MATLAB Coder 应用:转换 MATLAB 代码至 C/C++ | 实践步骤与问题解决
注:本文为 “ MATLAB 代码至 C/C++ 应用” 相关文章合辑。
未整理去重。
如有内容异常,请看原文。
MATLAB 代码转换为 C/C++ 代码的详细指南
随心 390 @zhihu 发布于 2020-07-12 12:39
在实际项目中,我们常常遇到需要将 MATLAB 代码转换为 C/C++ 代码的情况。例如,项目主体部分用 C++ 编写,但其中部分算法用 MATLAB 实现。此时,MATLAB Coder 提供了一种高效的解决方案。

本文将详细介绍如何使用 MATLAB Coder 将 MATLAB 代码转换为 C/C++ 代码,并指出一些常见的“雷区”。
1. 准备工作
在使用 MATLAB Coder 之前,需要对 MATLAB 代码进行以下处理:
-
删除注释:MATLAB 代码中的所有注释必须删除,否则无法成功转换。这是第一个“雷区”。
-
删除画图和打印部分的代码:包括
plot、disp等函数的调用。这些代码会导致转换失败,是第二个“雷区”。 -
处理动态矩阵分配:在 MATLAB 中,可以使用如下代码动态添加数据到矩阵中:
A = []; % 初始化矩阵 A 为空
A = [A; B]; % 将矩阵 B 添加到矩阵 A 的下方
然而,C/C++ 不支持这种动态分配方式。解决方案是先计算需要添加的行数 ( m ) 和列数 ( n ),然后初始化矩阵 ( A ),并通过循环添加数据:
A = zeros(1, n);
count = 1;
for i = 1:mA(count, :) = B;count = count + 1;
end
2. 封装主函数
MATLAB Coder 要求主函数是一个有明确输入和输出的函数,而不是脚本函数。以遗传算法(GA)求解旅行商问题(TSP)为例,原始主函数如下:
% 输入数据
x = [38.24, 39.57, 40.56, 36.26, 33.48, 37.56, 38.42, 37.52, 41.23, 41.17, 36.08, 38.47, 38.15, 37.51, 35.49, 39.36, 38.09, 36.09, 40.44, 40.33, 40.37, 37.57];
y = [20.42, 26.15, 25.32, 23.12, 10.54, 12.19, 13.11, 20.44, 9.100, 13.05, -5.210, 15.13, 15.35, 15.17, 14.32, 19.56, 24.36, 23, 13.57, 14.15, 14.23, 22.56];
vertexs = [x; y]';
n = length(x); % 城市数目
h = pdist(vertexs);
dist = squareform(h); % 距离矩阵
% 遗传算法参数设置
NIND = 50; % 种群大小
MAXGEN = 1000; % 迭代次数
Pc = 0.8; % 交叉概率
Pm = 0.2; % 变异概率
pSwap = 0.2; % 选择交换结构的概率
pReversion = 0.5; % 选择逆转结构的概率
pInsertion = 1 - pSwap - pReversion; % 选择插入结构的概率
N = n; % 染色体长度 = 城市数目
% 种群初始化
Chrom = InitPop(NIND, N);
% 优化
gen = 1; % 计数器
bestChrom = Chrom(1, :); % 初始全局最优个体
bestL = RouteLength(bestChrom, dist); % 初始全局最优个体的总距离
BestChrom = zeros(MAXGEN, N); % 记录每次迭代过程中全局最优个体
BestL = zeros(MAXGEN, 1); % 记录每次迭代过程中全局最优个体的总距离
while gen <= MAXGEN% 二元锦标赛选择SelCh = BinaryTourment_Select(Chrom, dist);% OX 交叉SelCh = Recombin(SelCh, Pc);% 变异SelCh = Mutate(SelCh, Pm, pSwap, pReversion, pInsertion);% 将 Chrom 更新为 SelChChrom = SelCh;% 计算当前代所有个体总距离Obj = ObjFunction(Chrom, dist);% 找出当前代中最优个体[minObj, minIndex] = min(Obj);% 将当前代中最优个体与全局最优个体进行比较,如果当前代最优个体更好,则将全局最优个体进行替换if minObj <= bestLbestChrom = Chrom(minIndex, :);bestL = minObj;end% 记录每一代全局最优个体,及其总距离BestChrom(gen, :) = bestChrom;BestL(gen, :) = bestL;% 显示外层循环每次迭代的信全局最优路线的总距离disp(['第' num2str(gen) '次迭代:全局最优路线总距离 = ' num2str(bestL)]);% 画出每次迭代的全局最优路线图figure(1);PlotRoute(bestChrom, x, y);pause(0.01);% 计数器加 1gen = gen + 1;
end
% 打印每次迭代的全局最优个体的总距离变化趋势图
figure;
plot(BestL, 'LineWidth', 1);
title('优化过程');
xlabel('迭代次数');
ylabel('总距离');
封装后的主函数如下:
% 输入 x, y:城市的 x, y 坐标
% 输入 NIND:种群大小
% 输入 MAXGEN:迭代次数
% 输入 Pc:交叉概率
% 输入 Pm:变异概率
% 输入 pSwap:选择交换结构的概率
% 输入 pReversion:选择逆转结构的概率
% 输入 pInsertion:选择插入结构的概率
% 输出 bestChrom:全局最优个体
function bestChrom = GA_TSP(x, y, NIND, MAXGEN, Pc, Pm, pSwap, pReversion, pInsertion)
% 输入数据
vertexs = [x; y]';
n = length(x); % 城市数目
h = pdist(vertexs);
dist = squareform(h); % 距离矩阵
N = n; % 染色体长度 = 城市数目
% 种群初始化
Chrom = InitPop(NIND, N);
% 优化
gen = 1; % 计数器
bestChrom = Chrom(1, :); % 初始全局最优个体
bestL = RouteLength(bestChrom, dist); % 初始全局最优个体的总距离
BestChrom = zeros(MAXGEN, N); % 记录每次迭代过程中全局最优个体
BestL = zeros(MAXGEN, 1); % 记录每次迭代过程中全局最优个体的总距离
while gen <= MAXGEN% 二元锦标赛选择SelCh = BinaryTourment_Select(Chrom, dist);% OX 交叉SelCh = Recombin(SelCh, Pc);% 变异SelCh = Mutate(SelCh, Pm, pSwap, pReversion, pInsertion);% 将 Chrom 更新为 SelChChrom = SelCh;% 计算当前代所有个体总距离Obj = ObjFunction(Chrom, dist);% 找出当前代中最优个体[minObj, minIndex] = min(Obj);% 将当前代中最优个体与全局最优个体进行比较,如果当前代最优个体更好,则将全局最优个体进行替换if minObj <= bestLbestChrom = Chrom(minIndex, :);bestL = minObj;end% 记录每一代全局最优个体,及其总距离BestChrom(gen, :) = bestChrom;BestL(gen, :) = bestL;% 显示外层循环每次迭代的信全局最优路线的总距离disp(['第' num2str(gen) '次迭代:全局最优路线总距离 = ' num2str(bestL)]);% 画出每次迭代的全局最优路线图figure(1);PlotRoute(bestChrom, x, y);pause(0.01);% 计数器加 1gen = gen + 1;
end
% 打印每次迭代的全局最优个体的总距离变化趋势图
figure;
plot(BestL, 'LineWidth', 1);
title('优化过程');
xlabel('迭代次数');
ylabel('总距离');
end
3. 新建一个脚本函数
封装主函数后,删除原来的脚本函数 GA_TSP,新建一个脚本函数 TEST,在其中提供封装后的主函数的输入数据:
clear;
clc;
x = [38.24, 39.57, 40.56, 36.26, 33.48, 37.56, 38.42, 37.52, 41.23, 41.17, 36.08, 38.47, 38.15, 37.51, 35.49, 39.36, 38.09, 36.09, 40.44, 40.33, 40.37, 37.57];
y = [20.42, 26.15, 25.32, 23.12, 10.54, 12.19, 13.11, 20.44, 9.100, 13.05, -5.210, 15.13, 15.35, 15.17, 14.32, 19.56, 24.36, 23, 13.57, 14.15, 14.23, 22.56];
NIND = 50;
MAXGEN = 1000;
Pc = 0.8;
Pm = 0.2;
pSwap = 0.2;
pReversion = 0.5;
pInsertion = 1 - pSwap - pReversion;
bestChrom = GA_TSP(x, y, NIND, MAXGEN, Pc, Pm, pSwap, pReversion, pInsertion);
4. 开始转换
4.1 点击 MATLAB Coder

4.2 添加封装后的 GA_TSP 函数
4.3 根据提示修改代码
在转换过程中,可能会遇到一些问题。例如,OX 函数需要进行修改。修改后的 OX 函数如下:
function [a0, b0] = OX(a, b)
L = length(a);
while 1r = randi([1, L], 1, 2);r1 = r(1);r2 = r(2);if r1 ~= r2s = min([r1, r2]);e = max([r1, r2]);a0 = zeros(1, L + e - s + 1);b0 = zeros(1, L + e - s + 1);a0(1:e - s + 1) = b(s:e);a0(e - s + 2:L + e - s + 1) = a;b0(1:e - s + 1) = a(s:e);b0(e - s + 2:L + e - s + 1) = b;for i = 1:length(a0)aindex = find(a0 == a0(i));bindex = find(b0 == b0(i));if length(aindex) > 1a0(aindex(2)) = [];endif length(bindex) > 1b0(bindex(2)) = [];endif i == length(a)breakendendbreakend
end
4.4 定义输入变量类型
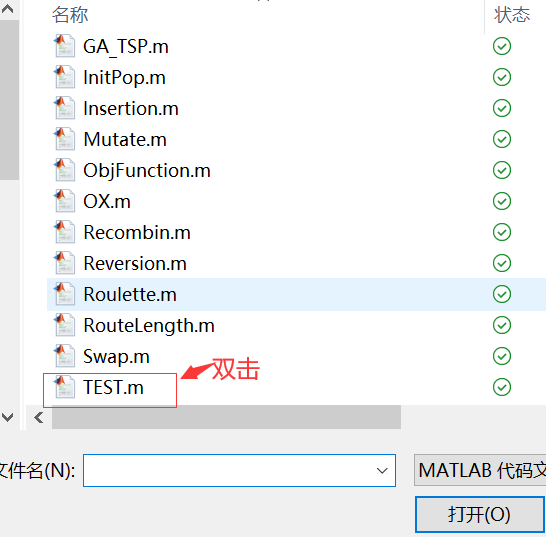
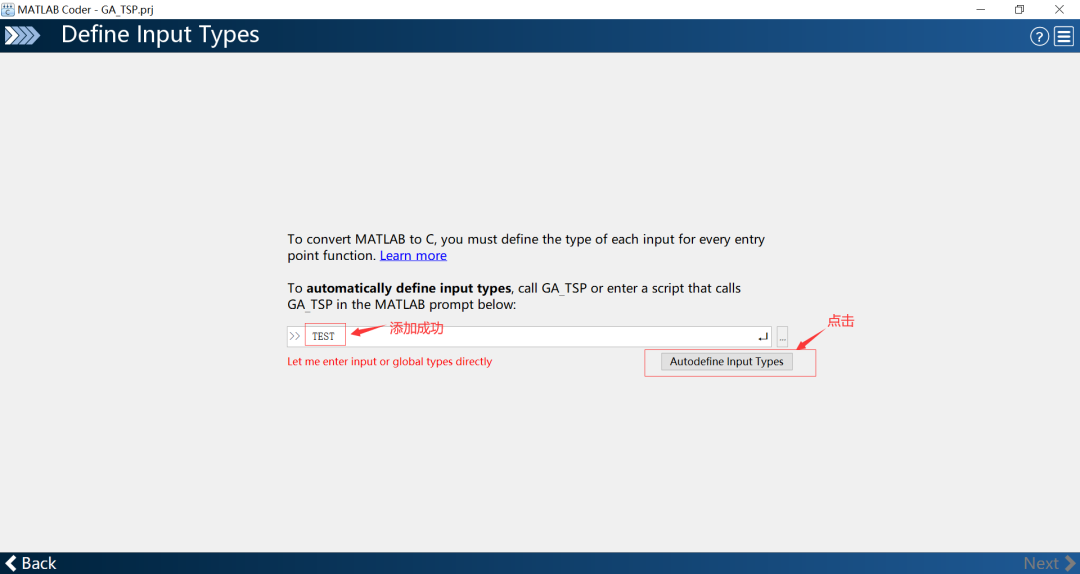
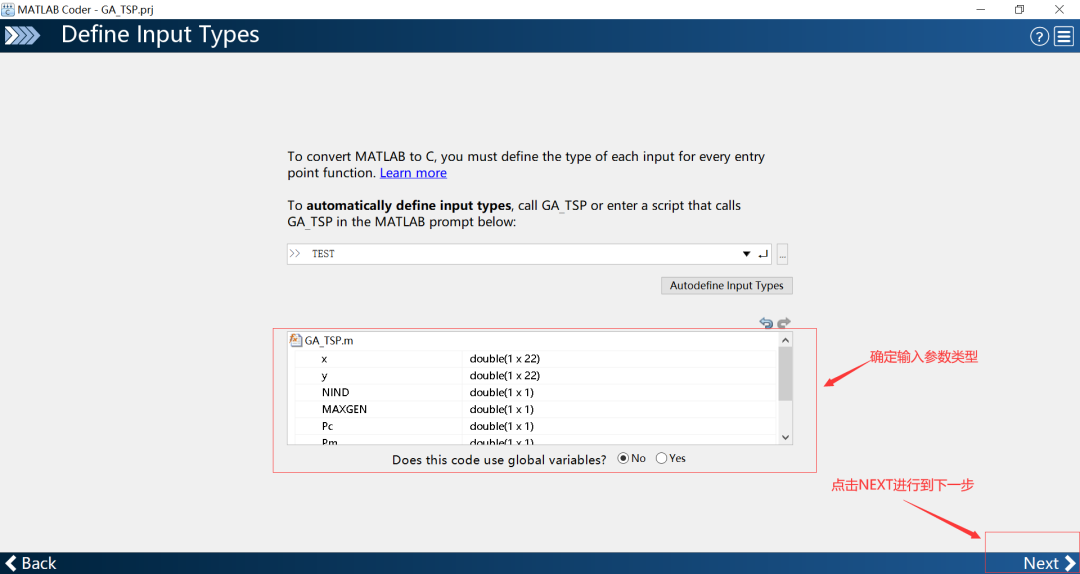
4.5 检验运行环境
在检验运行环境时,可能会遇到新的报错。例如,Mutate 函数需要进行修改。修改后的 Mutate 函数如下:
function SelCh = Mutate(SelCh, Pm, pSwap, pReversion, pInsertion)
NSel = size(SelCh, 1);
for i = 1:NSelif Pm >= randindex = Roulette(pSwap, pReversion, pInsertion);route1 = SelCh(i, :);flag = zeros(1, 3);flag(1) = index == 1;flag(2) = index == 2;flag(3) = index == 3;if flag(1)route2 = Swap(route1);elseif flag(2)route2 = Reversion(route1);elseroute2 = Insertion(route1);endSelCh(i, :) = route2;end
end
4.6 生成 C 代码
完成上述步骤后,点击 Generate 生成 C 代码。生成的 C 代码位于 MATLAB 代码文件夹下的 codegen 文件夹中,具体路径为:
codegen 文件夹 -> lib 文件夹 -> GA_TSP 文件夹
至此,使用 MATLAB Coder 成功将遗传算法(GA)求解旅行商问题(TSP)的 MATLAB 代码转换为 C 代码。
如何将 MATLAB 代码生成为 C/C++ 代码?
蚕与禅 已于 2024-05-11 16:41:55 修改
在 C/C++ 软件开发中,若部分核心算法用 MATLAB 编写,但不想逐行翻译,则可以使用 MATLAB 自带的 coder 命令进行代码自动翻译,以达到省时省力的目的。以下是详细步骤:
1. 封装 MATLAB 代码为函数:

function [aglA, aglB, aglC] = CalAglOfTriangle(a, b, c)
aglA = acosd((b^2 + c^2 - a^2) / (2 * b * c));
aglB = acosd((c^2 + a^2 - b^2) / (2 * c * a));
aglC = acosd((a^2 + b^2 - c^2) / (2 * a * b));
end
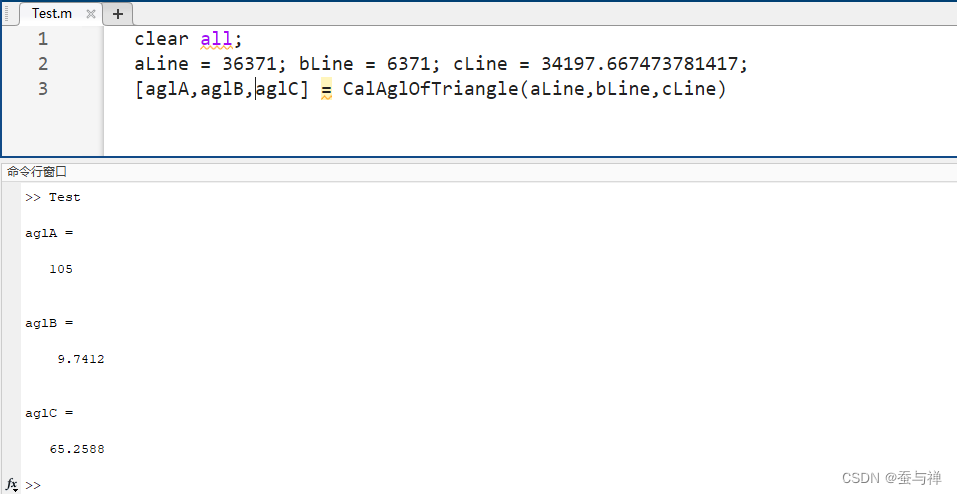
2. 新建一个 Test.m 脚本,调用封装的函数:

clear all;
aLine = 36371;
bLine = 6371;
cLine = 34197.667473781417;
[aglA, aglB, aglC] = CalAglOfTriangle(aLine, bLine, cLine);
3. 运行测试脚本,查看输出结果。
4. 在命令窗口输入 coder
5. 选择要转换的函数:
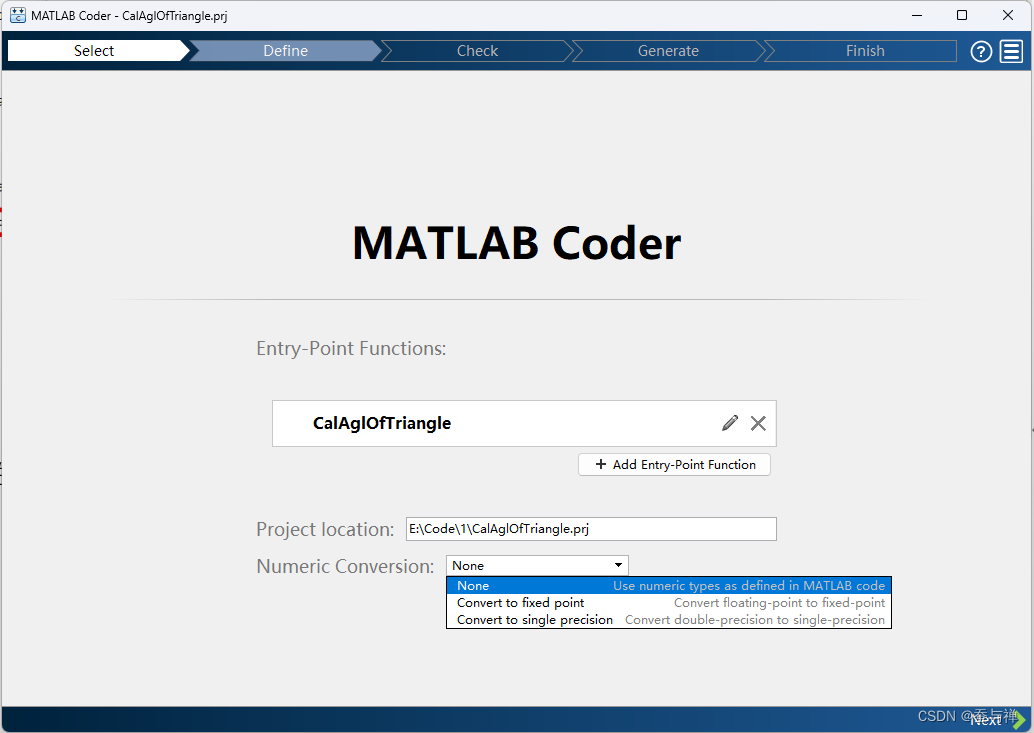
可以看到 .prj 工程所在的绝对路径,根据需要选择数值转换方式(通常使用默认方式)。
-
点击“Next”。
-
选择调用函数的脚本:
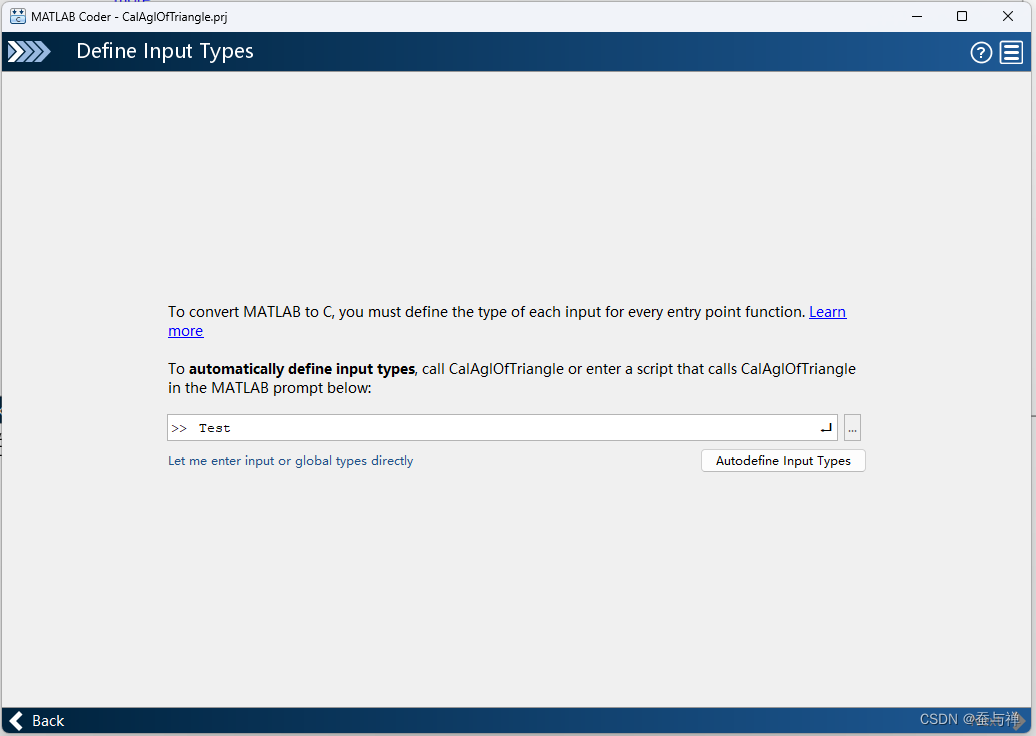
-
点击“自动定义输入类型”按钮:
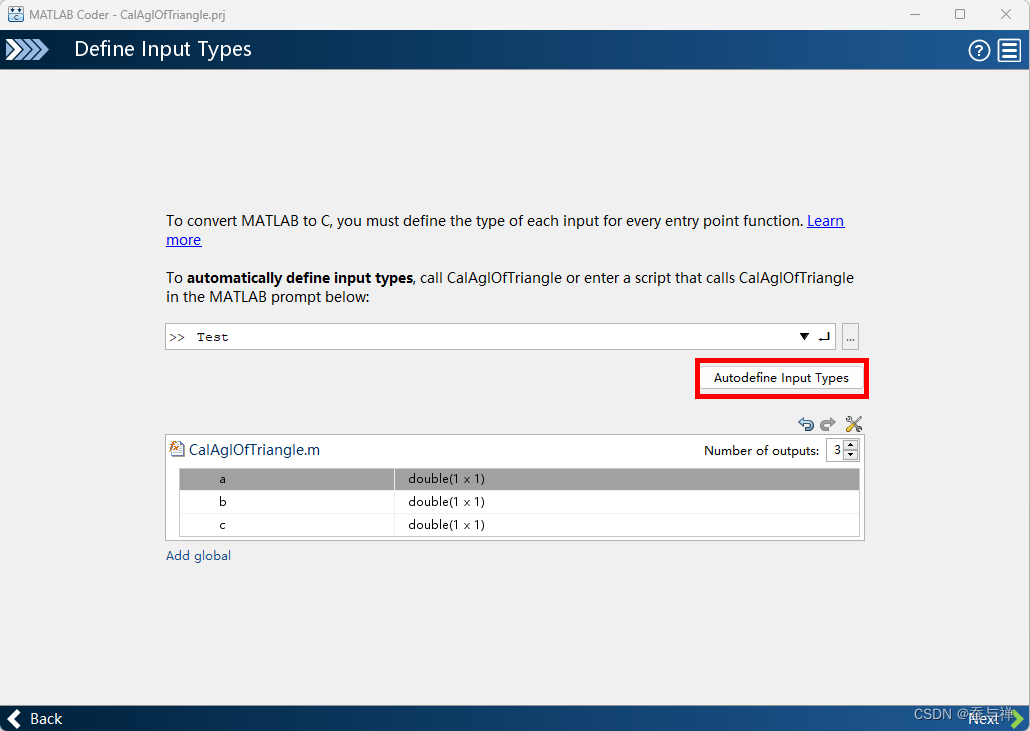
注意:这里是三个
double型,根据实际需求可以点击修改。 -
点击“Next”。
-
点击“检查问题”按钮:
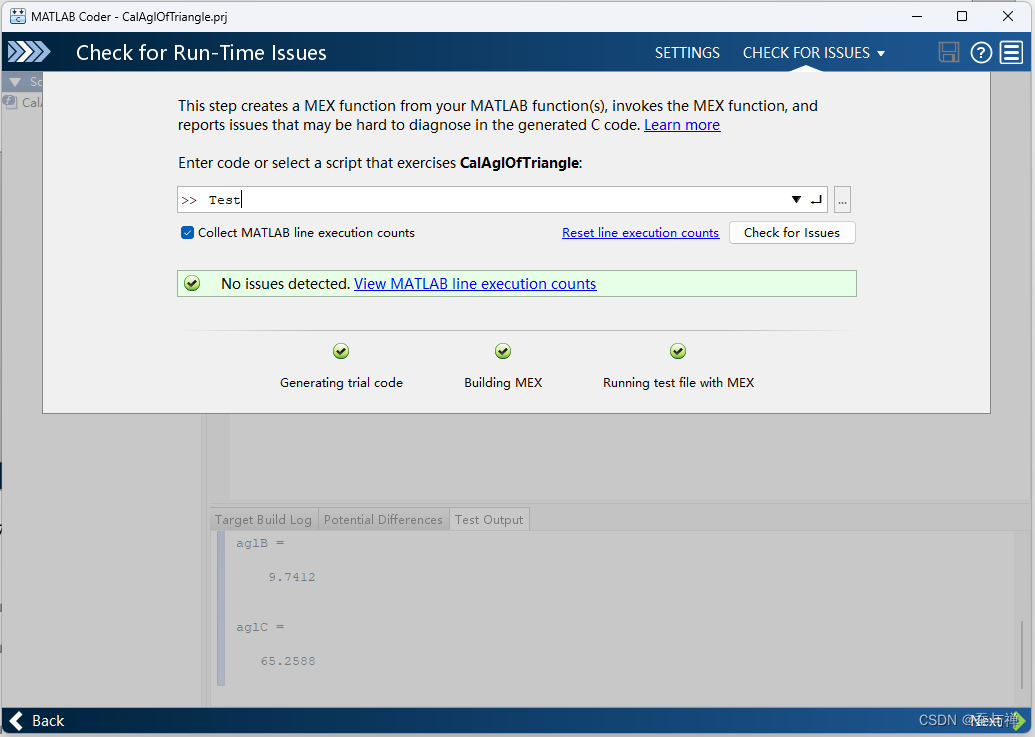
绿色对勾表示未检测到问题。若检测到问题,应根据提示进行处理。
-
点击“Next”。
-
选择要生成的语言(C 或 C++),点击“生成”:
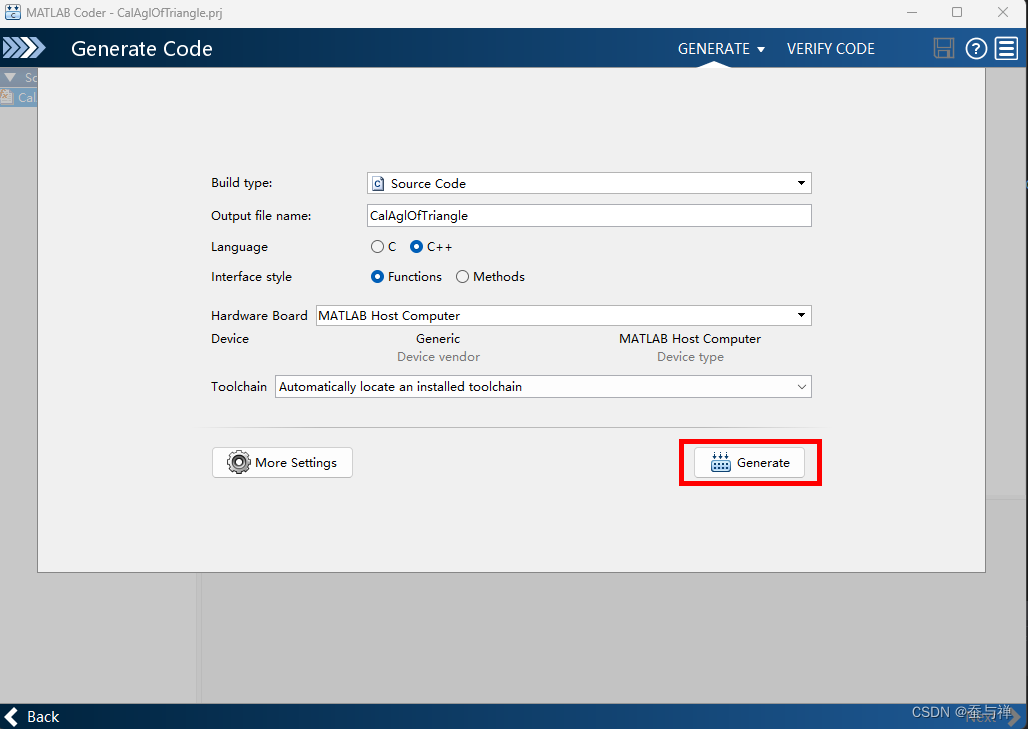
-
稍等片刻,出现如下界面:
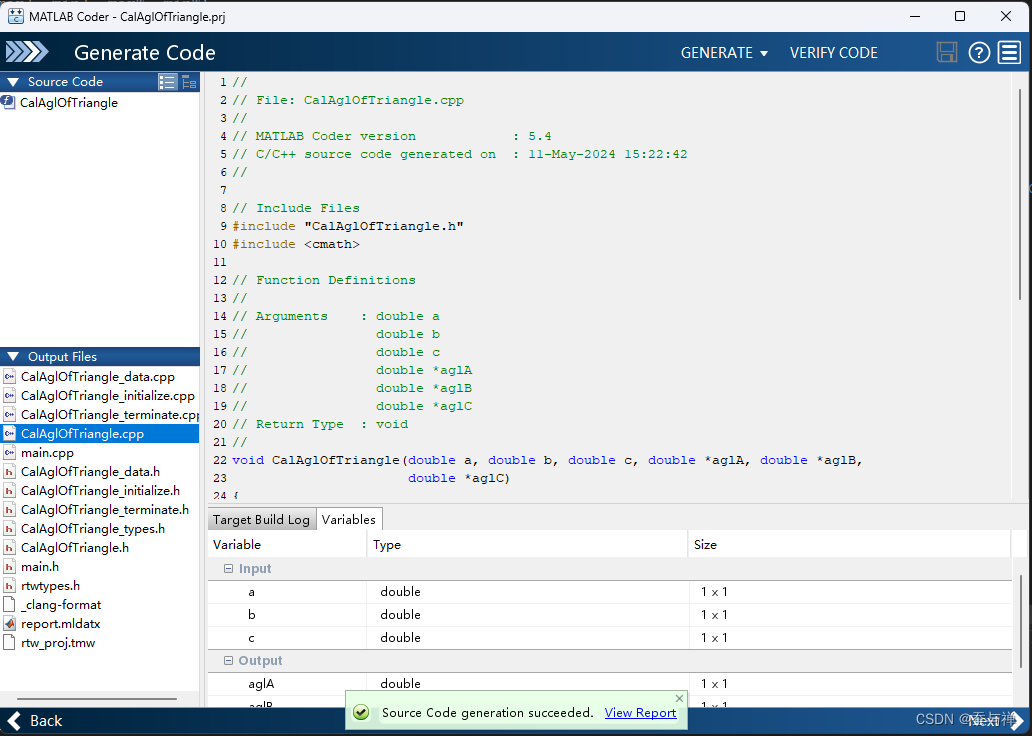
-
点击“Next”。
至此,转换成功!在提示的路径下可以找到转换后的代码以及示例。
-
找到对应的
.h和.cpp文件: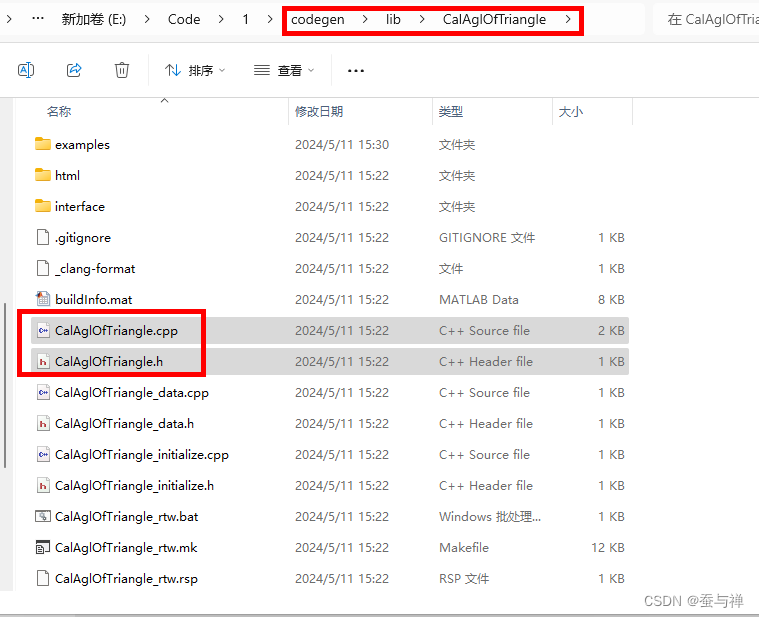
-
在 Visual Studio 中新建控制台工程,并将上述
.h和.cpp文件添加到工程中: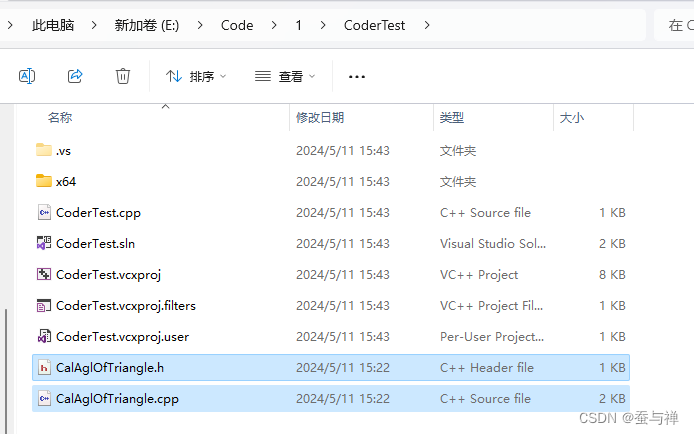
-
根据编译报错提示,补充缺失的文件:

-
在
main函数中调用自动生成的函数,运行结果正确: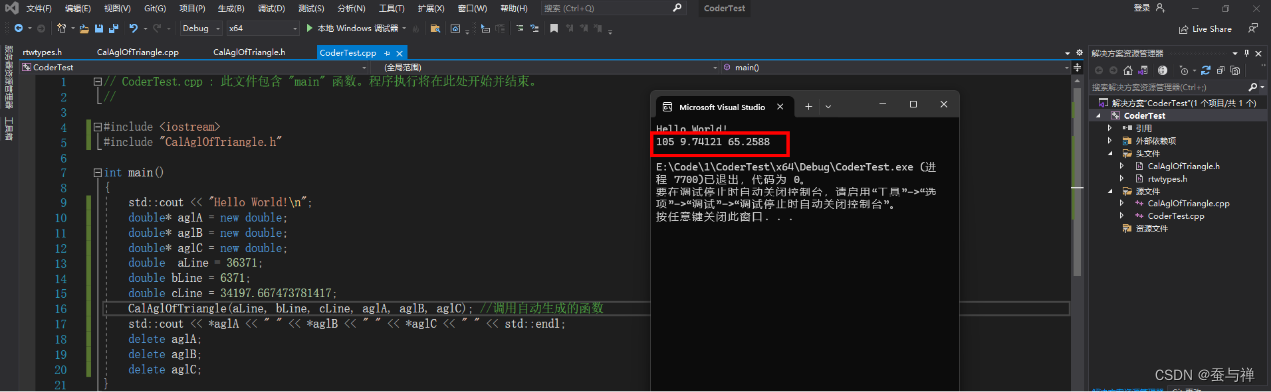
总结:本文演示的是一个简单的 MATLAB 函数(根据三角形三条边计算三个夹角)。实际的 MATLAB 代码或函数可能比较复杂,在根据 coder 命令提示进行问题检测时可能会遇到各种报错提示。此时无需慌张,静下心来分析,大部分报错都是可以屏蔽或修改的。笔者曾将十几个复杂的 MATLAB 函数整合封装为一个 C++ 类,删除多余的头文件后,最终只剩下一个 .h 和 .cpp 文件。
使用 MATLAB Coder Generation 将 m 语言转化为 C++ 过程中遇到的问题及解决
在使用 MATLAB Coder 时,可能会遇到一些问题。以下是一些常见问题及其解决方案:
一、MATLAB Coder 的使用步骤
在命令行窗口输入以下命令启动 MATLAB Coder:
>> coder


建议在定义(一维)变量数组的数据类型及大小时,定义为 double (1 × :inf),避免在数组运算过程中由于引入新的中间变量数组,导致数组计算的等式左右两端数组大小不对等。

下一步:


②:在点击“Generate”后,可能会遇到许多报错,需要根据提示修改 .m 文件代码。
二、遇到的问题及解决方案
1. cell2mat 和 quadprog 函数不支持代码生成
以自定义的 MPC 函数为例,其中调用了 quadprog 函数求解:
% 新的 A, B, C 矩阵
A_cell = cell(2, 2);
B_cell = cell(2, 1);
A_cell{1, 1} = a;
A_cell{1, 2} = b;
A_cell{2, 1} = zeros(Nu, Nx);
A_cell{2, 2} = eye(Nu);
B_cell{1, 1} = b;
B_cell{2, 1} = eye(Nu);
A = cell2mat(A_cell);
B = cell2mat(B_cell);
C = [eye(Nx), zeros(Nx, Nu)];
% PHI 矩阵及 THETA 矩阵
PHI_cell = cell(Np, 1);
THETA_cell = cell(Np, Nc);
for j = 1:1:NpPHI_cell{j, 1} = C * A^j; % cell 的引用必须用大括号 {},否则被看做 double 类型for k = 1:1:Ncif k <= jTHETA_cell{j, k} = C * A^(j - k) * B; % 左下角矩阵填充elseTHETA_cell{j, k} = zeros(Nx, Nu); % 矩阵左上角均为 0endend
end
PHI = cell2mat(PHI_cell); % size(PHI) = [Nx * Np, Nx + Nu]
THETA = cell2mat(THETA_cell); % size(THETA) = [Nx * Np, Nu * (Nc + 1)]
% 二次型目标函数的相关矩阵
H_cell = cell(2, 2);
H_cell{1, 1} = THETA' * Q * THETA + R;
H_cell{1, 2} = zeros(Nu * Nc, 1);
H_cell{2, 1} = zeros(1, Nu * Nc);
H_cell{2, 2} = row; % row 松弛因子,为了能够得到最优解,防止出现无解的情况
H = cell2mat(H_cell);
% 误差 E 矩阵
E = PHI * kesi; % 预测时域内的跟踪误差
% g 矩阵
g_cell = cell(1, 2);
g_cell{1, 1} = 2 * E' * Q * THETA;
g_cell{1, 2} = 0;
g = cell2mat(g_cell);
% 约束条件的相关矩阵
% A_I 矩阵
A_t = zeros(Nc, Nc); % 下三角矩阵
for p = 1:1:Ncfor q = 1:1:Ncif q <= pA_t(p, q) = 1;elseA_t(p, q) = 0;endend
end
A_I = kron(A_t, eye(Nu));
% Ut 矩阵
Ut = kron(ones(Nc, 1), U);
% 控制量和控制量变化量的约束
Umin = kron(ones(Nc, 1), u_min);
Umax = kron(ones(Nc, 1), u_max);
delta_Umin = kron(ones(Nc, 1), delta_min);
delta_Umax = kron(ones(Nc, 1), delta_max);
% 用于 quadprog 函数不等式约束 Ax <= b 的矩阵 A 和向量 b
A_cons_cell = {A_I zeros(Nu * Nc, 1); -A_I zeros(Nu * Nc, 1)}; % 为了和 H 的列数匹配,新添加一列 0
b_cons_cell = {Umax - Ut; -Umin + Ut};
A_cons = cell2mat(A_cons_cell);
b_cons = cell2mat(b_cons_cell);
% △U 的上下边界
lb = [delta_Umin; 0]; % (求解方程) 状态量下界,包含控制时域内控制增量和松弛因子
ub = [delta_Umax; 10]; % (求解方程) 状态量上界,包含控制时域内控制增量和松弛因子
% 开始求解过程
options = optimset('Algorithm', 'interior-point-convex');
% ↑内点法求解二次规划问题
delta_U = quadprog(H, g, A_cons, b_cons, [], [], lb, ub, [], options);
问题:编译代码时遇到“cell2mat 及 quadprog optimset is not supported for code generation”的问题。这是因为 MATLAB 自己封装的函数不支持 C++ 代码生成,需要将其定义为外部函数,即使用 coder.extrinsic 声明。
解决方案:
-
将
cell2mat替换为固定大小的矩阵分配方式。 -
将
quadprog和optimset声明为外部函数:coder.extrinsic('optimoptions'); coder.extrinsic('quadprog');并将
optimset替换为optimoptions:options = optimoptions('quadprog', 'Algorithm', 'interior-point-convex');
2. mxArray 类型变量的使用问题
问题:编译代码时遇到“Expected either a logical, char, int, fi, single, or double. Found an mxArray. MxArrays are returned from calls to the MATLAB interpreter and are not supported inside expressions. They may only be used on the right-hand side of assignments and as arguments to extrinsic functions.”
解决方案:
在 MATLAB 中,mxArray 是 MATLAB 解释器返回的数据类型,它不能直接用于表达式计算,只能用于赋值操作和作为外部函数的参数。因此,需要初始化被赋为 mxArray 的变量,将其转换为 double 类型,以便进行后续运算。
例如,对于变量 delta_U,可以进行如下初始化:
delta_U = zeros(size(lb)); % 初始化 delta_U 为与 lb 相同大小的零矩阵
这样,系统会将其识别为 double 类型,从而可以进行后续的运算。
3. cell2mat 和 quadprog 不能被生成 C++
问题:在代码生成过程中,cell2mat 和 quadprog 函数无法直接生成 C++ 代码。
解决方案:
-
替换
cell2mat:将所有cell类型的矩阵转换为固定大小的矩阵。例如,将以下代码:A = cell2mat(A_cell); B = cell2mat(B_cell); PHI = cell2mat(PHI_cell); THETA = cell2mat(THETA_cell); H = cell2mat(H_cell); g = cell2mat(g_cell); A_cons = cell2mat(A_cons_cell); b_cons = cell2mat(b_cons_cell);替换为固定大小的矩阵分配方式:
A = zeros(5); % 假设 A 的大小为 5x5 B = zeros(5, 2); % 假设 B 的大小为 5x2 PHI = zeros(Np * Nx, 5); % 假设 PHI 的大小为 Np*Nx x 5 THETA = zeros(Np * Nx, Nc * Nu); % 假设 THETA 的大小为 Np*Nx x Nc*Nu H = zeros(61); % 假设 H 的大小为 61x61 g = zeros(1, 61); % 假设 g 的大小为 1x61 A_cons = zeros(Nu * Nc * 2, Nu * Nc + 1); % 假设 A_cons 的大小为 Nu*Nc*2 x (Nu*Nc+1) b_cons = zeros(Nu * Nc * 2, 1); % 假设 b_cons 的大小为 Nu*Nc*2 x 1 -
处理
quadprog:由于quadprog函数不支持代码生成,可以将其声明为外部函数,并在生成的 C++ 代码中手动实现其功能。例如:coder.extrinsic('quadprog'); delta_U = quadprog(H, g, A_cons, b_cons, [], [], lb, ub, [], options);在生成的 C++ 代码中,可以使用第三方库(如 Eigen 或 Ceres Solver)来实现二次规划求解器的功能。
三、MATLAB 版本问题
问题:在 MATLAB 和 Visual Studio 版本不匹配时,可能会遇到代码生成失败的问题。例如,使用 MATLAB 2019 和 Visual Studio 2019 时,可能会遇到以下错误:
??? The extrinsic function 'ce112mat' is not available for standalone code generation.
解决方案:
-
升级 MATLAB 版本:建议使用更高版本的 MATLAB(例如 MATLAB 2022a 或更高版本)。高版本的 MATLAB 对代码生成的支持更好,同时也能更好地兼容 Visual Studio 的新版本。
-
配置 MATLAB 和 Visual Studio 的环境:确保 MATLAB 和 Visual Studio 的版本兼容。可以通过以下命令在 MATLAB 中配置编译器:
>> mex -setup C++如果配置成功,会显示类似以下信息:
“找到已安装的编译器 'Microsoft Visual C++ 2019 (C)'。 MEX 配置为使用 'Microsoft Visual C++ 2019 (C)' 以进行 C 语言编译。”
四、MATLAB 转 C/C++ 常见问题总结
-
使用变量前声明变量:在 MATLAB 中可以容忍未声明的变量,但在 C/C++ 中必须提前声明变量并分配内存。
tmp = zeros(6, 6); % 预分配内存 for i = 1:6tmp(:, i) = ones(6, 1); end -
避免内联嵌套 scripts:MATLAB 转 C/C++ 不支持内联嵌套 scripts。可以将嵌套的 scripts 内联到主函数中,或者将其写成无参函数调用。
-
避免离开变量作用域后使用变量:在 MATLAB 中,变量可以在离开其作用域后继续使用,但在 C/C++ 中这是不允许的。
-
避免动态分配内存语法:MATLAB 中的动态数组分配语法(如
array = [array, i])在 C/C++ 中不支持。可以使用预分配内存的方式替代。 -
避免使用
load和高级函数:load和一些高级函数(如care、fsolve等)不支持代码生成。如果需要使用这些函数,可以考虑从底层实现。 -
确保函数返回值有逻辑值:在 MATLAB 中,函数的返回值必须在所有逻辑分支中都有赋值。
-
尽量少用
global:虽然 MATLAB 转 C/C++ 支持global,但建议尽量避免使用,以提高代码的可读性和封装性。 -
注释掉无关代码:在转换代码时,建议注释掉与业务逻辑无关的代码,如画图和打印代码。
总结
“尽量用底层语言的编程思维来写 MATLAB”。通过遵循上述建议,可以有效减少 MATLAB 代码转换为 C/C++ 代码时的错误,提高代码的可移植性和可维护性。
利用硬件加速大规模科学计算 | 从 MATLAB 到 C/C++ 代码
作者 周拥华、MathWorks
2022 年发布
无论是传统的系统仿真还是如今火热的人工智能,都涉及到大量的科学计算,高手们也许对利用多处理器、集群和 GPU 的编程技术驾轻就熟,但对初学者而言怎么样利用硬件来加速大规模科学计算无疑是个门槛较高的问题。作者试图用这篇简单的文章,帮助初学者了解,从 MATLAB 到 C/C++ 代码,可供使用的一些简单快捷的选项,算是入门吧。
1. 用 CPU 做矩阵基本运算
假如我有两个10000x10000的矩阵(没错,1亿个元素),A和B,要对它俩进行相乘,得到C,用MATLAB表述是这样的:
A = rand(10000, 10000); % 随机产生10000x10000的矩阵
B = rand(10000, 10000);
C = A*B;
如果简单直白地用 C 来实现矩阵乘法,它大概是这样子的:
static double a[100000000];static double b[100000000];static double c[100000000];double d;int i;int k;int xpageoffset;for (i = 0; i < 10000; i++) {for (xpageoffset = 0; xpageoffset < 10000; xpageoffset++) {d = 0.0;for (k = 0; k < 10000; k++) {d += a[i + 10000 * k] * b[k + 10000 * xpageoffset];}c[i + 10000 * xpageoffset] = d;}}
事实上,上述代码正是我从 MATLAB 自动生成的 C 代码里删节出来的。
将一个 MATLAB 里编写的函数或脚本文件生成 C 代码很简单,你可以通过 APP 菜单里的 MATLAB Coder 按提示一步一步来做,也可以通过命令行来实现,譬如下面几行指令可以将一个名为 largeMatrixTest.m 的脚本文件转换成 C 代码,并编译为 exe(借助 MinGW 或 Visual C++):
cfg = coder.config('exe');
cfg.GenerateExampleMain = 'GenerateCodeAndCompile';
codegen largeMatrixTest -config cfg -report
如果你在同一台计算机上(譬如我的 Lenovo T480s),分别执行第一部分的 MATLAB 脚本和编译执行第二部分的 C 代码,效率会差多少呢?我得到的分别是 20.5 秒和…… 超过 30 分钟吧,真的没耐心等它执行完。那么问题来了,为啥 MATLAB 会比 C 还快?
如果你关注一下两者运行时 CPU 的占用率,你会发现,前者占用了你 CPU 的大多数核,CPU 总占用率达到了 70% 以上,而后者在我 4 核 8 线程的机器上只占用了 12% 的 CPU。MATLAB 是怎么做到的?答案是 BLAS(Basic Linear Algebra Subprograms),它是一个为底层向量与矩阵运算针对具体处理器高度优化实现的库,通过 BLAS,大规模矩阵运算便能利用计算机的多核来加速。BLAS 有 C 接口,我们当然可以手写 C 代码实现同样的加速,但显然没 MATLAB 那么容易.
有没有可能让 MATLAB 生成的 C 代码也能用到 BLAS 呢?答案是肯定的,参考这里就好: MATLAB 帮助文档
- Speed Up Matrix Operations in Generated Standalone Code by Using BLAS Calls
https://ww2.mathworks.cn/help/coder/ug/speed-up-matrix-operations-in-generated-standalone-code-by-using-blas-calls.html
参照上面的文档,从 MATLAB 生成的 C 代码文件中我们可以看到,矩阵乘法运算 C=A*B 对应的代码是这样的:
static double a[100000000];static double b[100000000];static double c[100000000];cblas_dgemm(CblasColMajor, CblasNoTrans, CblasNoTrans, (MKL_INT)10000,(MKL_INT)10000, (MKL_INT)10000, 1.0, &a[0], (MKL_INT)10000, &b[0],(MKL_INT)10000, 0.0, &c[0], (MKL_INT)10000);
通过代码生成的报告我们还可以了解 m 脚本和生成的 C 代码之间的对应关系(如本文开头的图片所示)。
经过 BLAS 加持的 C 代码,跑起来效率就跟 MATLAB 脚本一样快了。
2. 用 CPU 做矩阵求解
BLAS 就够用了吗?不够。BLAS 实现了一些底层的计算,但如果要对矩阵进行求解(如奇异值分解或求特征值),我们还得借助 LAPACK 来加速。
MATLAB 中的 LAPACK
LAPACK(线性代数包)是一个例程库,它为数值线性代数和矩阵计算提供快速、稳健的算法。MATLAB 中的线性代数函数和矩阵运算均基于 LAPACK 构建,并且继续受益于其例程的性能和精度。
-
简史
MATLAB 诞生于 20 世纪 70 年代后期,是一款基于 LINPACK 和 EISPACK 构建的交互式计算器,而 LINPACK 和 EISPACK 在当时是进行矩阵计算的最先进的 Fortran 子例程库。多年来,MATLAB 使用了 LINPACK 和 EISPACK 的十几个 Fortran 子例程的 C 语言版本。
2000 年,MATLAB 改用 LAPACK,这是 LINPACK 和 EISPACK 的现代替代品。它是一个用于数值线性代数的大型、多作者 Fortran 库。LAPACK 最初是为在超级计算机上使用而设计的,因为它能够一次计算矩阵的多个列。LAPACK 例程的速度与基本线性代数子例程 (BLAS) 的速度密切相关。BLAS 版本通常特定于硬件并经过高度优化。
-
详见:
- MATLAB Incorporates LAPACK - MATLAB & Simulink
https://www.mathworks.com/company/newsletters/articles/matlab-incorporates-lapack.html
参考 这个链接,可将 MATLAB 脚本中有关矩阵求解的函数(如 svd、eig 等)生成 LAPACK 调用。
- Speed Up Linear Algebra in Generated Standalone Code by Using LAPACK Calls
https://ww2.mathworks.cn/help/coder/ug/generate-code-that-calls-lapack-functions.html
- MATLAB Incorporates LAPACK - MATLAB & Simulink
3. 为 for 循环加速
看了前面两节的内容,我们已经知道,在 MATLAB 中,能直接对向量或矩阵做基本运算或调用某个函数去求解就不要自己写 for 循环来做了,因为 MATLAB 的向量 / 矩阵计算和求解基本都是 BLAS 和 LAPACK 加持过的。
但我们在实际计算中还是不可避免要有自己写的 for 循环,有些是顶层的循环,还有些可能是底层的没有可以直接拿来用的函数就自己写了。那么问题来了,自己 m 脚本里的 for 循环,无论是在 MATLAB 里还是生成 C 代码,跑起来都觉得慢怎么办?
我们知道,在 MATLAB 里把 for 换成 parfor,就可以通过并行计算工具箱利用单机多处理器或计算机集群硬件来加速,例如:
function a = test_parfor %#codegen
a=ones(10,256);
r=rand(10,256);
parfor (i=1:10, 4) % 指定4线程并发a(i,:)=real(fft(r(i,:)));
end% codegen -config:lib test_parfor
那如果对上述脚本生成 C 代码,还能利用单机多核来加速吗?可以!
我们也可以从生成的代码中看到(截取部分如下所示),parfor 被实现成了多线程(用到了 OpenMP,详情可查阅 parfor 的帮助文档)。我们还可以通过 parfor 的参数来指定线程的数量,如 parfor (i=1:10, 4),即指定为 4 线程。
#pragma omp parallel for \num_threads(4 > omp_get_max_threads() ? omp_get_max_threads() : 4) \private(b_i,yCol,b_r)for (i = 0; i < 10; i++) {/* 指定4线程并发 */for (b_i = 0; b_i < 256; b_i++) {b_r[b_i] = r[i + 10 * b_i];}c_FFTImplementationCallback_doH(b_r, 0, yCol);for (b_i = 0; b_i < 256; b_i++) {a[i + 10 * b_i] = yCol[b_i].re;}}
当然,如果你机器的CPU核数有限或者内存有限,尤其在BLAS和LAPACK或FFTW的并行化已经占用了大多数资源的情况下,期望再通过顶层的parfor提高整体运算效率可能就比较难了,此时你得先提高机器配置,让BLAS、LAPACK或FFTW能尽情施展后,再通过parfor激活for循环的并行化。又或者你的for循环里没有可通过BLAS、LAPACK或FFTW实现的并行化或者计算负载主要在非并行化的部分,可参考 这个链接 把 parfor 用起来。
- parfor
https://ww2.mathworks.cn/help/coder/ref/parfor.html
4. 用 GPU 加速
大家可能听说过深度学习往往要用 GPU 来加速,这是因为深度学习的模型训练和实时推断都有超大的计算量。先撇开深度学习,在我们经典的科学计算中,怎么用 GPU 来加速呢?
首先,MATLAB 中利用 GPU 的方法很简单,我们来看下面的例子,C = A*B 然后对 C 矩阵做奇异值分解,你需要做的只不过是把矩阵 A 和 B 放进 GPU 内存罢了,MATLAB 会自动将后续的矩阵相乘和奇异值分解分配到 GPU 上完成。看代码:
function s = largeMatrixTest()coder.gpu.kernelfun;a = rand(5000, 5000);b = rand(5000, 5000);%c = a * b;gpuA = gpuArray(a);gpuB = gpuArray(b);c = gpuA * gpuB;s = svd(c);
end
% 执行下面的指令,可以统计运算所耗时间(与CPU上不同,用GPU做计算要用wait):
dev=gpuDevice();tim=tic();largeMatrixTest;wait(dev);gpuTime=toc(tim);
尽管多出了两个内存搬运的操作,利用 NVIDIA GeForce GTX 1080 运行上面的脚本,结果比我 T480s 的 CPU 上跑相同的操作要 38 秒还是快了很多,只需要 11 秒了。那么大家应该知道,这归功于 CUDA。
上面的脚本能直接生成 CUDA 代码吗(C++)?然而并不能,因为 gpuArray 并不支持代码生成。那怎么才能生成调用 CUDA 库的 C++ 代码呢?答案是用最初的针对 CPU 的脚本,在生成时代码时指定用 GPU Coder 就行了。来看 m 代码:
%% largeMatrixTest.m
function s = largeMatrixTest()coder.gpu.kernelfun;a = rand(5000, 5000);b = rand(5000, 5000);c = a * b;%gpuA = gpuArray(a);%gpuB = gpuArray(b);%c = gpuA * gpuB;s = svd(c);
end%% generate standalone exe by using GPU Coder (gpuCodeGenTest.m)
cfg = coder.gpuConfig('exe');
cfg.GenerateExampleMain = 'GenerateCodeAndCompile';
codegen largeMatrixTest -config cfg -report
是不是太简单了,只是将 CPU 代码生成时的 coder.Config 换成了 coder.gpuConfig,没错,就这么简单!但生成的代码就复杂多了,限于篇幅,这里就只截取 C=A*B 对应的函数和 svd 奇异值分解对应的函数,分别如下:
cublasDgemm(getCublasGlobalHandle(), CUBLAS_OP_N, CUBLAS_OP_N, 5000, 5000,5000, (double *)gpu_alpha1, (double *)&(*gpu_a)[0], 5000, (double *)&(*gpu_b)[0], 5000, (double *)gpu_beta1, (double *)&(*gpu_c)[0],5000);cusolverDnDgesvd(getCuSolverGlobalHandle(), 'N', 'N', 5000, 5000, (double *)&(*gpu_c)[0], 5000, &(*gpu_s)[0], NULL, 1, NULL, 1, (double*)getCuSolverWorkspaceBuff(), *getCuSolverWorkspaceReq(), &(*gpu_superb)[0],gpu_info_t);
显然,这里分别用到了 CUDA 的 cuBLAS 和 cuSOLVER,另外,CUDA 也有 cuFFT。
如果你看的仔细,你可能还注意到了在 largeMatrixTest.m 这个脚本中,有一行特别的代码,coder.gpu.kernelfun,这是一行不影响执行但会影响代码生成的脚本,它告诉 GPU Coder,在为这个函数生成 C++ 代码时,将计算任务尽可能映射到 GPU 上去,MATLAB 会对脚本中的 for 循环进行分析,在允许的情况下为其生成为可并行化执行的函数。除此之位,我们还可以显式地通过 coder.gpu.kernel 将紧随其后的 for 循环加以并行化。
【备注】截至 R2020b,MATLAB 共提供 705 个可通过 gpuArray 利用 NVIDIA GPU 进行加速计算的函数;有 326 个函数可以生成利用 GPU 加速的 C++ 代码(即 CUDA 代码)。除此之外,MATLAB 内嵌并行化支持的函数也有 62 个,覆盖了深度学习训练、图像的非重复块处理、非线性优化、统计与机器学习、特征提取与工业统计等方方面面。众所周知,在计算性能方面,近 20 年来 MATLAB 的几乎每个版本更新都有所增强,如果你关心计算性能,用最新的版本是最好的选择。
5. 能支持 ARM 么?
上面的例子,无论是 Intel MKL 还是 CUDA,默认都是 x86/x86_64 平台的,操作系统可能是 Windows,也可能是 Linux,我不确切它们在 mac OS 会怎样,也许你可以自己尝试一下。
如果你在用基于 ARM 的系统,可以肯定的一点是,MATLAB 目前并没有能运行在 ARM 上的版本,也许以后会有,但如果你想把 MATLAB 上开发的算法生成 C/C++ 代码,跑到 ARM 上可以么?答案是肯定的。那如果要利用 ARM 上的特定核来加速行不行呢?
如果你的 ARM 上有 GPU 并支持 CUDA,那么可以肯定,上述第 4 节的内容依然适用,事实上,MATLAB 现在可以非常好地支持针对 NVIDIA Jetson 和 Drive 两个系列的产品的代码生成(参见 GPU Coder 相关文档)。
那如果没有 GPU,仅用 ARM 处理器能生成并行化加速的 C 代码么?答案应该是 ARM+Linux 架构上的 OpenBLAS、CLAPACK 和 FFT,以及 OpenMP 基础库。此外,ARM 也提供了一个 Arm Performance Libraries (commercial variant) ,大家可以去尝试一下。
【注】作者没有对 ARM 上的 BLAS、LAPACK 和 FFT 做任何测试,理论上可行,实际使用中如遇到问题,建议询问 MathWorks 中国办公室获得技术支持。
6. 其它
除了以上提到的内容,如今最热且重度依赖硬件加速的深度学习应用并没在本文中讨论,事实上 MATLAB 从 R2017b 就已经开始支持针对深度学习推断生成 C/C++ 代码,并可利用硬件来加速深度学习的推断,包括 NVIDIA 的桌面与服务器 GPU 及嵌入式 GPU(通过 CUDA 实现)、ARM Mali GPU 与 ARM Neon 核(通过 Arm Compute Library 实现),或者利用 x86_64 处理器的 SIMD(SSE/AVX,通过 Intel MKL-DNN 实现)。在最新的 R2020b 版本中,Deep Learning HDL Toolbox 还可以将训练好的深度学习模型生成为硬件描述语言,从而把深度学习部署到 FPGA 上。详情可参考 MATLAB 帮助文档或者咨询 MathWorks 中国办公室。
附录:利用 BLAS 和 LAPACK 的完整示例脚本
要从 MATLAB 生成 C 代码时支持 BLAS 和 LAPACK,你需要参照前面有关链接安装 INTEL MKL(含 BLAS 和 LAPACK),并从 coder.BLASCallback 和 coder.LAPACKCallback 分别派生自己的类,用来指定编译所需的头文件、库文件,它们的路径,以及所需的宏定义,最后在代码生成时指定这两个类,样例脚本如下:
%% example function for code generation (largeMatrixTest.m)
function largeMatrixTest()a = rand(5000, 5000);tic; b = a * a;c = sum(a);s = svd(a);e = eig(a);[maxValue, maxPos] = max(a);tCpu = toc;fprintf(' Time cost: %f\n', tCpu);
end%% define class for BLASCallback (useMyBLAS.m)
classdef useMyBLAS < coder.BLASCallbackmethods (Static)function updateBuildInfo(buildInfo, ~)libPath = 'C:\Program Files (x86)\IntelSWTools\compilers_and_libraries\windows\mkl\lib\intel64';libPriority = '';libPreCompiled = true;libLinkOnly = true;libs = {'mkl_intel_ilp64.lib' 'mkl_intel_thread.lib' 'mkl_core.lib'};buildInfo.addLinkObjects(libs, libPath, libPriority, libPreCompiled, ...libLinkOnly);buildInfo.addLinkObjects('libiomp5md.lib',fullfile(matlabroot,'bin', ...'win64'), libPriority, libPreCompiled, libLinkOnly);buildInfo.addIncludePaths('C:\Program Files (x86)\IntelSWTools\compilers_and_libraries_2020.1.216\windows\mkl\include');buildInfo.addDefines('-DMKL_ILP64');endfunction headerName = getHeaderFilename()headerName = 'mkl_cblas.h';endfunction intTypeName = getBLASIntTypeName()intTypeName = 'MKL_INT';endfunction doubleComplexTypeName = getBLASDoubleComplexTypeName()doubleComplexTypeName = 'my_double_complex_type';endfunction singleComplexTypeName = getBLASSingleComplexTypeName()singleComplexTypeName = 'my_single_complex_type';endfunction p = useEnumNameRatherThanTypedef()p = true;endend
end%% define class for LAPACKCallback (useMyLAPACK.m)
classdef useMyLAPACK < coder.LAPACKCallbackmethods (Static)function hn = getHeaderFilename()hn = 'mkl_lapacke.h';endfunction updateBuildInfo(buildInfo, buildctx)buildInfo.addIncludePaths(fullfile(pwd,'include'));libName = 'mkl_lapack95_ilp64';libPath = 'C:\Program Files (x86)\IntelSWTools\compilers_and_libraries\windows\mkl\lib\intel64';[~,linkLibExt] = buildctx.getStdLibInfo();buildInfo.addLinkObjects([libName linkLibExt], libPath, ...'', true, true);buildInfo.addIncludePaths('C:\Program Files (x86)\IntelSWTools\compilers_and_libraries_2020.1.216\windows\mkl\include');buildInfo.addDefines('HAVE_LAPACK_CONFIG_H');buildInfo.addDefines('LAPACK_COMPLEX_STRUCTURE');buildInfo.addDefines('LAPACK_ILP64'); endend
end%% generate standalone exe for above MATLAB function (genCodeTest.m)
cfg = coder.config('exe');
cfg.CustomBLASCallback = 'useMyBLAS';
cfg.CustomLAPACKCallback = 'useMyLAPACK';
cfg.GenerateExampleMain = 'GenerateCodeAndCompile';
codegen largeMatrixTest -config cfg -report
VIA:
-
不是吧,MATLAB 代码居然能直接转成 C/C++ 代码 - 知乎
https://zhuanlan.zhihu.com/p/158886548 -
如何将 matlab 代码生成为 C/C++ 代码?_matlab 转 c++ 语言 - CSDN 博客
https://blog.csdn.net/weixin_49300040/article/details/138720766 -
使用 MATLAB Coder Generation 将 m 语言转化为 C++ 过程遇到的问题及解决_m 语言转 c 语言 - CSDN 博客
https://blog.csdn.net/m0_46427461/article/details/124084542 -
MATLAB 转 C/C++ 常见问题总结_tmwtypes-CSDN 博客
https://blog.csdn.net/weixin_43145941/article/details/124592276 -
遗传算法(GA)求解旅行商问题(TSP)MATLAB 代码讲解
https://mp.weixin.qq.com/s/vB2mCh269YRUuiu5QonX6A -
利用 MATLAB Coder 将 M 代码生成 C/C++ 代码 - 知乎
https://zhuanlan.zhihu.com/p/44847255 -
利用硬件加速大规模科学计算 | 从 MATLAB 到 C/C++ 代码 - MATLAB & Simulink 2022 年发布
https://ww2.mathworks.cn/company/technical-articles/speed-up-large-scale-scientific-computation-with-hardware-from-matlab-to-c-c-code.html
相关文章:

MATLAB Coder 应用:转换 MATLAB 代码至 C/C++ | 实践步骤与问题解决
注:本文为 “ MATLAB 代码至 C/C 应用” 相关文章合辑。 未整理去重。 如有内容异常,请看原文。 MATLAB 代码转换为 C/C 代码的详细指南 随心 390 zhihu 发布于 2020-07-12 12:39 在实际项目中,我们常常遇到需要将 MATLAB 代码转换为 C/C …...

BLE 6.0 六大核心特性全解析
写在前面: 2025年1月15日,Bluetooth SIG发布了备受期待的 Bluetooth Core Specification 6.0。相比5.x系列,6.0在测距精度、能耗优化、扫描过滤、音频体验和协议灵活性等方面实现了重大突破。本文将以浅显易懂的语言、丰富的图示和真实案例,带你全面深入了解BLE 6.0的六大核…...

网络应用程序体系结构
本文来源 : 《计算机网络 自顶向下方法》 应用程序体系结构(application architecture)由应用程序研发者设计,规定了如何在各种端系统上组织该应用程序。 现代网络应用程序中使用的两种主流体系结构: (1)客户-服务器…...

Filename too long 错误
Filename too long 错误表明文件名超出了文件系统或版本控制系统允许的最大长度。 可能的原因 文件系统限制 不同的文件系统对文件名长度有不同的限制。例如,FAT32 文件名最长为 255 个字符,而 NTFS 虽然支持较长的文件名,但在某些情况下也…...

Linux学习——UDP
编程的整体框架 bind:绑定服务器:TCP地址和端口号 receivefrom():阻塞等待客户端数据 sendto():指定服务器的IP地址和端口号,要发送的数据 无连接尽力传输,UDP:是不可靠传输 实时的音视频传输&#x…...

C++:继承
目录 一:继承的概念 1.1 继承的定义 1.2 继承方式 1.3 可见性区别 公有方式 私有方式 保护方式 1.4 一般规则 二、继承中的隐藏规则 三、基类和派生类间的转换 四、派生类的默认成员函数 实现一个不能被继承的类 继承与友元 五、继承与静态成员 六、多…...

RSGISLib:一款功能强大的GIS与RS数据处理Python工具包
今天为大家介绍的软件是RSGISLib:一款功能丰富的遥感与GIS数据的python库。下面,我们将从软件的主要功能、支持的系统、软件官网等方面对其进行简单的介绍。 RSGISLib官网网址为:http://rsgislib.org/,它提供了一个丰富的工具集&…...

Git管理
1.创建git仓库 git init 2.让文件添加到暂存区 git add. 3.给暂存区文件添加说明,并提交到本地仓库 git commit -m 说明 4.查看历史记录 git log /git log --oneline 查看状态:git status 5. 引用旧版 git reset --hard commitid 6.创建分支 …...

Java中内部类
1.静态类与非静态类是内部类的区分,外部类不可以被static修饰。 2.类的加载过程:类只有被使用才会被类加载器加载,加载后类的信息放在元空间(方法区)中。类的使用包括初始化对象、静态方法的调用。 3.静态内部类与普…...

[U-Net-Dual]DEU-Net
论文题目:DEU-Net: Dual-Encoder U-Net for Automated Skin Lesion Segmentation 中文题目:DEU-Net:用于自动皮肤病变分割的双编码器U-Net 0摘要 皮肤病的计算机辅助诊断(CAD)在很大程度上依赖于皮肤病变的自动分割,尽管由于病变在形状、大小、颜色和纹理上的多样性以及…...

【数据结构】第五弹——Stack 和 Queue
文章目录 一. 栈(Stack)1.1 概念1.2 栈的使用1.3 栈的模拟实现1.3.1 顺序表结构1.3.2 进栈 压栈1.3.3 删除栈顶元素1.3.4 获取栈顶元素1.3.5 自定义异常 1.4 栈的应用场景1.改变元素序列2. 将递归转化为循环3. 四道习题 1.5 概念分区 二. 队列(Queue)2.1 概念2.2 队列的使用2.3…...

LSTM如何解决梯度消失问题
LSTM如何解决梯度消失问题 一、传统RNN的梯度消失困境 在标准RNN中,隐藏状态更新公式为: h t tanh ( W h h h t − 1 W x h x t b h ) h_t \tanh(W_{hh}h_{t-1} W_{xh}x_t b_h) httanh(Whhht−1Wxhxtbh) 梯度计算通过链式法则展…...

什么是管理思维?
管理思维是指在管理活动中形成的系统性、战略性和创造性的思考方式,帮助个人或团队更高效地达成目标。它不仅适用于企业管理,也适用于个人成长、项目执行和复杂问题解决。以下是关于管理思维的核心内容: 一、管理思维的核心特征 1. 系统性思…...

缓存与内存;缺页中断;缓存映射:组相联
文章目录 内存(RAM)与缓存(Cache)Memory Management Unit缺页中断 多级缓存缓存替换策略缓存的映射方式 内存(RAM)与缓存(Cache) 缓存: CPU 内部或非常靠近的高速存储&a…...

12.5/Q1,GBD高分文章解读
文章题目:Global, regional, and national burdens of early onset pancreatic cancer in adolescents and adults aged 15-49 years from 1990 to 2019 based on the Global Burden of Disease Study 2019: a cross-sectional stud DOI:10.1097/JS9.000…...

路由交换网络专题 | 第六章 | OSPF | BGP | BGP属性 | 防环机制
目录 拓扑图 (1)AS 400 内部使用 OSPF 路由协议,使 PC2 访问 PC3 的路径优先选择 AR2-AR4-AR3。 (2)AS 400 内部使用 RIP 路由协议,使 PC2 访问 PC3 的路径优先选择 AR2-AR4-AR3。 (3&#…...

ubuntu 安装 redis server
ubuntu 安装 redis server sudo apt update sudo apt install redis-server The following NEW packages will be installed:libhiredis0.14 libjemalloc2 liblua5.1-0 lua-bitop lua-cjson redis-server redis-toolssudo systemctl start redis-server sudo systemctl ena…...

基于 Spring Boot实现的图书管理系统
Spring Boot图书管理系统详细分析文档 1. 项目概述 本文档对基于Spring Boot实现的图书管理系统进行详细分析。该项目是一个典型的Web应用程序,采用了Spring Boot框架,结合MyBatis作为ORM工具,实现了图书信息的管理功能,包括图书…...
)
gradle可用的下载地址(免费)
这几天接手一个老项目,想找gradle老版本的,但一搜,虽然在CSDN上搜索出来一堆,但都是收费,有些甚至要几十积分(吃相有点难看了)。 我找了一个能访问的地址,特地分享出来,有需要的自取!…...

发送百度地图的定位
在vuephp写的聊天软件项目中,增加一个发送百度地图的定位功能 在 Vue PHP 的聊天软件中增加发送百度地图定位功能,需要从前端定位获取、地图API集成、后端存储到消息展示全流程实现。以下是详细步骤: 一、前端实现(Vue/Uni-app…...

滑动窗口学习
2090. 半径为 k 的子数组平均值 题目 问题分析 给定一个数组 nums 和一个整数 k,需要构建一个新的数组 avgs,其中 avgs[i] 表示以 nums[i] 为中心且半径为 k 的子数组的平均值。如果在 i 前或后不足 k 个元素,则 avgs[i] 的值为 -1。 思路…...
:Python Pandas索引技术详解)
python数据分析(二):Python Pandas索引技术详解
Python Pandas索引技术详解:从基础到多层索引 1. 引言 Pandas是Python数据分析的核心库,而索引技术是Pandas高效数据操作的关键。良好的索引使用可以显著提高数据查询和操作的效率。本文将系统介绍Pandas中的各种索引技术,包括基础索引、位…...
VTK C++开发示例 --- 生成随机数的首选方法)
(15)VTK C++开发示例 --- 生成随机数的首选方法
文章目录 1. 概述2. CMake链接VTK3. main.cpp文件4. 演示效果 更多精彩内容👉内容导航 👈👉VTK开发 👈 1. 概述 vtkMinimalStandardRandomSequence 是 VTK(Visualization Toolkit)库中的一个类,…...

华为S系列交换机CPU占用率高问题排查与解决方案
问题概述 在华为S系列交换机(V100&V200版本)运行过程中,CPU占用率过高是一个常见问题,可能导致设备性能下降甚至业务中断。根据华为官方维护宝典,导致CPU占用率高的主要原因可分为四大类:网络攻击、网络震荡、网络环路和硬件…...

为啥低速MCU单板辐射测试会有200M-1Ghz的辐射信号
低速MCU(如8位或16位单片机)单板在辐射测试中出现 200MHz~1GHz的高频辐射信号,看似不合理,但实际上是由多种因素共同导致的。以下是详细原因分析及解决方案: 1.根本原因分析: (1) 时钟谐波与开关噪声 低速MCU的时钟谐…...

docker本地虚拟机配置
docker 下载安装 yum install -y docker 如果报错 mv /etc/yum.repos.d/CentOS-Base.repo /etc/yum.repos.d/CentOS-Base.repo.backup curl -o /etc/yum.repos.d/CentOS-Base.repo http://mirrors.aliyun.com/repo/Centos-7.repo yum clean all yum makecache 修改docker 仓…...

【随机过程】柯尔莫哥洛夫微分方程总结
柯尔莫哥洛夫微分方程:用“水流扩散”理解概率演化 1. 核心思想 柯尔莫哥洛夫微分方程(Kolmogorov Equations)是描述**连续时间马尔可夫过程(CTMC)**中概率分布随时间演化的工具。 前向方程(Fokker-Planc…...

AI领域:MCP 与 A2A 协议的关系
一、为何会出现MCP和A2A 协议是非常重要的东西,只有大家都遵循统一的协议,整体生态才好发展,正如有了HTML,互联网才快速发展,有了OpenAPI, API才会快速发展。 Agent目前是发展最快的领域,从最初…...
:描述UI)
重学React(一):描述UI
背景:React现在已经更新到19了,文档地址也做了全面的更新,上一次系统性的学习还是在16-17的大版本更新。所以,现在就开始重新学习吧~ 学习内容: React官网教程:https://zh-hans.react.dev/lea…...
详解:以延迟加载图片为例)
代理模式(Proxy Pattern)详解:以延迟加载图片为例
在日常开发中,是否遇到过以下问题: “程序启动时图片太多,加载太慢!” “用户还没看到图片就已经开始加载了,性能浪费!” 此时,代理模式(Proxy Pattern)便派上了用场。本…...

Power BI企业运营分析——数据大屏搭建思路
Power BI企业运营分析——数据大屏搭建思路 欢迎来到Powerbi小课堂,在竞争激烈的市场环境中,企业运营分析平台成为提升竞争力的核心工具。 整合多源数据,实时监控关键指标,精准分析业务,快速识别问题机遇。其可视化看…...
)
HCIP-H12-821 核心知识梳理 (5)
Portal 认证场景中 AC 与 Portal 服务器通信使用的 Portal 协议基于 TCP;HTTP/HTTPS 可作为接入与认证协议;缺省情况下,接入设备处理 Portal 协议报文及向 Portal 服务器主动发送报文的目的端口号均为 50100 VRRP 协议心跳报文缺省发送间隔为…...

从M个元素中查找最小的N个元素时,使用大顶堆的效率比使用小顶堆更高,为什么?
我们有一个长度为 M 的数组,现在我们想从中找出 最小的 N 个元素。例如: int a[10] {12, 3, 5, 7, 19, 0, 8, 2, 4, 10};从中找出 最小的 4 个元素。 正确方法:使用大小为 N 的「大顶堆」 原因分析: 我们想保留最小的 4 个元素…...
)
【AI工具】2025年主流自动化技术(供参考)
背景 前面完成了AutoIT的自动化操作的尝试,有惊喜有惊吓,就是能进行自动化控制,但是有点“笨”,于是就想找找同类好用的技术,有了这篇自动化技术比较分析的文档,资料参考了AI总结的内容。 autoit的使用&am…...

1.微服务拆分与通信模式
目录 一、微服务拆分原则与策略 业务驱动拆分方法论 • DDD(领域驱动设计)中的限界上下文划分 • 业务功能正交性评估(高内聚、低耦合) 技术架构拆分策略 • 数据层拆分(垂直分库 vs 水平分表) • 服务粒…...

【Java面试笔记:基础】4.强引用、软引用、弱引用、幻象引用有什么区别?
1. 引用类型及其特点 强引用(Strong Reference): 定义:最常见的引用类型,通过new关键字直接创建。回收条件:只要强引用存在,对象不会被GC回收。示例:Object obj = new Object(); // 强引用特点: 强引用是导致内存泄漏的常见原因(如未及时置为null)。手动断开引用:…...

使用Python+OpenCV将多级嵌套文件夹下的视频文件抽帧为JPG图片
使用PythonOpenCV将多级嵌套文件夹下的视频文件抽帧为JPG图片 import os import cv2 import time# 存放视频文件的多层嵌套文件夹路径 videoPath D:\\videos\\ # 保存抽帧的图片的文件夹路径 savePath D:\\images\\if not os.path.exists(savePath):os.mkdir(savePath) vide…...

基于STM32的室内环境监测系统
目录 一、前言 二、项目功能说明 三、主要元器件 四、接线说明 五、原理图与PCB 六、手机APP 七、完整资料 一、前言 项目成品图片: 哔哩哔哩视频链接: 咸鱼商品链接: 基于STM32的室内环境监测系统商品链接 二、项目功能说明 基础功…...

乐迪电玩发卡查分与控制面板模块逻辑解析
本篇为《美乐迪电玩全套系统搭建》系列的第四篇,聚焦后台功能模块中的发卡与查分系统。针对运营侧常见需求(如玩家状态查验、补卡操作、积分调整等),本篇将完整剖析其 PHP 端实现逻辑、数据结构及权限管理机制。 一、模块结构与入…...

Spring 事务实现原理,Spring 的 ACID是如何实现的?如果让你用 JDBC 实现事务怎么实现?
Spring 事务实现原理 Spring 的事务管理基于 AOP(面向切面编程) 和 代理模式,通过以下核心组件实现: 事务管理器(PlatformTransactionManager) Spring 提供了统一的事务抽象接口(如 DataSource…...
)
网络原理 - 4(TCP - 1)
目录 TCP 协议 TCP 协议段格式 可靠传输 几个 TCP 协议中的机制 1. 确认应答 2. 超时重传 完! TCP 协议 TCP 全称为 “传输控制协议”(Transmission Control Protocol),要对数据的传输进行一个详细的控制。 TCP 协议段格…...

SVT-AV1编码器中的模块
一 模块列表 1 svt_input_cmd_creator 2 svt_input_buffer_header_creator 3 svt_input_y8b_creator 4 svt_output_buffer_header_creator 5 svt_output_recon_buffer_header_creator 6 svt_aom_resource_coordination_result_creator 7 svt_aom_picture_analysis_result_creat…...
个人学习笔记(12):网络爬虫)
金融数据分析(Python)个人学习笔记(12):网络爬虫
一、导入模块和函数 from bs4 import BeautifulSoup from urllib.request import urlopen import re from urllib.error import HTTPError from time import timebs4:用于解析HTML和XML文档的Python库。 BeautifulSoup:方便地从网页内容中提取和处理数据…...

子网划分的学习
定长子网划分(Fixed-length Subnetting) 也叫做固定长度子网划分,是指在一个IP网络中,把网络划分成若干个大小相等的子网,每个子网的子网掩码长度是一样的。 一、定长子网划分的背景 在早期的IP地址分配中࿰…...

Spark2 之 memorypool
cpp/core/memory/ArrowMemoryPool.cc cpp/core/memory/MemoryAllocator.cc VeloxMemoryManager cpp/velox/memory/VeloxMemoryManager.cc VeloxMemoryManager::VeloxMemoryManager(const std::string& kind, std::unique_ptr<AllocationListe...

短视频+直播商城系统源码全解析:音视频流、商品组件逻辑剖析
时下,无论是依托私域流量运营的品牌方,还是追求用户粘性与转化率的内容创作者,搭建一套完整的短视频直播商城系统源码,已成为提升用户体验、增加商业变现能力的关键。本文将围绕三大核心模块——音视频流技术架构、商品组件设计、…...

IO流详解
IO流 用于读写数据的(可以读写文件,或网络中的数据) 概述 I指 Input,称为输入流:负责从磁盘或网络上将数据读到内存中去 O指Output,称为输出流,负责写数据出去到网络或磁盘上 因此ÿ…...

linux下使用wireshark捕捉snmp报文
1、安装wireshark并解决wireshark权限不足问题 解决linux普通用户使用Wireshark的权限不足问题_麒麟系统中wireshark 运行显示权限不够-CSDN博客 2、Linux下安装并配置SNMP软件包 (deepseek给出的解答,目前会产生request包,但是会连接不上&a…...

ClickHouse 设计与细节
1. 引言 ClickHouse 是一款备受欢迎的开源列式在线分析处理 (OLAP) 数据库管理系统,专为在海量数据集上实现高性能实时分析而设计,并具备极高的数据摄取速率 1。其在各种行业中得到了广泛应用,包括众多知名企业,例如超过半数的财…...

Spring Boot 启动生命周期详解
Spring Boot 启动生命周期详解 1. 启动阶段划分 Spring Boot 启动过程分为 4个核心阶段,每个阶段涉及不同的核心类和执行逻辑: 阶段 1:预初始化(Pre-initialization) 目标:准备启动器和环境配置关键类&am…...