机器学习决策树
一、何为决策树
决策树(Decision Tree)是一种分类和回归方法,是基于各种情况发生的所需条件构成决策树,以实现期望最大化的一种图解法。由于这种决策分支画成图形很像一棵树的枝干,故称决策树。它的运行机制非常通俗易懂,因此被誉为机器学习中,最“友好”的算法。下面通过一个简单的例子来阐述它的执行流程。假设根据大量数据(含 3 个指标:天气、温度、风速)构建了一棵“可预测学校会不会举办运动会”的决策树(如下图所示)。
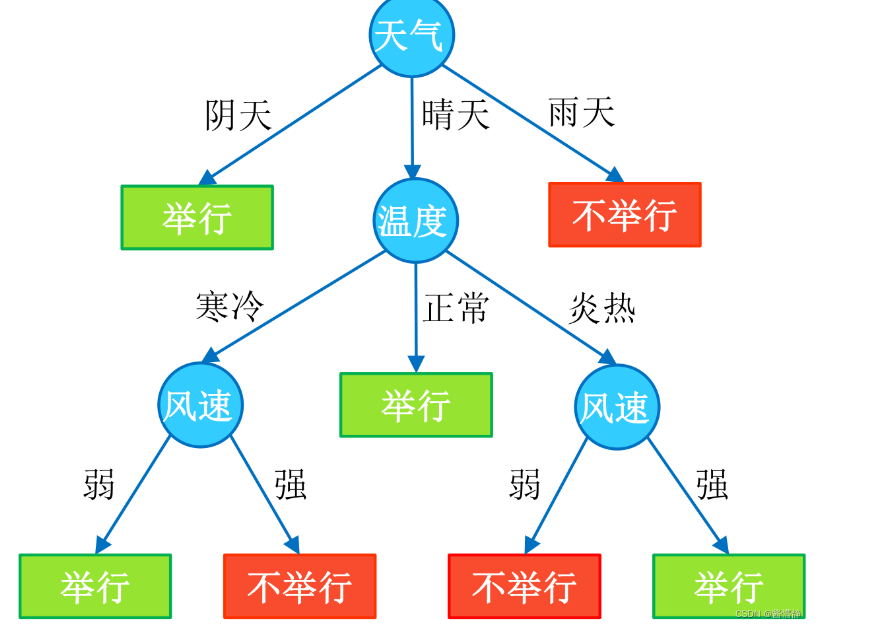
1、决策树的组成
决策树由结点和有向边组成。结点有两种类型:内部结点(圆)和叶结点(矩形)。其中,内部结点表示一个特征(属性);叶结点表示一个类别。而有向边则对应其所属内部结点的可选项(属性的取值范围),有非常好的可解释性。
2、决策树的构建
构建要求:
- 具有较好的泛化能力;
- 在 1 的基础上尽量不出现过拟合现象。
思路:
如果按照某个特征对数据进行划分时,它能最大程度地将原本混乱的结果尽可能划分为几个有序的大类,则就应该先以这个特征为决策树中的根结点。接着,不断重复这一过程,直到整棵决策树被构建完成为止。
二、熵
1、熵的作用
熵(Entropy)是表示随机变量不确定性的度量。说简单点就是物体内部的混乱程度。我们希望分类后的结果能使得整个样本集在各自的类别中尽可能有序,即希望某个特征在被用于分类后,能最大程度地降低样本数据的熵。
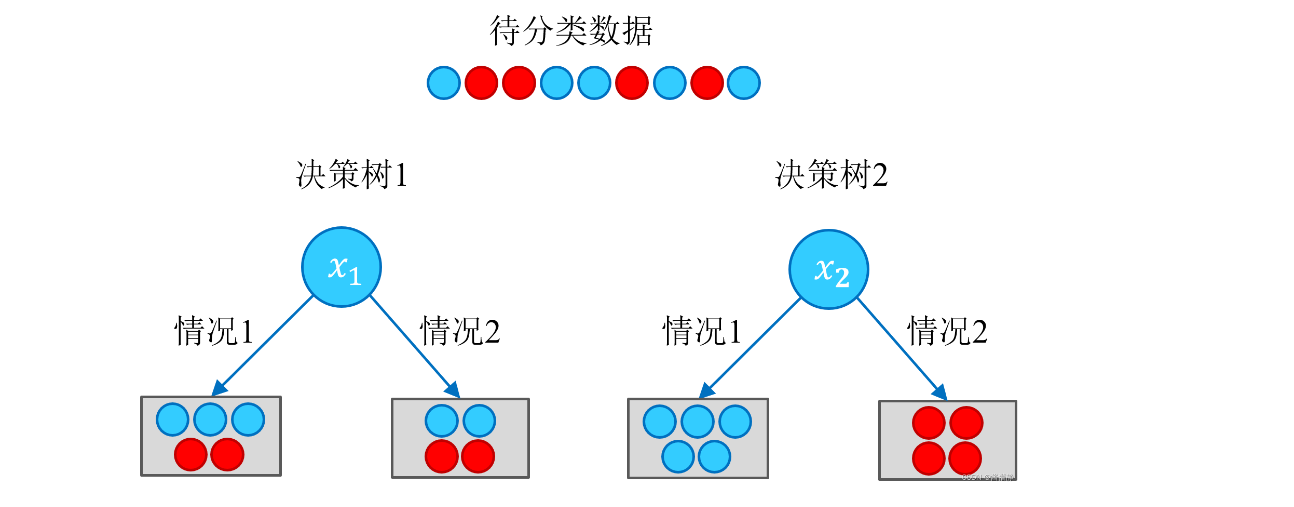
根据以上结果,可以很直观地认为,决策树 2 的分类效果优于决策树 1 。决策树 1 在通过特征 𝑥1 进行分类后,得到的分类结果依然混乱(甚至有熵增的情况),因此这个特征在现阶段被认为是无效特征。
2、熵的定义
设 𝑋 是取值在有限范围内的一个离散随机变量,其概率密度为:
随机变量 𝑋 的熵定义为:
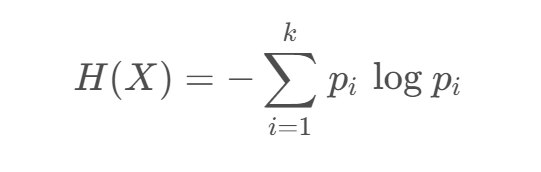
当某个集合含有多个类别时,此时 𝑘 较大, 𝑝𝑖 的数量过多;且整体的 𝑝𝑖 都会因 𝑘 的过大而普遍较小,从而使得 𝐻(X) 的值过大。这正好符合“熵值越大,事物越混乱”的定义。
3、条件熵
对于每个特征,都可以算出“该特征各项取值对运动会举办与否”的影响(而衡量各特征谁最合适的准则,即是熵)。
定义条件熵 𝐻(𝑌 | 𝑋) :在给定 𝑋 的条件下 𝑌 的条件概率分布对 𝑋 的数学期望,即
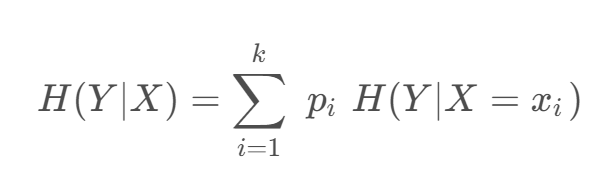
pi=P(X=xi) , i=1,2,…,k (表示指定集合中的元素类别) 。
三、划分选择
决策树学习的关键在于:如何选择最优划分属性。一般而言,随着划分过程的不断进行,我们自然希望决策树各分支结点所包含的样本尽可能属于同一类别,即结点的 “纯度” (purity) 越来越高。下面介绍几类较为主流的评选算法。
1、信息增益( ID3 算法选用的评估标准)
信息增益 𝑔(𝐷, 𝑋) :表示某特征 𝑋 使得数据集 𝐷 的不确定性减少程度,定义为集合 𝐷 的熵与在给定特征 𝑋 的条件下 𝐷 的条件熵 𝐻(𝐷 | 𝑋) 之差,即
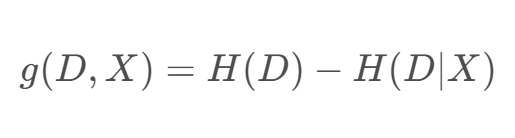
信息增益表达了样本数据在被分类后的专一性。因此,它可以作为选择当前最优特征的一个指标,依据该指标从大到小依次作为选择的特征。
2、信息增益率( C4.5 算法选用的评估标准)
以信息增益作为划分数据集的特征时,其偏向于选择取值较多的特征(特征下的类别很多)。比如,当在学校举办运动会的历史数据中加入一个新特征 “编号” 时,该特征将成为最优特征。因为给定 “编号” 就一定知道那天是否举行过运动会,因此 “编号” 的信息增益很高。
但实际我们知道,“编号” 对于类别的划分并没有实际意义。故此,引入信息增益率。
信息增益率 𝑔𝑅(𝐷, 𝑋) 定义为其信息增益 𝑔(𝐷, 𝑋) 与数据集 𝐷 在特征 𝑋 上值的熵 𝐻𝑋(𝐷) 之比,即:
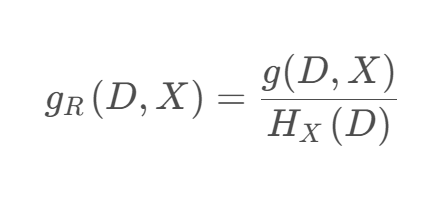
![]() 𝑘 是特征 𝑋 的取值类别个数。
𝑘 是特征 𝑋 的取值类别个数。
信息增益率能明显降低取值较多的特征偏好现象,从而更合理地评估各特征在划分数据集时取得的效果。
3、基尼系数( CART 算法选用的评估标准)
它通过使用基尼系数来代替信息增益率,从而避免复杂的对数运算。基尼系数代表了模型的不纯度,基尼系数越小,则不纯度越低,特征越好。注:这一点和信息增益(率)恰好相反。
对于给定数据集 𝐷 ,假设有 𝑘 个类别,且第 𝑘 个类别的数量为 𝐶𝑘 ,则该数据集的基尼系数为
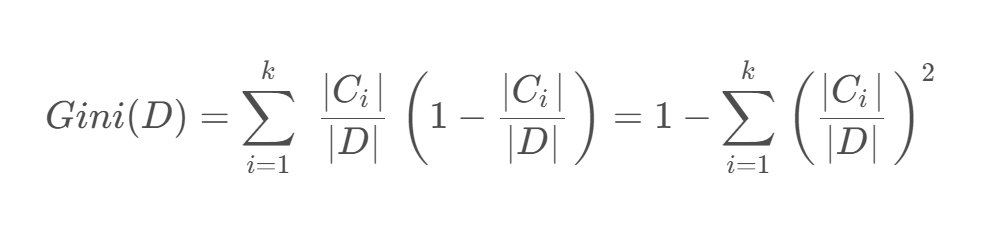
如果数据集 D DD 根据特征 X XX 的取值将其划分为 { D 1 , D 2 , … , D m },则在特征D的条件下划分过后的基尼系数为:
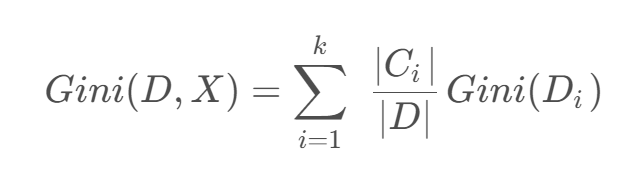
四、实战
data_loader.py
import numpy as np
import pandas as pd
from sklearn.model_selection import train_test_splitdef load_data():"""加载并预处理数据"""data = {'ID': [1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16],'年龄段': ['青年', '青年', '青年', '青年', '青年', '中年', '中年', '中年', '中年', '中年', '老年', '老年','老年', '老年', '老年', '老年'],'有工作': ['否', '否', '是', '是', '否', '否', '否', '是', '否', '否', '否', '否', '是', '是', '否', '否'],'有自己的房子': ['否', '否', '否', '是', '否', '否', '否', '是', '是', '是', '是', '是', '否', '否', '否','否'],'信贷情况': ['一般', '好', '好', '一般', '一般', '一般', '好', '好', '非常好', '非常好', '非常好', '好', '好','非常好', '一般', '非常好'],'类别(是否给贷款)': ['否', '否', '是', '是', '否', '否', '否', '是', '是', '是', '是', '是', '是', '是', '否','否']}df = pd.DataFrame(data)X = df.drop(['ID', '类别(是否给贷款)'], axis=1)y = df['类别(是否给贷款)']# 划分训练集和测试集X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)return X_train, X_test, y_train, y_test, X.columns.tolist()将原始贷款审批数据转换为结构化格式,划分训练集和测试集,为后续决策树建模提供可直接使用的输入。
具体分三步:
1) 用字典定义原始数据并转为Pandas DataFrame;
2) 分离特征(年龄段、工作、房产、信贷)和标签(是否贷款);
3) 按7:3比例随机拆分训练集和测试集(固定随机种子确保可复现),最终返回处理好的特征矩阵、标签向量及特征名称列表。
c45_tree.py
import numpy as np
from collections import Counterclass C45DecisionTree:def __init__(self, max_depth=None, min_samples_split=2):self.max_depth = max_depthself.min_samples_split = min_samples_splitself.tree = Noneself.label_encoders = Nonedef _entropy(self, y):"""计算熵"""counts = np.bincount(y)probabilities = counts / len(y)return -np.sum([p * np.log2(p) for p in probabilities if p > 0])def _information_gain(self, X, y, feature):"""计算信息增益"""total_entropy = self._entropy(y)values, counts = np.unique(X[feature], return_counts=True)weighted_entropy = 0for v, c in zip(values, counts):subset_y = y[X[feature] == v]weighted_entropy += (c / len(y)) * self._entropy(subset_y)return total_entropy - weighted_entropydef _split_info(self, X, feature):"""计算分裂信息"""_, counts = np.unique(X[feature], return_counts=True)probabilities = counts / len(X)return -np.sum([p * np.log2(p) for p in probabilities if p > 0])def _gain_ratio(self, X, y, feature):"""计算信息增益率"""gain = self._information_gain(X, y, feature)split = self._split_info(X, feature)return gain / split if split != 0 else 0def _choose_best_feature(self, X, y, features):"""选择最佳分裂特征"""gain_ratios = [self._gain_ratio(X, y, f) for f in features]best_idx = np.argmax(gain_ratios)return features[best_idx]def _build_tree(self, X, y, features, depth=0):"""递归构建决策树"""# 终止条件if (len(np.unique(y)) == 1 or(self.max_depth is not None and depth >= self.max_depth) orlen(y) < self.min_samples_split):return {'class': Counter(y).most_common(1)[0][0]}# 选择最佳特征best_feature = self._choose_best_feature(X, y, features)tree = {'feature': best_feature, 'children': {}}# 递归构建子树remaining_features = [f for f in features if f != best_feature]for value in np.unique(X[best_feature]):subset_X = X[X[best_feature] == value].drop(columns=[best_feature])subset_y = y[X[best_feature] == value]tree['children'][value] = self._build_tree(subset_X, subset_y, remaining_features, depth + 1)return treedef fit(self, X, y):"""训练模型"""# 将分类特征转换为数值(简化实现)self.label_encoders = {}X_encoded = X.copy()for col in X.columns:le = {val: idx for idx, val in enumerate(X[col].unique())}X_encoded[col] = X[col].map(le)self.label_encoders[col] = ley_encoded = y.map({'否': 0, '是': 1})self.tree = self._build_tree(X_encoded, y_encoded, X.columns.tolist())def predict(self, X):"""预测"""X_encoded = X.copy()for col in X.columns:X_encoded[col] = X[col].map(self.label_encoders[col])predictions = []for _, row in X_encoded.iterrows():node = self.treewhile 'children' in node:feature = node['feature']value = row[feature]if value in node['children']:node = node['children'][value]else:breakpredictions.append(node.get('class', 0))return ['是' if p == 1 else '否' for p in predictions]通过递归地选择信息增益率最大的特征进行节点分裂,构建树形决策结构。
主要流程分为四步:
1) 预处理阶段将分类特征编码为数值;
2) 基于信息熵计算各特征的信息增益率,选择最佳分裂特征;
3) 递归构建决策树,直到满足终止条件(纯度100%、达到最大深度或样本不足);
4) 预测时根据特征值沿树结构向下遍历至叶节点获取分类结果。该实现完整包含了C4.5算法的关键特性:使用增益率避免特征取值数目带来的偏差,支持预剪枝控制过拟合,并通过字典嵌套结构清晰表示树的分支关系。
cart_tree.py
import numpy as np
from collections import Counterclass CARTDecisionTree:def __init__(self, max_depth=None, min_samples_split=2):self.max_depth = max_depthself.min_samples_split = min_samples_splitself.tree = Noneself.label_encoders = Nonedef _gini(self, y):"""计算基尼系数"""counts = np.bincount(y)probabilities = counts / len(y)return 1 - np.sum([p ** 2 for p in probabilities if p > 0])def _gini_index(self, X, y, feature):"""计算基尼指数,基于指定特征 X XX 进行划分后,集合 𝐷 的不确定性"""values, counts = np.unique(X[feature], return_counts=True)weighted_gini = 0for v, c in zip(values, counts):subset_y = y[X[feature] == v]weighted_gini += (c / len(y)) * self._gini(subset_y)return weighted_ginidef _choose_best_feature(self, X, y, features):"""选择最佳分裂特征"""gini_indices = [self._gini_index(X, y, f) for f in features]best_idx = np.argmin(gini_indices)return features[best_idx]def _build_tree(self, X, y, features, depth=0):"""递归构建决策树"""# 终止条件if (len(np.unique(y)) == 1 or(self.max_depth is not None and depth >= self.max_depth) orlen(y) < self.min_samples_split):return {'class': Counter(y).most_common(1)[0][0]}# 选择最佳特征best_feature = self._choose_best_feature(X, y, features)tree = {'feature': best_feature, 'children': {}}# 递归构建子树remaining_features = [f for f in features if f != best_feature]for value in np.unique(X[best_feature]):subset_X = X[X[best_feature] == value].drop(columns=[best_feature])subset_y = y[X[best_feature] == value]tree['children'][value] = self._build_tree(subset_X, subset_y, remaining_features, depth + 1)return treedef fit(self, X, y):"""训练模型"""# 将分类特征转换为数值(简化实现)self.label_encoders = {}X_encoded = X.copy()for col in X.columns:le = {val: idx for idx, val in enumerate(X[col].unique())}X_encoded[col] = X[col].map(le)self.label_encoders[col] = ley_encoded = y.map({'否': 0, '是': 1})self.tree = self._build_tree(X_encoded, y_encoded, X.columns.tolist())def predict(self, X):"""预测"""X_encoded = X.copy()for col in X.columns:X_encoded[col] = X[col].map(self.label_encoders[col])predictions = []for _, row in X_encoded.iterrows():node = self.treewhile 'children' in node:feature = node['feature']value = row[feature]if value in node['children']:node = node['children'][value]else:breakpredictions.append(node.get('class', 0))return ['是' if p == 1 else '否' for p in predictions]通过递归地选择基尼指数最小的特征进行节点分裂,构建二叉树结构的决策模型。
主要流程分为四个关键步骤:
1) 数据预处理阶段将分类特征编码为数值形式;
2) 计算各特征的基尼指数,选择使数据不纯度降低最多的特征作为分裂节点;
3) 递归构建决策树,直到满足终止条件(节点样本纯净、达到最大深度或样本数不足);
4) 预测时根据特征值匹配树的分支结构,最终到达叶节点获得分类结果。该实现完整体现了CART算法的核心特点:使用基尼指数作为分裂标准、支持预剪枝参数控制过拟合、采用字典嵌套结构存储树形关系,并能处理分类特征,最终输出"是"/"否"的贷款审批决策。
main.py
import numpy as npfrom data_loader import load_data
from c45_tree import C45DecisionTree
from cart_tree import CARTDecisionTreedef accuracy(y_true, y_pred):return np.sum(y_true == y_pred) / len(y_true)def print_tree(node, feature_names, class_names, indent=""):"""打印决策树结构"""if 'class' in node:print(indent + "预测:", class_names[node['class']])else:print(indent + "特征:", feature_names[node['feature']] if isinstance(node['feature'], int) else node['feature'])for value, child in node['children'].items():print(indent + f"--> 值: {value}")print_tree(child, feature_names, class_names, indent + " ")if __name__ == "__main__":# 加载数据X_train, X_test, y_train, y_test, feature_names = load_data()class_names = ['否', '是']# 训练和评估C4.5print("\n=== C4.5决策树 ===")c45 = C45DecisionTree(max_depth=3)c45.fit(X_train, y_train)print("测试集准确率:", accuracy(y_test, c45.predict(X_test)))print("\n决策树结构:")print_tree(c45.tree, feature_names, class_names)# 训练和评估CARTprint("\n=== CART决策树 ===")cart = CARTDecisionTree(max_depth=3)cart.fit(X_train, y_train)print("测试集准确率:", accuracy(y_test, cart.predict(X_test)))print("\n决策树结构:")print_tree(cart.tree, feature_names, class_names)-
数据准备阶段:调用load_data()加载并划分训练集/测试集,同时获取特征名称和类别标签。
-
模型训练与评估:
-
分别实例化C4.5和CART决策树(限制最大深度为3)
-
在训练集上拟合模型
-
在测试集上计算预测准确率
-
-
结果展示:递归打印决策树结构,直观显示每个节点的分裂特征和分支条件,以及叶节点的预测结果。
相关文章:

机器学习决策树
一、何为决策树 决策树(Decision Tree)是一种分类和回归方法,是基于各种情况发生的所需条件构成决策树,以实现期望最大化的一种图解法。由于这种决策分支画成图形很像一棵树的枝干,故称决策树。它的运行机制非常通俗易…...

Java集合及面试题学习
知识来源沉默王二、小林coding、javaguide 1、ArrayList list.add("66") list.get(2) list.remove(1) list.set(1,"55") List<String> listnew ArrayList<>(); 底层是动态数组 添加元素流程:判断是否扩容…...

【内置函数】84个Python内置函数全整理
Python 内置函数全集(完整分类 参数详解 示例) 文章目录 Python 内置函数全集(完整分类 参数详解 示例)一、数值与数学函数abs(x)divmod(a, b)pow(x, y, modNone)round(number[, ndigits])sum(iterable, /, start0)hash(obj) …...

【LeetCode 热题 100】双指针 系列
📁283. 移动零 对于该题目,需要注意的是两个地方,一是保持非零元素的相对顺序,以及O(1)的空间复杂度。 采用双指针的思路,将数组划分成3个区间,。 [0 , left]:该区间内元素全是非零元素。 [left1 , right…...
)
实现批量图片文字识别(python+flask+EasyOCR)
话不多说,向上效果图 1)先说框架版本 为什么要先说框架版本呢,因为我在各种版本中尝试了两天,总算确定了如下版本适合我,至于其他的版本,各位自己去尝试 python 3.9.7 EasyOCR 1.7.2 flask 3.0.3 2)执行操作效果图 2.1)多选文件 2.2)图片预览 2.3)提取选中文件 2.4)提取所有文…...
 deny(1))
[Swift]pod install成功后运行项目报错问题error: Sandbox: bash(84760) deny(1)
操作: platform :ios, 14.0target ZKMKAPP do# Comment the next line if you dont want to use dynamic frameworksuse_frameworks!# Pods for ZKMKAPPpod Moyaend pod install成功后运行报错 报错: error: Sandbox: bash(84760) deny(1) file-writ…...

文档内容提取以及合成
如何从10个左右的docx文档中抽取内容,生成新的文档,抽取内容包括源文档的文字内容、图片、表格、公式等,以及目标文档的样式排版、字体、格式,还有目标文档的语言风格、用词规范、文法习惯等等。这是一个相当复杂的需求࿰…...

[Windows] Wireshark 网络抓包工具 v4.4.6
[Windows] Wireshark 网络抓包工具 链接:https://pan.xunlei.com/s/VOODTZ7Lm2gsNLoFNcOIqflzA1?pwdf3ea# 软件说明Wireshark(前称Ethereal)是一款免费开源的网络嗅探抓包东西,世界上最流行的网络协议剖析器!网络封…...

在Ubuntu中安装hadoop的详细过程
在Ubuntu中安装hadoop的详细过程 请自行安装Ubuntu系统(可参考:在VMWare中安装Linux虚拟机Ubuntu) 一、创建hadoop用户 如果在安装 Ubuntu 的时候不是用的 “hadoop” 用户,这时需要增加一个名为 hadoop 的用户。 首先打开终端…...

NOIP2017提高组.列队
目录 *数据结构模板题目算法标签: 模拟, 线段树, 线段树动态开点, 树状数组, 平衡树思路*前置代码完整注释代码精简注释代码 *数据结构模板 题目 530. 列队 算法标签: 模拟, 线段树, 线段树动态开点, 树状数组, 平衡树 思路 首先考虑简单情况, 如果只有一行, 删除一个位置…...
)
PSN港服跳过生日找回密码(需要英语对话,需要注册的id)
登陆这个网站 https://www.playstation.com/en-hk/support/contact-us/?categoryAcc&subCategorypw 随便输入点名字 firstname 跟lastname 勾选,然后打开机器人聊天 然后按照提示输入邮箱跟id,输入正确之后会分配真人客服 真人客服会要求提供第一次…...

服务治理-服务注册
一个服务在真实项目部署的时候,如果压力较大,会做多实例部署。 在IDEA里面做多实例部署的话,只需要配置多个启动项。...

Jinja2模板引擎SSTI漏洞
1. 引入 再研究大模型相关应用的漏洞CVE-2025-25362时(参考1),看到作者给了比较详细的分析(参考2)。下面对这个漏洞做个介绍。 2. 漏洞类型 这个漏洞属于CWE-1336,它主要关注在使用模板引擎进行脚本化处…...

STM32单片机教程:从零开始打造智能天气时钟
STM32单片机教程:从零开始打造智能天气时钟 大家好!今天我想为大家详细介绍一下我们的STM32课程,以及如何从零基础逐步掌握单片机开发技能,最终实现一个完整的智能天气时钟项目。 课程面向人群 本课程主要面向那些已经通过野火…...
)
c++_csp-j算法 (1)
DFS搜索(深度优先搜索) 讲解 第一部分:DFS搜索算法简介 深度优先搜索(Depth-First Search,DFS)是一种常用的图搜索算法,用于遍历或搜索图或树的所有节点。DFS算法的核心思想是尽可能深地搜索图的分支,直…...

word选中所有的表格——宏
Sub 选中所有表格()Dim aTable As TableApplication.ScreenUpdating FalseActiveDocument.DeleteAllEditableRanges wdEditorEveryoneFor Each aTable In ActiveDocument.TablesaTable.Range.Editors.Add wdEditorEveryoneNextActiveDocument.SelectAllEditableRanges wdEdito…...

16、堆基础知识点和priority_queue的模拟实现
一、priority_queue的使用方法 priority_queue的使用方法看这篇文章 二、堆 1、介绍 堆(Heap)是一种特殊的完全二叉树数据结构,满足以下性质: 堆序性质(Heap Property): 大顶堆(…...

20250419将405的机芯由4LANE的LVDS OUT配置为8LANE的步骤
20250419将405的机芯由4LANE的LVDS OUT配置为8LANE的步骤 2025/4/19 15:38 查询格式YUV/RGB 81 09 04 24 60 FF 90 50 00 00 FF 查询辨率帧率 81 09 04 24 72 FF 90 50 01 03 FF 查询LVDS mode : Singel output/Dual output 81 09 04 24 74 FF 90 50 00 00 FF 配置405的机…...
)
【信息系统项目管理师】高分论文:论信息系统项目的采购管理(信息化办公系统)
更多内容请见: 备考信息系统项目管理师-专栏介绍和目录 文章目录 论文1、规划采购管理2、实施采购3、管理采购论文 随着信息化技术的发展,从企业到政府,传统的办公模式正在悄然消失,信息化办公模式正成为主流。特别是国务院印发的《关于加快推广“互联网+政务服务”工作的…...

国产GPU生态现状评估:从寒武纪到壁仞的编程适配挑战
近年来,国产GPU厂商在硬件性能上持续突破,但软件生态的构建仍面临严峻挑战。本文以寒武纪、壁仞等代表性企业为例,对比分析其与CUDA生态的兼容性差异,并探讨技术突围路径。 一、编程适配的核心挑战 编程模型差异与开发成本 …...
mamba-ssm环境安装——一次成功!)
Linux(autoDL云服务器)mamba-ssm环境安装——一次成功!
1.创建环境选择torch2.0, cuda11.8,python3.8 2.从GitHub官网下载cp38对应的,causl_conv1d,和mamba-ssm2.2.2。下载入下图所示。 3.直接用finalshell 或者xshell连接服务器上传,到根目录下面。 直接用pip install *…...
实现交通标志识别)
手搓LeNet-5(基础模型)实现交通标志识别
手搓LeNet-5(基础模型)实现交通标志识别 一、环境准备1. 安装Python环境2. 安装CUDA(可选,仅需GPU加速时)3. 配置虚拟环境4. 安装PyTorch核心库5. 安装辅助库6. 验证安装7. 准备数据集8.常见问题处理 二、 数据集处理三…...

TV主板的拆解学习
下面是小米的电视机主板,电源采用PFCLLC方案,主控采用电视盒子主控采用晶晨半导体T962-H,搭配2G南亚DDR3L内存和8G三星eMMC存储器。 本文用来加深对TV主板的认识,学习于充电头网,链接在文末。 两颗蓝色插件Y电容来自S…...

PH热榜 | 2025-04-19
1. Omakase.ai Voice 标语:你的语音驱动销售助手。一个链接。 介绍:Omakase.ai Voice将您的网站转变为一个语音驱动的销售助手,它可以在客户浏览时进行对话、倾听并给出推荐。聊天机器人往往效果不佳——它们无法实现销售,而这个…...
—— 49.字符异位词分组题解)
LeetCode(Hot.2)—— 49.字符异位词分组题解
Problem: 49. 字母异位词分组 字母异位词的定义是:两个单词的字母组成一样,但顺序可以不同,比如 eat、tea 和 ate 就是一个组的。 思路 将每个字符串按字母排序,把排序后的字符串作为 key,相同 key 的放在一个 list 中…...

UE学习记录part19
231 insect: insect enemy type 创建dead动画资源 往insect head上添加socket 创建攻击root motion动画。motion warping需要与root motion合作使用 为buff_blue创建物理资产 设置simulate physic使sinsect死亡后能落到地板上而不是漂浮在空中,要将die函数设置为 -…...

不连续数据区间天数累计sql
计算不连续数据区间天数并且剔除重复天数 create table loan_data(loan_no varchar(10),cust_no varchar(10),start_date date,end_date date )INSERT INTO loan_data VALUES (LN001, CUST001, 2025-01-04, 2025-01-08); INSERT INTO loan_data VALUES (LN002, CUST001, 2025-…...
,源码可白嫖!)
django基于爬虫的网络新闻分析系统的设计与实现(源码+lw+部署文档+讲解),源码可白嫖!
摘要 本网络新闻分析系统采用B/S架构,数据库是MySQL,网站的搭建与开发采用了先进的Python进行编写,使用了Django框架。该系统从两个对象:由管理员和用户来对系统进行设计构建。前台主要功能包括:用户注册、登录、浏览…...

JAVA文件I/O
目录 一、三种路径的分类: 1、绝对路径: 2、相对路径: 3、基准目录: 二、文件的种类: 三、利用JAVA操作文件: 1、File类的构造方法: 2、File 类方法的使用: 使用例子&#…...

第七周作业
一、分别在前端和后端使用联合注入实现“库名-表名-字段名-数据”的注入过程,写清楚注入步骤 1、爆库 后端sql语句:select database(); 前端:1 order by 1#,1 order by 2#,1 order by 3# 判断显示位为两位1 union sel…...

Linux 进程信号详解
进程信号 信号是进程之间事件异步通知的一种方式,属于软中断。 kill -l //查看不同信号代表的事件 执行kill -l 可以看到共有62种信号,其中: 0-31号信号为非可靠信号(这部分信号借鉴于UNIX系统的信号);…...

MCP 应用案例-网络设备批量管理
案例背景 需求痛点 企业需管理数百台跨地域网络设备(交换机/路由器),传统方式存在: 人工SSH登录效率低脚本维护成本高(不同厂商CLI语法差异)状态监控依赖独立监控系统 解决方案 通过MCP协议构建智能网络…...

进程程序替换
fork() 之后,⽗⼦各⾃执⾏⽗进程代码的⼀部分如果⼦进程就想执⾏⼀个全新的程序呢?进程的程序 替换来完成这个功能! 程序替换是通过特定的接⼝,加载磁盘上的⼀个全新的程序(代码和数据),加载到调⽤进程的地址空间中!…...

6.7 ChatGPT自动生成定时任务脚本:Python与Cron双方案实战指南
ChatGPT自动生成定时任务脚本:Python与Cron双方案实战指南 关键词:定时任务调度, ChatGPT 代码生成, Cron 脚本开发, Python 调度器, 自动化更新系统 6.3 使用 ChatGPT 生成 Cron 调度脚本 在 GitHub Sentinel 的定期更新功能中,定时任务调度是核心模块。本节演示如何通过…...

废物九重境弱者学JS第十四天--构造函数以及常用的方法
目录 JavaScript 进阶 - 第2天 深入对象 构造函数 实例成员 静态成员 内置构造函数 Object Array 包装类型 String Number 案例 JavaScript 进阶 - 第2天 了解面向对象编程的基础概念及构造函数的作用,体会 JavaScript 一切皆对象的语言特征,…...

机器学习+深度学习
文章目录 一、机器学习(一)机器学习概念(二)机器学习基本流程(三)机器学习应用场景二、机器学习的常见工具与相关库(一)Python 机器学习库(二)数据处理库(三)可视化库三、聚类算法思想与模型搭建过程(一)K - Means 聚类算法(二)DBSCAN 聚类算法四、分类算法思想…...

docker基本使用命令
一、镜像 1、拉取镜像 docker pull busybox docker pull nginx:1.26-alpine 2、查看本地镜像 [rootRocky-1 ~]# docker images REPOSITORY TAG IMAGE ID CREATED SIZE nginx latest 4e1b6bae1e48 18 hours ago 192MB busybox lates…...

相机模型--CMOS和CCD的区别
1--CMOS和CCD的工作原理 CCD(Charge Coupled Device,电荷耦合器件): 1. 图像通过光电效应在感光单元中转化为电荷; 2. 每个像素上的电荷被依次“耦合”并传输到芯片的角落,通过一个或几个模拟输出放大器输…...
)
触发器(详解)
一:MySQL触发器 MySQL数据库中触发器是一个特殊的存储过程。 不同的是执行存储过程要使用 CALL 语句来调用,而触发器的执行不需要使用 CALL 语句来调用,也不需要手工启动,只要一个预定义的事件发生就会被 MySQL自动调用。 引发…...
的数据)
Vue 3 中将 ref 创建的响应式对象数据转换为普通(非响应式)的数据
Vue 3 中使用 ref 创建的响应式对象数据转换为普通(非响应式)的数据,有以下几种方法: 1. 访问 .value 属性: 这是最直接、最常见的方法。 由于 ref 对象的值存储在其 .value 属性中,直接访问该属性即可获得普通数据。…...
_键盘事件)
Vue基础(6)_键盘事件
普通键盘事件 键盘事件常用的有两个:keydown、keyup。 举例: <!DOCTYPE html> <html lang"zh"> <head><meta charset"UTF-8"><script type"text/javascript" src"../js/vue.js"&…...

Kubernetes控制平面组件:高可用 APIServer
云原生学习路线导航页(持续更新中) kubernetes学习系列快捷链接 Kubernetes架构原则和对象设计(一)Kubernetes架构原则和对象设计(二)Kubernetes架构原则和对象设计(三)Kubernetes控…...

这个是我的qss按钮样式 和之前的// 应用全局样式表 QString style = R“(是会冲突吗,导致我的按钮背景颜色是黑色,我该怎么修改
/* 样式 A */ *[style-type="A"] { background-color:#cfd1d4; border: none; border-radius: 50%; /* 圆形边框 */ padding: 7px 14px; } *[style-type="A"]:hover { background-color: #45a049; }这个是我的qss按钮样式 和之前的// 应用全局样式表 QStri…...
)
Kubernetes控制平面组件:API Server详解(二)
云原生学习路线导航页(持续更新中) kubernetes学习系列快捷链接 Kubernetes架构原则和对象设计(一)Kubernetes架构原则和对象设计(二)Kubernetes架构原则和对象设计(三)Kubernetes控…...

人工智能在智慧农业中的应用:从田间到餐桌的变革
农业是人类社会的基石,随着全球人口的增长和资源的日益紧张,传统农业面临着巨大的挑战。近年来,人工智能(AI)技术的快速发展为农业带来了新的机遇。智慧农业通过将AI技术与农业生产相结合,实现了从田间种植…...

多人3D游戏完整实现方案
以下是一份完整的代码实现方案,涵盖架构设计、核心模块实现和部署流程。我们以 多人3D游戏 为例,结合之前讨论的Nano服务端框架和Unity客户端: 技术栈 模块技术选型服务端Golang + Nano框架 + MongoDB客户端Unity 2022 + C# + Mirror Networking通信协议Protobuf + WebSock…...

FFUF指南
ffuf 的核心功能: 目录/文件发现: 通过暴力破解(使用字典)探测目标网站的隐藏目录或文件,例如: ffuf -w /path/to/wordlist.txt -u http://target.com/FUZZ 子域名枚举: 通过模糊测试发现目标…...

详细的PyCharm安装教程
详细的PyCharm安装教程 安装前准备 确认系统要求: Windows:Microsoft Windows 10 1809 64位或更高版本,Windows Server 2019 64位或更高版本。 macOS:12.0或更高版本。 Linux:满足以下要求的两个最新版本的Ubuntu LTS或…...

FPGA IO引脚 K7-认知4
UG475来知道bank, GTX, Pin数量, Package, Pinout 时钟 SRCC(Single-Region Clock Capable I/O)和MRCC(Multi-Region Clock Capable I/O)是专用的时钟输入/输出引脚。 如 2.DQS...

C++——异常
1. C语言错误处理机制 我们在曾经介绍过C语言下的错误码。错误码我们过去经常见到,错误码通常是指errno变量中的值,它表示特定操作(如系统调用或库函数)发生错误的原因。errno是一个全局变量,当出现错误时会自动将错误…...