C++高并发内存池ConcurrenMemoPool

一、介绍高并发内存池
本项目的原型是Google的开源项目tcmalloc,即线程缓存的malloc,相较于系统的内存分配函数malloc,free,本项目能达到高效的多线程内存管理
旨在学习其核心框架,借鉴其实现方式来模拟实现出一个我们自己的高并发内存池,主要是学习其精华。
其实我们在C++中常用的malloc就是一种池化技术,当然了new也是(其本质就是对malloc的封装嘛)
在最后我们会对比我们自己模拟出来的高并发内存池和malloc,我们拭目以待
池化技术
谈起池化技术,对于我们学计算机的人来说,再熟悉不过了,就是程序先向系统申请一定量的资源,交由自己管理,这样不需要频繁的去系统申请资源(系统也是很忙的,需要处理的事情是很多的),所以这就大大的提高了程序运行的效率!!在计算机中,有很多地方都使用了池化技术,比如内存池,线程池,连接池,对象池等等
内存池
内存池是程序先预先从操作系统申请一块足够大的内存,当程序需要一定的内存时,先去内存池里申请,如果不够的情况下再向系统申请,当还回内存时也就直接还给内存池,这样轻易都不会去系统申请内存,一定程度上减轻了系统的压力,从而使系统能够有时间去处理其他操作
解决的问题
我们做事,最重要的就是效率,所以首当其冲一定是效率问题!
1 效率问题
2 内存碎片问题
比如我们向系统申请了几块连续的内存,但是零零散散的还回了一部分,我们又需要申请时,就可能会遇到这些零散的碎片化的内存加起来是足够的,但是由于他们并不连续,就没办法继续完成申请,这样的空间就是被浪费掉了,所以这个问题也待解决。这种情况就是外碎片内存,还有一种叫做内碎片问题,内碎片是指,我们要申请一段段小内存时,内存会有一定的规则来对齐,方便使用,所以在对齐时会使一定量的内存没有被使用,这就是内碎片,学过C/C++的都应该知道内存对齐原则,这种对齐原则虽然浪费了一定的内存,但是解决的两个问题,平台移植的问题和效率的问题,实质上也是一种空间换时间的方法,所以保留了这种内存对齐规则,优化了外碎片问题

3 多线程环境下,锁竞争的问题
要求
C/C++、数据结构、操作系统的内存管理、单例模式(饿汉模式,懒汉模式)、多线程、锁,基本上要熟练掌握
主体结构框架
主要分为三层 一 thread cache
二 central cache
三 page cache
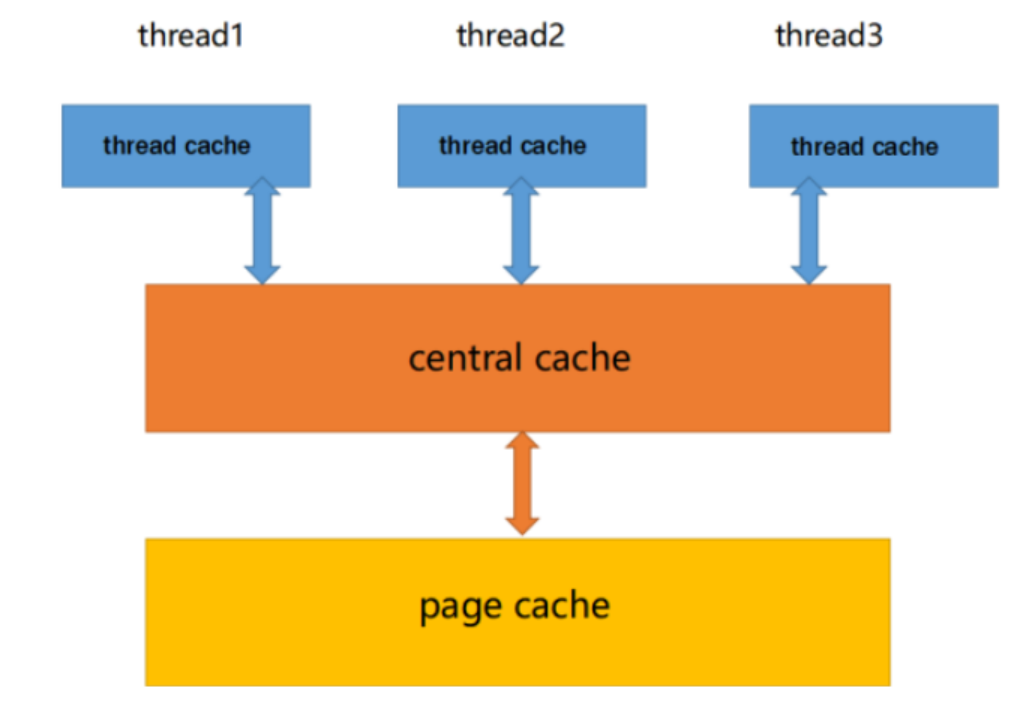
第一层:thread cache 线程缓存是每个线程独有的,用于小于256KB内存的分配(这里的内存大小可以自行根据需求进行更改),线程从这里申请内存不需要加锁,每个线程独享一个cache,这样也减少了锁的竞争
第二层:central cache “中心缓存” ,它是所有线程所共享的,thread cache需要从central cache进行申请,合适的时候也会对thread cache中的内存进行回收,避免一个线程占用了过多的内存而其他线程内存不够用的情况,这里需要加锁,但是会用到一种比较巧妙地加锁方式
第三层:page cache 类似于第二层,具体实现方式会在下面细讲
核心流程框架
申请内存过程(看不懂没关系,先了解一个大概,后面会细细讲解)

释放内存过程

二、定长内存池
在C/C++里面,申请内存使用的是malloc,但是我们也知道,malloc是一个通用的接口,也就意味着它是一个性能不会很高的接口,设计一个高并发内存池相对比较复杂,我们这里先由浅入深,从一个简单的定长内存池入手
为了方便我们后续的使用,我们把他设计成一个类模板(ObjectPool)
有两个功能,申请+构造(New)释放+析构(Delete)类似于C++
分为两部分,用于内存申请的一个定长内存,以及申请的内存换回来之后要去的地方(自由链表)
第一部分是一个定长内存,这个很简单,当调用New时,如果自由自由链表里有对象的话,直接取走一个,如果没有的话,调用相应的系统函数去申请一块内存
第二部分 释放,直接将不用的内存挂到自由链表上即可(至于怎么挂,头插,尾插都可以,当然头插的效率要比尾插高,因为我们采用的单链表,尾插遍历时,效率不高)
自由链表的结构:我前一块小内存的一个指针大小的空间存一个指针,指针指向后一个小块内存
这里可能有人会问,不同平台下,指针所占空间大小也不相同啊?再分类讨论多麻烦啊,这里我找到一个巧妙的方法,就是利用(void*)指针,不同平台之间指针大小是不同,但是我直接利用二级指针来开大小呢?*(void**)

系统的内存申请和释放
inline static void* SystemAlloc(size_t kpage)
{
#ifdef _WIN32void* ptr = VirtualAlloc(0, kpage << 13, MEM_COMMIT | MEM_RESERVE, PAGE_READWRITE);
#else
#endifif(ptr == nullptr)throw std::bad_alloc();return ptr;
}inline static void SystemFree(void* ptr)
{
#ifdef _WIN32VirtualFree(ptr, 0, MEM_RELEASE);
#else// sbrk unmmap等
#endif
}
申请内存
T* New()
{T* obj = nullptr;//如果自由链表里有对象,直接取走一个if (_freeList){void* next = *((void**)_freeList);obj = (T*)_freeList;_freeList = next;}else{if (_remainBytes < sizeof(T)){_remainBytes = 128 * 1024;_memory = (char*)SystemAlloc(_remainBytes >> 13);if (_memory == nullptr){throw std::bad_alloc();}}obj = (T*)_memory;size_t objSize = sizeof(T) < sizeof(void*) ? sizeof(void*) : sizeof(T);_memory += objSize;_remainBytes -= objSize;}new(obj)T;return obj;
}
释放内存,挂到自由链表
void Delete(T* obj)
{obj->~T();*(void**)obj = _freeList;_freeList = obj;
}
成员变量
char* _memory = nullptr; //指向大块内存
size_t _remainBytes = 0; //大块内存在被切分的过程中剩余字节数
void* _freeList = nullptr; //还回的自由链表头指针
三、thread cache
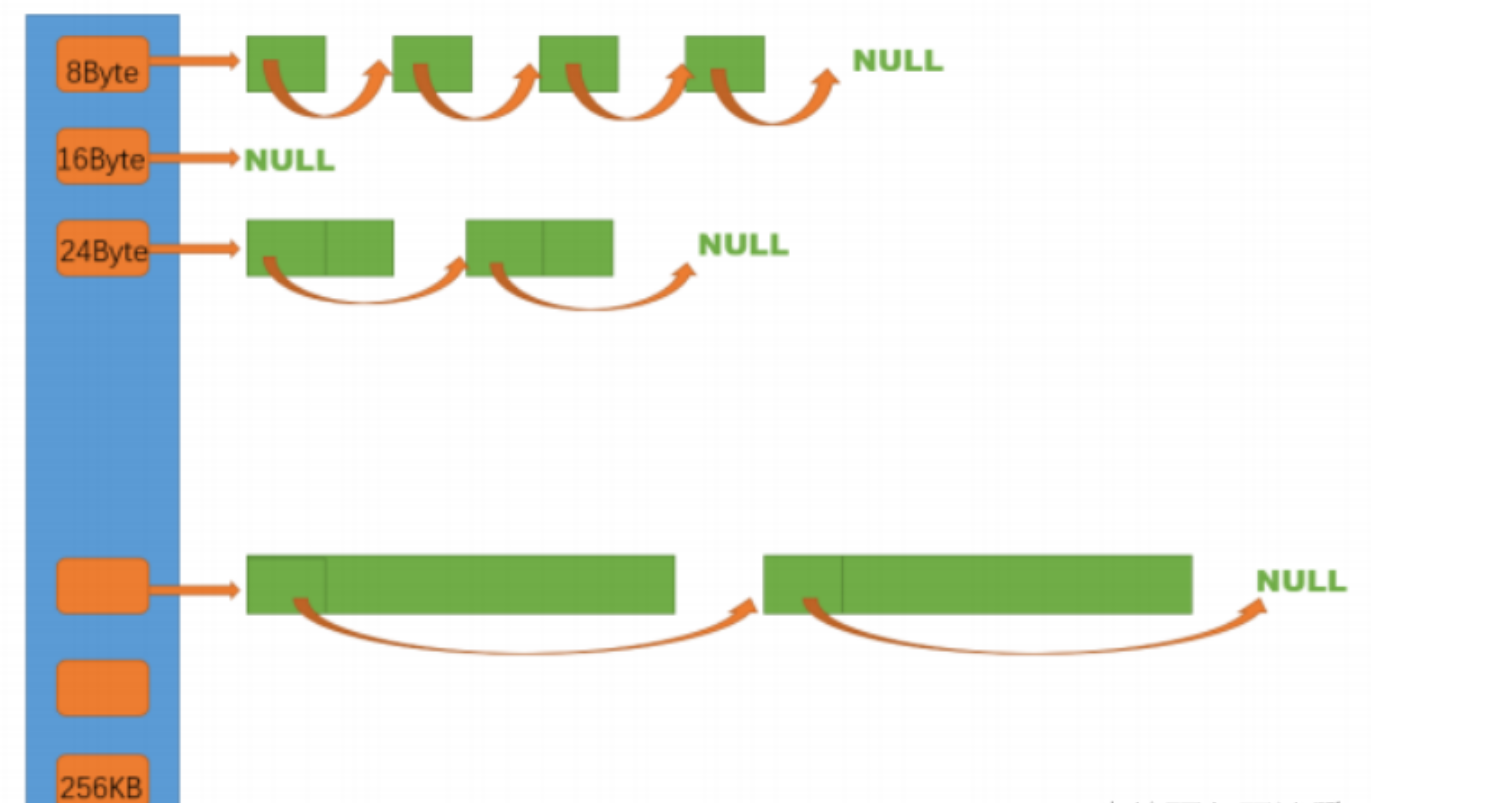
thread cache 是哈希桶的结构,每个桶是一个按桶位置映射大小的内存块对象的自由链表,每个线程都会有一个thread cache对象,每个线程需要获取和还回对象都是在自己的thread cache中进行操作,所以这里不需要上锁
这里我设计了四个接口
1 Allocate 申请内存
2 Deallocate 释放内存
3 FetchFromCentralCache 从 central cache中申请内存(当thread cache中不满足我的要求时)
4 ListTooLong 当达到一定的要求时(自由链表过长时),可以适当的还回一些内存给central cache
申请内存
当内存申请的大小size<=256KB时,先获取thread cache中的内存,计算size所映射的哈希桶,如果自由链表中能找到一块内存供我使用,直接删除(Pop)自由链表中的一块内存给我即可,如果没有,那么就向central cache中获取一定数量的内存,插入到自由链表中,并返回一个对象
释放内存
当释放内存小于256KB时,将内存释放回thread cache,计算相应的哈希桶,插入即可,但大于256KB时,回收一部分还给central cache
class ThreadCache
{
public://申请void* Allocate(size_t size);//释放void Deallocate(void* ptr, size_t size);//从central cache中获取对象void* FetchFromCentralCache(size_t index, size_t size);//释放对象时,链表过长的话,回收内存还回给central cachevoid ListTooLong(FreeList& list, size_t size);private:FreeList _freeLists[BarrelNum];
};
这里我们要用到TLS(线程局部存储),也就是一种允许每个线程拥有变量独立副本的机制
//TLS 线程局部存储 静态
static _declspec(thread) ThreadCache* pTLSThreadCache = nullptr;
对齐规则
整体控制在最多10%左右的内碎片浪费
[1,128] 8byte对齐 freelist[0,16)
[128+1,1024] 16byte对齐 freelist[16,72)
[1024+1,81024] 128byte对齐 freelist[72,128)
[81024+1,641024] 1024byte对齐 freelist[128,184)
[641024+1,2561024] 81024byte对齐 freelist[184,208)
总的来说,这种对齐规则,内碎片浪费不会超过百分之十,我们这里需要209个桶
这里在计算时,用到了一些位运算,这里主要是借鉴一些巧妙的方法,这种方法能想到的人还是少数,重要的不是方法怎么来的,重要的是我们要学着去使用它!随便带入一些数据我们就可以理解这种方法
static inline size_t _RoundUp(size_t bytes, size_t alignNum)
{return ((bytes + alignNum - 1) & ~(alignNum - 1));
}
static inline size_t RoundUp(size_t size)
{if (size <= 128){return _RoundUp(size, 8);}else if (size <= 1024){return _RoundUp(size, 16);}else if (size <= (long long)8 * 1024){return _RoundUp(size, 128);}else if (size <= (long long)64 * 1024){return _RoundUp(size, 1024);}else if (size <= (long long)256 * 1024){return _RoundUp(size, (long long)8 * 1024);}else{assert(false);return -1;}
}
static const size_t BarrelNum = 208; //桶数
我们也可以把上面定长内存池中的自由链表中的指针进行一下封装
static void*& NextObj(void* obj)
{return *(void**)obj;//因为在不同平台上指针所占空间不同,void**解引用后是一个指针所占的大小,就不用再考虑他们的区别了
}
自由链表也需要进行统一管理
class FreeList
{
public://头插void Push(void* obj){assert(obj);NextObj(obj) = _freeList;_freeList = obj;++_size;}void PushRange(void* start, void* end,size_t n){NextObj(end) = _freeList;_freeList = start;_size += n;}//头删void* Pop(){assert(_freeList);void* obj = _freeList;_freeList = NextObj(obj);--_size;return obj;}void PopRange(void*& start, void*& end,size_t n){assert(n <= _size);start = _freeList;end = start;for (size_t i = 0; i < n - 1; ++i){end = NextObj(end);}_freeList = NextObj(end);NextObj(end) = nullptr;_size -= n;}bool Empty(){return _freeList == nullptr;}size_t& MaxSize(){return _maxSize;}size_t Size(){return _size;}
private:void* _freeList = nullptr;size_t _maxSize = 1;size_t _size = 0;
};
我们也需要计算其具体在哪个桶中
static inline size_t _Index(size_t bytes, size_t align_shift)
{return ((bytes + ((long long)1 << align_shift) - 1) >> align_shift) - 1;
}
static inline size_t Index(size_t bytes)
{assert(bytes < MAX_BYTES);static int group_array[4] = { 16,56,56,56 };if (bytes <= 128){return _Index(bytes, 3);//2^3=8}else if (bytes <= 1024) {return _Index(bytes - 128, 4) + group_array[0];}else if (bytes <= (long long)8 * 1024) {return _Index(bytes - 1024, 7) + group_array[1] + group_array[0];}else if (bytes <= (long long)64 * 1024){return _Index(bytes - (long long)8 * 1024, 10) + group_array[2] + group_array[1] + group_array[0];}else if (bytes <= (long long)256 * 1024){return _Index(bytes - (long long)64 * 1024, 13) + group_array[3] + group_array[2] + group_array[1] + group_array[0];}else {return _RoundUp(bytes, 1 << PAGE_SHIFT);}return -1;
}
申请内存:先计算好对齐之后的内存大小,计算其所在的桶,如果这个桶中有内存可以用,直接将该桶中的这一块内存Pop,如果没有的话,就去上一层中(central cache)中取
void* ThreadCache::Allocate(size_t size)
{assert(size <= MAX_BYTES);size_t alignSize = SizeClass::RoundUp(size);//对象对齐size_t index = SizeClass::Index(size);//桶个数if (!_freeLists[index].Empty()){return _freeLists[index].Pop();}else{return FetchFromCentralCache(index, alignSize);}
}
释放内存:计算其应该放回哪个桶,Push进去即可,顺便检查一下,当链表长度大于一次批量申请的内存时就开始还一段list给central cache
void ThreadCache::Deallocate(void* ptr, size_t size)
{assert(ptr);assert(size <= MAX_BYTES);size_t index = SizeClass::Index(size);_freeLists[index].Push(ptr);//当链表长度大于一次批量申请的内存时就开始还一段list给central cacheif (_freeLists[index].Size() >= _freeLists[index].MaxSize()){ListTooLong(_freeLists[index], size);}
}
FetchFromCentralCache 从 central cache中申请内存(当thread cache中不满足我的要求时),这里用一个慢开始调节算法,一开始不会一下就取很多,防止浪费,后面会慢慢增加,你取的次数越多就会随之增加,但也不会超过上限值,如果central cache中有,拿给我thread cache用,如果没有,central cache 再去向page cache 取
void* ThreadCache::FetchFromCentralCache(size_t index, size_t size)
{//慢开始反馈调节//一开始不会一下就取很多,防止浪费,后面会慢慢增加,你取的次数越多就会随之增加,但也不会超过上限值size_t batchNum = min(_freeLists[index].MaxSize(), SizeClass::NumMoveSize(size));if (_freeLists[index].MaxSize() == batchNum){_freeLists[index].MaxSize() += 1;}void* start = nullptr;void* end = nullptr;size_t actualNum = CentralCache::GetInstance()->FetchRangeObj(start, end, batchNum, size);assert(actualNum > 0);if (actualNum == 1){assert(start == end);return start;}else{_freeLists[index].PushRange(NextObj(start), end, actualNum-1);return start;}
}
当thread cache中的自由链表过长时,摘取下来给central cache ,至于怎么处理,交给central cache去处理
void ThreadCache::ListTooLong(FreeList& list, size_t size)
{void* start = nullptr;void* end = nullptr;list.PopRange(start, end, list.MaxSize());//从Thread cache中拿走CentralCache::GetInstance()->ReleaseListToSpans(start, size);//交给central cache
}
四、central cache
central cache也是一个哈希桶结构,映射关系和thread cache是一样的,不同的是,central cache 中每个桶中挂的是一个双向带头循环链表,由一个个span组成,而一个span上挂着一个个小块内存组成的自由链表
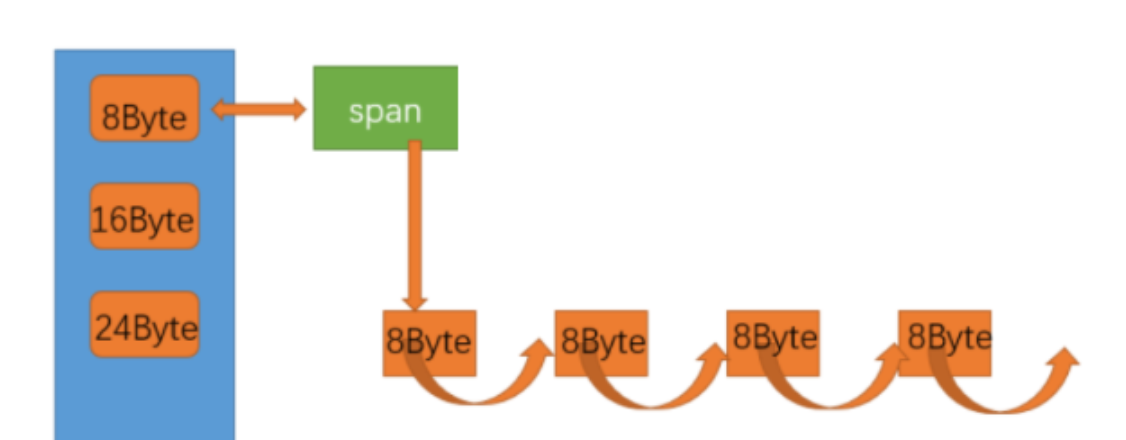
申请内存
当thread cache向central cache申请内存时,这个过程是要加锁的,但是我们这里采用的桶锁的方式,只有不同线程同时访问同一个桶时才会发生锁的竞争,这样既保证安全,又提高了效率,当central cache中也没有内存供给thread cache时,就可以向page cache中申请内存,central cache中设置变量记录分配了多少个对象出去,分配一个对象出去就让其++,这里主要是为了归还做铺垫
释放内存
当thread cache的自由链表过长时,会归还一部分给central cache,central cache中也有变量记录分配出去的内存,当分配出去的内存都回来后,可以把他们全都交给page cache ,交由page cache进行处理
central cache的设计采用了单例模式
三个接口
1 GetOneSpan 获取一个非空的span
2 FetchRangeObj 从central cache 中获取一定对象给 Thread cache
3 ReleaseListToSpans 将由thread cache还回的对象释放到span
//单例模式(饿汉模式)
class CentralCache
{
public:static CentralCache* GetInstance(){return &_sInst;}//获取一个非空的spanSpan* GetOneSpan(SpanList& list, size_t size);//从central cache 中获取一定对象给 Thread cachesize_t FetchRangeObj(void*& start, void*& end, size_t batchNum, size_t size);//将由thread cache还回的对象释放到spanvoid ReleaseListToSpans(void* start,size_t size);
private:SpanList _spanLists[BarrelNum]; //Span 桶
private:CentralCache(){}CentralCache(const CentralCache&) = delete;static CentralCache _sInst;
};
Span 的结构
#ifdef _WIN64
typedef unsigned long long PAGE_ID;
#elif _WIN32
typedef size_t PAGE_ID;
#endif
struct Span
{PAGE_ID _pageId = 0; //大块内存起始页的页号size_t _n = 0; //页的数量Span* _next = nullptr;Span* _prev = nullptr;size_t _useCount = 0; //小块内存被分配出去的数量,每分出去一块++,还回来一块--void* _freeList = nullptr; //小快内存的自由链表bool _isUse = false; //是否被使用size_t _objSize = 0; // 切好的小对象的大小};
span链表,采用双向带头循环链表
class SpanList
{
public:SpanList(){_head = new Span;_head->_next = _head;_head->_prev = _head;}Span* Begin(){return _head->_next;}Span* End(){return _head;}bool Empty(){return _head->_next == _head;}void PushFront(Span* span){Insert(Begin(), span);}Span* PopFront(){Span* front = _head->_next;Erase(front);return front;}void Insert(Span* pos, Span* newSpan){assert(pos);assert(newSpan);Span* prev = pos->_prev;prev->_next = newSpan;newSpan->_prev = prev;newSpan->_next = pos;pos->_prev = newSpan;}void Erase(Span* pos){assert(pos);assert(pos != _head);Span* prev = pos->_prev;Span* next = pos->_next;prev->_next = next;next->_prev = prev;}
private:Span* _head;
public:std::mutex _mtx; //这里用的是桶锁,只有在不同线程找到central cache的同一个桶时才会出现锁的竞争//而在不同的桶上时不会发生锁的竞争,从而也提高了效率,这里public主要是给其他使用
};
这些都是一些简单的关于链表的数据结构的知识
GetOneSpan 申请一个span
当thread cache的内存不够用时,就会去central cache中申请一个span,先去检查spanlist中是否有span可以给我呢?如果有直接给我,如果没有呢?那我就去page cache中找来一部分切分好挂在central cache的span上
这里在向page cache申请的时候可以顺便把central cache的桶锁解掉,这时候不会影响到其他归还的情况,也是一个小优化
Span* CentralCache::GetOneSpan(SpanList& list, size_t size)
{//检查当前的spanlist中是否有未被使用的span,如果有,直接给出,如果没有,去page cache去拿Span* it = list.Begin();while (it != list.End()){if (it->_freeList != nullptr){return it;}else{it = it->_next;}}// 可以先把central cache中的桶锁解除,在其他线程还回的时候不会阻塞list._mtx.unlock();//去page cache 中取PageCache::GetInstance()->_pageMtx.lock();Span* span = PageCache::GetInstance()->NewSpan(SizeClass::NumMovePage(size));span->_isUse = true;span->_objSize = size;PageCache::GetInstance()->_pageMtx.unlock();//取来之后对其进行切分,这里不需要加锁,因为这里只有当前线程能看到char* start = (char*)(span->_pageId << PAGE_SHIFT);//起始页号*每个页的大小=开始的地址size_t bytes = span->_n << PAGE_SHIFT; //总大小=页的数量*每个页的大小char* end = start + bytes;//把一个大块内存切成小块内存后连接起来,尾插span->_freeList = start;start += size;void* tail = span->_freeList;//先切下一块当做头,然后循环不断尾插int i = 1;while (start < end){++i;NextObj(tail) = start;tail = NextObj(tail);start += size;}NextObj(tail) = nullptr;list._mtx.lock();list.PushFront(span);return span;
}从central cache中获取一定数量的对象给thread cache
size_t CentralCache::FetchRangeObj(void*& start, void*& end, size_t batchNum, size_t size)
{size_t index = SizeClass::Index(size);_spanLists[index]._mtx.lock();//上锁Span* span = GetOneSpan(_spanLists[index], size);assert(span);assert(span->_freeList);start = span->_freeList;end = start;size_t i = 0;size_t actualNum = 1;while (i < batchNum - 1 && NextObj(end) != nullptr){end = NextObj(end);++i;++actualNum;}span->_freeList = NextObj(end);NextObj(end) = nullptr;span->_useCount += actualNum;_spanLists[index]._mtx.unlock();//解锁return actualNum;}
useCount来记录的内存情况,当他为0时,说明所有申请出去的内存都已经回来了,就可以还回到page cache了,再由page cache进行后续的处理
void CentralCache::ReleaseListToSpans(void* start, size_t size)
{size_t index = SizeClass::Index(size);_spanLists[index]._mtx.lock();while (start){void* next = NextObj(start);Span* span = PageCache::GetInstance()->MapObjectToSpan(start);NextObj(start) = span->_freeList;span->_freeList = start;span->_useCount--;//span切分出去的所有小块内存都已经回来了// 这里就可以回收给page Cache,Page Cache可以再合并前后解决外内存碎片问题if (span->_useCount == 0){_spanLists[index].Erase(span);span->_freeList = nullptr;span->_prev = nullptr;span->_next = nullptr;//这时就可以把桶锁关闭,Page cache上锁_spanLists[index]._mtx.unlock();PageCache::GetInstance()->_pageMtx.lock();PageCache::GetInstance()->ReleaseSpanToPageCache(span);PageCache::GetInstance()->_pageMtx.unlock();_spanLists[index]._mtx.lock();}start = next;}_spanLists[index]._mtx.unlock();
}
五、page cache
page cache 的结构是根据页进行划分桶,每个同上挂着一个个span
申请内存
当central cache 向page cache申请内存时,page cache先检查对应的位置有没有span,如果有,直接分配一个span给central cache,如果没有,去顺着找更大的页的,找到的话就把其分成两部分,一部分是central cache需要的,另一部分则挂到符合要求的页桶上去,比如我需要一个5页的,找不到5页的,5页后面有个6页的,就把6页的分为一个5页的一个1页的,5页的拿走,1页的挂到1页的桶上去,如果一直都没有找到,就向系统进行申请一个128页的
释放内存
central cache 还回的span 看是否能和前后的桶上的span进行合并,如果能合并,就变成更大的页,这是解决外碎片问题的关键!!
同样,page cache也是使用单例模式
class PageCache
{
public:static PageCache* GetInstance(){return &_sInst;}//申请一个spanSpan* NewSpan(size_t k);//对象到span的映射Span* MapObjectToSpan(void* obj);//把空闲的span释放回Page cache 并在Page cache进行前后合并成更大的spanvoid ReleaseSpanToPageCache(Span* span);std::mutex _pageMtx;
private:SpanList _spanLists[NPAGES];ObjectPool<Span> _spanPool;TCMalloc_PageMap1<32 - PAGE_SHIFT>_idSpanMap;PageCache(){}PageCache(const PageCache&) = delete;//std::unordered_map<PAGE_ID, Span*> _idSpanMap;//大块内存起始页的页号 与 Span 相映射static PageCache _sInst;
};
三个接口
1 NewSpan 申请一个span
2 MapObjectToSpan 哈希表,页号和对应span的映射
3 ReleaseSpanToPageCache 把空闲的span释放回Page cache 并在Page cache进行前后合并成更大的span
申请一个span,首先看申请的这个span大小是否大于128页,如果大于128页直接由系统去堆栈上申请,如果不是,首先看对应的桶上是否有能用的,有的话直接返回即可,没有的话,顺着找更大的页,有的话,切分,没有的话系统申请一个128页的span,然后再重新执行上述操作,即可完成一次span的申请
Span* PageCache::NewSpan(size_t k)
{//大于128页时直接向堆申请assert(k > 0);if (k > NPAGES - 1){void* ptr = SystemAlloc(k);Span* span = _spanPool.New();span->_pageId = (PAGE_ID)ptr >> PAGE_SHIFT;span->_n = k;_idSpanMap.set(span->_pageId, span);return span;}//assert(k > 0 && k < NPAGES);//先检查第k个桶里面是否有spanif (!_spanLists[k].Empty()){Span* kSpan = _spanLists[k].PopFront();for (PAGE_ID i = 0; i < kSpan->_n; ++i){_idSpanMap.set(kSpan->_pageId + i, kSpan);}return kSpan;}//没有span的话,去顺着往下找for (size_t i = k+1; i < NPAGES; ++i){if (!_spanLists[i].Empty()){//进行切割,切成两部分,一部分是我们需要的k页的span,另一部分挂到应该挂的地方Span* nSpan = _spanLists[i].PopFront();//Span* kSpan = new Span;Span* kSpan = _spanPool.New();kSpan->_pageId = nSpan->_pageId;kSpan->_n = k;nSpan->_pageId += k;nSpan->_n -= k;_spanLists[nSpan->_n].PushFront(nSpan);_idSpanMap.set(nSpan->_pageId, nSpan);_idSpanMap.set(nSpan->_pageId+nSpan->_n-1, nSpan);for (PAGE_ID i = 0; i < kSpan->_n; ++i){_idSpanMap.set(kSpan->_pageId + i, kSpan);}return kSpan;}}//到这没有return的话就是遍历之后并没有找到一个合适的span,这就需要向堆申请一个128页的span//Span* bigSpan = new Span;Span* bigSpan = _spanPool.New();void* ptr = SystemAlloc(NPAGES - 1);bigSpan->_pageId = (PAGE_ID)ptr >> PAGE_SHIFT;//通过地址得出其起始页号bigSpan->_n = NPAGES - 1;_spanLists[bigSpan->_n].PushFront(bigSpan);return NewSpan(k);
}
哈希表(页号与span的映射)
Span* PageCache::MapObjectToSpan(void* obj)
{PAGE_ID id = ((PAGE_ID)obj >> PAGE_SHIFT);auto ret = _idSpanMap.find(id);if (ret != _idSpanMap.end()){return ret->second;}else{assert(false);return nullptr;}return ret;
}
将central cache还回的span进行前后的合并成一个更大页
void PageCache::ReleaseSpanToPageCache(Span* span)
{if (span->_n > NPAGES - 1){void* ptr = (void*)(span->_pageId << PAGE_SHIFT);SystemFree(ptr);_spanPool.Delete(span);return;}//向前while (1){PAGE_ID prevId = span->_pageId - 1;auto ret = (Span*)_idSpanMap.get(prevId);if (ret == nullptr){break;}Span* prevSpan = ret;if (prevSpan->_isUse == true){break;}if (prevSpan->_n + span->_n > NPAGES - 1){break;}span->_pageId = prevSpan->_pageId;span->_n += prevSpan->_n;_spanLists[prevSpan->_n].Erase(prevSpan);_spanPool.Delete(prevSpan);}//向后while (1){PAGE_ID nextId = span->_pageId + span->_n;auto ret = (Span*)_idSpanMap.get(nextId);if (ret == nullptr){break;}Span* nextSpan = ret;if (nextSpan->_isUse == true){break;}if (nextSpan->_n + span->_n > NPAGES - 1){break;}span->_n += nextSpan->_n;_spanLists[nextSpan->_n].Erase(nextSpan);_spanPool.Delete(nextSpan);}//前后合并完之后,把他挂到该挂的地方,并标记未使用,修改对应的映射关系_spanLists[span->_n].PushFront(span);span->_isUse = false;_idSpanMap.set(span->_pageId, span);_idSpanMap.set(span->_pageId + span->_n - 1, span);
}
六、性能测试及优化
基本上大体的逻辑已经很清晰,这时候我们就可以试着测试一下他的性能如何,对比malloc,效率如何?
封装后的代码,方便我们直接调用
static void* ConcurrentAlloc(size_t size)
{//大于256k时if (size > MAX_BYTES){size_t alignSize = SizeClass::RoundUp(size);size_t kpage = alignSize >> PAGE_SHIFT;PageCache::GetInstance()->_pageMtx.lock();Span* span = PageCache::GetInstance()->NewSpan(kpage);span->_objSize = size;PageCache::GetInstance()->_pageMtx.unlock();void* ptr = (void*)(span->_pageId << PAGE_SHIFT);return ptr;}//TLS来使每个线程在无锁的情况下获取自己专属的ThreadCache对象else{if (pTLSThreadCache == nullptr){static ObjectPool<ThreadCache> tcPool;pTLSThreadCache = tcPool.New();}return pTLSThreadCache->Allocate(size);}
}
static void ConcurrentFree(void* ptr)
{Span* span = PageCache::GetInstance()->MapObjectToSpan(ptr);size_t size = span->_objSize;if (size > MAX_BYTES){PageCache::GetInstance()->_pageMtx.lock();PageCache::GetInstance()->ReleaseSpanToPageCache(span);PageCache::GetInstance()->_pageMtx.unlock();}else{assert(pTLSThreadCache);pTLSThreadCache->Deallocate(ptr, size);}
}测试代码
void BenchmarkMalloc(size_t ntimes, size_t nworks, size_t rounds)
{std::vector<std::thread> vthread(nworks);std::atomic<size_t> malloc_costtime = 0;std::atomic<size_t> free_costtime = 0;for (size_t k = 0; k < nworks; ++k){vthread[k] = std::thread([&, k]() {std::vector<void*> v;v.reserve(ntimes);for (size_t j = 0; j < rounds; ++j){size_t begin1 = clock();for (size_t i = 0; i < ntimes; i++){v.push_back(malloc(16));//v.push_back(malloc((16 + i) % 8192 + 1));}size_t end1 = clock();size_t begin2 = clock();for (size_t i = 0; i < ntimes; i++){free(v[i]);}size_t end2 = clock();v.clear();malloc_costtime += (end1 - begin1);free_costtime += (end2 - begin2);}});}for (auto& t : vthread){t.join();}printf("%u个线程并发执行%u轮次,每轮次malloc %u次: 花费:%u ms\n",nworks, rounds, ntimes, malloc_costtime.load());printf("%u个线程并发执行%u轮次,每轮次free %u次: 花费:%u ms\n",nworks, rounds, ntimes, free_costtime.load());printf("%u个线程并发malloc&free %u次,总计花费:%u ms\n",nworks, nworks * rounds * ntimes, malloc_costtime.load() + free_costtime.load());
}// 单轮次申请释放次数 线程数 轮次
void BenchmarkConcurrentMalloc(size_t ntimes, size_t nworks, size_t rounds)
{std::vector<std::thread> vthread(nworks);std::atomic<size_t> malloc_costtime = 0;std::atomic<size_t> free_costtime = 0;for (size_t k = 0; k < nworks; ++k){vthread[k] = std::thread([&]() {std::vector<void*> v;v.reserve(ntimes);for (size_t j = 0; j < rounds; ++j){size_t begin1 = clock();for (size_t i = 0; i < ntimes; i++){v.push_back(ConcurrentAlloc(16));//v.push_back(ConcurrentAlloc((16 + i) % 8192 + 1));}size_t end1 = clock();size_t begin2 = clock();for (size_t i = 0; i < ntimes; i++){ConcurrentFree(v[i]);}size_t end2 = clock();v.clear();malloc_costtime += (end1 - begin1);free_costtime += (end2 - begin2);}});}for (auto& t : vthread){t.join();}printf("%u个线程并发执行%u轮次,每轮次concurrent alloc %u次: 花费:%u ms\n",nworks, rounds, ntimes, malloc_costtime.load());printf("%u个线程并发执行%u轮次,每轮次concurrent dealloc %u次: 花费:%u ms\n",nworks, rounds, ntimes, free_costtime.load());printf("%u个线程并发concurrent alloc&dealloc %u次,总计花费:%u ms\n",nworks, nworks * rounds * ntimes, malloc_costtime.load() + free_costtime.load());
}int main()
{size_t n = 100000;cout << "==========================================================" << endl;BenchmarkConcurrentMalloc(n, 4, 10);cout << endl << endl;BenchmarkMalloc(n, 4, 10);cout << "==========================================================" << endl;return 0;
}
测试结果
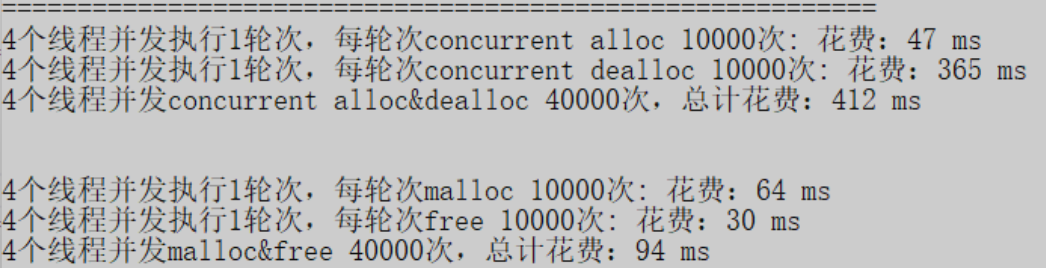
这样看来,我们写的还是差点意思,分析一下,是哪里还可以优化呢?我们的花费主要在哪里?
仔细分析我们会发现,很多时间都花在了,哈希映射上,以及锁的竞争上
这里我就要引入一个新的东西,基数树,分为单层基数树和双层基数树,其实后面也有三层等等,与我们而言单双层足矣
单层的基数树最简单了,就是一个数组,严格的来说就是一个哈希表,一个用直接定址法来映射的哈希表,其中的 K-V 关系就是 页号-span*。
两层基数树,一共19位,前5位作为第一层数组进行哈希映射,在前五位确定后,再通过后14位进行哈希映射
//一层
template <int BITS>
class TCMalloc_PageMap1 {
private:static const int LENGTH = 1 << BITS;void** array_;public:typedef uintptr_t Number;//explicit TCMalloc_PageMap1(void* (*allocator)(size_t)) {explicit TCMalloc_PageMap1() {//array_ = reinterpret_cast<void**>((*allocator)(sizeof(void*) << BITS));size_t size = sizeof(void*) << BITS;size_t alignSize = SizeClass::_RoundUp(size, 1 << PAGE_SHIFT);array_ = (void**)SystemAlloc(alignSize >> PAGE_SHIFT);memset(array_, 0, sizeof(void*) << BITS);}// Return the current value for KEY. Returns NULL if not yet set,// or if k is out of range.void* get(Number k) const {if ((k >> BITS) > 0) {return NULL;}return array_[k];}// REQUIRES "k" is in range "[0,2^BITS-1]".// REQUIRES "k" has been ensured before.//// Sets the value 'v' for key 'k'.void set(Number k, void* v) {array_[k] = v;}
};//两层
template <int BITS>
class TCMalloc_PageMap2
{
public:typedef uintptr_t Number;explicit TCMalloc_PageMap2() {memset(root_, 0, sizeof(root_));PreallocateMoreMemory();}void* get(Number k) const {const Number i1 = k >> LEAF_BITS;const Number i2 = k & (LEAF_LENGTH - 1);if ((k >> BITS) > 0 || root_[i1] == NULL){return NULL;}return root_[i1]->values[i2];}void set(Number k, void* v) {const Number i1 = k >> LEAF_BITS;const Number i2 = k & (LEAF_LENGTH - 1);ASSERT(i1 < ROOT_LENGTH);root_[i1]->values[i2] = v;}bool Ensure(Number start, size_t n) {for (Number key = start; key <= start + n - 1;) {const Number i1 = key >> LEAF_BITS;if (i1 >= ROOT_LENGTH)return false;if (root_[i1] == NULL) {static ObjectPool<Leaf> leafPool;Leaf* leaf = (Leaf*)leafPool.New();memset(leaf, 0, sizeof(*leaf));root_[i1] = leaf;}key = ((key >> LEAF_BITS) + 1) << LEAF_BITS;}return true;}void PreallocateMoreMemory() {Ensure(0, 1 << BITS);}
private:static const int ROOT_BITS = 5;static const int ROOT_LENGTH = 1 << ROOT_BITS;static const int LEAF_BITS = BITS - ROOT_BITS;static const int LEAF_LENGTH = 1 << LEAF_BITS;struct Leaf {void* values[LEAF_LENGTH];};Leaf* root_[ROOT_LENGTH]; // Pointers to 32 child nodesvoid* (*allocator_)(size_t); // Memory allocator
};只有在申请和释放两个函数中回去建立id和span的映射
基数树写之前会提前开好空间,写数据过程中不会动结构
读和写是分离的,一个线程对其读的时候,别的线程一定不会对其写


我们可以看到,优化后的效果是要比malloc好上不少的
七、总结
我们在做项目时,不是为了做一个多厉害的东西,重要的事我们在每一个细节中学到了什么,如果要比优劣,我们是一定比不过tcmalloc的,重要的是一件事的处理方法,站在巨人的肩膀上,我们才能看的更远,所以,学习应该是贯彻我们一生的一件事,不断的通过一些新鲜的事务来开阔自己的眼界,从而使自己成长!
八、源码
高并发内存池源码
相关文章:

C++高并发内存池ConcurrenMemoPool
一、介绍高并发内存池 本项目的原型是Google的开源项目tcmalloc,即线程缓存的malloc,相较于系统的内存分配函数malloc,free,本项目能达到高效的多线程内存管理 旨在学习其核心框架,借鉴其实现方式来模拟实现出一个我们…...

ubuntu下gcc/g++安装及不同版本切换
1. 查看当前gcc版本 $ gcc --version# 查看当前系统中已安装版本 $ ls /usr/bin/gcc*2. 安装新版本gcc $ sudo apt-get update# 这里以版本12为依据(也可以通过源码方式安装,请自行Google!) $ sudo apt-get install -y gcc-12 g…...

React-在使用map循环数组渲染列表时须指定唯一且稳定值的key
在渲染列表的时候,我们须给组件或者元素分配一个唯一值的key, key是一个特殊的属性,不会最终加在元素上面,也无法通过props.key来获取,仅在react内部使用。react中的key本质是服务于diff算法, 它的默认值是null, 在diff算法过程中…...
Vue的常用指令)
(03)Vue的常用指令
文章目录 第3章 Vue的常用指令3.1 v-text与v-html3.2 v-for3.3 v-if与v-show3.4 MVVM双向绑定3.4.1 v-bind3.4.2 v-model 第3章 Vue的常用指令 3.1 v-text与v-html v-text:不会渲染字符串里面的HTML内容v-html:会渲染字符串里面的HTML内容 <body s…...

从代码学习深度学习 - 优化算法 PyTorch 版
文章目录 前言一、小批量梯度下降(Mini-batch Gradient Descent)1.1 公式1.2 PyTorch 实现二、动量法(Momentum)2.1 公式2.2 PyTorch 实现三、AdaGrad 算法3.1 公式3.2 PyTorch 实现四、RMSProp 算法4.1 公式4.2 PyTorch 实现五、Adadelta 算法5.1 公式5.2 PyTorch 实现六、…...
适配器模式)
JAVA设计模式——(1)适配器模式
JAVA设计模式——(1)适配器模式 目的理解实现优势 目的 将一个类的接口变换成客户端所期待的另一种接口,从而使原本因接口不匹配而无法一起工作的两个类能够在一起工作。 理解 可以想象成一个国标的插头,结果插座是德标的&…...

深入Docker核心技术:从Namespace到容器逃逸防御
深入Docker核心技术:从Namespace到容器逃逸防御 引言:容器技术的本质突破 Docker作为容器技术的代表,其革命性不仅在于轻量级虚拟化,更在于重新定义了应用交付的标准范式。本文将穿透表象,深入剖析Docker的核心技术实…...

面向对象设计中的类的分类:实体类、控制类和边界类
目录 前言1. 实体类(Entity Class)1.1 定义和作用1.2 实体类的特点1.3 实体类的示例 2. 控制类(Control Class)2.1 定义和作用2.2 控制类的特点2.3 控制类的示例 3. 边界类(Boundary Class)3.1 定义和作用3…...

【MySQL】004.MySQL数据类型
文章目录 1. 数据类型分类2. 数值类型2.1 tinyint类型2.2 bit类型2.3 小数类型2.3.1 float2.3.2 decimal 2.4 字符串类型2.4.1 char2.4.2 varchar2.4.3 char和varchar比较 2.5 日期和时间类型2.6 enum和set2.7 enum和set类型查找 1. 数据类型分类 2. 数值类型 2.1 tinyint类型 …...

使用docker在manjaro linux系统上运行windows和ubuntu
因为最近项目必须要使用指定版本的solidworks和maxwell(都只能在win系统上使用), 且目前的ubuntu容器是没有桌面的,导致我运行不了一些带图形的ros2功能。无奈之下,决定使用docker-compose写一下配置文件,彻底解决问题…...

Flask应用部署通用指南
IIS 部署 Python Flask 应用通用指南 目录 概述环境准备应用准备wfastcgi 配置IIS 网站配置权限配置静态文件处理安全配置性能优化常见问题与解决方案生产环境最佳实践 概述 将 Flask 应用部署到 Windows IIS 服务器上需要使用 WSGI 适配器(如 wfastcgi…...

数据驱动增长:大数据与营销自动化的结合之道
数据驱动增长:大数据与营销自动化的结合之道 在这个信息爆炸的时代,企业如果还靠拍脑袋做营销决策,那基本等同于闭着眼睛开车,撞上南墙只是时间问题。大数据和营销自动化的结合,让营销从传统的经验主义走向科学决策&a…...

[Java微服务组件]注册中心P3-Nacos中的设计模式1-观察者模式
在P1-简单注册中心实现和P2-Nacos解析中,我们分别实现了简单的注册中心并总结了Nacos的一些设计。 本篇继续看Nacos源码,了解一下Nacos中的设计模式。 目录 Nacos 观察者模式 Observer Pattern观察者模式总结 Nacos 观察者模式 Observer Pattern 模式定…...

Java—— 常见API介绍 第二期
Runtime 说明: Runtime表示当前虚拟机的运行环境 获取Runtime对象的方法是静态的,可以用类名调用 不能用new关键字创建Runtime对象,只能调用获取Runtime对象的方法获取对象 其他的方法不是静态的,不能直接用类名调用,…...
)
意志力的源头——AMCC(前部中扣带皮层)
AMCC(前部中扣带皮层)在面对痛苦需要坚持的事情时会被激活。它的存在能够使人类个体在面临困难的事、本能感到不愿意的麻烦事情时,能够自愿地去做这些事——这些事必须是局部痛苦或宏观的痛苦,即微小的痛苦micro-sucks。 AMCC更多…...

ProfiNet转DeviceNet边缘计算网关多品牌集成实践:污水处理厂设备网络融合全流程解析
一、行业背景 随着环保政策趋严,污水处理行业对自动化、数据实时性和设备兼容性需求激增。传统污水处理厂普遍存在设备协议异构(如DeviceNet、ProfiNet混用)、数据孤岛严重的问题,现需通过捷米特DeviceNet转ProfiNet协议转换网关…...

CCLinkIE转EtherCAT边缘计算网关构建智能产线:跨协议设备动态组网与数据优化传输
一、行业背景 随着新能源汽车市场爆发式增长,汽车制造企业对产线效率、设备协同性及柔性生产能力的要求显著提升。传统产线多采用CC-LinkIEFieldBasic(CCLINKIEFB)协议的三菱PLC控制系统,而新一代伺服驱动设备普遍采用EtherCAT协…...

C 语言中的高级数据结构与内存管理
一、引言 C 语言作为一种广泛应用的系统级编程语言,以其高效性和灵活性著称。在 C 语言编程中,高级数据结构和内存管理是两个至关重要的方面。高级数据结构能够帮助我们更高效地组织和处理数据,而合理的内存管理则是保证程序性能和稳定性的关…...

Django 实现服务器主动给客户端发送消息的几种常见方式及其区别
Django Channels 原理 :Django Channels 是 Django 的一个扩展,它通过使用 WebSockets 等协议来处理长连接,使服务器能够与客户端建立持久连接,从而实现双向通信。一旦连接建立,服务器可以随时主动向客户端发送消息。…...
)
BR_频谱20dB 带宽(RF/TRM/CA/BV-05-C [TX Output Spectrum – 20 dB Bandwidth])
目录 一、规范要求 1、协议章节 2、测试目的 二、测试方法 1、样机初值条件: 2、测试步骤: 方法一:频谱仪 方法二:综测仪CMW500 3、预期结果 一、规范要求 1、协议章节 4.5.5 RF/TRM/CA/BV-05-C [TX Output Spectrum – 20 dB Ba…...

rabbitmq 面试题
一、基础概念 1. 什么是 RabbitMQ? - 基于 AMQP 协议的开源消息中间件,用于实现系统间的异步通信和解耦,支持多种消息模式(如发布/订阅、路由、主题等)。 1. 你了解那个rabbitmq, rabbitmq 的 虚拟机是…...

论文阅读:2025 arxiv AI Alignment: A Comprehensive Survey
总目录 大模型安全相关研究:https://blog.csdn.net/WhiffeYF/article/details/142132328 AI Alignment: A Comprehensive Survey https://arxiv.org/pdf/2310.19852 https://alignmentsurvey.com/ https://www.doubao.com/chat/3367091682540290 速览 研究动机…...

spring事务事务传播
POROPAGATION_REQUIRED(必须) 解释: 存在事务时 当前方法已在事务中运行,直接加入该事务 无事务 则自动开启一个新事物,并在方法执行结束后提交或者回滚 举例 java Transactional public void transfer() {accountService.reduceBalance…...

JMeter介绍
文章目录 1. JMeter简介2. JMeter 下载3. JMeter修改编码集4. 启动并运行JMeter 1. JMeter简介 JMeter 是 Apache 组织使用 Java 开发的一款测试工具: 1、可以用于对服务器、网络或对象模拟巨大的负载 2、通过创建带有断言的脚本来验证程序是否能返回期望的结果 优…...

Elasticsearch:使用 ES|QL 进行搜索和过滤
本教程展示了 ES|QL 语法的示例。请参考 Query DSL 版本,以获得等效的 Query DSL 语法示例。 这是一个使用 ES|QL 进行全文搜索和语义搜索基础知识的实践介绍。 有关 ES|QL 中所有搜索功能的概述,请参考《使用 ES|QL 进行搜索》。 在这个场景中&#x…...
应用的物联网框架)
面向新一代扩展现实(XR)应用的物联网框架
中文标题: 面向新一代扩展现实(XR)应用的物联网框架 英文标题: Towards an IoT Framework for the New Generation of XR Applications 作者信息 Joo A. Dias,UNIDCOM - IADE,欧洲大学,里斯本&…...
)
Docker Overlay 网络的核心工作(以跨节点容器通信为例)
Docker 的 overlay 网络是一种基于 VXLAN(Virtual Extensible LAN)的多主机网络模式,专为 Docker Swarm 集群设计,用于实现跨节点的容器通信。它通过虚拟二层网络,允许容器在不同主机上像在同一局域网内一样通信。Dock…...

开发基于python的商品推荐系统,前端框架和后端框架的选择比较
开发一个基于Python的商品推荐系统时,前端和后端框架的选择需要综合考虑项目需求、开发效率、团队熟悉度以及系统的可扩展性等因素。 以下是一些推荐的框架和建议: 后端框架 Flask 优点: 轻量级:Flask的核心非常简洁,…...

CSRF 请求伪造Referer 同源置空配合 XSSToken 值校验复用删除
#CSRF- 无检测防护 - 检测 & 生成 & 利用(那数据包怎么整 找相似源码自己搭建整) 检测:黑盒手工利用测试,白盒看代码检验(有无 token ,来源检验等) 生成: BurpSuite->Engagement t…...
Task1)
Datawhale AI春训营】AI + 新能源(发电功率预测)Task1
赛题链接 官网 新能源发电功率预测赛题进阶方案 下面是ai给的一些建议 新能源发电功率预测赛题进阶方案 一、时序特性深度挖掘 1. 多尺度周期特征 # 分钟级周期编码 train[15min_index] (train[hour]*4 train[minute]//15)# 周周期特征 train[weekday] pd.to_datetime…...

@EnableAsync+@Async源码学习笔记之二
从本文开始,就正式进入源码追踪阶段了,上一篇的最后我们提到了 EnableAsync 注解上的 Import(AsyncConfigurationSelector.class)了,本文就来看下它,源码如下: package org.springframework.scheduling.annotation;im…...

C++ STL 环形队列模拟实现
C STL 环形队列模拟实现 下面是一个使用C STL实现的环形队列(Circular Queue)的完整示例: #include <iostream> #include <vector> #include <stdexcept>template <typename T> class CircularQueue { private:std…...

每天五分钟深度学习PyTorch:0填充函数在搭建神经网络中的应用
本文重点 在深度学习中,神经网络的搭建涉及对输入数据、权重矩阵以及中间计算结果的处理。masked_fill 是 PyTorch 等深度学习框架中常用的张量操作函数,它通过布尔掩码(mask)对张量中的指定元素进行填充。当将矩阵元素填充为 0 时,masked_fill 在神经网络中发挥着重要作…...

pycharm中怎么解决系统cuda版本高于pytorch可以支持的版本的问题?
在PyCharm中安装与系统CUDA版本不一致的PyTorch是可行的。以下是解决方案的步骤: 1. 确认系统驱动兼容性 检查NVIDIA驱动支持的CUDA版本:运行 nvidia-smi,右上角显示的CUDA版本是驱动支持的最高版本。只要该版本不低于PyTorch所需的CUDA版本…...

【概率论】条件期望
在高等概率论中,给定一个概率空间 ( Ω , F , P ) (\Omega, \mathcal{F}, P) (Ω,F,P) 和其子 σ \sigma σ-代数 G ⊆ F \mathcal{G} \subseteq \mathcal{F} G⊆F,随机变量 X X X 关于 G \mathcal{G} G 的 条件期望 E [ X ∣ G ] E[X|\mathcal{G}…...

【java实现+4种变体完整例子】排序算法中【计数排序】的详细解析,包含基础实现、常见变体的完整代码示例,以及各变体的对比表格
以下是计数排序的详细解析,包含基础实现、常见变体的完整代码示例,以及各变体的对比表格: 一、计数排序基础实现 原理 通过统计每个元素的出现次数,按顺序累加得到每个元素的最终位置,并填充到结果数组中。 代码示…...

Qt C++ 解析和处理 XML 文件示例
使用 Qt C 解析和处理 XML 文件 以下是使用 Qt C 实现 XML 文件处理的几种方法,包括解析、创建和修改 XML 文件。 1. 使用 QXmlStreamReader (推荐方式) #include <QFile> #include <QXmlStreamReader> #include <QDebug>void parseXmlWithStr…...

在服务器上部署MinIO Server
MinIO的优势 高性能:MinIO号称是目前速度最快的对象存储服务器,据称在标准硬件上,对象存储的读/写速度最高可以高达183 GB/s和171 GB/s,可惜我的磁盘跟不上 兼容性:MinIO基于Amazon S3协议,并提供了与S3兼…...

第二十七讲:AI+农学导论
关键词:人工智能、农业、作物识别、遥感、机器学习、案例实战 目录 📌 一、为什么农业需要人工智能? 📈 二、AI在农学中的典型应用场景 🧪 三、实战案例:AI识别作物类型(以随机森林为例) ✅ 数据集:iris(模拟作物种类识别) 📦 所需包: 🚀 数据准备: …...

医院科研科AI智能科研支撑平台系统设计架构方案探析
一、系统设计概述 1.1 系统定位 本系统是基于MCP(Model Context Protocol,模型上下文协议)协议构建的智能科研支撑平台,旨在为医院科研科室提供全流程AI辅助能力,覆盖课题立项、数据采集、分析建模到成果转化的完整科研生命周期。系统通过MCP协议实现与医院信息系统的深…...
之条件语句)
Python基础总结(七)之条件语句
文章目录 条件语句if一、Python中的真假二、条件语句格式2.1 if语句格式2.2 if-else语句2.3 if-elif-else语句 三、if语句嵌套 条件语句if 条件语句其实就是if语句,在讲解if语句之前需要知道Python中对于真假的判断。 一、Python中的真假 在Python中非0的都为真&…...

Day10【基于encoder- decoder架构实现新闻文本摘要的提取】
实现新闻文本摘要的提取 1. 概述与背景2.参数配置3.数据准备4.数据加载5.主程序6.预测评估7.生成效果8.总结 1. 概述与背景 新闻摘要生成是自然语言处理(NLP)中的一个重要任务,其目标是自动从长篇的新闻文章中提取出简洁、准确的摘要。近年来…...
)
深度解析算法之二分查找(2)
17.二分查找 题目链接 给定一个 n 个元素有序的(升序)整型数组 nums 和一个目标值 target ,写一个函数搜索 nums 中的 target,如果目标值存在返回下标,否则返回 -1。 示例 1: 输入: nums [-1,0,3,5,9,12], target…...

前端工程化之自动化测试
自动化测试 自动化测试为什么需要测试?什么时候需要考虑测试测试类型前端测试框架单元测试Jest 重点掌握项目示例package.jsonsrc/utils/math.tssrc/utils/math.test.ts进行测试jest.config.js覆盖率直观看覆盖率coverage/lcov-report/index.html src/main.test.tst…...

CANFD技术在新能源汽车通信网络中的应用与可靠性分析
一、引言 新能源汽车产业正处于快速发展阶段,其电子系统复杂度不断攀升,涵盖众多传感器、控制器与执行器。高效通信网络成为确保新能源汽车安全运行与智能功能实现的核心要素。传统CAN总线因带宽限制,难以满足高级驾驶辅助系统(A…...

【机器学习】朴素贝叶斯算法:原理剖析与实战应用
引言 朴素贝叶斯算法就像是一位善于从经验中学习的侦探,根据已有的线索来推断未知事件的概率。这是一种基于概率论的分类算法,以贝叶斯定理为基础,却做了一个"朴素"的假设:认为所有特征彼此独立。虽然这个假设在现实中…...

【更新完毕】2025妈妈杯C题 mathercup数学建模挑战赛C题数学建模思路代码文章教学:音频文件的高质量读写与去噪优化
完整内容请看文章最下面的推广群 我将先给出文章、代码、结果的完整展示, 再给出四个问题详细的模型 面向音频质量优化与存储效率提升的自适应编码与去噪模型研究 摘 要 随着数字媒体技术的迅速发展,音频处理技术在信息时代的应用愈加广泛,特别是在存储…...

UI键盘操作
1、Selenium中send_keys除了可以模拟键盘输入之外,还有些时候需要操作键盘上的按键,甚至是组合键,比如CTRLA,CTRLC等, 所以我们需要代码操作键盘。使用的是send_keys里的Keys的类。 from selenium.webdriver.common.keys import …...

【正则表达式】正则表达式使用总结
正则表达式除了匹配普通字符外,还可以匹配特殊字符,这些特殊字符被称为“元字符”。 特殊字符(元字符) 限定符:用于指定正则表达式中某个组件的出现次数。常见的限定符包括: *:0次或多次 +:1次或多次 ?:0次或1次 {n}:恰好n次…...

Qt编写推流程序/支持webrtc265/从此不用再转码/打开新世界的大门
一、前言 在推流领域,尤其是监控行业,现在主流设备基本上都是265格式的视频流,想要在网页上直接显示监控流,之前的方案是,要么转成hls,要么魔改支持265格式的flv,要么265转成264,如…...