Federated Weakly Supervised Video Anomaly Detection with Multimodal Prompt

标题:联邦弱监督视频异常检测的多模态提示方法
原文链接:https://ojs.aaai.org/index.php/AAAI/article/view/35398
源码链接:https://github.com/wbfwonderful/Fed-WSVAD
发表:AAAI-2025
摘要(Abstract)
视频异常检测(Video Anomaly Detection, VAD)旨在定位视频中的异常事件。近年来,弱监督视频异常检测(Weakly Supervised VAD)取得了显著进展,其在训练时仅需视频级标签。在实际应用中,不同机构可能拥有不同类型的异常视频。然而,出于隐私保护的考虑,这些异常视频无法在互联网上流通。为了训练一个能够识别多种异常类型的更具泛化能力的异常检测器,将联邦学习引入 WSVAD 是合理的。在本文中,我们提出了一种基于全局与局部上下文驱动的联邦学习方法,这是一种新的隐私保护弱监督视频异常检测范式。具体而言,我们利用 CLIP 的视觉-语言关联能力来检测视频帧是否异常。不同于使用人工设计的文本提示,我们提出了一种文本提示生成器。所生成的提示同时受到文本和视觉的影响:一方面,文本提供与异常相关的全局上下文,增强模型的泛化能力;另一方面,视觉提供个性化的局部上下文,因为不同客户端可能拥有不同类型的异常视频或场景。该提示能够在处理来自不同客户端的个性化数据时,同时保持全局泛化性。大量实验证明,所提出的方法具有显著性能。
代码链接:https://github.com/wbfwonderful/Fed-WSVAD
引言(Introduction)
视频异常检测(Video Anomaly Detection, VAD)是计算机视觉领域中的一项重要任务(Zhang, Qing, and Miao 2019; Huang et al. 2021, 2022b,c)。例如,VAD 可应用于智能监控系统,用于检测异常事件以减少财产损失。此外,VAD 还可用于视频内容审查系统,以更好地检测不良内容。弱监督视频异常检测(WSVAD)(Sultani, Chen, and Shah 2018; Huang et al. 2022a; Zhang et al. 2022; Wu et al. 2023)是 VAD 的一个重要分支。对于 WSVAD,模型会同时以正常视频和异常视频作为输入,但仅提供视频级标签。现有方法通常通过多实例学习(Multiple Instance Learning, MIL)(Sultani, Chen, and Shah 2018)将帧级异常分数适配到视频级标签。WSVAD 在标注成本极低的前提下取得了良好性能。然而,传统的 WSVAD 仅利用单一模态信息。
近年来,以 CLIP(Contrastive Language-Image Pretraining)(Radford et al. 2021)为代表的大规模视觉-语言预训练模型在多个下游任务中展现出强大性能,如目标检测(Du et al. 2022; Zhao et al. 2022; Kim et al. 2024)、图像分割(Xu et al. 2022; Yun et al. 2023; Luo et al. 2024)和视频理解(Wu, Sun, and Ouyang 2023; Jin et al. 2024)。CLIP 的核心思想是通过对比学习在嵌入空间中对齐图像和文本。一些研究尝试将 CLIP 应用于 WSVAD(Wu et al. 2024a,b,c; Yang, Liu, and Wu 2024)。尽管这些基于 CLIP 的方法由于利用了视觉-语言关联性而优于传统方法,但它们仅适用于集中式训练,即所有视频必须上传至中心服务器,这将无法保证数据隐私。
联邦学习(Federated Learning, FL)(McMahan et al. 2017)是一种分布式机器学习方法,其目标是在不共享原始数据的前提下,在多个客户端之间训练统一模型,以实现隐私保护。近年来,一些研究已将联邦学习应用于计算机视觉任务,如图像分类(Hsu, Qi, and Brown 2020; Su et al. 2024)和识别(Liu et al. 2020; Dutto et al. 2024)。在 VAD 场景中,异常视频可能分布于不同机构或数据拥有者之间。由于视频内容的敏感性或隐私保护,难以将这些视频集中收集用于训练。例如,交通部门可能拥有交通事故的监控视频,但为了保护事故当事人,该类视频禁止在互联网上传播。此外,公安部门可能拥有执法记录仪拍摄的视频,由于其中包含暴力或恐怖画面,也无法传播。因此,将 WSVAD 引入联邦学习环境以训练统一的异常检测模型是合理的选择。
为了在联邦学习环境中实现隐私保护的 WSVAD,并激活 CLIP 在该任务中的潜力,需解决以下三个挑战:
- 如何将 CLIP 适配到 WSVAD 任务;
- 如何在联邦学习环境中利用 CLIP;
- 如何提升联邦模型的性能。
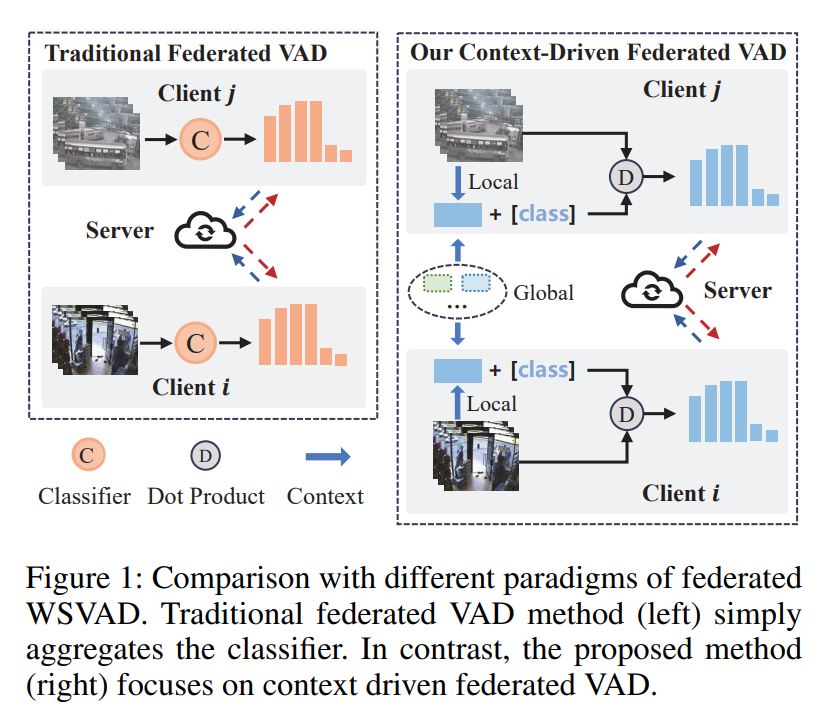
在本文中,我们提出了一种基于全局与局部上下文驱动的联邦学习框架,用于隐私保护的视频异常检测。图 1 展示了我们提出的方法与传统联邦 WSVAD 方法之间的差异。具体而言,对于第一个挑战,我们提出了一个时序建模模块,用于捕捉异常事件的时间依赖性,因为视频中的异常帧通常是连续相关的。之后,引入文本来利用 CLIP 的视觉-语言关联性。类似于 CLIP 的零样本图像分类方式,我们计算文本和视觉特征之间的相似度。最终,该相似度图表示了多类别的帧级异常置信度。同时,由于 WSVAD 仅有视频级标注,我们采用 MIL 策略选取最具异常性的帧来代表整段视频。
对于第二个挑战,CLIP 由于其强大的表征能力,能够适配来自不同客户端的多样数据,因此适用于联邦学习(Cui et al. 2024b)。然而,在联邦学习中完整训练 CLIP 计算与传输代价过高。Prompt Learning 技术(如 Context Optimization, CoOp)(Zhou et al. 2022b)通过引入可训练参数适配 CLIP 于下游任务,从而在保持 CLIP 原有能力的同时提取任务相关信息。一些研究(Zhao et al. 2023; Yang, Wang, and Wang 2023; Li et al. 2024)已将 Prompt Learning 扩展至联邦学习环境,在保留 CLIP 能力的同时为每个客户端学习个性化 Prompt。然而,这些 Prompt 的表达仍存在局限。因此,我们提出了一种生成器,能够根据上下文动态生成唯一的 Prompt。
对于第三个挑战,我们提出的 Prompt 生成器由全局与局部上下文共同驱动:一方面,全局上下文由来自所有客户端的异常类别构成,具备全局任务相关性;在全局聚合过程中,受到全局上下文调节的 Prompt 生成器能够保持尽可能快的泛化能力,也就是说,生成的 Prompt 可泛化至其他客户端的异常类别。另一方面,局部上下文来自于客户端间不同特征的视频。例如,客户端 i i i 拥有街道监控视频,而客户端 j j j 拥有商店监控视频。局部上下文引导生成的 Prompt 关注来自不同客户端视频的平均分布,即模型在保持泛化的前提下,适度地识别客户端特有的特征。总之,全局与局部上下文的结合,在全局最优与局部最优之间取得平衡。
相关工作(Related Work)
弱监督视频异常检测(Weakly Supervised Video Anomaly Detection)
训练 WSVAD 模型时仅提供视频级别的标注。为了解决这一限制,Sultani 等人(Sultani, Chen, and Shah 2018)首次提出了一种多实例学习(Multiple Instance Learning, MIL)框架用于 WSVAD,将视频视为“包”(bags),将视频片段(snippets)视为“实例”(instances)。MIL 的核心思想是选择异常置信度最高的片段来代表整个视频。随后,引入了排序损失(rank loss)以拉开正常视频与异常视频中代表性片段之间的距离。在此基础上,许多后续研究做出了改进。例如,Huang 等人(Huang et al. 2022a)提出了一种基于 Transformer 的时序特征聚合器,用于捕捉不同嵌入空间中片段的语义相似性与位置相关性;Zhou 等人(Zhou, Yu, and Yang 2023)提出了一种记忆机制,用于存储正常和异常原型,以更好地区分难分类样本;Lv 等人(Lv et al. 2023)提出了一种无偏 MIL 框架,引导模型关注无偏异常。
近年来,多模态学习(Xu et al. 2023; Ling et al. 2023; Cui et al. 2023, 2024a)取得显著进展。一些研究引入了如 CLIP 等预训练视觉-语言模型到 WSVAD 中。具体而言,Wu 等人(Wu et al. 2024c)提出了一种名为 VadCLIP 的新范式,通过两种 Prompt 机制适配 CLIP 至 WSVAD;Yang 等人(Yang, Liu, and Wu 2024)提出了一个框架,用于将 CLIP 的能力迁移至伪标签生成,从而服务于 WSVAD。
此外,还有少量研究尝试将 WSVAD 应用于联邦学习场景。具体而言,Doshi 等人(Doshi and Yilmaz 2023)提出了一种基于 Transformer 的联邦学习框架,用于视频异常检测与视频动作识别;Al-Lahham 等人(Al-Lahham et al. 2024)提出了一种名为 CLAP 的新基线,该方法为联邦 VAD 提供了新的测试与评估场景。然而,联邦 VAD 的性能仍有进一步探索空间。
用于 CLIP 的联邦 Prompt 学习(Federated Prompt Learning for CLIP)
Prompt 调优技术能有效地将 CLIP 适配至下游任务。例如,CoOp(Zhou et al. 2022b)将人工设计的 Prompt 替换为一组可学习向量,用于 CLIP 的文本编码器。进一步地,CoCoOp(Zhou et al. 2022a)通过图像输入动态调整所学习的 Prompt。一些研究(Guo et al. 2023;Zhao et al. 2023)将 Prompt 调优引入联邦学习,既保持了 CLIP 的强大能力,又降低了通信成本。此外,pFedPG(Yang, Wang, and Wang 2023)学习了一个网络,用于生成个性化 Prompt,以应对客户端之间的个性化数据问题;FedTPG(Qiu et al. 2024)则训练了一个条件于任务上下文的 Prompt 生成器,使模型具备对未见类别和数据集的泛化能力;FedAPT(Su et al. 2024)解决了跨域挑战,通过在 Prompt 中注入个性化信息,引导 CLIP 激活领域相关知识;Fed-DPT(Wei et al. 2023)通过自注意力机制将视觉和文本表征耦合的方式进行领域特定 Prompt 学习,以促进领域适应。
然而,在联邦环境中,关键挑战在于如何使每个客户端能够适配或生成适合其个性化数据的 Prompt,同时仍对全局模型做出贡献,确保其具有鲁棒且泛化的能力。一些研究致力于泛化与个性化之间的平衡。例如,FedOTP(Li et al. 2024)利用非均衡最优传输(Unbalanced Optimal Transport)对齐全局与局部 Prompt,同时引导 Prompt 更多关注图像中的类别相关信息;FedPGP(Cui et al. 2024b)采用低秩分解方式,在保证鲁棒泛化的同时引入对比损失。
所提方法(Proposed Method)
在本节中,我们将详细介绍本文提出的方法,如图 2 所示。我们的方法通过全局与局部上下文驱动的 Prompt,适配 CLIP 于联邦弱监督视频异常检测(WSVAD)任务。
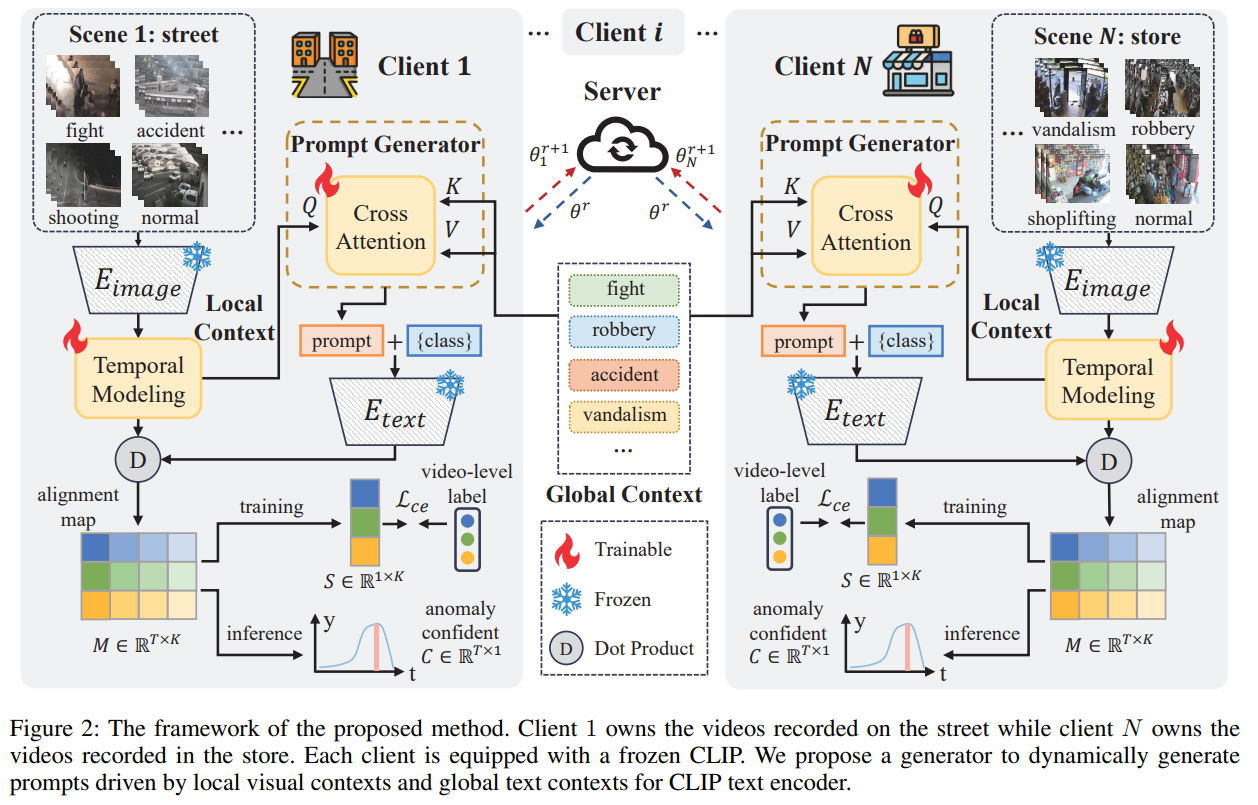
图2:所提方法的框架示意图。客户端1拥有街道录制的视频,而客户端N拥有商店录制的视频。每个客户端均配备一个冻结的CLIP模型。我们提出一个生成器,用于动态生成由局部视觉上下文和全局文本上下文驱动的提示,供CLIP文本编码器使用。
将 CLIP 适配至 WSVAD(Adapting CLIP for WSVAD)
在训练阶段,WSVAD 仅提供视频级别的标签。给定一个视频 v v v,若至少存在一个帧包含异常,则该视频被定义为异常,标签 y = 1 y=1 y=1;反之,若所有帧均为正常,则标签为 y = 0 y=0 y=0。WSVAD 的目标是训练一个异常检测器 f ( ⋅ ) f(\cdot) f(⋅),在仅有视频级标签的情况下预测帧级异常置信度。
以往研究通常使用预训练的 C3D(Tran et al., 2015)或 I3D(Carreira and Zisserman, 2017)提取视频特征。为了获得更好的特征表示并利用视觉-语言关联性,我们采用 CLIP 的图像编码器提取视频帧特征。具体而言,提取的特征可表示为:
I ∈ R T × D I \in \mathbb{R}^{T \times D} I∈RT×D
其中 T T T 表示帧数, D D D 是嵌入维度。CLIP 在大规模图文对上训练,在多种图像处理任务中表现优异。然而,若仅使用 CLIP 处理视频帧,则会忽略时间上的依赖性。对于 WSVAD,异常事件往往持续一段时间,若仅以独立帧检测异常将难以奏效。
为了解决 CLIP 缺乏时间建模的问题,一些研究(Huang et al. 2022a;Wu et al. 2024c)提出了各种时序建模模块。类似地,我们引入一个轻量级的时序建模模块,具体做法为:在 CLIP 图像编码器提取特征后,接入一个 Transformer 编码器 ϕ ( ⋅ ) \phi(\cdot) ϕ(⋅),得到具有时序信息的视频特征:
V = ϕ ( I ) , V ∈ R T × D V = \phi(I), \quad V \in \mathbb{R}^{T \times D} V=ϕ(I),V∈RT×D
然后,文本标签通过 CLIP 的文本编码器进行编码,得到:
L ∈ R K × D L \in \mathbb{R}^{K \times D} L∈RK×D
其中 K K K 表示标签类别数量。随后,计算帧特征与文本特征之间的对齐图(alignment map)如下:
M = V ⋅ L ⊤ (1) M = V \cdot L^\top \tag{1} M=V⋅L⊤(1)
其中 M ∈ R T × K M \in \mathbb{R}^{T \times K} M∈RT×K 表示每帧与各类别文本之间的相似度。
接下来,我们对齐图 M M M 进行处理,以适配视频级标签。具体而言, M M M 的每一列表示视频帧与某一类别的相似度。我们取每列中前 k k k 大值的平均,衡量视频与该类别的匹配程度,得到:
S = { s 1 , s 2 , … , s K } S = \{s_1, s_2, \dots, s_K\} S={s1,s2,…,sK}
最终,计算多类别预测结果:
p i = exp ( s i / τ ) ∑ j exp ( s j / τ ) (2) p_i = \frac{\exp(s_i / \tau)}{\sum_j \exp(s_j / \tau)} \tag{2} pi=∑jexp(sj/τ)exp(si/τ)(2)
其中, p i p_i pi 表示视频属于第 i i i 类的概率, τ \tau τ 为温度超参数。最终采用交叉熵损失训练模型。
在推理阶段,对于对齐图 M M M,我们关注其与“正常”类别之间的相似度。若相似度越高,说明当前帧越可能是正常的,对应的异常置信度应越低。因此,我们将其相似度从 1 中减去,作为异常置信度输出。
联邦 WSVAD 中的 Prompt 生成(Generating Prompts in Federated WSVAD)
CoOp(Zhou et al. 2022b)通过将手工设计的文本提示替换为可学习的向量,有效提升了 CLIP 在下游任务中的性能。类似地,我们为 CLIP 文本编码器引入文本 Prompt,以适配多种异常类别。但在联邦学习环境下,单纯可学习的 Prompt 表达能力受限。
为更好适配联邦 WSVAD,我们提出一种 Prompt 生成器,用于动态生成文本 Prompt。具体过程如下:
-
首先,原始类别标签 l l l 经过 CLIP 的分词器处理:
tokens = Tokenizer ( l ) \text{tokens} = \text{Tokenizer}(l) tokens=Tokenizer(l)
-
然后,将生成的 Prompt 表示为 P = { p 1 , . . . , p n } P = \{p_1, ..., p_n\} P={p1,...,pn},与分词后的类别标签拼接,作为 CLIP 文本编码器的输入:
t = { p 1 , . . . , token , . . . , p n } t = \{p_1, ..., \text{token}, ..., p_n\} t={p1,...,token,...,pn}
接下来我们讨论 Prompt 生成器在联邦 WSVAD 中的训练过程。设联邦学习包含 N N N 个客户端,每个客户端 i i i 拥有本地数据集 D i D_i Di,且配备预训练的 CLIP 模型。每个客户端的可训练参数包括上一节提到的时序建模模块和 Prompt 生成器,而 CLIP 本体始终被冻结。
第 r r r 轮训练的交互流程如下:
-
步骤 I:每个客户端从服务器接收并加载全局模型参数 θ r \theta_r θr;
-
步骤 II:每个客户端 i i i 利用 Prompt 与类别标签拼接后输入文本编码器,按公式(2)计算预测 P P P,并使用以下损失函数训练模型:
L i = − E ( v , Y ) ∈ D i Y log P (3) \mathcal{L}_i = - \mathbb{E}_{(v, Y) \in D_i} \, Y \log P \tag{3} Li=−E(v,Y)∈DiYlogP(3)
其中 Y ∈ R K Y \in \mathbb{R}^K Y∈RK 为多标签表示。
-
步骤 III:客户端在本地训练若干轮后,将本地参数 θ r i \theta_r^i θri 发送至服务器,服务器按加权平均规则聚合为全局参数:
θ r + 1 = ∑ i ∣ D i ∣ ∑ j ∣ D j ∣ θ r i (4) \theta_{r+1} = \sum_i \frac{|D_i|}{\sum_j |D_j|} \theta_r^i \tag{4} θr+1=i∑∑j∣Dj∣∣Di∣θri(4)
全局与局部上下文驱动的 Prompt(Global and Local Context-driven Prompt)
联邦学习旨在利用分布式数据训练统一模型。但实际中,各客户端间数据分布通常不同。例如,不同机构可能拥有风格各异的异常视频。因此,为同时实现局部个性化和全局泛化,我们提出一种全局与局部上下文驱动的 Prompt 学习策略。
-
全局上下文:受 FedTPG(Qiu et al. 2024)启发,任务相关文本可为联邦 Prompt 学习提供语义上下文。在 WSVAD 中,来自各客户端的异常类别文本构成的全局上下文,包含了对整个任务的概括性描述。即使某些客户端未见过某些异常类别,全局上下文也能激活冻结的 CLIP,赋予其一定的识别能力。
-
局部上下文:本地视觉特征提供客户端特有的视频平均语义,引导模型学习本地数据分布,从而避免模型偏向某个具体类别。
两者结合后,Prompt 学习可在个性化与泛化之间取得平衡。
具体而言,Prompt 生成器由一个 Cross-Attention 模块组成:
-
对于全局上下文,类别文本首先编码为:
T ∈ R K × D T \in \mathbb{R}^{K \times D} T∈RK×D
然后映射为 Key 和 Value:
K T = T × W K , V T = T × W V K_T = T \times W_K,\quad V_T = T \times W_V KT=T×WK,VT=T×WV
-
对于局部上下文,考虑一批视频帧特征 V ∈ R B × T × D V \in \mathbb{R}^{B \times T \times D} V∈RB×T×D,对 batch 维度进行平均得到:
V ˉ ∈ R T × D , Q V ˉ = V ˉ × W Q \bar{V} \in \mathbb{R}^{T \times D}, \quad Q_{\bar{V}} = \bar{V} \times W_Q Vˉ∈RT×D,QVˉ=Vˉ×WQ
最终,Prompt P P P 通过 Cross-Attention 融合得到:
P = CrossAttention ( Q V ˉ , K T , V T ) (5) P = \text{CrossAttention}(Q_{\bar{V}}, K_T, V_T) \tag{5} P=CrossAttention(QVˉ,KT,VT)(5)
实验(Experiment)

实验设置(Experimental Settings)
数据集与评估指标(Datasets and Evaluation Metrics)
我们在两个大规模数据集上进行了大量实验:UCF-Crime(Sultani, Chen, and Shah 2018)和 XD-Violence(Wu et al. 2020)。此外,我们还在未见过的数据集 ShanghaiTech(Luo, Liu, and Gao 2017)的测试集上评估了方法的泛化能力。ShanghaiTech 最初设计用于半监督 VAD,我们采用 Zhong 等人(Zhong et al. 2019)重构后的测试集。
参考 CLAP(Al-Lahham et al. 2024),我们对 UCF-Crime 和 XD-Violence 进行了三种数据划分策略:
- 随机划分(Random Split):作为基线设定,每个客户端持有数量相同的视频;
- 基于事件划分(Event-Based Split):每个客户端拥有不同类型异常的视频。例如,客户端 i i i 包含爆炸类视频,而客户端 j j j 包含打斗类视频;
- 基于场景划分(Scene-Based Split):最贴近真实应用场景,每个客户端的视频来自特定场景。例如,客户端 i i i 拥有商店中发生如抢劫、偷窃等异常的视频,而客户端 j j j 拥有街道上发生如交通事故、枪击事件的视频。
更多划分细节见附录材料。
评估指标方面,遵循以往工作(Wu et al. 2020, 2024c),我们在 UCF-Crime 和 ShanghaiTech 上采用帧级 ROC 曲线的 AUC(Area Under Curve)作为指标,而在 XD-Violence 上使用帧级 PR 曲线的 AP(Average Precision)作为指标。
训练设定(Training Settings)
我们在以下三种训练设定下对所提方法与现有 SOTA 方法进行比较:
- 集中式训练(Centralized Training):将所有数据集中训练异常检测器,不考虑隐私问题;
- 本地训练(Local Training):每个客户端仅在本地数据上训练自身模型,隐私安全但可能损失全局性能;
- 联邦训练(Federated Training):多个客户端共同训练一个联合异常检测器,同时保障本地数据隐私。本论文中仅使用全局测试集,即每个客户端仅持有本地训练集。
实现细节(Implementation Details)
我们使用预训练的 CLIP(ViT-B/16)提取视觉与文本特征,嵌入维度 D = 512 D=512 D=512。Prompt 生成器由一个四头 Cross-Attention、LayerNorm 以及一个线性投影层组成,嵌入维度同样为 512。我们在单张 NVIDIA RTX 3090 GPU 上使用 PyTorch 进行训练,batch size 设为 128,学习率为 1 × 1 0 − 5 1\times10^{-5} 1×10−5。全局聚合轮数为 15,每轮本地训练 epoch 为 10。
在不同划分策略上的对比(Comparisons on Different Data Splits)
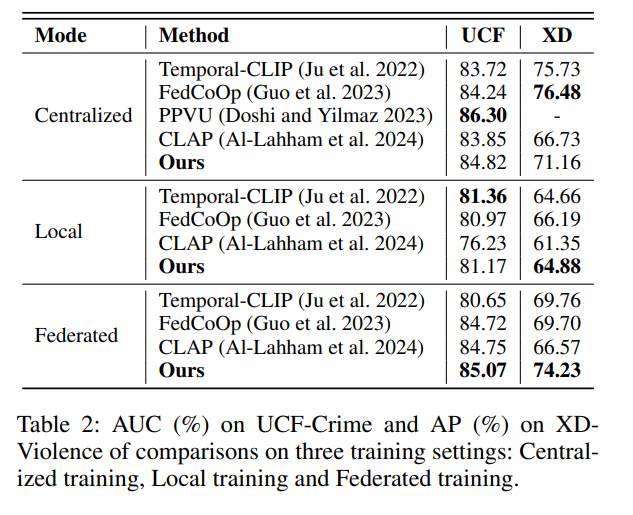
表 1 显示了在 UCF-Crime 和 XD-Violence 上,分别以随机划分、事件划分和场景划分进行测试的结果。我们的方法相较于手工 Prompt 的 ZS-CLIP(Radford et al. 2021)和使用可学习 Prompt 向量的 FedCoOp(Guo et al. 2023)性能更优,说明我们提出的 Prompt 生成器在联邦学习环境中更具灵活性。
此外,我们的方法相比于其他联邦 WSVAD 方法如 PPVU(Doshi and Yilmaz 2023)和 CLAP(Al-Lahham et al. 2024)表现更佳。PPVU 基于 Transformer,在联邦环境中仅训练分类器;CLAP 利用聚类生成伪标签,但只考虑视觉信息,忽视联邦学习中泛化与个性化的平衡。而我们的方法结合视觉-语言关联性与上下文调控,在全局泛化与局部个性化之间做出更优权衡。
在不同训练设定下的对比(Comparisons on Different Training Settings)
表 2 显示了我们方法在集中式、本地和联邦训练三种设定下的性能。为保证公平性,我们对比方法均在三种设定下重新实现。
- 一方面,希望联邦训练尽可能逼近集中式训练性能,后者具有全局泛化能力;
- 另一方面,虽然本地训练具有隐私保护优势,但若每个客户端只训练本地模型,则其在全局测试集上的表现通常不佳。
作为折中方案,联邦训练既聚合了全局性能,又保留了本地数据隐私。与本地训练相比,我们在 UCF-Crime 和 XD-Violence 上分别获得了 2.89% AUC 和 10.44% AP 的提升。由于我们的 Prompt 生成器同时受全局和局部上下文驱动,特别适合联邦学习,因此在集中式训练中可能略显劣势。
泛化能力评估(Generalization to Unseen Datasets)
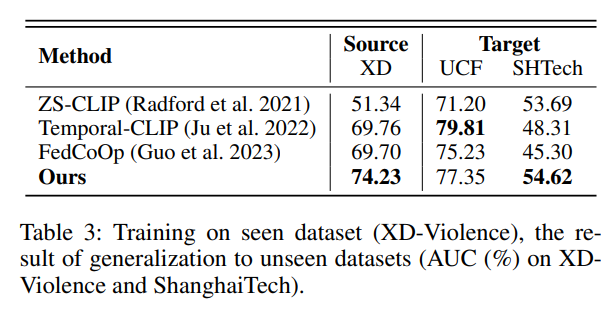
我们评估了模型对未见数据集的泛化能力。具体做法是在 UCF-Crime 或 XD-Violence 上进行联邦训练,在 ShanghaiTech 测试集上进行测试。
- 表 3 显示在 XD-Violence 上训练后,在未见数据集上的测试结果;
- 表 4 显示在 UCF-Crime 上训练后的测试结果。
我们方法在 ShanghaiTech 上分别取得了 54.62% 和 60.42% 的 AUC,平均超越 ZS-CLIP 与 Temporal-CLIP 分别为 3.83% 和 9.32%。这种泛化能力来自两个方面:
- CLIP 的预训练模型提供了稳健的语义特征表示;
- 我们提出的 Prompt 生成器由全局与局部上下文共同驱动,其中全局上下文激活了模型对未见类别的识别能力。
好的,以下是论文的 消融实验(Ablation Studies) 和 可视化分析(Qualitative Analyses) 部分的完整翻译,继续保持学术风格和 KaTeX 格式。
消融实验(Ablation Studies)
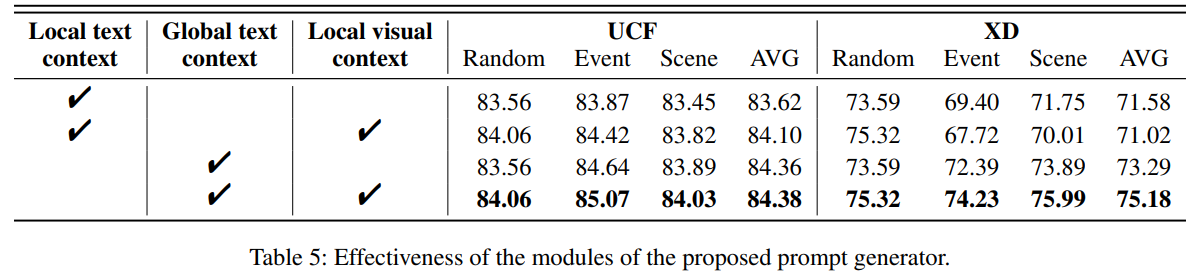
在本节中,我们重点评估所提方法中各个模块的有效性,实验结果如表 5 所示。
首先,我们比较了**局部文本上下文(Local Text Context)与全局文本上下文(Global Text Context)**的差异。类似于 FedTPG(Qiu et al. 2024),当仅提供当前客户端所拥有的类别文本作为 Prompt 生成上下文时,在 UCF-Crime 和 XD-Violence 上的平均性能分别下降了 0.28%(AUC)和 4.16%(AP)。这是因为全局上下文能提供完整的任务相关信息,而局部上下文则相对有限,难以提供任务的全面语义表示。
需要注意的是,在**随机划分(random split)**下,局部上下文和全局上下文在本质上是一致的,因此这两种设置在该场景下没有差异。
其次,我们评估了**局部视觉上下文(Local Visual Context)**的作用。将局部视觉上下文替换为一组可学习向量时,在 XD-Violence 上平均性能下降了 1.89%(AP)。这是因为在缺乏局部视觉信息的引导下,模型难以适应本地数据分布。
可视化分析(Qualitative Analyses)
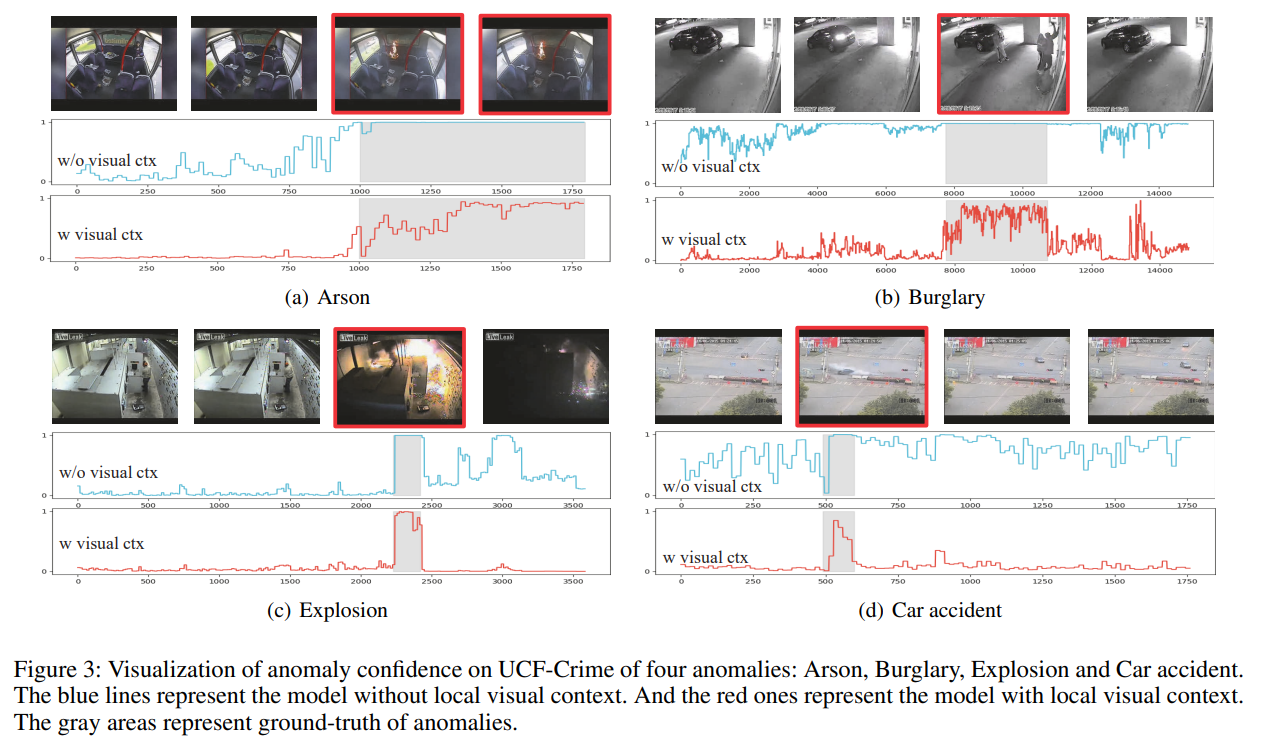
图 3 展示了我们在 UCF-Crime 数据集上四类异常事件的可视化异常置信度:纵火(Arson)、入室盗窃(Burglary)、爆炸(Explosion)和车祸(Car Accident)。
- 蓝色曲线表示不使用局部视觉上下文的模型;
- 红色曲线表示结合局部视觉上下文与全局文本上下文的模型;
- 灰色区域表示异常事件的真实发生区间(Ground Truth)。
从图中可以观察到:
- 未使用局部视觉上下文时,模型在正常帧上有时会产生较高的异常置信度,即误报率较高;
- 结合局部视觉上下文时,模型的异常置信度曲线更加平滑,对异常事件的定位更加准确,误报率显著降低。
这进一步验证了我们所提出的局部视觉上下文驱动 Prompt 生成器的有效性。
结论(Conclusion)
在本工作中,我们提出了一个基于全局与局部上下文驱动的联邦学习框架,用于隐私保护的视频异常检测。具体而言:
- 我们利用 CLIP 的视觉-语言关联能力进行异常检测;
- 为了在联邦学习环境中保留 CLIP 的强大表达能力,我们提出了一种动态 Prompt 生成器,替代手工设计的文本模板;
- 此外,为了在联邦环境下兼顾全局泛化能力与局部个性化适应性,我们设计了一个结合全局文本上下文与局部视觉上下文的 Prompt 学习策略。
在这两种上下文的共同驱动下,所生成的 Prompt 更适用于联邦环境,具备更强的表达力与适应性。
未来,我们将继续探索**隐私保护的视频异常检测(VAD)**方法。
相关文章:

Federated Weakly Supervised Video Anomaly Detection with Multimodal Prompt
标题:联邦弱监督视频异常检测的多模态提示方法 原文链接:https://ojs.aaai.org/index.php/AAAI/article/view/35398 源码链接:https://github.com/wbfwonderful/Fed-WSVAD 发表:AAAI-2025 摘要(Abstract) …...

计算机视觉与深度学习 | LSTM原理,公式,代码,应用
LSTM(长短期记忆网络)详解 一、原理 LSTM(Long Short-Term Memory)是RNN的改进版本,通过引入门控机制(输入门、遗忘门、输出门)和细胞状态(Cell State),有效解决传统RNN的梯度消失/爆炸问题,擅长捕捉长距离依赖关系。 核心思想: 细胞状态(C_t):贯穿整个时间步…...

UI界面工程,如何使用控制台
我们通常会使用print函数向控制台输出调试信息。但创建UI界面工程时,默认不会显示控制台。 通过如下方法切换到控制台 项目属性—链接器—系统—子系统—窗口改为控制台...

mysql——基础知识
关键字大小写不敏感 查看表结构中的 desc describe 描述 降序中的 desc descend 1. 数据库的操作 1. 创建数据库 create database 数据库名;为防止创建的数据库重复 CREATE DATABASE IF NOT EXISTS 数据库名;手动设置数据库采用的字符集 character set 字符集名;chars…...

UE虚幻4虚幻5动画蓝图调试,触发FellOutOfWorld事件和打印输出,继续DeepSeek输出
找到了一个pdf,本来想写个翻译的,但还是算了,大概看了下,这类文档很全面,内容很多,但都不是我要的,我想要一个动画蓝图,搜索Montage,或者Anim 只占了一行(几百…...

52单片机LED实验
文章目录 前言点亮一个LEDLED闪烁 LED灯亮灭交替LED流水灯 前言 我所用的板子是普中的STC89C52RC,创建文件的过程中如果你发现keil文件找不到单片机依赖,那怎么办呢 下面从创建新项目讲起 首先打开keil软件,点击project new一个新的projec…...
命名空间、缺省参数、函数重载)
【C++详解】C++入门(一)命名空间、缺省参数、函数重载
文章目录 一、命名空间命名空间的基本特性命名空间的使用 二、C输入输出用法三、缺省参数(默认参数)定义用法 四、函数重载 一、命名空间 命名空间的基本特性 #include <stdio.h> #include <stdlib.h>int rand 10;int main() {// 编译报错:error C23…...

AWS Linux快速指南:5分钟搭建多用户图形界面
一、概述 本指南将帮助您在AWS上快速部署一个支持多用户、带图形界面和浏览器的Linux环境。我们将使用Ubuntu Server作为基础,配合轻量级的Xfce桌面环境和VNC服务。同时,我们还将提供不同用户规模下的实例规格推荐。 二、实例规格推荐 根据您的用户规模,我们推荐以下EC2实例…...

kotlin,编码、解码
kotlin写程序确实简洁,就是函数式编程对我这种用惯了过程的,换思想有难度。package org.exampleimport java.io.File import java.io.FileNotFoundExceptionval byteToHanzi mapOf(0x00 to "凡", 0x01 to "周", 0x02 to "张&q…...
)
从零创建 Docker 镜像(基于 OCI 格式)
更现代的 OCI 镜像格式,采用了 OCI Image Format Specification,其中文件引用使用 blobs/sha256/<hash> 的形式,层和配置存储在 blobs/sha256/ 目录下,并且包含 LayerSources 字段。这种格式在较新的 Docker 版本和 OCI 兼容…...

JavaScript 版本号比较
问题描述: 实现 : <script>const compare function(v1,v2){const arr1 v1.split(.)const arr2 v2.split(.)for(let i 0;i<arr1.length||i<arr2.length;i){const a arr1[i]||0const b arr2[i]||0if(a>b){return 1}else if(a<b){…...

MySQL为什么默认使用RR隔离级别?
大家好,我是锋哥。今天分享关于【MySQL为什么默认使用RR隔离级别?】面试题。希望对大家有帮助; MySQL为什么默认使用RR隔离级别? 1000道 互联网大厂Java工程师 精选面试题-Java资源分享网 MySQL 默认使用 RR(Repeatable Read)…...

第37讲|AI+农业气象建模:预测极端天气对农业的影响
目录 ✨ 导语:天气不可控,但影响可以预测 📦 一、数据准备:融合农业与气象 ⚡ 二、极端天气如何“定义”? 🔧 三、模型选择与结构设计 🔁 时间序列模型:LSTM 🎯 非时序模型:XGBoost / LightGBM 🧪 四、案例实战:用LSTM预测小麦产量下降风险(受极端天气…...
 吴恩达版提示词工程 1. 引言 (Base LLM 和 Instruction Tuned LLM))
(done) 吴恩达版提示词工程 1. 引言 (Base LLM 和 Instruction Tuned LLM)
url: https://www.bilibili.com/video/BV1Z14y1Z7LJ/?spm_id_from333.337.search-card.all.click&vd_source7a1a0bc74158c6993c7355c5490fc600 LLM 有两种: 1.基础 LLM,通过文本训练数据预测后面的内容。 这种 LLM 当你给它提问:What is…...

Vue如何实现样式隔离
1. 使用 CSS Modules CSS Modules 允许你在 Vue 组件中定义局部作用域的 CSS,这样可以避免全局样式的冲突 步骤如下: 在你的 Vue 组件中,创建一个 <style> 标签并添加 module 属性。 <template><div :class"$style.c…...

Sentinel源码—6.熔断降级和数据统计的实现二
大纲 1.DegradeSlot实现熔断降级的原理与源码 2.Sentinel数据指标统计的滑动窗口算法 2.Sentinel数据指标统计的滑动窗口算法 (1)滑动窗口介绍 (2)StatisticSlot使用滑动窗口算法进行数据统计 (1)滑动窗口介绍 一.滑动窗口原理 滑动窗口不会指定固定的时间窗口起点与终点…...

B+树删除和测试
B树删除和测试 5.1 高级接口:B 树作为键值存储 在本章中,我们将实现 B 树的高级接口,使其能够作为键值存储(Key-Value Store)使用。这些接口包括插入和删除操作,并处理根节点的维护。 1. 插入接口 1.1 I…...

常用算法解析:从基础排序到图论应用
一、算法基础与设计原则 算法是计算机解决问题的核心工具,其五大基本特性决定了程序的可靠性: 有穷性:算法必须能在有限步骤内终止确定性:每步操作无歧义可行性:可被计算机执行输入输出:具备数据交互能力…...
)
Java Web项目(一)
框架 java web项目总工分为两部分:客户端(前端)和服务端(后端) 客户端发起请求,服务端接受请求并进行处理 发起请求的方式:from表单、jQuery ajax from表单 造成全局的变化,在发…...

兴达易控DP主站网关数据映射快速配置案例
兴达易控DP主站网关数据映射快速配置案例 在工业自动化的领域,不同通讯协议之间的转换是常见的需求。特别是Profibus DP与Modbus-RTU这两种广泛应用于不同系统和设备的通讯协议,它们之间的数据转换显得尤为重要。本文将详细探讨兴达易控Profibus DP主站…...

Tailwindcss 入门 v4.1
以 react 为例,步骤如下: npm create vitelatest my-app -- --template react 选择 React 和 JavaScript 根据上述命令的输出提示,运行以下命令 cd my-app npm install npm run dev 一个 React App 初始化完成。 安装 Tailwindcss theme …...

通过 WebSocket 接收和播放 WSS 协议视频流
1.创建wss协议视频 1.1必备包 npm install ws ffmpeg-installer/ffmpeg fluent-ffmpeg 说明:安装以下三个包。 1.2代码实现 说明:创建WebSocket服务器,端口为8080 import { WebSocket, WebSocketServer } from ws; // 导入 WebSocket 和 W…...

HTML 如何改变字体颜色?深入解析与实践指南
网页上的字体颜色是网页设计中至关重要的元素之一,它像字体大小一样,对于提升用户体验起着举足轻重的作用。精心选择和运用字体颜色,能够增强页面的可读性、突出重点信息、营造特定的情感氛围,甚至直接影响用户的视觉感受和品牌认…...

tigase源码学习杂记-组件化设计
前言 tigase官方号称高度抽象和组件化。这篇文章就记录一下我研究组件化的相关设计 概述 我的理解tigase高度组件化是所有的关键的功能的类,它都称之为组件,即只要继承于BasicComponent,它都可以成为组件,BasicComponent类实现…...

十二、人工神经网络及其应用
写在前面 这部分内容老师说很重要,不管是实验还是考试占比都非常大 AIGC的全称是“Artificial Intelligence Generated Content”,即人工智能生成内容。这一术语通常用于指代通过人工智能技术自动生成的各种类型的内容,如文本、图像、音频和视频等。随着AI技术的发展,AIG…...

vscode使用技巧
一、符号定位技巧 跳转到定义 F12 或右键「Go to Definition」跳转到符号定义位置CtrlClick 直接点击符号跳转(支持变量/函数/类) 符号大纲视图 CtrlShiftO 打开文件符号大纲,支持模糊搜索符号名输入: 分类显示符号(…...

测试基础笔记第七天
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档 文章目录 一、cat命令二、ls -al命令三、>重定向符号四、>>追加重定向符号五、less/more命令六、grep命令七、|管道符八、clear命令九、head命令十、tail命令十一、…...

FOC控制中的正弦PWM和空间矢量PWM对比与理解
参考: simple foc:https://docs.simplefoc.com/docs_chinese/foc_theory博客:https://blog.csdn.net/qq_43332314/article/details/126449398 一、无刷电机基础原理 1., 原理图:至少三个绕组线圈(定子&…...

【Oracle专栏】函数中SQL拼接参数 报错处理
Oracle相关文档,希望互相学习,共同进步 风123456789~-CSDN博客 1.背景 最近同事反馈了一个很奇怪的问题,即有一个函数,入参是当前年月,主要作用是通过SQL语句将不合规的数据插入到指定表中,插入数据时带上入参的年月参数。当前问题:单独测试SQL没有问题可以执行成功,…...

无意间发现的宝藏项目:开源世界中的演示项目精选合集
🌟无意间发现的宝藏项目:开源世界中的演示项目精选合集 最近在 GitHub 上随手翻了翻 Spring 官方代码仓库,意外发现一个超有趣的演示项目 —— spring-petclinic。一个轻量但结构完整的 Spring 全家桶演示,让人忍不住一探究竟。 这…...

OpenCSG AutoHub v0.5.0 版本发布
OpenCSG AutoHub v0.5.0 版本发布 作为一款智能化自动化操作的浏览器插件,AutoHub不断致力于为用户提供更加高效、便捷的网页浏览体验。本次 v0.5.0版本 的发布,不仅进一步强化了核心功能,还引入了一些创新特性,旨在帮助用户更智…...

基于Python智能体API的Word自动化排版系统:从零构建全流程模块化工作流与版本控制研究
基于Python智能体API的Word自动化排版系统:从零构建全流程模块化工作流与版本控制实践研究 1. 引言2. 研究背景与意义3. 自动排版工作流的设计原理3.1 文档内容提取与解析3.2 样式参数与格式化规则3.3 智能体API接口调用3.4 自动生成与批量处理3.5 与生成式AI的协同4. 系统架构…...

在 Node.js 中设置响应的 MIME 类型
在 Node.js 中设置响应的 MIME 类型是为了让浏览器正确解析服务器返回的内容,比如 HTML、CSS、图片、JSON 等。我们通常通过设置响应头中的 Content-Type 字段来完成。 ✅ 一、什么是 MIME 类型(Content-Type)? MIME(…...
)
jsch(shell终端Java版)
学习笔记 Java SSH库使用简介:Apache sshd和JSch(Java Secure Channel) github - fork of the popular jsch library JSch学习笔记 web-shell - gitee代码 - 纯Java实现一个web shell登录Linux远程主机,技术选型 SpringBoot …...

Redis分布式锁RedLock机制详解
一、RedLock机制解决的问题 核心场景:解决传统Redis单节点/主从架构下分布式锁的不可靠问题。当主节点故障时,若从节点未同步锁信息,可能导致多个客户端同时持有锁,破坏互斥性。 典型问题案例: 主从切换锁丢失&…...
调试注意的问题)
Vivado中Tri_mode_ethernet_mac的时序约束、分析、调整——(五)调试注意的问题
一、几个注意点 1、每个bank中IO的组织形式 1Bank的52Pins分4 Byte Group,每Byte Group 13PinsNibble_up 7Pins Nibble_low 6Pins。 每个nibble一个bitslice_control管理自己的6~7个pins 。 每个pin对应一个bitslice,它内部又包含多个component&#…...

MFC文件-写MP4
下载本文件 本文件将创作MP4视频文件代码整合到两个文件中(Mp4Writer.h和Mp4Writer.cpp),将IYUV视频流,PCM音频流写入MP4文件。本文件仅适用于MFC程序。 使用方法 1.创建MFC项目。 2.将Mp4Writer.h和Mp4Writer.cpp文件复制到项目目录下。 3…...
:归一化技术对比(BN/LN/IN/GN))
PyTorch 深度学习实战(39):归一化技术对比(BN/LN/IN/GN)
在上一篇文章中,我们全面解析了注意力机制的发展历程。本文将深入探讨深度学习中的归一化技术,对比分析BatchNorm、LayerNorm、InstanceNorm和GroupNorm四种主流方法,并通过PyTorch实现它们在图像分类和生成任务中的应用效果。 一、归一化技术…...
)
C#/.NET/.NET Core技术前沿周刊 | 第 35 期(2025年4.14-4.20)
前言 C#/.NET/.NET Core技术前沿周刊,你的每周技术指南针!记录、追踪C#/.NET/.NET Core领域、生态的每周最新、最实用、最有价值的技术文章、社区动态、优质项目和学习资源等。让你时刻站在技术前沿,助力技术成长与视野拓宽。 欢迎投稿、推荐…...

柱状图QCPBars
一、QCPBars 概述 QCPBars 是 QCustomPlot 中用于绘制柱状图/条形图的类,支持单组或多组柱状图显示,可自定义宽度、颜色和间距等属性。 二、主要属性 属性类型描述widthdouble柱子的宽度(坐标轴单位)widthTypeWidthType宽度计算…...

2025-04-20 李沐深度学习4 —— 自动求导
文章目录 1 导数拓展1.1 标量导数1.2 梯度:向量的导数1.3 扩展到矩阵1.4 链式法则 2 自动求导2.1 计算图2.2 正向模式2.3 反向模式 3 实战:自动求导3.1 简单示例3.2 非标量的反向传播3.3 分离计算3.4 Python 控制流 硬件配置: Windows 11Inte…...
中的强大作用)
Nginx在微服务架构项目(Spring Cloud)中的强大作用
文章目录 一、Nginx是什么?二、Nginx在微服务架构(Spring Cloud)项目中的作用1.前端静态资源托管2.反向代理后端 API3.负载均衡4.SSL 证书与 HTTPS 支持5.缓存与压缩优化6.安全防护7.灰度发布与流量控制8.跨域处理(CORS࿰…...

Mysql相关知识2:Mysql隔离级别、MVCC、锁
文章目录 MySQL的隔离级别可重复读的实现原理Mysql锁按锁的粒度分类按锁的使用方式分类按锁的状态分类 MySQL的隔离级别 在 MySQL 中,隔离级别定义了事务之间相互隔离的程度,用于控制一个事务对数据的修改在何时以及如何被其他事务可见。MySQL 支持四种…...

解决IDEA创建SpringBoot项目没有Java版本8
问题:idea2023版本创建springboot的过程中,选择java版本时发现没有java8版本,只有java17和java20 原因:spring2.X版本在2023年11月24日停止维护了,因此创建spring项目时不再有2.X版本的选项,只能从3.1.X版本…...

第十章:Agent 的评估、调试与可观测性:确保可靠与高效
引言 随着我们一步步构建出越来越复杂的 AI Agent,赋予它们高级工具和更智能的策略,一个至关重要的问题浮出水面:我们如何知道这些 Agent 是否真的有效、可靠?当它们行为不符合预期时,我们又该如何诊断和修复问题&…...

8节串联锂离子电池组可重构buck-boost均衡拓扑结构 simulink模型仿真
8节串联锂离子电池组 极具创新性 动态分组均衡策略,支持3种均衡模式 1.最高SOC电池给最低SOC电池均衡 2.高能电池组电池给最低SOC电池均衡 3.高能电池组电池给低能电池组电池均衡 支持手动设置均衡开启阈值和终止阈值 均衡效果非常好...
)
Oracle EBS COGS Recognition重复生成(一借一贷)
背景 月结用户反馈“发出商品”(实际为递延销货成本)不平,本月都是正常操作月结程序,如正常操作步骤如下: 记录订单管理事务处理 (Record Order Management Transactions)收集收入确认信息 (Collect Revenue Recognition Information)生成销货成本确认事件 (Generate COGS …...

Linux命令--将控制台的输入写入文件
原文网址:Linux命令--将控制台的输入写入文件-CSDN博客 简介 本文介绍Linux将控制台的输入写入文件的方法。 方案1:cat > file1(推荐) 普通用法 cat > file1 输入结束后,用CtrlD退出。 示例 使用root权限…...

使用BQ76PL455和STM32的SAE电动方程式电动汽车智能BMS
BMS对任何电动汽车来说都是必不可少的,它可以监控电池的行为,确保安全行驶。 该项目旨在降低成本,同时为每个电池模块提供可扩展的BMS。BQ76PL455具有监测6-16个单元的能力,8通道辅助输入(用于温度监测)和多达15个其他ic用于Daisy…...
)
OpenCV 模板与多个对象匹配方法详解(继OpenCV 模板匹配方法详解)
文章目录 前言1.导入库2.图片预处理3.输出模板图片的宽和高4.模板匹配5.获取匹配结果中所有符合阈值的点的坐标5.1 threshold 0.9:5.2 loc np.where(res > threshold): 6.遍历所有匹配点6.1 loc 的结构回顾6.2 loc[::-1] 的作用6.2.1 为什么需要反转…...