豆瓣图书数据采集与可视化分析(二)- 豆瓣图书数据清洗与处理
文章目录
- 前言
- 一、查看数据基本信息
- 二、拆分pub列
- 三、日期列处理
- 四、价格列处理
- 五、出版社列处理
- 六、评价人数列处理
- 七、缺失值处理
- 八、重复数据处理
- 九、异常值处理
- 十、完整代码
- 十一、清洗与处理后的数据集展示
前言
豆瓣作为国内知名的文化社区,拥有庞大且丰富的图书数据资源。这些数据涵盖了图书的分类、标签、详细信息以及用户的评价等多个维度,为我们深入了解图书世界提供了宝贵的素材。然而,原始的豆瓣图书数据往往存在格式不规范、信息缺失、数据重复以及异常值等问题,这些问题会严重影响数据的质量和后续的分析与应用。
为了充分挖掘豆瓣图书数据的价值,我们需要对其进行一系列的清洗和处理工作。通过对数据的全面检查和针对性处理,我们可以解决数据中存在的各种问题,使数据更加完整、准确和一致。本项目围绕豆瓣图书数据集展开,详细阐述了从数据的初步查看、各列数据的处理(包括拆分、格式转换、异常值处理等),到缺失值和重复值的处理,以及最终将处理后的数据保存到数据库的整个过程。
一、查看数据基本信息
def data_info(data):"""打印数据的前几行、列名和基本信息。:param data: 待分析的DataFrame数据"""print("数据前几行:")print(data.head().to_csv(sep='\t', na_rep='nan')) # 使用制表符分隔,方便查看,缺失值用nan表示print("数据列名:")print(data.columns)print("数据基本信息:")data.info()
数据前几行如下所示:
数据前几行:category_name url img_url name pub rating rating_count plot buy_info
0 J.K.罗琳 https://book.douban.com/subject/35671734/ https://img9.doubanio.com/view/subject/s/public/s34048686.jpg 哈利·波特与死亡圣器 J.K. 罗琳 / 中国图书进出口总公司 / 2016-8-1 / 30.00元 9.6 (310人评价) 「“把哈利·波特交出来,”伏地魔的声音说,“你们谁也不会受伤。把哈利·波特交出来,我会让学校安然无恙。把哈利·波特交出来,你们会得到奖赏。”」当哈利·波特攀... nan
1 J.K.罗琳 https://book.douban.com/subject/27625554/ https://img3.doubanio.com/view/subject/s/public/s33973792.jpg 神奇动物在哪里(插图版) [英]纽特·斯卡曼德 / 一目、马爱农 / 人民文学出版社 / 2018-3 / 45.00 8.5 (483人评价) 《神奇动物在哪里》是“哈利·波特”系列*著名的官方衍生书。它是哈利·波特在霍格沃茨魔法学校的指定教材,由J.K.罗琳(化名纽特·斯卡曼德)撰写。 这一全新的... 纸质版 25.00元
2 J.K.罗琳 https://book.douban.com/subject/27594566/ https://img1.doubanio.com/view/subject/s/public/s32311010.jpg 诗翁彼豆故事集(插图版) [英]J.K.罗琳 / 马爱农 / 人民文学出版社 / 2018-3 8.9 (721人评价) 《诗翁彼豆故事集》是“哈利·波特”系列的官方衍生书。它是魔法世界家喻户晓的床边故事集,也是邓布利多留给赫敏·格兰杰的礼物。书中故事均由J.K.罗琳撰写。 这... 纸质版 25.00元
3 J.K.罗琳 https://book.douban.com/subject/35909174/ https://img1.doubanio.com/view/subject/s/public/s34330260.jpg 哈利·波特与被诅咒的孩子 [英] J.K.罗琳、[英] 约翰·蒂法尼、[英] 杰克·索恩 / 马爱农 / 人民文学出版社 / 2022-6 / 69.00元 7.0 (84人评价) 第八个故事。 十九年后。 十九年前,哈利·波特、罗恩·韦斯莱和赫敏·格兰杰携手拯救了魔法世界;如今,他们再次踏上了一场非同寻常的冒险旅程。这次与他们同行的,... 纸质版 40.40元
4 J.K.罗琳 https://book.douban.com/subject/26984868/ https://img9.doubanio.com/view/subject/s/public/s29443244.jpg 神奇动物在哪里 [英] J. K. 罗琳 / 马爱农、马珈 / 人民文学出版社 / 2017-4 / 58 8.3 (1346人评价) 读懂“哈利·波特”,从前传开始 《神奇动物在哪里》 J.K.罗琳首次挑战电影编剧 纽特·斯卡曼德邀请你一同探索魔法世界新纪元! 冒险家、神奇动物学家纽特·... 纸质版 32.00元
数据列名如下所示:
数据列名:
Index(['category_name', 'url', 'img_url', 'name', 'pub', 'rating','rating_count', 'plot', 'buy_info'],dtype='object')
数据基本信息如下所示:
数据基本信息:
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 129839 entries, 0 to 129838
Data columns (total 9 columns):# Column Non-Null Count Dtype
--- ------ -------------- ----- 0 category_name 129839 non-null object 1 url 129839 non-null object 2 img_url 129839 non-null object 3 name 129827 non-null object 4 pub 129436 non-null object 5 rating 111810 non-null float646 rating_count 129839 non-null object 7 plot 119919 non-null object 8 buy_info 93330 non-null object
dtypes: float64(1), object(8)
memory usage: 8.9+ MB
二、拆分pub列
# 拆分pub列的函数
def split_pub(pub):"""拆分pub列,根据不同的分隔符和格式提取作者、译者、出版社、出版日期和价格信息。:param pub: pub列的单个值:return: 包含提取信息的Series"""if pd.isna(pub):return pd.Series([None, None, None, None, None],index=['author', 'translator', 'publisher', 'publish_date', 'price'])author = translator = publisher = publish_date = price = Noneif '/' in pub:parts = pub.split('/')if len(parts) == 5:author, translator, publisher, publish_date, price = partselif len(parts) == 4:if '.' in pub:author, publisher, publish_date, price = partselse:author, translator, publisher, publish_date = partselif len(parts) == 3:if '.' in pub:author, publish_date, price = partselse:author, publisher, publish_date = partselif len(parts) == 2:if '-' in pub and '.' in pub:publish_date, price = partselse:publisher, publish_date = partselse:if '-' in pub:publish_date = pubelif '出版社' in pub:publisher = pubelse:price = pubreturn pd.Series([author, translator, publisher, publish_date, price],index=['author', 'translator', 'publisher', 'publish_date', 'price'])
三、日期列处理
此函数用于处理日期列,将日期字符串转换为有效的图书发布年份。会对输入的日期字符串进行格式检查,提取年份部分,并验证年份是否处于合理范围(1900 - 2025),若不符合要求则返回 None。
def process_date(date_str):"""处理日期列,提取年份并进行有效性检查。:param date_str: 日期字符串:return: 有效的年份或None"""if pd.notna(date_str):date_str = date_str.strip()try:year_str = date_str[:4]if len(year_str.strip()) != 4:return Noneyear = int(year_str)if 1900 <= year <= 2025: # 检查年份范围return yearexcept ValueError:passreturn None
四、价格列处理
此函数的作用是处理包含价格信息的字符串,从其中提取有效的价格,并对提取出的价格进行有效性检查。 包含价格信息的字符串,通常是类似 “纸质版 39.8 元” 这样的格式。若字符串中包含有效的价格信息且价格在合理范围内,返回该价格(浮点数类型);若价格超出合理范围,返回设定的上限价格 2000;若字符串为空值、格式不符合要求或在处理过程中出现错误,返回 None。
def process_buy_info(buy_info_str):"""处理价格信息,提取价格并进行有效性检查。:param buy_info_str: 包含价格信息的字符串:return: 有效的价格或None"""if pd.notna(buy_info_str):buy_info_str = buy_info_str.strip()try:price_str = buy_info_str.split(' ')[1].split('元')[0]price = float(price_str)if price <= 2000: # 检查价格范围return pricereturn 2000except (IndexError, ValueError):passreturn None
五、出版社列处理
该函数用于处理数据集中的出版社列信息,对传入的出版社信息字符串进行检查,去除其中包含无效信息的部分,筛选出有效的出版社信息。出版社信息的字符串可能是正确的出版社名称,也可能包含如日期等无效信息。若字符串是有效的出版社信息,则返回该字符串;若字符串为缺失值或者包含无效信息(如“年”或“-”),则返回 None。
def process_publish(publish_str):"""处理出版社列,去除无效信息。:param publish_str: 出版社信息字符串:return: 有效的出版社信息或None"""if pd.notna(publish_str):publish_str = publish_str.strip()if '年' not in publish_str and '-' not in publish_str:return publish_strreturn None
六、评价人数列处理
该函数的主要作用是处理包含评价人数信息的字符串,将不同格式的评价人数描述转换为对应的整数形式,以便后续的数据处理和分析。如果输入的字符串为空值或者无法正确转换为整数,则返回 None。
def process_rating_count(rating_count_str):"""处理评价人数列,将不同格式的评价人数转换为整数。:param rating_count_str: 评价人数信息字符串:return: 评价人数的整数表示或None"""if pd.notna(rating_count_str):rating_count_str = rating_count_str.strip()if rating_count_str == '(少于10人评价)':return 10elif rating_count_str == '(目前无人评价)':return 0try:rating_count = int(rating_count_str.split('(')[1].split('人')[0])return rating_countexcept (IndexError, ValueError):passreturn None
七、缺失值处理
该函数的主要功能是处理输入的DataFrame数据中的缺失值。针对数据中的不同列,采用不同的策略来处理缺失值,以提高数据的质量和可用性。
缺失值统计情况如下:
缺失值情况:
category_name 0
url 0
img_url 0
name 12
rating 18029
rating_count 0
plot 9920
author 3842
translator 63390
publisher 15669
publish_year 15801
price 36509
dtype: int64
对于图书名称列的缺失值,使用dropna方法,指定subset为[‘name’],即删除’name’列中值为缺失值的行。
对于作者列的缺失值,首先使用replace方法,利用正则表达式r’^\s*$'匹配空字符串(包括只包含空白字符的字符串),将其替换为pd.NA(表示缺失值)。然后再使用dropna方法,删除’author’列中值为缺失值的行。
对于评分列的缺失值,使用groupby方法按’category_name’分组,然后对每个组内的’rating’列进行操作。通过transform方法,对每个组内的缺失值使用该组的评分均值(保留一位小数)进行填充。
对于情节简介列的缺失值,使用fillna方法,将’plot’列中的缺失值填充为字符串’未知’。
对于译者列的缺失值,先使用replace方法,将空字符串(包括只包含空白字符的字符串)替换为pd.NA。然后使用fillna方法,将缺失值填充为字符串’无译者’。最后使用apply方法,对每一个译者字符串应用lambda函数,去除字符串前后的空格。
对于出版社列的缺失值,类似作者列的处理方式,先将空字符串替换为pd.NA,然后删除该列中值为缺失值的行。
对于出版年份列的缺失值,按’category_name’分组,对每个组内的’publish_year’列的缺失值使用该组的中位数进行填充。
对于价格列的缺失值,按’category_name’分组,对每个组内的’price’列的缺失值使用该组的均值(保留两位小数)进行填充。
缺失值统计及处理代码如下:
def process_null_data(data):"""处理数据中的缺失值,根据不同列采用不同的处理方法。:param data: 待处理的DataFrame数据"""# data_info(data) # 查看处理前的数据信息print("缺失值情况:")print(data.isnull().sum())# 处理各列的缺失值data.dropna(subset=['name'], inplace=True) # 删除图书名称缺失的行data['author'] = data['author'].replace(r'^\s*$', pd.NA, regex=True)data.dropna(subset=['author'], inplace=True) # 删除作者缺失的行data['rating'] = data.groupby('category_name')['rating'].transform(lambda x: x.fillna(x.mean().round(1))) # 按类别填充评分缺失值data['plot'].fillna('未知', inplace=True) # 填充情节简介缺失值data['translator'] = data['translator'].replace(r'^\s*$', pd.NA, regex=True)data['translator'].fillna('无译者', inplace=True)data['translator'] = data['translator'].apply(lambda x: x.strip()) # 去除译者前后空格data['publisher'] = data['publisher'].replace(r'^\s*$', pd.NA, regex=True)data.dropna(subset=['publisher'], inplace=True) # 删除出版社缺失的行data['publish_year'] = data.groupby('category_name')['publish_year'].transform(lambda x: x.fillna(x.median())) # 按类别填充出版年份缺失值data['price'] = data.groupby('category_name')['price'].transform(lambda x: x.fillna(x.mean().round(2))) # 按类别填充价格缺失值print("处理后缺失值情况:")print(data.isnull().sum())
处理后缺失值情况如下,可以看到已经没有缺失值。
处理后缺失值情况:
category_name 0
url 0
img_url 0
name 0
rating 0
rating_count 0
plot 0
author 0
translator 0
publisher 0
publish_year 0
price 0
dtype: int64
八、重复数据处理
def process_repeat_data(data):"""处理数据中的重复值,删除重复行。:param data: 待处理的DataFrame数据:return: 处理后的DataFrame数据"""print("重复值情况:")count = data.duplicated().sum()print(count)if count > 0:data.drop_duplicates(inplace=True)return data
九、异常值处理
def process_outliers(data):"""处理数据中的异常值,对评分进行范围限制。:param data: 待处理的DataFrame数据"""print("异常值情况:")print(data.describe())data['rating'] = data['rating'].clip(0, 10) # 限制评分范围在0-10之间
十、完整代码
豆瓣图书数据清洗与处理的完整代码如下:
import pandas as pd
from sqlalchemy import create_engine# 查看数据基本信息的函数
def data_info(data):"""打印数据的前几行、列名和基本信息。:param data: 待分析的DataFrame数据"""print("数据前几行:")print(data.head().to_csv(sep='\t', na_rep='nan')) # 使用制表符分隔,方便查看,缺失值用nan表示print("数据列名:")print(data.columns)print("数据基本信息:")data.info()# 拆分pub列的函数
def split_pub(pub):"""拆分pub列,根据不同的分隔符和格式提取作者、译者、出版社、出版日期和价格信息。:param pub: pub列的单个值:return: 包含提取信息的Series"""if pd.isna(pub):return pd.Series([None, None, None, None, None],index=['author', 'translator', 'publisher', 'publish_date', 'price'])author = translator = publisher = publish_date = price = Noneif '/' in pub:parts = pub.split('/')if len(parts) == 5:author, translator, publisher, publish_date, price = partselif len(parts) == 4:if '.' in pub:author, publisher, publish_date, price = partselse:author, translator, publisher, publish_date = partselif len(parts) == 3:if '.' in pub:author, publish_date, price = partselse:author, publisher, publish_date = partselif len(parts) == 2:if '-' in pub and '.' in pub:publish_date, price = partselse:publisher, publish_date = partselse:if '-' in pub:publish_date = pubelif '出版社' in pub:publisher = pubelse:price = pubreturn pd.Series([author, translator, publisher, publish_date, price],index=['author', 'translator', 'publisher', 'publish_date', 'price'])# 日期列处理函数
def process_date(date_str):"""处理日期列,提取年份并进行有效性检查。:param date_str: 日期字符串:return: 有效的年份或None"""if pd.notna(date_str):date_str = date_str.strip()try:year_str = date_str[:4]if len(year_str.strip()) != 4:return Noneyear = int(year_str)if 1900 <= year <= 2025: # 检查年份范围return yearexcept ValueError:passreturn None# 价格列处理函数
def process_buy_info(buy_info_str):"""处理价格信息,提取价格并进行有效性检查。:param buy_info_str: 包含价格信息的字符串:return: 有效的价格或None"""if pd.notna(buy_info_str):buy_info_str = buy_info_str.strip()try:price_str = buy_info_str.split(' ')[1].split('元')[0]price = float(price_str)if price <= 2000: # 检查价格范围return pricereturn 2000except (IndexError, ValueError):passreturn None# 出版社列处理函数
def process_publish(publish_str):"""处理出版社列,去除无效信息。:param publish_str: 出版社信息字符串:return: 有效的出版社信息或None"""if pd.notna(publish_str):publish_str = publish_str.strip()if '年' not in publish_str and '-' not in publish_str:return publish_strreturn None# 评价人数列处理函数
def process_rating_count(rating_count_str):"""处理评价人数列,将不同格式的评价人数转换为整数。:param rating_count_str: 评价人数信息字符串:return: 评价人数的整数表示或None"""if pd.notna(rating_count_str):rating_count_str = rating_count_str.strip()if rating_count_str == '(少于10人评价)':return 10elif rating_count_str == '(目前无人评价)':return 0try:rating_count = int(rating_count_str.split('(')[1].split('人')[0])return rating_countexcept (IndexError, ValueError):passreturn None# 空值处理函数
def process_null_data(data):"""处理数据中的缺失值,根据不同列采用不同的处理方法。:param data: 待处理的DataFrame数据"""# data_info(data) # 查看处理前的数据信息print("缺失值情况:")print(data.isnull().sum())# 处理各列的缺失值data.dropna(subset=['name'], inplace=True) # 删除图书名称缺失的行data['author'] = data['author'].replace(r'^\s*$', pd.NA, regex=True)data.dropna(subset=['author'], inplace=True) # 删除作者缺失的行data['rating'] = data.groupby('category_name')['rating'].transform(lambda x: x.fillna(x.mean().round(1))) # 按类别填充评分缺失值data['plot'].fillna('未知', inplace=True) # 填充情节简介缺失值data['translator'] = data['translator'].replace(r'^\s*$', pd.NA, regex=True)data['translator'].fillna('无译者', inplace=True)data['translator'] = data['translator'].apply(lambda x: x.strip()) # 去除译者前后空格data['publisher'] = data['publisher'].replace(r'^\s*$', pd.NA, regex=True)data.dropna(subset=['publisher'], inplace=True) # 删除出版社缺失的行data['publish_year'] = data.groupby('category_name')['publish_year'].transform(lambda x: x.fillna(x.median())) # 按类别填充出版年份缺失值data['price'] = data.groupby('category_name')['price'].transform(lambda x: x.fillna(x.mean().round(2))) # 按类别填充价格缺失值print("处理后缺失值情况:")print(data.isnull().sum())# 重复数据处理函数
def process_repeat_data(data):"""处理数据中的重复值,删除重复行。:param data: 待处理的DataFrame数据:return: 处理后的DataFrame数据"""print("重复值情况:")count = data.duplicated().sum()print(count)if count > 0:data.drop_duplicates(inplace=True)return data# 异常值处理函数
def process_outliers(data):"""处理数据中的异常值,对评分进行范围限制。:param data: 待处理的DataFrame数据"""print("异常值情况:")print(data.describe())data['rating'] = data['rating'].clip(0, 10) # 限制评分范围在0-10之间# 保存数据到MySQL数据库的函数
def save_to_mysql(data, table_name):"""将处理后的数据保存到MySQL数据库。:param data: 待保存的DataFrame数据:param table_name: 数据库表名"""engine = create_engine(f'mysql+mysqlconnector://root:zxcvbq@127.0.0.1:3306/douban')try:data.to_sql(table_name, con=engine, index=False, if_exists='replace')print(f'清洗后的数据已保存到 {table_name} 表')except Exception as e:print(f"保存数据到数据库时出错: {e}")if __name__ == '__main__':# 读取数据data = pd.read_csv('./原始数据层/豆瓣图书数据集.csv')# 查看数据基本信息data_info(data)# 拆分pub列data[['author', 'translator', 'publisher', 'publish_date', 'price']] = data['pub'].apply(split_pub)data.drop(['pub'], axis=1, inplace=True)data.drop(['price'], axis=1, inplace=True)data.to_csv('./中间处理层/拆分列后的豆瓣图书数据集.csv', index=False)data = pd.read_csv('./中间处理层/拆分列后的豆瓣图书数据集.csv')# 日期列处理data['publish_date'] = data['publish_date'].apply(process_date)data.rename(columns={'publish_date': 'publish_year'}, inplace=True)# 价格列处理data['price'] = data['buy_info'].apply(process_buy_info)data.drop(['buy_info'], axis=1, inplace=True)# 出版社列处理data['publisher'] = data['publisher'].apply(process_publish)# 评价人数列处理data['rating_count'] = data['rating_count'].apply(process_rating_count)# 空值处理process_null_data(data)# 重复数据处理data = process_repeat_data(data)# 异常值处理process_outliers(data)# 保存处理后的数据data.to_csv('./中间处理层/清洗后的豆瓣图书数据集.csv', index=False, encoding='utf-8-sig')# 保存分析后的数据到MySQL数据库save_to_mysql(data, '清洗后的豆瓣图书数据集')
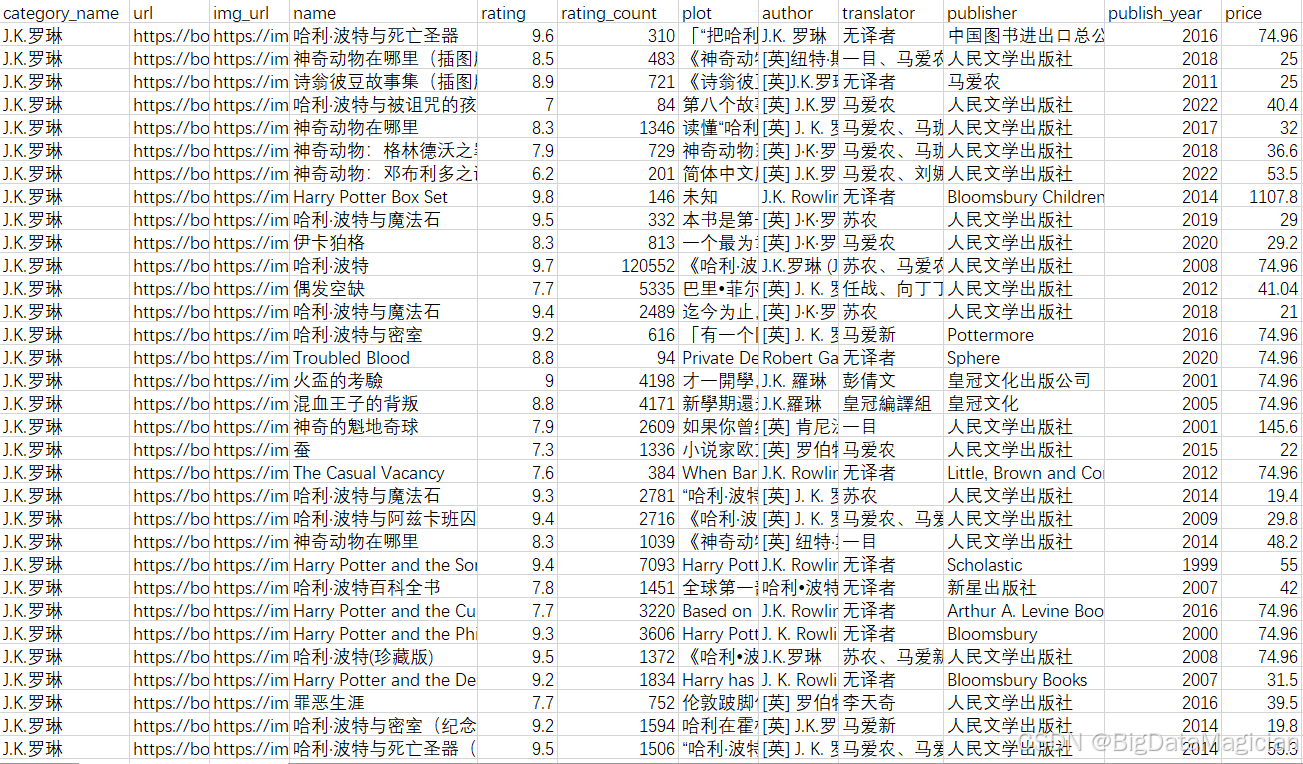
十一、清洗与处理后的数据集展示
清洗与处理后的数据集部分数据如下图所示:
相关文章:
- 豆瓣图书数据清洗与处理)
豆瓣图书数据采集与可视化分析(二)- 豆瓣图书数据清洗与处理
文章目录 前言一、查看数据基本信息二、拆分pub列三、日期列处理四、价格列处理五、出版社列处理六、评价人数列处理七、缺失值处理八、重复数据处理九、异常值处理十、完整代码十一、清洗与处理后的数据集展示 前言 豆瓣作为国内知名的文化社区,拥有庞大且丰富的图…...

【Sa-Token】学习笔记05 - 踢人下线源码解析
目录 前言 强制注销 踢人下线 源码解析 前言 所谓踢人下线,核心操作就是找到指定 loginId 对应的 Token,并设置其失效。 上图为踢人下线后,前端应该用图像给出来让用户重新登录,而不是让前端收到一个描述着被下线 的JSON 强…...

Linux | I.MX6ULL 文件系统
01 本节所有的测试程序需要开发板有 Qt 环境来运行。我们提供的文件系统是由 yocto 裁剪整理得来的。之后我们会整理一份单独移植的 qt 系统。方便用户移植第三方软件。如果用户的文件系统非我们的出厂版本,请参考之前烧写章节重新烧写出厂文件系统。开发板启动需要输入登录…...

Python3基础语法
一:注释 Python中用#表示单行注释,#之后的同行的内容都会被注释掉。 使用三个连续的双引号表示多行注释,两个多行注释标识之间内容会被视作是注释。 二:基础变量类型与操作符 1. 除法 * 除法 / python3中就算是两个整数相除&a…...
)
QEMU源码全解析 —— 块设备虚拟化(20)
接前一篇文章:QEMU源码全解析 —— 块设备虚拟化(19) 本文内容参考: 《趣谈Linux操作系统》 —— 刘超,极客时间 《QEMU/KVM源码解析与应用》 —— 李强,机械工业出版社 特此致谢! 上一回大致解析了drive_new函数,本回重点对于drive_new函数中调用的blockdev_init函…...
)
JavaScript 笔记 --- part 4 --- Web API (part 2)
(webAPI part2) DOM 基本操作 事件流 定义: 指的是事件完整执行过程中的流动路径 捕获阶段: 事件从最外层的窗口对象开始,逐层向内传播到目标元素,并触发相应的事件处理程序。 冒泡阶段: 事件从目标元素开始,逐层向外传播到最外层的窗口对象…...
)
从入门到精通汇编语言 第六章(中断及外部设备操作)
参考教程:通俗易懂的汇编语言(王爽老师的书)_哔哩哔哩_bilibili 一、移位指令 1、8个移位指令 (1)逻辑左移指令SHL:SHL OPR, CNT。 ①OPR为操作数,CNT为左移位数,该指令将OPR视作…...
)
PySide6 GUI 学习笔记——常用类及控件使用方法(常用类尺寸QSizeF)
QSizeF 类(浮点尺寸类) 文章目录 QSizeF 类(浮点尺寸类)概述主要方法列表详细说明及应用举例注意事项 概述 QSizeF 类使用浮点精度定义二维对象的尺寸。官方文档在这里。 主要方法列表 __init__(self) …...

操作系统中的虚拟化技术深度对话
操作系统中的虚拟化技术深度对话 参与者:系统工程师(Engineer)、开发者(Developer)、学生(Student) 1. 虚拟化的基本概念 Student:虚拟化到底是什么?为什么操作系统需要…...

第35讲:构建属于自己的遥感大模型平台,并接入地理数据工作流
目录 🌍 写在前面 一、为什么要构建属于自己的遥感大模型平台? 二、核心技术选型推荐 ✅ 前端部分 ✅ 后端部分 ✅ 部署平台 三、平台架构设计思路 四、案例实战:构建一个在线遥感分割平台 📌 第一步:模型服务封装(FastAPI) 📌 第二步:前端上传与展示(L…...

langchain-nextjs-template 模板安装与配置
前提条件: node安装yarn 安装:npm install -g yarn 目录 1. 克隆项目2. 安装依赖3. 配置环境变量4. 修改模型配置5. 启动开发服务器6. 项目结构说明7. 功能说明8. 自定义提示模板部分过程文件截图 1. 克隆项目 首先,从 GitHub 克隆 LangCha…...

安卓单机斗地主,具备休闲挑战等多模式
软件介绍 斗地主单机版是一款超适合在安卓设备上玩的游戏。当你周末玩网游玩累了的时候,它就是个很不错的选择哦。 多种模式可选 这个斗地主单机版有不同的模式呢,有休闲模式、挑战模式、炸弹场和大师赛。你可以根据自己的喜好随意挑选模式,…...

电解电容失效分析过程、失效分析报告
参考: 深度剖析关键电子元器件电解电容内部故障隐患 电解电容的参数指标 电路板中电解电容是存在寿命的,电解电容中的电解液随着时间会慢慢减少导致电容容值降低,最终导致电源出现问题。相信大家都见过电解电容鼓包的情况。 所以做设计的时…...

Ubuntu修改Swap交换空间大小
前言: 安装Ubuntu系统时,选择了默认空间分配方案,Swap空间仅1G,而实际的物理内存有32G,分给Swap空间至少为内存的1倍,最好是内存值的2倍,系统相当卡顿,重做系统后,费力部…...

SpringBoot 知识图谱
预警:本文非常长,建议先 mark 后看,也许是最后一次写这么长的文章说明:前面有 4 个小节关于 Spring 的基础知识,分别是:IOC 容器、JavaConfig、事件监听、SpringFactoriesLoader 详解,它们占据了本文的大部分内容,虽然它们之间可能没有太多的联系,但这些知识对于理解 …...

智谱开源新一代GLM模型,全面布局AI智能体生态
2024年4月15日,智谱在中关村论坛上正式发布了全球首个集深度研究与实际操作能力于一体的AI智能体——AutoGLM沉思。这一革命性技术的发布标志着智谱在AGI(通用人工智能)领域的又一次重要突破。智谱的最新模型不仅推动了AI智能体技术的升级&am…...
)
一文读懂Python之numpy模块(34)
一、模块简介 numpy是Python语言中做科学计算的基础库,重在于数值计算,有一个强大的N维数组对象Array,同时NumPy 提供了大量的库函数和操作,可以帮助程序员轻松地进行Array数值计算。 numpy在数据分析和机器学习领域被广泛使用。…...

Lora 微调自定义device_map
Lora 微调自定义device_map 首先查看模型权重参数配置model.safetensors.index.json 查看多少解码器 这里的layer可以理解为解码器层,后面有qkv,bais,layernomal等 # 显卡数量 num_gpus = 5 # 总层数 num_layers = 28layers_per_gpu = num_layers // num...

二叉树的顺序结构及实现
一.二叉树的顺序结构 二.堆的概念及结构 三.堆的实现 一.二叉树的顺序结构 普通的二叉树是不适合用数组来存储的,因为可能会存在大量的空间浪费。而完全二叉树更适合使用顺序结构存储。现实中我们通常把堆 ( 一种二叉树 ) 使用顺序结构的数组来存储。 二.堆的概念…...

python生成项目依赖文件requirements.txt
文章目录 通过pip freeze去生成通过pipreqs去生成 通过pip freeze去生成 pip freeze > requirements.txt会将整个python的Interceptor的环境下lib包下所有的依赖都生成到这个文件当中,取决于我们使用的python的版本下所有的安装包。不建议使用这种方式ÿ…...

Cribl 对Windows-xml log 进行 -flatten-03
The Flatten Function Description The Flatten Function is used to flatten fields out of a nested structure. Lets flatten the _raw JSON object, to further reduce the events size before we send it to the intended destination(s). Steps – Adding a Flatten…...

Java优雅实现判空方法
在 Java 开发中,频繁的 if (obj ! null) 判空代码会导致代码冗余、可读性差,且容易遗漏判空导致 NullPointerException。以下从 语言特性、设计模式、工具类 和 编码规范 四个维度,结合实际案例,详解如何优雅处理空值问题。 一、…...

leetcode 1035. Uncrossed Lines
题目描述 本题本质上就是求nums1和nums2的最长公共子序列的长度。因此本题本质上与第1143题一模一样。 代码: class Solution { public:int maxUncrossedLines(vector<int>& nums1, vector<int>& nums2) {//本题等价于求nums1和nums2的最长公…...
ollama + docker + ragflow方案)
windows上部署本地知识库(RAG)ollama + docker + ragflow方案
一、部署ollama 如何部署本地部署ollama参照我另一篇博客:Windows安装ollama部署本地大模型_ollama 在哪里运行的大模型-CSDN博客 二、部署docker 1、下载docker: 下载地址: Docker: Accelerated Container Application Development 2、winds(winds11)安装或者更新ws…...

多Agent框架及协作机制详解
文章目录 一、多智能体系统介绍1.1 多智能体系统定义1.2 多智能体协作1.3 协作类型1.4 协作策略1.5 通信结构1.6 协调与编排 1.3 多智能体与单智能体对比1.4 应用场景 二、多Agent开发框架AutoGenMetaGPTLangGraphSwarmCrewAI 三、多智能体协作方式3.1 MetaGPT:SOP驱…...

Cribl 对Windows-xml log 进行 -Removing filed-06
Removing Fields Description The Eval Function can be used to add or remove fields. In this example we will remove the extracted fields while preserving _raw, _time,index,source, sourcetype. Steps - Adding an Eval Function...

Linux 常用指令用户手册
Linux 常用指令用户手册 适合新手入门 & 日常速查 目录 基础操作文件与目录管理权限与所有权文本处理压缩与解压系统监控网络操作进程管理实用小技巧 1. 基础操作 1.1 查看系统信息 # 查看内核版本 uname -a# 查看系统发行版信息(适用于 Debian/Ubuntu&…...
——线程安全——ThreadLocal)
Java EE(20)——线程安全——ThreadLocal
1.前言 在面的线程安全相关的博文中,解决线程安全问题的方法主要使用synchronized和volatile两个关键字。引发线程安全问题的根本原因是多个线程同时对共享变量进行写操作,而上述两个关键字并没有改变"多个线程写同一个变量"这个情况。以sync…...
树莓派条件过滤器设置)
树莓派超全系列教程文档--(36)树莓派条件过滤器设置
树莓派条件过滤器设置 条件过滤器[all] 过滤器型号过滤器[none] 过滤器[tryboot] 过滤器[EDID*] 过滤器序列号过滤器GPIO过滤器组合条件过滤器 文章来源: http://raspberry.dns8844.cn/documentation 原文网址 条件过滤器 当将单个 SD 卡(或卡图像&am…...

Vue3核心源码解析
/packages/complier-core 定位:编译时核心,处理 Vue 模板的编译逻辑。核心功能: 模板解析:将 .vue 文件的模板语法(HTML-like)解析为 抽象语法树 (AST)。转换优化…...

JavaScript解密实战指南:从基础到进阶技巧
JavaScript加密技术广泛应用于数据保护、反爬虫和代码混淆,但掌握解密方法能帮助开发者突破技术壁垒。本文结合爬虫实战与安全分析场景,系统梳理JS解密的核心方法与工具。 一、基础解密方法 1. Base64解码 适用于简单编码场景,如Cookie加密…...
)
指针(2)
1.数组名的理解 使用指针访问数组的内容时,有这样的代码: int arr[10]{1,2,3,4,5,6,7,8,9,10}int * p&arr[0]; &arr[0] 的方式拿到了数组的第一个元素的地址,但是其实数组名本来就是地址,而且还是首元素的地址…...
技术详解)
Android开发中广播(Broadcast)技术详解
在 Android 开发中,广播(Broadcast) 是一种广泛使用的组件通信机制,它允许应用程序在不直接交互的情况下传递消息。本文将详细讲解 Android 广播的基本概念、类型、发送与接收流程、使用场景及注意事项,并结合具体的代…...
)
Python网络爬虫设计(三)
目录 一、需要登录的爬虫 二、pyppeteer与requests库结合 1、cookie和session 三、其他 1、绝对网址和相对网址 2、sleep函数 一、需要登录的爬虫 在众多种类的页面中,不同的页面有不同的功能,有的是进行展示的,而有的则是登录类的。在…...

【深度学习—李宏毅教程笔记】各式各样的 Attention
目录 一、普通 Self-Attention 的痛点 二、对 Self-Attention 的优化方式 1、Local Attention / Truncated Attention 2、Stride Attention 3、Global Attention 4、知名的 Self-Attention 的变形的应用 (1)Longformer (2)…...

leetcode 1143. Longest Common Subsequence
目录 题目描述 第一步,明确并理解dp数组及下标的含义 第二步,分析明确并理解递推公式 第三步,理解dp数组如何初始化 第四步,理解遍历顺序 代码 题目描述 这道题和第718题的区别就是,本题求的是最长公共子序列的长…...
)
Unity C\# 实战:从零开始为游戏添加背景音乐与音效 (AudioSource/AudioClip/AudioMixer 详解)
Langchain系列文章目录 01-玩转LangChain:从模型调用到Prompt模板与输出解析的完整指南 02-玩转 LangChain Memory 模块:四种记忆类型详解及应用场景全覆盖 03-全面掌握 LangChain:从核心链条构建到动态任务分配的实战指南 04-玩转 LangChai…...

【代码解读】开源模型 minimind之pretrain
minimind原模型地址: https://github.com/jingyaogong/minimind 本文解读下开源模型minimind的预训练代码 train_pretrain.py,解释以代码注释的形式添加 1. 参数配置代码 parser argparse.ArgumentParser(description"MiniMind Pretraining") parser.ad…...

wordpress独立站的产品详情页添加WhatsApp链接按钮
在WordPress外贸独立站的产品展示页添加WhatsApp链接按钮,可以帮助客户更方便地与你联系。以下是实现这一功能的步骤: 方法一:使用HTML代码添加按钮 编辑产品展示页 进入WordPress后台,找到需要添加WhatsApp按钮的产品展示页。…...
)
从入门到精通汇编语言 第五章(流程转移与子程序)
参考教程:通俗易懂的汇编语言(王爽老师的书)_哔哩哔哩_bilibili 一、“转移”概述 1、转移的概念 (1)般情况下指令是顺序地逐条执行的,而在实际中,常需要改变程序的执行流程,这就…...

Redis下载
目录 安装包 1、使用.msi方式安装 2.使用zip方式安装【推荐方式】 添加环境变量 配置后台运行 启动: 1.startup.cmd的文件 2.cmd窗口运行 3.linux源码安装 (1)准备安装环境 (2)上传安装文件 (3&…...

硬件工程师笔记——电子器件汇总大全
目录 1、电阻 工作原理 欧姆定律 电阻的物理本质 一、限制电流 二、分压作用 三、消耗电能(将电能转化为热能) 2、压敏电阻 伏安特性 1. 过压保护 2. 电压调节 3. 浪涌吸收 4. 消噪与消火花 5. 高频应用 3、电容 工作原理 (…...

第一章,HCIA复习
抽象语言---->电信号抽象语言---编码 编码------二进制 二进制----电信号 OSI参考模型 TCP/IP模型(4参考5对等) 应用层:程序的编译过程;人机交互的接口。 表示层:数据格式化--->二进制 会话层:维护网…...

在 Debian 12 中恢复被删除的 smb.conf 配置文件
https://forum.ubuntu.com.cn/viewtopic.php?t494763 本文结合ai输出,内容中可能有些错误,但确实解决了我的问题,我采取保留完整输出的方式摘录。 在 Debian 12 中恢复被删除的 smb.conf 配置文件,需结合 dpkg 和 ucf(…...

Java开发软件
Main.java // 主类,用于测试学生管理系统 public class Main { public static void main(String[] args) { StudentManagementSystem sms new StudentManagementSystem(); // 添加学生 sms.addStudent(new Student(1, "Alice", 20)…...

SSRF学习
靶场 fofa搜:“重庆橙子科技”,里面找SSRF。 SSRF基础知识 绕过127限制 要查看127.0.0.1/flag.php,但是127被过滤。 绕过方法:使用不同的进制表示127.0.0.1即可。 二进制:01111111.00000000.00000000.00000001 八…...

使用virtualbox的HostOnly建立共享网络-实现虚拟机上网
目录 环境描述解决方案具体步骤1.新建一个virtual host-only ethernet adapter2.设置windows的wifi信号网络共享3.确认winows宿主网络信息3.1.wifi适配器的信息3.2.虚拟网卡的信息3.3.确认virtualbox中虚拟网卡的ip地址 4.虚拟机网卡设置5.虚拟机网络设置5.1.本地连接设置5.2.u…...

RNN的理解
对于RNN的理解 import torch import torch.nn as nn import torch.nn.functional as F# 手动实现一个简单的RNN class RNN(nn.Module):def __init__(self, input_size, hidden_size, output_size):super(RNN, self).__init__()# 定义权重矩阵和偏置项self.hidden_size hidden…...
Transformers是一种基于自注意力机制的神经网络模型
概述与发展历程 背景介绍 Transformers是一种基于自注意力机制的神经网络模型,最早由Google团队在2017年的论文《Attention Is All You Need》中提出。该模型旨在解决传统循环神经网络(RNNs)在处理长距离依赖关系时的低效性问题,…...

leetcode0078. 子集-medium
1 题目:子集 官方标定难度:中 给你一个整数数组 nums ,数组中的元素 互不相同 。返回该数组所有可能的子集(幂集)。 解集 不能 包含重复的子集。你可以按 任意顺序 返回解集。 示例 1: 输入࿱…...