HADOOP 3.4.1安装和搭建(尚硅谷版~)
目录
1.配置模版虚拟机
2.克隆虚拟机
3.在hadoop102安装JDK
4.完全分布式运行模式
1.配置模版虚拟机
1.安装模板虚拟机,IP地址192.168.10.100、主机名称hadoop100、内存2G、硬盘20G(有需求的可以配置4G内存,50G硬盘)
2.hadoop100虚拟机配置要求(本文Linux系统以CentOS-7.5-x86_64-DVD-1804.iso为例)
(1)先看能否正常上网
[root@hadoop100 ~]# ping www.baidu.com
PING www.a.shifen.com (183.2.172.177) 56(84) bytes of data.
64 bytes from 183.2.172.177 (183.2.172.177): icmp_seq=1 ttl=128 time=20.6 ms
64 bytes from 183.2.172.177 (183.2.172.177): icmp_seq=2 ttl=128 time=21.3 ms
64 bytes from 183.2.172.177 (183.2.172.177): icmp_seq=3 ttl=128 time=23.4 ms
(2)然后安装epel-release
[root@hadoop100 ~]# yum install -y epel-release
Loaded plugins: fastestmirror, langpacks
Determining fastest mirrors
epel/x86_64/metalink | 5.1 kB 00:00:00
* epel: d2lzkl7pfhq30w.cloudfront.net
base | 3.6 kB 00:00:00
extras | 2.9 kB 00:00:00
updates | 2.9 kB 00:00:00
Package epel-release-7-14.noarch already installed and latest version
Nothing to do
我这个是已经安装过了的
(3)检查是否有ifconfig和vim等命令,没有则下载
[root@hadoop100 ~]# yum install -y net-tools
Loaded plugins: fastestmirror, langpacks
Loading mirror speeds from cached hostfile
* epel: d2lzkl7pfhq30w.cloudfront.net
Resolving Dependencies
[root@hadoop100 ~]# yum install -y net-tools
Loaded plugins: fastestmirror, langpacks
Loading mirror speeds from cached hostfile
* epel: d2lzkl7pfhq30w.cloudfront.net
Resolving Dependencies
--> Running transaction check
---> Package net-tools.x86_64 0:2.0-0.22.20131004git.el7 will be updated
(4)关闭防火墙
[root@hadoop100 ~]# sudo systemctl stop firewalld
关闭防火墙
[root@hadoop100 ~]# sudo systemctl disable firewalld
Removed symlink /etc/systemd/system/multi-user.target.wants/firewalld.service.
Removed symlink /etc/systemd/system/dbus-org.fedoraproject.FirewallD1.service.
关闭自启动
验证是否关闭防火墙
[root@hadoop100 ~]# systemctl status firewalld
● firewalld.service - firewalld - dynamic firewall daemon
Loaded: loaded (/usr/lib/systemd/system/firewalld.service; enabled; vendor preset: enabled)
Active: inactive (dead) since Mon 2025-04-21 02:54:55 PDT; 3min 55s ago
Docs: man:firewalld(1)
Process: 677 ExecStart=/usr/sbin/firewalld --nofork --nopid $FIREWALLD_ARGS (code=exited, status=0/SUCCESS)
Main PID: 677 (code=exited, status=0/SUCCESS)
Apr 21 02:43:14 hadoop100 systemd[1]: Starting firewalld - dynamic firewall daemon...
Apr 21 02:43:14 hadoop100 systemd[1]: Started firewalld - dynamic firewall daemon.
Apr 21 02:54:54 hadoop100 systemd[1]: Stopping firewalld - dynamic firewall daemon...
Apr 21 02:54:55 hadoop100 systemd[1]: Stopped firewalld - dynamic firewall daemon.
这个就显示已经关闭防火墙了,不过会开机自启
[root@hadoop100 ~]# systemctl status firewalld
● firewalld.service - firewalld - dynamic firewall daemon
Loaded: loaded (/usr/lib/systemd/system/firewalld.service; disabled; vendor preset: enabled)
Active: inactive (dead)
Docs: man:firewalld(1)
Apr 21 02:43:14 hadoop100 systemd[1]: Starting firewalld - dynamic firewall daemon...
Apr 21 02:43:14 hadoop100 systemd[1]: Started firewalld - dynamic firewall daemon.
Apr 21 02:54:54 hadoop100 systemd[1]: Stopping firewalld - dynamic firewall daemon...
Apr 21 02:54:55 hadoop100 systemd[1]: Stopped firewalld - dynamic firewall daemon.
这个则显示关闭防火墙,并且不会开机自启
如果你想打开防火墙,你可以
sudo systemctl start firewalld
如果要打开开机自启
sudo systemctl enable firewalld
(5)创建用户,并且更改密码,我用的是perf1,你们可以自由选择
[root@hadoop100 ~]# useradd perf1
[root@hadoop100 ~]# passwd perf1
Changing password for user perf1.
New password:
BAD PASSWORD: The password is shorter than 8 characters
Retype new password:
passwd: all authentication tokens updated successfully.
(6)给我们的用户添加root权限(添加免密功能),方便后期加sudo执行root权限的命令
[root@hadoop100 ~]# vim /etc/sudoers
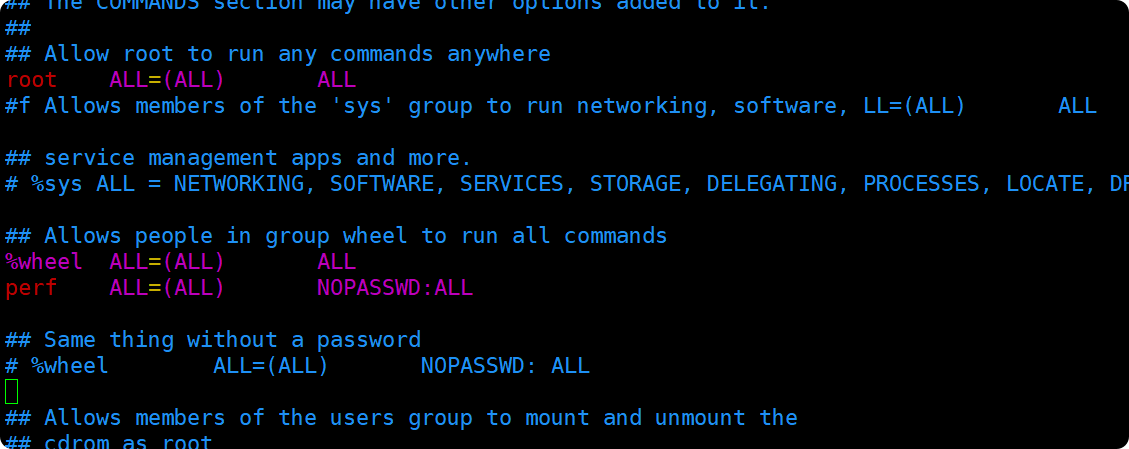
在%wheel这行下面添加一行,
perf ALL=(ALL) NOPASSWD:ALL
要注意,不要添加到root下方,因为所有的用户都在%wheel组那里,如果添加到root下面,后面仍然还是要输密码
(7)在 /opt 目录下创建module、software文件夹,然后修改他们所属主和所属组
mkdir /opt/module
mkdir /opt/software
用这两串代码创建文件夹,然后
chown perf:perf /opt/module
chown perf:perf /opt/software
用这两串代码把他们的所属组和主都为自己的用户,我是perf,你们用自己的用户就好
(8)卸载虚拟机自带的jdk
[root@hadoop100 ~]# rpm -qa | grep -i java | xargs -n1 rpm -e --nodeps
rpm -qa:查询所安装的所有rpm软件包
grep -i:忽略大小写
xargs -n1:表示每次只传递一个参数
rpm -e –nodeps:强制卸载软件
(9)重启虚拟机
reboot
2.克隆虚拟机
1.在关闭hadoop100的条件下,克隆三个虚拟机,我的是命名为hadoop102,hadoop103,hadoop104
2.修改克隆机IP,以下以hadoop102举例说明
(1)修改克隆虚拟机的静态IP
[root@hadoop102 ~]# vim /etc/sysconfig/network-scripts/ifcfg-ens33
改成
TYPE="Ethernet"
PROXY_METHOD="none"
BROWSER_ONLY="no"
BOOTPROTO="static"
DEFROUTE="yes"
IPV4_FAILURE_FATAL="no"
IPV6INIT="yes"
IPV6_AUTOCONF="yes"
IPV6_DEFROUTE="yes"
IPV6_FAILURE_FATAL="no"
IPV6_ADDR_GEN_MODE="stable-privacy"
NAME="ens33"
UUID="9687cc8e-3361-48c3-831d-bb57555426e0"
DEVICE="ens33"
ONBOOT="yes"
IPADDR=192.168.10.102
GATEWAY=192.168.10.2
DNS1=192.168.10.2
你对照着改就好了,然后对应不同机子,就是不同的192.168.10.103->hadoop103。
(2)查看Linux虚拟机的虚拟网络编辑器,编辑->虚拟网络编辑器->VMnet8
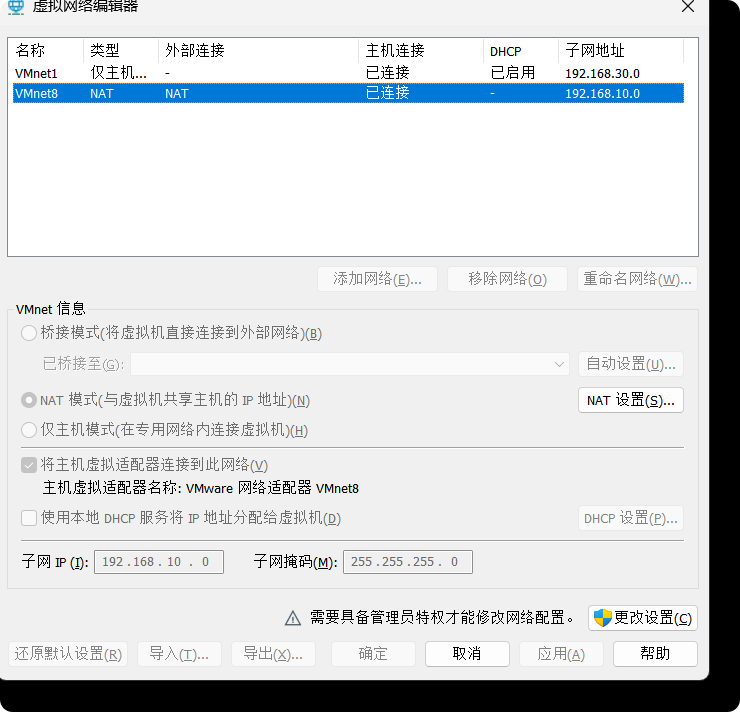
进入管理员模式
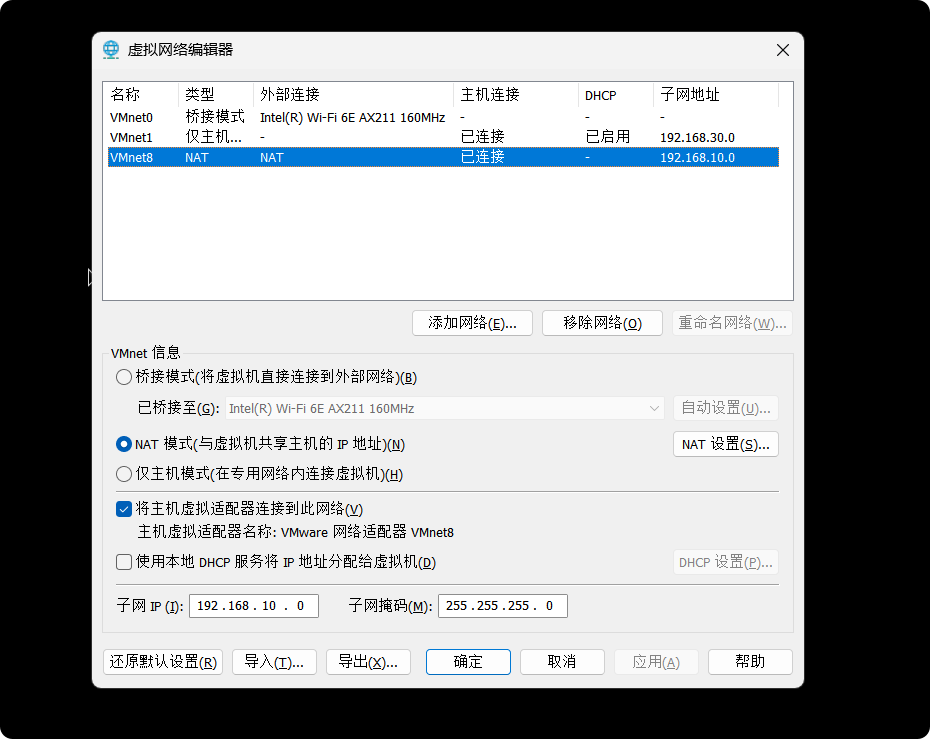
然后把VMnet8改为NAT模式,把子网和掩码改好
进入NAT设置
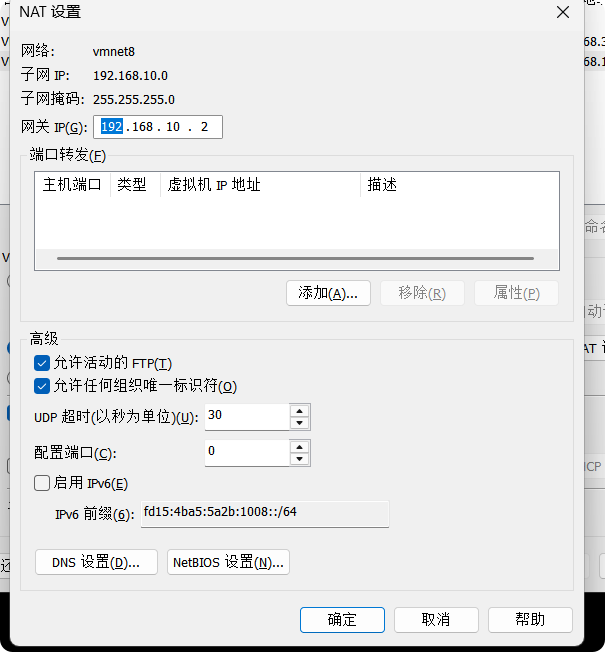
检查一下是否有问题,然后点击确定
(3)接下来就是把Windows系统的系统适配器VMware Network Adapter VMnet8的IP地址改好
进入控制面板->网络和internet->网络和共享中心,然后点击更改适配器选项。
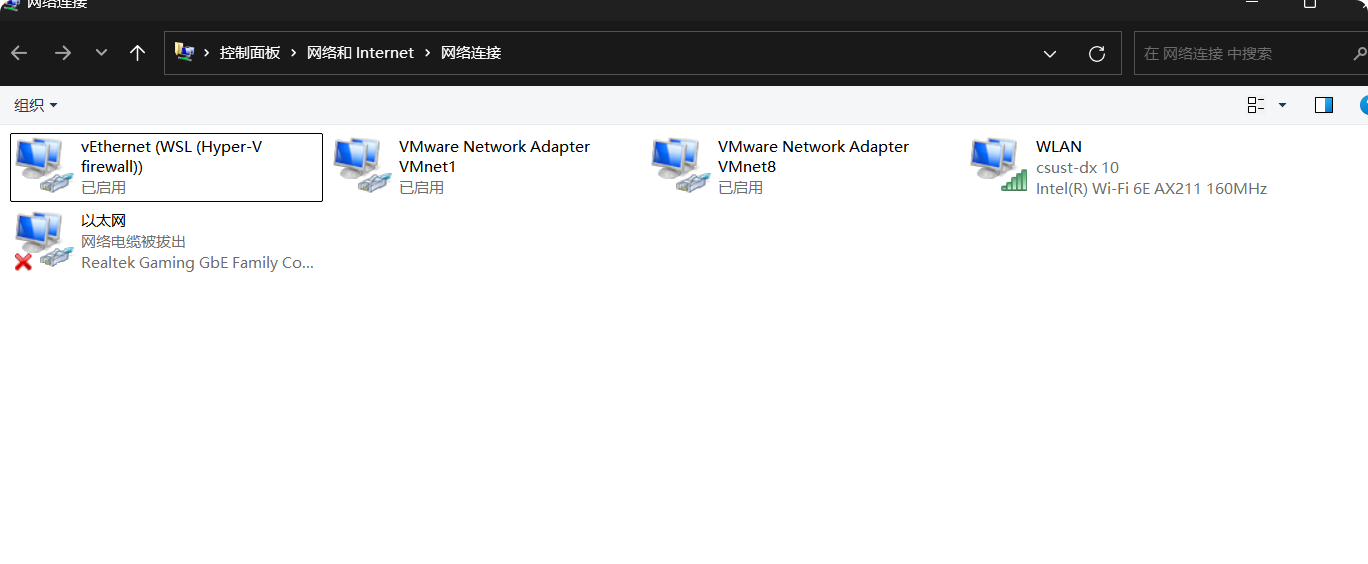
右键该配置,然后点击属性,找到ipv4的协议
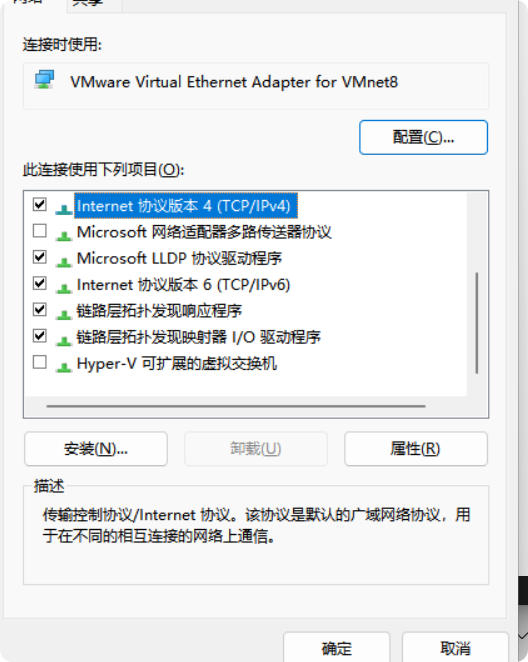
然后点击属性
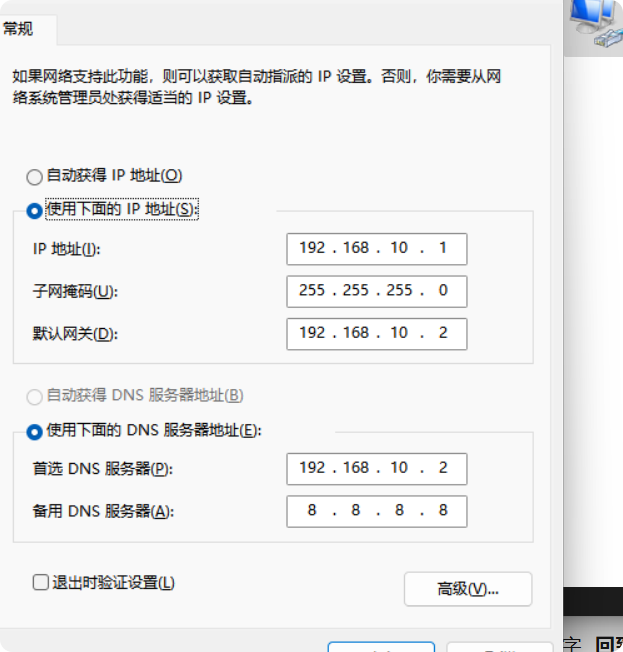
按照这样更改就好了,一定要保证Linux系统ifcfg-ens33文件中IP地址、虚拟网络编辑器地址和Windows系统VM8网络IP地址相同。
3.修改克隆机主机名,我以hadoop102举例说明
(1)修改主机名称
[root@hadoop100 ~]# vim /etc/hostname
hadoop102
(2)配置Linux克隆机主机名称映射hosts文件,打开/etc/hosts
[root@hadoop100 ~]# vim /etc/hosts
添加如下内容
192.168.10.102 hadoop102
192.168.10.103 hadoop103
192.168.10.104 hadoop104
然后重启(reboot)克隆机
4.修改windows的主机映射文件(hosts文件),不这样的话到时候无法直接在网页上用hadoop102![]() http://hadoop102:9870/
http://hadoop102:9870/
访问,到那时候也不要着急,因为你配置了前面的文件,你仍然可以用
http://192.168.10.102/![]() http://192.168.10.102:9870/
http://192.168.10.102:9870/
访问你的hadoop
我举例window11
(1)进入C:\Windows\System32\drivers\etc路径
(2)拷贝hosts文件到桌面
(3)打开桌面hosts文件并添加如下内容
192.168.10.102 hadoop102
192.168.10.103 hadoop103
192.168.10.104 hadoop104
(4)将桌面hosts文件覆盖C:\Windows\System32\drivers\etc路径hosts文件
3.在hadoop102安装JDK
1.用XShell传输工具将JDK导入到opt目录下面的software文件夹下面
XShell和XFTP下载地址:
家庭/学校免费 - NetSarang Website
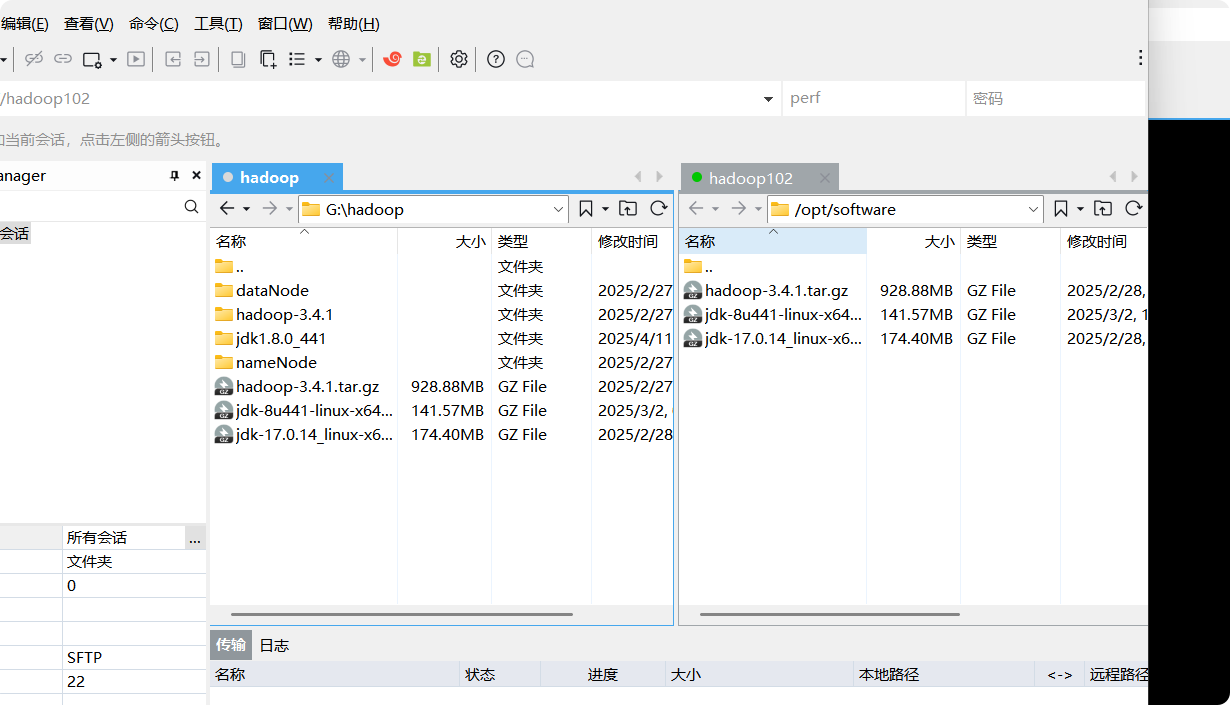
我们直接把hadoop-3.4.1.tar.gz和jdk-8u441-linux-x64.tar.gz复制过去
2.在Linux系统下的software目录中查看软件包是否导入成功
[perf@hadoop102 software]$ cd /opt/software/
[perf@hadoop102 software]$ ll

3.解压我们的导入
tar -zxvf jdk-8u441-linux-x64.tar.gz -C /opt/module/
tar -zxvf hadoop-3.4.1.tar.gz -C /opt/module/
4.配置环境变量和hadoop
(1)新建/etc/profile.d/my_env.sh文件
[perf@hadoop102 ~]$ sudo vim /etc/profile.d/my_env.sh
添加如下内容
#JAVA_HOME
export JAVA_HOME=/opt/module/jdk1.8.0_441
export PATH=$PATH:$JAVA_HOME/bin
#HADOOP_HOME
export HADOOP_HOME=/opt/module/hadoop-3.4.1
export PATH=$PATH:$HADOOP_HOME/bin
export PATH=$PATH:$HADOOP_HOME/sbin
(2)保存后退出
:wq
(3)source一下/etc/profile文件,让新的环境变量PATH生效
[perf@hadoop102 ~]$ source /etc/profile
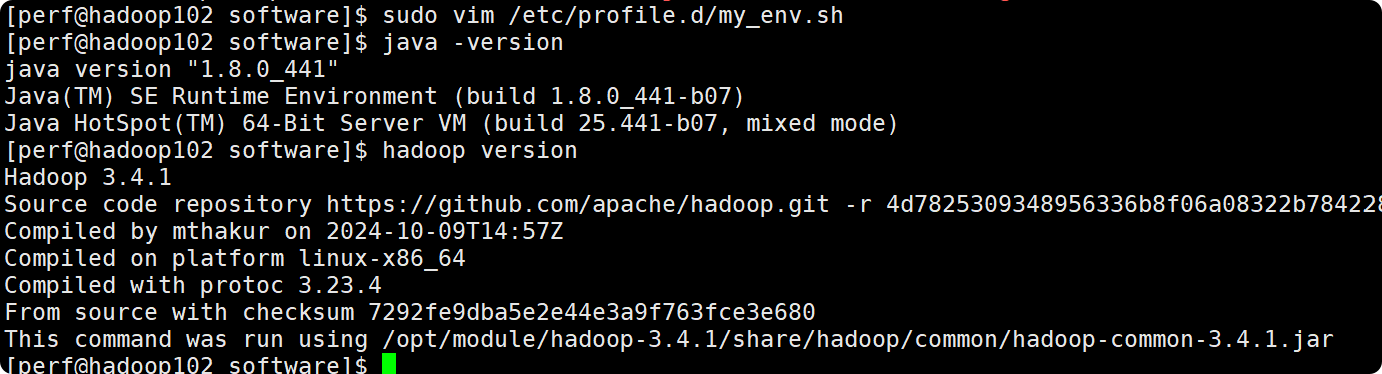
5.测试是否安装成功
[perf@hadoop102 ~]$ java -version
[perf@hadoop102 hadoop-3.1.3]$ hadoop version
出现以下内容,代表成功:
6.sudo reboot,重启,如果命令可以用,那就不要重启
4.完全分布式运行模式
1.SSH无密登录配置
(1)配置ssh
(1)基本语法
ssh另一台电脑的IP地址
(2)ssh连接时出现Host key verification failed的解决方法
[perf@hadoop102 ~]$ ssh hadoop103
如果出现如下内容
Are you sure you want to continue connecting (yes/no)?
输入yes,并回车
(3)退回到hadoop102
[perf@hadoop103 ~]$ exit
(2)无密钥配置
(1)
[perf@hadoop102 ~]$ cd /home/perf/.ssh/
[perf@hadoop102 .ssh]$ ll
total 16
-rw-------. 1 perf perf 1188 Mar 1 00:44 authorized_keys
-rw-------. 1 perf perf 1679 Mar 1 00:19 id_rsa
-rw-r--r--. 1 perf perf 396 Mar 1 00:19 id_rsa.pub
-rw-r--r--. 1 perf perf 558 Feb 28 23:08 known_hosts
[perf@hadoop102 .ssh]$ ssh-keygen -t rsa
然后敲(三个回车),就会生成两个文件id_rsa(私钥)、id_rsa.pub(公钥)
[perf@hadoop102 .ssh]$ ssh-copy-id hadoop102
[perf@hadoop102 .ssh]$ ssh-copy-id hadoop103
[perf@hadoop102 .ssh]$ ssh-copy-id hadoop104
然后分别在hadoop103和hadoop104的perf用户进行一样的操作,然后在hadoop102的root也做一个一样的。
2.集群配置
|
| hadoop102 | hadoop103 | hadoop104 |
| HDFS
| NameNode DataNode |
DataNode | SecondaryNameNode DataNode |
| YARN |
NodeManager | ResourceManager NodeManager |
NodeManager |
(1)核心配置文件
[perf@hadoop102 .ssh]$ cd $HADOOP_HOME/etc/hadoop
[perf@hadoop102 hadoop]$ vim core-site.xml
更改文件内容:
<configuration>
<!-- HDFS默认访问地址 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://hadoop102:9000</value>
</property>
<!-- Hadoop目录(所有节点) -->
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/module/hadoop-3.4.1/data</value>
<!--配置HDFS网页静态用户为perf-->
</property>
<property>
<name>hadoop.http.staticuser.user</name>
<value>perf</value>
</property>
</configuration>
(2)HDFS配置文件
[perf@hadoop102 hadoop]$ vim hdfs-site.xml
更改文件内容:
<configuration>
<!-- NameNode HTTP Web UI地址 -->
<property>
<name>dfs.namenode.http-address</name>
<value>hadoop102:9870</value> <!-- 绑定到主节点的主机名和端口 -->
</property>
<!-- NameNode HTTPS Web UI地址(可选) -->
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>hadoop104:9871</value>
</property>
<property>
<name>dfs.webhdfs.enabled</name>
<value>true</value>
</property>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
</configuration>
(3)YARN配置文件
[perf@hadoop102 hadoop]$ vim yarn-site.xml
更改文件配置:
<!-- 环境变量白名单(修正后) -->
<property>
<name>yarn.nodemanager.env-whitelist</name>
<value>JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,HADOOP_YARN_HOME,HADOOP_MAPRED_HOME,CLASSPATH_PREPEND_DISTCACHE</value>
</property>
<!-- 新增配置:启用日志聚集功能 -->
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<!-- 新增配置:日志保留时间(7 天) -->
<property>
<name>yarn.log-aggregation.retain-seconds</name>
<value>604800</value>
</property>
<property>
<name>yarn.log.server.url</name>
<value>http://hadoop102:19888/jobhistory/logs</value>
</property>
</configuration>
(4)MapReduce配置文件
[perf@hadoop102 hadoop]$ vim mapred-site.xml
更改文件配置:
<configuration>
<!-- 指定使用YARN -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>hadoop102:10020</value> <!-- 历史服务器RPC地址 -->
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>hadoop102:19888</value> <!-- 历史服务器Web UI地址 -->
</property>
</configuration>
3.分发配置到其他节点
(1)编写xsync集群分发脚本(循环复制文件到所有节点的相同目录下)
这是原始拷贝:rsync -av /opt/module perf@hadoop103:/opt/
现在我们编写脚本实现便利分发:
(1)在/home/perf/bin目录下创建xsync文件
[perf@hadoop102 opt]$ cd /home/perf
[perf@hadoop102 ~]$ mkdir bin
[perf@hadoop102 ~]$ cd bin
[perf@hadoop102 bin]$ vim xsync
#!/bin/bash
# 检查参数是否为空
if [ $# -lt 1 ]; then
echo "请提供要同步的文件或目录!"
exit 1
fi
# 定义要同步的服务器列表,这里需要根据实际情况修改
servers=(hadoop102 hadoop103 hadoop104)
# 获取当前执行脚本的用户
user=$(whoami)
# 获取要同步的文件或目录的绝对路径
pdir=$(cd -P "$(dirname "$1")" && pwd)
fname=$(basename "$1")
# 检查路径是否有效
if [ -z "$pdir" ] || [ -z "$fname" ]; then
echo "无法获取有效的文件或目录路径,请检查输入。"
exit 1
fi
# 遍历服务器列表
for server in "${servers[@]}"; do
echo "================== $server =================="
# 使用 rsync 命令进行同步
rsync -avzP "$pdir/$fname" "$user@$server:$pdir"
rsync_status=$?
# 检查同步是否成功
if [ $rsync_status -eq 0 ]; then
echo "$server 同步成功!"
else
case $rsync_status in
1)
echo "$server 同步失败:协议错误。"
;;
2)
echo "$server 同步失败:语法错误。"
;;
10)
echo "$server 同步失败:无法连接到远程主机。请检查网络连接和 SSH 服务是否正常。"
;;
11)
echo "$server 同步失败:远程主机上的 rsync 服务未运行。"
;;
12)
echo "$server 同步失败:请求的操作不支持。"
;;
13)
echo "$server 同步失败:读取本地文件时出错。"
;;
*)
echo "$server 同步失败:未知错误,错误码 $rsync_status。"
;;
esac
fi
done
(2)修改权限
chmod +x xsync
(3)测试脚本
[perf@hadoop102 ~]$ xsync /home/perf/bin
(d)将脚本复制到/bin中,以便全局调用
[perf@hadoop102 bin]$ sudo cp xsync /bin/
(e)同步环境变量配置(root所有者)
[perf@hadoop102 ~]$ sudo ./bin/xsync /etc/profile.d/my_env.sh
注意:如果用了sudo,那么xsync一定要给它的路径补全。
让环境变量生效
[perf@hadoop103 ~]$ source /etc/profile
[perf@hadoop104 ~]$ source /etc/profile
接下来,你可以用这个同步各个位置的东西了。由于前面关于环境的配置没有分发,所以你可以一次性分发
[perf@hadoop102 bin]$ xsync /opt
4.建起集群
(1)配置workers
[perf@hadoop102 bin]$ vim /opt/module/hadoop-3.4.1/etc/hadoop/workers
hadoop103
hadoop104
hadoop102
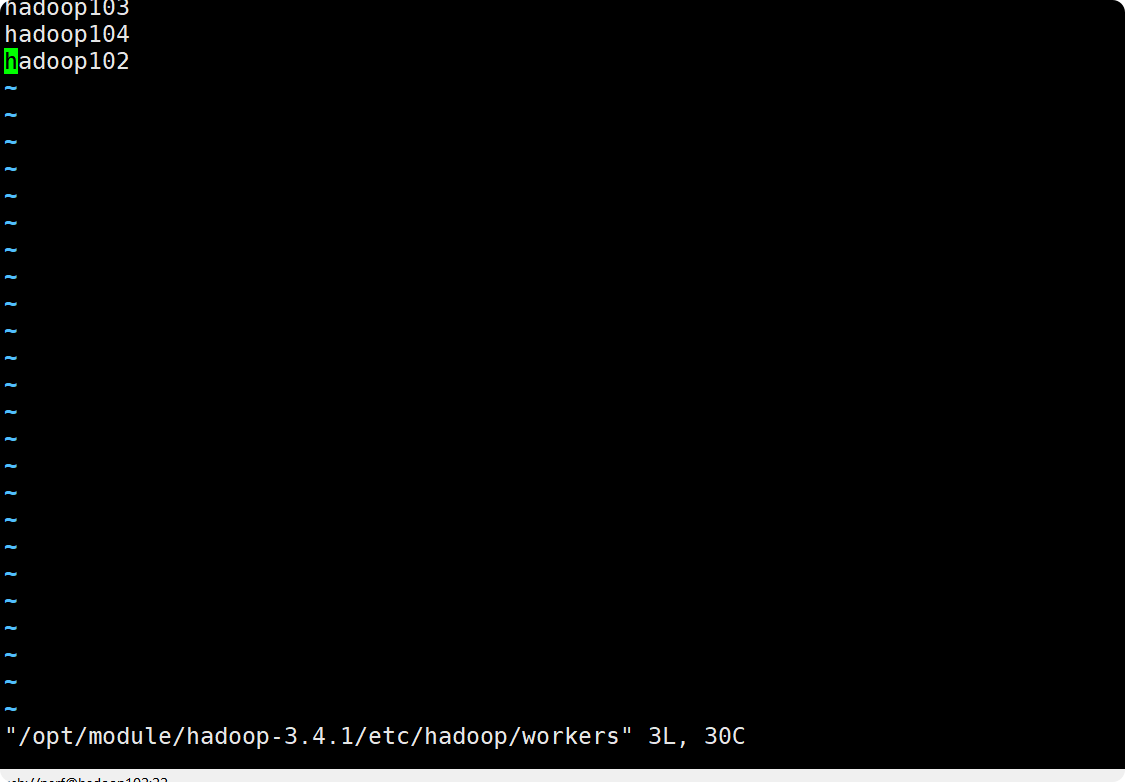
注意:该文件中添加的内容结尾不允许有空格,文件中不允许有空行。
(2)启动集群
如果集群是第一次启动,需要在hadoop102节点格式化NameNode(注意:格式化NameNode,会产生新的集群id,导致NameNode和DataNode的集群id不一致,集群找不到已往数据。如果集群在运行过程中报错,需要重新格式化NameNode的话,一定要先停止namenode和datanode进程,并且要删除所有机器的data和logs目录,然后再进行格式化。)
[perf@hadoop102 hadoop-3.4.1]$ hdfs namenode -format
启动HDFS
[perf@hadoop102 hadoop-3.4.1]$ sbin/start-dfs.sh
在配置了ResourceManager的节点(hadoop103)启动YARN
[perf@hadoop103 hadoop-3.4.1]$ sbin/start-yarn.sh
在Web端查看HDFS的NameNode
(1)浏览器中输入:http://hadoop102:9870
(2)查看HDFS上存储的数据信息
在Web端查看YARN的ResourceManager
(1)浏览器中输入:http://hadoop103:8088
(2)查看YARN上运行的Job信息
注意:如果有点击无法打开的,可以试试把hadoop102改为原始192.168.10.102.如果可以打开,说明原来的hosts配置有问题。
整个集群就简单配置好了!
相关文章:
)
HADOOP 3.4.1安装和搭建(尚硅谷版~)
目录 1.配置模版虚拟机 2.克隆虚拟机 3.在hadoop102安装JDK 4.完全分布式运行模式 1.配置模版虚拟机 1.安装模板虚拟机,IP地址192.168.10.100、主机名称hadoop100、内存2G、硬盘20G(有需求的可以配置4G内存,50G硬盘) 2.hado…...
)
通过Docker Desktop配置OpenGauss数据库的方法(详细版+图文结合)
文章目录 通过Docker Desktop配置OpenGauss数据库的方法**一、下载Docker Desktop,并完成安装**docker官网:https://www.docker.com/ **二、下载OpenGauss压缩包**安装包下载链接:https://opengauss.obs.cn-south-1.myhuaweicloud.com/7.0.0-…...

文件有几十个T,需要做rag,用ragFlow能否快速落地呢?
一、RAGFlow的优势 1、RAGFlow处理大规模数据性能: (1)、RAGFlow支持分布式索引构建,采用分片技术,能够处理TB级数据。 (2)、它结合向量搜索和关键词搜索,提高检索效率。 …...

SystemVerilog语法之内建数据类型
简介:SystemVerilog引进了一些新的数据类型,具有以下的优点:(1)双状态数据类型,更好的性能,更低的内存消耗;(2)队列、动态和关联数组,减少内存消耗…...

TensorFlow和PyTorch学习原理解析
这里写目录标题 TensorFlow和PyTorch学习&原理解析TensorFlow介绍原理部署适用场景 PyTorch介绍原理部署适用场景 Keras模型格式SavedModelONNX格式 TensorFlow和PyTorch学习&原理解析 TensorFlow 介绍 由 Google Brain 团队开发并于 2015 年开源。由于 Google 的强…...

悬空引用和之道、之禅-《分析模式》漫谈57
DDD领域驱动设计批评文集 做强化自测题获得“软件方法建模师”称号 《软件方法》各章合集 “Analysis Patterns”的第5章“对象引用”原文: Unless you can catch all such references, there is the risk of a dangling reference, which often has painful con…...

江湖密码术:Rust中的 bcrypt 加密秘籍
前言 江湖险恶,黑客如雨,昔日密码“123456”早被各路大侠怒斥为“纸糊轻功”。若还执迷不悟,用明文密码闯荡江湖,无异于身披藏宝图在集市上狂奔,目标大到闪瞎黑客双眼。 为护你安然度过每一场数据风波,特献上一门绝学《Rust加密神功》。核心招式正是传说中的 bcrypt 密…...
大语言模型中的思维链(CoT)技术详解)
NLP高频面试题(四十八)大语言模型中的思维链(CoT)技术详解
引言 大语言模型(LLM)在近年的飞速发展,让机器在各种任务上表现出令人瞩目的能力。然而,与人类不同,传统的语言模型往往倾向于直接给出答案,而缺乏可解释的中间推理过程。这在复杂推理任务中成为瓶颈:模型可能由于一步推理不当而得出错误结论,却没有过程可供检查。为了…...

对接点餐接口需要有哪些准备?
以下是一般点餐接口对接的相关信息,包括常见的接口功能、对接步骤及注意事项等: 常见接口功能 餐厅信息查询:获取合作餐厅的基本信息,如餐厅名称、地址、营业时间、联系电话、菜单等。菜品查询:查询具体餐厅的菜品详情…...

LintCode第192题-通配符匹配
描述 给定一个字符串 s 和一个字符模式 p ,实现一个支持 ? 和 * 的通配符匹配。匹配规则如下: ? 可以匹配任何单个字符。* 可以匹配任意字符串(包括空字符串)。 两个串完全匹配才算匹配成功。 样例 样例1 输入: "aa&q…...

uv运行一个MCP Server的完整流程
uv是一个高性能的Python包管理器,专注于性能提升。与pip相比,uv利用全局模块缓存,减少磁盘空间使用,并支持Linux、Windows和macOS系统。安装uv可以通过多种方式实现,例如使用Homebrew、Pacman、pip等。 step 1 安装uv:…...

ts中的类型
在 TypeScript 中,类型是静态类型系统的核心,用于在编译阶段检查代码的正确性。TypeScript 提供了丰富的类型系统,包括基本的原始类型、复合类型、以及用户自定义的类型。以下是对 TypeScript 中各种类型的详细分类和说明: 1. 原…...

把dll模块注入到游戏进程的方法_基于文件修改的注入方式
1、概述 本文主要是介绍两种基于文件修改的注入方式,一种是“DLL劫持”,另一种是“修改导入表”。这两种注入方式都是利用操作系统加载PE时的特点来实现的,我们在实现这两种注入方式时只需专注于注入dll的实现,而不用花费额外的精力去关注注入器的实现。要想深入了解这两种…...

判断点是否在多边形内
代码段解析: const intersect = ((yi > y) !== (yj > y)) && (x < (xj - xi) * (y - yi) / (yj - yi) + xi); 第一部分:(yi > y) !== (yj > y) 作用:检查点 (x,y) 的垂直位置是否跨越多边形的当前边。 yi > y 和 yj > y 分别检查边的两个端…...
介绍)
【形式化验证基础】活跃属性Liveness Property和安全性质(Safety Property)介绍
文章目录 一、Liveness Property1、概念介绍2、形式化定义二、Safety Property1. 定义回顾2. 核心概念解析3. 为什么强调“有限前缀”4. 示例说明4.1 示例1:交通信号灯系统4.2 示例2:银行账户管理系统5. 实际应用的意义三. 总结一、Liveness Property 1、概念介绍 在系统的…...
信号保存与捕捉)
Linux——信号(2)信号保存与捕捉
一、信号的保存 上次我们说到,捕捉一个信号后有三种处理方式:默认、忽略、自定义,其中自定义我们用signal系统调用完成,至于忽略信号,也需要signal实现,比如我现在想忽略2号信号,则:…...

Vue的模板编译过程
👨 作者简介:大家好,我是Taro,全栈领域创作者 ✒️ 个人主页:唐璜Taro 🚀 支持我:点赞👍📝 评论 ⭐️收藏 文章目录 前言一、编程范式的分类1.编程范式分为声明式和命令…...

空间应用中心AI4S空间科学实验研究成果发表于《中国科学院院刊》
编者寄语: 和鲸基于旗下数据科学协同平台ModelWhale赋能,助力了中国科学院空间应用工程与技术中心系统开展了基于空间科学实验领域的AI4S创新研究。中国科学院空间应用工程与技术中心在空间科学实验领域的研究覆盖了多模态空间科学实验数据模式挖掘、领…...

【Python网络爬虫开发】从基础到实战的完整指南
目录 前言:技术背景与价值当前技术痛点解决方案概述目标读者说明 一、技术原理剖析核心概念图解核心作用讲解关键技术模块技术选型对比 二、实战演示环境配置要求核心代码实现(10个案例)案例1:基础静态页面抓取案例2:动…...

乐家桌面纯净版刷机ROM下载 乐家桌面纯净版2025官方最新下载
还在苦苦寻找一款好用的电视桌面,为智能电视焕新体验?别在乐家桌面纯净版刷机 ROM 下载和官方最新版下载上纠结啦,试试乐看家桌面,给你带来意想不到的惊喜! 乐家桌面纯净版或许曾吸引过你,但乐看家桌面在众…...

深度学习-全连接神经网络
四、参数初始化 神经网络的参数初始化是训练深度学习模型的关键步骤之一。初始化参数(通常是权重和偏置)会对模型的训练速度、收敛性以及最终的性能产生重要影响。下面是关于神经网络参数初始化的一些常见方法及其相关知识点。 官方文档参考࿱…...

n2n 搭建虚拟局域网,实现内网穿透
一、ubuntu linux系统上通过源码安装 1、下载源码 git clone https://github.com/ntop/n2n 2、 进入源码目录n2n,依次执行下列命令 ./autogen.sh # 如果提示命令不存在,需要运行命令:apt-get update && apt-get install autoconf…...

SystemVerilog语法之定宽数组
1.2定宽数组 1.2.1定宽数组的声明和初始化 Verilog要求在声明中必须给出数组的上下界。因为几乎所有数组都使用0作为索引下界,所以SystemVerilog允许只给出数组宽度的便捷声明方式。SystemVerilog的$clog2()函数可以计算以2为底的对数向上舍入值。你可以通过在变量…...

SQL 使用 UPDATE FROM 语法进行更新
UPDATE FROM 是一种常见的 SQL 语法模式,允许你基于其他表的数据来更新目标表。这种语法在不同数据库系统中有所不同,下面我将介绍几种主要数据库的实现方式。 PostgreSQL/SQL Server 语法 UPDATE target_table SET target_column source_table.source…...

如何在LangChain中构建并使用自定义向量数据库
1. 自定义向量数据库对接 向量数据库的发展非常迅速,几乎每隔几天就会出现新的向量数据库产品。LangChain 不可能集成所有的向量数据库,此外,一些封装好的数据库可能存在 bug 或者其他问题。这种情况下,我们需要考虑创建自定义向…...

极狐GitLab Git LFS 速率限制如何设置?
极狐GitLab 是 GitLab 在中国的发行版,关于中文参考文档和资料有: 极狐GitLab 中文文档极狐GitLab 中文论坛极狐GitLab 官网 Git LFS 速率限制 (BASIC SELF) Git LFS (Large File Storage) 是一个用于处理大文件的Git扩展。如果您在仓库中使用 Git LF…...

如何查询IP地址是否被占用?
IP地址占用查询的重要性 在当前高度发达的网络环境下,IP地址作为网络设备间通信的基础,其管理显得尤为重要。IP地址占用查询作为网络管理的一个重要环节,具有以下几点重要性: 预防IP冲突:当两个或多个设备使用相同的I…...

数字后端实现教程 | 时钟树综合IMPCCOPT-1304错误Debug思路和解决方案
今天上午有学员在做公司自己项目CTS时发现跑不下去,报了如下所示的错误IMPCCOPT-4375。 复杂时钟设计时钟树综合(clock tree synthesis)常见20个典型案例 第一次遇到这种错误,其实可以从提示信息上入手。 Term CLK_AVDD_SS is power /ground ÿ…...

AI 大模型在教育革命中的角色重塑:从知识传递者到认知伙伴
📝个人主页🌹:一ge科研小菜鸡-CSDN博客 🌹🌹期待您的关注 🌹🌹 一、引言:从“教”与“学”到“共知”时代的开启 教育的本质是什么?是教师传授知识,学生被动接受?还是引导思维、激发潜能、陪伴成长? 在过去数百年里,教育形式经历了从口述、印刷、广播到互…...

Spring如何通过XML注册Bean
在上一篇当中我们完成了对三种资源文件的读写 上篇内容:Spring是如何实现资源文件的加载 Test public void testClassPathResource() throws IOException { DefaultResourceLoader defaultResourceLoader new DefaultResourceLoader(); Resource resource …...

Compose Multiplatform Android Logcat工具
一、通过adb发送指令,收集设备日志并保存 二、UI 三、代码 /*** 获取设备列表*/fun getDevices(): List<String> {val process ProcessBuilder("adb", "devices").redirectErrorStream(true).start()val output process.inputStream.…...

智能照明系统:照亮智慧生活的多重价值
在当今科技飞速发展的时代,智能照明系统正以其独特的优势改变着人们的生活和工作方式。这套集成了物联网、人工智能等先进技术的照明解决方案,不仅实现了基本的照明功能,更在节能环保、健康舒适、安全防护等多个维度展现出卓越价值。 从能源管…...

XMC4800 芯片深度解读:架构、特性、应用与开发指南
一、芯片定位与核心优势 XMC4800是英飞凌(Infineon)推出的高性能微控制器(MCU),属于 XMC4000系列,基于 ARM Cortex-M4内核,主打 工业控制、电机驱动、物联网(IoT) 和 嵌入式系统 应用。其核心优势在于: 多核异构处理:集成Cortex-M4(144MHz,带FPU和DSP指令集)与专…...

class com.alibaba.fastjson.JSONObject cannot be cast to class
class com.alibaba.fastjson.JSONObject cannot be cast to class 在做接口测试的时候,携带一个可用的token,打算debug看看代码的执行过程,由于Redis配置类的不完整导致报错 这是原本的Redis配置类 Configuration public class RedisConfig {BeanSuppressWarnings(value {&…...

二叉树操作与遍历实现
二叉树操作与遍历实现 二叉树操作与遍历实现树的相关概念1.树的相关术语2.二叉树的概念3.二叉树的存储结构1.顺序结构2.链式结构 1. 二叉树的创建树的表示1.1 创建节点1.2 构建二叉树 2. 二叉树的销毁3. 二叉树的遍历3.1 前序遍历3.2 中序遍历3.3 后序遍历3.4 层序遍历 4. 二叉…...
)
VSCode连接服务器跑深度学习代码相关问题(研0大模型学习第八天)
VS Code 远程连接服务器:从环境配置到代码运行与常见问题解决实录 在使用 VS Code 通过 Remote-SSH 连接到远程服务器进行 Python 开发,特别是涉及 Anaconda 环境和深度学习项目时,可能会遇到各种各样的问题。本文记录并解答了我在配置和运行…...

软件工程中的维护类型
目录 前言1. 排错性维护1.1 排错性维护的定义与重要性1.2 排错性维护的实践与挑战 2. 适应性维护2.1 适应性维护的定义与背景2.2 适应性维护的实施策略 3. 完善性维护3.1 完善性维护的定义与目标3.2 完善性维护的实施挑战与技巧 4. 预防性维护4.1 预防性维护的定义与作用4.2 预…...
)
软件工程(1)
#灵感# 记录一下软件工程的相关基础知识。 按马哲的说法,不能光有实践,也需要相关理论。 定义:软件工程涉及软件开发、维护、管理等多方面的原理、方法、工具和环境。此篇主要讲软件开发中的基本方法。 已知问题:旧的软件开发主要…...
)
递归的模板 (以反转链表为例)
我们再来回顾一下递归的模板,终止条件,递归调用,逻辑处理。 func reverseList(head *ListNode) *ListNode {// 终止条件if head nil || head.Next nil {return head}// 逻辑处理(可能有,也可能没有,具体…...

02-HTML结构
一、URL 1.1.URL的格式 1.2.URL和URI的区别 URI指逻辑或资源的标识符,URL是地址,URL是URI的子集 二、HTML文件结构 2.1.文档声明 默认告诉浏览器是html5页面,必须放在文档最前面 <!DOCTYPE html>2.2.HTML各元素结构 是根元素&…...

C++ vector 核心功能解析与实现
目录 整体结构概述 赋值运算符重载 下标运算符重载 内存管理函数 元素访问函数 插入和删除操作 完整代码 在C标准库中, vector 是一个非常常用的动态数组容器,它能够自动管理内存,并且提供了丰富的操作接口。本文将通过分析一段手写 …...

【Linux网络】构建UDP服务器与字典翻译系统
📢博客主页:https://blog.csdn.net/2301_779549673 📢博客仓库:https://gitee.com/JohnKingW/linux_test/tree/master/lesson 📢欢迎点赞 👍 收藏 ⭐留言 📝 如有错误敬请指正! &…...

DeepSeek 大模型 + LlamaIndex + MySQL 数据库 + 知识文档 实现简单 RAG 系统
DeepSeek 大模型 LlamaIndex MySQL 数据库 知识文档 实现简单 RAG 系统 以下是一个使用 DeepSeek 大模型(假设为一个高性能的中文大模型)、LlamaIndex、MySQL 数据库 和 知识文档 实现简单 RAG(检索增强生成)系统的完整示例。该…...

【FFmpeg从入门到精通】第四章-FFmpeg转码
1 FFmpeg 软编码H.264与H.265 当前网络中常见的视频编码格式要数H.264最为火热,支持H.264的封装格式有很多,如FLV、MP4、HLS(M3U8)、MKV、TS等格式;FFmpeg本身并不支持H.264的编码器,而是由FFmpeg的第三方模块对其进行支持,例如x…...

爱普生RX8130CE实时时钟成为智能家居系统的理想解决方案
智能家居的本质是让生活更便捷、舒适与智能,而精准的时间管理是实现这一目标的重要基础。爱普生 RX8130CE 实时时钟(RTC)以其卓越的性能和丰富的功能,成为智能家居系统的理想时间解决方案,为用户打造更加智能化、人性化…...

Discuz!与DeepSeek的深度融合:打造智能网址导航新标杆
引言 在数字化信息爆炸的时代,网址导航网站作为用户获取优质资源、高效浏览互联网的重要入口,其信息筛选能力、用户体验和商业化潜力成为了决定其竞争力的核心要素。Discuz!作为国内应用广泛的社区论坛系统,以其强大的功能扩展性和用户管理能…...
)
23种设计模式-结构型模式之代理模式(Java版本)
Java 代理模式(Proxy Pattern)详解 🧭 什么是代理模式? 代理模式是结构型设计模式之一,为其他对象提供一个代理以控制对这个对象的访问。 就像生活中的“经纪人”,你无法直接联系明星,但可以…...

网络不可达network unreachable问题解决过程
问题:访问一个环境中的路由器172.16.1.1,发现ssh无法访问,ping发现回网络不可达 C:\Windows\System32>ping 172.16.1.1 正在 Ping 172.16.1.1 具有 32 字节的数据: 来自 172.16.81.1 的回复: 无法访问目标网。 来自 172.16.81.1 的回复:…...

@RefreshScope 和@nacosvalue 的区别
文章目录 1. RefreshScope定义与作用工作原理适用场景示例代码 2. NacosValue定义与作用工作原理适用场景示例代码 3. 主要区别4. 如何选择?5. 注意事项 在 Spring 框架中, RefreshScope 和 NacosValue 是两个不同的注解,分别用于不同的场景…...

Oracle EBS R12.2 安装 -- Step by Step
一、引言 在计算机应用已经非常普及的今天,对于绝大部分个人来说,学习并掌握ORACLE ERP系统是一件“实践性”很强的事情,仅仅“纸上谈兵”而不在系统中进行具体的操作,犹如捧着一本“驾驶手册”苦读,但却没有一辆车进行上路演练,是肯定无法学会开车的道理一样,能够为自…...