IO流详解
IO流
-
用于读写数据的(可以读写文件,或网络中的数据)
概述
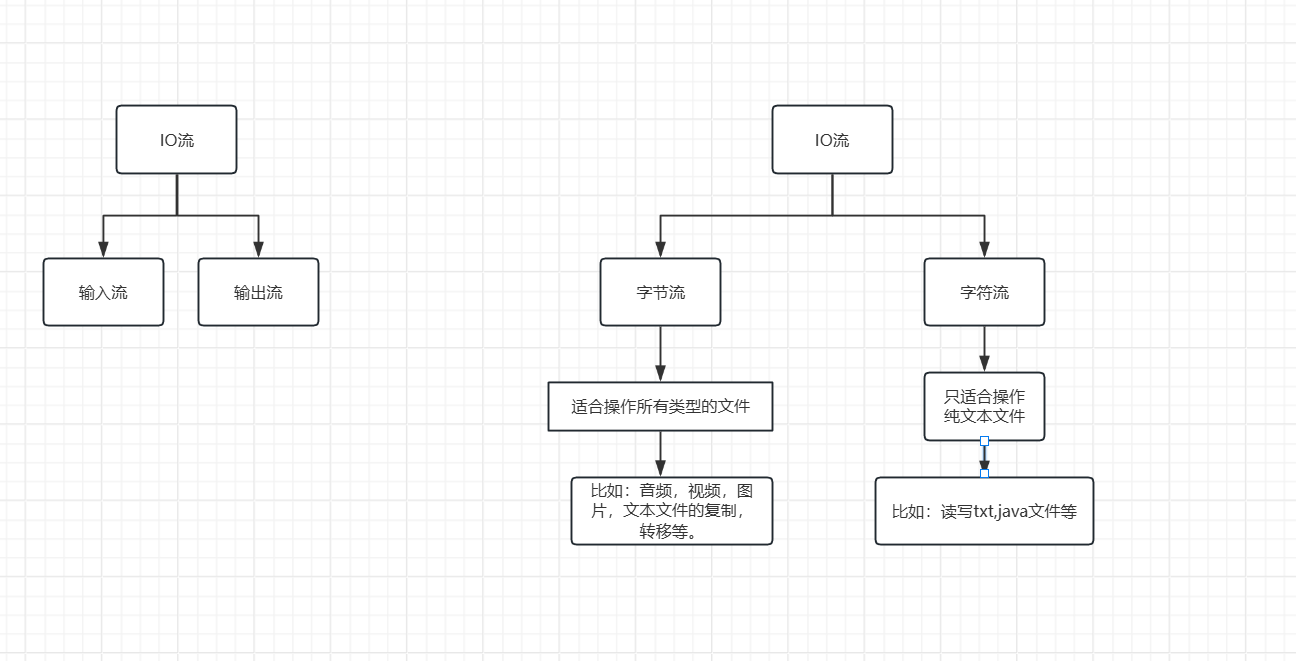
I指 Input,称为输入流:负责从磁盘或网络上将数据读到内存中去
O指Output,称为输出流,负责写数据出去到网络或磁盘上
因此,IO流总体来看就有四大流
-
字节输入流:以内存为基准,在管道中,以一个一个字节的形式,从外部读取数据到内存中的流。
-
字节输出流:以内存为基准,在管道中,以一个一个字节的形式,将数据从内存中读取到外部磁盘或网络中的流。
-
字符输入流:以内存为基准,在管道中,以一个一个字符的形式,从外部读取数据到内存中,只适合操作纯文本文件的流。
-
字符输出流:以内存为基准,在管道中,以一个一个字符的形式,把内存中的数据写出到磁盘文件或者网络介质中的流。
前置知识:File
-
File是java.io.包下的类,File类的对象,用于代表当前操作系统的文件(可以是文件、或文件夹)。
-
File类提供的主要功能:
-
获取文件信息(大小,文件名,修改时间)
-
判断文件的类型
-
创建文件/文件夹
-
删除文件/文件夹
-
注:File类只能对文件本身进行操作,不能读写文件里面存储的数据
File类:对象的创建
常用方法
| 构造器 | 说明 |
|---|---|
| public File(String pathname) | 根据文件路径创建文件对象 |
| public File(String parent,String child) | 根据父路径与子路径名字创建文件对象 |
| public File(File parent, String child) | 根据父路径对应文件对象和子路径名字创建文件对象 |
代码展示:
package com.lyc.io;import java.io.File;//测试file类的构造器public class FileTest1 {public static void main(String[] args) {//1.创建一个File对象,指代某个具体的文件 绝对路径 带盘符File file = new File("D:\\IdeaProjects\\collectionTest\\src\\main\\java\\com\\lyc\\io\\test.txt");//也可以使用/ 来表示file = new File("D:/IdeaProjects/collectionTest/src/main/java/com/lyc/io/test.txt");//也可以使用File.separator来表示分隔符,这个分隔符是系统相关的,具有兼容性System.out.println(file.length());//返回的是文件的字节个数//2.创建一个File对象,指代某个具体的文件夹File file1 = new File("D:\\IdeaProjects\\collectionTest");System.out.println(file1.length());//4096 是指这个文件夹本身的字节数,不包括里面的文件//注意:File对象只带一个不存在的文件路径File file2 = new File("D:\\IdeaProjects\\collectionTest\\src\\main\\java\\com\\lyc\\io\\test1.txt");System.out.println(file2.length()); //为0//3.判断文件是否存在System.out.println(file2.exists());//使用相对路径创建文件对象File file3 = new File("src/main/java/com/lyc/io/test.txt");System.out.println(file3.exists());}}注意:
-
File对象既可以代表文件,也可以代表文件夹
-
File封装的对象仅仅是一个路径名,这个路径可以是存在的,也允许是不存在的
绝对路径、相对路径
-
绝对路径:从盘符开始
-
相对路径:不带盘符,默认直接到当前工程的目录下寻找文件
File类:常用方法
| 方法名称 | 说明 |
|---|---|
public boolean exists() | 判断当前文件对象,对应的文件路径是否存在,存在则返回true |
public boolan isFile() | 判断当前文件对象指代的是否为文件,是文件返回true,反之false |
public boolean isDirectory() | 判断当前文件对象指代的是否是文件夹,是文件夹返回true,反之false |
public String getName() | 获取文件的名称(包含后缀) |
public long length() | 获取文件的大小,返回字节个数 |
public long lastModified() | 获取文件的最后修改时间 |
public String getPath() | 获取创建文件对象时,使用的路径 |
public String getAbsolutePath() | 获取绝对路径 |
public boolean createNewFile() | 创建一个新文件(文件内容为空) |
public boolean mkdir() | 用于创建文件夹,注意:只能创建一级文件夹 |
public boolean mkdirs() | 用于创建多级文件夹 |
public boolean delete() | 删除文件 或者空文件夹 注意:不能删除非空文件夹,而且删除后的文件不会进入回收站 |
File类提供的遍历文件夹的功能
| 方法名称 | 说明 |
|---|---|
public String[] list() | 返回一个String数组,获取当前目录下所有的“一级文件名称” |
public File[] listFiles() | 返回一个File数组,获取当前目录下所有的“一级文件对象” |
使用listFiles方法时的注意事项:
-
当主调是文件,或者路径不存在时,返回null
-
当主调是空文件夹时,返回一个长度为零的数组
-
当主调是一个有内容的文件夹时,将里面所有一级文件和文件夹的路径放在File数组中返回
-
当主调是一个文件夹,且里面有隐藏文件时,将里面所有文件和文件夹的路径放在File数组中返回,包含隐藏文件
-
当主调是一个文件夹,但是没有权限访问该文件夹时,返回null
代码展示:
package com.lyc.io;import java.io.File;import java.text.SimpleDateFormat;import java.util.logging.SimpleFormatter;//测试文件类的常用方法public class FileTest2 {public static void main(String[] args) {//1.创建文件对象File file = new File("src/main/java/com/lyc/io/test.txt");//2:判断文件是否存在 public boolean exists()System.out.println(file.exists());//3.判断文件是否是文件 public boolean isFile()System.out.println(file.isFile());//4.判断文件是否是目录 public boolean isDirectory()System.out.println(file.isDirectory());//5.获取文件或者目录的名称 public String getName()System.out.println(file.getName());//6.获取文件的绝对路径 public String getAbsolutePath()System.out.println(file.getAbsolutePath());//7.获取文件的长度 public long length()System.out.println(file.length());//8.获取文件的最后修改时间 public long lastModified() 返回的是毫秒值 需要转换为日期格式SimpleDateFormat simpleDateFormat = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss");long l = file.lastModified();System.out.println(simpleDateFormat.format(l));//9.获取创建文件对象时,使用的路径 public String getPath()System.out.println(file.getPath());//11.创建文件 public boolean createNewFile() 创建文件成功返回true 文件为空File file2 = new File("src/main/java/com/lyc/io/test2.txt");try {System.out.println(file2.createNewFile());} catch (Exception e) {e.printStackTrace();}//12.创建目录 public boolean mkdir()File file3 = new File("src/main/java/com/lyc/io/test3");System.out.println(file3.mkdir());//13.创建多级目录 public boolean mkdirs()File file4 = new File("src/main/java/com/lyc/io/test3/test4/test5");System.out.println(file4.mkdirs());//14.删除文件或者目录 public boolean delete()System.out.println(file2.delete());}}案例展示:
package com.lyc.io;import java.io.File;//测试:改变某个文件夹下视频的序号public class fileTest {public static void main(String[] args) {//1.拿到所有的文件,以及对象File file = new File("E:\\桌面\\java学习");//2.拿到所有的文件对象File[] files = file.listFiles();//遍历for (File file1 : files) {String name = file1.getName();//截取开始到需要截的地方之间的文件名String index = name.substring(0, name.indexOf("的"));//截取需要截取的地方到最后的部分,最后将其拼接String lastName = name.substring(name.indexOf("的"));String newName = index + lastName;//3.修改文件名if (file1.isFile()) {file1.renameTo(new File(file,newName));}}}}那么文件搜索需要访问不只一级文件夹,我们可以使用方法递归来遍历文件夹
前置知识:方法递归
-
递归是一种算法,在程序设计语言中广泛应用
-
从形式上讲,方法调用自身的形式称为方法递归
-
直接递归:方法自己调用自己
-
间接递归:方法调用其他方法,其他方法又回调方法自己
使用方法递归时需要注意的问题:
-
递归如果没有控制好终止条件,会出现递归死循环,导致栈内存溢出错误
案例1:计算n的阶乘
代码展示:
public static void main(String[] args) {System.out.println(f(5));}public static int f(int n){if(n==1){return 1;}else {return n * f(n-1);}}}案例2:斐波那契数列
斐波那契数列的是这样一个数列:1、1、2、3、5、8、13、21、34…,即第一项 f(1) = 1,第二项 f(2) = 1…,第 n 项目为 f(n) = f(n-1) + f(n-2)。求第 n 项的值是多少。
代码展示:
//斐波那契数列//1、1、2、3、5、8、13、21、34public class test1 {public static void main(String[] args) {for (int i = 1; i < 10; i++) {System.out.println(fib(i));}}public static int fib(int n){if (n==1||n==2){return 1;}else{return fib(n-1)+fib(n-2);}}}文件搜索
要求:从D:盘中,搜索”QQ.exe“这个文件,找到后直接输出其位置
分析:
-
先找出D:盘下的所有一级文件对象
-
遍历全部一级文件对象
-
如果是文件,判断是否是自己想要的
-
如果是文件夹,需要继续进入到该文件夹,重复上述过程
代码展示:
package com.lyc.io;import java.io.File;/*要求:从D:盘中,搜索”QQ.exe“这个文件,找到后直接输出其位置分析:1. 先找出D:盘下的所有一级文件对象2. 遍历全部一级文件对象3. 如果是文件,判断是否是自己想要的4. 如果是文件夹,需要继续进入到该文件夹,重复上述过程* */public class FileSearch {public static void main(String[] args) {search(new File("D:/"),"QQ.exe");}public static void search(File file,String fileName){//将非法情况拦截if (!file.exists() || file.isFile()){return;//无法搜索}//1.public File[] listFiles() 返回一个File数组,获取当前目录下所有的“一级文件对象”File[] files = file.listFiles();//判断当前目录下是否有文件,以及是否可以拿到文件if (files != null){for (File file1 : files) {//2.遍历全部一级文件对象if (file1.isFile()){//3.如果是文件,判断是否是自己想要的if (file1.getName().equals(fileName)){System.out.println("路径是:"+file1.getAbsolutePath());}}else {//3.如果当前是文件夹,需要继续进入到该文件夹,重复上述过程search(file1,fileName);}}}}}拓展案例:
需求:删除非空文件夹
分析:
File默认不可以删除非空文件夹,需要使用递归删除
1.递归删除文件夹中的内容
2.删除文件夹
代码展示:
public static void main(String[] args) {File file = new File("E:\\桌面\\deleteDemo");System.out.println(file.exists());deleteFile(file);}public static void deleteFile(File file) {if (!file.exists()) {return;}if (file.isFile()) {file.delete();return;}File[] files = file.listFiles();if (files != null) {for (File file1 : files) {deleteFile(file1);}}// 删除文件夹本身file.delete();}前置知识:字符集
美国人制造了计算机,并在其中存储了128个码点用来表达数字,标点符号,特殊字符,英文字母(大小写),其中'a'是97,'0'为48...
被称为ASII字符集
原理就是将这些码点直接转译成二进制,只有8位,正好是1字节,所以ASII字符集使用一个字节存储
标准ASCII字符集
-
ASII:美国信息交换标准代码,包括了英文,符号等
-
标准ASII码使用1个字节存储一个字符,首位是0,总共可以表示128个字符
GBK(汉字内码扩展规范,国标)
-
汉字编码字符集,包含2万多个汉字等字符,GBK中一个中文字符编码成两个字节的形式存储
-
注意:GBK兼容了ASCII字符集,GBK规定:汉字的第一个字节的第一位必须是1
Unicode字符集(统一码,也叫万国码)
-
Unicode是国际组织制定的,可以容纳世界上所有文字、符号的字符集
-
UTF-32 4个字节表示一个字符,容量大,但缺点:占用太多的存储空间,通信效率降低
-
UTF-8 (重点)
UTF-8
-
是Unicode字符集的一种编码方案,采取可变长编码方案,共分成四个长度区:1个字节,2个字节,3个字节,4个字节
-
英文字符、数字等只占一个字节(兼容标准ASII码),汉字字符占用3个字节
拓展:那英文与中文在一起该如何区分?
UTF-8有自己的编码规则
-
在遇见ASII码时,直接就以一个字节的形式编译成二进制,不做其他处理
-
如果是两个字节,编译时要求第一个字节的前三位为110 ,第二个字节的前两位为10,
-
如果是三个字节,编译时要求第一个字节的前四位为1110,后两个字节的前两位为10.
-
如果是四个字节,编译时要求第一个字节的前五位为11110,后三个字节的前两位为10
-
技术人员在开发时都已应该使用UTF-8编码
注意:
-
字符编码时使用的字符集,和解码时使用的字符集必须一致,否则会出现乱码
-
英文,数字一般不会乱码,因为很多字符集都兼容了ASCII编码
字符集的编码,解码
编码:把字符按照指定字符编码成字节
解码:把字节按照指定字符集解码成字符
Java代码完成对字符的编码
| String提供了以下方法 | 说明 |
|---|---|
byte[] getBytes() | 使用平台的默认字符集将该String编码为一系列字节,将结果存储到新的字节数组中 |
byte[] getBytes(String charsetName) | 使用指定的字符集将String编码为一系列字节,将结果存储到新的字节数组中 |
java代码完成对字符的解码
| String提供了以下方法 | 说明 |
|---|---|
String(byte[] bytes) | 通过使用平台的默认字符集解码指定的字节数组来构造新的String |
String(byte[] bytes,String charsetName) | 通过指定的字符集解码指定的字节数组来构造新的String |
代码展示:
package com.lyc.io;import java.io.UnsupportedEncodingException;import java.util.Arrays;//掌握如何使用Java代码完成对字符的编码与解码public class charsetTest {public static void main(String[] args) throws UnsupportedEncodingException {//1.编码String data = "a我b";byte[] bytes = data.getBytes();//默认是按照平台字符集(UTF-8)进行编码的System.out.println(Arrays.toString(bytes));//[97, -26, -120, -111, 98] a我b ASCII码 在UTF-8编码中只占一个字节,而汉字在UTF-8编码中占三个字节 负数是因为首字母为1// 2.按照指定字符集进行编码byte[] bytes1 = data.getBytes("GBK");System.out.println(Arrays.toString(bytes1));//[97, -50, -46, 98]//a我b GBK编码中,汉字占两个字节,而a占一个字节//3.解码String s = new String(bytes);//默认按照平台字符集(UTF-8)进行解码System.out.println(s);//a我bString s1 = new String(bytes1,"GBK");//按照GBK进行解码System.out.println(s1);//a我b}}IO流--字节流
文件字节输入流(FileInputStream)
-
作用:以内存为基准,可以把磁盘文件的数据以字节的形式读入到内存中去
| 构造器 | 说明 |
|---|---|
FileInputStream(File file) | 通过打开与实际文件的连接创建一个 FileInputStream ,该文件由文件系统中的 File对象 file命名。 |
FileInputStream(String name) | 通过打开与实际文件的连接来创建一个 FileInputStream ,该文件由文件系统中的路径名 name命名 |
| 方法名称 | 说明 |
|---|---|
int read() | 从该输入流读取一个字节的数据。没有数据返回-1 |
int read(byte[] b) | 从该输入流读取最多 b.length个字节的数据为字节数组。返回字节数组读取了多少字节,如果为空返回-1 |
注意事项:
-
使用FileInputStream每次读取一个字节,读取性能较差,并且读取汉字会有乱码
-
使用字节数组读取的话也可能出现读取汉字乱码,因为字节数组如果正好卡在汉字的字节之间,就会乱码
1.使用字节流读取中文,如何保证输出不乱码,怎么解决?
-
定义一个与文件一样大的字节数组,一次性读取完文件的全部字节
-
Java官方为Input Stream提供了如下方法,可以把文件的全部字节读取到一个字节数组中返回
问题:
-
如果文件过大,创建的字节数组也会过大,可能引出内存溢出
读写文本内容更适合用字符流 字节流更适合做数据的转移,:如文件复制
byte[]readAllBytes() throws IOException: 直接将当前字节输入流对应的文件对象的字节数据装到一个字节数组中返回。
public static void main(String[] args) throws Exception {//一次性读取完文件的全部字节到一个字节数组中File file = new File("src/main/java/com/lyc/io/test.cpp");InputStream is = new FileInputStream(file);//1.创建一个字节数组,大小与文件的大小一致// long length = file.length();// byte[] b = new byte[(int)length];// int len;// while((len=is.read(b))!=-1){// System.out.println(new String(b,0,len));// }//第二种方法 一次性读取完文件的全部字节到一个字节数组中byte[] bytes = is.readAllBytes();System.out.println(new String(bytes));is.close();}}代码展示:
package com.lyc.io;import java.io.File;import java.io.FileInputStream;import java.io.FileNotFoundException;import java.io.InputStream;//测试文件字节输入流public class FileInputStreamTest {public static void main(String[] args) throws Exception {//1. 创建文件字节输入流管道,与源文件绑定File file = new File("src/main/java/com/lyc/io/test.txt");InputStream fis = new FileInputStream(file);//2. 从文件字节输入流管道中读取数据//创建空字节数组byte[] buffer = new byte[1024];// int read = fis.read();// System.out.println((char)read);//读取文件字节返回一个int类型数据,读取到文件末尾返回-1//循环读取int b;while ((b = fis.read(buffer)) != -1) {if (b > 0) {//注意:字节数组buffer中,有可能有0,也有可能有数据,所以需要使用字节数组的参数构造方法,指定读取的长度//所以,offset:0,length:b,从0开始,读取b个字节System.out.print(new String(buffer, 0, b));}}fis.close();//关闭流}}文件字节输出流(FileOutputStream)
-
作用:以内存为基准,把内存中的数据以字节的形式写出到文件中去
| 构造器 | 说明 |
|---|---|
FileOutputStream(File file) | 创建文件输出流以写入由指定的 File对象表示的文件。 |
FileOutputStream(File file , boolean append) | 创建字节输出流管道与源文件接通,可追加数据 |
FileOutputStream(String name) | 创建文件输出流以指定的名称写入文件。 |
FileOutputStream(String name, boolean append) | 创建文件输出流以指定的名称写入文件。 可追加数据 |
| 方法名称 | 说明 |
|---|---|
void write(int b) | 将指定的字节写入此文件输出流。 |
void write(byte[] b) | 将 b.length个字节从指定的字节数组写入此文件输出流。 |
void write(byte[] b, int off, int len) | 将 len字节从位于偏移量 off的指定字节数组写入此文件输出流。 |
void close() | 关闭此文件输出流并释放与此流相关联的任何系统资源。 |
代码展示:
package com.lyc.io;import java.io.*;//测试文件字节输出流的使用public class FileOutputStreamTest {public static void main(String[] args) throws Exception {//创建一个文件字节输出流对象OutputStream os = new FileOutputStream("D:\\IdeaProjects\\collectionTest\\src\\main\\java\\com\\lyc\\io\\test2.txt",true);//true 表示追加数据InputStream is = new FileInputStream("src/main/java/com/lyc/io/test.txt");int len;byte[] b = new byte[1024];while ((len=is.read(b))!=-1){os.write(b,0,len);}//写入数据os.write(97);os.write('b');byte[] bytes = "我爱你但...".getBytes();os.write(bytes);//写入换行符 os.write("\r\n".getBytes());os.close();//关闭流is.close();}}案例:文件复制
代码展示:
package com.lyc.io;import java.io.*;// 文件复制public class copyTest {public static void main(String[] args) throws Exception {// 复制照片File file = new File("E:\\桌面\\3D旋转魔方相册\\001.jpg");System.out.println(file.exists());// 1,创建一个字节输入流管道与源文件接通InputStream is = new FileInputStream(file);// 2,创建一个字节输出流管道与目标文件接通// 修改:将目标路径改为有效的文件路径String targetFilePath = "src/main/java/com/lyc/io/001_copy.jpg";OutputStream os = new FileOutputStream(targetFilePath);// 3,把输入流的数据复制到输出流中,一次读写一个字节数组byte[] b = new byte[1024];int len;while ((len = is.read(b)) != -1) {os.write(b, 0, len);}os.close();is.close();}}小结:字节流非常适合做一切文件的复制操作,任何文件的底层都是字节,字节流做复制,是一字不漏的转移完所有字节,只要复制后的文件格式一致就没问题。
释放资源的方式
-
try-catch-finally
try {......} catch (IOException e) {e.printStackTrace();}finally {}finally代码区的特点:无论try中的程序是正常执行了,还是出现了异常,最后一定会执行finally区,除非JVM终止
代码展示:
package com.lyc.io;public class TryTest {public static void main(String[] args) {try {int a = 110/2;return;//跳出整个方法//System.exit(0);//退出虚拟机}catch (Exception e){e.printStackTrace();}finally {System.out.println("finally");//始终会执行,除非虚拟机停止}}public static int test(int a, int b) {try {return a * b;} catch (Exception e) {e.printStackTrace();return -1;} finally {System.out.println("finally");//不要再finally中返回数据,不然整个方法最终返回的finally语句块中的数据,而不是方法中的数据}}}使用场景:一般用于程序执行完成后进行资源的释放操作。
代码优化:
package com.lyc.io;import java.io.*;// 文件复制public class copyTest {public static void main(String[] args) throws Exception {OutputStream os = null;InputStream is = null;// 复制照片try {File file = new File("E:\\桌面\\3D旋转魔方相册\\001.jpg");System.out.println(file.exists());// 1,创建一个字节输入流管道与源文件接通is = new FileInputStream(file);// 2,创建一个字节输出流管道与目标文件接通// 修改:将目标路径改为有效的文件路径String targetFilePath = "src/main/java/com/lyc/io/001_copy.jpg";os = new FileOutputStream(targetFilePath);// 3,把输入流的数据复制到输出流中,一次读写一个字节数组byte[] b = new byte[1024];int len;while ((len = is.read(b)) != -1) {os.write(b, 0, len);}} catch (Exception e) {throw new RuntimeException(e);} finally {if (os != null) {os.close();}if (is != null) {is.close();}}}}-
try-with-resource
try-catch-finally资源释放很专业,但是代码过于臃肿,在JDK7中推出了更简单的资源释放方案:try-with-resource
try(定义资源1;定义资源2){可能出现的异常代码;}catch(异常类名 变量名){异常的处理代码;}代码展示:
package com.lyc.io;import java.io.*;//测试文件字节输出流的使用public class FileOutputStreamTest {public static void main(String[] args) throws Exception {try(//创建一个文件字节输出流对象OutputStream os = new FileOutputStream("D:\\IdeaProjects\\collectionTest\\src\\main\\java\\com\\lyc\\io\\test2.txt",true);//true 表示追加数据InputStream is = new FileInputStream("src/main/java/com/lyc/io/test.txt"); ) {int len;byte[] b = new byte[1024];while ((len=is.read(b))!=-1){os.write(b,0,len);}//写入数据os.write(97);os.write('b');byte[] bytes = "我爱你但...".getBytes();os.write(bytes);//写入换行符os.write("\r\n".getBytes());} catch (IOException e) {throw new RuntimeException(e);}}}注意事项:try后面只能放置资源对象(流对象),资源:都是会实现AutoCloseable接口 资源都会有close方法
该资源使用完毕后,会自动调用其close()方法,完成对资源的释放
IO流--字符流
文件字符输入流(FileReader)
-
作用:以内存为基准,可以把文件中的数据以字符的形式读入到内存中去
| 构造器 | 说明 |
|---|---|
FileReader(String fileName) | ` 创建一个新的 FileReader ,给定要读取的文件的名称。 |
FileReader(File file) | 创建一个新的 FileReader ,给出 File读取。 |
| 方法名称 | 说明 |
|---|---|
int read(char[] b) | 从该输入流读取最多 b.length个字符的数据为字符数组。返回字符数组读取了多少字符,如果为空返回-1 |
int read() | 从该输入流读取一个字符的数据。没有数据返回-1 |
代码展示:
package com.lyc.io;import java.io.FileReader;import java.io.Reader;//测试文件输入字符流public class FileReaderTest {public static void main(String[] args) throws Exception{try(//创建一个文件输入字符流Reader fr = new FileReader("src/main/java/com/lyc/io/test.cpp");){//读取文件内容int c;while ((c=fr.read())!=-1){System.out.print((char)c);}//每次读取一个字符的形式,性能很差//第二种方法char[] chars = new char[1024];int len;while ((len = fr.read(chars))!=-1){System.out.println(new String(chars,0,len));}//性能不错}catch (Exception e){e.printStackTrace();}}}文件字符输出流(FileWriter)
-
作用:以内存为基准,把内存中的数据以字符的形式写到文件中去
| 构造器 | 说明 |
|---|---|
FileWriter(File file) | 给一个File对象构造一个FileWriter对象。 |
FileWriter(File file, boolean append) | 给一个File对象构造一个FileWriter对象。 |
FileWriter(String fileName) | 构造一个给定文件名的FileWriter对象。 |
FileWriter(String fileName, boolean append) | 构造一个FileWriter对象,给出一个带有布尔值的文件名,表示是否附加写入的数据 |
| 方法名称 | 说明 |
|---|---|
void write(int c) | 写一个字符 |
void write(char[] c) | 写入一个字符数组 |
void write(char[] c, int off, int len) | 写一个字符数组的一部分 |
void write( String str) | 写一个字符串 |
void write(String str, int off, int len) | 写一个字符串的部分 |
void flush() | 刷新流,将内存中缓存的数据立即写到文件中去 |
void close() | 关闭流的操作,包含了刷新 |
代码展示:
package com.lyc.io;import java.io.FileWriter;import java.io.Writer;//测试文件字符输出流public class FileWriterTest {public static void main(String[] args) {try(Writer fw = new FileWriter("src/main/java/com/lyc/io/text3.txt",true);//true 表示追加内容,false表示覆盖内容){//1.写一个字符 void write(int c)fw.write('a');fw.write('b');fw.write('你');fw.write("\r\n");//2.写一个字符串 void write(String str)fw.write("hello");fw.write("world");fw.write("java");fw.write("\r\n");//3.写一个字符串的指定部分 void write(String str,int off,int len)fw.write("hello",2,2);fw.write("\r\n");//4.写一个字符数组 void write(char[] cbuf)char[] chars = {'a','b','c','d','e'};fw.write(chars);fw.write("\r\n");//5.写一个字符数组的指定部分 void write(char[] cbuf,int off,int len)fw.write(chars,2,2);fw.write("\r\n");}catch(Exception e){e.printStackTrace();}}}注意事项:
字符输出流写出数据后,必须刷新流,或者关闭流,写出去的数据才会生效(类似事务回滚)
原因:因为我们在程序中写入的数据不是直接存入文件中,而是先放在缓冲区,等刷新或者关闭(其中包含刷新操作)后会存入文件,一旦缓冲区满了之后,会将多余的数据直接写入文件中
f.flush() //刷新流 f.close()区别:flush之后流还可以使用,而关闭之后就不可以使用了
小结:
-
字节流适合做一切文件的拷贝(音视频,文本);字节流不适合读取中文内容输出
-
字符流适合作文本文件的读写.
IO流--缓冲流
作用:对原始流进行包装,以提高原始流读写数据的性能
字节缓冲流(BufferedInputStream BufferedOutputStream)
作用:提高字节流读写的性能
示意图:
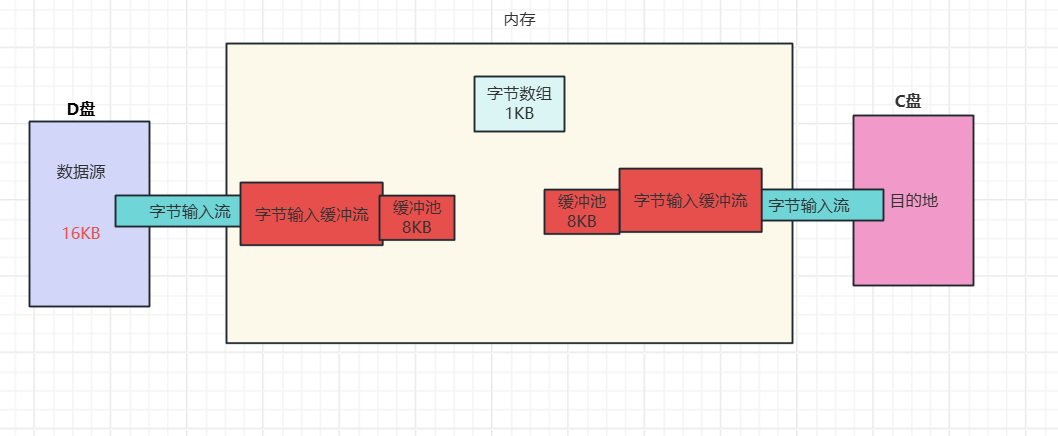
如果再没有缓冲流的情况下,字节输入流需要读取16次,字节输出流写入16次,需要进行32次调用系统
而如果有缓冲流的情况,缓冲流会自带8KB的缓冲池,那么16KB的数据源只需要存储两次,写出两次,而且是在内存中的缓冲池进行的,因此性能是非常快的。
原理:字节缓冲输入流自带了8KB缓冲池;字节缓冲输出流也自带了8KB缓冲池。
| 构造器 | 说明 |
|---|---|
BufferedInputStream(InputStream in) | 创建一个 BufferedInputStream并保存其参数,输入流 in ,供以后使用。 |
BufferedInputStream(InputStream in, int size) | 创建 BufferedInputStream具有指定缓冲区大小,并保存其参数,输入流 in ,供以后使用。 |
BufferedOutputStream(OutputStream out) | 创建一个新的缓冲输出流,以将数据写入指定的底层输出流 |
BufferedOutputStream(OutputStream out, int size) | 创建一个新的缓冲输出流,以便以指定的缓冲区大小将数据写入指定的底层输出流。 |
代码展示:
package buffer;import java.io.*;//掌握字节缓冲流的作用public class BufferedInputStreamTest {public static void main(String[] args) {try(InputStream is= new FileInputStream("src/main/java/buffer/test.txt");InputStream bis = new BufferedInputStream(is);OutputStream os = new FileOutputStream("src/main/java/buffer/test2.txt");OutputStream bos = new BufferedOutputStream(os);){byte[] b = new byte[1024];int len;while((len = bis.read(b))!=-1){bos.write(b,0,len);}} catch(Exception e){e.printStackTrace();}}}字符缓冲流(BufferedReader BufferedWriter)
-
作用:自带8KB(8192)的字符缓冲池,可以提高字符输入流读取字符数据的性能。
与字节缓冲流原理一致
构造器 说明 BufferedReader(Reader in)创建使用默认大小的输入缓冲区的缓冲字符输入流。 BufferedReader(Reader in, int sz)创建使用指定大小的输入缓冲区的缓冲字符输入流 BufferedWriter(Writer out)创建使用默认大小的输出缓冲区的缓冲字符输出流。 BufferedWriter(Writer out, int sz)创建一个新的缓冲字符输出流,使用给定大小的输出缓冲区。 字符缓冲输入流方法
| 方法 | 说明 |
|---|---|
long``skip(long n) | 跳过字符 |
void``close() | 关闭流并释放与之相关联的任何系统资源。 |
Stream<String>``lines() | 返回一个 Stream ,其元素是从这个 BufferedReader读取的行。 |
void``mark(int readAheadLimit) | 标记流中的当前位置。 |
boolean``markSupported() | 告诉这个流是否支持mark()操作。 |
int``read() | 读一个字符 |
int``read(char[] cbuf, int off, int len) | 将字符读入数组的一部分。 |
String``readLine() | 读一行文字。如果没有数据,返回null |
boolean``ready() | 告诉这个流是否准备好被读取。 |
void``reset() | 将流重置为最近的标记 |
字符缓冲输出流方法
| 方法 | 说明 |
|---|---|
void``close()。 | 关闭流,先刷新 |
void``write(char[] cbuf, int off, int len) | 写入字符数组的一部分。 |
void``write(int c) | 写一个字符 |
void``write(String s, int off, int len) | 写一个字符串的一部分。 |
void``newLine() | 写一行行分隔符。 |
void``flush() | 刷新流。 |
(字符缓冲输入流)代码展示
package buffer;import java.io.BufferedReader;import java.io.FileReader;import java.io.Reader;//掌握BufferedReader的使用public class BufferedReaderTest {public static void main(String[] args) {try (Reader fr= new FileReader("src/main/java/buffer/test2.txt");BufferedReader br = new BufferedReader(fr);){// char[] chars = new char[1024];// int len;// while ((len = br.read(chars))!=-1){// System.out.println(new String(chars,0,len));// }// 读取一行 readLine()String s ;while ((s =br.readLine())!=null){System.out.println(s);}}catch (Exception e){e.printStackTrace();}}}(字符缓冲输出流) 代码展示:
package buffer;import com.lyc.io.FileWriterTest;import java.io.BufferedWriter;import java.io.FileWriter;import java.io.Writer;//目标:测试BufferedWriter类public class BufferedWriterTest {public static void main(String[] args) {try(Writer fw = new FileWriter("src/main/java/buffer/test3.txt");BufferedWriter bw = new BufferedWriter(fw);){bw.write("你好");bw.write(new char[]{'a','b','c'});bw.write("你好");bw.newLine();//换行bw.write("你好");}catch (Exception e){e.printStackTrace();}}}原始流、缓冲流的性能分析(重点)
测试用例:
-
分别使用原始的字节流,异界字节缓冲流复制一个很大的文件
测试步骤:
-
使用低级的字节流按照一个一个字节的形式复制文件
-
使用低级的字节流按照字节数组的形式复制文件
-
使用高级的缓冲字节流按照一个一个字节的形式复制文件
-
使用高级缓冲字节流按照字节数组的形式复制文件
代码展示:
package buffer;import java.io.*;//测试原始流与缓冲流的性能对比public class PowerTest {//复制的文件路径private static final String SRC_FILE = "E:\\视频\\Captures\\v.f100830.mp4";//复制后的文件路径private static final String DEST_FILE = "src/main/java/buffer/";public static void main(String[] args) {//copy01(); //原始流复制一个字节文件耗时:太慢,不建议使用copy02();//速度较慢copy03();//速度适中copy04();//速度最快}private static void copy01(){long startTime = System.currentTimeMillis();try(InputStream fis = new FileInputStream(SRC_FILE);OutputStream fos= new FileOutputStream(DEST_FILE+"1.mp4");){int b;while((b = fis.read()) != -1){fos.write(b);}}catch (Exception e){e.printStackTrace();}long endTime = System.currentTimeMillis();System.out.println("原始流一个字节复制文件耗时:"+(endTime-startTime)/1000.0 +"s");}private static void copy02(){long startTime = System.currentTimeMillis();try(InputStream fis = new FileInputStream(SRC_FILE);OutputStream fos= new FileOutputStream(DEST_FILE+"2.mp4");){byte[] b = new byte[1024];//1KBint len;while((len = fis.read()) != -1){fos.write(b,0,len);}}catch (Exception e){e.printStackTrace();}long endTime = System.currentTimeMillis();System.out.println("原始流复制字节数组文件耗时:"+(endTime-startTime)/1000.0 +"s");}private static void copy03(){long startTime = System.currentTimeMillis();try(InputStream fis = new FileInputStream(SRC_FILE);OutputStream fos= new FileOutputStream(DEST_FILE+"3.mp4");BufferedInputStream bis = new BufferedInputStream(fis);BufferedOutputStream bos = new BufferedOutputStream(fos);){int b;while((b = bis.read()) != -1){bos.write(b);}}catch (Exception e){e.printStackTrace();}long endTime = System.currentTimeMillis();System.out.println("缓冲流复制一个字节文件耗时:"+(endTime-startTime)/1000.0 +"s");}private static void copy04(){long startTime = System.currentTimeMillis();try(InputStream fis = new FileInputStream(SRC_FILE);OutputStream fos= new FileOutputStream(DEST_FILE+"4.mp4");BufferedInputStream bis = new BufferedInputStream(fis);BufferedOutputStream bos = new BufferedOutputStream(fos);) {byte[] b = new byte[1024];int len;while((len = bis.read(b)) != -1){bos.write(b,0,len);}}catch (Exception e){e.printStackTrace();}long endTime = System.currentTimeMillis();System.out.println("缓冲流复制字节数组文件耗时:"+(endTime-startTime)/1000.0 +"s");}}一般情况下定义的字节数组越大,速度越快,运行效率越高。但是字符数组越大,把数据往字符数组里倒入倒出也需要时间,所以在字符数组大到一定程度时,再增加它的大小,效率也不会有提升。
结论:建议使用字节缓冲输入流、字节缓冲输出流,结合字节数组的方式,目前来看是性能最优的组合。
IO--转换流
引出问题:不同编码出现乱码的问题如何解决?
在日常编程中,如果代码编码和被读取的文本文件的编码是不一致的,使用字符流读取文件时就会出现乱码情况
代码展示:
package buffer;import java.io.BufferedReader;import java.io.FileInputStream;import java.io.FileReader;import java.io.Reader;//测试不同编码读取乱码问题public class test {public static void main(String[] args) {try(Reader fr= new FileReader("src/main/java/buffer/test.txt");BufferedReader br= new BufferedReader(fr);Reader fr1= new FileReader("src/main/java/buffer/text4.txt");BufferedReader br1= new BufferedReader(fr1);){String line;String line1;while((line=br.readLine())!=null){System.out.println(line);}//并没有出现乱码问题while((line1=br1.readLine())!=null){System.out.println(line1);}//出现乱码问题 乱码问题在于编码格式不同 //原因:编码格式不同 GBK 和 UTF-8,GBK中汉字占两个字节,UTF-8中占三个字节,所以乱码问题}catch (Exception e){e.printStackTrace();}}}解决方案:1.将编码格式改成相同的即可
2.字符输入转换流
字符输入转换流(InputStreamReader)
-
解决不同编码时,字符流读取文本内容乱码的问题
-
解决思路:先获取文本的原始字节流,再将其按真实的字符集编码转成字符输入流,这样字符输入流的字符就不乱码了
| 构造器 | 说明 |
|---|---|
InputStreamReader(InputStream in) | 创建一个使用默认字符集的InputStreamReader。 |
InputStreamReader(InputStream in, Charset cs) | 创建一个使用给定字符集的InputStreamReader。 |
InputStreamReader(InputStream in, CharsetDecoder dec) | 创建一个使用给定字符集解码器的InputStreamReader。 |
InputStreamReader(InputStream in, String charsetName) | 创建一个使用命名字符集的InputStreamReader。 |
代码展示:
package buffer;import java.io.*;//测试InputStreamReader字符转换输入流public class InputStreamReaderTest {public static void main(String[] args) {//1.得到文件的原始字节流try(InputStream is= new FileInputStream("src/main/java/buffer/text4.txt");//2.将字节流按照指定的字符集转换为字符流InputStreamReader isr= new InputStreamReader(is,"GBK");BufferedReader br= new BufferedReader(isr);) {char[] c=new char[1024];int len;while((len=br.read(c))!=-1){String s = new String(c, 0, len);System.out.println(s);}} catch (Exception e) {throw new RuntimeException(e);}}}问题引出:在日常编程中,需要控制写出去的字符使用什么字符集编码,该咋整?
方法1:调用String提供的getBytes()方法解决
String data = "cnqINQW"byte[] bytes = data.getBytes("GBK");方法2.使用“字符输出转换流”实现
字符输出转换流(OutputStreamWriter)
-
作用:控制写出去的字符使用特定的字符集编码
-
解决思路:获取原始字节输出流,再按照指定的字符集编码将其转换成字符输出流,以后写出去的字符就会用该字符集编码了
| 构造器 | 说明 |
|---|---|
OutputStreamWriter(OutputStream out) | 创建一个使用默认字符编码的OutputStreamWriter。 |
OutputStreamWriter(OutputStream out, Charset cs) | 创建一个使用给定字符集的OutputStreamWriter。 |
OutputStreamWriter(OutputStream out, CharsetEncoder enc) | 创建一个使用给定字符集编码器的OutputStreamWriter。 |
OutputStreamWriter(OutputStream out, String charsetName) | 创建一个使用命名字符集的OutputStreamWriter。 |
代码展示:
package buffer;import java.io.*;//测试字符转换输出流public class OutputStreamWriterTest {public static void main(String[] args) {try(//字节流OutputStream os=new FileOutputStream("src/main/java/buffer/test5.txt");//字符转换流OutputStreamWriter ow= new OutputStreamWriter(os,"GBK");BufferedWriter bw= new BufferedWriter(ow);) {bw.write("我才能测五年");} catch (Exception e) {throw new RuntimeException(e);}}}IO流--打印流
-
作用:打印流可以实现更方便,更高效的打印数据出去,能实现打印啥出去就是啥出去
字节打印流(PrintStream)
| 构造器 | 说明 |
|---|---|
PrintStream(File file, String csn) | 使用指定的文件和字符集创建新的打印流,而不需要自动换行。 |
PrintStream(OutputStream out) | 创建一个新的打印流。 |
PrintStream(OutputStream out, boolean autoFlush) | 创建一个新的打印流。自动刷新 |
PrintStream(String fileName, String csn) | 创建一个新的打印流,不需要自动换行,具有指定的文件名和字符集。 |
PrintStream(OutputStream out, boolean autoFlush, String encoding) | 创建一个新的打印流。需要自动换行,具有指定的文件名和字符集。 |
PrintStream(File file) | 使用指定的文件创建一个新的打印流,而不需要自动换行。 |
PrintStream(String fileName) | 使用指定的文件名创建新的打印流,无需自动换行。 |
| 方法 | 说明 |
|---|---|
void println(Xxx xx) | 打印任意类型的数据出去 |
void write(int/byte[]/byte[]一部分) | 支持写字节数据出去 |
PrintStream``append(char c) | 将指定的字符附加到此输出流。 |
PrintStream``format(Locale l, String format, Object... args) | 使用指定的格式字符串和参数将格式化的字符串写入此输出流。 |
代码展示:
package buffer;import java.io.PrintStream;import java.nio.charset.StandardCharsets;public class printStreamTest {public static void main(String[] args) {try(PrintStream ps= new PrintStream("src/main/java/buffer/test3.txt", StandardCharsets.UTF_8);PrintStream ps1= new PrintStream("src/main/java/buffer/test5.txt");){ps.println(97);ps.println('a');ps.println("你好ab");ps.println(true);ps.println(1.2);ps1.println("你好");ps1.write("你好".getBytes());ps1.write(97);//'a'}catch (Exception e){e.printStackTrace();}}}字符打印流(PrintWriter)
| 构造器 | 说明 |
|---|---|
PrintWriter(File file) | 使用指定的文件创建一个新的PrintWriter,而不需要自动的线路刷新。 |
PrintWriter(Writer out, boolean autoFlush) | 创建一个新的PrintWriter。 |
PrintWriter(Writer out) | 创建一个新的PrintWriter,没有自动线冲洗。 |
PrintWriter(String fileName) | 使用指定的文件名创建一个新的PrintWriter,而不需要自动执行行刷新。 |
PrintWriter(OutputStream out, boolean autoFlush) | 从现有的OutputStream创建一个新的PrintWriter。 |
PrintWriter(File file, String csn) | 使用指定的文件和字符集创建一个新的PrintWriter,而不需要自动进行线条刷新。 |
PrintWriter(String fileName, String csn) | 使用指定的文件名和字符集创建一个新的PrintWriter,而不需要自动线路刷新。 |
PrintWriter(OutputStream out) | 从现有的OutputStream创建一个新的PrintWriter,而不需要自动线路刷新。 |
PrintWriter(OutputStream out, boolean autoFlush, Charset charset) | 可以指定实现自动刷新,并可以指定字符的编码 |
| 方法 | 说明 |
|---|---|
void println(Xxx xx) | 打印任意类型的数据出去 |
void write(int/String/char[]/...) | 支持写字符数据出去 |
字符打印流和字节打印流在打印上没有区别,使用方便,性能高效(核心优势),只是在写数据中,字节打印流继承字节输出流,写字节数据,字符打印流继承字符输出流,写字符数据。
拓展--打印流应用:输出语句的重定向
-
可以把输出语句的打印位置改到某个文件中去
代码展示:
package buffer;import java.io.BufferedReader;import java.io.FileInputStream;import java.io.FileReader;import java.io.Reader;//测试不同编码读取乱码问题public class test {public static void main(String[] args) {try(Reader fr= new FileReader("src/main/java/buffer/test.txt");BufferedReader br= new BufferedReader(fr);Reader fr1= new FileReader("src/main/java/buffer/text4.txt");BufferedReader br1= new BufferedReader(fr1);){String line;String line1;while((line=br.readLine())!=null){System.out.println(line);}//并没有出现乱码问题while((line1=br1.readLine())!=null){System.out.println(line1);}//出现乱码问题 乱码问题在于编码格式不同//原因:编码格式不同 GBK 和 UTF-8,GBK中汉字占两个字节,UTF-8中占三个字节,所以乱码问题}catch (Exception e){e.printStackTrace();}}}IO--数据流
数据输出流(DataOutputStream)
-
允许把数据和其类型一并写出去
| 构造器 | 说明 |
|---|---|
DataOutputStream(OutputStream out) 。 | 创建一个新的数据输出流,以将数据写入指定的底层输出流 |
| 方法 | 说明 |
|---|---|
void``writeUTF(String str) | 使用 UTF-8编码以机器无关的方式将字符串写入基础输出流。 |
void``flush() | 刷新此数据输出流。 |
int``size() | 返回计数器的当前值 written ,到目前为止写入此数据输出流的字节数。 |
void``write(byte[] b, int off, int len) | 写入 len从指定的字节数组起始于偏移 off基础输出流。 |
void``write(int b) | 将指定的字节写入底层输出流。 |
void``writeBoolean(boolean v) | 将 boolean写入底层输出流作为1字节值。 |
void``writeByte(int v) | 将 byte作为1字节值写入底层输出流。 |
void``writeBytes(String s) | 将字符串作为字节序列写入基础输出流。 |
void``writeChar(int v) | 将 char写入底层输出流作为2字节值,高字节优先。 |
void``writeChars(String s) | 将字符串写入底层输出流作为一系列字符。 |
void``writeDouble(double v) | 双参数传递给转换 long使用 doubleToLongBits方法在类 Double ,然后写入该 long值基础输出流作为8字节的数量,高字节。 |
void``writeFloat(float v) | 浮子参数的转换 int使用 floatToIntBits方法在类 Float ,然后写入该 int值基础输出流作为一个4字节的数量,高字节。 |
void``writeInt(int v) | 将底层输出流写入 int作为四字节,高位字节。 |
void``writeLong(long v) | 将 long写入底层输出流,为8字节,高字节为首。 |
void``writeShort(int v) | 将 short写入底层输出流作为两个字节,高字节优先。 |
数据输入流(DataInputStream)
-
用于读取数据输出流写出去的数据
| 构造器 | 说明 |
|---|---|
DataInputStream(InputStream in) | 创建使用指定的底层InputStream的DataInputStream。 |
| 方法 | 说明 |
|---|---|
int``read(byte[] b) | 从包含的输入流中读取一些字节数,并将它们存储到缓冲区数组 b 。 |
byte``readByte() | 读取字节数据返回 |
char``readChar() | 读取char类型的数据返回 |
double``readDouble() | 读取double类型的数据返回 |
float``readFloat() | 读取Float类型的数据返回 |
boolean``readBoolean() | 读取布尔值类型的数据返回 |
int``read(byte[] b, int off, int len) | 支持都字节数据进来 |
package buffer;import java.io.DataInputStream;import java.io.FileInputStream;import java.io.FileNotFoundException;// 测试 DataInputStreampublic class DataInputStreamTest {public static void main(String[] args) {try (DataInputStream dis = new DataInputStream(new FileInputStream("src/main/java/buffer/test3.txt"));){int i = dis.readInt();System.out.println(i);double v = dis.readDouble();System.out.println(v);boolean b = dis.readBoolean();System.out.println(b);String s = dis.readUTF();System.out.println(s);} catch (Exception e) {throw new RuntimeException(e);}}}IO流--序列化流
对象序列化:把Java对象写入到文件中去
对象反序列化:把文件里的Java对象读出来
对象字节输出流(ObjectOutputStream)
-
可以把Java对象进行序列化:把Java对象存在文件中去
构造器 说明 protected ``ObjectOutputStream()为完全重新实现ObjectOutputStream的子类提供一种方法,不必分配刚刚被ObjectOutputStream实现使用的私有数据。 ``ObjectOutputStream(OutputStream out)创建一个写入指定的OutputStream的ObjectOutputStream。 方法 说明 void``writeObject(Object obj)将指定的对象写入ObjectOutputStream。
代码展示:
package com.lyc.Object;import java.io.FileOutputStream;import java.io.IOException;import java.io.ObjectOutputStream;//掌握对象字节输出流的使用,序列化对象public class ObjectOutputStreamTest {public static void main(String[] args) {// 创建对象//创建一个对象字节输出流对象try (ObjectOutputStream oos = new ObjectOutputStream(new FileOutputStream("src\\main\\java\\com\\lyc\\Object\\user.txt"));){User user = new User("admin", 18, "男", "123456");oos.writeObject(user);System.out.println("序列化成功");} catch (Exception e) {throw new RuntimeException(e);}}}注意:如果要序列化对象的话,就一定要在实体类中实现序列化接口(Serializable),否则会报错
对象字节输入流(ObjectInputStream)
-
可以把Java对象进行反序列化:把存储在文件中的Java对象读到内存中去
构造器 说明 ``ObjectInputStream(InputStream out)创建一个写入指定的InputputStream的ObjectInputStream。 方法 说明 Object readObject()把存储在文件中的Java对象读出来
代码展示:
package com.lyc.Object;import java.io.FileInputStream;import java.io.ObjectInputStream;//测试对象输入流public class ObjectInputStreamTest {public static void main(String[] args) {try(//创建对象输入流管道,包装低级的字节输入流与源文件接通ObjectInputStream ois= new ObjectInputStream(new FileInputStream("src/main/java/com/lyc/Object/user.txt"));){Object o = ois.readObject();if(o instanceof User){User u= (User) o;System.out.println(u);}}catch (Exception e){e.printStackTrace();}}}注意事项:如果想让实体类中的某一属性不序列化,可以使用transient关键字来修饰属性
拓展:如果要一次性序列化多个对象,怎么办?
用一个ArrayList集合存储多个对象,然后直接对集合进行序列化即可
注意:ArrayList集合已经实现了序列化接口
希望对大家有所帮助!
相关文章:

IO流详解
IO流 用于读写数据的(可以读写文件,或网络中的数据) 概述 I指 Input,称为输入流:负责从磁盘或网络上将数据读到内存中去 O指Output,称为输出流,负责写数据出去到网络或磁盘上 因此ÿ…...

linux下使用wireshark捕捉snmp报文
1、安装wireshark并解决wireshark权限不足问题 解决linux普通用户使用Wireshark的权限不足问题_麒麟系统中wireshark 运行显示权限不够-CSDN博客 2、Linux下安装并配置SNMP软件包 (deepseek给出的解答,目前会产生request包,但是会连接不上&a…...

ClickHouse 设计与细节
1. 引言 ClickHouse 是一款备受欢迎的开源列式在线分析处理 (OLAP) 数据库管理系统,专为在海量数据集上实现高性能实时分析而设计,并具备极高的数据摄取速率 1。其在各种行业中得到了广泛应用,包括众多知名企业,例如超过半数的财…...

Spring Boot 启动生命周期详解
Spring Boot 启动生命周期详解 1. 启动阶段划分 Spring Boot 启动过程分为 4个核心阶段,每个阶段涉及不同的核心类和执行逻辑: 阶段 1:预初始化(Pre-initialization) 目标:准备启动器和环境配置关键类&am…...

使用Java对接StockTV全球金融数据API。马来西亚金融数据API
以下是一篇关于如何使用Java对接StockTV API的教程博客,基于您提供的接口文档编写: 使用Java对接StockTV全球金融数据API 一、API简介 StockTV提供覆盖全球40交易所的实时金融市场数据,包括: 股票:印度、美股、A股等…...

逐位逼近法计算对数的小数部分
逐位逼近法(Bit-by-Bit Approximation)是一种通过 迭代和位操作 高效计算数学函数(如对数、平方根等)的方法。它特别适用于 不支持浮点运算的环境(如区块链智能合约),因为所有计算均通过 整数乘…...
)
SpringbootWeb开发(注解和依赖配置)
Lombok 工具 Spring Web web开发相关依赖 MyBatis Framework MyBatis驱动 MySQL Driver MySql驱动包 Restful 风格 Slf4j 记录日志对象 RequestMapping(value “/depts”, method RequestMethod.GET) //指定请求方式为GET method 指定请求方式 GetMapping 限定请求方式为Get…...

【AI News | 20250422】每日AI进展
AI Repos 1、no-ocr 不需要复杂文本提取的 AI 文档处理工具,只需上传 PDF 文件,即可快速搜索或询问关于多个文档集合中的内容,无需依赖传统 OCR 技术,大大提升文档分析效率。创建和管理 PDF/文档集合,按"案例&qu…...

110. 平衡二叉树
目录 一、问题描述 二、解题思路 三、代码 四、复杂度分析 一、问题描述 给定一个二叉树,判断它是否是 平衡二叉树 二、解题思路 ✅ 平衡二叉树的定义 一棵二叉树是平衡的,满足以下两个条件: 左子树是平衡二叉树; 右子树…...

yarn的介绍与操作,yarn和npm的选择
🧶 一、Yarn 是什么? Yarn 是由 Facebook(Meta)开发的 JavaScript 包管理工具,用于替代 npm,解决它在早期版本中存在的一些问题。 ✅ Yarn 的优势(v1.x): ὎…...

人工智能赋能医疗影像诊断:开启精准医疗新时代
在当今数字化、智能化飞速发展的时代,人工智能(AI)技术正逐渐渗透到各个行业,其中医疗领域更是成为了 AI 技术大展身手的重要舞台,而医疗影像诊断作为医疗行业中的关键环节,正因 AI 的赋能而发生着深刻变革…...

【汽车ECU电控数据管理篇】S19文件格式解析篇章
一、S19格式是啥 在电控文件管理的初期阶段,我首次接触到的是 A2L 和 HEX 文件。其中,A2L 文件主要承担着描述性功能,它详细地描述了各种参数和配置等相关信息。而 HEX 文件则是一种刷写文件,其内部明确记录了具体的地址以及对应的…...

快速定位达梦缓存的执行计划并清理
开发告诉你一个sql慢,你想看看缓存中执行计划时,怎么精准快速定位? 可能一般人通过文本内容模糊搜索 select cache_item, substr(sqlstr,1,60)stmt from v$cachepln where sqlstr like %YOUR SQL STRING%; 搜出来的内容比较多,研…...

Windows 同步-Windows 单向链表和互锁链表
Windows 单向链表(SList)同步机制详解 核心概念 SList(Singly-Linked List)是一种基于非阻塞算法实现的线程安全链表结构,具有以下特性: 原子性操作:所有插入/删除操作均通过硬件级原…...

Trent硬件工程师培训完整135讲
课程大小:44.2G 课程下载:https://download.csdn.net/download/m0_66047725/90616401 更多资源下载:关注我 ├──135讲配套资料 | ├──4620afc.pdf 707.58kb | ├──4620fa_chs.pdf 880.23kb | ├──4630fa.pdf 695.36kb | ├─…...

[PTA]2025 CCCC-GPLT天梯赛 胖达的山头
来源:L2-055 胖达的山头-Pintia题意:给定 n n n 个事件的起始和终止时刻(以hh:mm:ss给出),求最多并行事件数。关键词:差分(签到,模板题)题解:将所有时刻转换为秒,当某事件开始1,结束则-1。按时…...

CSS 记载
CSS优先级 是通过一个权重值来决定的,这个权重值由以下几个部分组成: 内联样式:直接写在HTML元素的style属性中,权重最高。ID选择器:权重值为100。类选择器、属性选择器和伪类:权重值为10。元素选择器和伪…...
实测调整(ESP-IDF 5.4))
ESP32音频识别(FFT)实测调整(ESP-IDF 5.4)
#ifndef YC_AUDIO_H #define YC_AUDIO_H // I2S配置(根据硬件调整) #define I2S_CHANNEL I2S_NUM_0 #define I2S_BCK_PIN 42 #define I2S_WS_PIN 41 #define I2S_DATA_PIN 2 /*======= 系统配置 =======*/ #define FFT_SIZE 4096 // …...

解决找不到字体的问题
PlayerView在创建的时候回生成一个PlayerControlView,PlayerControlView构造方法中会用到字体。这个字体在某些机型上找不到。导致应用崩溃。报错信息大概是这样的 Binary XML file line #14: Error inflating class androidx.media3.ui.PlayerView androidx.media…...

交易所开发:构建高效数字交易枢纽
数字资产交易所在全球数字经济浪潮中已成为价值流通的核心枢纽。本文基于2025年最新技术标准和行业实践,从微秒级撮合引擎到跨链互操作性,从AI增强型风控到合规化路径,系统解析高效数字交易枢纽的构建方法论。 一、技术架构设计:…...

极狐GitLab 项目功能和权限解读
极狐GitLab 是 GitLab 在中国的发行版,关于中文参考文档和资料有: 极狐GitLab 中文文档极狐GitLab 中文论坛极狐GitLab 官网 项目功能和权限 (FREE ALL) 配置项目功能和权限 要配置项目的功能和权限: 1.在左侧边栏中,选择 搜…...

pdf多文件合并
【第三方工具】点我传送:https://www.ilovepdf.com/ 【java功能实现】 导入jar包 <!-- https://mvnrepository.com/artifact/com.itextpdf/itextpdf --><dependency><groupId>com.itextpdf</groupId><artifactId>itextpdf</artif…...

AI日报 - 2025年4月23日
🌟 今日概览(60秒速览) ▎🤖 AGI突破 | Sam Altman称指向AGI的系统初现端倪,强调安全标准紧迫性;DeepMind CEO预测AI 5-10年内具备科学猜想能力。 AGI定义及测试标准引关注 (Dario Amodei),AI安全与非扩散方法成讨论焦…...
)
【RAG】一篇文章介绍多模态RAG(MRAG)
一、引言 研究背景与动机:随着大语言模型(LLMs)的广泛应用,其在处理复杂任务时暴露出如产生幻觉、算术能力不足和缺乏可解释性等问题。多模态学习的兴起为解决这些问题提供了新方向,通过融合图像、文本、音频等多种模…...
)
学习笔记:黑马程序员JavaWeb开发教程(2025.3.25)
11.3 案例-文件上传-本地存储 文件名后缀解决,找到文件最后一个点的位置,截取点及其后面的字符,得到扩展名。代码实现,找到最后一个点的位置,使用方法originalFilename.lastIndexOf(“.”),括号里面是指…...

启动当前文件夹下所有快捷方式批处理bat文件
新建文本文件写入下列代码 echo off chcp 65001 >nul setlocal enabledelayedexpansionfor %%F in (*.lnk) do (echo 正在运行:%%Fstart "" "%%F" )echo 所有快捷方式已启动。 exit 将文件重命名为 start.bat 双击运行...

蓝桥杯算法实战分享:C/C++ 题型解析与实战技巧
蓝桥杯全国软件和信息技术专业人才大赛,作为国内知名的算法竞赛之一,吸引了众多编程爱好者参与。在蓝桥杯的赛场上,C/C 因其高效性和灵活性,成为了众多选手的首选语言。本文将结合蓝桥杯的赛制特点、常见题型以及实战案例…...

IDEA下载kotlin-compiler-embeddable特别慢
问题: 在创建IDEA插件项目时发现 下载kotlin-compiler-embeddable特别慢,然后等待几十分钟然后失败 可以先用控制台显示正在下载的链接,下载好 jar包: https://repo.maven.apache.org/maven2/org/jetbrains/kotlin/kotlin-compi…...

武装Burp Suite工具:HaE 分析辅助类_插件.【高亮标记和信息提取利器】
武装 Burp Suite 插件:HaE 分析辅助类. HaE 分析辅助类是一款基于正则表达式的高效数据提取与标记工具,常用于安全测试、日志分析等场景,通过预定义规则快速定位敏感信息(如API密钥、URL参数),提升…...

使用Nacos 打造微服务配置中心
一、背景介绍 Nacos 作为服务注册中心的使用方式,同时 Nacos 还可以作为服务配置中心,用于集中式维护各个业务微服务的配置资源。 作为服务配置中心的交互流程图如下。 这样设计的目的,有一个明显的好处就是:有利于对各个微服务…...

C++——多态、抽象类和接口
目录 多态的基本概念 如何实现多态 在C中,派生类对象可以被当作基类对象使用 编程示例 关键概念总结 抽象类 一、抽象类的定义 基本语法 二、抽象类的核心特性 1. 不能直接实例化 2. 派生类必须实现所有纯虚函数才能成为具体类 3. 可以包含普通成员函数和…...

模拟实现strncat、qsort、atoi
目录 前言 一、模拟实现strncat 参数 代码演示: 二、模拟实现qsort 参数 代码演示: 前言 本文主要是对strncat,qsort,atoi的模拟实现 一、模拟实现strncat C 库函数 char *strncat(char *dest, const char *src, size_t n…...

记录学习的第三十天
今天终于又开始写博客了。 还是滑动窗口问题,这段时间不出意外都是这了 上面的思路是我自己做的,但是不知道为什么不行,有没有大佬能指点一下我。 接下来这道题是进阶的。不过我之前的基础都做的很艰难,道阻且长啊。...

图像预处理-直方图均衡化
一.什么是直方图 反映图像像素分布的统计图,横坐标就是图像像素的取值,纵坐标是该像素的个数。 二.绘制直方图 histcv2.calcHist(images, channels, mask, histSize, ranges) - images:输入图像列表(必须用[ ]包裹)&a…...

应用案例|兵器重工:某体系需求视图模型开发
某体系需求视图模型开发 一、项目背景 本项目为某体系的需求视图模型开发,其中体系设计建模过程可以分解为7大部分,即建模前期准备、全景视点模型正向设计、能力视点模型正向设计、作战视点模型正向设计、系统视点模型正向设计、体系模型反向追溯设计以…...

YOLOv8改进:ShapeIoU与InnerShapeIoU损失函数的理论与实践
文章目录 YOLOv8 损失函数概述ShapeIoU 与 InnerShapeIoU 损失介绍ShapeIoU 损失InnerShapeIoU 损失 ShapeIoU 和 InnerShapeIoU 损失函数的实现ShapeIoU 损失函数代码实现InnerShapeIoU 损失函数代码实现损失函数在 YOLOv8 中的应用 实验效果与分析ShapeIoU 和 InnerShapeIoU …...

用Go语言正则,如何爬取数据
文章精选推荐 1 JetBrains Ai assistant 编程工具让你的工作效率翻倍 2 Extra Icons:JetBrains IDE的图标增强神器 3 IDEA插件推荐-SequenceDiagram,自动生成时序图 4 BashSupport Pro 这个ides插件主要是用来干嘛的 ? 5 IDEA必装的插件&…...

Java中实现单例模式的多种方法:原理、实践与优化
单例模式(Singleton Pattern)是设计模式中最简单且最常用的模式之一,旨在确保一个类只有一个实例,并提供全局访问点。在 Java 开发中,单例模式广泛应用于配置管理、日志记录、数据库连接池和线程池等场景。然而&#x…...

Pikachu靶场-RCE漏洞
1. RCE漏洞原理 核心问题:应用程序未对用户输入进行严格过滤,直接将输入内容拼接至系统命令、代码执行函数或反序列化过程中。常见触发场景:命令注入:用户输入被拼接到操作系统命令(如system()、exec())。代…...
——图像拼接)
OpenCv高阶(七)——图像拼接
目录 一、图像拼接的原理过程 1. 特征检测与描述(Feature Detection & Description) 2. 特征匹配(Feature Matching) 3. 图像配准(Image Registration) 4. 图像变换与投影(Warping&…...
)
电商系统用户需求报告(示例)
目录 电商系统用户需求报告 1. 引言 1.1 目的 1.2 范围 2. 用户角色与核心需求 2.1 消费者 2.2 商家 2.3 平台管理方 3. 非功能性需求 4. 业务流程 4.1 消费者购物流程 4.2 商家入驻流程…...

图像挖掘课程笔记-第一章:了解机器视觉
一、什么是图像挖掘(Image Mining)? 图像挖掘是一种从大量图像中自动提取有用信息、知识或模式的技术,它融合了图像处理、机器学习、数据库、人工智能、数据挖掘等多个领域的内容。 🧠 图像挖掘与图像处理的区别 图像…...

Spring集合注入Bean
Spring框架中实现Bean集合注入的详细方法 1. 基础自动注入方式1.1 使用Autowired注入List1.2 使用Autowired注入Map 2. 更精细的控制方式2.1 使用Qualifier进行筛选2.2 使用自定义注解筛选 3. Java配置类方式4. 排序注入的Bean集合4.1 使用Order注解4.2 实现Ordered接口 5. 条件…...

实验一 进程控制实验
一、实验目的 1、掌握进程的概念,理解进程和程序的区别。 2、认识和了解并发执行的实质。 3、学习使用系统调用fork()创建新的子进程方法,理解进程树的概念。 4、学习使用系统调用wait()或waitpid()实现父子进程同步。 5、学习使用getpid()和getppi…...

[预备知识]4. 概率基础
概率基础 本章节介绍深度学习中的概率基础知识,包括基本概念、概率分布和统计推断。 1. 概率基础 1.1 基本概念 随机变量:可以取不同值的变量,其值由随机试验的结果决定概率分布:描述随机变量取值的可能性分布条件概率&#x…...

第33周JavaSpringCloud微服务 电商进阶开发
一、课程介绍 1. 定时任务 课程主题 :Spring Cloud 电商进阶开发定时任务定义 :学习什么是定时任务。定时任务学习内容 :定时任务实现方法、cron 表达式。定时任务实践 :在 Spring 中使用 schedule 注解,定期关闭过期…...

基于cubeMX的hal库STM32实现硬件IIC通信控制OLED屏
1、通常的方法是使用软件模拟IIC来实现OLED屏的显示控制,这里用STM32单片机的硬件IIC来实现OLED屏的显示,主控芯片为STM32F103RCT6,正点原子mini开发板。 2、cubemx配置过程 (1)配置时钟和下载 (2&#x…...

游戏工作室为何要更换IP进行多开?工作室使用代理IP要注意什么?
在当今的游戏产业中,游戏工作室为了提升效率、规避风险或突破平台限制,常常需要通过更换IP进行多开操作。这一现象背后涉及技术、商业规则和网络安全等多重因素,而代理IP的选择与使用也成为工作室运营中的关键环节。以下是关于游戏工作室为何…...

postgreSQL 如何使用 dblink
SELECT b.id, flow_name, user_id,u.name FROM bpm_form_info b JOIN vrms_user u on b.user_idu.id dblink SELECT b.id, flow_name, user_id,u.name FROM bpm_form_info b – vrms_user u on b.user_idu.id JOIN dblink( ‘dbnameuser_db userpostgres passwordWs199612’,…...

121.在 Vue3 中使用 OpenLayers 实现去掉鼠标右键默认菜单并显示 Feature 信息
🎯 实现效果 👇 本文最终实现的效果如下: ✅ 地图初始化时绘制一个多边形; ✅ 鼠标 右键点击地图任意位置; ✅ 若命中 Feature,则弹出该图形的详细信息; ✅ 移除浏览器默认的右键菜单,保留地图交互的完整控制。 💡 整个功能基于 Vue3 + OpenLayers 完成,采用 Com…...