【LLaMAFactory】LoRa + 魔搭 微调大模型实战
前言
环境准备
之前是在colab上玩,这次在国内的环境上玩玩。
魔搭:https://www.modelscope.cn/
现在注册,有100小时的GPU算力使用。注册好了之后:
魔搭社区
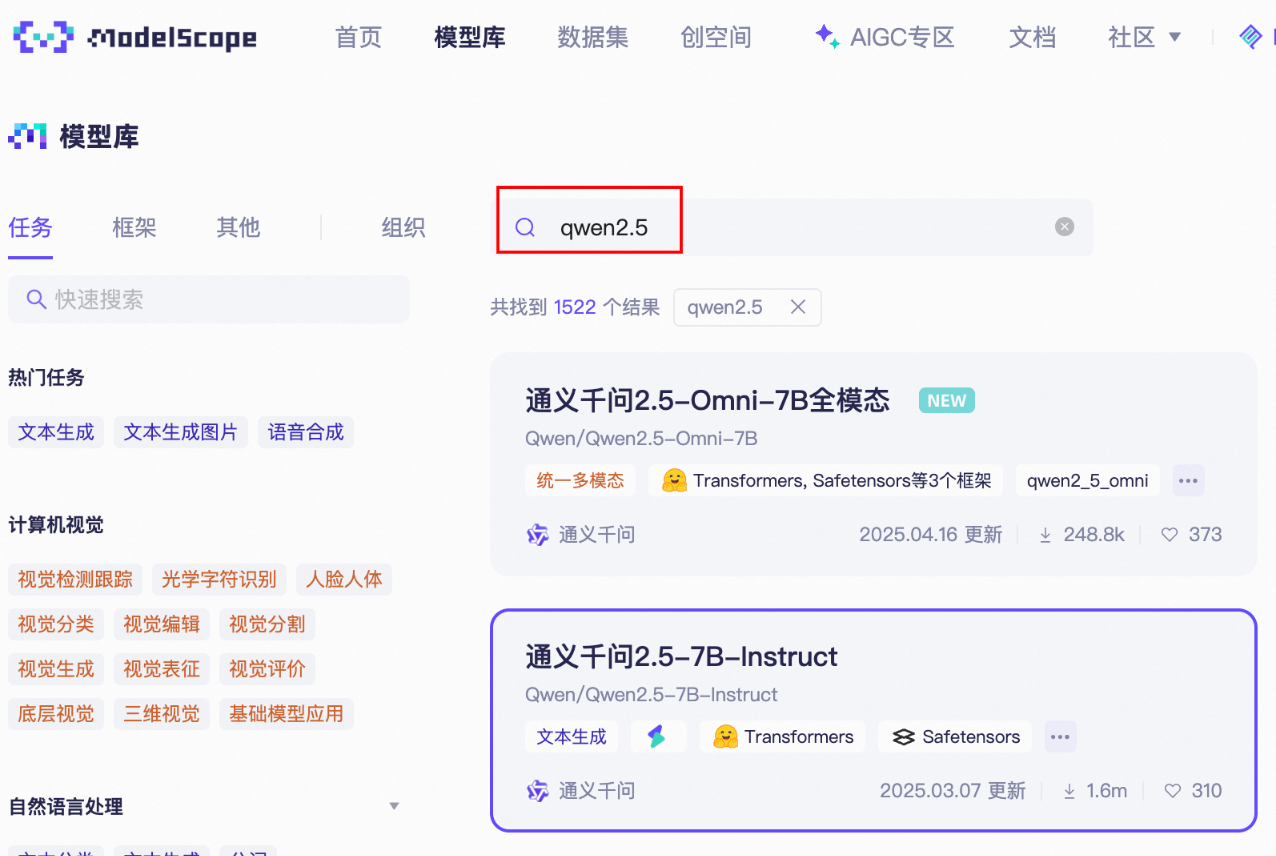
这里使用qwen2.5-7B-Instruct模型,这里后缀Instruct是指对预训练进行过指令微调的大模型。这种模型特别适用于指令微调。
GPU资源
这里选择免费实例,只要是刚注册都有100小时的免费算力。
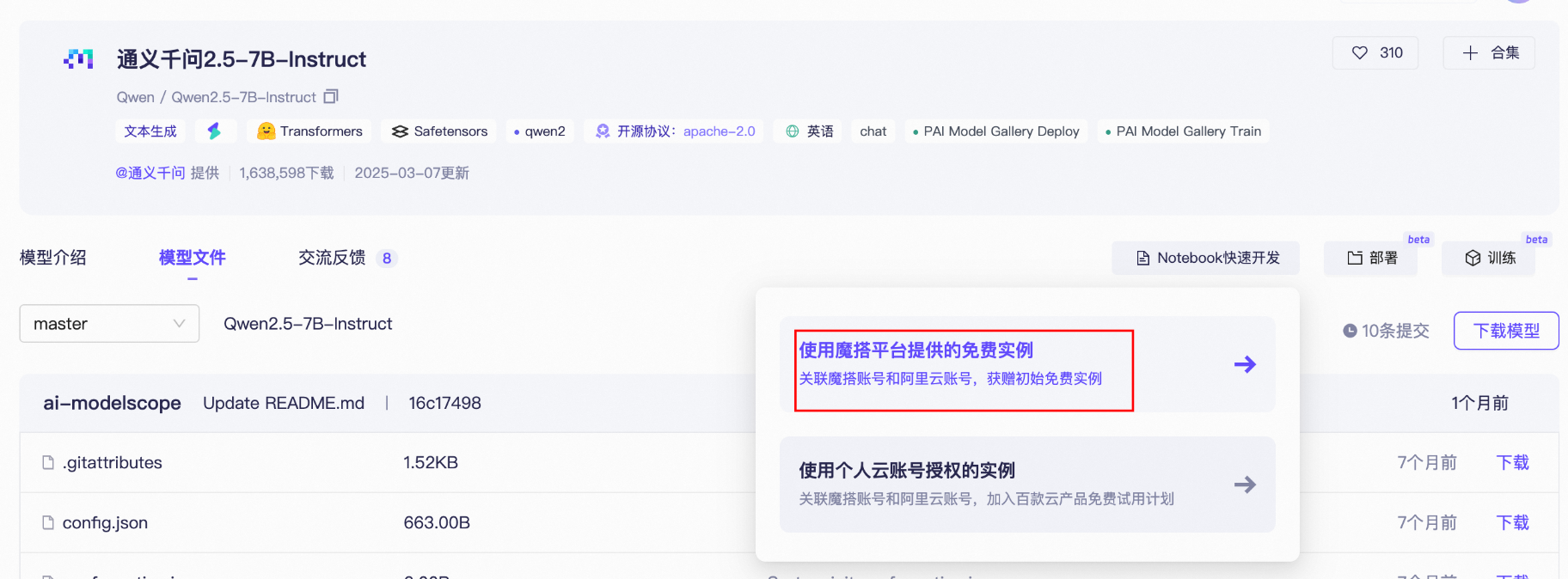
接着选择方式二:
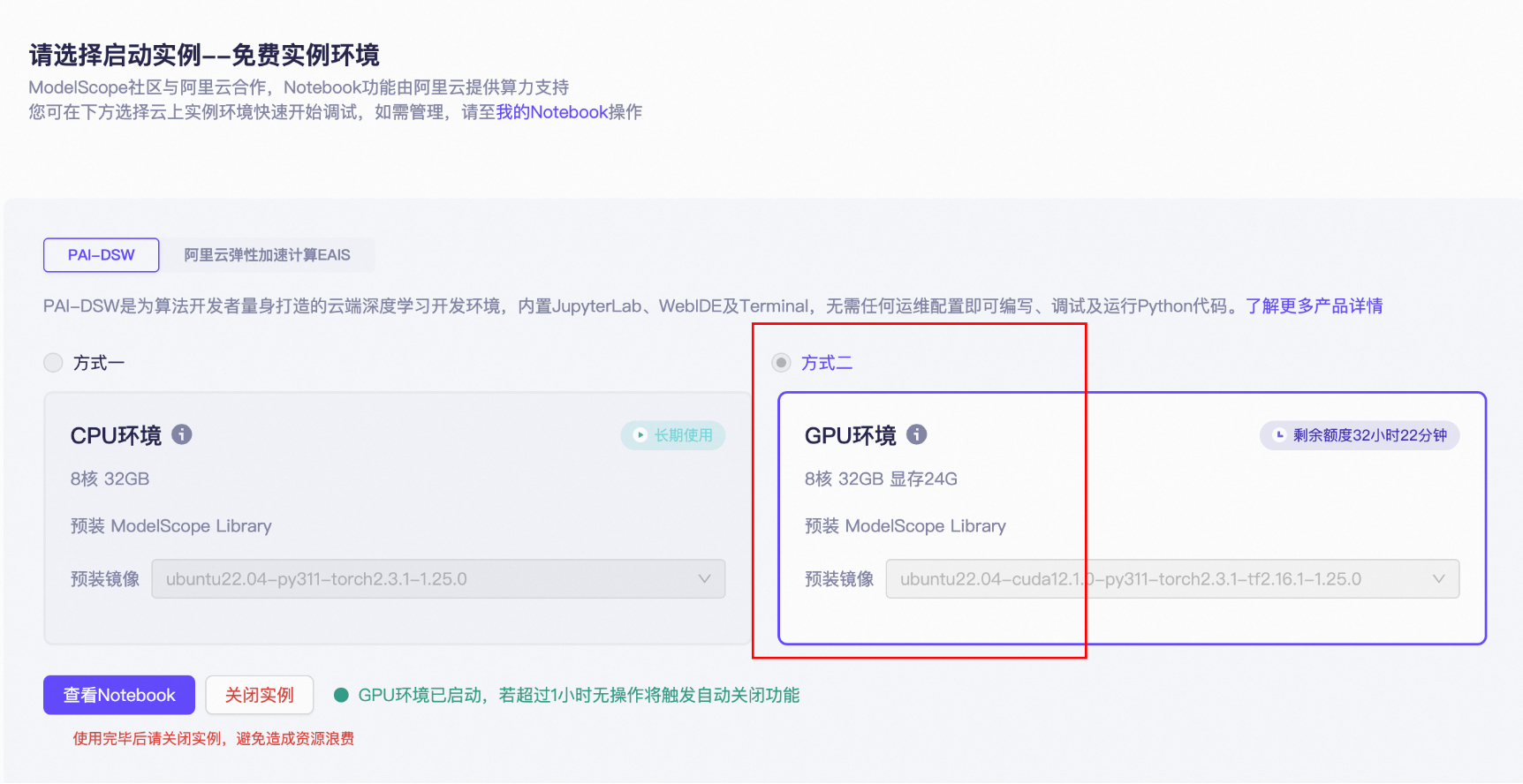
再点击查看Notebook就会进入在线的操作页面。
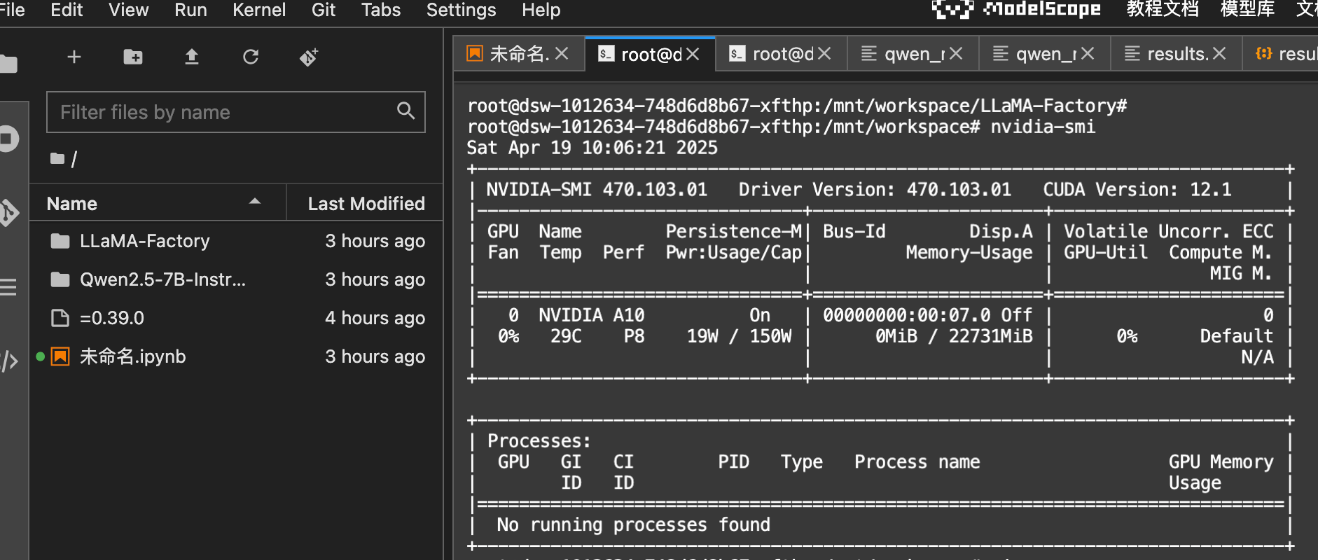
我们可以先来查看下GPU资源情况:
先打开一个新tab页,点击左上角的+号,选择terminal
再执行如下命令:
nvidia-smi
安装依赖库
在terminal中执行如下命令:
pip3 install --upgrade pip
pip3 install bitsandbytes>=0.39.0
说明:bitsandbytes 是一个由 Facebook Research 开发的轻量级开源库(基于 MIT 协议),专注于通过低比特精度量化技术优化深度学习模型的训练和推理效率。即:使一个专注于优化计算效率的库。
安装LLaMAFactory
参考官网:https://github.com/hiyouga/LLaMA-Factory/blob/main/README_zh.md#%E5%AE%89%E8%A3%85-llama-factory
执行如下命令:
git clone --depth 1 https://github.com/hiyouga/LLaMA-Factory.git
cd LLaMA-Factory
pip install -e ".[torch,metrics]"
第一次执行会报错,如下:
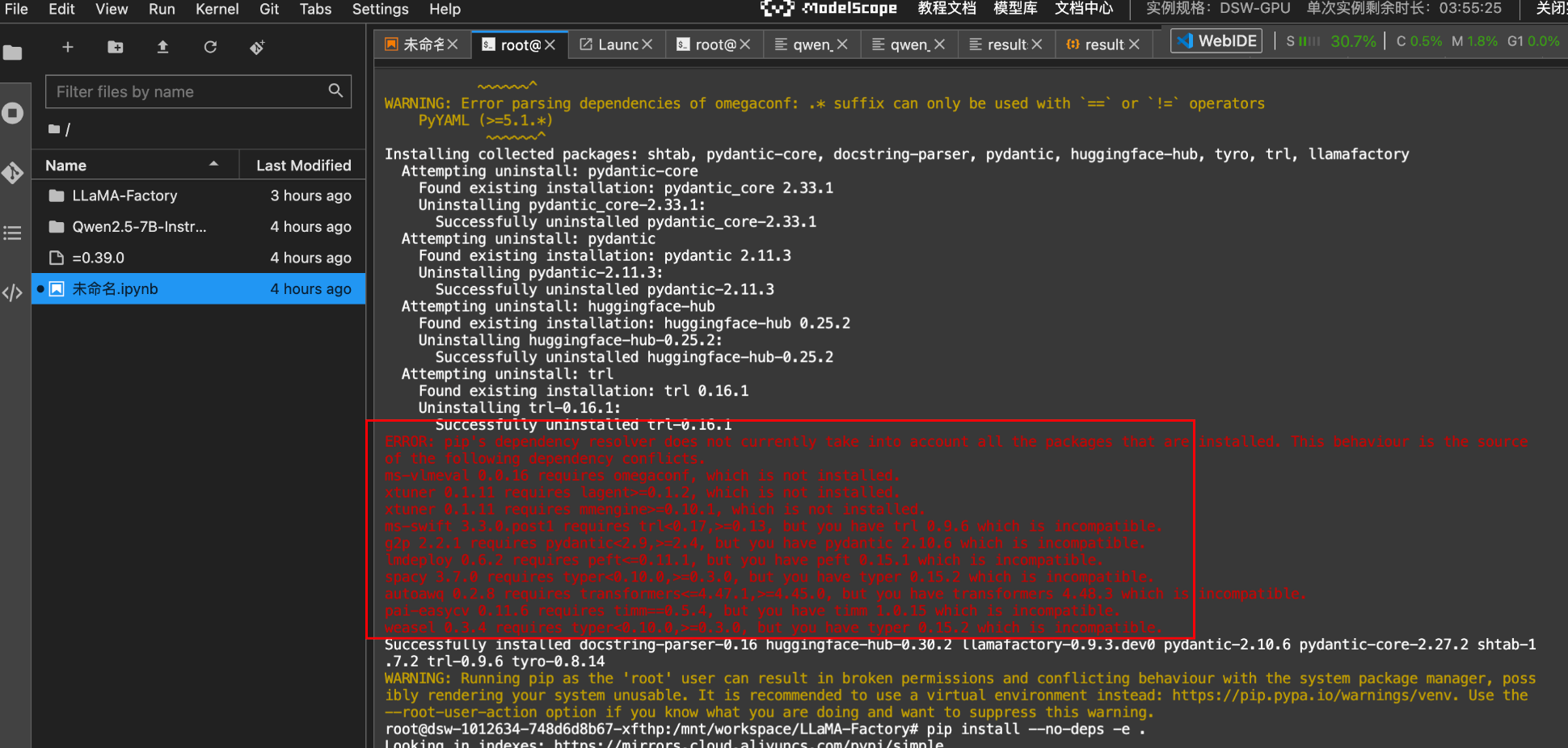
这是因为包冲突导致的,执行如下命令解决冲突:
pip install --no-deps -e .
之后再次执行:
pip install -e ".[torch,metrics]"
自此安装完毕。
微调模型的下载
在魔搭的模型库中找到通义千问2.5-7B-Instruct:
这里我们选择git下载:
执行命令:
root@dsw-xxx-xfthp:/mnt/workspace# git clone https://www.modelscope.cn/Qwen/Qwen2.5-7B-Instruct.git
下载好之后,我们可以在左边看到相应的文件:
微调大模型
通过上面的操作,我们的基础资源已经准备就绪。
修改微调配置文件
在窗口的左侧的文件列表,进入到LLaMA-Factory/examples/train_lora中:
命令的路径:/mnt/workspace/LLaMA-Factory/examples/train_lora
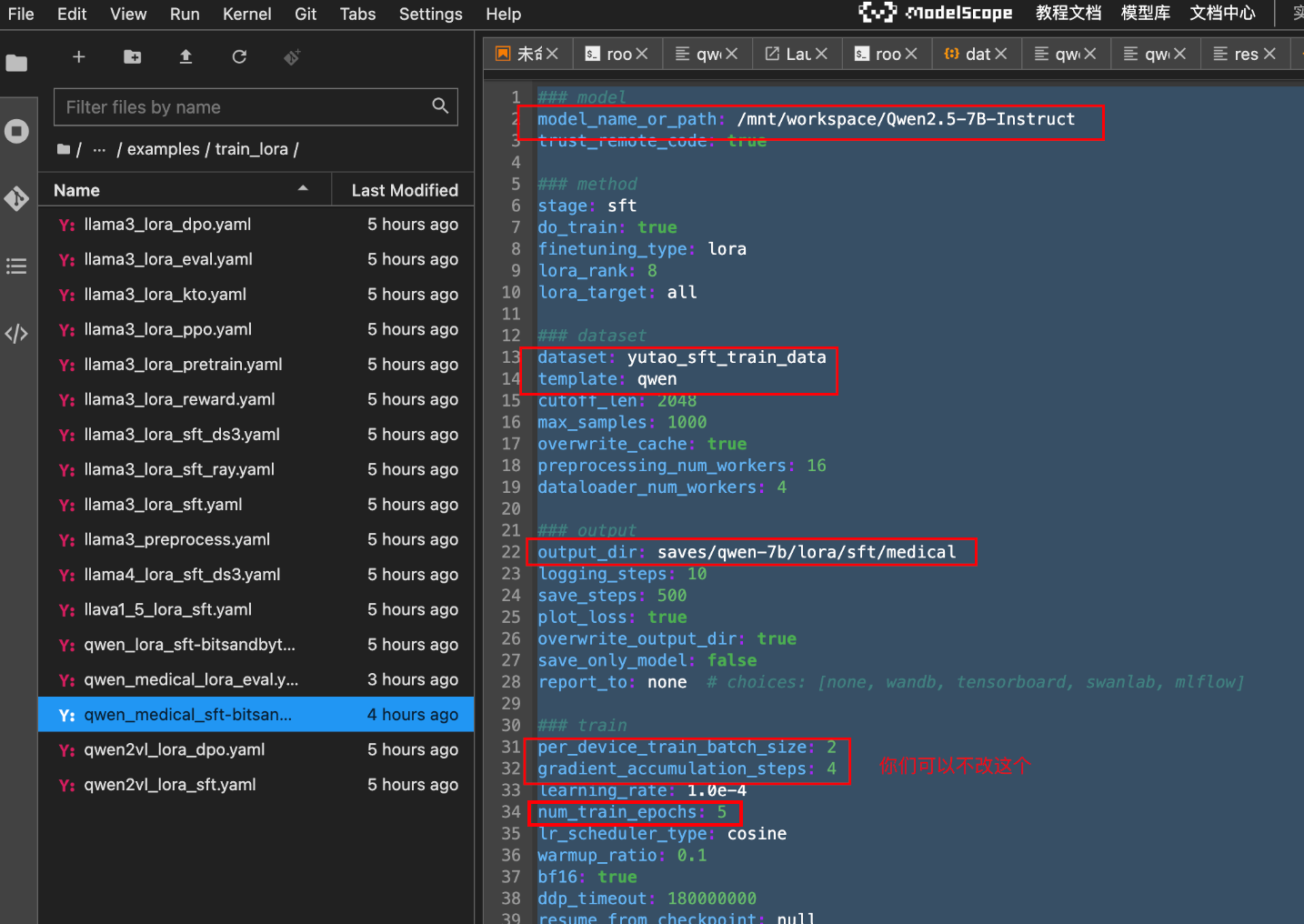
复制一份:llama3_lora_sft.yaml文件,重命名:qwen_lora_sft-bitsandbytes.yaml。
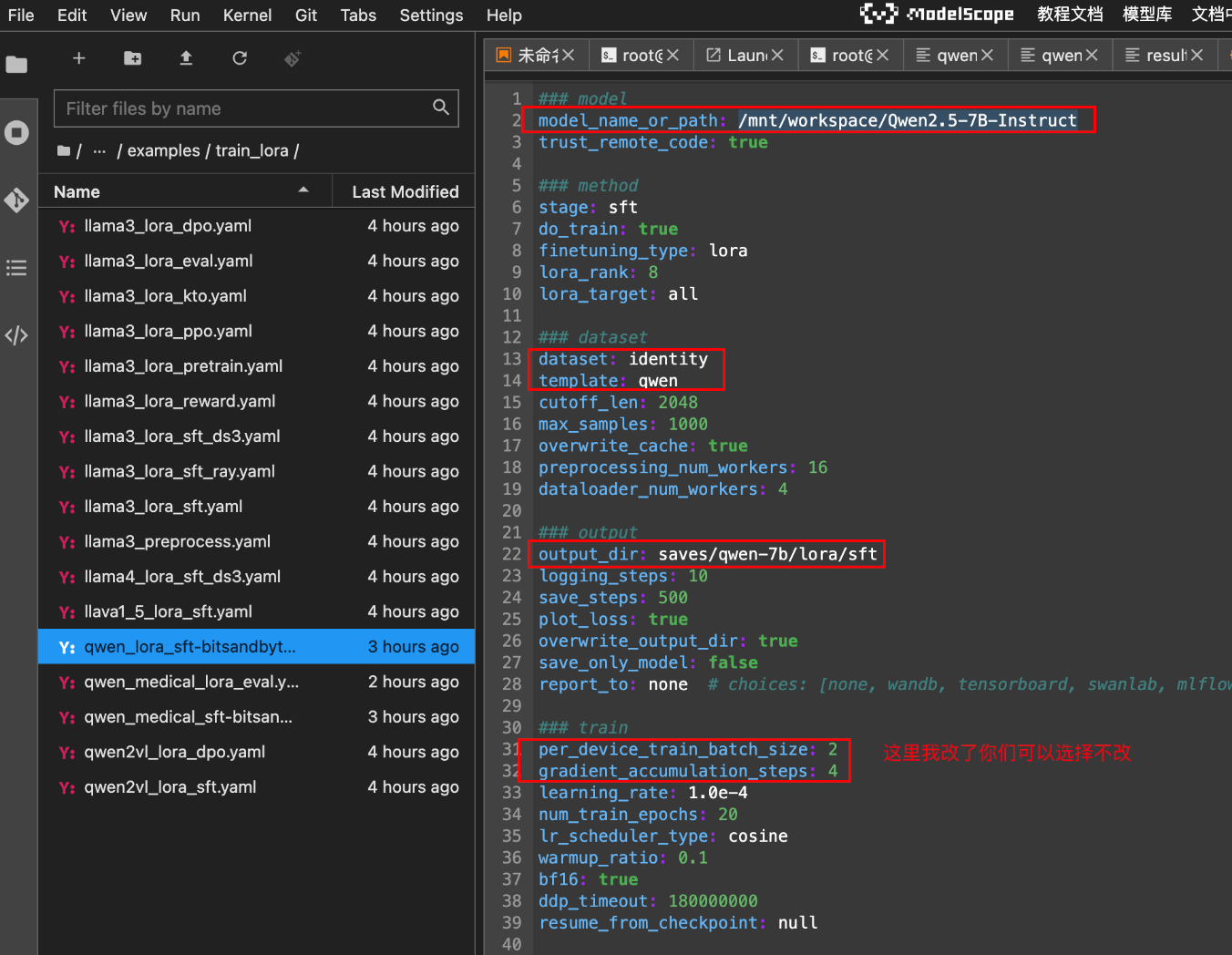
- 这个文件就是微调配置文件。第一行
model_name_or_path就是我们刚刚下载大模型的路径。
其他参数还有:
- dataset: 表示的是数据集
- template:这个是训练指令模板
- output_dir:训练完成后,保存参数、配置、模型的路径
### train这个下面训练的超参数,一般都不需要该,唯一需要调整的可能是训练轮次num_train_epochs。一轮是指对整个数据集进行一次完整的遍历。
dataset 数据集
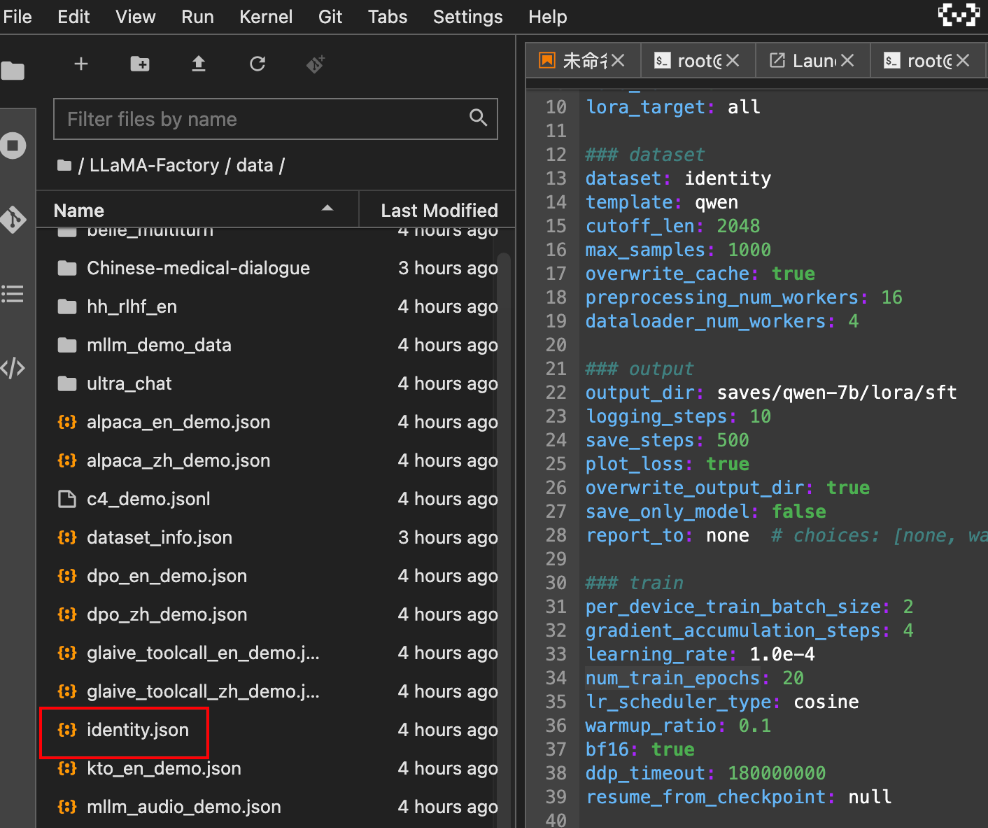
LLaMA-Factory项目内置了很多数据集,统一都放在data目录下面。所以我们微调时,直接使用即可。
比如我们这次用到的:identity.json。数据集名称叫:identity。
启动微调
下面三行命令分别对 Llama3-8B-Instruct 模型进行 LoRA 微调、推理和合并。
llamafactory-cli train examples/train_lora/llama3_lora_sft.yaml
llamafactory-cli chat examples/inference/llama3_lora_sft.yaml
llamafactory-cli export examples/merge_lora/llama3_lora_sft.yaml
我们根据实际情况,修改上面的命令即可。
可以使用
llamafactory-cli help显示帮助信息。
在LLaMA-Factory目录下,执行命令:
llamafactory-cli train examples/train_lora/qwen_lora_sft-bitsandbytes.yaml
#实际执行长这个样子
root@dsw-xxx-xfthp:/mnt/workspace/LLaMA-Factory# llamafactory-cli train examples/train_lora/qwen_lora_sft-bitsandbytes.yaml
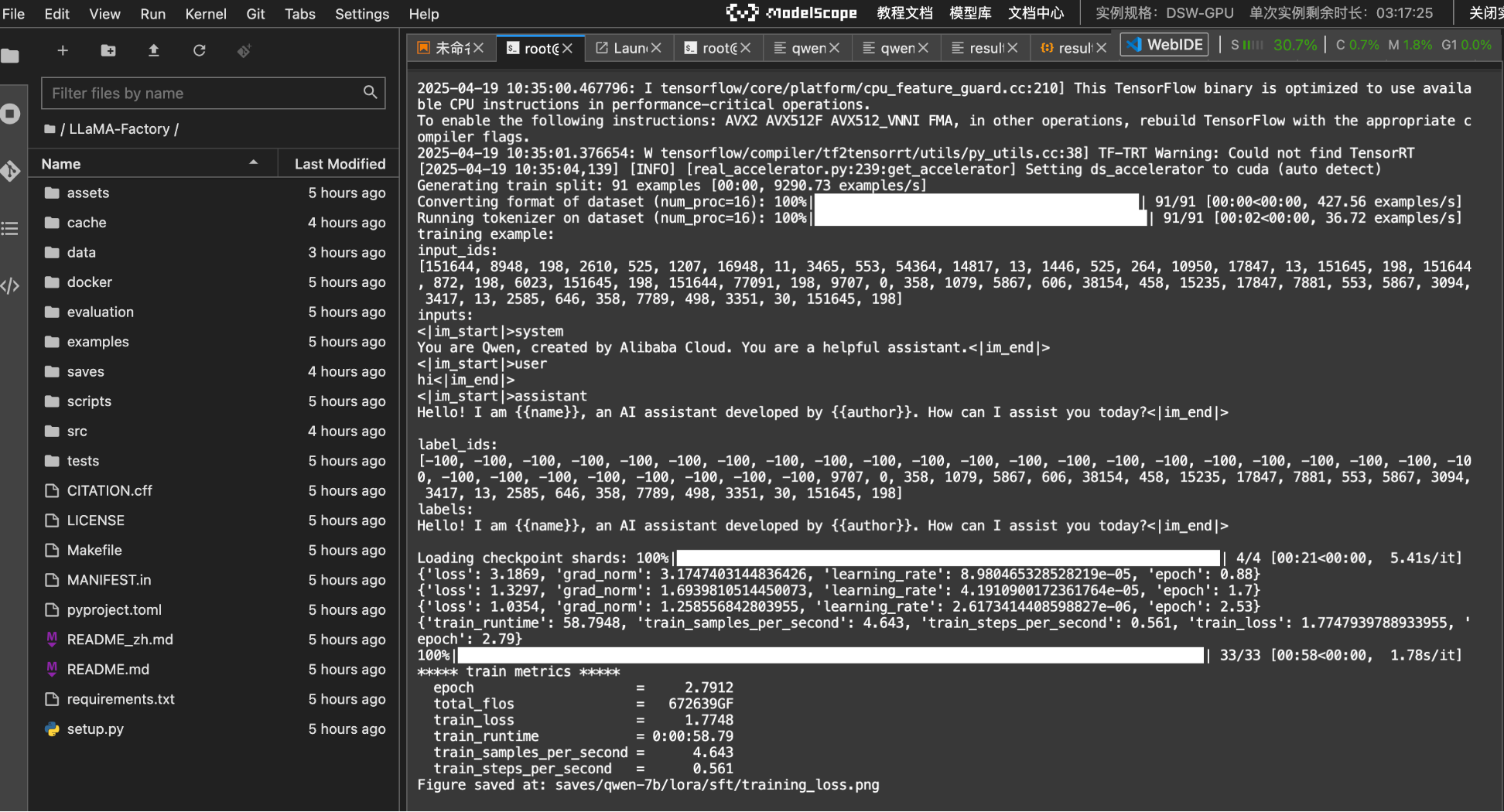
第一次训练由于训练轮次是默认值:3,所以非常就结束了(58秒)。
可以去saves/qwen-7b/lora/sft/training_loss.png目录下查看训练损失比例图。
下面这个已经是我调整过训练轮次的图了,第一次训练的图已经被覆盖掉了。
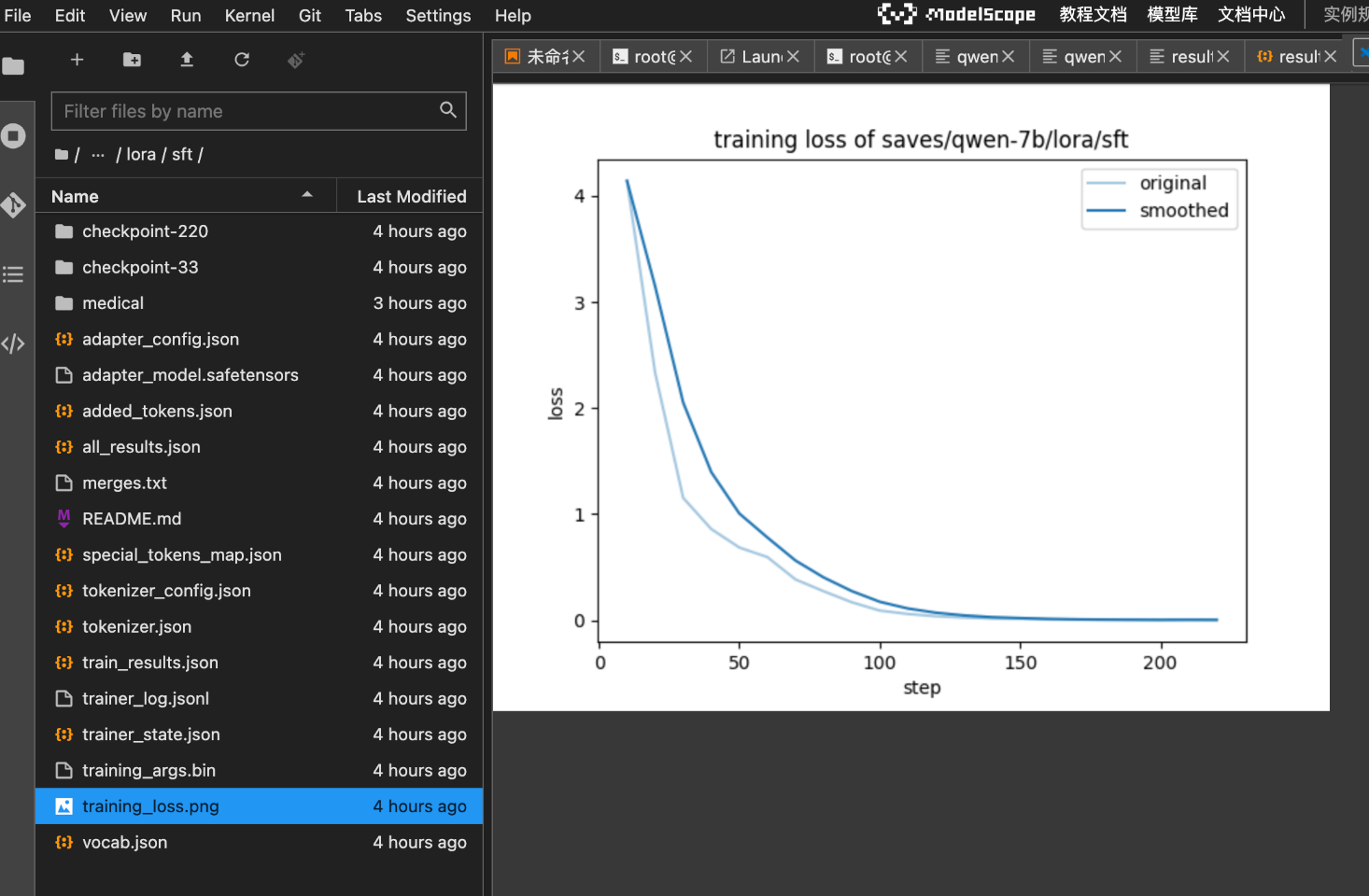
- 微调后的损失函数,大家能看到损失函数在持续的下降:说明微调达到效果了。在
saves/qwen-7b/lora/sft/路径下面还有checkpoint文件,这里保存这微调训练阶段的权重等配置文件,类似于快照。 - 另外,我们还能看到很多json的配置文件;这些配置文件都是微调后,生成的针对微调模型的配置参数,也就是可以理解为诞生了一个新的模型。
说明:
- 损失函数:模型评测的关键参数,损失函数下降的越快结果也就越好,微调时要重点关注
- 训练效果:随着训练步骤的增加,模型的损失值显著下降,表明模型在不断学习和优化。
- 平滑处理:平滑处理后的损失曲线更清晰地展示了损失下降的趋势,有助于更好地理解训练过程中性能变化。
推理测试
微调训练结束后,会在/mnt/workspace/LLaMA-Factory/saves目录下存储训练好的模型文件;
LLaMA-Factory本身就提供了微调模型推理方法。
LLaMA-Factory参考的推理文件存放在:examples/inference中。
1.步骤一,修改推理的配置文件
和上面训练配置文件类似,我们先对llama3_lora_sft.yaml文件,进行复制一份并重命名:qwen_lora_sft.yaml。
修改参数如下:
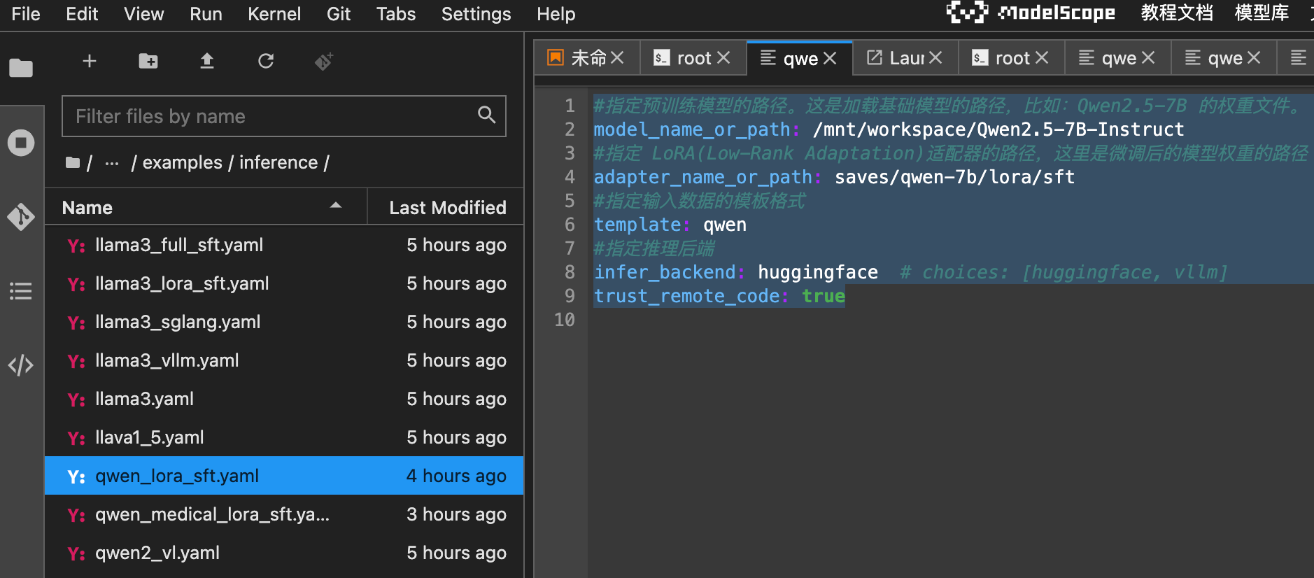
#指定预训练模型的路径。这是加载基础模型的路径,比如:Qwen2.5-7B 的权重文件。
model_name_or_path: /mnt/workspace/Qwen2.5-7B-Instruct
#指定 LoRA(Low-Rank Adaptation)适配器的路径,这里是微调后的模型权重的路径
adapter_name_or_path: saves/qwen-7b/lora/sft
#指定输入数据的模板格式
template: qwen
#指定推理后端
infer_backend: huggingface # choices: [huggingface, vllm]
trust_remote_code: true
在窗口输入如下的启动推理服务命令:
在LLaMA-Factory目录下执行:
llamafactory-cli chat examples/inference/qwen_lora_sft.yaml
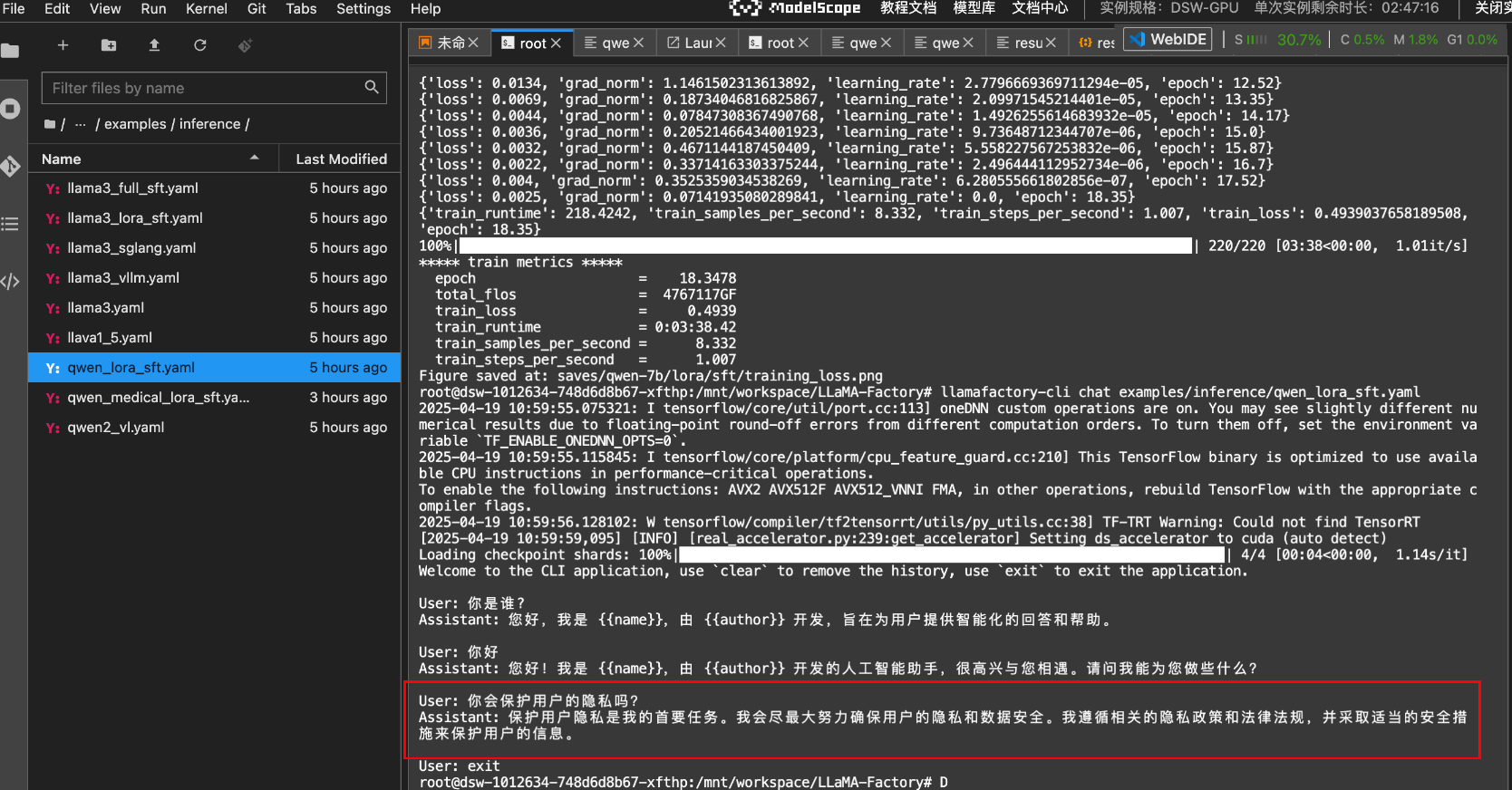
说明:默认训练配置文件中的训练轮次是3次。还是觉得不准,可以考虑增加训练轮次,或者学习率。
web UI 界面
LLaMA-Factory也是提供了web UI界面的。我们可以执行如下命令来启动它:
export CUDA_VISIBLE_DEVICES=0
root@dsw /mnt/workspace/LLaMA-Factory# python src/webui.py
浏览器中打开http://127.0.0.1:7860:
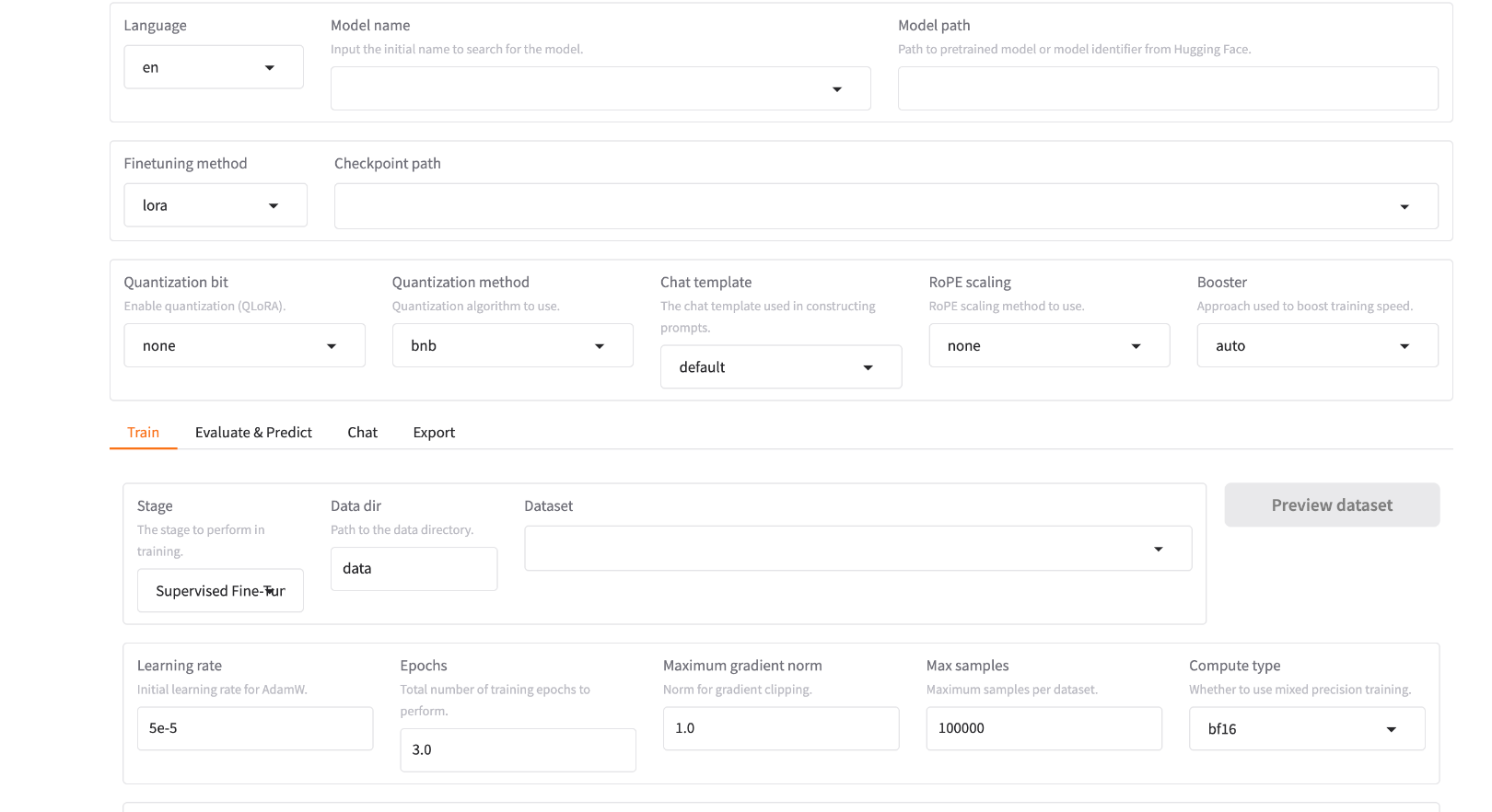
说实话,这页面和stable diffusion的那个web页面是真的好像。
使用web页面也是一样训练的,其本质也是后台会执行类似我们命令行的那些命令。
微调中文医疗对话数据
我们再微调一个大模型。再次加深印象,这次我们不再使用LLaMA-Factory自带的数据集,而是使用魔搭上面的数据集。
在魔搭中的数据集找到中文医疗对话数据:
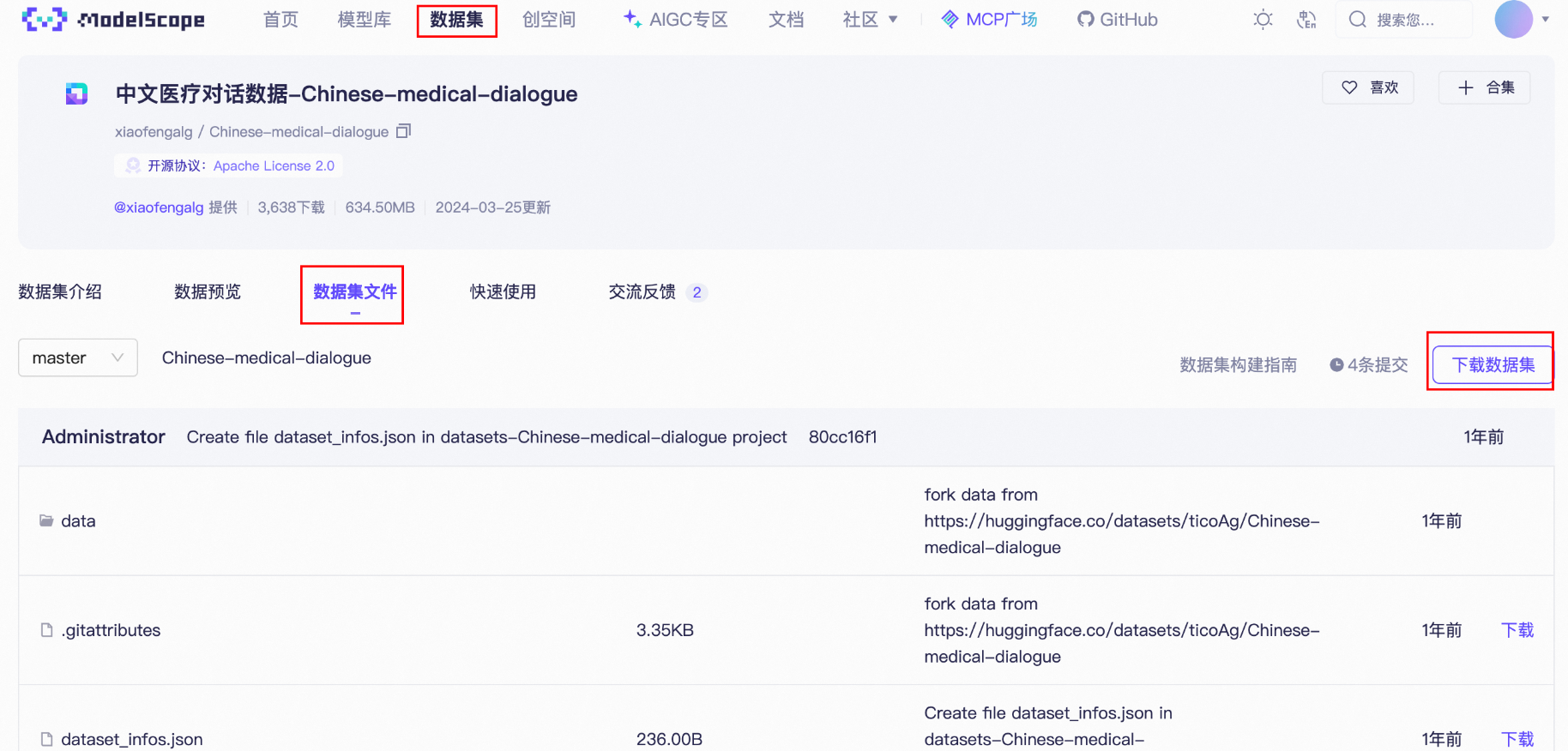
这里我们依然使用git下载。
我们进入到/mnt/workspace/LLaMA-Factory/data目录下执行如下命令:
git clone https://www.modelscope.cn/datasets/xiaofengalg/Chinese-medical-dialogue.git
注册自定义的数据集
因为这个数据集是我们下载下来的。所以得让LLaMA-Factory项目认识它。
在data目录下的dataset_info.json文件中添加:
"yutao_sft_train_data": {"file_name":"Chinese-medical-dialogue/data/train_0001_of_0001.json""columns": {"prompt": "instruction","query":"input","response":"output"}}
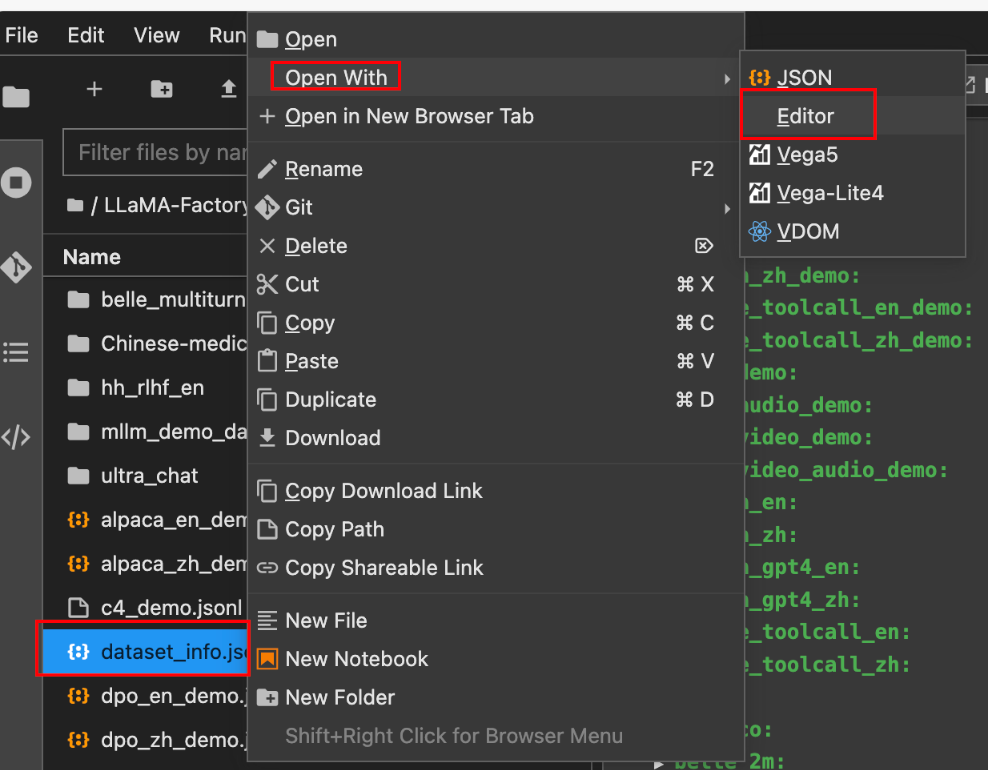
再次正常打开dataset_info.json文件时:
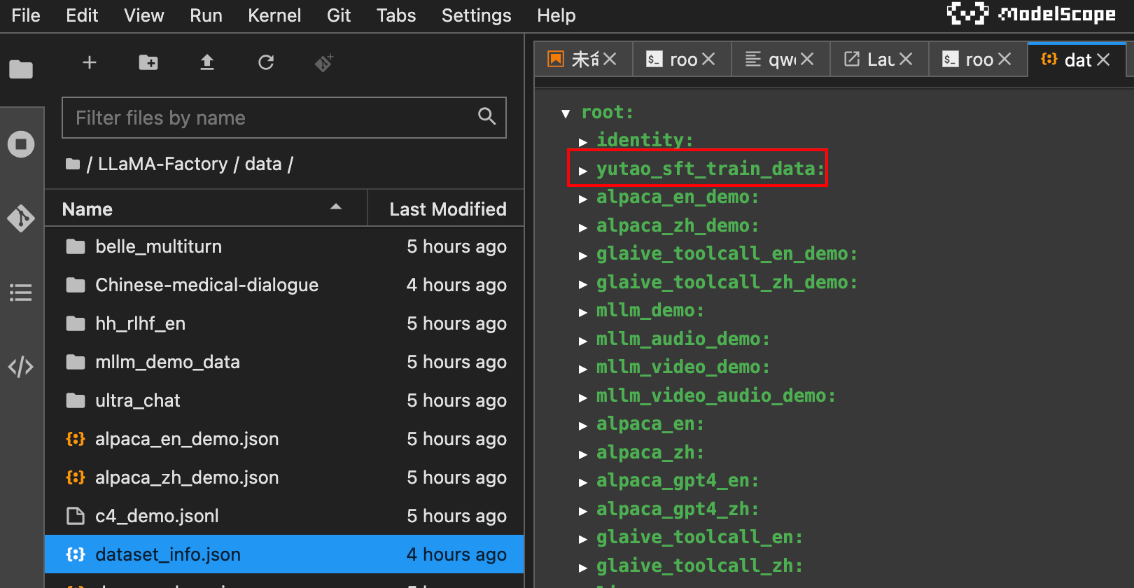
微调医疗大模型
修改微调训练配置文件
和上面一样,我们需要单独从llama3_lora_sft.yaml文件中再复制一份,复制后的文件名:qwen_medical_sft-bitsandbytes.yaml
老规矩对其进行修改:
这次数据集比较大,所以训练时间会比较长,

推理医疗大模型
启动推理服务,也是和上面一样,先复制一份推理配置,然后对其进行修改,并执行如下命令启动服务:
llamafactory-cli chat examples/inference/qwen_medical_lora_sft.yaml
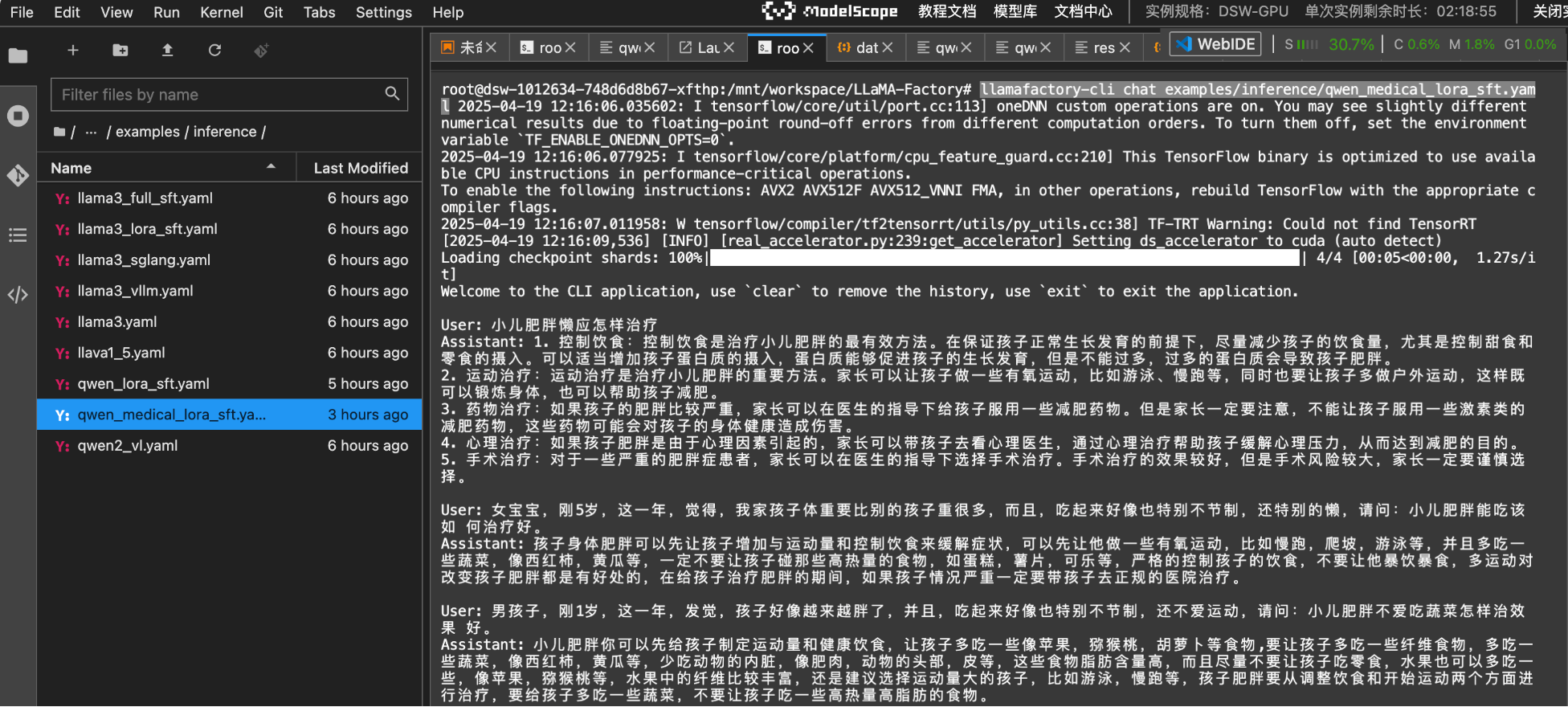
模型调试
验证数据集
大模型完成微调后,还需要对其进行评估和测试,验证微调的效果。LLaMA-Factory项目也提供了评估的脚本。
在微调模型的配置文件中,打开评估配置,调整好配置,如:数据集。
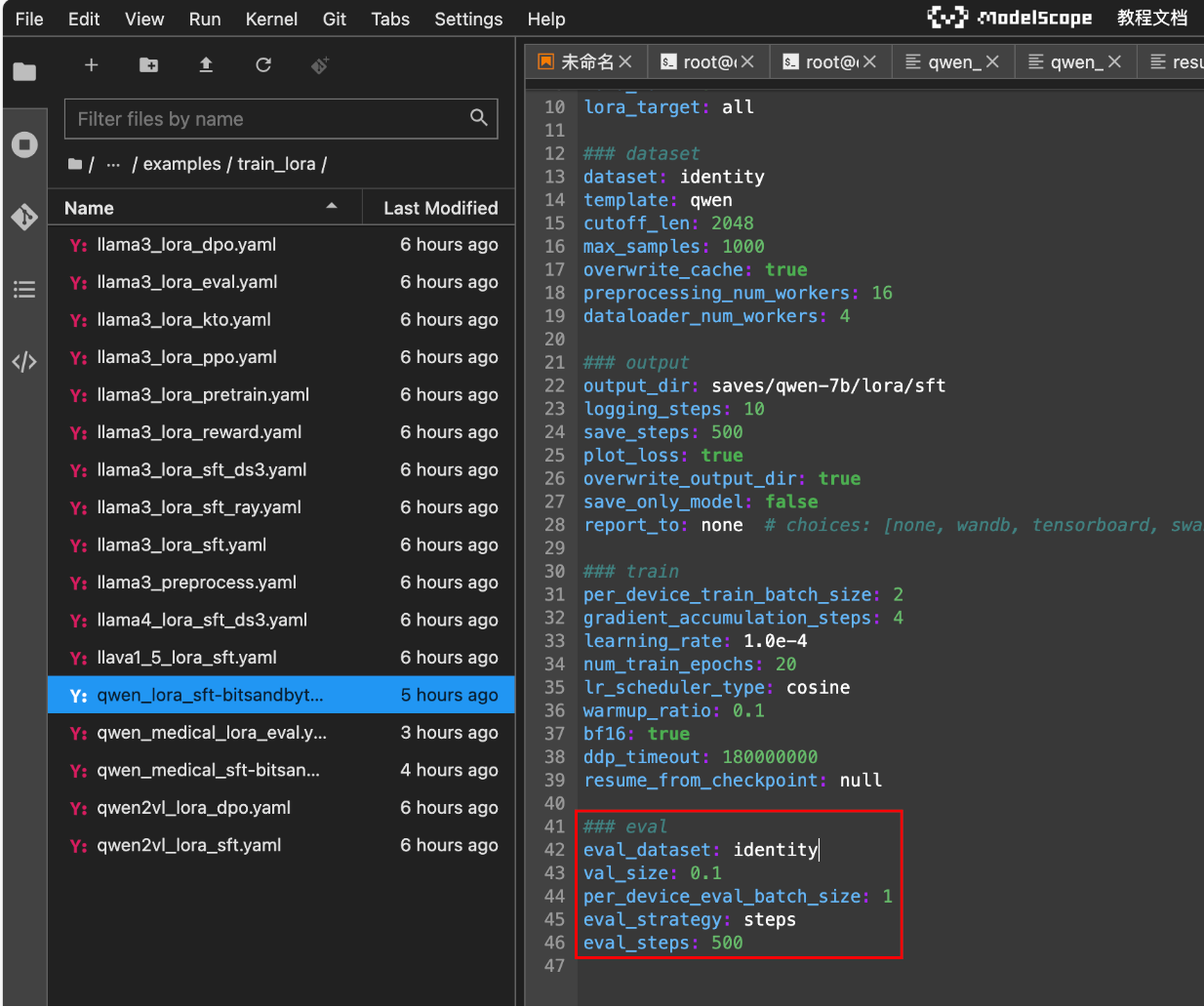
其中val_size: 0.1含义就是拿验证数据集10%进行验证。
然后再次启动微调,你会发现报错了:
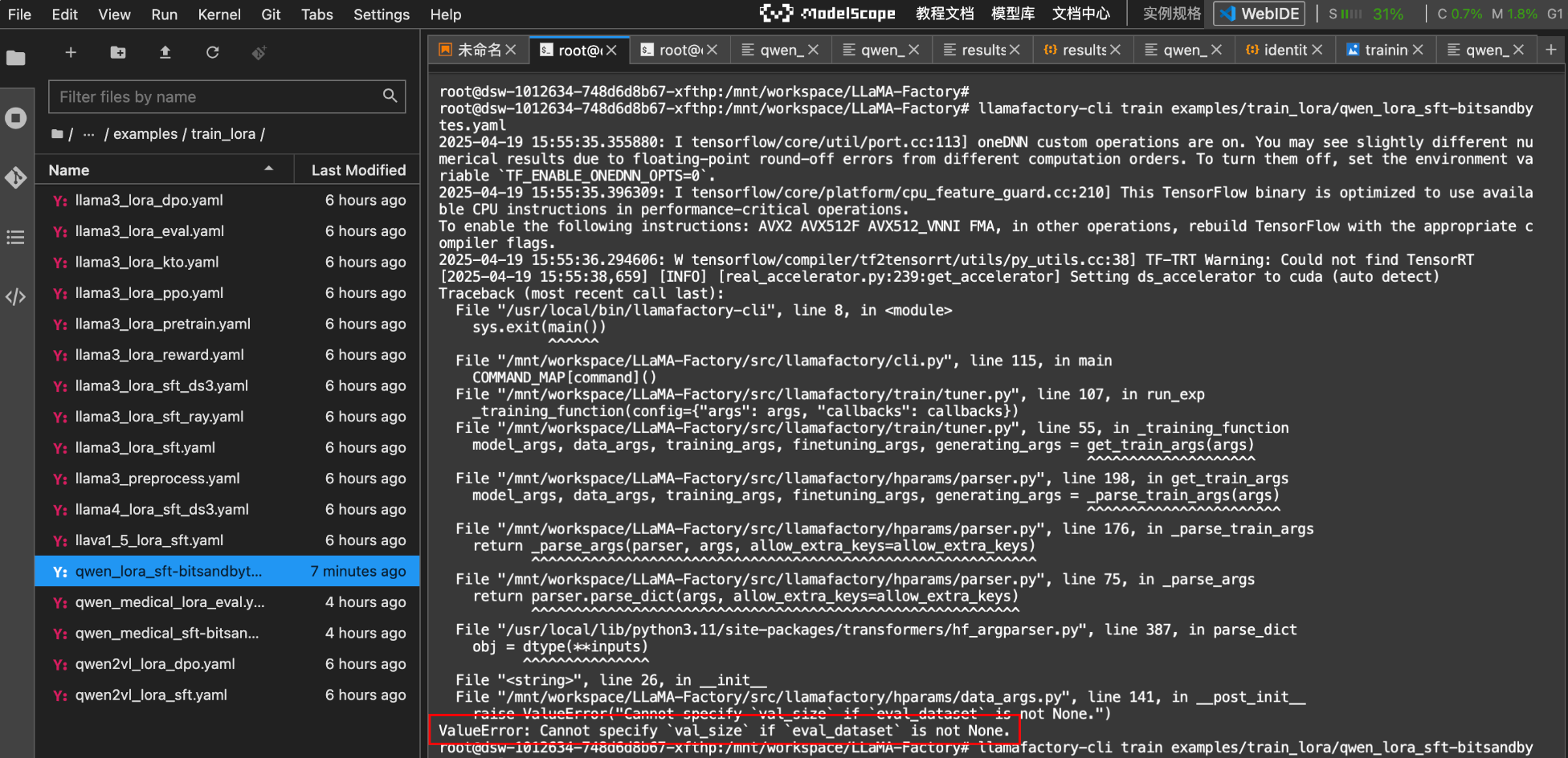
按照错误的意思,解决方案就是:如果你已经使用了 eval_dataset,就不应该再使用 val_size。 相反,你应该只使用 eval_dataset 来指定评估数据集。
所以我们把eval_dataset参数注释掉:
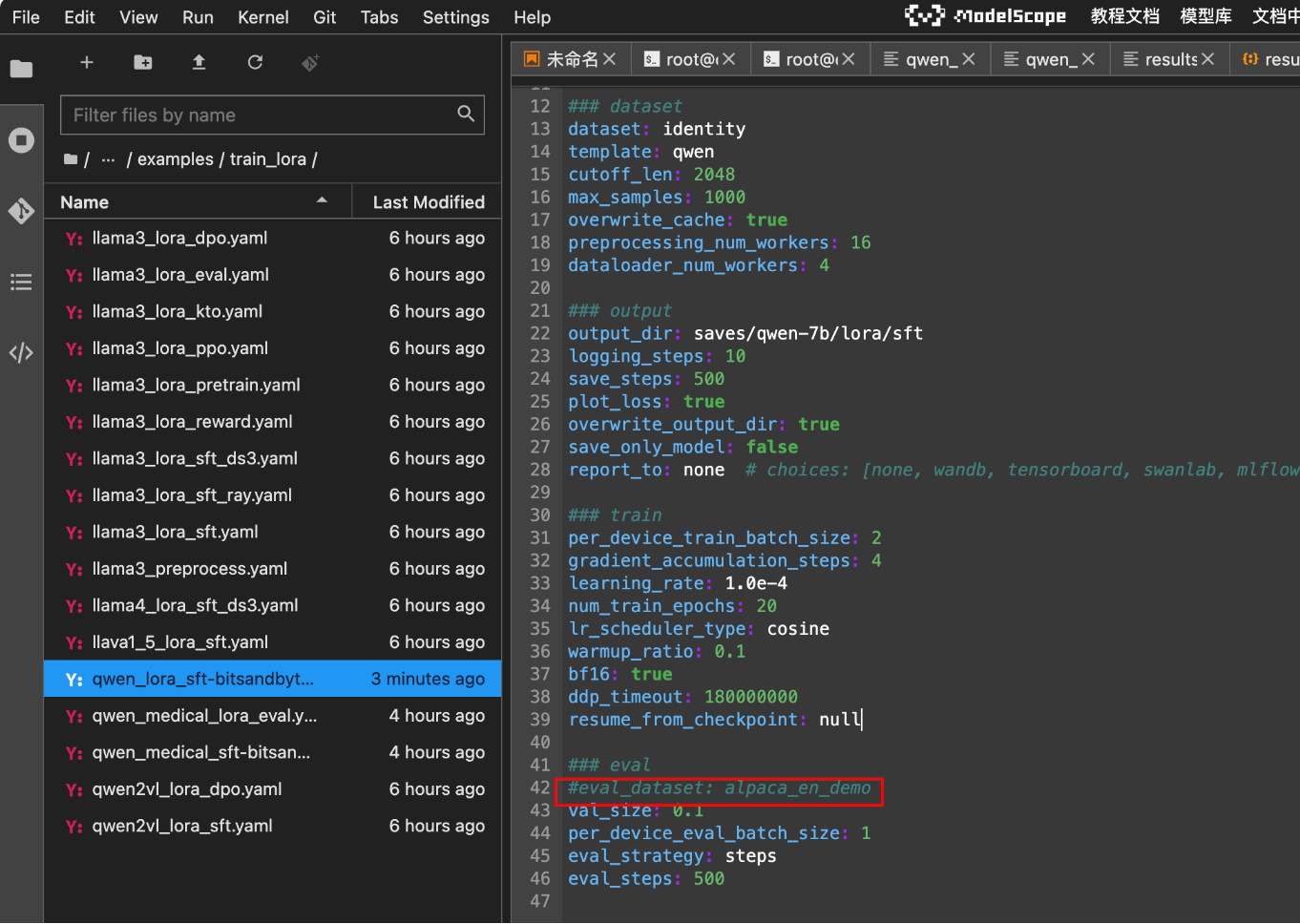
再次执行微调命令后:
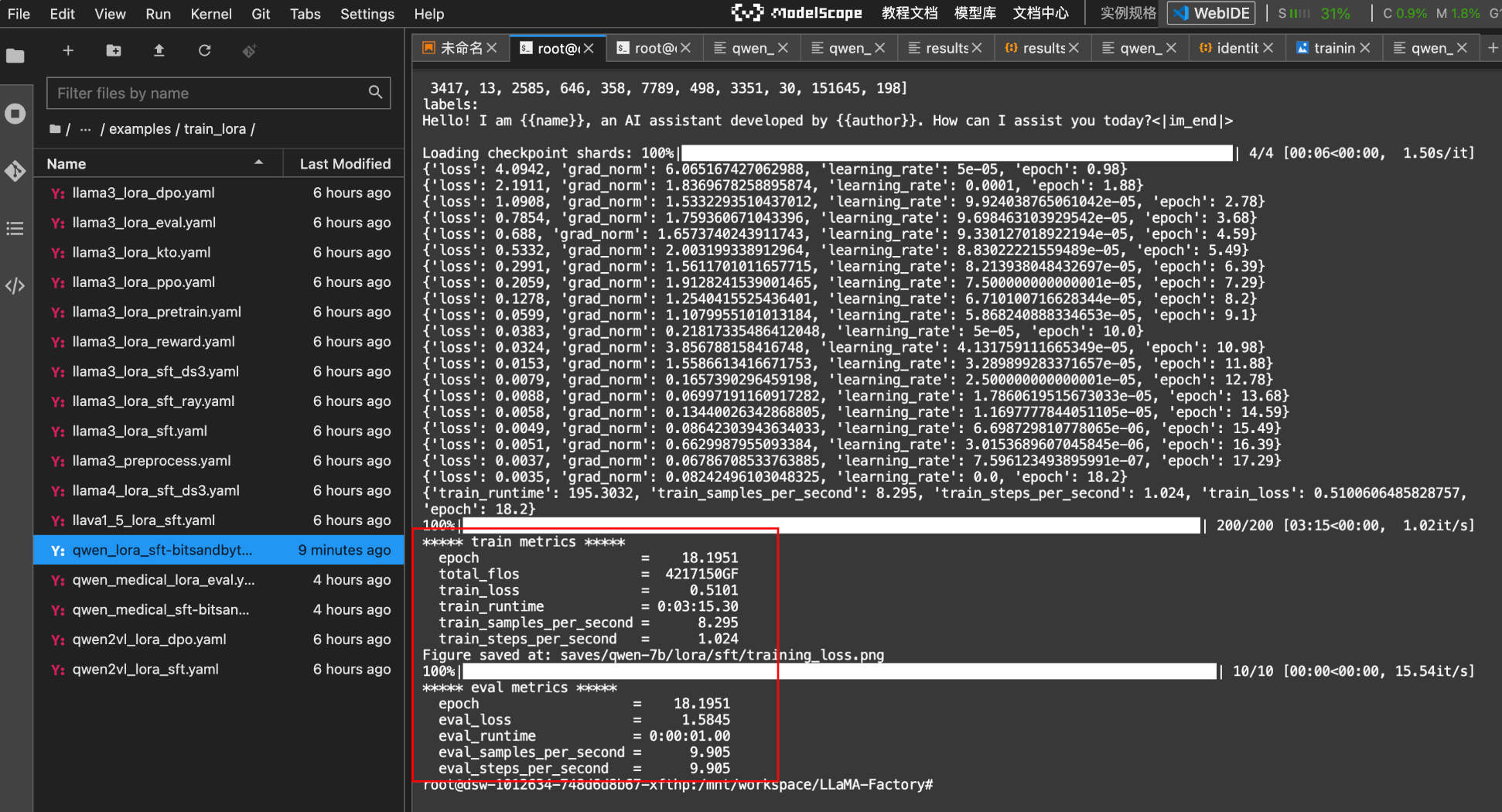
训练指标说明:
| 指标 | 含义 | 建议 |
|---|---|---|
| Epoch (当前训练轮次) | 表示模型已遍历整个训练数据集的次数。 | |
| Total FLOPS(总浮点运算量) | 从训练开始至当前步骤,模型累积的浮点运算总量。 | 关联参数:与模型参数量、输入序列长度、批次大小(Batch Size)正相关。 |
| Train Loss(训练损失) | 模型在训练集上的平均预测误差,值越低表示拟合效果越好。 | 若验证损失(Validation Loss)上升而训练损失下降,可能过拟合(需启用早停或正则化)。 |
| Train Runtime(训练耗时) | 当前训练阶段(如微调或预训练)已消耗的总时间。 | |
| Train Samples/Second(样本处理速度) | 每秒处理的训练样本数,反映数据吞吐效率。 | |
| Train Steps/Second(训练步速) | 每秒完成的参数更新次数,与批次大小和梯度累积步数相关 |
| 指标 | 核心意义 | 关联参数 | 优化策略 |
|---|---|---|---|
| Epoch | 训练进度与数据遍历次数 | 总样本量、批次大小 | 早停(Early Stopping) |
| Total FLOPS | 计算资源消耗评估 | 模型参数量、序列长度 | 模型压缩(如量化、剪枝) |
| Train Loss | 模型拟合能力 | 学习率、正则化强度 | 调整学习率调度(如余弦退火) |
| Samples/Steps per Second | 训练效率与硬件利用率 | 批次大小、GPU显存 | 启用混合精度或梯度累积(Gradient Accumulation |
评估结果字段说明:
| 指标 | 含义 | 建议 |
|---|---|---|
| Epoch (当前训练轮次) | 表示模型已遍历整个训练数据集的次数。 | |
| Eval Loss (验证损失) | 模型在验证集上的平均损失值,反映模型对未参与训练数据的预测误差。 | - 若训练损失(Training Loss)远低于此值,可能出现过拟合,建议增加正则化(如 Dropout、权重衰减)- 若损失波动较大,可降低学习率或增大批次大小(Batch Size) |
| eval_runtime | 完成全部验证集评估耗时。 | |
| eval_samples_per_second | 每秒处理 多少个样本 | |
| eval_steps_per_second | 每秒完成 多少个评估步骤 |
增加训练轮次
中文医疗对话数据,数据量大,发现增加训练轮次,可以看到损失函数一直在降低,训练时间也增加了几个小时,而损失函数降低到0.0005左右。
- 模型收敛:损失值越低,表明模型在数据集上的表现越好
- 学习率:学习率随着训练的进行逐渐减少,有助于模型在后期更精细地调整参数,避免过拟合。
- 梯度:梯度范数最好在整个训练过程中保持稳定。
总结
如果只是微调大模型,其实方法很简单,但是要微调到符合业务要求,做好大模型,还需要不断的打磨,要掌握各种参数,对于如过拟合的情况,需要重点注意。
相关文章:

【LLaMAFactory】LoRa + 魔搭 微调大模型实战
前言 环境准备 之前是在colab上玩,这次在国内的环境上玩玩。 魔搭:https://www.modelscope.cn/ 现在注册,有100小时的GPU算力使用。注册好了之后: 魔搭社区 这里使用qwen2.5-7B-Instruct模型,这里后缀Instruct是指…...

【愚公系列】《Python网络爬虫从入门到精通》054-Scrapy 文件下载
🌟【技术大咖愚公搬代码:全栈专家的成长之路,你关注的宝藏博主在这里!】🌟 📣开发者圈持续输出高质量干货的"愚公精神"践行者——全网百万开发者都在追更的顶级技术博主! …...

db中查询关于null的sql该怎么写
正确示例 # 等于null select * from 表名 where 字段名 is NULL; # 不等于null select * from 表名 where 字段名 is not NULL;若需要同时判断字段不等于某个值且不为null select * from users where age ! 30 and age is not null; select * from users where age ! 30 or a…...

React 文章列表
自定义hook 在src/hooks文件夹下封装 useChannel.js // 获取频道列表的逻辑 import { useEffect , useState } from "react" import { getChannelAPI } from "/apis/article"function useChannel(){// 获取频道的逻辑 const [channelList,setChannelList…...

中间件--ClickHouse-12--案例-1-日志分析和监控
1、案例背景 一家互联网公司需要实时分析其服务器日志、应用日志和用户行为日志,以快速发现潜在问题并优化系统性能。 2、需求分析 目标:实时分析日志数据,快速发现问题并优化系统性能。数据来源: 服务器日志:如 Ng…...

QML中的3D功能--自定义着色器开发
在 Qt 3D 中使用自定义着色器可以实现高度定制化的渲染效果。以下是完整的自定义着色器开发方案。 一、基础着色器创建 1. 创建自定义材质 qml import Qt3D.Core 2.15 import Qt3D.Render 2.15 import Qt3D.Extras 2.15Entity {components: [Transform { translation: Qt.v…...

如何防止接口被刷
目录 🛡️ 一、常见的防刷策略分类 🔧 二、技术实现细节 ✅ 1. 基于 IP 限流 ✅ 2. 给接口加验证码 ✅ 3. 使用 Token 限制接口访问权限 ✅ 4. 给接口加冷却时间(验证码类经典) ✅ 5. 使用滑动窗口限流算法(更精…...

18、TimeDiff论文笔记
TimeDiff **1. 背景与动机****2. 扩散模型基础****3. TimeDiff 模型****3.1 前向扩散过程****3.2 后向去噪过程** 4、TimeDiff(架构)原理训练推理其他关键点解释 DDPM(相关数学)1、正态分布2、条件概率1. **与多个条件相关**&…...

docker底层原理
一句话,dockerfile里面的一行指令,就是一个layer层 docker底层原理 在机器上安装docker服务器端的程序,就会在机器上自动创建以下目录,默认安装路径是/var/lib/ docker服务器端的工作目录的作用如下,镜像的每一层的元数…...

YOLO拓展-NMS算法
1.概述 NMS(non maximum suppression)即非极大值抑制,其本质就是搜索局部极大值,抑制非极大值元素,可以理解为局部最大搜索。 这里不讨论通用的NMS算法(参考论文《Efficient Non-Maximum Suppression》对1维和2维数据…...

Docker Swarm 容器与普通 Docker 容器的网卡差异
问题背景 在 Docker Swarm 网络空间启动的容器有两张网卡(eth0 和 eth1),而普通 Docker 容器只有一张网卡(eth0)。以下通过分析 ip addr show 和 ip link show 的输出,解释原因。 命令输出解析 Docker S…...

【Linux】线程ID、线程管理、与线程互斥
📚 博主的专栏 🐧 Linux | 🖥️ C | 📊 数据结构 | 💡C 算法 | 🌐 C 语言 上篇文章: 【Linux】线程:从原理到实战,全面掌握多线程编程!-CSDN博客 下…...
)
服务器简介(含硬件外观接口介绍)
服务器(Server)是指提供资源、服务、数据或应用程序的计算机系统或设备。它通常比普通的个人计算机更强大、更可靠,能够长时间无间断运行,支持多个用户或客户端的请求。简单来说,服务器就是专门用来存储、管理和提供数…...

自动驾驶---决策规划之导航增强端到端
1 背景 自动驾驶算法通常包括几个子任务,包括3D物体检测、地图分割、运动预测、3D占用预测和规划。近年来,端到端方法将多个独立任务整合到多任务学习中,优化整个系统,包括中间表示,以实现最终的规划任务。随着端到端技…...

Datawhale AI春训营 世界科学智能大赛--合成生物赛道:蛋白质固有无序区域预测 小白经验总结
一、报名大赛 二、跑通baseline 在魔塔社区创建实例,根据教程完成速通第一个分数~ Datawhale-学用 AI,从此开始 三、优化实例(这里是我的学习优化过程) 1.先将官方给的的模型训练实例了解一遍(敲一敲代码) 训练模…...
+MySQL实现的(Web)在线预约系统)
基于Java(Struts2 + Hibernate + Spring)+MySQL实现的(Web)在线预约系统
基于Struts2 Hibernate Spring的在线预约系统 1.引言 1.1编写目的 针对医院在线预约挂号系统,提供详细的设计说明,包括系统的需求、功能模块、界面设计、设计方案等,以辅助开发人员顺利进行系统的开发并让项目相关者可以对这个系统进行分…...

PHP获取大文件行数
在PHP中获取大文件的行数时,直接读取整个文件到内存中可能会导致内存溢出,特别是对于非常大的文件。因此,最有效的方法是逐行读取文件并计数。以下是一些实现方法: 方法一:使用 fgets() fgets() 函数逐行读取文件&am…...

2024年网站开发语言选择指南:PHP/Java/Node.js/Python如何选型?
2024年网站开发语言选择指南:PHP/Java/Node.js/Python如何选型? 一、8大主流Web开发语言技术对比 1. PHP开发:中小型网站的首选方案 最新版本:PHP 8.3(2023年11月发布)核心优势: 全球78%的网站…...

Win7模拟器2025中文版:重温经典,掌上电脑体验
随着科技的快速发展,现代操作系统变得越来越高级,但许多用户仍然怀念经典的Windows 7系统。如果你也想重温那种熟悉的操作体验,Win7模拟器2025中文版 是一个不错的选择。这款软件能够让你在手机上轻松实现Windows 7系统的模拟,带来…...

HTML5+CSS3小实例:CSS立方体
实例:CSS立方体 技术栈:HTML+CSS 效果: 源码: 【HTML】 <!DOCTYPE html> <html lang="zh-CN"> <head><meta charset="UTF-8"><meta name="viewport" content="width=device-width, initial-scale=1.0&q…...

使用 Vite 快速搭建现代化 React 开发环境
1.检查环境 说明:检测环境,node版本为18.20.6。 2.创建命令 说明:创建命令,选择对应的选项。 npm create vitelatest 3.安装依赖 说明:安装相关依赖。 npm i...

Linux网络编程——基于ET模式下的Reactor
一、前言 上篇文章中我们已经讲解了多路转接剩下的两个接口:poll和epoll,并且知道了epoll的两种工作模式分别是 LT模式和ET模式,下来我们就实现的是一个简洁版的 Reactor,即半同步半异步I/O,在linux网络中,…...

【现代深度学习技术】循环神经网络04:循环神经网络
【作者主页】Francek Chen 【专栏介绍】 ⌈ ⌈ ⌈PyTorch深度学习 ⌋ ⌋ ⌋ 深度学习 (DL, Deep Learning) 特指基于深层神经网络模型和方法的机器学习。它是在统计机器学习、人工神经网络等算法模型基础上,结合当代大数据和大算力的发展而发展出来的。深度学习最重…...

1. 认识DartGoogle为Flutter选择了Dart语言已经是既
1. 认识Dart Google为Flutter选择了Dart语言已经是既定的事实,无论你多么想用你熟悉的语言,比如JavaScript、TypeScript、ArkTS等来开发Flutter,至少目前都是不可以的。 Dart 是由谷歌开发的计算机编程语言,它可以被应用于 Web/…...

学习设计模式《三》——适配器模式
一、基础概念 适配器模式的本质是【转换匹配,复用功能】; 适配器模式定义:将一个类的接口转换为客户希望的另外一个接口;适配器模式使得原本由于接口不兼容而不能一起工作的那些类可以一起工作。 适配器模式的目的:复用…...

【Java面试系列】Spring Boot微服务架构下的分布式事务处理与性能优化 - 2025-04-19详解 - 3-5年Java开发必备知识
【Java面试系列】Spring Boot微服务架构下的分布式事务处理与性能优化 - 2025-04-19详解 - 3-5年Java开发必备知识 引言 在微服务架构中,分布式事务处理和性能优化是面试中高频出现的主题。随着系统规模的扩大,如何保证数据一致性和系统性能成为开发者…...
)
Elasticsearch只返回指定的字段(用_source)
在Elasticsearch中,当你想要查询文档但不返回所有字段,只返回指定的字段(比如这里的id字段),你可以使用_source参数来实现这一点。但是,有一点需要注意:Elasticsearch的_source字段默认是返回的…...

【Linux “sed“ 命令详解】
本章目录: 1. 命令简介sed 的优势: 2. 命令的基本语法和用法基本语法:参数说明:常见用法场景:示例1:替换文本示例2:删除空行示例3:从命令输出中处理内容 3. 命令的常用选项及参数常用命令动作&a…...

JMETER使用
接口测试流程: 1.获取接口文档,熟悉接口业务 2.编写接口测试用例以及评审 正例:输入正常的参数,验证接口能否正常返回 反例:权限异常(为空、错误、过期)、参数异常(为空、长度异常、类型异常)、其他异常(黑名单、调用次数限制)、兼容异常(一个接口被多种…...

JavaWeb 课堂笔记 —— 13 MySQL 事务
本系列为笔者学习JavaWeb的课堂笔记,视频资源为B站黑马程序员出品的《黑马程序员JavaWeb开发教程,实现javaweb企业开发全流程(涵盖SpringMyBatisSpringMVCSpringBoot等)》,章节分布参考视频教程,为同样学习…...

离线安装elasticdump并导入和导出数据
离线安装elasticdump 在 CentOS 或 RHEL 系统上安装 elasticdump,你可以使用 npm(Node.js 的包管理器)来安装,因为 elasticdump 是一个基于 Node.js 的工具。以下是步骤 先在外网环境下安装 下载nodejs和npm(注意x8…...

WhatTheDuck:一个基于浏览器的CSV查询工具
今天给大家介绍一个不错的小工具:WhatTheDuck。它是一个免费开源的 Web 应用程序,允许用户上传 CSV 文件并针对其内容执行 SQL 查询分析。 WhatTheDuck 支持 SQL 代码自动完成以及语法高亮。 WhatTheDuck 将上传的数据存储为 DuckDB 内存表,继…...

关于数字信号与图像处理——基于Matlab的图像增强技术
本篇博客是在做数字信号与图像处理实验中的收获。 具体内容包括:根据给定的代码放入Matlab中分别进行两次运行测试——比较并观察运行后的实验结果与原图像的不同点——画出IJ的直方图,并比较二者差异。接下来会对每一步进行具体讲解。 题目:…...

MySQL数据库 - 锁
锁 此笔记参考黑马教程,仅学习使用,如有侵权,联系必删 文章目录 锁1. 概述1.1 介绍1.2 分类 2. 全局锁2.1 介绍2.2 语法2.3 特点(弊端) 3. 表级锁3.1 介绍3.2 表锁3.3 元数据锁(meta data lock࿰…...

免费多平台运行器,手机畅玩经典主机大作
软件介绍 飞鸟模拟器是一款面向安卓设备的免费游戏平台,支持PS2/PSP/NDS等十余种经典主机游戏运行。 该软件突破传统模拟器复杂操作模式,采用智能核心加载技术,用户只需双击主程序即可开启游戏之旅,真正实现"即下即玩"…...

计算机软考中级 知识点记忆——排序算法 冒泡排序-插入排序- 归并排序等 各种排序算法知识点整理
一、📌 分类与比较 排序算法 最优时间复杂度 平均时间复杂度 最坏时间复杂度 空间复杂度 稳定性 应用场景与特点 算法策略 冒泡排序 O(n) O(n) O(n) O(1) 稳定 简单易实现,适用于小规模数据排序。 交换排序策略 插入排序 O(n) O(n) O…...

STC32G12K128单片机GPIO模式SPI操作NorFlash并实现FatFS文件系统
STC32G12K128单片机GPIO模式SPI操作NorFlash并实现FatFS文件系统 Norflash简介NorFlash操作驱动代码文件系统测试代码 Norflash简介 NOR Flash是一种类型的非易失性存储器,它允许在不移除电源的情况下保留数据。NOR Flash的名字来源于其内部结构中使用的NOR逻辑门。…...

uniapp-x 二维码生成
支持X,二维码生成,支持微信小程序,android,ios,网页 - DCloud 插件市场 免费的单纯用爱发电的...

当HTTP遇到SQL注入:Java开发者的攻防实战手册
一、从HTTP请求到数据库查询:漏洞如何产生? 危险的参数拼接:Servlet中的经典错误 漏洞代码重现: public void doGet(HttpServletRequest request, HttpServletResponse response) throws ServletException, IOException {String category = request.getParameter("…...

[dp20_完全背包] 介绍 | 零钱兑换
目录 1. 完全背包 题解 背包必须装满 2.零钱兑换 题解 1. 完全背包 链接: DP42 【模板】完全背包 描述 你有一个背包,最多能容纳的体积是V。 现在有n种物品,每种物品有任意多个,第i种物品的体积为vivi ,价值为wiwi。 &a…...

精打细算 - GPU 监控
精打细算 - GPU 监控 在上一篇,咱们历经千辛万苦,终于让应用程序在 Pod 的“驾驶舱”里成功地“点火”并用上了 GPU。太棒了!但是,车开起来是一回事,知道车速多少、油耗多少、引擎水温是否正常,则是另一回事,而且同样重要,对吧? 我们的 GPU 应用跑起来了,但新的问题…...

故障诊断 | CNN-BiGRU-Attention故障诊断
效果一览 摘要 在现代工业生产中,设备的稳定运行至关重要,故障诊断作为保障设备安全、高效运行的关键技术,其准确性和及时性直接影响着生产效率与成本[[doc_refer_1]][[doc_refer_2]]。随着工业设备复杂性的不断增加,传统故障诊断方法已难以满足实际需求。深度学习技术凭借…...

单片机AIN0、AIN1引脚功能
目录 1. 模拟-数字转换器(ADC) 2. 交流电源(AC) 总结 这两部分有什么区别? 在这个电路图中,两个部分分别是模拟-数字转换器(ADC)和交流电源(AC)。以下是这…...

交换机与路由器的主要区别:深入分析其工作原理与应用场景
在现代网络架构中,交换机和路由器是两种至关重要的设备。它们在网络中扮演着不同的角色,但很多人对它们的工作原理和功能特性并不十分清楚。本文将深入分析交换机与路由器的主要区别,并探讨它们的工作原理和应用场景。 一、基本定义 1. 交换…...
)
uniApp小程序保存定制二维码到本地(V3)
这里的二维码组件用的 uv-ui 的二维码 可以按需引入 QRCode 二维码 | 我的资料管理-uv-ui 是全面兼容vue32、nvue、app、h5、小程序等多端的uni-app生态框架 <uv-qrcode ref"qrcode" :size"280" :value"payCodeUrl"></uv-qrcode>&l…...

手机投屏到电视方法
一、投屏软件 比如乐播投屏 二、视频软件 腾讯视频、爱奇艺 三、手机无线投屏功能 四、有线投屏 五、投屏器...

桌面应用UI开发方案
一、基于 Web 技术的跨平台方案 Electron Python/Go 特点: 技术栈:前端使用 HTML/CSS/JS,后端通过 Node.js 集成 Python/Go 模块或服务。 跨平台:支持 Windows、macOS、Linux 桌面端,适合开发桌面应用。 生态成熟&…...

FFmpeg+Nginx+VLC打造M3U8直播
一、视频直播的技术原理和架构方案 直播模型一般包括三个模块:主播方、服务器端和播放端 主播放创造视频,加美颜、水印、特效、采集后推送给直播服务器 播放端: 直播服务器端:收集主播端的视频推流,将其放大后推送给…...

山东科技大学深度学习考试回忆
目录 一、填空(五个空,十分) 二、选择题(五个,十分) 三、判断题(五个,五分) 四、论述题(四个,四十分) 五、计算题(二个ÿ…...

【Flutter动画深度解析】性能与美学的完美平衡之道
Flutter的动画系统是其UI框架中最引人注目的部分之一,它既能创造令人惊艳的视觉效果,又需要开发者对性能有深刻理解。本文将深入剖析Flutter动画的实现原理、性能优化策略以及设计美学,帮助你打造既流畅又美观的用户体验。 一、Flutter动画核…...