【现代深度学习技术】循环神经网络04:循环神经网络

【作者主页】Francek Chen
【专栏介绍】 ⌈ ⌈ ⌈PyTorch深度学习 ⌋ ⌋ ⌋ 深度学习 (DL, Deep Learning) 特指基于深层神经网络模型和方法的机器学习。它是在统计机器学习、人工神经网络等算法模型基础上,结合当代大数据和大算力的发展而发展出来的。深度学习最重要的技术特征是具有自动提取特征的能力。神经网络算法、算力和数据是开展深度学习的三要素。深度学习在计算机视觉、自然语言处理、多模态数据分析、科学探索等领域都取得了很多成果。本专栏介绍基于PyTorch的深度学习算法实现。
【GitCode】专栏资源保存在我的GitCode仓库:https://gitcode.com/Morse_Chen/PyTorch_deep_learning。
文章目录
- 一、无隐状态的神经网络
- 二、有隐状态的循环神经网络
- 三、基于循环神经网络的字符级语言模型
- 四、困惑度(Perplexity)
- 小结
在语言模型和数据集中,我们介绍了 n n n元语法模型,其中单词 x t x_t xt在时间步 t t t的条件概率仅取决于前面 n − 1 n-1 n−1个单词。对于时间步 t − ( n − 1 ) t-(n-1) t−(n−1)之前的单词,如果我们想将其可能产生的影响合并到 x t x_t xt上,需要增加 n n n,然而模型参数的数量也会随之呈指数增长,因为词表 V \mathcal{V} V需要存储 ∣ V ∣ n |\mathcal{V}|^n ∣V∣n个数字,因此与其将 P ( x t ∣ x t − 1 , … , x t − n + 1 ) P(x_t \mid x_{t-1}, \ldots, x_{t-n+1}) P(xt∣xt−1,…,xt−n+1)模型化,不如使用隐变量模型:
P ( x t ∣ x t − 1 , … , x 1 ) ≈ P ( x t ∣ h t − 1 ) (1) P(x_t \mid x_{t-1}, \ldots, x_1) \approx P(x_t \mid h_{t-1}) \tag{1} P(xt∣xt−1,…,x1)≈P(xt∣ht−1)(1) 其中 h t − 1 h_{t-1} ht−1是隐状态(hidden state),也称为隐藏变量(hidden variable),它存储了到时间步 t − 1 t-1 t−1的序列信息。通常,我们可以基于当前输入 x t x_{t} xt和先前隐状态 h t − 1 h_{t-1} ht−1来计算时间步 t t t处的任何时间的隐状态:
h t = f ( x t , h t − 1 ) (2) h_t = f(x_{t}, h_{t-1}) \tag{2} ht=f(xt,ht−1)(2)
对于式(2)中的函数 f f f,隐变量模型不是近似值。毕竟 h t h_t ht是可以仅仅存储到目前为止观察到的所有数据,然而这样的操作可能会使计算和存储的代价都变得昂贵。
回想一下,我们在多层感知机中讨论过的具有隐藏单元的隐藏层。值得注意的是,隐藏层和隐状态指的是两个截然不同的概念。如上所述,隐藏层是在从输入到输出的路径上(以观测角度来理解)的隐藏的层,而隐状态则是在给定步骤所做的任何事情(以技术角度来定义)的输入,并且这些状态只能通过先前时间步的数据来计算。
循环神经网络(recurrent neural networks,RNNs)是具有隐状态的神经网络。在介绍循环神经网络模型之前,我们首先回顾多层感知机概述中介绍的多层感知机模型。
一、无隐状态的神经网络
我们来看一看只有单隐藏层的多层感知机。设隐藏层的激活函数为 ϕ \phi ϕ,给定一个小批量样本 X ∈ R n × d \mathbf{X} \in \mathbb{R}^{n \times d} X∈Rn×d,其中批量大小为 n n n,输入维度为 d d d,则隐藏层的输出 H ∈ R n × h \mathbf{H} \in \mathbb{R}^{n \times h} H∈Rn×h通过下式计算:
H = ϕ ( X W x h + b h ) (3) \mathbf{H} = \phi(\mathbf{X} \mathbf{W}_{xh} + \mathbf{b}_h) \tag{3} H=ϕ(XWxh+bh)(3)
在式(3)中,我们拥有的隐藏层权重参数为 W x h ∈ R d × h \mathbf{W}_{xh} \in \mathbb{R}^{d \times h} Wxh∈Rd×h,偏置参数为 b h ∈ R 1 × h \mathbf{b}_h \in \mathbb{R}^{1 \times h} bh∈R1×h,以及隐藏单元的数目为 h h h。因此求和时可以应用广播机制(见数据操作)。接下来,将隐藏变量 H \mathbf{H} H用作输出层的输入。输出层由下式给出:
O = H W h q + b q (4) \mathbf{O} = \mathbf{H} \mathbf{W}_{hq} + \mathbf{b}_q \tag{4} O=HWhq+bq(4) 其中, O ∈ R n × q \mathbf{O} \in \mathbb{R}^{n \times q} O∈Rn×q是输出变量, W h q ∈ R h × q \mathbf{W}_{hq} \in \mathbb{R}^{h \times q} Whq∈Rh×q是权重参数, b q ∈ R 1 × q \mathbf{b}_q \in \mathbb{R}^{1 \times q} bq∈R1×q是输出层的偏置参数。如果是分类问题,我们可以用 softmax ( O ) \text{softmax}(\mathbf{O}) softmax(O)来计算输出类别的概率分布。
这完全类似于之前在序列模型中解决的回归问题,因此我们省略了细节。无须多言,只要可以随机选择“特征-标签”对,并且通过自动微分和随机梯度下降能够学习网络参数就可以了。
二、有隐状态的循环神经网络
有了隐状态后,情况就完全不同了。假设我们在时间步 t t t有小批量输入 X t ∈ R n × d \mathbf{X}_t \in \mathbb{R}^{n \times d} Xt∈Rn×d。换言之,对于 n n n个序列样本的小批量, X t \mathbf{X}_t Xt的每一行对应于来自该序列的时间步 t t t处的一个样本。接下来,用 H t ∈ R n × h \mathbf{H}_t \in \mathbb{R}^{n \times h} Ht∈Rn×h表示时间步 t t t的隐藏变量。与多层感知机不同的是,我们在这里保存了前一个时间步的隐藏变量 H t − 1 \mathbf{H}_{t-1} Ht−1,并引入了一个新的权重参数 W h h ∈ R h × h \mathbf{W}_{hh} \in \mathbb{R}^{h \times h} Whh∈Rh×h,来描述如何在当前时间步中使用前一个时间步的隐藏变量。具体地说,当前时间步隐藏变量由当前时间步的输入与前一个时间步的隐藏变量一起计算得出:
H t = ϕ ( X t W x h + H t − 1 W h h + b h ) (5) \mathbf{H}_t = \phi(\mathbf{X}_t \mathbf{W}_{xh} + \mathbf{H}_{t-1} \mathbf{W}_{hh} + \mathbf{b}_h) \tag{5} Ht=ϕ(XtWxh+Ht−1Whh+bh)(5)
与式(3)相比,式(5)多添加了一项 H t − 1 W h h \mathbf{H}_{t-1} \mathbf{W}_{hh} Ht−1Whh,从而实例化了式(2)。从相邻时间步的隐藏变量 H t \mathbf{H}_t Ht和 H t − 1 \mathbf{H}_{t-1} Ht−1之间的关系可知,这些变量捕获并保留了序列直到其当前时间步的历史信息,就如当前时间步下神经网络的状态或记忆,因此这样的隐藏变量被称为隐状态(hidden state)。由于在当前时间步中,隐状态使用的定义与前一个时间步中使用的定义相同,因此式(5)的计算是循环的(recurrent)。于是基于循环计算的隐状态神经网络被命名为循环神经网络(recurrent neural network)。在循环神经网络中执行式(5)计算的层称为循环层(recurrent layer)。
有许多不同的方法可以构建循环神经网络,由式(5)定义的隐状态的循环神经网络是非常常见的一种。对于时间步 t t t,输出层的输出类似于多层感知机中的计算: O t = H t W h q + b q (6) \mathbf{O}_t = \mathbf{H}_t \mathbf{W}_{hq} + \mathbf{b}_q \tag{6} Ot=HtWhq+bq(6)
循环神经网络的参数包括隐藏层的权重 W x h ∈ R d × h , W h h ∈ R h × h \mathbf{W}_{xh} \in \mathbb{R}^{d \times h}, \mathbf{W}_{hh} \in \mathbb{R}^{h \times h} Wxh∈Rd×h,Whh∈Rh×h和偏置 b h ∈ R 1 × h \mathbf{b}_h \in \mathbb{R}^{1 \times h} bh∈R1×h,以及输出层的权重 W h q ∈ R h × q \mathbf{W}_{hq} \in \mathbb{R}^{h \times q} Whq∈Rh×q和偏置 b q ∈ R 1 × q \mathbf{b}_q \in \mathbb{R}^{1 \times q} bq∈R1×q。值得一提的是,即使在不同的时间步,循环神经网络也总是使用这些模型参数。因此,循环神经网络的参数开销不会随着时间步的增加而增加。
图1展示了循环神经网络在3个相邻时间步的计算逻辑。在任意时间步 t t t,隐状态的计算可以被视为:(1)拼接当前时间步 t t t的输入 X t \mathbf{X}_t Xt和前一时间步 t − 1 t-1 t−1的隐状态 H t − 1 \mathbf{H}_{t-1} Ht−1;(2)将拼接的结果送入带有激活函数 ϕ \phi ϕ的全连接层。全连接层的输出是当前时间步 t t t的隐状态 H t \mathbf{H}_t Ht。
在本例中,模型参数是 W x h \mathbf{W}_{xh} Wxh和 W h h \mathbf{W}_{hh} Whh的拼接,以及 b h \mathbf{b}_h bh的偏置,所有这些参数都来自式(5)。当前时间步 t t t的隐状态 H t \mathbf{H}_t Ht将参与计算下一时间步 t + 1 t+1 t+1的隐状态 H t + 1 \mathbf{H}_{t+1} Ht+1。而且 H t \mathbf{H}_t Ht还将送入全连接输出层,用于计算当前时间步 t t t的输出 O t \mathbf{O}_t Ot。

我们刚才提到,隐状态中 X t W x h + H t − 1 W h h \mathbf{X}_t \mathbf{W}_{xh} + \mathbf{H}_{t-1} \mathbf{W}_{hh} XtWxh+Ht−1Whh的计算,相当于 X t \mathbf{X}_t Xt和 H t − 1 \mathbf{H}_{t-1} Ht−1的拼接与 W x h \mathbf{W}_{xh} Wxh和 W h h \mathbf{W}_{hh} Whh的拼接的矩阵乘法。虽然这个性质可以通过数学证明,但在下面我们使用一个简单的代码来说明一下。首先,我们定义矩阵X、W_xh、H和W_hh,它们的形状分别为 ( 3 , 1 ) (3,1) (3,1)、 ( 1 , 4 ) (1,4) (1,4)、 ( 3 , 4 ) (3,4) (3,4)和 ( 4 , 4 ) (4,4) (4,4)。分别将X乘以W_xh,将H乘以W_hh,然后将这两个乘法相加,我们得到一个形状为 ( 3 , 4 ) (3,4) (3,4)的矩阵。
import torch
from d2l import torch as d2l
X, W_xh = torch.normal(0, 1, (3, 1)), torch.normal(0, 1, (1, 4))
H, W_hh = torch.normal(0, 1, (3, 4)), torch.normal(0, 1, (4, 4))
torch.matmul(X, W_xh) + torch.matmul(H, W_hh)
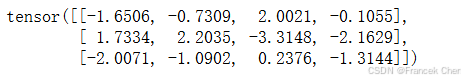
现在,我们沿列(轴1)拼接矩阵X和H,沿行(轴0)拼接矩阵W_xh和W_hh。这两个拼接分别产生形状 ( 3 , 5 ) (3, 5) (3,5)和形状 ( 5 , 4 ) (5, 4) (5,4)的矩阵。再将这两个拼接的矩阵相乘,我们得到与上面相同形状 ( 3 , 4 ) (3, 4) (3,4)的输出矩阵。
torch.matmul(torch.cat((X, H), 1), torch.cat((W_xh, W_hh), 0))
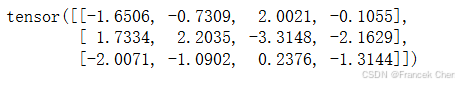
三、基于循环神经网络的字符级语言模型
回想一下语言模型和数据集中的语言模型,我们的目标是根据过去的和当前的词元预测下一个词元,因此我们将原始序列移位一个词元作为标签。Bengio等人首先提出使用神经网络进行语言建模。接下来,我们看一下如何使用循环神经网络来构建语言模型。设小批量大小为1,批量中的文本序列为“machine”。为了简化后续部分的训练,我们考虑使用字符级语言模型(character-level language model),将文本词元化为字符而不是单词。图2演示了如何通过基于字符级语言建模的循环神经网络,使用当前的和先前的字符预测下一个字符。

在训练过程中,我们对每个时间步的输出层的输出进行softmax操作,然后利用交叉熵损失计算模型输出和标签之间的误差。由于隐藏层中隐状态的循环计算,图2中的第 3 3 3个时间步的输出 O 3 \mathbf{O}_3 O3由文本序列“m”“a”和“c”确定。由于训练数据中这个文本序列的下一个字符是“h”,因此第 3 3 3个时间步的损失将取决于下一个字符的概率分布,而下一个字符是基于特征序列“m”“a”“c”和这个时间步的标签“h”生成的。
在实践中,我们使用的批量大小为 n > 1 n>1 n>1,每个词元都由一个 d d d维向量表示。因此,在时间步 t t t输入 X t \mathbf X_t Xt将是一个 n × d n\times d n×d矩阵,这与我们在有隐状态的循环神经网络中的讨论相同。
四、困惑度(Perplexity)
最后,让我们讨论如何度量语言模型的质量,这将在后续部分中用于评估基于循环神经网络的模型。一个好的语言模型能够用高度准确的词元来预测我们接下来会看到什么。考虑一下由不同的语言模型给出的对“It is raining …”(“…下雨了”)的续写:
- “It is raining outside”(外面下雨了);
- “It is raining banana tree”(香蕉树下雨了);
- “It is raining piouw;kcj pwepoiut”(piouw;kcj pwepoiut下雨了)。
就质量而言,例 1 1 1显然是最合乎情理、在逻辑上最连贯的。虽然这个模型可能没有很准确地反映出后续词的语义,比如,“It is raining in San Francisco”(旧金山下雨了)和“It is raining in winter”(冬天下雨了)可能才是更完美的合理扩展,但该模型已经能够捕捉到跟在后面的是哪类单词。例 2 2 2则要糟糕得多,因为其产生了一个无意义的续写。尽管如此,至少该模型已经学会了如何拼写单词,以及单词之间的某种程度的相关性。最后,例 3 3 3表明了训练不足的模型是无法正确地拟合数据的。
我们可以通过计算序列的似然概率来度量模型的质量。然而这是一个难以理解、难以比较的数字。毕竟,较短的序列比较长的序列更有可能出现,因此评估模型产生托尔斯泰的巨著《战争与和平》的可能性不可避免地会比产生圣埃克苏佩里的中篇小说《小王子》可能性要小得多。而缺少的可能性值相当于平均数。
在这里,信息论可以派上用场了。我们在引入softmax回归(信息论基础)时定义了熵、惊异和交叉熵。如果想要压缩文本,我们可以根据当前词元集预测的下一个词元。一个更好的语言模型应该能让我们更准确地预测下一个词元。因此,它应该允许我们在压缩序列时花费更少的比特。所以我们可以通过一个序列中所有的 n n n个词元的交叉熵损失的平均值来衡量: 1 n ∑ t = 1 n − log P ( x t ∣ x t − 1 , … , x 1 ) (7) \frac{1}{n} \sum_{t=1}^n -\log P(x_t \mid x_{t-1}, \ldots, x_1) \tag{7} n1t=1∑n−logP(xt∣xt−1,…,x1)(7) 其中 P P P由语言模型给出, x t x_t xt是在时间步 t t t从该序列中观察到的实际词元。这使得不同长度的文档的性能具有了可比性。由于历史原因,自然语言处理的科学家更喜欢使用一个叫做困惑度(perplexity)的量。简而言之,它是对式(7)的指数运算结果: exp ( − 1 n ∑ t = 1 n log P ( x t ∣ x t − 1 , … , x 1 ) ) (8) \exp\left(-\frac{1}{n} \sum_{t=1}^n \log P(x_t \mid x_{t-1}, \ldots, x_1)\right) \tag{8} exp(−n1t=1∑nlogP(xt∣xt−1,…,x1))(8)
困惑度的最好的理解是“下一个词元的实际选择数的调和平均数”。我们看看一些案例。
- 在最好的情况下,模型总是完美地估计标签词元的概率为1。在这种情况下,模型的困惑度为1。
- 在最坏的情况下,模型总是预测标签词元的概率为0。在这种情况下,困惑度是正无穷大。
- 在基线上,该模型的预测是词表的所有可用词元上的均匀分布。在这种情况下,困惑度等于词表中唯一词元的数量。事实上,如果我们在没有任何压缩的情况下存储序列,这将是我们能做的最好的编码方式。因此,这种方式提供了一个重要的上限,而任何实际模型都必须超越这个上限。
在接下来的小节中,我们将基于循环神经网络实现字符级语言模型,并使用困惑度来评估这样的模型。
小结
- 对隐状态使用循环计算的神经网络称为循环神经网络(RNN)。
- 循环神经网络的隐状态可以捕获直到当前时间步序列的历史信息。
- 循环神经网络模型的参数数量不会随着时间步的增加而增加。
- 我们可以使用循环神经网络创建字符级语言模型。
- 我们可以使用困惑度来评价语言模型的质量。
相关文章:

【现代深度学习技术】循环神经网络04:循环神经网络
【作者主页】Francek Chen 【专栏介绍】 ⌈ ⌈ ⌈PyTorch深度学习 ⌋ ⌋ ⌋ 深度学习 (DL, Deep Learning) 特指基于深层神经网络模型和方法的机器学习。它是在统计机器学习、人工神经网络等算法模型基础上,结合当代大数据和大算力的发展而发展出来的。深度学习最重…...

1. 认识DartGoogle为Flutter选择了Dart语言已经是既
1. 认识Dart Google为Flutter选择了Dart语言已经是既定的事实,无论你多么想用你熟悉的语言,比如JavaScript、TypeScript、ArkTS等来开发Flutter,至少目前都是不可以的。 Dart 是由谷歌开发的计算机编程语言,它可以被应用于 Web/…...

学习设计模式《三》——适配器模式
一、基础概念 适配器模式的本质是【转换匹配,复用功能】; 适配器模式定义:将一个类的接口转换为客户希望的另外一个接口;适配器模式使得原本由于接口不兼容而不能一起工作的那些类可以一起工作。 适配器模式的目的:复用…...

【Java面试系列】Spring Boot微服务架构下的分布式事务处理与性能优化 - 2025-04-19详解 - 3-5年Java开发必备知识
【Java面试系列】Spring Boot微服务架构下的分布式事务处理与性能优化 - 2025-04-19详解 - 3-5年Java开发必备知识 引言 在微服务架构中,分布式事务处理和性能优化是面试中高频出现的主题。随着系统规模的扩大,如何保证数据一致性和系统性能成为开发者…...
)
Elasticsearch只返回指定的字段(用_source)
在Elasticsearch中,当你想要查询文档但不返回所有字段,只返回指定的字段(比如这里的id字段),你可以使用_source参数来实现这一点。但是,有一点需要注意:Elasticsearch的_source字段默认是返回的…...

【Linux “sed“ 命令详解】
本章目录: 1. 命令简介sed 的优势: 2. 命令的基本语法和用法基本语法:参数说明:常见用法场景:示例1:替换文本示例2:删除空行示例3:从命令输出中处理内容 3. 命令的常用选项及参数常用命令动作&a…...

JMETER使用
接口测试流程: 1.获取接口文档,熟悉接口业务 2.编写接口测试用例以及评审 正例:输入正常的参数,验证接口能否正常返回 反例:权限异常(为空、错误、过期)、参数异常(为空、长度异常、类型异常)、其他异常(黑名单、调用次数限制)、兼容异常(一个接口被多种…...

JavaWeb 课堂笔记 —— 13 MySQL 事务
本系列为笔者学习JavaWeb的课堂笔记,视频资源为B站黑马程序员出品的《黑马程序员JavaWeb开发教程,实现javaweb企业开发全流程(涵盖SpringMyBatisSpringMVCSpringBoot等)》,章节分布参考视频教程,为同样学习…...

离线安装elasticdump并导入和导出数据
离线安装elasticdump 在 CentOS 或 RHEL 系统上安装 elasticdump,你可以使用 npm(Node.js 的包管理器)来安装,因为 elasticdump 是一个基于 Node.js 的工具。以下是步骤 先在外网环境下安装 下载nodejs和npm(注意x8…...

WhatTheDuck:一个基于浏览器的CSV查询工具
今天给大家介绍一个不错的小工具:WhatTheDuck。它是一个免费开源的 Web 应用程序,允许用户上传 CSV 文件并针对其内容执行 SQL 查询分析。 WhatTheDuck 支持 SQL 代码自动完成以及语法高亮。 WhatTheDuck 将上传的数据存储为 DuckDB 内存表,继…...

关于数字信号与图像处理——基于Matlab的图像增强技术
本篇博客是在做数字信号与图像处理实验中的收获。 具体内容包括:根据给定的代码放入Matlab中分别进行两次运行测试——比较并观察运行后的实验结果与原图像的不同点——画出IJ的直方图,并比较二者差异。接下来会对每一步进行具体讲解。 题目:…...

MySQL数据库 - 锁
锁 此笔记参考黑马教程,仅学习使用,如有侵权,联系必删 文章目录 锁1. 概述1.1 介绍1.2 分类 2. 全局锁2.1 介绍2.2 语法2.3 特点(弊端) 3. 表级锁3.1 介绍3.2 表锁3.3 元数据锁(meta data lock࿰…...

免费多平台运行器,手机畅玩经典主机大作
软件介绍 飞鸟模拟器是一款面向安卓设备的免费游戏平台,支持PS2/PSP/NDS等十余种经典主机游戏运行。 该软件突破传统模拟器复杂操作模式,采用智能核心加载技术,用户只需双击主程序即可开启游戏之旅,真正实现"即下即玩"…...

计算机软考中级 知识点记忆——排序算法 冒泡排序-插入排序- 归并排序等 各种排序算法知识点整理
一、📌 分类与比较 排序算法 最优时间复杂度 平均时间复杂度 最坏时间复杂度 空间复杂度 稳定性 应用场景与特点 算法策略 冒泡排序 O(n) O(n) O(n) O(1) 稳定 简单易实现,适用于小规模数据排序。 交换排序策略 插入排序 O(n) O(n) O…...

STC32G12K128单片机GPIO模式SPI操作NorFlash并实现FatFS文件系统
STC32G12K128单片机GPIO模式SPI操作NorFlash并实现FatFS文件系统 Norflash简介NorFlash操作驱动代码文件系统测试代码 Norflash简介 NOR Flash是一种类型的非易失性存储器,它允许在不移除电源的情况下保留数据。NOR Flash的名字来源于其内部结构中使用的NOR逻辑门。…...

uniapp-x 二维码生成
支持X,二维码生成,支持微信小程序,android,ios,网页 - DCloud 插件市场 免费的单纯用爱发电的...

当HTTP遇到SQL注入:Java开发者的攻防实战手册
一、从HTTP请求到数据库查询:漏洞如何产生? 危险的参数拼接:Servlet中的经典错误 漏洞代码重现: public void doGet(HttpServletRequest request, HttpServletResponse response) throws ServletException, IOException {String category = request.getParameter("…...

[dp20_完全背包] 介绍 | 零钱兑换
目录 1. 完全背包 题解 背包必须装满 2.零钱兑换 题解 1. 完全背包 链接: DP42 【模板】完全背包 描述 你有一个背包,最多能容纳的体积是V。 现在有n种物品,每种物品有任意多个,第i种物品的体积为vivi ,价值为wiwi。 &a…...

精打细算 - GPU 监控
精打细算 - GPU 监控 在上一篇,咱们历经千辛万苦,终于让应用程序在 Pod 的“驾驶舱”里成功地“点火”并用上了 GPU。太棒了!但是,车开起来是一回事,知道车速多少、油耗多少、引擎水温是否正常,则是另一回事,而且同样重要,对吧? 我们的 GPU 应用跑起来了,但新的问题…...

故障诊断 | CNN-BiGRU-Attention故障诊断
效果一览 摘要 在现代工业生产中,设备的稳定运行至关重要,故障诊断作为保障设备安全、高效运行的关键技术,其准确性和及时性直接影响着生产效率与成本[[doc_refer_1]][[doc_refer_2]]。随着工业设备复杂性的不断增加,传统故障诊断方法已难以满足实际需求。深度学习技术凭借…...

单片机AIN0、AIN1引脚功能
目录 1. 模拟-数字转换器(ADC) 2. 交流电源(AC) 总结 这两部分有什么区别? 在这个电路图中,两个部分分别是模拟-数字转换器(ADC)和交流电源(AC)。以下是这…...

交换机与路由器的主要区别:深入分析其工作原理与应用场景
在现代网络架构中,交换机和路由器是两种至关重要的设备。它们在网络中扮演着不同的角色,但很多人对它们的工作原理和功能特性并不十分清楚。本文将深入分析交换机与路由器的主要区别,并探讨它们的工作原理和应用场景。 一、基本定义 1. 交换…...
)
uniApp小程序保存定制二维码到本地(V3)
这里的二维码组件用的 uv-ui 的二维码 可以按需引入 QRCode 二维码 | 我的资料管理-uv-ui 是全面兼容vue32、nvue、app、h5、小程序等多端的uni-app生态框架 <uv-qrcode ref"qrcode" :size"280" :value"payCodeUrl"></uv-qrcode>&l…...

手机投屏到电视方法
一、投屏软件 比如乐播投屏 二、视频软件 腾讯视频、爱奇艺 三、手机无线投屏功能 四、有线投屏 五、投屏器...

桌面应用UI开发方案
一、基于 Web 技术的跨平台方案 Electron Python/Go 特点: 技术栈:前端使用 HTML/CSS/JS,后端通过 Node.js 集成 Python/Go 模块或服务。 跨平台:支持 Windows、macOS、Linux 桌面端,适合开发桌面应用。 生态成熟&…...

FFmpeg+Nginx+VLC打造M3U8直播
一、视频直播的技术原理和架构方案 直播模型一般包括三个模块:主播方、服务器端和播放端 主播放创造视频,加美颜、水印、特效、采集后推送给直播服务器 播放端: 直播服务器端:收集主播端的视频推流,将其放大后推送给…...

山东科技大学深度学习考试回忆
目录 一、填空(五个空,十分) 二、选择题(五个,十分) 三、判断题(五个,五分) 四、论述题(四个,四十分) 五、计算题(二个ÿ…...

【Flutter动画深度解析】性能与美学的完美平衡之道
Flutter的动画系统是其UI框架中最引人注目的部分之一,它既能创造令人惊艳的视觉效果,又需要开发者对性能有深刻理解。本文将深入剖析Flutter动画的实现原理、性能优化策略以及设计美学,帮助你打造既流畅又美观的用户体验。 一、Flutter动画核…...

【嵌入式】——Linux系统远程操作和程序编译
目录 一、虚拟机配置网络设置 二、使用PuTTY登录新建的账户 1、在ubuntu下开启ssh服务 2、使用PuTTY连接 三、树莓派实现远程登录 四、树莓派使用VNC viewer登录 五、Linux使用talk聊天程序 1、使用linux自带的talk命令 2、使用c语言编写一个talk程序 一、虚拟机配置网络…...

零、HarmonyOS应用开发者基础学习总览
零、HarmonyOS应用开发者基础认证 1 整体学习内容概览 1 整体学习内容概览 通过系统化的课程学习,熟练掌握 DevEco Studio,ArkTS,ArkUI,预览器,模拟器,SDK 等 HarmonyOS 应用开发的关键概念,具…...

记录一次项目中使用pdf预览过程以及遇到问题以及如何解决
背景 项目中现有的pdf浏览解析不能正确解析展示一些pdf文件,要么内容一直在加载中展示不出来,要么展示的格式很凌乱 解决 方式一:(优点:比较无脑,缺点:不能解决遇到的一些特殊问题࿰…...

致远OA——自定义开发rest接口
文章目录 :apple: 业务流程 🍎 业务流程 代码案例: https://pan.quark.cn/s/57fa808c823f 官方文档: https://open.seeyoncloud.com/seeyonapi/781/https://open.seeyoncloud.com/v5devCTP/39/783.html 登录系统 —— 后台管理 —— 切换系…...

STL之vector基本操作
写在前面 我使用的编译器版本是 g 11.4.0 (Ubuntu 22.04 默认版本),支持C17的全部特性,支持C20的部分特性。 vector的作用 我们知道vector是动态数组(同时在堆上存储数组元素),我们在不确定数…...

dac直通线还是aoc直通线? sfp使用
"DAC直通线" 和 "AOC直通线" 都是高速互连线缆,用于数据中心、服务器、交换机等设备之间的高速互连。它们的选择主要取决于以下几个方面: 🔌 DAC(Direct Attach Cable,直连铜缆) 材质&…...

【Linux篇】探索进程间通信:如何使用匿名管道构建高效的进程池
从零开始:通过匿名管道实现进程池的基本原理 一. 进程间通信1.1 基本概念1.2 通信目的1.3 通信种类1.3.1 同步通信1.3.2 异步通信 1.4 如何通信 二. 管道2.1 什么是管道2.2 匿名管道2.2.1 pipe()2.2.2 示例代码:使用 pipe() 进行父子进程通信2.2.3 管道容…...

Mixture-of-Experts with Expert Choice Routing:专家混合模型与专家选择路由
摘要 稀疏激活的专家混合模型(MoE)允许在保持每个token或每个样本计算量不变的情况下,大幅增加参数数量。然而,糟糕的专家路由策略可能导致某些专家未被充分训练,从而使得专家在特定任务上过度或不足专业化。先前的研究通过使用top-k函数为每个token分配固定数量的专家,…...

ai学习中收藏网址【1】
https://github.com/xuwenhao/geektime-ai-course课程⾥所有的代码部分,通过 Jupyter Notebook 的形式放在了 GitHub 上 https://github.com/xuwenhao/geektime-ai-course 图片创作 https://www.midjourney.com/explore?tabtop 创建填⾊本 How to Create Midjour…...
)
【滑动窗口】最⼤连续 1 的个数 III(medium)
⼤连续 1 的个数 III(medium) 题⽬描述:解法(滑动窗⼝):算法思路:算法流程: C 算法代码:Java 算法代码: 题⽬链接:1004. 最⼤连续 1 的个数 III …...
)
ClawCloud的免费空间(github用户登录可以获得$5元/月的免费额度)
免费的空间 Welcome to ClawCloud Lets create your workspace 官网:ClawCloud | Cloud Infrastructure And Platform for Developers 区域选择新加坡 然后这个页面会变成新加坡区域,再按一次确定,就创建好了工作台。 初始界面࿰…...
))
sql之DML(insert、delete、truncate、update、replace))
🎯 本文专栏:MySQL深入浅出 🚀 作者主页:小度爱学习 数据库使用时,大多数情况下,开发者只会操作数据,也是就增删改查(CRUD)。 增删改查四条语句,最重要的是查…...

Spring Boot常用注解全解析:从入门到实战
🌱 Spring Boot常用注解全解析:从入门到实战 #SpringBoot核心 #注解详解 #开发技巧 #高效编程 一、核心启动与配置注解 1. SpringBootApplication 作用:标记主启动类,整合了Configuration、EnableAutoConfiguration和Component…...

Python 赋能区块链教育:打造去中心化学习平台
Python 赋能区块链教育:打造去中心化学习平台 引言 区块链技术正在重塑全球多个行业,而教育领域也不例外。传统的在线学习平台往往依赖中心化存储和管理模式,导致数据安全、用户隐私、资源共享等问题难以解决。而随着 Web 3.0 的发展,区块链在教育场景中的应用逐渐受到关…...

verilog float mult
module pipe_float_mul(input wire clk ,// 时钟信号input wire en ,// 使能信号input wire rst_n ,// 复位信号input wire round_cfg ,// 决…...

Android开发四大组件和生命周期及setFlags
文章目录 Android开发四大组件1. Activity(活动)2. Service(服务)3. BroadcastReceiver(广播接收器)4. ContentProvider(内容提供者)共同特点 Activity 生命周期详解完整的生命周期方…...
)
mysql的函数(第二期)
九、窗口函数(MySQL 8.0) 适用于对结果集的子集(窗口)进行计算,常用于数据分析场景。 ROW_NUMBER() 作用:为每一行生成唯一的序号。示例:按分数降序排名 SELECT n…...

MATLAB 控制系统设计与仿真 - 39
多变量系统控制器设计实例2 假如原系统对象中有位于虚轴上的极点,则不能直接应用鲁棒控制设计来设计控制器。 在这样的情况下,需引入一个新的变量p,使得 即可在对象模型中用p变量取代s变量,这样的变换称为双线性变换,…...

深入理解C++ 中的vector容器
一、引言 在C 的标准模板库(STL)中, vector 是一个极为常用且功能强大的序列容器。它就像是一个动态数组,既能享受数组随机访问元素的高效性,又能灵活地动态调整大小。在本文中,我们将深入探讨 vector …...
)
ESP-ADF外设子系统深度解析:esp_peripherals组件架构与核心设计(显示输出类外设之LED)
目录 ESP-ADF外设子系统深度解析:esp_peripherals组件架构与核心设计(显示输出类外设之LED)简介模块概述功能定义架构位置核心特性 LED外设分析LED外设概述LED外设功能特点常见应用场景LED外设架构图 LED外设API和数据结构公共API事件类型配置…...

[特殊字符] Kotlin与C的类型别名终极对决:typealias vs typedef,如何让代码脱胎换骨?
在 Kotlin 中,typealias 是一个非常实用的关键字,它可以为已有的类型定义一个新的名称,起到简化代码和提升可读性的作用。比如: // 定义一个复杂函数类型的别名 typealias ClickListener (View, Int) -> Unitfun setOnClickL…...
详解)
第9期:文本条件生成(CLIP + Diffusion)详解
“让我们用一句话,让模型画出一幅画。” 在前几期中我们学习了 Denoising Diffusion Probabilistic Models(DDPM)如何在无条件情况下生成图像。而在本期,我们将跨入更具挑战性但也更酷的领域 —— 文本条件图像生成(Te…...