TDengine 存储引擎设计
简介
TDengine 的核心竞争力在于其卓越的写入和查询性能。相较于传统的通用型数据库,TDengine 在诞生之初便专注于深入挖掘时序数据场景的独特性。它充分利用了时序数据的时间有序性、连续性和高并发特点,自主研发了一套专为时序数据定制的写入及存储算法。
这套算法针对时序数据的特性进行了精心的预处理和压缩,不仅大幅提高了数据的写入速度,还显著降低了存储空间的占用。这种优化设计确保了在面对大量实时数据持续涌入的场景时,TDengine 仍能保持超高的吞吐能力和极快的响应速度。
行列格式
行列格式是 TDengine 中用来表示数据的最重要的数据结构之一。业内已经有许多开源的标准化的行列格式库,如 Apache Arrow 等。但 TDengine 面临的场景更加聚焦,且对于性能的要求也更高。因此,设计并实现自己的行列格式库有助于 TDengine 充分利用场景特点,实现高性能、低空间占用的行列格式数据结构。行列格式的需求有以下几点。
- 支持未指定值(NONE)与空值(NULL)的区分。
- 支持 NONE、NULL 以及有值共存的不同场景。
- 对于稀疏数据和稠密数据的高效处理。
行格式
TDengine 中的行格式有两种编码格式—Tuple 编码格式和 Key-Value 编码格式。具体采用哪种编码格式是由数据的特征决定的,以求最高效地处理不同数据特征的场景。
- Tuple 编码格式
Tuple 编码格式主要用于非稀疏数据的场景,如所有列数据全部非 None 或少量 None 的场景。Tuple 编码的行直接根据表的 schema 提供的偏移量信息访问列数据,时间复杂度为 O(1),访问速度快。如下图所示:

- Key-Value 编码格式
Key-Value 编码格式特别适合于稀疏数据的场景,即在表的 schema 中定义了大量列(例如数千列),但实际有值的列却非常少的情况。在这种情形下,如果采用传统的 Tuple 编码格式,会造成极大的空间浪费。相比之下,采用 Key-Value 编码格式可以显著减少行数据所占用的存储空间。如下图所示。
Key-Value 编码的行数据通过一个 offset 数组来索引各列的值,虽然这种方式的访问速度相对于直接访问列数据较慢,但它能显著减少存储空间的占用。在实际编码实现中,通过引入 flag 选项,进一步优化了空间占用。具体来说,当所有 offset 值均小于 256 时,Key-Value 编码行的 offset 数组采用 uint8_t 类型;若所有 offset 值均小于 65536 时,则使用 uint16_t 类型;在其他情况下,则使用 uint32_t 类型。这样的设计使得空间利用率得到进一步提升。

列格式
在 TDengine 中,列格式的定长数据可以被视为数组,但由于存在 NONE、NULL 和有值的并存情况,列格式中还需要一个 bitmap 来标识各个索引位置的值是 NONE、NULL 还是有值。而对于变长类型的数据,列格式则有所不同。除了数据数组以外,变长类型的数据列格式还包含一个 offset 数组,用于索引变长数据的起始位置。变长数据的长度可以通过两个相邻 offset 值之差来获得。这种设计使得数据的存储和访问更加高效,如下图所示:

vnode 存储
vnode 存储架构
vnode 是 TDengine 中数据存储、查询以及备份的基本单元。每个 vnode 中都存储了部分表的元数据信息以及属于这些表的全部时序数据。表在 vnode 上的分布是由一致性哈希决定的。每个 vnode 都可以被看作一个单机数据库。vnode 的存储可以分为如下 3 部分,如下图所示。
- WAL 文件的存储。
- 元数据的存储。
- 时序数据的存储。
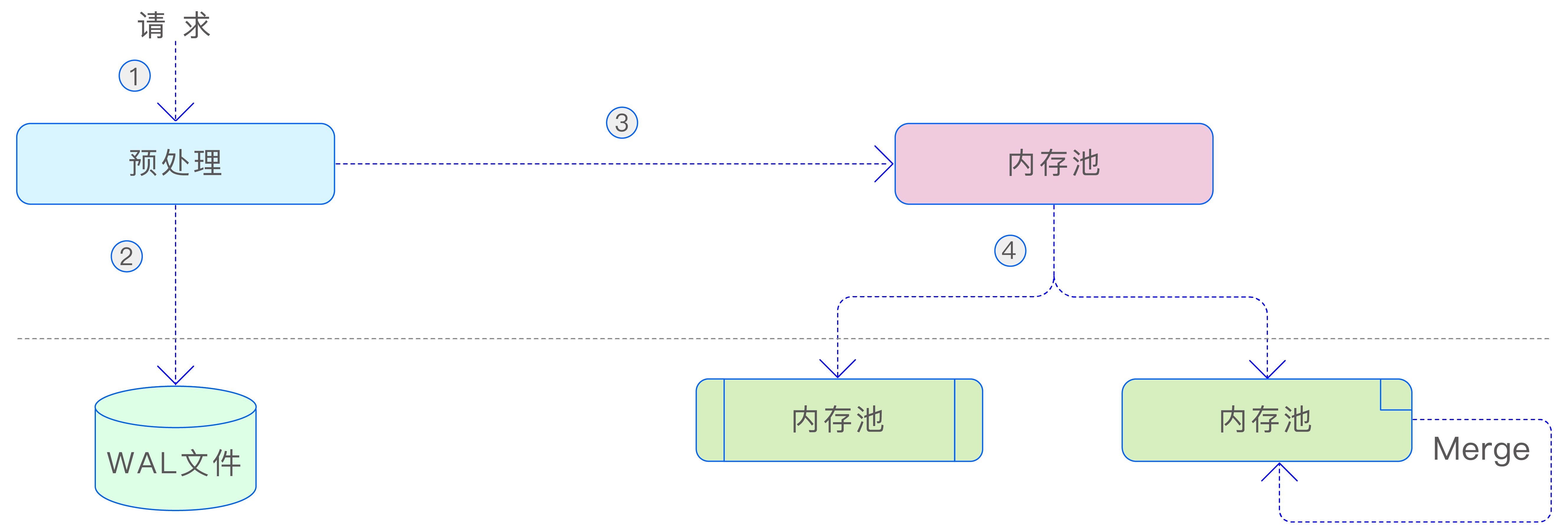
当 vnode 收到写入数据请求时,首先会对请求进行预处理,以确保多副本上的数据保持一致。预处理的目的在于确保数据的安全性和一致性。在预处理完成后,数据会被写入到 WAL 文件中,以确保数据的持久性。接着,数据会被写入 vnode 的内存池中。当内存池的空间占用达到一定阈值时,后台线程会将写入的数据刷新到硬盘上(META 和 TSDB),以便持久化。同时,标记内存中对应的 WAL 编号为已落盘。此外,TSDB 采用了 LSM(Log-Structured Merge-Tree,日志结构合并树)存储结构,这种结构在打开数据库的多表低频参数时,后台还会对 TSDB 的数据文件进行合并,以减少文件数量并提高查询性能。这种设计使得数据的存储和访问更加高效。
元数据的存储
vnode 中存储的元数据主要涉及表的元数据信息,包括超级表的名称、超级表的 schema 定义、标签 schema 的定义、子表的名称、子表的标签信息以及标签的索引等。由于元数据的查询操作远多于写入操作,因此 TDengine 采用 B+Tree 作为元数据的存储结构。B+Tree 以其高效的查询性能和稳定的插入、删除操作,非常适合于处理这类读多
写少的场景,确保了元数据管理的效率和稳定性。元数据的写入过程如下图所示:

当 META 模块接收到元数据写入请求时,它会生成多个 Key-Value 数据对,并将这些数据对存储在底层的 TDB 存储引擎中。TDB 是 TDengine 根据自身需求研发的 B+Tree 存储引擎,它由 3 个主要部分组成——内置 Cache、TDB 存储主文件和 TDB 的日志文件。数据在写入 TDB 时,首先被写入内置 Cache,如果 Cache 内存不足,系统会向 vnode 的内存池请求额外的内存分配。如果写入操作涉及已有数据页的更改,系统会在修改数据页之前,先将未更改的数据页写入 TDB 的日志文件,作为备份。这样做可以在断电或其他故障发生时,通过日志文件回滚到原始数据,确保数据更新的原子性和数据完整性。
由于 vnode 存储了各种元数据信息,并且元数据的查询需求多样化,vnode 内部会创建多个 B+Tree,用于存储不同维度的索引信息。这些 B+Tree 都存储在一个共享的存储文件中,并通过一个根页编号为 1 的索引 B+Tree 来索引各个 B+Tree 的根页编号,如下图所示:
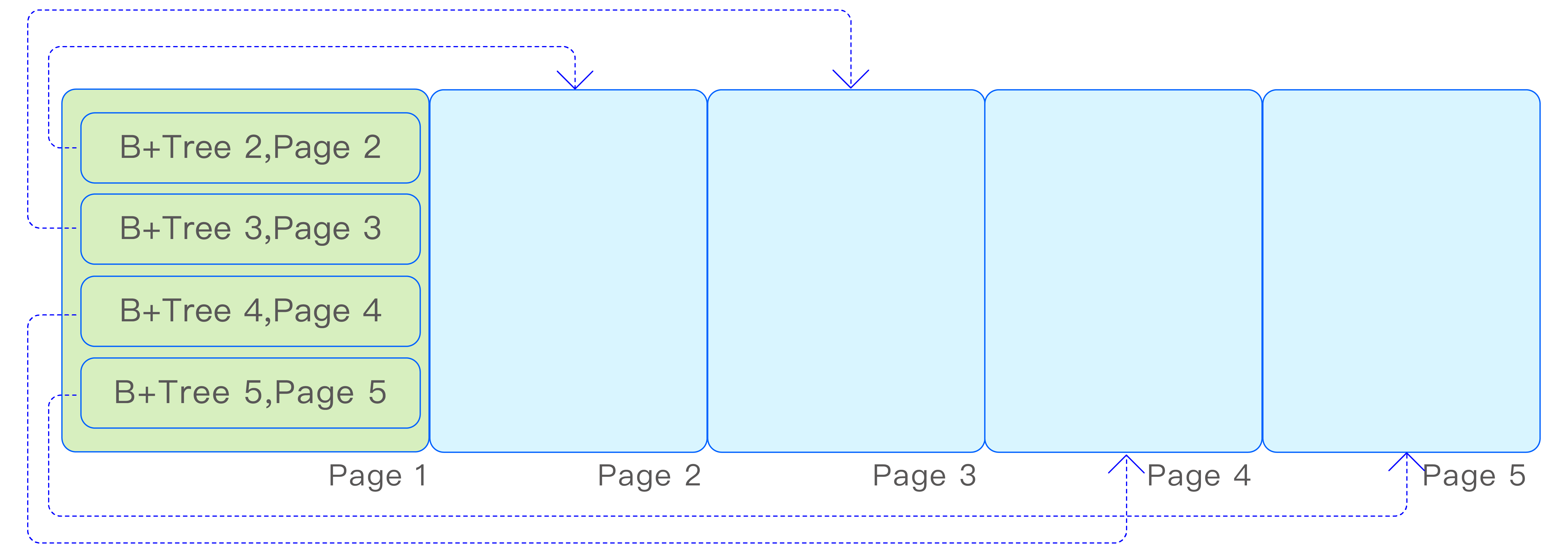
B+ Tree 的页结构如下图所示:

在 TDB 中,Key 和 Value 都具有变长的特性。为了处理超长 Key 或 Value 的情况,当它们超过文件页的大小时,TDB 采用了溢出页的设计来容纳超出部分的数据。此外,为了有效控制 B+Tree 的高度,TDB 限制了非溢出页中 Key 和 Value 的最大长度,确保 B+Tree 的扇出度至少为 4。
时序数据的存储
时序数据在 vnode 中是通过 TSDB 引擎进行存储的。鉴于时序数据的海量特性及其持续的写入流量,若使用传统的 B+Tree 结构来存储,随着数据量的增长,树的高度会迅速增加,这将导致查询和写入性能的急剧下降,最终可能使引擎变得不可用。鉴于此,TDengine 选择了 LSM 存储结构来处理时序数据。LSM 通过日志结构的存储方式,优化了数据的写入性能,并通过后台合并操作来减少存储空间的占用和提高查询效率,从而确保了时序数据的存储和访问性能。TSDB 引擎的写入流程如下图所示:
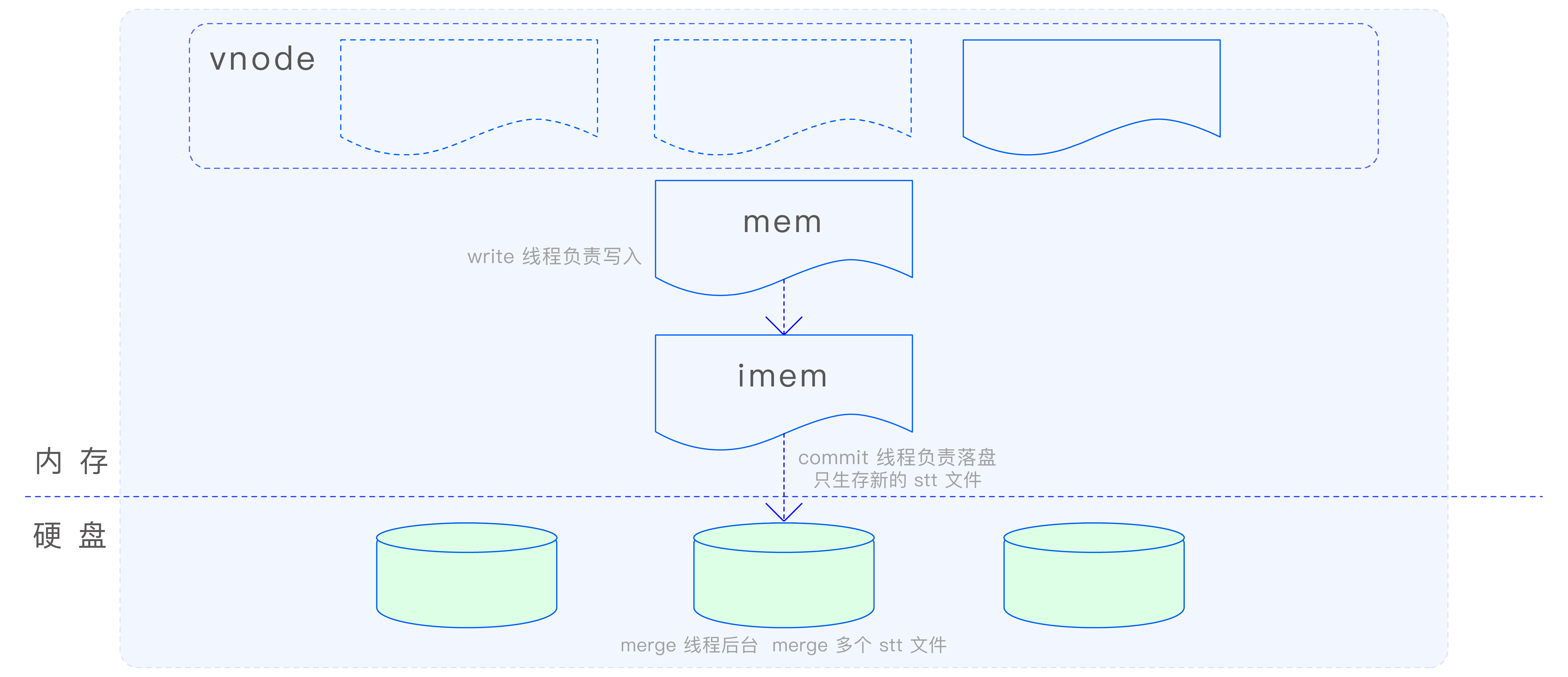
在 MemTable 中,数据采用了 Red-Black Tree(红黑树)和 SkipList 相结合的索引方式。不同表的数据索引存储在 Red-Black Tree 中,而同一张表的数据索引则存储在 SkipList 中。这种设计方式充分利用了时序数据的特点,提高了数据的存储和访问效率。
Red-Black Tree 是一种自平衡的二叉树,它通过对节点进行着色和旋转操作来保持树的平衡,从而确保了查询、插入和删除操作的时间复杂度为 O(logn)。在 MemTable 中,Red-Black Tree 用于存储不同表
SkipList 是一种基于有序链表的数据结构,它通过在链表的基础上添加多级索引来实现快速查找。SkipList 的查询、插入和删除操作的时间复杂度为 O(logn),与 Red-Black Tree 相当。在 MemTable 中,SkipList 用于存储同一张表的数据索引,这样可以快速定位到特定时间范围内的数据,为时序数据的查询和写入提供高效支持。
通过将 Red-Black Tree 和 SkipList 相结合,TDengine 在 MemTable 中实现了一种高效的数据索引方式,既能够快速定位到不同表的数据,又能够快速定位到同一张表中特定时间范围内的数据。SkipList 索引如下图所示:

在 TSDB 引擎中,无论是在内存中还是数据文件中,数据都按照(ts, version)元组进行排序。为了更好地管理和组织这些按时间排序的数据,TSDB 引擎将数据文件按照时间范围切分为多个数据文件组。每个数据文件组覆盖一定时间范围的数据,这样可以确保数据的连续性和完整性,同时也便于对数据进行分片和分区操作。通过将数据按时间范围划分为多个文件组,TSDB 引擎可以更有效地管理和访问存储在硬盘上的数据。文件组如下图所示:

在查询数据时,根据查询数据的时间范围,可以快速计算文件组编号,从而快速定位所要查询的数据文件组。这种设计方式可以显著提高查询性能,因为它可以减少不必要的文件扫描和数据加载,直接定位到包含所需数据的文件组。接下来分别介绍数据文件组包含的文件:
head 文件
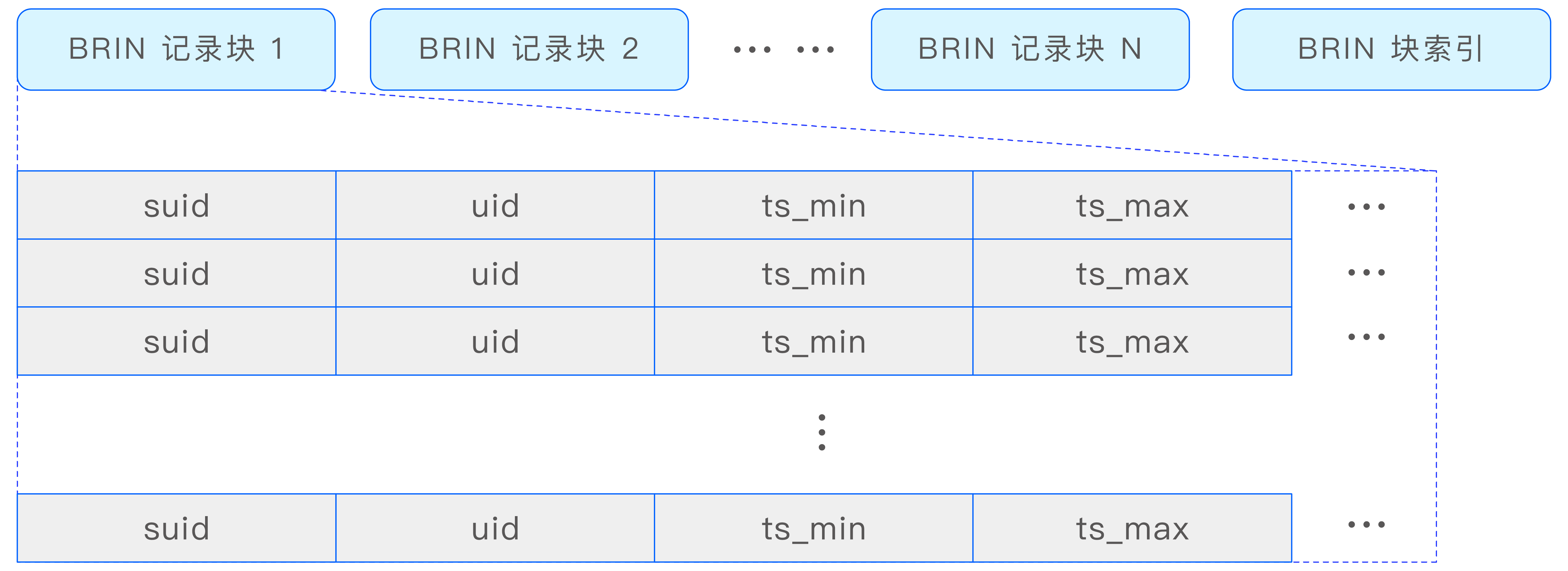
head 文件是时序数据存储文件(data 文件)的 BRIN(Block Range Index,块范围索引)文件,其中存储了每个数据块的时间范围、偏移量(offset)和长度等信息。
查询引擎根据 head 文件中的信息,可以高效地过滤要查询的数据块所包含的时间范围,并获取这些数据块的位置信息。
head 文件中存储了多个 BRIN 记录块及其索引。BRIN 记录块采用列存压缩的方式,这种方式可以大大减少空间占用,同时保持较高的查询性能。BRIN 索引结构如下图所示:
data 文件
data 文件是实际存储时序数据的文件。在 data 文件中,时序数据以数据块的形式进行存储,每个数据块包含了一定量数据的列式存储。根据数据类型和压缩配置,数据块采用了不同的压缩算法进行压缩,以减少存储空间的占用并提高数据传输的效率。
与 stt 文件不同,每个数据块在 data 文件中独立存储,代表了一张表在特定时间范围内的数据。这种设计方式使得数据的管理和查询更加灵活和高效。通过将数据按块存储,并结合列式存储和压缩技术,TSDB 引擎可以更有效地处理和访问时序数据,从而满足大数据量和高速查询的需求。
sma 文件
预计算文件,用于存储各个数据块中每列数据的预计算结果。这些预计算结果包括每列数据的总和(sum)、最小值(min)、最大值(max)等统计信息。通过预先计算并存储这些信息,查询引擎可以在执行某些查询时直接利用这些预计算结果,从而避免了读取原始数据的需要。
tomb 文件
用于存储删除记录的文件。存储记录为(suid, uid, start_timestamp, end_timestamp, version)元组。
stt 文件
在少表高频的场景下,系统仅维护一个 stt 文件。该文件专门用于存储每次数据落盘后剩余的碎片数据。这样,在下一次数据落盘时,这些碎片数据可以与内存中的新数据合并,形成较大的数据块,随后一并写入 data 文件中。这种机制有效地避免了数据文件的碎片化,确保了数据存储的连续性和高效性。
对于多表低频的场景,建议配置多个 stt 文件。这种场景下的核心思想是,尽管单张表每次落盘的数据量可能不大,但同一超级表下的所有子表累积的数据量却相当可观。通过合并这些数据,可以生成较大的数据块,从而减少数据块的碎片化。这不仅提升了数据的写入效率,还能显著提高查询性能,因为连续的数据存储更有利于快速的数据检索和访问。
访问官网
更多内容欢迎访问 TDengine 官网
相关文章:

TDengine 存储引擎设计
简介 TDengine 的核心竞争力在于其卓越的写入和查询性能。相较于传统的通用型数据库,TDengine 在诞生之初便专注于深入挖掘时序数据场景的独特性。它充分利用了时序数据的时间有序性、连续性和高并发特点,自主研发了一套专为时序数据定制的写入及存储算…...

C++回溯算法详解
文章目录 引言第一题1.1 题目解析1.2 解题思路回溯解法队列解法 1.3 解题代码回溯解法队列解法 引言 回溯算法是一种通过深度优先搜索系统性地遍历问题解空间的算法。它的核心思想是"试错":逐步构建候选解,当发现当前选择无法得到有效解时&am…...

前端Javascript模块化 CommonJS与ES Module区别
一、模块化规范的演进历程 IIFE(立即执行函数)阶段 早期通过立即执行函数实现模块化,利用函数作用域隔离变量,解决全局命名冲突问题。例如通过(function(){})()包裹代码,形成独立作用域。 CommonJS(Node.js)阶段 CommonJS规范以同步加载为核心,通过require和module.exp…...

问题 | RAIM + LSTM 你怎么看???
github:https://github.com/MichaelBeechan CSDN:https://blog.csdn.net/u011344545 RAIM LSTM import numpy as np import tensorflow as tf from tensorflow.keras.layers import LSTM, Dense# RAIM-LSTM 融合模型 class RAIM_LSTM(tf.keras.Model):d…...

进程与线程:03 用户级线程
多进程与操作系统基础 上一个内容我们讲了多进程图像,强调多进程图像是操作系统最核心的图像。我们还通过Windows任务管理器,实际观察了操作系统里的进程。 进程是操作系统的核心内容,管理好多个进程,就能管理好操作系统和CPU。…...

四种阻抗匹配的方式
一、串联端接方式 即靠近输出端的位置串联一个电阻。 要达到匹配效果,串联电阻和驱动端输出阻抗的总和应等于传输线的特征Z0 二、并联端接方式 并联端接又被称为终端匹配。 要达到阻抗匹配的要求,端接电阻应该和传输线的特征阻抗Z0相等。 三、AC并联端…...

WebRTC通信技术EasyRTC音视频实时通话安全巡检搭建低延迟、高可靠的智能巡检新体系
一、方案背景 在现代安防和工业领域,安全巡检是确保设施正常运行和保障人员安全的关键环节。传统的巡检方式往往依赖人工,效率低下且容易出现遗漏。随着技术的发展,实时通信技术EasyRTC为安全巡检提供了更加高效和智能化的解决方案。 二、方…...

使用json_repair修复大模型的json输出错误
json_repair 有些 LLM 在返回格式正确的 JSON 数据时会有些问题,有时会漏掉括号,有时会在数据中添加一些单词。不至于这种错误每次都要丢弃,再次生成太浪费时间了,因此能修复错误时还是要尽量修复。这就是 json_repair 的主要目的…...

聊透多线程编程-线程互斥与同步-12. C# Monitor类实现线程互斥
目录 一、什么是临界区? 二、Monitor类的用途 三、Monitor的基本用法 四、Monitor的工作原理 五、使用示例1-保护共享变量 解释: 六、使用示例2-线程间信号传递 解释: 七、注意事项 八、总结 在多线程编程中,线程之间的…...

鸿蒙系统的 “成长烦恼“:生态突围与技术迭代的双重挑战
一、应用生态:从 "有没有" 到 "好不好" 的漫长爬坡 作为一款诞生于中美科技博弈背景下的国产操作系统,鸿蒙(HarmonyOS)自 2019 年发布以来,已在设备装机量上取得突破 —— 截至 2023 年底…...

ESP8266_ESP32 Smartconfig一键配网功能
目录 SmartConfig一键配网基本原理设备绑定流程 ESP8266/ESP32 SmartConfig配网AT指令配置方式Arduino程序配置方式 总结 SmartConfig一键配网 SmartConfigTM 是由 TI 开发的配网技术,用于将新的 Wi-Fi 设备连接到 Wi-Fi 网络。它使用移动应用程序将无线网凭据从智…...
)
图解Agent2Agent(A2A)
🧠 向所有学习者致敬! “学习不是装满一桶水,而是点燃一把火。” —— 叶芝 我的博客主页: https://lizheng.blog.csdn.net 🌐 欢迎点击加入AI人工智能社区! 🚀 让我们一起努力,共创AI未来! 🚀 嘿,朋友们!今天咱们来聊聊 Agentic 应用背后的两大神器:A2A 和 …...
)
Kotlin基础(①)
open 关键字:打破 Kotlin 的“默认封闭”规则 // 基类必须加 open 才能被继承 open class Animal {// 方法也要加 open 才能被子类重写open fun makeSound() {println("Some sound")} }class Dog : Animal() {override fun makeSound() {println("W…...

Android Kotlin+Compose首个应用
本教程将创建一个简单的基于 Kotlin 语言的 APP,并使用 Compose 来管理 UI。 创建一个基于 Kotlin 的Android 应用 打开 Android Studio,选择New Project来创建一个应用,然后在Phone and Tablet选项卡,选择 Empty Activity&…...

《AI大模型应知应会100篇》第30篇:大模型进行数据分析的方法与局限:从实战到边界探索
大模型进行数据分析的方法与局限:从实战到边界探索 摘要 在金融分析师用自然语言询问季度财报趋势,电商平台通过对话生成用户画像的今天,大模型正在重塑数据分析的协作模式。本文通过实战代码与行业案例,揭示大模型如何成为数据…...

基于SSM+Vue的社群交流市场服务平台【提供源码+论文1.5W字+答辩PPT+项目部署】
作者简介:✌CSDN新星计划导师、Java领域优质创作者、掘金/华为云/阿里云/InfoQ等平台优质作者、专注于Java技术领域和学生毕业项目实战,高校老师/讲师/同行前辈交流。✌ 主要内容:🌟Java项目、Python项目、前端项目、PHP、ASP.NET、人工智能…...

Python Cookbook-6.7 有命名子项的元组
任务 Python 元组可以很方便地被用来将信息分组,但是访问每个子项都需要使用数字索引,所以这种用法有点不便。你希望能够创建一种可以通过名字属性访问的元组。 解决方案 工厂函数是生成符合要求的元组的子类的最简单方法: #若在2.4中可使用operator…...

软件功能测试和非功能测试有什么区别和联系?
软件测试是保障软件质量的核心环节,而软件功能测试和非功能测试作为测试领域的两大重要组成部分,承担着不同但又相互关联的职责。 软件功能测试指的是通过验证软件系统的各项功能是否按照需求规格说明书来正确实现,确保软件的功能和业务流程…...

Java Lambda表达式指南
一、Lambda表达式基础 1. 什么是Lambda表达式? 匿名函数:没有名称的函数函数式编程:可作为参数传递的代码块简洁语法:替代匿名内部类的更紧凑写法 2. 基本语法 (parameters) -> expression 或 (parameters) -> { statem…...

K8s使用LIRA插件更新安全组交互流程
在Kubernetes集群中,当使用Lira作为CNI(容器网络接口)插件,并且需要更新ConfigMap中的安全组()securityGroups字段)时,实际上你是在配置与Pod网络相关的高级选项。Lira作为一种支持P…...

利用TCP+多进程技术实现私聊信息
服务器: import socket from multiprocessing import Process from threading import Threaduser_dic {}def send_recv(client_conn, client_addr):while 1:# 接收客户端发送的消息res client_conn.recv(1024).decode("utf-8")print("客户端发送…...

【图问答】DeepSeek-VL 论文阅读笔记
《DeepSeek-VL: Towards Real-World Vision-Language Understanding》 1. 摘要/引言 基于图片问答(Visual Question Answering,VQA)的任务 2. 模型结构 和 三段式训练 1)使用 SigLIP 和 SAM 作为混合的vision encoder…...

深度学习预训练和微调
目录 1. 预训练(Pre-training)是什么? 2. 微调(Fine-tuning)是什么? 3. 预训练和微调的对象 4. 特征提取如何实现? 预训练阶段: 微调阶段: 5. 这样做的作用和意义 …...

面经-浏览器/网络/HTML/CSS
目录 1. http缓存机制 缓存机制 流程概述 2. 常见的http状态码 1xx(信息性状态码) 3xx(重定向状态码) 4xx(客户端错误状态码) 5xx(服务器错误状态码) 3. http和https的区别…...

轻松实现文件批量命名的实用工具
软件介绍 今天要给大家介绍一款超实用的批量文件重命名小工具,它完全可以称得上是同类产品的绝佳替代品。 软件特性 这小工具叫 MiniRenamer,身材十分苗条,大小还不到 300KB 呢。解压完后,不用任何复杂操作,直接就能…...

基于Redis实现高并发抢券系统的数据同步方案详解
在高并发抢券系统中,我们通常会将用户的抢券结果优先写入 Redis,以保证系统响应速度和并发处理能力。但数据的最终一致性要求我们必须将这些结果最终同步到 MySQL 的持久化库中。本文将详细介绍一种基于线程池 Redis Hash 扫描的异步数据同步方案&#…...

【Pandas】pandas DataFrame sub
Pandas2.2 DataFrame Binary operator functions 方法描述DataFrame.add(other)用于执行 DataFrame 与另一个对象(如 DataFrame、Series 或标量)的逐元素加法操作DataFrame.add(other[, axis, level, fill_value])用于执行 DataFrame 与另一个对象&…...

4.21总结
正式开始设计和实现前端页面 1.目标效果 2.今日实现内容 在前端编写了相应的store,api,utils文件,以便后续的组件复用 2.编写了相应的css文件...
PointVLA: Injecting the 3D World into Vision-Language-Action Models)
VLA论文精读(十四)PointVLA: Injecting the 3D World into Vision-Language-Action Models
这篇论文瞄准的是2025年在arxiv上发布的一篇VLA领域论文。这篇文章最大的创新点在于将3D点云信息作为补充条件送入模型,而不是DP3一样只用纯3D数据从头训练模型,按照作者的说法这样可以在保留模型原有2D解释能力的同时添加了其3D能力,并且可以…...

BEVDet4D: Exploit Temporal Cues in Multi-camera 3D Object Detection
背景 对于现有的BEVDet方法,它对于速度的预测误差要高于基于点云的方法,对于像速度这种与时间有关的属性,仅靠单帧数据很难预测好。因此本文提出了BEVDet4D,旨在获取时间维度上的丰富信息。它是在BEVDet的基础上进行拓展,保留了之前帧的BEV特征,并将其进行空间对齐后与当…...

Java学习路线--自用--带链接
1.Java基础 黑马:黑马程序员Java零基础视频教程_下部 2.MySQL 尚硅谷:MySQL数据库入门到大牛,mysql安装到优化,百科全书级,全网天花板 3.Redis 黑马:黑马程序员Redis入门到实战教程,深度透…...
)
【锂电池容量特征提取】NASA数据集锂电池容量特征提取(Matlab完整源码)
目录 效果一览程序获取程序内容代码分享研究内容基于NASA数据集的锂电池容量特征提取方法研究摘要关键词 1. 引言1.1 研究背景1.2 研究意义1.3 研究目的 2. 文献综述2.1 锂电池容量特征提取相关理论基础2.2 国内外研究现状 3. NASA数据集介绍3.1 数据集来源与构成3.2 数据采集方…...

vue2使用markdown-it解析markdown文本
1.安装markdown-it npm instal markdown-it 2. 页面中引用 import MarkdownIt from markdown-it ...const mdRender MarkdownIt(); ...data {return {md: new MarkdownIt(),} } 3. html <p v-html"md.render(conetnt)" ></p>...

云服务器怎么选择防御最合适
用户问的是怎么选择云服务器的防御最合适。这个问题看起来是关于云安全方面的,尤其是如何配置防御措施来保护云服务器免受攻击。首先,我需要理解用户的需求可能是什么。他们可能是一个企业或者个人用户,正在考虑上云,但担心安全问…...

ubuntu20.04安装安装x11vnc服务基于gdm3或lightdm这两种主流的显示管理器。
前言:在服务端安装vnc服务,可以方便的远程操作服务器,而不用非要插上显示器才行。所以在服务器上安装vnc是很重要的。在ubuntu20中,默认的显示管理器已经变为gdm3,它可以带来与 GNOME 无缝衔接的体验,强调功…...

汽车动力转向器落锤冲击试验台
汽车动力转向器落锤冲击试验台依据标准:QC/T29096-1992《汽车转向器总成台架试验方法》;以工控机为控制核心,采用步进电机举升机构,高精度的光电编码器为位置反馈元件。能够自动完成落锤的起吊、精确的定位、释放、冲击过程的测量…...

Mybatis延迟加载、懒加载、二级缓存
DAY22.2 Java核心基础 Mybatis 延迟加载、懒加载 提高程序运行效率的技术 延迟加载,也叫惰性加载或者懒加载 延迟加载如何提升程序的运行效率? 持久层操作有一个原则:Java 程序和数据库交互频率越低越好 Java 程序每次和数据库进行交互…...

Linux网络编程 多进程UDP聊天室:共享内存与多进程间通信实战解析
知识点1【项目功能介绍】 今天我们写一个 UDP ,多进程与不同进程间通信的综合练习 我这里说一下 这个项目的功能: 1、群发(有设备个数的限制):发送数据,其他所有客户端都要受到数据 2、其他客户端 都 可…...

网络结构及安全科普
文章目录 终端联网网络硬件基础网络协议示例:用户访问网页 OSI七层模型网络攻击(Hack)网络攻击的主要类别(一)按攻击目标分类(二)按攻击技术分类 网络安全防御 典型攻击案例相关名词介绍网络连接…...

CAD文件如何导入BigemapPro
问题描述 在使用 BigemapPro 加载 CAD 文件的过程中,会出现两种不同的情况:部分文件能够被软件自动识别投影并顺利加载;而另一部分文件则无法自动识别投影,需要手动干预才能准确加载到影像上。下面为您详细介绍这两种情况的具体操…...

Spring-AOP分析
Spring分析-AOP 1.案例引入 在上一篇文章中,【Spring–IOC】【https://www.cnblogs.com/jackjavacpp/p/18829545】,我们了解到了IOC容器的创建过程,在文末也提到了AOP相关,但是没有作细致分析,这篇文章就结合示例&am…...

opencv 对图片的操作
对图片的操作 1.图片镜像旋转(cv2.flip())2 图像的矫正 1.图片镜像旋转(cv2.flip()) 图像的旋转是围绕一个特定点进行的,而图像的镜像旋转则是围绕坐标轴进行的。图像的镜像旋转分为水平翻转、垂直翻转、水平垂直翻转…...

Python第一周作业
Python第一周作业 文章目录 Python第一周作业 如何在命令行中创建一个名为venv的虚拟环境?请写出具体命令编写一段代码,判断变量x是否为偶数,如果是则返回"Even",否则返回"Odd"编写代码,使用分支结…...

jinjia2将后端传至前端的字典变量转换为JS变量
后端 country_dict {AE: .amazon.ae, AU: .amazon.com.au} 前端 const country_list JSON.parse({{ country_list | tojson | safe }});...

[渗透测试]渗透测试靶场docker搭建 — —全集
[渗透测试]渗透测试靶场docker搭建 — —全集 对于初学者来说,仅仅了解漏洞原理是不够的,还需要进行实操。对于公网上的服务我们肯定不能轻易验证某些漏洞,否则可能触犯法律。这是就需要用到靶场。 本文主要给大家介绍几种常见漏洞对应的靶场…...

二分查找、分块查找、冒泡排序、选择排序、插入排序、快速排序
二分查找/折半查找 前提条件:数组中的数据必须是有序的 核心逻辑:每次排除一半的查找范围 优点:提高查找效率 代码 public static int binarySearch(int[] arr, int num) {int start 0;int end arr.length - 1;while (start < end) {…...

【AI】SpringAI 第三弹:接入通用大模型平台
1.添加依赖 <dependency><groupId>org.springframework.ai</groupId><artifactId>spring-ai-starter-model-openai</artifactId> </dependency> 2.设置 yml 配置文件 在 application.yml 中添加 DeepSeek 的配置信息: spr…...

C++常用函数合集
万能头文件:#include<bits/stdc.h> 1. 输入输出流(I/O)函数 1.1cin 用于从标准输入流读取数据。 1.2cout 用于向标准输出流写入数据。 // 输入输出流(I/O)函数 #include <iostream> using namespace…...

22. git show
基本概述 git show 的作用是:显示各种 Git 对象(如提交、标签、树对象、文件对象等)的详细信息 基本用法 1.基本语法 git show [选项] [对象]2.查看提交的详细信息 git show <commit-hash> # 示例 git show a1b2c3d # 显示某…...

使用blob文件流
1.后端 GetMapping(value "/static/**")public void view(HttpServletRequest request, HttpServletResponse response) {// ISO-8859-1 > UTF-8 进行编码转换String imgPath extractPathFromPattern(request);if(oConvertUtils.isEmpty(imgPath) || imgPath&q…...