DS B/B+/B*树及其应用(21)
文章目录
- 前言
- 一、常见的搜索结构
- 内查找
- 外查找
- 二、B树的概念
- 三、B树的插入分析
- 四、B树的插入实现
- B树的节点设计
- B树的查找
- B树插入Key / Key & Value的过程
- B树的完整插入代码
- B树的中序遍历
- B树的删除
- B树的性能分析
- 五、B+树
- 六、B*树
- 七、B树系列总结及其应用
- 总结
前言
我们计算机界有自己的3b1b!!!
附上链接:
B树(B-树) - 来由, 定义, 插入, 构建
B树(B-树) - 删除
数据结构合集 - B+树
这个真的是难死我了,还得是我,谢谢DeepSeek老师!
一、常见的搜索结构
内查找
| 种类 | 数据格式 | 时间复杂度 |
|---|---|---|
| 顺序查找 | 无要求 | O(N) |
| 二分查找 | 有序 | O(logN) |
| 二叉搜索树 | 无要求 | O(N) |
| 二叉平衡树(AVL树和红黑树) | 无要求 | O(logN) |
| 哈希 | 无要求 | O(1) |
外查找
以上结构适合用于数据量相对不是很大,能够一次性存放在内存中,进行数据查找的场景。如果数据量很大,比如有100G数据,无法一次放进内存中,那就只能放在磁盘上了,如果放在磁盘上,有需要搜索某些数据,那么如何处理呢?那么我们可以考虑将存放关键字及其映射的数据的地址放到一个内存中的搜索树的节点中,找数据时比较关键字,找到关键字也就找到这个数据在磁盘的地址,然后去这个地址去磁盘访问数据。
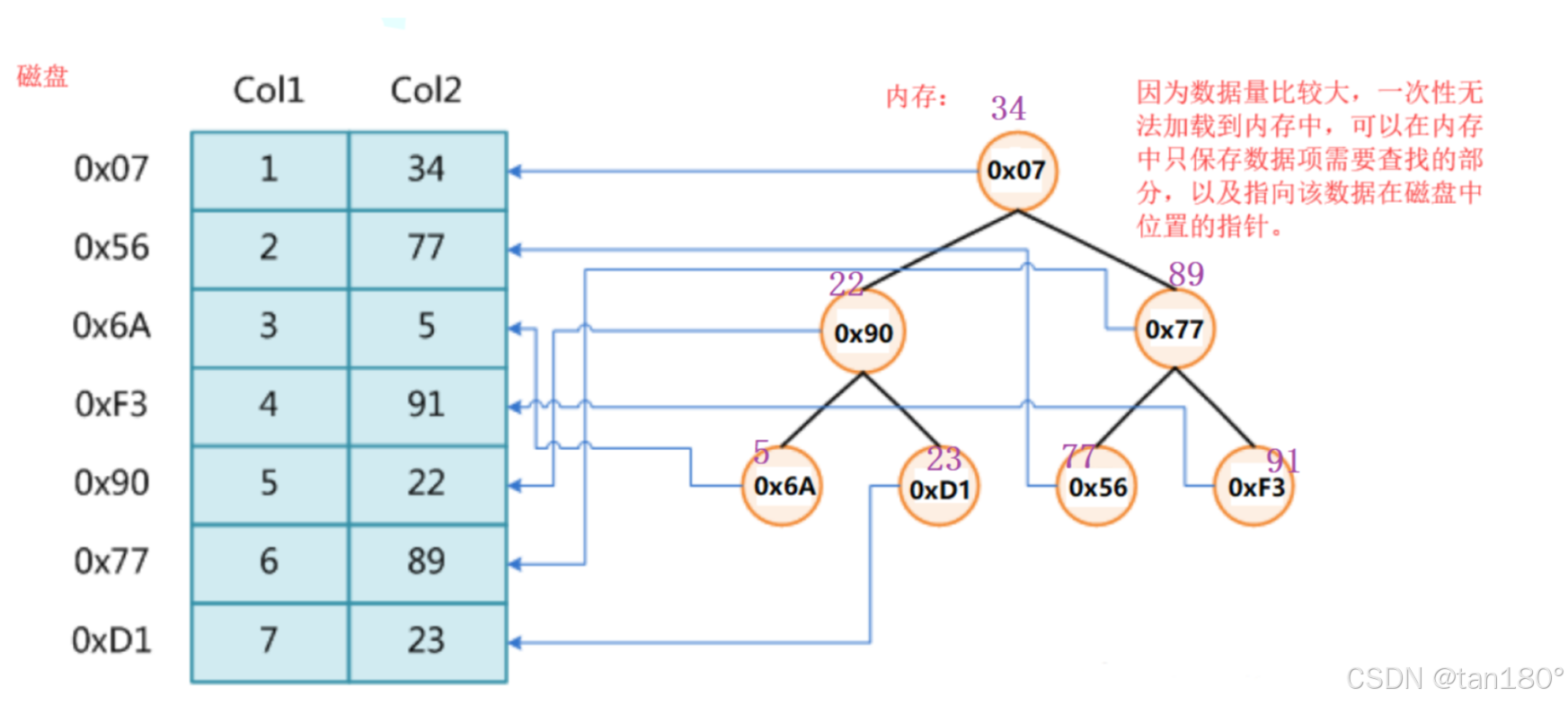
节点可以不存关键字, 只存对应磁盘的地址。这个时候查找就要拿着地址去访问磁盘然后看关键字是否匹配。这个时候还是一样关键字比当前节点关键字大往右走,否则往左走。每一次比较节点都是一次IO
但是这里的问题是,要走高度次磁盘IO,因为节点里面只有地址要进行关键字比较就要读一次磁盘。这个时候 AVL/红黑树 就不适合了,都是O(logN),虽然在内存中查找比较快,10亿个数字需要30次。但是在磁盘中如果是30次IO,那就很慢了。还有哈希表,虽然查找说是O(1),但是这个O(1)并不是一次而是常数次,更大的问题是极端场景下哈希冲突可能会非常严重,效率会下降很多。即使哈希表挂的是红黑树还是O(logN)。
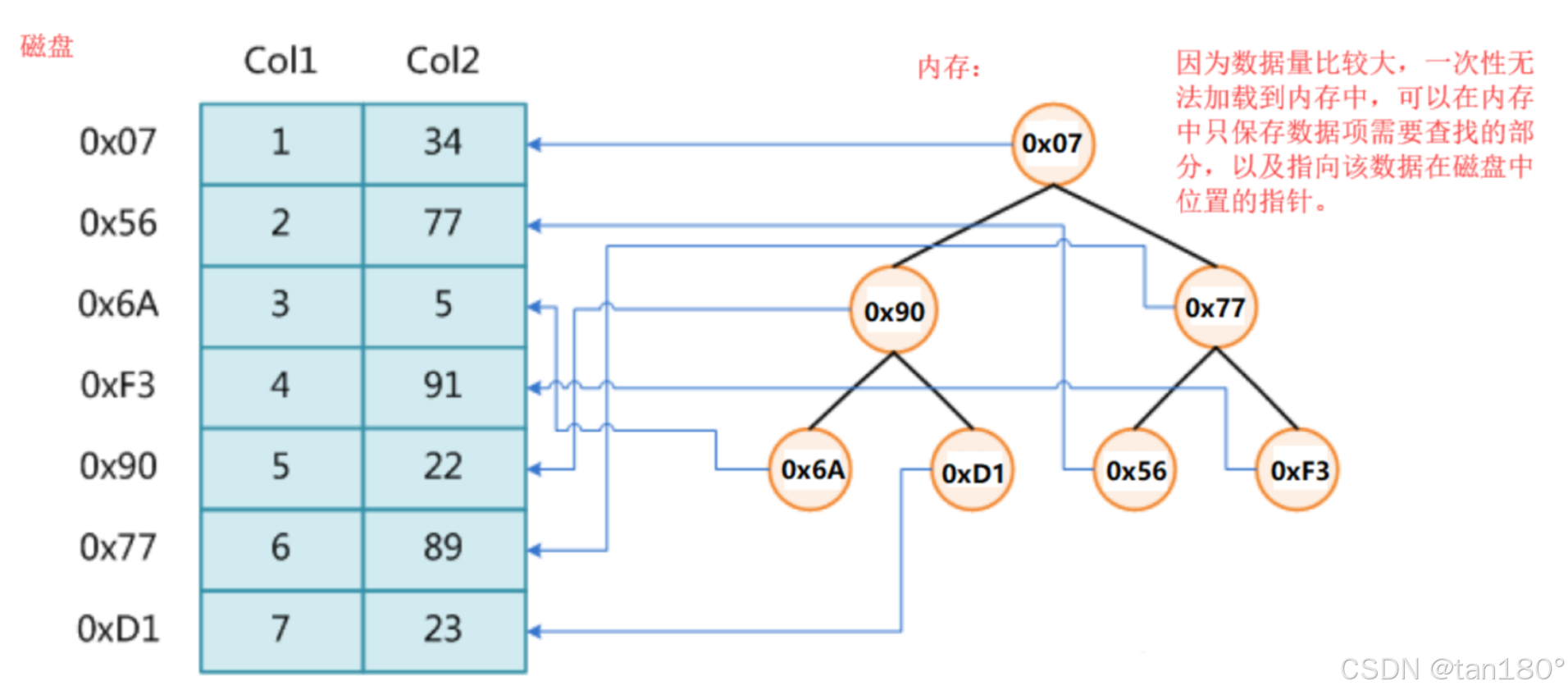
使用平衡二叉树搜索树的缺陷:
平衡二叉树搜索树的高度是logN,这个查找次数在内存中是很快的。但是当数据都在磁盘中时,访问磁盘速度很慢,在数据量很大时,logN次的磁盘访问,是一个难以接受的结果。
使用哈希表的缺陷:
哈希表的效率很高是O(1),但是一些极端场景下某个位置冲突很多,导致访问次数剧增,也是难以接受的。
那有没有更好的数据结构能够替代上面的东西呢?
就是我们今天讲得内容,B树及其系列!!!
对于磁盘IO来说,其实我们是IO定位需要较长的时间,于是我们可以在此基础上去做文章
- 压缩高度,二叉变多叉
- 一个节点存有多个关键字及映射的值
二、B树的概念
1970年,R.Bayer和E.mccreight提出了一种适合外查找的树,它是一种平衡的多叉树,称为B树(后面有一个B的改进版本B+树,然后有些地方的B树写的的是B-树,注意不要误读成"B减树")。一棵m阶( m > 2 )的B树,是一棵平衡的M路平衡搜索树,可以是空树或者满足一下性质:
- 根节点至少有两个孩子
- 每个分支节点都包含k-1个关键字和k个孩子,其中 ceil(m/2) ≤ k ≤ m ceil是向上取整函数(分支节点,孩子比关键字保持多一个的关系)
- 每个叶子节点都包含k-1个关键字,其中 ceil(m/2) ≤ k ≤ m
- 所有的叶子节点都在同一层
- 每个节点中的关键字从小到大排列,节点当中k-1个元素正好是k个孩子包含的元素的值域划分
- 每个结点的结构为:(n,A0,K1,A1,K2,A2,… ,Kn,An) 其中,Ki(1≤i≤n)为关键字,且Ki<Ki+1(1≤i≤n-1)。Ai(0≤i≤n)为指向子树根结点的指针。且Ai所指子树所有结点中的关键字均小于Ki+1。n为结点中关键字的个数,满足ceil(m/2)-1≤n≤m-1。
Ai是指向孩子的指针,Ki是关键字,从每个结点的结构上我们就可以看到孩子的数量比关键字多一个。
总结:
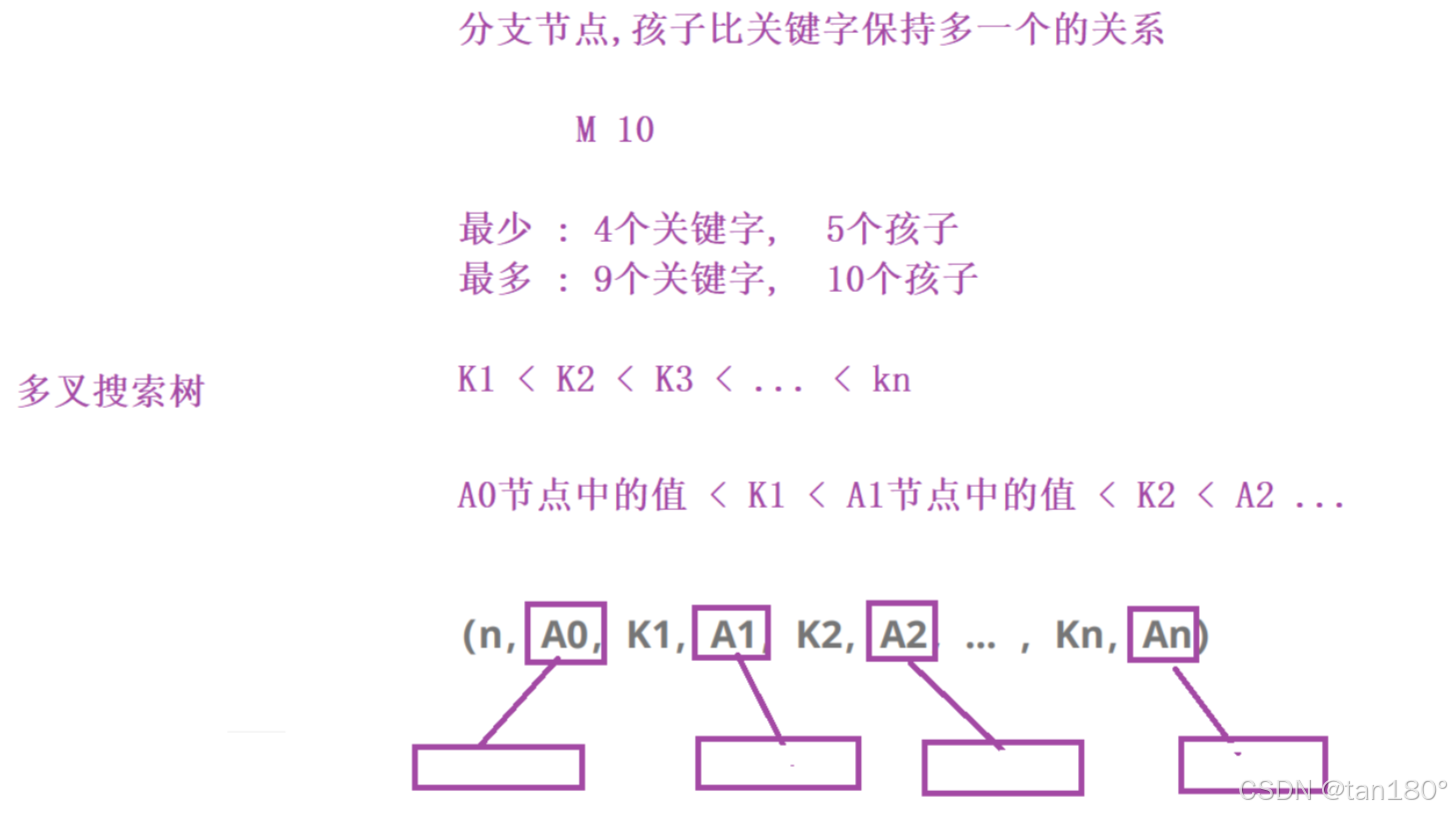
实际上M通常会设计的比较大,M = 1024,一个节点1023个关键字,1024个孩子。
三、B树的插入分析
最难的要来咯!
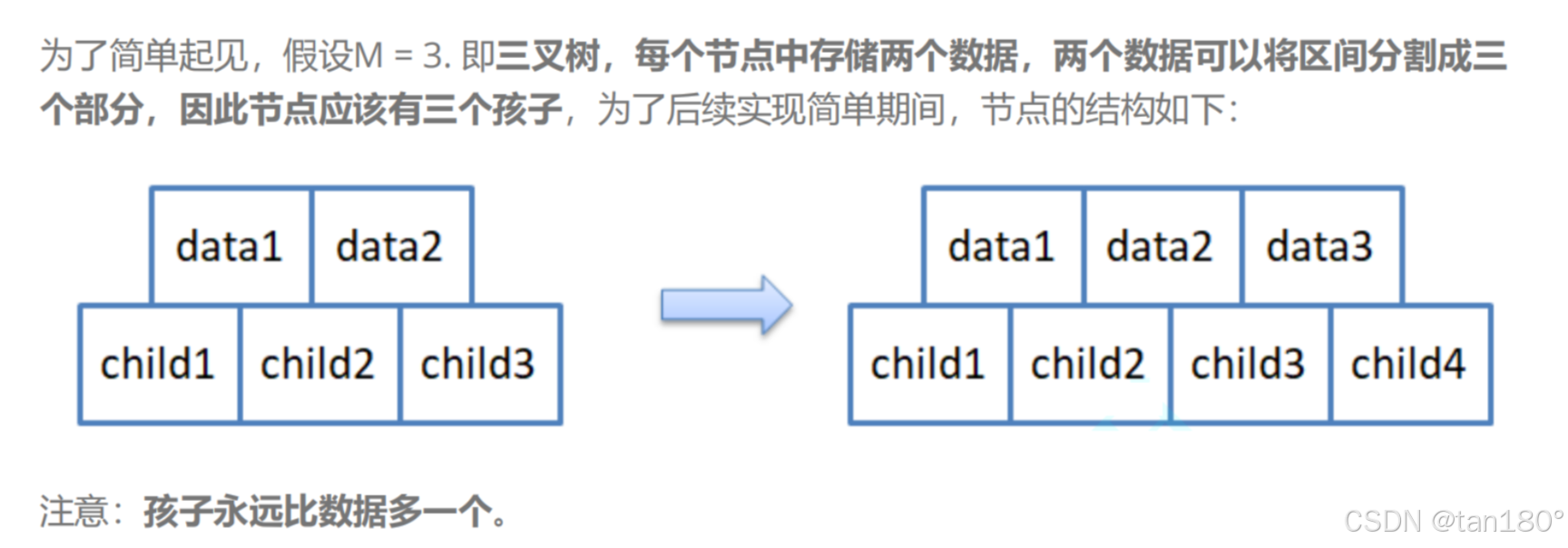
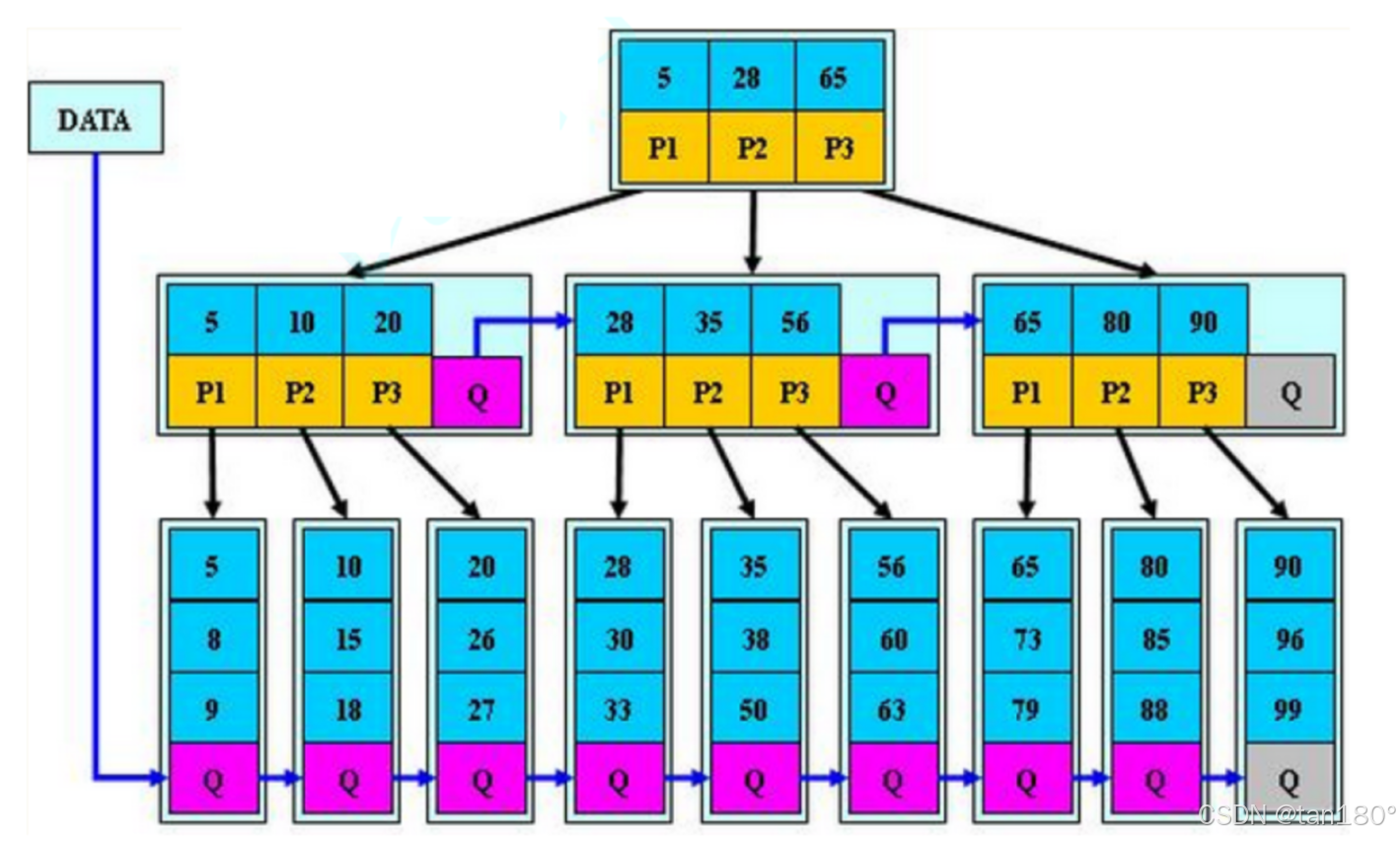
为了简单起见,假设M = 3. 即三叉树,正常来说每个节点中最多存储两个关键字,最少一个关键字,两个关键字可以将区间分割成三个部分,因此节点应该有三个孩子。
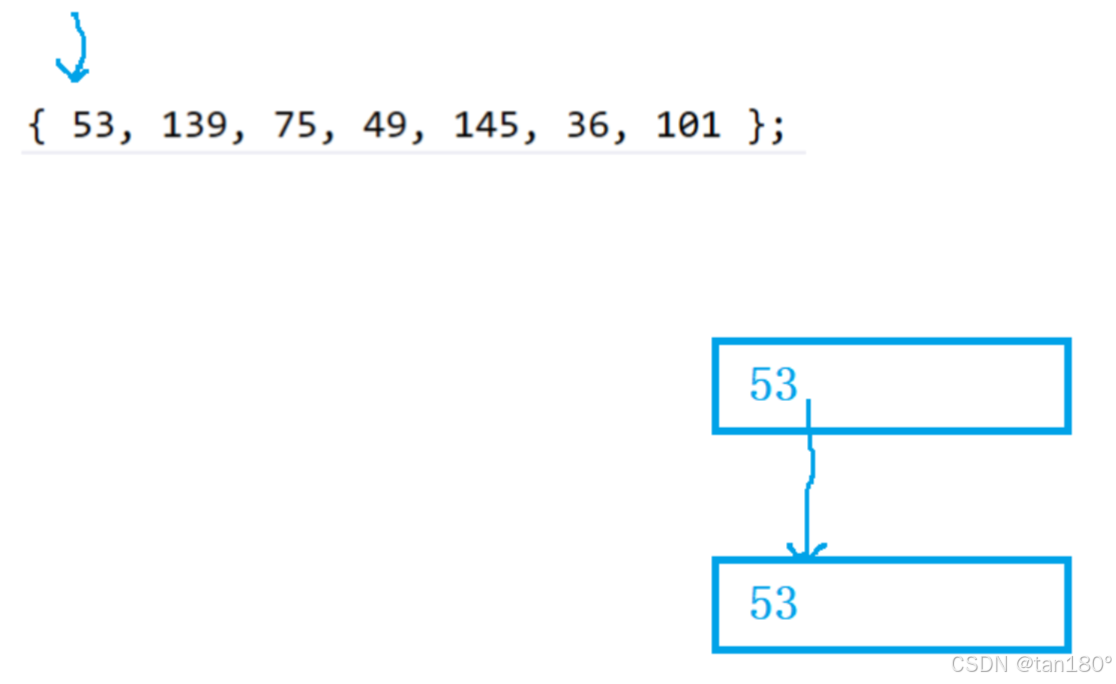
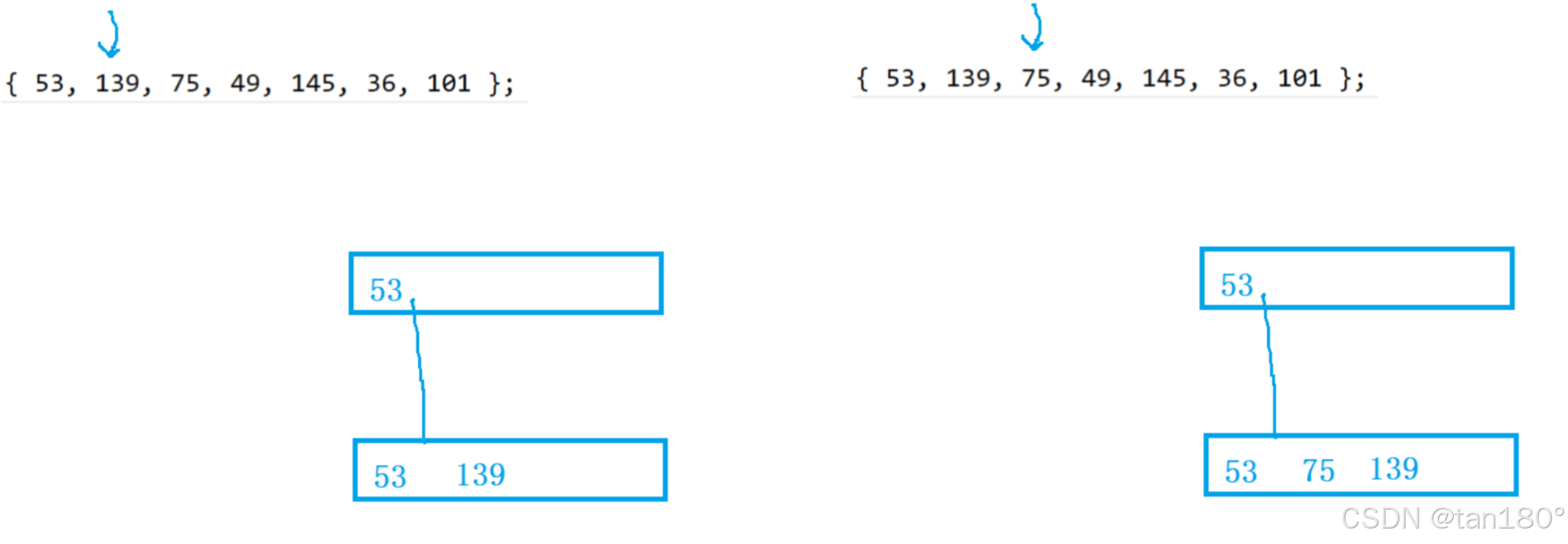
用序列 {53, 139, 75, 49, 145, 36, 101} 构建B树的过程如下:
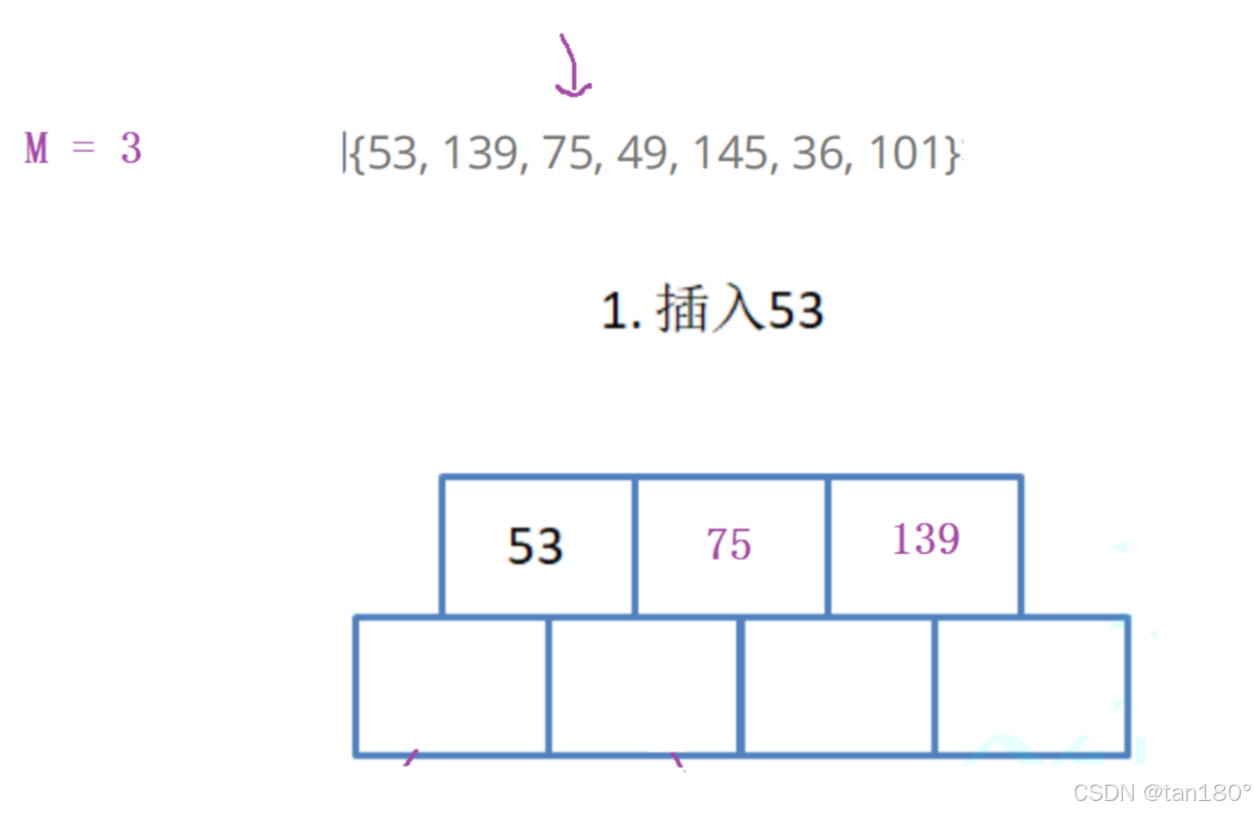
根节点至少有两个孩子,这里可以这样理解,最开始插入一个关键字,它有两个孩子,可以认为是空。所以根节点要单独拿出来。
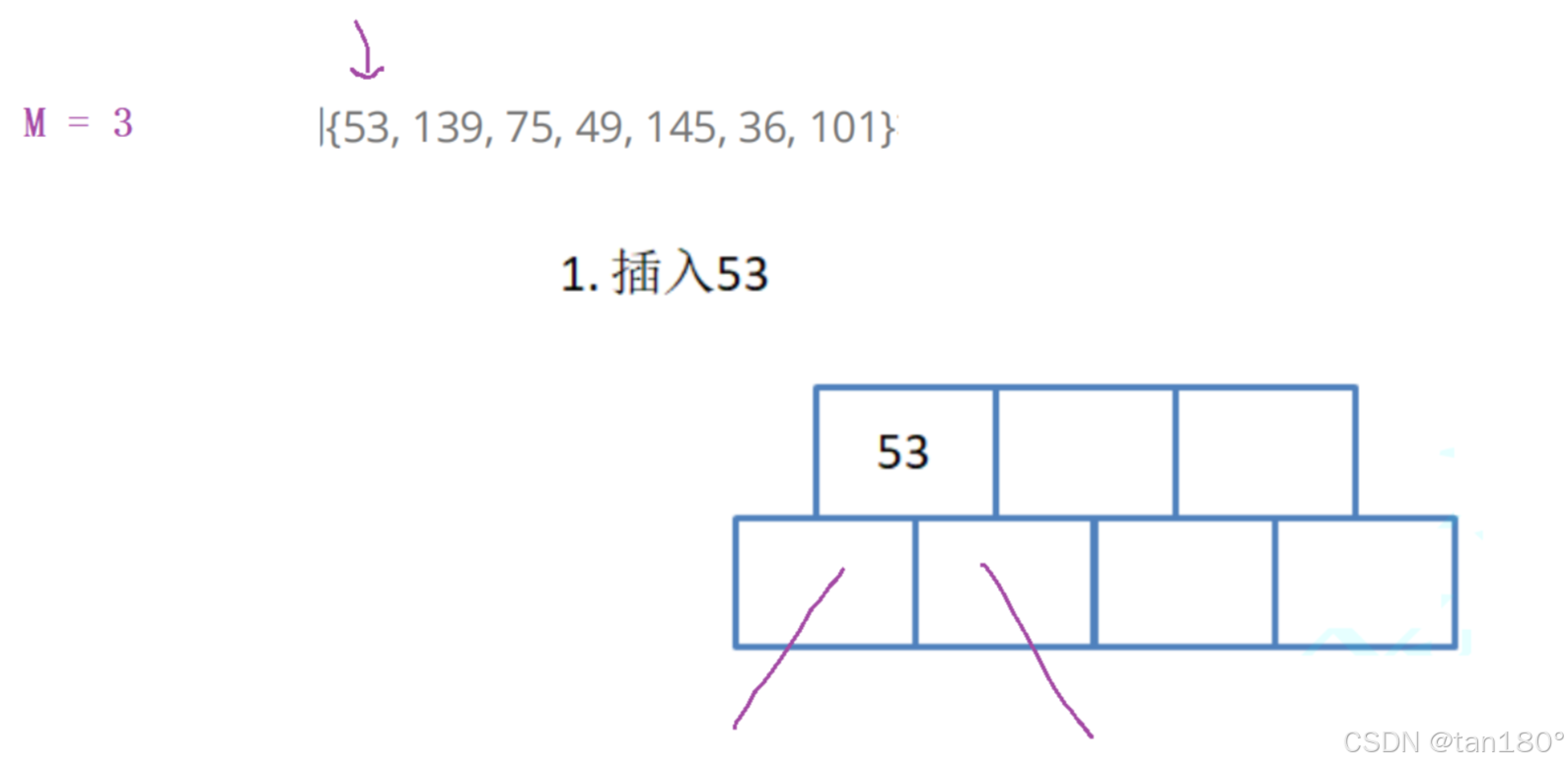
注意到 M = 3,正常来说不应该是2个关键字和3个孩子吗,为什么这里是3个关键字和4个孩子?多放一个是有原因的。
插入139没有什么影响
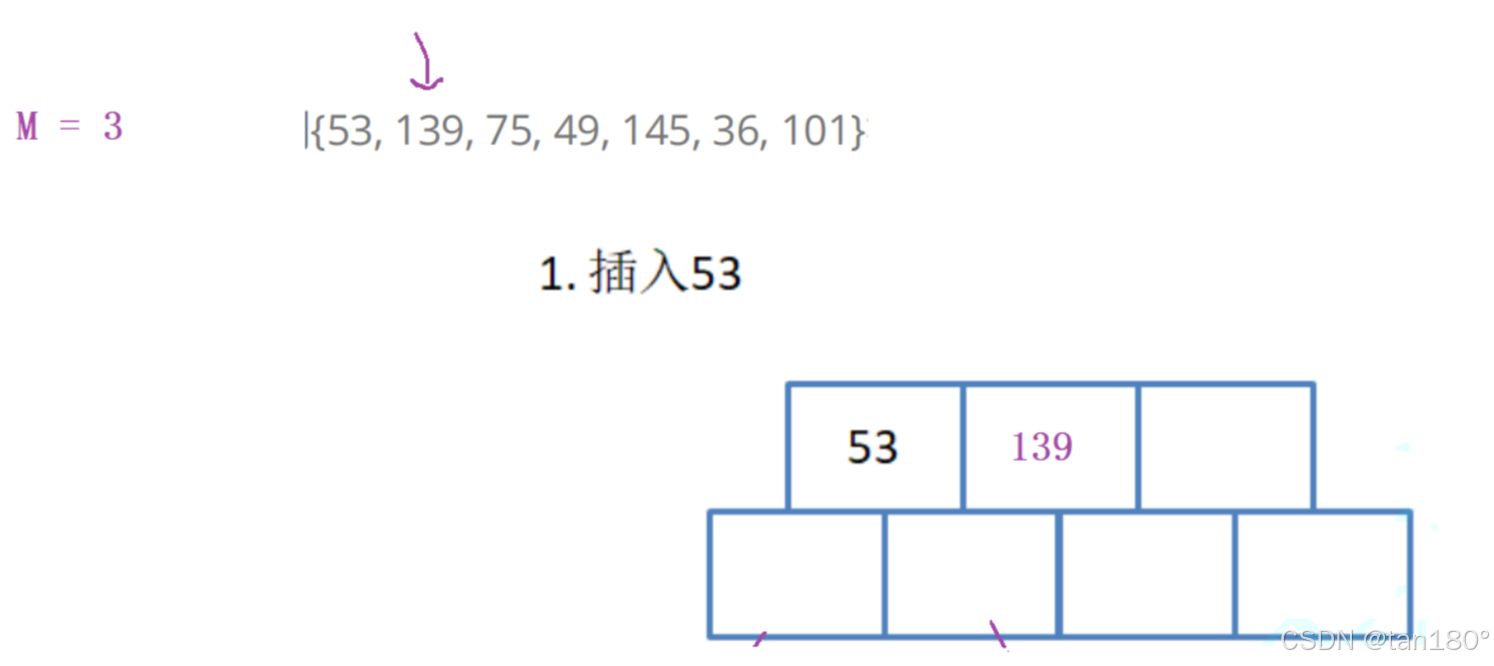
在插75,如果不多开一个,这个地方待会实现会变得复杂。插入的值因为要保证是有序的,所以可能在最前面,可能在中间,可能在最后面。但是现在并不敢就直接插入,一插入就要越界了。关键字个数等于M,关键字最多只能有M-1个。
基于这里的原因,我们就多给一个。
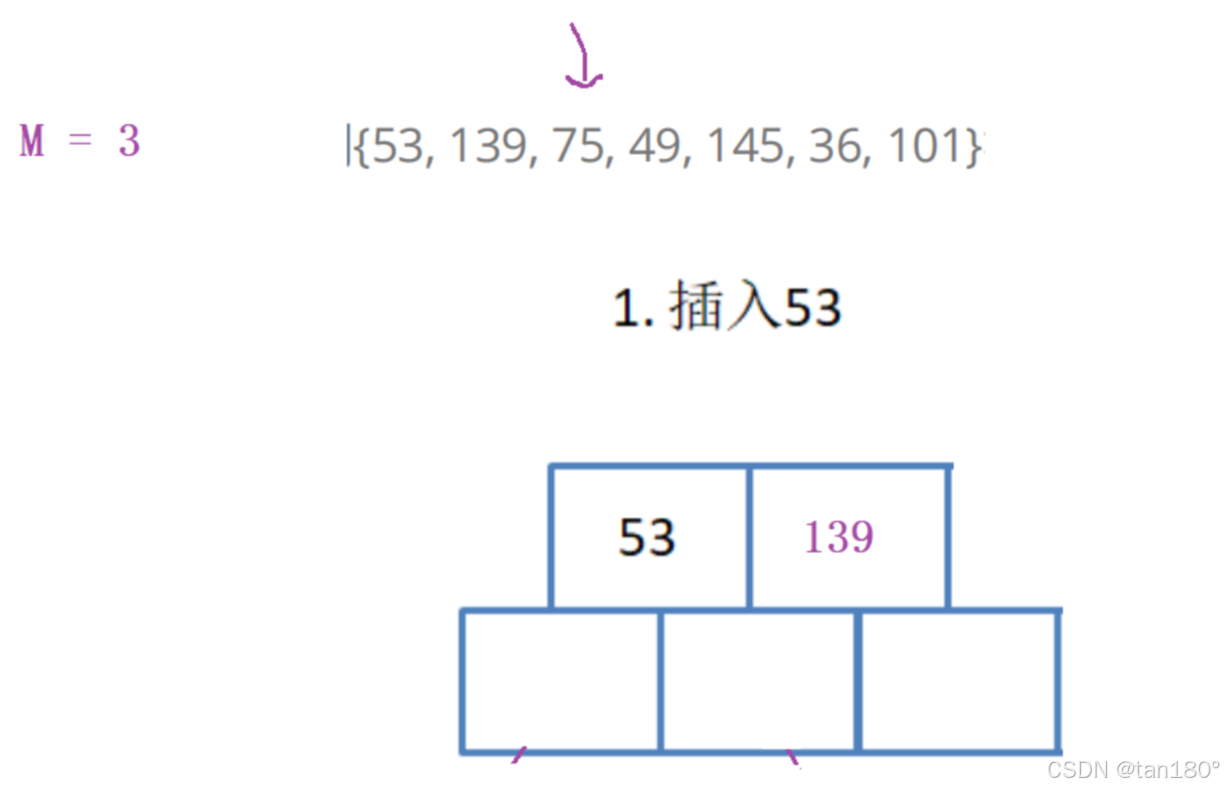
多给一个空间的好处是,方便插入,直接插入满了在分裂,不用管插在哪要挪动那些数据,也不怕越界。浪费一个空间不算啥。
关键字的数量等于M,则满了,满了就分裂出一个兄弟,提取中位数M/2,将中位数右边值和孩子拷贝给兄弟。将中位数给父亲,如果没有父亲就创建新的根。
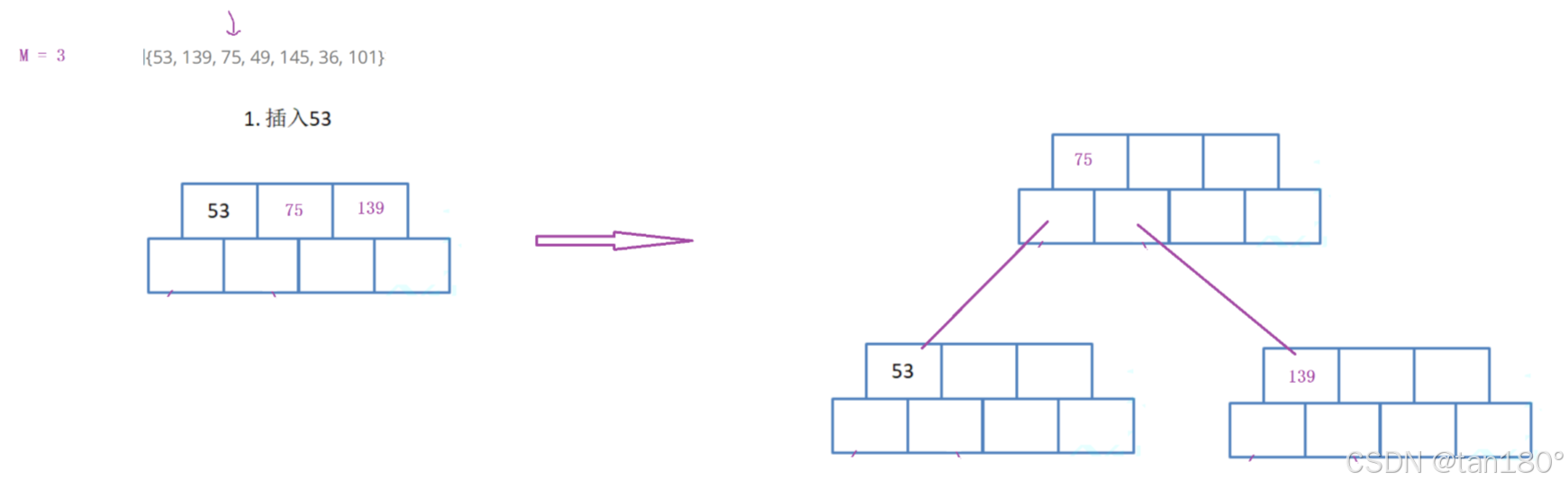
插入49,注意新增节点只能在叶子节点插入。要保证节点内关键字是有序的,内部可以用直接插入排序挪动关键字和孩子。
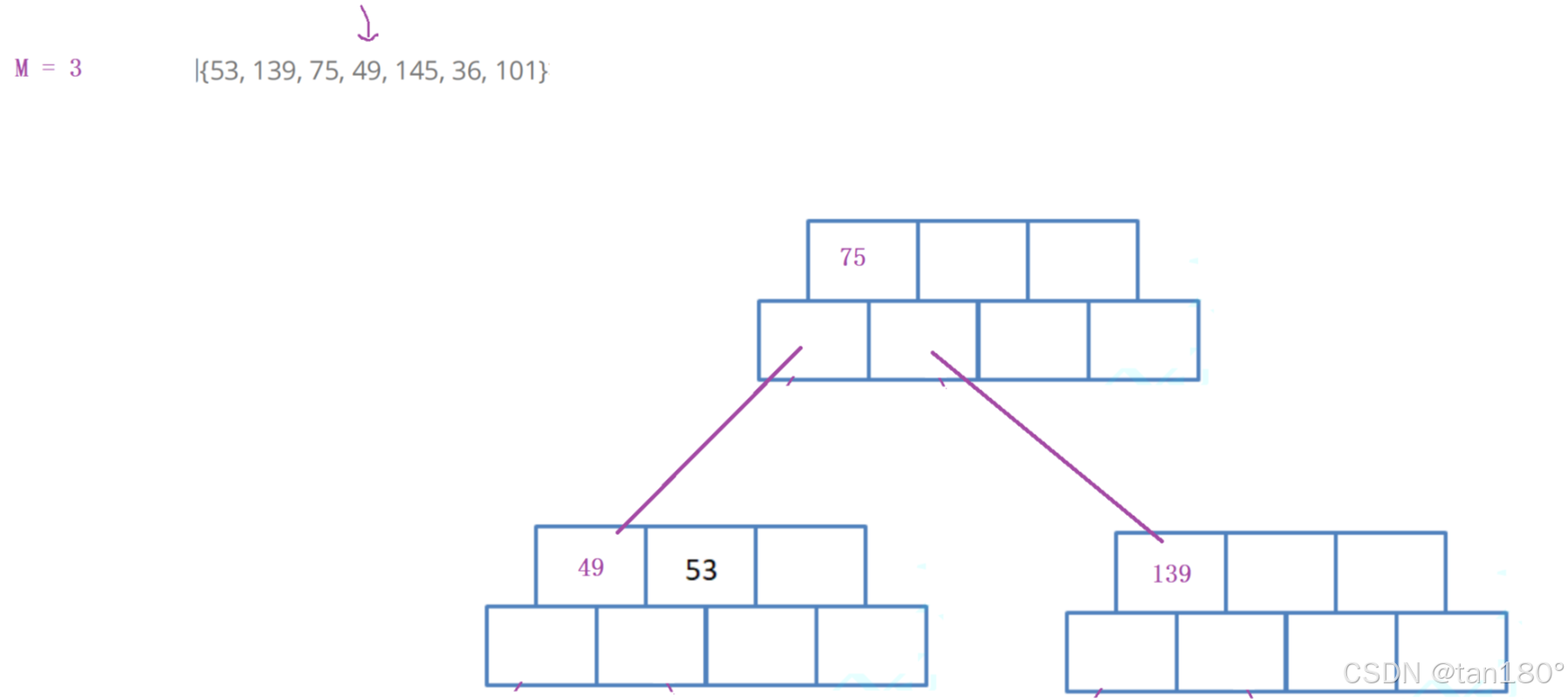
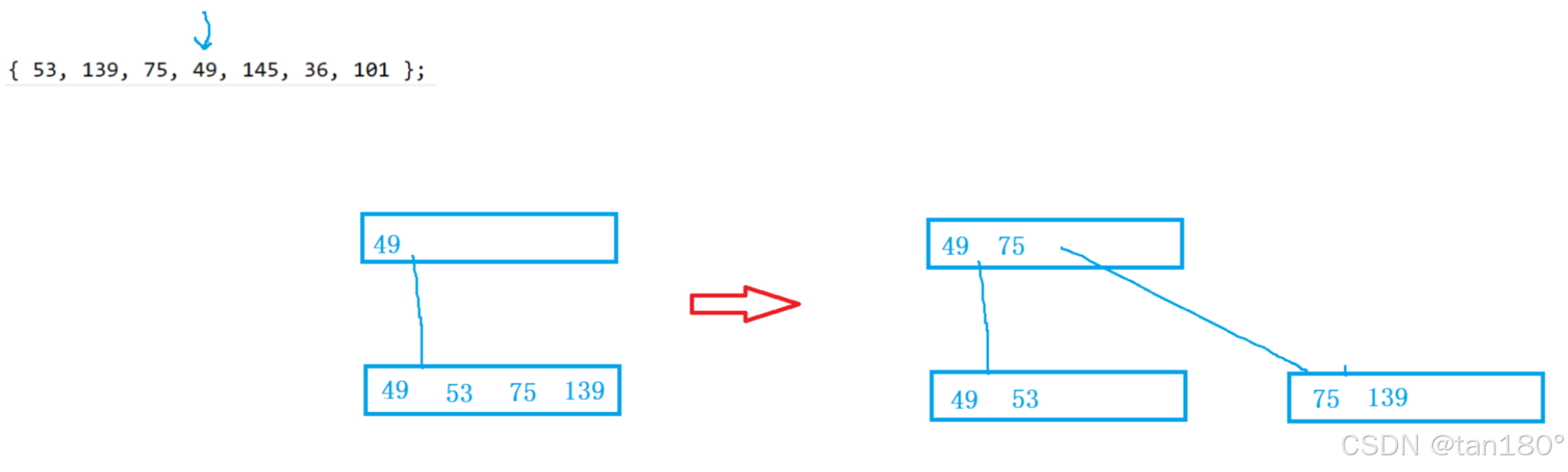
插入145
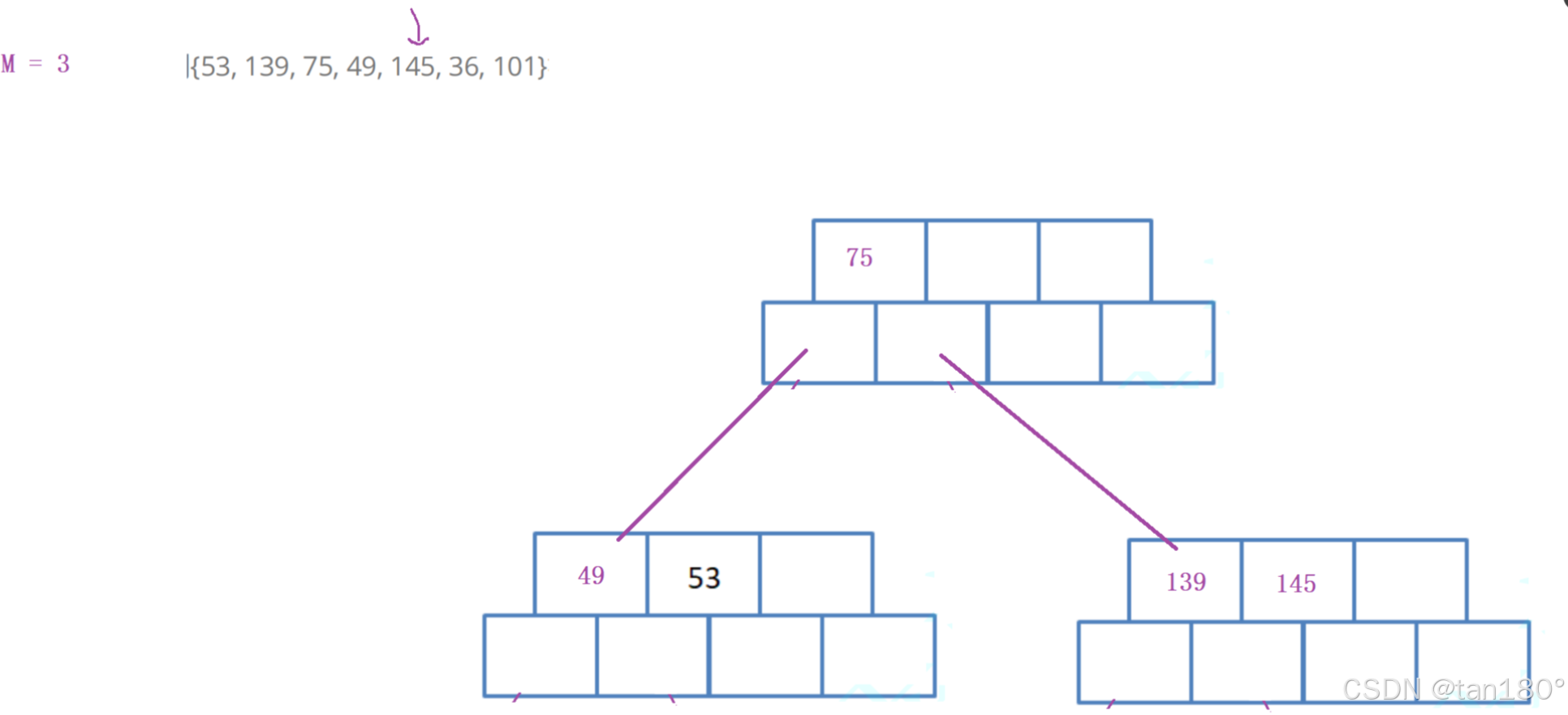
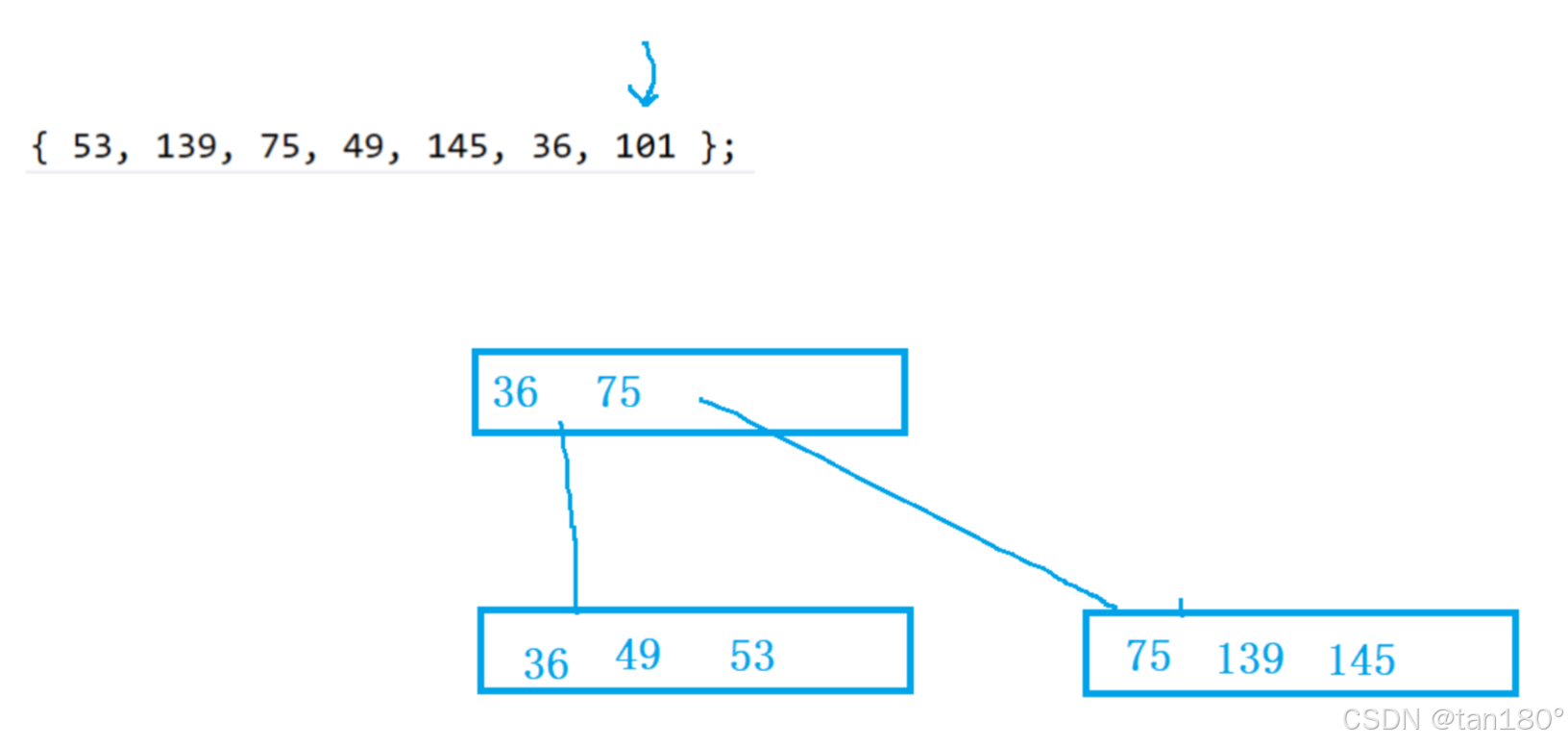
插入36,发现关键字个数等于M,申请一个兄弟,找到中位数,将中位数右边的关键字和孩子分裂拷贝兄弟,提取中位数插入到父亲。插入要移动关键字和它的右孩子。 插入之后别忘记最后要连接兄弟节点。
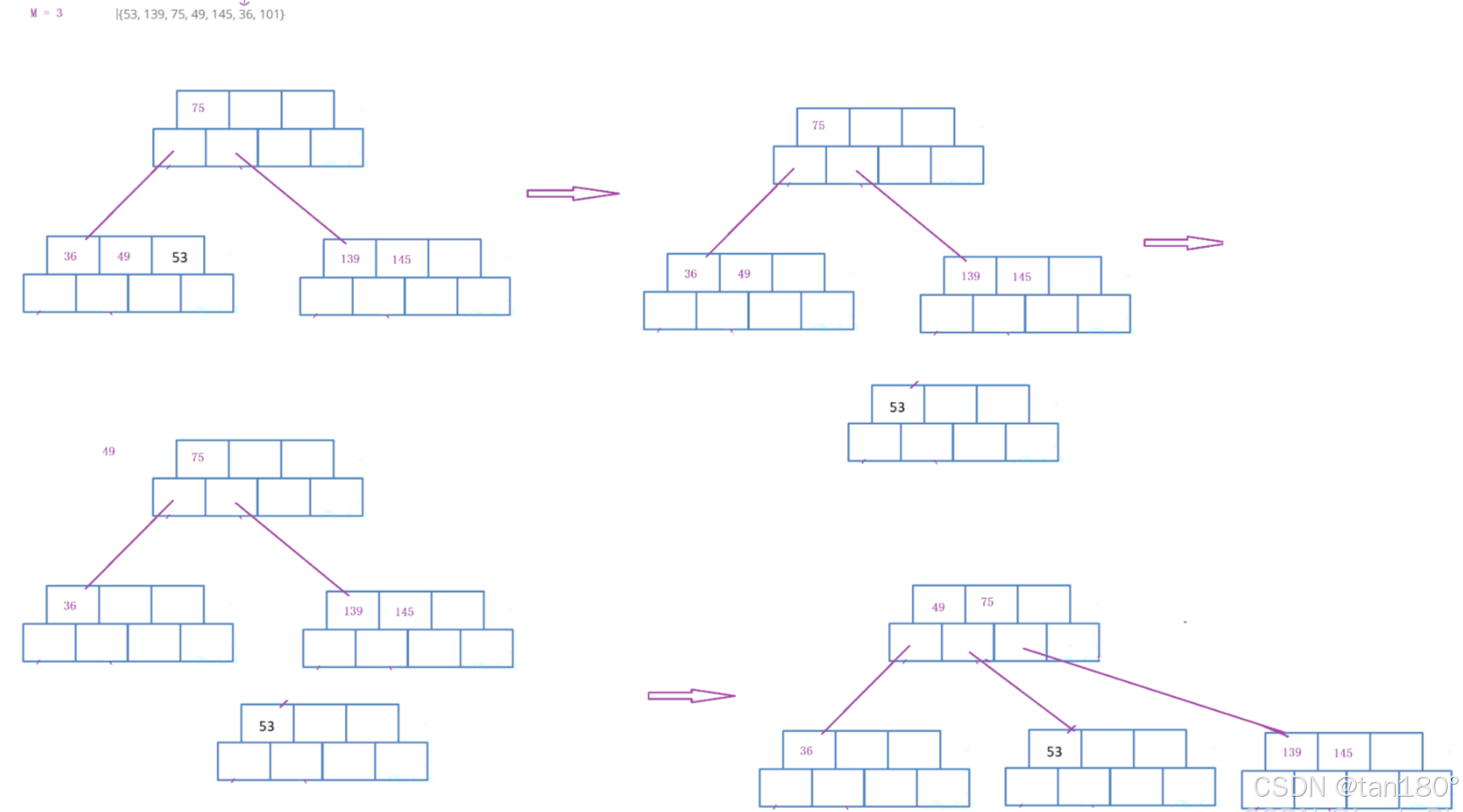
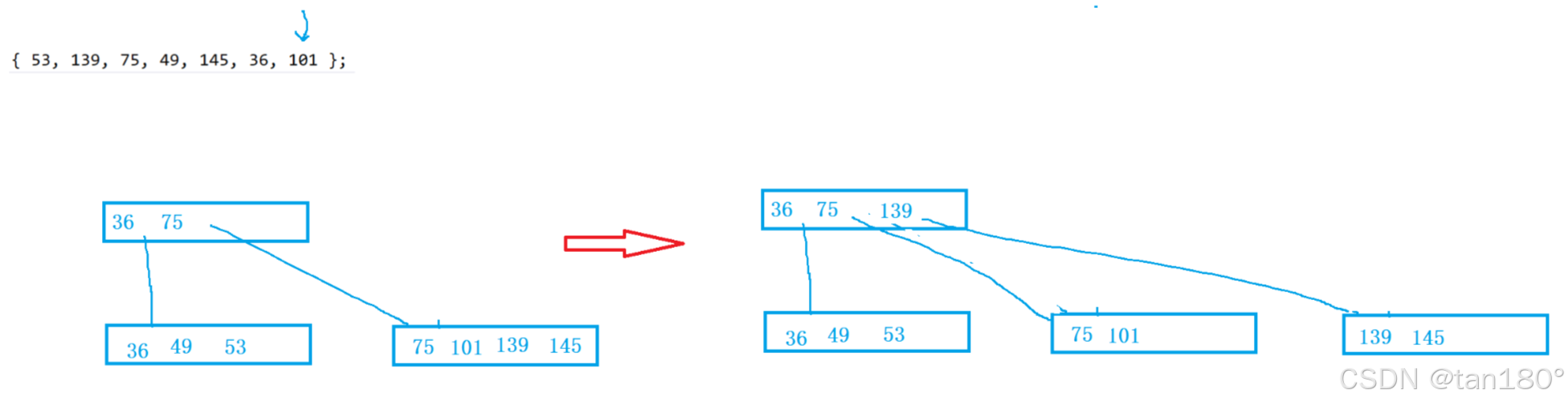
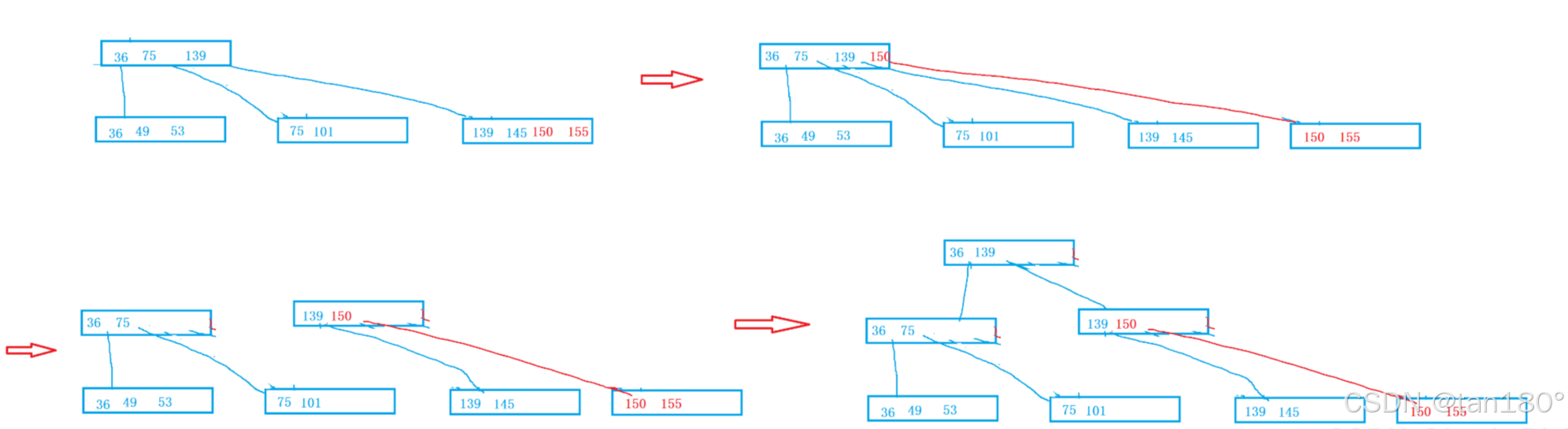
插入101,关键字等于M会分裂拷贝给兄弟,然后提取中位数给父亲,父亲插入之后,父亲的关键字也等于M了,也会分裂。分裂拷贝,找到中位数 M/2 ,申请兄弟节点,将中位数右边的关键字以及左孩子拷贝给兄弟,最后还要在将最后一个孩子也要拷贝给兄弟。然后提取中位数给父亲,父亲插入之后,如果父亲不满就结束,如果满就持续分裂。
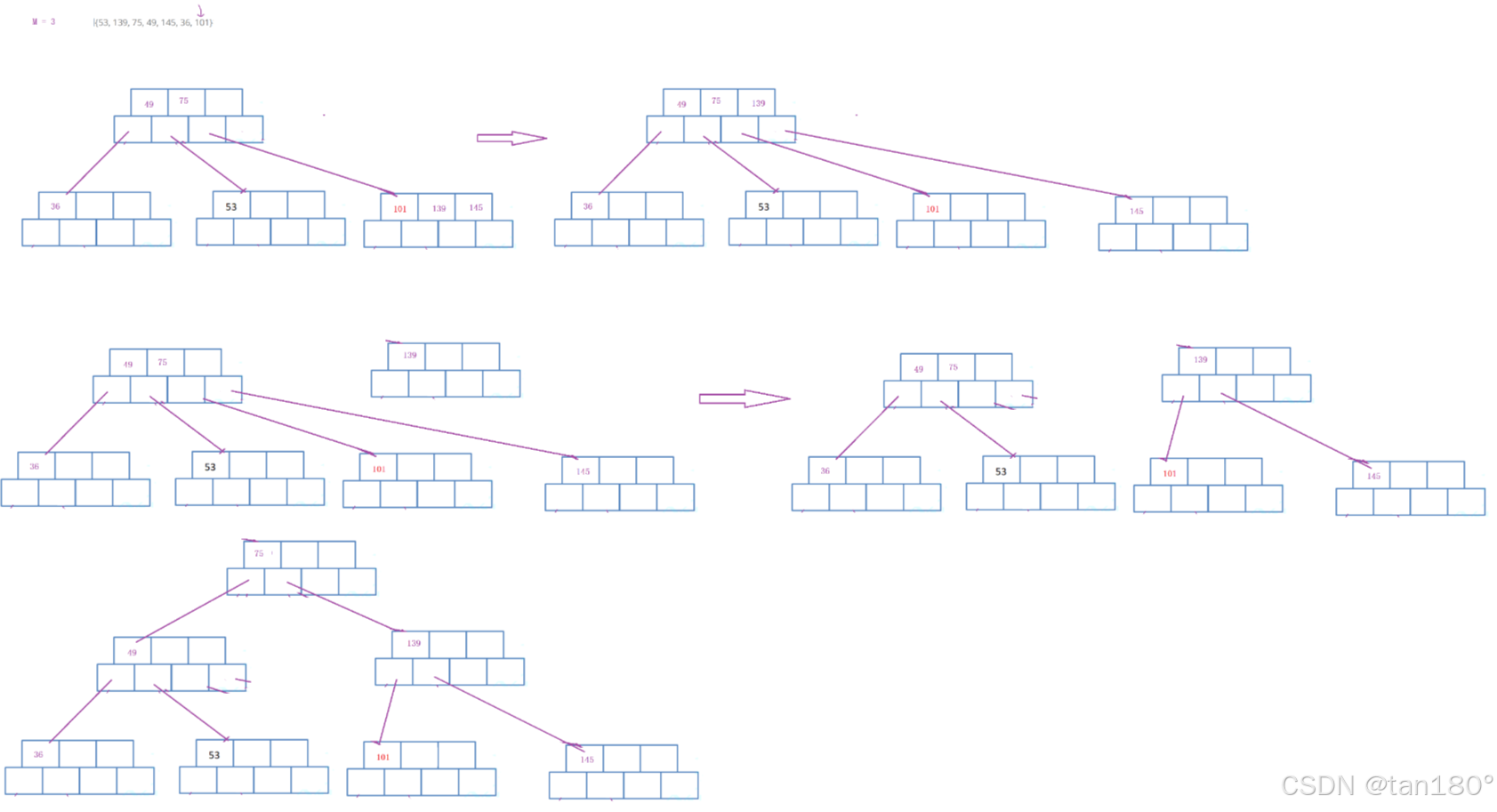
B树的插入,你会发现它是天然平衡,因为它是向右和向上生长。
新插入的节点,一定是在叶子节点。因为叶子节点没有孩子,不影响关键字和孩子的关系。分支节点孩子保持比关键字多一个的关系。叶子节点满了,分裂出一个兄弟,提取中位数,向父亲插入一个值和孩子。
根节点分裂,增加一层。 越到最后根节点越不容易分裂。
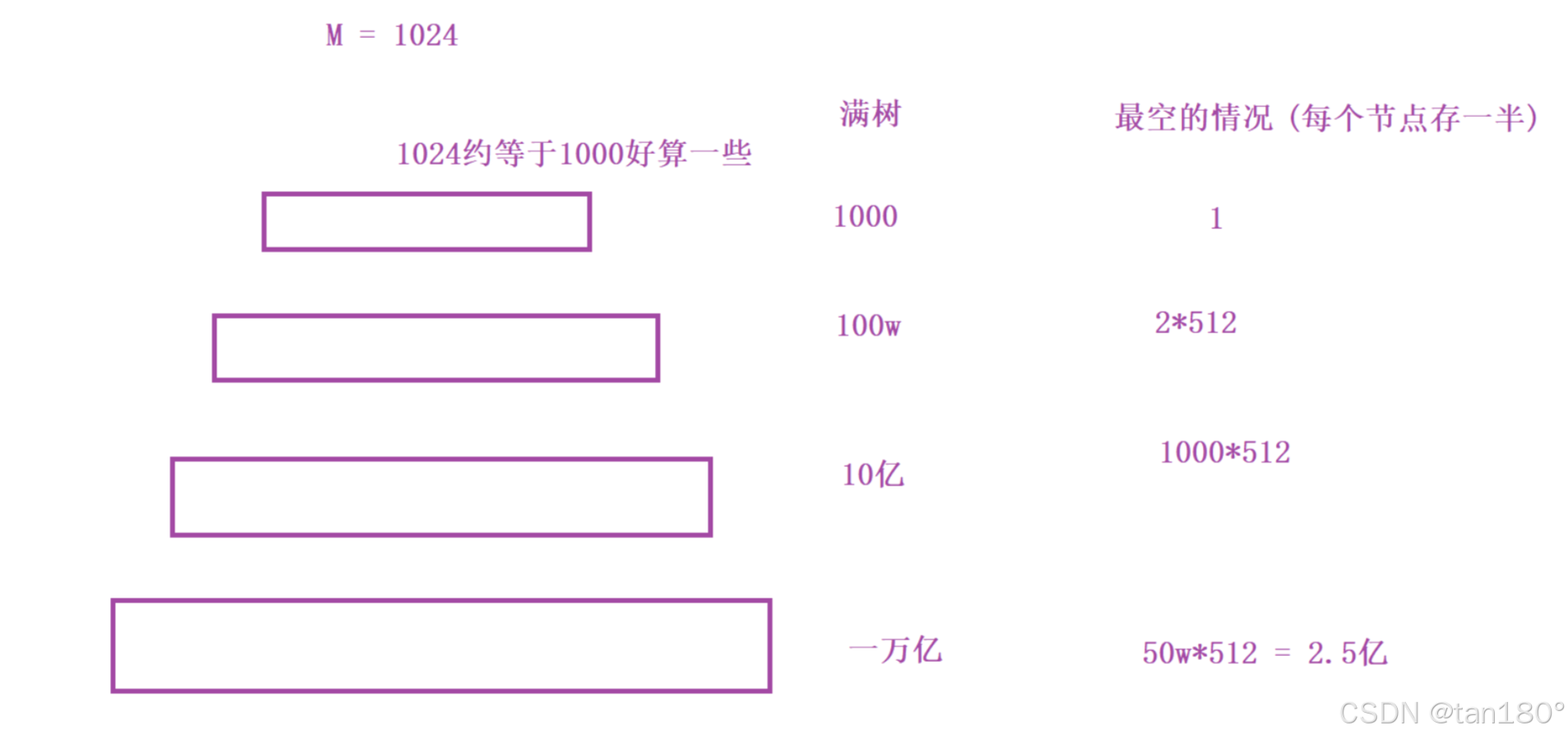
假设 M = 1024。一个节点最多放1023个关键字,1024个孩子,4层M路B树,就可以放一万亿个关键字和孩子了。
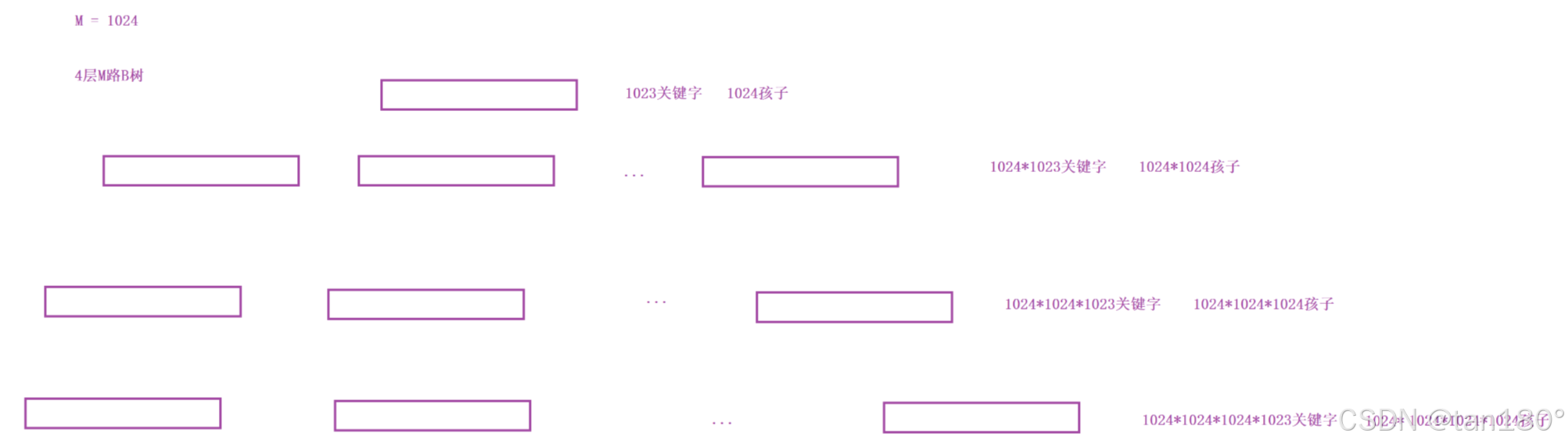
当然这是满的情况,不满我们也可以看一下,然后对比
插入过程总结:
- 如果树为空,直接插入新节点中,该节点为树的根节点
- 树非空,找待插入元素在树中的插入位置(注意:找到的插入节点位置一定在叶子节点中)
- 检测是否找到插入位置(假设树中的key唯一,即该元素已经存在时则不插入)
- 按照插入排序的思想将该元素插入到找到的节点中
- 检测该节点是否满足B-树的性质:即该节点中的元素个数是否等于M,如果小于则满足
- 如果插入后节点不满足B树的性质,需要对该节点进行分裂:
申请新节点
找到该节点的中间位置
将该节点中间位置右侧的元素以及其孩子搬移到新节点中
将中间位置元素以及新节点往该节点的双亲节点中插入,即继续4 - 如果向上已经分裂到根节点的位置,插入结束
四、B树的插入实现
B树的节点设计
template<class K, class V, size_t M>
struct BTreeNode
{// 孩子的数量比关键字的数量多一个/*pair<K, V> _kvs[M - 1];BTreeNode<K, V, M>* _subs[M];*/// 空间一个空间,方便分裂,方便我们插入以后在分裂pair<K, V> _kvs[M];BTreeNode<K, V, M>* _subs[M + 1];BTreeNode<K, V, M>* _parent;size_t _kvSize;BTreeNode():_kvSize(0),_parent(nullptr){for (size_t i = 0; i < M + 1; ++i){_subs[i] = nullptr;}}
};
B树的查找
比当前关键字小一定在它的左边,比它大就往右继续找,如果越界了,就往最后一个关键字的右孩子去找。走到叶子节点的nullptr说明没找到。
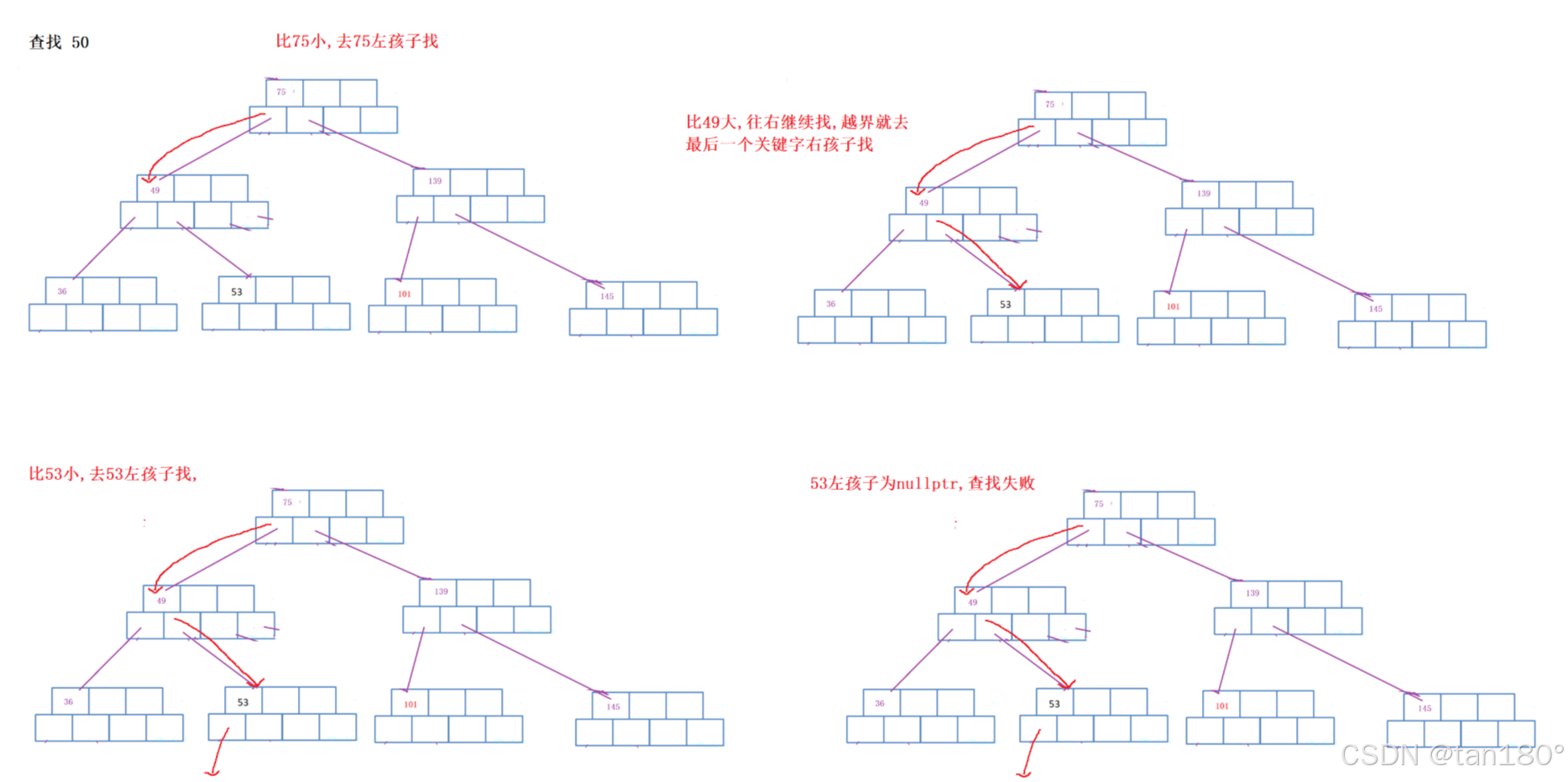
// 第i个key的左孩子是subs[i]// 第i个key的右孩子是subs[i + 1]pair<Node*, int> Find(const K& key){Node* parent = nullptr;Node* cur = _root;while (cur){size_t i = 0;while (i < cur->_kvSize) // 如果M比较大,这里应该改一改换成二分查找会快一些{if (cur->_kvs[i].first < key) // key大于当前位置key,往右找++i;else if (cur->_kvs[i].first > key) // key小于当前位置key,就往左孩子去找break;elsereturn make_pair(cur, i);}parent = cur;cur = cur->_subs[i];}// 没有找到return make_pair(parent, -1);}
B树插入Key / Key & Value的过程
按照直接插入排序的思想插入key,移动key也要移动它的右孩子,最后在把中位数和孩子插入
// 往cur里面插入一个kv和subvoid InsertKV(Node* cur, const pair<K, V>& kv, Node* sub){// 将kv找到合适的位置插入进去int i = cur->_kvSize - 1;for (; i >= 0; ){if (cur->_kvs[i].first < kv.first){break;}else{// kv[i]往后挪动,kv[i]的右孩子也挪动cur->_kvs[i + 1] = cur->_kvs[i];cur->_subs[i + 2] = cur->_subs[i + 1];--i;}}cur->_kvs[i + 1] = kv;cur->_subs[i + 2] = sub;cur->_kvSize++;if (sub){sub->_parent = cur;}}

B树的完整插入代码
bool Insert(const pair<K, V>& kv){// 初始处理// 处理空树情况if (_root == nullptr){_root = new Node;_root->_kvs[0] = kv;_root->_kvSize = 1;return true;}// 查找键是否存在// 返回一个pair,包含节点指针和键的索引(若找到)pair<Node*, int> ret = Find(kv.first);// 已经有了,不能插入 (当前如果允许插入就是mutil版本)if (ret.second >= 0){return false;}// 往cur节点中插入一个newkv和sub// 1、如果cur没满就结束// 2、如果满了就分裂,分裂出兄弟以后,往父亲插入一个关键字和孩子,再满还要继续分裂// 3、最坏的情况就是分裂到根,原来根分裂,产生出一个新的根,就结束了// 也就是说,我们最多分裂高度次Node* cur = ret.first;pair<K, V> newkv = kv;Node* sub = nullptr;while (1){InsertKV(cur, newkv, sub); // 1、如果cur没满就结束if (cur->_kvSize < M){return true;}else // 2、满了,需要分裂{// 分裂出一个兄弟节点Node* newnode = new Node;// 1、拷贝右半区间给分裂的兄弟节点int mid = M / 2;int j = 0;int i = mid + 1;newkv = cur->_kvs[mid];cur->_kvs[mid] = pair<K, V>();for (; i < M; ++i){newnode->_kvs[j] = cur->_kvs[i];cur->_kvs[i] = pair<K, V>();newnode->_subs[j] = cur->_subs[i];cur->_subs[i] = nullptr;if (newnode->_subs[j]){newnode->_subs[j]->_parent = newnode;}j++;newnode->_kvSize++;}// 还剩最后一个右孩子// 指针比键多一个,所以最后一个右孩子需要单独处理newnode->_subs[j] = cur->_subs[i];if (newnode->_subs[j]){newnode->_subs[j]->_parent = newnode;}cur->_kvSize = cur->_kvSize - newnode->_kvSize - 1;// 1、如果cur没有父亲,那么cur就是根,产生新的根// 2、如果cur有父亲,那么就要转换成往cur的父亲中插入一个key和一个孩子newnodeif (cur->_parent == nullptr){_root = new Node;_root->_kvs[0] = newkv;_root->_subs[0] = cur;_root->_subs[1] = newnode;cur->_parent = _root;newnode->_parent = _root;_root->_kvSize = 1;return true;}else{// 往父亲去插入newkv和newnode,转换成迭代逻辑sub = newnode;cur = cur->_parent;}}}return true;}
B树的中序遍历
void InOrder(){_InOrder(_root);}void _InOrder(Node* cur){if (cur == nullptr){return;}size_t i = 0;while (i < cur->_kvSize){// 先访问左子树,再访问当前值_InOrder(cur->_subs[i]);cout << cur->_kvs[i].first << " ";++i;}// 再访问最后一个右子树_InOrder(cur->_subs[i]);}

B树的删除
这里就不细说了,大家可自行看开篇的视频,如果说插入要防上溢出,这里就要防止下溢出
B树的性能分析
B树上搜索一个值时间复杂度最坏就是走高度次假设每层结点关键字都是满的设为M,孩子也是M。忽略掉孩子比关键字多1。
设有h层,一层一层下去这就是一个等比数列。

这里我们可以用错位相减法来算
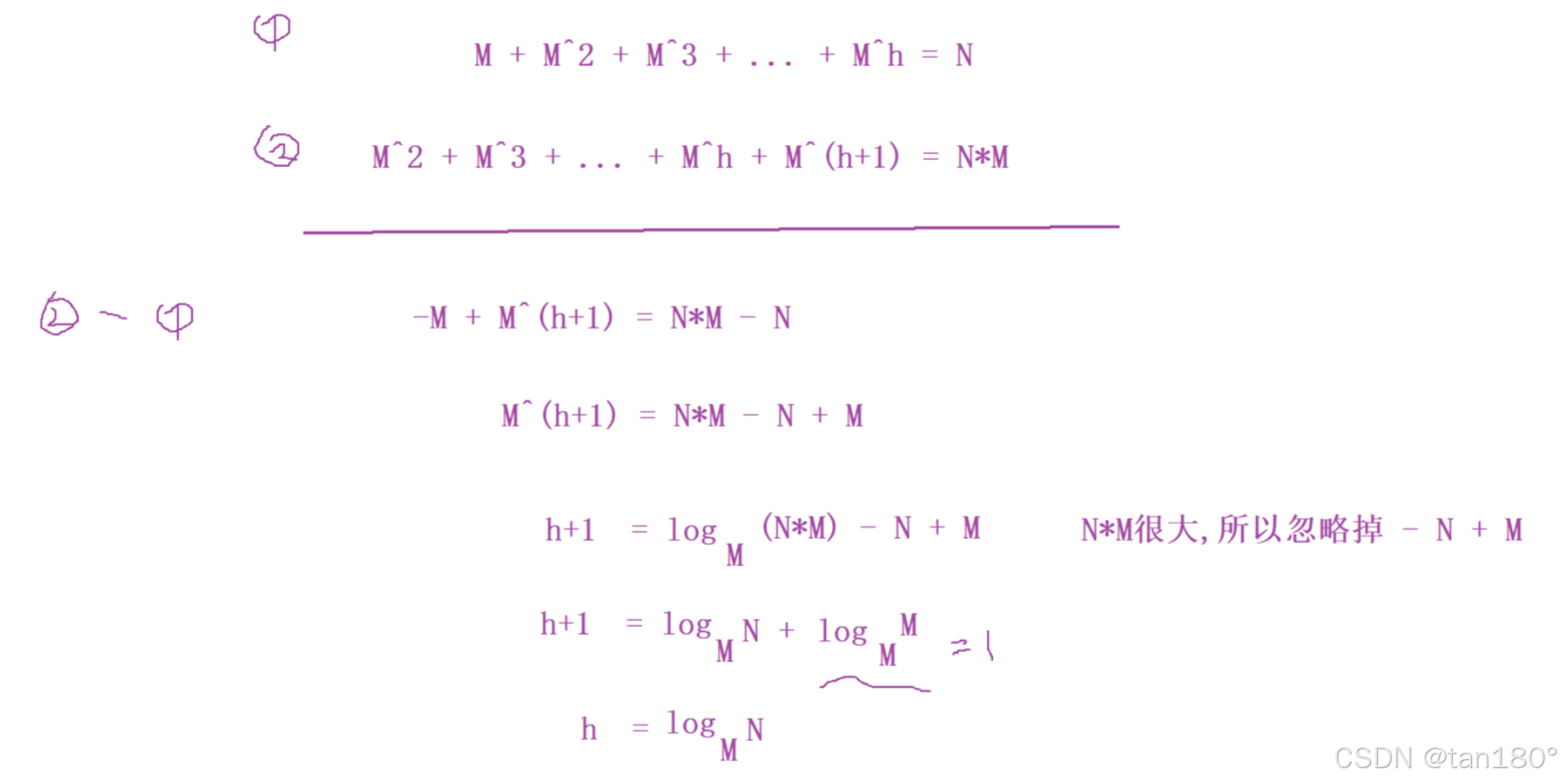
不满的情况

可以看出B树的效率是很高的!
五、B+树
B树总体来说还是非常依赖于搜索树,还区分左孩子右孩子。并且分支节点孩子的数量比关键字多一个,整体而言反而让结构变得复杂了不少。基于一系列原因大佬又对B树进行了优化。
B+树是B树的变形,是在B树基础上优化的多路平衡搜索树,B+树的规则跟B树基本类似,但是又在B树的基础上做了以下几点改进优化:
- 分支节点的子树指针与关键字个数相同
- 分支节点的子树指针p[i]指向关键字值大小在[k[i],k[i+1])区间之间
- 所有叶子节点增加一个链接指针链接在一起
- 所有关键字及其映射数据都在叶子节点出现
- 方便了去遍历,不需要从根开始了
- 所有关键字及其映射数据都在叶子节点出现
1也就是说孩子与关键字个数相等, 2也就是说B树以前下标和我相等是我的左孩子,现在在[k[i],k[i+1])之间。1、2合在一起相当于取消了最左边的那个子树。
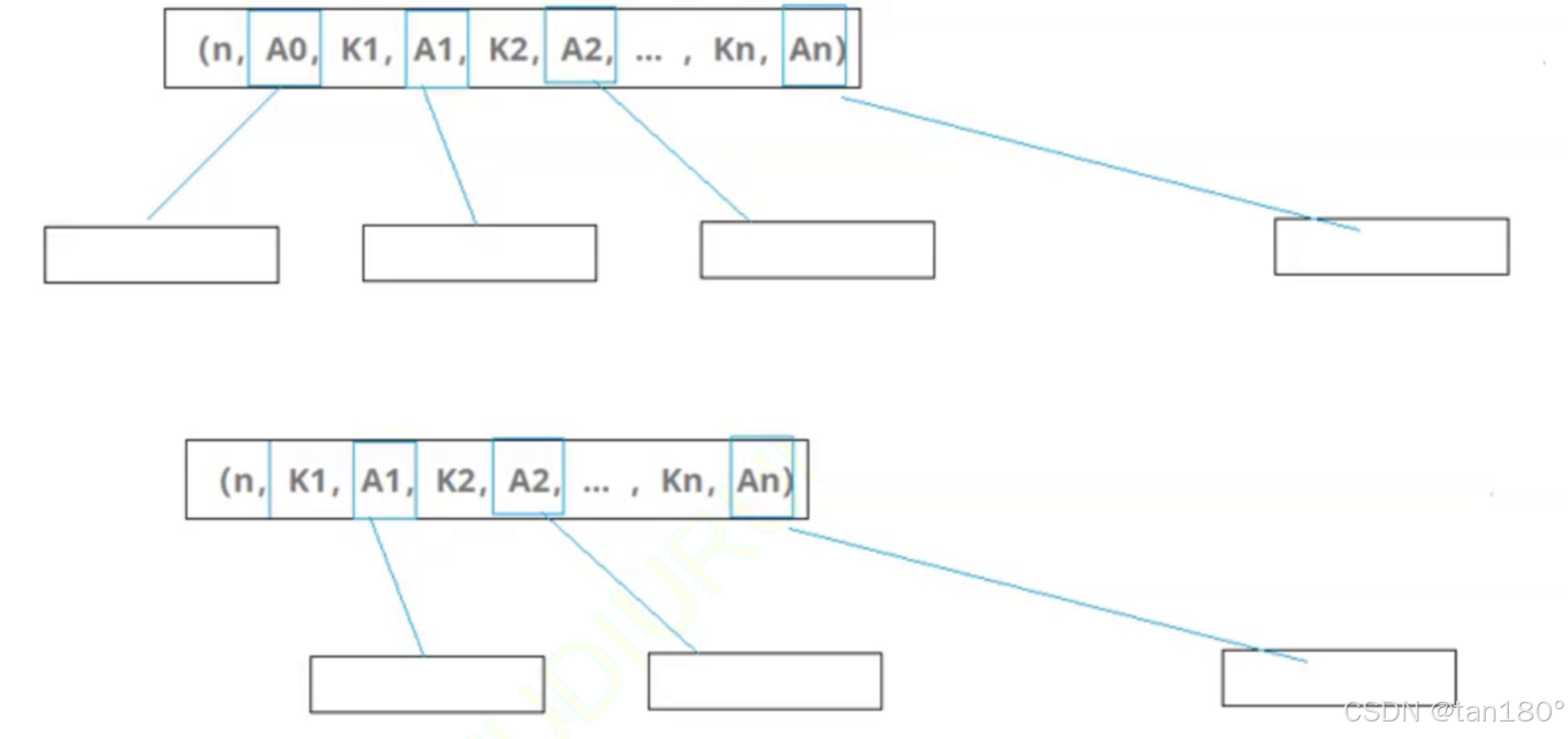
分支节点根叶子节点有重复的值,分支节点存的是叶子节点索引。
父亲中存的是孩子节点中的最小值做索引。
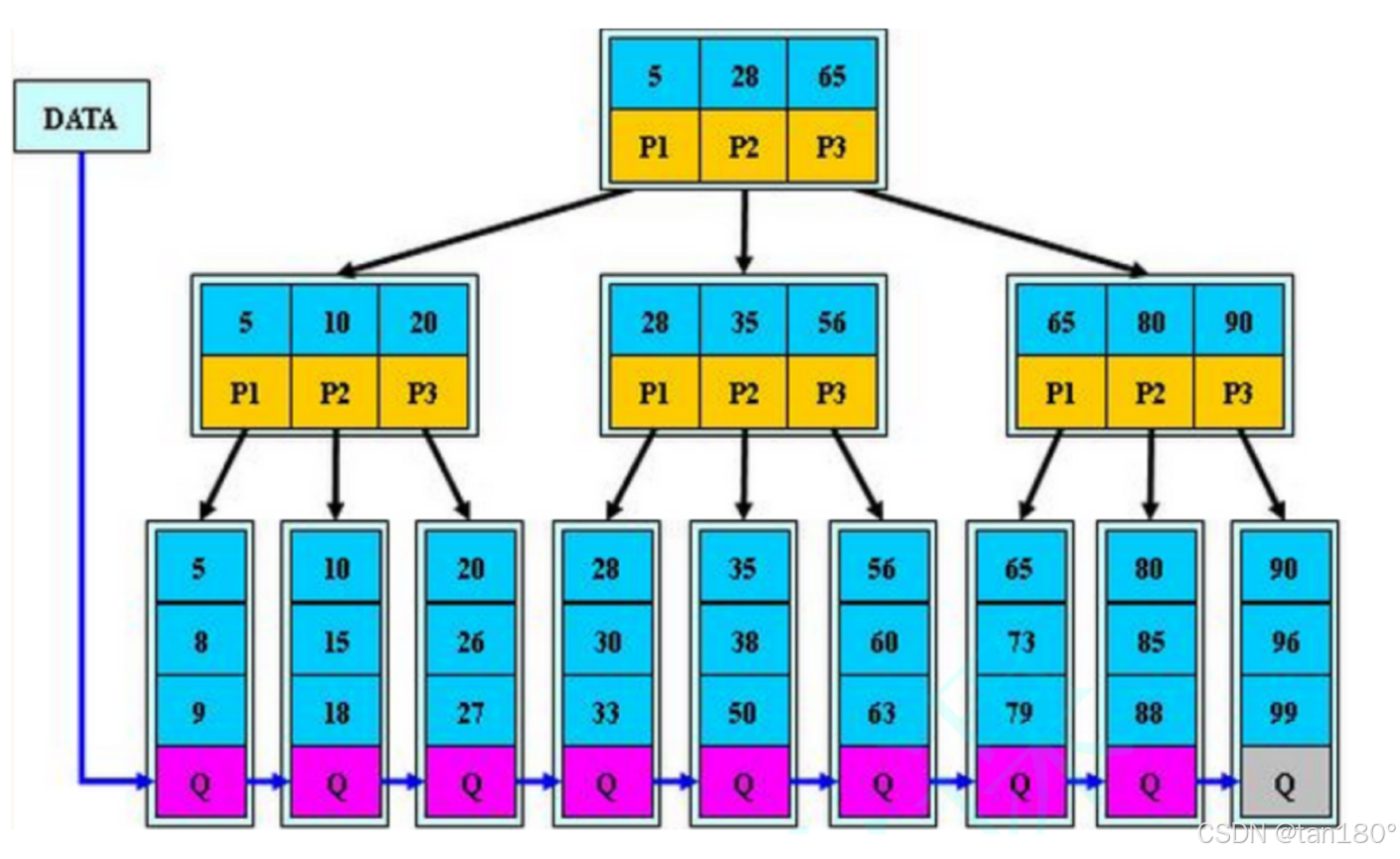
比如在这颗B+树搜索一个33,是如何搜索的呢?
先找到根,如果比5还小根本不存在,5已经是最小的了。
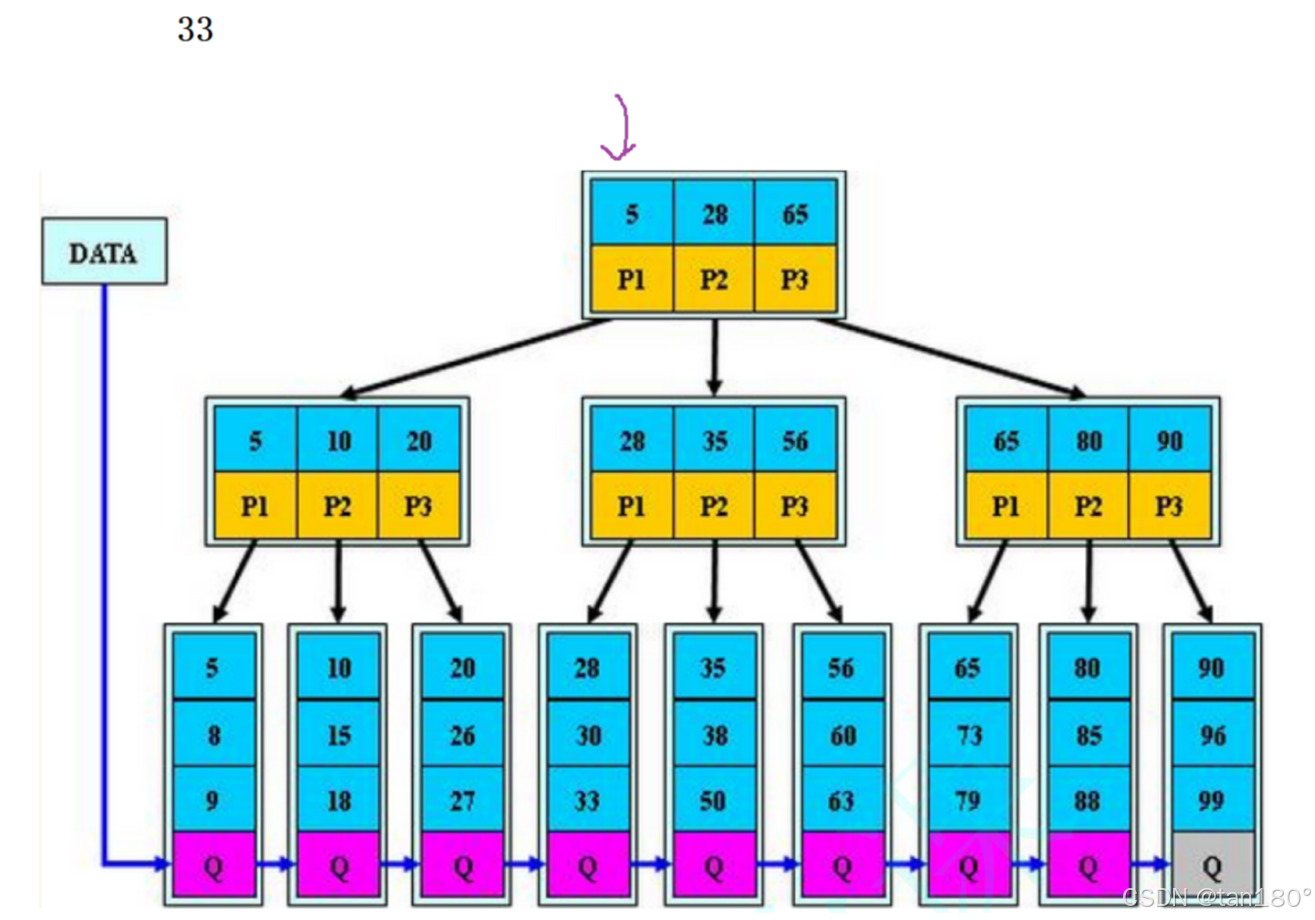
如果比5大,往下一个。比28大还往下一个。比65小说明在65的左边。去P2找
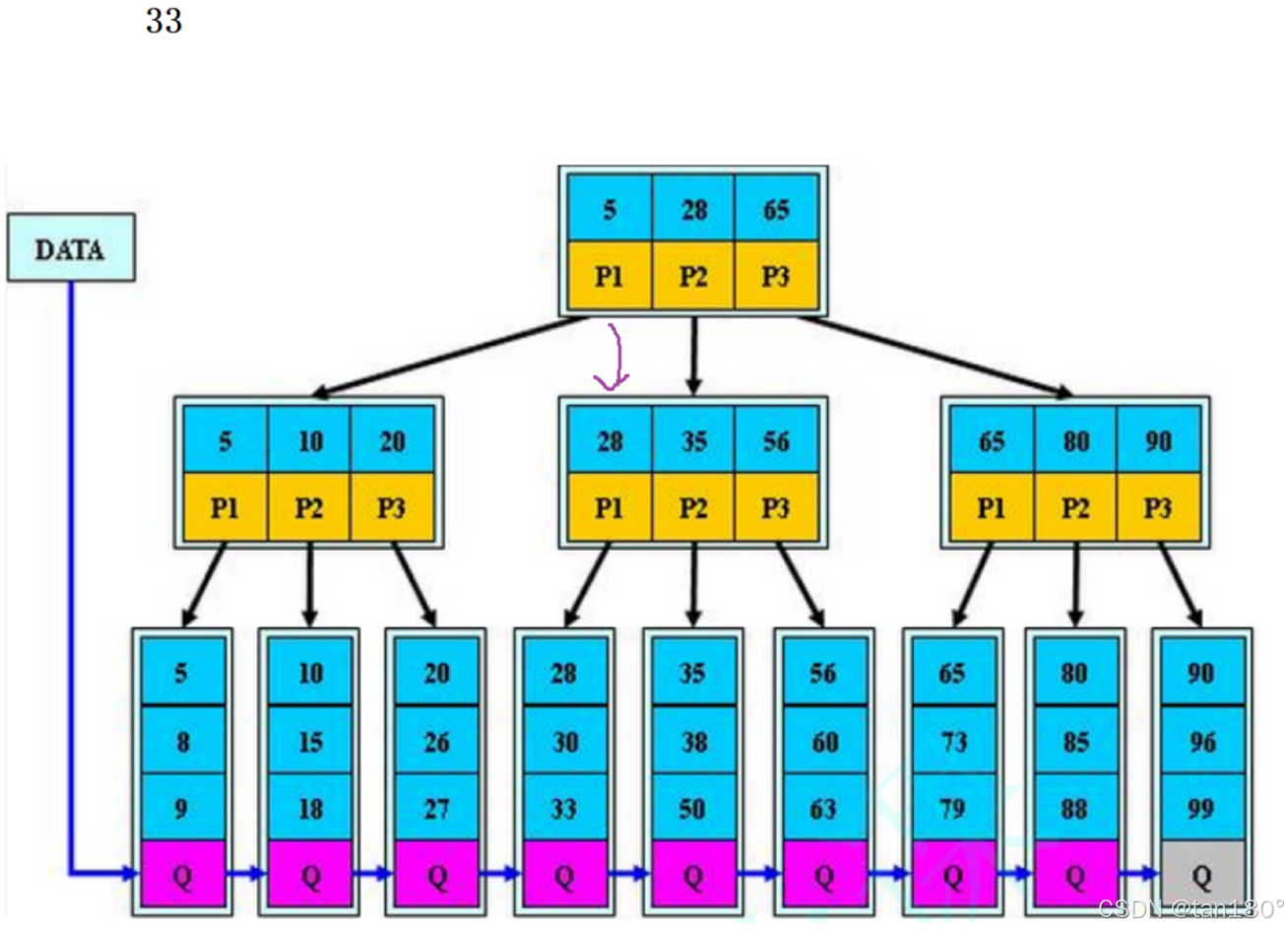
比28大往下一个,比35小说明在55的左边。去P1找。最终找到33。如果是34,最终就是去33的右孩子去找,但33右孩子是空,所以找不到
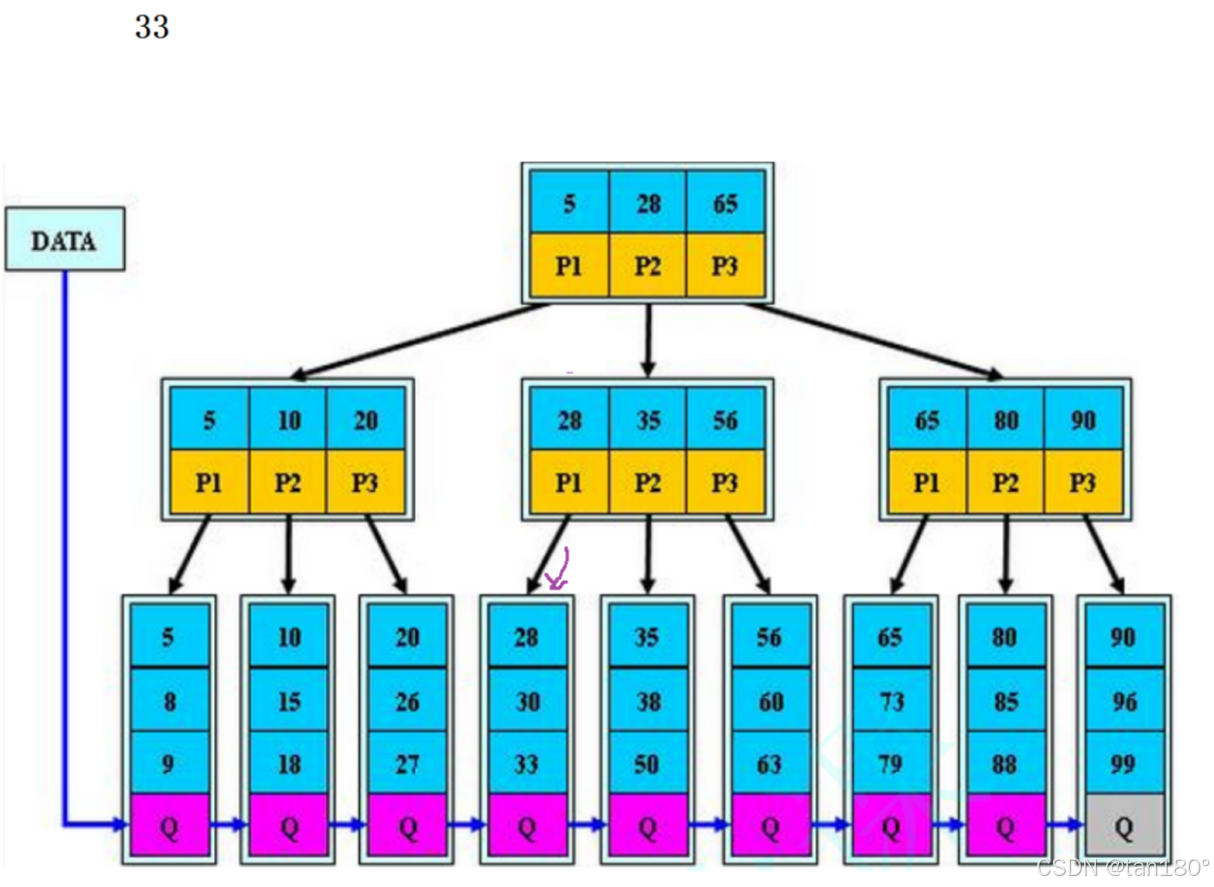
插入的过程也是类似的。这里简单了解一下 M == 3 B+树分裂过程,它这里的结构搞的简单一些
刚开始插入要两层节点,一层做分支,一层做根
插入到139。目前关键字是3个了。因为B+树分支节点孩子和关键字个数相同所以不用分裂。只有当 关键字个数 > M 才分裂
插入 49,关键字个数 > M 分裂
插入满了之后分裂一半给兄弟,转换成往父亲插入一个key和一个孩子,孩子就是兄弟,key就是兄弟的第一个最小值的key。
插入145,36
插入101,第二次分裂
再来两个数150、155,我们看看连续分裂的情况
B+树的插入过程根B树基本是类型的,细节区别在于,第一次插入两层节点,一层做分支,一层做根。后面一样往叶子去插入,插入满了之后分裂一半给兄弟,转换成往父亲插入一个key和一个孩子,孩子就是兄弟,key就是兄弟的第一个最小值的key。
总结:
- 简化B树孩子比关键字多一个的规则,变成相等
- 所有值都在叶子节点,方便遍历查找所有值
六、B*树
- 在B+树的分支节点增加指向兄弟节点的指针。
- B+树节点原来关键字个数最少是1/2M,B*树要求节点关键字最少是2/3M,最多是M
B+树的分裂:
当一个结点满时,分配一个新的结点,并将原结点中1/2的数据复制到新结点,最后在父结点中增加新结点的指针;B+树的分裂只影响原结点和父结点,而不会影响兄弟结点,所以它不需要指向兄弟的指针
B*树最大的改变就是让每个节点更满。因为B树和B+树都有一个缺陷,可能会浪费一半的空间
B*树的结点关键字和孩子数量 -> [2/3M,M]
B*树的分裂:
当一个结点满时,如果它的下一个兄弟结点未满,那么将一部分数据移到兄弟结点中,再在原结点插入关键字,最后修改父结点中兄弟结点的关键字(因为兄弟结点的关键字范围改变了);如果兄弟也满了,则在原结点与兄弟结点之间增加新结点,并各复制1/3的数据到新结点,最后在父结点增加新结点的指针。

所以,B*树分配新结点的概率比B+树要低,空间使用率更高
七、B树系列总结及其应用
B树:有序数组+平衡多叉树;
B+树:有序数组链表+平衡多叉树;
B*树:一棵更丰满的,空间利用率更高的B+树
B树最常见的应用就是用来做索引。索引通俗的说就是为了方便用户快速找到所寻之物,比如:书籍目录可以让读者快速找到相关信息,hao123网页导航网站,为了让用户能够快速的找到有价值的分类网站,本质上就是互联网页面中的索引结构
当数据量很大时,为了能够方便管理数据,提高数据查询的效率,一般都会选择将数据保存到数据库,因此数据库不仅仅是帮助用户管理数据,而且数据库系统还维护着满足特定查找算法的数据结构,这些数据结构以某种方式引用数据,这样就可以在这些数据结构上实现高级查找算法,该数据结构就是索引
数据库有一个 Cathes&Buffers ,意思是数据存在磁盘中直接访问太慢, 所以建一个缓存(可以考虑使用LRU)。对于B+树而言可以把所有分支节点存储到Cache里,搜索必然要走分支。如果使用B树缓存就没有多大意义,因为太大了(B树的分支节点存 key & value),分支节点既有数据也要数据所在磁盘的地址。B+树相比于B树而言,分支节点只存key,分支节点比较小。分支节点映射的磁盘数据块就可以尽量加载Cache。
总结
难死我了这个,大家一定要好好理解!!!
相关文章:
)
DS B/B+/B*树及其应用(21)
文章目录 前言一、常见的搜索结构内查找外查找 二、B树的概念三、B树的插入分析四、B树的插入实现B树的节点设计B树的查找B树插入Key / Key & Value的过程B树的完整插入代码B树的中序遍历B树的删除B树的性能分析 五、B树六、B*树七、B树系列总结及其应用总结 前言 我们计算…...

04-stm32的标准外设库
一、概述 1、STM32标准外设库(Standard Peripheral Library)是STMicroelectronics为STM32系列微控制器提供的一个软件库,它提供了一组API函数来简化对STM32微控制器硬件的访问。这个库包含了对各种外设(如GPIO、USART、SPI、I2C等…...

ORACLE RAC环境使用ASM机制零宕机时间更换存储的实践
ORACLE RAC使用存储,随时系统的发展,磁盘空间以及存储的老化、更换是一个典型的动作;基于ASM数据自动均衡分配到各个磁盘LUN的特性,可以使用此方式进行在线的迁移,ORACLE MOS上有一个文档:中文版࿱…...

03_JavaScript
文章目录 一、概述1.1、JavaScript简介1.2、JavaScript组成部分1.3、为什么要学习JavaScript1.4、学习的目的1.5、JavaScript与Java的关系 二、使用位置及运行说明2.1、使用位置2.2、如何运行 三、JavaScript基础语法3.1、变量3.2、运算符3.3、控制流程3.3.1、分支结构3.3.2、循…...

Kafka消息可视化工具Offset Explorer
参考文献 Kafka消息可视化工具:Offset Explorer(原名kafka Tool)的使用方法【转】 - paul_hch - 博客园 https://zhuanlan.zhihu.com/p/722232008 正文 官网下载地址为Offset Explorer 双击offsetexplorer_64bit.exe 安装 双击 使用kafka…...

AXP2101入门
目录 核心功能与特性封装与配置安全与可靠性 AXP2101 是一款由全志公司开发的单电池 NVDC 电源管理集成电路(PMIC),专为锂离子/锂聚合物单电池应用设计,适用于需要多通道电源输出的设备。 核心功能与特性 1.输入与充电管理 输入…...

Bytebase 取得 SOC 2 Type 1 认证
我们很高兴地宣布,Bytebase 已成功取得 SOC 2 Type 1 认证,印证了我们在数据库 DevSecOps 平台始终以最高标准保障安全性、可用性和保密性的承诺。 为了实现并维持 SOC 2 合规性,我们与 Vanta 合作进行自动安全监控和合规性验证。审计由独立…...

反爬系列 IP 限制与频率封禁应对指南
在数据采集领域,IP 限制与频率封禁是反爬机制中最常见的防御手段。随着网站安全策略的升级,单靠传统爬虫技术已难以应对高强度的检测。本文将从反爬机制解析、实战应对策略两个维度,系统讲解如何突破 IP 限制与频率封禁。 一、反爬机制解析 …...

Java的进阶学习
注解 Java注解(Annotation)又称为Java标注,是JDK5.0引入的一种注释机制,可以用在类、方法、变量、参数成员上,在编译期间,会被编译到字节码文件中,运行时通过反射机制获得注解内容进行解析。 内置注解 Java语言已经定…...

从零开始学习SLAM|技术路线
概念 视觉SLAM(Simultaneous Localization and Mapping)系统中,整个过程通常分为 前端 和 后端 两个主要部分。前端处理的是从传感器数据(如相机图像、激光雷达等)中提取和处理信息,用于实时定位和建图&am…...
)
vue3:十一、主页面布局(修改顶部导航栏样式-右侧:用户信息+退出登录+全屏显示)
一、效果 完成效果,增加顶部导航栏,右侧用户信息(其中个人中心需要后续进行页面开发,这里只写了退出登录功能),以及全屏功能 二、搭建并引入右侧组件 将右侧内容封装到单独的组件,直接引入(像左侧导航条等内容也是可以做成这种形式) 1、新建右侧组件的页面 在layout中…...

车载客流记录仪简介
一、产品概述 车载客流记录仪技术是采用智能视频分析算法,通过人体形态特征(头部和肩部)及上下车的运动规律研判,在设定区域内分析出上下车人数数量,实现相关人数数据的统计和记录。能够为公共交通企业、公共交通管理…...

2025新版懒人精灵零基础及各板块核心系统视频教程-全分辨率免ROOT自动化开发
2025新版懒人精灵零基础安装调试lua基础UI设计交互常用方法封装项目实战项目打包安装板块-视频教程(初学者必修课) 1.懒人精灵核心API基础和lua基础视频教程:https://www.bilibili.com/video/BV1Vm9kYJEfM/ 其它板块教程(包含:对接AI、实战、插件、UI、…...

从 Java 到 Kotlin:在现有项目中迁移的最佳实践!
全文目录: 开篇语 1. 为什么选择 Kotlin?1.1 Kotlin 与 Java 的兼容性1.2 Kotlin 的优势1.3 Kotlin 的挑战 2. Kotlin 迁移最佳实践2.1 渐进式迁移2.1.1 步骤一:将 Kotlin 集成到现有的构建工具中2.1.2 步骤二:逐步迁移2.1.3 步骤…...

矩阵运营的限流问题本质上是平台与创作者之间的流量博弈
矩阵运营的限流问题本质上是平台与创作者之间的流量博弈,要系统性解决这一问题,需从技术规避、内容优化、运营策略三个维度构建防御体系。以下结合平台算法逻辑与实战案例,深度解析限流成因及破解之道: 一、技术层:突…...

一种Spark程序运行指标的采集与任务诊断实现方式
一种Spark程序运行指标的采集与任务诊断实现方式 编写时间:2023年8月2日 第一次校准时间:2023年8月2日 文章目录 一种Spark程序运行指标的采集与任务诊断实现方式数据链路采集器的类图CustomSparkListener采集的指标task相关stage相关Job相关Executors相关诊断诊断分类调度阶…...
:环境安装与基础使用)
Gazebo 仿真环境系列教程(一):环境安装与基础使用
文章目录 一、版本说明与技术背景1.1 Gazebo 版本分支1.2 版本选择建议 二、系统环境准备2.1 硬件要求2.2 软件依赖 三、Gazebo Garden 安装流程3.1 添加官方软件源3.2 执行安装命令3.3 环境验证 四、Gazebo Classic 安装方法4.1 添加软件仓库4.2 安装核心组件4.3 验证安装 五、…...

Nginx 中间件
Nginx(发音为 "engine-x")是一款开源的高性能 HTTP 服务器和反向代理服务器,最初由 Igor Sysoev 开发。 它以其高性能、稳定性、丰富的功能集和低资源消耗而闻名,广泛应用于全球的 Web 服务架构中。 作为中间件&#…...

记录学习的第三十一天
今天只做了一道每日一题。 说实话,根本不会做呀,该怎么办? 以下是我看了题解之后的思路(适合新手): 1.首先肯定是要求出整个数组的不同数字有多少个的使用set来操作 2.右指针开始进入窗口,把元素放进哈希…...

Framework.jar里的类无法通过Class.forName反射某个类的问题排查
1,背景 我们想要在system_server进程里扩展一些我们自己的功能。 考虑到解耦和编译依赖的问题,我们用PRODUCT_SYSTEM_SERVER_JARS预置我们的类,然后用反射jar里面的类的方式来实现代码引用。 2,遇到的问题 在SystemServer.jav…...

架构-信息安全技术基础知识
一、信息安全基础 1. 信息安全的5个基本要素(重点) 机密性:确保信息不泄露给未授权的人或程序。 ▶ 举例:银行用户的账户密码必须保密,防止黑客窃取。完整性:保证信息不被非法修改,保持准确和…...

项目班——0419——chrono时间库
1、写日志需要时间库 C11时间库chrono源自于boost 1.时间间隔 duration 2.时间点 timepoint 3.时钟 clock 系统时钟system_clock,稳定时钟steady_clock,高精度时钟high_resolution_clock 例子 1、休眠100毫秒 2、输出当前时间 获取当前时间戳 s…...

Unity后处理全解析:从入门到优化
在游戏开发的世界里,Unity作为一款强大的游戏引擎,为开发者们提供了丰富的功能和工具。其中,后处理(Post-Processing)技术是提升游戏画面质量和视觉效果的重要手段之一。今天,我们就来深入探讨一下Unity后处理的相关内容,包括基本概念、使用说明、常见效果、优化技巧以及…...

得物业务参数配置中心架构综述
一、背景 现状与痛点 在目前互联网飞速发展的今天,企业对用人的要求越来越高,尤其是后端的开发同学大部分精力都要投入在对复杂需求的处理,以及代码架构,稳定性的工作中,在对比下,简单且重复的CRUD就显得…...

针对密码学的 EM 侧信道攻击
基于电磁的侧信道攻击是非侵入式的,这意味着攻击者无需物理接触设备即可窃取信息。我们将了解这些电磁侧信道攻击的工作原理。 我们之前介绍了侧信道攻击的概念:它们是什么,以及为什么它们会成为重大的硬件安全威胁。在众多形式的侧信道攻击中,最强大的一种是电磁 (EM) 攻…...
)
el-setup- 修改样式(vue3)
一 第一步 <template><el-steps :active"activeStep" align-center><el-stepv-for"item in stepData":key"item.value":class"{ currentStep: activeStep item.value }"><template #icon><div class"…...

CPT204 Advanced Obejct-Oriented Programming 高级面向对象编程 Pt.8 排序算法
文章目录 1. 排序算法1.1 冒泡排序(Bubble sort)1.2 归并排序(Merge Sort)1.3 快速排序(Quick Sort)1.4 堆排序(Heap Sort) 2. 在面向对象编程中终身学习2.1 记录和反思学习过程2.2 …...

【低配置电脑预训练minimind的实践】
低配置电脑预训练minimind的实践 概要 minimind是一个轻量级的LLM大语言模型,项目的初衷是拉低LLM的学习门槛,让每个人都能从理解每一行代码开始, 从零开始亲手训练一个极小的语言模型。对于很多初学者而言,电脑配置仅能够满足日…...

flutter 小知识
FractionallySizedBox组件 FractionallySizedBox是Flutter中的一个特殊布局小部件,它允许子组件的尺寸基于父组件的尺寸来计算。这意味着子组件的尺寸是父组件尺寸的一个比例,这使得布局在不同屏幕尺寸下保持一致性1。 ListWheelScrollView Lis…...

高性能服务器配置经验指南3——安装服务器可能遇到的问题及解决方法
文章目录 1、重装系统后VScode远程连接失败问题2、XRDP连接黑屏问题1. 打开文件2. 添加配置3. 重启xrdp服务 在完成 服务器基本配置和 深度学习环境准备后,大家应该就可以正常使用服务器了,推荐使用VScode远程连接使用,比较稳定方便&#x…...
解决 Vue 项目中路径别名 `@` 在 IDE 中报错无法识别的问题)
Vue实战(08)解决 Vue 项目中路径别名 `@` 在 IDE 中报错无法识别的问题
一、引言 在 Vue 项目开发过程中,路径别名是一个非常实用的特性,它能够帮助开发者简化文件引用路径,提高代码的可读性和可维护性。其中, 作为一个常见的路径别名,通常被用来指向项目的 src 目录。然而,…...

处理任务“无需等待”:集成RabbitMQ实现异步通信与系统解耦
在前几篇文章中,我们构建的Web应用遵循了一个常见的同步处理模式:用户发出HTTP请求 -> Controller接收 -> Service处理(可能涉及数据库操作、调用其他内部方法)-> Controller返回HTTP响应。这个流程简单直接,…...

ASP.NET Core 主机模型详解:Host、WebHost与WebApplication的对比与实践【代码之美】
🎀🎀🎀代码之美系列目录🎀🎀🎀 一、C# 命名规则规范 二、C# 代码约定规范 三、C# 参数类型约束 四、浅析 B/S 应用程序体系结构原则 五、浅析 C# Async 和 Await 六、浅析 ASP.NET Core SignalR 双工通信 …...

编译型语言、解释型语言与混合型语言:原理、区别与应用场景详解
编译型语言、解释型语言与混合型语言:原理、区别与应用场景详解 文章目录 编译型语言、解释型语言与混合型语言:原理、区别与应用场景详解引言一、编译型语言1.1 工作原理1.2 典型的编译型语言1.3 优点1.4 缺点 二、解释型语言2.1 工作原理2.2 典型的解释…...

AI工程pytorch小白TorchServe部署模型服务
注意:该博客仅是介绍整体流程和环境部署,不能直接拿来即用(避免公司代码外泄)请理解。并且当前流程是公司notebook运行&本机windows,后面可以使用docker 部署镜像到k8s,敬请期待~ 前提提要:工程要放弃采购的AI平台…...

Ubuntu 一站式部署 RabbitMQ 4 并“彻底”迁移数据目录的终极实践
1 安装前准备 sudo apt update -y sudo apt install -y curl gnupg apt-transport-https lsb-release jq若计划将数据放到新磁盘(如 /dev/nvme0n1p1): sudo mkfs.xfs /dev/nvme0n1p1 sudo mkdir /data echo /dev/nvme0n1p1 /data xfs defau…...

华为手机怎么进行音频降噪?音频降噪技巧分享:提升听觉体验
在当今数字化时代,音频质量对于提升用户体验至关重要,无论是在通话、视频录制还是音频文件播放中,清晰的音频都能带来更佳的听觉享受。 而华为手机凭借其强大的音频处理技术,为用户提供了多种音频降噪功能,帮助用户在…...

拥抱健康生活,解锁养生之道
在生活节奏日益加快的当下,健康养生已成为人们关注的焦点。科学的养生方法,能帮助我们增强体质、预防疾病,以更饱满的精神状态拥抱生活。 合理饮食是养生的基石。《黄帝内经》中提到 “五谷为养,五果为助,五畜为益&…...

深入理解Java阻塞队列:原理、使用场景及代码实战
🚀 文章提示 你将在这篇文章中收获: 阻塞队列的核心特性:队列空/满时的阻塞机制 四种操作方式对比:抛异常、返回特殊值、永久阻塞、超时阻塞 SynchronousQueue的独特设计:同步队列的生产者-消费者强耦合 代码实战&a…...

vue3--手写手机屏组件
<!--* 手机预览* Author: Hanyang* Date: 2022-12-09 09:13:00* LastEditors: Hanyang* LastEditTime: 2023-01-12 15:37:00 --> <template><divclass"public-preview-mobile"ref"previewMobileRef":class"showMobile ? animation-sh…...

【Elasticsearch】入门篇
Elasticsearch 入门 前言 官方地址:Elastic — 搜索 AI 公司 | Elastic ES 下载地址:Past Releases of Elastic Stack Software | Elastic 文档:什么是 Elasticsearch?|Elasticsearch 指南 简介 Elasticsearch 是一个分布式、…...

Unity 使用 ADB 实时查看手机运行性能
Unity 使用 ADB 实时查看手机运行性能 前言操作步骤ADB工具下载ADB工具配置手机进入开发者模式并开启USB调试使用ADB连接手机Unity打包设置使用Profiler实时查看性能情况优化建议 常见问题 前言 通过 ADB(Android Debug Bridge)连接安卓设备,…...

蓝桥杯 1. 四平方和
四平方和 原题目链接 题目描述 四平方和定理(又称拉格朗日定理)指出: 每个正整数都可以表示为 至多 4 个正整数的平方和。 如果将 0 包括进去,则每个正整数都可以恰好表示为 4 个非负整数的平方和。 例如: 5 0 …...

Nginx 配置参数全解版:Nginx 反向代理与负载均衡;Nginx 配置规范与 Header 透传实践指南;Nginx 配置参数详解
Nginx 配置参数全解版:Nginx 反向代理与负载均衡;Nginx 配置规范与 Header 透传实践指南;Nginx 配置参数详解 Nginx 反向代理与负载均衡配置,Header 透传到后端应用(参数全解版)一、Nginx 反向代理与负载均…...

数据分析之技术干货业务价值 powerquery 分组排序后取TOP
在电商中,我们要对货品进行分析,由于所有的销售数据都在一起,货品信息也在一起,两个表建立了关系之后,要看每个品类的TOP款有哪些,每个品类的TOP款是什么要怎么做呢? 下面是我做数据的思路&…...

windows中kafka4.0集群搭建
参考文献 Apache Kafka windows启动kafka4.0(不再需要zookeeper)_kafka压缩包-CSDN博客 Kafka 4.0 KRaft集群部署_kafka4.0集群部署-CSDN博客 正文 注意jdk需要17版本以上的 修改D:\software\kafka_2.13-4.0.0\node1\config\server.properties配置文…...

数据分析案例:医疗健康数据分析
目录 数据分析案例:医疗健康数据分析1. 项目背景2. 数据加载与预处理2.1 加载数据2.2 数据清洗3. 探索性数据分析(EDA)3.1 再入院率概览3.2 按年龄分组的再入院率3.3 住院时长与再入院4. 特征工程与可视化5. 模型构建与评估5.1 数据划分5.2 训练逻辑回归5.3 模型评估6. 业务…...

数据分析之 商品价格分层之添加价格带
在分析货品数据的时候,我们会对商品的价格进行分层汇总,也叫价格带, 一、价格带的定义 价格带(Price Band):将商品按价格区间划分(如0-50元、50-100元、100-200元等ÿ…...

跨浏览器音频录制:实现兼容的音频捕获与WAV格式生成
在现代Web开发中,音频录制功能越来越受到开发者的关注。无论是在线会议、语音识别还是简单的语音留言,音频录制都是一个重要的功能。然而,实现一个跨浏览器的音频录制功能并非易事,因为不同浏览器对音频录制API的支持存在差异。本…...
)
JavaScript 的“世界模型”:深入理解对象 (Objects)
引言:超越简单值,构建复杂实体 到目前为止,我们学习的变量大多存储的是单一的值,比如一个数字 (let age 30;)、一个字符串 (let name "Alice";) 或一个布尔值 (let isActive true;)。这对于简单场景足够了&am…...