transformer注意力机制

单头注意力机制
import torch
import torch.nn.functional as Fdef scaled_dot_product_attention(Q, K, V):# Q: (batch_size, seq_len, d_k)# K: (batch_size, seq_len, d_k)# V: (batch_size, seq_len, d_v)
batch_size: 一次输入的句子数。
seq_len: 每个句子的词数。
d_model: 每个词的表示维度,比如 512。
d_k 是 Query 和 Key 向量的维度。
# 计算点积 QK^T 并进行缩放d_k = Q.size(-1) # 获取 Key 的维度scores = torch.matmul(Q, K.transpose(-2, -1)) / torch.sqrt(torch.tensor(d_k, dtype=torch.float32))
Q = torch.tensor([
[[1.0, 0.0], # The
[0.0, 1.0], # cat
[1.0, 1.0]] # sat
]) # shape = (1, 3, 2) batch=1, seq_len=3, d_k=2
获取最后一维(每个词的维度),这里是 2
(新例子)原本 Q 和 K 都是形状 (1, 3, 2),即 batch=1,3个词,每个词2维。
matmul 就是 矩阵乘法
transpose(-2, -1) 表示 交换最后两个维度
Q = (1, 3, 4):1 个样本,3 个词,每个词是 4 维向量
K = (1, 3, 4):同样 3 个词,每个词是 4 维向量
K.transpose(-2, -1) → (1, 4, 3)
torch.matmul(Q, K^T) → (1, 3, 4) @ (1, 4, 3) → (1, 3, 3)
# 计算 softmax 得到注意力权重attention_weights = F.softmax(scores, dim=-1) # 对最后一个维度进行 softmax
“打分矩阵”scores 变成“权重矩阵”attention_weights,决定每个词该关注谁、关注多少。
F 是 PyTorch 的一个模块,torch.nn.functional 的简称。
它提供了一大堆“函数式的操作”,比如:F.relu()、F.softmax()、F.cross_entropy()
Softmax 是一个数学函数,它把一组“任意的实数”变成“总和为 1 的概率分布”。
它会让大的值变成更大的概率,小的值变成更小的概率
所有值会被缩放到 0 到 1 之间,并且总和是 1
dim=-1 表示在最后一个维度上做 softmax。
在注意力机制中,scores 是形状 (batch_size, seq_len, seq_len),比如 (1, 3, 3)
scores = torch.tensor([[
[10.0, 2.0, -1.0], # 第一个词对其他词的打分
[5.0, 0.0, -2.0], # 第二个词对其他词的打分
[0.0, 0.0, 0.0] # 第三个词平等看待其他词
]]) # shape = (1, 3, 3)
softmax([10, 2, -1]) = [e^10, e^2, e^-1] / (e^10 + e^2 + e^-1)
e^10 ≈ 22026.5
e^2 ≈ 7.389
e^-1 ≈ 0.367
总和 ≈ 22026.5 + 7.389 + 0.367 ≈ 22034.3
所以 softmax ≈ [0.9996, 0.00033, 0.000016]
tensor([[
[0.9996, 0.0003, 0.0000],
[0.9933, 0.0066, 0.0000],
[0.3333, 0.3333, 0.3333]
]])
对 dim = -1 做 softmax
意思是:对于每个 Query 的“对别人的打分”那一行,我们做 softmax
# 使用注意力权重对 V 进行加权求和output = torch.matmul(attention_weights, V)
每个 Query 位置根据它对所有词的注意力权重,对 Value 做加权平均,输出一个 2 维向量。
return output, attention_weights# 示例输入
batch_size, seq_len, d_k, d_v = 2, 5, 8, 8 # 批量大小、序列长度、Key 维度、Value 维度
Q = torch.randn(batch_size, seq_len, d_k) # Query
K = torch.randn(batch_size, seq_len, d_k) # Key
V = torch.randn(batch_size, seq_len, d_v) # Valueoutput, attention_weights = scaled_dot_product_attention(Q, K, V)
print("Output shape:", output.shape) # 输出形状应为 (batch_size, seq_len, d_v)
print("Attention weights shape:", attention_weights.shape) # 注意力权重形状应为 (batch_size, seq_len, seq_len)
多头注意力机制
class MultiHeadAttention(nn.Module):def __init__(self, d_model, num_heads):super(MultiHeadAttention, self).__init__()assert d_model % num_heads == 0, "d_model must be divisible by num_heads"self.d_model = d_model # 输入向量维度 = 8self.num_heads = num_heads # 头的数量self.depth = d_model // num_heads # 每个头的维度# 定义线性变换矩阵self.W_Q = nn.Linear(d_model, d_model) # Query 线性变换self.W_K = nn.Linear(d_model, d_model) # Key 线性变换self.W_V = nn.Linear(d_model, d_model) # Value 线性变换self.W_O = nn.Linear(d_model, d_model) # 输出线性变换
Linear 是 PyTorch 里的线性变换层(全连接层 / 仿射变换)
def split_heads(self, x, batch_size):# 将输入张量分割为多个头# 输入形状: (batch_size = 2, seq_len = 2, d_model = 16)# 输出形状: (batch_size2, num_heads8, seq_len2, depth = 2)x = x.view(batch_size, -1, self.num_heads, self.depth)return x.permute(0, 2, 1, 3)
所以要把每个 16 维向量,切分成 8 个头,每个头是 2 维,方便后面“并行注意力”。
view:原始张量先展平成一维向量 然后按给的新形状,按行依次填进去
-1 在 view 中的作用是–让 PyTorch 自动推导这一维的大小,只要其余维度的乘积是对得上的
permute:维度重新排列
def forward(self, Q, K, V):batch_size = Q.size(0)# 线性变换Q = self.W_Q(Q) # (batch_size, seq_len, d_model)K = self.W_K(K) # (batch_size, seq_len, d_model)V = self.W_V(V) # (batch_size, seq_len, d_model)# 分割为多个头Q = self.split_heads(Q, batch_size) # (batch_size, num_heads, seq_len, depth)K = self.split_heads(K, batch_size) # (batch_size, num_heads, seq_len, depth)V = self.split_heads(V, batch_size) # (batch_size, num_heads, seq_len, depth)# 计算每个头的注意力# 就是使用上述的注意力的公式scaled_attention, _ = scaled_dot_product_attention(Q, K, V)# 拼接多个头的输出# 返回一个内存连续的张量副本scaled_attention = scaled_attention.permute(0, 2, 1, 3).contiguous() # (batch_size, seq_len, num_heads, depth)concat_attention = scaled_attention.view(batch_size, -1, self.d_model) # (batch_size, seq_len, d_model)
你把 8 个头的 summary 合并,就是一份完整的理解(512 维)
# 最终线性变换output = self.W_O(concat_attention) # (batch_size, seq_len, d_model)
concat_attention = [1.0, 2.0, 3.0, 4.0]
有个线性层(随机初始化):
W_O = [
[0.1, 0.2, 0.3, 0.4],
[0.5, 0.6, 0.7, 0.8],
[0.9, 1.0, 1.1, 1.2],
[1.3, 1.4, 1.5, 1.6]
]
执行线性变换:
output = concat_attention @ W_O^T
return output# 示例输入
batch_size, seq_len, d_model, num_heads = 2, 5, 8, 4 # 批量大小、序列长度、模型维度、头数量
Q = torch.randn(batch_size, seq_len, d_model) # Query
K = torch.randn(batch_size, seq_len, d_model) # Key
V = torch.randn(batch_size, seq_len, d_model) # Value# 实例化多头注意力
mha = MultiHeadAttention(d_model, num_heads)# 前向传播
output = mha(Q, K, V)
print("Output shape:", output.shape) # 输出形状应为 (batch_size, seq_len, d_model)
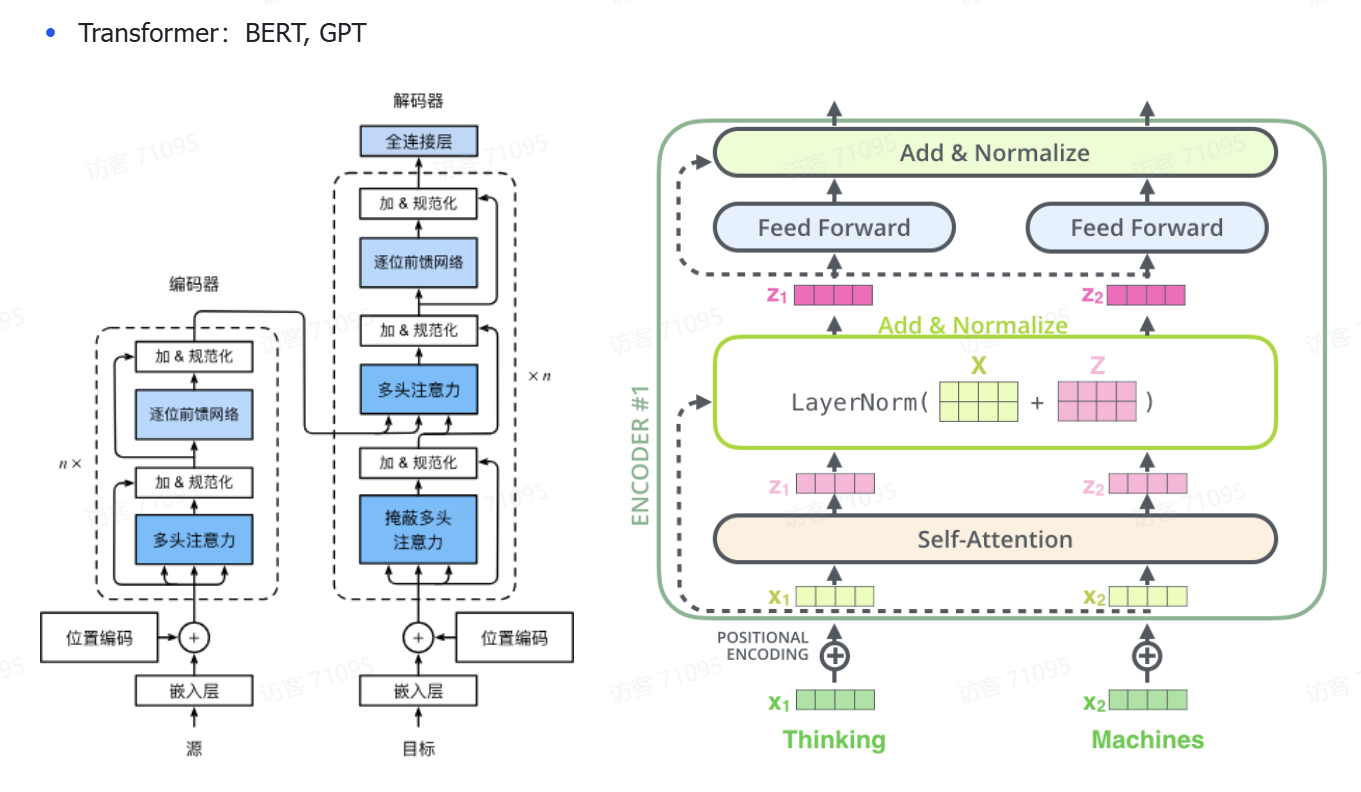
左图:
编码器(Encoder):
左边一列是 Encoder,作用是处理输入序列(比如一句话)。
每一层包含:
多头注意力(Self-Attention):让每个词关注上下文中其他词的信息(注意力机制的核心)。
前馈神经网络(Feed Forward):对每个词做单独的非线性变换。
加法残差连接 + LayerNorm(加 & 规范化):提升训练稳定性。
👉 这些结构堆叠 n 层,输出的是编码后的向量表示。
解码器(Decoder):
用于生成输出序列(例如翻译一句话)。
每层包括:
掩蔽多头注意力(Masked Multi-Head Attention):阻止看到未来词,适用于生成任务。
跨注意力(对编码器输出):Decoder 的词可以关注 Encoder 的词。
前馈网络 + 加法规范化:和 Encoder 一样。
右图
输入:x₁ = “Thinking”, x₂ = “Machines”
第一步:Self-Attention
这里会用多头注意力(Q, K, V 都来自同一个输入)
计算每个词该关注谁,输出一个“上下文相关的向量”
第二步:残差连接 + LayerNorm
text
复制
编辑
Z1 = Self-Attention(x)
LayerNorm(x + Z1)
原始输入 x 和 Attention 输出相加,再归一化
保证梯度稳定,避免训练时梯度爆炸或消失
第三步:Feed Forward
一个两层的全连接网络(对每个位置独立操作)
x = Linear → ReLU → Linear
再加一次残差 + LayerNorm:
Z2 = FeedForward()
LayerNorm(Z1 + Z2)
第四步:
输出是:编码后的向量序列(包含上下文信息),可以喂给 Decoder 或下游任务。
相关文章:
transformer注意力机制
单头注意力机制 import torch import torch.nn.functional as Fdef scaled_dot_product_attention(Q, K, V):# Q: (batch_size, seq_len, d_k)# K: (batch_size, seq_len, d_k)# V: (batch_size, seq_len, d_v)batch_size: 一次输入的句子数。 seq_len: 每个句子的词数。 d_mo…...

Ubuntu 22.04 更换 Nvidia 显卡后启动无法进入桌面问题的解决
原显卡为 R7 240, 更换为 3060Ti 后, 开机进桌面时卡在了黑屏界面, 键盘有反应, 但是无法进入 shell. 解决方案为 https://askubuntu.com/questions/1538108/cant-install-rtx-4060-ti-on-ubuntu-22-04-lts 启动后在开机菜单中(如果没有开机菜单, 需要按shift键), 进入recove…...

ROS机器人开发实践->机器人建模与仿真
前言: 这篇博客知识一个整体性的了解对于机器人建模和仿真,更多详细的细节,见 6.4.2 Xacro_语法详解 Autolabor-ROS机器人入门课程《ROS理论与实践》零基础教程 一、整体框架 机器人模型分为两个部分具体的形状和插件。有了这个具体的形状…...

中国占全球工业机器人装机量的52%,国产机器人崛起加速洗牌,拆分机器人业务独立上市,软硬件协同增强,AI工业机械臂催生业务再增长
一、内部战略优化:聚焦核心业务与释放增长潜力 业务协同效应有限 ABB的机器人业务(全球市场份额第二)与集团其他业务(如电气化、过程自动化)的协同性较低。机器人业务专注于柔性制造和智能自动化,而其他业务更偏向能源效率和大型工业系统。分拆后,ABB集团可更聚焦于电气…...
)
C#森林中的兔子(力扣题目)
C#森林中的兔子(力扣题目) 题目介绍 森林中有未知数量的兔子。提问其中若干只兔子 “还有多少只兔子与你(指被提问的兔子)颜色相同?” ,将答案收集到一个整数数组 answers 中,其中 answers[i] 是第 i 只兔子的回答。 给你数组…...

OSPF特殊区域
四种特殊区域 1、stub 2、完全stub 3、nssa 4、完全nssa 作用:用于优化OSPF的LSDB空间 stub: [R2-ospf-1-area-0.0.0.1]stub //配置一个区域为stub区域 只在ABR上配置的话会导致OSPF邻居关系断开,因为此时Option选项中Nbit和Ebit置位不一致所…...

深入理解 CICD 与 Jenkins 流水线:从原理到实践
前言:在当今数字化飞速发展的时代,软件开发行业的竞争日益激烈。为了能够快速响应市场需求,及时交付高质量的软件产品,开发团队们不断探索和采用新的开发模式与工具。CICD(持续集成、持续交付 / 部署)作为一…...
)
1.Vue自动化工具安装(Vue-cli)
目录 1.node.js 安装: 2 npm 安装 3 安装Vue-cli 4总结: 一般情况下,单文件组件,我们运行在 自动化工具vue-CLI中,可以帮我们编译单文件组件。所以我们在学习时一般需要在系统中先搭建vue-CLI工具 下面就是一些我…...

前端亮点:大文件上传技术详解及问题解析
大片文件上传 文件上传 大片文件上传需考虑问题 一、核心实现步骤 分片唯一标识计算 (优化比较时间) • Hash生成:使用SparkMD5或crypto.subtle.digest计算文件整体Hash(秒传依据)及分片Hash(断点续传依据)。 • 优化:通过Web Worker多线程计算,避免主线程阻塞(如…...

每日一题——最小测试用例集覆盖问题
最小测试用例集覆盖问题(C语言实现) 问题描述 假设我们有一系列测试用例,每个测试用例会覆盖若干个代码模块。 我们使用一个二维数组来表示这些测试用例的覆盖情况: 如果某个测试用例 i 能覆盖代码模块 j,则数组中…...

React 文章 分页
删除功能 携带路由参数跳转到新的路由项 const navigate useNavigate() 根据文章ID条件渲染...

【技术派后端篇】Redis实现统计计数
在互联网项目中,计数器有着广泛的应用场景。以技术派项目为例,诸如文章点赞数、收藏数、评论数以及用户粉丝数等都离不开计数器的支持。在技术派源码中,提供了基于数据库操作记录实时更新和基于 Redis 的 incr 特性实现计数器这两种方案&…...

NHANES指标推荐:RFM
文章题目:Higher relative fat mass was associated with a higher prevalence of gallstones in US adults DOI:10.1186/s12876-025-03715-3 中文标题:在美国成年人中,相对脂肪质量越高,胆结石患病率就越高 发表杂志&…...

嵌入式人工智能应用-第三章 opencv操作 4 灰度处理
嵌入式人工智能应用 嵌入式人工智能应用-第三章 opencv操作 4 灰度处理 嵌入式人工智能应用1 灰度处理2 算法2.1 均值方法2.2 最大值法2.3 分量法2.4 加权平均法(Weighted Average Method)2.5 系统自带方法 3 总结 1 灰度处理 图像灰处理即是将一幅彩色…...

AI Agent破局:智能化与生态系统标准化的颠覆性融合!
Hi!好久不见 云边有个稻草人-个人主页 热门文章_云边有个稻草人的博客-本篇文章所属专栏~ 目录 一、引言 二、AI Agent的基本概念 2.1 定义与分类 2.2 AI Agent的工作原理 2.3 示例代码:AI Agent的基本实现 三、AI Agent在企业数字化转型中的应用 …...
)
UniFlash以串口方式烧录MSPM0G3507(无需仿真器)
材料:MSPM0G3507黑钢版,只要有UART的其他版本亦可(PA14需接LED) 下载软件:UniFlash 9.1.0.5175,网址:UNIFLASH 软件编程工具 | 德州仪器 TI.com.cn 测试文件:MSPM0G30…...

坐标轴刻度QCPAxisTicker
一、QCPAxisTicker 概述 QCPAxisTicker 是 QCustomPlot 中控制坐标轴刻度生成和显示的基类,负责计算刻度位置和生成刻度标签。 二、主要派生类 类名描述QCPAxisTickerFixed固定步长的刻度生成器QCPAxisTickerLog对数坐标刻度生成器QCPAxisTickerPi专门显示π倍数…...

Spring Boot 版本与对应 JDK 版本兼容性
Spring Boot 版本与对应 JDK 版本兼容性 以下是 Spring Boot 主要版本与所需 JDK 版本的对应关系,以及长期支持(LTS)信息: 最新版本对应关系 (截至2024年) Spring Boot 版本发布日期支持的 JDK 版本备注3.2.x (最新)2023-11JDK 17-21推荐使用 JDK 173…...

【MySQL】MySQL的基础语法及其语句的介绍
1、基础语法 mysql -h【主机名】 -u【用户名】 -p //登录MySQL exit或quit; //退出MySQL show database; //查看MySQL下的所有数据库 use 【数据库名】; //进入数据库 show tables; //查看数据库下的所有表名 *MySQL的启动和关闭 &am…...

《汽车理论》第四章作业MATLAB部分
1.计算并绘制利用附着系数曲线和制动效率曲线 clc close all %空载(no load)-1 ;满载(full load)-2 m14080; m29290; hg10.845; hg21.170; L3.950; a12.100; a22.950; b1L-a1; b2L-a2; beta0.38; %利用附着系数与制动强度的关系曲线 z0:0.01:1; phi_f1L*beta.*z./(b1z*hg1);%前…...

SpringCloud实战
环境准备: 1. 一台虚拟机,部署好centos7操作系统、安装好docker 2. 使用docker安装mysql数据库且启动mysql容器 3. IDEA配置的JDK版本是11 4. 前端代码启动Nginx 一、单体架构和微服务的区别? 1. 单体架构 将业务的所有功能集中在一个项目中…...

Cribl 对Windows-xml log 进行 -Serialize-05
The Serialize Function Description The Serialize Function is designed to transform an events content into a predefined format. Steps - Adding a Serialize Function important Select the Add Function<...
、弹性布局(Flex)、层叠布局(Stack),详细用法)
鸿蒙ArkUI之布局实战,线性布局(Column,Row)、弹性布局(Flex)、层叠布局(Stack),详细用法
本文聚焦于ArkUI的布局实战,三种十分重要的布局,线性布局、弹性布局、层叠布局,在实际开发过程中这几种布局方法都十分常见,下面直接上手 线性布局 垂直布局(Column) 官方文档: Column-行列…...

缓存 --- 内存缓存 or 分布式缓存
缓存 --- 内存缓存 or 分布式缓存 内存缓存(In-Memory Cache)分布式缓存(Distributed Cache)内存缓存 vs 分布式缓存 内存缓存和分布式缓存是两种常见的缓存策略,它们在存储位置、访问速度和适用场景上有所不同。下面分…...

【Qt】QMainWindow类
🌈 个人主页:Zfox_ 🔥 系列专栏:Qt 目录 一:🔥 QMainWindow 概述 🦋 菜单栏🎀 具体使用🎀 综合案例 🦋 工具栏🦋 状态栏🦋 窗口布局&a…...

缓存 --- 缓存击穿, 缓存雪崩, 缓存穿透
缓存 --- 缓存击穿, 缓存雪崩, 缓存穿透 缓存击穿(Cache Breakdown)概念原理实际场景代码实现(互斥锁方案) 缓存雪崩(Cache Avalanche)概念原理实际场景代码实现(随机过期时间) 缓存…...

第五章 SQLite数据库:5、SQLite 进阶用法:ALTER 命令、TRUNCATE 操作、视图创建、事务控制和子查询的操作
1. SQLite ALTER 命令 SQLite 的 ALTER TABLE 命令允许在不完全重建表的情况下修改现有的表结构。通过 ALTER TABLE,您可以执行如重命名表名、添加新列等操作,但无法执行复杂的修改,如删除列或修改列的数据类型。 语法 重命名表 用于重命名…...

【2】Kubernetes 架构总览
Kubernetes 架构总览 主节点与工作节点 主节点 Kubernetes 的主节点(Master)是组成集群控制平面的关键部分,负责整个集群的调度、状态管理和决策。控制平面由多个核心组件构成,包括: kube-apiserver:集…...

【数据结构】红黑树
红黑树( R e d B l a c k T r e e Red\ Black\ Tree Red Black Tree)是一种自平衡二叉搜索树,也可以看作一种特化的 A V L AVL AVL 树(通过颜色规则来实现自平衡功能),都是在进行插入和删除操作时通过特定…...

ThreadLocal - 原理与应用场景详解
ThreadLocal 的基础概念 在 Java 的多线程世界里,线程之间的数据共享与隔离一直是一个关键话题。如果处理不当,很容易引发线程安全问题,比如数据混乱、脏读等。而 ThreadLocal 这个工具类,就像是为线程量身定制的 “私人储物柜”…...
)
VS Code 远程连接服务器:Anaconda 环境与 Python/Jupyter 运行全指南。研0大模型学习(第六、第七天)
VS Code 远程连接服务器:Anaconda 环境与 Python/Jupyter 运行全指南 在使用 VS Code 通过 SSH 远程连接到服务器进行开发时,尤其是在进行深度学习等需要特定环境的工作时,正确配置和使用 Anaconda 环境以及理解不同的代码运行方式非常关键。…...

chili3d调试6 添加左侧面板
注释前 一个一个注释看对应哪个窗口 无事发生 子方法不是显示的窗口 注释掉看看 没了 注释这个看看 零件页面没了 这个浏览器居然完全不用关的,刷新就重载了 注释看看 无工具栏版本 sidebar: 往框框里面加入 div({ className: style.input }, user_…...

Python变量全解析:从基础到高级的命名规则与数据类型指南
一、变量基础与内存机制 1.1 变量的三元构成 每个Python变量由三个核心要素构成: 标识(Identity):对象的内存地址,通过id(obj)获取(如id(name)输出0x5a1b2c3d)类型(Type&am…...

组装一台intel n95纯Linux Server服务器
前言 笔者自己的电脑是macmini m4,平时都是使用虚拟机来充当Linux服务器(系统Ubuntu Server),但是毕竟是ARM CPU,而且黄金内存,开不了几个虚拟机(加内存不划算),所以组装…...

计算机网络中的网络层:架构、功能与重要性
一、网络层概述 在计算机网络的分层模型中,网络层(Network Layer)位于 数据链路层 之上,传输层 之下。网络层的主要任务是处理数据包的路由选择、转发以及分段,使得信息能够从源设备传送到目标设备。它还通过 IP协议&…...
Transformer系列(一):NLP中放弃使用循环神经网络架构
NLP中放弃使用循环神经网络架构 一、符号表示与概念基础二、循环神经网络1. 依赖序列索引存在的并行计算问题2. 线性交互距离 三、总结 该系列笔记阐述了自然语言处理(NLP)中不再采用循环架构(recurrent architectures)的原因&…...
Linux 库制作与原理)
(学习总结34)Linux 库制作与原理
Linux 库制作与原理 库的概念静态库操作归档文件命令 ar静态库制作静态库使用 动态库动态库制作动态库使用与运行搜索路径问题解决方案方案2:建立同名软链接方案3:使用环境变量 LD_LIBRARY_PATH方案4:ldconfig 方案 使用外部库目标文件ELF 文…...

【QT】 QT中的列表框-横向列表框-树状列表框-表格列表框
QT中的列表框-横向列表框-树状列表框-表格列表框 1.横向列表框(1)主要方法(2)信号(3) 示例代码1:(4) 现象:(5) 示例代码2:加载目录项在横向列表框显示(6) 现象: 2.树状列表框 QTreeWidget(1)使用思路(2)信号(3)常用的接口函数(4) 示例代码&am…...

使用DeepSeek的AIGC的内容创作者,如何看待陈望道先生所著的《修辞学发凡》?
目录 1.从修辞手法的运用角度 2.从语言风格的塑造角度 3.从提高创作效率角度 4.从文化传承与创新角度 大家好这里是AIWritePaper官方账号,官网👉AIWritePaper~ 《修辞学发凡》是陈望道 1932 年出版的中国第一部系统的修辞学著作,科学地总…...
的自动化跨平台打包)
使用 GitHub Actions 和 Nuitka 实现 Python 应用(customtkinter ui库)的自动化跨平台打包
目录 引言前置准备配置文件详解实现细节CustomTkinter 打包注意事项完整配置示例常见问题 引言 在 Python 应用开发中,将源代码打包成可执行文件是一个常见需求。本文将详细介绍如何使用 GitHub Actions 和 Nuitka 实现自动化的跨平台打包流程,支持 W…...

【Part 2安卓原生360°VR播放器开发实战】第一节|通过传感器实现VR的3DOF效果
《VR 360全景视频开发》专栏 将带你深入探索从全景视频制作到Unity眼镜端应用开发的全流程技术。专栏内容涵盖安卓原生VR播放器开发、Unity VR视频渲染与手势交互、360全景视频制作与优化,以及高分辨率视频性能优化等实战技巧。 📝 希望通过这个专栏&am…...

【1】云原生,kubernetes 与 Docker 的关系
Kubernetes?K8s? Kubernetes经常被写作K8s。其中的数字8替代了K和s中的8个字母——这一点倒是方便了发推,也方便了像我这样懒惰的人。 什么是云原生? 云原生: 它是一种构建和运行应用程序的方法,它包含&am…...

基于Redis实现RAG架构的技术解析与实践指南
一、Redis在RAG架构中的核心作用 1.1 Redis作为向量数据库的独特优势 Redis在RAG架构中扮演着向量数据库的核心角色,其技术特性完美契合RAG需求: 特性技术实现RAG应用价值高性能内存存储基于内存的键值存储架构支持每秒百万级的向量检索请求分布式架构…...

trivy开源安全漏洞扫描器——筑梦之路
开源地址:https://github.com/aquasecurity/trivy.git 可扫描的对象 容器镜像文件系统Git存储库(远程)虚拟机镜像Kubernetes 在容器镜像安全方面使用广泛,其他使用相对较少。 能够发现的问题 正在使用的操作系统包和软件依赖项…...

pnpm确认全局下载安装了还是显示cnpm不是内部或外部命令,也不是可运行的程序
刚开始是正常使用的。突然开始用不了了一直报错 1.在确保自己node和npm都一直正常使用并且全局安装pnpm的情况下 打开cmd查看npm的环境所在位置 npm config get prefix 2.接着打开高级系统设置 查看自己的path配置有没有问题 确认下载了之后pnpm -v还报错说明没有查询到位置 …...

基于 pnpm + Monorepo + Turbo + 无界微前端 + Vite 的企业级前端工程实践
基于 pnpm Monorepo Turbo 无界微前端 Vite 的企业级前端工程实践 一、技术演进:为什么引入 Vite? 在微前端与 Monorepo 架构落地后,构建性能成为新的优化重点: Webpack 构建瓶颈:复杂配置导致开发启动慢&#…...

软考高级系统架构设计师-第15章 知识产权与标准化
【本章学习建议】 根据考试大纲,本章主要考查系统架构设计师单选题,预计考3分左右,较为简单。 15.1 标准化基础知识 1. 标准的分类 分类 内容 国际标准(IS) 国际标准化组织(ISO)、国际电工…...

MySQL 视图
核心目标: 学习如何创建和使用视图,以简化复杂的查询、提供数据访问控制、实现逻辑数据独立性,并通过 WITH CHECK OPTION 保证数据一致性。 什么是视图? 视图(View)是一种虚拟表,其内容由一个 …...

[操作系统] 信号
信号 vs IPC 板书最后提到了 “信号 vs IPC”,暗示了信号也是一种进程间通信 (Inter-Process Communication, IPC) 的机制。虽然信号的主要目的是事件通知,但它也可以携带少量的信息(即信号的类型)。 初探“信号”——操作系统的“…...
)
网络基础(协议,地址,OSI模型、Socket编程......)
目录 一、计算机网络发展 二、协议 1.认识协议 2.OSI七层模型 3.TCP/IP 五层(或四层)模型 4.协议本质 三、网络传输流程 1.MAC地址 2.协议栈 3.IP地址 IP地址 vs MAC地址 1. 核心区别 2. 具体通信过程类比 3. 关键总结 为什么需要两者? 4.协议栈图解…...