CPT204 Advanced Obejct-Oriented Programming 高级面向对象编程 Pt.8 排序算法
文章目录
- 1. 排序算法
- 1.1 冒泡排序(Bubble sort)
- 1.2 归并排序(Merge Sort)
- 1.3 快速排序(Quick Sort)
- 1.4 堆排序(Heap Sort)
- 2. 在面向对象编程中终身学习
- 2.1 记录和反思学习过程
- 2.2 EDI 原则
- 2.3 人工智能辅助的管理工具进行软件开发
- 3. 练习
- 3.1 基础练习
- 3.2 进阶练习
- 3.2.1 编写两个泛型方法来实现归并排序(Merge Sort)
- 3.2.2 编写两个泛型方法来实现插入排序(Insertion Sort)
1. 排序算法
我们之前的学习已经对所有排序方法都有了了解,这里稍微复习一下。
1.1 冒泡排序(Bubble sort)
冒泡排序是一种简单的排序算法,它重复地遍历待排序的列表,比较每一对相邻的元素,如果它们的顺序错误就交换它们。每次遍历都会让最大的元素“冒泡”到列表的末尾。这个过程会重复进行,直到整个列表有序。
代码如下。
public class BubbleSort {public static void bubbleSort(int[] list) {for (int k = 1; k < list.length; k++) { // 外层循环控制趟数for (int i = 0; i < list.length - k; i++) { // 内层循环比较相邻元素if (list[i] > list[i + 1]) { // 如果当前元素大于后面的元素// 交换它们int temp = list[i];list[i] = list[i + 1];list[i + 1] = temp;}}}}public static void main(String[] args) {int[] list = {64, 34, 25, 12, 22, 11, 90};bubbleSort(list); // 调用冒泡排序System.out.println("Sorted list:");for (int num : list) {System.out.print(num + " ");}}
}
如果列表几乎已经排序好了,或者已经完全排序好了,传统的冒泡排序算法仍然会进行不必要的遍历和比较,这会浪费计算资源。
下面的代码会引入一个布尔变量 needNextPass 来检测数组是否可能已经排序好了,从而避免不必要的遍历。
public class BubbleSort {public static void bubbleSort(int[] list) {boolean needNextPass = true;for (int k = 1; k < list.length && needNextPass; k++) {needNextPass = false; // 假设这一轮不需要再排序for (int i = 0; i < list.length - k; i++) {if (list[i] > list[i + 1]) {int temp = list[i];list[i] = list[i + 1];list[i + 1] = temp;needNextPass = true; // 发生了交换,说明还需要继续排序}}}}public static void main(String[] args) {int[] list = {1, 2, 3, 4};bubbleSort(list);System.out.println("Sorted list:");for (int num : list) {System.out.print(num + " ");}}
}
冒泡排序的时间复杂度再最佳情况下是 O ( n ) O(n) O(n),在最坏情况下(数组完全逆序)是 O ( n 2 ) O(n^2) O(n2)。
1.2 归并排序(Merge Sort)
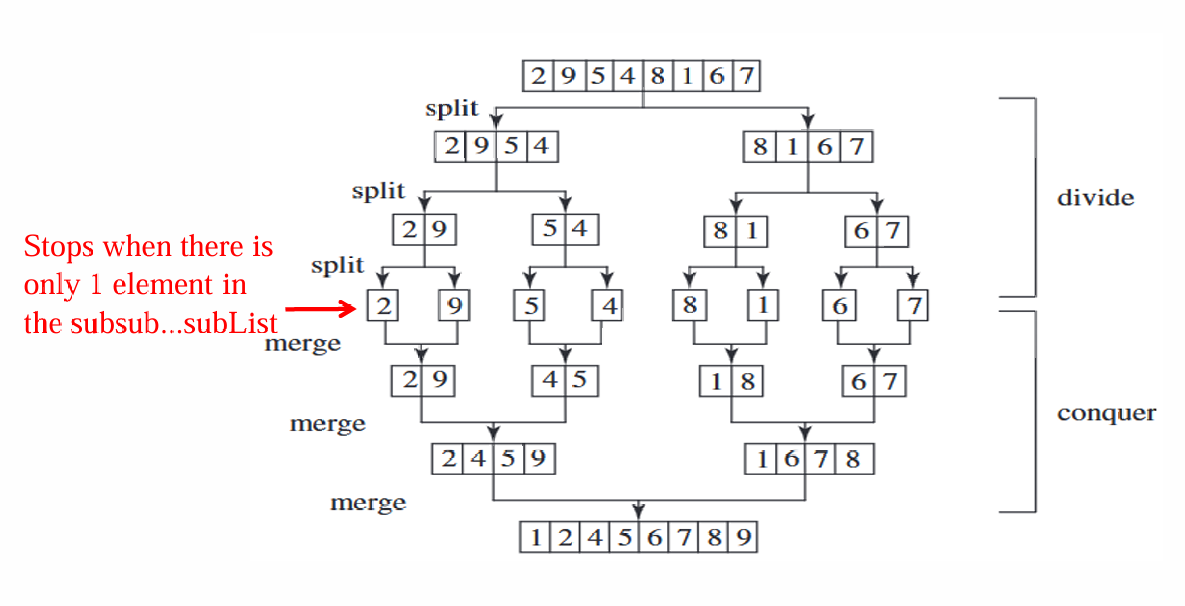
归并排序使用分治法(Divide and Conquer)策略,因此详细步骤如下:
- 分解(Divide):
将数组分成两半。如果数组的长度是奇数,那么可以将中间的元素单独处理,或者将其归入左边或右边的子数组。
这个过程是递归进行的,即对每个子数组继续进行分解,直到每个子数组只包含一个元素。由于只有一个元素的数组自然是有序的,所以这是递归的终止条件。 - 解决(Conquer):
对每个子数组进行排序。由于子数组是由原始数组分解而来,且每个子数组只包含一个元素,所以这一步实际上是在递归地对子数组进行排序。 - 合并(Combine):
将排序好的子数组合并成一个有序数组。这一步是归并排序的核心,需要将两个已排序的子数组合并成一个有序数组。
合并过程是通过比较两个子数组的首元素,将较小的元素放入新数组中,然后从相应的子数组中移除该元素,重复这个过程直到两个子数组中的元素都被合并到新数组中。
代码如下。
public class MergeSortTest {public static void mergeSort(int[] list) {if (list.length > 1) {// 分解第一个子数组int[] firstHalf = new int[list.length / 2];System.arraycopy(list, 0, firstHalf, 0, list.length / 2);mergeSort(firstHalf); // 递归排序第一个子数组// 分解第二个子数组int secondHalfLength = list.length - list.length / 2;int[] secondHalf = new int[secondHalfLength];System.arraycopy(list, list.length / 2, secondHalf, 0, secondHalfLength);mergeSort(secondHalf); // 递归排序第二个子数组// 合并两个子数组到原数组merge(firstHalf, secondHalf, list);}}public static void merge(int[] list1, int[] list2, int[] list) {int current1 = 0; // 当前索引在 list1 中int current2 = 0; // 当前索引在 list2 中int current3 = 0; // 当前索引在 list 中// 合并两个子数组while (current1 < list1.length && current2 < list2.length) {if (list1[current1] < list2[current2]) {list[current3++] = list1[current1++];} else {list[current3++] = list2[current2++];}}// 复制剩余的元素(如果有的话)while (current1 < list1.length) {list[current3++] = list1[current1++];}while (current2 < list2.length) {list[current3++] = list2[current2++];}}public static void main(String[] args) {int size = 100000;int[] a = new int[size];randomInitiate(a);long startTime = System.currentTimeMillis();mergeSort(a);long endTime = System.currentTimeMillis();System.out.println((endTime - startTime) + "ms");}private static void randomInitiate(int[] a) {for (int i = 0; i < a.length; i++) {a[i] = (int) (Math.random() * a.length);}}
}
归并排序的递归关系式为:
T ( n ) = T ( n / 2 ) + T ( n / 2 ) + 2 n − 1 T(n)=T(n/2)+T(n/2)+2n−1 T(n)=T(n/2)+T(n/2)+2n−1
其中:
第一个 T ( n / 2 ) T(n/2) T(n/2)表示对数组的前半部分进行排序所需的时间。
第二个 T ( n / 2 ) T(n/2) T(n/2) 表示对数组的后半部分进行排序所需的时间。
2 n − 1 2n−1 2n−1表示合并两个已排序子数组所需的时间,包括 n − 1 n−1 n−1次比较(用于比较两个子数组的元素)和 n n n次移动(将每个元素放入临时数组)。
因此归并排序的时间复杂度为 O ( n l o g n ) O(nlogn) O(nlogn)。
1.3 快速排序(Quick Sort)
快速排序也是使用分治法(Divide and Conquer)策略来实现排序。
- 算法从数组中选择一个元素,称为基准(pivot)。
- 将数组分成两部分:
第一部分(list1)包含所有小于或等于基准的元素。
第二部分(list2)包含所有大于基准的元素。
这个过程称为分区(partitioning)。 - 递归排序:
对第一部分(list1)和第二部分(list2)分别递归地应用快速排序算法,直到每个子数组只包含一个元素或为空。

代码如下。
public class QuickSortTest {public static void quickSort(int[] list) {quickSort(list, 0, list.length - 1);}public static void quickSort(int[] list, int first, int last) {if (last > first) {int pivotIndex = partition(list, first, last);quickSort(list, first, pivotIndex - 1);quickSort(list, pivotIndex + 1, last);}}public static int partition(int[] list, int first, int last) {int pivot = list[first]; // Choose the first element as pivotint low = first + 1; // Index for forward searchint high = last; // Index for backward searchwhile (high > low) {// Search forward from leftwhile (low <= high && list[low] <= pivot)low++;// Search backward from rightwhile (low <= high && list[high] > pivot)high--;// Swap two elements in the listif (high > low) {int temp = list[high];list[high] = list[low];list[low] = temp;}}// Account for duplicated elements:while (high > first && list[high] >= pivot)high--;// Swap pivot with list[high]if (pivot > list[high]) {list[first] = list[high];list[high] = pivot;return high;} else {return first;}}public static void main(String[] args) {int size = 100000;int[] a = new int[size];randomInitiate(a);long startTime = System.currentTimeMillis();quickSort(a);long endTime = System.currentTimeMillis();System.out.println((endTime - startTime) + "ms");}private static void randomInitiate(int[] a) {for (int i = 0; i < a.length; i++)a[i] = (int) (Math.random() * a.length);}
}
快速排序的递归关系式为:
T ( n ) = T ( n / 2 ) + T ( n / 2 ) + n T(n)=T(n/2)+T(n/2)+n T(n)=T(n/2)+T(n/2)+n
其中:
第一个 T ( n / 2 ) T(n/2) T(n/2)表示对数组的前半部分进行排序所需的时间。
第二个 T ( n / 2 ) T(n/2) T(n/2) 表示对数组的后半部分进行排序所需的时间。
n n n表示分区所需的时间。
因此快速排序的时间复杂度为 O ( n l o g n ) O(nlogn) O(nlogn)。
然而在最坏情况下,每次分区都将数组分成一个非常大的子数组和一个空的子数组。如,假设数组的第一个元素是分区的基准:
[ 1 , 2 , 3 , 4 , 5 , … , n ] , s i z e = n [1,2,3,4,5,…,n], size=n [1,2,3,4,5,…,n],size=n
第一次分区,基准为 1 1 1:
左侧:空,右侧: [ 2 , 3 , 4 , 5 , … , n ] [2, 3, 4, 5, …, n] [2,3,4,5,…,n],右侧子数组大小为 n − 1 n−1 n−1。
第二次分区,基准为 2 2 2:
左侧:空,右侧: [ 3 , 4 , 5 , 6 , … , n ] [3, 4, 5, 6, …, n] [3,4,5,6,…,n],右侧子数组大小为 n − 2 n−2 n−2。
以此类推,直到子数组大小为 1 1 1。
由于每次分区都将数组分成一个非常大的子数组和一个空的子数组,因此需要递归地对 n − 1 n−1 n−1个子数组进行分区操作。
每个分区操作的时间复杂度为 O ( n ) O(n) O(n),因此总的时间复杂度为 O ( n 2 ) O(n^2) O(n2)。
1.4 堆排序(Heap Sort)
这个算法在本学期的算法课上详细介绍过。可以看这里的文章。
相关文章
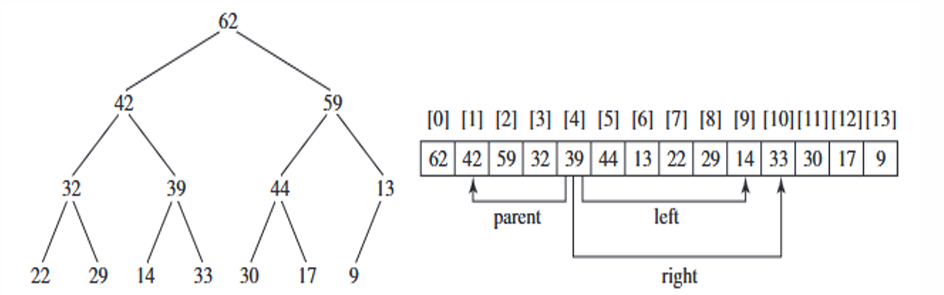
在堆排序算法中,通常使用完全二叉树(Complete Binary Tree)来实现堆结构。完全二叉树是一种特殊的二叉树,其中除了最后一层外,每一层都是满的,并且最后一层的节点尽可能地集中在左侧。
堆排序算法通过维护一个堆结构来实现排序,堆结构有两种类型:
最大堆(Max Heap):每个节点的值都大于或等于其子节点的值。
最小堆(Min Heap):每个节点的值都小于或等于其子节点的值。
堆可以存储在 ArrayList 或数组中,前提是堆的大小是已知的。
对于数组中位置为 i i i的节点,其左子节点的位置是 2 i + 1 2i + 1 2i+1,右子节点的位置是 2 i + 2 2i + 2 2i+2,父节点的位置是 ( i − 1 ) / 2 (i - 1) / 2 (i−1)/2(注意使用整数除法)。
以位置为 4 4 4的节点为例,其两个子节点的位置分别是 2 ∗ 4 + 1 = 9 2 * 4 + 1 = 9 2∗4+1=9和 2 ∗ 4 + 2 = 10 2 * 4 + 2 = 10 2∗4+2=10,其父节点的位置是 ( 4 − 1 ) / 2 = 1 (4 - 1)/ 2 = 1 (4−1)/2=1(注意这里使用的是整数除法,结果为 1 1 1,而不是 1.5 1.5 1.5)。
在堆排序中,通常使用最大堆来实现。算法的基本步骤如下:
- 将待排序的数组转换为最大堆。
- 将堆顶元素(最大值)与数组的最后一个元素交换,然后将数组缩小一个元素。
- 重新调整堆,使其满足最大堆的性质。
- 重复步骤 2 和 3,直到数组完全有序。
因此实现这个算法需要依赖于堆(Heap)这种数据结构。
其UML图如下。

代码如下。
import java.util.ArrayList;public class Heap<E extends Comparable> {private ArrayList<E> list = new ArrayList<E>();// Create a default heappublic Heap() {}// Create a heap from an array of objectspublic Heap(E[] objects) {for (int i = 0; i < objects.length; i++)add(objects[i]);}// Add a new object into the heappublic void add(E newObject) {list.add(newObject); // Append to the end of the heapint currentIndex = list.size() - 1; // The index of the last nodewhile (currentIndex > 0) {int parentIndex = (currentIndex - 1) / 2;// Swap if the current object is greater than its parentif (list.get(currentIndex).compareTo(list.get(parentIndex)) > 0) {E temp = list.get(currentIndex);list.set(currentIndex, list.get(parentIndex));list.set(parentIndex, temp);} elsebreak; // the tree is a heap nowcurrentIndex = parentIndex;}}// Remove the root from the heappublic E remove() {if (list.size() == 0) return null;E removedObject = list.get(0);list.set(0, list.get(list.size() - 1));list.remove(list.size() - 1);int currentIndex = 0;while (currentIndex < list.size()) {int leftChildIndex = 2 * currentIndex + 1;int rightChildIndex = 2 * currentIndex + 2;// Find the maximum between two childrenif (leftChildIndex >= list.size())break; // The tree is a heapint maxIndex = leftChildIndex;if (rightChildIndex < list.size())if (list.get(maxIndex).compareTo(list.get(rightChildIndex)) < 0)maxIndex = rightChildIndex;// Swap if the current node is less than the maximumif (list.get(currentIndex).compareTo(list.get(maxIndex)) < 0) {E temp = list.get(maxIndex);list.set(maxIndex, list.get(currentIndex));list.set(currentIndex, temp);currentIndex = maxIndex;} elsebreak; // The tree is a heap}return removedObject;}// Get the number of nodes in the treepublic int getSize() {return list.size();}
}
所以堆排序的完整代码如下。
import java.util.ArrayList;public class HeapSort {public static <E extends Comparable> void heapSort(E[] list) {// Create a Heap of EHeap<E> heap = new Heap<E>();// Add elements to the heapfor (int i = 0; i < list.length; i++)heap.add(list[i]);// Remove the highest elements from the heap// and store them in the list from end to startfor (int i = list.length - 1; i >= 0; i--)list[i] = heap.remove();}/** A test method */public static void main(String[] args) {Integer[] list = {2, 3, 2, 5, 6, 1, -2, 3, 14, 12};heapSort(list);for (int i = 0; i < list.length; i++)System.out.print(list[i] + " ");}
}class Heap<E extends Comparable> {private ArrayList<E> list = new ArrayList<E>();// Create a default heappublic Heap() {}// Create a heap from an array of objectspublic Heap(E[] objects) {for (int i = 0; i < objects.length; i++)add(objects[i]);}// Add a new object into the heappublic void add(E newObject) {list.add(newObject); // Append to the end of the heapint currentIndex = list.size() - 1; // The index of the last nodewhile (currentIndex > 0) {int parentIndex = (currentIndex - 1) / 2;// Swap if the current object is greater than its parentif (list.get(currentIndex).compareTo(list.get(parentIndex)) > 0) {E temp = list.get(currentIndex);list.set(currentIndex, list.get(parentIndex));list.set(parentIndex, temp);} elsebreak; // the tree is a heap nowcurrentIndex = parentIndex;}}// Remove the root from the heappublic E remove() {if (list.size() == 0) return null;E removedObject = list.get(0);list.set(0, list.get(list.size() - 1));list.remove(list.size() - 1);int currentIndex = 0;while (currentIndex < list.size()) {int leftChildIndex = 2 * currentIndex + 1;int rightChildIndex = 2 * currentIndex + 2;// Find the maximum between two childrenif (leftChildIndex >= list.size())break; // The tree is a heapint maxIndex = leftChildIndex;if (rightChildIndex < list.size())if (list.get(maxIndex).compareTo(list.get(rightChildIndex)) < 0)maxIndex = rightChildIndex;// Swap if the current node is less than the maximumif (list.get(currentIndex).compareTo(list.get(maxIndex)) < 0) {E temp = list.get(maxIndex);list.set(maxIndex, list.get(currentIndex));list.set(currentIndex, temp);currentIndex = maxIndex;} elsebreak; // The tree is a heap}return removedObject;}// Get the number of nodes in the treepublic int getSize() {return list.size();}
}
堆排序算法的时间复杂度为 O ( n l o g n ) O(nlogn) O(nlogn)。
需要一个临时数组来合并两个子数组。这个临时数组的大小与原数组相同,因此归并排序的空间复杂度是 O(n),其中 n 是数组的长度。
而堆排序不需要额外的数组空间,因此在空间效率上优于归并排序。
2. 在面向对象编程中终身学习
终身学习:指的是持续的、自愿的、自我激励的知识追求,目的是为了个人或职业发展。
在 OOP 领域的应用:终身学习鼓励开发者跟上不断发展的概念、技术和工具,以提高他们在设计、实现和维护软件系统方面的熟练程度。
终身学习的重要性如下:
- 不断演变的技术环境:
终身学习确保开发者能够跟上最新的最佳实践、框架和设计模式。 - 提高专业能力:
终身学习增强了你解决复杂问题、优化代码和设计健壮系统的能力。 - 适应新工具:
学习 OOP 中的新工具使你保持敏捷,并为你打开新的职业机会。 - 个人成长:
不断提高你的 OOP 技能不仅增强了你的技术专长,还发展了其他宝贵的技能,如批判性思维、解决问题和有效沟通。
2.1 记录和反思学习过程
我们可以记录和反思学习过程。
- 维护反思日志/记录:
记录每个学习阶段的关键收获。
记录在解决编程挑战后获得的见解和思考。
记录需要进一步澄清的问题或领域。
记录你已经工作过的代码片段和示例。
日志有助于巩固你的学习,并为未来的问题提供参考。 - 定期自我评估:
定期评估你与设定目标的进展。你是否掌握了基础知识,或者需要重新审视某些概念。
诚实地面对挑战。你是否在复杂的设计模式或高级 OOP 原则的实现上遇到困难?接下来专注于这些领域。
认可你的成就。完成课程或参与 OOP 项目是一个值得庆祝的重要里程碑。 - 加入社区和论坛:
加入像 StackOverflow、Reddit 、GitHub 或 CSDN 这样的专注于 OOP 的社区。
参与讨论,提问,并与他人分享你的知识。
2.2 EDI 原则
- 平等(Equality):
在 OOP 中,平等意味着所有开发者,无论性别、种族、性取向或残疾状况,都有平等的职业机会和参与软件开发过程的能力。 - 多样性(Diversity):
在 OOP 中,多样性通过汇集来自不同背景、经验和观点的人来丰富问题解决。这种多样性导致更创造性和创新性的解决方案来应对复杂的软件设计挑战。 - 包容性(Inclusion):
在 OOP 中,包容性超越了代表性和平等;它强调创造一个每个人都感到尊重和有价值的环境。
将 EDI 融入 OOP 实践便是:
- 采用包容性编码实践:
在代码、注释和文档中使用包容性语言。避免可能无意中疏远或排除个体的术语或实践。 - 实施可访问的设计模式:
确保你构建的软件设计对广泛受众可访问。纳入可访问性功能,如可定制的 UI 选项、语音识别和高对比度主题。 - 鼓励跨多样化团队的协作:
积极寻求来自不同背景和经验的团队成员。这可能意味着促进科技领域的女性、支持 LGBTQ+ 个体,或与包括来自不同种族和文化的人的团队合作。 - 利用 EDI 聚焦资源:
利用专注于软件开发社区多样性和包容性的资源、课程和材料。这些资源帮助开发者更意识到编码实践中的潜在偏见,并提供减轻它们的策略。
2.3 人工智能辅助的管理工具进行软件开发
我们可以使用 JIRA 等 AI 辅助管理工具来规划和跟踪软件开发过程中的各种任务和问题。通过这些工具,团队可以更有效地管理项目进度,分配任务,跟踪问题,并确保项目按计划进行。这些工具不仅提高了团队的协作效率,还帮助团队成员更好地理解和执行项目需求。
3. 练习
3.1 基础练习
1.给定列表:{2, 9, 5, 4, 8, 1}
冒泡排序算法第一步后,结果是什么?
答案是{2, 5, 4, 8, 1, 9}。因为 2 < 9 2 < 9 2<9,所以不需要交换。
2.对于堆来问号处可以是多少?
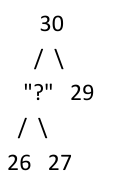
答案是28/29。
3.2 进阶练习
3.2.1 编写两个泛型方法来实现归并排序(Merge Sort)
第一个方法使用 Comparable 接口进行排序,第二个方法使用 Comparator 接口进行排序。
示例代码如下。
import java.util.Comparator;public class MergeSortExample {// 使用 Comparable 接口进行排序public static <E extends Comparable<E>> void mergeSort(E[] list) {if (list.length > 1) {int middle = list.length / 2;@SuppressWarnings("unchecked")E[] firstHalf = (E[]) new Comparable[middle];@SuppressWarnings("unchecked")E[] secondHalf = (E[]) new Comparable[list.length - middle];System.arraycopy(list, 0, firstHalf, 0, middle);System.arraycopy(list, middle, secondHalf, 0, list.length - middle);mergeSort(firstHalf);mergeSort(secondHalf);merge(list, firstHalf, secondHalf);}}// 使用 Comparator 接口进行排序public static <E> void mergeSort(E[] list, Comparator<? super E> comparator) {if (list.length > 1) {int middle = list.length / 2;@SuppressWarnings("unchecked")E[] firstHalf = (E[]) new Comparable[middle];@SuppressWarnings("unchecked")E[] secondHalf = (E[]) new Comparable[list.length - middle];System.arraycopy(list, 0, firstHalf, 0, middle);System.arraycopy(list, middle, secondHalf, 0, list.length - middle);mergeSort(firstHalf, comparator);mergeSort(secondHalf, comparator);merge(list, firstHalf, secondHalf, comparator);}}// 合并两个已排序的子数组private static <E extends Comparable<E>> void merge(E[] list, E[] firstHalf, E[] secondHalf) {int i = 0, j = 0, k = 0;while (i < firstHalf.length && j < secondHalf.length) {if (firstHalf[i].compareTo(secondHalf[j]) <= 0) {list[k++] = firstHalf[i++];} else {list[k++] = secondHalf[j++];}}while (i < firstHalf.length) {list[k++] = firstHalf[i++];}while (j < secondHalf.length) {list[k++] = secondHalf[j++];}}// 合并两个已排序的子数组,使用 Comparatorprivate static <E> void merge(E[] list, E[] firstHalf, E[] secondHalf, Comparator<? super E> comparator) {int i = 0, j = 0, k = 0;while (i < firstHalf.length && j < secondHalf.length) {if (comparator.compare(firstHalf[i], secondHalf[j]) <= 0) {list[k++] = firstHalf[i++];} else {list[k++] = secondHalf[j++];}}while (i < firstHalf.length) {list[k++] = firstHalf[i++];}while (j < secondHalf.length) {list[k++] = secondHalf[j++];}}public static void main(String[] args) {Integer[] list = {2, 3, 2, 5, 6, 1, -2, 3, 14, 12};System.out.println("Original list: " + java.util.Arrays.toString(list));mergeSort(list);System.out.println("Sorted list using Comparable: " + java.util.Arrays.toString(list));String[] stringList = {"banana", "apple", "cherry", "date"};System.out.println("Original string list: " + java.util.Arrays.toString(stringList));mergeSort(stringList, (a, b) -> b.compareTo(a));System.out.println("Sorted string list using Comparator: " + java.util.Arrays.toString(stringList));}
}
3.2.2 编写两个泛型方法来实现插入排序(Insertion Sort)
第一个方法使用 Comparable 接口进行排序,第二个方法使用 Comparator 接口进行排序。
示例代码如下。
import java.util.Comparator;public class InsertionSortExample {// 使用 Comparable 接口进行排序public static <E extends Comparable<E>> void insertionSort(E[] list) {for (int i = 1; i < list.length; i++) {E current = list[i];int j = i - 1;while (j >= 0 && list[j].compareTo(current) > 0) {list[j + 1] = list[j];j--;}list[j + 1] = current;}}// 使用 Comparator 接口进行排序public static <E> void insertionSort(E[] list, Comparator<? super E> comparator) {for (int i = 1; i < list.length; i++) {E current = list[i];int j = i - 1;while (j >= 0 && comparator.compare(list[j], current) > 0) {list[j + 1] = list[j];j--;}list[j + 1] = current;}}public static void main(String[] args) {Integer[] list = {2, 3, 2, 5, 6, 1, -2, 3, 14, 12};System.out.println("Original list: " + java.util.Arrays.toString(list));insertionSort(list);System.out.println("Sorted list using Comparable: " + java.util.Arrays.toString(list));String[] stringList = {"banana", "apple", "cherry", "date"};System.out.println("Original string list: " + java.util.Arrays.toString(stringList));insertionSort(stringList, (a, b) -> b.compareTo(a));System.out.println("Sorted string list using Comparator: " + java.util.Arrays.toString(stringList));}
}
相关文章:

CPT204 Advanced Obejct-Oriented Programming 高级面向对象编程 Pt.8 排序算法
文章目录 1. 排序算法1.1 冒泡排序(Bubble sort)1.2 归并排序(Merge Sort)1.3 快速排序(Quick Sort)1.4 堆排序(Heap Sort) 2. 在面向对象编程中终身学习2.1 记录和反思学习过程2.2 …...

【低配置电脑预训练minimind的实践】
低配置电脑预训练minimind的实践 概要 minimind是一个轻量级的LLM大语言模型,项目的初衷是拉低LLM的学习门槛,让每个人都能从理解每一行代码开始, 从零开始亲手训练一个极小的语言模型。对于很多初学者而言,电脑配置仅能够满足日…...

flutter 小知识
FractionallySizedBox组件 FractionallySizedBox是Flutter中的一个特殊布局小部件,它允许子组件的尺寸基于父组件的尺寸来计算。这意味着子组件的尺寸是父组件尺寸的一个比例,这使得布局在不同屏幕尺寸下保持一致性1。 ListWheelScrollView Lis…...

高性能服务器配置经验指南3——安装服务器可能遇到的问题及解决方法
文章目录 1、重装系统后VScode远程连接失败问题2、XRDP连接黑屏问题1. 打开文件2. 添加配置3. 重启xrdp服务 在完成 服务器基本配置和 深度学习环境准备后,大家应该就可以正常使用服务器了,推荐使用VScode远程连接使用,比较稳定方便&#x…...
解决 Vue 项目中路径别名 `@` 在 IDE 中报错无法识别的问题)
Vue实战(08)解决 Vue 项目中路径别名 `@` 在 IDE 中报错无法识别的问题
一、引言 在 Vue 项目开发过程中,路径别名是一个非常实用的特性,它能够帮助开发者简化文件引用路径,提高代码的可读性和可维护性。其中, 作为一个常见的路径别名,通常被用来指向项目的 src 目录。然而,…...

处理任务“无需等待”:集成RabbitMQ实现异步通信与系统解耦
在前几篇文章中,我们构建的Web应用遵循了一个常见的同步处理模式:用户发出HTTP请求 -> Controller接收 -> Service处理(可能涉及数据库操作、调用其他内部方法)-> Controller返回HTTP响应。这个流程简单直接,…...

ASP.NET Core 主机模型详解:Host、WebHost与WebApplication的对比与实践【代码之美】
🎀🎀🎀代码之美系列目录🎀🎀🎀 一、C# 命名规则规范 二、C# 代码约定规范 三、C# 参数类型约束 四、浅析 B/S 应用程序体系结构原则 五、浅析 C# Async 和 Await 六、浅析 ASP.NET Core SignalR 双工通信 …...

编译型语言、解释型语言与混合型语言:原理、区别与应用场景详解
编译型语言、解释型语言与混合型语言:原理、区别与应用场景详解 文章目录 编译型语言、解释型语言与混合型语言:原理、区别与应用场景详解引言一、编译型语言1.1 工作原理1.2 典型的编译型语言1.3 优点1.4 缺点 二、解释型语言2.1 工作原理2.2 典型的解释…...

AI工程pytorch小白TorchServe部署模型服务
注意:该博客仅是介绍整体流程和环境部署,不能直接拿来即用(避免公司代码外泄)请理解。并且当前流程是公司notebook运行&本机windows,后面可以使用docker 部署镜像到k8s,敬请期待~ 前提提要:工程要放弃采购的AI平台…...

Ubuntu 一站式部署 RabbitMQ 4 并“彻底”迁移数据目录的终极实践
1 安装前准备 sudo apt update -y sudo apt install -y curl gnupg apt-transport-https lsb-release jq若计划将数据放到新磁盘(如 /dev/nvme0n1p1): sudo mkfs.xfs /dev/nvme0n1p1 sudo mkdir /data echo /dev/nvme0n1p1 /data xfs defau…...

华为手机怎么进行音频降噪?音频降噪技巧分享:提升听觉体验
在当今数字化时代,音频质量对于提升用户体验至关重要,无论是在通话、视频录制还是音频文件播放中,清晰的音频都能带来更佳的听觉享受。 而华为手机凭借其强大的音频处理技术,为用户提供了多种音频降噪功能,帮助用户在…...

拥抱健康生活,解锁养生之道
在生活节奏日益加快的当下,健康养生已成为人们关注的焦点。科学的养生方法,能帮助我们增强体质、预防疾病,以更饱满的精神状态拥抱生活。 合理饮食是养生的基石。《黄帝内经》中提到 “五谷为养,五果为助,五畜为益&…...

深入理解Java阻塞队列:原理、使用场景及代码实战
🚀 文章提示 你将在这篇文章中收获: 阻塞队列的核心特性:队列空/满时的阻塞机制 四种操作方式对比:抛异常、返回特殊值、永久阻塞、超时阻塞 SynchronousQueue的独特设计:同步队列的生产者-消费者强耦合 代码实战&a…...

vue3--手写手机屏组件
<!--* 手机预览* Author: Hanyang* Date: 2022-12-09 09:13:00* LastEditors: Hanyang* LastEditTime: 2023-01-12 15:37:00 --> <template><divclass"public-preview-mobile"ref"previewMobileRef":class"showMobile ? animation-sh…...

【Elasticsearch】入门篇
Elasticsearch 入门 前言 官方地址:Elastic — 搜索 AI 公司 | Elastic ES 下载地址:Past Releases of Elastic Stack Software | Elastic 文档:什么是 Elasticsearch?|Elasticsearch 指南 简介 Elasticsearch 是一个分布式、…...

Unity 使用 ADB 实时查看手机运行性能
Unity 使用 ADB 实时查看手机运行性能 前言操作步骤ADB工具下载ADB工具配置手机进入开发者模式并开启USB调试使用ADB连接手机Unity打包设置使用Profiler实时查看性能情况优化建议 常见问题 前言 通过 ADB(Android Debug Bridge)连接安卓设备,…...

蓝桥杯 1. 四平方和
四平方和 原题目链接 题目描述 四平方和定理(又称拉格朗日定理)指出: 每个正整数都可以表示为 至多 4 个正整数的平方和。 如果将 0 包括进去,则每个正整数都可以恰好表示为 4 个非负整数的平方和。 例如: 5 0 …...

Nginx 配置参数全解版:Nginx 反向代理与负载均衡;Nginx 配置规范与 Header 透传实践指南;Nginx 配置参数详解
Nginx 配置参数全解版:Nginx 反向代理与负载均衡;Nginx 配置规范与 Header 透传实践指南;Nginx 配置参数详解 Nginx 反向代理与负载均衡配置,Header 透传到后端应用(参数全解版)一、Nginx 反向代理与负载均…...

数据分析之技术干货业务价值 powerquery 分组排序后取TOP
在电商中,我们要对货品进行分析,由于所有的销售数据都在一起,货品信息也在一起,两个表建立了关系之后,要看每个品类的TOP款有哪些,每个品类的TOP款是什么要怎么做呢? 下面是我做数据的思路&…...

windows中kafka4.0集群搭建
参考文献 Apache Kafka windows启动kafka4.0(不再需要zookeeper)_kafka压缩包-CSDN博客 Kafka 4.0 KRaft集群部署_kafka4.0集群部署-CSDN博客 正文 注意jdk需要17版本以上的 修改D:\software\kafka_2.13-4.0.0\node1\config\server.properties配置文…...

数据分析案例:医疗健康数据分析
目录 数据分析案例:医疗健康数据分析1. 项目背景2. 数据加载与预处理2.1 加载数据2.2 数据清洗3. 探索性数据分析(EDA)3.1 再入院率概览3.2 按年龄分组的再入院率3.3 住院时长与再入院4. 特征工程与可视化5. 模型构建与评估5.1 数据划分5.2 训练逻辑回归5.3 模型评估6. 业务…...

数据分析之 商品价格分层之添加价格带
在分析货品数据的时候,我们会对商品的价格进行分层汇总,也叫价格带, 一、价格带的定义 价格带(Price Band):将商品按价格区间划分(如0-50元、50-100元、100-200元等ÿ…...

跨浏览器音频录制:实现兼容的音频捕获与WAV格式生成
在现代Web开发中,音频录制功能越来越受到开发者的关注。无论是在线会议、语音识别还是简单的语音留言,音频录制都是一个重要的功能。然而,实现一个跨浏览器的音频录制功能并非易事,因为不同浏览器对音频录制API的支持存在差异。本…...
)
JavaScript 的“世界模型”:深入理解对象 (Objects)
引言:超越简单值,构建复杂实体 到目前为止,我们学习的变量大多存储的是单一的值,比如一个数字 (let age 30;)、一个字符串 (let name "Alice";) 或一个布尔值 (let isActive true;)。这对于简单场景足够了&am…...

【国产化之路】VPX-3U :基于D2000 /FT2000的硬件架构到操作系统兼容
在国产化和高性能计算、嵌入式系统领域日益受到重视的今天,VPX3U架构以其标准化和模块化的特性广受关注。本文将从硬件架构、系统软件、接口拓展及典型应用等方面,深入剖析整体设计思路与工程实现,供友友们参考和讨论。 一、总体架构与设计目…...
模型的优化技巧)
深入探索RAG(检索增强生成)模型的优化技巧
📌 友情提示: 本文内容由银河易创AI(https://ai.eaigx.com)创作平台的gpt-4o-mini模型生成,旨在提供技术参考与灵感启发。文中观点或代码示例需结合实际情况验证,建议读者通过官方文档或实践进一步确认其准…...

架构-软件架构设计
一、软件架构基础概念 1. 软件架构的定义 通俗理解:软件架构是软件系统的“骨架”,定义了系统的结构、行为和属性,就像盖房子的设计图纸,规划了房间布局、承重结构和功能分区。核心作用: 沟通桥梁:让技术…...

免费的 HTML 网页托管服务
字根云平台最近上线了一项新的服务: HTML 网页托管。 HTML 网页免费托管 免费HTML静态页面文件托管-字根秀秀 www.cuobiezi.net/showshow/ 网页托管主要支持的功能: 1. 托管静态的 HTML 网页(不包含图片,图片请使用专业图床&a…...

Ubuntu服务器上如何监控Oracle数据库
在 Ubuntu 服务器上监控 Oracle 数据库,虽然不像在 Windows 或某些企业 Linux(如 RHEL)那样有现成的 GUI 工具,但你完全可以通过命令行工具、脚本、开源监控平台来实现全面监控,包含: 数据库性能指标&#…...

什么是CMMI认证?CMMI评估内容?CMMI认证能带来哪些好处?
CMMI认证详解:概念、评估内容与核心价值 一、什么是CMMI认证? CMMI(Capability Maturity Model Integration,能力成熟度模型集成)是由美国卡内基梅隆大学软件工程研究所(SEI)开发的一套全球公…...
)
PySide6 GUI 学习笔记——常用类及控件使用方法(常用类矩阵QRectF)
文章目录 类描述构造方法主要方法1. 基础属性2. 边界操作3. 几何运算4. 坐标调整5. 转换方法6. 状态判断 类特点总结1. 浮点精度:2. 坐标系统:3. 有效性判断:4. 几何运算:5. 类型转换:6. 特殊处理: 典型应用…...

arm64适配系列文章-第五章-arm64环境上redis的部署
ARM64适配系列文章 第一章 arm64环境上kubesphere和k8s的部署 第二章 arm64环境上nfs-subdir-external-provisioner的部署 第三章 arm64环境上mariadb的部署 第四章 arm64环境上nacos的部署 第五章 arm64环境上redis的部署 第六章 arm64环境上rabbitmq-management的部署 第七章…...

Ubuntu / WSL 安装pipx
一、安装pipx 在 Ubuntu / WSL 上可以用两种方式安装,推荐第二种(官方脚本)或第三种(pip 安装最新版本并自动配置 PATH)。 1. apt 安装(最快,但版本往往偏旧) sudo apt update su…...

10天学会嵌入式技术之51单片机-day-6
第十五章 点阵LED 15.1 点阵 LED 概述 15.1.1 实物图 15.1.1 原理图 15.2 点阵 LED 静态显示 15.2.1 需求描述 使用点阵 LED 显示一排由左上到右下的斜线,具体效果如下图所示。 15.2.2 硬件设计 15.2.2.1 硬件原理图 根据内部原理可知,点阵 LED 的…...

【数据可视化-28】2017-2025 年每月产品零售价数据可视化分析
🧑 博主简介:曾任某智慧城市类企业算法总监,目前在美国市场的物流公司从事高级算法工程师一职,深耕人工智能领域,精通python数据挖掘、可视化、机器学习等,发表过AI相关的专利并多次在AI类比赛中获奖。CSDN…...

【JavaScript】`Object` 对象静态方法详解
在 JavaScript 中,Object 对象提供了许多静态方法,用于操作和处理对象。以下是一些常用的 Object.xxx 方法及其用途和示例: 1. 属性相关方法 Object.keys(obj) 返回对象自身的所有可枚举属性的键组成的数组。 const obj = {a: 1, b: 2 }; console.log(Object.keys(obj)); //…...

音视频之H.265/HEVC量化
H.265/HEVC系列文章: 1、音视频之H.265/HEVC编码框架及编码视频格式 2、音视频之H.265码流分析及解析 3、音视频之H.265/HEVC预测编码 4、音视频之H.265/HEVC变换编码 5、音视频之H.265/HEVC量化 量化 (Quantization) 是指将信号的连续取值(或大量可能的离散取…...

Tomcat:从零理解Java Web应用的“心脏”
目录 一、Tomcat是什么?为什么需要它? 二、Tomcat的核心架构(餐厅运营图) 1. 两大核心组件 2. 请求处理全流程(从点餐到上菜) 三、手把手搭建第一个网站(厨房开张实录) 环境准备…...
)
第七届能源系统与电气电力国际学术会议(ICESEP 2025)
重要信息 时间:2025年6月20-22日 地点:中国-武汉 官网:www.icesep.net 主题 能源系统 节能技术、能源存储技术、可再生能源、热能与动力工程 、能源工程、可再生能源技术和系统、风力发…...

【基础】Node.js 介绍、安装及npm 和 npx功能了解
前言 后面安装n8n要用到,做一点技术储备。主要是它的两个工具:npm 和 npx。 Node.js介绍 Node.js 是一个免费的、开源的、跨平台的 JavaScript 运行时环境,允许开发人员在浏览器之外编写命令行工具和服务器端脚本,是一个基于 C…...

【硬核干货】SonarQube安全功能
原文链接:【硬核干货】SonarQube安全功能 关于晓数神州 晓数神州坚持以“客户为中心”的宗旨,为客户提供专业的解决方案和技术服务,构建多引擎数字化体系。 核心业务1:聚焦DevOps全栈产品,打造需求管理、项目管理、开…...

微信小程序 tabbar底部导航栏
官方文档:https://developers.weixin.qq.com/miniprogram/dev/reference/configuration/app.html#tabBar 一、常规菜单格式 在app.json 文件中配置,其他关键点详见官方文档,后续更新不规则图标的写法...

如何将极狐GitLab 议题导出为 CSV?
极狐GitLab 是 GitLab 在中国的发行版,关于中文参考文档和资料有: 极狐GitLab 中文文档极狐GitLab 中文论坛极狐GitLab 官网 导出议题到 CSV (BASIC ALL) 您可以将问题从极狐GitLab 导出为 CSV 文件,这些文件将作为附件发送到您的默认通知…...

nodejs之Express-介绍、路由
五、Express 1、express 介绍 express 是一个基于 Node.js 平台的极简、灵活的 WEB 应用开发框架,官方网址: https://www.expressjs.com.cn/ 简单来说,express 是一个封装好的工具包,封装了很多功能,便于我们开发 WEB 应用(HTTP 服务) (1)基本使用 第一步:初始化项目并…...

极狐GitLab 如何从 CSV 导入议题?
极狐GitLab 是 GitLab 在中国的发行版,关于中文参考文档和资料有: 极狐GitLab 中文文档极狐GitLab 中文论坛极狐GitLab 官网 从 CSV 导入议题 (BASIC ALL) 您可以通过上传包含以下列的 CSV 文件将议题导入项目: 名称是否必需?…...
)
JW01三合一传感器详解(STM32)
目录 一、介绍 二、传感器原理 1.原理图 2.引脚描述 三、程序设计 main文件 usart3.h文件 usart3.c文件 四、实验效果 五、资料获取 项目分享 一、介绍 JW01三合一检测模块是一种用于检测空气中二氧化碳浓度的传感器模块。它可以广泛应用于室内空气质量检测、智能家…...
)
23种设计模式-行为型模式之策略模式(Java版本)
Java 策略模式(Strategy Pattern)详解 🧠 什么是策略模式? 策略模式是一种行为型设计模式,它定义了一系列算法,把它们一个个封装起来,并且使它们可以互相替换。策略模式让算法独立于使用它的客…...
)
ActiveMQ 快速上手:安装配置与基础通信实践(一)
一、引言 在当今分布式系统和微服务架构盛行的时代,消息通信作为实现系统间解耦、异步处理和可靠传输的关键技术,显得尤为重要。ActiveMQ 作为一款广泛应用的开源消息中间件,凭借其对 JMS 规范的全面支持、丰富的特性以及出色的性能…...

究竟什么是自动化测试?
自动化测试是一种软件测试方法,旨在通过使用自动化工具和脚本来执行测试任务,以减少人工操作,提高测试效率和准确性。 以下是对自动化测试的详细介绍: 一、定义与特点 定义:自动化测试是指利用自动化工具和脚本来执…...

【LLM+Code】Github Copilot Agent/VsCode Agent 模式PromptTools详细解读
一、前言 github copilot agent mode现在和vscode是强绑定的关系, 其实是一个东西: https://github.blog/news-insights/product-news/github-copilot-the-agent-awakens/https://code.visualstudio.com/docs/copilot/chat/chat-agent-mode 二、Syste…...