基于Transformer与随机森林的多变量时间序列预测
哈喽,我不是小upper,今天和大家聊聊基于Transformer与随机森林的多变量时间序列预测。
不懂Transformer的小伙伴可以看我上篇文章:一文带你彻底搞懂!Transformer !!![]() https://blog.csdn.net/qq_70350287/article/details/147404686?spm=1001.2014.3001.5501
https://blog.csdn.net/qq_70350287/article/details/147404686?spm=1001.2014.3001.5501
在多变量时间序列预测领域,我们常常需要依据历史数据来预估多个变量在未来的取值。打个比方,在分析城市交通流量时,就涉及到多个变量,像不同路段的车流量、车速等,我们要预测这些变量未来的变化情况。
以往常用的时间序列预测方法,比如 ARIMA 和 SARIMA ,存在一定的局限性。它们一般假定数据之间呈现线性关系,可在实际的复杂系统中,数据间的关系往往并非如此简单。现实中的数据不仅存在非线性关系,还具有长期依赖特征,就好比今天的交通流量情况可能会受到一周前特殊事件的影响,而这些传统方法很难有效捕捉到这些复杂的关系,所以在面对复杂的多变量时间序列预测任务时,效果可能不太理想 。
在当下的技术发展进程中,基于深度学习的 Transformer 和基于机器学习的随机森林(Random Forest,简称 RF)在众多任务领域得到了极为广泛的应用。这两种技术各有所长,若将它们有机结合,便能够充分发挥各自的优势,实现更出色的效果。
Transformer 模型的核心亮点在于其独特的自注意力机制。这一机制赋予了 Transformer 强大的能力,使其能够精准且高效地捕捉时间序列中的长期依赖关系。在处理如自然语言文本、金融时间序列数据这类包含复杂时间依赖信息的任务时,Transformer 可以轻松关注到序列中不同位置之间的关联,从而理解整体的语义或趋势。例如在机器翻译中,它能理解句子中相隔较远词汇之间的语法和语义联系,提升翻译的准确性。
而随机森林(RF)模型则是通过构建多棵决策树的方式来进行工作。在面对高维特征空间时,它能够进行有效的回归操作。并且,RF 模型具有很强的鲁棒性,这使得它在处理包含噪声的数据时表现出色。即使数据中存在一些干扰信息,它也能凭借自身的结构和算法,尽量减少噪声对结果的影响,给出相对可靠的预测。比如在预测房屋价格时,面对包含测量误差等噪声的数据,随机森林模型依然能较好地捕捉到房价与其他因素之间的关系。
接下来,让我们一起深入了解这两种技术结合的细节内容。
多变量时间序列预测的问题建模
- 滑动窗口与样本构造:在多变量时间序列预测中,我们从给定的观测序列出发,通过设定窗口长度来构建样本。这一操作的目标是为后续的模型训练提供合适的数据形式,使模型能够学习到时间序列中的规律和特征。
- 归一化与去趋势:为了让数据更适合模型训练,我们对每个变量进行 Z-score 标准化处理。这种标准化方法能够将数据转化为均值为 0、标准差为 1 的标准形式,有助于提升模型的训练效果和稳定性。
- 变量相关性分析:计算皮尔逊相关系数矩阵是分析变量之间相关性的重要手段。通过这个矩阵,我们可以判断哪些变量之间关系紧密,进而选择对预测结果有重要影响的输入变量,去除那些相关性较低的变量,提高模型的效率和预测准确性。
模型融合策略
- 加权平均(Weighted Averaging):这是一种直观且简单的模型融合方法,它的优点是所需的参数较少。在融合多个模型的预测结果时,为每个模型分配一个权重,然后根据这些权重对各模型的预测值进行加权求和,得到最终的预测结果。权重的选择可以通过交叉验证等方式进行调优,以达到最佳的融合效果。
- 堆叠泛化(Stacking):该方法分为两层进行模型融合。在第一层,使用 Transformer、随机森林(RF)等不同模型分别对数据进行处理并输出预测结果。然后,在第二层使用元学习器,例如线性回归模型或小型多层感知机(MLP)。具体操作是,先通过交叉验证的方式获得第一层各个模型对验证集的预测结果,再利用这些结果来训练元学习器,使元学习器能够学习到不同模型预测结果之间的关系,从而更好地融合这些结果,提升整体的预测性能。
- 误差协方差分析:误差协方差分析用于评估不同模型之间的互补性。如果两个模型的误差相关性较低,说明它们在预测过程中犯错误的情况有所不同,这种情况下将它们融合,往往能获得更好的预测效果。因为不同模型可以在不同方面发挥优势,相互补充,减少整体的预测误差。
小结
| 模块 | 关键组件 | 细节要点 |
|---|---|---|
| 序列预处理 | 滑动窗口、归一化、相关性分析 | 利用滑动窗口构造样本,通过 Z-score 进行标准化,借助皮尔逊相关矩阵筛选特征 |
| Transformer 编码器 | 位置编码(PosEnc)、多头注意力、前馈神经网络(FFN)、层归一化(LayerNorm) | 采用正余弦位置编码,利用防未来信息掩码避免信息泄露,结合残差连接和归一化;多头注意力并行捕捉多尺度依赖关系;逐位置前馈网络增强模型的非线性表达能力 |
| 随机森林回归 | 自助采样(Bootstrap)、分类与回归树(CART)分裂、子特征随机选择 | 树间差异源于有放回采样和特征随机子集;回归树依据最小化节点内均方误差(MSE)进行分裂;通过平均化减少预测方差 |
| 融合策略 | 加权平均、堆叠泛化、误差协方差分析 | 加权平均的系数可通过交叉验证调优;堆叠泛化借助元学习器捕获二级特征;误差协方差分析揭示模型间的互补性 |
| 评估指标 | 均方误差(MSE)、均方根误差(RMSE)、平均绝对误差(MAE)、平均绝对百分比误差(MAPE)、多变量加权评估 | MSE 对大误差较为敏感,MAE 更稳健,MAPE 以百分比形式呈现便于解读,多变量加权评估可综合考虑不同变量的重要性进行全面评估 |
在这里,我们将基于 Transformer 与随机森林的集成方法,开展多变量时间序列的预测任务。为了更便捷地展示整个过程,我们使用虚拟数据集来完成数据生成、模型训练、预测、评估等环节,同时还会生成多种可视化图形,以此深入分析模型的表现,最后给出算法的优化要点和调参流程。
1. 数据集 & 预处理
为构建一个多变量时间序列数据集,我们生成包含三个变量的虚拟时间序列数据。其中一个变量是呈周期性变化的正弦波,一个是余弦波,还有一个是添加了噪声的随机信号。具体代码如下:
# 生成虚拟多变量时间序列数据:3个变量,长度为T
import numpy as np
T = 1200 # 时间步数
t = np.arange(T)
x1 = np.sin(0.02 * t) # 正弦波
x2 = np.cos(0.02 * t) # 余弦波
x3 = 0.1 * np.random.randn(T) # 高斯噪声# 数据合并,形状为(T, 3)
data = np.stack([x1, x2, x3], axis=1)接下来,对生成的数据进行标准化处理(Z-score),使数据具有统一的尺度,便于后续模型训练。
from sklearn.preprocessing import StandardScaler
# 标准化处理(Z-score)
scaler = StandardScaler()
data_norm = scaler.fit_transform(data) # 标准化后的数据数据集拆分与窗口化
我们把时间序列数据拆分成滑动窗口样本,进而生成训练集和测试集。在这个过程中,我们构建特征数据X和目标数据Y:
window_size = 30 # 假设窗口大小为30
horizon = 1 # 预测步长为1
X, Y = [], []
for i in range(T - window_size - horizon + 1):X.append(data_norm[i:i + window_size]) # 选择窗口内的数据Y.append(data_norm[i + window_size:i + window_size + horizon]) # 预测窗口后的数据
X = np.array(X) # shape: (samples, window_size, features)
Y = np.array(Y).squeeze(axis=1) # shape: (samples, features)# 划分训练集与测试集
train_ratio = 0.8
n_train = int(len(X) * train_ratio)
X_train, X_test = X[:n_train], X[n_train:]
Y_train, Y_test = Y[:n_train], Y[n_train:]# 转换为PyTorch Tensor
import torch
from torch.utils.data import TensorDataset, DataLoader
X_train_t = torch.tensor(X_train, dtype=torch.float32)
Y_train_t = torch.tensor(Y_train, dtype=torch.float32)
X_test_t = torch.tensor(X_test, dtype=torch.float32)
Y_test_t = torch.tensor(Y_test, dtype=torch.float32)train_dataset = TensorDataset(X_train_t, Y_train_t)
train_loader = DataLoader(train_dataset, batch_size=32, shuffle=True)可视化数据
我们先绘制数据集的原始图形,以此清晰展示三个变量的时间序列变化情况。
import matplotlib.pyplot as plt
# 可视化原始数据
plt.figure(figsize=(12, 6))
plt.plot(t, data_norm[:, 0], label='Var1', color='magenta')
plt.plot(t, data_norm[:, 1], label='Var2', color='cyan')
plt.plot(t, data_norm[:, 2], label='Var3', color='lime')
plt.title("Raw Multivariate Time Series")
plt.xlabel("Time")
plt.ylabel("Normalized Value")
plt.legend()
plt.show()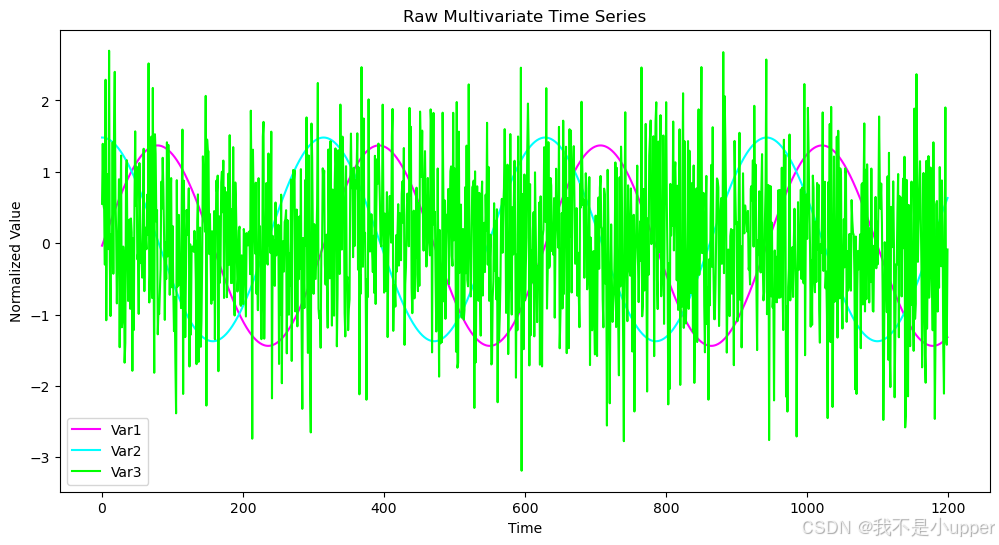
可视化展示的横坐标是时间(Time),从 0 到 1200,代表时间步数;纵坐标是标准化后的值(Normalized Value) ,范围从 - 3 到 2 。图中有三条线,紫色线代表 Var1,是一条正弦波曲线,呈现周期性波动;蓝色线代表 Var2,是余弦波曲线,也呈周期性波动,但和正弦波有相位差;绿色线代表 Var3,是加了高斯噪声的随机信号,波动非常剧烈且杂乱无章,不像前两条线那样有明显规律 。
2. Transformer 模型实现
Transformer 回归模型
Transformer 模型借助自注意力机制,能有效捕捉序列中的长期依赖关系。我们使用 PyTorch 搭建一个简洁的 Transformer Encoder 架构。代码如下:
# Transformer回归模型
import torch
import torch.nn as nn
import mathclass TransformerRegressor(nn.Module):def __init__(self, input_dim, d_model, nhead, num_layers, dim_feedforward):super().__init__()# 输入映射层self.input_linear = nn.Linear(input_dim, d_model)# Transformer编码器层encoder_layer = nn.TransformerEncoderLayer(d_model=d_model, nhead=nhead, dim_feedforward=dim_feedforward)self.transformer = nn.TransformerEncoder(encoder_layer, num_layers=num_layers)# 输出映射层self.output_linear = nn.Linear(d_model, input_dim)def forward(self, src):x = self.input_linear(src) * math.sqrt(self.input_linear.out_features) # 线性变换x = x.permute(1, 0, 2) # 转置为 (seq_len, batch, d_model)x = self.transformer(x) # Transformer编码x = x.mean(dim=0) # 平均池化 (batch, d_model)return self.output_linear(x) # 预测输出 (batch, input_dim)在这个模型中,input_linear负责将输入数据映射到指定维度,transformer进行核心的编码操作,output_linear则输出预测结果。
模型训练
接下来定义训练所需参数并开始训练模型:
# 定义训练参数
input_dim = 3
model = TransformerRegressor(input_dim, d_model=64, nhead=4, num_layers=2, dim_feedforward=128)
optimizer = torch.optim.Adam(model.parameters(), lr=0.001)
criterion = nn.MSELoss()# 训练模型
num_epochs = 50
loss_list = []model.train()
for epoch in range(1, num_epochs+1):epoch_loss = 0.0for xb, yb in train_loader:optimizer.zero_grad()pred = model(xb)loss = criterion(pred, yb)loss.backward()optimizer.step()epoch_loss += loss.item() * xb.size(0)epoch_loss /= len(train_loader.dataset)loss_list.append(epoch_loss)if epoch % 10 == 0:print(f"Epoch {epoch}/{num_epochs}, Loss: {epoch_loss:.4f}")
这里,我们设置了模型的具体参数,选用 Adam 优化器和均方误差损失函数(MSELoss) 。在训练循环中,每个 epoch 都会计算平均损失,并记录下来,方便后续观察模型训练情况。
3. 随机森林模型实现
随机森林回归器
对于随机森林模型,我们先对数据进行预处理,然后训练和预测:
# 随机森林训练与预测
from sklearn.ensemble import RandomForestRegressor
from sklearn.metrics import mean_squared_error, mean_absolute_error
import numpy as npX_rf_train = X_train.reshape(n_train, -1)
X_rf_test = X_test.reshape(len(X_test), -1)rf = RandomForestRegressor(n_estimators=200, max_depth=12, random_state=42)
rf.fit(X_rf_train, Y_train)
rf_pred = rf.predict(X_rf_test)这里将训练数据和测试数据调整为适合随机森林模型输入的形状,然后使用指定参数训练随机森林回归器,并得到测试集上的预测结果。
评估模型性能
通过计算均方误差(MSE)和平均绝对误差(MAE)来衡量 Transformer 模型和随机森林模型在测试集上的表现:
# model是已经训练好的TransformerRegressor模型,X_test_t是测试集数据
model.eval() # 将模型设置为评估模式
with torch.no_grad(): # 不计算梯度,节省内存并加快计算tf_pred_test = model(X_test_t).cpu().numpy() # 对测试集进行预测并转换为numpy数组mse_tf = mean_squared_error(Y_test, tf_pred_test)
mae_tf = mean_absolute_error(Y_test, tf_pred_test)
mse_rf = mean_squared_error(Y_test, rf_pred)
mae_rf = mean_absolute_error(Y_test, rf_pred)print(f"Transformer -> MSE: {mse_tf:.4f}, MAE: {mae_tf:.4f}")
print(f"Random Forest -> MSE: {mse_rf:.4f}, MAE: {mae_rf:.4f}")通过调整加权系数alpha,综合两个模型的优势,得到集成模型的预测结果,并再次计算评估指标,判断融合效果。
 从输出结果看,Transformer 模型的均方误差(MSE)为 0.3988 ,平均绝对误差(MAE)为 0.3221 ;随机森林模型的 MSE 是 0.3889 ,MAE 是 0.3071 。这表明在这个多变量时间序列预测任务中,随机森林模型在衡量预测值与真实值偏离程度的 MSE 和 MAE 指标上,表现略优于 Transformer 模型 ,即随机森林模型的预测值相对更接近真实值 。
从输出结果看,Transformer 模型的均方误差(MSE)为 0.3988 ,平均绝对误差(MAE)为 0.3221 ;随机森林模型的 MSE 是 0.3889 ,MAE 是 0.3071 。这表明在这个多变量时间序列预测任务中,随机森林模型在衡量预测值与真实值偏离程度的 MSE 和 MAE 指标上,表现略优于 Transformer 模型 ,即随机森林模型的预测值相对更接近真实值 。
5. 可视化分析
原始数据可视化
为了更好地理解数据的变化趋势,我们再次展示标准化后的多变量时间序列:
import matplotlib.pyplot as pltplt.figure(figsize=(12, 6))
plt.plot(t, data_norm[:, 0], label='Var1', color='magenta')
plt.plot(t, data_norm[:, 1], label='Var2', color='cyan')
plt.plot(t, data_norm[:, 2], label='Var3', color='lime')
plt.title("Raw Multivariate Time Series")
plt.xlabel("Time")
plt.ylabel("Normalized Value")
plt.legend()
plt.show()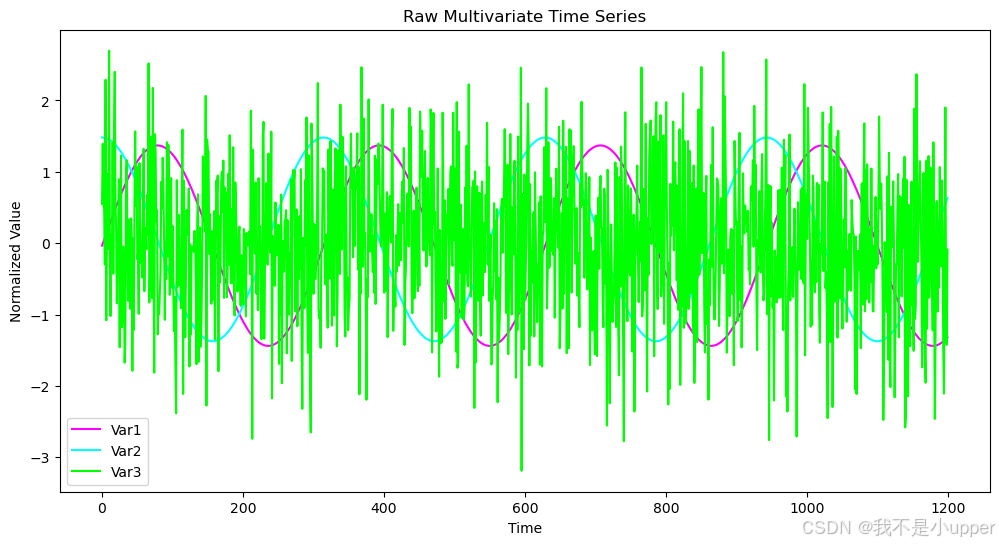
这张图展示了标准化后的多变量时间序列,横坐标为时间,从 0 到 1200,纵坐标是标准化值。紫色线代表 Var1,是正弦波,呈现周期性起伏;蓝色线是 Var2,为余弦波,同样周期性波动,和正弦波有相位差异;绿色线的 Var3 是加了高斯噪声的随机信号,波动剧烈且无明显规律。通过该图能直观看到各变量的变化特征,Var1 和 Var2 的周期性可帮助预测,而 Var3 的随机性增加了预测难度 。
Transformer 训练损失曲线
为了观察 Transformer 模型的收敛情况,我们绘制其训练损失曲线。具体代码如下:
import matplotlib.pyplot as pltplt.figure(figsize=(8, 4))
plt.plot(range(1, num_epochs+1), loss_list, color='orange', label='Train Loss')
plt.title("Transformer Training Loss")
plt.xlabel("Epoch")
plt.ylabel("MSE Loss")
plt.legend()
plt.show()运行后得到一张直方图,横坐标是预测误差,纵坐标是误差出现的频率。通过观察直方图的形状和分布,我们可以了解融合模型预测误差的集中程度和离散情况。比如,如果直方图呈现近似正态分布,说明误差分布相对稳定;若存在长尾或异常值,可能表示模型在某些情况下预测效果不佳,需要进一步分析和改进。
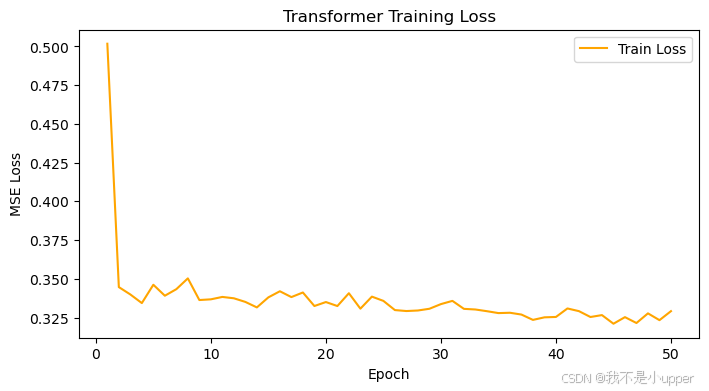
图中输出的是 Transformer 模型的训练损失曲线。横坐标是训练轮次(Epoch),从 0 到 50 ,纵坐标是均方误差损失(MSE Loss) 。可以看到,在训练初期,损失值从接近 0.5 迅速下降,随后在不同轮次间有小幅度波动。整体趋势是逐渐降低并趋于平稳,说明 Transformer 模型在训练过程中不断学习,尽管过程中有起伏,但最终损失稳定在一定范围内,模型在朝着收敛方向发展。
真实与预测值对比(融合模型)
我们来展示融合模型(Transformer 和随机森林融合)的预测结果与真实值的对比情况。代码如下:
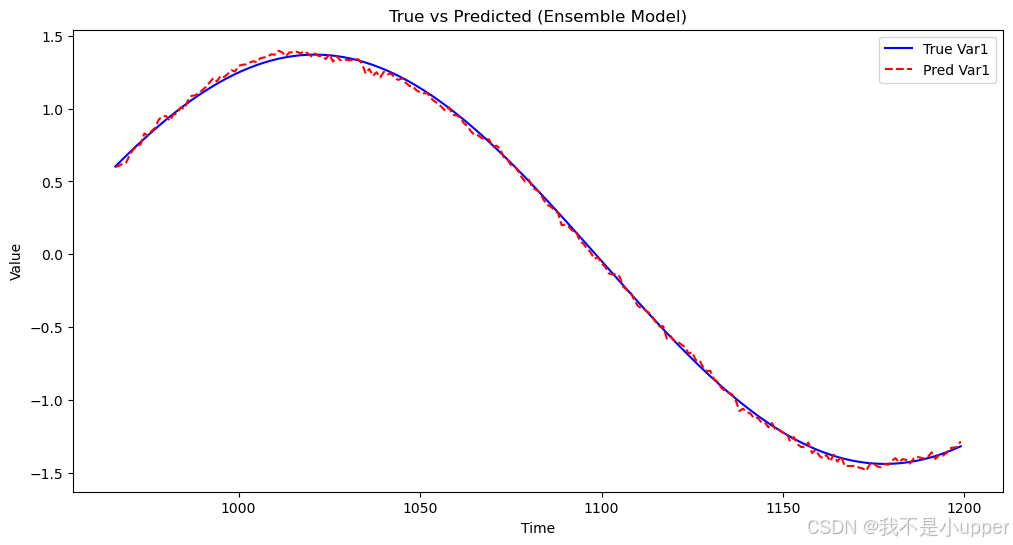
plt.figure(figsize=(12, 6))
plt.plot(np.arange(n_train+window_size, T-horizon+1), Y_test[:, 0], color='blue', label='True Var1')
plt.plot(np.arange(n_train+window_size, T-horizon+1), ensemble_pred[:, 0], color='red', linestyle='--', label='Pred Var1')
plt.title("True vs Predicted (Ensemble Model)")
plt.xlabel("Time")
plt.ylabel("Value")
plt.legend()
plt.show()执行后得到一张折线图,横坐标是时间,纵坐标是变量的值。蓝色实线代表真实值(True Var1),红色虚线代表融合模型的预测值(Pred Var1) 。通过对比这两条线,我们可以直观地看出融合模型的预测效果。如果两条线贴合度高,说明模型预测准确;若偏差较大,则表明模型在预测该变量时存在一定误差。
随机森林特征重要性
为了了解随机森林模型中各个特征的贡献情况,也就是哪些历史数据对预测最重要,我们绘制特征重要性图,代码如下:
importances = rf.feature_importances_
indices = np.argsort(importances)[-10:]
plt.figure(figsize=(8, 6))
plt.barh(range(len(indices)), importances[indices], color='teal')
plt.yticks(range(len(indices)), [f"Feature {i}" for i in indices])
plt.title("Random Forest Feature Importances")
plt.xlabel("Importance")
plt.ylabel("Feature")
plt.show()这会生成下图的横向条形图,横坐标是特征的重要性程度,纵坐标是特征编号。条形的长度代表对应特征的重要性,越长说明该特征对随机森林模型的预测越关键。通过这张图,我们可以清晰地看到不同特征在模型中的重要程度,有助于进一步优化模型和理解数据。
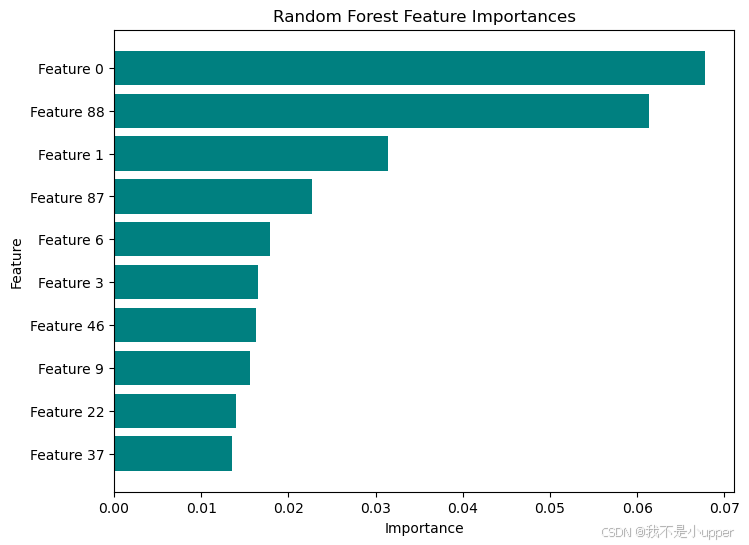 可以看出上图展示了不同特征对模型预测的贡献。横坐标是重要性数值,纵坐标是特征编号。可见,Feature 0 和 Feature 88 重要性较高,对预测影响大;其余特征重要性相对较低。
可以看出上图展示了不同特征对模型预测的贡献。横坐标是重要性数值,纵坐标是特征编号。可见,Feature 0 和 Feature 88 重要性较高,对预测影响大;其余特征重要性相对较低。
融合模型误差分布
我们通过绘制误差的直方图来分析融合模型预测误差的分布情况,代码如下:
errors = ensemble_pred.flatten() - Y_test.flatten()
plt.figure(figsize=(8, 6))
plt.hist(errors, bins=30, color='violet', edgecolor='black')
plt.title("Error Distribution (Ensemble)")
plt.xlabel("Prediction Error")
plt.ylabel("Frequency")
plt.show()本代码运行后输出一张直方图,横坐标是预测误差,纵坐标是误差出现的频率。通过观察直方图的形状和分布,我们可以了解融合模型预测误差的集中程度和离散情况。比如,如果直方图呈现近似正态分布,说明误差分布相对稳定;若存在长尾或异常值,可能表示模型在某些情况下预测效果不佳,需要进一步分析和改进。
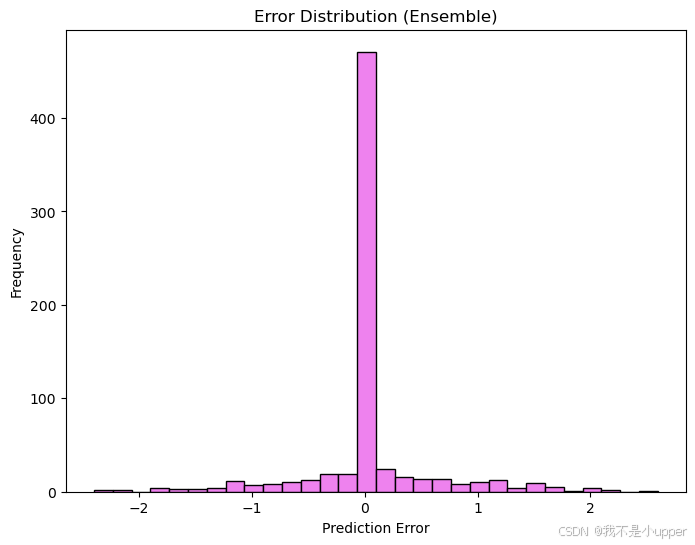
横坐标为预测误差,纵坐标是误差出现的频率。图中显示,大部分误差集中在 0 附近,说明融合模型的预测值与真实值较为接近,模型预测效果较好 ,仅有少量误差分布在远离 0 的两侧,表明模型在少数情况下会出现较大偏差 。
6. 算法优化点与调参流程
融合策略优化
- 加权系数调优:可运用网格搜索或交叉验证等方法,对加权系数
alpha进行精细调节,以找出能使融合模型性能最优的取值。 - 堆叠(Stacking):在融合模型中,尝试采用更复杂的回归器,如 XGBoost、Lasso 等,取代简单的线性回归或小型 MLP,从而更精准地学习不同模型间的最优组合方式。
调参流程
- 基线评估:率先针对单独的 Transformer 模型和随机森林(RF)模型进行调参,确定它们各自的基础性能表现,为后续融合模型的优化提供参照。
- 组合调参:在明确基线模型性能的前提下,对加权系数
alpha进行调节,优化加权平均融合效果;或者引入堆叠模型,进一步挖掘提升模型整体性能的潜力。 - 交叉验证:在模型训练阶段,采用 k 折交叉验证法,全面评估模型的泛化能力,确保模型在不同数据子集上都能有稳定的表现。
- 模型监控与调整:密切关注训练过程中损失值的变化情况,依据变化趋势,及时、适当地调整模型结构或超参数,使模型始终保持良好的训练状态。
本案例完整呈现了基于 Transformer 与随机森林的多变量时间序列预测过程,涵盖数据生成、模型训练、评估以及优化等各个环节。通过数据可视化和模型分析,我们能够深入理解模型的实际表现,并据此对模型进行针对性的调整与优化。
相关文章:
基于Transformer与随机森林的多变量时间序列预测
哈喽,我不是小upper,今天和大家聊聊基于Transformer与随机森林的多变量时间序列预测。 不懂Transformer的小伙伴可以看我上篇文章:一文带你彻底搞懂!Transformer !!https://blog.csdn.net/qq_70350287/article/detail…...
)
【程序员 NLP 入门】词嵌入 - 上下文中的窗口大小是什么意思? (★小白必会版★)
🌟 嗨,你好,我是 青松 ! 🌈 希望用我的经验,让“程序猿”的AI学习之路走的更容易些,若我的经验能为你前行的道路增添一丝轻松,我将倍感荣幸!共勉~ 【程序员 NLP 入门】词…...

MATLAB Coder 应用:转换 MATLAB 代码至 C/C++ | 实践步骤与问题解决
注:本文为 “ MATLAB 代码至 C/C 应用” 相关文章合辑。 未整理去重。 如有内容异常,请看原文。 MATLAB 代码转换为 C/C 代码的详细指南 随心 390 zhihu 发布于 2020-07-12 12:39 在实际项目中,我们常常遇到需要将 MATLAB 代码转换为 C/C …...

BLE 6.0 六大核心特性全解析
写在前面: 2025年1月15日,Bluetooth SIG发布了备受期待的 Bluetooth Core Specification 6.0。相比5.x系列,6.0在测距精度、能耗优化、扫描过滤、音频体验和协议灵活性等方面实现了重大突破。本文将以浅显易懂的语言、丰富的图示和真实案例,带你全面深入了解BLE 6.0的六大核…...

网络应用程序体系结构
本文来源 : 《计算机网络 自顶向下方法》 应用程序体系结构(application architecture)由应用程序研发者设计,规定了如何在各种端系统上组织该应用程序。 现代网络应用程序中使用的两种主流体系结构: (1)客户-服务器…...

Filename too long 错误
Filename too long 错误表明文件名超出了文件系统或版本控制系统允许的最大长度。 可能的原因 文件系统限制 不同的文件系统对文件名长度有不同的限制。例如,FAT32 文件名最长为 255 个字符,而 NTFS 虽然支持较长的文件名,但在某些情况下也…...

Linux学习——UDP
编程的整体框架 bind:绑定服务器:TCP地址和端口号 receivefrom():阻塞等待客户端数据 sendto():指定服务器的IP地址和端口号,要发送的数据 无连接尽力传输,UDP:是不可靠传输 实时的音视频传输&#x…...

C++:继承
目录 一:继承的概念 1.1 继承的定义 1.2 继承方式 1.3 可见性区别 公有方式 私有方式 保护方式 1.4 一般规则 二、继承中的隐藏规则 三、基类和派生类间的转换 四、派生类的默认成员函数 实现一个不能被继承的类 继承与友元 五、继承与静态成员 六、多…...

RSGISLib:一款功能强大的GIS与RS数据处理Python工具包
今天为大家介绍的软件是RSGISLib:一款功能丰富的遥感与GIS数据的python库。下面,我们将从软件的主要功能、支持的系统、软件官网等方面对其进行简单的介绍。 RSGISLib官网网址为:http://rsgislib.org/,它提供了一个丰富的工具集&…...

Git管理
1.创建git仓库 git init 2.让文件添加到暂存区 git add. 3.给暂存区文件添加说明,并提交到本地仓库 git commit -m 说明 4.查看历史记录 git log /git log --oneline 查看状态:git status 5. 引用旧版 git reset --hard commitid 6.创建分支 …...

Java中内部类
1.静态类与非静态类是内部类的区分,外部类不可以被static修饰。 2.类的加载过程:类只有被使用才会被类加载器加载,加载后类的信息放在元空间(方法区)中。类的使用包括初始化对象、静态方法的调用。 3.静态内部类与普…...

[U-Net-Dual]DEU-Net
论文题目:DEU-Net: Dual-Encoder U-Net for Automated Skin Lesion Segmentation 中文题目:DEU-Net:用于自动皮肤病变分割的双编码器U-Net 0摘要 皮肤病的计算机辅助诊断(CAD)在很大程度上依赖于皮肤病变的自动分割,尽管由于病变在形状、大小、颜色和纹理上的多样性以及…...

【数据结构】第五弹——Stack 和 Queue
文章目录 一. 栈(Stack)1.1 概念1.2 栈的使用1.3 栈的模拟实现1.3.1 顺序表结构1.3.2 进栈 压栈1.3.3 删除栈顶元素1.3.4 获取栈顶元素1.3.5 自定义异常 1.4 栈的应用场景1.改变元素序列2. 将递归转化为循环3. 四道习题 1.5 概念分区 二. 队列(Queue)2.1 概念2.2 队列的使用2.3…...

LSTM如何解决梯度消失问题
LSTM如何解决梯度消失问题 一、传统RNN的梯度消失困境 在标准RNN中,隐藏状态更新公式为: h t tanh ( W h h h t − 1 W x h x t b h ) h_t \tanh(W_{hh}h_{t-1} W_{xh}x_t b_h) httanh(Whhht−1Wxhxtbh) 梯度计算通过链式法则展…...

什么是管理思维?
管理思维是指在管理活动中形成的系统性、战略性和创造性的思考方式,帮助个人或团队更高效地达成目标。它不仅适用于企业管理,也适用于个人成长、项目执行和复杂问题解决。以下是关于管理思维的核心内容: 一、管理思维的核心特征 1. 系统性思…...

缓存与内存;缺页中断;缓存映射:组相联
文章目录 内存(RAM)与缓存(Cache)Memory Management Unit缺页中断 多级缓存缓存替换策略缓存的映射方式 内存(RAM)与缓存(Cache) 缓存: CPU 内部或非常靠近的高速存储&a…...

12.5/Q1,GBD高分文章解读
文章题目:Global, regional, and national burdens of early onset pancreatic cancer in adolescents and adults aged 15-49 years from 1990 to 2019 based on the Global Burden of Disease Study 2019: a cross-sectional stud DOI:10.1097/JS9.000…...

路由交换网络专题 | 第六章 | OSPF | BGP | BGP属性 | 防环机制
目录 拓扑图 (1)AS 400 内部使用 OSPF 路由协议,使 PC2 访问 PC3 的路径优先选择 AR2-AR4-AR3。 (2)AS 400 内部使用 RIP 路由协议,使 PC2 访问 PC3 的路径优先选择 AR2-AR4-AR3。 (3&#…...

ubuntu 安装 redis server
ubuntu 安装 redis server sudo apt update sudo apt install redis-server The following NEW packages will be installed:libhiredis0.14 libjemalloc2 liblua5.1-0 lua-bitop lua-cjson redis-server redis-toolssudo systemctl start redis-server sudo systemctl ena…...

基于 Spring Boot实现的图书管理系统
Spring Boot图书管理系统详细分析文档 1. 项目概述 本文档对基于Spring Boot实现的图书管理系统进行详细分析。该项目是一个典型的Web应用程序,采用了Spring Boot框架,结合MyBatis作为ORM工具,实现了图书信息的管理功能,包括图书…...
)
gradle可用的下载地址(免费)
这几天接手一个老项目,想找gradle老版本的,但一搜,虽然在CSDN上搜索出来一堆,但都是收费,有些甚至要几十积分(吃相有点难看了)。 我找了一个能访问的地址,特地分享出来,有需要的自取!…...

发送百度地图的定位
在vuephp写的聊天软件项目中,增加一个发送百度地图的定位功能 在 Vue PHP 的聊天软件中增加发送百度地图定位功能,需要从前端定位获取、地图API集成、后端存储到消息展示全流程实现。以下是详细步骤: 一、前端实现(Vue/Uni-app…...

滑动窗口学习
2090. 半径为 k 的子数组平均值 题目 问题分析 给定一个数组 nums 和一个整数 k,需要构建一个新的数组 avgs,其中 avgs[i] 表示以 nums[i] 为中心且半径为 k 的子数组的平均值。如果在 i 前或后不足 k 个元素,则 avgs[i] 的值为 -1。 思路…...
:Python Pandas索引技术详解)
python数据分析(二):Python Pandas索引技术详解
Python Pandas索引技术详解:从基础到多层索引 1. 引言 Pandas是Python数据分析的核心库,而索引技术是Pandas高效数据操作的关键。良好的索引使用可以显著提高数据查询和操作的效率。本文将系统介绍Pandas中的各种索引技术,包括基础索引、位…...
VTK C++开发示例 --- 生成随机数的首选方法)
(15)VTK C++开发示例 --- 生成随机数的首选方法
文章目录 1. 概述2. CMake链接VTK3. main.cpp文件4. 演示效果 更多精彩内容👉内容导航 👈👉VTK开发 👈 1. 概述 vtkMinimalStandardRandomSequence 是 VTK(Visualization Toolkit)库中的一个类,…...

华为S系列交换机CPU占用率高问题排查与解决方案
问题概述 在华为S系列交换机(V100&V200版本)运行过程中,CPU占用率过高是一个常见问题,可能导致设备性能下降甚至业务中断。根据华为官方维护宝典,导致CPU占用率高的主要原因可分为四大类:网络攻击、网络震荡、网络环路和硬件…...

为啥低速MCU单板辐射测试会有200M-1Ghz的辐射信号
低速MCU(如8位或16位单片机)单板在辐射测试中出现 200MHz~1GHz的高频辐射信号,看似不合理,但实际上是由多种因素共同导致的。以下是详细原因分析及解决方案: 1.根本原因分析: (1) 时钟谐波与开关噪声 低速MCU的时钟谐…...

docker本地虚拟机配置
docker 下载安装 yum install -y docker 如果报错 mv /etc/yum.repos.d/CentOS-Base.repo /etc/yum.repos.d/CentOS-Base.repo.backup curl -o /etc/yum.repos.d/CentOS-Base.repo http://mirrors.aliyun.com/repo/Centos-7.repo yum clean all yum makecache 修改docker 仓…...

【随机过程】柯尔莫哥洛夫微分方程总结
柯尔莫哥洛夫微分方程:用“水流扩散”理解概率演化 1. 核心思想 柯尔莫哥洛夫微分方程(Kolmogorov Equations)是描述**连续时间马尔可夫过程(CTMC)**中概率分布随时间演化的工具。 前向方程(Fokker-Planc…...

AI领域:MCP 与 A2A 协议的关系
一、为何会出现MCP和A2A 协议是非常重要的东西,只有大家都遵循统一的协议,整体生态才好发展,正如有了HTML,互联网才快速发展,有了OpenAPI, API才会快速发展。 Agent目前是发展最快的领域,从最初…...
:描述UI)
重学React(一):描述UI
背景:React现在已经更新到19了,文档地址也做了全面的更新,上一次系统性的学习还是在16-17的大版本更新。所以,现在就开始重新学习吧~ 学习内容: React官网教程:https://zh-hans.react.dev/lea…...
详解:以延迟加载图片为例)
代理模式(Proxy Pattern)详解:以延迟加载图片为例
在日常开发中,是否遇到过以下问题: “程序启动时图片太多,加载太慢!” “用户还没看到图片就已经开始加载了,性能浪费!” 此时,代理模式(Proxy Pattern)便派上了用场。本…...

Power BI企业运营分析——数据大屏搭建思路
Power BI企业运营分析——数据大屏搭建思路 欢迎来到Powerbi小课堂,在竞争激烈的市场环境中,企业运营分析平台成为提升竞争力的核心工具。 整合多源数据,实时监控关键指标,精准分析业务,快速识别问题机遇。其可视化看…...
)
HCIP-H12-821 核心知识梳理 (5)
Portal 认证场景中 AC 与 Portal 服务器通信使用的 Portal 协议基于 TCP;HTTP/HTTPS 可作为接入与认证协议;缺省情况下,接入设备处理 Portal 协议报文及向 Portal 服务器主动发送报文的目的端口号均为 50100 VRRP 协议心跳报文缺省发送间隔为…...

从M个元素中查找最小的N个元素时,使用大顶堆的效率比使用小顶堆更高,为什么?
我们有一个长度为 M 的数组,现在我们想从中找出 最小的 N 个元素。例如: int a[10] {12, 3, 5, 7, 19, 0, 8, 2, 4, 10};从中找出 最小的 4 个元素。 正确方法:使用大小为 N 的「大顶堆」 原因分析: 我们想保留最小的 4 个元素…...
)
【AI工具】2025年主流自动化技术(供参考)
背景 前面完成了AutoIT的自动化操作的尝试,有惊喜有惊吓,就是能进行自动化控制,但是有点“笨”,于是就想找找同类好用的技术,有了这篇自动化技术比较分析的文档,资料参考了AI总结的内容。 autoit的使用&am…...

1.微服务拆分与通信模式
目录 一、微服务拆分原则与策略 业务驱动拆分方法论 • DDD(领域驱动设计)中的限界上下文划分 • 业务功能正交性评估(高内聚、低耦合) 技术架构拆分策略 • 数据层拆分(垂直分库 vs 水平分表) • 服务粒…...

【Java面试笔记:基础】4.强引用、软引用、弱引用、幻象引用有什么区别?
1. 引用类型及其特点 强引用(Strong Reference): 定义:最常见的引用类型,通过new关键字直接创建。回收条件:只要强引用存在,对象不会被GC回收。示例:Object obj = new Object(); // 强引用特点: 强引用是导致内存泄漏的常见原因(如未及时置为null)。手动断开引用:…...

使用Python+OpenCV将多级嵌套文件夹下的视频文件抽帧为JPG图片
使用PythonOpenCV将多级嵌套文件夹下的视频文件抽帧为JPG图片 import os import cv2 import time# 存放视频文件的多层嵌套文件夹路径 videoPath D:\\videos\\ # 保存抽帧的图片的文件夹路径 savePath D:\\images\\if not os.path.exists(savePath):os.mkdir(savePath) vide…...

基于STM32的室内环境监测系统
目录 一、前言 二、项目功能说明 三、主要元器件 四、接线说明 五、原理图与PCB 六、手机APP 七、完整资料 一、前言 项目成品图片: 哔哩哔哩视频链接: 咸鱼商品链接: 基于STM32的室内环境监测系统商品链接 二、项目功能说明 基础功…...

乐迪电玩发卡查分与控制面板模块逻辑解析
本篇为《美乐迪电玩全套系统搭建》系列的第四篇,聚焦后台功能模块中的发卡与查分系统。针对运营侧常见需求(如玩家状态查验、补卡操作、积分调整等),本篇将完整剖析其 PHP 端实现逻辑、数据结构及权限管理机制。 一、模块结构与入…...

Spring 事务实现原理,Spring 的 ACID是如何实现的?如果让你用 JDBC 实现事务怎么实现?
Spring 事务实现原理 Spring 的事务管理基于 AOP(面向切面编程) 和 代理模式,通过以下核心组件实现: 事务管理器(PlatformTransactionManager) Spring 提供了统一的事务抽象接口(如 DataSource…...
)
网络原理 - 4(TCP - 1)
目录 TCP 协议 TCP 协议段格式 可靠传输 几个 TCP 协议中的机制 1. 确认应答 2. 超时重传 完! TCP 协议 TCP 全称为 “传输控制协议”(Transmission Control Protocol),要对数据的传输进行一个详细的控制。 TCP 协议段格…...

SVT-AV1编码器中的模块
一 模块列表 1 svt_input_cmd_creator 2 svt_input_buffer_header_creator 3 svt_input_y8b_creator 4 svt_output_buffer_header_creator 5 svt_output_recon_buffer_header_creator 6 svt_aom_resource_coordination_result_creator 7 svt_aom_picture_analysis_result_creat…...
个人学习笔记(12):网络爬虫)
金融数据分析(Python)个人学习笔记(12):网络爬虫
一、导入模块和函数 from bs4 import BeautifulSoup from urllib.request import urlopen import re from urllib.error import HTTPError from time import timebs4:用于解析HTML和XML文档的Python库。 BeautifulSoup:方便地从网页内容中提取和处理数据…...

子网划分的学习
定长子网划分(Fixed-length Subnetting) 也叫做固定长度子网划分,是指在一个IP网络中,把网络划分成若干个大小相等的子网,每个子网的子网掩码长度是一样的。 一、定长子网划分的背景 在早期的IP地址分配中࿰…...

Spark2 之 memorypool
cpp/core/memory/ArrowMemoryPool.cc cpp/core/memory/MemoryAllocator.cc VeloxMemoryManager cpp/velox/memory/VeloxMemoryManager.cc VeloxMemoryManager::VeloxMemoryManager(const std::string& kind, std::unique_ptr<AllocationListe...

短视频+直播商城系统源码全解析:音视频流、商品组件逻辑剖析
时下,无论是依托私域流量运营的品牌方,还是追求用户粘性与转化率的内容创作者,搭建一套完整的短视频直播商城系统源码,已成为提升用户体验、增加商业变现能力的关键。本文将围绕三大核心模块——音视频流技术架构、商品组件设计、…...

IO流详解
IO流 用于读写数据的(可以读写文件,或网络中的数据) 概述 I指 Input,称为输入流:负责从磁盘或网络上将数据读到内存中去 O指Output,称为输出流,负责写数据出去到网络或磁盘上 因此ÿ…...

linux下使用wireshark捕捉snmp报文
1、安装wireshark并解决wireshark权限不足问题 解决linux普通用户使用Wireshark的权限不足问题_麒麟系统中wireshark 运行显示权限不够-CSDN博客 2、Linux下安装并配置SNMP软件包 (deepseek给出的解答,目前会产生request包,但是会连接不上&a…...