第1讲:Transformers 的崛起:从RNN到Self-Attention
序列建模的演进之路
一、RNN( Recurrent Neural Networks):序列处理的开拓者
循环神经网络(RNN)是最早处理序列数据的深度学习结构。RNN的核心思想是在处理序列的每个时间步时保持一个"记忆"状态。
h_t = tanh(W_x * x_t + W_h * h_{t-1} + b)
这里,h_t是当前时间步的隐藏状态,x_t是当前输入,而h_{t-1}是上一时间步的隐藏状态。这种结构允许RNN理论上能够捕获任意长度的上下文信息。
局限性:然而,由于梯度消失问题,普通RNN很难学习长距离依赖。随着序列长度增加,早期输入的信息会迅速衰减或爆炸。
RNN的深层原理解析
RNN的核心思想是将序列信息压缩到一个固定维度的向量中。从计算图的角度看,
RNN可以展开成一个深层前馈网络,每一层对应序列的一个时间步:
#####RNN 的“循环”机制详解
RNN 的精髓在于:循环地使用相同的网络结构来处理序列中的每一个元素。
比如处理一句话 “我 → 爱 → AI”:
- 第一步:读到“我”,生成 h₁(初始状态 h₀ 为0)
- 第二步:读到“爱”,用“我”的状态 h₁ + “爱”作为输入
- 第三步:读到“AI”,继续传播状态…
这个机制就像人类阅读——当前词的理解,受到前面词语的影响。
x_1 → RNN → h_1 → RNN → h_2 → ... → h_n↑ ↑ ↑x_1 x_2 x_n
当我们展开这个计算过程并应用反向传播算法时,梯度需要通过所有时间步传播,从而导致两个根本问题:
- 梯度消失:由于重复乘以权重矩阵W_h,如果其特征值小于1,梯度会呈指数衰减
- 梯度爆炸:相反,如果特征值大于1,梯度会呈指数增长
这导致了RNN在实践中面临的两难选择:
- 如果保持稳定的梯度流,就难以学习长距离依赖
- 如果允许梯度自由流动,模型又难以训练稳定
二、LSTM(Long short-term memory networks):记忆的守卫者
🔁 LSTM 的循环图解:
xₜ↓
+---------------------+
| 输入门 / 遗忘门 / 输出门 |
+---------------------+↓cₜ₋₁ →→→→→→→→ cₜ ←(记忆传递)↓hₜ → 输出
长短期记忆网络(LSTM)通过引入门控机制来解决RNN的梯度问题:
- 输入门:控制新信息添加到单元状态
- 遗忘门:控制丢弃哪些信息
- 输出门:控制输出哪部分单元状态
# 遗忘门
f_t = σ(W_f · [h_{t-1}, x_t] + b_f)
# 输入门
i_t = σ(W_i · [h_{t-1}, x_t] + b_i)
# 候选状态
C̃_t = tanh(W_C · [h_{t-1}, x_t] + b_C)
# 单元状态更新
C_t = f_t * C_{t-1} + i_t * C̃_t
# 输出门
o_t = σ(W_o · [h_{t-1}, x_t] + b_o)
# 隐藏状态
h_t = o_t * tanh(C_t)
LSTM的设计使其能够更好地处理长期依赖问题,但序列处理本质上仍是顺序的,这限制了并行计算能力。
LSTM的信息流与梯度路径
LSTM通过细胞状态(cell state)C_t提供了一条梯度高速公路(gradient highway)。从数学角度分析,当遗忘门f_t接近1时,梯度可以几乎无损地流过许多时间步:
∂C_t/∂C_{t-k} = ∏_{i=t-k+1}^t f_i
这意味着即使序列很长,重要信息仍可以从早期时间步传递到后面的时间步,同时允许模型有选择地丢弃不相关信息。
三、Transformer:注意力改变一切
2017年,Google提出的论文《Attention Is All You Need》引入了Transformer架构,彻底改变了序列建模范式。
核心创新:摒弃了递归结构,完全依赖注意力机制并行处理序列。
3.1、Transformer的设计哲学
Transformer架构的设计体现了几个关键思想:
- 并行计算优先:放弃顺序处理,使模型能够大规模并行训练
- 全局上下文访问:每个位置都可以直接访问所有其他位置
- 模块化与层次化:通过堆叠相同的组件构建深层网络
- 可解释性:注意力权重提供了模型决策过程的直观解释
这些设计选择使得Transformer不仅性能优越,而且在计算效率和可扩展性方面都超越了RNN类模型。
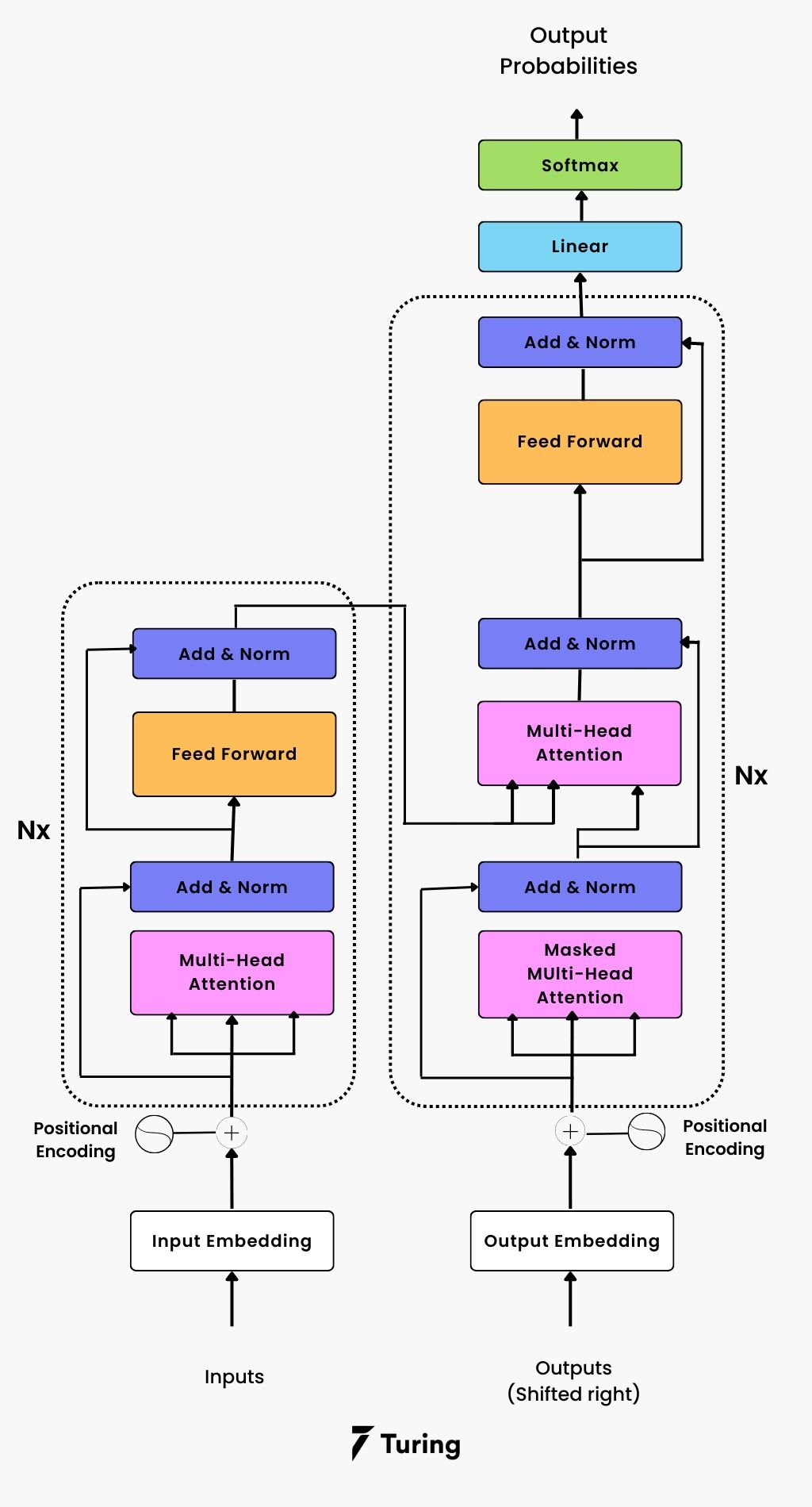
核心原理图:
Self-Attention:长依赖问题的解决方案
直接建立全局连接
Self-Attention机制允许序列中的每个元素直接关注序列中的所有其他元素,
从而建立全局依赖关系。
数学表达
- 首先,对每个输入向量计算三种不同的投影:Query(Q)、Key(K)和Value(V)
Q = X·W^Q
K = X·W^K
V = X·W^V
- 计算注意力分数并应用Softmax获取权重
Attention(Q, K, V) = softmax(QK^T/√d_k)·V
其中√d_k是缩放因子,防止梯度过大。
为什么Self-Attention解决了长依赖问题?
- 并行计算:不像RNN需要顺序处理,Self-Attention可以并行计算所有位置
- 路径长度恒定:任意两个位置之间的信息传递只需一步操作
- 加权求和:通过自适应权重聚合所有位置的信息
Self-Attention的计算复杂度分析
对于长度为n的序列和维度为d的特征,Self-Attention的计算复杂度为:
- 时间复杂度:O(n²·d),主要来自于计算注意力矩阵QK^T
- 空间复杂度:O(n²),需要存储n×n的注意力权重矩阵
虽然RNN的复杂度为O(n·d²),对较长序列看似更有优势,但Self-Attention具有两个关键优点:
- 并行计算:RNN必须顺序计算n步,而Self-Attention可以一次性计算
- 优化友好:矩阵乘法高度优化,在现代GPU/TPU上执行效率远高于递归操作
注意力机制的信息论解释
从信息论角度看,Self-Attention可以理解为一种自适应信息流控制机制。
如果将输入序列视为信息源,注意力权重可以看作是一种动态路由策略,根据当前查询(query)将信息从相关位置(key)传递到当前位置。
这种机制的信息熵(entropy)远低于固定模式的信息传递(如RNN),因为它可以根据内容自适应地选择信息流路径。
多头注意力(Multi-Head Attention)的深层原理
多头注意力是Self-Attention的一个关键扩展,其核心思想是允许模型同时在不同表示子空间中学习不同类型的关系模式:
MultiHead(Q, K, V) = Concat(head_1, head_2, ..., head_h)·W^O
where head_i = Attention(Q·W_i^Q, K·W_i^K, V·W_i^V)
多头机制可以从多个角度解释:
- 集成学习视角:每个头可以看作是一个独立的"弱学习器",共同形成一个"强学习器"
- 特征工程视角:不同的头学习捕获不同类型的特征和关系
- 优化视角:多头结构提供了更丰富的梯度流路径,减轻了优化困难
- 表示学习视角:增加了模型的表达能力,可以捕获更复杂的序列模式
实验表明,在Transformer中,不同的注意力头确实学习到了不同类型的语言关系,包括:
- 语法依赖关系
- 共指关系
- 语义相似性
- 实体关系
- 层次结构关系
Transformer架构概览
Transformer由编码器和解码器组成:
编码器
- 多头自注意力层:允许模型同时关注不同位置的不同表示子空间
- 前馈神经网络:对每个位置独立应用相同的FFN
- 残差连接与层归一化:稳定训练并促进梯度流动
解码器
- 多头自注意力层:处理已生成的输出序列
- 多头交叉注意力层:将解码器的查询与编码器的键和值结合
- 前馈神经网络:与编码器类似
位置编码
由于Self-Attention没有序列位置的概念,Transformer引入位置编码:
PE_(pos,2i) = sin(pos/10000^(2i/d_model))
PE_(pos,2i+1) = cos(pos/10000^(2i/d_model))
Transformer编码器的深度解析
Transformer编码器由N个相同的层堆叠而成,每个层包含两个子层:
- 多头自注意力层
- 前馈神经网络
每个子层都应用了残差连接和层归一化:
LayerNorm(x + Sublayer(x))
这种设计使得信息可以在不同层之间有效流动,减轻了深层网络训练的困难。
前馈神经网络(FFN)的作用
FFN子层是Transformer中常被忽视但非常重要的组件:
FFN(x) = max(0, x·W_1 + b_1)·W_2 + b_2
从功能角度看,FFN可以理解为:
- 特征变换:将注意力机制获得的上下文信息进一步变换
- 非线性引入:通过ReLU激活函数引入非线性,增强模型表达能力
- 参数容量:FFN通常占据模型大部分参数,提供了主要的模型容量
层归一化(Layer Normalization)的重要性
层归一化对每个样本独立地进行归一化处理:
LayerNorm(x) = γ · (x - μ) / (σ + ε) + β
这一操作带来几个关键好处:
- 稳定训练过程,允许使用更高的学习率
- 减少内部协变量偏移(internal covariate shift)
- 使模型对输入规模不敏感
- 帮助梯度平稳流动,尤其在与残差连接结合时
Transformer解码器的特殊设计
解码器在编码器基础上增加了一个关键组件:掩码自注意力(Masked Self-Attention)。
掩码自注意力通过在注意力分数矩阵中添加一个掩码,确保位置i只能关注位置0到i-1的信息:
Mask = np.triu(np.ones((seq_len, seq_len)), k=1) * (-1e9)
Attention = softmax((QK^T/√d_k) + Mask)·V
这一设计使得解码器成为一个自回归(autoregressive)模型,适合生成任务。解码器还包含交叉注意力层,将解码器的查询与编码器的键和值结合,实现编码器-解码器的信息流动。
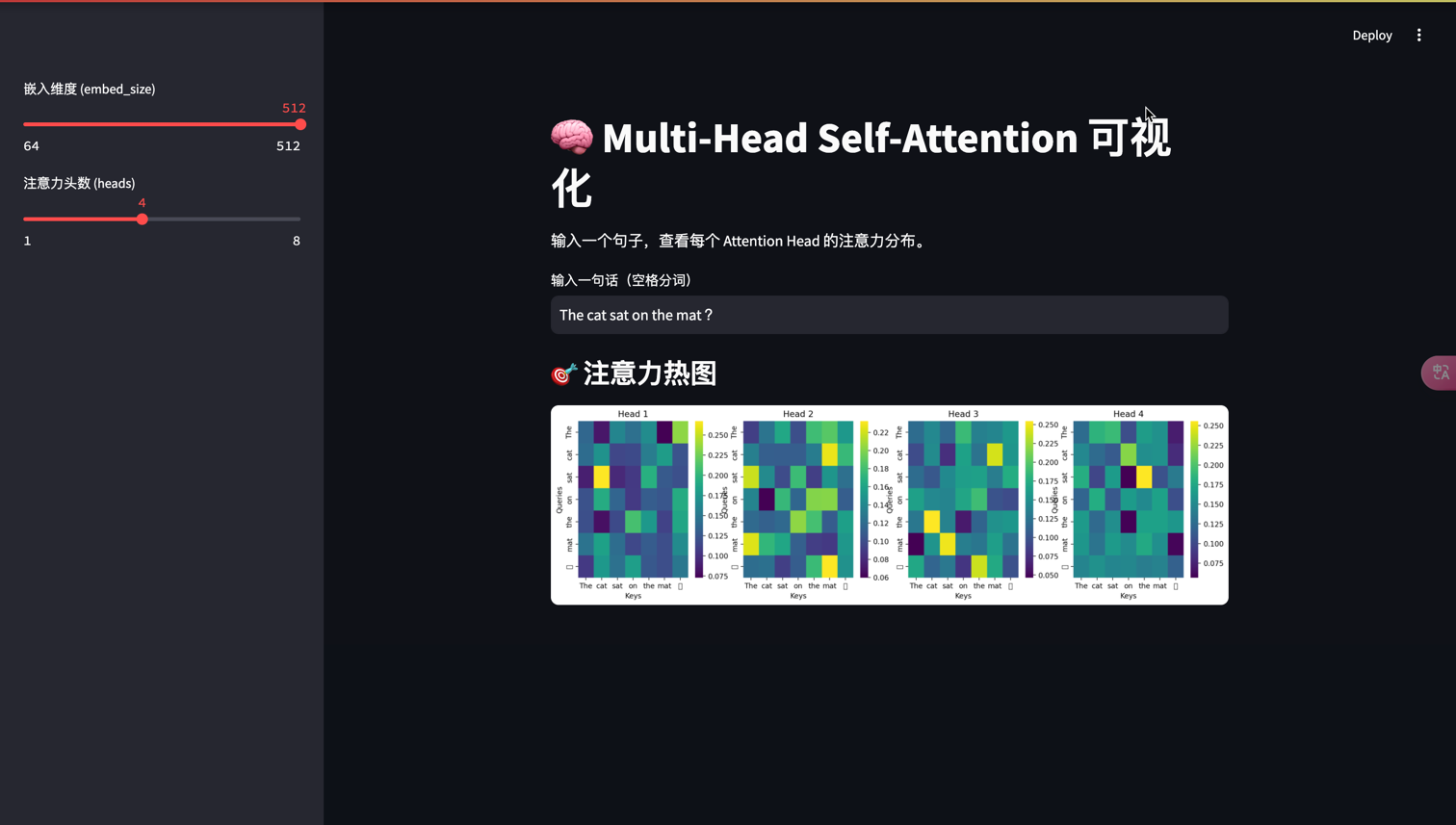
🧪 Self-Attention可视化实现
下面我们用PyTorch实现一个简单的Self-Attention模块并可视化其注意力权重:
import streamlit as st
import torch
import torch.nn as nn
import numpy as np
import seaborn as sns
import matplotlib.pyplot as plt# ===== Self-Attention 模块 =====
class SelfAttention(nn.Module):def __init__(self, embed_size, heads):super(SelfAttention, self).__init__()self.embed_size = embed_sizeself.heads = headsself.head_dim = embed_size // headsassert self.head_dim * heads == embed_size, "Embed size needs to be divisible by heads"self.values = nn.Linear(self.head_dim, self.head_dim, bias=False)self.keys = nn.Linear(self.head_dim, self.head_dim, bias=False)self.queries = nn.Linear(self.head_dim, self.head_dim, bias=False)self.fc_out = nn.Linear(heads * self.head_dim, embed_size)def forward(self, values, keys, query):N = query.shape[0]value_len, key_len, query_len = values.shape[1], keys.shape[1], query.shape[1]# 多头分割values = values.reshape(N, value_len, self.heads, self.head_dim)keys = keys.reshape(N, key_len, self.heads, self.head_dim)query = query.reshape(N, query_len, self.heads, self.head_dim)values = self.values(values)keys = self.keys(keys)queries = self.queries(query)energy = torch.einsum("nqhd,nkhd->nhqk", [queries, keys])attention = torch.softmax(energy / (self.head_dim ** 0.5), dim=3)self.attention_weights = attention.detach().cpu().numpy()out = torch.einsum("nhql,nlhd->nqhd", [attention, values])out = out.reshape(N, query_len, self.heads * self.head_dim)out = self.fc_out(out)return out# ===== Streamlit 界面 =====
st.title("🧠 Multi-Head Self-Attention 可视化")
st.markdown("输入一个句子,查看每个 Attention Head 的注意力分布。")sentence = st.text_input("输入一句话(空格分词)", "The cat sat on the mat")embed_size = st.sidebar.slider("嵌入维度 (embed_size)", 64, 512, 256, step=64)
heads = st.sidebar.slider("注意力头数 (heads)", 1, 8, 4)tokens = sentence.strip().split()
seq_len = len(tokens)if seq_len < 2:st.warning("请输入至少两个词。")st.stop()model = SelfAttention(embed_size, heads)
x = torch.randn(1, seq_len, embed_size) # 模拟输入with torch.no_grad():_ = model(x, x, x)# ===== 可视化 Attention Head =====
st.subheader("🎯 注意力热图")fig, axes = plt.subplots(1, heads, figsize=(4 * heads, 4))
if heads == 1:axes = [axes]for h in range(heads):attn = model.attention_weights[0, h]ax = axes[h]sns.heatmap(attn, ax=ax, cmap="viridis", xticklabels=tokens, yticklabels=tokens)ax.set_title(f"Head {h+1}")ax.set_xlabel("Keys")ax.set_ylabel("Queries")st.pyplot(fig)
Self-Attention代码解析
我们的实现包含了Self-Attention的核心组件,让我们逐步分析其工作原理:
-
初始化:创建Q、K、V的线性投影和输出的全连接层
self.values = nn.Linear(self.head_dim, self.head_dim, bias=False) self.keys = nn.Linear(self.head_dim, self.head_dim, bias=False) self.queries = nn.Linear(self.head_dim, self.head_dim, bias=False) self.fc_out = nn.Linear(heads * self.head_dim, embed_size) -
多头分割:将输入张量分割成多个头
values = values.reshape(N, value_len, self.heads, self.head_dim)这使得每个头可以专注于学习不同类型的关系。
-
注意力分数计算:使用爱因斯坦求和约定高效计算注意力分数
energy = torch.einsum("nqhd,nkhd->nhqk", [queries, keys])einsum允许我们以简洁方式表达复杂的张量运算,大大提高代码可读性。 -
缩放与Softmax:缩放注意力分数并应用Softmax
attention = torch.softmax(energy / (self.head_dim ** (1/2)), dim=3)缩放因子防止梯度在大维度下消失。
-
加权聚合:使用注意力权重聚合Value值
out = torch.einsum("nhql,nlhd->nqhd", [attention, values])这是Self-Attention的核心步骤,每个位置通过加权组合获得上下文信息。
-
拼接与线性变换:合并多头注意力结果
out = out.reshape(N, query_len, self.heads * self.head_dim) out = self.fc_out(out)将多头结果拼接并通过线性变换映射回原始维度。
可视化方法解析
visualize_attention方法展示了不同注意力头的权重分布:
def visualize_attention(self, words=None):# ... existing code ...
通过热力图,我们可以直观观察到:
- 哪些单词之间有强相互作用
- 不同注意力头关注的不同模式
- 模型如何捕获句法和语义关系
完整Transformer架构实现
下面我们实现一个完整的Transformer编码器架构,包括多头注意力、前馈网络、残差连接和层归一化:
import streamlit as st
import torch
import torch.nn as nn
import numpy as np
import seaborn as sns
import matplotlib.pyplot as plt# ===== Self-Attention 模块 =====
class SelfAttention(nn.Module):# 多头自注意力机制实现def __init__(self, embed_size, heads):super(SelfAttention, self).__init__()self.embed_size = embed_sizeself.heads = headsself.head_dim = embed_size // headsassert self.head_dim * heads == embed_size, "Embed size needs to be divisible by heads"# Q, K, V线性变换self.values = nn.Linear(self.head_dim, self.head_dim, bias=False)self.keys = nn.Linear(self.head_dim, self.head_dim, bias=False)self.queries = nn.Linear(self.head_dim, self.head_dim, bias=False)# 多头输出合并变换self.fc_out = nn.Linear(heads * self.head_dim, embed_size)def forward(self, values, keys, query):N = query.shape[0] # 批次大小value_len, key_len, query_len = values.shape[1], keys.shape[1], query.shape[1]# 重塑为多头格式 [批次, 序列长, 头数, 头维度]values = values.reshape(N, value_len, self.heads, self.head_dim)keys = keys.reshape(N, key_len, self.heads, self.head_dim)query = query.reshape(N, query_len, self.heads, self.head_dim)# 线性投影values = self.values(values)keys = self.keys(keys)queries = self.queries(query)# 计算注意力分数 (Q·K^T)energy = torch.einsum("nqhd,nkhd->nhqk", [queries, keys])# 应用缩放和softmaxattention = torch.softmax(energy / (self.head_dim ** 0.5), dim=3)# 保存权重用于可视化self.attention_weights = attention.detach().cpu().numpy()# 注意力加权求和 (Attention·V)out = torch.einsum("nhql,nlhd->nqhd", [attention, values])out = out.reshape(N, query_len, self.heads * self.head_dim)out = self.fc_out(out)return out# ===== Transformer Block =====
class TransformerBlock(nn.Module):# Transformer基本构建块:自注意力+前馈网络def __init__(self, embed_size, heads, dropout, forward_expansion):super(TransformerBlock, self).__init__()self.attention = SelfAttention(embed_size, heads)self.norm1 = nn.LayerNorm(embed_size) # 第一层归一化self.norm2 = nn.LayerNorm(embed_size) # 第二层归一化# 前馈神经网络self.feed_forward = nn.Sequential(nn.Linear(embed_size, forward_expansion * embed_size),nn.ReLU(),nn.Linear(forward_expansion * embed_size, embed_size))self.dropout = nn.Dropout(dropout)def forward(self, value, key, query, mask=None):# 自注意力计算attention = self.attention(value, key, query)# 第一个残差连接x = self.norm1(attention + query)x = self.dropout(x)# 前馈网络forward = self.feed_forward(x)# 第二个残差连接out = self.norm2(forward + x)out = self.dropout(out)return out# ===== Encoder =====
class Encoder(nn.Module):# Transformer编码器def __init__(self, src_vocab_size, embed_size, num_layers, heads, device, forward_expansion, dropout, max_length):super(Encoder, self).__init__()self.embed_size = embed_sizeself.device = device# 词嵌入和位置编码self.word_embedding = nn.Embedding(src_vocab_size, embed_size)self.position_embedding = nn.Embedding(max_length, embed_size)# 堆叠多层Transformer块self.layers = nn.ModuleList([TransformerBlock(embed_size, heads, dropout, forward_expansion)for _ in range(num_layers)])self.dropout = nn.Dropout(dropout)def forward(self, x, mask=None):N, seq_length = x.shape# 生成位置编码positions = torch.arange(0, seq_length).expand(N, seq_length).to(self.device)# 词嵌入+位置编码out = self.word_embedding(x) + self.position_embedding(positions)out = self.dropout(out)# 通过每个Transformer层for layer in self.layers:out = layer(out, out, out, mask)return out# ===== Transformer Encoder 顶层封装 =====
class TransformerEncoder(nn.Module):# Transformer编码器封装类def __init__(self, src_vocab_size, embed_size, num_layers, heads, forward_expansion, dropout, max_length, device="cpu"):super(TransformerEncoder, self).__init__()self.encoder = Encoder(src_vocab_size, embed_size, num_layers, heads, device, forward_expansion, dropout, max_length)self.device = devicedef forward(self, src, src_mask=None):src = src.to(self.device)return self.encoder(src, src_mask)# ===== Streamlit 页面展示 =====
st.title("📚 Transformer Encoder - 多头注意力可视化")
st.markdown("输入一个句子(以空格分词),查看 Transformer 编码器的注意力图。")# 用户输入
sentence = st.text_input("输入句子", "The cat sat on the mat")# 模型参数设置
embed_size = st.sidebar.slider("嵌入维度", 64, 512, 256, step=64)
heads = st.sidebar.slider("注意力头数", 1, 8, 4)
num_layers = st.sidebar.slider("编码器层数", 1, 6, 2)
forward_expansion = st.sidebar.slider("前馈扩展比例", 2, 8, 4)
dropout = st.sidebar.slider("Dropout", 0.0, 0.5, 0.1)# 处理输入文本
words = sentence.strip().split()
vocab = {word: i + 1 for i, word in enumerate(set(words))} # 词到索引映射
reverse_vocab = {v: k for k, v in vocab.items()}# 输入校验
if len(words) < 2:st.warning("请输入不少于两个词。")st.stop()# 准备输入数据
x = torch.tensor([[vocab[w] for w in words]])
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")# 初始化模型
model = TransformerEncoder(len(vocab) + 1, embed_size, num_layers, heads, forward_expansion, dropout, max_length=100, device=device).to(device)# 前向传播
with torch.no_grad():_ = model(x.to(device))# 获取注意力权重
last_attn_layer = model.encoder.layers[-1].attention
attn_weights = last_attn_layer.attention_weights[0] # shape: [heads, seq_len, seq_len]# 绘制注意力热力图
fig, axes = plt.subplots(1, heads, figsize=(4 * heads, 4))
if heads == 1:axes = [axes] # 处理单头情况# 为每个头绘制热力图
for h in range(heads):ax = axes[h]sns.heatmap(attn_weights[h], ax=ax, cmap="viridis", xticklabels=words, yticklabels=words)ax.set_title(f"Head {h+1}")ax.set_xlabel("Keys")ax.set_ylabel("Queries")# 显示图表
st.pyplot(fig)st.success("🎉 可视化完成!")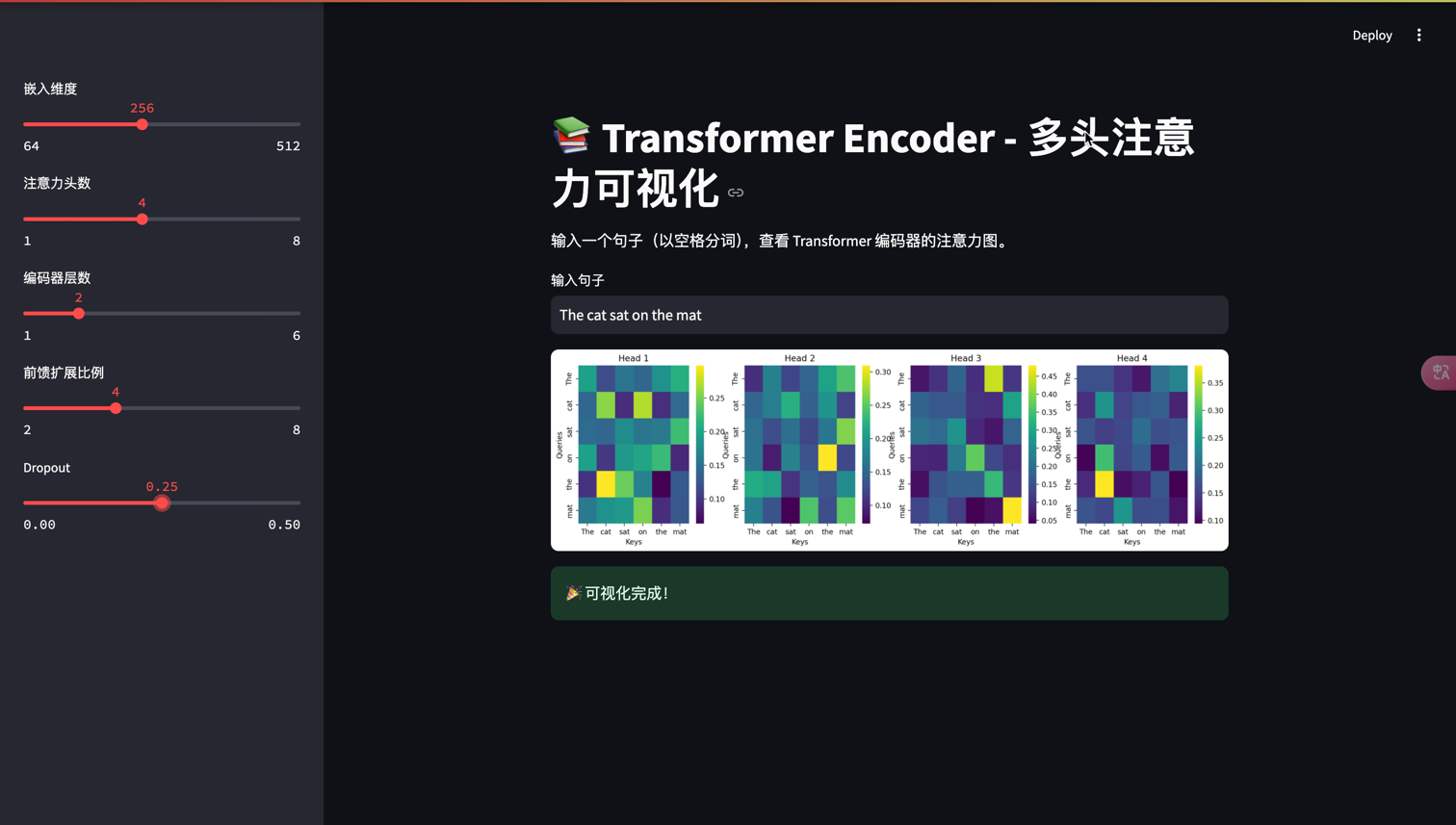
实现要点解析
-
TransformerBlock类实现了注意力层与前馈网络的组合:
- 使用残差连接保持信息流动
- 应用层归一化稳定训练
- 包含dropout降低过拟合风险
-
Encoder类实现了完整的编码器:
- 词嵌入和位置嵌入的组合
- 多个Transformer层的堆叠
- 可选的掩码机制支持
-
位置编码的实现:
positions = torch.arange(0, seq_length).expand(N, seq_length).to(self.device) out = self.word_embedding(x) + self.position_embedding(positions)虽然原论文使用正弦余弦函数生成位置编码,但可学习的位置嵌入通常在实践中表现更好。
-
多层堆叠:
self.layers = nn.ModuleList([TransformerBlock(...) for _ in range(num_layers)])这种设计允许信息在多个层之间流动,逐步提炼出更复杂的特征表示。
训练与优化技巧
Transformer的训练有许多关键技巧:
-
学习率预热(Warmup):
def get_lr(step, d_model, warmup_steps):return d_model**(-0.5) * min(step**(-0.5), step * warmup_steps**(-1.5))在最初几步使用较小学习率,然后逐步增大,最后按步数的平方根衰减。
-
标签平滑(Label Smoothing):
def loss_with_label_smoothing(logits, targets, smoothing=0.1):log_probs = F.log_softmax(logits, dim=-1)targets = torch.zeros_like(log_probs).scatter_(-1, targets.unsqueeze(-1), 1)targets = (1 - smoothing) * targets + smoothing / logits.size(-1)return -torch.sum(targets * log_probs, dim=-1).mean()通过将硬标签转换为软标签,提高模型泛化能力。
-
梯度裁剪(Gradient Clipping):
torch.nn.utils.clip_grad_norm_(model.parameters(), max_norm=1.0)防止梯度爆炸,特别是在训练深层Transformer时。
-
大批量训练(Large Batch Training):使用累积梯度技术模拟大批量训练:
for i, batch in enumerate(dataloader):outputs = model(batch)loss = criterion(outputs, targets) / accumulation_stepsloss.backward()if (i + 1) % accumulation_steps == 0:optimizer.step()optimizer.zero_grad()
小结
从RNN到Transformer的演进代表了序列建模的范式转变:
- RNN依赖顺序处理,难以捕获长距离依赖
- LSTM通过门控机制改善记忆能力,但仍受限于顺序处理
- Transformer利用Self-Attention建立全局连接,彻底解决长依赖问题
Transformer的成功不仅在于其强大的性能,也在于其可并行化的设计,这使得训练更大规模的模型成为可能,
为后续GPT、BERT等大型语言模型奠定了基础。
Transformer的影响与扩展
Transformer架构已经催生了多个重要的模型家族:
- 编码器类模型:以BERT为代表,专注于理解任务
- 解码器类模型:以GPT为代表,专注于生成任务
- 编码器-解码器模型:以T5为代表,适用于翻译、摘要等序列转换任务
这些模型通过预训练-微调范式,在各自领域取得了突破性进展,彻底改变了NLP和其他序列建模任务的研究与应用格局。
在下一讲中,我们将更深入探讨Transformer的架构细节、训练技巧和最新变体,包括Transformer-XL、Reformer等针对长序列建模的优化方案。
相关文章:
第1讲:Transformers 的崛起:从RNN到Self-Attention
序列建模的演进之路 一、RNN( Recurrent Neural Networks):序列处理的开拓者 循环神经网络(RNN)是最早处理序列数据的深度学习结构。RNN的核心思想是在处理序列的每个时间步时保持一个"记忆"状态。 h_t tanh(W_x * x_t W_h * …...

经验分享 | 如何高效使用 `git commit --amend` 修改提交记录
背景 在「地面智能观测项目」这种多模块协作的物联网系统中,版本迭代频率高达每周3次。每个部署包(如v0.3.19)都包含硬件控制脚本、数据处理模块和部署工具,任何提交遗漏都可能导致部署失败。传统的新建提交方式会造成冗余记录&a…...

生物创新药研发为何要上电子实验记录本?
前言:数据驱动的生物创新药研发新范式 在精准医疗时代,生物创新药以其靶向性强、疗效确切的优势,成为肿瘤、自身免疫性疾病等复杂病症的核心治疗方案。国家"十四五" 规划明确将生物制药列为战略性新兴产业,各地政府纷纷…...

PH热榜 | 2025-04-24
1. Peek 标语:AI个人财务教练,帮你做出明智的财务决策。 介绍:Peek的人工智能助手能够主动进行财务检查,分析你的消费模式,并以一种细腻而积极的方式帮助你改善习惯。完全没有评判,也没有负罪感。就像为你…...

民锋视角下的节奏判断与资金行为建模
民锋视角下的节奏判断与资金行为建模 在市场节奏的研判中,行为模型始终是构建逻辑核心。以民锋为代表的一类研究视角,更关注的是微观结构中的资金行为痕迹,而非单一技术形态。 节奏并非由K线决定,而是由成交密度与换手效率共同塑…...

Debian服务器上JSP页面无法加载如何解决?
如果你在 Debian 服务器上部署 JSP 页面无法加载,可以按以下步骤排查和解决问题: 1. 确认安装了 Java 环境 JSP 需要 Java 支持,先确认 Java 是否安装并配置好: java -version如果未安装,使用如下命令安装 OpenJDK&…...

第三篇:Django创建表关系及生命周期流程图
第三篇:Django创建表关系及生命周期流程图 文章目录 第三篇:Django创建表关系及生命周期流程图一、Django中orm创建表关系一、数据库中的表关系二、创建表 二、Django请求生命周期流程图 一、Django中orm创建表关系 一、数据库中的表关系 我们可以通过…...
音视频,yt-dlp下载工具、parole播放器)
【玩泰山派】7、玩linux桌面环境xfce - (2)音视频,yt-dlp下载工具、parole播放器
文章目录 前言yt-dlpyt-dlp概述发展背景特点应用场景使用方式局限性 安装yt-dlpyt-dlp常用命令直接下载默认格式指定格式 查看视频所有分辨率下载指定分辨率参考 parole播放器使用Parole概述源码地址使用 前言 前面安装了ubuntu Xfce桌面环境(xubuntu-desktop),现在…...

【文献速递】NMR代谢组寻找预测DR发展的候选标志物
2024年7月5日,中山大学中山眼科中心王伟教授团队在Ophthalmology(IF:13.2)上发表了题为“Plasma Metabolomics Identifies Key Metabolites and Improves Prediction of Diabetic Retinopathy:Development and Validat…...
)
flask学习(1)
1.基本框架 from flask import Flask app Flask(__name__)app.route(/) def hello():return "<h1>Hello, Flask in Conda!</h1>"if __name__ __main__:app.run(host0.0.0.0, port5000, debugTrue) # 关键行! 在此基础上 from flask imp…...

详解springcloudalibaba采用prometheus+grafana实现服务监控
1.官网下载安装 prometheus和grafana promethus 官网:https://prometheus.io/ 1.下载windows版本安装包 2.双击启动 3.访问地址 http://localhost:9090 grafana 官网:https://grafana.com/ 1.下载windows版本安装包 2.启动 ,默认windo…...

Java查询数据库表信息导出Word
参考: POI生成Word多级标题格式_poi设置word标题-CSDN博客 1.概述 使用jdbc查询数据库把表信息导出为word文档, 导出为word时需要下载word模板文件。 已实现数据库: KingbaseES, 实现代码: 点击跳转 2.效果图 2.1.生成word内容 所有数据库合并 数据库不合并 2.2.生成文件…...

【金仓数据库征文】从云计算到区块链:金仓数据库的颠覆性创新之路
目录 一、引言 二、金仓数据库概述 2.1 金仓数据库的背景 2.2 核心技术特点 2.3 行业应用案例 三、金仓数据库的产品优化提案 3.1 性能优化 3.1.1 查询优化 3.1.2 索引优化 3.1.3 缓存优化 3.2 可扩展性优化 3.2.1 水平扩展与分区设计 3.2.2 负载均衡与读写分离 …...

Kotlin函数体详解:表达式函数体 vs 代码块函数体——使用场景与最佳实践
🧩 什么是表达式函数体(Expression Body)? 表达式函数体指的是使用 号直接返回一个表达式结果的函数写法。 ✅ 示例: fun add(x: Int, y: Int): Int x y这个函数的意思是:传入两个整数,返…...

【bug修复】一次诡异的接口数据显示 bug 排查之旅
一次诡异的接口数据显示 bug 排查之旅 在后端开发的日常中,总会遇到一些让人摸不着头脑的 bug,最近我就经历了一个颇为诡异的情况。接口接收到的响应 data 对象里字段明明都有值,但直接打印到控制台却显示空字符串,最后通过一个简…...

C++ RPC以及cmake
目录 1.RPC概念 2.RPC实现计算举例 3.python进行rpc调用 4.thrift实现分布式容器创建 5.阶段总结 6.cmake简介 7.cmake使用的一般步骤 8.cmake编译多层次文件 9.cmake编译多种交付件 1.RPC概念 # 1.需求分析 靠谱的商用项目不是只有一个可执行程序就够了的。好的商用…...

数字隔离器,筑牢AC-DC数字电源中的“安全防线”
在传统工业与现代科技高速交融的发展浪潮中,AC-DC数字电源作为电能转换的核心枢纽,不仅能将交流电精准地转化为直流电,还可通过软件编程实现电流限制、过温保护与设定输出电压等多种功能,是现代众多电力电子基础设施中不可或缺的精…...

使用“复合索引”和不使用“复合索引”的优化对比
目录 1.创建数据库 2.未创建索引 3.创建索引 4.结论 1.创建数据库 CREATE TABLE orders (order_id INT AUTO_INCREMENT PRIMARY KEY,customer_id INT,order_date DATE,total_amount DECIMAL(10, 2));插入数据: INSERT INTO orders (customer_id, order_date, t…...

.NETCore部署流程
资料下载:https://download.csdn.net/download/ly1h1/90684992 1.下载托管包托管捆绑包 | Microsoft Learn,下载后点击安装即可。 2.安装IIS 3.打开VS2022,新建项目,选择ASP.NET Core Web API 5.Program修改启动项,取…...

深入解析微软MarkitDown:原理、应用与二次开发指南
一、项目背景与技术定位 微软开源的MarkitDown并非简单的又一个Markdown解析器,而是针对现代文档处理需求设计的工具链核心组件。该项目诞生于微软内部大规模文档系统的开发实践,旨在解决以下技术痛点: 大规模文档处理性能:能够高…...

Rust 2025:内存安全革命与异步编程新纪元
Rust 2025 Edition通过区域内存管理、泛型关联类型和零成本异步框架三大革新,重新定义系统级编程语言的能力边界。本次升级不仅将内存安全验证效率提升80%,更通过异步执行器架构优化实现微秒级任务切换。本文从编译器原理、运行时机制、编程范式转型三个…...

Vue3 setup、计算属性、侦听器、响应式API
一、setup 一、setup 函数基础 作用:组合式 API 的入口,用于定义响应式数据、方法和生命周期钩子 执行时机:在 beforeCreate 之前调用,此时组件实例尚未创建 基本结构: export default {setup(props, context) {/…...
)
从内核到应用层:深度剖析信号捕捉技术栈(含sigaction系统调用/SIGCHLD回收/volatile内存屏障)
Linux系列 文章目录 Linux系列前言一、进程对信号的捕捉1.1 内核对信号的捕捉1.2 sigaction()函数1.3 信号集的修改时机 二、可重入函数三、volatile关键字四、SIGCHLD信号 前言 Linux系统中,信号捕捉是指进程可以通过设置信号处理函数来响应特定信号。通过信号捕捉…...

【KWDB 创作者计划】_嵌入式硬件篇---寄存器与存储器截断与溢出
文章目录 前言一、寄存器与存储器1. 定义与基本概念寄存器(Register)位置功能特点存储器(Memory)位置功能特点2. 关键区别3. 层级关系与协作存储层次结构协作示例4. 为什么需要寄存器性能优化指令支持减少总线竞争5. 其他寄存器类型专用寄存器程序计数器(PC)栈指针(SP)…...

Python torchvision.datasets 下常用数据集配置和使用方法
torchvision.datasets 提供了许多常用的数据集类,以下是一些常用方法(datasets中有大量数据集处理方法,这里仅展示了部分数据集处理方法)及其实现类的介绍、用法和输入参数解释: CIFAR CIFAR10 :包含 10 个…...

unity使用iTextSharp生成PDF文件
iTextSharp 可以在VS中工具下面得NuGet包管理器中下载 ,具体操作可以搜一下 很多 , 我直接把我得生成pdf代码附上 我这个是生成我一个csv文件内容和图片 using System.IO; using UnityEngine; using iTextSharp.text; using iTextSharp.text.pdf; using…...

django admin 添加自定义页面
在Django中,你可以通过多种方式向Django Admin添加自定义页面。以下是一些常见的方法: 方法1:使用ModelAdmin的get_urls()方法 如果你只是想添加一个简单的页面来展示信息,你可以在你的ModelAdmin类中重写get_urls()方法。 from…...

Java并发编程|CompletableFuture原理与实战:从链式操作到异步编排
🔥 本文系统讲解Java并发编程核心类CompletableFuture,涵盖线程池配置策略、异步编程实践、异常处理机制等关键技术。通过电商订单系统与物流调度实战案例,深度解析:1)CompletableFuture链式操作与异步编排 2)多线程任务聚合与结果处理 3)生产级异常处理方案 4)组合操…...
设计流程详解)
动态自适应分区算法(DAPS)设计流程详解
动态自适应分区算法(Dynamic Adaptive Partitioning System, DAPS)是一种通过实时监测系统状态并动态调整资源分配策略的智能算法,广泛应用于缓存优化、分布式系统、工业制造等领域。本文将从设计流程的核心步骤出发,结合数学模型…...

优雅实现网页弹窗提示功能:JavaScript与CSS完美结合
在现代Web开发中,弹窗提示是提升用户体验的重要元素之一。本文将深入探讨如何实现一个优雅、可复用的弹窗提示系统,避免常见问题如重复触发、样式混乱等。 核心代码解析 // 控制弹窗是否可以显示的标志 let alertStatus true;// 显示提示信息 functio…...

LeetCode-Hot100
数组 1.数组——最大子数组和 解题思路:动态规划 动态规划解决问题的步骤:1.理解题意。题目要求只返回结果,不要求得到最大的连续子数组的哪一个,这样的问题常常可以用动态规划。 2.定义子问题:eg:以 −…...

【Redis】有序集合类型Sortedset 常用命令详解
此类型和 set 一样也是 string 类型元素的集合,且不允许重复的元素 不同的是每个元素都会关联一个double类型的分数,redis正是通过分数来为集合中的成员进行从小到大的排序 有序集合的成员是唯一,但分数(score)却可以重复 1. zadd - 添加 语法…...
)
前缀和-724.寻找数组的中心下标-力扣(LeetCode)
一、题目解析 我们需要求出中心下标处两边的和是否相等。 二、算法解析 解法1:暴力枚举 O(n*2)(时间复杂度) 固定i,计算[0,i-1]的和,计算[i1,n-1]的和,然后比较是否相等。遍历i为n次,每次计算n-1个数据的值ÿ…...

缓存与数据库数据一致性:旁路缓存、读写穿透和异步写入模式解析
旁路缓存模式、读写穿透模式和异步缓存写入模式是三种常见的缓存使用模式,以下是对三种经典缓存使用模式在缓存与数据库数据一致性方面更全面的分析: 一、旁路缓存模式(Cache - Aside Pattern) 1.数据读取流程 应用程序首先向缓…...

HTML邮件背景图兼容 Outlook
在 HTML 邮件中设置背景图片时,Outlook(尤其是桌面版的 Outlook for Windows)经常不会正确显示背景图,这是因为outlook 是使用 Word 作为邮件渲染引擎,而不是标准的 HTML/CSS 渲染方式。 推荐的解决方案:使…...
)
Linux之七大难命令(The Seven Difficult Commands of Linux)
Linux之七大难命令 、背景 作为Linux的初学者,肯定要先掌握高频使用的指令,这样才能让Linux的学习在短时间内事半功倍。但是,有些指令虽然功能强大,但因参数多而让初学者们很害怕,今天介绍Linux中高频使用࿰…...

每日Html 4.24
📚 每日一个Html小知识 🐍 每天花1分钟,解锁一个Html实用技巧/冷知识!无论是新手还是老手,这里都有让你眼前一亮的编程干货。 ✨ 今日主题:<dialog> 标签 💡 你知道吗? 浏览…...

YOLOv11改进-双Backbone架构:利用双backbone提高yolo11目标检测的精度
一、引言:为什么我们需要双Backbone? 在目标检测任务中,YOLO系列模型因其高效的端到端检测能力而备受青睐。然而,传统YOLO模型大多采用单一Backbone结构,即利用一个卷积神经网络(CNN)作为特征提…...

嵌入式Linux驱动开发:LED实验
在嵌入式Linux驱动开发中,LED实验可以通过多种方式实现,主要包括设备树下的LED实验、新字符设备驱动的LED实验和GPIO子系统的LED实验。这三种方式在硬件资源管理、驱动架构和开发流程上有显著区别,下面从多个维度进行对比分析: 1.…...
)
系统与网络安全------弹性交换网络(2)
资料整理于网络资料、书本资料、AI,仅供个人学习参考。 Eth-Trunk 组网中经常会遇到的问题 链路聚合技术 概述 Eth-Trunk(链路聚合技术)作为一种捆绑技术,可以把多个独立的物理接口绑定在一起,作为一个大带宽的逻辑…...

Kotlin Multiplatform--01:项目结构基础
Kotlin Multiplatform--01:项目结构基础 引言Common CodeTargetsExpected 和 actual1.使用函数2.使用接口 引言 以下为使用 Android Studio 创建的默认 Kotlin Multiplatform 的项目结构,本章将对项目结构进行简单介绍,让读者对 Kotlin Multi…...
相关知识点)
SEO(Search Engine Optimization,搜索引擎优化)相关知识点
SEO(Search Engine Optimization)是指搜索引擎优化,是计算机领域中通过技术手段和内容策略,提升网站在搜索引擎(如Google、Bing、百度)中自然(非付费)排名的系统性方法。是一种通过优…...

轻松完成视频创作,在线视频编辑器,无需下载软件,功能多样实用!
小白工具的在线视频编辑https://www.xiaobaitool.net/videos/edit/ 功能丰富、操作简便,在线裁剪或编辑视频工具,轻松完成视频创作能满足多种视频编辑需求。 格式支持广泛:可编辑超百种视频格式,基本涵盖常见和小众视频格式&#…...
)
typescript学习笔记(全)
1.安装 全局安装 npm i -g typescript局部安装 npm i typescript初始化 tsc --init就会在所在目录下创建出一个tsconfig.json的ts配置文件 2.编译 如果是全局安装 tsc index.ts就会在同目录下编译出一个index.js文件 如果是局部安装 npx tsc index.ts3.特性 1.静态类…...

centos挂载新的硬盘
如果要将 nvme0n1 挂载到 /data 目录(而不是 /),操作会更简单,无需迁移系统文件。以下是详细步骤: 1. 检查磁盘情况 lsblk输出: NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT sda 8:0 …...

客户案例 | 西昊智能家具:日事清【目标】【日程】【项目】助力高效OKR管理
随着社会现代化、科技化的发展,人们越来越青睐智能化的家具产品,以此来提升家居的安全性、便利性与舒适性。目前,智能家具的行业规模正在不断扩张,产业也逐渐步入高质量增长模式。面对繁荣的市场前景,西昊智能家具与日…...

16.磁环在EMC设计中的选型与运用
磁环在EMC设计中的选型与运用 1. 磁环选型的参数和注意事项2. 磁环的选型方法3. 非晶磁环 1. 磁环选型的参数和注意事项 (1)损耗电阻R(f)和L(f)是频率的函数,因此IL也是频率的函数; (2)fL段,R(f…...

oralce 查询未提交事务和终止提交事务
查询提交记录 SELECT s.sid,s.serial#,s.username,s.status,t.start_time,t.used_ublk,t.log_io,t.phy_io FROM v$session sJOIN v$transaction t ON s.saddr t.ses_addr; 查到的记录如下: 如果要终止第一次提交,如下操作 ALTER SYSTEM KILL SESSION…...

智能小助手部署 Win10 + ollama的Deepseek + CentOS+ maxKB
一、适用场景 1、企业内部知识管理 (1)快速查询政策与流程文档: 员工通过自然语言提问,MaxKB 能迅速定位相关文档并给出准确答案,减少人工检索成本,提升企业内部知识获取的效率。 (2࿰…...

CentOS 7 系统中,防火墙要怎么使用?
在 CentOS 7 系统中,默认有两个防火墙管理工具: firewalld(默认的动态防火墙,基于 D-Bus 管理) iptables(传统的静态防火墙,底层由 netfilter 提供支持) 是否需要关闭这两个防火墙…...