DSA数据结构与算法 4
第2章 排序技术
2.1 排序简介
排序是将数据按照特定顺序(升序或降序)排列的过程,它不仅是计算机科学中的基础操作,也是日常生活中不可或缺的工具。举个例子,想象一个图书馆里的书籍,如果这些书籍没有按照作者的姓氏或书名的字母顺序排列,我们在寻找一本特定的书时将会面临极大的困扰,甚至可能根本找不到目标书籍。排序的作用就在于通过建立明确的顺序,使得大量数据在存储和访问时能够更加高效,减少搜索所需的时间和精力。
排序分为两种类型:
- 内部排序:如果要排序的数据能够一次性放入内存中,那么就是进行内部排序。
- 外部排序:当要排序的数据过大,不能一次性加载到内存时,这些数据会被存储在辅助存储器(如硬盘、软盘、磁带等)中,然后使用外部排序方法进行排序。
排序的应用
排序在许多应用中都非常有用,特别是在数据库应用中,可以根据需要对数据进行排序。例如:
- 数据库应用中,排序用于将数据按照指定顺序排列。
- 在字典类应用中,数据需要按字母顺序排列。
- 排序也有助于从一组元素中快速搜索目标元素。
- 检查元素的唯一性时,排序也能提供帮助。
- 在某些算法中,寻找最接近的一对数据需要排序。
2.2 排序技术
- 冒泡排序
- 插入排序
- 基数排序
- 快速排序
- 归并排序
- 堆排序
- 选择排序
- 希尔排序
2.2.1 冒泡排序
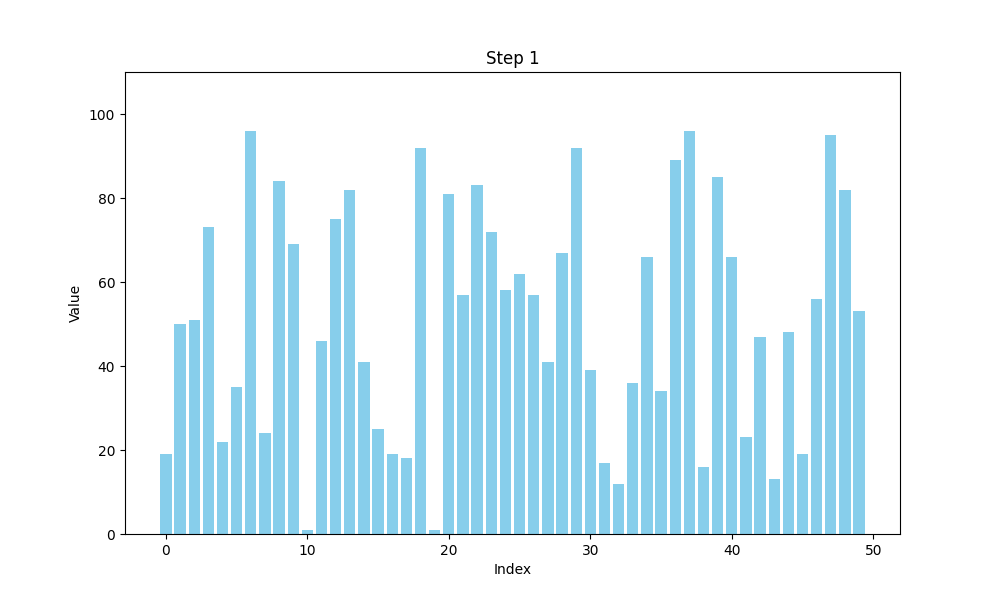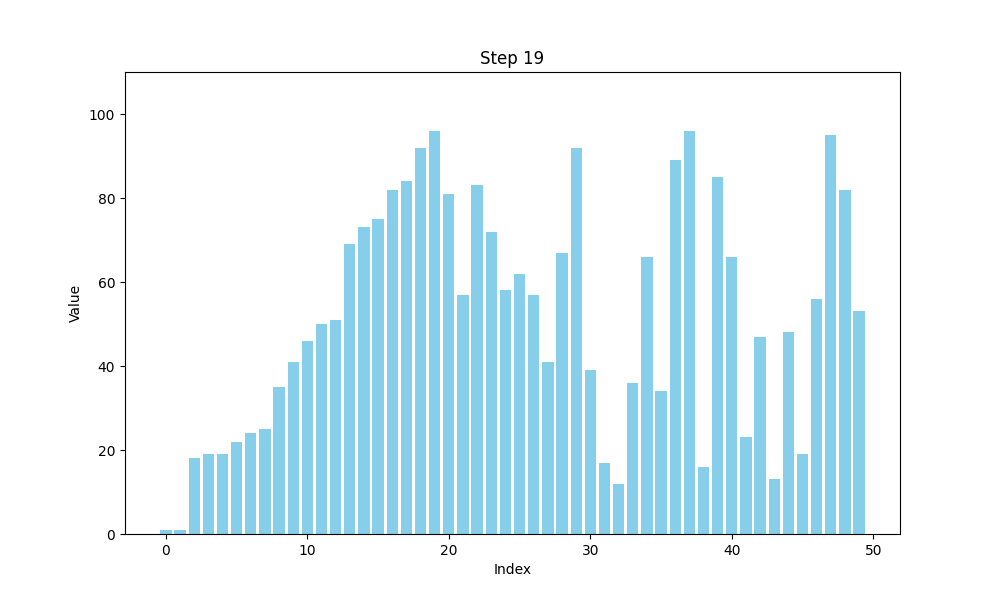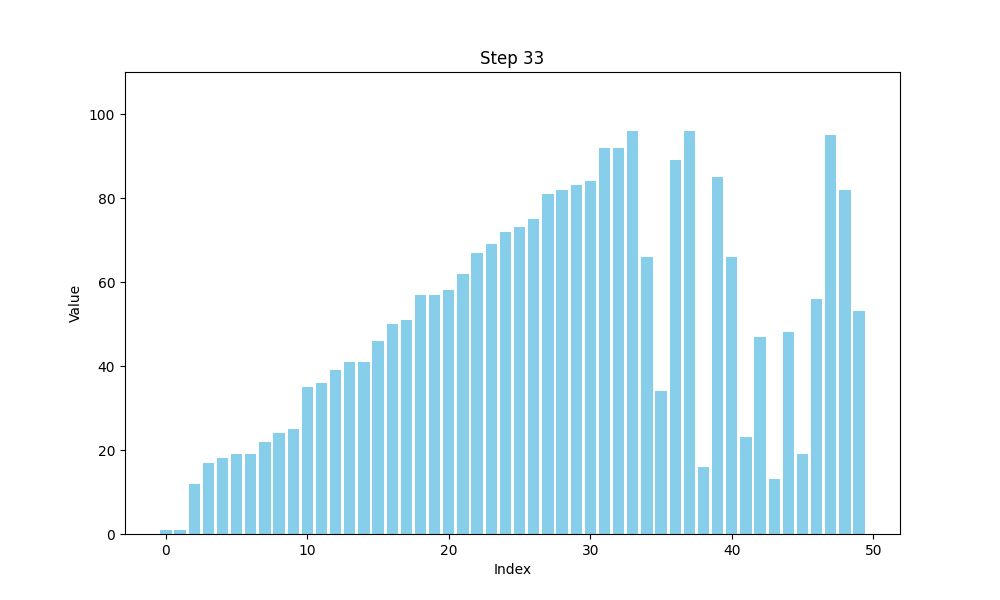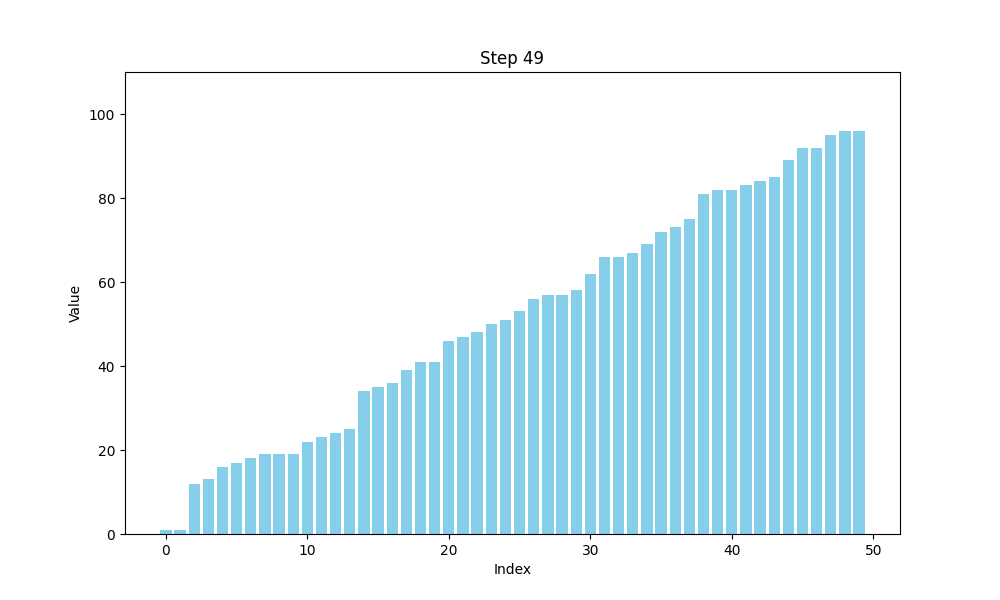
冒泡排序的核心思想是:通过逐一比较数组中相邻的两个元素,如果前面的元素比后面的元素大,就交换它们的位置。这个过程会继续进行,直到没有需要交换的元素为止。冒泡排序得名于元素像气泡一样“浮”到列表的顶端。通过这种方法,经过一轮排序后,最大的元素会被移到数组的末尾。
值得注意的是,如果要将元素按降序排列,那么在第一轮排序中,最小的元素将被移到数组的最高位置。
例子:
假设我们有一个数字数组 A[] = {30, 52, 29, 87, 63, 27, 19, 54},我们可以将其看作一群人在排队等候时,按照身高(数值大小)进行排序。每次比较两个相邻的人,如果前一个人的身高比后一个人高,那么他们就交换位置。每一轮结束后,身高最高的人就像气泡一样“浮”到队伍的最后。
这种方式的好处是,虽然每次只移动少数元素,但最终会将所有元素按正确的顺序排列。冒泡排序的时间复杂度是 O ( n 2 ) O(n^2) O(n2),因此当数据量较大时,它的效率较低。对于小规模数据,冒泡排序足够有效,但对于大规模数据集,通常需要更高效的排序算法。
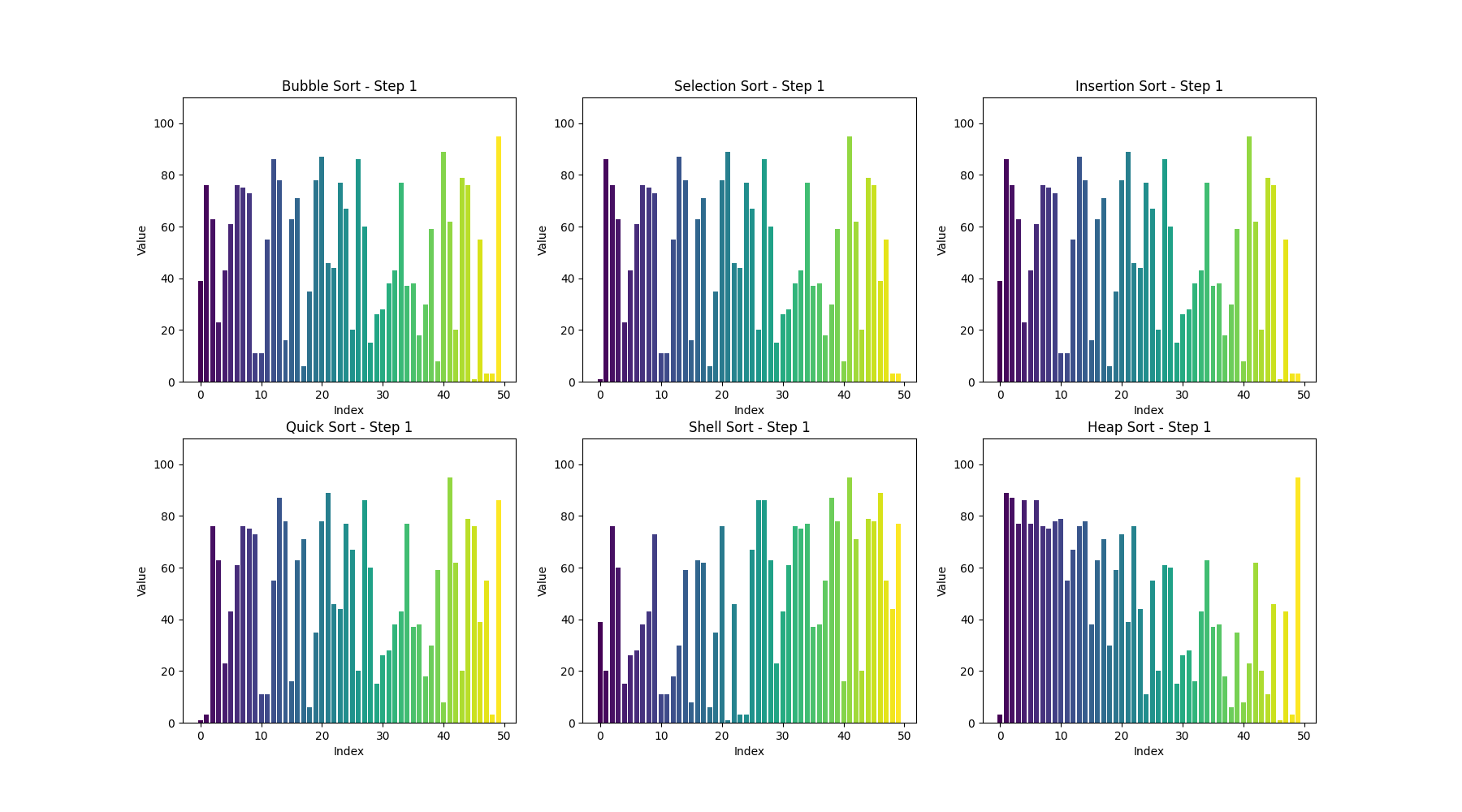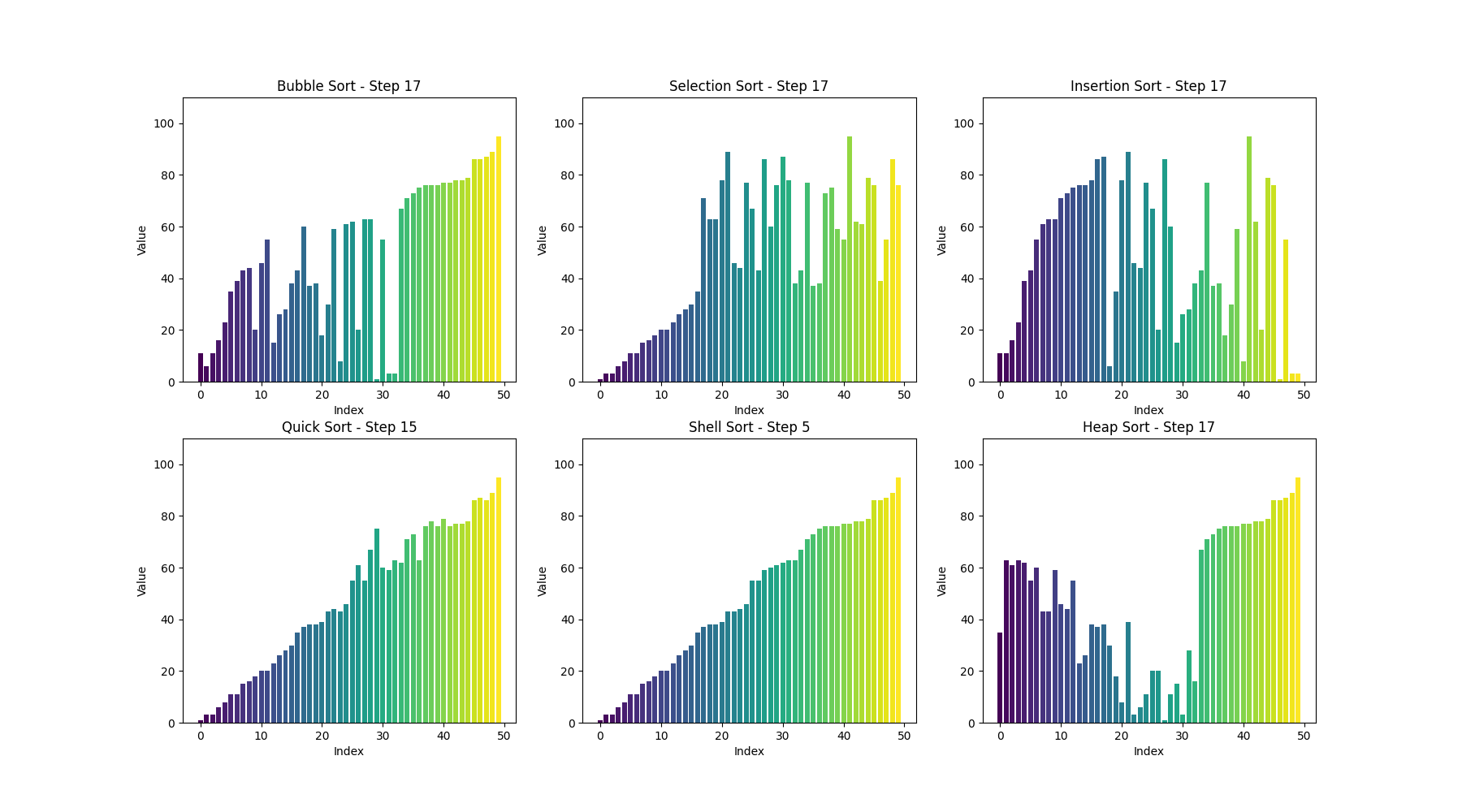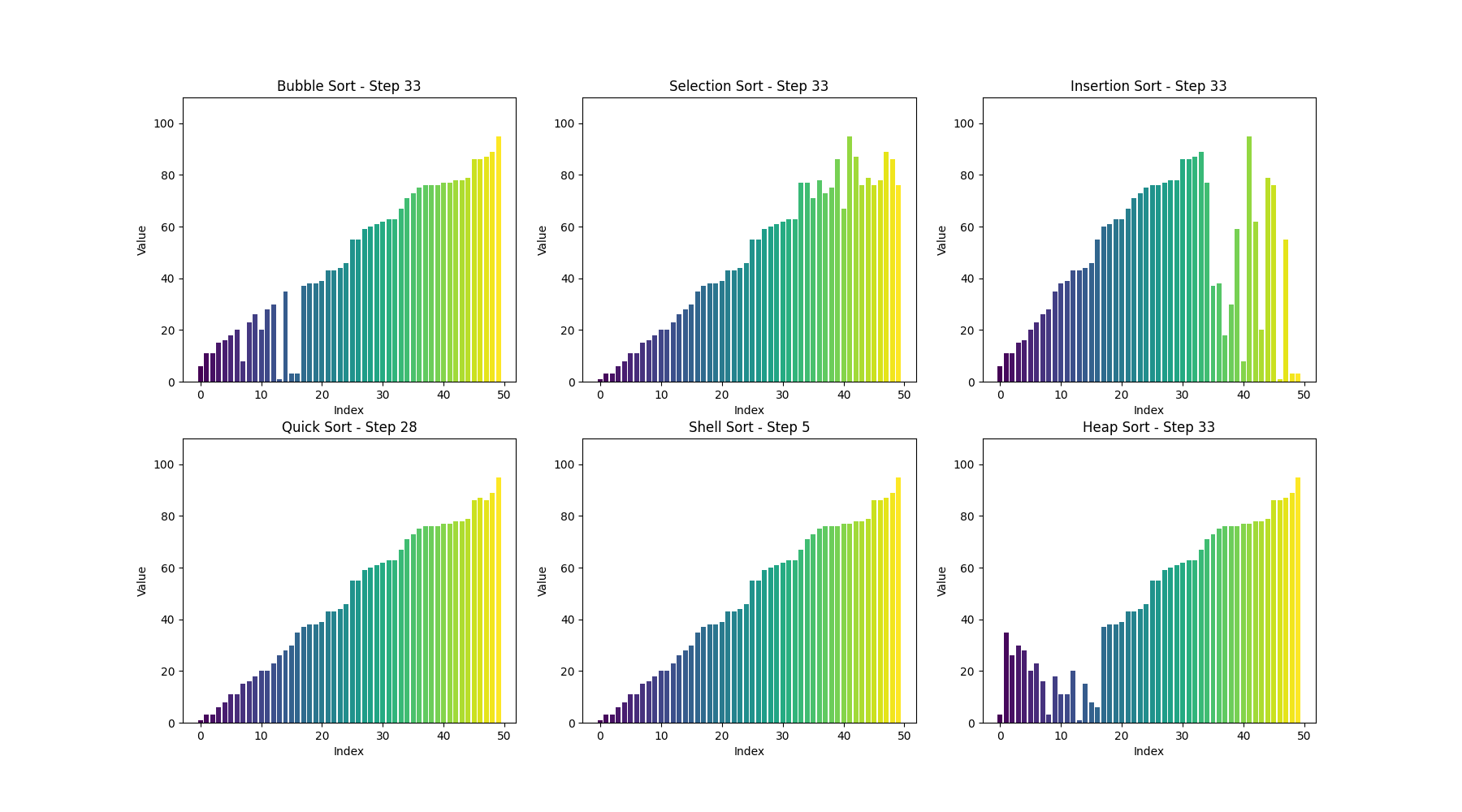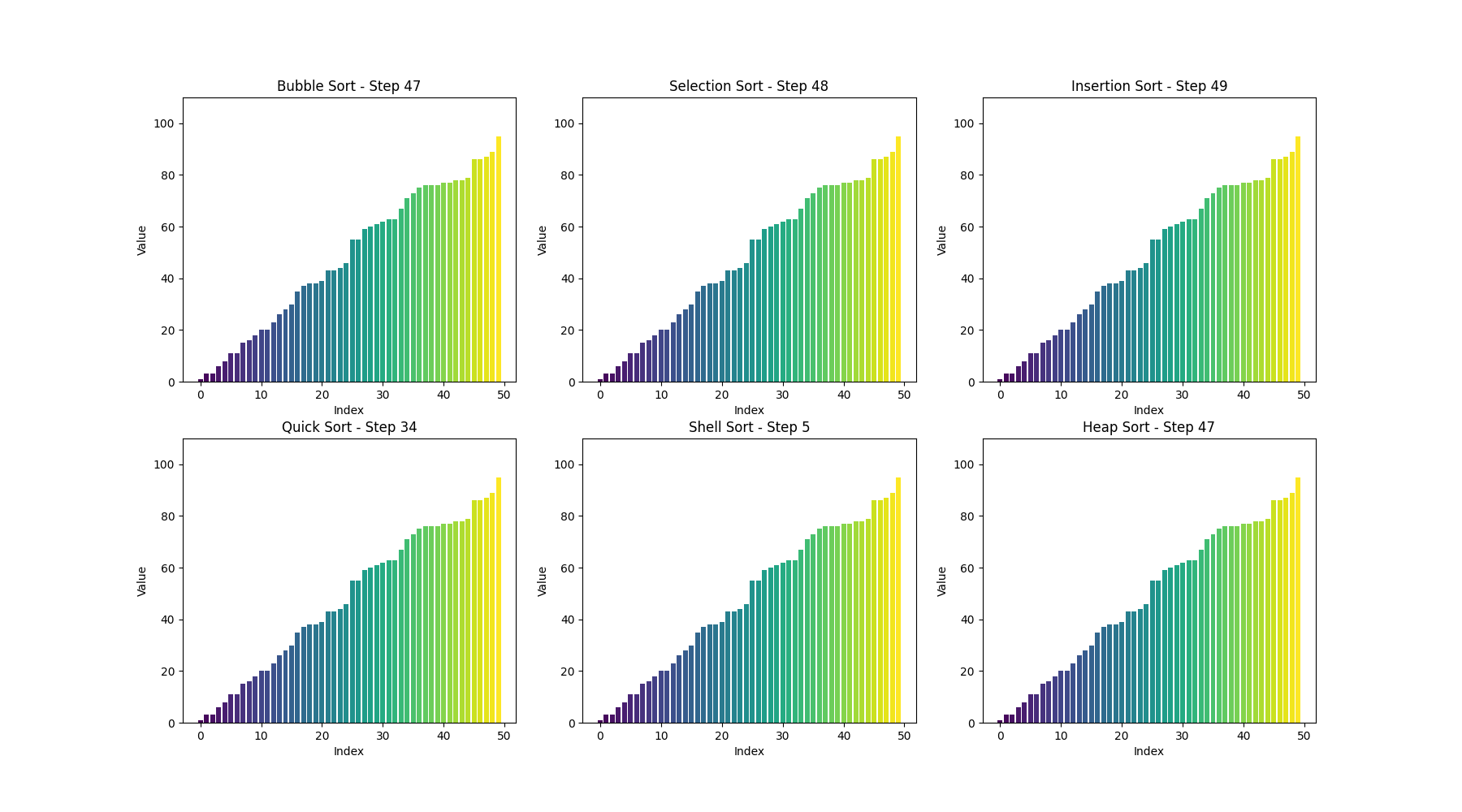
可视化bubble sort
def bubble_sort(arr):n = len(arr)# 用于存储每一步的数组状态steps = []# 外层循环,控制排序的趟数for i in range(n):swapped = False # 标记是否发生了交换for j in range(0, n-i-1):if arr[j] > arr[j+1]:arr[j], arr[j+1] = arr[j+1], arr[j] # 交换元素swapped = Truesteps.append(arr.copy()) # 保存每一步的状态# 如果一趟排序没有交换任何元素,说明数组已经有序,提前结束if not swapped:breakreturn steps
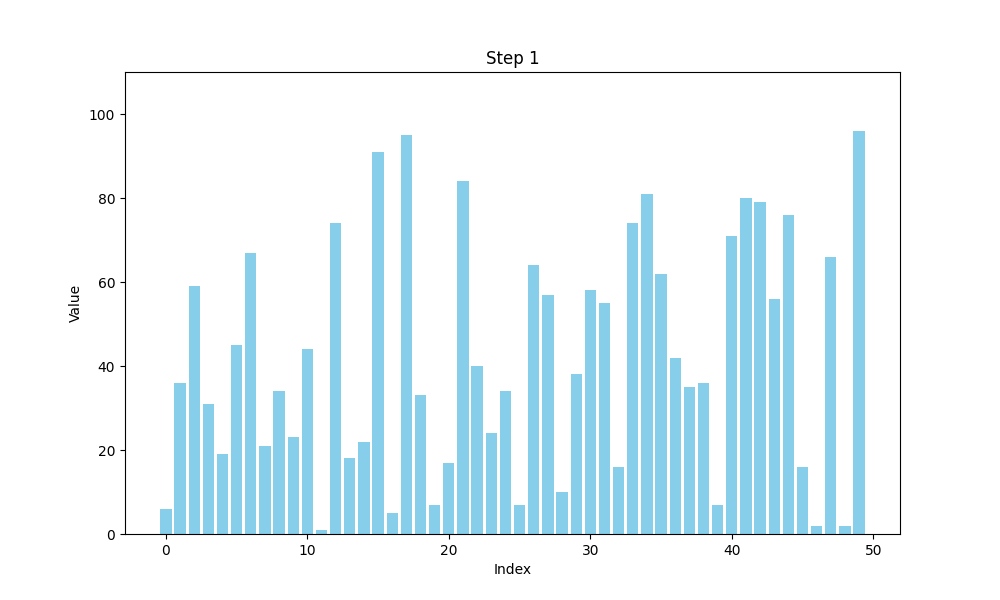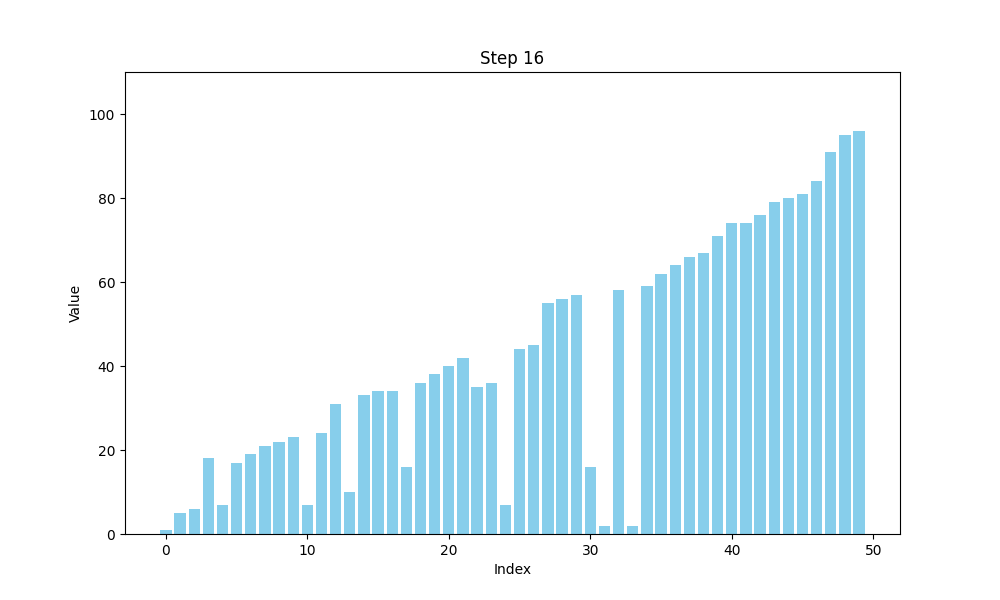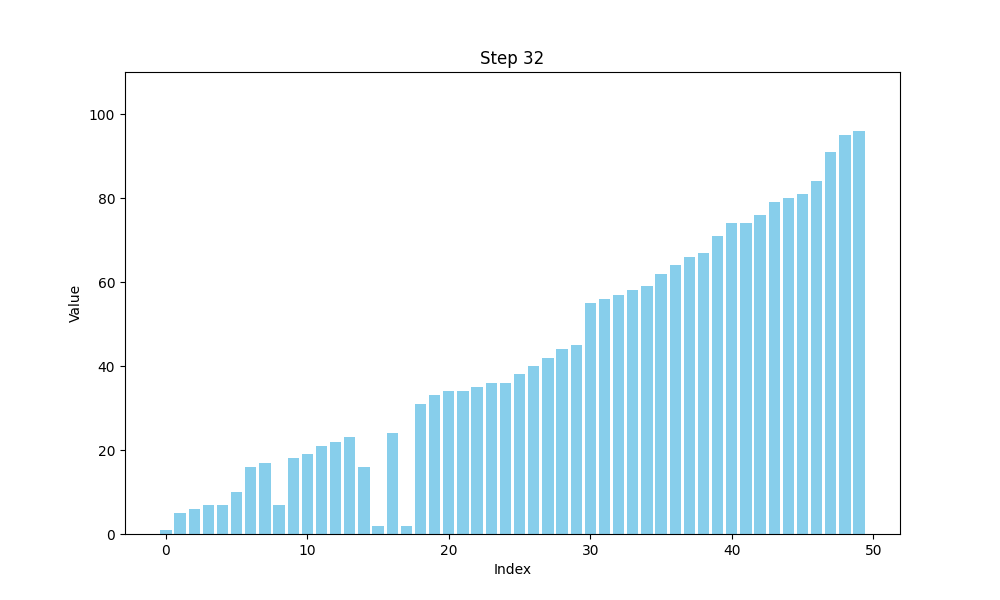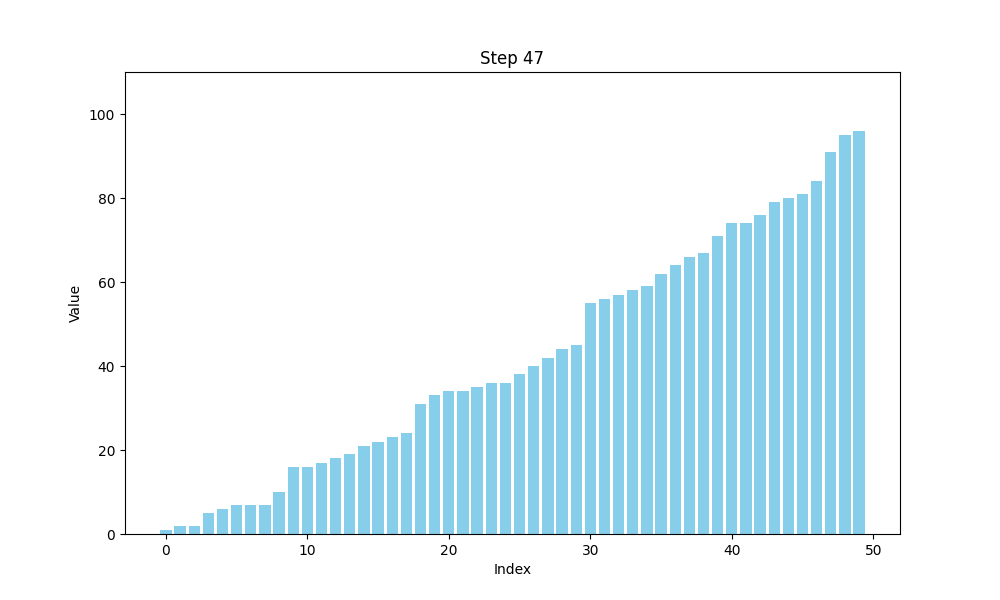
冒泡排序的时间复杂度分析
排序算法的复杂度通常与比较次数密切相关。冒泡排序的时间复杂度也不例外。我们可以通过分析冒泡排序中的比较次数来得出其复杂度。
冒泡排序的核心思想是通过不断比较相邻的元素,如果前面的元素比后面的元素大,则交换它们的位置。经过每一轮比较后,最大的元素逐步“浮”到列表的末尾。可以理解为,冒泡排序就像一个逐步筛选出最大元素的过程,每一轮都会将一个最大的元素“冒”到最顶端。
假设我们有一个包含 n n n 个元素的数组。冒泡排序的过程可以分为 n − 1 n-1 n−1 轮比较。具体来说:
- 第一轮:需要进行 n − 1 n-1 n−1 次比较,将最大的元素“冒”到最后一个位置。
- 第二轮:剩余的 n − 1 n-1 n−1 个元素中,再进行 n − 2 n-2 n−2 次比较,将第二大的元素放到倒数第二个位置。
- 以此类推,直到第 n − 1 n-1 n−1 轮,只剩下两个元素进行一次比较。
因此,冒泡排序的比较次数总和为:
f ( n ) = ( n − 1 ) + ( n − 2 ) + ( n − 3 ) + ⋯ + 2 + 1 f(n) = (n-1) + (n-2) + (n-3) + \dots + 2 + 1 f(n)=(n−1)+(n−2)+(n−3)+⋯+2+1
这个求和可以简化为:
f ( n ) = n ( n − 1 ) 2 f(n) = \frac{n(n-1)}{2} f(n)=2n(n−1)
进一步展开这个公式,我们可以得到:
f ( n ) = n 2 2 + O ( n ) f(n) = \frac{n^2}{2} + O(n) f(n)=2n2+O(n)
其中 O ( n ) O(n) O(n) 表示在最坏情况下的线性时间消耗,通常可以忽略不计。因此,冒泡排序的时间复杂度是:
O ( n 2 ) O(n^2) O(n2)
这意味着,随着元素数量 n n n 的增加,冒泡排序的执行时间会按 n 2 n^2 n2 的比例增长。换句话说,元素数量翻倍时,冒泡排序所需的时间将增加四倍。这也说明了冒泡排序在处理大规模数据时效率较低。
比喻
想象你正在整理一堆乱放的书,每本书上都有一个编号。在每一轮整理中,你从头到尾检查两本相邻的书,确保它们按照编号顺序排列。如果发现有一本编号较大的书排在了前面,你就交换它们的位置。每完成一轮整理,你就确定了一本最大的书在正确的位置。这样,你需要重复 n − 1 n-1 n−1 次整理,才能确保所有书本按顺序排好。
这就像冒泡排序一样,每一轮比较和交换会“将”最大的元素移动到正确的位置。整个过程需要多轮排序,每一轮减少了一个需要排序的元素。最终,所有元素都排好了顺序。
插入排序(Insertion Sort)
插入排序是一种非常简单的排序算法,它通过逐个将元素插入到已排序好的数组(或列表)中,来完成排序的过程。我们对这种排序方法并不陌生,实际上,当我们玩扑克牌时,通常会使用这种排序技巧。比如在打桥牌时,我们需要将手中的牌按照大小排序,插入排序就是一种非常直观的方式。
插入排序的基本思想是将每一个元素插入到其在已排序部分中的正确位置。在第一次迭代中,插入排序将第一个元素与第零个元素进行比较;在第二次迭代中,将第二个元素与第零个和第一个元素进行比较,依此类推。在每次迭代中,当前元素都要与前面的所有元素进行比较,直到找到其适合的位置。总之,插入排序的每一步都将当前元素插入到已排序部分的正确位置。
举例
假设我们有一个数组,需要使用插入排序对其进行排序:
23, 29, 11, 1
在第一轮迭代中,23 和 29 比较,23 已经是正确的位置;接着,29 与 23 比较;之后,再将 11 插入已排序部分,逐个元素与前面的元素进行比较,最终插入到正确的位置。
可视化插入排序
# 插入排序算法
def insertion_sort(arr):n = len(arr)# 用于存储每一步的数组状态steps = []# 从第二个元素开始,逐一插入到已排序部分for i in range(1, n):key = arr[i] # 当前要插入的元素j = i - 1# 找到key元素的插入位置while j >= 0 and arr[j] > key:arr[j + 1] = arr[j] # 将比key大的元素右移j -= 1arr[j + 1] = key # 将key插入到正确的位置steps.append(arr.copy()) # 保存每一步的状态return steps
插入排序的时间复杂度
如果初始数组已经是排序好的,那么每一次迭代中仅需要进行一次比较,因此排序的复杂度是 O ( n ) O(n) O(n),即线性时间。然而,如果初始数组是完全逆序的,最坏情况下,复杂度就会达到 O ( n 2 ) O(n^2) O(n2)。
最坏情况下,插入排序的比较次数总和为:
( n − 1 ) + ( n − 2 ) + ⋯ + 3 + 2 + 1 = ( n − 1 ) ∗ n 2 (n-1) + (n-2) + \dots + 3 + 2 + 1 = \frac{(n-1) * n}{2} (n−1)+(n−2)+⋯+3+2+1=2(n−1)∗n
这就意味着最坏情况的时间复杂度是 O ( n 2 ) O(n^2) O(n2)。
平均情况下,插入排序的比较次数也接近 O ( n 2 ) O(n^2) O(n2),因为每次都可能需要进行多次比较才能找到合适的位置。因此,插入排序的平均时间复杂度也是 O ( n 2 ) O(n^2) O(n2)。
比喻
我们可以将插入排序想象成整理一个乱序的扑克牌堆。你手里有一副散乱的扑克牌,每次从手里拿出一张新牌,然后将它插入到已经排序好的部分。你会从已经排序的牌堆中,逐一比较新牌和已排序牌堆中的牌,直到找到一个位置,把这张新牌插入其中。随着你不断进行这个过程,最终你会将所有牌都整理成有序的状态。
这就像插入排序一样,每次从未排序部分取出一个元素,将其插入到已排序部分的合适位置。整个过程逐渐构建起一个有序的序列。
选择排序(Selection Sort)
选择排序是最简单的排序算法之一。它的基本思想是:首先找到数组中最小的元素,并将它与第一个位置的元素交换;接着找到第二小的元素,并将其与第二个位置的元素交换,依此类推,直到整个数组被排序完成。通过这种方式,选择排序逐步将最小的元素放到已排序部分的末尾,直到所有元素都有序。
选择排序的过程
选择排序的操作可以理解为在每一轮排序中,选择一个最小的元素并将其放到正确的位置。每一轮的操作就像是挑选一个元素,放到最前面的位置,剩下的元素继续重复此过程。我们可以想象自己在整理一堆书,每次从中找出一本最薄的书,放到书架的最前面,直到书架上的书全部按照从薄到厚的顺序排列。
def selection_sort(arr):n = len(arr)# 用于存储每一步的数组状态steps = []# 外层循环,控制排序的趟数for i in range(n):min_idx = i # 假设当前元素为最小值for j in range(i+1, n):if arr[j] < arr[min_idx]: # 找到更小的元素min_idx = j# 交换元素arr[i], arr[min_idx] = arr[min_idx], arr[i]steps.append(arr.copy()) # 保存每一步的状态return steps
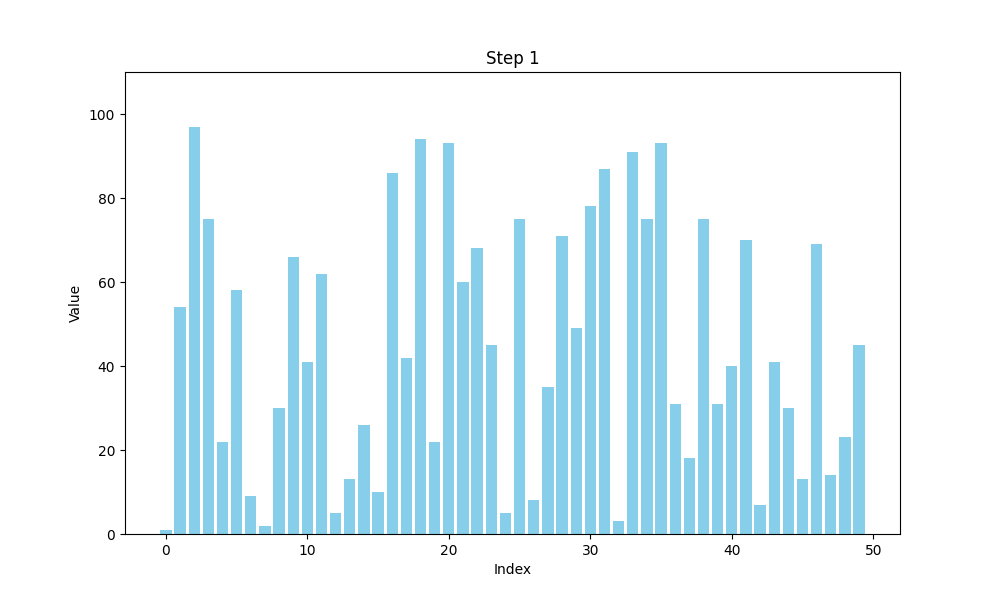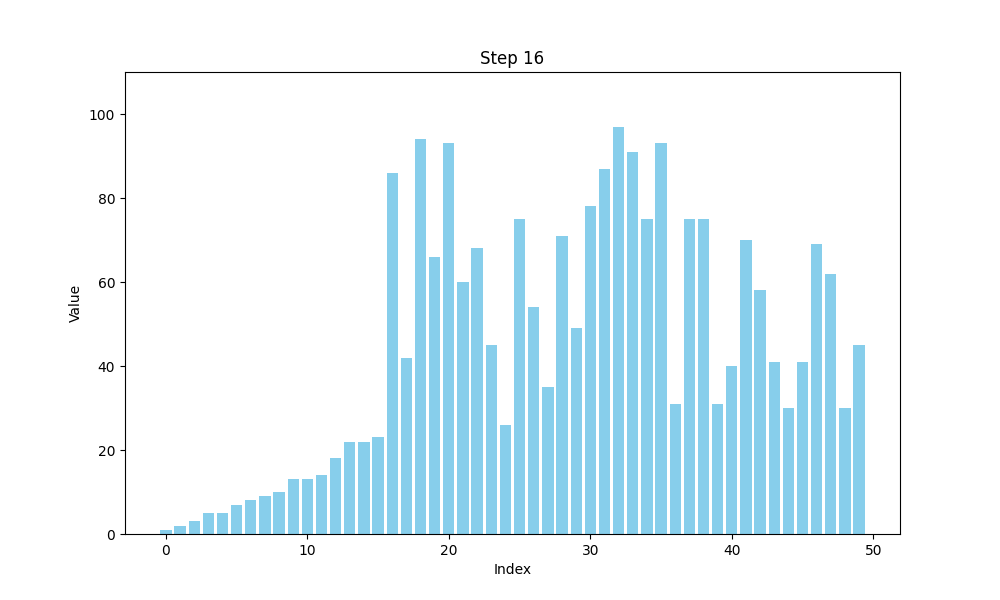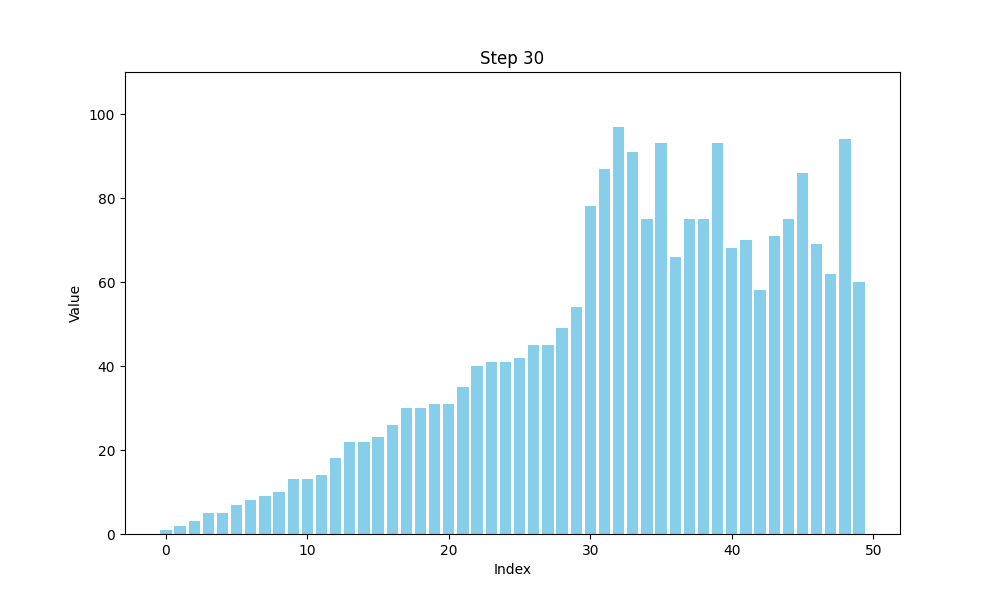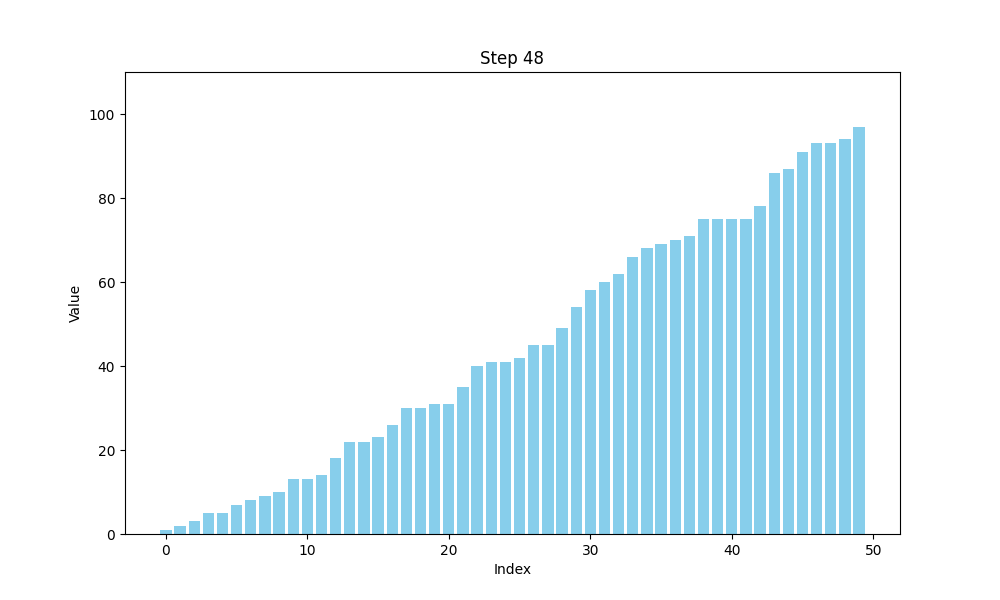
选择排序的时间复杂度
选择排序的时间复杂度可以通过比较次数来计算。假设我们有一个包含 n n n 个元素的数组:
- 在第一轮中,第一个元素与剩余的 n − 1 n-1 n−1 个元素进行比较。
- 在第二轮中,第二个元素与剩下的 n − 2 n-2 n−2 个元素比较。
- 这个过程会一直持续,直到最后一个元素为止。
这些比较的次数可以用数学公式表示为:
( n − 1 ) + ( n − 2 ) + ⋯ + ( n − ( n − 1 ) ) (n-1) + (n-2) + \dots + (n-(n-1)) (n−1)+(n−2)+⋯+(n−(n−1))
这个求和可以简化为:
n ( n − 1 ) 2 \frac{n(n-1)}{2} 2n(n−1)
这意味着选择排序的比较次数是与 n 2 n^2 n2 成正比的,因此它的时间复杂度为:
O ( n 2 ) O(n^2) O(n2)
这表明,随着元素数量的增加,选择排序的执行时间将按 n 2 n^2 n2 的比例增长。换句话说,当元素数量翻倍时,排序所需的时间将增加四倍。
比喻
我们可以将选择排序比作挑选和整理书架上的书。想象你有一堆乱七八糟的书,目标是按照书的厚度从薄到厚排列好。每次你都会从中挑选出一本最薄的书,然后将它放到书架的最前面。接着,你继续在剩下的书中挑选出最薄的一本,放到第二个位置,直到所有书都排列好。每一次挑选书的过程就像是在寻找最小的元素,并将其放到正确的位置,这样逐步完成整个排序过程。
相关文章:

DSA数据结构与算法 4
第2章 排序技术 2.1 排序简介 排序是将数据按照特定顺序(升序或降序)排列的过程,它不仅是计算机科学中的基础操作,也是日常生活中不可或缺的工具。举个例子,想象一个图书馆里的书籍,如果这些书籍没有按照作…...

23种设计模式全解析及其在自动驾驶开发中的应用
一、创建型模式(5种) 目标:解耦对象创建过程,提升系统灵活性 模式名称核心思想典型场景自动驾驶应用示例工厂方法子类决定实例化对象类型日志系统、数据库连接器创建激光雷达/摄像头等传感器实例抽象工厂创建相关对象家族GUI组件…...

基于WiFi的智能教室数据监测系统的设计与实现
标题:基于WiFi的智能教室数据监测系统的设计与实现 内容:1.摘要 随着教育信息化的发展,对教室环境及设备数据监测的智能化需求日益增长。本文的目的是设计并实现一种基于WiFi的智能教室数据监测系统。方法上,采用WiFi模块实现数据的无线传输,…...

Linux操作系统--环境变量
目录 基本概念: 常见环境变量: 查看环境变量的方法: 测试PATH 测试HOME 和环境变量相关的命令 环境变量的组织方式:编辑 通过代码如何获取环境变量 通过系统调用获取或设置环境变量 环境变量通常具有全局属性 基本概念…...

备份jenkins
jenkins用熟了很爽,jenkins用熟了很香,jenkins用熟了可以起飞…… 但~你们是否有过这种经历? 庚子年四月初一 路人甲小手一抖,不小心把配置删了,然后只能重新配置,再然后发现鬼记得太古时代都做了哪些配置…...

纯FPGA实现AD9361控制的思路和实现 UART实现AXI_MASTER
这里用一个串口接收PC机传过来的读写寄存器的控制指令,对地址地址的AXI_sLAVE进行读写后返回其结果。 串口收发器用的代码还是经典的FPGA4FUN上的。fpga4fun.com - Serial interface (RS-232) 我做了极小修改,直接贴出来代码: // RS-232 RX…...
)
计算机网络期中复习笔记(自用)
复习大纲 –第一章 概述 计算机网络的组成 网络边缘:主机和网络应用程序(又称为“端系统”) 端系统中运行的程序之间的通信方式可划分为两大类: 客户/服务器方式(C/S方式) 对等方式(P2P方式…...

MFC文件-屏幕录像
下载本文件 本文件将获取屏幕图像数据的所有代码整合到两个文件中(ScreenRecorder.h和ScreenRecorder.cpp),使获取屏幕图像数据变得简单。输出IYUV视频流。还可以获取系统播放的声音,输出PCM音频流。由于使用了MFC类,本…...

JAVA的泛型
为什么引入泛型 有两个作用: 适用于多种数据类型执行相同的代码(代码复用)泛型中的类型在使用时指定,不需要强制类型转换(类型安全,编译器会检查类型)消除强制类型转换兼容性与类型擦除更灵活…...

【UniApp】Vue2 scss 预编译器默认已由 node-sass 更换为 dart-sass
从 HBuilderX 4.56 ,vue2 项目也将默认使用 dart-sass 预编译器。 vue2开发者sass预处理注意: sass的预处理器,早年使用node-sass,也就是vue2最初默认的编译器。 sass官方推出了dart-sass来替代。node-sass已经停维很久了。 另…...

【sylar-webserver】8 HOOK模块
文章目录 知识点HOOK实现方式非侵入式hook侵入式hook ⭐⭐⭐ 覆盖系统调用接口获取被全局符号介入机制覆盖的系统调用接口 具体实现 在写之前模块的时候,我一直在困惑 协程是如何高效工作的,毕竟协程阻塞线程也就阻塞了。 HOOK模块解开了我的困惑。&…...
 / 最大子矩阵(二维前缀和) / 小葱的01串(滑动窗口))
【今日三题】判断是不是平衡二叉树(递归) / 最大子矩阵(二维前缀和) / 小葱的01串(滑动窗口)
⭐️个人主页:小羊 ⭐️所属专栏:每日两三题 很荣幸您能阅读我的文章,诚请评论指点,欢迎欢迎 ~ 目录 判断是不是平衡二叉树(递归)最大子矩阵(二维前缀和)小葱的01串(滑动窗口) 判断是不是平衡二叉树(递归) 判断是不是平衡二叉…...

交易系统的构建与实战法则
Ⅰ 交易哲学:理解市场本质 时间的艺术:鳄鱼法则的启示80%的交易时间应用于观察和等待日均有效交易机会不超过3次(以A股为例)杰西利弗莫尔的棉花合约案例(1907年等待11周)波动率与交易频率的黄金分割比例Ⅱ 形态识别系统:双轨交易模型 A. 趋势引擎 三级趋势验证体系: 均…...

C++高并发内存池ConcurrenMemoPool
一、介绍高并发内存池 本项目的原型是Google的开源项目tcmalloc,即线程缓存的malloc,相较于系统的内存分配函数malloc,free,本项目能达到高效的多线程内存管理 旨在学习其核心框架,借鉴其实现方式来模拟实现出一个我们…...

ubuntu下gcc/g++安装及不同版本切换
1. 查看当前gcc版本 $ gcc --version# 查看当前系统中已安装版本 $ ls /usr/bin/gcc*2. 安装新版本gcc $ sudo apt-get update# 这里以版本12为依据(也可以通过源码方式安装,请自行Google!) $ sudo apt-get install -y gcc-12 g…...

React-在使用map循环数组渲染列表时须指定唯一且稳定值的key
在渲染列表的时候,我们须给组件或者元素分配一个唯一值的key, key是一个特殊的属性,不会最终加在元素上面,也无法通过props.key来获取,仅在react内部使用。react中的key本质是服务于diff算法, 它的默认值是null, 在diff算法过程中…...
Vue的常用指令)
(03)Vue的常用指令
文章目录 第3章 Vue的常用指令3.1 v-text与v-html3.2 v-for3.3 v-if与v-show3.4 MVVM双向绑定3.4.1 v-bind3.4.2 v-model 第3章 Vue的常用指令 3.1 v-text与v-html v-text:不会渲染字符串里面的HTML内容v-html:会渲染字符串里面的HTML内容 <body s…...

从代码学习深度学习 - 优化算法 PyTorch 版
文章目录 前言一、小批量梯度下降(Mini-batch Gradient Descent)1.1 公式1.2 PyTorch 实现二、动量法(Momentum)2.1 公式2.2 PyTorch 实现三、AdaGrad 算法3.1 公式3.2 PyTorch 实现四、RMSProp 算法4.1 公式4.2 PyTorch 实现五、Adadelta 算法5.1 公式5.2 PyTorch 实现六、…...
适配器模式)
JAVA设计模式——(1)适配器模式
JAVA设计模式——(1)适配器模式 目的理解实现优势 目的 将一个类的接口变换成客户端所期待的另一种接口,从而使原本因接口不匹配而无法一起工作的两个类能够在一起工作。 理解 可以想象成一个国标的插头,结果插座是德标的&…...

深入Docker核心技术:从Namespace到容器逃逸防御
深入Docker核心技术:从Namespace到容器逃逸防御 引言:容器技术的本质突破 Docker作为容器技术的代表,其革命性不仅在于轻量级虚拟化,更在于重新定义了应用交付的标准范式。本文将穿透表象,深入剖析Docker的核心技术实…...

面向对象设计中的类的分类:实体类、控制类和边界类
目录 前言1. 实体类(Entity Class)1.1 定义和作用1.2 实体类的特点1.3 实体类的示例 2. 控制类(Control Class)2.1 定义和作用2.2 控制类的特点2.3 控制类的示例 3. 边界类(Boundary Class)3.1 定义和作用3…...

【MySQL】004.MySQL数据类型
文章目录 1. 数据类型分类2. 数值类型2.1 tinyint类型2.2 bit类型2.3 小数类型2.3.1 float2.3.2 decimal 2.4 字符串类型2.4.1 char2.4.2 varchar2.4.3 char和varchar比较 2.5 日期和时间类型2.6 enum和set2.7 enum和set类型查找 1. 数据类型分类 2. 数值类型 2.1 tinyint类型 …...

使用docker在manjaro linux系统上运行windows和ubuntu
因为最近项目必须要使用指定版本的solidworks和maxwell(都只能在win系统上使用), 且目前的ubuntu容器是没有桌面的,导致我运行不了一些带图形的ros2功能。无奈之下,决定使用docker-compose写一下配置文件,彻底解决问题…...

Flask应用部署通用指南
IIS 部署 Python Flask 应用通用指南 目录 概述环境准备应用准备wfastcgi 配置IIS 网站配置权限配置静态文件处理安全配置性能优化常见问题与解决方案生产环境最佳实践 概述 将 Flask 应用部署到 Windows IIS 服务器上需要使用 WSGI 适配器(如 wfastcgi…...

数据驱动增长:大数据与营销自动化的结合之道
数据驱动增长:大数据与营销自动化的结合之道 在这个信息爆炸的时代,企业如果还靠拍脑袋做营销决策,那基本等同于闭着眼睛开车,撞上南墙只是时间问题。大数据和营销自动化的结合,让营销从传统的经验主义走向科学决策&a…...

[Java微服务组件]注册中心P3-Nacos中的设计模式1-观察者模式
在P1-简单注册中心实现和P2-Nacos解析中,我们分别实现了简单的注册中心并总结了Nacos的一些设计。 本篇继续看Nacos源码,了解一下Nacos中的设计模式。 目录 Nacos 观察者模式 Observer Pattern观察者模式总结 Nacos 观察者模式 Observer Pattern 模式定…...

Java—— 常见API介绍 第二期
Runtime 说明: Runtime表示当前虚拟机的运行环境 获取Runtime对象的方法是静态的,可以用类名调用 不能用new关键字创建Runtime对象,只能调用获取Runtime对象的方法获取对象 其他的方法不是静态的,不能直接用类名调用,…...
)
意志力的源头——AMCC(前部中扣带皮层)
AMCC(前部中扣带皮层)在面对痛苦需要坚持的事情时会被激活。它的存在能够使人类个体在面临困难的事、本能感到不愿意的麻烦事情时,能够自愿地去做这些事——这些事必须是局部痛苦或宏观的痛苦,即微小的痛苦micro-sucks。 AMCC更多…...

ProfiNet转DeviceNet边缘计算网关多品牌集成实践:污水处理厂设备网络融合全流程解析
一、行业背景 随着环保政策趋严,污水处理行业对自动化、数据实时性和设备兼容性需求激增。传统污水处理厂普遍存在设备协议异构(如DeviceNet、ProfiNet混用)、数据孤岛严重的问题,现需通过捷米特DeviceNet转ProfiNet协议转换网关…...

CCLinkIE转EtherCAT边缘计算网关构建智能产线:跨协议设备动态组网与数据优化传输
一、行业背景 随着新能源汽车市场爆发式增长,汽车制造企业对产线效率、设备协同性及柔性生产能力的要求显著提升。传统产线多采用CC-LinkIEFieldBasic(CCLINKIEFB)协议的三菱PLC控制系统,而新一代伺服驱动设备普遍采用EtherCAT协…...

C 语言中的高级数据结构与内存管理
一、引言 C 语言作为一种广泛应用的系统级编程语言,以其高效性和灵活性著称。在 C 语言编程中,高级数据结构和内存管理是两个至关重要的方面。高级数据结构能够帮助我们更高效地组织和处理数据,而合理的内存管理则是保证程序性能和稳定性的关…...

Django 实现服务器主动给客户端发送消息的几种常见方式及其区别
Django Channels 原理 :Django Channels 是 Django 的一个扩展,它通过使用 WebSockets 等协议来处理长连接,使服务器能够与客户端建立持久连接,从而实现双向通信。一旦连接建立,服务器可以随时主动向客户端发送消息。…...
)
BR_频谱20dB 带宽(RF/TRM/CA/BV-05-C [TX Output Spectrum – 20 dB Bandwidth])
目录 一、规范要求 1、协议章节 2、测试目的 二、测试方法 1、样机初值条件: 2、测试步骤: 方法一:频谱仪 方法二:综测仪CMW500 3、预期结果 一、规范要求 1、协议章节 4.5.5 RF/TRM/CA/BV-05-C [TX Output Spectrum – 20 dB Ba…...

rabbitmq 面试题
一、基础概念 1. 什么是 RabbitMQ? - 基于 AMQP 协议的开源消息中间件,用于实现系统间的异步通信和解耦,支持多种消息模式(如发布/订阅、路由、主题等)。 1. 你了解那个rabbitmq, rabbitmq 的 虚拟机是…...

论文阅读:2025 arxiv AI Alignment: A Comprehensive Survey
总目录 大模型安全相关研究:https://blog.csdn.net/WhiffeYF/article/details/142132328 AI Alignment: A Comprehensive Survey https://arxiv.org/pdf/2310.19852 https://alignmentsurvey.com/ https://www.doubao.com/chat/3367091682540290 速览 研究动机…...

spring事务事务传播
POROPAGATION_REQUIRED(必须) 解释: 存在事务时 当前方法已在事务中运行,直接加入该事务 无事务 则自动开启一个新事物,并在方法执行结束后提交或者回滚 举例 java Transactional public void transfer() {accountService.reduceBalance…...

JMeter介绍
文章目录 1. JMeter简介2. JMeter 下载3. JMeter修改编码集4. 启动并运行JMeter 1. JMeter简介 JMeter 是 Apache 组织使用 Java 开发的一款测试工具: 1、可以用于对服务器、网络或对象模拟巨大的负载 2、通过创建带有断言的脚本来验证程序是否能返回期望的结果 优…...

Elasticsearch:使用 ES|QL 进行搜索和过滤
本教程展示了 ES|QL 语法的示例。请参考 Query DSL 版本,以获得等效的 Query DSL 语法示例。 这是一个使用 ES|QL 进行全文搜索和语义搜索基础知识的实践介绍。 有关 ES|QL 中所有搜索功能的概述,请参考《使用 ES|QL 进行搜索》。 在这个场景中&#x…...
应用的物联网框架)
面向新一代扩展现实(XR)应用的物联网框架
中文标题: 面向新一代扩展现实(XR)应用的物联网框架 英文标题: Towards an IoT Framework for the New Generation of XR Applications 作者信息 Joo A. Dias,UNIDCOM - IADE,欧洲大学,里斯本&…...
)
Docker Overlay 网络的核心工作(以跨节点容器通信为例)
Docker 的 overlay 网络是一种基于 VXLAN(Virtual Extensible LAN)的多主机网络模式,专为 Docker Swarm 集群设计,用于实现跨节点的容器通信。它通过虚拟二层网络,允许容器在不同主机上像在同一局域网内一样通信。Dock…...

开发基于python的商品推荐系统,前端框架和后端框架的选择比较
开发一个基于Python的商品推荐系统时,前端和后端框架的选择需要综合考虑项目需求、开发效率、团队熟悉度以及系统的可扩展性等因素。 以下是一些推荐的框架和建议: 后端框架 Flask 优点: 轻量级:Flask的核心非常简洁,…...

CSRF 请求伪造Referer 同源置空配合 XSSToken 值校验复用删除
#CSRF- 无检测防护 - 检测 & 生成 & 利用(那数据包怎么整 找相似源码自己搭建整) 检测:黑盒手工利用测试,白盒看代码检验(有无 token ,来源检验等) 生成: BurpSuite->Engagement t…...
Task1)
Datawhale AI春训营】AI + 新能源(发电功率预测)Task1
赛题链接 官网 新能源发电功率预测赛题进阶方案 下面是ai给的一些建议 新能源发电功率预测赛题进阶方案 一、时序特性深度挖掘 1. 多尺度周期特征 # 分钟级周期编码 train[15min_index] (train[hour]*4 train[minute]//15)# 周周期特征 train[weekday] pd.to_datetime…...

@EnableAsync+@Async源码学习笔记之二
从本文开始,就正式进入源码追踪阶段了,上一篇的最后我们提到了 EnableAsync 注解上的 Import(AsyncConfigurationSelector.class)了,本文就来看下它,源码如下: package org.springframework.scheduling.annotation;im…...

C++ STL 环形队列模拟实现
C STL 环形队列模拟实现 下面是一个使用C STL实现的环形队列(Circular Queue)的完整示例: #include <iostream> #include <vector> #include <stdexcept>template <typename T> class CircularQueue { private:std…...

每天五分钟深度学习PyTorch:0填充函数在搭建神经网络中的应用
本文重点 在深度学习中,神经网络的搭建涉及对输入数据、权重矩阵以及中间计算结果的处理。masked_fill 是 PyTorch 等深度学习框架中常用的张量操作函数,它通过布尔掩码(mask)对张量中的指定元素进行填充。当将矩阵元素填充为 0 时,masked_fill 在神经网络中发挥着重要作…...

pycharm中怎么解决系统cuda版本高于pytorch可以支持的版本的问题?
在PyCharm中安装与系统CUDA版本不一致的PyTorch是可行的。以下是解决方案的步骤: 1. 确认系统驱动兼容性 检查NVIDIA驱动支持的CUDA版本:运行 nvidia-smi,右上角显示的CUDA版本是驱动支持的最高版本。只要该版本不低于PyTorch所需的CUDA版本…...

【概率论】条件期望
在高等概率论中,给定一个概率空间 ( Ω , F , P ) (\Omega, \mathcal{F}, P) (Ω,F,P) 和其子 σ \sigma σ-代数 G ⊆ F \mathcal{G} \subseteq \mathcal{F} G⊆F,随机变量 X X X 关于 G \mathcal{G} G 的 条件期望 E [ X ∣ G ] E[X|\mathcal{G}…...

【java实现+4种变体完整例子】排序算法中【计数排序】的详细解析,包含基础实现、常见变体的完整代码示例,以及各变体的对比表格
以下是计数排序的详细解析,包含基础实现、常见变体的完整代码示例,以及各变体的对比表格: 一、计数排序基础实现 原理 通过统计每个元素的出现次数,按顺序累加得到每个元素的最终位置,并填充到结果数组中。 代码示…...

Qt C++ 解析和处理 XML 文件示例
使用 Qt C 解析和处理 XML 文件 以下是使用 Qt C 实现 XML 文件处理的几种方法,包括解析、创建和修改 XML 文件。 1. 使用 QXmlStreamReader (推荐方式) #include <QFile> #include <QXmlStreamReader> #include <QDebug>void parseXmlWithStr…...