【深度学习—李宏毅教程笔记】各式各样的 Attention
目录
一、普通 Self-Attention 的痛点
二、对 Self-Attention 的优化方式
1、Local Attention / Truncated Attention
2、Stride Attention
3、Global Attention
4、知名的 Self-Attention 的变形的应用
(1)Longformer
(2)Big Bird
5、data driven 的方式决定注意力的计算范围
(1)第一种方法是聚类的方法
(2)第二种方法是用训练的方式
6、Linformer—对原 Attention 矩阵进行去冗
7、从矩阵运算方面优化 Self-Attention 的计算量
(1)先回顾一下 Self-Attention 的矩阵运算过程
(2)先来一个简单的,假设忽略 softmax 这个非线性的过程
(3)放回 softmax 后,如何简化 Attention 的运算呢?
(4)这里的核方法如何实现?
8、Synthesizer — 不使用 k 和 q 来生成注意力矩阵
9、一些相关的丢掉 Attention 的研究
三、总结
一、普通 Self-Attention 的痛点
普通 Self-Attention 的痛点就是在计算 注意力矩阵时的计算量会随着序列长度的上升而迅速上升。特别是图像方面,比如说一个 256×256 的图像,那么序列的长度 N 就是 ,那么注意力矩阵的大小就是
×
,如下图:
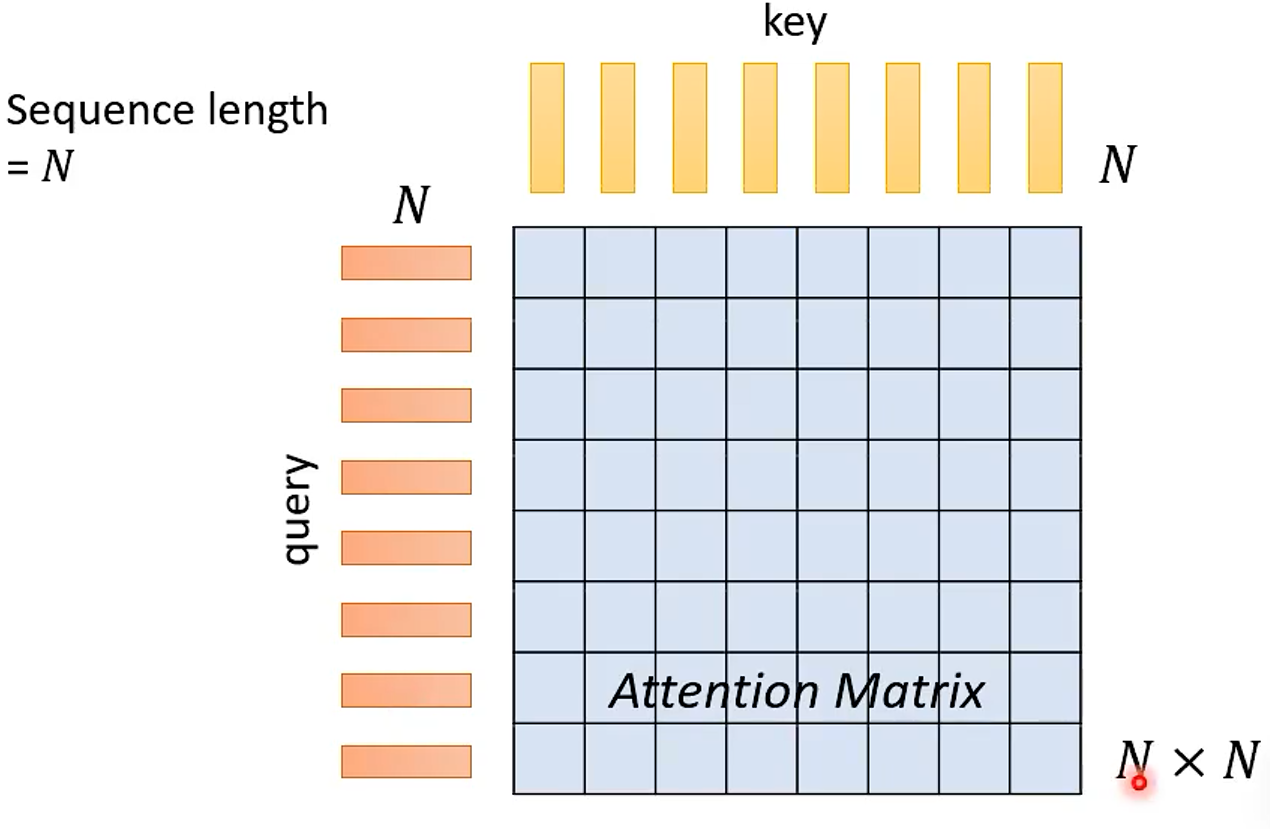
所以简化注意力矩阵的运算量,优化 Attention 的计算就成了一个很必要的事情,特别是图像方面。
Self-Attention 的计算量知识整个模型计算量的一部分,假设模型是 Transformer ,Self-Attention所带来的计算量也只是模型整体计算量的一部分,Transformer 的计算量还包括 Feed Forward 、softmax 等,序列的长度越长,Self-Attention 的计算量在整个模型中的占比越大。所以说,对 Self-Attention 的优化最早是出现在影像处理方面。
二、对 Self-Attention 的优化方式
在计算 Self-Attention 时,一般是计算所有输入序列之间的 Attention ,构造 Attention 矩阵,但其实序列很长时,比较远的元素之间的 Attention 的计算可能是没有必要的。
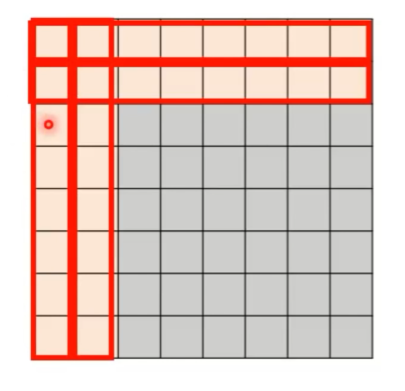
1、Local Attention / Truncated Attention
Truncated:截断
Local:当地
即只计算序列中每个元素与其相邻的元素的 Attention ,其他的 Attention 不进行计算,如下图:
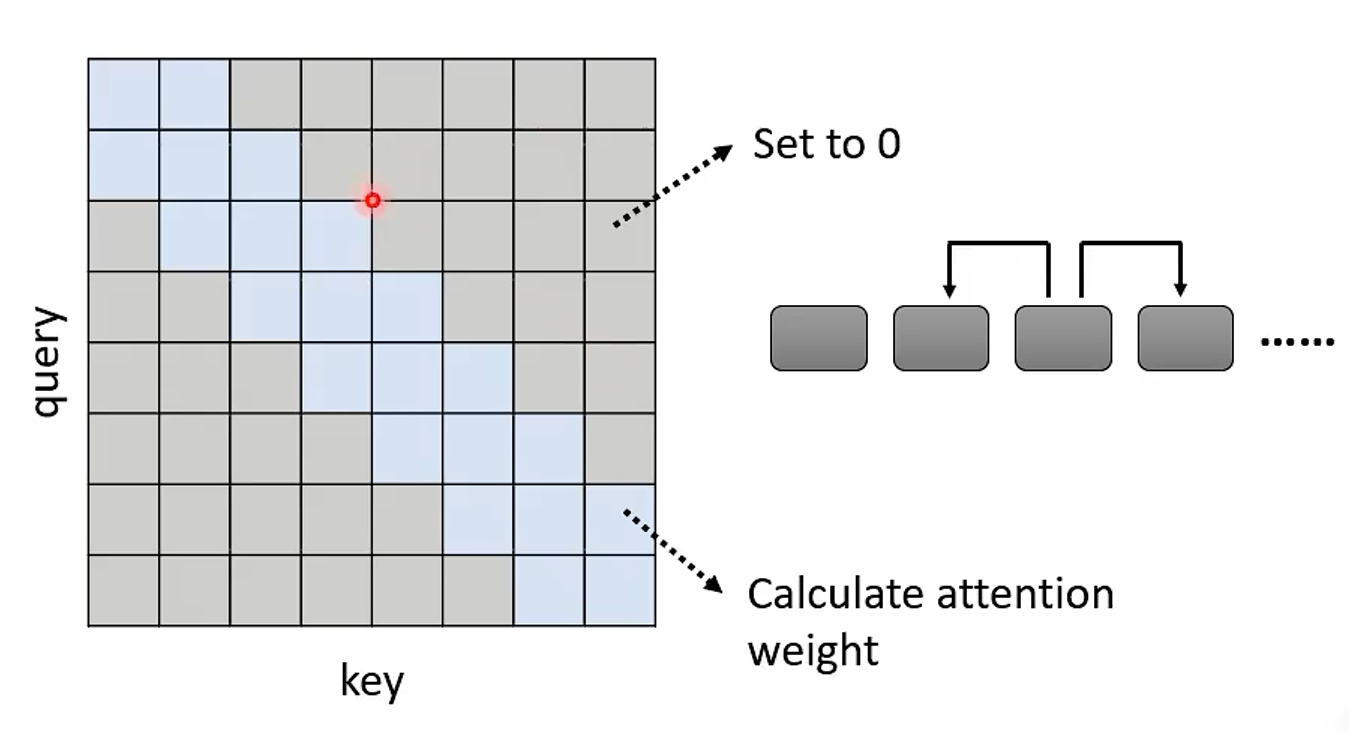
和 cnn 很像,可以加快运算,但不一定效果好。
2、Stride Attention
Stride :跨
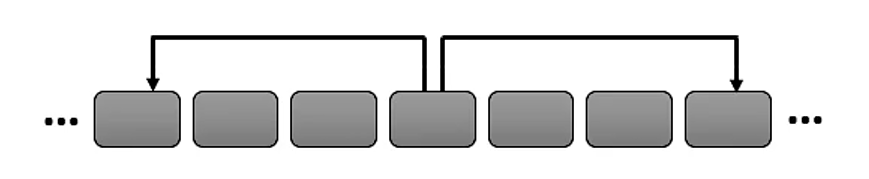
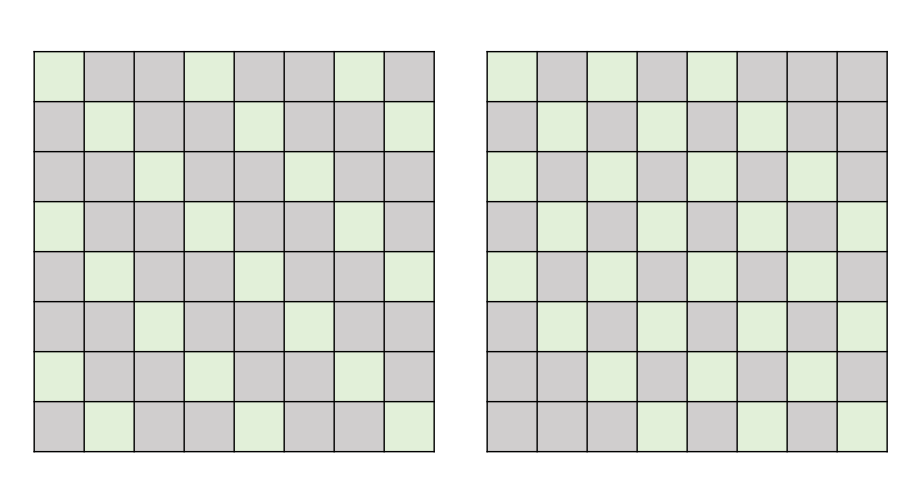
中间空着格做 Attention ,类似于空洞卷积。
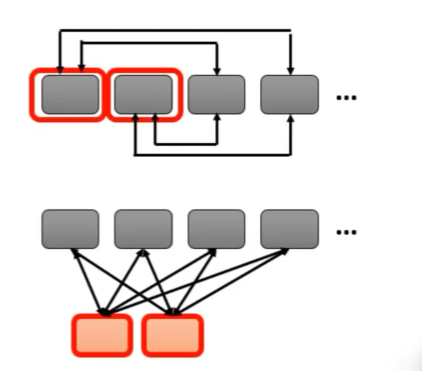
3、Global Attention
增加特别的 token 到原序列,这些特别的 token 做两件事情:
- 它们的 Query(q值)去 “询问” 所有 token 的 Key(k值)。
- 它们的 Key 被所有 token 的 Query 去“询问”。
特别的 token 可以额外加几个,或者让原序列的某几个设为特殊的 token ,如下图所示:
要计算的 Attention 为:
4、知名的 Self-Attention 的变形的应用
(1)Longformer
地址:(这里)
其中的 Attention :
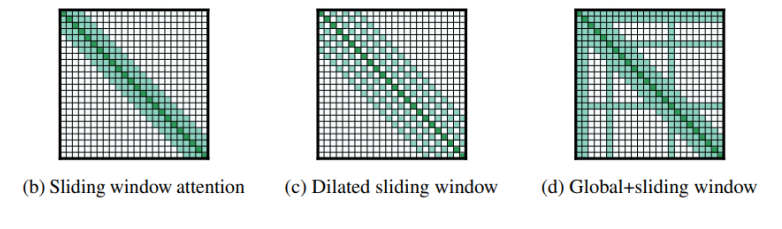
用了很多种 Attention 的变形
(2)Big Bird
这个名字可能是作者随便起的名字。
地址:(这里)
其中的 Attention :
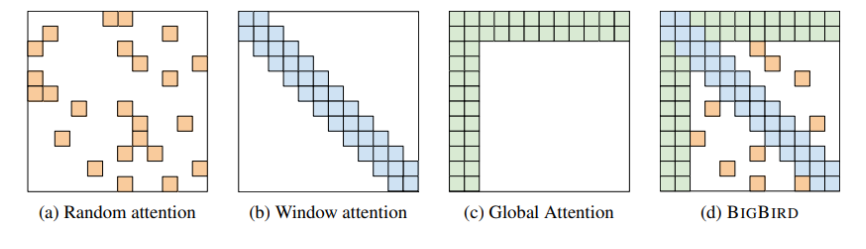
5、data driven 的方式决定注意力的计算范围
data driven:数据驱动
前边介绍的注意力的计算范围都是人为确定的范围,下面将介绍数据驱动的注意力的计算范围。
数据驱动的方式就是将可能注意力小的地方设为零,只计算注意力可能大的地方,即:
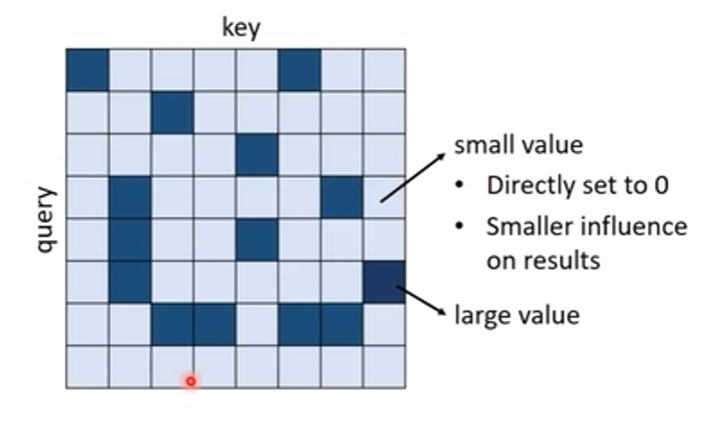
如何知道哪些地方注意力小,哪些地方注意力大呢?
(1)第一种方法是聚类的方法
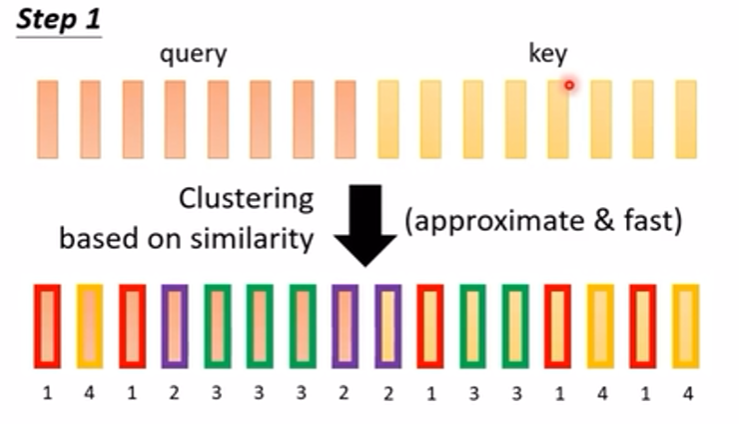
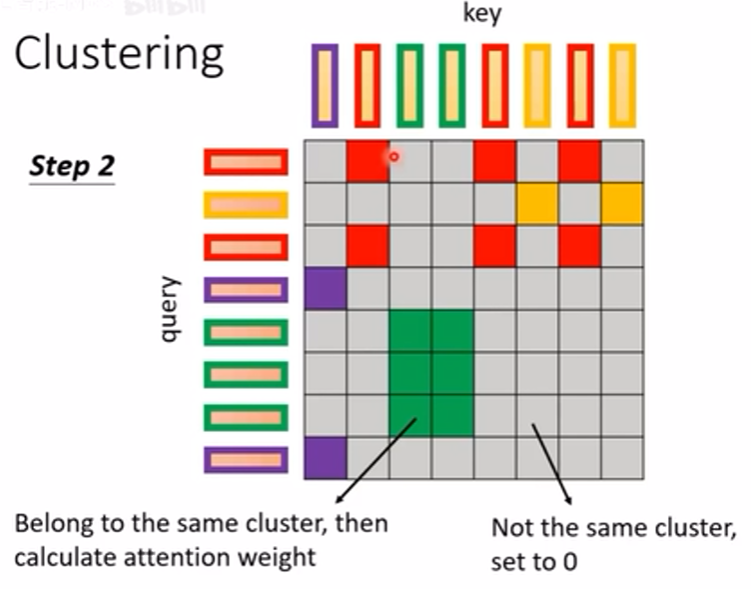
在一些论文中,(论文 Reformer(这里)、论文Routing Transformer(这里)),使用 Clustering(聚类)的方法,让所有 token 的 query 值和 Key 值放在一起进行聚类,只让在一个簇内的计算 Attention ,其他的都设为 0,这样的话,聚类的计算会带来很大的计算量吗?对聚类的计算有很多的优化方式,上面的两篇论文就是对聚类的优化方式不一样,如下图:
(2)第二种方法是用训练的方式
即用另一个 NN 模型 “ 硬 train 一发 ”。
相关论文:(这里)
这里的另一个 NN 模型的输入是输入序列,输出是一个和原始 Attention 矩阵大小一样的矩阵,这个输出决定哪里要计算 Attention ,如下图:
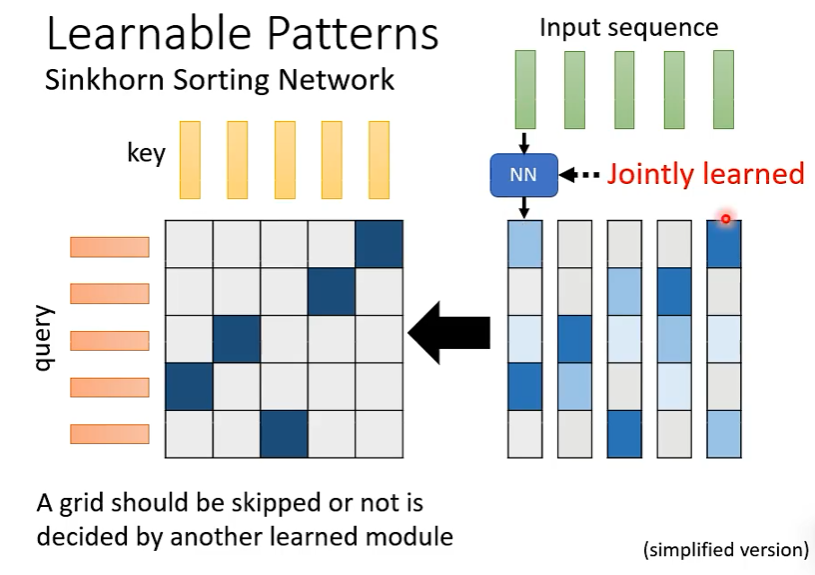
这里有一个疑问?既然 NN 网络生成了一个和 Attention 矩阵一样大的矩阵,那么直接把他当作 Attention 矩阵不行吗?不行,这个 NN 网络生成的矩阵的解析度是比较低的,也就是说,如果把这个矩阵作为 Attention 矩阵,那么会导致模型弹性不够。
6、Linformer—对原 Attention 矩阵进行去冗
在计算出的 Attention 矩阵中,很多信息都是冗余的,Linformer 实现了对冗余信息的消除,不计算 full attention matrix ,只计算重要的部分。
论文Linformer:(这里)
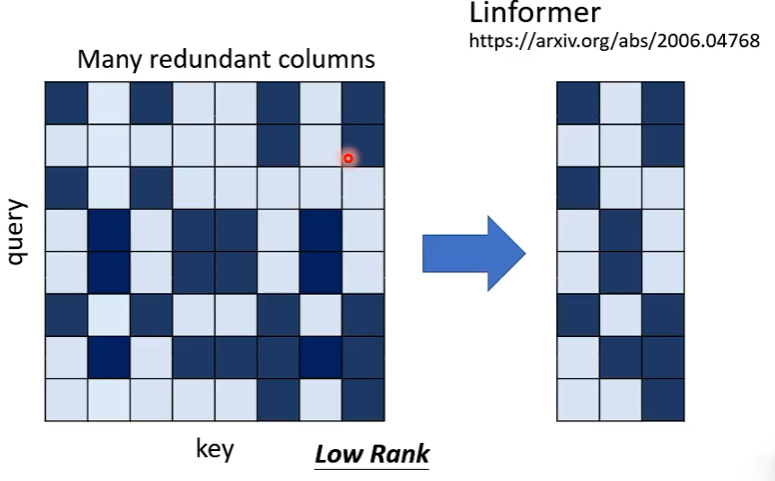
具体做法是什么呢?
实际上,总共有 N 个 Key,从其中挑选 K 个作为代表来和 query 计算注意力,同样也挑出相应的 K 个 value 进行后续的计算得到输出,如下图:
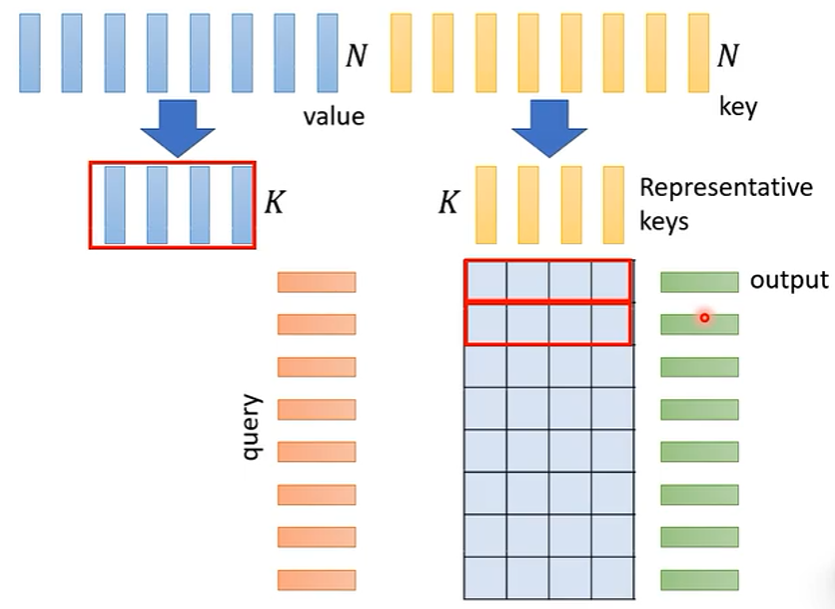
怎么选出有代表性的 Key 呢?
有不同种方式:
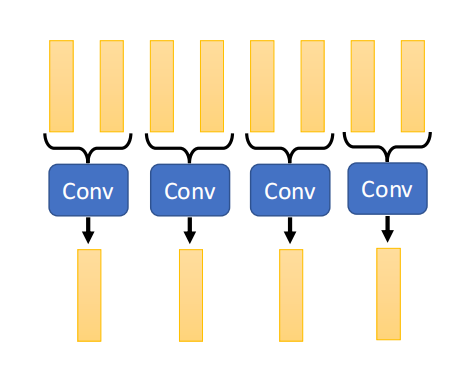
- 在 Compressed Attention 中(论文:(这里)),仍然是通过 train 的方式,通过 cnn 将长的序列 Key 变成短的,如下图
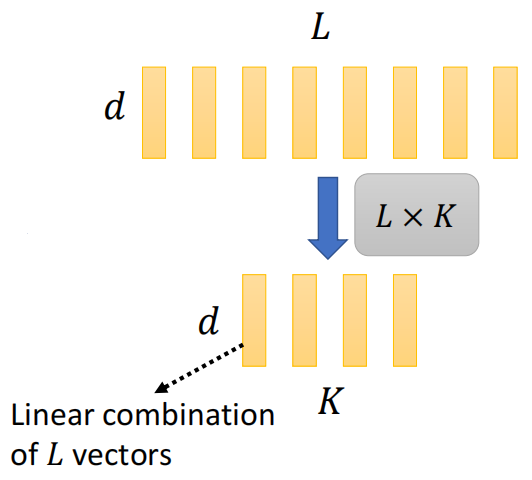
- 在 Linformer 中(论文:(这里)),将序列 Key 乘上一个矩阵,让它变短(进行 K 次线性变换),如下图
7、从矩阵运算方面优化 Self-Attention 的计算量
(1)先回顾一下 Self-Attention 的矩阵运算过程
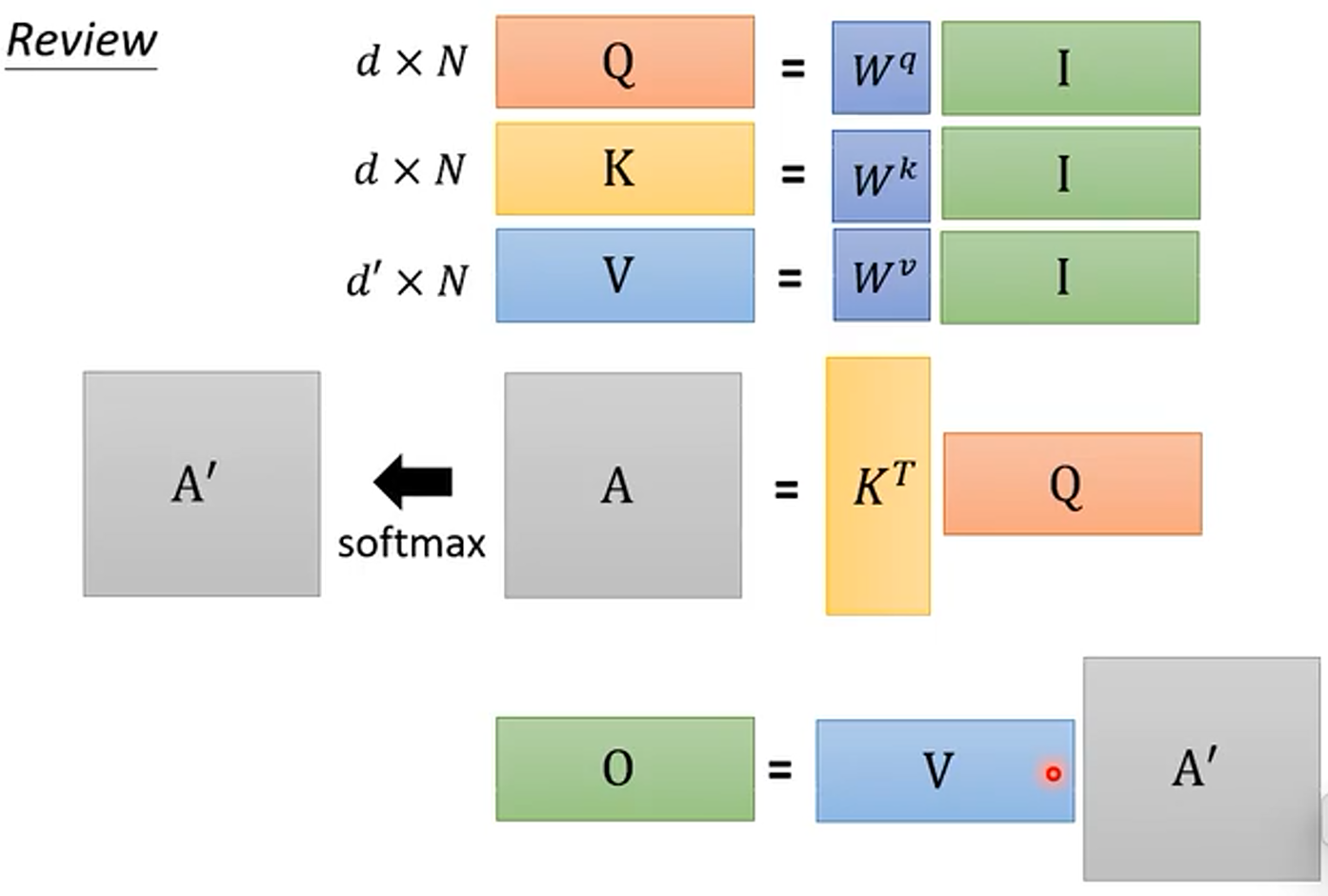
(2)先来一个简单的,假设忽略 softmax 这个非线性的过程
忽略 softmax 这个非线性的过程后,这个矩阵运算过程就变成了:
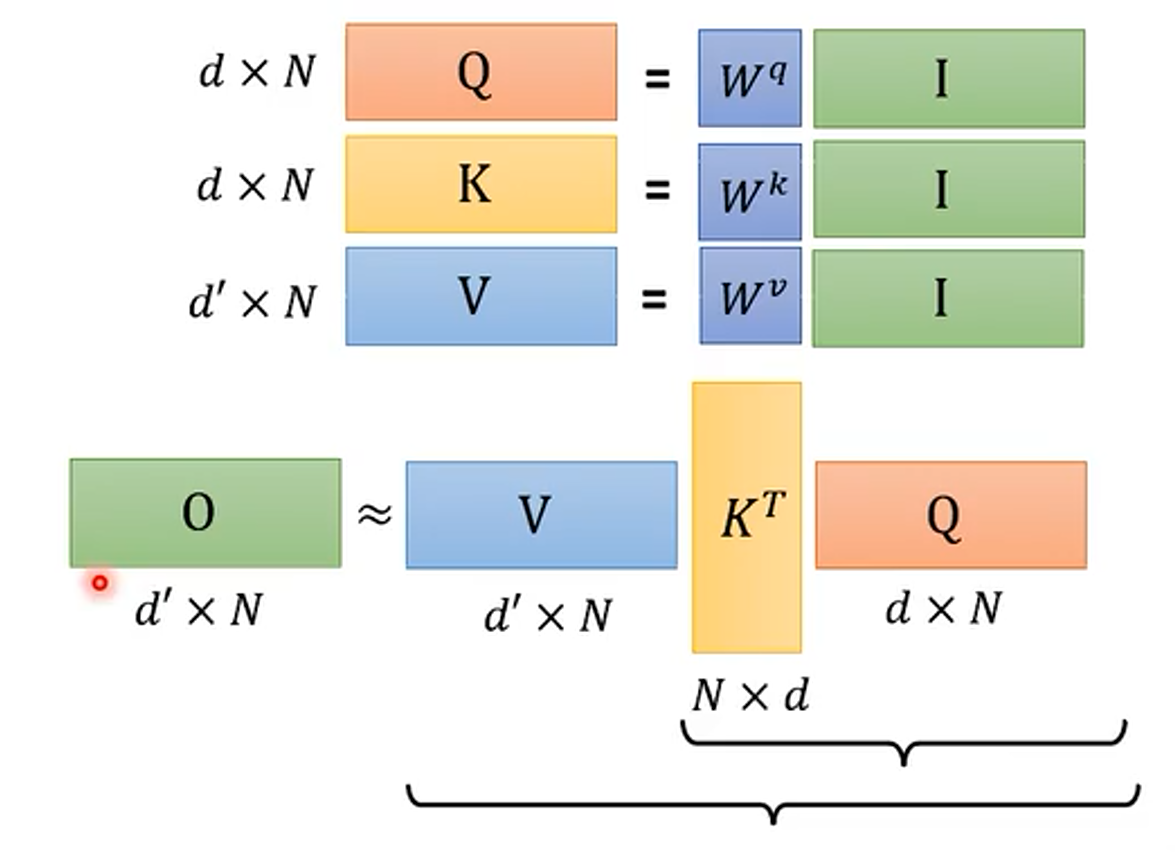
其中的额 d 是序列中每个 token 的维度,也就是编码的长度,N 是序列的长度。
这个矩阵运算过程是:
首先输入 乘上参数矩阵
、
、
得到三个矩阵
、
、
,随后从右到左计算
,得到结果后再左乘上矩阵
。
这个运算过程是可能可以简化的,即 先把 和
相乘,得到结果再和
相乘,为什么呢?
解决为什么?
对于
,乘法运算的次数为
,得到的矩阵的形状为
然后再与
相乘,乘法运算的次数为

所有总的乘法次数为
同理先把
相乘,得到结果再和
相乘的乘法次数为:
所以说,当序列长度
很大时。改变矩阵的运算次序可以简化 Attention 的计算量。
(3)放回 softmax 后,如何简化 Attention 的运算呢?
视频链接:(这里)(时间 0:47:00 ~ 1:04:00)
核心思想:没放回 softmax 时,全部都是线性变换,放回 softmax 后,加入了非线性变换,这时使用 核方法 ,让非线性变回线性。在计算 、
、
、
过程中 ,中间有很多计算不需要重复计算,可简化。
这里的 softmax 是对注意力矩阵进行的,所以 的计算过程如下:
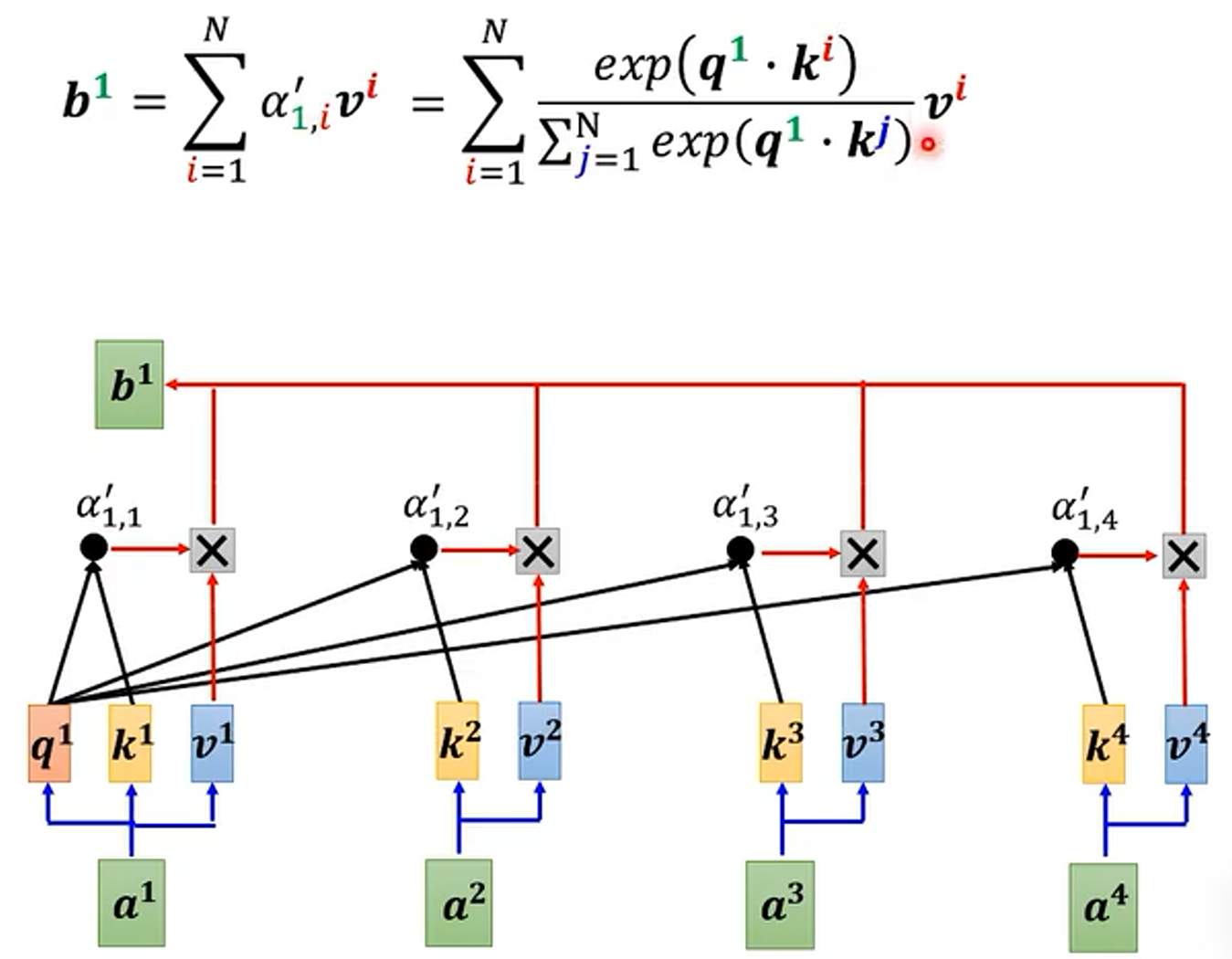
这时只要找到一个函数 使得:
,那么
的计算可化为:
...
后续太繁琐了,见视频。
(4)这里的核方法如何实现?
有很多种方法,在不同的论文中实现:
8、Synthesizer — 不使用 k 和 q 来生成注意力矩阵
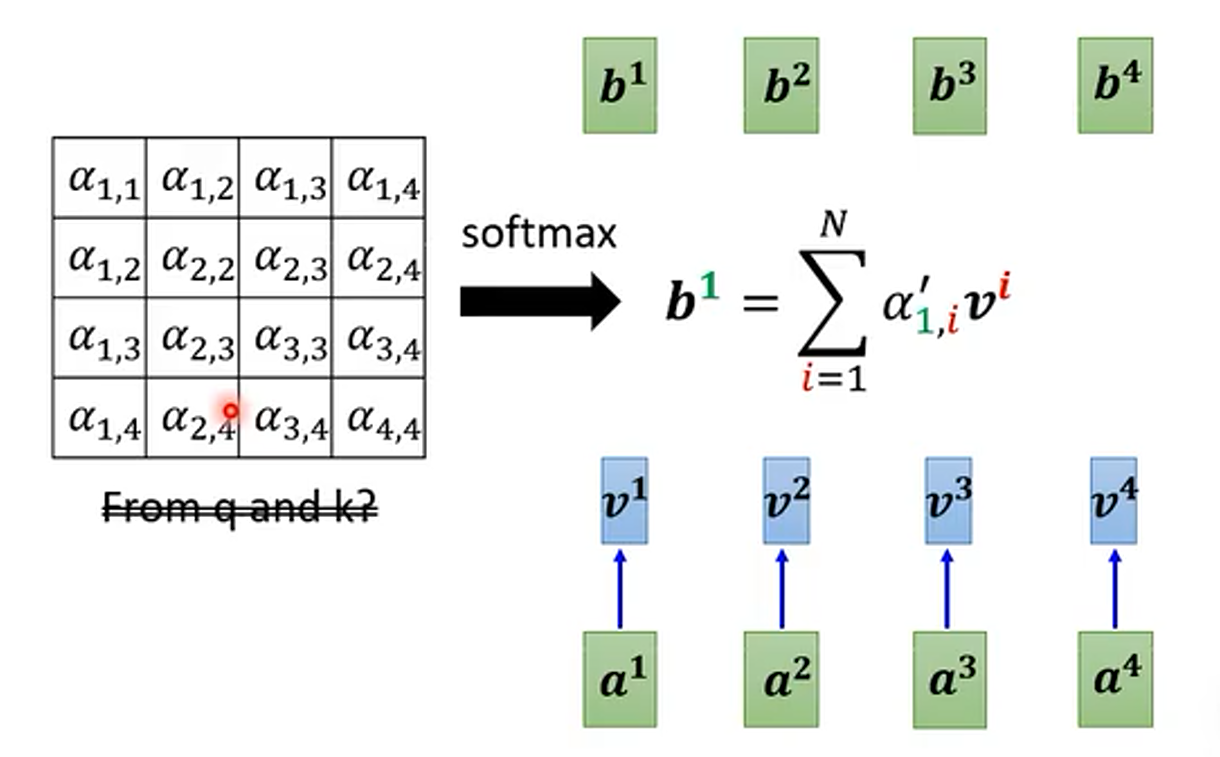
如上图,和普通 Self-Attention 一样,但左侧的注意力矩阵不是 k 和 q 产生的。那是如何得到的呢?
一种方法是直接 train 得到,即 “ 硬 train 一发 ”
另一种方法是把 这个矩阵当作 network 的一部分,把它当作 network 的参数,其中的 ×
个数值就是 network 的
×
个参数,即不再计算 Attention 矩阵,直接用 network 的参数代替。
9、一些相关的丢掉 Attention 的研究
论文:
Fnet: Mixing tokens with Fourier transforms:(这里)
Pay Attention to MLPs:(这里)
MLP-Mixer: An all-MLP Architecture for Vision:(这里)
三、总结
关于 Attention 相关的改进优化都在下面这个图中:
圈的大小代表使用的多少,纵轴代表性能,横轴代表速度(越往右越快)
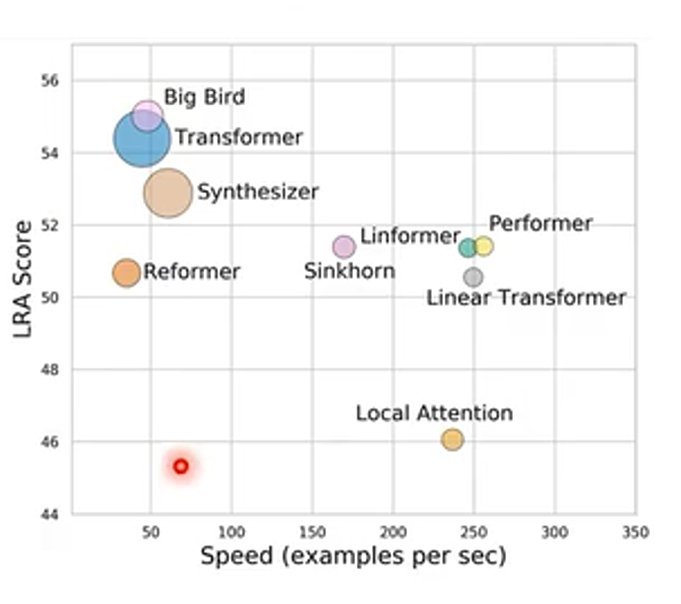
- Big Bird:把不同人设计的局部注意力矩阵放在一起组成多头注意力机制
- Local Attention:只计算部分的注意力矩阵,其他不计算设为 0 ,速度很快,性能不好
- Synthesizer:新的框架,即不使用 k 和 q 来生成注意力矩阵,其他与普通注意力机制一样
- Reformer:对 k 和 q 做聚类,只计算聚类内的注意力分数,图中可见其速度和性能都不如普通transformer
- Sinkform:直接用一个 network 来决定要计算哪些注意力分数,数据驱动,性能不如transformer,但速度比较快
- Linformer:只选一些有代表性的 Key,性能比 Transformer 差了一点,但速度快很多
- Linear Transformer:从先算
,改为先算
,即从矩阵运算方面加速 Attention 的计算,性能比 Transformer 差了一点,但速度快很多
- Performer:从先算
相关文章:

【深度学习—李宏毅教程笔记】各式各样的 Attention
目录 一、普通 Self-Attention 的痛点 二、对 Self-Attention 的优化方式 1、Local Attention / Truncated Attention 2、Stride Attention 3、Global Attention 4、知名的 Self-Attention 的变形的应用 (1)Longformer (2)…...

leetcode 1143. Longest Common Subsequence
目录 题目描述 第一步,明确并理解dp数组及下标的含义 第二步,分析明确并理解递推公式 第三步,理解dp数组如何初始化 第四步,理解遍历顺序 代码 题目描述 这道题和第718题的区别就是,本题求的是最长公共子序列的长…...
)
Unity C\# 实战:从零开始为游戏添加背景音乐与音效 (AudioSource/AudioClip/AudioMixer 详解)
Langchain系列文章目录 01-玩转LangChain:从模型调用到Prompt模板与输出解析的完整指南 02-玩转 LangChain Memory 模块:四种记忆类型详解及应用场景全覆盖 03-全面掌握 LangChain:从核心链条构建到动态任务分配的实战指南 04-玩转 LangChai…...

【代码解读】开源模型 minimind之pretrain
minimind原模型地址: https://github.com/jingyaogong/minimind 本文解读下开源模型minimind的预训练代码 train_pretrain.py,解释以代码注释的形式添加 1. 参数配置代码 parser argparse.ArgumentParser(description"MiniMind Pretraining") parser.ad…...

wordpress独立站的产品详情页添加WhatsApp链接按钮
在WordPress外贸独立站的产品展示页添加WhatsApp链接按钮,可以帮助客户更方便地与你联系。以下是实现这一功能的步骤: 方法一:使用HTML代码添加按钮 编辑产品展示页 进入WordPress后台,找到需要添加WhatsApp按钮的产品展示页。…...
)
从入门到精通汇编语言 第五章(流程转移与子程序)
参考教程:通俗易懂的汇编语言(王爽老师的书)_哔哩哔哩_bilibili 一、“转移”概述 1、转移的概念 (1)般情况下指令是顺序地逐条执行的,而在实际中,常需要改变程序的执行流程,这就…...

Redis下载
目录 安装包 1、使用.msi方式安装 2.使用zip方式安装【推荐方式】 添加环境变量 配置后台运行 启动: 1.startup.cmd的文件 2.cmd窗口运行 3.linux源码安装 (1)准备安装环境 (2)上传安装文件 (3&…...

硬件工程师笔记——电子器件汇总大全
目录 1、电阻 工作原理 欧姆定律 电阻的物理本质 一、限制电流 二、分压作用 三、消耗电能(将电能转化为热能) 2、压敏电阻 伏安特性 1. 过压保护 2. 电压调节 3. 浪涌吸收 4. 消噪与消火花 5. 高频应用 3、电容 工作原理 (…...

第一章,HCIA复习
抽象语言---->电信号抽象语言---编码 编码------二进制 二进制----电信号 OSI参考模型 TCP/IP模型(4参考5对等) 应用层:程序的编译过程;人机交互的接口。 表示层:数据格式化--->二进制 会话层:维护网…...

在 Debian 12 中恢复被删除的 smb.conf 配置文件
https://forum.ubuntu.com.cn/viewtopic.php?t494763 本文结合ai输出,内容中可能有些错误,但确实解决了我的问题,我采取保留完整输出的方式摘录。 在 Debian 12 中恢复被删除的 smb.conf 配置文件,需结合 dpkg 和 ucf(…...

Java开发软件
Main.java // 主类,用于测试学生管理系统 public class Main { public static void main(String[] args) { StudentManagementSystem sms new StudentManagementSystem(); // 添加学生 sms.addStudent(new Student(1, "Alice", 20)…...

SSRF学习
靶场 fofa搜:“重庆橙子科技”,里面找SSRF。 SSRF基础知识 绕过127限制 要查看127.0.0.1/flag.php,但是127被过滤。 绕过方法:使用不同的进制表示127.0.0.1即可。 二进制:01111111.00000000.00000000.00000001 八…...

使用virtualbox的HostOnly建立共享网络-实现虚拟机上网
目录 环境描述解决方案具体步骤1.新建一个virtual host-only ethernet adapter2.设置windows的wifi信号网络共享3.确认winows宿主网络信息3.1.wifi适配器的信息3.2.虚拟网卡的信息3.3.确认virtualbox中虚拟网卡的ip地址 4.虚拟机网卡设置5.虚拟机网络设置5.1.本地连接设置5.2.u…...

RNN的理解
对于RNN的理解 import torch import torch.nn as nn import torch.nn.functional as F# 手动实现一个简单的RNN class RNN(nn.Module):def __init__(self, input_size, hidden_size, output_size):super(RNN, self).__init__()# 定义权重矩阵和偏置项self.hidden_size hidden…...
Transformers是一种基于自注意力机制的神经网络模型
概述与发展历程 背景介绍 Transformers是一种基于自注意力机制的神经网络模型,最早由Google团队在2017年的论文《Attention Is All You Need》中提出。该模型旨在解决传统循环神经网络(RNNs)在处理长距离依赖关系时的低效性问题,…...

leetcode0078. 子集-medium
1 题目:子集 官方标定难度:中 给你一个整数数组 nums ,数组中的元素 互不相同 。返回该数组所有可能的子集(幂集)。 解集 不能 包含重复的子集。你可以按 任意顺序 返回解集。 示例 1: 输入࿱…...

C++编程 希尔排序
步骤: 1.先选定一个小于N的整数gap作为第一增量,然后将所有距离为gap的元素分在同一组,并对每一组的元素进行直接插入排序。然后再取一个比第一增量小的整数作为第二增量,重复上述操作… 2.当增量的大小减到1时,就相当…...

网络操作系统与应用服务器
1.通过PTR实现IP地址到主机域名的映射 2.在windows中,可以使用事件查看器来游览日志文件 3.IMAP即交互式邮件存取协议,邮件客户端可以使用其同步服务器和客户端之间的邮件列表 4.DHCP Discover ->DHCP Offer->DHCP Request->DHCP Ack 5.在DNS的资源记录中,类型A表…...

不确定与非单调推理的模糊推理
模糊推理是利用模糊性知识进行的一种不确定性推理。 模糊推理与前面讨论的不确定性推理的概率方法、可信度方法、D-S理论有着实质性的区别。前面那几种不确定性推理的理论基础是概率论,它所研究的事件本身有明确而确定的含义,只是由于发生的条件不充分,使得在条件与事件之间…...

Vite打包原理: Tree-shaking在Vue3项目中的实际效果
Vite打包原理: Tree-shaking在Vue3项目中的实际效果 随着前端开发技术的不断进步,Vue框架在国内外都备受青睐。而在Vue3项目中,Vite作为一款新型的构建工具,其支持的Tree-shaking技术成为了开发者关注的焦点之一。那么,Vite中Tree…...

LangChain4j语言模型选型指南:主流模型能力全景对比
LangChain4j语言模型选型指南:主流模型能力全景对比 前言 在大语言模型应用开发中,选择合适的底层模型提供商是架构设计的关键决策。LangChain4j作为Java生态的重要AI框架,其支持的20模型提供商各有独特的优势场景。本文通过功能矩阵深度解…...

聚宽策略----国九条后中小板微盘小改,年化135.40%
最近在研究的聚宽策略,一般技术分析的我直接转qmt了,财务因子有一点麻烦,我直接利用我开发强大的服务器系统,直接读取信号,最近在优化一下系统,最近在开发对接bigquant的交易系统,完成了api数据…...

FreeRTOS中断管理
中断优先级 任何中断的优先级都大于任务! 在我们的操作系统,中断同样是具有优先级的,并且我们也可以设置它的优先级,但是他的优先级并不是从 0 ~ 5 ,默认情况下它是从 5 ~ 15 , 0 ~ 4 这5个中断优先级不是FreeRTOS控…...

键入网址到网页显示,期间发生了什么?
文章目录 2.键入网址到网页显示,期间发生了什么?2.1真实地址查询DNS:2.2**协议栈:**上半部分是负责收发数据的TCP和UDP协议,下面一半是用IP协议控制网络包收发操作,在互联网上传数据时,数据会倍…...
)
代理模式(Proxy Pattern)
文章目录 1. 概述1.1 基本概念1.2 为什么需要代理模式1.3 代理模式的四个角色2. 代理模式的类型2.1 静态代理2.2 JDK动态代理2.3 CGLIB动态代理3. 代理模式的UML类图和基本实现3.1 UML类图3.2 基本实现3.2.1 静态代理基本实现3.2.2 JDK动态代理基本实现3.2.3 CGLIB动态代理基本…...
)
9.QT-显示类控件|Label|显示不同格式的文本|显示图片|文本对齐|自动换行|缩进|边距|设置伙伴(C++)
Label QLabel 可以⽤来显⽰⽂本和图⽚ 属性说明textQLabel中的⽂本textFormat⽂本的格式.• Qt::PlainText 纯⽂本• Qt::RichText 富⽂本(⽀持html标签)• Qt::MarkdownText markdown格式• Qt::AutoText 根据⽂本内容⾃动决定⽂本格式pixmapQLabel 内部包含的图⽚.scaledCo…...

Python多任务编程:进程全面详解与实战指南
1. 进程基础概念 1.1 什么是进程? 进程(Process)是指正在执行的程序,是程序执行过程中的一次指令、数据集等的集合。简单来说,进程就是程序的一次执行过程,它是一个动态的概念。 想象你打开电脑上的音乐播放器听歌,…...

【英语语法】词法---副词
目录 副词1. 副词的核心功能2. 副词的分类(1) 按意义分类(2) 按形式分类 3. 副词的构成(1) 形容词变副词的规则(2) 不规则变化 4. 副词的位置(1) 修饰动词时的位置(2) 多个副词的排列顺序 5. 副词的比较级与最高级(1) 规则变化(同形容词)(2) 不规则变化(…...

51c大模型~合集119
我自己的原文哦~ https://blog.51cto.com/whaosoft/13852062 #264页智能体综述 MetaGPT等20家顶尖机构、47位学者参与 近期,大模型智能体(Agent)的相关话题爆火 —— 不论是 Anthropic 抢先 MCP 范式的快速普及,还是 OpenAI…...

Day3:个人中心页面布局前端项目uniapp壁纸实战
接下来我们来弄一下个人中心页面布局user.vue <template><view class"userLayout"><view class"userInfo"><view class"avatar"><image src"../../static/Kx.jpg" mode"aspectFill"></im…...

多元协同网络拓扑模型
一、组织逻辑架构解构 1.1 多元协同网络拓扑模型 (1)产业链价值链重构图谱 阶段核心节点技术耦合系数商业转化周期基础层云服务供应商(阿里云/ECS集群)0.8512-24个月中台层开发者生态(百炼平台/API网关)…...

基于 Elasticsearch 8.12.0 集群创建索引
索引创建 创建一个产品的索引 解释: productId: 产品的唯一标识符,使用 keyword 类型,适合精确匹配和聚合操作。name: 产品名称,使用 text 类型进行全文搜索,同时包含一个 keyword 子字段用于精确匹配。description:…...

LeetCode283.移动零
给定一个数组 arr,编写一个函数将所有 0 移动到数组的末尾,同时保持非零元素的相对顺序。 请注意 ,必须在不复制数组的情况下原地对数组进行操作 示例 1: 输入: nums [0,1,0,3,12] 输出: [1,3,12,0,0] 示例 2 输入: nums [0] 输出: [0…...

select、poll、epoll实现多路复用IO并对比差异
目录 一、select实现多路复用 1.select函数介绍 2.select优缺点 3.select使用示例 二、poll实现多路复用 1.poll函数介绍 2.poll优缺点 3.poll使用示例 三、epoll实现多路复用 1.epoll函数介绍 2.epoll工作原理 3.epoll工作模式 (1)水平触发LT模式 (2)边缘触发ET模…...

FastAPI-MCP
介绍 开源地址: https://github.com/tadata-org/fastapi_mcp FastAPI-MCP 是一个开源项目,旨在简化 FastAPI 应用与现代 AI 代理(如基于大语言模型的系统)之间的集成。它通过自动将 FastAPI 的所有 API 端点暴露为符合 Model Co…...

Matlab 复合模糊PID
1、内容简介 Matlab 209-复合模糊PID 可以交流、咨询、答疑 2、内容说明 略摘 要:在并联型模糊 PID 复合控制器设计中,必须根据偏差大小及时地调整模糊控制部分和 PID 控制 部分的比例,而这种较为复杂的控制策略利用普通的 Simulink 模块是很难实现的.采用S-函数来解决 这个问…...

javaSE.队列
链表:屁股入队,头部出队 链尾入队👇 是while(tail.next!null) 👇 链首出队(head.next)👇 仅获取队首👇...

c++基础·左值右值
一、左值与右值的本质特征 1. 基础定义 左值 (lvalue) ✅ 可出现在赋值运算符左侧 ✅ 可被取地址(有明确存储位置) ✅ 通常为具名变量(如int a 10;中的a) 右值 (rvalue) ❌ 不可出现在赋值左侧 ❌ 不可取地址(无持久…...

From RAG to Memory: Non-Parametric Continual Learning for Large Language Models
从RAG到记忆:大语言模型的无参数持续学习 原文链接:https://arxiv.org/pdf/2502.14802 Code: https://github.com/OSU-NLP-Group/HippoRAG 🧠 HippoRAG 2 流程概述 1. 离线索引(Offline Indexing) 在此阶段,HippoRAG 2 构建一个开放式知识图谱(Open KG)以存储知识…...

STM32配置系统时钟
1、STM32配置系统时钟的步骤 1、系统时钟配置步骤 先配置系统时钟,后面的总线才能使用时钟频率 2、外设时钟使能和失能 STM32为了低功耗,一开始是关闭了所有的外设的时钟,所以外设想要工作,首先就要打开时钟,所以后面…...
)
Docker 安装配置教程(配置国内源)
## 一、Windows 安装 Docker Desktop 1. 系统要求: - Windows 10 64位:专业版、企业版或教育版 - 必须开启 Hyper-V 和容器功能 - 至少 4GB 内存 2. 安装步骤: - 访问 Docker 官网下载 Docker Desktop - 双击安装程序 - 按照向导完成安装 - 重启电脑 ## 二、macOS 安装 Dock…...

016-C语言内存函数
C语言内存函数 文章目录 C语言内存函数1. memcpy2. memmove3. memset4. memcmp 注意: 使用这些函数需要包含 string.h头文件。 1. memcpy void * memcpy ( void * destination, const void * source, size_t num );从source指向的位置开始,向后复制num…...

[FPGA]设计一个DDS信号发生器
一、DDS DDS(Data Distribution Service) 是一种面向实时分布式系统的通信中间件标准,专为高性能、高可靠性、低延迟的数据传输场景设计。它由对象管理组织(OMG) 制定并维护,广泛应用于物联网(…...
)
MySQL 线上大表 DDL 如何避免锁表(pt-online-schema-change)
文章目录 1、锁表问题2、pt-online-schema-change 原理3、pt-online-schema-change 实战3.1、准备数据3.2、安装工具3.3、模拟锁表3.4、解决锁表 1、锁表问题 在系统研发过程中,随着业务需求千变万化,避免不了调整线上MySQL DDL数据表的操作,…...

脚本中**通配符用法解析
在文件路径匹配中,** 是一种特殊的通配符(Glob Pattern),主要用于表示递归匹配任意层级的子目录。这种语法常见于以下场景: 1. 典型应用场景 .gitignore 文件: **/__pycache__ 表示匹配项目根目录下所有层…...

5 提示词工程指南-计划与行动
5 提示词工程指南-计划与行动 计划与行动 Cline 有两种模式: Plan 描述目标和需求、提问与回答、讨论、抽象项目的各个方面、确定技术路线、确定计划 计划与确认相当于架构师,不编写代码Act 按计划编写代码 按照计划编码Plan 模式的本质是构建实际编码前的上下文,Act 的本…...

62页华为IPD-MM流程:市场调研理论与实践方案精读【附全文阅读】
本文围绕市场调研展开,介绍其是联系市场和企业的纽带,具有收集陈述事实、解释信息、预测市场变化的作用,在 IPD 产品开发流程各阶段有不同应用。市场调研类型包括定性和定量研究,一般程序涵盖定义问题、拟定计划、抽样设计等多个环节。常用调研方法多样,各有特点和适用项目…...
mac中Grafana监控Linux上的CPU等(Node_exporter 安装使用))
(一)mac中Grafana监控Linux上的CPU等(Node_exporter 安装使用)
机器状态监控(监控服务器CPU,硬盘,网络等状态) Node_exporter安装在被测服务器上,启动服务 各步骤的IP地址要换为被测服务器的IP地址Prometheus.yml的 targets值网页访问的ip部分grafana添加数据源的URL 注意:只需要在被监听的服务器安装 n…...

STM32单片机入门学习——第44节: [13-1] PWR电源控制
写这个文章是用来学习的,记录一下我的学习过程。希望我能一直坚持下去,我只是一个小白,只是想好好学习,我知道这会很难,但我还是想去做! 本文写于:2025.04.20 STM32开发板学习——第44节: [13-1] PWR电源控制 前言开发板说明引用解答和科普一…...

Windows 10 上安装 Spring Boot CLI详细步骤
在 Windows 10 上安装 Spring Boot CLI 可以通过以下几种方式完成。以下是详细的步骤说明: 1. 手动安装(推荐) 步骤 1:下载 Spring Boot CLI 访问 Spring Boot CLI 官方发布页面。下载最新版本的 .zip 文件(例如 sp…...