]=πminEx∼D,y∼π[logπ∗(y∣x)π(y∣x)]=πminEx∼D[DKL(π(y∣x) ∣∣ π∗(y∣x))]因此,最优解 π r ( y ∣ x ) \pi_r(y|x) πr(y∣x)为 π ∗ ( y ∣ x ) \pi^*(y|x) π∗(y∣x),得证。
即使我们使用MLE估计奖励函数 r ∗ r^* r∗的真值 r ϕ r_\phi rϕ,配分函数 Z ( x ) Z(x) Z(x)仍难以估计,使得这种表示方法实际上难以应用。然而,我们可以重新整理公式4,将奖励函数表示为最优策略 π r \pi_r πr、参考策略 π ref \pi_\text{ref} πref和未知配分函数 Z ( ⋅ ) Z(\cdot) Z(⋅)的函数。具体来说,我们先对公式4两边取对数,然后进行一些代数运算可以得到:
r ( x , y ) = β log π r ( y ∣ x ) π ref ( y ∣ x ) + β log Z ( x ) (5) r(x,y)=\beta\log\frac{\pi_r(y|x)}{\pi_\text{ref}(y|x)}+\beta\log Z(x) \tag 5 r(x,y)=βlogπref(y∣x)πr(y∣x)+βlogZ(x)(5)
我们可以将这个重参数化的模型应用到真实奖励 r ∗ r^* r∗和对应的最优模型 π ∗ \pi^* π∗。幸运的是,Bradley-Terry模型仅依赖于两种回复的奖励差异,见公式1。将公式5带入公式1参考模型,可消去配分函数。此时,我们可以仅使用优化策略 π ∗ \pi^* π∗和参考策略 π ref \pi_\text{ref} πref表示人类偏好概率。因此,BT模型下的最优RLHF策略 π ∗ \pi^* π∗满足参考模型:
p ∗ ( y 1 > y 2 ∣ x ) = 1 1 + exp ( β log π ∗ ( y 2 ∣ x ) π ref ( y 2 ∣ x ) − β log π ∗ ( y 1 ∣ x ) π ref ( y 1 ∣ x ) ) (6) p^*(y_1>y_2|x)=\frac{1}{1+\exp\Big(\beta\log\frac{\pi^*(y_2|x)}{\pi_\text{ref}(y_2|x)}-\beta\log\frac{\pi^*(y_1|x)}{\pi_\text{ref}(y_1|x)}\Big)} \tag 6 p∗(y1>y2∣x)=1+exp(βlogπref(y2∣x)π∗(y2∣x)−βlogπref(y1∣x)π∗(y1∣x))1(6)
推导过程详见附录A.2。尽管公式6使用BT模型,但我们仍可以在更通用的Plackett-Luce下推演出相似的表达,详见附录A.3。
现在我们有优化策略形式的人类偏好数据的概率,而不是奖励模型,我们可以为参数策略 π θ \pi_\theta πθ定义形式化的最大似然目标。类似于奖励建模方法(即公式2),我们的策略目标变为:
L DPO ( π θ ; π ref ) = − E ( x , y w , y l ) ∼ D [ log σ ( β log π θ ( y w ∣ x ) π ref ( y w ∣ x ) − β log π θ ( y l ∣ x ) π ref ( y l ∣ x ) ) ] = − E ( x , y w , y l ) ∼ D [ σ ( β ( log π θ ( y w ∣ x ) − log π θ ( y l ∣ x ) ) − β ( log π ref ( y w ∣ x ) − log π ref ( y l ∣ x ) ) ) ] \begin{align} \mathcal L_\text{DPO}(\pi_\theta;\pi_\text{ref}) &=-\mathbb E_{(x,y_w,y_l)\sim\mathcal D}\Big[\log\sigma\Big(\beta\log\frac{\pi_\theta(y_w|x)}{\pi_\text{ref}(y_w|x)}-\beta\log\frac{\pi_\theta(y_l|x)}{\pi_\text{ref} (y_l|x)}\Big)\Big] \\ \tag 7 &=-\mathbb E_{(x, y_w, y_l)\sim \mathcal D}\Big[\sigma\Big(\beta (\log\pi_\theta(y_w|x) - \log\pi_\theta(y_l|x)) - \beta(\log\pi_\text{ref}(y_w|x) -\log\pi_\text{ref}(y_l|x))\Big)\Big] \end{align} LDPO(πθ;πref)=−E(x,yw,yl)∼D[logσ(βlogπref(yw∣x)πθ(yw∣x)−βlogπref(yl∣x)πθ(yl∣x))]=−E(x,yw,yl)∼D[σ(β(logπθ(yw∣x)−logπθ(yl∣x))−β(logπref(yw∣x)−logπref(yl∣x)))](7)
以这种方式,我们使用一种替代的参数化拟合隐式奖励,其最优策略是简单的 π θ \pi_\theta πθ。而且,由于我们的流程等价于拟合一个重参数化的BT模型,它具有理论支持,例如适当的偏好数据分布下具有一致性。在第5节,我们进一步讨论在其他相关工作中DPO的理论性。
DPO更新做了什么?
为理解DPO的机制,有必要分析下损失函数 L DPO \mathcal L_\text{DPO} LDPO的梯度。参数 θ \theta θ的梯度可以写为:
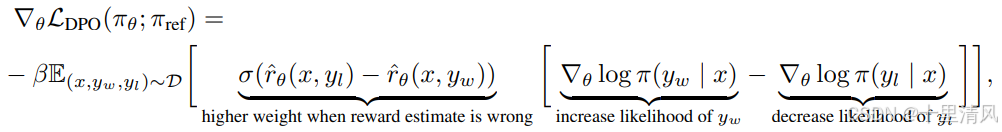
其中, r ^ θ ( x , y ) = β log π θ ( y ∣ x ) π ref ( y ∣ x ) \hat r_\theta(x,y)=\beta\log\frac{\pi_\theta(y|x)}{\pi_\text{ref}(y|x)} r^θ(x,y)=βlogπref(y∣x)πθ(y∣x)是由语言模型 π θ \pi_\theta πθ和参考模型 π ref \pi_\text{ref} πref隐式定义的奖励(详见第5节)。直觉上,损失函数 L DPO \mathcal L_\text{DPO} LDPO的梯度增加了偏好回复 y w y_w yw的似然,减少了非偏好回复 y l y_l yl的似然。重要的是,示例的权重取决于隐式奖励模型对非偏好回复评分的高低,通过 β \beta β缩放,即隐式奖励模型对回复排序的不正确程度,归因于KL约束的作用。我们实验证明了这种加权的重要性,因为没有加权系数的朴素方法会导致语言模型退化。
DPO概述
常见的DPO流程如下:
- 对于每一个 x x x,采样参考模型的回复 y 1 , y 2 ∼ π ref ( ⋅ ∣ x ) y1,y2\sim\pi_\text{ref}(\cdot|x) y1,y2∼πref(⋅∣x),人工标注构建离线偏好数据集 D = { x ( i ) , y w ( i ) , y l ( i ) } i = 1 N \mathcal D=\{x^{(i)},y_w^{(i)},y_l^{(i)}\}_{i=1}^N D={x(i),yw(i),yl(i)}i=1N
- 基于给定的参考模型 π ref \pi_\text{ref} πref、数据集 D \mathcal D D和期望 β \beta β,最小化损失 L DPO \mathcal L_\text{DPO} LDPO,优化语言模型 π θ \pi_\theta πθ
实际上,我们希望重新利用公开可用的偏好数据集,而不是生成样本再收集人类偏好。由于偏好数据集是从 π SFT \pi^\text{SFT} πSFT中采样获取的,我们始终初始化 π ref = π SFT \pi_\text{ref}=\pi^\text{SFT} πref=πSFT。然而,当 π SFT \pi^\text{SFT} πSFT模型不可用时,我们通过偏好回复的最大似然初始化 π ref \pi_\text{ref} πref,即 π ref = arg max π E x , y w ∼ D [ log π ( y w ∣ x ) ] \pi_\text{ref}=\arg\max_\pi\mathbb E_{x,y_w\sim\mathcal D}[\log\pi(y_w|x)] πref=argmaxπEx,yw∼D[logπ(yw∣x)]。这一过程有助于缓解未知真实参考分布和DPO使用的 π ref \pi_\text{ref} πref之间的分布偏移。
5 DPO理论分析
本章节,我们对DPO方法做进一步解释,并提供理论支持,将DPO的优势与RLHF使用的actor-critic算法的问题联系起来。
5.1 你的语言模型其实是一种奖励模型
DPO使用单个最大似然目标函数,可避免拟合显式的奖励模型以及执行RL学习策略。公式5优化目标等价于包含奖励参数 r ∗ ( x , y ) = β log π θ ∗ ( y ∣ x ) π ref ( y ∣ x ) r^*(x,y)=\beta\log\dfrac{\pi_\theta^*(y|x)}{\pi_\text{ref}(y|x)} r∗(x,y)=βlogπref(y∣x)πθ∗(y∣x)的BT模型,我们优化参数化模型 π θ \pi_\theta πθ,这等效于在变量变换下对公式2中的奖励模型进行优化。
本章节中,我们将构建重参数化背后的理论,展示它并不限制学习奖励模型的方法,以及允许准确恢复最优策略。我们首先定义奖励函数之间的的等价关系。
定义1 如果存在函数 f f f使得 r ( x , y ) − r ′ ( x , y ) = f ( x ) r(x,y)-r'(x,y)=f(x) r(x,y)−r′(x,y)=f(x) ,则奖励函数 r ( x , y ) r(x,y) r(x,y)和 r ′ ( x , y ) r'(x,y) r′(x,y)等价。
显而易见,这确实是等价关系,它将奖励函数划分为类。我们可以声明以下两个引理:
引理1 在Plackett-Luce下,特别是在Bradley-Terry偏好框架下,来自同一类别的两个奖励函数将产生相同的偏好分布。
引理2 在约束的强化学习问题下,来自同一类别的两个奖励函数将产生相同的最优策略。
DPO源码解析
样本集 { x , y w , y l } \{x, y_w, y_l\} {x,yw,yl},构造dataloader:
- build_dataset: 对于每一条样本,预处理后的样本集(dataloader中的dataset)为[{‘chosen_input_ids’: […], ‘chosen_attention_mask’: […], ‘chosen_labels’: […], ‘rejected_input_ids’: […], ‘rejected_attention_mask’: […], ‘rejected_labels’: […]}]
- 从dataset中采样batch,经collator转换并padding为[{“input_ids”: …, “attention_mask”: …, “labels”: …}, …, {“input_ids”: …, “attention_mask”: …, “labels”: …}],其中前半部分为接受样本,后半部分为对应的拒绝样本,依次类推
核心训练代码:
def concatenated_forward(model, batch: dict):logits = model(**batch).logitsper_token_logps = torch.gather(logits.log_softmax(-1), dim=2, index=batch["labels"].unsqueeze(2)).squeeze(2)loss_mask = batch["labels"] != -100logps = (per_token_logps * loss_mask).sum(-1)logps_avg = logps / loss_mask.sum(-1) # 对数似然,可作为SFT Lossbatch_size = batch["input_ids"].size(0) // 2chosen_logps, rejected_logps = logps.split(batch_size, dim=0)chosen_logps_avg = logps_avg[:batch_size]return chosen_logps, rejected_logps, chosen_logps_avg# policy model前向
policy_chosen_logps, policy_rejected_logps, policy_chosen_logps_avg = concatenated_forward(model, batch)# 使用lora算法的reference model前向
ref_context = accelerator.unwrap_model(model).disable_adapter()
with torch.no_grad(), ref_context:reference_chosen_logps, reference_rejected_logps, *_ = concatenated_forward(model, batch)# 计算每条样本对的偏好损失
pi_logratios = policy_chosen_logps - policy_rejected_logps
ref_logratios = reference_chosen_logps - reference_rejected_logps
logits = pi_logratios - ref_logratios
losses = (-F.logsigmoid(beta * logits) * (1 - label_smoothing) - F.logsigmoid(-beta * logits) * label_smoothing)# 添加sft loss
if ftx_gamma > 1e-6:sft_loss = -policy_chosen_logps_avglosses += ftx_gamma * sft_loss# 计算平均loss
loss = losses.mean()
相关文章:
:论文与源码解析)
直接偏好优化(Direct Preference Optimization,DPO):论文与源码解析
简介 虽然大规模无监督语言模型(LMs)学习了广泛的世界知识和一些推理技能,但由于它们是基于完全无监督训练,仍很难控制其行为。 微调无监督LM使其对齐偏好,尽管大规模无监督的语言模型(LMs)能…...

uniapp-商城-34-shop 购物车 选好了 进行订单确认
在shop页面选中商品添加到购物车,可选好后,进行确认和支付。具体呈现在shop页面。 1 购物车栏 shop页面代码: 购物车代码: 代码: <template><view><view class"carlayout"><!-- 车里…...
)
Kafka命令行的使用/Spark-Streaming核心编程(二)
Kafka命令行的使用 创建topic kafka-topics.sh --create --zookeeper node01:2181,node02:2181,node03:2181 --topic test1 --partitions 3 --replication-factor 3 分区数量,副本数量,都是必须的。 数据的形式: 主题名称-分区编号。 在…...

虚拟机详解
虚拟机详解 1. 虚拟机(Virtual Machine)的定义 系统虚拟机:通过软件模拟完整计算机系统(CPU、内存、外设等),如 VMware、VirtualBox。进程级虚拟机:为单个应用提供虚拟执行环境,如 …...

NOIP2013 提高组.转圈游戏
目录 题目算法标签: 数论, 模运算思路代码 题目 504. 转圈游戏 算法标签: 数论, 模运算 思路 看题意不难看出, 计算的是 ( x 1 0 k m ) m o d n (x 10 ^ k \times m) \mod n (x10km)modn, 如果直接计算一定会超时, 因此可以使用快速幂进行优化 代码 #include <iost…...

【金仓数据库征文】加速数字化转型:金仓数据库在金融与能源领域强势崛起
目录 一、引言 二、金仓数据库(KingbaseES)概述 1. 发展历程与市场地位 2. 核心技术架构 3. 金仓数据库的特点 三、金仓数据库在金融行业的应用 1. 金融行业的挑战与需求 2. 金仓数据库在金融行业的优势 3. 金仓数据库在金融行业的实际应用案例 …...

济南国网数字化培训班学习笔记-第二组-5节-输电线路设计
输电线路设计 工程设计阶段划分 35kv及以上输变电工程勘测设计全过程 可行性研究(包括规划、工程选站)(包括电力系统一次二次,站址选择及工程设想,线路工程选择及工程设想,节能降耗分析,环境…...

【前端】【业务场景】【面试】在前端开发中,如何实现一个可拖动和可缩放的元素,并且处理好边界限制和性能优化?
问题:在前端开发中,如何实现一个可拖动和可缩放的元素,并且处理好边界限制和性能优化? 一、实现可拖动和可缩放元素 HTML 和 CSS 基础设置: 创建一个 HTML 元素,并为其设置基本样式,使其在页面…...
)
BOM与DOM(解疑document window关系)
BOM(浏览器对象模型) 定义与作用 BOM(Browser Object Model)提供与浏览器窗口交互的接口,用于控制导航、窗口尺寸、历史记录等浏览器行为 window:浏览器窗口的顶层对象,包含全局属性和方法&am…...

504 nginx解决方案
当遇到 504 Gateway Time-out 错误时,通常是因为 Nginx 作为反向代理等待后端服务(如 PHP-FPM、Java 应用等)响应的时间超过了预设的超时阈值。以下是详细的解决方案,结合知识库中的信息整理而成: 一、核心原因分析 后…...

【LLM+Code】Windsurf Agent 模式PromptTools详细解读
一、前言 https://windsurf.com/ https://windsurf.com/blog/why-we-built-windsurf https://github.com/x1xhlol/system-prompts-and-models-of-ai-tools/tree/main/Windsurf 二、System Prompt 相比于cursor和claude code, windsurf的system prompt非常长&am…...
第三章:Transport Mechanisms
Chapter 3: Transport Mechanisms 🌟 从上一章到本章 在第二章:MCP服务器分类中,我们学会了如何根据需求选择不同类别的服务器(如文件系统、数据库等)。现在想象这样一个场景:你有一个本地文件服务器和一个…...
)
shell练习题(1)
练习: 1.建立脚本service.sh,当执行的时候要求输入(1、2、3、4、5)时安装对应的httpd、vim、wget、更换aliyum等功能,当输入错误 时会提示你,应该输入正确的值 [rootbogon yy]# cat service.sh #!/bin/bash cat <<-EOF ----------------------…...

【解决】Android Gradle Sync 报错 Could not read workspace metadata
异常信息 Caused by: java.io.UncheckedIOException:Could not read workspace metadata from C:\Users\xxx\.gradle\caches\transforms-4\69955912123c68eecd096b71c66ee211\metadata.bin 异常原因 看字面意思是不能读取metadata文件,原因可能是因为缓存目录异常…...

Python中的 for 与 迭代器
文章目录 一、for 循环的底层机制示例:手动模拟 for 循环 二、可迭代对象 vs 迭代器关键区别: 三、for 循环的典型应用场景1. 遍历序列类型2. 遍历字典3. 结合 range() 生成数字序列4. 遍历文件内容 四、迭代器的自定义实现示例:生成斐波那契…...
)
上篇:深入剖析 BLE 底层物理层与链路层(约5000字)
引言 在无线通信领域,Bluetooth Low Energy(BLE)以其超低功耗、灵活的连接模式和良好的生态支持,成为 IoT 与可穿戴设备的首选技术。要想在实际项目中优化性能、控制功耗、保证可靠通信,必须对 BLE 协议栈的底层细节有深入了解。本篇将重点围绕物理层(PHY)与链路层(Li…...

ArcGIS Pro跨图层复制粘贴
在map视图中,点击selection中的Select按钮,保持选择状态。 点击需要复制的要素,保持选中状态。右击点击copy,或CtrlC进行复制。 在Clipboard下拉框中点击Paste Special,选择需要粘贴的图层后点击OK。...

今日CSS学习浮动->定位
------------------------------------------------------------------------------------------------------- CSS的浮动 float 属性用于创建浮动框,将其移动到一边,直到左边缘或右边缘触及包含块或另一个浮动框的边缘。 float 属性定义元素在哪个方向浮…...

性行为同意协议系统网站源码
性行为同意协议系统网站源码 一个用于创建、签署和管理性行为同意协议的 Web 应用程序。该应用允许用户在线创建详细的性行为同意协议,并通过数字签名方式进行签署,同时支持导出为 PDF 格式保存。 功能特性 创建自定义性同意协议 多步骤表单引导用户完…...

项目自动化测试
一.设计测试用例(细致全面) 二.先引入所需要的pom.xml依赖 1.selenium依赖 2.webdrivermanager依赖 3.commons-io依赖 编写测试用例–按照页面对用例进行划分,每个页面是Java文件,页面下的所有用例统一管理 三.common包(放入公用包) 类1utils 可以调用driver对象,访问url …...
【DCNv1、DCNv2、DCNv3】)
可变形卷积(可以观察到变形图片的卷积)【DCNv1、DCNv2、DCNv3】
一、DCNv1——可以观察到扭曲的图片 1.传统卷积的问题 在普通的卷积操作中,比如 33 卷积,采样的位置总是固定的:就是中间一个点,四周八个点,整齐地排成一个小网格。 但现实中的图像并不整齐——比如猫的身体弯着、车…...

vue3,element ui框架中为el-table表格实现自动滚动,并实现表头汇总数据
基础用法不太明白的请参考官网文档 ;element ui Plus官网:Table 表格 | Element PlusA Vue 3 based component library for designers and developershttps://element-plus.org/zh-CN/component/table.html 1、添加一个基础表格 <template><e…...

Selenium 怎么加入代理IP,以及怎么检测爬虫运行的时候,是否用了代理IP?
使用selenium爬虫的时候,如果不加入代理IP,很容易会被网站识别,容易封号; 最近去了解了一下买代理ip,但是还是有一些不太懂的东西。 例如有了代理ip以后,怎么用在爬虫上,requests 和selenium的…...

【Python爬虫实战篇】--Selenium爬取Mysteel数据
任务:爬取我的钢铁网的钢材价格指数数据,需要输入时间和钢材类型 网站:钢铁价格指数_今日钢铁价格指数实时行情走势_我的钢铁指数 目录 1.环境搭建 2.打开网站 3.点击右侧按钮展开 4.点击需要的钢材数据 5.点击“按日查询” 6.输入日查…...

LLM学习笔记4——本地部署Docker、vLLM和Qwen2.5-32B-Instruct实现OpenManus的使用
系列文章目录 参考博客 参考博客 参考博客 参考博客 文章目录 系列文章目录前言一、OpenManus介绍二、环境搭建1.DockervLLM2.搭建OpenManus1)安装anaconda虚拟环境2)安装OpenManus3)下载并配置Qwen2.5-32B-Instruct模型4)配置与…...
)
aarcpy 列表函数的使用(1)
arcpy.ListFeatureClasses() 该函数用于列出指定工作空间中的所有要素类。可以通过通配符和过滤条件进一步筛选结果。 语法: python arcpy.ListFeatureClasses(wild_cardNone, feature_typeNone)• wild_card:用于筛选要素类名称的通配符,…...

maven工程中引入外部jar
1、引入模块下的jar 1.负责打包的模块,pom中加上这个插件,这个可以把外部jar包打入工程中。 <!-- 打包 --> <build><finalName>xxx-send-admin</finalName><resources><resource><directory>${project.base…...

C++智能指针上
一、裸指针 “裸指针”是最基础的,直接存储内存地址的指针类型。特点:①它本身没有自动的内存管理机制:如它不会自动释放内存,也不会检查是否指向有效的内存区域;②直接操作内存地址,不进行任何的边界检查&…...

flutter 中各种日志
日志方法对比 输出方式调试模式控制台输出发布模式控制台输出DevTools Logging 视图print()✅ 显示✅ 显示❌ 不显示debugPrint()✅ 显示✅ 显示❌ 不显示stderr.writeln()✅ 显示✅ 显示✅ 显示dart:developer.log()✅ 显示❌ 不显示✅ 显示 详细说明: print()&a…...

Java面试:从Spring Boot到微服务的全面考核
Java面试:从Spring Boot到微服务的全面考核 场景设定: 在一家互联网大厂的面试室内,严肃的面试官正准备开始对前来面试的赵大宝进行技术考核。赵大宝是一位自称在Java开发方面经验丰富的求职者,不过却是个搞笑的水货程序员。 第…...

安卓adb shell串口基础指令
目录 前言一、列出串口设备节点二、修改串口设备权限三、串口参数配置(stty命令)3.1 基本配置3.2 其他常用参数3.3 查看当前配置 四、数据收发操作4.1 发送数据4.2 接受数据 参考链接: 前言 在 Android 设备上,ADB提供了一系列命令用于与设备…...

大模型技术全景解析:从基础架构到Prompt工程
大模型技术全景解析:从基础架构到Prompt工程 引言 近年来,大型语言模型(LLMs)如GPT、BERT等取得了突破性进展,彻底改变了自然语言处理领域。本文将全面剖析大模型的核心技术要素,包括三要素构成、系统架构、机器学习范式演进、P…...
翻滚盒子)
404页面精选(一)翻滚盒子
内容很详细,直接上代码 效果演示 源码 <!DOCTYPE html> <html><head><meta http-equiv"Content-Type" content"text/html; charsetUTF-8"><title>翻滚盒子</title><style>body {background: #000;h…...

LJF-Framework 第15章 想想搞点啥-若依管理系统兼容一下
LJF-Framework 第15章 想想搞点啥-若依管理系统兼容一下 一、下载后端源码 我们学习一下他的前后端分离的项目吧RuoYi-Vue,我看他有单独的Vue3版本的项目,我们就整这新的吧,向新新势力低头。 1、下载地址 git clone https://gitcode.com/yangzongzhuan/RuoYi-Vue.git2、…...

Hadoop基础知识
Hadoop 是由 Apache 基金会开发的开源分布式计算框架,主要用于处理海量数据的存储和计算问题。其核心设计基于 Google 的 MapReduce 编程模型和 GFS(Google File System),旨在通过集群化的廉价硬件实现高可靠性、高扩展性的大数据…...
第1讲:Transformers 的崛起:从RNN到Self-Attention
序列建模的演进之路 一、RNN( Recurrent Neural Networks):序列处理的开拓者 循环神经网络(RNN)是最早处理序列数据的深度学习结构。RNN的核心思想是在处理序列的每个时间步时保持一个"记忆"状态。 h_t tanh(W_x * x_t W_h * …...

经验分享 | 如何高效使用 `git commit --amend` 修改提交记录
背景 在「地面智能观测项目」这种多模块协作的物联网系统中,版本迭代频率高达每周3次。每个部署包(如v0.3.19)都包含硬件控制脚本、数据处理模块和部署工具,任何提交遗漏都可能导致部署失败。传统的新建提交方式会造成冗余记录&a…...

生物创新药研发为何要上电子实验记录本?
前言:数据驱动的生物创新药研发新范式 在精准医疗时代,生物创新药以其靶向性强、疗效确切的优势,成为肿瘤、自身免疫性疾病等复杂病症的核心治疗方案。国家"十四五" 规划明确将生物制药列为战略性新兴产业,各地政府纷纷…...

PH热榜 | 2025-04-24
1. Peek 标语:AI个人财务教练,帮你做出明智的财务决策。 介绍:Peek的人工智能助手能够主动进行财务检查,分析你的消费模式,并以一种细腻而积极的方式帮助你改善习惯。完全没有评判,也没有负罪感。就像为你…...

民锋视角下的节奏判断与资金行为建模
民锋视角下的节奏判断与资金行为建模 在市场节奏的研判中,行为模型始终是构建逻辑核心。以民锋为代表的一类研究视角,更关注的是微观结构中的资金行为痕迹,而非单一技术形态。 节奏并非由K线决定,而是由成交密度与换手效率共同塑…...

Debian服务器上JSP页面无法加载如何解决?
如果你在 Debian 服务器上部署 JSP 页面无法加载,可以按以下步骤排查和解决问题: 1. 确认安装了 Java 环境 JSP 需要 Java 支持,先确认 Java 是否安装并配置好: java -version如果未安装,使用如下命令安装 OpenJDK&…...

第三篇:Django创建表关系及生命周期流程图
第三篇:Django创建表关系及生命周期流程图 文章目录 第三篇:Django创建表关系及生命周期流程图一、Django中orm创建表关系一、数据库中的表关系二、创建表 二、Django请求生命周期流程图 一、Django中orm创建表关系 一、数据库中的表关系 我们可以通过…...
音视频,yt-dlp下载工具、parole播放器)
【玩泰山派】7、玩linux桌面环境xfce - (2)音视频,yt-dlp下载工具、parole播放器
文章目录 前言yt-dlpyt-dlp概述发展背景特点应用场景使用方式局限性 安装yt-dlpyt-dlp常用命令直接下载默认格式指定格式 查看视频所有分辨率下载指定分辨率参考 parole播放器使用Parole概述源码地址使用 前言 前面安装了ubuntu Xfce桌面环境(xubuntu-desktop),现在…...

【文献速递】NMR代谢组寻找预测DR发展的候选标志物
2024年7月5日,中山大学中山眼科中心王伟教授团队在Ophthalmology(IF:13.2)上发表了题为“Plasma Metabolomics Identifies Key Metabolites and Improves Prediction of Diabetic Retinopathy:Development and Validat…...
)
flask学习(1)
1.基本框架 from flask import Flask app Flask(__name__)app.route(/) def hello():return "<h1>Hello, Flask in Conda!</h1>"if __name__ __main__:app.run(host0.0.0.0, port5000, debugTrue) # 关键行! 在此基础上 from flask imp…...

详解springcloudalibaba采用prometheus+grafana实现服务监控
1.官网下载安装 prometheus和grafana promethus 官网:https://prometheus.io/ 1.下载windows版本安装包 2.双击启动 3.访问地址 http://localhost:9090 grafana 官网:https://grafana.com/ 1.下载windows版本安装包 2.启动 ,默认windo…...

Java查询数据库表信息导出Word
参考: POI生成Word多级标题格式_poi设置word标题-CSDN博客 1.概述 使用jdbc查询数据库把表信息导出为word文档, 导出为word时需要下载word模板文件。 已实现数据库: KingbaseES, 实现代码: 点击跳转 2.效果图 2.1.生成word内容 所有数据库合并 数据库不合并 2.2.生成文件…...

【金仓数据库征文】从云计算到区块链:金仓数据库的颠覆性创新之路
目录 一、引言 二、金仓数据库概述 2.1 金仓数据库的背景 2.2 核心技术特点 2.3 行业应用案例 三、金仓数据库的产品优化提案 3.1 性能优化 3.1.1 查询优化 3.1.2 索引优化 3.1.3 缓存优化 3.2 可扩展性优化 3.2.1 水平扩展与分区设计 3.2.2 负载均衡与读写分离 …...

Kotlin函数体详解:表达式函数体 vs 代码块函数体——使用场景与最佳实践
🧩 什么是表达式函数体(Expression Body)? 表达式函数体指的是使用 号直接返回一个表达式结果的函数写法。 ✅ 示例: fun add(x: Int, y: Int): Int x y这个函数的意思是:传入两个整数,返…...

【bug修复】一次诡异的接口数据显示 bug 排查之旅
一次诡异的接口数据显示 bug 排查之旅 在后端开发的日常中,总会遇到一些让人摸不着头脑的 bug,最近我就经历了一个颇为诡异的情况。接口接收到的响应 data 对象里字段明明都有值,但直接打印到控制台却显示空字符串,最后通过一个简…...