【NCCL】transport建立(一)
transport建立
NCCL transport建立主要在ncclTransportP2pSetup函数中实现。
概况
先简单概括一下ncclTransportP2pSetup函数做了哪些事,方便理解代码流程。
recvpeer 表示本卡作为接收端的对端,sendpeer 表示本卡作为发送端的对端。假设8个rank全连接,第一次循环时,rank0的recvpeer就是7,rank0的sendpeer就是1,第二次循环,rank0的recvpeer就是6,rank1的sendpeer就是2,以此类推。
ncclTransportP2pSetup函数中会根据recvpeer去索引通道mask,根据mask来判断两个rank之间有多少通道,对于每个 channel ,rank与rank之间要建立通信,先通过调用 selectTransport<0>()设置接收方向相关通信数据,再通过selectTransport<1>()设置发送方向相关通信数据。
注意,对于ring连接来说,只有第一次循环中mask是有值的,也就是上面举例recvpeer为7和sendpeer为1时,对应的索引mask有值。
每一次调用selectTransport函数,都会遍历所有的transport,包含有以下:
struct ncclTransport* ncclTransports[NTRANSPORTS] = {&p2pTransport,&shmTransport,&netTransport,&collNetTransport
};
依次调用transport中canConnect接口,判断当前两个rank之间是否可以通过该协议通信,如果可以通信,则依次调用setup接口和proxySetup接口。
接收方向相关通信数据和发送方向相关通信数据都设置好之后,会和recvpeer以及sendpeer交换这些数据。注意,不同transport,这些数据内容和用途是不一样的。
凑齐maxPeers(默认128)个数或nrank个数,则一次完成connect操作。maxPeers的出现是为了防止一直建链太多导致资源不够或超时。
transport中接口调用流程:
本端作为接收端 CanConnect() -> RecvSetup() -> RecvProxySetup() -> 交换数据 -> RecvConnect()
本端作为发送端 CanConnect() -> SendSetup() -> SendProxySetup() -> 交换数据 -> SendConnect()
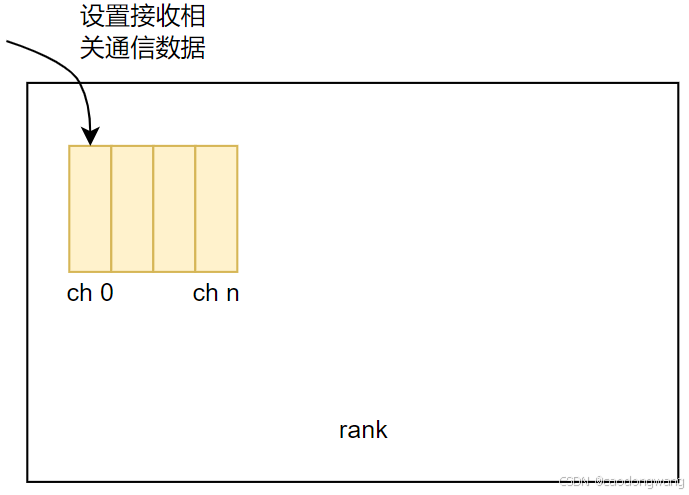
本端作为接收端设置接收方向相关通信数据
对于本端作为接收端,调用以下流程:
for (int c=0; c<MAXCHANNELS; c++) {if (recvMask & (1UL<<c)) {//根据通道掩码建链//0表示接收//先调用接口判断两个rank之间可以通过什么传输层来建立连接//然后调用传输层setup接口//最后setup接口中又会调用 ProxySetup 接口NCCLCHECKGOTO(selectTransport<0>(comm, graph, recvData[p]+recvChannels++, c, recvPeer, connIndex, &type), ret, fail);}}
上面流程其实就是为每个接收方向通道设置相关通信数据,如下图所示:
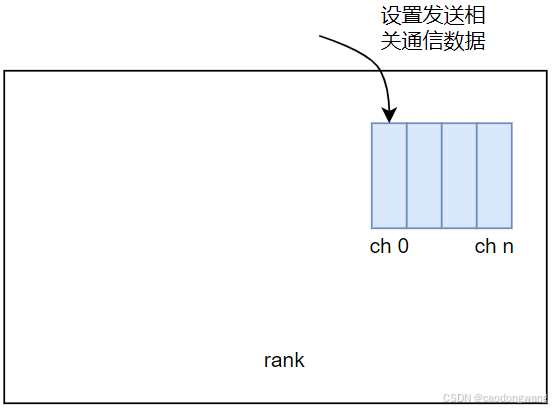
本端作为发送端设置发送方向相关通信数据
对于本端作为发送端,调用以下流程:
for (int c=0; c<MAXCHANNELS; c++) {if (sendMask & (1UL<<c)) {//1表示发送//先调用接口判断两个rank之间可以通过什么传输层来建立连接//然后调用传输层setup接口//最后setup接口中又会调用 ProxySetup 接口NCCLCHECKGOTO(selectTransport<1>(comm, graph, sendData[p]+sendChannels++, c, sendPeer, connIndex, &type), ret, fail);}}
上面流程其实就是为每个发送方向通道设置相关通信数据,如下图所示:
交换数据
将本rank和前后rank之间数据进行交换,如下图所示:

交换之后,本rank就拿到了前后两个rank通信相关数据,凑齐maxPeers(默认128)个数或nrank个数,则调用transport中的connect接口一次完成connect操作,connect函数会根据交换得来的数据做一些初始化操作,为数据传输准备控制面数据。

接下来看看p2pTransport和netTransport具体干了什么事,对于其他transport,本文暂且不表。
p2pTransport
调用p2pCanConnect接口来判断两个rank是否能支持P2P连接。
ncclResult_t p2pCanConnect(int* ret, struct ncclComm* comm, struct ncclTopoGraph* graph, struct ncclPeerInfo* info1, struct ncclPeerInfo* info2) {initCeOperation();// Check topology / p2p level.int intermediateRank;//用于检查两个 GPU 是否支持点对点(P2P)通信,主要检查路径类型是否小于等于PATH_PXB、当前连接状态是否okNCCLCHECK(ncclTopoCheckP2p(comm, comm->topo, info1->rank, info2->rank, ret, NULL, &intermediateRank));if (*ret == 0) return ncclSuccess;if (intermediateRank != -1) {if (useMemcpy) *ret = 0;return ncclSuccess;}// Check if NET would work better,使用net是否能更好的工作// 路径类型小于等于PATH_PXB,带宽更大,则使用netint useNet = 0;NCCLCHECK(ncclTopoCheckNet(comm->topo, info1->rank, info2->rank, &useNet));if (useNet) {*ret = 0;return ncclSuccess;}if (info1->hostHash != comm->peerInfo[comm->rank].hostHash ||info1->hostHash != info2->hostHash) {//如果不是同一个主机// If either peer is non-local then we are done.return ncclSuccess;}// Convert the peer's busId into a local cudaDev index (cf. CUDA_VISIBLE_DEVICES)int cudaDev1 = busIdToCudaDev(info1->busId);int cudaDev2 = busIdToCudaDev(info2->busId);if (cudaDev1 == -1 || cudaDev2 == -1) {
#if CUDART_VERSION >= 10010// CUDA 10.1 and later can use P2P with invisible devices.return ncclSuccess;
#else// Peer's CUDA device is not visible in this process : we can't communicate with it.*ret = 0;return ncclSuccess;
#endif}// Check that CUDA can do P2Pint p2p;//检查两个 GPU 设备之间是否支持点对点(P2P)直接内存访问, 1 表示支持 P2P,0 表示不支持if (cudaDeviceCanAccessPeer(&p2p, cudaDev1, cudaDev2) != cudaSuccess) {INFO(NCCL_INIT|NCCL_P2P,"peer query failed between dev %d(=%lx) and dev %d(=%lx)",cudaDev1, info1->busId, cudaDev2, info2->busId);*ret = 0;return ncclSuccess;}// This will always fail when using NCCL_CUMEM_ENABLE=1if (p2p != 0 && !ncclCuMemEnable()) {//ncclCuMemEnable默认使能// Cached result of the legacyIPC detectionstatic int legacyIPC = -1;if (legacyIPC >= 0) {*ret = legacyIPC;return ncclSuccess;}// Check that legacy IPC support is available (WSL WAR)char *dummy;cudaIpcMemHandle_t ipc;NCCLCHECK(ncclCudaMalloc(&dummy, CUDA_IPC_MIN));if (cudaIpcGetMemHandle(&ipc, dummy) != cudaSuccess) {INFO(NCCL_INIT|NCCL_P2P,"Legacy IPC not supported");*ret = 0;}NCCLCHECK(ncclCudaFree(dummy));legacyIPC = *ret;return ncclSuccess;}if (p2p == 0) {INFO(NCCL_INIT|NCCL_P2P,"Could not enable P2P between dev %d(=%lx) and dev %d(=%lx)",cudaDev1, info1->busId, cudaDev2, info2->busId);*ret = 0;return ncclSuccess;}return ncclSuccess;
}
在交换信息之后,执行p2pRecvConnect动作,代码如下:
static ncclResult_t p2pSendConnect(struct ncclComm* comm, struct ncclConnect* connectInfo, int nranks, int rank, struct ncclConnector* send) {struct p2pResources* resources = (struct p2pResources*)send->transportResources;struct ncclRecvMem* remDevMem = NULL;struct p2pConnectInfo* info = (struct p2pConnectInfo*)connectInfo;//对端作为接收方申请的通道信息,如内存//本端存储对端作为接收端申请的内存到remDevMemNCCLCHECK(p2pMap(comm, &send->proxyConn, comm->peerInfo+rank, comm->peerInfo+info->rank, &info->p2pBuff, (void**)&remDevMem, &resources->recvMemIpc));resources->recvMemSameProc = P2P_SAME_PID((comm->peerInfo + rank), (comm->peerInfo + info->rank));char* buff = (char*)(remDevMem+1);for (int p=0; p<NCCL_NUM_PROTOCOLS; p++) {if (info->read && p == NCCL_PROTO_SIMPLE) {/* For P2P Read the SIMPLE buffer is local (ncclSendMem) */if (resources->sendDevMem == NULL) return ncclInternalError; // We should not use read + memcpysend->conn.buffs[p] = (char*)(resources->sendDevMem+1);//当NCCL_PROTO_SIMPLE,接收地址在本端} else {send->conn.buffs[p] = buff;//为本端数据结构中记录对端接收BUF地址,该地址是对端申请出来的buff += comm->buffSizes[p];}}send->conn.stepSize = comm->buffSizes[NCCL_PROTO_SIMPLE]/NCCL_STEPS;//默认512kif (useMemcpy) {send->conn.tail = &resources->proxyInfo.ceRecvMem->tail;send->conn.connFifo = resources->proxyInfo.ceRecvMem->connFifo;send->conn.head = &resources->proxyInfo.devShm->sendMem.head;// Send SIMPLE buff to proxy, and replace it by local bufferNCCLCHECK(ncclProxyCallBlocking(comm, &send->proxyConn, ncclProxyMsgConnect, &send->conn.buffs[NCCL_PROTO_SIMPLE], sizeof(void*), NULL, 0));send->conn.buffs[NCCL_PROTO_SIMPLE] = resources->proxyInfo.ceDevBuff;} else {send->conn.tail = &remDevMem->tail;//设置tail地址为对端内存tail变量地址send->conn.head = &resources->sendDevMem->head;//设置head地址为本端内存head变量地址send->conn.ptrExchange = &resources->sendDevMem->ptrExchange;send->conn.redOpArgExchange = resources->sendDevMem->redOpArgExchange;}// We must assign the proxyConn's proxyProgress property for proper checking at enqueue-timesend->proxyConn.proxyProgress = p2pTransport.send.proxyProgress;return ncclSuccess;
}
整体图解
直接看代码可能比较难以理解,还是用图来解释清晰点。
后续以单通道且支持P2P read举例。
recv/send执行完 CanConnect() -> Setup() -> ProxySetup()之后,结果如下图所示。
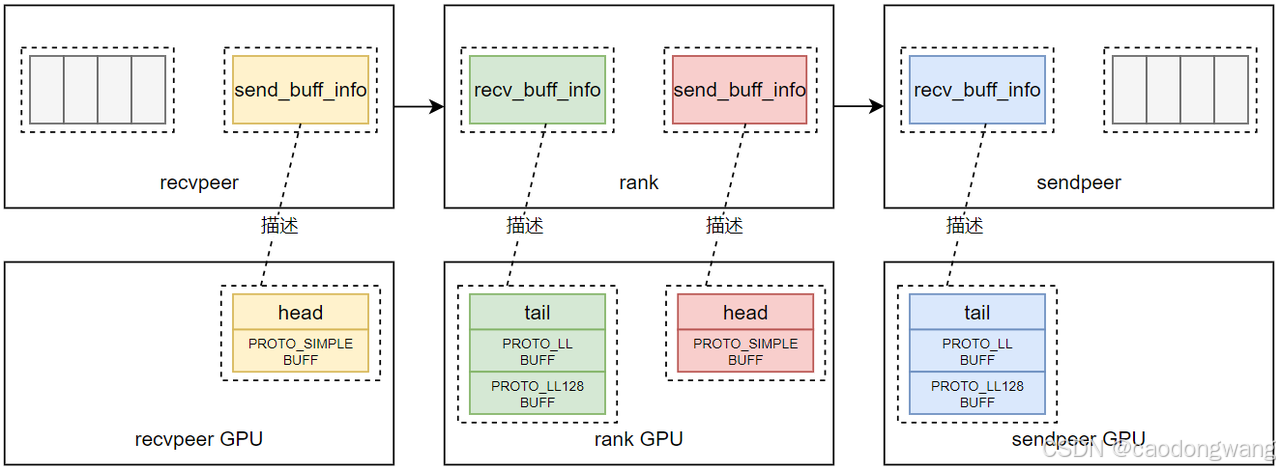
rank执行CanConnect() -> RecvSetup() -> RecvProxySetup()之后,将在GPU上创建一块BUFF,里面包含一些变量和接收缓存区,变量中最重要的就是tail,接收缓存区分为两种,一种是PROTO_LL用的缓存区,另一种是PROTO_LL128用的缓冲区。rank在host内存中会用一个p2pConnectInfo结构描述GPU分配的接收内存,这里为了区分recv和send,用recv_buff_info表征描述接收内存。
rank执行CanConnect() -> SendSetup() -> SendProxySetup()之后,将在GPU上创建一块BUFF,里面包含一些变量和发送缓存区,变量中最重要的就是head,发送缓存区是PROTO_SIMPLE用的缓存区。rank在host内存中会用一个p2pConnectInfo结构描述GPU分配的接收内存,这里为了区分recv和send,用send_buff_info表征描述发送内存。
交换数据之后如图所示。
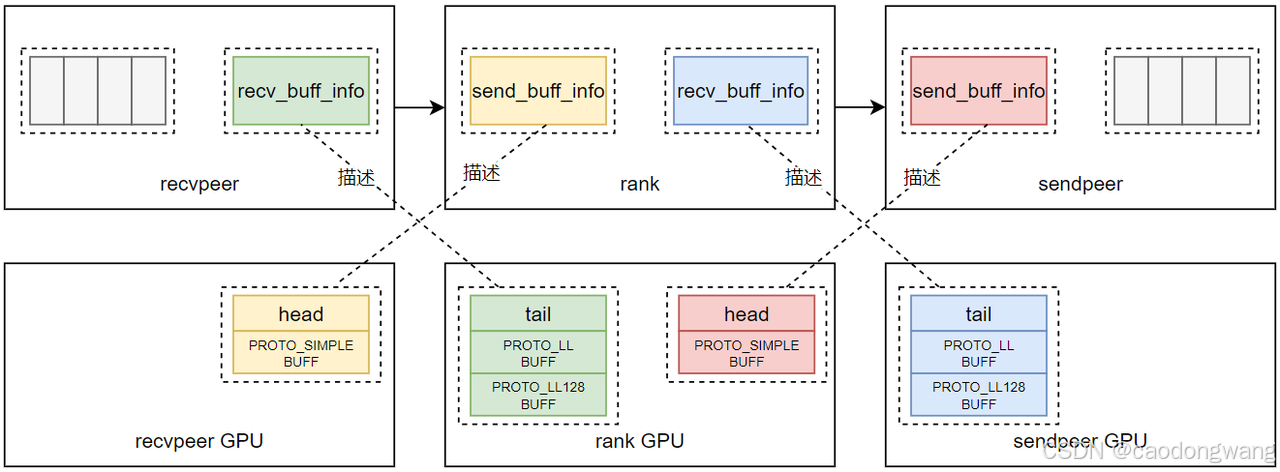
这样rank拿到了前后两个rank相应buff描述结构。
执行connect之后如下所示。

rank根据send_buff_info和recv_buff_info信息,将recvpeer GPU send buff内存和sendpeer GPU recv bufff内存导入到自己的虚拟地址空间,让rank和rank GPU都能直接访问两个buff。
接下来就是将信息规整一下,为数据传输做准备,如下所示。
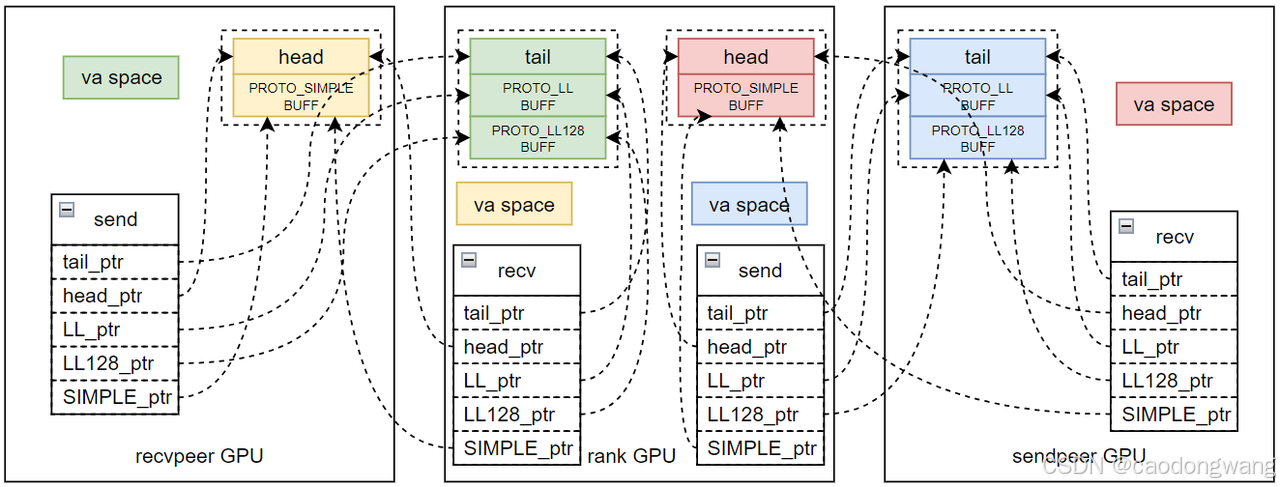
P2P数据传输使用生产者消费者模型,即recvpeer GPU将数据写入rank GPU的某个buff中并更新rank GPU的tail,然后rank GPU检测到tail更新,则将数据取出放到真正的数据buff中,接着更新recvpeer GPU的head,完成一轮交互(拷贝方式)。
netTransport
接下来说说netTransport是怎么玩的。
调用canConnect接口来判断两个rank是否能支持net连接。
static ncclResult_t canConnect(int* ret, struct ncclComm* comm, struct ncclTopoGraph* graph, struct ncclPeerInfo* info1, struct ncclPeerInfo* info2) {*ret = 1;if (info1->hostHash == info2->hostHash) {// If on the same host, check intra-node net is not disabled.NCCLCHECK(ncclTopoCheckNet(comm->topo, info1->rank, info2->rank, ret));}return ncclSuccess;
}
判断方法很简单,对于不同主机,默认可以建立连接,对于同一主机,检查用户是否通过环境变量关闭主机内net连接即可。
本端作为接收端设置接收方向相关通信数据
先调用recvSetup,代码如下。
static ncclResult_t recvSetup(struct ncclComm* comm, struct ncclTopoGraph* graph, struct ncclPeerInfo* myInfo, struct ncclPeerInfo* peerInfo, struct ncclConnect* connectInfo, struct ncclConnector* recv, int channelId, int connIndex) {struct setupReq req = { 0 };recv->conn.shared = req.shared = graph || connIndex == 0 ? 0 : ncclParamNetSharedBuffers() != -2 ? ncclParamNetSharedBuffers() : 1;req.channelId = channelId;req.connIndex = connIndex;// Use myInfo->rank as the receiver uses its own NICint proxyRank;int64_t netId;NCCLCHECK(ncclTopoGetNetDev(comm, myInfo->rank, graph, channelId, myInfo->rank, &netId, &req.netDev, &proxyRank));//检查是否支持GDR,即gpu和net都支持gdr且路径小于等于PATH_PXBNCCLCHECK(ncclTopoCheckGdr(comm->topo, myInfo->rank, netId, 0, &req.useGdr));recv->conn.flags |= req.useGdr ? NCCL_DIRECT_NIC : 0;if (!req.useGdr && connIndex == 0) comm->useGdr = 0;// Determine whether we need to flush the GDR buffer on recv or not//确定是否需要在接收时刷新GDR缓冲区,某些gpu不需要flush动作if (req.useGdr) NCCLCHECK(ncclTopoNeedFlush(comm, req.netDev, myInfo->rank, &req.needFlush));// We don't support PXN on receive yet//连接本地网络,为调用ncclProxyCallBlocking做准备,会创建一个proxyProgress代理线程NCCLCHECK(ncclProxyConnect(comm, TRANSPORT_NET, 0, myInfo->rank, &recv->proxyConn));req.tpLocalRank = comm->topParentLocalRanks[comm->localRank];req.tpRank = comm->topParentRanks[myInfo->rank];req.tpRemoteRank = comm->topParentRanks[peerInfo->rank];//调用 recvProxySetupNCCLCHECK(ncclProxyCallBlocking(comm, &recv->proxyConn, ncclProxyMsgSetup, &req, sizeof(req), connectInfo, sizeof(ncclNetHandle_t)));memcpy((uint8_t*)connectInfo + sizeof(ncclNetHandle_t), &req.useGdr, sizeof(int));INFO(NCCL_INIT|NCCL_NET,"Channel %02d/%d : %d[%d] -> %d[%d] [receive] via NET/%s/%d%s%s", channelId, connIndex, peerInfo->rank, peerInfo->nvmlDev, myInfo->rank, myInfo->nvmlDev, comm->ncclNet->name, req.netDev,req.useGdr ? "/GDRDMA" : "", req.shared ? "/Shared" : "");return ncclSuccess;
}
其中最主要的是调用了ncclProxyConnect和ncclProxyCallBlocking,我们先看ncclProxyConnect做了什么,代码如下。
ncclResult_t ncclProxyConnect(struct ncclComm* comm, int transport, int send, int proxyRank, struct ncclProxyConnector* proxyConn) {struct ncclSocket* sock;int ready;struct ncclProxyState* sharedProxyState = comm->proxyState;int tpProxyRank = comm->topParentRanks[proxyRank];//获取rank的父节点proxyConn->sameProcess = ((comm->peerInfo[proxyRank].hostHash == comm->peerInfo[comm->rank].hostHash) &&(comm->peerInfo[proxyRank].pidHash == comm->peerInfo[comm->rank].pidHash)) ? 1 : 0;// Keep one connection per local rankproxyConn->connection = NULL;proxyConn->tpRank = tpProxyRank;proxyConn->rank = proxyRank;if (sharedProxyState->peerSocks == NULL) {NCCLCHECK(ncclCalloc(&sharedProxyState->peerSocks, comm->sharedRes->tpNLocalRanks));NCCLCHECK(ncclCalloc(&sharedProxyState->proxyOps, comm->sharedRes->tpNLocalRanks));NCCLCHECK(ncclCalloc(&sharedProxyState->sharedDevMems, comm->sharedRes->tpNLocalRanks));for (int i = 0; i < comm->sharedRes->tpNLocalRanks; ++i) {//确保每个本地 Rank 有独立的 Socket 和资源,避免竞争。NCCLCHECK(ncclSocketSetFd(-1, &sharedProxyState->peerSocks[i]));}}//初始化并连接到目标代理的 SocketproxyConn->tpLocalRank = comm->sharedRes->tpRankToLocalRank[proxyConn->tpRank];sock = sharedProxyState->peerSocks + proxyConn->tpLocalRank;NCCLCHECK(ncclSocketReady(sock, &ready));if (!ready) {NCCLCHECK(ncclSocketInit(sock, sharedProxyState->peerAddresses+proxyConn->tpRank, comm->sharedRes->magic, ncclSocketTypeProxy, comm->abortFlag));NCCLCHECK(ncclSocketConnect(sock));}struct ncclProxyInitReq req = {0};req.transport = transport;req.send = send;req.tpLocalRank = comm->topParentLocalRanks[comm->localRank];req.tpRank = comm->topParentRanks[comm->rank];req.sameProcess = proxyConn->sameProcess;struct ncclProxyInitResp resp = {0};// This usually sends proxyConn->connection to identify which connection this is.// However, this is part of the response and therefore is ignored//连接ProxyServer线程,初始化connection相关信息,如果传输层支持ProxyProgress,则创建ProxyProgress线程(NET)NCCLCHECK(ncclProxyCallBlocking(comm, proxyConn, ncclProxyMsgInit, &req, sizeof(req), &resp, sizeof(resp)));proxyConn->connection = resp.connection;// If we need proxy progress, map progress opsstruct ncclTransportComm* tcomm = send ? &ncclTransports[transport]->send : &ncclTransports[transport]->recv;if (tcomm->proxyProgress) {char poolPath[] = "/dev/shm/nccl-XXXXXX";strncpy(poolPath+sizeof("/dev/shm/nccl-")-1, resp.devShmPath, sizeof("XXXXXX")-1);struct ncclProxyOps* proxyOps = sharedProxyState->proxyOps + proxyConn->tpLocalRank;if (proxyOps->pool == NULL) {NCCLCHECK(ncclShmOpen(poolPath, sizeof(poolPath), sizeof(struct ncclProxyOpsPool), (void**)(&proxyOps->pool), NULL, -1, &proxyOps->handle));proxyOps->nextOps = proxyOps->nextOpsEnd = proxyOps->freeOp = -1;}}proxyConn->initialized = true;INFO(NCCL_NET|NCCL_PROXY, "Connected to proxy localRank %d -> connection %p", proxyConn->tpLocalRank, proxyConn->connection);return ncclSuccess;
}static ncclResult_t proxyConnInit(struct ncclProxyLocalPeer* peer, struct ncclProxyConnectionPool* connectionPool, struct ncclProxyState* proxyState, ncclProxyInitReq* req, ncclProxyInitResp* resp, struct ncclProxyConnection** connection) {int id;NCCLCHECK(ncclProxyNewConnection(connectionPool, &id));NCCLCHECK(ncclProxyGetConnection(connectionPool, id, connection));(*connection)->sock = &peer->sock;(*connection)->transport = req->transport;(*connection)->send = req->send;(*connection)->tpLocalRank = req->tpLocalRank;(*connection)->sameProcess = req->sameProcess;peer->tpLocalRank = req->tpLocalRank;peer->tpRank = req->tpRank;resp->connection = *connection;(*connection)->tcomm = (*connection)->send ? &ncclTransports[(*connection)->transport]->send : &ncclTransports[(*connection)->transport]->recv;// If we need proxy progress, let's allocate ops and start the threadif ((*connection)->tcomm->proxyProgress) {NCCLCHECK(proxyProgressInit(proxyState));struct ncclProxyProgressState* state = &proxyState->progressState;strncpy(resp->devShmPath, state->opsPoolShmSuffix, sizeof(resp->devShmPath));}INFO(NCCL_NET|NCCL_PROXY, "New proxy %s connection %d from local rank %d, transport %d", (*connection)->send ? "send":"recv", id, (*connection)->tpLocalRank, (*connection)->transport);__atomic_store_n(&(*connection)->state, connInitialized, __ATOMIC_RELEASE);return ncclSuccess;
}static ncclResult_t proxyProgressInit(struct ncclProxyState* proxyState) {struct ncclProxyProgressState* state = &proxyState->progressState;if (state->opsPool == NULL) {int size = sizeof(struct ncclProxyOpsPool);struct ncclProxyOpsPool* pool = NULL;char shmPath[sizeof("/dev/shm/nccl-XXXXXX")];shmPath[0] = '\0';NCCLCHECK(ncclShmOpen(shmPath, sizeof(shmPath), size, (void**)&pool, NULL, proxyState->tpLocalnRanks, &state->handle));// Init poolpool->nextOps = -1;for (int r = 0; r < proxyState->tpLocalnRanks; r++) {pool->freeOps[r] = r*MAX_OPS_PER_PEER;for (int i=0; i<MAX_OPS_PER_PEER-1; i++) pool->ops[r*MAX_OPS_PER_PEER+i].next = r*MAX_OPS_PER_PEER+i+1;pool->ops[(r+1)*MAX_OPS_PER_PEER-1].next = -1;}// Setup mutex/cond to work inter-processpthread_mutexattr_t mutexAttr;pthread_mutexattr_init(&mutexAttr);pthread_mutexattr_setpshared(&mutexAttr, PTHREAD_PROCESS_SHARED);pthread_mutex_init(&pool->mutex, &mutexAttr);pthread_condattr_t condAttr;pthread_condattr_setpshared(&condAttr, PTHREAD_PROCESS_SHARED);pthread_cond_init(&pool->cond, &condAttr);state->opsPool = pool;memcpy(state->opsPoolShmSuffix, shmPath+sizeof("/dev/shm/nccl-")-1, sizeof("XXXXXX")-1);// All ops structures are created, we can start the progress threadNCCLCHECK(ncclProxyProgressCreate(proxyState));//创建线程}return ncclSuccess;
}
对于netTransport来说,ncclProxyConnect最主要的就是创建一个ncclProxyProgress线程,后面我们再说这个线程是干啥用的。
回到recvSetup函数中,另一个调用的接口是ncclProxyCallBlocking,其实就是回调recvProxySetup函数,代码如下:
static ncclResult_t recvProxySetup(struct ncclProxyConnection* connection, struct ncclProxyState* proxyState, void* reqBuff, int reqSize, void* respBuff, int respSize, int* done) {struct setupReq* req = (struct setupReq*) reqBuff;if (reqSize != sizeof(struct setupReq)) return ncclInternalError;struct recvNetResources* resources;NCCLCHECK(ncclCalloc(&resources, 1));connection->transportResources = resources;//存储信息resources->tpRank = req->tpRank;resources->tpLocalRank = req->tpLocalRank;resources->tpRemoteRank = req->tpRemoteRank;resources->netDev = req->netDev;resources->shared = connection->shared = req->shared;resources->useGdr = req->useGdr;resources->needFlush = req->needFlush;resources->channelId = req->channelId;resources->connIndex = req->connIndex;ncclNetProperties_t props;//查询net相关属性NCCLCHECK(proxyState->ncclNet->getProperties(req->netDev, &props));/* DMA-BUF support */resources->useDmaBuf = resources->useGdr && proxyState->dmaBufSupport && (props.ptrSupport & NCCL_PTR_DMABUF);resources->maxRecvs = props.maxRecvs;resources->netDeviceVersion = props.netDeviceVersion;resources->netDeviceType = props.netDeviceType;/* point-to-point size limits*/resources->maxP2pBytes = props.maxP2pBytes;if((resources->maxP2pBytes <= 0) || (resources->maxP2pBytes > NCCL_MAX_NET_SIZE_BYTES)) {WARN("recvProxySetup: net plugin returned invalid value for maxP2pBytes %ld \[allowed range: %ld - %ld] \n", resources->maxP2pBytes, 0L, NCCL_MAX_NET_SIZE_BYTES);return ncclInternalError;}if (respSize != sizeof(ncclNetHandle_t)) return ncclInternalError;//调用 ncclIbListen 接口NCCLCHECK(proxyState->ncclNet->listen(req->netDev, respBuff, &resources->netListenComm));*done = 1;return ncclSuccess;
}ncclResult_t ncclIbListen(int dev, void* opaqueHandle, void** listenComm) {ncclResult_t ret = ncclSuccess;struct ncclIbListenComm* comm;NCCLCHECK(ncclCalloc(&comm, 1));struct ncclIbHandle* handle = (struct ncclIbHandle*) opaqueHandle;//respBuffstatic_assert(sizeof(struct ncclIbHandle) < NCCL_NET_HANDLE_MAXSIZE, "ncclIbHandle size too large");memset(handle, 0, sizeof(struct ncclIbHandle));comm->dev = dev;//net设备handle->magic = NCCL_SOCKET_MAGIC;//ncclIbIfAddr一般就是bootstrap使用的IPNCCLCHECKGOTO(ncclSocketInit(&comm->sock, &ncclIbIfAddr, handle->magic, ncclSocketTypeNetIb, NULL, 1), ret, fail);//建立socket linsten,后续rdma信息交换就通过这个套接字NCCLCHECKGOTO(ncclSocketListen(&comm->sock), ret, fail);//将socket监听地址拷贝到 handle->connectAddr,其实就是 ncclIbIfAddrNCCLCHECKGOTO(ncclSocketGetAddr(&comm->sock, &handle->connectAddr), ret, fail);*listenComm = comm;
exit:return ret;
fail:(void)ncclSocketClose(&comm->sock);free(comm);goto exit;
}
recvProxySetup和ncclIbListen主要是初始化一些信息,建立了一个socket监听,这个socket用来交换rdma建链以及发送缓存区信息的。
交换信息之后调用recvConnect -> recvProxyConnect -> ncclIbAccept,代码如下:
static ncclResult_t recvConnect(struct ncclComm* comm, struct ncclConnect* connectInfo, int nranks, int rank, struct ncclConnector* recv) {struct connectMap* map = (connectMap*) recv->transportResources;void* opId;int sendUseGdr;//connectInfo是发送端建立连接前填充的数据//拿到发送端gdr属性memcpy(&sendUseGdr, (uint8_t*)connectInfo + sizeof(ncclNetHandle_t), sizeof(int));if (!sendUseGdr) recv->conn.flags &= ~NCCL_DIRECT_NIC;if (!map) {NCCLCHECK(ncclCalloc(&map, 1));recv->transportResources = map;// Use recv connector as unique identifieropId = recv;INFO(NCCL_PROXY, "recvConnect ncclProxyCallAsync opId=%p &recv->proxyConn=%p connectInfo=%p",opId, &recv->proxyConn, connectInfo);netRecvConnectArgs args = {0};args.proxyRank = *((int*)connectInfo);//异步调用 recvProxyConnectNCCLCHECK(ncclProxyCallAsync(comm, &recv->proxyConn, ncclProxyMsgConnect, &args, sizeof(netRecvConnectArgs), sizeof(struct connectMap), opId));} else {opId = recv;}ncclResult_t ret;NCCLCHECK(ret = ncclPollProxyResponse(comm, &recv->proxyConn, map, opId));if (ret != ncclSuccess) {if (ret != ncclInProgress) {free(map);recv->transportResources = NULL;}return ret;}INFO(NCCL_PROXY, "recvConnect ncclPollProxyResponse opId=%p", opId);//NCCLCHECK(netDumpMap(map));struct ncclSendMem *sendMem = (struct ncclSendMem*) NCCL_NET_MAP_GET_POINTER(map, gpu, sendMem);recv->conn.head = &sendMem->head;//将host ddr中sendMem 的 head存储struct ncclRecvMem *recvMem = (struct ncclRecvMem*) NCCL_NET_MAP_GET_POINTER(map, gpu, recvMem);void* gdcMem = map->mems[NCCL_NET_MAP_GDCMEM].gpuPtr;//空recv->conn.tail = gdcMem ? (uint64_t*)gdcMem : &recvMem->tail;//将host recvMem 的 tail 存储recv->conn.stepSize = comm->buffSizes[NCCL_PROTO_SIMPLE]/NCCL_STEPS;//512krecv->conn.connFifo = recvMem->connFifo;// Only fuse P2P buffers, continue to allocate dedicated buffers for ring/treefor (int i=0; i<NCCL_STEPS; i++) {recvMem->connFifo[i].mode = map->shared ? NCCL_MODE_OFFSET : NCCL_MODE_NORMAL;}for (int p=0; p<NCCL_NUM_PROTOCOLS; p++)//获取buf的GPU访问指针recv->conn.buffs[p] = NCCL_NET_MAP_GET_POINTER(map, gpu, buffs[p]);if (recv->proxyConn.sameProcess) {//一般不会是同一个进程if (recv->proxyConn.connection->netDeviceHandle) {recv->conn.netDeviceHandle = *recv->proxyConn.connection->netDeviceHandle;for (int p=0; p<NCCL_NUM_PROTOCOLS; p++)recv->conn.mhandles[p] = recv->proxyConn.connection->mhandles[p];}if (recv->proxyConn.connection->needsProxyProgress) {recv->proxyConn.proxyProgress = recvProxyProgress;} else {recv->proxyConn.proxyProgress = NULL;}} else {recv->proxyConn.proxyProgress = recvProxyProgress;}return ncclSuccess;
}static ncclResult_t recvProxyConnect(struct ncclProxyConnection* connection, struct ncclProxyState* proxyState, void* reqBuff, int reqSize, void* respBuff, int respSize, int* done) {if (reqSize != sizeof(netRecvConnectArgs)) return ncclInternalError;struct recvNetResources* resources = (struct recvNetResources*)(connection->transportResources);netRecvConnectArgs* req = (netRecvConnectArgs*) reqBuff;resources->tpRemoteProxyRank = req->proxyRank;ncclResult_t ret = ncclSuccess;NCCLCHECK(ncclNetGetDeviceHandle(resources->netDeviceType, resources->netDeviceVersion, true /*isRecv*/, &resources->netDeviceHandle));// Finish connection establishment from remote peerif (resources->shared) {//为0// Shared buffersstruct ncclProxyProgressState* progressState = &proxyState->progressState;if (progressState->localPeers == NULL) {NCCLCHECK(ncclCalloc(&progressState->localPeers, proxyState->tpLocalnRanks));}struct ncclProxyPeer** localPeers = progressState->localPeers;if (localPeers[resources->tpLocalRank] == NULL) {NCCLCHECK(ncclCalloc(localPeers + resources->tpLocalRank, 1));}connection->proxyAppendPtr = localPeers[resources->tpLocalRank]->recv.proxyAppend + resources->channelId;if (resources->maxRecvs > 1 && ncclParamNetSharedComms()) {// Connect or reuse connection for a netdev/remote rank.if (progressState->netComms[resources->netDev] == NULL) {NCCLCHECK(ncclCalloc(progressState->netComms + resources->netDev, proxyState->tpnRanks));}struct ncclSharedNetComms* comms = progressState->netComms[resources->netDev] + resources->tpRemoteProxyRank;if (comms->recvComm[resources->channelId] == NULL) ret = proxyState->ncclNet->accept(resources->netListenComm, comms->recvComm+resources->channelId, &resources->netDeviceHandle);resources->netRecvComm = comms->recvComm[resources->channelId];if (comms->recvComm[resources->channelId]) comms->recvRefCount[resources->channelId]++;} else {ret = proxyState->ncclNet->accept(resources->netListenComm, &resources->netRecvComm, &resources->netDeviceHandle);}} else {// Connect to remote peer//调用 ncclIbAcceptret = proxyState->ncclNet->accept(resources->netListenComm, &resources->netRecvComm, &resources->netDeviceHandle);connection->proxyAppendPtr = &connection->proxyAppend;}NCCLCHECK(ret);if (resources->netRecvComm == NULL) {*done = 0;return ncclInProgress;}*done = 1;if (resources->netDeviceHandle) {connection->netDeviceHandle = resources->netDeviceHandle;connection->needsProxyProgress = connection->netDeviceHandle->needsProxyProgress;} else {connection->needsProxyProgress = 1;}NCCLCHECK(proxyState->ncclNet->closeListen(resources->netListenComm));// Create structuresstruct connectMap* map = &resources->map;map->sameProcess = connection->sameProcess;if (map->sameProcess == 0) return ncclInternalError; // We don't support remote proxy for recvmap->shared = resources->shared;if (resources->shared == 0) { // Only allocate dedicated buffers for ring/tree, not for p2p// gdr为1,所以buff会创建在GPU内部for (int p=0; p<NCCL_NUM_PROTOCOLS; p++) {//LL:512k, LL128:>4M, simple: 4mNCCL_NET_MAP_ADD_POINTER(map, 0, resources->useGdr, proxyState->buffSizes[p], buffs[p]);resources->buffSizes[p] = proxyState->buffSizes[p];}} else {// Get shared buffersint bank = resources->useGdr ? NCCL_NET_MAP_SHARED_DEVMEM : NCCL_NET_MAP_SHARED_HOSTMEM;struct connectMapMem* mapMem = map->mems+bank;NCCLCHECK(sharedNetBuffersInit(proxyState, resources->useGdr, resources->tpLocalRank, 1, 1, proxyState->p2pnChannels,&mapMem->gpuPtr, &mapMem->cpuPtr, &mapMem->size, NULL));resources->buffSizes[NCCL_PROTO_SIMPLE] = mapMem->size;NCCL_NET_MAP_ADD_POINTER(map, 1, resources->useGdr, mapMem->size, buffs[NCCL_PROTO_SIMPLE]);}//对于recv侧来说,sendMem、recvMem位于host DDRNCCL_NET_MAP_ADD_POINTER(map, 0, 0, sizeof(struct ncclSendMem), sendMem);NCCL_NET_MAP_ADD_POINTER(map, 0, 0, sizeof(struct ncclRecvMem), recvMem);if (proxyState->allocP2pNetLLBuffers) {NCCL_NET_MAP_ADD_POINTER(map, 0, 0 /*resources->useGdr*/, proxyState->buffSizes[NCCL_PROTO_LL], buffs[NCCL_PROTO_LL]);resources->buffSizes[NCCL_PROTO_LL] = proxyState->buffSizes[NCCL_PROTO_LL];}if (map->mems[NCCL_NET_MAP_DEVMEM].size) {//LL:512k, LL128:>4M, simple: 4mif (resources->shared == 0) {if (ncclCuMemEnable()) {//从GPU中分配内存NCCLCHECK(ncclP2pAllocateShareableBuffer(map->mems[NCCL_NET_MAP_DEVMEM].size, 0, &map->mems[NCCL_NET_MAP_DEVMEM].ipcDesc,(void**)&map->mems[NCCL_NET_MAP_DEVMEM].gpuPtr));} else {NCCLCHECK(ncclCudaCalloc(&map->mems[NCCL_NET_MAP_DEVMEM].gpuPtr, map->mems[NCCL_NET_MAP_DEVMEM].size));}map->mems[NCCL_NET_MAP_DEVMEM].cpuPtr = map->mems[NCCL_NET_MAP_DEVMEM].gpuPtr;}}//sendMem、recvMem位于host DDRNCCLCHECK(ncclCudaHostCalloc(&map->mems[NCCL_NET_MAP_HOSTMEM].cpuPtr, map->mems[NCCL_NET_MAP_HOSTMEM].size));map->mems[NCCL_NET_MAP_HOSTMEM].gpuPtr = map->mems[NCCL_NET_MAP_HOSTMEM].cpuPtr;if (ncclGdrCopy && map->sameProcess) {//不使用uint64_t *cpuPtr, *gpuPtr;NCCLCHECK(ncclGdrCudaCalloc(&cpuPtr, &gpuPtr, 2, &resources->gdrDesc));if (ncclParamGdrCopySyncEnable()) {resources->gdcSync = cpuPtr;struct connectMapMem* gdcMem = map->mems+NCCL_NET_MAP_GDCMEM;gdcMem->cpuPtr = (char*)cpuPtr;gdcMem->gpuPtr = (char*)gpuPtr;gdcMem->size = sizeof(uint64_t);}if (ncclParamGdrCopyFlushEnable()) resources->gdcFlush = cpuPtr + 1;}//对于recv侧来说,sendMem、recvMem位于host DDRresources->sendMem = (struct ncclSendMem*) NCCL_NET_MAP_GET_POINTER(map, cpu, sendMem);resources->recvMem = (struct ncclRecvMem*) NCCL_NET_MAP_GET_POINTER(map, cpu, recvMem);for (int i = 0; i < NCCL_STEPS; i++) resources->recvMem->connFifo[i].size = -1;//初始化size大小for (int p=0; p<NCCL_NUM_PROTOCOLS; p++) {resources->buffers[p] = NCCL_NET_MAP_GET_POINTER(map, cpu, buffs[p]);if (resources->buffers[p]) {
#if CUDA_VERSION >= 11070/* DMA-BUF support */int type = NCCL_NET_MAP_DEV_MEM(map, buffs[p]) ? NCCL_PTR_CUDA : NCCL_PTR_HOST;if (type == NCCL_PTR_CUDA && resources->useDmaBuf) {int dmabuf_fd;CUCHECK(cuMemGetHandleForAddressRange((void *)&dmabuf_fd, (CUdeviceptr)resources->buffers[p], resources->buffSizes[p], CU_MEM_RANGE_HANDLE_TYPE_DMA_BUF_FD, 0));NCCLCHECK(proxyState->ncclNet->regMrDmaBuf(resources->netRecvComm, resources->buffers[p], resources->buffSizes[p], type, 0ULL, dmabuf_fd, &resources->mhandles[p]));(void)close(dmabuf_fd);} else // FALL-THROUGH to nv_peermem GDR path
#endif{//将buf注册到RDMA mr中NCCLCHECK(proxyState->ncclNet->regMr(resources->netRecvComm, resources->buffers[p], resources->buffSizes[p], NCCL_NET_MAP_DEV_MEM(map, buffs[p]) ? NCCL_PTR_CUDA : NCCL_PTR_HOST, &resources->mhandles[p]));}// Copy the mhandle dptr,不进入if (resources->netDeviceType != NCCL_NET_DEVICE_HOST && proxyState->ncclNet->getDeviceMr)NCCLCHECK(proxyState->ncclNet->getDeviceMr(resources->netRecvComm, resources->mhandles[p], &connection->mhandles[p]));}}//NCCLCHECK(netDumpMap(map));if (respSize != sizeof(struct connectMap)) return ncclInternalError;memcpy(respBuff, map, sizeof(struct connectMap));return ncclSuccess;
}ncclResult_t ncclIbAccept(void* listenComm, void** recvComm, ncclNetDeviceHandle_t** /*recvDevComm*/) {ncclResult_t ret = ncclSuccess;struct ncclIbListenComm* lComm = (struct ncclIbListenComm*)listenComm;struct ncclIbCommStage* stage = &lComm->stage;struct ncclIbRecvComm* rComm = (struct ncclIbRecvComm*)stage->comm;int ready;*recvComm = NULL;if (stage->state == ncclIbCommStateAccept) goto ib_accept_check;if (stage->state == ncclIbCommStateRecvDevList) goto ib_recv_dev_list;if (stage->state == ncclIbCommStateSendDevList) goto ib_send_dev_list;if (stage->state == ncclIbCommStateRecv) goto ib_recv;if (stage->state == ncclIbCommStateSend) goto ib_send;if (stage->state == ncclIbCommStatePendingReady) goto ib_recv_ready;if (stage->state != ncclIbCommStateStart) {WARN("Listencomm in unknown state %d", stage->state);return ncclInternalError;}NCCLCHECK(ncclIbMalloc((void**)&rComm, sizeof(struct ncclIbRecvComm)));NCCLCHECKGOTO(ncclIbStatsInit(&rComm->base.stats), ret, fail);stage->comm = rComm;stage->state = ncclIbCommStateAccept;NCCLCHECKGOTO(ncclSocketInit(&rComm->base.sock), ret, fail);NCCLCHECKGOTO(ncclSocketAccept(&rComm->base.sock, &lComm->sock), ret, fail);// Alloc stage->buffer here to be used for all following stepsstruct ncclIbConnectionMetadata remMeta;stage->offset = 0;NCCLCHECK(ncclIbMalloc((void**)&stage->buffer, sizeof(remMeta)));ib_accept_check:NCCLCHECKGOTO(ncclSocketReady(&rComm->base.sock, &ready), ret, fail);if (!ready) return ncclSuccess;stage->state = ncclIbCommStateRecvDevList;stage->offset = 0;// In the case of mismatched nDevs, we will make sure that both sides of a logical connection have the same number of RC qps
ib_recv_dev_list://获取对端设备信息,主要为net设备个数NCCLCHECK(ncclSocketProgress(NCCL_SOCKET_RECV, &rComm->base.sock, stage->buffer, sizeof(ncclNetVDeviceProps_t), &stage->offset));if (stage->offset != sizeof(ncclNetVDeviceProps_t)) return ncclSuccess;ncclNetVDeviceProps_t remoteVProps;memcpy(&remoteVProps, stage->buffer, sizeof(ncclNetVDeviceProps_t));//保存对端设备信息,主要为net设备个数if (lComm->dev >= ncclNMergedIbDevs) {WARN("NET/IB : Trying to use non-existant virtual device %d", lComm->dev);return ncclInternalError;}// Reduce the physical device list and store in the connection basestruct ncclIbMergedDev* mergedDev;mergedDev = ncclIbMergedDevs + lComm->dev;NCCLCHECK(ncclIbCheckVProps(&mergedDev->vProps, &remoteVProps));rComm->base.vProps = mergedDev->vProps;memcpy(stage->buffer, &rComm->base.vProps, sizeof(ncclNetVDeviceProps_t));//将本端设备信息存放到buffer,主要为net设备个数rComm->base.isSend = false;int localNqps, remoteNqps;localNqps = ncclParamIbQpsPerConn() * rComm->base.vProps.ndevs; // We must have at least 1 qp per-deviceremoteNqps = ncclParamIbQpsPerConn() * remoteVProps.ndevs;//计算一共需要建链多少rdma QPrComm->base.nqps = remoteNqps > localNqps ? remoteNqps : localNqps; // Select max nqps (local or remote)stage->offset = 0;stage->state = ncclIbCommStateSendDevList;ib_send_dev_list://将本端设备个数信息发送NCCLCHECKGOTO(ncclSocketProgress(NCCL_SOCKET_SEND, &rComm->base.sock, stage->buffer, sizeof(ncclNetVDeviceProps_t), &stage->offset), ret, fail);if (stage->offset != sizeof(ncclNetVDeviceProps_t)) return ncclSuccess;stage->offset = 0;stage->state = ncclIbCommStateRecv;ib_recv:NCCLCHECKGOTO(ncclSocketProgress(NCCL_SOCKET_RECV, &rComm->base.sock, stage->buffer, sizeof(remMeta), &stage->offset), ret, fail);if (stage->offset != sizeof(remMeta)) return ncclSuccess;/* copy back the received info */memcpy(&remMeta, stage->buffer, sizeof(struct ncclIbConnectionMetadata));// IB setup// Pre-declare variables because of gotostruct ncclIbDev* ibDev;int ibDevN;struct ncclIbRecvCommDev* rCommDev;struct ncclIbDevInfo* remDevInfo;struct ncclIbQp* qp;mergedDev = ncclIbMergedDevs + lComm->dev;rComm->base.nRemDevs = remMeta.ndevs;if (rComm->base.nRemDevs != rComm->base.vProps.ndevs) {INFO(NCCL_NET, "NET/IB : Local mergedDev %s has a different number of devices=%d as remote %s %d",mergedDev->devName, rComm->base.vProps.ndevs, remMeta.devName, rComm->base.nRemDevs);}// Metadata to send back to requestor (sender)struct ncclIbConnectionMetadata meta;memset(&meta, 0, sizeof(meta));for (int i = 0; i < rComm->base.vProps.ndevs; i++) {rCommDev = rComm->devs + i;ibDevN = rComm->base.vProps.devs[i];NCCLCHECKGOTO(ncclIbInitCommDevBase(ibDevN, &rCommDev->base, &rComm->base.stats), ret, fail);ibDev = ncclIbDevs + ibDevN;NCCLCHECKGOTO(ncclIbGetGidIndex(ibDev->context, ibDev->portNum, &ibDev->portAttr, &rCommDev->base.gidInfo.localGidIndex), ret, fail);NCCLCHECKGOTO(wrap_ibv_query_gid(ibDev->context, ibDev->portNum, rCommDev->base.gidInfo.localGidIndex, &rCommDev->base.gidInfo.localGid), ret, fail);}// Copy remDevInfo for things like remGidInfo, remFifoAddr, etc.for (int i = 0; i < remMeta.ndevs; i++) {rComm->base.remDevs[i] = remMeta.devs[i];rComm->base.remDevs[i].remoteGid.global.interface_id = rComm->base.remDevs[i].gid.global.interface_id;rComm->base.remDevs[i].remoteGid.global.subnet_prefix = rComm->base.remDevs[i].gid.global.subnet_prefix;}// Stripe QP creation across merged devs// Make sure to get correct remote peer dev and QP infoint remDevIndex;int devIndex;devIndex = 0;//根据QP个数创建QPfor (int q = 0; q < rComm->base.nqps; q++) {remDevIndex = remMeta.qpInfo[q].devIndex;remDevInfo = remMeta.devs + remDevIndex;qp = rComm->base.qps+q;rCommDev = rComm->devs + devIndex;qp->remDevIdx = remDevIndex;//本端这个qp连接对端哪个net设备索引,这个索引是卡内的,即一张mlx卡最多支持4个net// Local ibDevNibDevN = rComm->devs[devIndex].base.ibDevN;ibDev = ncclIbDevs + ibDevN;//创建qp,允许QP接收对端写操作NCCLCHECKGOTO(ncclIbCreateQp(ibDev->portNum, &rCommDev->base, IBV_ACCESS_REMOTE_WRITE, &rComm->base.stats, qp), ret, fail);qp->devIndex = devIndex;devIndex = (devIndex + 1) % rComm->base.vProps.ndevs;// Set the ece (enhanced connection establishment) on this QP before RTRif (remMeta.qpInfo[q].ece_supported) {// Coverity suspects a copy-paste error below due to the use of remMeta in one argument and meta in another.// However, this has been confirmed to be intentional.// coverity[copy_paste_error]NCCLCHECKGOTO(wrap_ibv_set_ece(qp->qp, &remMeta.qpInfo[q].ece, &meta.qpInfo[q].ece_supported), ret, fail);// Query the reduced ece for this QP (matching enhancements between the requestor and the responder)// Store this in our own qpInfo for returning to the requestorif (meta.qpInfo[q].ece_supported)NCCLCHECKGOTO(wrap_ibv_query_ece(qp->qp, &meta.qpInfo[q].ece, &meta.qpInfo[q].ece_supported), ret, fail);} else {meta.qpInfo[q].ece_supported = 0;}//根据对端QP信息,完成QP绑定建链NCCLCHECKGOTO(ncclIbRtrQp(qp->qp, &rCommDev->base.gidInfo, remMeta.qpInfo[q].qpn, remDevInfo, true), ret, fail);NCCLCHECKGOTO(ncclIbRtsQp(qp->qp), ret, fail);}rComm->flushEnabled = ((ncclIbGdrSupport() == ncclSuccess || ncclIbDmaBufSupport(lComm->dev) == ncclSuccess)&& (ncclParamIbGdrFlushDisable() == 0)) ? 1 : 0;for (int i = 0; i < rComm->base.vProps.ndevs; i++) {rCommDev = rComm->devs + i;ibDev = ncclIbDevs + rCommDev->base.ibDevN;// Retain remote fifo info and prepare my RDMA opsrComm->remFifo.addr = remMeta.fifoAddr;//保存对端 FIFO MR对应虚拟地址//本端注册 elems mr,用来数据传输前将本地数据buf地址写入到对端 FIFO 中NCCLCHECKGOTO(wrap_ibv_reg_mr(&rCommDev->fifoMr, rCommDev->base.pd, &rComm->remFifo.elems, sizeof(struct ncclIbSendFifo)*MAX_REQUESTS*NCCL_NET_IB_MAX_RECVS, IBV_ACCESS_REMOTE_WRITE|IBV_ACCESS_LOCAL_WRITE|IBV_ACCESS_REMOTE_READ), ret, fail);rCommDev->fifoSge.lkey = rCommDev->fifoMr->lkey;if (ncclParamIbUseInline()) rComm->remFifo.flags = IBV_SEND_INLINE;// Allocate Flush dummy buffer for GPU Direct RDMAif (rComm->flushEnabled) {//申请一个本端QP用来数据传输完成后执行read操作,确保数据写入HBMNCCLCHECKGOTO(wrap_ibv_reg_mr(&rCommDev->gpuFlush.hostMr, rCommDev->base.pd, &rComm->gpuFlushHostMem, sizeof(int), IBV_ACCESS_LOCAL_WRITE), ret, fail);rCommDev->gpuFlush.sge.addr = (uint64_t)&rComm->gpuFlushHostMem;rCommDev->gpuFlush.sge.length = 1;rCommDev->gpuFlush.sge.lkey = rCommDev->gpuFlush.hostMr->lkey;NCCLCHECKGOTO(ncclIbCreateQp(ibDev->portNum, &rCommDev->base, IBV_ACCESS_LOCAL_WRITE | IBV_ACCESS_REMOTE_READ, &rComm->base.stats, &rCommDev->gpuFlush.qp), ret, fail);struct ncclIbDevInfo devInfo;devInfo.lid = ibDev->portAttr.lid;devInfo.link_layer = ibDev->portAttr.link_layer;devInfo.ib_port = ibDev->portNum;devInfo.gid.global.subnet_prefix = rCommDev->base.gidInfo.localGid.global.subnet_prefix;devInfo.gid.global.interface_id = rCommDev->base.gidInfo.localGid.global.interface_id;devInfo.mtu = ibDev->portAttr.active_mtu;NCCLCHECKGOTO(ncclIbRtrQp(rCommDev->gpuFlush.qp.qp, &rCommDev->base.gidInfo, rCommDev->gpuFlush.qp.qp->qp_num, &devInfo, false), ret, fail);NCCLCHECKGOTO(ncclIbRtsQp(rCommDev->gpuFlush.qp.qp), ret, fail);}// Fill Handle//填充设备信息,比较重要的是gidmeta.devs[i].lid = ibDev->portAttr.lid;meta.devs[i].link_layer = rCommDev->base.gidInfo.link_layer = ibDev->portAttr.link_layer;meta.devs[i].ib_port = ibDev->portNum;meta.devs[i].gid.global.subnet_prefix = rCommDev->base.gidInfo.localGid.global.subnet_prefix;meta.devs[i].gid.global.interface_id = rCommDev->base.gidInfo.localGid.global.interface_id;meta.devs[i].mtu = ibDev->portAttr.active_mtu;// Prepare sizes fifo//注册size FIFO 的mrNCCLCHECKGOTO(wrap_ibv_reg_mr(&rComm->devs[i].sizesFifoMr, rComm->devs[i].base.pd, rComm->sizesFifo, sizeof(int)*MAX_REQUESTS*NCCL_NET_IB_MAX_RECVS, IBV_ACCESS_LOCAL_WRITE|IBV_ACCESS_REMOTE_WRITE|IBV_ACCESS_REMOTE_READ), ret, fail);meta.devs[i].fifoRkey = rComm->devs[i].sizesFifoMr->rkey;//将sizeFIFO的rkey填入}meta.fifoAddr = (uint64_t)rComm->sizesFifo;//将本端size fifo的虚拟地址填入for (int q = 0; q < rComm->base.nqps; q++) {meta.qpInfo[q].qpn = rComm->base.qps[q].qp->qp_num;meta.qpInfo[q].devIndex = rComm->base.qps[q].devIndex;}meta.ndevs = rComm->base.vProps.ndevs;strncpy(meta.devName, mergedDev->devName, MAX_MERGED_DEV_NAME);rComm->base.nDataQps = std::max(rComm->base.vProps.ndevs, rComm->base.nRemDevs);stage->state = ncclIbCommStateSend;stage->offset = 0;if (stage->buffer) {free(stage->buffer);stage->buffer = NULL;}NCCLCHECKGOTO(ncclIbMalloc((void**)&stage->buffer, sizeof(struct ncclIbConnectionMetadata)), ret, fail);memcpy(stage->buffer, &meta, sizeof(struct ncclIbConnectionMetadata));ib_send://将本端qp和size fifo信息发送给对端NCCLCHECKGOTO(ncclSocketProgress(NCCL_SOCKET_SEND, &rComm->base.sock, stage->buffer, sizeof(struct ncclIbConnectionMetadata), &stage->offset), ret, fail);if (stage->offset < sizeof(struct ncclIbConnectionMetadata)) return ncclSuccess;stage->offset = 0;stage->state = ncclIbCommStatePendingReady;ib_recv_ready://同步,确认对端已经建链完毕NCCLCHECKGOTO(ncclSocketProgress(NCCL_SOCKET_RECV, &rComm->base.sock, &rComm->base.ready, sizeof(int), &stage->offset), ret, fail);if (stage->offset != sizeof(int)) return ncclSuccess;*recvComm = rComm;
exit:/* reset lComm stage */if (stage->buffer) free(stage->buffer);stage->state = ncclIbCommStateStart;stage->offset = 0;stage->comm = NULL;stage->buffer = NULL;return ret;
fail:free(rComm);goto exit;
}
上面代码较多,其实现的内容为:1)socket监听到对端连接,接收net设备信息,决定使用多QP建链;2)交换QP信息,完成QP绑定建链;3)创建iflush使用的本地QP;4)将本端sizeFIFO(给对端写数据传输大小)注册mr产生的相关信息发给对端,获取对端FIFO(本端写数据接收buff信息)注册mr产生的相关信息;5)本端在GPU上分配接收缓存区内存;6)host DDR上分配head、tail相关内存(用于协调本端和kernel数据传输交互);7)将tail、head、接收缓存区等信息填写到GPU内存。
本端作为发送端设置发送方向相关通信数据
先调用sendSetup,代码如下。
static ncclResult_t sendSetup(struct ncclComm* comm, struct ncclTopoGraph* graph, struct ncclPeerInfo* myInfo, struct ncclPeerInfo* peerInfo, struct ncclConnect* connectInfo, struct ncclConnector* send, int channelId, int connIndex) {struct setupReq req = { 0 };send->conn.shared = req.shared = graph || connIndex == 0 ? 0 : ncclParamNetSharedBuffers() != -2 ? ncclParamNetSharedBuffers() : 1;req.channelId = channelId;req.connIndex = connIndex;int proxyRank;int64_t netId;//获取使用的net id,从拓扑中NCCLCHECK(ncclTopoGetNetDev(comm, myInfo->rank, graph, channelId, peerInfo->rank, &netId, &req.netDev, &proxyRank));NCCLCHECK(ncclTopoCheckGdr(comm->topo, myInfo->rank, netId, 1, &req.useGdr));//检查gdr支持send->conn.flags |= req.useGdr ? NCCL_DIRECT_NIC : 0;if (!req.useGdr && connIndex == 0) comm->useGdr = 0;if (proxyRank != myInfo->rank && connIndex == 0) comm->useNetPXN = true;//不启用//连接本地网络,为调用ncclProxyCallBlocking做准备,会创建一个proxyProgress代理线程NCCLCHECK(ncclProxyConnect(comm, TRANSPORT_NET, 1, proxyRank, &send->proxyConn));req.tpLocalRank = comm->topParentLocalRanks[comm->localRank];req.tpRank = comm->topParentRanks[myInfo->rank];req.tpRemoteRank = comm->topParentRanks[peerInfo->rank];// 调用 sendProxySetupNCCLCHECK(ncclProxyCallBlocking(comm, &send->proxyConn, ncclProxyMsgSetup, &req, sizeof(req), NULL, 0));if (proxyRank == myInfo->rank) {INFO(NCCL_INIT|NCCL_NET,"Channel %02d/%d : %d[%d] -> %d[%d] [send] via NET/%s/%d%s%s", channelId, connIndex, myInfo->rank, myInfo->nvmlDev, peerInfo->rank, peerInfo->nvmlDev, comm->ncclNet->name, req.netDev,req.useGdr ? "/GDRDMA" : "", req.shared ? "/Shared" : "");} else {INFO(NCCL_INIT|NCCL_NET,"Channel %02d/%d : %d[%d] -> %d[%d] [send] via NET/%s/%d(%d)%s%s", channelId, connIndex, myInfo->rank, myInfo->nvmlDev, peerInfo->rank, peerInfo->nvmlDev, comm->ncclNet->name, req.netDev,proxyRank, req.useGdr ? "/GDRDMA" : "", req.shared ? "/Shared" : "");}//connectInfo 是用来交换给recv端的数据*((int*)connectInfo) = comm->topParentRanks[proxyRank];//存储本rank父节点的全局rank idmemcpy((uint8_t*)connectInfo + sizeof(ncclNetHandle_t), &req.useGdr, sizeof(int));//将本端gdr信息告诉对端return ncclSuccess;
}
其中最主要的是调用了ncclProxyConnect和ncclProxyCallBlocking,其中ncclProxyConnect在recv部分已经介绍了,最主要的就是创建了ncclProxyProgress线程。
ncclProxyCallBlocking接口回调的是sendProxySetup,代码如下。
static ncclResult_t sendProxySetup(struct ncclProxyConnection* connection, struct ncclProxyState* proxyState, void* reqBuff, int reqSize, void* respBuff, int respSize, int* done) {struct setupReq* req = (struct setupReq*) reqBuff;if (reqSize != sizeof(struct setupReq)) return ncclInternalError;struct sendNetResources* resources;NCCLCHECK(ncclCalloc(&resources, 1));connection->transportResources = resources;//存储信息resources->tpRank = req->tpRank;resources->tpLocalRank = req->tpLocalRank;resources->tpRemoteRank = req->tpRemoteRank;resources->netDev = req->netDev;resources->shared = connection->shared = req->shared;resources->useGdr = req->useGdr;resources->channelId = req->channelId;resources->connIndex = req->connIndex;ncclNetProperties_t props;//查询net相关属性NCCLCHECK(proxyState->ncclNet->getProperties(req->netDev, &props));/* DMA-BUF support */resources->useDmaBuf = resources->useGdr && proxyState->dmaBufSupport && (props.ptrSupport & NCCL_PTR_DMABUF);resources->maxRecvs = props.maxRecvs;resources->netDeviceVersion = props.netDeviceVersion;resources->netDeviceType = props.netDeviceType;resources->netDeviceVersion = props.netDeviceVersion;resources->netDeviceType = props.netDeviceType;/* point-to-point size limits*/resources->maxP2pBytes = props.maxP2pBytes;if((resources->maxP2pBytes <= 0) || (resources->maxP2pBytes > NCCL_MAX_NET_SIZE_BYTES)) {WARN("sendProxySetup: net plugin returned invalid value for maxP2pBytes %ld \[allowed range: %ld - %ld] \n", resources->maxP2pBytes, 0L, NCCL_MAX_NET_SIZE_BYTES);return ncclInternalError;}// We don't return any dataif (respSize != 0) return ncclInternalError;*done = 1;return ncclSuccess;
}
sendProxySetup主要是初始化一些信息。
交换信息之后调用sendConnect -> snedProxyConnect -> ncclIbConnect,代码如下:
static ncclResult_t sendConnect(struct ncclComm* comm, struct ncclConnect* connectInfo, int nranks, int rank, struct ncclConnector* send) {struct connectMap* map = (connectMap*) send->transportResources;void* opId;int recvUseGdr;//connectInfo存储对端接收端填充的信息//获取recv端gdr支持memcpy(&recvUseGdr, (uint8_t*)connectInfo + sizeof(ncclNetHandle_t), sizeof(int));if (!recvUseGdr) send->conn.flags &= ~NCCL_DIRECT_NIC;// map isn't allocated thus this op hasn't been submitted yetif (!map) {// Setup device pointersNCCLCHECK(ncclCalloc(&map, 1));send->transportResources = map;opId = send;INFO(NCCL_PROXY, "sendConnect ncclProxyCallAsync opId=%p", opId);netSendConnectArgs args = {0};memcpy(&args.handle, connectInfo, sizeof(ncclNetHandle_t));//调用snedProxyConnectNCCLCHECK(ncclProxyCallAsync(comm, &send->proxyConn, ncclProxyMsgConnect, &args, sizeof(netSendConnectArgs), sizeof(struct connectMap), opId));} else {opId = send;}ncclResult_t ret;ret = ncclPollProxyResponse(comm, &send->proxyConn, map, opId);//异步接收map数据if (ret != ncclSuccess) {if (ret != ncclInProgress) {free(map);send->transportResources = NULL;}return ret;}INFO(NCCL_PROXY, "sendConnect ncclPollProxyResponse opId=%p", opId);if (map->sameProcess && !ncclCuMemEnable()) {//ncclCuMemEnable为1,不进入if (map->cudaDev != comm->cudaDev) {// Enable P2P access for Legacy IPCcudaError_t err = cudaDeviceEnablePeerAccess(map->cudaDev, 0);if (err == cudaErrorPeerAccessAlreadyEnabled) {cudaGetLastError();} else if (err != cudaSuccess) {WARN("failed to peer with device %d: %d %s", map->cudaDev, err, cudaGetErrorString(err));return ncclInternalError;}}} else if (!(map->sameProcess && map->cudaDev == comm->cudaDev)) {//sameProcess为0,进入if (!map->sameProcess) NCCLCHECK(netMapShm(comm, map->mems + NCCL_NET_MAP_HOSTMEM));//导入net共享buffif (map->mems[NCCL_NET_MAP_DEVMEM].size) {map->mems[NCCL_NET_MAP_DEVMEM].gpuPtr = NULL;//导入设备内存,因为有可能是多进程NCCLCHECK(ncclP2pImportShareableBuffer(comm, send->proxyConn.rank,map->mems[NCCL_NET_MAP_DEVMEM].size,&map->mems[NCCL_NET_MAP_DEVMEM].ipcDesc,(void**)&map->mems[NCCL_NET_MAP_DEVMEM].gpuPtr));map->mems[NCCL_NET_MAP_DEVMEM].cpuPtr = NULL;//host 不会访问,多进程时候,也不能访问}if (map->mems[NCCL_NET_MAP_SHARED_DEVMEM].size) {//无void** sharedDevMemPtr = comm->proxyState->sharedDevMems + send->proxyConn.tpLocalRank;if (*sharedDevMemPtr == NULL) {map->mems[NCCL_NET_MAP_SHARED_DEVMEM].gpuPtr = NULL;NCCLCHECK(ncclP2pImportShareableBuffer(comm, send->proxyConn.rank,map->mems[NCCL_NET_MAP_SHARED_DEVMEM].size,&map->mems[NCCL_NET_MAP_SHARED_DEVMEM].ipcDesc,sharedDevMemPtr));}map->mems[NCCL_NET_MAP_SHARED_DEVMEM].gpuPtr = (char*)(*sharedDevMemPtr);map->mems[NCCL_NET_MAP_SHARED_DEVMEM].cpuPtr = NULL;}}//NCCLCHECK(netDumpMap(map));struct ncclSendMem *sendMem = (struct ncclSendMem*) NCCL_NET_MAP_GET_POINTER(map, gpu, sendMem);void* gdcMem = map->mems[NCCL_NET_MAP_GDCMEM].gpuPtr;//无send->conn.head = gdcMem ? (uint64_t*)gdcMem : &sendMem->head;struct ncclRecvMem *recvMem = (struct ncclRecvMem*) NCCL_NET_MAP_GET_POINTER(map, gpu, recvMem);send->conn.tail = &recvMem->tail;send->conn.stepSize = comm->buffSizes[NCCL_PROTO_SIMPLE]/NCCL_STEPS;send->conn.connFifo = recvMem->connFifo;// Only fuse P2P buffers, continue to allocate dedicated buffers for ring/treefor (int i=0; i<NCCL_STEPS; i++) {send->conn.connFifo[i].offset = -1;recvMem->connFifo[i].mode = map->shared ? NCCL_MODE_OFFSET : NCCL_MODE_NORMAL;//NCCL_MODE_NORMAL}for (int p=0; p<NCCL_NUM_PROTOCOLS; p++)send->conn.buffs[p] = NCCL_NET_MAP_GET_POINTER(map, gpu, buffs[p]);//将gpd访问buff的指针填入buffs,给GPU使用的if (send->proxyConn.sameProcess) {if (send->proxyConn.connection->netDeviceHandle) {send->conn.netDeviceHandle = *send->proxyConn.connection->netDeviceHandle;for (int p=0; p<NCCL_NUM_PROTOCOLS; p++)send->conn.mhandles[p] = send->proxyConn.connection->mhandles[p];}if (send->proxyConn.connection->needsProxyProgress) {send->proxyConn.proxyProgress = sendProxyProgress;} else {send->proxyConn.proxyProgress = NULL;}} else {send->proxyConn.proxyProgress = sendProxyProgress;//赋值}return ncclSuccess;
}static ncclResult_t sendProxyConnect(struct ncclProxyConnection* connection, struct ncclProxyState* proxyState, void* reqBuff, int reqSize, void* respBuff, int respSize, int* done) {struct sendNetResources* resources = (struct sendNetResources*)(connection->transportResources);if (reqSize != sizeof(netSendConnectArgs)) return ncclInternalError;ncclResult_t ret = ncclSuccess;netSendConnectArgs* req = (netSendConnectArgs*) reqBuff;NCCLCHECK(ncclNetGetDeviceHandle(resources->netDeviceType, resources->netDeviceVersion, false /*isRecv*/, &resources->netDeviceHandle));if (resources->shared) {//为0// Shared buffersstruct ncclProxyProgressState* progressState = &proxyState->progressState;if (progressState->localPeers == NULL) {NCCLCHECK(ncclCalloc(&progressState->localPeers, proxyState->tpLocalnRanks));}struct ncclProxyPeer** localPeers = progressState->localPeers;if (localPeers[resources->tpLocalRank] == NULL) {NCCLCHECK(ncclCalloc(localPeers + resources->tpLocalRank, 1));}connection->proxyAppendPtr = localPeers[resources->tpLocalRank]->send.proxyAppend + resources->channelId;if (resources->maxRecvs > 1 && ncclParamNetSharedComms()) {// Connect or reuse connection for a netdev/remote rank.if (progressState->netComms[resources->netDev] == NULL) {NCCLCHECK(ncclCalloc(progressState->netComms + resources->netDev, proxyState->tpnRanks));}struct ncclSharedNetComms* comms = progressState->netComms[resources->netDev] + resources->tpRemoteRank;if (comms->sendComm[resources->channelId] == NULL) ret = proxyState->ncclNet->connect(resources->netDev, req->handle, comms->sendComm + resources->channelId, &resources->netDeviceHandle);resources->netSendComm = comms->sendComm[resources->channelId];if (comms->sendComm[resources->channelId]) comms->sendRefCount[resources->channelId]++;} else {ret = proxyState->ncclNet->connect(resources->netDev, req->handle, &resources->netSendComm, &resources->netDeviceHandle);}} else {// Connect to remote peer//调用 ncclIbConnectret = proxyState->ncclNet->connect(resources->netDev, req->handle, &resources->netSendComm, &resources->netDeviceHandle);connection->proxyAppendPtr = &connection->proxyAppend;}NCCLCHECK(ret);if (resources->netSendComm == NULL) {*done = 0;return ncclInProgress;}*done = 1;if (resources->netDeviceHandle) {//为0connection->netDeviceHandle = resources->netDeviceHandle;connection->needsProxyProgress = connection->netDeviceHandle->needsProxyProgress;} else {connection->needsProxyProgress = 1;}// Create structuresstruct connectMap* map = &resources->map;map->sameProcess = connection->sameProcess;map->shared = resources->shared;CUDACHECK(cudaGetDevice(&map->cudaDev));if (resources->shared == 0) { // Only allocate dedicated buffers for ring/tree, not for p2pfor (int p=0; p<NCCL_NUM_PROTOCOLS; p++) {//除了 NCCL_PROTO_LL 创建在host,其他都在GPUNCCL_NET_MAP_ADD_POINTER(map, 0, p!= NCCL_PROTO_LL && resources->useGdr, proxyState->buffSizes[p], buffs[p]);resources->buffSizes[p] = proxyState->buffSizes[p];}} else {// Get shared buffersint bank = resources->useGdr ? NCCL_NET_MAP_SHARED_DEVMEM : NCCL_NET_MAP_SHARED_HOSTMEM;struct connectMapMem* mapMem = map->mems+bank;NCCLCHECK(sharedNetBuffersInit(proxyState, resources->useGdr, resources->tpLocalRank, 0, map->sameProcess, proxyState->p2pnChannels,&mapMem->gpuPtr, &mapMem->cpuPtr, &mapMem->size, &mapMem->ipcDesc));resources->buffSizes[NCCL_PROTO_SIMPLE] = mapMem->size;if (proxyState->allocP2pNetLLBuffers) {NCCL_NET_MAP_ADD_POINTER(map, 0, 0 /*p == NCCL_PROTO_LL*/, proxyState->buffSizes[NCCL_PROTO_LL], buffs[NCCL_PROTO_LL]);resources->buffSizes[NCCL_PROTO_LL] = proxyState->buffSizes[NCCL_PROTO_LL];}NCCL_NET_MAP_ADD_POINTER(map, 1, resources->useGdr, mapMem->size, buffs[NCCL_PROTO_SIMPLE]);}//sendMem和recvMem的内存都创建在cpuNCCL_NET_MAP_ADD_POINTER(map, 0, 0, sizeof(struct ncclSendMem), sendMem);NCCL_NET_MAP_ADD_POINTER(map, 0, 0, sizeof(struct ncclRecvMem), recvMem);if (map->mems[NCCL_NET_MAP_DEVMEM].size) {if (resources->shared == 0) {if (!map->sameProcess || ncclCuMemEnable()) {ALIGN_SIZE(map->mems[NCCL_NET_MAP_DEVMEM].size, CUDA_IPC_MIN);//申请 NCCL_PROTO_LL128 和 NCCL_PROTO_SIMPLE 内存在GPUNCCLCHECK(ncclP2pAllocateShareableBuffer(map->mems[NCCL_NET_MAP_DEVMEM].size, 0, &map->mems[NCCL_NET_MAP_DEVMEM].ipcDesc,(void**)&map->mems[NCCL_NET_MAP_DEVMEM].gpuPtr));} else {NCCLCHECK(ncclCudaCalloc(&map->mems[NCCL_NET_MAP_DEVMEM].gpuPtr, map->mems[NCCL_NET_MAP_DEVMEM].size));}map->mems[NCCL_NET_MAP_DEVMEM].cpuPtr = map->mems[NCCL_NET_MAP_DEVMEM].gpuPtr;}}if (map->sameProcess) {NCCLCHECK(ncclCudaHostCalloc(&map->mems[NCCL_NET_MAP_HOSTMEM].cpuPtr, map->mems[NCCL_NET_MAP_HOSTMEM].size));map->mems[NCCL_NET_MAP_HOSTMEM].gpuPtr = map->mems[NCCL_NET_MAP_HOSTMEM].cpuPtr;} else {//创建共享内存,用于单节点多进程共享,包含sendMem、recvMem、NCCL_PROTO_LLNCCLCHECK(netCreateShm(proxyState, map->mems+NCCL_NET_MAP_HOSTMEM));void* sendMem = (void*)NCCL_NET_MAP_GET_POINTER(map, cpu, sendMem);void* recvMem = (void*)NCCL_NET_MAP_GET_POINTER(map, cpu, recvMem);memset(sendMem, 0, sizeof(struct ncclSendMem));memset(recvMem, 0, sizeof(struct ncclRecvMem));}if (ncclGdrCopy && map->sameProcess && ncclParamGdrCopySyncEnable()) {uint64_t *cpuPtr, *gpuPtr;NCCLCHECK(ncclGdrCudaCalloc(&cpuPtr, &gpuPtr, 1, &resources->gdrDesc));resources->gdcSync = cpuPtr;struct connectMapMem* gdcMem = map->mems+NCCL_NET_MAP_GDCMEM;gdcMem->cpuPtr = (char*)cpuPtr;gdcMem->gpuPtr = (char*)gpuPtr;gdcMem->size = sizeof(uint64_t); // sendMem->head}//填充 sendMem 和 recvMem 内存指针resources->sendMem = (struct ncclSendMem*) NCCL_NET_MAP_GET_POINTER(map, cpu, sendMem);resources->recvMem = (struct ncclRecvMem*) NCCL_NET_MAP_GET_POINTER(map, cpu, recvMem);// Don't give credits yet in shared mode.(resources->gdcSync ? *resources->gdcSync : resources->sendMem->head) =(map->shared ? -NCCL_STEPS : 0);//head清零for (int i=0; i<NCCL_STEPS; i++) resources->recvMem->connFifo[i].size = -1;for (int p=0; p<NCCL_NUM_PROTOCOLS; p++) {resources->buffers[p] = NCCL_NET_MAP_GET_POINTER(map, cpu, buffs[p]);if (resources->buffers[p]) {
#if CUDA_VERSION >= 11070/* DMA-BUF support */int type = NCCL_NET_MAP_DEV_MEM(map, buffs[p]) ? NCCL_PTR_CUDA : NCCL_PTR_HOST;if (type == NCCL_PTR_CUDA && resources->useDmaBuf) {int dmabuf_fd;CUCHECK(cuMemGetHandleForAddressRange((void *)&dmabuf_fd, (CUdeviceptr)resources->buffers[p], resources->buffSizes[p], CU_MEM_RANGE_HANDLE_TYPE_DMA_BUF_FD, 0));NCCLCHECK(proxyState->ncclNet->regMrDmaBuf(resources->netSendComm, resources->buffers[p], resources->buffSizes[p], type, 0ULL, dmabuf_fd, &resources->mhandles[p]));(void)close(dmabuf_fd);} else // FALL-THROUGH to nv_peermem GDR path
#endif{//数据缓存区注册mrNCCLCHECK(proxyState->ncclNet->regMr(resources->netSendComm, resources->buffers[p], resources->buffSizes[p], NCCL_NET_MAP_DEV_MEM(map, buffs[p]) ? NCCL_PTR_CUDA : NCCL_PTR_HOST, &resources->mhandles[p]));}// Copy the mhandle dptr, if implemented,不进入if (resources->netDeviceHandle && proxyState->ncclNet->getDeviceMr)NCCLCHECK(proxyState->ncclNet->getDeviceMr(resources->netSendComm, resources->mhandles[p], &connection->mhandles[p]));}}//NCCLCHECK(netDumpMap(map));if (respSize != sizeof(struct connectMap)) return ncclInternalError;memcpy(respBuff, map, sizeof(struct connectMap));return ncclSuccess;
}ncclResult_t ncclIbConnect(int dev, void* opaqueHandle, void** sendComm, ncclNetDeviceHandle_t** /*sendDevComm*/) {ncclResult_t ret = ncclSuccess;struct ncclIbHandle* handle = (struct ncclIbHandle*) opaqueHandle;//从recv端拿到的数据struct ncclIbCommStage* stage = &handle->stage;struct ncclIbSendComm* comm = (struct ncclIbSendComm*)stage->comm;int ready;*sendComm = NULL;if (stage->state == ncclIbCommStateConnect) goto ib_connect_check;if (stage->state == ncclIbCommStateSendDevList) goto ib_send_dev_list;if (stage->state == ncclIbCommStateRecvDevList) goto ib_recv_dev_list;if (stage->state == ncclIbCommStateSend) goto ib_send;if (stage->state == ncclIbCommStateConnecting) goto ib_connect;if (stage->state == ncclIbCommStateConnected) goto ib_send_ready;if (stage->state != ncclIbCommStateStart) {WARN("Error: trying to connect already connected sendComm");return ncclInternalError;}stage->buffer = NULL;NCCLCHECK(ncclIbMalloc((void**)&comm, sizeof(struct ncclIbSendComm)));NCCLCHECKGOTO(ncclIbStatsInit(&comm->base.stats), ret, fail);//初始化sock,填写连接地址connectAddr,其实就是recv端监听地址NCCLCHECKGOTO(ncclSocketInit(&comm->base.sock, &handle->connectAddr, handle->magic, ncclSocketTypeNetIb, NULL, 1), ret, fail);stage->comm = comm;stage->state = ncclIbCommStateConnect;//TCP连接recv端NCCLCHECKGOTO(ncclSocketConnect(&comm->base.sock), ret, fail);ib_connect_check:/* since ncclSocketConnect is async, we must check if connection is complete */NCCLCHECKGOTO(ncclSocketReady(&comm->base.sock, &ready), ret, fail);if (!ready) return ncclSuccess;// IB Setupstruct ncclIbMergedDev* mergedDev;if (dev >= ncclNMergedIbDevs) {WARN("NET/IB : Trying to use non-existant virtual device %d", dev);return ncclInternalError;}mergedDev = ncclIbMergedDevs + dev;comm->base.vProps = mergedDev->vProps;comm->base.isSend = true;stage->state = ncclIbCommStateSendDevList;stage->offset = 0;struct ncclIbConnectionMetadata meta;NCCLCHECKGOTO(ncclIbMalloc((void**)&stage->buffer, sizeof(meta)), ret, fail);//将本rank使用的net设备信息保存到buffer,主要是设备个数memcpy(stage->buffer, &mergedDev->vProps, sizeof(ncclNetVDeviceProps_t));// In the case of mismatched nDevs, we will make sure that both sides of a logical connection have the same number of RC qps
ib_send_dev_list://net信息发送给recv端NCCLCHECK(ncclSocketProgress(NCCL_SOCKET_SEND, &comm->base.sock, stage->buffer, sizeof(ncclNetVDeviceProps_t), &stage->offset));if (stage->offset != sizeof(ncclNetVDeviceProps_t)) return ncclSuccess;stage->state = ncclIbCommStateRecvDevList;stage->offset = 0;ib_recv_dev_list://从recv端读取对端rank使用的net信息NCCLCHECK(ncclSocketProgress(NCCL_SOCKET_RECV, &comm->base.sock, stage->buffer, sizeof(ncclNetVDeviceProps_t), &stage->offset));if (stage->offset != sizeof(ncclNetVDeviceProps_t)) return ncclSuccess;stage->offset = 0;ncclNetVDeviceProps_t remoteVProps;memcpy(&remoteVProps, stage->buffer, sizeof(ncclNetVDeviceProps_t));mergedDev = ncclIbMergedDevs + dev;comm->base.vProps = mergedDev->vProps;int localNqps, remoteNqps;//计算使用多QP建链localNqps = ncclParamIbQpsPerConn() * comm->base.vProps.ndevs; // We must have at least 1 qp per-deviceremoteNqps = ncclParamIbQpsPerConn() * remoteVProps.ndevs;comm->base.nqps = remoteNqps > localNqps ? remoteNqps : localNqps; // Select max nqps (local or remote)// Init PD, Ctx for each IB devicecomm->ar = 1; // Set to 1 for logicfor (int i = 0; i < comm->base.vProps.ndevs; i++) {int ibDevN = comm->base.vProps.devs[i];//为每个ib设备创建pd和cqNCCLCHECKGOTO(ncclIbInitCommDevBase(ibDevN, &comm->devs[i].base, &comm->base.stats), ret, fail);comm->ar = comm->ar && ncclIbDevs[ibDevN].ar; // ADAPTIVE_ROUTING - if all merged devs have it enabled}memset(&meta, 0, sizeof(meta));meta.ndevs = comm->base.vProps.ndevs;// Alternate QPs between devicesint devIndex;devIndex = 0;//创建qp,填充qp信息到metafor (int q = 0; q < comm->base.nqps; q++) {ncclIbSendCommDev* commDev = comm->devs + devIndex;ncclIbDev* ibDev = ncclIbDevs + commDev->base.ibDevN;NCCLCHECKGOTO(ncclIbCreateQp(ibDev->portNum, &commDev->base, IBV_ACCESS_REMOTE_WRITE, &comm->base.stats, comm->base.qps + q), ret, fail);comm->base.qps[q].devIndex = devIndex;meta.qpInfo[q].qpn = comm->base.qps[q].qp->qp_num;meta.qpInfo[q].devIndex = comm->base.qps[q].devIndex;if (ncclParamIbEceEnable()) {// Query ece capabilities (enhanced connection establishment)NCCLCHECKGOTO(wrap_ibv_query_ece(comm->base.qps[q].qp, &meta.qpInfo[q].ece, &meta.qpInfo[q].ece_supported), ret, fail);} else {meta.qpInfo[q].ece_supported = 0;}devIndex = (devIndex + 1) % comm->base.vProps.ndevs;}//将fifo注册到每个ib设备for (int i = 0; i < comm->base.vProps.ndevs; i++) {ncclIbSendCommDev* commDev = comm->devs + i;ncclIbDev* ibDev = ncclIbDevs + commDev->base.ibDevN;// Write to the metadata struct via this pointerncclIbDevInfo* devInfo = meta.devs + i;devInfo->ib_port = ibDev->portNum;devInfo->mtu = ibDev->portAttr.active_mtu;devInfo->lid = ibDev->portAttr.lid;// Prepare my fifoNCCLCHECKGOTO(wrap_ibv_reg_mr(&commDev->fifoMr, commDev->base.pd, comm->fifo, sizeof(struct ncclIbSendFifo)*MAX_REQUESTS*NCCL_NET_IB_MAX_RECVS, IBV_ACCESS_LOCAL_WRITE|IBV_ACCESS_REMOTE_WRITE|IBV_ACCESS_REMOTE_READ), ret, fail);devInfo->fifoRkey = commDev->fifoMr->rkey;// Pack local GID infodevInfo->link_layer = commDev->base.gidInfo.link_layer = ibDev->portAttr.link_layer;NCCLCHECKGOTO(ncclIbGetGidIndex(ibDev->context, ibDev->portNum, &ibDev->portAttr, &commDev->base.gidInfo.localGidIndex), ret, fail);NCCLCHECKGOTO(wrap_ibv_query_gid(ibDev->context, ibDev->portNum, commDev->base.gidInfo.localGidIndex, &commDev->base.gidInfo.localGid), ret, fail);//获取ib设备的gid信息,用于qp建链使用devInfo->gid.global.subnet_prefix = commDev->base.gidInfo.localGid.global.subnet_prefix;devInfo->gid.global.interface_id = commDev->base.gidInfo.localGid.global.interface_id;// info loggingif (devInfo->link_layer == IBV_LINK_LAYER_INFINIBAND) { // IBfor (int q = 0; q < comm->base.nqps; q++) {// Print just the QPs for this devif (comm->base.qps[q].devIndex == i)INFO(NCCL_NET,"NET/IB: %s %d IbDev %d Port %d qpn %d mtu %d LID %d subnet-prefix %lu FLID %d fifoRkey=0x%x fifoLkey=0x%x",comm->base.vProps.ndevs > 2 ? "NCCL MergedDev" : "NCCL Dev",dev, commDev->base.ibDevN, ibDev->portNum, meta.qpInfo[q].qpn, devInfo->mtu, devInfo->lid,devInfo->gid.global.subnet_prefix, ncclIbExtractFlid(&devInfo->gid), devInfo->fifoRkey, commDev->fifoMr->lkey);}} else { // RoCEfor (int q = 0; q < comm->base.nqps; q++) {// Print just the QPs for this devif (comm->base.qps[q].devIndex == i)INFO(NCCL_NET,"NET/IB: %s %d IbDev %d Port %d qpn %d mtu %d query_ece={supported=%d, vendor_id=0x%x, options=0x%x, comp_mask=0x%x} GID %ld (%lX/%lX) fifoRkey=0x%x fifoLkey=0x%x",comm->base.vProps.ndevs > 2 ? "NCCL MergedDev" : "NCCL Dev", dev,commDev->base.ibDevN, ibDev->portNum, meta.qpInfo[q].qpn, devInfo->mtu, meta.qpInfo[q].ece_supported, meta.qpInfo[q].ece.vendor_id, meta.qpInfo[q].ece.options, meta.qpInfo[q].ece.comp_mask, (int64_t)commDev->base.gidInfo.localGidIndex,devInfo->gid.global.subnet_prefix, devInfo->gid.global.interface_id, devInfo->fifoRkey, commDev->fifoMr->lkey);}}}meta.fifoAddr = (uint64_t)comm->fifo;//fifo的虚拟地址只有一个strncpy(meta.devName, mergedDev->devName, MAX_MERGED_DEV_NAME);stage->state = ncclIbCommStateSend;stage->offset = 0;memcpy(stage->buffer, &meta, sizeof(meta));ib_send://qp和fifo信息发送给recv端NCCLCHECKGOTO(ncclSocketProgress(NCCL_SOCKET_SEND, &comm->base.sock, stage->buffer, sizeof(meta), &stage->offset), ret, fail);if (stage->offset != sizeof(meta)) return ncclSuccess;stage->state = ncclIbCommStateConnecting;stage->offset = 0;// Clear the staging buffer for re-usememset(stage->buffer, 0, sizeof(meta));ib_connect:struct ncclIbConnectionMetadata remMeta;//接收recv端发送过来的qp信息和sizeFIFO信息NCCLCHECKGOTO(ncclSocketProgress(NCCL_SOCKET_RECV, &comm->base.sock, stage->buffer, sizeof(ncclIbConnectionMetadata), &stage->offset), ret, fail);if (stage->offset != sizeof(remMeta)) return ncclSuccess;memcpy(&remMeta, stage->buffer, sizeof(ncclIbConnectionMetadata));comm->base.nRemDevs = remMeta.ndevs;int link_layer;link_layer = remMeta.devs[0].link_layer;for (int i = 1; i < remMeta.ndevs; i++) {if (remMeta.devs[i].link_layer != link_layer) {WARN("NET/IB : Can't connect net devices with different link_layer. i=%d remMeta.ndevs=%d link_layer=%d rem_link_layer=%d",i, remMeta.ndevs, link_layer, remMeta.devs[i].link_layer);return ncclInternalError;}}// Copy remDevInfo for things like remGidInfo, remFifoAddr, etc. 保存recv端控制信息for (int i = 0; i < remMeta.ndevs; i++) {comm->base.remDevs[i] = remMeta.devs[i];comm->base.remDevs[i].remoteGid.global.interface_id = comm->base.remDevs[i].gid.global.interface_id;comm->base.remDevs[i].remoteGid.global.subnet_prefix = comm->base.remDevs[i].gid.global.subnet_prefix;// Retain remote sizes fifo info and prepare RDMA opscomm->remSizesFifo.rkeys[i] = remMeta.devs[i].fifoRkey;comm->remSizesFifo.addr = remMeta.fifoAddr;}//注册sizeFIFO elements的mr,用于告诉recv端,一次传输数据的大小for (int i=0; i < comm->base.vProps.ndevs; i++) {NCCLCHECKGOTO(wrap_ibv_reg_mr(comm->remSizesFifo.mrs+i, comm->devs[i].base.pd, &comm->remSizesFifo.elems, sizeof(int)*MAX_REQUESTS*NCCL_NET_IB_MAX_RECVS, IBV_ACCESS_REMOTE_WRITE|IBV_ACCESS_LOCAL_WRITE|IBV_ACCESS_REMOTE_READ), ret, fail);}comm->base.nRemDevs = remMeta.ndevs;//根据远端QP信息,绑定包本端QP中,完成QP建链绑定for (int q = 0; q < comm->base.nqps; q++) {struct ncclIbQpInfo* remQpInfo = remMeta.qpInfo + q;struct ncclIbDevInfo* remDevInfo = remMeta.devs + remQpInfo->devIndex;// Assign per-QP remDevcomm->base.qps[q].remDevIdx = remQpInfo->devIndex;int devIndex = comm->base.qps[q].devIndex;ncclIbSendCommDev* commDev = comm->devs + devIndex;struct ibv_qp* qp = comm->base.qps[q].qp;if (remQpInfo->ece_supported)NCCLCHECKGOTO(wrap_ibv_set_ece(qp, &remQpInfo->ece, &remQpInfo->ece_supported), ret, fail);ncclIbDev* ibDev = ncclIbDevs + commDev->base.ibDevN;remDevInfo->mtu = std::min(remDevInfo->mtu, ibDev->portAttr.active_mtu);NCCLCHECKGOTO(ncclIbRtrQp(qp, &commDev->base.gidInfo, remQpInfo->qpn, remDevInfo, false), ret, fail);NCCLCHECKGOTO(ncclIbRtsQp(qp), ret, fail);}if (link_layer == IBV_LINK_LAYER_ETHERNET ) { // RoCEfor (int q = 0; q < comm->base.nqps; q++) {struct ncclIbQp* qp = comm->base.qps + q;int ibDevN = comm->devs[qp->devIndex].base.ibDevN;struct ncclIbDev* ibDev = ncclIbDevs + ibDevN;INFO(NCCL_NET,"NET/IB: IbDev %d Port %d qpn %d set_ece={supported=%d, vendor_id=0x%x, options=0x%x, comp_mask=0x%x}",ibDevN, ibDev->portNum, remMeta.qpInfo[q].qpn, remMeta.qpInfo[q].ece_supported, remMeta.qpInfo[q].ece.vendor_id, remMeta.qpInfo[q].ece.options, remMeta.qpInfo[q].ece.comp_mask);}}comm->base.nDataQps = std::max(comm->base.vProps.ndevs, comm->base.nRemDevs);comm->base.ready = 1;stage->state = ncclIbCommStateConnected;stage->offset = 0;ib_send_ready://告诉recv端,send端已经read,recv端会一直等这个消息,本质上就是一次同步NCCLCHECKGOTO(ncclSocketProgress(NCCL_SOCKET_SEND, &comm->base.sock, &comm->base.ready, sizeof(int), &stage->offset), ret, fail);if (stage->offset != sizeof(int)) return ncclSuccess;*sendComm = comm;
exit:if (stage->buffer) free(stage->buffer);stage->state = ncclIbCommStateStart;return ret;
fail:free(comm);goto exit;
}
上面代码较多,其实现的内容为:1)从recv端拿到监听地址,然后初始化一个sock和recv端建立TCP连接;2)通过TCP发送本rank使用的net设备信息,接收recv端发过来的net信息;3)通过net信息决定使用多少QP建链;4)创建QP并将信息发送给recv;5)接收recv发过来的QP信息和sizefifo信息;6)完成QP建链绑定;7)注册FIFO mr产生的相关信息发给recv;8)在GPU上分配 NCCL_PROTO_LL128 和 NCCL_PROTO_SIMPLE 类型发送缓存区;9)在host上分配head、tail以及NCCL_PROTO_LL类型发送缓存区;10)将head、tail、发送缓存区等信息填写到GPU内存。
整体图解
直接看代码可能比较难以理解,还是用图来解释清晰点。
后续三node且每个node一个rank来举例,都支持GDR。
recv/send执行完 CanConnect() -> Setup() -> ProxySetup()之后,结果如下图所示。

rank执行recvSetup -> ncclProxyConnect -> recvProxySetup -> ncclIbListen之后,创建了一个recvProxyProgress线程(用来协调rdma、kernel收发数据),同时也建立了一个TCP监听服务,将监听地址和useGdr标志放入到通道数据中,准备交换。
rank执行sendSetup -> ncclProxyConnect -> sendProxySetup之后,创建了一个sendProxyProgress线程(用来协调rdma、kernel收发数据),然后将rank顶层父节点的全局rank id和useGdr标志放入到通道数据中,准备交换。
交换数据之后,建立socket连接。
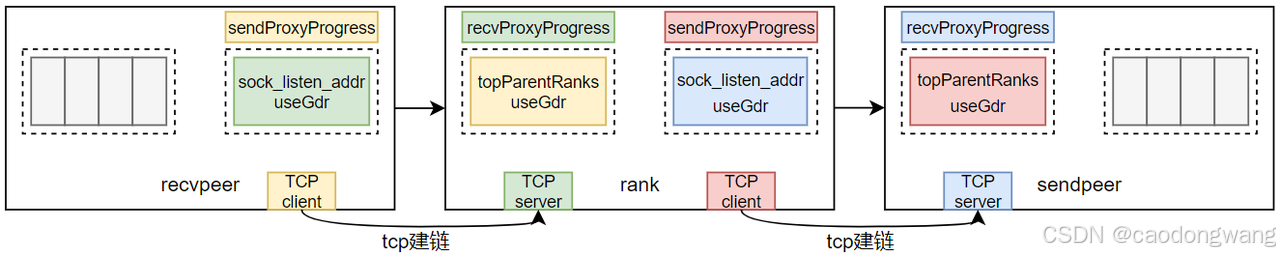
TCP建立之后就可以交换QP、FIFO相关数据。作为recv时,需要注册sizeFIFO MR,作为send时,需要注册FIFO MR,并将它们注册后产生的信息和QP信息一起交换给对端,如下图所示。
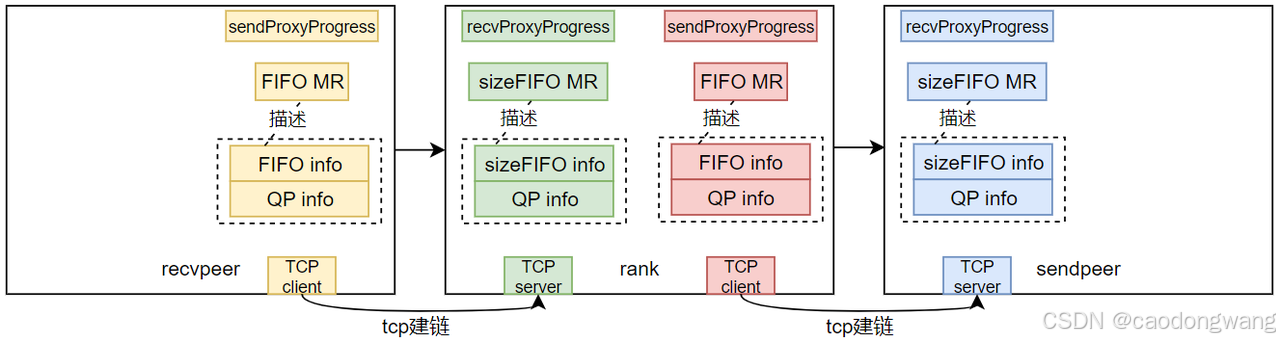
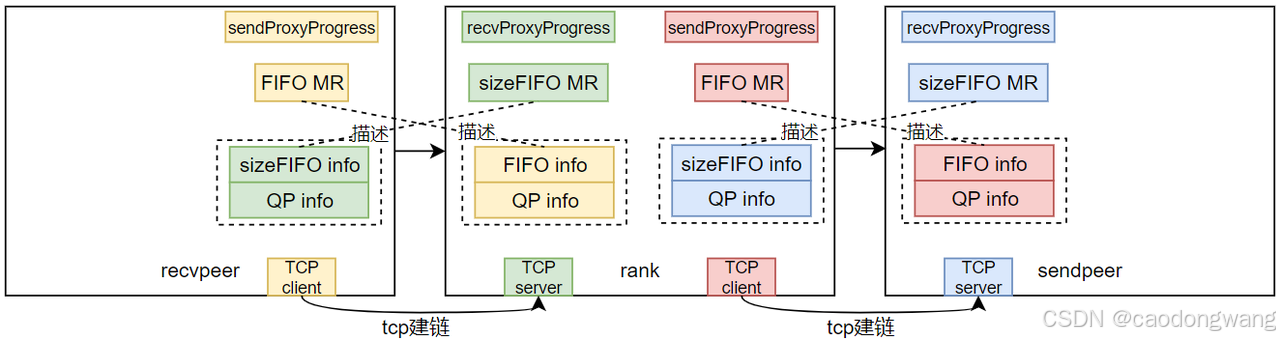
注意,交换不是通过bootstrap网络,而是上述TCP建链通道。rank拿到前后两个rank的QP信息,就可以完成QP建链绑定,如下图所示。
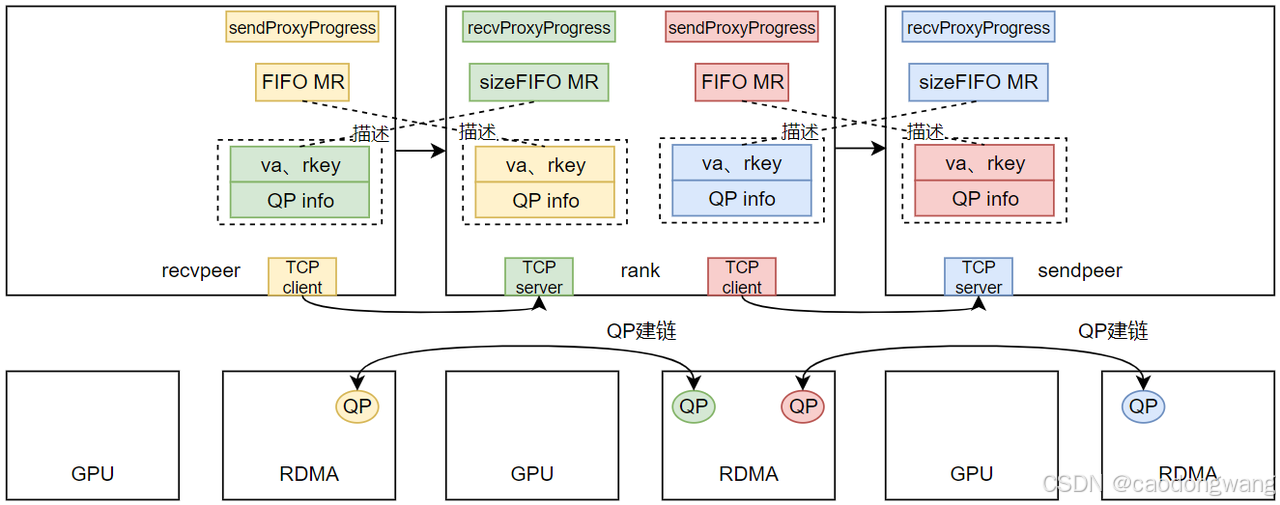
信息交换完毕,QP也完成建链了,那TCP连接就可以关闭了。另外,上面那些FIFO info其实就是MR的va和rkey,这里简化一下。
接下来就是准备收发数据的buff了,如下图所示。
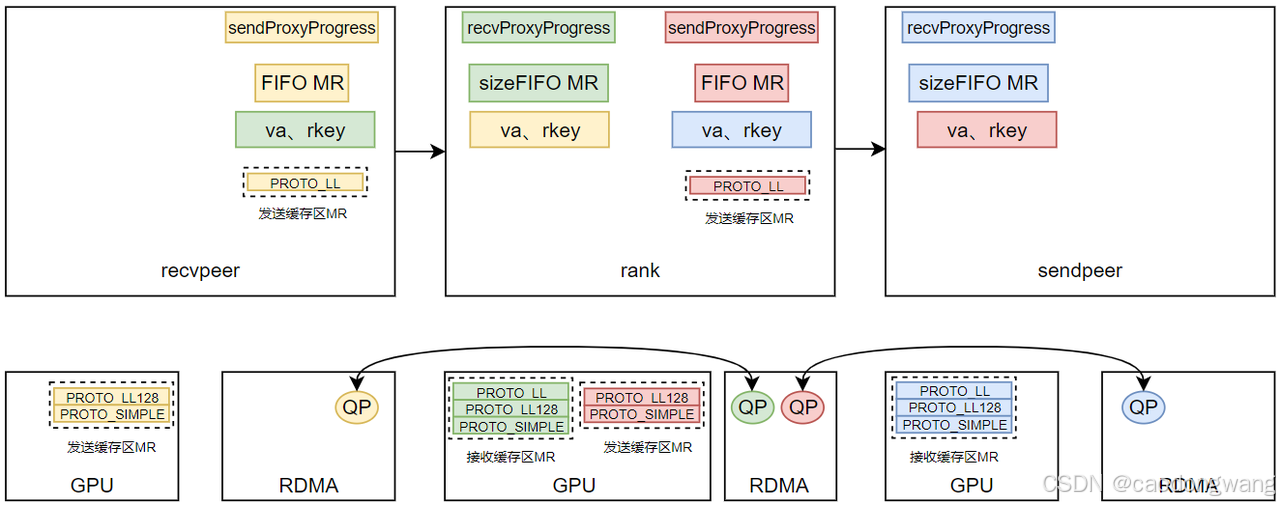
对于作为recv端来说,所有的接收缓存区buff都是位于GPU内存。对于作为send端来说,PROTO_LL128和PROTO_SIMPLE两种协议的buff位于GPU内存,而PROTO_LL协议内存则位于host内存。
如同P2P传输数据一样,kernel和代理线程progress也需要head、tail来协调数据收发,如下图所示。
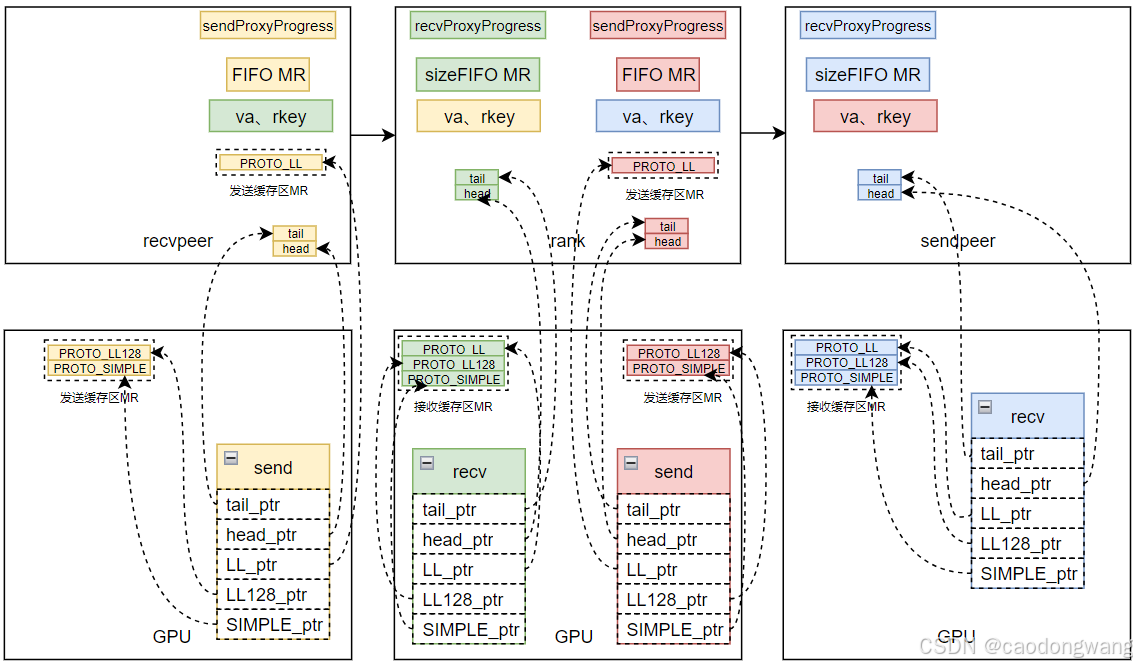
同样是生产者消费者模型,send端GPU kernel产生数据告诉send端ProxyProgress线程,由ProxyProgress线程调用rdma接口将数据传输给recv端ProxyProgress线程,然后recv端ProxyProgress线程告诉recv端kernel有数据产生,最后recv端kernel将数据消费。
相关文章:
【NCCL】transport建立(一)
transport建立 NCCL transport建立主要在ncclTransportP2pSetup函数中实现。 概况 先简单概括一下ncclTransportP2pSetup函数做了哪些事,方便理解代码流程。 recvpeer 表示本卡作为接收端的对端,sendpeer 表示本卡作为发送端的对端。假设8个rank全连接…...

智慧能源安全新纪元:当能源监测遇上视频联网的无限可能
引言:在数字化浪潮席卷全球的今天,能源安全已成为国家安全战略的重要组成部分。如何构建更加智能、高效的能源安全保障体系?能源安全监测平台与视频监控联网平台的深度融合,正为我们开启一扇通向未来能源管理新世界的大门。这种创…...

腾讯一面-软件开发实习-PC客户端开发方向
1.自我介绍就不多赘述了 2. 请介绍一下你的项目经历 - 介绍了专辑鉴赏项目,前端使用html语言编写,后端基于http协议使用C语言进行网页开发。此外,还提及项目中涉及处理多线程问题以及做过内存池管理项目。 3. 项目中HTTP协议是使用库实现的…...

Cad c# 射线法判断点在多边形内外
1、向量叉乘法 2、射线法原理 射线法是判断点与多边形位置关系的经典算法,核心思想是: 从目标点发出一条水平向右的射线(数学上可视为 y p_y, x \geq p_x 的射线),统计该射线与多边形边的交点数量: - 偶…...

【第16届蓝桥杯软件赛】CB组第一次省赛
个人主页:Guiat 归属专栏:算法竞赛 文章目录 A. 移动距离(5分填空题)B. 客流量上限(5分填空题)C. 可分解的正整数D. 产值调整E. 画展布置F. 水质检测G. 生产车间H. 装修报价 正文 总共10道题。 A. 移动距离…...

DePIN驱动的分布式AI资源网络
GAEA通过通证经济模型激励全球用户共享闲置带宽、算力、存储资源,构建覆盖150多个国家/地区的分布式AI基础设施网络。相比传统云服务,GAEA具有显著优势: 成本降低70%:通过利用边缘设备资源,避免了集中式数据中心所需…...

CC注入Tomcat Upgrade/Executor/WebSocket内存马
学习一下Tomcat中和组件内存马不一样的马。除了学习注入原理外,其payload还在一些缩短payload的场景有应用,比如shiro CC注入Tomcat Upgrade/Executor/WebSocket内存马 漏洞所用环境及测试全部代码https://github.com/godownio/TomcatMemshell 漏洞路…...
)
算法工程师面试题与参考答案资料(2025年版)
一、核心技术能力 1. 编程能力与工具 问题 1(选择题): 下列哪种Python数据类型是通过哈希表实现的? A. 列表 (list)...

烂土豆Juicypotato提权原理和利用
烂土豆Juicypotato提权原理和利用 0x00 Potato(烂土豆)提权的原理: 所谓的烂土豆提权就是俗称的MS16-075 可以将Windows工作站上的特权从最低级别提升到“ NT AUTHORITY \ SYSTEM” – Windows计算机上可用的最高特权级别。 一、简单的原…...

基于LangChain4J的AI Services实践:用声明式接口重构LLM应用开发
基于LangChain4J的AI Services实践:用声明式接口重构LLM应用开发 前言:当Java开发遇上LLM编程困境 在LLM应用开发领域,Java开发者常面临两大痛点:一是需要手动编排Prompt工程、记忆管理和结果解析等底层组件,二是复杂…...

重构便携钢琴专业边界丨特伦斯便携钢琴V30Pro定义新一代便携电钢琴
在便携电钢琴领域,特伦斯推出的V30Pro折叠钢琴以"技术革新场景适配"的双重升级引发关注。这款产品不仅延续了品牌标志性的折叠结构,更通过声学系统重构与智能交互优化,重新定义了便携乐器的专业边界。 ▶ 核心特点:技术…...

【uniapp-兼容性处理】安卓uView组件中u-input后置插槽不展示
【日期】2025-04-21 【问题】 在小程序上u-input后置插槽展示,真机运行安卓机上不展示 【原因】: 原代码:(插槽写法惯性使用#,此处在APP上不兼容该写法) <u-input v-model"currentScore"…...
:cut)
每天学一个 Linux 命令(30):cut
可访问网站查看,视觉品味拉满: http://www.616vip.cn/28/index.html cut 命令用于从文件或输入流中提取文本的特定部分(如列、字符或字节位置)。它常用于处理结构化数据(如 CSV、TSV)或按固定格式分割的文本。以下是详细说明和示例: 命令格式 cut [选项] [文件...]…...

部署本地Dify
本文我们来演示一下Dify的部署安装。 一、安装docker环境 Dify只是一个dashboard,所以这里的话咱们一般不用使用物理部署了,直接使用docker启动一个即可,所以一定要先确保服务器上有docker环境和docker-compose环境。 docker的安装可参考&…...

大数据组件学习之--Kafka 安装搭建
一、前置环境 在搭建kafka之前,请确认自己的hadoop、zookeeper是否搭建完成且可正常运行 二、下载并上传安装包(链接为百度网盘) kafka安装包 tar -zxvf /opt/software/kafka_2.12-2.4.1.tgz -C /opt/module/ 进入解压后的目录更改文件名…...

RK3588芯片NPU的使用:PPOCRv4例子在安卓系统部署
本文的目标 将PPOCRv4 C语言例子适配安卓端,提供选择图片后进行OCR识别功能。PPOCRv4 C语言例子请参考之前的博文《RK3588芯片NPU的使用:Windows11 Docker中运行PPOCRv4例子》。 开发环境说明 主机系统:Windows 11目标设备:搭载RK3588芯片的安卓开发板核心工具:Android …...
与强化学习的结合研究)
算法 | 鲸鱼优化算法(WOA)与强化学习的结合研究
===================================================== github:https://github.com/MichaelBeechan CSDN:https://blog.csdn.net/u011344545 ===================================================== 鲸鱼优化算法与强化学习 一、结合机制与关键方向1、 参数动态调整2、…...
)
Spring AI 框架-快速搭建以及会话日志(笔记)
概述: Spring AI是Spring生态中应用于人工智能领域的应用框架,它的目标是将Spring 生态系统的设计原则(如可移植性、模块化设计)应用于AI领域,Spring AI更新迭代非常快,对Spring生态非常友好,可以大大简化…...

一段式端到端自动驾驶:VAD:Vectorized Scene Representation for Efficient Autonomous Driving
论文地址:https://github.com/hustvl/VAD 代码地址:https://arxiv.org/pdf/2303.12077 1. 摘要 自动驾驶需要对周围环境进行全面理解,以实现可靠的轨迹规划。以往的方法依赖于密集的栅格化场景表示(如:占据图、语义…...

CMake execute_process用法详解
execute_process 是 CMake 中的一个命令,用于在 CMake 配置阶段(即运行 cmake 命令时)执行外部进程。它与 add_custom_command 或 add_custom_target 不同,后者是在构建阶段(如 make 或 ninja)执行命令。ex…...

使用Postman调测“获取IAM用户Token”接口实际操作
概述 Postman是网页调试与辅助接口调用的工具,具有界面简洁清晰、操作方便快捷的特性,可以处理用户发送的HTTP请求,例如:GET,PUT、POST,DELETE等,支持用户修改HTTP请求中的参数并返回响应数据。…...
)
大模型面经 | 春招、秋招算法面试常考八股文附答案(三)
大家好,我是皮先生!! 今天给大家分享一些关于大模型面试常见的面试题,希望对大家的面试有所帮助。 往期回顾: 大模型面经 | 春招、秋招算法面试常考八股文附答案(RAG专题一) 大模型面经 | 春招、秋招算法面试常考八股文附答案(RAG专题二) 大模型面经 | 春招、秋招算法…...
)
高效Java面试题(附答案)
Java全家桶 Java基础 1. Java为什么被称为平台无关性语言? 2. 解释下什么是面向对象?面向对象和面向过程的区别 3. 面向对象的三大特性?分别解释下? 4. Java 中的参数传递时传值呢?还是传引用? 5. JD…...

Unreal如何使用后处理材质实现一个黑屏渐变效果
文章目录 前言相机后期处理材质创建材质相机设置动态修改FadeAlpha参数使用示例最后前言 UE5 开发VR ,如何通过PostProcess轻松实现黑屏渐变效果 最简单的办法,其实是使用一个半球形模型,遮挡住相机,然后控制这个半球形遮罩的颜色透明度,至少Unity中默认的Tunneling是这么…...

【自然语言处理与大模型】模型压缩技术之剪枝
一、什么是模型剪枝? 模型剪枝(Model Pruning)是一种神经网络模型压缩技术,其核心思想是通过删除或稀疏化模型中冗余的部分(如不重要的参数或神经元连接),在尽量保持模型性能的前提下࿰…...

OOA-CNN-LSTM-Attention、CNN-LSTM-Attention、OOA-CNN-LSTM、CNN-LSTM四模型多变量时序预测一键对比
OOA-CNN-LSTM-Attention、CNN-LSTM-Attention、OOA-CNN-LSTM、CNN-LSTM四模型多变量时序预测一键对比 目录 OOA-CNN-LSTM-Attention、CNN-LSTM-Attention、OOA-CNN-LSTM、CNN-LSTM四模型多变量时序预测一键对比预测效果基本介绍程序设计参考资料 预测效果 基本介绍 基于OOA-CN…...

Android Studio 国内镜像使用与 SDK 下载速度优化指南
本文适用于刚装好 Android Studio、SDK 下载缓慢、更新困难,以及 Gradle 构建缓慢的开发者。我们会讲: 如何替换国内镜像源(包括 SDK 和 Gradle) 如何解决 emulator 镜像下载失败的问题 一些终极提速技巧(比如代理配…...

PyCharm 在 Linux 上的完整安装与使用指南
PyCharm 在 Linux 上的完整安装与使用指南—目录 一、PyCharm 简介二、下载与安装1. 下载 PyCharm2. 安装前的依赖准备3. 安装步骤方法 1:通过 Snap 安装(推荐)方法 2:手动安装(从官网下载 .tar.gz 文件)方…...
与深度强化学习(Deep Reinforcement Learning, DRL))
强化学习(Reinforcement Learning, RL)与深度强化学习(Deep Reinforcement Learning, DRL)
1. 基本概念 强化学习(RL) 定义:通过试错与环境交互,学习策略以最大化累积奖励的机器学习范式。核心思想:智能体在环境中执行动作,接收奖励信号并更新策略,最…...

初识Redis · C++客户端set和zset
目录 前言: set sadd sismember smembers spop scard sinter sinterstore zset zadd zrange zcard zrem zrank zscore 前言: 前文我们已经介绍了string list hash在Redis-plus-plus的使用,本文我们开始介绍set和zset在redis-plus-pl…...
2022/30)
平板电脑做欧盟网络安全法案(EU)2022/30
平板电脑做欧盟网络安全法案(EU)2022/30 平板电脑做EN18031,平板电脑做无障碍法规EU2019/882 欧盟委员会于2022年通过补充授权法案 (EU) 2022/30,明确要求无线电设备需满足网络安全、隐私保护及反欺诈要求。 新规时间轴…...

GeoJSON 格式详解与使用指南
一、引言 GeoJSON 是一种对各种地理数据结构进行编码的格式,它基于 JavaScript 对象表示法(JSON),被广泛应用于地理信息系统(GIS)、地图应用开发以及地理数据的存储和交换。本文将详细介绍 GeoJSON 的格式…...

JavaScript与TypeScript
TypeScript 和 JavaScript 都是用于构建 Web 应用的编程语言,但它们有着不同的设计目标和特性。 一、JavaScript 1. 定义与特点 动态脚本语言:由 Brendan Eich 在 1995 年创建,最初用于浏览器端的交互逻辑。弱类型/动态类型:变量…...

ArcGIS、ArcMap查看.shp文件时属性表中文乱码
Shapefile(.shp): 根本错误原因: Shapefile 的属性数据 .dbf 是老旧格式,默认不含编码信息 解决方法: 在shapefile文件夹目录上,创建一个同名的.cpg文件,内容"oem" 使用ArcGIS再右键打开属性表,…...
)
C++学习:六个月从基础到就业——内存管理:自定义内存管理(上篇)
C学习:六个月从基础到就业——内存管理:自定义内存管理(上篇) 本文是我C学习之旅系列的第二十一篇技术文章,也是第二阶段"C进阶特性"的第六篇,主要介绍C中的自定义内存管理技术(上篇&…...

大模型基础
1、提示词 典型构成: - **角色**:给 AI 定义一个最匹配任务的角色,比如:「你是一位软件工程师」「你是一位小学数学老师」 - **指示**:对任务进行描述 - **上下文**:给出与任务相关的其它背景信息&#x…...

TDengine 存储引擎设计
简介 TDengine 的核心竞争力在于其卓越的写入和查询性能。相较于传统的通用型数据库,TDengine 在诞生之初便专注于深入挖掘时序数据场景的独特性。它充分利用了时序数据的时间有序性、连续性和高并发特点,自主研发了一套专为时序数据定制的写入及存储算…...

C++回溯算法详解
文章目录 引言第一题1.1 题目解析1.2 解题思路回溯解法队列解法 1.3 解题代码回溯解法队列解法 引言 回溯算法是一种通过深度优先搜索系统性地遍历问题解空间的算法。它的核心思想是"试错":逐步构建候选解,当发现当前选择无法得到有效解时&am…...

前端Javascript模块化 CommonJS与ES Module区别
一、模块化规范的演进历程 IIFE(立即执行函数)阶段 早期通过立即执行函数实现模块化,利用函数作用域隔离变量,解决全局命名冲突问题。例如通过(function(){})()包裹代码,形成独立作用域。 CommonJS(Node.js)阶段 CommonJS规范以同步加载为核心,通过require和module.exp…...

问题 | RAIM + LSTM 你怎么看???
github:https://github.com/MichaelBeechan CSDN:https://blog.csdn.net/u011344545 RAIM LSTM import numpy as np import tensorflow as tf from tensorflow.keras.layers import LSTM, Dense# RAIM-LSTM 融合模型 class RAIM_LSTM(tf.keras.Model):d…...

进程与线程:03 用户级线程
多进程与操作系统基础 上一个内容我们讲了多进程图像,强调多进程图像是操作系统最核心的图像。我们还通过Windows任务管理器,实际观察了操作系统里的进程。 进程是操作系统的核心内容,管理好多个进程,就能管理好操作系统和CPU。…...

四种阻抗匹配的方式
一、串联端接方式 即靠近输出端的位置串联一个电阻。 要达到匹配效果,串联电阻和驱动端输出阻抗的总和应等于传输线的特征Z0 二、并联端接方式 并联端接又被称为终端匹配。 要达到阻抗匹配的要求,端接电阻应该和传输线的特征阻抗Z0相等。 三、AC并联端…...

WebRTC通信技术EasyRTC音视频实时通话安全巡检搭建低延迟、高可靠的智能巡检新体系
一、方案背景 在现代安防和工业领域,安全巡检是确保设施正常运行和保障人员安全的关键环节。传统的巡检方式往往依赖人工,效率低下且容易出现遗漏。随着技术的发展,实时通信技术EasyRTC为安全巡检提供了更加高效和智能化的解决方案。 二、方…...

使用json_repair修复大模型的json输出错误
json_repair 有些 LLM 在返回格式正确的 JSON 数据时会有些问题,有时会漏掉括号,有时会在数据中添加一些单词。不至于这种错误每次都要丢弃,再次生成太浪费时间了,因此能修复错误时还是要尽量修复。这就是 json_repair 的主要目的…...

聊透多线程编程-线程互斥与同步-12. C# Monitor类实现线程互斥
目录 一、什么是临界区? 二、Monitor类的用途 三、Monitor的基本用法 四、Monitor的工作原理 五、使用示例1-保护共享变量 解释: 六、使用示例2-线程间信号传递 解释: 七、注意事项 八、总结 在多线程编程中,线程之间的…...

鸿蒙系统的 “成长烦恼“:生态突围与技术迭代的双重挑战
一、应用生态:从 "有没有" 到 "好不好" 的漫长爬坡 作为一款诞生于中美科技博弈背景下的国产操作系统,鸿蒙(HarmonyOS)自 2019 年发布以来,已在设备装机量上取得突破 —— 截至 2023 年底…...

ESP8266_ESP32 Smartconfig一键配网功能
目录 SmartConfig一键配网基本原理设备绑定流程 ESP8266/ESP32 SmartConfig配网AT指令配置方式Arduino程序配置方式 总结 SmartConfig一键配网 SmartConfigTM 是由 TI 开发的配网技术,用于将新的 Wi-Fi 设备连接到 Wi-Fi 网络。它使用移动应用程序将无线网凭据从智…...
)
图解Agent2Agent(A2A)
🧠 向所有学习者致敬! “学习不是装满一桶水,而是点燃一把火。” —— 叶芝 我的博客主页: https://lizheng.blog.csdn.net 🌐 欢迎点击加入AI人工智能社区! 🚀 让我们一起努力,共创AI未来! 🚀 嘿,朋友们!今天咱们来聊聊 Agentic 应用背后的两大神器:A2A 和 …...
)
Kotlin基础(①)
open 关键字:打破 Kotlin 的“默认封闭”规则 // 基类必须加 open 才能被继承 open class Animal {// 方法也要加 open 才能被子类重写open fun makeSound() {println("Some sound")} }class Dog : Animal() {override fun makeSound() {println("W…...

Android Kotlin+Compose首个应用
本教程将创建一个简单的基于 Kotlin 语言的 APP,并使用 Compose 来管理 UI。 创建一个基于 Kotlin 的Android 应用 打开 Android Studio,选择New Project来创建一个应用,然后在Phone and Tablet选项卡,选择 Empty Activity&…...