JavaEE--2.多线程
1.认识线程(Thread)
1.1概念
1)什么是线程
⼀个线程就是⼀个 "执行流". 每个线程之间都可以按照顺序执行自己的代码. 多个线程之间 "同时" 执行着多份代码.
2)为什么要有线程
首先, "并发编程" 成为 "刚需".
1. 单核 CPU 的发展遇到了瓶颈. 要想提⾼算⼒, 就需要多核 CPU. ⽽并发编程能更充分利⽤多核 CPU 资源.
2. 有些任务场景需要 "等待 IO", 为了让等待 IO 的时间能够去做⼀些其他的⼯作, 也需要⽤到并发编程
其次, 虽然多进程也能实现 并发编程, 但是线程比进程更轻量
创建线程比创建进程更快.
销毁线程比销毁进程更快.
调度线程比调度进程更快.
最后, 线程虽然比进程轻量, 但是⼈们还不满足, 于是又有了 "线程池"(ThreadPool) 和 "协程" (Coroutine)
多进程的问题就是太"重"
创建/销毁进程的开销比较大(时间,空间)
一旦需求常见,需要频繁地创建销毁进程,开销非常明显.
最典型的例子就是服务器的开发:针对每个发送请求的客户端都创建一个单独的进程,由这个进程负责给客户端进行服务
为了解决进程开销比较大的问题,发明了"线程"(Thread)
线程可以理解成更轻量的进程,也能实现并发编程,创建/销毁的开销比进程更低.
因此,多线程的编程就成了当下主流的并发编程方式.
所谓的进程,在系统中是以PCB(进程控制块)这样的结构体来描述的,通过链表的形式来组织的
对于系统中,线程同样也是通过PCB来描述的(Linux)
一个进程其实是一组PCB
一个线程是一个PCB
所以,其中存在"包含关系”,一个进程中,可以包含多个线程
此时每个线程都可以独立的到CPU上调度执行
线程是系统“调度执行”的基本单位
进程是系统“资源分配”的基本单位
解释:一个可执行程序,运行的时候(双击),操作系统就会创建进程,给这个程序分配各种系统资源(CPU,内存,硬盘,网络带宽......),同时,也会在这个进程中,创建出一个或者多个线程,这些线程再去CPU上调度执行.
上个文章提到的"进程调度"相当于"线程调度",针对"只包含一个线程的进程来说"
如果有多个线程在一个进程中,每个线程,都会有自己的状态,优先级,上下文,记账信息,每个都会各自独立的在CPU上调度执行
进程要么包含一个线程,要么包含多个线程,不能没有线程
同一个进程的这些线程,共用着同一个系统资源
线程比进程更轻量,主要就在与创建线程省去了"分配资源"过程,销毁线程也省去了"释放资源"过程.
分配资源这个操作的开销大
一旦创建进程,同时也会创建第一个线程=>就会负责分配资源
一旦后续创建第二个第三个线程,就不必再重新分配资源了....
从微观角度看,多个核心,每个核心都可以执行一个线程,这些核心之间的执行过程是"同时执行的",这时称之为"并行"
一个核心,也可以按照"分时复用",来切换多个线程,从微观上来看.多个线程是"一个接一个"的执行的,由于调度速度足够快,宏观上看起来好像"同时执行",这时称之为"并发"
提升效率的关键是在于充分利用多核心进行"并行执行"
如果只是"微观并发",速度是没有提升的
真正能提升速度的是"并行"
线程有关的问题:
1.线程数目太多
如果线程数目太多,比如超出了CPU核心数目.此时就无法在微观上完成"并行"执行,势必会存在严重的"竞争".
2.进程资源"冲突"
当线程数目多了之后,此时就容易发生"冲突",由于多个线程,使用的是同一份资源(内存资源)
内存资源指的是代码中定义的变量/对象,如果多个线程同时对一个变量进行读写操作(尤其是写操作)容易发生冲突
一旦发生冲突,就可能使程序出现问题("线程安全问题"[重点内容,难点内容])
3.线程异常
当一个进程中有多个线程的时候,一旦某个线程抛出异常,这个时候,如果未能妥善处理,可能导致整个进程崩溃,其他线程就会随之崩溃
总结下(这也是高频的面试题)
进程线程的概念和区别
1.进程包含线程
一个进程里可以有一个线程,也可以有多个线程,不能没有线程
2.进程是系统资源分配的基本单位
线程是系统调度执行的基本单位
3.同一个进程里的线程之间,共用着同一份系统资源(内存,硬盘,网络带宽等...)
尤其是"内存资源",就是代码中定义的变量/对象...
编程中,多个线程,是可以共用同一份变量的
4.线程是当下实现并发编程的主流方式,通过多线程,就可以充分利用好多核CPU
但是不是线程数目越多越好,线程数目达到一定程度,把多个核心都充分利用了之后,此时继续增加线程无法再提高效率,甚至可能会影响效率(线程调度也是有开销的)
5.多个线程之间,可能会互相影响,线程安全问题,一个线程抛出异常,也可能会把其他线程也一起带走
6.多个进程之间,一般不会相互影响,一个进程崩溃了,不会影响到其他进程(这一点也称为"进程的隔离性")
3)进程和线程的区别
进程是包含线程的,每个进程至少有一个线程,即主线程.
进程和进程之间不共享内存空间,同一进程的线程之间共享同一个内存空间
进程是资源分配的基本单位,线程是系统调度的基本单位
一个进程挂了一般不会影响到其他进程,一个线程挂了可能会把同进程的其他线程一起带走(整个进程崩溃).
4)Java的线程和操作系统线程的关系
线程是操作系统中的概念,操作系统内核实现了线程这样的机制,并且对用户提供了一些API供用户使用(例如Linux的pthread库).
Java标准库中的Thread类可以视为对操作系统提供的API进行了进一步的抽象和封装.
Java(JVM)把这些系统API封装好了,咱们不需要关注系统原生API,只需要了解好Java提供的这一套API就行了
1.2第一个多线程程序
Thread标准库:
这个类就负责完成多线程相关的开发.

此处Thread类可以直接使用,不需要导入任何的包
(因为有的类比较特殊,默认已经导入了,比如String)
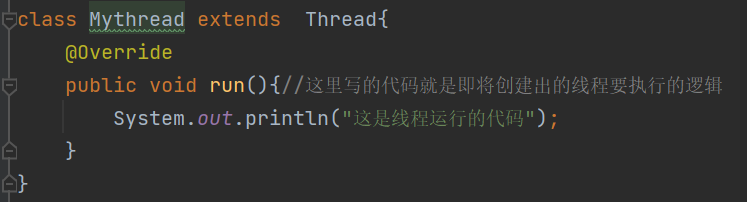
此处的继承不是主要目的,更主要的目的是为了重写run方法
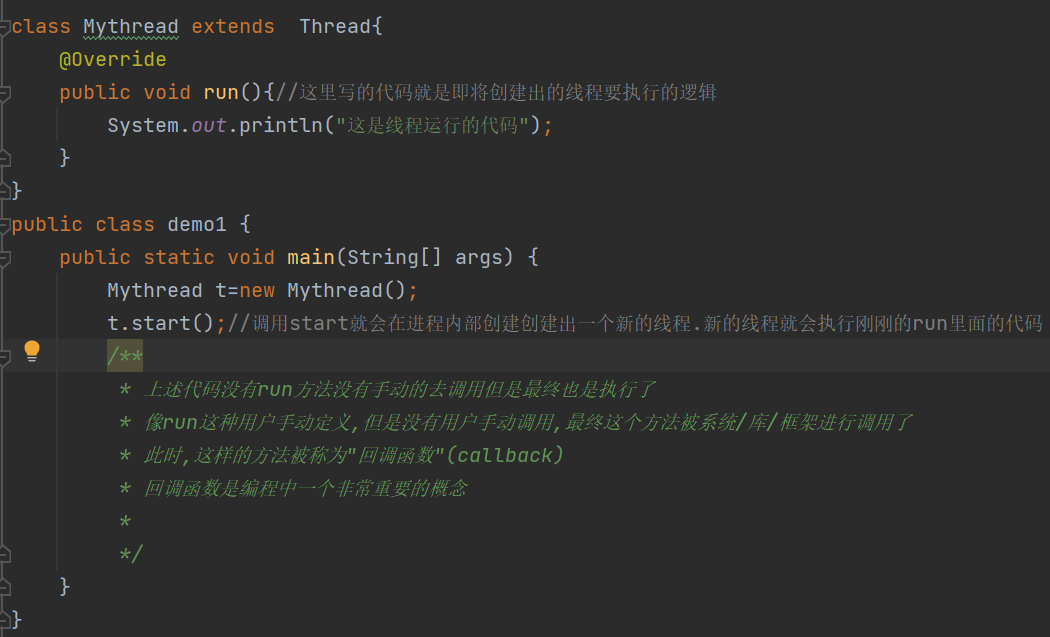
调用start就会在进程内部创建出新的线程,新的线程就会执行刚才run里面的代码

上述代码没有run方法没有手动的去调用但是最终也是执行了像run这种用户手动定义,但是没有用户手动调用,最终这个方法被系统/库/框架进行调用了此时,这样的方法被称为"回调函数"(callback)回调函数是编程中一个非常重要的概念
回调函数是一个非常重要的概念!!
回调函数概念其实目前至少遇到过两次
1.C语言中的函数指针
函数指针主要有两个用途
a)作为回调函数
b)实现转移表--降低代码的复杂程度
2.Java数据结构中的优先级队列
优先级队列必须先定义好对象的"比较规则" Comparable Compareto
Comparator Compare
自己定义了这些比较规则,但是并没有调用,此时都是标准库本身内部的逻辑负责调用
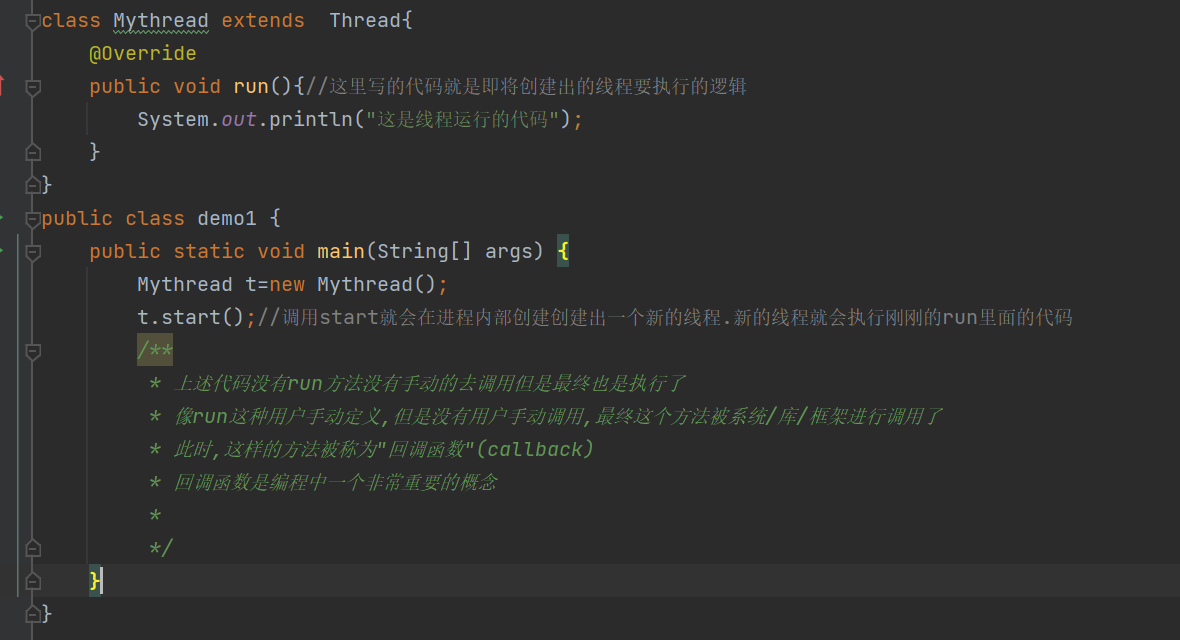
这个代码运行起来,是一个进程,但是这个进程实际上是包含了两个线程!
调用main方法的线程称为"主线程"
一个进程至少得包含一个线程,至少这一个线程就是主线程
t.start() 这里又手动的创建了新的线程
主线程和新线程都并发/并行的在CPU上执行
Thread,sleep();是Thread的静态方法 类名.方法名
Java标准库提供的方法
C语言中也有类似的,Sleep() (Windows的系统函数)
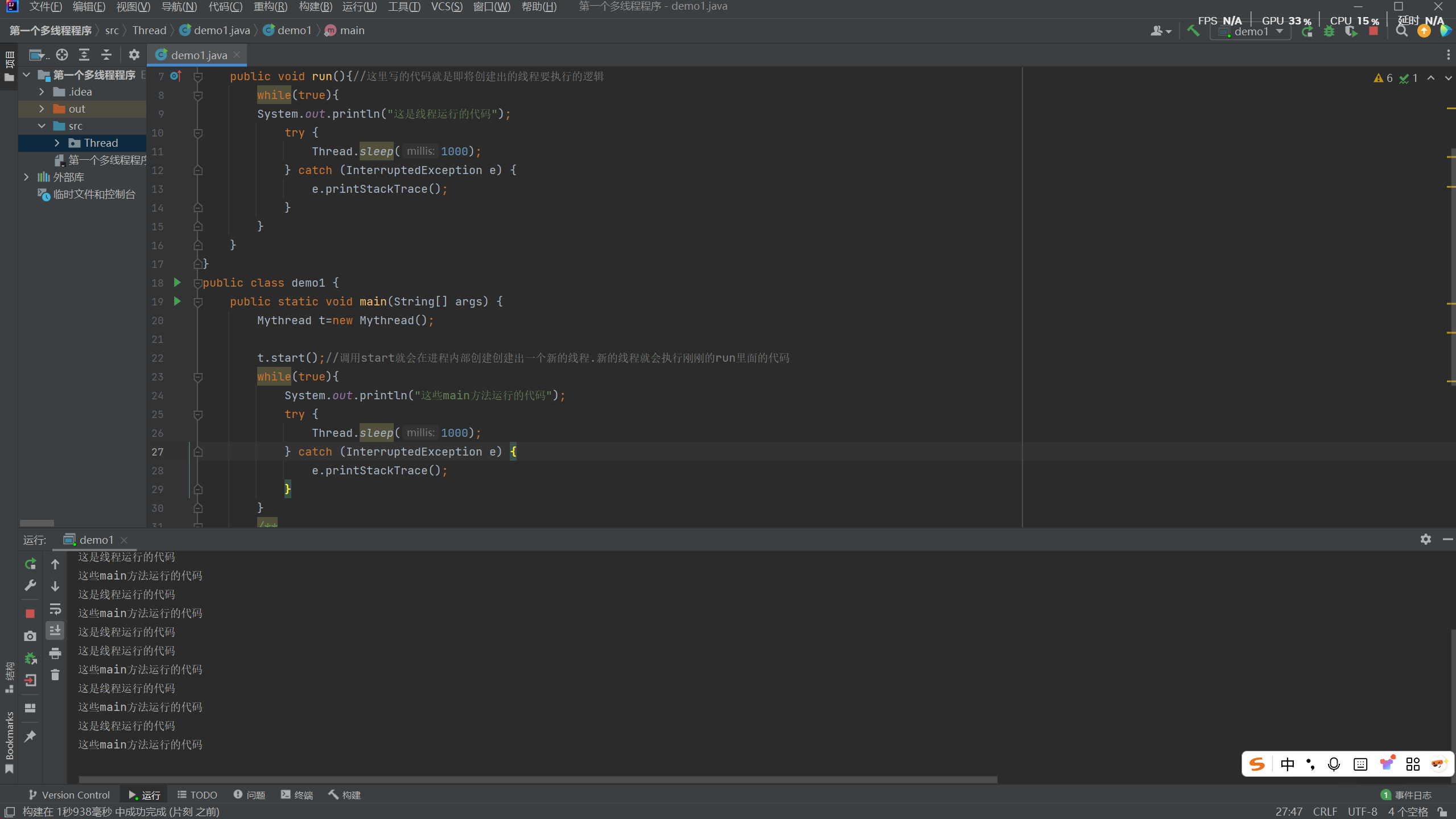
多线程之间谁先去CPU上调度执行,这个过程是"不确定的"(不是数学意义上的随机)
而是这个调度顺序取决于操作系统,内核里"调度器"的实现
调度器里有一套规则,咱们作为应用程序开发没办法进行干预,也感受不到
只能将这个过程近似的视为"随机" "抢占式执行"
借助第三方工具更直观的来看这两个线程的情况
在jdk的bin目录中打开jconsole
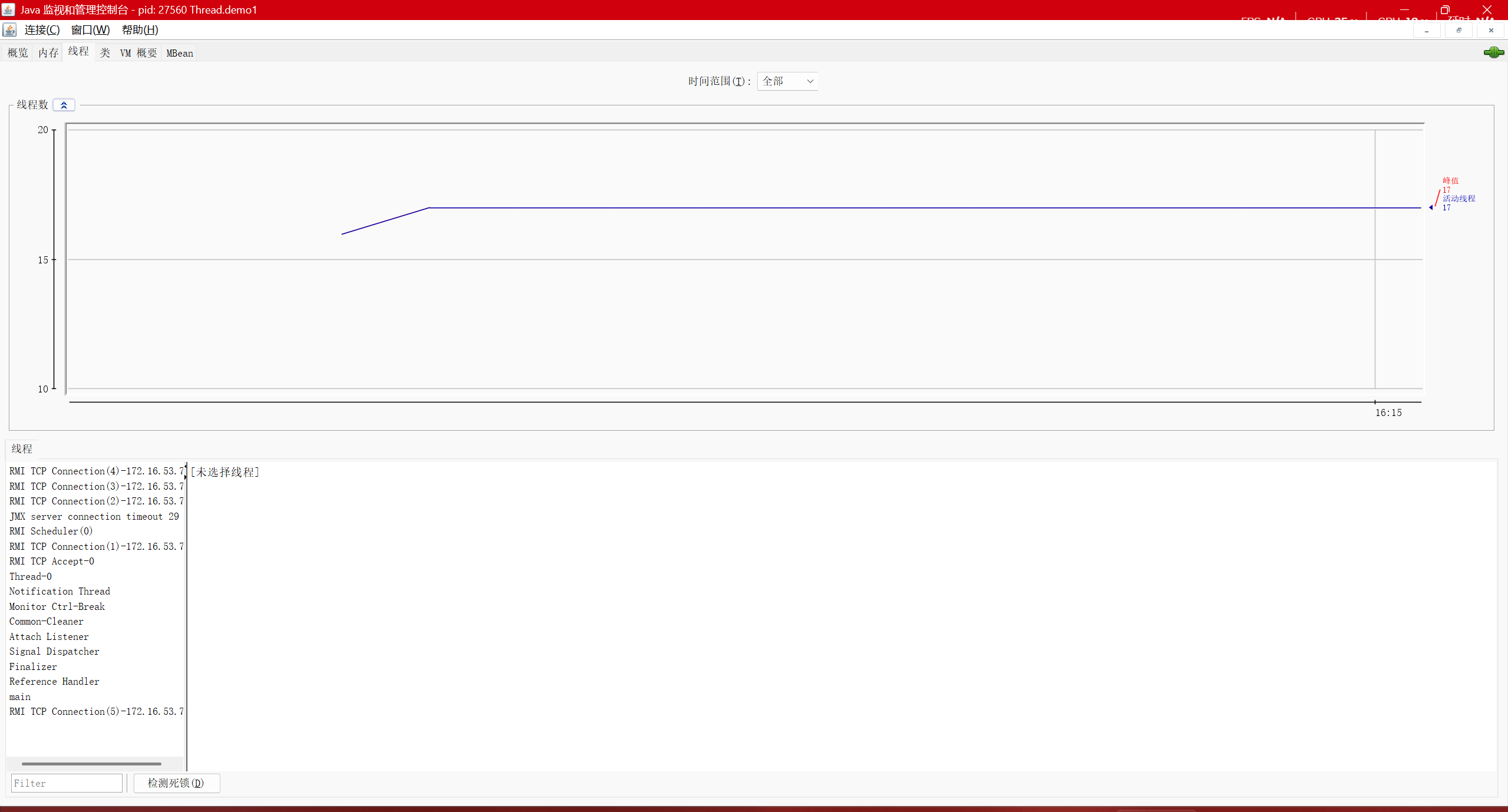
可以看出当前java进程中线程的情况,左下角可以看出一个java进程中不只有两个线程,还有别的
main是主线程,调用main方法的
Thread-0是代码中自己创建的线程,它的命名规律是Thread-数字
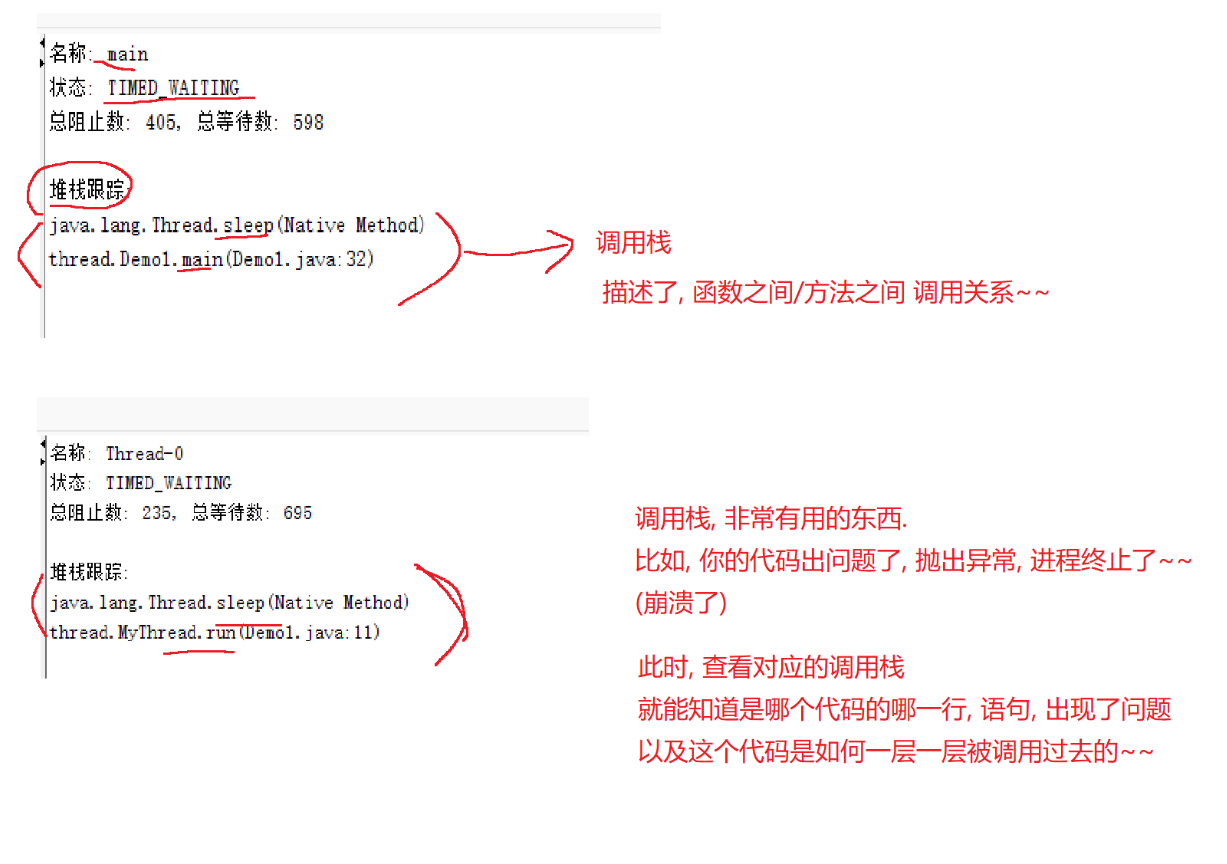

在IDEA的调试器,也能看到类似的信息
就可以手动的切换都某个线程上,看你需要关注的一些信息
创建线程的写法
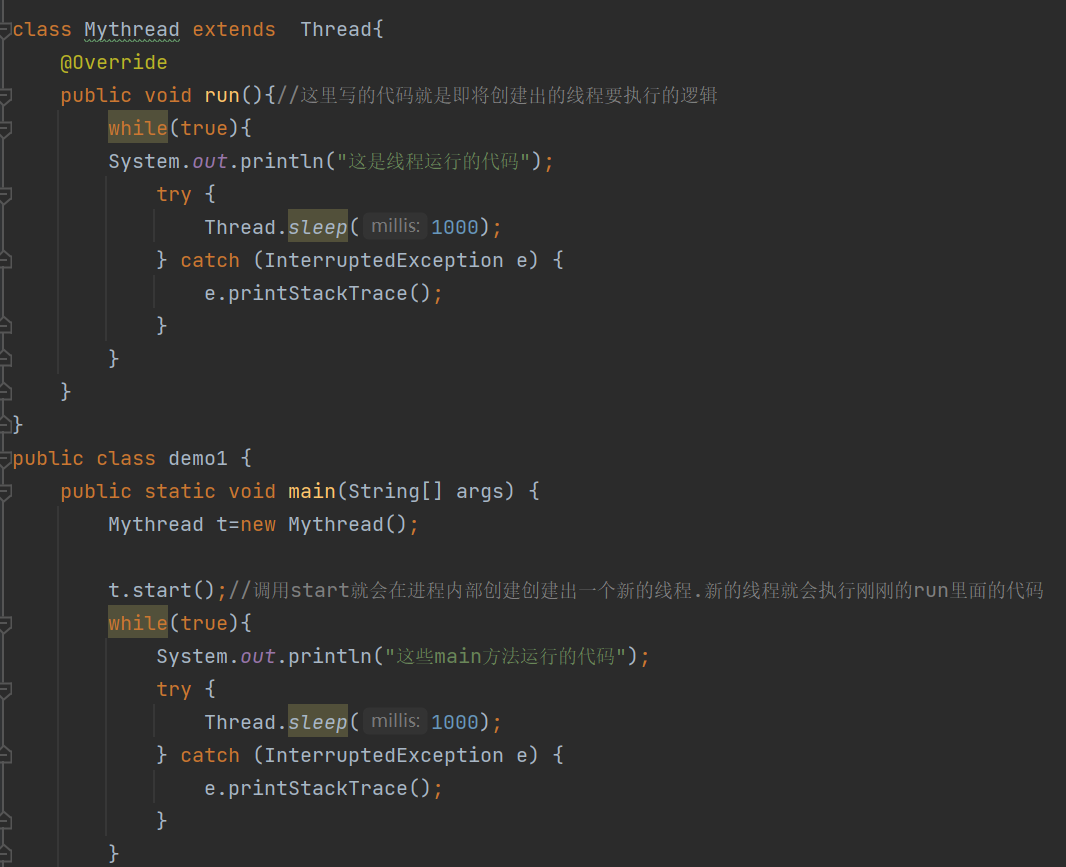
1)继承Thread,重写run
上面的写法就是继承Thread类
1.继承 Thread 来创建⼀个线程类.
class MyThread extends Thread {@Overridepublic void run() {System.out.println("这⾥是线程运⾏的代码");}
}2.创建 MyThread 类的实例
MyThread t = new MyThread();3.调用 start 方法启动线程
t.start();全部代码:
2)实现Runnable接口,重写run
1.实现 Runnable 接口
class MyRunnable implements Runnable {@Overridepublic void run() {System.out.println("这⾥是线程运⾏的代码");}
}2.创建 Thread 类实例, 调⽤ Thread 的构造⽅法时将 Runnable 对象作为 target 参数.
Thread t = new Thread(new MyRunnable());3.调用 start 方法
t.start();全部代码:
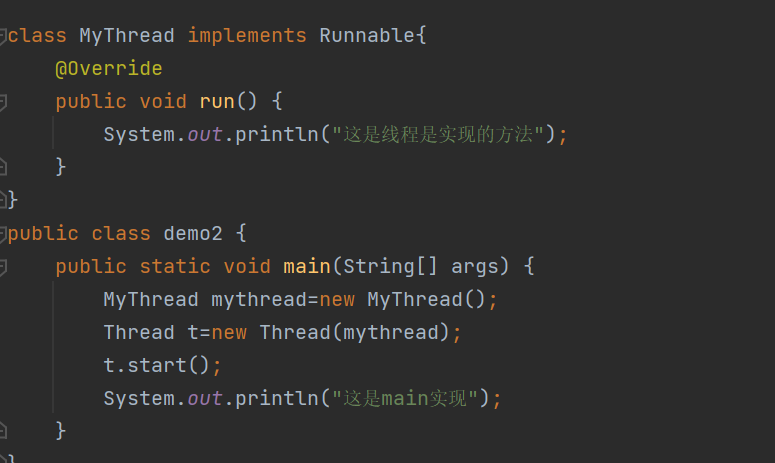
Runnable就是用来描述"要执行的任务" 是什么
有人认为Runnable这种做法更有利于"解耦合",这只是一个任务,并不是和"线程"这样的概念强相关
后续执行这个任务的载体可以是线程也可以是别的
别的在这里比如后续会介绍的线程池来执行任务
再比如可以通过"虚拟线程"(协程)来执行~~
线程是轻量级进程,因为进程太重量了,随着对于性能要求进一步提高,开始嫌弃线程也太重量了
于是引入了"协程".(轻量级线程,纤程)
这个协程的概念在后续的java版本中就被引入了,起的名叫做"虚拟线程"
3)内部匿名类
内部匿名类没有类目
Runnable子类对象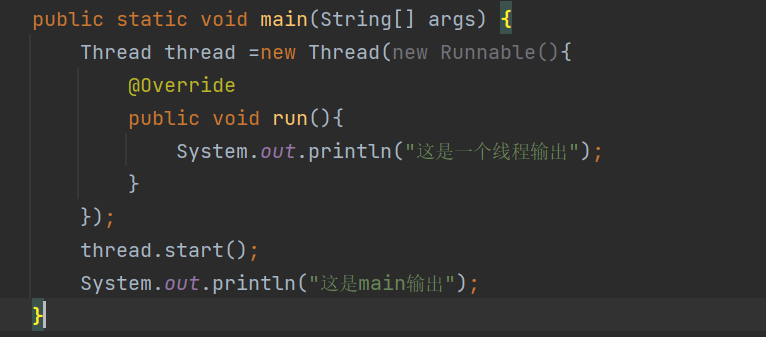
Thread子类对象
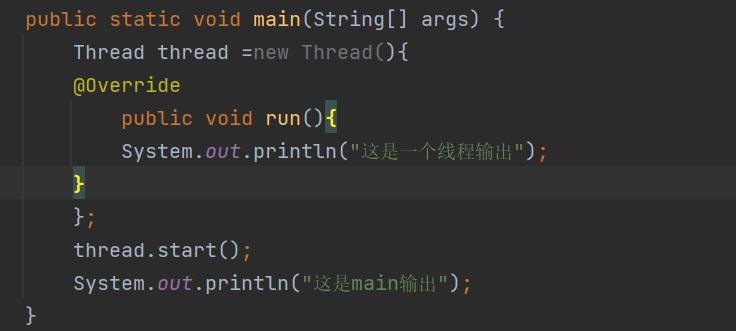
1.定义匿名内部类,这个类是Thread的子类
2.类的内部重写的父类run方法
3.创建了一个子类的实例,并且把实例的引用赋值给了t
匿名内部类就是一次性使用的类,用完就丢
4.lambda表达式创建Runnable子类
Thread thread=new Thread(() -> {while(true){System.out.println("这是线程输出的");try {Thread.sleep(1000);} catch (InterruptedException e) {e.printStackTrace();}}});thread.start();while(true){System.out.println("这是main运行的代码");try {Thread.sleep(1000);} catch (InterruptedException e) {e.printStackTrace();}}这也是推荐的写法
后续多以lambda表达式来创建多线程
2.1Thread的常见构造方法
| 方法 | 说明 |
| Thread() | 创建线程对象 |
| Tread(Runnable target) | 使用Runnable对象创建线程对象 |
| Thread(String name) | 创建线程对象,并命名 |
| Tread(Runnable target,String name) | 使用Runnable对象创建线程对象,并命名 |
| [了解]Thread(ThreadGoup goup,Runnable target) | 线程可以被用来分组管理,方便统一的设置线程的一些属性 |
注:给线程起名字不会影响到线程的执行效果,但是有一个合适的名字有利于调试的结果
不起名字默认就是Thread-0,Thread-1...
现在很少会使用线程组,线程的相关属性用的也不多,现在更多的是会使用线程池
2.2Thread的几个常见的属性
| 属性 | 获取方法 |
| ID | getId() |
| 名称 | getName() |
| 状态 | getState() |
| 优先级 | getPriority() |
| 是否后台线程 | isDaemon() |
| 是否存活 | isAlive() |
| 是否被中断 | isInterrupted() |
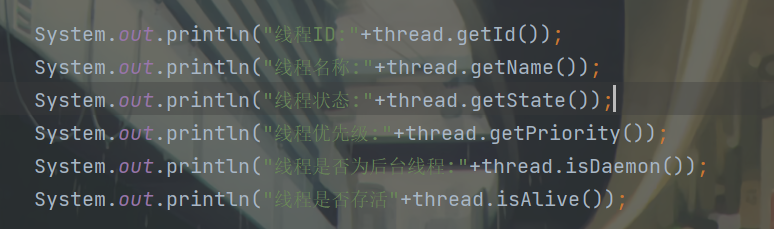
1.ID是线程的唯一标识,不同的线程不会重复
JVM自动分配的,Thread对象的身份标识
2.名称是各种调试工具用到的
3.状态表示线程当前所处的一个情况,下面我们会具体说明
就绪/阻塞状态 就绪状态的名字为RUNNABLE
通常情况下,一个Thread对象,就是对应到系统内部的一个线程(PCB),但是也可能会存在一个情况,Thread对象存在,但是系统内部的线程已经没了/还没有创建
4.优先级高的线程理论上来说更容易被调度到
设计不同的优先级影响系统的调度,这里的影响是基于"统计"规则的影响,直接肉眼观察河南观察到效果
5.关于后台线程,需要记住一点:JVM会在一个进程的所有非后台线程结束后才会结束运行
后台线程:如果这个线程执行的过程中不能阻止进程结束(虽然线程在执行,但是进程结束了,这个线程也会被随之带走),这样的线程就是"后台线程"
前台线程:如果某个线程在执行的过程中,能够阻止进程的结束,这个线程就是"前台进程 "
6.是否存活,即简单的理解run的方法是否结束了
true为存在,false为无了
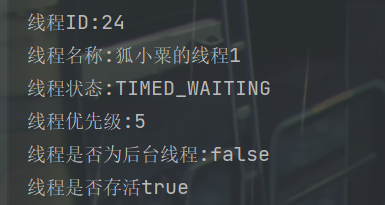
由于主线程和thread线程并发执行,主线程执行上述4个操作,执行了一部分的时候thread线程就执行打印了
RUNNABLE正在运行,实际上Java没有RUNNABLE这个线程状态,把正在CPU上运行和随时调度到CPU上运行的都统称为RUNNABLE
后台线程:
1)进程要结束(前台线程要结束),无力阻止
2)后台线程先结束也不影响进程的结束(其他前台进程的结束)
前台进程:
1)前台线程结束,此时进程就结束,后台线程也就随之结束
2)前台线程不结束,后台线程结束了不影响
一个进程中,前台线程可以有很多个(创建的线程默认就是前台的),必须所有的前台线程都结束,进程才能结束
代码中,创建的new Thread对象生命周期和内核中的实际的线程是不一定一样的
可能会出现Thread对象仍然存在,但是内核中的线程不存在的情况但是不会出现(Thread对象不存在,线程还在的情况)
1.调用start之前,内核中还没创建线程
2.线程的run执行完毕,内核的线程就没了,但是Thread对象仍然存在
2.3启动一个线程
调用start方法,才真正的在操作系统的底层创建出一个线程.
经典问题:start和run之间的区别
start:调用系统函数,真正的在操作系统内核中创建线程(创建PCB,加入到链表中),此处的start会根据不同的系统,分别调出不同的api(windows,linux,mac...),创建好新的线程之后再单独执行run
run:描述了线程要执行的的任务,也可以成为"线程的入口"
start的执行速度一般是比较快的(创建线程 比较轻量)
一旦start执行完毕,新线程就会开始执行,调用start的线程也会继续执行main
两个线程分别个做个的
调用start不一定非得是main线程调用的,任何线程都可以创建其他线程
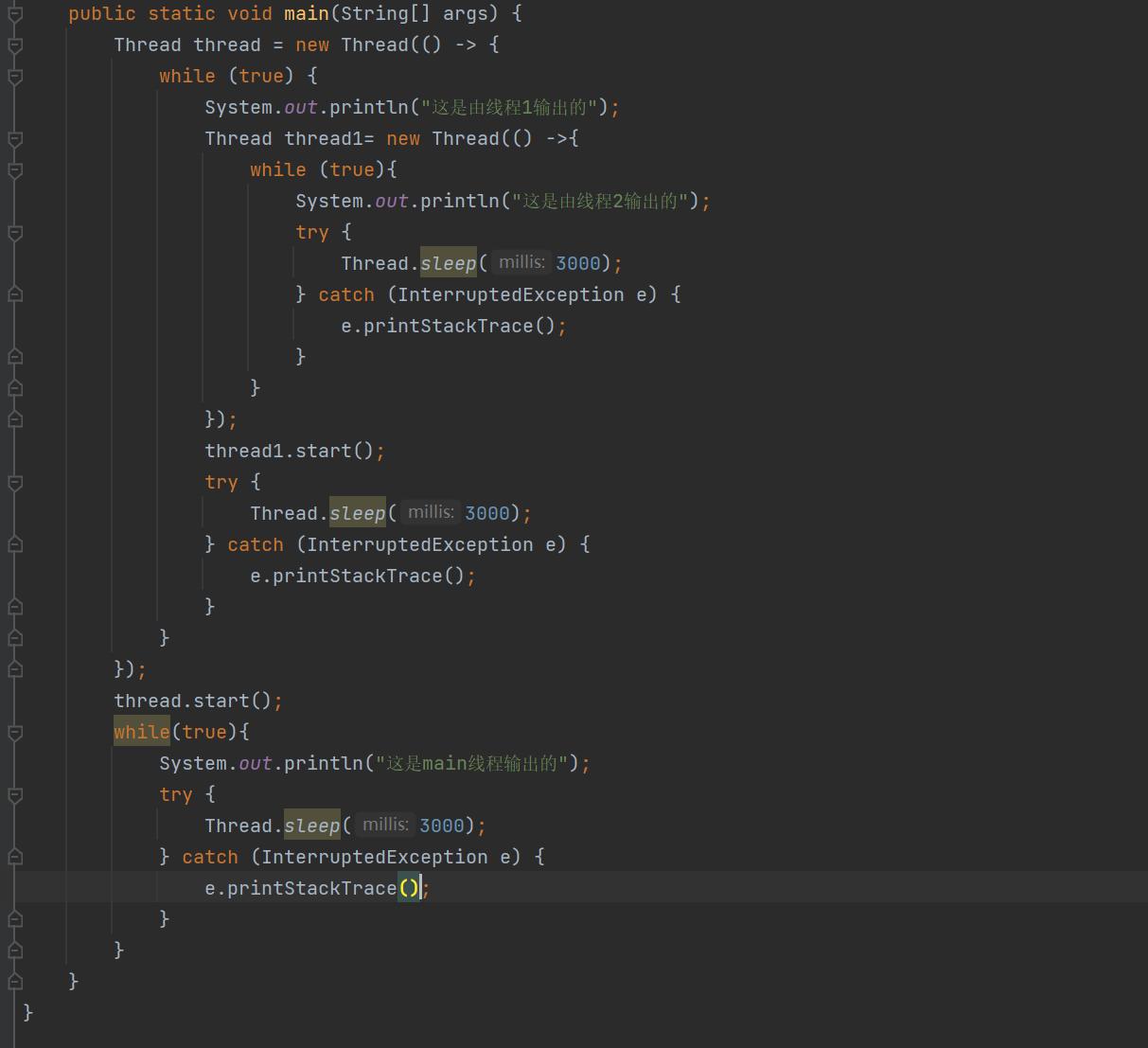
如图:这里就是由thread调用了thread1线程
如果系统资源充裕,就可以任意的创建线程,(当然,线程不是越多越好);
一个Thread对象只能调用一次start,如果多次调用start就会出现问题(一个Thread对象只能对应系统中的一个线程)
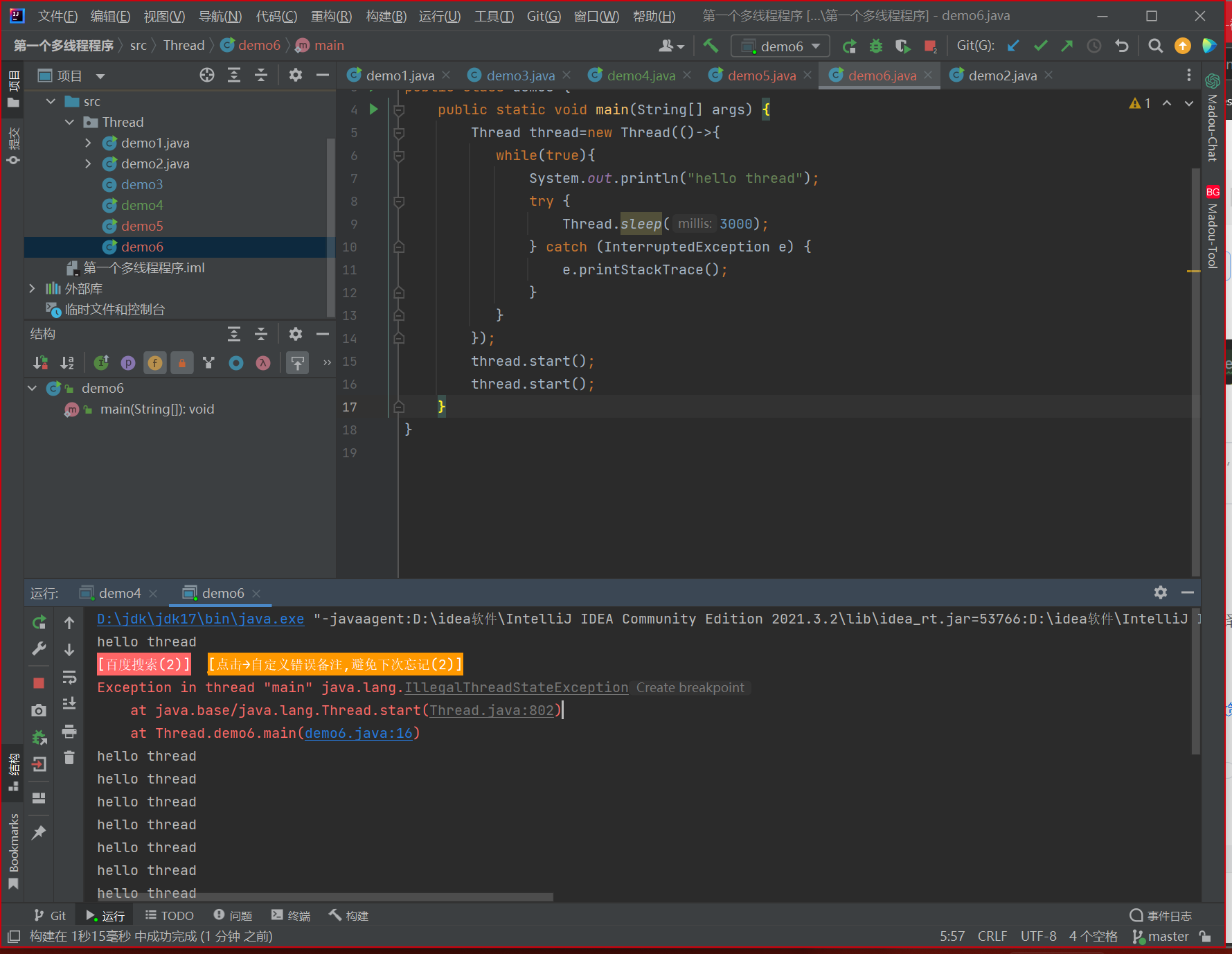
IllegalThreadStateException 报错
由于Java中希望一个Thread对象能够对应到一个系统中的线程,因此就会 start中根据线程状态做出判定:如果Thread对象是没有start,此时的状态是一个NEW状态,接下来可以顺利调用start,如果已经调用过start,就会进入其他状态,只要不是NEW状态,接下来执行start都会抛出异常
2.4程序的中断(程序的终止)
目前常见的有以下的两种方法:
1.通过共享的标记来进行沟通
2.调用interrupt()方法来停止
例如:A,B两个线程,B正在运行,A想让B结束,核心在于A让B的run方法直接完毕,此时B就自然结束了,而不是说B的run执行一般,A直接把B强制结束了
用共享标记结束,例如:
private static boolean isQuit=false;public static void main(String[] args) throws InterruptedException {Thread thread=new Thread(()->{while(!isQuit){System.out.println("hello thread");try {Thread.sleep(3000);} catch (InterruptedException e) {e.printStackTrace();}}});thread.start();Thread.sleep(3000);System.out.println("main方法开始中断程序");isQuit=true;}用isQuit来作为标志位
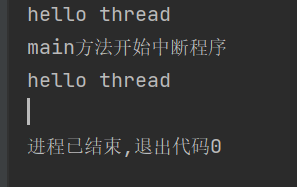
如果将isQuit放在main方法里面,作为局部变量,代码会报错
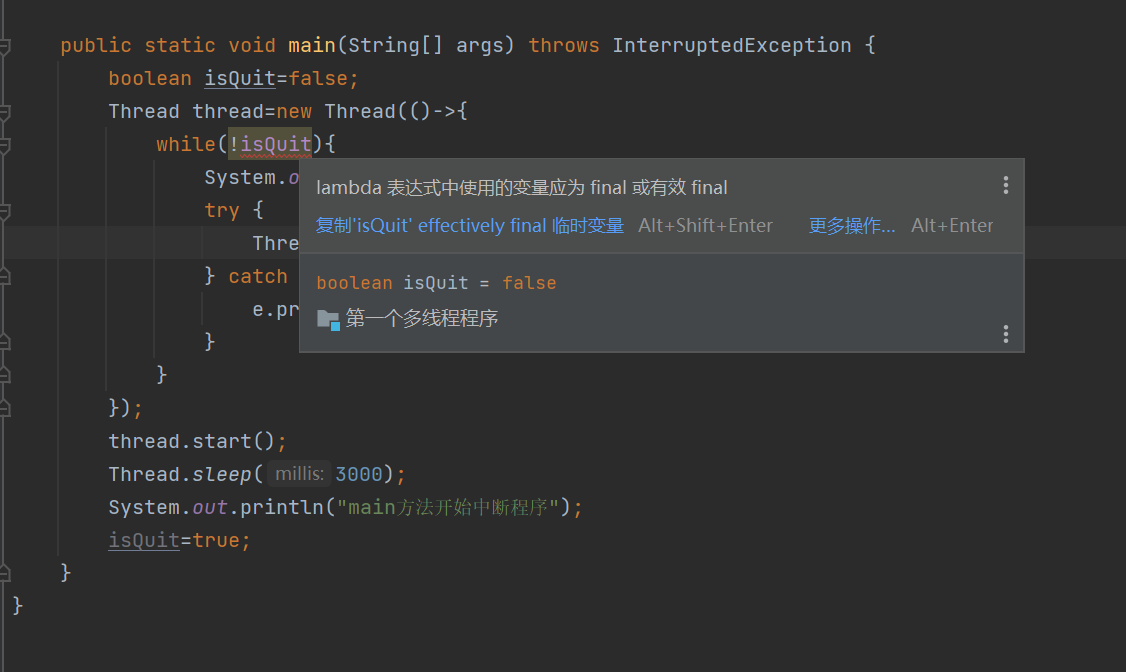
变量捕捉,是lambda表达式/匿名内部类的一个语法规则
isQuit和lambda定义在一个作用域中,此时lambda是可以访问到lambda外部(和lambda同一个作用域的变量),Java的变量捕捉有特殊要求,要求捕捉的变量得是final/事实final
写成成员变量之后就可以了是因为此时走的语法是"内部类访问外部类的成员"
lambda表达式本质上是一个"函数式接口"产生的"匿名内部类"
2.调用interrupt来终止
1)interrupt方法能够设置标志位,也能唤醒sleep等阻塞的方法(会抛出异常)
2)sleep被唤醒后,会清空标志位
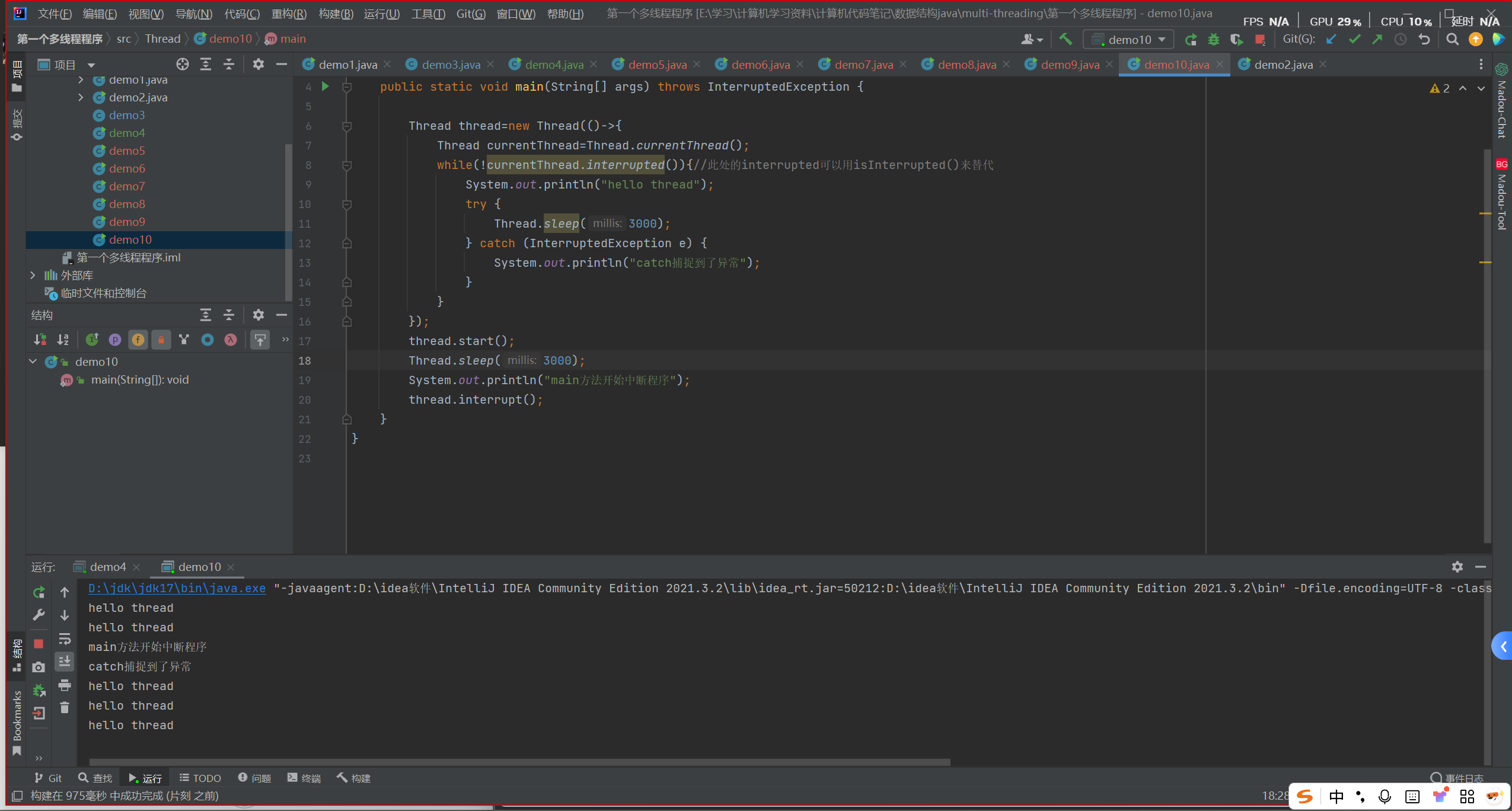 如图可以看出,标志位被sleep清空,并没有中断此线程
如图可以看出,标志位被sleep清空,并没有中断此线程
线程A和线程B,A希望B线程终止
1)如果B线程想无视A线程,就直接catch中啥也不做
B线程仍然会继续执行
sleep清除标志位,就可以使B能做出这种选择,如果sleep不清楚标志位,B势必会结束,无法写出继续让线程继续的代码
2)如果B线程想立即结束就直接在catch中写上return或者break
此时B线程就会立即结束
3)如果B想稍后再结束,就可以在catch中写上一些其他的逻辑(比如释放资源,清除硬一些数据,提交一些结果....收尾工作)
这些逻辑完成之后再进行return/break;
这些给了程序员更多的操作空间
2.5等待一个线程-join()
操作系统针对多个线程的执行是一个"随机调度,抢占式执行"的过程
线程等待就是在确定两个线程的结束顺序
无法确定两个线程调度执行顺序,但是可以控制谁先结束,谁后结束
让后结束的线程等待先结束的线程即可,此时后结束的线程会进入阻塞,一直到先结束的线程真的结束了,阻塞才结束
| 方法 | 说明 |
| public void join() | 等待线程结束 |
| public void join(long millis) | 等待线程结束,醉倒等millis毫秒 |
| public boid join(long millis,int nanos) 一般不用,后面是精确到纳秒 | 同理,但可以更高精度 |
因为计算机很难做到精确计时,一般能精准到ms就不错了
和操作系统相关像windows,linux系统,线程调度开销比较大,操作系统中还有一类系统"实时操作系统"就能把调度开销尽可能降低,开销小于一定的误差要求,从而可以做到更精准
Thread thread1=new Thread(()->{for(int i=0;i<3;i++){System.out.println("Hello thread1");try {Thread.sleep(1000);} catch (InterruptedException e) {e.printStackTrace();}}});Thread thread2=new Thread(()->{for(int i=0;i<4;i++){System.out.println("Hello thread2");try {Thread.sleep(1000);} catch (InterruptedException e) {e.printStackTrace();}}});System.out.println("main开始");thread1.start();thread2.start();try {thread1.join();} catch (InterruptedException e) {e.printStackTrace();}try {thread2.join();} catch (InterruptedException e) {e.printStackTrace();}System.out.println("main结束");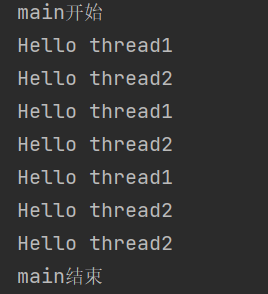
此代码为例,就是main线程等待thread1和thread2结束后才往下运行
当然不一定是main去等待,thread1也可以去等待thread2结束后再继续
代码如下
public static void main(String[] args) {Thread thread1=new Thread(()->{for(int i=0;i<3;i++){System.out.println("Hello thread1");try {Thread.sleep(1000);} catch (InterruptedException e) {e.printStackTrace();}}});Thread thread2=new Thread(()->{try {thread1.join();} catch (InterruptedException e) {e.printStackTrace();}for(int i=0;i<4;i++){System.out.println("Hello thread2");try {Thread.sleep(1000);} catch (InterruptedException e) {e.printStackTrace();}}});System.out.println("main开始");thread2.start();thread1.start();try {thread2.join();} catch (InterruptedException e) {e.printStackTrace();}System.out.println("main结束");}这里就是thread2中等待thread1
2.6获取当前线程的引用
| 方法 | 说明 |
| public static Thread currentThread(); | 返回当前线程对象的引用 |


2.7休眠当前线程
线程执行sleep,就会使得这个线程不参与CPU调度,从而把资源让出来给别人使用
"放权"
| 方法 | 说明 |
| public static void sleep(long millis) throws InterruptedException | 休眠当前线程 |
| public static void sleep(long millis,int nanos) throws InterruptedException | 可以更高精度精确到纳秒 |
3.线程的状态
进程的状态:
就绪:正在CPU上执行,或者随时可以去CPU上执行
阻塞:暂时不能去参与CPU执行
Java的线程对于状态做了更详细的区分,不仅仅是就绪和阻塞了
六种状态
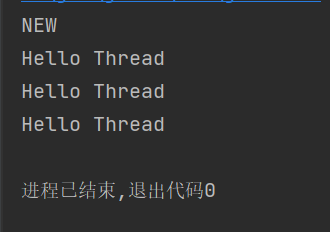
1.NEW 这种Thread对象虽然有了,但是内核的线程还没有(还没有调用start)
public static void main(String[] args) {//匿名内部类的lambda表达式创建Runnable子类对象,备份下Thread thread=new Thread(() -> {for (int i=0;i<3;i++){System.out.println("Hello Thread");try {Thread.sleep(1000);} catch (InterruptedException e) {e.printStackTrace();}}});System.out.println(thread.getState());thread.start();
}
2.TERMINATED 当前Thread对象虽然还在,但是内核的线程已经销毁(线程已经结束了)
public static void main(String[] args) {//匿名内部类的lambda表达式创建Runnable子类对象,备份下Thread thread=new Thread(() -> {for (int i=0;i<3;i++){System.out.println("Hello Thread");try {Thread.sleep(1000);} catch (InterruptedException e) {e.printStackTrace();}}});thread.start();try {Thread.sleep(5000);} catch (InterruptedException e) {e.printStackTrace();}System.out.println(thread.getState());}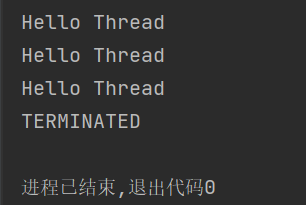
3.RUNNABLE 就绪状态.正在CPU上运行+随时可以去CPU上去运行
public static void main(String[] args) {//匿名内部类的lambda表达式创建Runnable子类对象,备份下Thread thread=new Thread(() -> {while(true){}});thread.start();System.out.println(thread.getState());}
4.BKLOCKED 因为锁竞争引起的阻塞
public static void main(String[] args) throws InterruptedException {//匿名内部类的lambda表达式创建Runnable子类对象,备份下Thread thread1=new Thread(() -> {synchronized (Locker) {for (int i = 0; i < 50000; i++) {count++;}}});Thread thread2=new Thread(()->{synchronized(Locker){for(int i=0;i<50000;i++) {System.out.println(thread1.getState());count++;}}});thread1.start();thread2.start();thread1.join();thread2.join();System.out.println(count);}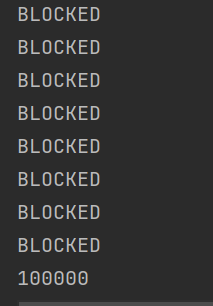
5.TIMED_WAITING 有超时时间的阻塞等待,比如sleep或者join带参数版本
public static void main(String[] args) {//匿名内部类的lambda表达式创建Runnable子类对象,备份下Thread thread=new Thread(() -> {while(true){System.out.println("hello thread");try {Thread.sleep(3000);} catch (InterruptedException e) {e.printStackTrace();}}});thread.start();try {Thread.sleep(1000);} catch (InterruptedException e) {e.printStackTrace();}System.out.println(thread.getState());}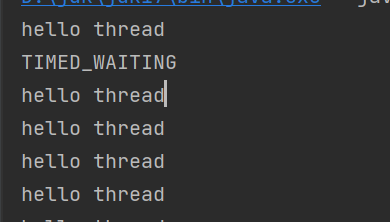
6.WAITING 没有超时时间的阻塞等待,join/wait
public static void main(String[] args) throws InterruptedException {//匿名内部类的lambda表达式创建Runnable子类对象,备份下Thread thread=new Thread(() -> {while(true){}});Thread thread2=new Thread(()->{try {thread.start();thread.join();} catch (InterruptedException e) {e.printStackTrace();}});thread2.start();Thread.sleep(3000);System.out.println(thread2.getState());}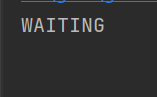
学习线程状态主要就是为了调试,比如遇到某个代码功能没有执行就可以观察对应线程的状态,看看是否是因为一些原因阻塞了.
相关文章:

JavaEE--2.多线程
1.认识线程(Thread) 1.1概念 1)什么是线程 ⼀个线程就是⼀个 "执行流". 每个线程之间都可以按照顺序执行自己的代码. 多个线程之间 "同时" 执行着多份代码. 2)为什么要有线程 首先, "并发编程" 成为 "刚需". 1. 单核 CPU 的发展遇到…...

沐渥氮气柜控制板温湿度氧含量氮气流量四显智控系统
氮气柜控制板通常用于实时监控和调节柜内环境参数,确保存储物品如电子元件、精密仪器、化学品等,处于低氧、干燥的稳定状态。以下是沐渥氮气柜控制板核心参数的详细介绍及控制逻辑: 一、控制板核心参数显示模块 1)温度显示&am…...

线性代数-矩阵的秩
矩阵的秩(Rank)是线性代数中的一个重要概念,表示矩阵中线性无关的行(或列)的最大数量。它反映了矩阵所包含的“有效信息”的维度,是矩阵的核心特征之一。 直观理解 行秩与列秩: 行秩࿱…...

【自然语言处理与大模型】模型压缩技术之量化
在这篇文章中想和大家分享什么是量化?为什么要量化?以及如何实现量化?通过这三个基本问题,我们不仅可以全面了解量化的内涵和外延,还能更清晰地认识到它在实践中的重要性和应用价值。 一、什么是量化呢? 大…...

OneClicker脚本自动运行工具
工作的时候,有很多琐碎的事情需要重复的做 比如打开某个文件,打开某个网站,打开某个软件 这个时候可以写个自动脚本,把机械琐碎的事情交给脚本处理 但是脚本一多,不好管理,而且要选择哪个脚本也是个麻烦的事…...

Activity之间交互
Backgroud: 想要实现Activity之间的交互,需要用到intent工具 本博客中所有第二Activity均为SecActivity,需要预先进行创建 本博客所使用的开发语言为Kotlin 使用intent调用Activity 显式调用 val intent Intent(this, SecActivity::class.…...

【React】搜索时高亮被搜索选中的文案
文章目录 代码实现 代码实现 函数封装: export function highlightKeyword(input: string, keyword: string | undefined) {if (!keyword || !input || !input.includes(keyword)) return input;const startIndex input.indexOf(keyword);return React.createEle…...
完全指南:从入门到精通)
MCP(Minecraft Coder Pack)完全指南:从入门到精通
1. 什么是MCP? Minecraft Coder Pack(简称MCP)是一套用于反编译、修改和重新编译Minecraft Java版源代码的工具集。它允许开发者深入研究Minecraft的底层代码,并在此基础上进行模组(Mod)开发、代码分析或自…...

stm32week12
stm32学习 九.stm32与HAL库 2.HAL库框架 总架构: 文件介绍: ppp是某一外设,ex是拓展功能 HAL库API函数和变量命名规则: HAL库对寄存器位操作的相关宏定义: HAL库的回调函数: 3.STM32启动过程 MDK编译过…...

mindspeed-rl使用注意事项
1、安装 参考1:docs/install_guide.md R1-CLM/MindSpeed-RL - Gitee.com 参考2:VLLM x Ascend框架_vllm-ascend-CSDN博客 2、SFT微调 整体参考docs/supervised_finetune.md 自定义数据格式同:AUTO-DL 910B mindspeed-llm 4层DeepSeek …...

第 4 篇:平稳性 - 时间序列分析的基石
第 4 篇:平稳性 - 时间序列分析的基石 在上一篇中,我们学习了如何将时间序列分解为趋势、季节性和残差。我们看到,很多真实世界的时间序列(比如 CO2 浓度)都包含明显的趋势(长期向上或向下)和/…...

KRaft面试思路引导
Kafka实在2.8之后就用KRaft进行集群管理了 Conroller负责选举Leader,同时Controller管理集群元数据状态信息,并将元数据信息同步给各个分区的Leader 和Zookeeper管理一样,会选出一个Broker作为Controller去管理整个集群,但是元数…...

怎么建立自然语言领域的评价标准
怎么建立自然语言领域的评价标准 明确评价目标与对象 首先要清晰界定评价的目标,比如是评估模型对文本语义的理解能力、生成文本的质量,还是系统在信息检索中的表现等。同时,明确评价对象,可能是一个语言模型、一个问答系统、一个机器翻译工具等。确定评价维度与指标 语言…...

EMQX学习笔记
MQTT简介 MQTT是一种基于发布订阅模式的消息传输协议 消息:设备和设备之间传输的数据,或者服务和服务之间传输的数据 协议:传输数据时所遵循的规则 轻量级:MQTT协议占用的请求源较少,数据报文较小 可靠较强ÿ…...
:虚拟列表-VirtualList)
组件是怎样写的(1):虚拟列表-VirtualList
本篇文章是《组件是怎样写的》系列文章的第一篇,该系列文章主要说一下各组件实现的具体逻辑,组件种类取自 element-plus 和 antd 组件库。 每个组件都会有 vue 和 react 两种实现方式,可以点击 https://hhk-png.github.io/components-show/ …...
)
CGAL 计算直线之间的距离(3D)
文章目录 一、简介二、实现代码三、实现效果一、简介 这里的计算思路很简单: 1、首先将两个三维直线均平移至过原点处,这里两条直线可以构成一个平面normal。 2、如果两个直线平行,那么两条直线之间的距离就转换为直线上一点到另一直线的距离。 3、如果两个直线不平行,则可…...

定期检查滚珠丝杆的频率是多久?
定期检查滚珠丝杆的频率通常是每半年进行一次,根据不同的使用环境和设备类型,滚珠丝杆的检查周期有所不同。接下来我们一起看看滚珠丝杆的维护保养方法: 1、清洗:每隔一段时间对滚珠丝杆进行清洁,将滚珠丝杆拆…...

Spark-SQL连接Hive全攻略
在大数据处理领域,Spark-SQL与Hive的结合能发挥强大的功能。今天就来给大家分享一下Spark-SQL连接Hive的多种方式。 Spark SQL编译时可选择包含Hive支持,这样就能使用Hive表访问、UDF、HQL等特性,而且无需提前安装Hive。其连接方式丰富多样…...

在Ubuntu 18.04下编译OpenJDK 11
在Ubuntu 18.04下编译OpenJDK 11 源码下载地址: 链接: https://pan.baidu.com/s/1QAdu-B6n9KqeBakGlpBS3Q 密码: 8lho Linux下的环境要求 不同版本的jdk会要求在不同版本的Ubuntu下编译,不要用太高版本的Ubuntu或者gcc,特别是gcc…...

Spring MVC 一个简单的多文件上传
原始代码逐行解释 PostMapping("/uploads") // ① 声明处理POST请求,路径为"/uploads" ResponseBody // ② 直接返回数据到响应体,不进行视图解析 public String uploads(MultipartFile[] files, // …...

FreeRTos学习记录--1.工程创建与源码概述
1.工程创建与源码概述 1.1 工程创建 使用STM32CubeMX,可以手工添加任务、队列、信号量、互斥锁、定时器等等。但是本课程不想严重依赖STM32CubeMX,所以不会使用STM32CubeMX来添加这些对象,而是手写代码来使用这些对象。 使用STM32CubeMX时&…...

Vmware esxi 给现有磁盘增加空间后并扩展系统里磁盘空间
当前EXSI上虚拟机所在的单独数据磁盘空间满了,需要对空间进行扩容,我们先在主机对磁盘容量进行调整,然后在系统里面对磁盘空间进行拓展,这些操作需要保留数据并且不改变现有的磁盘格局。 遵循大致操作流程是: 1.先登录…...

Linux基础学习--linux的文件权限与目录配置
linux的文件权限与目录配置 1.用户与用户组 在Linux中,每个文件都有相当多的属性和权限,其中最重要的概念就是文件的拥有者。 1.1 文件拥有者 Linux是一个多人多任务的系统,常常有多人共用一台主机的情况出现,因此在系统中可以…...

LLM大模型中的基础数学工具—— 约束优化
Q26: 推导拉格朗日乘子法 的 KKT 条件 拉格朗日乘子法与 KKT 条件是啥? 拉格朗日乘子法是解决约束优化问题的利器。比如,想最小化函数 ,同时满足约束 ,就构造拉格朗日函数 ( 是乘子)。KKT 条件是解这类问…...

涨薪技术|0到1学会性能测试第20课-关联技术
前面的推文我们掌握了性能测试脚本开发参数化技术一系列知识,今天开始给大家分享关联技术知识,后续文章都会系统分享干货,带大家从0到1学会性能测试! 关联是LoadRunner中一个很重要的应用,对于初学者来说也是最容易犯错的地方,但是很遗憾的是,并没有任何特定的错误与关联…...

SpringAI入门示例
AI编程简介 纯Prompt模式 纯Prompt模式是AI编程中最基础的交互架构。用户通过输入自然语言文本(即Prompt)向AI模型发出指令,模型依据自身预训练所积累的知识和语言理解能力,直接生成相应的文本响应。其工作原理是,用…...

SQL 中 ROLLUP 的使用方法
ROLLUP 是 SQL 中一种分组操作,它生成多个分组集的小计行和总计行,提供层次化的汇总数据。 基本语法 SELECT column1, column2, ..., aggregate_function(column) FROM table GROUP BY ROLLUP (column1, column2, ...); 使用示例 假设有一个销售表 sal…...
)
Web前端:Overflow属性(超出裁剪属性)
一、什么是 Overflow? 在网页布局中,容器(如 <div>、<section> 等)通常有固定尺寸(如 width 和 height)。当容器内的内容(文本、图片等)超出容器边界时,就会…...

20250421在荣品的PRO-RK3566开发板的Android13下使用io命令控制GPIO
20250421在荣品的PRO-RK3566开发板的Android13下使用io命令控制GPIO 2025/4/21 10:44 【本文只打开了io命令。通过io控制GPIO放到下一篇了】 缘起:需要在荣品的PRO-RK3566开发板的Android13的u-boot中来控制GPIO3A1【配置以太网RTL8211F-CG】。 直接使用GPIO库函数 …...

20250421在荣品的PRO-RK3566开发板的Android13下频繁重启RKNPU fde40000.npu: Adding to iommu gr
20250421在荣品的PRO-RK3566开发板的Android13下频繁重启RKNPU fde40000.npu: Adding to iommu gr 2025/4/21 14:50 缘起:电池没电了,导致荣品的PRO-RK3566的核心板频繁重启。 内核时间4s就重启。100%复现。 PRO-RK3566 Android13启动到这里 复位&#…...

在 8MHz 的时钟电路中挂接电阻,电容
匹配电阻:在晶体振荡电路中,用于匹配晶体和振荡电路的阻抗,确保振荡的稳定性,阻值通常在几十千欧到几百千欧,例如 1MΩ、33KΩ、47KΩ 等。 在一些电子电路中,尤其是涉及到时钟信号的产生和传输时…...

卸载工具:IObit Uninstaller Pro v14.3.0 中文绿色专业便携版
IObit Uninstaller 是一种功能强大的卸载工具,可帮助您快速方便地从计算机中移除不需要的程序和文件夹。它不仅仅可以从计算机中卸载应用程序,还可以移除它们的卸载残留。可以检测和分类所有已安装的程序,并可以批量卸载,只需一键…...

【目标检测】目标检测综述 目标检测技巧
I. 目标检测中标注的关键作用 A. 目标检测数据标注的定义 目标检测是计算机视觉领域的一项基础且核心的任务,其目标是在图像或视频中准确识别并定位出预定义类别的目标实例 1。数据标注,在目标检测的语境下,指的是为原始视觉数据࿰…...

c++基础·move作用,原理
目录 一、代码结构概览 二、逐层解析实现逻辑 1. 模板参数推导 2. 返回类型设计 3. 类型转换逻辑 三、关键特性与设计思想 1. 移动语义的本质 2. 为何必须用 remove_reference 3. 万能引用的兼容性 四、边界场景与注意事项 1. 对 const 对象的处理 2. 返回值优化&a…...

考研系列-计算机网络-第四章、网络层
一、网络层的概述和功能 1.功能概述 2.SDN的基本概念...

服务器在国外国内用户访问慢会影响谷歌排名吗?
谷歌明确将“页面加载速度”和“用户体验”作为排名核心指标,但当服务器物理距离过远时,国内用户动辄3秒以上的加载延迟,可能导致跳出率飙升、爬虫抓取困难等连锁反应。 但盲目将服务器迁回国内,又会面临备案成本、运维门槛等新难…...

iFable,AI角色扮演互动平台,自动生成沉浸式故事游戏
iFable是什么 iFable 是一个以动漫角色为主题的互动角色扮演游戏平台,旨在为用户提供沉浸式的故事冒险体验。平台允许玩家通过简单的创意输入,利用AI技术生成独特的互动故事与游戏体验。iFable 的设计宗旨在于帮助玩家与虚拟角色建立情感连接࿰…...

Nginx反向代理用自定义Header参数
【啰嗦两句】 也不知道为啥,我仅仅想在Nginx的反向代理中使用自己定义的“x-api-key”做Header参数,却发现会被忽略,网上搜的资料都是说用“proxy_set_header”,却只愿意介绍最基本的几个参数,你懂的,那些资…...
)
Spark SQL概述(专业解释+生活化比喻)
专业解释 一、什么是Spark SQL? 一句话定义: Spark SQL是Apache Spark中专门处理结构化数据的模块,可以让你像操作数据库表一样处理数据,支持用SQL查询或编程API(DataFrame/DataSet)分析数据。 通俗理解…...

LX3-初识是单片机
初识单片机 一 什么是单片机 单片机:单片微型计算机单片机的组成:CPU,RAM(内存),flash(硬盘),总线,时钟,外设…… 二 Coretex-M系列介绍 了解ARM公司与ST公司ARM内核系列: A 高性能应用,如手机,电脑…R 实时性强,如汽车电子,军工…M 超低功耗,如消费电子,家电,医疗器械 三…...
)
第二章 Logback的架构(一)
Logback的架构 Logback作为一个通用框架,可以应对不同场景的日志记录。目前,Logback 被划分为三个模块:logback-core、logback-classic 和 logback-access。 Logback的core模块为其他两个模块提供基础支持。classic模块扩展了core模块&…...

开发指南:构建结合数字孪生、大语言模型与知识图谱的智能设备日志分析及生产异常预警系统
1. 引言:数字孪生、大语言模型与知识图谱在智能制造中的融合 智能制造和工业4.0的浪潮正在重塑全球制造业格局,其核心在于利用先进的数字技术实现生产过程的实时决策、效率提升、灵活性增强和敏捷性改进。在这一转型过程中,数字孪生…...

【TeamFlow】4.1 Git使用指南
以下是 Git 在 Windows 系统上的配置和使用指南,包含详细步骤和注意事项: 安装 Git for Windows 下载与安装 前往 Git 官网 下载 Windows 版安装包 双击安装,关键选项建议: 选择 Use Git from Git Bash only(推荐&…...
)
HADOOP 3.4.1安装和搭建(尚硅谷版~)
目录 1.配置模版虚拟机 2.克隆虚拟机 3.在hadoop102安装JDK 4.完全分布式运行模式 1.配置模版虚拟机 1.安装模板虚拟机,IP地址192.168.10.100、主机名称hadoop100、内存2G、硬盘20G(有需求的可以配置4G内存,50G硬盘) 2.hado…...
)
通过Docker Desktop配置OpenGauss数据库的方法(详细版+图文结合)
文章目录 通过Docker Desktop配置OpenGauss数据库的方法**一、下载Docker Desktop,并完成安装**docker官网:https://www.docker.com/ **二、下载OpenGauss压缩包**安装包下载链接:https://opengauss.obs.cn-south-1.myhuaweicloud.com/7.0.0-…...

文件有几十个T,需要做rag,用ragFlow能否快速落地呢?
一、RAGFlow的优势 1、RAGFlow处理大规模数据性能: (1)、RAGFlow支持分布式索引构建,采用分片技术,能够处理TB级数据。 (2)、它结合向量搜索和关键词搜索,提高检索效率。 …...

SystemVerilog语法之内建数据类型
简介:SystemVerilog引进了一些新的数据类型,具有以下的优点:(1)双状态数据类型,更好的性能,更低的内存消耗;(2)队列、动态和关联数组,减少内存消耗…...

TensorFlow和PyTorch学习原理解析
这里写目录标题 TensorFlow和PyTorch学习&原理解析TensorFlow介绍原理部署适用场景 PyTorch介绍原理部署适用场景 Keras模型格式SavedModelONNX格式 TensorFlow和PyTorch学习&原理解析 TensorFlow 介绍 由 Google Brain 团队开发并于 2015 年开源。由于 Google 的强…...

悬空引用和之道、之禅-《分析模式》漫谈57
DDD领域驱动设计批评文集 做强化自测题获得“软件方法建模师”称号 《软件方法》各章合集 “Analysis Patterns”的第5章“对象引用”原文: Unless you can catch all such references, there is the risk of a dangling reference, which often has painful con…...

江湖密码术:Rust中的 bcrypt 加密秘籍
前言 江湖险恶,黑客如雨,昔日密码“123456”早被各路大侠怒斥为“纸糊轻功”。若还执迷不悟,用明文密码闯荡江湖,无异于身披藏宝图在集市上狂奔,目标大到闪瞎黑客双眼。 为护你安然度过每一场数据风波,特献上一门绝学《Rust加密神功》。核心招式正是传说中的 bcrypt 密…...