(学习总结34)Linux 库制作与原理
Linux 库制作与原理
- 库的概念
- 静态库
- 操作归档文件命令 ar
- 静态库制作
- 静态库使用
- 动态库
- 动态库制作
- 动态库使用与运行搜索路径问题
- 解决方案
- 方案2:建立同名软链接
- 方案3:使用环境变量 LD_LIBRARY_PATH
- 方案4:ldconfig 方案
- 使用外部库
- 目标文件
- ELF 文件介绍
- ELF 形成与加载
- ELF 形成可执行文件
- ELF 可执行文件加载
- 理解链接与加载
- 静态链接
- ELF 加载与进程地址空间
- 虚拟地址 / 逻辑地址
- 进程虚拟地址空间
- 进程使用与共享动态库
- 动态链接与动态库加载
- 编译器在可执行程序中嵌入其它操作
- 动态库中的相对地址
- 程序与动态库的具体映射
- 可执行程序进行动态库函数调用
- 全局偏移量表 GOT(global offset table)
- 库间依赖
- 总结
库的概念
库是写好的、现有的、成熟的、可以复用的代码。现实中每个程序都要依赖很多基础的底层库,不可能每个人的代码都从零开始,因此库的存在非常重要。
本质上来说库是一种可执行代码的二进制形式,可以被操作系统载入内存执行。
库有两种:
-
静态库,如:
.a (Linux 静态库后缀)、.lib (windows 静态库后缀) -
动态库,如:
.so (Linux 动态库后缀)、.dll (windows 动态库后缀)
使用库时,库与应用程序两者的比例为 库 : 应用程序 == 1 : n 。且在 Linux 中默认安装大部分库时,都是优先使用动态库的形式。
静态库
静态库:程序在编译链接时把库的代码链接到可执行文件中,程序运行时将不再需要静态库。
gcc 编译默认使用动态链接库,只有在该库下找不到动态 .so 的时候才会采用同名静态库。我们也可以使用 gcc 的 -static 强制采用链接静态库(若找不到对应静态库则会报错)。
接下来先介绍一下制作静态库命令 ar。
操作归档文件命令 ar
语法:ar [选项] [归档文件] [成员文件...]
功能:创建、修改和提取归档文件的命令行工具,常使用于制作静态库。
选项:
- r :插入文件到归档(替换同名文件,若不存在则添加)
- c :静默创建归档文件(不提示警告)
- s :生成或更新符号索引(等同 ranlib 命令)
- t :列出归档中的文件
- v :显示详细信息(如时间戳、权限)
- x :提取所有文件(或指定文件)到当前目录
- d :从归档中删除指定文件
- q :快速添加文件(不检查是否重复)
静态库制作
Linux 静态库的格式一般为:lib[库的名称].a,前缀和后缀都是规定格式,中间部分才是静态库的名称。
无论是动态库还是静态库,本质都是源文件对应的 .o 文件,而静态库的本质就是将众多的 .o 文件打了一个包。
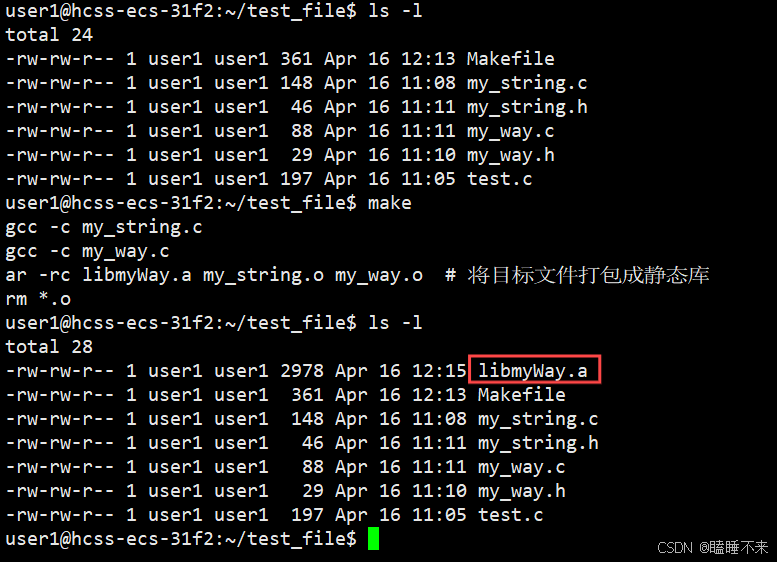
我们使用命令 ar -rc 命令制作静态库,首先准备自己的库文件:
// my_way.h#pragma oncevoid my_way(); // my_way.c#include "my_way.h"
#include <stdio.h>void my_way()
{printf("Hello Linux!\n");
} // my_string.h#pragma onceint my_strlen(const char* str); // my_string.c#include "my_string.h"int my_strlen(const char* str)
{int len = 0;while (str[len] != '\0'){ ++len;} return len;
}使用 Makefile 自动化构建:
libmyWay.a:my_string.o my_way.oar -rc $@ $^ # 将目标文件打包成静态库rm *.o%.o:%.cgcc -c $<.PHONY:clean
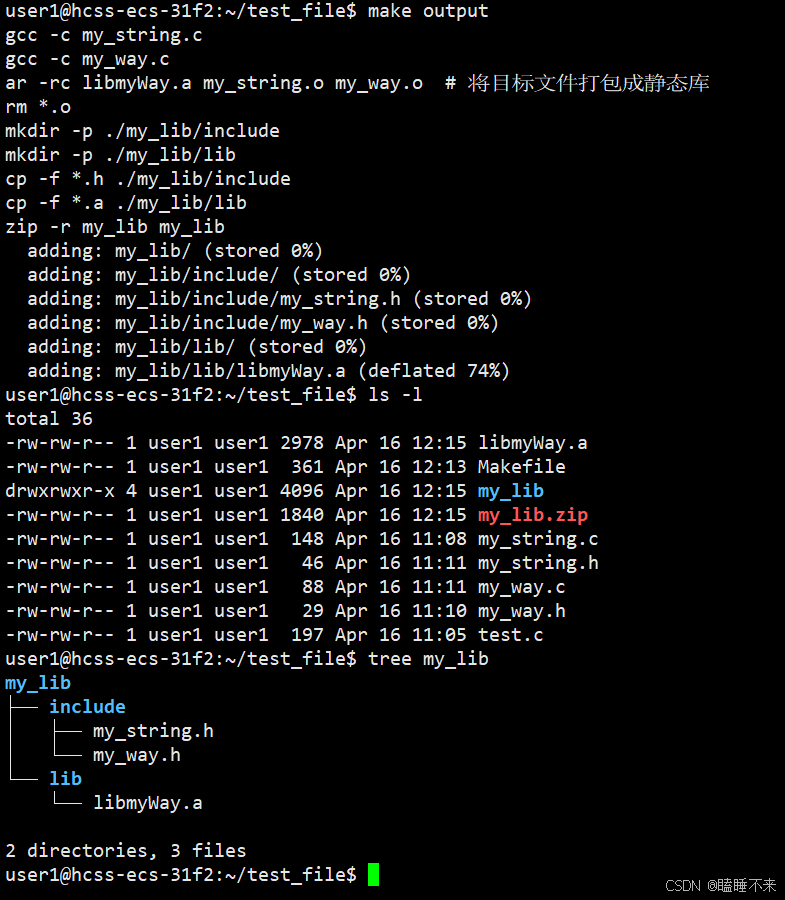
clean:rm libmyWay.a output:libmyWay.a my_string.h my_way.h # 将头文件与静态库打包压缩成 zip 包mkdir -p ./my_lib/includemkdir -p ./my_lib/libcp -f *.h ./my_lib/includecp -f *.a ./my_lib/libzip -r my_lib my_lib
简单制作静态库:
将静态库与头文件一起打包:
静态库使用
静态库是一种归档文件,不需要将其拆开使用,只需要 gcc/g++ 使用链接即可:
// test.c 源文件
#include "my_string.h"
#include "my_way.h"
#include <stdio.h>int main()
{const char* str = "Hello Linux!\n";printf("str 长度: %d\n", my_strlen(str));my_way();return 0;
}test.c 调用头文件 my_string.h 和 my_way.h 中的函数,此时需要链接打包好的静态库,使用命令 gcc -o test test.c -L . -l myWay 命令编译形成可执行文件:
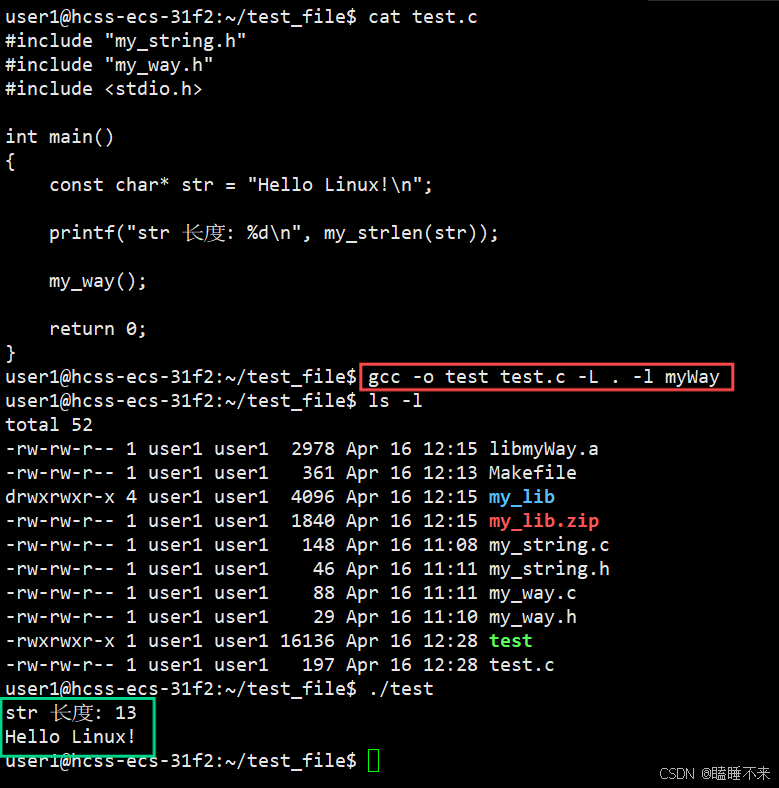
其中的 -L 选项表示指定库的路径,-l 表示库的名称。
测试目标文件生成后,即便静态库删掉,程序照样也可以运行。
想了解 gcc/g++ 命令的更多选项可以参考:(学习总结25)Linux工具:vim 编辑器 和 gcc/g++ 编译器
动态库
动态库:程序在运行时链接动态库的代码,多个程序共享动态库的代码。
-
一个与动态库链接的可执行文件仅仅包含它用到的函数入口地址的一个表,而不是外部函数所在目标文件的整个机器码。
-
在可执行文件开始运行以前,外部函数的机器码由操作系统从磁盘上的该动态库中复制到内存中,这个过程称为动态链接(dynamic linking)
-
动态库可以在多个程序间共享,所以动态链接使得可执行文件更小,节省了磁盘空间。操作系统采用虚拟内存机制,允许物理内存中的一份动态库被需要使用该库的所有进程共用,节省内存和磁盘空间。
动态库制作
同理于静态库,动态库格式一般为:lib[库的名称].so。
gcc/g++ 带上 -shared 选项即可制作动态库,但文件从 .c 编译成 .o 时需要加上 -fPIC(position independent code) 选项:
libmyWay.so:my_string.o my_way.ogcc -o $@ $^ -shared # 将目标文件打包成动态库rm *.o%.o:%.cgcc -fPIC -c $< # -fPIC 选项作用为产生位置无关码 .PHONY:clean
clean:rm libmyWay.sooutput:libmyWay.so my_string.h my_way.h # 将头文件与动态库打包压缩成 zip 包mkdir -p ./my_lib/includemkdir -p ./my_lib/libcp -f *.h ./my_lib/includecp -f *.so ./my_lib/libzip -r my_lib.zip my_lib
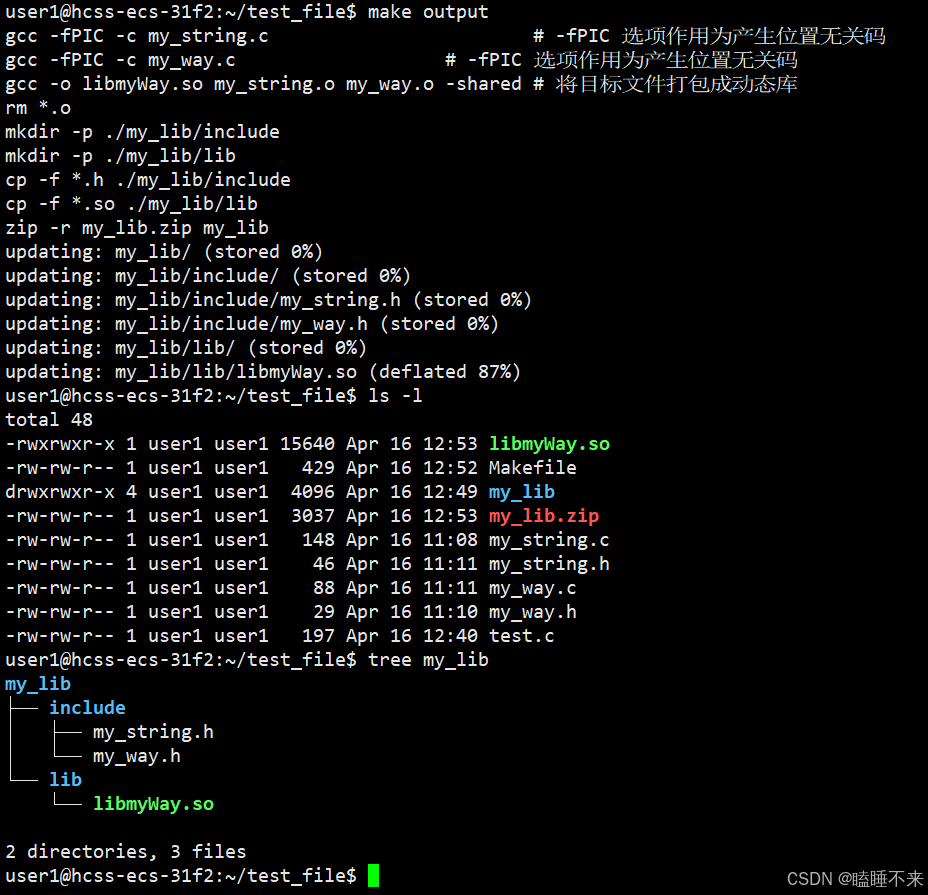
动态库使用与运行搜索路径问题
其它文件使用动态库时,gcc/g++ 执行的命令同静态库一样,使用命令 gcc -o test test.c -L . -l myWay,但当编译执行 test 时却会报错:
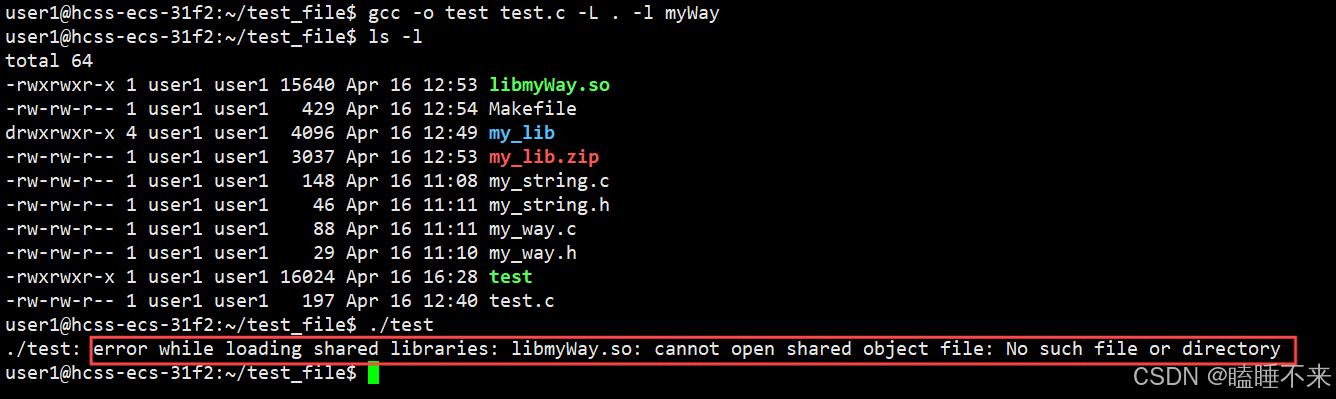
其表示 test 文件加载 libmyWay.so 共享库时找不到 libmyWay.so 而出错。
这是因为我们只告诉了 gcc/g++ 动态库的路径,gcc/g++ 编译通过了,但系统并不知道动态库的路径在哪。
解决方案
我们可以使用命令 ldd 查看 test 需要的动态库:

可以看到,系统并没有寻找到 libmyWay.so 的路径。
动态库搜索路径解决方案:
-
拷贝对应
.so文件到系统共享库路径下,一般指/usr/lib、/usr/local/lib、/lib64库路径等 -
向系统共享库路径下建立同名软链接
-
更改环境变量
LD_LIBRARY_PATH,但这个环境变量一般不存在,使用export命令可以创建环境变量 -
ldconfig 方案:在
/etc/ld.so.conf.d/中配置自己的文件,且在文件中写入对应动态库的路径,并使用命令ldconfig更新
方案 1 的这里省略,我们来看看其它 3 个解决动态库路径的方案。
方案2:建立同名软链接

在 /usr/lib 等路径下建立文件需要提升权限,使用 sudo + ln -s 命令解决。
方案3:使用环境变量 LD_LIBRARY_PATH
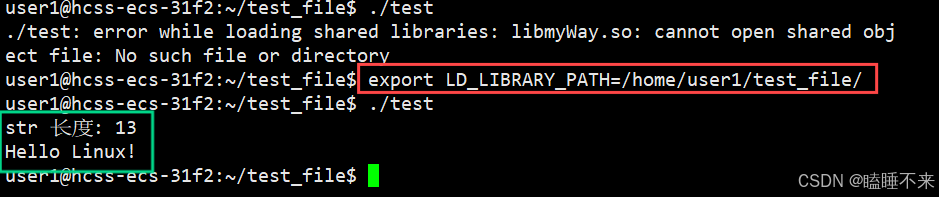
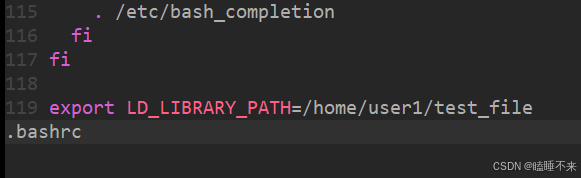
但是要注意,这种方法只是内存级记录路径,结束 shell 会话后重启环境变量就没有了。如果想一直保存,可以在当前用户家目录的 .bashrc 文件末尾加入 export LD_LIBRARY_PATH=/home/user1/test_file,之后每次登录当前用户时 shell 便会从 .bashrc 文件中获取对应的环境变量,则可以一直保存:
方案4:ldconfig 方案
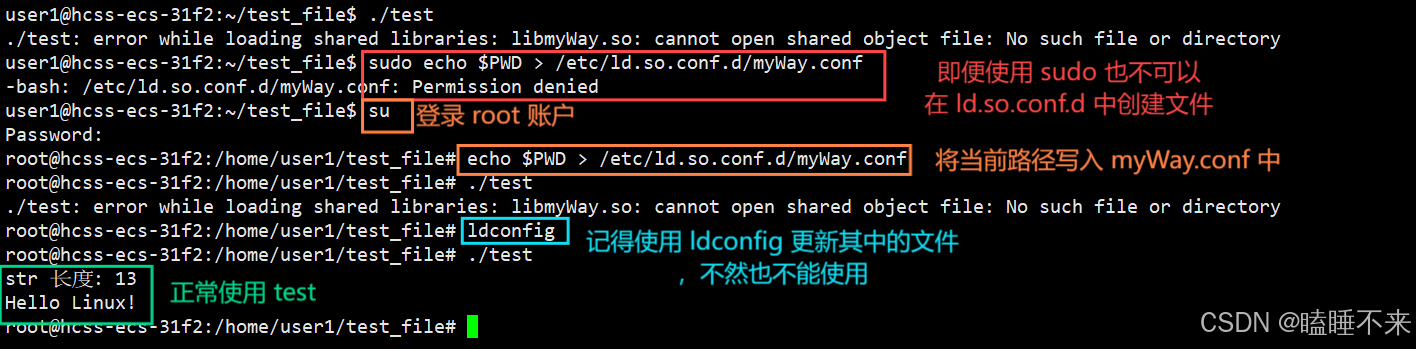
在 /etc/ld.so.conf.d/ 中配置好后使用 ldconfig 动态链接库管理命令,更新共享库缓存的搜索路径,便可以使用动态库了。
使用外部库
这里推荐一个 Linux 的图形库:ncurses。
# Centos 安装
sudo yum install -y ncurses-devel# ubuntu 安装
sudo apt install -y libncurses-dev
系统中其实有很多库,它们通常由一组互相关联的用来完成某项常见工作的函数构成。比如用来处理屏幕显示情况的函数(ncurses库)
这里有一个介绍 ncurse 库相关函数的文章:ncurse编程指南
目标文件
目标文件是一个二进制的文件,文件的格式是 ELF ,是对二进制代码的一种封装:

编译和链接这两个步骤,在 Windows 下被 IDE 封装的很完美(如 VS2022)。用户一般都是一键构建非常方便,但遇到错误时尤其是链接相关的错误,很多人可能就束手无策了。在 Linux 下,我们之前也分析过如何通过 gcc/g++ 编译器来完成这一系列操作。
之前的文章也介绍过动静态库,接下来我们再简单分析一下编译和链接的过程,来理解一下动静态库的使用原理。
编译:编译的过程其实就是将程序的源代码翻译成 CPU 能够直接运行的机器代码。
链接:多个文件链接形成可执行文件,对于库文件:
-
对于静态库,文件中需要的方法会直接拷贝静态库中的方法,执行时只需调用自己拷贝的那份。
-
对于动态库,文件中需要的方法只会拷贝找到动态库方法的地址,执行时会寻找动态库的方法。
比如:上面的使用案例中,源文件 test.c 里调用了 my_way 函数,而这个函数被定义在另一个源文件 my_way.c 中。当我们修改 test.c 时,只需要单独编译 test.c ,不用浪费时间重新编译整个工程,从而节省了时间。
ELF 文件介绍
要理解编译链接的细节,我们不得不了解一下 ELF 文件。其实有以下四种文件其实都是 ELF 文件:
-
可重定位文件(Relocatable File):即
.o文件,包含适合于与其他目标文件链接来创建可执行文件或者共享目标文件的代码和数据。 -
可执行文件(Executable File):即可执行程序。
-
共享目标文件(Shared Object File):即
.so文件。 -
内核转储(Core Dumps):存放当前进程的执行上下文,用于 dump 信号触发。
也就是说上部分的动静态库、可执行程序、.o 文件都是 ELF 格式。
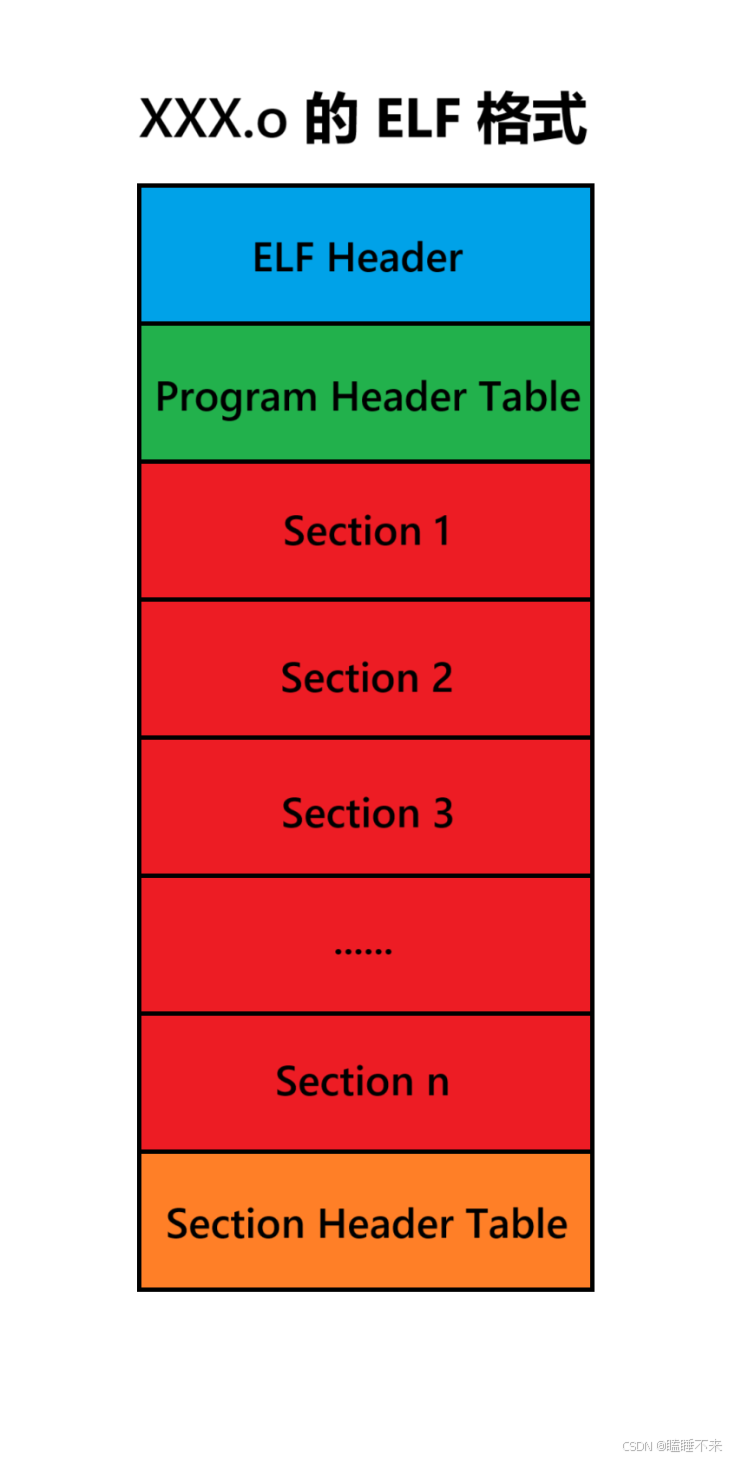
一个 ELF 文件由以下四部分组成:
-
ELF 头(ELF header):包含 ELF 文件的基本信息,其位于文件的开始位置,它的主要目的是定位、描述文件的其它部分。比如文件类型、机器类型、版本、入口点地址、程序头表和节头表的位置和大小等。
-
程序头表(Program Header Table):列举了所有有效的段(segments) 和它们的属性。表里记着每个段开始的位置和位移(offset) 、长度。毕竟这些段都是紧密的放在二进制文件中,需要段表的描述信息,才能把它们每个段分割开。
-
节头表(Section Header Table):包含对节(sections) 的描述。如描述了 ELF 文件的各个节的起始地址、大小、标志等信息。
-
节(Section):ELF 文件中的基本组成单位,包含了特定类型的数据。ELF 文件的各种信息和数据都存储在不同的节中。如代码节存储了可执行代码,数据节存储了全局变量和静态数据等。
最常见的节:
-
代码节(.text):用于保存机器指令,是程序的主要执行部分。
-
数据节(.data):保存已初始化的全局变量和局部静态变量。
ELF 形成与加载
ELF 形成可执行文件
ELF 形成可执行文件会将多份 .o 文件的 section 进行合并:
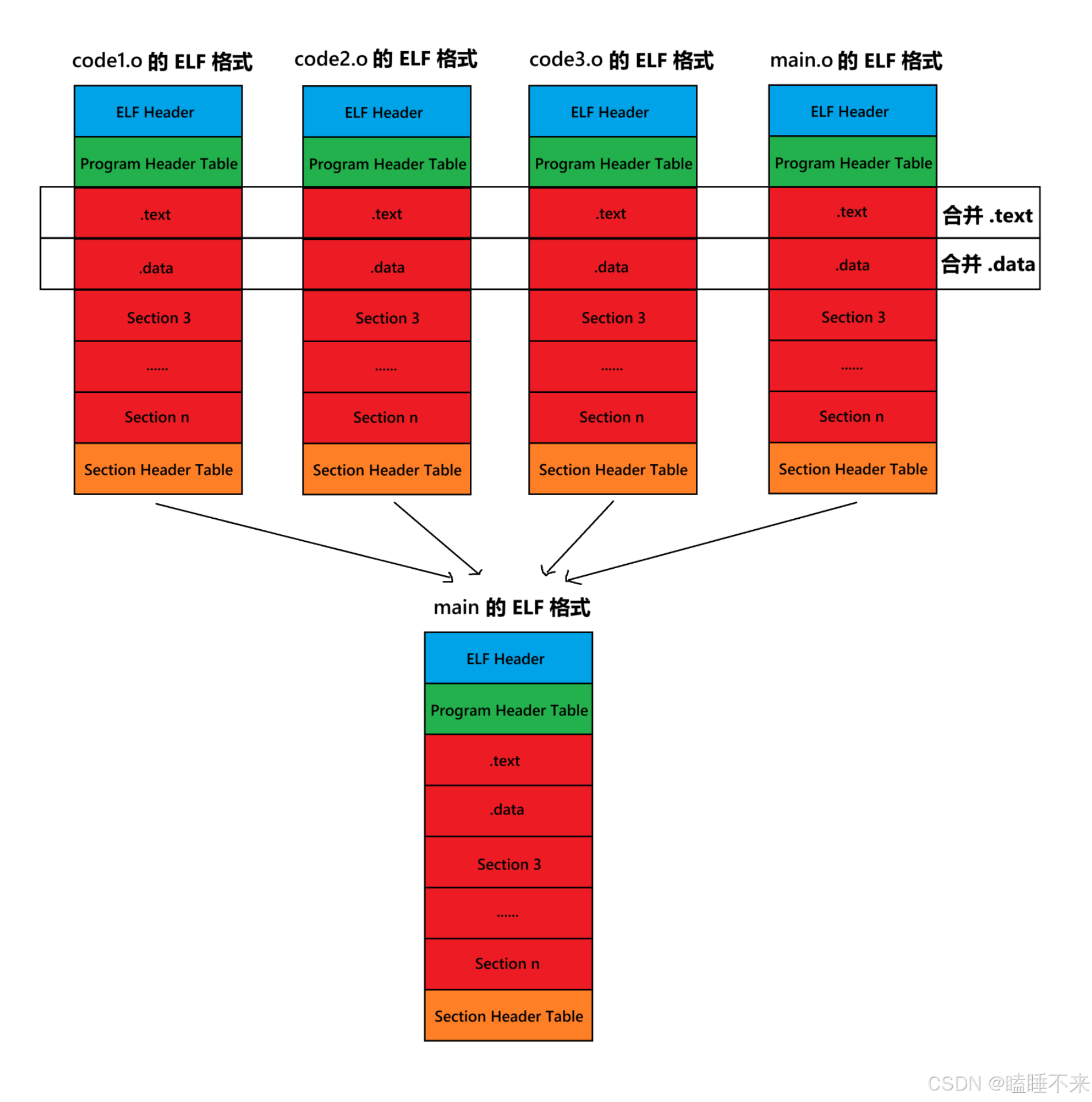
实际合并是在链接时进行的,但是并不是上图这么简单的合并。也会涉及对库合并,此处不做过多分析。
ELF 可执行文件加载
一个 ELF 会有多种不同的 Section,在加载到内存的时候也会进行 Section 合并,形成segment 。合并原则要求是相同属性,如:可读、可写、可执行、需要加载时申请空间等。
这样即便是不同的 Section,在加载到内存中,可能会以 segment 的形式加载到一起。
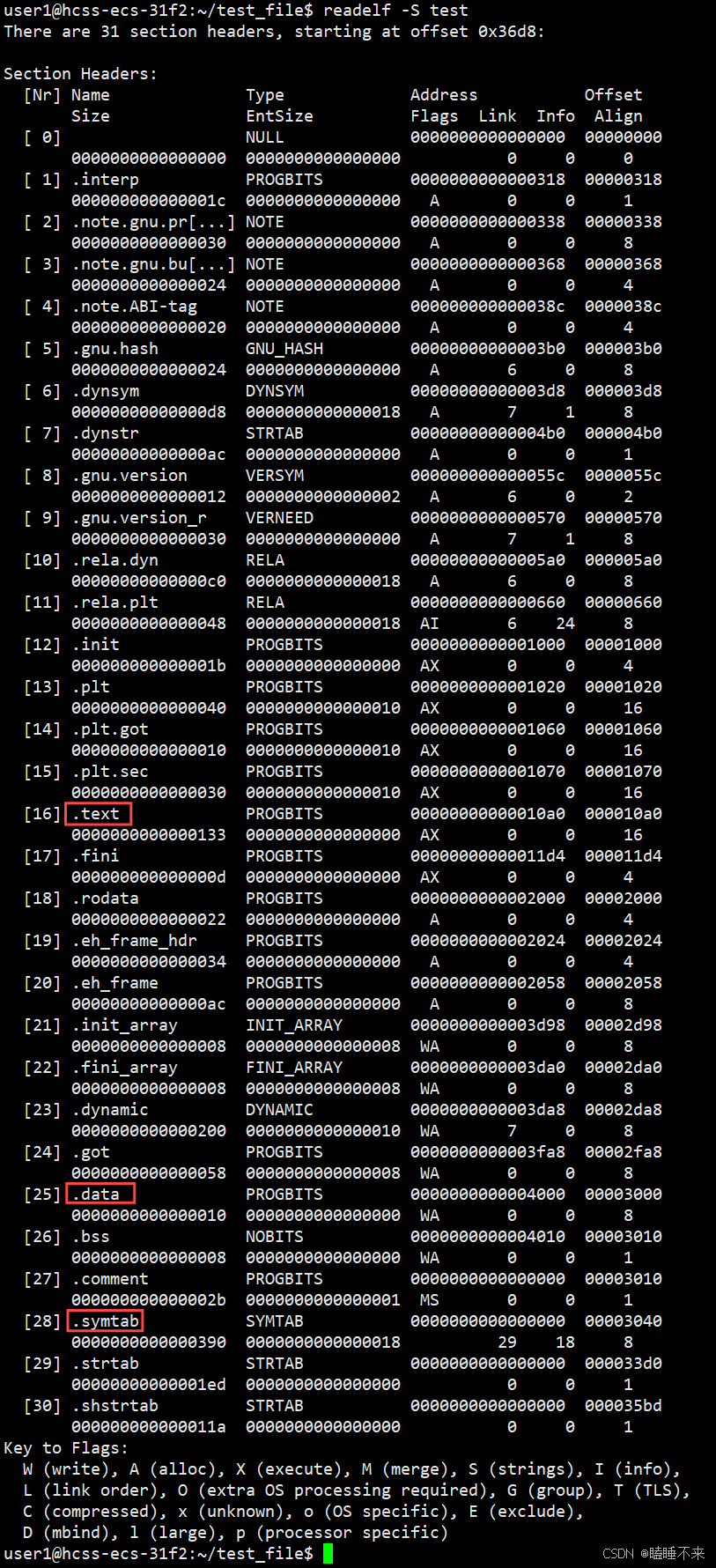
很显然这个合并工作在形成 ELF 时其合并方式已经确定了,具体合并原则被记录在了 ELF 的程序头表(Program Header Table) 中,使用命令 readelf -S [文件] 可以查看对应文件的 Sections 信息:
但为什么要将 Section 合并成为 segment 呢?
- Section 合并的主要原因是为了减少页面碎片,提高内存使用效率。如果不进行合并,假设页面大小为 4096 字节(内存块基本大小、加载、管理的基本单位),如果
.text部分为 4097 字节,.init部分为 512 字节,那么它们将占用 3 个页面,而合并后,它们只需 2 个页面。 - 此外操作系统在加载程序时,会将具有相同属性的 Section 合并成一个大的 segment,这样就可以实现不同的访问权限,从而优化内存管理和权限访问控制。
对于 程序头表 和 节头表 又有什么用呢,其实 ELF 文件提供 2 个不同的 视图 / 视角 来让我们理解这两个部分:
-
链接视图(Linking view) 对应节头表 Section Header Table:
- 文件结构的粒度更细,将文件按功能模块的差异进行划分,静态链接分析的时候一般关注的是链接视图,能够理解 ELF 文件中包含的各个部分的信息。
- 为了空间布局上的效率,将来在链接目标文件时,链接器会把很多节(section)合并,规整成可执行的段(segment)、可读写的段、只读段等。合并后空间利用率就大大提高了,否则很小的一段会导致物理内存页浪费太大,所以链接器趁着链接就把小块都合并了。
-
执行视图(Execution view) 对应程序头表 Program Header Table:
- 其会告诉操作系统,如何加载可执行文件,完成进程内存的初始化。一个可执行程序的格式中,一定有 Program Header Table 。
-
总结来说就是:一个在链接时作用,一个在运行加载时作用。
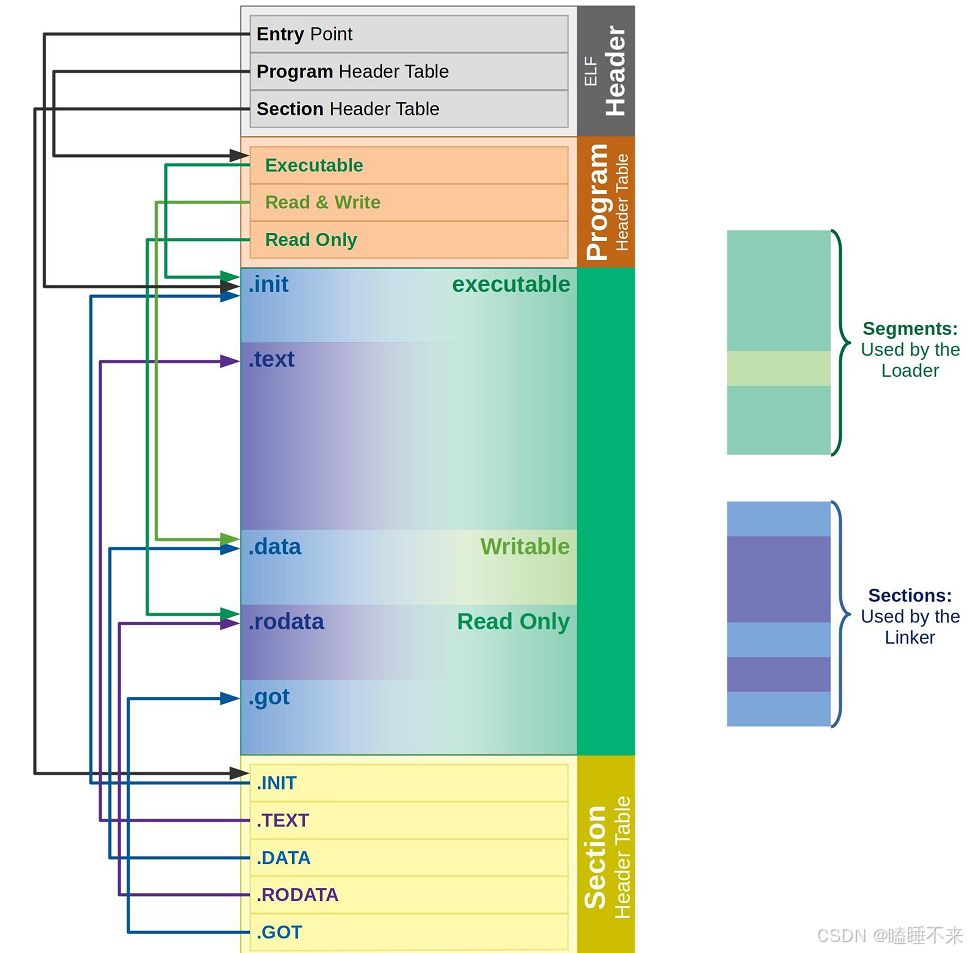
从 链接视图 来看:
-
.text节:保存了程序代码指令的代码节。 -
.data节:保存了初始化的全局变量和局部静态变量等数据。 -
.rodata节:保存了只读的数据,如一行C语言代码中的字符串。由于.rodata节是只读的,所以只能存在于一个可执行文件的只读段中。因此,只能是在text段(不是data段)中找到.rodata 节。 -
.bss节:为未初始化的全局变量和局部静态变量预留位置。 -
.symtab节:Symbol Table 符号表,就是源码里面那些函数名、变量名和代码的对应关系。其会用一个字符串将它们保存,中间用\0分隔开。 -
.got.plt节 (全局偏移表 - 过程链接表):.got节保存了全局偏移表。.got节和.plt节一起提供了对导入的共享库函数的访问入口,由动态链接器在运行时进行修改。
从 执行视图 来看:
-
告诉操作系统哪些模块可以被加载进内存。
-
加载进内存之后哪些分段是可读可写,哪些分段是只读,哪些分段是可执行的。
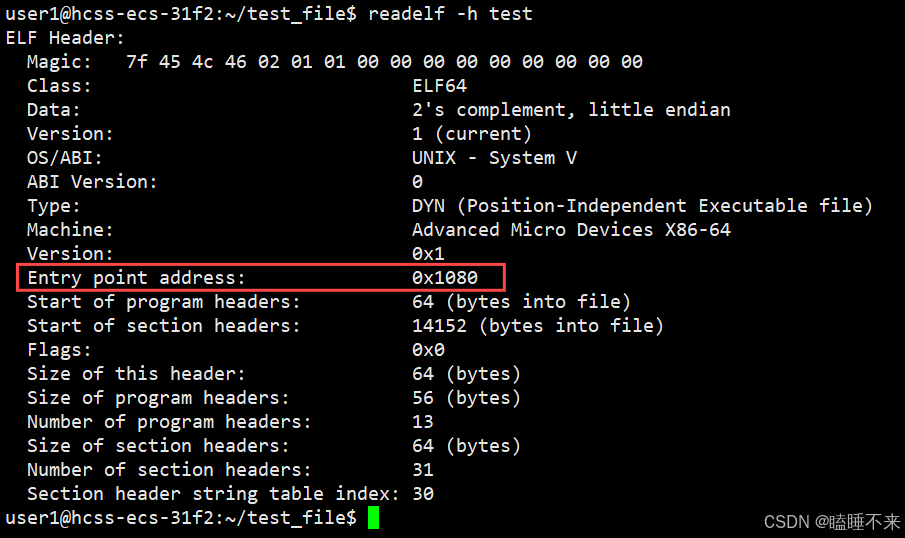
在 ELF 头中可以找到文件的基本信息,以及可以看到 ELF 头是如何定位程序头表和节头表的。我们可以使用命令 readelf -h [文件] 查看可重定位文件的 ELF 头信息:
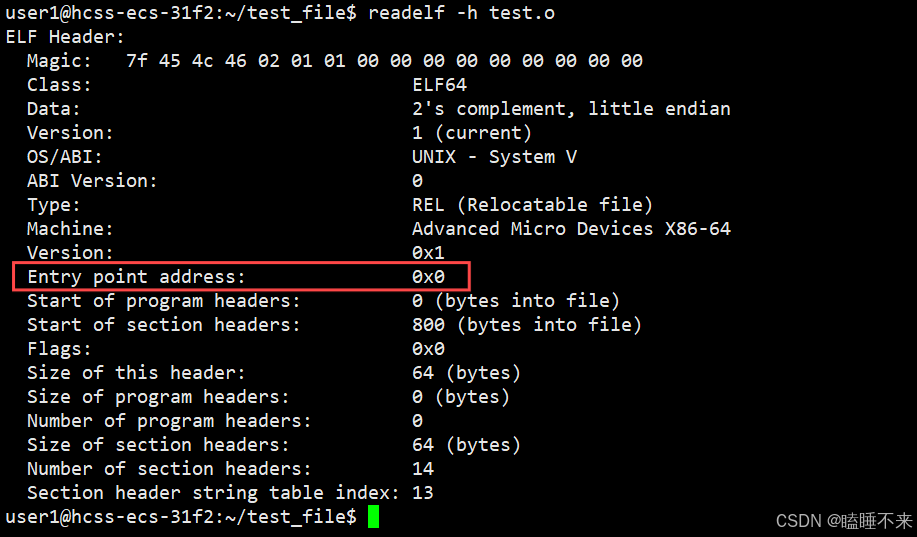
其中:
-
Magic :为 ELF 文件的标识符,用于验证文件是否为有效的 ELF 格式
-
Class :文件类型
-
Data :指定的编码方式
-
Type :指出 ELF 文件的类型
-
Machine :该程序需要的体系结构
-
Entry point address:系统第一个传输控制的虚拟地址,在这启动进程。假如文件没有如何关联的入口点,该成员就保持为 0。 -
Size of this header :保存 ELF 头大小(以字节计数)
-
Size of program headers :保存着在文件的程序头表中一个入口的大小
-
Number of program headers :保存着在程序头表中入口的个数。因此 e_phentsize 和 e_phnum 的乘机就是表的大小(以字节计数),假如没有程序头表,变量为 0。
-
Size of section headers :保存着 section 头的大小(以字节计数)。一个 section 头是在 section 头表的一个入口。
-
Number of section headers :保存着在 section header table 中的入口数目。因此 e_shentsize 和 e_shnum 的乘积就是 section 头表的大小(以字节计数)。假如文件没有 section 头表,值为 0。
-
Section header string table index :保存着跟 section 名字字符表相关入口的 section 头表索引。
总之 ELF header 的主要目的是定位文件的其它部分。
注意:
虚拟地址空间不仅仅是进程看待内存的方式,在磁盘中没有加载到内存的一个可执行程序,代码和数据也是采用虚拟地址统一编址。
并且所有的可执行程序,都是一个 segment。Linux 使用的是平坦模式编址,所有函数、变量的编址起始偏移量都从 0 开始。
理解链接与加载
静态链接
无论是自己的 .o 文件,还是静态库中的 .o 文件,本质都是把 .o 文件进行链接的过程。所以研究静态链接,本质就是研究 .o 文件是如何链接的。
使用 objdump -d [文件] 命令会将代码段 .text 进行反汇编查看,这样可以查看编译后的 .o 目标文件:
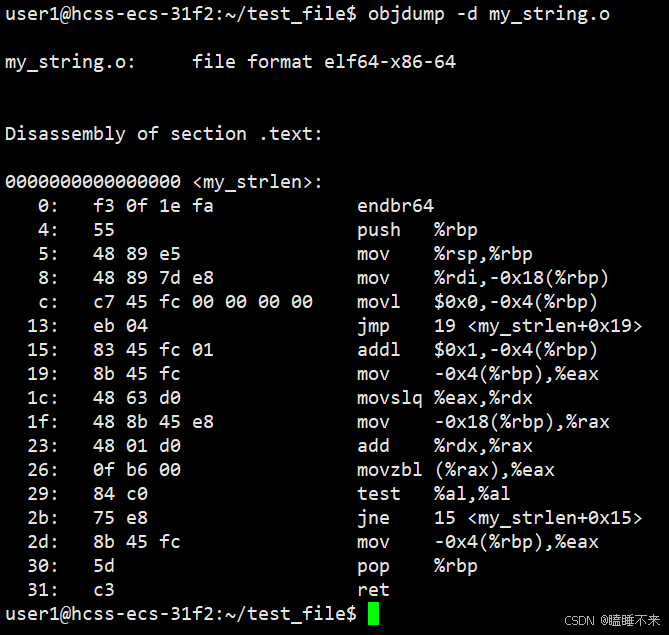
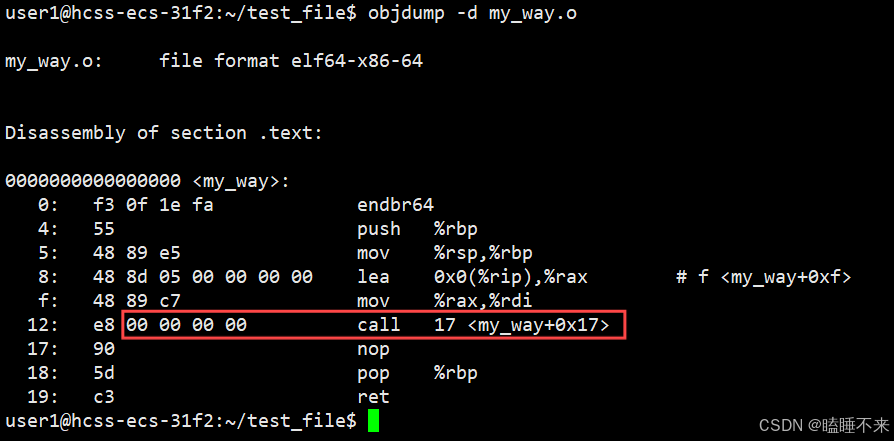
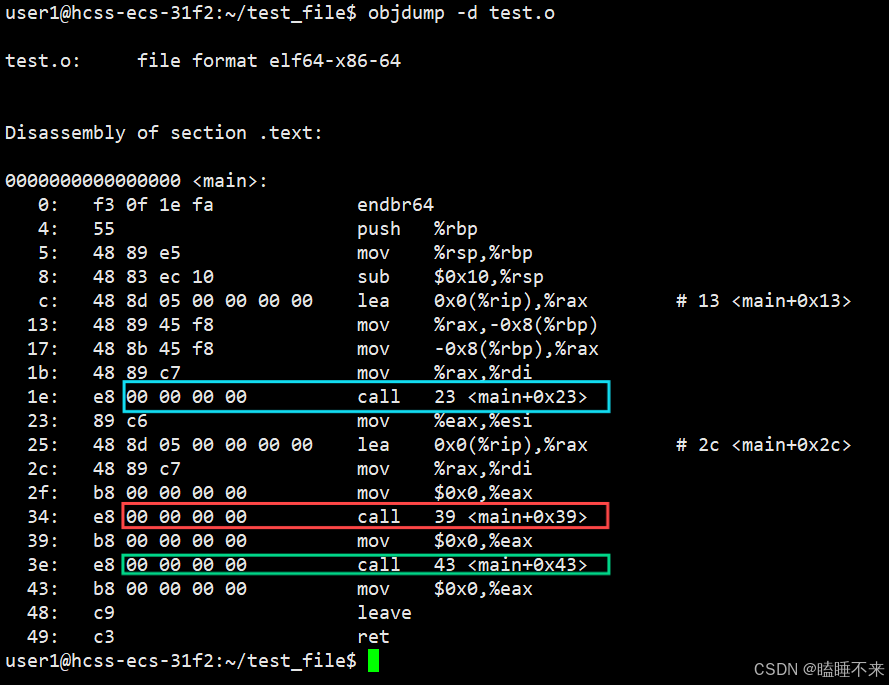
我们可以看到这里的 call 指令,在 test.c 中它们对应之前调用的 printf、my_string 和 my_way 函数,但是我们发现它们的跳转地址都被设成 0。
这是因为在编译 test.c 的时候,编译器是完全不知道 printf、my_string 和 my_way 函数的存在。比如位于内存的哪个区块,具体代码都是不知道的。因此,编辑器只能将这两个函数的跳转地址先暂时设为 0。
这个跳转地址会在链接的时候被修正,为了让链接器将来在链接时能够正确定位到这些被修正的地址,在代码块 .data 中还存在一个重定位表。这张表在链接时,会根据表里记录的地址将其修正。注意 printf 函数涉及到动态库,这里不讨论。
而静态链接就是把库中的 .o 进行合并。和上述过程一样所以链接其实是将编译之后的所有目标文件连同用到的一些静态库运行时库组合,拼装成一个独立的可执行文件。其中就包括我们提到的地址修正,当所有模块组合在一起之后,链接器会根据我们的 .o 文件或者静态库中的重定位表找到那些需要被重定位的函数全局变量,从而修正它们的地址。这其实就是静态链接的过程。
静态库:
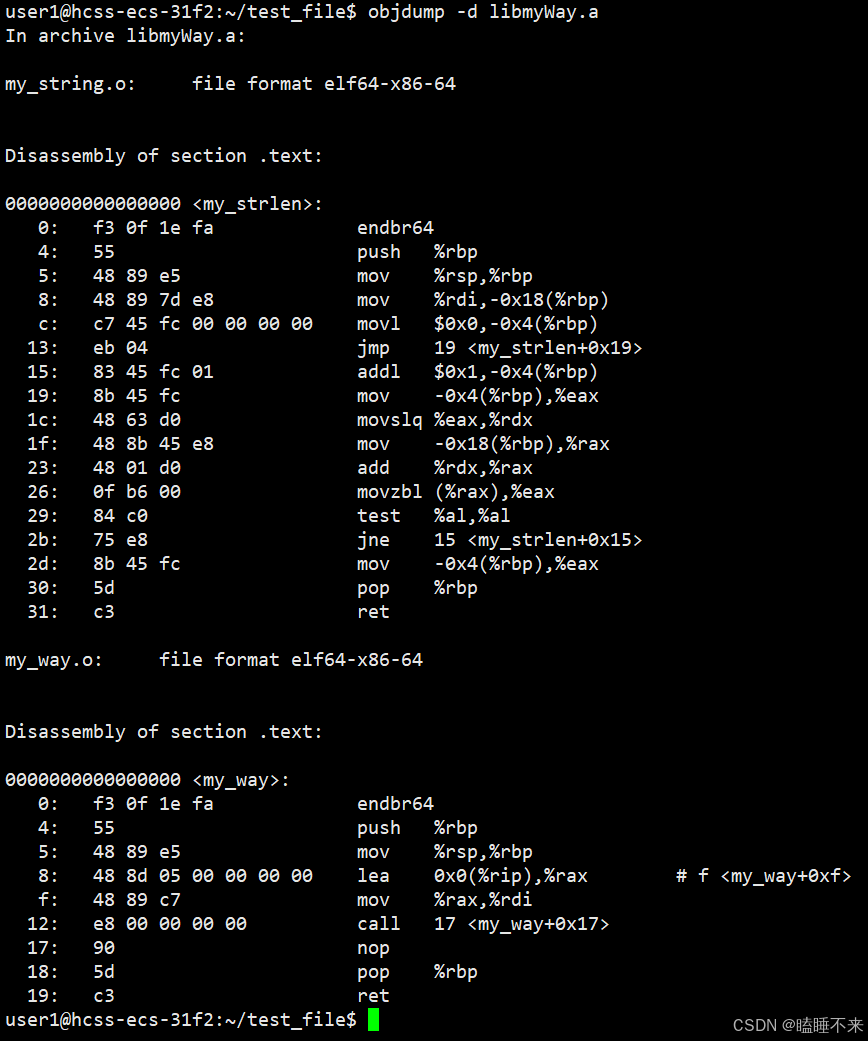
静态链接的 test 可执行文件:
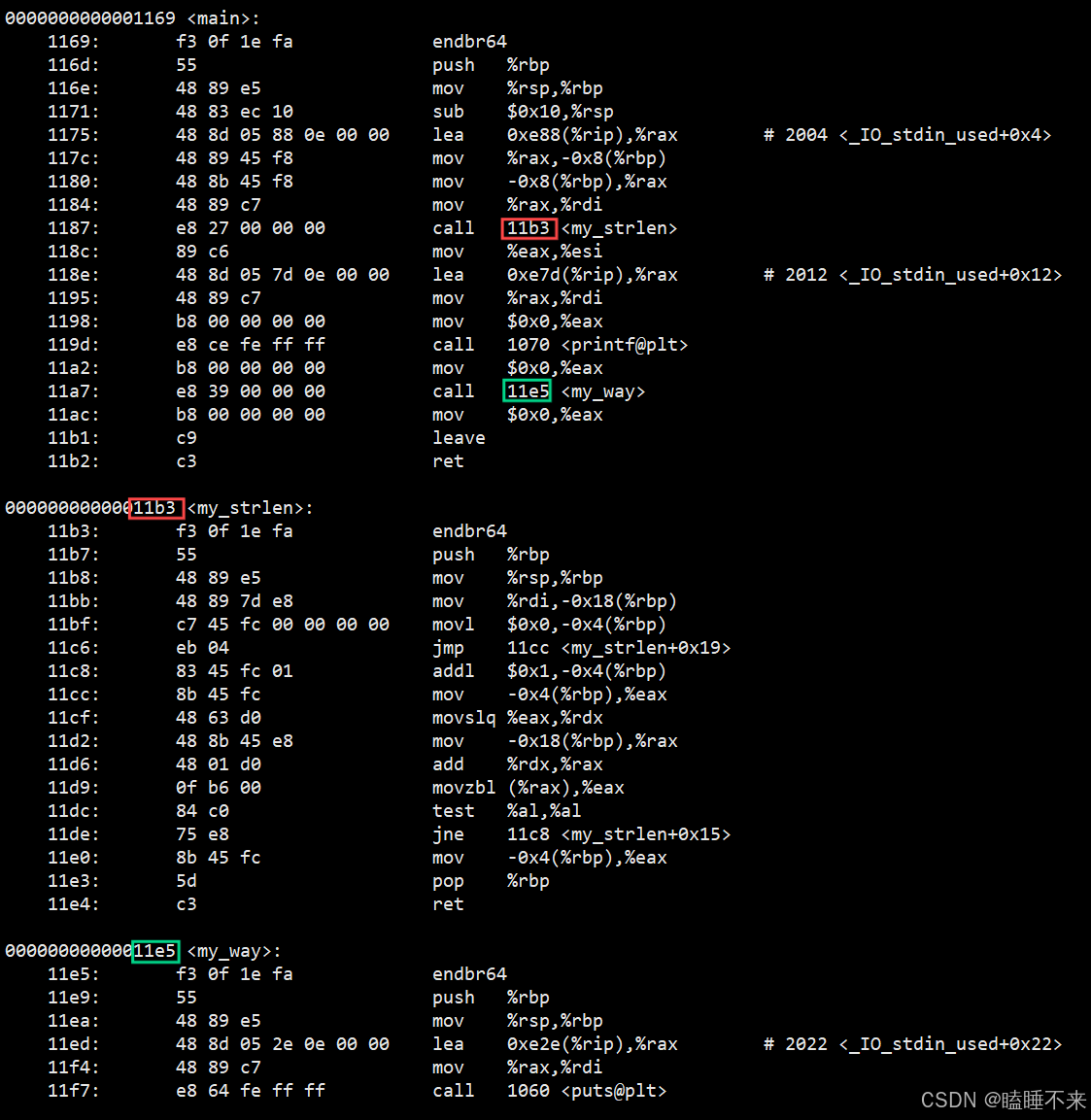
所以,链接过程中会涉及到对 .o 中外部符号进行地址重定位。
ELF 加载与进程地址空间
虚拟地址 / 逻辑地址
一个 ELF 程序在没被加载到内存时,本来就有地址。当代计算机工作的时候,都采用 " 平坦模式 " 进行工作。所以也要求 ELF 对自己的代码和数据进行统一编址。其实严格意义上应该叫做逻辑地址(起始地址 + 偏移量),但是我们认为起始地址是 0。可以说虚拟地址在程序还没加载到内存时,就已经把可执行程序进行统一编址了。
下面是 objdump -S 反汇编之后的代码,最左侧的就是 ELF 的虚拟地址:
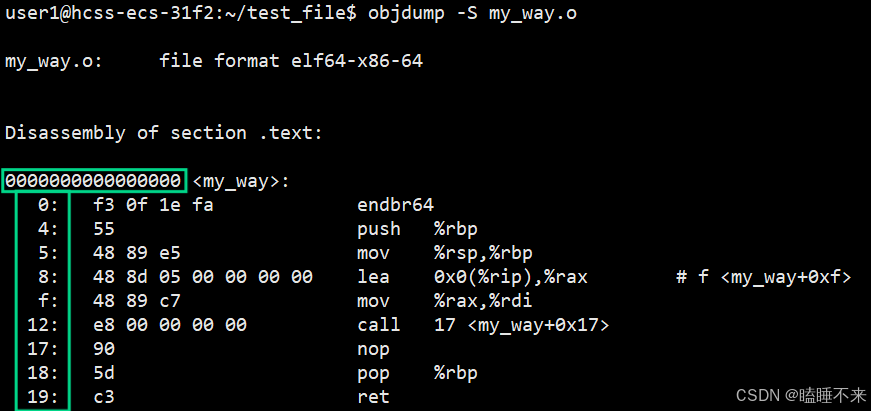
进程 mm_struct、vm_area_struct 在进程刚刚创建的时候,初始化数据从 ELF 各个 segment 获取,每个 segment 有自己的起始地址和自己的长度,用来初始化内核结构中的 [start,end] 等范围数据,另外再用详细地址填充页表。
所以虚拟地址机制不仅操作系统要支持,编译器也要支持。
进程虚拟地址空间
ELF 在被编译好之后,会把自己未来程序的入口地址记录在 ELF header 的 Entry 字段中,CPU 执行程序时,只需要记录此地址便可以运行程序:
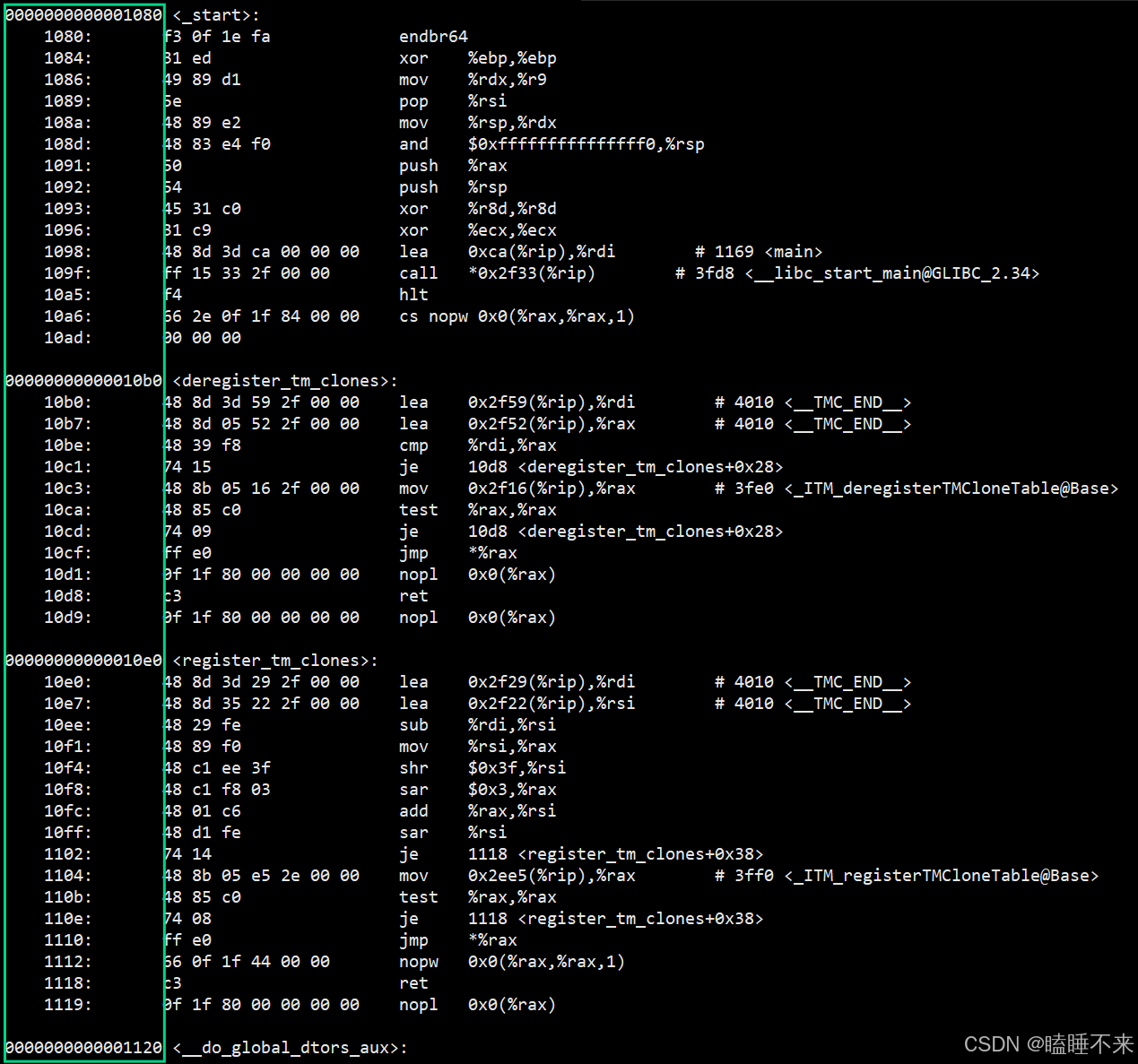
进程虚拟地址空间讲解在 (学习总结31)Linux 进程地址空间与进程控制 ,这里不赘述。
进程使用与共享动态库
第一个进程使用动态库时,先将该库的代码段(.text) 和 只读数据段(.rodata) 映射到物理内存,使用时需要在页表中建立地址对应的映射关系即可使用动态库。而后续的进程使用此动态库,只需要页表映射,直接复用这块物理内存:
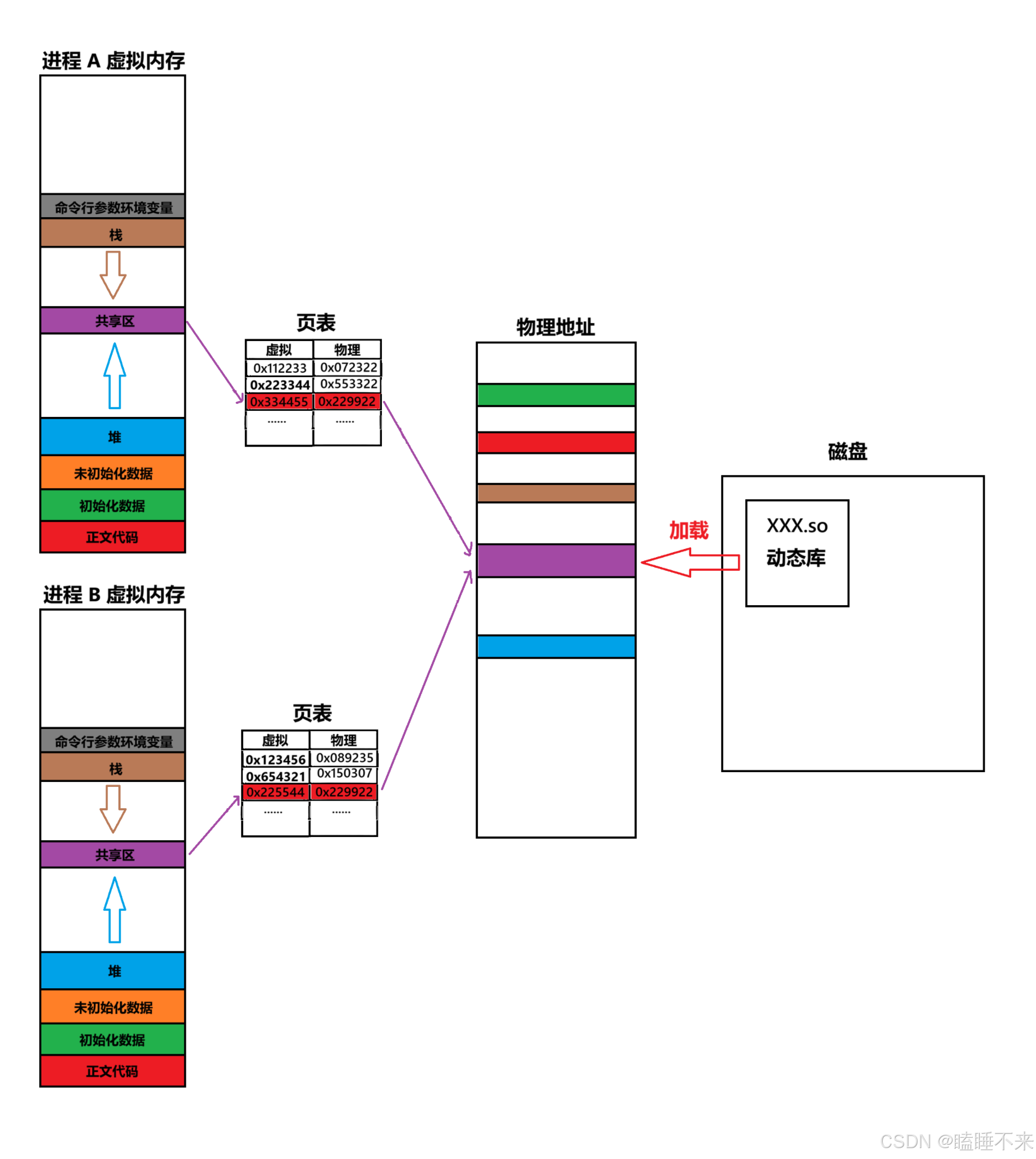
动态链接与动态库加载
动态链接远比静态链接要常用得多。静态链接由于会将编译产生的所有目标文件,连同用到的各种库,合并形成一个独立的可执行文件,虽然不需要额外的依赖就可以运行,但最大的问题在于生成的文件体积大,相当耗费内存资源。
随着软件复杂度的提升,操作系统也越来越臃肿,不同的软件很有可能包含了相同的功能和代码,使用静态链接将会浪费大量的内存和硬盘空间。
这时动态链接的优势就体现出来了,我们可以将需要共享的代码单独提取出来,保存成一个独立的动态链接库,等到程序运行的时候再将它们加载到内存。这样可以节省大量空间,因为同一个模块在内存中只需要保留一份副本,可以被不同的进程所共享。
那动态链接是如何工作的?
首先要说明一点,动态链接是将链接的整个过程推迟到了程序加载的时候。比如运行一个程序,操作系统会先将程序的数据代码连同它用到的一系列动态库先加载到内存,其中每个动态库的加载地址都是不固定的,操作系统会根据当前地址空间的使用情况为它们动态分配一段内存。
当动态库被加载到内存以后,一旦它的内存地址被确定,就可以去修正动态库中的那些函数跳转地址了。
编译器在可执行程序中嵌入其它操作
在 C/C++ 程序开始执行时,首先并不会直接跳转到 main 函数。而是 _start 函数,这是一个由 C 运行时库(通常是 glibc)或链接器(如 ld)提供的特殊函数。
在 _start 函数中会执行一系列初始化操作:
-
设置堆栈:为程序创建一个初始的堆栈环境。
-
初始化数据段:将程序的数据段(如全局变量和静态变量)从初始化数据段复制到相应的内存位置,并清零未初始化的数据段。
-
动态链接:这是很关键的一步, _start 函数会调用动态链接器的代码来解析和加载程序所依赖的动态库(shared libraries)。动态链接器会处理所有的符号解析和重定位,确保程序中的函数调用和变量访问能够正确地映射到动态库中的实际地址。
-
调用 __libc_start_main :一旦动态链接完成, _start 函数会调用 __libc_start_main(这是 glibc 提供的一个函数)。 __libc_start_main 函数负责执行一些额外的初始化工作,比如设置信号处理函数、初始化线程库(如果使用了线程)等。
-
调用 main 函数:最后 __libc_start_main 函数会调用程序的 main 函数,此时程序的执行控制权才正式交给用户编写的代码。
-
处理 main 函数的返回值:当 main 函数返回时, __libc_start_main 会负责处理这个返回值,并最终调用 _exit 函数来终止程序。
其中的动态链接:
-
动态链接器:
-
动态链接器(如 ld-linux.so)负责在程序运行时加载动态库。
-
当程序启动时,动态链接器会解析程序中的动态库依赖,并加载这些库到内存中。
-
-
环境变量和配置文件:
-
Linux 系统通过环境变量(如
LD_LIBRARY_PATH)和配置文件(如/etc/ld.so.conf及其子配置文件)来指定动态库的搜索路径。 -
这些路径会被动态链接器在加载动态库时搜索。
-
-
缓存文件:
-
为了提高动态库的加载效率,Linux 系统会维护一个名为
/etc/ld.so.cache的缓存文件。 -
该文件包含了系统中所有已知动态库的路径和相关信息,动态链接器在加载动态库时会首先搜索这个缓存文件。
-
上述过程描述了 C/C++ 程序在 main 函数之前执行的一系列操作,但这些操作对于大多数程序员来说是不透明的。程序员通常只需要关注 main 函数中的代码,而不需要关心底层的初始化过程。然而了解这些底层细节有助于更好地理解程序的执行流程和调试问题。
动态库中的相对地址
动态库为了 能随时进行加载 和 支持并映射到任意进程的任意位置,对其中的方法进行统一编址,采用相对编址的方案进行编址的(可执行程序也一样,都遵守平坦模式,只不过 exe 是直接加载的)。
但注意每个独立模块起始地址都是 0,合并时只需确定谁先谁后,再将自己的起始到结束地址整体的加上前一个模块最后的地址即可串联起来。
程序与动态库的具体映射
动态库也是一个文件,要访问也是要被先加载,要加载也是要被打开的。
让进程找到动态库的本质也是文件操作。不过访问库函数时,是通过虚拟地址进行跳转访问的,所以需要把动态库映射到进程的地址空间中。
在 vm_area_struct 中有一个 struct file 指针,其指向的 file 有 struct path 类型,而这个 struct path 其中一个变量就是 struct dentry 指针类型。
我们在 (学习总结33)Linux Ext2 文件系统与软硬链接 - 路径缓存 曾提到过 struct dentry,它维护树状路径结构并记录对应文件的 inode,通过 inode 的 i_block 寻址便可以找到磁盘文件中动态库的数据块,但注意库内容是在文件内核缓冲区中。
可执行程序进行动态库函数调用
动态库被我们映射到当前进程的地址空间中时,库的虚拟起始地址进程已经知道,库中每一个方法的偏移量地址进程也知道。则可以说,所有访问库中任意的方法,只需要知道 库的起始虚拟地址 + 方法偏移量 即可定位库中的方法。
而且调用过程是从代码区跳转到共享区,调用完毕再返回到代码区,整个过程完全在进程地址空间中进行的。
全局偏移量表 GOT(global offset table)
可执行程序运行之前会先把所有库加载并映射,所有库的起始虚拟地址都应该提前让进程知道,然后对程序里加载到内存中的库函数调用进行地址修改,在内存中二次完成地址设置(这个叫做加载地址重定位)。
但是我们知道代码区在进程中是只读的,所以动态链接采用的做法是在 .data 或 .got(可执行程序或者库自己)中专门预留一片区域用来存放函数的跳转地址,它也被叫做 全局偏移表GOT。表中每一项都是运行模块要引用的一个全局变量或函数的地址。
又因为 .data 和 .got 区域是可读写的,所以可以支持动态进行修改。
注意:
-
由于代码段只读不能直接修改代码段。但有了 GOT表,代码便可以被所有进程共享。考虑到不同进程的地址空间中各动态库的绝对地址、相对位置都不同,反映到 GOT表 上就是每个进程的每个动态库都有独立的 GOT表 ,所以进程间不能共享 GOT表。
-
在单个
.so下,由于 GOT表 与.text的相对位置是固定的,我们完全可以利用 CPU 的相对寻址来找到 GOT表。 -
在调用函数的时候会首先查 GOT表,然后根据表中的地址来进行跳转,这些地址在动态库加载的时候会被修改为真正的地址。
-
这种方式实现的动态链接就被叫做
PIC 地址无关代码。或者说我们的动态库不需要做任何修改,被加载到任意内存地址都能够正常运行,并且能够被所有进程共享。这也是为什么之前我们在动态库制作部分,给编译器将.c编译成.o时指定-fPIC参数的原因,而PIC = 相对编址 + GOT。
库间依赖
注意不仅仅只有可执行程序调用库。库之间是有依赖的,则库也会调用其它库。
而且库和可执行程序一样都是 ELF 的格式,即也有 GOT表,则可以做到库和库之间互相调用也是与地址无关的。
GOT表 中的映射地址会在运行时修改,我们可以通过 gdb 调试去观察 GOT表 的地址变化。有兴趣的读者可以参考:通过GDB学透PLT与GOT
由于动态链接在程序加载的时候需要对大量函数进行重定位,这一步是非常耗时的。为了进一步降低开销,操作系统还做了一些其它的优化,比如延迟绑定,或者也叫 PLT 过程连接表(Procedure Linkage Table)。与其在程序一开始就对所有函数进行重定位,不如将这个过程推迟到函数第一次被调用的时候,因为动态库中绝大多数的函数在程序运行期间可能一次都不会被调用。
PLT 大致思路是:GOT 的跳转地址默认会指向一段辅助代码,它也被叫做 桩代码/stub。在第一次调用函数时,这段代码会负责查询真正函数的跳转地址,并且去更新 GOT 。于是再次调用函数时,就会直接跳转到动态库中真正的函数实现。
总而言之,动态链接实际上将链接的整个过程,比如符号查询、地址的重定位从编译时推迟到了程序的运行时。它虽然牺牲了一定的性能和程序加载时间,但绝对是值得的。因为动态链接能够更有效的利用磁盘空间和内存资源,也极大方便了代码的更新和维护,更关键的是它实现了二进制级别的代码复用。
系统在解析其中的依赖关系时,就是加载并完善动态库之间的 GOT 过程。
总结
-
静态链接的出现,提高了程序的模块化水平。对于一个大的项目,不同的人可以独立地测试和开发自己的模块。通过静态链接,生成最终的可执行文件。
-
静态链接会将编译产生的所有目标文件,和用到的各种库合并成一个独立的可执行文件,其中链接器会去修正模块间函数的跳转地址,也被叫做编译重定位(也叫做静态重定位)。
-
而动态链接将链接的整个过程推迟到程序加载的时候。比如我们去运行一个程序,操作系统会首先将程序的数据代码连同它用到的一系列动态库先加载到内存,其中每个动态库的加载地址都是不固定的,但是无论加载到什么地方,都要映射到进程对应的地址空间,然后通过 GOT 方式进行调用(运行重定位,也叫做动态地址重定位)。
相关文章:
Linux 库制作与原理)
(学习总结34)Linux 库制作与原理
Linux 库制作与原理 库的概念静态库操作归档文件命令 ar静态库制作静态库使用 动态库动态库制作动态库使用与运行搜索路径问题解决方案方案2:建立同名软链接方案3:使用环境变量 LD_LIBRARY_PATH方案4:ldconfig 方案 使用外部库目标文件ELF 文…...

【QT】 QT中的列表框-横向列表框-树状列表框-表格列表框
QT中的列表框-横向列表框-树状列表框-表格列表框 1.横向列表框(1)主要方法(2)信号(3) 示例代码1:(4) 现象:(5) 示例代码2:加载目录项在横向列表框显示(6) 现象: 2.树状列表框 QTreeWidget(1)使用思路(2)信号(3)常用的接口函数(4) 示例代码&am…...

使用DeepSeek的AIGC的内容创作者,如何看待陈望道先生所著的《修辞学发凡》?
目录 1.从修辞手法的运用角度 2.从语言风格的塑造角度 3.从提高创作效率角度 4.从文化传承与创新角度 大家好这里是AIWritePaper官方账号,官网👉AIWritePaper~ 《修辞学发凡》是陈望道 1932 年出版的中国第一部系统的修辞学著作,科学地总…...
的自动化跨平台打包)
使用 GitHub Actions 和 Nuitka 实现 Python 应用(customtkinter ui库)的自动化跨平台打包
目录 引言前置准备配置文件详解实现细节CustomTkinter 打包注意事项完整配置示例常见问题 引言 在 Python 应用开发中,将源代码打包成可执行文件是一个常见需求。本文将详细介绍如何使用 GitHub Actions 和 Nuitka 实现自动化的跨平台打包流程,支持 W…...

【Part 2安卓原生360°VR播放器开发实战】第一节|通过传感器实现VR的3DOF效果
《VR 360全景视频开发》专栏 将带你深入探索从全景视频制作到Unity眼镜端应用开发的全流程技术。专栏内容涵盖安卓原生VR播放器开发、Unity VR视频渲染与手势交互、360全景视频制作与优化,以及高分辨率视频性能优化等实战技巧。 📝 希望通过这个专栏&am…...

【1】云原生,kubernetes 与 Docker 的关系
Kubernetes?K8s? Kubernetes经常被写作K8s。其中的数字8替代了K和s中的8个字母——这一点倒是方便了发推,也方便了像我这样懒惰的人。 什么是云原生? 云原生: 它是一种构建和运行应用程序的方法,它包含&am…...

基于Redis实现RAG架构的技术解析与实践指南
一、Redis在RAG架构中的核心作用 1.1 Redis作为向量数据库的独特优势 Redis在RAG架构中扮演着向量数据库的核心角色,其技术特性完美契合RAG需求: 特性技术实现RAG应用价值高性能内存存储基于内存的键值存储架构支持每秒百万级的向量检索请求分布式架构…...

trivy开源安全漏洞扫描器——筑梦之路
开源地址:https://github.com/aquasecurity/trivy.git 可扫描的对象 容器镜像文件系统Git存储库(远程)虚拟机镜像Kubernetes 在容器镜像安全方面使用广泛,其他使用相对较少。 能够发现的问题 正在使用的操作系统包和软件依赖项…...

pnpm确认全局下载安装了还是显示cnpm不是内部或外部命令,也不是可运行的程序
刚开始是正常使用的。突然开始用不了了一直报错 1.在确保自己node和npm都一直正常使用并且全局安装pnpm的情况下 打开cmd查看npm的环境所在位置 npm config get prefix 2.接着打开高级系统设置 查看自己的path配置有没有问题 确认下载了之后pnpm -v还报错说明没有查询到位置 …...

基于 pnpm + Monorepo + Turbo + 无界微前端 + Vite 的企业级前端工程实践
基于 pnpm Monorepo Turbo 无界微前端 Vite 的企业级前端工程实践 一、技术演进:为什么引入 Vite? 在微前端与 Monorepo 架构落地后,构建性能成为新的优化重点: Webpack 构建瓶颈:复杂配置导致开发启动慢&#…...

软考高级系统架构设计师-第15章 知识产权与标准化
【本章学习建议】 根据考试大纲,本章主要考查系统架构设计师单选题,预计考3分左右,较为简单。 15.1 标准化基础知识 1. 标准的分类 分类 内容 国际标准(IS) 国际标准化组织(ISO)、国际电工…...

MySQL 视图
核心目标: 学习如何创建和使用视图,以简化复杂的查询、提供数据访问控制、实现逻辑数据独立性,并通过 WITH CHECK OPTION 保证数据一致性。 什么是视图? 视图(View)是一种虚拟表,其内容由一个 …...

[操作系统] 信号
信号 vs IPC 板书最后提到了 “信号 vs IPC”,暗示了信号也是一种进程间通信 (Inter-Process Communication, IPC) 的机制。虽然信号的主要目的是事件通知,但它也可以携带少量的信息(即信号的类型)。 初探“信号”——操作系统的“…...
)
网络基础(协议,地址,OSI模型、Socket编程......)
目录 一、计算机网络发展 二、协议 1.认识协议 2.OSI七层模型 3.TCP/IP 五层(或四层)模型 4.协议本质 三、网络传输流程 1.MAC地址 2.协议栈 3.IP地址 IP地址 vs MAC地址 1. 核心区别 2. 具体通信过程类比 3. 关键总结 为什么需要两者? 4.协议栈图解…...

产品经理学习过程
一:扫盲篇(初始产品经理) 阶段1:了解产品经理 了解产品经理是做什么的、产品经理的分类、产品经理在实际工作中都会接触什么样的岗位、以及产品经理在实际工作中具体要做什么事情。 二:准备篇 阶段2:工…...

深入理解Java包装类:自动装箱拆箱与缓存池机制
深入理解Java包装类:自动装箱拆箱与缓存池机制 对象包装器 Java中的数据类型可以分为两类:基本类型和引用类型。作为一门面向对象编程语言, 一切皆对象是Java语言的设计理念之一。但基本类型不是对象,无法直接参与面向对象操作&…...

Linux中的信号量
目录 信号量概念 定义 操作 类型 应用 信号量封装 一、创建信号量 头文件 函数原型 参数说明 返回值 示例 二、设置信号量初始值 头文件 函数原型 参数解释 返回值 示例 三、信号量的P操作 头文件 函数原型 参数解释 返回值 示例 四、信号量的V操作 示…...

深入理解linux操作系统---第15讲 Web 服务器 Nginx
15.1 Nginx 概述 核心特性与历史背景 Nginx由俄罗斯工程师Igor Sysoev于2002年开发,2004年正式发布,旨在解决传统服务器(如Apache)的C10K问题(即单机万级并发连接处理)。其采用事件驱动(Event…...

深度解析算法之前缀和
25.【模版】一维前缀和 题目链接 描述 输入描述 输出描述 输出q行,每行代表一次查询的结果. 示例 输入: 3 2 1 2 4 1 2 2 3 复制 输出: 3 6 这个题的话就是下面的样子,我们第一行输入 3 2的意思即是这个数组是3个元素大小的数组&…...

混合精度训练中的算力浪费分析:FP16/FP8/BF16的隐藏成本
在大模型训练场景中,混合精度训练已成为降低显存占用的标准方案。然而,通过NVIDIA Nsight Compute深度剖析发现,精度转换的隐藏成本可能使理论算力利用率下降40%以上。本文基于真实硬件测试数据,揭示不同精度格式的计算陷阱。…...

6.8 Python定时任务实战:APScheduler+Cron实现每日/每周自动化调度
Python定时任务实战:APScheduler+Cron实现每日/每周自动化调度 实现每日和每周定时任务 关键词:定时任务调度、Python 原生调度器、Cron 脚本、异常重试机制、任务队列管理 1. 定时任务架构设计 采用 分层调度架构 实现灵活的任务管理: #mermaid-svg-PnZcDOgOklVieQ8X {f…...

[Android] 豆包爱学v4.5.0小学到研究生 题目Ai解析
[Android] 豆包爱学 链接:https://pan.xunlei.com/s/VOODT6IclGPsC7leCzDFz521A1?pwdjxd8# 拍照解析答案 【应用名称】豆包爱学 【应用版本】4.5.0 【软件大小】95mb 【适用平台】安卓 【应用简介】豆包爱学,一般又称河马爱学教育平台app,河马爱学。 关…...

swift-12-Error处理、关联类型、assert、泛型_
一、错误类型 开发过程常见的错误 语法错误(编译报错) 逻辑错误 运行时错误(可能会导致闪退,一般也叫做异常) 2.1 通过结构体 第一步 struct MyError : Errort { var msg: String } 第二步 func divide(_ …...
20250409 - 20250419)
每日定投40刀BTC(14)20250409 - 20250419
定投 坚持 《磨剑篇》浮生多坎壈,志业久盘桓。松柏凌霜易,骅骝涉险难。砺锋临刃缺,淬火取金残。但使精魂在,重开万象端。...
)
【刷题Day20】TCP和UDP(浅)
TCP 和 UDP 有什么区别? TCP提供了可靠、面向连接的传输,适用于需要数据完整性和顺序的场景。 UDP提供了更轻量、面向报文的传输,适用于实时性要求高的场景。 特性TCPUDP连接方式面向连接无连接可靠性提供可靠性,保证数据按顺序…...

大数据建模与评估
文章目录 实战案例:电商用户分群与价值预测核心工具与库总结一、常见数据挖掘模型原理及应用(一)决策树模型(二)随机森林模型(三)支持向量机(SVM)模型(四)K - Means聚类模型(五)K - Nearest Neighbors(KNN)模型二、运用Python机器学习知识实现数据建模与评估(一…...

Python语法系列博客 · 第6期[特殊字符] 文件读写与文本处理基础
上一期小练习解答(第5期回顾) ✅ 练习1:字符串反转模块 string_tools.py # string_tools.py def reverse_string(s):return s[::-1]调用: import string_tools print(string_tools.reverse_string("Hello")) # 输出…...

Pandas取代Excel?
有人在知乎上提问:为什么大公司不用pandas取代excel? 而且列出了几个理由:Pandas功能比Excel强大,运行速度更快,Excel除了简单和可视化界面外,没有其他更多的优势。 有个可怕的现实是,对比Exce…...

《解锁图像“高清密码”:超分辨率重建之路》
在图像的世界里,高分辨率意味着更多细节、更清晰的画面,就像用高清望远镜眺望远方,一切都纤毫毕现。可现实中,我们常被低分辨率图像困扰,模糊的监控画面、老旧照片里难以辨认的面容……不过别担心,图像超分…...

杨校老师课堂之C++入门练习题梳理
采用C完成下列题目,要求每题目的时间限制:1秒 内存限制:128M 1. 交换个位与十位的数字 时间限制:1秒 内存限制:128M 题目描述 试编写一个程序,输入一个两位数,交换十位与个位上的数字并输出。 …...

基于springboot的老年医疗保健系统
博主介绍:java高级开发,从事互联网行业六年,熟悉各种主流语言,精通java、python、php、爬虫、web开发,已经做了六年的毕业设计程序开发,开发过上千套毕业设计程序,没有什么华丽的语言࿰…...

数据分析与挖掘
一 Python 基本语法 变量与数据类型 : Python 中变量无需声明,直接赋值即可。 常见的数据类型有数值型(整型 int、浮点型 float、复数型 complex)、字符串型(str,用单引号、双引号或三引号括起来ÿ…...

RoBoflow数据集的介绍
https://public.roboflow.com/object-detection(该数据集的网址) 可以看到一些基本情况 如果我们想要下载,直接点击 点击图像可以看到一些基本情况 可以点击红色箭头所指,右边是可供选择的一些yolo模型的格式 如果你想下载…...

大模型Rag - 两大检索技术
一、稀疏检索:关键词匹配的经典代表 稀疏检索是一种基于关键词统计的传统检索方法。其基本思想是:通过词频和文档频率来衡量一个文档与查询的相关性。 核心原理 文档和查询都被表示为稀疏向量(如词袋模型),只有在词…...

【T型三电平仿真】SVPWM调制
目录 仿真模型分析 克拉克变换 大扇区判断编辑 小区域判断 计算基本电压矢量作用时间 确定基本电压矢量的作用顺序 作用时间和矢量作用顺序对应 七段式化生成阶梯图 矢量状态分布 本人学习过程中提出的问题和解释 SVPWM调制实现了什么功能 SVPWM的算法步骤是什么…...

树莓派5-开发应用笔记
0.树莓派系统目录 /home:用户目录。 除了root用户外,其他所有的使用者的数据都存放在这个目录下,在树莓派的系统中,/home目录中有一个pi的子目录,这个就是pi用户的默认目录。 /bin: 主要放置系统的必备执行文件目录。 …...

[Java实战经验]异常处理最佳实践
一些好的异常处理实践。 目录 异常设计自定义异常为异常设计错误代码(状态码)设计粒度全局异常处理异常日志信息保留 异常处理时机资源管理try-with-resources异常中的事务 异常设计 自定义异常 自定义异常设计,如业务异常定义BusinessExce…...

AOSP的Doze模式-LightIdle初识
前言 从Android 6.0开始,谷歌引入了Doze模式(打盹模式)的省电技术延长电池使用时间。根据第三方测试显示,两台同样的Nexus 5,开启的Doze的一台待机能达到533小时,而未开启Doze的一台待机只能达到200小时。Doze省电效果十分明显。…...

QML动画--ParticleSystem
ParticleSystem 是 QML 中用于创建和管理粒子系统的组件,可以制作各种粒子效果如火焰、烟雾、爆炸等。 基本用法 qml import QtQuick.Particles 2.15ParticleSystem {id: particleSystemImageParticle {source: "particle.png"color: "red"a…...

Win 11 重装 Ubuntu 双系统方法
有时候 Ubuntu 环境崩溃了,或者版本过低,需要卸载重装。本文介绍重装的方法,默认已经有一个双系统。 1. 删除原先 Ubuntu 分区 首先打开 Win 的磁盘管理,找到 Ubuntu 的分区,右键删除分区(注意不要错删 wi…...

单例模式:懒汉式的两种优化写法
单例模式:全局唯一实例 懒汉式:获取时才初始化 ①静态局部变量实现(Meyer’s Singleton)【推荐】 /* 类内创建自身实例的可行性分析:在C中,类可以通过静态成员函数创建自身实例。这种机制的核心在于&…...

详细解释浏览器是如何渲染页面的?
渲染流程概述 渲染的目标:将HTML文本转化为可以看到的像素点 当浏览器的网络线程收到 HTML 文档后,会产生一个渲染任务,并将其传递给渲染主线程的消息队列。在事件循环机制的作用下,渲染主线程取出消息队列中的渲染任务࿰…...

高速系统设计简介
1.1 PCB 设计技术回顾 1981 年 8 月 12 日,IBM 正式发布了历史上第一台个人电脑,自此之后,个人电脑融入了人们生活和工作的各个角落,人类从此进入了个人电脑时代。个人电脑的出现,不仅促进了电子产品在消费领域的发展…...

不规则曲面上两点距离求取
背景 在CT中求皮肤上两点间的弧长。由于人体表面并不是规则的曲面,不可能用圆的弧长求取方法来计算出两点间的弧长。 而在不规则的曲面上求两点的距离,都可以用类似测地线距离求取的方式来求取(积分),而转化为搜索路…...

用usb网卡 虚拟机无法开到全双工的解决办法
今天突发奇想 给unraid宿主机插了两个一摸一样的usb网卡 2.5g的 直通给不同的虚拟机 这里unraid需要安装"USB Manager" 请给unraid自备环境 直通的时候 第一次还没生效 看不到网卡 我又在unraid的管理界面 顶部可以看到多出来一个 "usb"页面 打开可…...

webpack 中 chunks详解
webpack 中 chunks详解 在 Webpack 项目中,webpack.config.js 是核心配置文件,而非 webpack.json。chunks 的概念与 Webpack 的代码分割(Code Splitting)功能密切相关,通过 optimization.splitChunks 配置项可以实现对…...

Java @Serial 注解深度解析
Java Serial 注解深度解析 1. 注解本质 Serial 是 Java 14 引入的编译时校验注解,用于标记序列化相关成员,帮助开发者避免常见的序列化错误。 2. 核心作用 (1) 主要用途 标记序列化相关的特殊方法/字段 提供编译时检查 替代传统的命名约定验证 (…...

齐次坐标变换+Unity矩阵变换
矩阵变换 变换(transform):指的是我们把一些数据,如点,方向向量甚至是颜色,通过某种方式(矩阵运算),进行转换的过程。 变换类型 线性变换:保留矢量加和标量乘的计算 f(x)…...

Python语法系列博客 · 第9期[特殊字符] 函数参数进阶:*args、**kwargs 与参数解包技巧
上一期小练习解答(第8期回顾) ✅ 练习1:整数转字符串列表 nums [1, 2, 3, 4, 5] str_list list(map(str, nums))✅ 练习2:筛选回文字符串 words ["madam", "hello", "noon", "python&qu…...

Python语法系列博客 · 第4期[特殊字符] 函数的定义与使用:构建可复用的模块
上一期小练习解答(第3期回顾) ✅ 练习1:创建一个列表,添加5个名字,并用循环打印 names ["Alice", "Bob", "Charlie", "David", "Eva"] for name in names:print…...