TDengine 流计算引擎设计
流计算架构
TDengine 流计算的架构如下图所示。当用户输入用于创建流的 SQL 后,首先,该 SQL 将在客户端进行解析,并生成流计算执行所需的逻辑执行计划及其相关属性信息。其次,客户端将这些信息发送至 mnode。mnode 利用来自数据源(超级)表所在数据库的 vgroups 信息,将逻辑执行计划动态转换为物理执行计划,并进一步生成流任务的有向无环图(Directed Acyclic Graph,DAG)。最后,mnode 启动分布式事务,将任务分发至每个 vgroup,从而启动整个流计算流程。
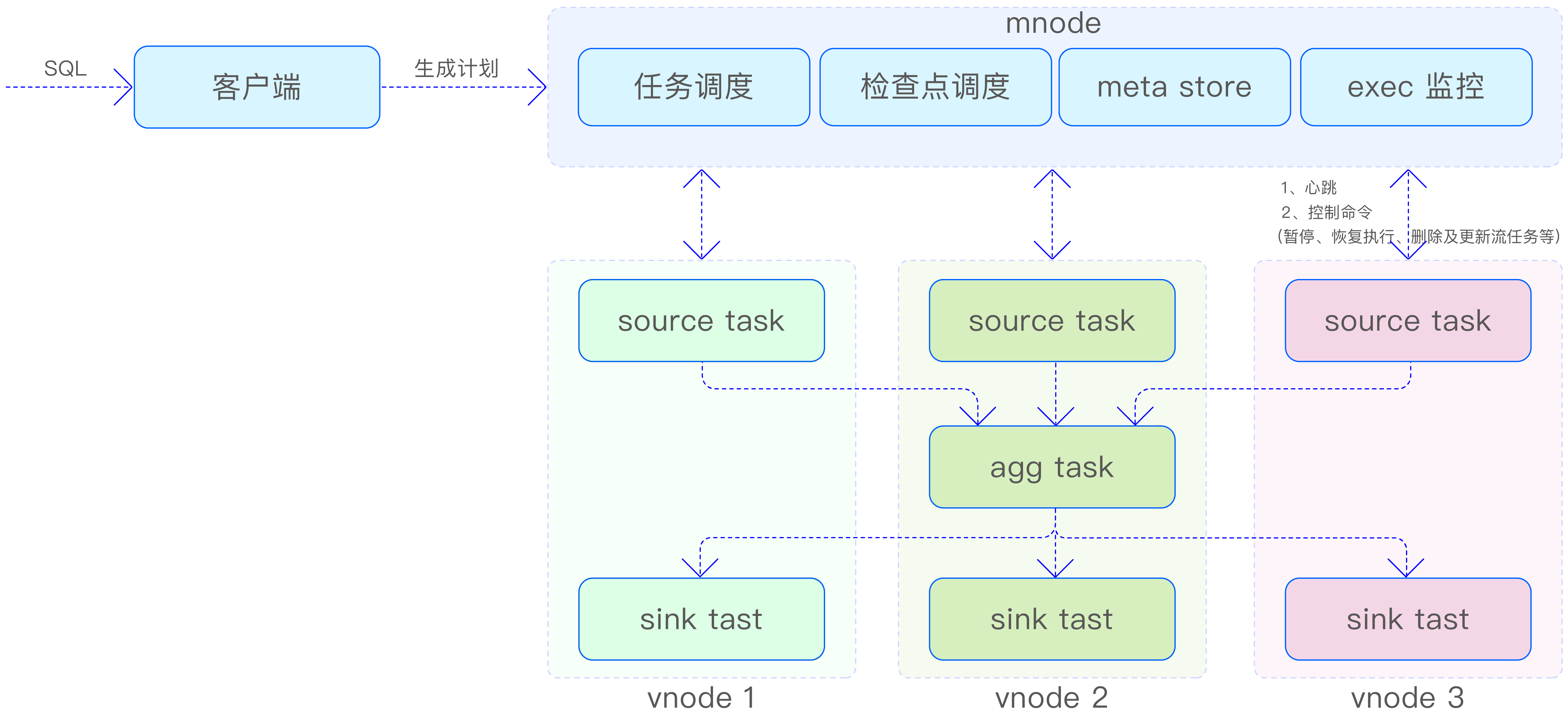
mnode 包含与流计算相关的如下 4 个逻辑模块。
- 任务调度,负责将逻辑执行计划转化为物理执行计划,并下发到每个 vnode。
- meta store,负责存储流计算任务的元数据信息以及流任务相应的 DAG 信息。
- 检查点调度,负责定期生成检查点(checkpoint)事务,并下发到各 source task(源任务)。
- exec 监控,负责接收上报的心跳、更新 mnode 中各任务的执行状态,以及定期监控检查点执行状态和 DAG 变动信息。
此外,mnode 还承担着向流计算任务下发控制命令的重要角色,这些命令包括但不限于暂停、恢复执行、删除流任务及更新流任务的上下游信息等。
在每个 vnode 上,至少部署两个流任务:一个是 source task,它负责从 WAL(在必要时也会从 TSDB)中读取数据,以供后续任务处理,并将处理结果分发给下游任务;另一个是 sink task(写回任务),它的职责是将收到的数据写入所在的 vnode。为了确保数据流的稳定性和系统的可扩展性,每个 sink task 都配备了流量控制功能,以便根据实际情况调整数据写入速度。
基本概念
有状态的流计算
流计算引擎具备强大的标量函数计算能力,它处理的数据在时间序列上相互独立,无须保留计算的中间状态。这意味着,对于所有输入数据,引擎可以执行固定的变换操
作,如简单的数值加法,并直接输出结果。
同时,流计算引擎也支持对数据进行聚合计算,这类计算需要在执行过程中维护中间状态。以统计设备的日运行时间为例,由于统计周期可能跨越多天,应用程序必须持续追踪并更新当前的运行状态,直至统计周期结束,才能得出准确的结果。这正是有状态的流计算的一个典型应用场景,它要求引擎在执行过程中保持对中间状态的跟踪和管理,以确保最终结果的准确性。
预写日志
当数据写入 TDengine 时,首先会被存储在 WAL 文件中。每个 vnode 都拥有自己的 WAL 文件,并按照时序数据到达的顺序进行保存。由于 WAL 文件保留了数据到达的顺序,因此它成为流计算的重要数据来源。此外,WAL 文件具有自己的数据保留策略,通过数据库的参数进行控制,超过保留时长的数据将会被从 WAL 文件中清除。这种设计确保了数据的完整性和系统的可靠性,同时为流计算提供了稳定的数据来源。
事件驱动
事件在系统中指的是状态的变化或转换。在流计算架构中,触发流计算流程的事件是(超级)表数据的写入消息。在这一阶段,数据可能尚未完全写入 TSDB,而是在多个副本之间进行协商并最终达成一致。
流计算采用事件驱动的模式执行,其数据源并非直接来自 TSDB,而是 WAL。数据一旦写入 WAL 文件,就会被提取出来并加入待处理的队列中,等待流计算任务的进一步处理。这种数据写入后立即触发流计算引擎执行的方式,确保数据一旦到达就能得到及时处理,并能够在最短时间内将处理结果存储到目标表中。
时间
在流计算领域,时间是一个至关重要的概念。TDengine 的流计算中涉及 3 个关键的时间概念,分别是事件时间、写入时间和处理时间。
- 事件时间(Event Time):这是时序数据中每条记录的主时间戳(也称为 Primary Timestamp),通常由生成数据的传感器或上报数据的网关提供,用以精确标记记录的生成时刻。事件时间是流计算结果更新和推送策略的决定性因素。
- 写入时间(Ingestion Time):指的是记录被写入数据库的时刻。写入时间与事件时间通常是独立的,一般情况下,写入时间晚于或等于事件时间(除非出于特定目的,用户写入了未来时刻的数据)。
- 处理时间(Processing Time):这是流计算引擎开始处理写入 WAL 文件中数据的时间点。对于那些设置了 max_delay 选项以控制流计算结果返回策略的场景,处理时间直接决定了结果返回的时间。值得注意的是,在 at_once 和 window_close 这两种计算触发模式下,数据一旦到达 WAL 文件,就会立即被写入 source task 的输入队列并开始计算。
这些时间概念的区分确保了流计算能够准确地处理时间序列数据,并根据不同时间点的特性采取相应的处理策略
时间窗口聚合
TDengine 的流计算功能允许根据记录的事件时间将数据划分到不同的时间窗口中。通过应用指定的聚合函数,计算出每个时间窗口内的聚合结果。当窗口中有新的记录到达时,系统会触发对应窗口的聚合结果更新,并根据预先设定的推送策略,将更新后的结果传递给下游流计算任务。
当聚合结果需要写入预设的超级表时,系统首先会根据分组规则生成相应的子表名称,然后将结果写入对应的子表中。值得一提的是,流计算中的时间窗口划分策略与批量查询中的窗口生成与划分策略保持一致,确保了数据处理的一致性和效率。
乱序处理
在网络传输和数据路由等复杂因素的影响下,写入数据库的数据可能无法维持事件时间的单调递增特性。这种现象,即在写入过程中出现的非单调递增数据,被称为乱序写入。
乱序写入是否会影响相应时间窗口的流计算结果,取决于创建流计算任务时设置的 watermark(水位线)参数以及是否忽略 ignore expired(过期数据)参数的配置。这两个参数共同作用于确定是丢弃这些乱序数据,还是将其纳入并增量更新所属时间窗口的计算结果。通过这种方式,系统能够在保持流计算结果准确性的同时,灵活处理乱序数据,确保数据的完整性和一致性。
流计算任务
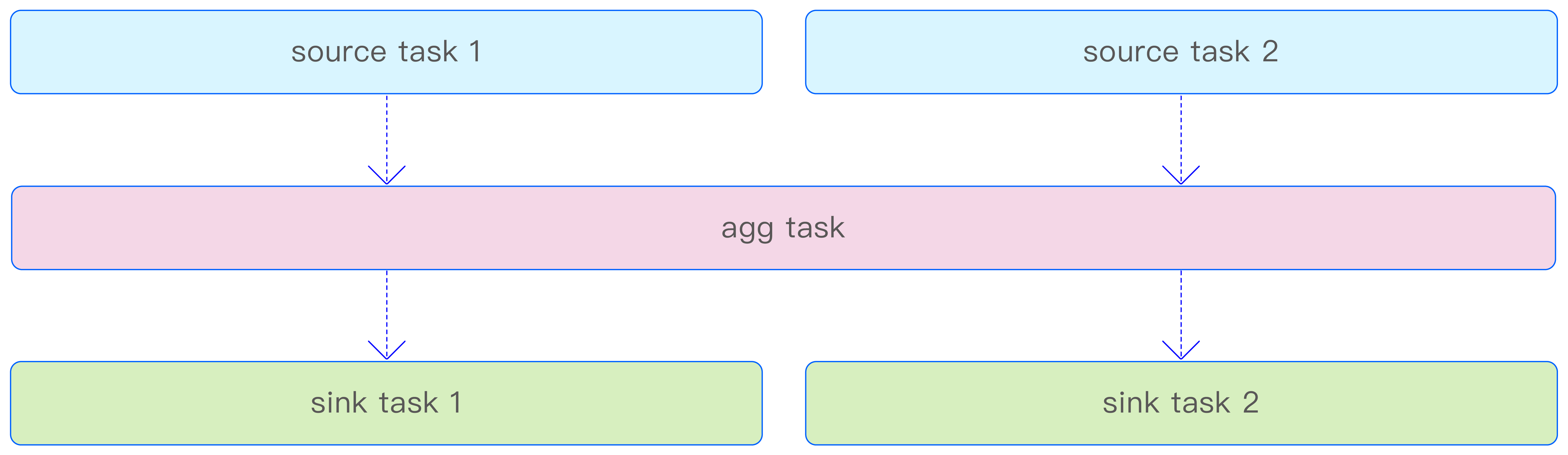
每个激活的流计算实例都是由分布在不同 vnode 上的多个流任务组成的。这些流任务在整体架构上呈现出相似性,均包含一个全内存驻留的输入队列和输出队列,用于执行时序数据的执行器系统,以及用于存储本地状态的存储系统,如下图所示。这种设计确保了流计算任务的高性能和低延迟,同时提供了良好的可扩展性和容错性。

按照流任务承担任务的不同,可将其划分为 3 个类别:source task(源任务)、agg task(聚合任务)和 sink task(写回任务)。
source task
流计算的数据处理始于本地 WAL 文件中的数据读取,这些数据随后在本地节点上进行局部计算。source task 遵循数据到达的自然顺序,依次扫描 WAL 文件,并从中筛选出符合特定要求的数据。随后,source task 对这些时序数据进行顺序处理。因此,流计算的数据源(超级)表无论分布在多少个 vnode 上,集群中都会相应地部署同等数量的源任务。这种分布式的处理方式确保了数据的并行处理和高效利用集群资源。
agg task
source task 的下游任务是接收源任务聚合后的结果,并对这些结果进行进一步的汇总以生成最终输出。在集群中配置 snode 的情况下,agg task 会被优先安排在 snode 上执行,以利用其存储和处理能力。如果集群中没有 snode,mnode 则会随机选择一个 vnode,在该 vnode 上调度执行 agg task。值得注意的是,agg task 并非在所有情况下都是必需的。对于那些不涉及窗口聚合的流计算场景(例如,仅包含标量运算的流计算,或者在数据库只有一个 vnode 时的聚合流计算),就不会出现 agg task。在这种情况下,流计算的拓扑结构将简化为仅包含两级流计算任务,即 source task 和直接输出结果的下游任务。
sink task
sink task 承担着接收 agg task 或 source task 输出结果的重任,并将其妥善写入本地 vnode,以此完成数据的写回过程。与 source task 类似,每个结果(超级)表所分布的 vnode 都将配备一个专门的 sink task。用户可以通过配置参数来调节 sink task 的吞吐量,以满足不同的性能需求。
上述 3 类任务在流计算架构中各司其职,分布在不同的层级。显然,source task 的数量直接取决于 vnode 的数量,每个 source task 独立负责处理各自 vnode 中的数据,与其他 source task 互不干扰,不存在顺序性的约束。然而,值得指出的是,如果最终的流计算结果汇聚到一张表中,那么在该表所在的 vnode 上只会部署一个 sink task。这 3 种类型的任务之间的协作关系如下图所示,共同构成了流计算任务的完整执行流程。
流计算节点
snode 是一个专为流计算服务的独立 taosd 进程,它专门用于部署 agg task。snode 不仅具备本地状态管理能力,还内置了远程备份数据的功能。这使得 snode 能够收集并存储分散在各个 vgroup 中的检查点数据,并在需要时,将这些数据远程下载到重新启动流计算的节点上,从而确保流计算状态的一致性和数据的完整性。
状态与容错处理
检查点
在流计算过程中,系统采用分布式检查点机制来定期(默认为每 3min)保存计算过程中各个任务内部算子的状态。这些状态的快照即检查点(checkpoint)。生成检查点的操作仅与处理时间相关联,与事件时间无关。
在假定所有流任务均正常运行的前提下,mnode 会定期发起生成检查点的事务,并将这些事务分发至每个流的最顶层任务。负责处理这些事务的消息随后会进入数据处理队列。
TDengine 中的检查点生成方式与业界主流的流计算引擎保持一致,每次生成的检查点都包含完整的算子状态信息。对于每个任务,检查点数据仅在任务运行的节点上保留一份副本,与时序数据存储引擎的副本设置完全独立。值得注意的是,流任务的元数据信息也采用了多副本保存机制,并被纳入时序数据存储引擎的管理范畴。因此,在多副本集群上执行流计算任务时,其元数据信息也将实现多副本冗余。
为确保检查点数据的可靠性,TDengine 流计算引擎提供了远程备份检查点数据的功能,支持将检查点数据异步上传至远程存储系统。这样一来,即便本地保留的检查点数据受损,也能从远程存储系统下载相应数据,并在全新的节点上重启流计算,继续执行计算任务。这一措施进一步增强了流计算系统的容错能力和数据安全性。
状态存储后端
流任务中算子的计算状态信息以文件的方式持久化存储在本地硬盘中。
内存管理
每个非 sink task 都配备有相应的输入队列和输出队列,而 sink task 则只有输入队列,不设输出队列。这两种队列的数据容量上限均设定为 60MB,它们根据实际需求动态占用存储空间,当队列为空时,不会占用任何存储空间。此外,agg task 在内部保存计算状态时也会消耗一定的内存空间。这一内存占用可以通过设置参数 streamBufferSize 进行调整,该参数用于控制内存中窗口状态缓存的大小,默认值为 128MB。而参数 maxStreamBackendCache 用于限制后端存储在内存中的最大占用存储空间,默认同样为 128MB,用户可以根据需要将其调整为 16MB 至 1024MB 之间的任意值。
流量控制
流计算引擎在 sink task 中实现了流量控制机制,以优化数据写入性能并防止资源过度消耗。该机制主要通过以下两个指标来控制流量。
- 每秒写入操作调用次数:sink task 负责将处理结果写入其所属的 vnode。该指标的上限被固定为每秒 50 次,以确保写入操作的稳定性和系统资源的合理分配。
- 每秒写入数据吞吐量:通过配置参数 streamSinkDataRate,用户可以控制每秒写入的数据量,该参数的可调范围是 0.1MB/s 至 5MB/s,默认值为 2MB/s。这意味着对于单个 vnode,每个 sink task 每秒最多可以写入 2MB 的数据。
sink task 的流量控制机制不仅能够防止在多副本场景下因高频率写入导致的同步协商缓冲区溢出,还能避免写入队列中数据堆积过多而消耗大量内存空间。这样做可以有效减少输入队列的内存占用。得益于整体计算框架中应用的反压机制,sink task 能够将流量控制的效果直接反馈给最上层的任务,从而降低流计算任务对设备计算资源的占用,避免过度消耗资源,确保系统整体的稳定性和效率。
反压机制
TDengine 的流计算框架部署在多个计算节点上,为了协调这些节点上的任务执行进度并防止上游任务的数据持续涌入导致下游任务过载,系统在任务内部以及上下游任务之间均实施了反压机制。
在任务内部,反压机制通过监控输出队列的满载情况来实现。一旦任务的输出队列达到存储上限,当前计算任务便会进入等待状态,暂停处理新数据,直至输出队列有足够空间容纳新的计算结果,然后恢复数据处理流程。
而在上下游任务之间,反压机制则是通过消息传递来触发的。当下游任务的输入队列达到存储上限时(即流入下游的数据量持续超过下游任务的最大处理能力),上游任务将接收到下游任务发出的输入队列满载信号。此时,上游任务将适时暂停其计算处理,直到下游任务处理完毕并允许数据继续分发,上游任务才会重新开始计算。这种机制有效地平衡了任务间的数据流动,确保整个流计算系统的稳定性和高效性。
访问官网
更多内容欢迎访问 TDengine 官网
相关文章:

TDengine 流计算引擎设计
流计算架构 TDengine 流计算的架构如下图所示。当用户输入用于创建流的 SQL 后,首先,该 SQL 将在客户端进行解析,并生成流计算执行所需的逻辑执行计划及其相关属性信息。其次,客户端将这些信息发送至 mnode。mnode 利用来自数据源…...

扩展中国剩余定理
中国剩余定理 中国剩余定理 考虑一组模线性同余方程: { x ≡ a 1 ( m o d m 1 ) x ≡ a 2 ( m o d m 2 ) . . . x ≡ a k ( m o d m k ) \begin{cases} x\equiv a_1\pmod{m1} \\ x\equiv a_2\pmod{m2}\\ .\\ .\\ .\\ x\equiv a_k\pmod{mk}\\ \end{cases} ⎩ ⎨ ⎧…...

git检查提交分支和package.json的version版本是否一致
这里写自定义目录标题 一、核心实现步骤1.安装必要依赖2.初始化 Husky3.创建校验脚本4.配置 lint-staged5.更新 Husky 钩子 三、工作流程说明四、注意事项 以下是基于 Git Hooks 的完整解决方案,通过 husky 和自定义脚本实现分支名与版本号一致性校…...
)
Git 详细使用说明文档(适合小白)
Git 详细使用说明文档(适合小白) 1. 什么是 Git? Git 是一个版本控制系统,帮助你管理和跟踪代码的变更。无论是个人项目还是团队协作,Git 都能帮助你记录代码的历史版本,方便回溯和协作。 2. 安装 Git …...
】第二章:嵌入式系统硬件基础知识(2))
【嵌入式系统设计师(软考中级)】第二章:嵌入式系统硬件基础知识(2)
文章目录 3.嵌入式系统的存储体系3.1 存储系统的层次结构3.2 内存管理单元(MMU)3.3 RAM和ROM的种类3.3.1 RAM类型对比3.3.2 ROM类型对比 3.4 高速缓存(Cache)3.5 其他存储设备3.5.1 新型存储技术3.5.2 外存接口技术 3.嵌入式系统的…...
第五章 新字符设备驱动实验)
rk3588 驱动开发(三)第五章 新字符设备驱动实验
register_chrdev 和 unregister_chrdev 这两个函数是老版本驱动使用的函数,现在新的字符设备驱动已经不再使用这两个函数,而是使用 Linux 内核推荐的新字符设备驱动 API 函数。本节我们就来学习一下如何编写新字符设备驱动,并且在驱动模块加载…...

文件上传--WAF绕过干货
本文主要内容 绕过WAF上传文件 -- 安全狗 -- 宝塔 Burp抓包解析 #上传参数名解析:明确哪些东西能修改? Content-Disposition:—般可更改 name:表单参数值,不能更改 filename:文件名ÿ…...

BERT BERT
BERT ***** 2020年3月11日更新:更小的BERT模型 ***** 这是在《深阅读的学生学得更好:预训练紧凑模型的重要性》(arXiv:1908.08962)中提到的24种较小规模的英文未分词BERT模型的发布。 我们已经证明,标准的BERT架构和…...

Kotlin Multiplatform--02:项目结构进阶
Kotlin Multiplatform--02:项目结构进阶 引言正文 引言 在上一章中,我们对 Kotlin Multiplatform 项目有了基本的了解,已经可以进行开发了。但我们只是使用了系统默认的项目结构。本章介绍了如何进行更复杂的项目结构管理。 正文 在上一章中&…...

【ES实战】Elasticsearch中模糊匹配类的查询
Elasticsearch中模糊匹配类的查询 文章目录 Elasticsearch中模糊匹配类的查询通配符查询前缀匹配查询正则匹配查询标准的正则操作特殊运算符操作 模糊化查询Fuzziness text类型同时配置keyword类型 Elasticsearch中模糊类查询主要有以下 Wildcard Query:通配符查询P…...

纯真社区IP库离线版发布更新
纯真社区IP库离线版发布更新 发布者:技术分享 2005年,随着中国互联网的蓬勃发展,纯真IP库诞生了。作为全球网络空间地理测绘技术的领先者,纯真开源项目为中国互联网行业提供了高质量的网络空间IP库数据。纯真IP库目前已经覆盖超…...
:论文与源码解析)
直接偏好优化(Direct Preference Optimization,DPO):论文与源码解析
简介 虽然大规模无监督语言模型(LMs)学习了广泛的世界知识和一些推理技能,但由于它们是基于完全无监督训练,仍很难控制其行为。 微调无监督LM使其对齐偏好,尽管大规模无监督的语言模型(LMs)能…...

uniapp-商城-34-shop 购物车 选好了 进行订单确认
在shop页面选中商品添加到购物车,可选好后,进行确认和支付。具体呈现在shop页面。 1 购物车栏 shop页面代码: 购物车代码: 代码: <template><view><view class"carlayout"><!-- 车里…...
)
Kafka命令行的使用/Spark-Streaming核心编程(二)
Kafka命令行的使用 创建topic kafka-topics.sh --create --zookeeper node01:2181,node02:2181,node03:2181 --topic test1 --partitions 3 --replication-factor 3 分区数量,副本数量,都是必须的。 数据的形式: 主题名称-分区编号。 在…...

虚拟机详解
虚拟机详解 1. 虚拟机(Virtual Machine)的定义 系统虚拟机:通过软件模拟完整计算机系统(CPU、内存、外设等),如 VMware、VirtualBox。进程级虚拟机:为单个应用提供虚拟执行环境,如 …...

NOIP2013 提高组.转圈游戏
目录 题目算法标签: 数论, 模运算思路代码 题目 504. 转圈游戏 算法标签: 数论, 模运算 思路 看题意不难看出, 计算的是 ( x 1 0 k m ) m o d n (x 10 ^ k \times m) \mod n (x10km)modn, 如果直接计算一定会超时, 因此可以使用快速幂进行优化 代码 #include <iost…...

【金仓数据库征文】加速数字化转型:金仓数据库在金融与能源领域强势崛起
目录 一、引言 二、金仓数据库(KingbaseES)概述 1. 发展历程与市场地位 2. 核心技术架构 3. 金仓数据库的特点 三、金仓数据库在金融行业的应用 1. 金融行业的挑战与需求 2. 金仓数据库在金融行业的优势 3. 金仓数据库在金融行业的实际应用案例 …...

济南国网数字化培训班学习笔记-第二组-5节-输电线路设计
输电线路设计 工程设计阶段划分 35kv及以上输变电工程勘测设计全过程 可行性研究(包括规划、工程选站)(包括电力系统一次二次,站址选择及工程设想,线路工程选择及工程设想,节能降耗分析,环境…...

【前端】【业务场景】【面试】在前端开发中,如何实现一个可拖动和可缩放的元素,并且处理好边界限制和性能优化?
问题:在前端开发中,如何实现一个可拖动和可缩放的元素,并且处理好边界限制和性能优化? 一、实现可拖动和可缩放元素 HTML 和 CSS 基础设置: 创建一个 HTML 元素,并为其设置基本样式,使其在页面…...
)
BOM与DOM(解疑document window关系)
BOM(浏览器对象模型) 定义与作用 BOM(Browser Object Model)提供与浏览器窗口交互的接口,用于控制导航、窗口尺寸、历史记录等浏览器行为 window:浏览器窗口的顶层对象,包含全局属性和方法&am…...

504 nginx解决方案
当遇到 504 Gateway Time-out 错误时,通常是因为 Nginx 作为反向代理等待后端服务(如 PHP-FPM、Java 应用等)响应的时间超过了预设的超时阈值。以下是详细的解决方案,结合知识库中的信息整理而成: 一、核心原因分析 后…...

【LLM+Code】Windsurf Agent 模式PromptTools详细解读
一、前言 https://windsurf.com/ https://windsurf.com/blog/why-we-built-windsurf https://github.com/x1xhlol/system-prompts-and-models-of-ai-tools/tree/main/Windsurf 二、System Prompt 相比于cursor和claude code, windsurf的system prompt非常长&am…...
第三章:Transport Mechanisms
Chapter 3: Transport Mechanisms 🌟 从上一章到本章 在第二章:MCP服务器分类中,我们学会了如何根据需求选择不同类别的服务器(如文件系统、数据库等)。现在想象这样一个场景:你有一个本地文件服务器和一个…...
)
shell练习题(1)
练习: 1.建立脚本service.sh,当执行的时候要求输入(1、2、3、4、5)时安装对应的httpd、vim、wget、更换aliyum等功能,当输入错误 时会提示你,应该输入正确的值 [rootbogon yy]# cat service.sh #!/bin/bash cat <<-EOF ----------------------…...

【解决】Android Gradle Sync 报错 Could not read workspace metadata
异常信息 Caused by: java.io.UncheckedIOException:Could not read workspace metadata from C:\Users\xxx\.gradle\caches\transforms-4\69955912123c68eecd096b71c66ee211\metadata.bin 异常原因 看字面意思是不能读取metadata文件,原因可能是因为缓存目录异常…...

Python中的 for 与 迭代器
文章目录 一、for 循环的底层机制示例:手动模拟 for 循环 二、可迭代对象 vs 迭代器关键区别: 三、for 循环的典型应用场景1. 遍历序列类型2. 遍历字典3. 结合 range() 生成数字序列4. 遍历文件内容 四、迭代器的自定义实现示例:生成斐波那契…...
)
上篇:深入剖析 BLE 底层物理层与链路层(约5000字)
引言 在无线通信领域,Bluetooth Low Energy(BLE)以其超低功耗、灵活的连接模式和良好的生态支持,成为 IoT 与可穿戴设备的首选技术。要想在实际项目中优化性能、控制功耗、保证可靠通信,必须对 BLE 协议栈的底层细节有深入了解。本篇将重点围绕物理层(PHY)与链路层(Li…...

ArcGIS Pro跨图层复制粘贴
在map视图中,点击selection中的Select按钮,保持选择状态。 点击需要复制的要素,保持选中状态。右击点击copy,或CtrlC进行复制。 在Clipboard下拉框中点击Paste Special,选择需要粘贴的图层后点击OK。...

今日CSS学习浮动->定位
------------------------------------------------------------------------------------------------------- CSS的浮动 float 属性用于创建浮动框,将其移动到一边,直到左边缘或右边缘触及包含块或另一个浮动框的边缘。 float 属性定义元素在哪个方向浮…...

性行为同意协议系统网站源码
性行为同意协议系统网站源码 一个用于创建、签署和管理性行为同意协议的 Web 应用程序。该应用允许用户在线创建详细的性行为同意协议,并通过数字签名方式进行签署,同时支持导出为 PDF 格式保存。 功能特性 创建自定义性同意协议 多步骤表单引导用户完…...

项目自动化测试
一.设计测试用例(细致全面) 二.先引入所需要的pom.xml依赖 1.selenium依赖 2.webdrivermanager依赖 3.commons-io依赖 编写测试用例–按照页面对用例进行划分,每个页面是Java文件,页面下的所有用例统一管理 三.common包(放入公用包) 类1utils 可以调用driver对象,访问url …...
【DCNv1、DCNv2、DCNv3】)
可变形卷积(可以观察到变形图片的卷积)【DCNv1、DCNv2、DCNv3】
一、DCNv1——可以观察到扭曲的图片 1.传统卷积的问题 在普通的卷积操作中,比如 33 卷积,采样的位置总是固定的:就是中间一个点,四周八个点,整齐地排成一个小网格。 但现实中的图像并不整齐——比如猫的身体弯着、车…...

vue3,element ui框架中为el-table表格实现自动滚动,并实现表头汇总数据
基础用法不太明白的请参考官网文档 ;element ui Plus官网:Table 表格 | Element PlusA Vue 3 based component library for designers and developershttps://element-plus.org/zh-CN/component/table.html 1、添加一个基础表格 <template><e…...

Selenium 怎么加入代理IP,以及怎么检测爬虫运行的时候,是否用了代理IP?
使用selenium爬虫的时候,如果不加入代理IP,很容易会被网站识别,容易封号; 最近去了解了一下买代理ip,但是还是有一些不太懂的东西。 例如有了代理ip以后,怎么用在爬虫上,requests 和selenium的…...

【Python爬虫实战篇】--Selenium爬取Mysteel数据
任务:爬取我的钢铁网的钢材价格指数数据,需要输入时间和钢材类型 网站:钢铁价格指数_今日钢铁价格指数实时行情走势_我的钢铁指数 目录 1.环境搭建 2.打开网站 3.点击右侧按钮展开 4.点击需要的钢材数据 5.点击“按日查询” 6.输入日查…...

LLM学习笔记4——本地部署Docker、vLLM和Qwen2.5-32B-Instruct实现OpenManus的使用
系列文章目录 参考博客 参考博客 参考博客 参考博客 文章目录 系列文章目录前言一、OpenManus介绍二、环境搭建1.DockervLLM2.搭建OpenManus1)安装anaconda虚拟环境2)安装OpenManus3)下载并配置Qwen2.5-32B-Instruct模型4)配置与…...
)
aarcpy 列表函数的使用(1)
arcpy.ListFeatureClasses() 该函数用于列出指定工作空间中的所有要素类。可以通过通配符和过滤条件进一步筛选结果。 语法: python arcpy.ListFeatureClasses(wild_cardNone, feature_typeNone)• wild_card:用于筛选要素类名称的通配符,…...

maven工程中引入外部jar
1、引入模块下的jar 1.负责打包的模块,pom中加上这个插件,这个可以把外部jar包打入工程中。 <!-- 打包 --> <build><finalName>xxx-send-admin</finalName><resources><resource><directory>${project.base…...

C++智能指针上
一、裸指针 “裸指针”是最基础的,直接存储内存地址的指针类型。特点:①它本身没有自动的内存管理机制:如它不会自动释放内存,也不会检查是否指向有效的内存区域;②直接操作内存地址,不进行任何的边界检查&…...

flutter 中各种日志
日志方法对比 输出方式调试模式控制台输出发布模式控制台输出DevTools Logging 视图print()✅ 显示✅ 显示❌ 不显示debugPrint()✅ 显示✅ 显示❌ 不显示stderr.writeln()✅ 显示✅ 显示✅ 显示dart:developer.log()✅ 显示❌ 不显示✅ 显示 详细说明: print()&a…...

Java面试:从Spring Boot到微服务的全面考核
Java面试:从Spring Boot到微服务的全面考核 场景设定: 在一家互联网大厂的面试室内,严肃的面试官正准备开始对前来面试的赵大宝进行技术考核。赵大宝是一位自称在Java开发方面经验丰富的求职者,不过却是个搞笑的水货程序员。 第…...

安卓adb shell串口基础指令
目录 前言一、列出串口设备节点二、修改串口设备权限三、串口参数配置(stty命令)3.1 基本配置3.2 其他常用参数3.3 查看当前配置 四、数据收发操作4.1 发送数据4.2 接受数据 参考链接: 前言 在 Android 设备上,ADB提供了一系列命令用于与设备…...

大模型技术全景解析:从基础架构到Prompt工程
大模型技术全景解析:从基础架构到Prompt工程 引言 近年来,大型语言模型(LLMs)如GPT、BERT等取得了突破性进展,彻底改变了自然语言处理领域。本文将全面剖析大模型的核心技术要素,包括三要素构成、系统架构、机器学习范式演进、P…...
翻滚盒子)
404页面精选(一)翻滚盒子
内容很详细,直接上代码 效果演示 源码 <!DOCTYPE html> <html><head><meta http-equiv"Content-Type" content"text/html; charsetUTF-8"><title>翻滚盒子</title><style>body {background: #000;h…...

LJF-Framework 第15章 想想搞点啥-若依管理系统兼容一下
LJF-Framework 第15章 想想搞点啥-若依管理系统兼容一下 一、下载后端源码 我们学习一下他的前后端分离的项目吧RuoYi-Vue,我看他有单独的Vue3版本的项目,我们就整这新的吧,向新新势力低头。 1、下载地址 git clone https://gitcode.com/yangzongzhuan/RuoYi-Vue.git2、…...

Hadoop基础知识
Hadoop 是由 Apache 基金会开发的开源分布式计算框架,主要用于处理海量数据的存储和计算问题。其核心设计基于 Google 的 MapReduce 编程模型和 GFS(Google File System),旨在通过集群化的廉价硬件实现高可靠性、高扩展性的大数据…...
第1讲:Transformers 的崛起:从RNN到Self-Attention
序列建模的演进之路 一、RNN( Recurrent Neural Networks):序列处理的开拓者 循环神经网络(RNN)是最早处理序列数据的深度学习结构。RNN的核心思想是在处理序列的每个时间步时保持一个"记忆"状态。 h_t tanh(W_x * x_t W_h * …...

经验分享 | 如何高效使用 `git commit --amend` 修改提交记录
背景 在「地面智能观测项目」这种多模块协作的物联网系统中,版本迭代频率高达每周3次。每个部署包(如v0.3.19)都包含硬件控制脚本、数据处理模块和部署工具,任何提交遗漏都可能导致部署失败。传统的新建提交方式会造成冗余记录&a…...

生物创新药研发为何要上电子实验记录本?
前言:数据驱动的生物创新药研发新范式 在精准医疗时代,生物创新药以其靶向性强、疗效确切的优势,成为肿瘤、自身免疫性疾病等复杂病症的核心治疗方案。国家"十四五" 规划明确将生物制药列为战略性新兴产业,各地政府纷纷…...

PH热榜 | 2025-04-24
1. Peek 标语:AI个人财务教练,帮你做出明智的财务决策。 介绍:Peek的人工智能助手能够主动进行财务检查,分析你的消费模式,并以一种细腻而积极的方式帮助你改善习惯。完全没有评判,也没有负罪感。就像为你…...