windows中kafka4.0集群搭建
参考文献
Apache Kafka
windows启动kafka4.0(不再需要zookeeper)_kafka压缩包-CSDN博客
Kafka 4.0 KRaft集群部署_kafka4.0集群部署-CSDN博客
正文
注意jdk需要17版本以上的

修改D:\software\kafka_2.13-4.0.0\node1\config\server.properties配置文件
# Licensed to the Apache Software Foundation (ASF) under one or more
# contributor license agreements. See the NOTICE file distributed with
# this work for additional information regarding copyright ownership.
# The ASF licenses this file to You under the Apache License, Version 2.0
# (the "License"); you may not use this file except in compliance with
# the License. You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.############################# Server Basics ############################## The role of this server. Setting this puts us in KRaft mode
process.roles=broker,controller# The node id associated with this instance's roles
node.id=1# List of controller endpoints used connect to the controller cluster
controller.quorum.bootstrap.servers=localhost:19093############################# Socket Server Settings ############################## The address the socket server listens on.
# Combined nodes (i.e. those with `process.roles=broker,controller`) must list the controller listener here at a minimum.
# If the broker listener is not defined, the default listener will use a host name that is equal to the value of java.net.InetAddress.getCanonicalHostName(),
# with PLAINTEXT listener name, and port 9092.
# FORMAT:
# listeners = listener_name://host_name:port
# EXAMPLE:
# listeners = PLAINTEXT://your.host.name:9092
listeners=PLAINTEXT://localhost:19092,CONTROLLER://localhost:19093# Name of listener used for communication between brokers.
inter.broker.listener.name=PLAINTEXT# Listener name, hostname and port the broker or the controller will advertise to clients.
# If not set, it uses the value for "listeners".
advertised.listeners=PLAINTEXT://localhost:19092,CONTROLLER://localhost:19093# A comma-separated list of the names of the listeners used by the controller.
# If no explicit mapping set in `listener.security.protocol.map`, default will be using PLAINTEXT protocol
# This is required if running in KRaft mode.
controller.listener.names=CONTROLLER# Maps listener names to security protocols, the default is for them to be the same. See the config documentation for more details
listener.security.protocol.map=CONTROLLER:PLAINTEXT,PLAINTEXT:PLAINTEXT,SSL:SSL,SASL_PLAINTEXT:SASL_PLAINTEXT,SASL_SSL:SASL_SSL# The number of threads that the server uses for receiving requests from the network and sending responses to the network
num.network.threads=3# The number of threads that the server uses for processing requests, which may include disk I/O
num.io.threads=8# The send buffer (SO_SNDBUF) used by the socket server
socket.send.buffer.bytes=102400# The receive buffer (SO_RCVBUF) used by the socket server
socket.receive.buffer.bytes=102400# The maximum size of a request that the socket server will accept (protection against OOM)
socket.request.max.bytes=104857600############################# Log Basics ############################## A comma separated list of directories under which to store log files
log.dirs=D:\\software\\kafka_2.13-4.0.0\\node1\\kraft-combined-logs
# The default number of log partitions per topic. More partitions allow greater
# parallelism for consumption, but this will also result in more files across
# the brokers.
num.partitions=1# The number of threads per data directory to be used for log recovery at startup and flushing at shutdown.
# This value is recommended to be increased for installations with data dirs located in RAID array.
num.recovery.threads.per.data.dir=1############################# Internal Topic Settings #############################
# The replication factor for the group metadata internal topics "__consumer_offsets", "__share_group_state" and "__transaction_state"
# For anything other than development testing, a value greater than 1 is recommended to ensure availability such as 3.
offsets.topic.replication.factor=1
share.coordinator.state.topic.replication.factor=1
share.coordinator.state.topic.min.isr=1
transaction.state.log.replication.factor=1
transaction.state.log.min.isr=1############################# Log Flush Policy ############################## Messages are immediately written to the filesystem but by default we only fsync() to sync
# the OS cache lazily. The following configurations control the flush of data to disk.
# There are a few important trade-offs here:
# 1. Durability: Unflushed data may be lost if you are not using replication.
# 2. Latency: Very large flush intervals may lead to latency spikes when the flush does occur as there will be a lot of data to flush.
# 3. Throughput: The flush is generally the most expensive operation, and a small flush interval may lead to excessive seeks.
# The settings below allow one to configure the flush policy to flush data after a period of time or
# every N messages (or both). This can be done globally and overridden on a per-topic basis.# The number of messages to accept before forcing a flush of data to disk
#log.flush.interval.messages=10000# The maximum amount of time a message can sit in a log before we force a flush
#log.flush.interval.ms=1000############################# Log Retention Policy ############################## The following configurations control the disposal of log segments. The policy can
# be set to delete segments after a period of time, or after a given size has accumulated.
# A segment will be deleted whenever *either* of these criteria are met. Deletion always happens
# from the end of the log.# The minimum age of a log file to be eligible for deletion due to age
log.retention.hours=168# A size-based retention policy for logs. Segments are pruned from the log unless the remaining
# segments drop below log.retention.bytes. Functions independently of log.retention.hours.
#log.retention.bytes=1073741824# The maximum size of a log segment file. When this size is reached a new log segment will be created.
log.segment.bytes=1073741824# The interval at which log segments are checked to see if they can be deleted according
# to the retention policies
log.retention.check.interval.ms=300000controller.quorum.voters=1@127.0.0.1:19093,2@127.0.0.1:29093,3@127.0.0.1:39093修改D:\software\kafka_2.13-4.0.0\node2\config\server.properties配置文件
# Licensed to the Apache Software Foundation (ASF) under one or more
# contributor license agreements. See the NOTICE file distributed with
# this work for additional information regarding copyright ownership.
# The ASF licenses this file to You under the Apache License, Version 2.0
# (the "License"); you may not use this file except in compliance with
# the License. You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.############################# Server Basics ############################## The role of this server. Setting this puts us in KRaft mode
process.roles=broker,controller# The node id associated with this instance's roles
node.id=2# List of controller endpoints used connect to the controller cluster
controller.quorum.bootstrap.servers=localhost:29093,localhost:39093############################# Socket Server Settings ############################## The address the socket server listens on.
# Combined nodes (i.e. those with `process.roles=broker,controller`) must list the controller listener here at a minimum.
# If the broker listener is not defined, the default listener will use a host name that is equal to the value of java.net.InetAddress.getCanonicalHostName(),
# with PLAINTEXT listener name, and port 9092.
# FORMAT:
# listeners = listener_name://host_name:port
# EXAMPLE:
# listeners = PLAINTEXT://your.host.name:9092
listeners=PLAINTEXT://localhost:29092,CONTROLLER://localhost:29093# Name of listener used for communication between brokers.
inter.broker.listener.name=PLAINTEXT# Listener name, hostname and port the broker or the controller will advertise to clients.
# If not set, it uses the value for "listeners".
advertised.listeners=PLAINTEXT://localhost:29092,CONTROLLER://localhost:29093# A comma-separated list of the names of the listeners used by the controller.
# If no explicit mapping set in `listener.security.protocol.map`, default will be using PLAINTEXT protocol
# This is required if running in KRaft mode.
controller.listener.names=CONTROLLER# Maps listener names to security protocols, the default is for them to be the same. See the config documentation for more details
listener.security.protocol.map=CONTROLLER:PLAINTEXT,PLAINTEXT:PLAINTEXT,SSL:SSL,SASL_PLAINTEXT:SASL_PLAINTEXT,SASL_SSL:SASL_SSL# The number of threads that the server uses for receiving requests from the network and sending responses to the network
num.network.threads=3# The number of threads that the server uses for processing requests, which may include disk I/O
num.io.threads=8# The send buffer (SO_SNDBUF) used by the socket server
socket.send.buffer.bytes=102400# The receive buffer (SO_RCVBUF) used by the socket server
socket.receive.buffer.bytes=102400# The maximum size of a request that the socket server will accept (protection against OOM)
socket.request.max.bytes=104857600############################# Log Basics ############################## A comma separated list of directories under which to store log files
log.dirs=D:\\software\\kafka_2.13-4.0.0\\node2\\kraft-combined-logs# The default number of log partitions per topic. More partitions allow greater
# parallelism for consumption, but this will also result in more files across
# the brokers.
num.partitions=1# The number of threads per data directory to be used for log recovery at startup and flushing at shutdown.
# This value is recommended to be increased for installations with data dirs located in RAID array.
num.recovery.threads.per.data.dir=1############################# Internal Topic Settings #############################
# The replication factor for the group metadata internal topics "__consumer_offsets", "__share_group_state" and "__transaction_state"
# For anything other than development testing, a value greater than 1 is recommended to ensure availability such as 3.
offsets.topic.replication.factor=1
share.coordinator.state.topic.replication.factor=1
share.coordinator.state.topic.min.isr=1
transaction.state.log.replication.factor=1
transaction.state.log.min.isr=1############################# Log Flush Policy ############################## Messages are immediately written to the filesystem but by default we only fsync() to sync
# the OS cache lazily. The following configurations control the flush of data to disk.
# There are a few important trade-offs here:
# 1. Durability: Unflushed data may be lost if you are not using replication.
# 2. Latency: Very large flush intervals may lead to latency spikes when the flush does occur as there will be a lot of data to flush.
# 3. Throughput: The flush is generally the most expensive operation, and a small flush interval may lead to excessive seeks.
# The settings below allow one to configure the flush policy to flush data after a period of time or
# every N messages (or both). This can be done globally and overridden on a per-topic basis.# The number of messages to accept before forcing a flush of data to disk
#log.flush.interval.messages=10000# The maximum amount of time a message can sit in a log before we force a flush
#log.flush.interval.ms=1000############################# Log Retention Policy ############################## The following configurations control the disposal of log segments. The policy can
# be set to delete segments after a period of time, or after a given size has accumulated.
# A segment will be deleted whenever *either* of these criteria are met. Deletion always happens
# from the end of the log.# The minimum age of a log file to be eligible for deletion due to age
log.retention.hours=168# A size-based retention policy for logs. Segments are pruned from the log unless the remaining
# segments drop below log.retention.bytes. Functions independently of log.retention.hours.
#log.retention.bytes=1073741824# The maximum size of a log segment file. When this size is reached a new log segment will be created.
log.segment.bytes=1073741824# The interval at which log segments are checked to see if they can be deleted according
# to the retention policies
log.retention.check.interval.ms=300000controller.quorum.voters=1@127.0.0.1:19093,2@127.0.0.1:29093,3@127.0.0.1:39093修改D:\software\kafka_2.13-4.0.0\node3\config\server.properties配置文件
# Licensed to the Apache Software Foundation (ASF) under one or more
# contributor license agreements. See the NOTICE file distributed with
# this work for additional information regarding copyright ownership.
# The ASF licenses this file to You under the Apache License, Version 2.0
# (the "License"); you may not use this file except in compliance with
# the License. You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.############################# Server Basics ############################## The role of this server. Setting this puts us in KRaft mode
process.roles=broker,controller# The node id associated with this instance's roles
node.id=3# List of controller endpoints used connect to the controller cluster
controller.quorum.bootstrap.servers=localhost:39093
############################# Socket Server Settings ############################## The address the socket server listens on.
# Combined nodes (i.e. those with `process.roles=broker,controller`) must list the controller listener here at a minimum.
# If the broker listener is not defined, the default listener will use a host name that is equal to the value of java.net.InetAddress.getCanonicalHostName(),
# with PLAINTEXT listener name, and port 9092.
# FORMAT:
# listeners = listener_name://host_name:port
# EXAMPLE:
# listeners = PLAINTEXT://your.host.name:9092
listeners=PLAINTEXT://localhost:39092,CONTROLLER://localhost:39093# Name of listener used for communication between brokers.
inter.broker.listener.name=PLAINTEXT# Listener name, hostname and port the broker or the controller will advertise to clients.
# If not set, it uses the value for "listeners".
advertised.listeners=PLAINTEXT://localhost:39092,CONTROLLER://localhost:39093# A comma-separated list of the names of the listeners used by the controller.
# If no explicit mapping set in `listener.security.protocol.map`, default will be using PLAINTEXT protocol
# This is required if running in KRaft mode.
controller.listener.names=CONTROLLER# Maps listener names to security protocols, the default is for them to be the same. See the config documentation for more details
listener.security.protocol.map=CONTROLLER:PLAINTEXT,PLAINTEXT:PLAINTEXT,SSL:SSL,SASL_PLAINTEXT:SASL_PLAINTEXT,SASL_SSL:SASL_SSL# The number of threads that the server uses for receiving requests from the network and sending responses to the network
num.network.threads=3# The number of threads that the server uses for processing requests, which may include disk I/O
num.io.threads=8# The send buffer (SO_SNDBUF) used by the socket server
socket.send.buffer.bytes=102400# The receive buffer (SO_RCVBUF) used by the socket server
socket.receive.buffer.bytes=102400# The maximum size of a request that the socket server will accept (protection against OOM)
socket.request.max.bytes=104857600############################# Log Basics ############################## A comma separated list of directories under which to store log files
log.dirs=/tmp/kraft-combined-logs# The default number of log partitions per topic. More partitions allow greater
# parallelism for consumption, but this will also result in more files across
# the brokers.
num.partitions=1# The number of threads per data directory to be used for log recovery at startup and flushing at shutdown.
# This value is recommended to be increased for installations with data dirs located in RAID array.
num.recovery.threads.per.data.dir=1############################# Internal Topic Settings #############################
# The replication factor for the group metadata internal topics "__consumer_offsets", "__share_group_state" and "__transaction_state"
# For anything other than development testing, a value greater than 1 is recommended to ensure availability such as 3.
offsets.topic.replication.factor=1
share.coordinator.state.topic.replication.factor=1
share.coordinator.state.topic.min.isr=1
transaction.state.log.replication.factor=1
transaction.state.log.min.isr=1############################# Log Flush Policy ############################## Messages are immediately written to the filesystem but by default we only fsync() to sync
# the OS cache lazily. The following configurations control the flush of data to disk.
# There are a few important trade-offs here:
# 1. Durability: Unflushed data may be lost if you are not using replication.
# 2. Latency: Very large flush intervals may lead to latency spikes when the flush does occur as there will be a lot of data to flush.
# 3. Throughput: The flush is generally the most expensive operation, and a small flush interval may lead to excessive seeks.
# The settings below allow one to configure the flush policy to flush data after a period of time or
# every N messages (or both). This can be done globally and overridden on a per-topic basis.# The number of messages to accept before forcing a flush of data to disk
#log.flush.interval.messages=10000# The maximum amount of time a message can sit in a log before we force a flush
#log.flush.interval.ms=1000############################# Log Retention Policy ############################## The following configurations control the disposal of log segments. The policy can
# be set to delete segments after a period of time, or after a given size has accumulated.
# A segment will be deleted whenever *either* of these criteria are met. Deletion always happens
# from the end of the log.# The minimum age of a log file to be eligible for deletion due to age
log.retention.hours=168# A size-based retention policy for logs. Segments are pruned from the log unless the remaining
# segments drop below log.retention.bytes. Functions independently of log.retention.hours.
#log.retention.bytes=1073741824# The maximum size of a log segment file. When this size is reached a new log segment will be created.
log.segment.bytes=1073741824# The interval at which log segments are checked to see if they can be deleted according
# to the retention policies
log.retention.check.interval.ms=300000controller.quorum.voters=1@127.0.0.1:19093,2@127.0.0.1:29093,3@127.0.0.1:39093会生成一个随机的cluster.id(集群id)
.\bin\windows\kafka-storage.bat random-uuid
虽然有error错误信息,但是这个不影响。我的uuid是xDd-c_vwSCOda91tgPLX2g
下面用这个uuid来作为cluster.id(集群id)来格式化日志
.\bin\windows\kafka-storage.bat format -t xDd-c_vwSCOda91tgPLX2g -c .\config\server.properties


启动kafka
.\bin\windows\kafka-server-start.bat .\config\server.properties![]()
![]()
![]()
Create a topic to store your events
.\bin\windows\kafka-topics.bat --create --topic quickstart-events --bootstrap-server localhost:19092,localhost:29092,localhost:39092
Write some events into the topic
.\bin\windows\kafka-console-producer.bat --topic quickstart-events --bootstrap-server localhost:19092,localhost:29092,localhost:39092
Read the events
.\bin\windows\kafka-console-consumer.bat --topic quickstart-events --from-beginning --bootstrap-server localhost:19092,localhost:29092,localhost:39092
使用kafka消息可视化工具offset Explorer进行连接
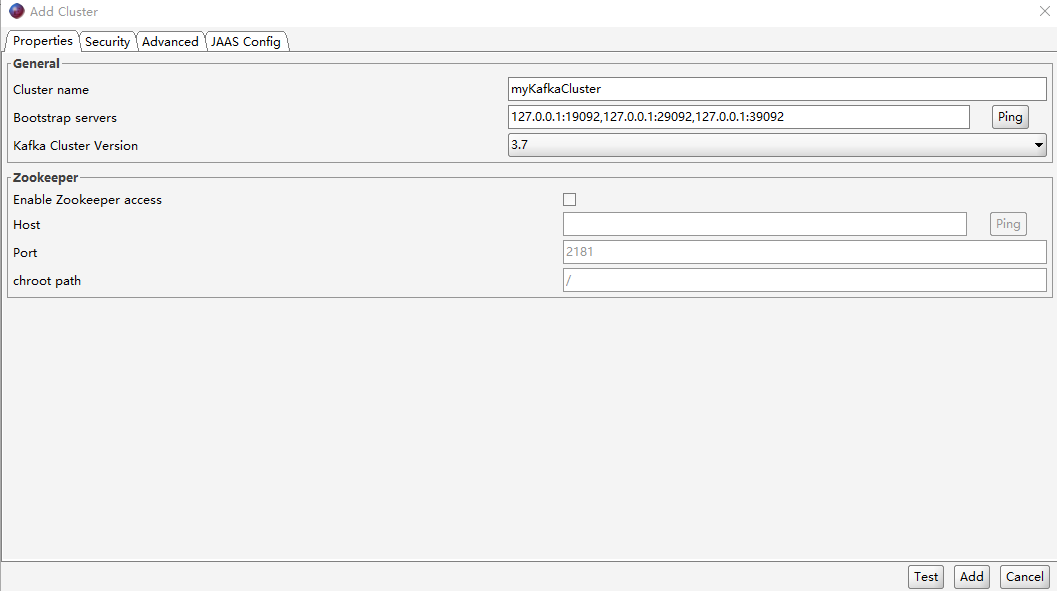
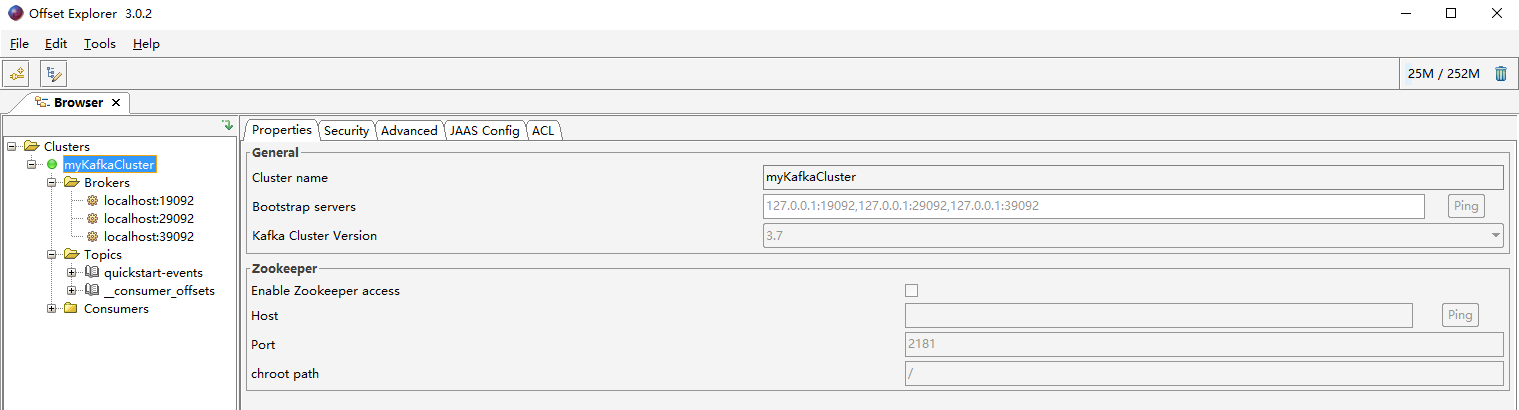
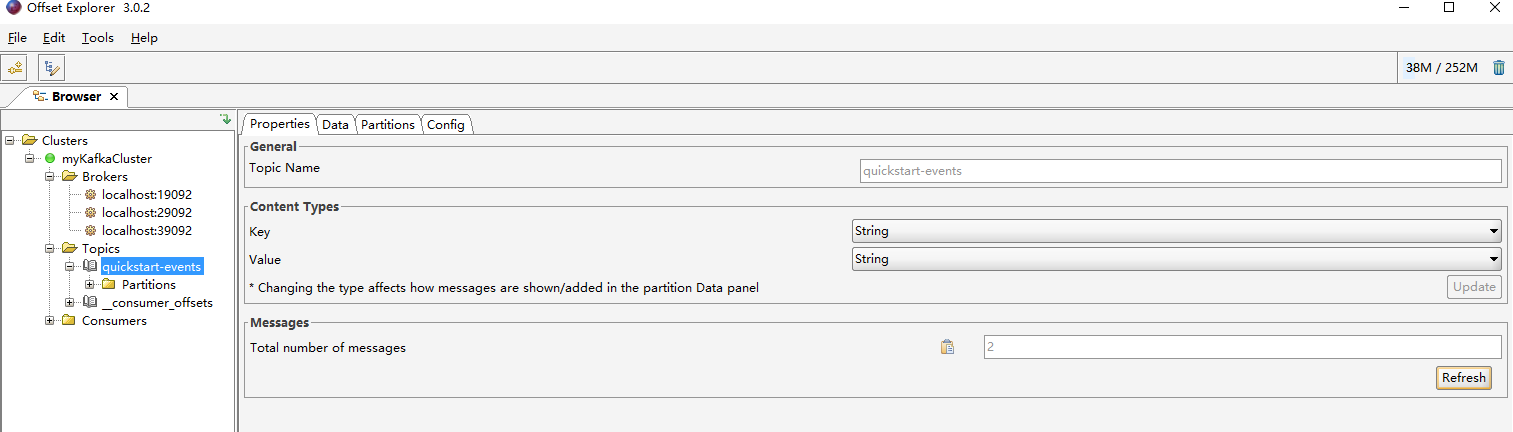
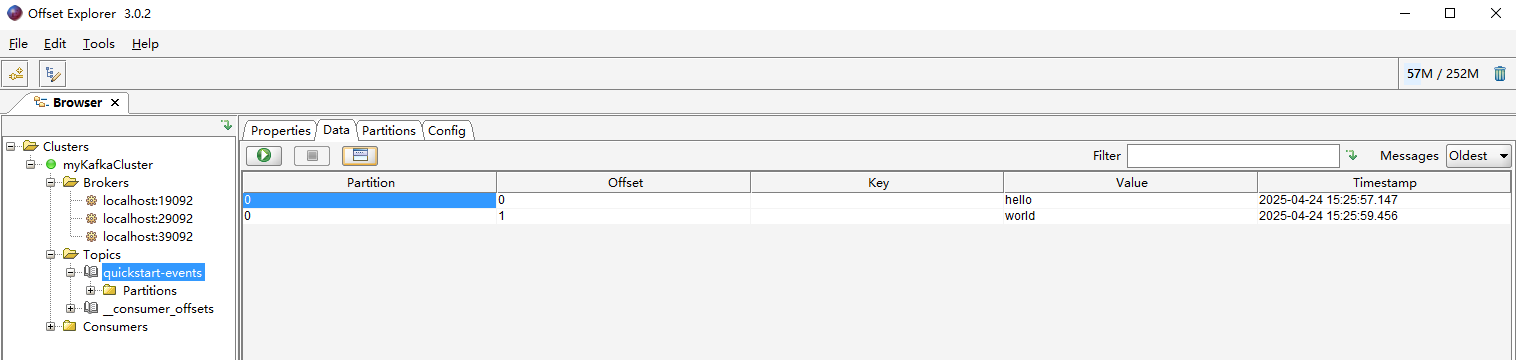
相关文章:

windows中kafka4.0集群搭建
参考文献 Apache Kafka windows启动kafka4.0(不再需要zookeeper)_kafka压缩包-CSDN博客 Kafka 4.0 KRaft集群部署_kafka4.0集群部署-CSDN博客 正文 注意jdk需要17版本以上的 修改D:\software\kafka_2.13-4.0.0\node1\config\server.properties配置文…...

数据分析案例:医疗健康数据分析
目录 数据分析案例:医疗健康数据分析1. 项目背景2. 数据加载与预处理2.1 加载数据2.2 数据清洗3. 探索性数据分析(EDA)3.1 再入院率概览3.2 按年龄分组的再入院率3.3 住院时长与再入院4. 特征工程与可视化5. 模型构建与评估5.1 数据划分5.2 训练逻辑回归5.3 模型评估6. 业务…...

数据分析之 商品价格分层之添加价格带
在分析货品数据的时候,我们会对商品的价格进行分层汇总,也叫价格带, 一、价格带的定义 价格带(Price Band):将商品按价格区间划分(如0-50元、50-100元、100-200元等ÿ…...

跨浏览器音频录制:实现兼容的音频捕获与WAV格式生成
在现代Web开发中,音频录制功能越来越受到开发者的关注。无论是在线会议、语音识别还是简单的语音留言,音频录制都是一个重要的功能。然而,实现一个跨浏览器的音频录制功能并非易事,因为不同浏览器对音频录制API的支持存在差异。本…...
)
JavaScript 的“世界模型”:深入理解对象 (Objects)
引言:超越简单值,构建复杂实体 到目前为止,我们学习的变量大多存储的是单一的值,比如一个数字 (let age 30;)、一个字符串 (let name "Alice";) 或一个布尔值 (let isActive true;)。这对于简单场景足够了&am…...

【国产化之路】VPX-3U :基于D2000 /FT2000的硬件架构到操作系统兼容
在国产化和高性能计算、嵌入式系统领域日益受到重视的今天,VPX3U架构以其标准化和模块化的特性广受关注。本文将从硬件架构、系统软件、接口拓展及典型应用等方面,深入剖析整体设计思路与工程实现,供友友们参考和讨论。 一、总体架构与设计目…...
模型的优化技巧)
深入探索RAG(检索增强生成)模型的优化技巧
📌 友情提示: 本文内容由银河易创AI(https://ai.eaigx.com)创作平台的gpt-4o-mini模型生成,旨在提供技术参考与灵感启发。文中观点或代码示例需结合实际情况验证,建议读者通过官方文档或实践进一步确认其准…...

架构-软件架构设计
一、软件架构基础概念 1. 软件架构的定义 通俗理解:软件架构是软件系统的“骨架”,定义了系统的结构、行为和属性,就像盖房子的设计图纸,规划了房间布局、承重结构和功能分区。核心作用: 沟通桥梁:让技术…...

免费的 HTML 网页托管服务
字根云平台最近上线了一项新的服务: HTML 网页托管。 HTML 网页免费托管 免费HTML静态页面文件托管-字根秀秀 www.cuobiezi.net/showshow/ 网页托管主要支持的功能: 1. 托管静态的 HTML 网页(不包含图片,图片请使用专业图床&a…...

Ubuntu服务器上如何监控Oracle数据库
在 Ubuntu 服务器上监控 Oracle 数据库,虽然不像在 Windows 或某些企业 Linux(如 RHEL)那样有现成的 GUI 工具,但你完全可以通过命令行工具、脚本、开源监控平台来实现全面监控,包含: 数据库性能指标&#…...

什么是CMMI认证?CMMI评估内容?CMMI认证能带来哪些好处?
CMMI认证详解:概念、评估内容与核心价值 一、什么是CMMI认证? CMMI(Capability Maturity Model Integration,能力成熟度模型集成)是由美国卡内基梅隆大学软件工程研究所(SEI)开发的一套全球公…...
)
PySide6 GUI 学习笔记——常用类及控件使用方法(常用类矩阵QRectF)
文章目录 类描述构造方法主要方法1. 基础属性2. 边界操作3. 几何运算4. 坐标调整5. 转换方法6. 状态判断 类特点总结1. 浮点精度:2. 坐标系统:3. 有效性判断:4. 几何运算:5. 类型转换:6. 特殊处理: 典型应用…...

arm64适配系列文章-第五章-arm64环境上redis的部署
ARM64适配系列文章 第一章 arm64环境上kubesphere和k8s的部署 第二章 arm64环境上nfs-subdir-external-provisioner的部署 第三章 arm64环境上mariadb的部署 第四章 arm64环境上nacos的部署 第五章 arm64环境上redis的部署 第六章 arm64环境上rabbitmq-management的部署 第七章…...

Ubuntu / WSL 安装pipx
一、安装pipx 在 Ubuntu / WSL 上可以用两种方式安装,推荐第二种(官方脚本)或第三种(pip 安装最新版本并自动配置 PATH)。 1. apt 安装(最快,但版本往往偏旧) sudo apt update su…...

10天学会嵌入式技术之51单片机-day-6
第十五章 点阵LED 15.1 点阵 LED 概述 15.1.1 实物图 15.1.1 原理图 15.2 点阵 LED 静态显示 15.2.1 需求描述 使用点阵 LED 显示一排由左上到右下的斜线,具体效果如下图所示。 15.2.2 硬件设计 15.2.2.1 硬件原理图 根据内部原理可知,点阵 LED 的…...

【数据可视化-28】2017-2025 年每月产品零售价数据可视化分析
🧑 博主简介:曾任某智慧城市类企业算法总监,目前在美国市场的物流公司从事高级算法工程师一职,深耕人工智能领域,精通python数据挖掘、可视化、机器学习等,发表过AI相关的专利并多次在AI类比赛中获奖。CSDN…...

【JavaScript】`Object` 对象静态方法详解
在 JavaScript 中,Object 对象提供了许多静态方法,用于操作和处理对象。以下是一些常用的 Object.xxx 方法及其用途和示例: 1. 属性相关方法 Object.keys(obj) 返回对象自身的所有可枚举属性的键组成的数组。 const obj = {a: 1, b: 2 }; console.log(Object.keys(obj)); //…...

音视频之H.265/HEVC量化
H.265/HEVC系列文章: 1、音视频之H.265/HEVC编码框架及编码视频格式 2、音视频之H.265码流分析及解析 3、音视频之H.265/HEVC预测编码 4、音视频之H.265/HEVC变换编码 5、音视频之H.265/HEVC量化 量化 (Quantization) 是指将信号的连续取值(或大量可能的离散取…...

Tomcat:从零理解Java Web应用的“心脏”
目录 一、Tomcat是什么?为什么需要它? 二、Tomcat的核心架构(餐厅运营图) 1. 两大核心组件 2. 请求处理全流程(从点餐到上菜) 三、手把手搭建第一个网站(厨房开张实录) 环境准备…...
)
第七届能源系统与电气电力国际学术会议(ICESEP 2025)
重要信息 时间:2025年6月20-22日 地点:中国-武汉 官网:www.icesep.net 主题 能源系统 节能技术、能源存储技术、可再生能源、热能与动力工程 、能源工程、可再生能源技术和系统、风力发…...

【基础】Node.js 介绍、安装及npm 和 npx功能了解
前言 后面安装n8n要用到,做一点技术储备。主要是它的两个工具:npm 和 npx。 Node.js介绍 Node.js 是一个免费的、开源的、跨平台的 JavaScript 运行时环境,允许开发人员在浏览器之外编写命令行工具和服务器端脚本,是一个基于 C…...

【硬核干货】SonarQube安全功能
原文链接:【硬核干货】SonarQube安全功能 关于晓数神州 晓数神州坚持以“客户为中心”的宗旨,为客户提供专业的解决方案和技术服务,构建多引擎数字化体系。 核心业务1:聚焦DevOps全栈产品,打造需求管理、项目管理、开…...

微信小程序 tabbar底部导航栏
官方文档:https://developers.weixin.qq.com/miniprogram/dev/reference/configuration/app.html#tabBar 一、常规菜单格式 在app.json 文件中配置,其他关键点详见官方文档,后续更新不规则图标的写法...

如何将极狐GitLab 议题导出为 CSV?
极狐GitLab 是 GitLab 在中国的发行版,关于中文参考文档和资料有: 极狐GitLab 中文文档极狐GitLab 中文论坛极狐GitLab 官网 导出议题到 CSV (BASIC ALL) 您可以将问题从极狐GitLab 导出为 CSV 文件,这些文件将作为附件发送到您的默认通知…...

nodejs之Express-介绍、路由
五、Express 1、express 介绍 express 是一个基于 Node.js 平台的极简、灵活的 WEB 应用开发框架,官方网址: https://www.expressjs.com.cn/ 简单来说,express 是一个封装好的工具包,封装了很多功能,便于我们开发 WEB 应用(HTTP 服务) (1)基本使用 第一步:初始化项目并…...

极狐GitLab 如何从 CSV 导入议题?
极狐GitLab 是 GitLab 在中国的发行版,关于中文参考文档和资料有: 极狐GitLab 中文文档极狐GitLab 中文论坛极狐GitLab 官网 从 CSV 导入议题 (BASIC ALL) 您可以通过上传包含以下列的 CSV 文件将议题导入项目: 名称是否必需?…...
)
JW01三合一传感器详解(STM32)
目录 一、介绍 二、传感器原理 1.原理图 2.引脚描述 三、程序设计 main文件 usart3.h文件 usart3.c文件 四、实验效果 五、资料获取 项目分享 一、介绍 JW01三合一检测模块是一种用于检测空气中二氧化碳浓度的传感器模块。它可以广泛应用于室内空气质量检测、智能家…...
)
23种设计模式-行为型模式之策略模式(Java版本)
Java 策略模式(Strategy Pattern)详解 🧠 什么是策略模式? 策略模式是一种行为型设计模式,它定义了一系列算法,把它们一个个封装起来,并且使它们可以互相替换。策略模式让算法独立于使用它的客…...
)
ActiveMQ 快速上手:安装配置与基础通信实践(一)
一、引言 在当今分布式系统和微服务架构盛行的时代,消息通信作为实现系统间解耦、异步处理和可靠传输的关键技术,显得尤为重要。ActiveMQ 作为一款广泛应用的开源消息中间件,凭借其对 JMS 规范的全面支持、丰富的特性以及出色的性能…...

究竟什么是自动化测试?
自动化测试是一种软件测试方法,旨在通过使用自动化工具和脚本来执行测试任务,以减少人工操作,提高测试效率和准确性。 以下是对自动化测试的详细介绍: 一、定义与特点 定义:自动化测试是指利用自动化工具和脚本来执…...

【LLM+Code】Github Copilot Agent/VsCode Agent 模式PromptTools详细解读
一、前言 github copilot agent mode现在和vscode是强绑定的关系, 其实是一个东西: https://github.blog/news-insights/product-news/github-copilot-the-agent-awakens/https://code.visualstudio.com/docs/copilot/chat/chat-agent-mode 二、Syste…...

IDEA将本地的JAR文件手动安装到 Maven的本地仓库
例如这是要导入的依赖: mvn install:install-file -DfileD:\aliyun-java-sdk-ding.jar -DgroupIdcom.aliyun -DartifactIdaliyun-java-sdk-ding -Dversion1.0.0 -Dpackagingjar-DfileD:\aliyun-java-sdk-ding.jar 含义:指定要安装到本地 Maven 仓库的 …...

redis集群的三种部署方式
一、主从同步 redis的主从同步工作原理简单概括为: 1、从服务器(Slave Server)向(主服务器,Master)发送sync(同步)命令 2、master启动后台存盘进程,并收集所有修改数据命令 3、master完成存盘后,传送整个数据文件到slave 4、slave接受数据文件,加载到内存中完成首次…...

【GIT】github中的仓库如何删除?
你可以按照以下步骤删除 GitHub 上的仓库(repository): 🚨 注意事项: ❗️删除仓库是不可恢复的操作,所有代码、issue、pull request、release 等内容都会被永久删除。 🧭 删除 GitHub 仓库步骤…...
---数据加载load_cifar10)
CIFAR10图像分类学习笔记(三)---数据加载load_cifar10
新创建一个load_cifar10源文件 需要导入的包 import glob from torchvision import transforms from torch.utils.data import DataLoader ,Dataset import os #读取工具 from PIL import Image import numpy as np 01同样定义10个类别的标签名数组 label_name ["airpl…...

基于Matlab的车牌识别系统
1.程序简介 本模型基于MATLAB,通过编程创建GUI界面,基于Matlab的数字图像处理,对静止的车牌图像进行分割并识别,通过编写matlab程序对图像进行灰度处理、二值化、腐蚀膨胀和边缘化处理等,并定位车牌的文字,实现字符的…...

【农气项目】基于适宜度的产量预报
直接上干货(复制到开发工具即可运行的代码) 1. 适宜度模型及作物適宜度计算方法 2. 产量分离 3. 基于适宜度计算产量预报 1. 适宜度模型及作物適宜度计算方法 // 三基点温度配置private final double tempMin;private final double tempOpt;private f…...

C#中实现JSON解析器
JSON(JavaScript Object Notation)即 JavaScript 对象表示法,是一种轻量级的数据交换格式。 起源与发展 JSON 源于 JavaScript 编程语言,是 JavaScript 对象字面量语法的一个子集。但如今它已经独立于 JavaScript,成…...
--okhttp的网络通信的使用)
Android studio进阶开发(四)--okhttp的网络通信的使用
我们之前学过了socket服务器,这次我们继续来学习网络热门编程http/https的使用与交互 1)什么是Http协议? 答:hypertext transfer protocol(超文本传输协议),TCP/IP协议的一个应用层协议&#x…...

untiy 实现点击按钮切换天空盒子
1.新建材质DaySkybox和NightSkybox 设置 Shader 为 Skybox/6 Sided 2.创建ui 切换按钮,编写天空 盒子的脚本 using UnityEngine; using UnityEngine.UI;public class SkyboxSwitcher : MonoBehaviour {public Material daySkybox; // 拖入白天的天空盒材质publi…...
)
Docker从0-1搭建个人云盘(支持Android iOS PC)
一、Docker位置配置【遇到再大的事,先备份MYSQL数据库,说了多少遍】 ******************************************************************************************************************************************* docker rm -f $(docker ps -a -q…...

Java Agent 注入 WebSocket 篇
Agent 如果要对其进行Agent注入的编写,需要先理解三个名字premain,agentmain,Instrumentation premain方法在 JVM 启动阶段调用,一般维持权限的时候不会使用 agentmain方法在 JVM 运行时调用 常用的 Instrumentation实例为代理…...

Linux:git和gdb/cgdb
一:在XShell上使用git 步骤1:安装git命令行 sudo yum install git 步骤2:注册git账户和仓库,并点击克隆/下载,把HTTPS复制 步骤3: 在显示屏上输入下面命令,然后按提示输入自己的用户名和邮箱…...
 vs Dify - 自动化工作流工具全解析)
深度对比评测:n8n vs Coze(扣子) vs Dify - 自动化工作流工具全解析
引言 在当今数字化转型的浪潮中,自动化工作流工具已成为企业和个人提升效率的关键利器。n8n、Coze(扣子)和Dify作为三款各具特色的自动化工具,在开发者社区和商业用户中都引起了广泛关注。本文将为您带来这三款工具的深度对比评测…...
三维建模“橡胶座椅”?)
如何用国产CAD软件皇冠CAD(CrownCAD)三维建模“橡胶座椅”?
皇冠CAD(CrownCAD)以『橡胶座椅』为例讲解“曲面设计、填充曲面、投影曲线、扫描曲面、放样曲面”等三维CAD操作技巧。 在现有模型边线、草图或曲面所定义的边框内填充一曲面。 点击进入填充曲面命令,其界面如下图所示: 各界面参…...

Whisper微调及制作方言数据集
本文不生产技术,只做技术的搬运工!!! 前言 最近在进行whisper微调实验,这个网上有很多成功案例,作者随机找了一个进行了复现,但是由于微调目的是适配本地方言,数据集的采集成为了一…...

实现营销投放全流程自动化 超级汇川推出信息流智能投放产品“AI智投“
随着消费者行为模式的多样化和媒体渠道的日益分散,数字营销行业面临挑战。传统人工数据分析效率低、误差率高,大幅制约广告预算效能。针对上述痛点,近期阿里巴巴旗下超级汇川广告平台推出“AI智投”信息流智能投放产品,基于AI大模…...

shell脚本2
条件测试分类 测试特定的表达式是否成立,当条件成立时,测试语句的返回值为0,否则为其他数值 测试命令格式:[ 条件表达式 ] 文件测试 格式:[ 操作符 文件或目录 ] -d:测试是否为目录(Di…...
等级考试试卷-理论综合)
2025年3月电子学会青少年机器人技术(五级)等级考试试卷-理论综合
青少年机器人技术等级考试理论综合试卷(五级) 分数:100 题数:30 一、单选题(共20题,共80分) 1. 2025年初,中国科技初创公司深度求索在大模型领域迅速崛起,其开源的大模型成为全球AI领域的焦…...

E3650工具链生态再增强,IAR全面支持芯驰科技新一代旗舰智控MCU
近日,全球嵌入式软件开发解决方案领导者IAR与全场景智能车芯引领者芯驰科技正式宣布,IAR Embedded Workbench for Arm已全面支持芯驰E3650,为这一旗舰智控MCU提供开发和调试一站式服务,进一步丰富芯驰E3系列智控芯片工具链生态&am…...