Elasticsearch:使用 ES|QL 进行搜索和过滤
本教程展示了 ES|QL 语法的示例。请参考 Query DSL 版本,以获得等效的 Query DSL 语法示例。
这是一个使用 ES|QL 进行全文搜索和语义搜索基础知识的实践介绍。
有关 ES|QL 中所有搜索功能的概述,请参考《使用 ES|QL 进行搜索》。
在这个场景中,我们为一个烹饪博客实现搜索功能。该博客包含各种属性的食谱,包括文本内容、分类数据和数字评分。
安装
如果你还没有安装好自己的 Elasticsearch 及 Kibana,请参考如下的文章来进行安装。你可以选择 Elastic Stack 8.x 的安装步骤来进行安装:
-
如何在 Linux,MacOS 及 Windows 上进行安装 Elasticsearch
-
Kibana:如何在 Linux,MacOS 及 Windows 上安装 Elastic 栈中的 Kibana
如果你想使用 docker 来进行一键安装,请参考文章 “使用 start-local 脚本在本地运行 Elasticsearch”。
运行 ES|QL 查询
在本教程中,你将看到以下格式的 ES|QL 示例:
FROM cooking_blog
| WHERE description:"fluffy pancakes"
| LIMIT 1000如果你想在 Dev Tools 控制台中运行这些查询,你需要使用以下语法:
POST /_query?format=txt
{"query": """FROM cooking_blog| WHERE description:"fluffy pancakes"| LIMIT 1000"""
}如果你更喜欢使用你最喜欢的编程语言,请参考客户端库,以获取官方和社区支持的客户端列表。
步骤 1:创建索引
创建 cooking_blog 索引以开始:
PUT /cooking_blog现在为索引定义映射:
PUT /cooking_blog/_mapping
{"properties": {"title": {"type": "text","analyzer": "standard", /* 1 */"fields": { /* 2 */"keyword": {"type": "keyword","ignore_above": 256 /* 3 */}}},"description": {"type": "text","fields": {"keyword": {"type": "keyword"}}},"author": {"type": "text","fields": {"keyword": {"type": "keyword"}}},"date": {"type": "date","format": "yyyy-MM-dd"},"category": {"type": "text","fields": {"keyword": {"type": "keyword"}}},"tags": {"type": "text","fields": {"keyword": {"type": "keyword"}}},"rating": {"type": "float"}}
}- 如果未指定 analyzer,文本字段默认使用 standard analyzer。这里包含它是为了演示目的。
- 这里使用 multi-fields 将文本字段同时索引为 text 和 keyword 数据类型。这使得在同一个字段上既能进行全文搜索,也能进行精确匹配 / 过滤。注意,如果使用动态映射,这些 multi-fields 会自动创建。
- ignore_above 参数会防止在 keyword 字段中索引长度超过 256 个字符的值。同样,这是默认值,这里包含它是为了演示目的。它有助于节省磁盘空间,并避免 Lucene 的 term 字节长度限制所带来的潜在问题。
提示:全文搜索依赖于文本分析。文本分析会对文本数据进行规范化和标准化处理,从而可以高效地存储到倒排索引中,并实现近实时搜索。分析会在索引时和搜索时同时进行。本教程不会详细介绍分析过程,但了解文本是如何被处理的对于创建高效的搜索查询非常重要。
步骤 2:向索引添加示例博客文章
现在你需要使用 Bulk API 索引一些示例博客文章。注意,文本字段会在索引时进行分析,并生成 multi-fields。
POST /cooking_blog/_bulk?refresh=wait_for
{"index":{"_id":"1"}}
{"title":"Perfect Pancakes: A Fluffy Breakfast Delight","description":"Learn the secrets to making the fluffiest pancakes, so amazing you won't believe your tastebuds. This recipe uses buttermilk and a special folding technique to create light, airy pancakes that are perfect for lazy Sunday mornings.","author":"Maria Rodriguez","date":"2023-05-01","category":"Breakfast","tags":["pancakes","breakfast","easy recipes"],"rating":4.8}
{"index":{"_id":"2"}}
{"title":"Spicy Thai Green Curry: A Vegetarian Adventure","description":"Dive into the flavors of Thailand with this vibrant green curry. Packed with vegetables and aromatic herbs, this dish is both healthy and satisfying. Don't worry about the heat - you can easily adjust the spice level to your liking.","author":"Liam Chen","date":"2023-05-05","category":"Main Course","tags":["thai","vegetarian","curry","spicy"],"rating":4.6}
{"index":{"_id":"3"}}
{"title":"Classic Beef Stroganoff: A Creamy Comfort Food","description":"Indulge in this rich and creamy beef stroganoff. Tender strips of beef in a savory mushroom sauce, served over a bed of egg noodles. It's the ultimate comfort food for chilly evenings.","author":"Emma Watson","date":"2023-05-10","category":"Main Course","tags":["beef","pasta","comfort food"],"rating":4.7}
{"index":{"_id":"4"}}
{"title":"Vegan Chocolate Avocado Mousse","description":"Discover the magic of avocado in this rich, vegan chocolate mousse. Creamy, indulgent, and secretly healthy, it's the perfect guilt-free dessert for chocolate lovers.","author":"Alex Green","date":"2023-05-15","category":"Dessert","tags":["vegan","chocolate","avocado","healthy dessert"],"rating":4.5}
{"index":{"_id":"5"}}
{"title":"Crispy Oven-Fried Chicken","description":"Get that perfect crunch without the deep fryer! This oven-fried chicken recipe delivers crispy, juicy results every time. A healthier take on the classic comfort food.","author":"Maria Rodriguez","date":"2023-05-20","category":"Main Course","tags":["chicken","oven-fried","healthy"],"rating":4.9}步骤 3:执行基本的全文搜索
全文搜索涉及在一个或多个文档字段上执行基于文本的查询。这些查询会根据文档内容与搜索词的匹配程度为每个匹配的文档计算相关性评分。Elasticsearch 提供了多种查询类型,每种类型都有其自己的文本匹配方式和相关性评分机制。
ES|QL 提供两种方式来执行全文搜索:
- 完整 match 函数语法: match(field, "search terms")
- 使用 match 运算符的简洁语法: field::"search terms"
两种方式是等效的,可以互换使用。简洁语法更简洁,而函数语法则允许更多配置选项。为了简洁,我们将在大多数示例中使用简洁语法。
有关函数语法可用的高级参数,请参考 match 函数参考文档。
基本全文查询
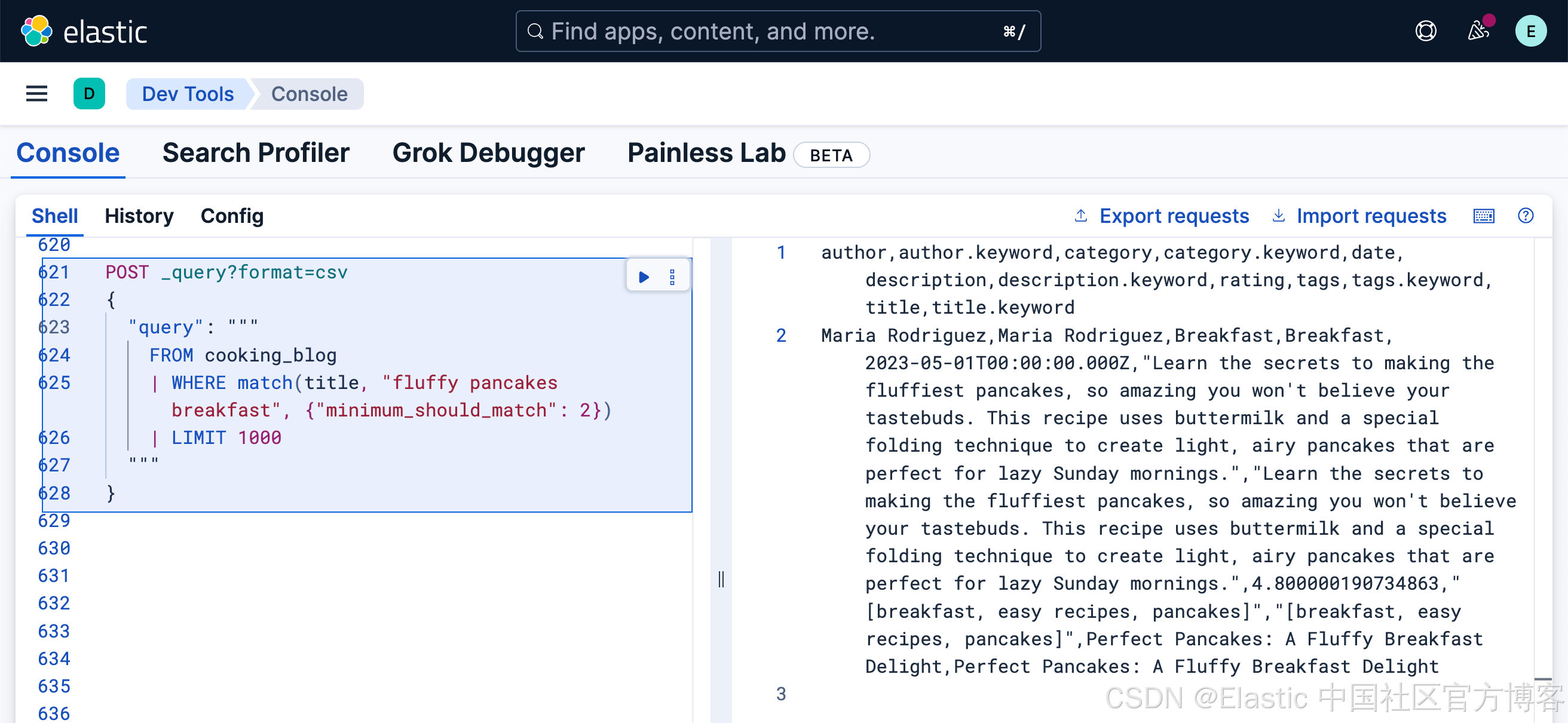
以下是在 description 字段中搜索 "fluffy pancakes" 的方法:
FROM cooking_blog /* 1 */
| WHERE description:"fluffy pancakes" /* 2 */
| LIMIT 1000 /* 3 */- 指定要搜索的索引
- 全文搜索默认使用 OR 逻辑
- 返回最多 1000 条结果
注意:结果的排序不是按相关性,因为我们尚未请求 _score 元数据字段。我们将在下一节中介绍相关性评分。
默认情况下,就像 Query DSL 的 match 查询一样,ES|QL 在词项之间使用 OR 逻辑。这意味着它会匹配在 description 字段中包含 "fluffy" 或 "pancakes",或两者都有的文档。
提示:你可以使用 KEEP 命令控制响应中包含哪些字段:
FROM cooking_blog | WHERE description:"fluffy pancakes" | KEEP title, description, rating | LIMIT 1000更多有关 ES|QL 的查阅,请阅读 “Elasticsearch:ES|QL 查询展示”。
在匹配查询中要求所有词项
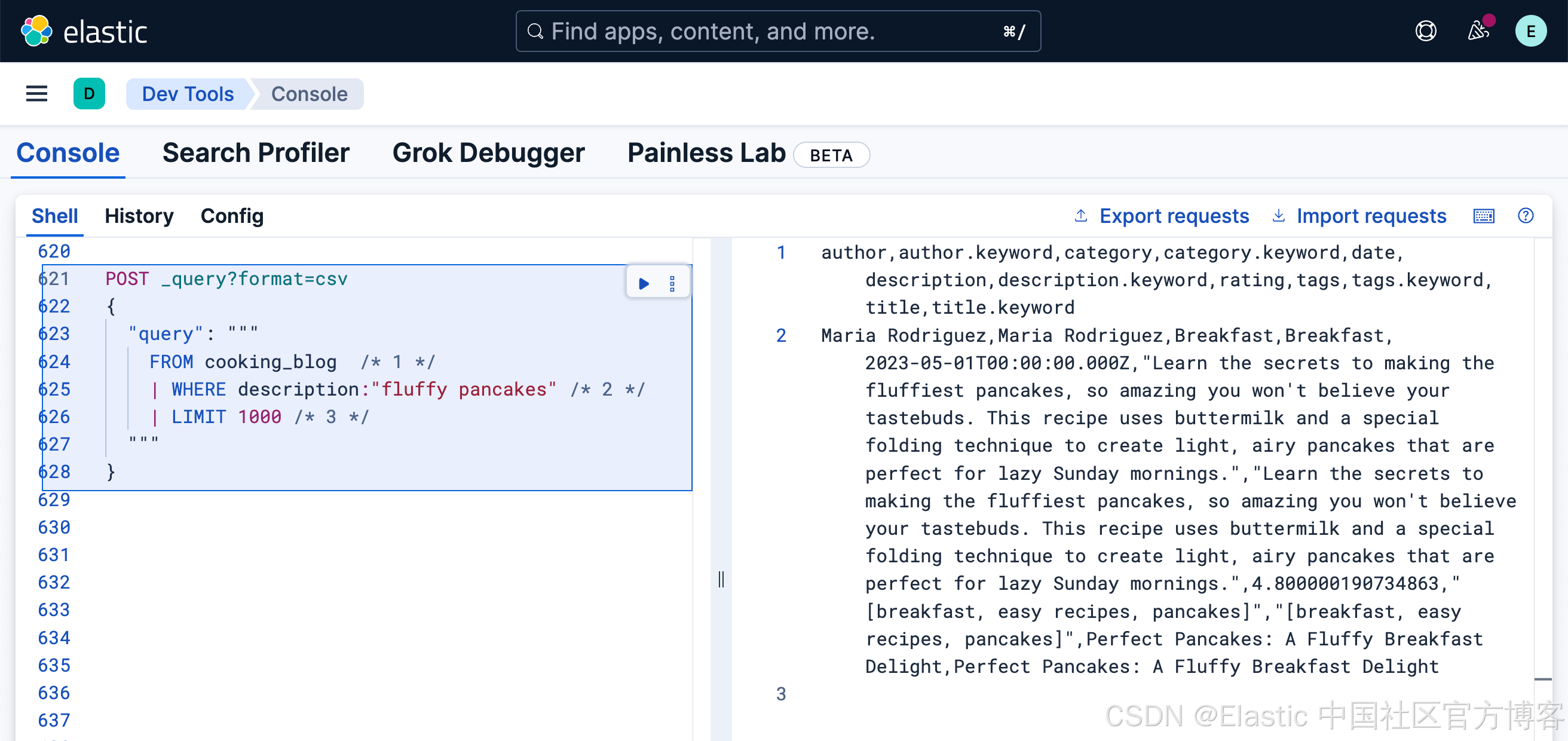
有时你需要确保所有搜索词都出现在匹配的文档中。以下是使用函数语法和 operator 参数实现这一点的方法:
FROM cooking_blog
| WHERE match(description, "fluffy pancakes", {"operator": "AND"})
| LIMIT 1000POST _query?format=csv
{"query": """FROM cooking_blog| WHERE match(description, "fluffy pancakes", {"operator": "AND"}) | LIMIT 1000"""
}
由于没有文档在 description 中同时包含 "fluffy" 和 "pancakes",因此这个更严格的搜索在我们的示例数据中返回零条结果。
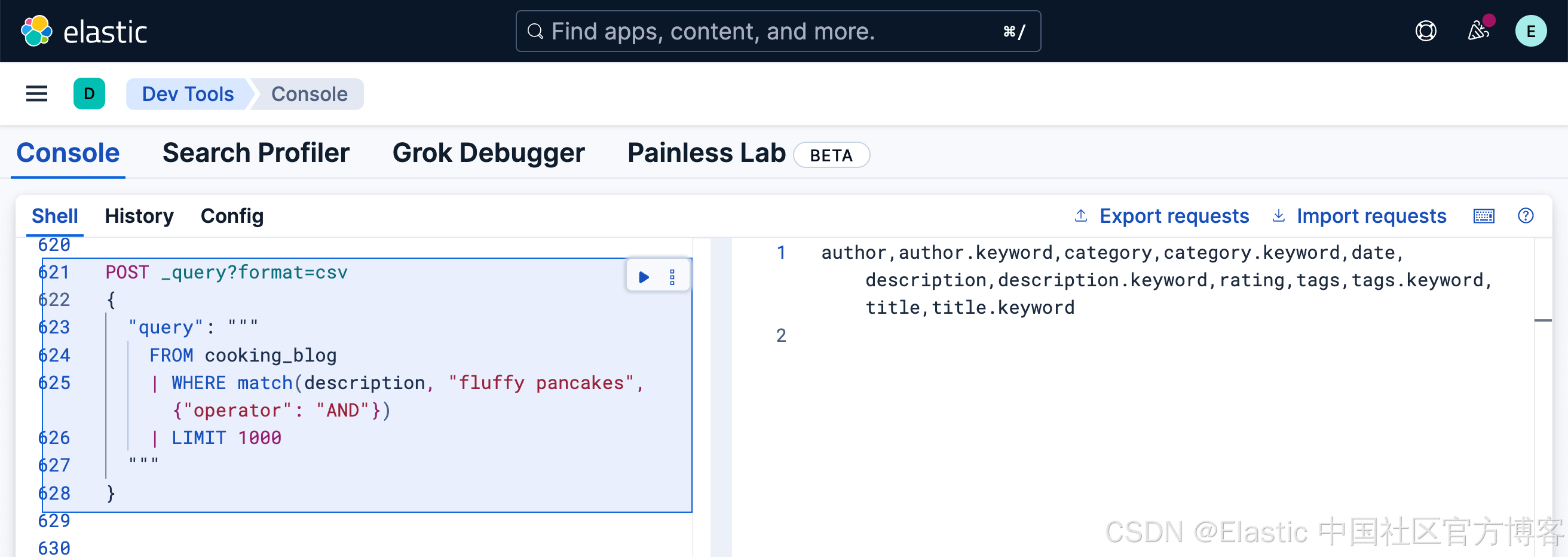
指定匹配的最小词项数
有时,要求所有词项匹配过于严格,而默认的 OR 行为又过于宽松。你可以指定必须匹配的最小词项数:
FROM cooking_blog
| WHERE match(title, "fluffy pancakes breakfast", {"minimum_should_match": 2})
| LIMIT 1000此查询搜索 title 字段,要求至少匹配 3 个词项中的 2 个:"fluffy"、"pancakes" 或 "breakfast"。
步骤 4:语义搜索和混合搜索
索引语义内容
Elasticsearch 允许你根据文本的意义进行语义搜索,而不仅仅是依赖特定关键词的存在。当你希望找到与给定查询在概念上相似的文档时,即使它们不包含精确的搜索词,也非常有用。
当你的映射中包含 semantic_text 类型的字段时,ES|QL 支持语义搜索。这个示例映射更新添加了一个名为 semantic_description 的新字段,类型为 semantic_text:
PUT /cooking_blog/_mapping
{"properties": {"semantic_description": {"type": "semantic_text"}}
}接下来,将包含内容的文档索引到新字段中:
POST /cooking_blog/_doc
{"title": "Mediterranean Quinoa Bowl","semantic_description": "A protein-rich bowl with quinoa, chickpeas, fresh vegetables, and herbs. This nutritious Mediterranean-inspired dish is easy to prepare and perfect for a quick, healthy dinner.","author": "Jamie Oliver","date": "2023-06-01","category": "Main Course","tags": ["vegetarian", "healthy", "mediterranean", "quinoa"],"rating": 4.7
}注意:在上面,我们并没有指名是使用什么方法进行的向量化。在默认的情况下,它使用的是 ELSER 模型。你需要启动 ELSER。详细的部署,请参考文章 “Elasticsearch:部署 ELSER - Elastic Learned Sparse EncoderR”。
执行语义搜索
一旦文档被底层模型处理并运行在推理端点上,你就可以执行语义搜索。以下是针对 semantic_description 字段的一个自然语言查询示例:
FROM cooking_blog
| WHERE semantic_description:"What are some easy to prepare but nutritious plant-based meals?"
| LIMIT 5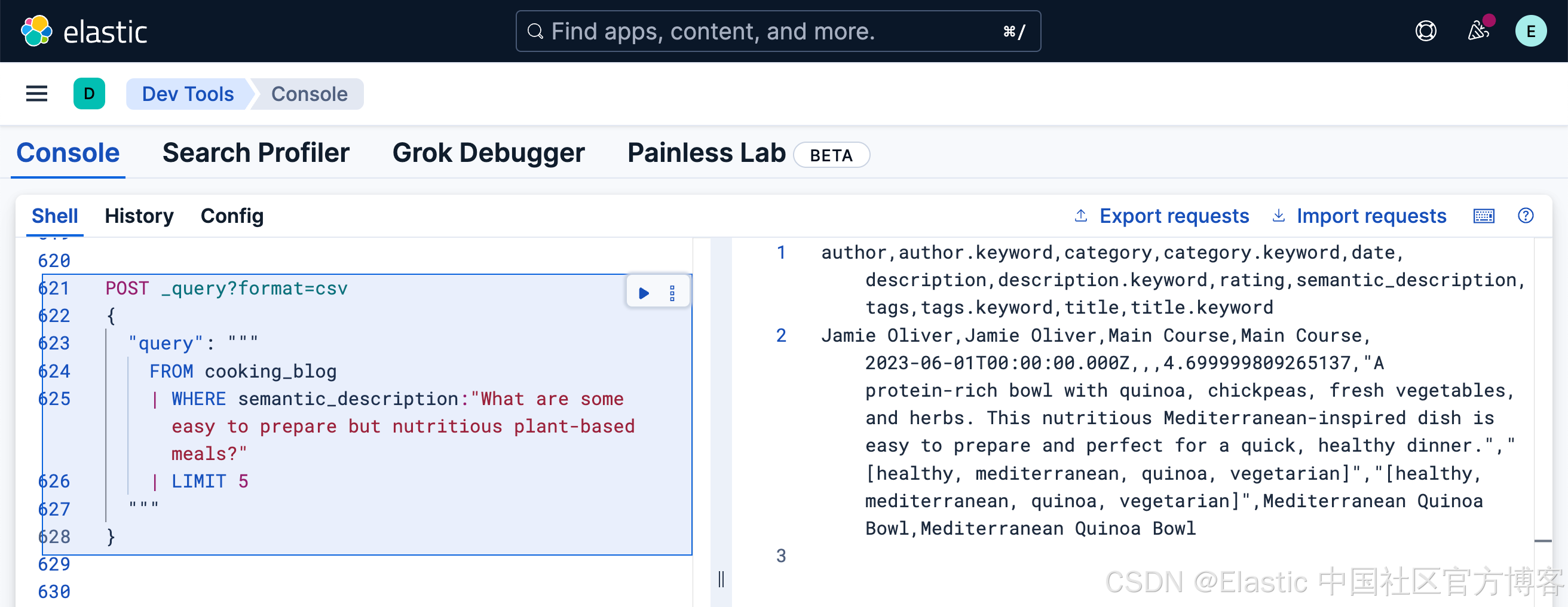
执行混合搜索
你可以将全文搜索和语义查询结合起来。在这个示例中,我们结合了全文搜索和语义搜索,并使用了自定义权重:
FROM cooking_blog METADATA _score
| WHERE match(semantic_description, "easy to prepare vegetarian meals", { "boost": 0.75 })OR match(tags, "vegetarian", { "boost": 0.25 })
| SORT _score DESC
| LIMIT 5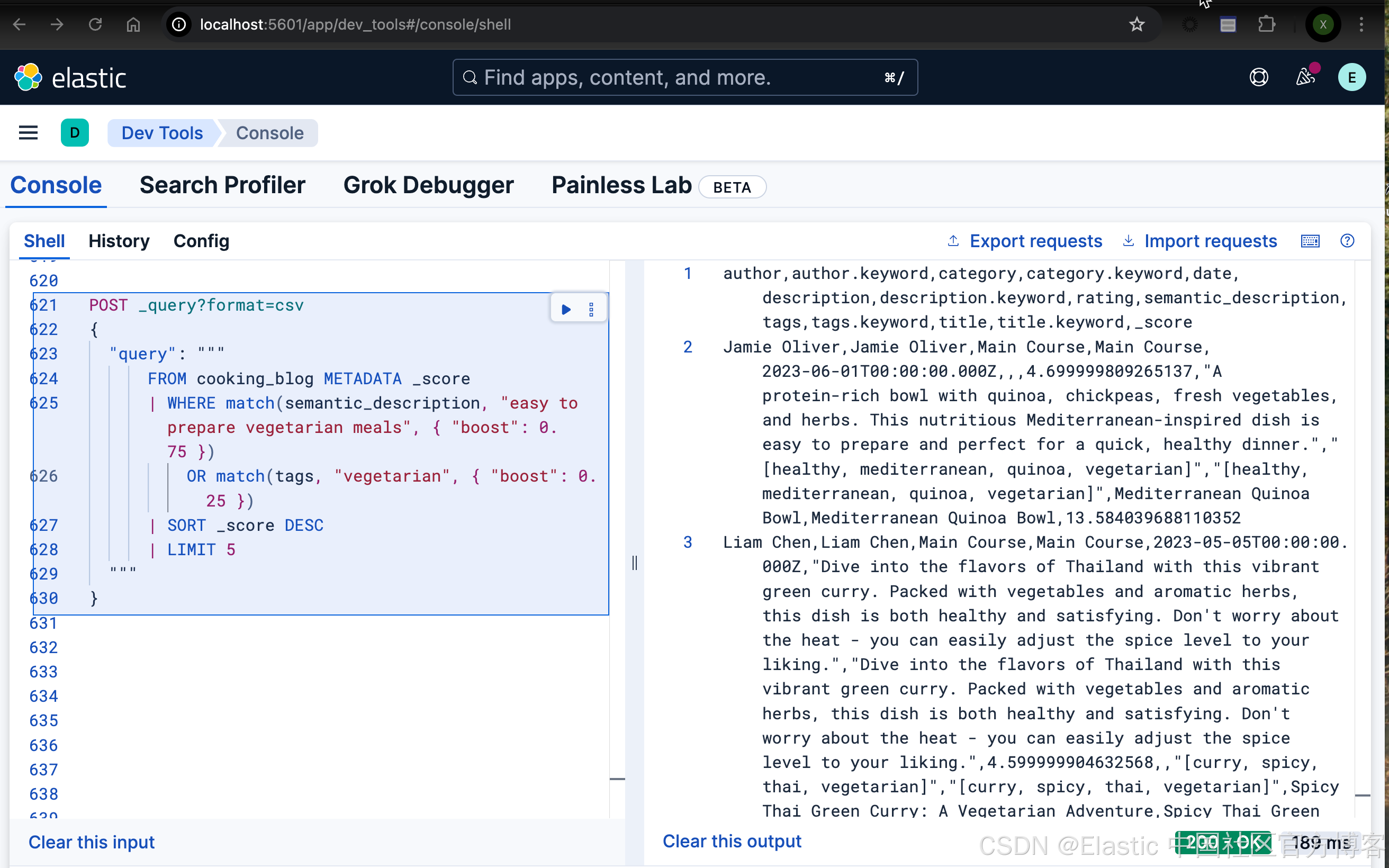
步骤 5:一次搜索多个字段
当用户输入搜索查询时,他们通常不知道(或不关心)他们的搜索词是否出现在特定字段中。ES|QL 提供了同时在多个字段中进行搜索的方法:
FROM cooking_blog
| WHERE title:"vegetarian curry" OR description:"vegetarian curry" OR tags:"vegetarian curry"
| LIMIT 1000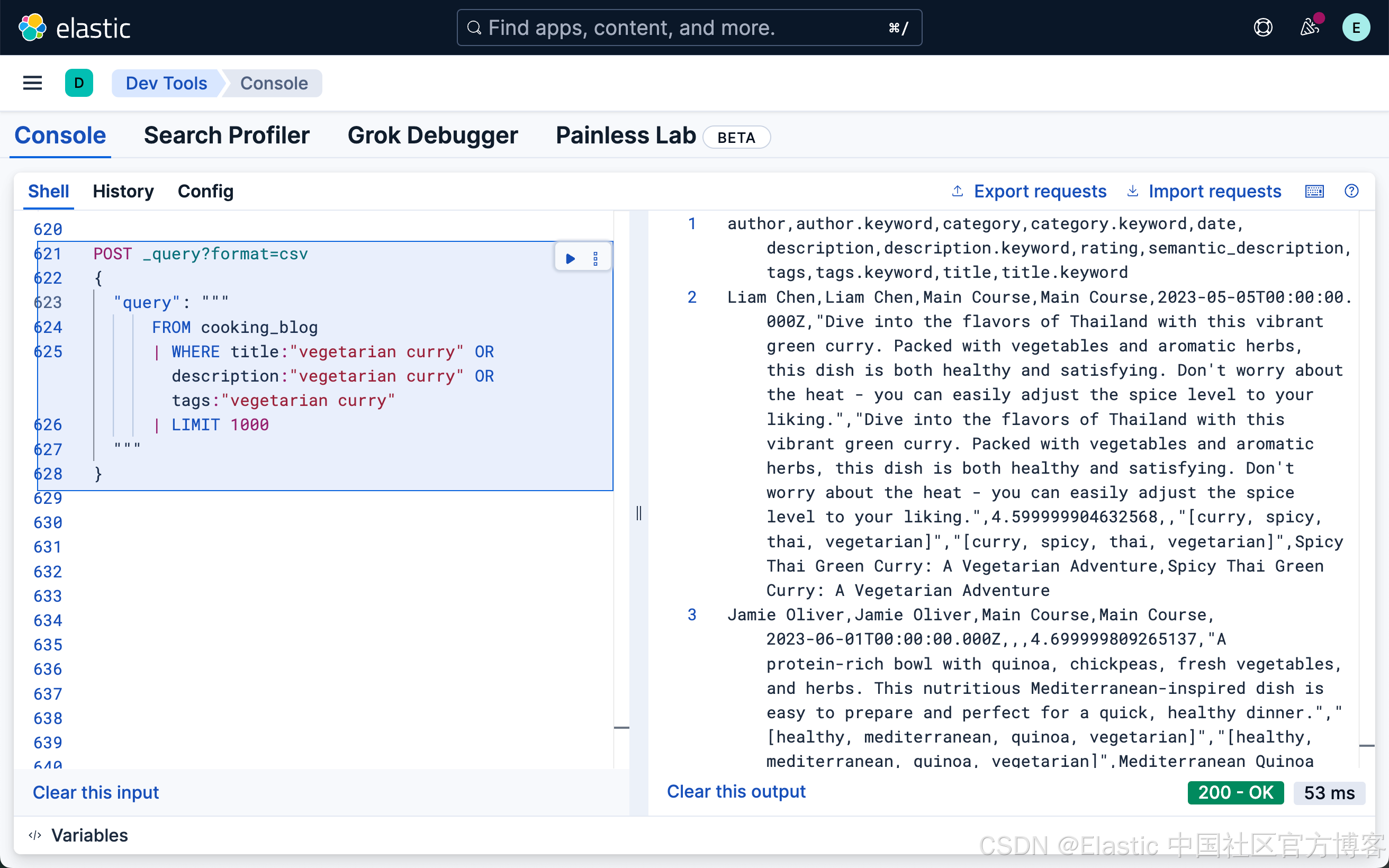
这个查询在 title、description 和 tags 字段中搜索 "vegetarian curry"。每个字段的重要性相同。
然而,在许多情况下,某些字段(如标题)中的匹配可能比其他字段更相关。我们可以通过评分来调整每个字段的重要性:
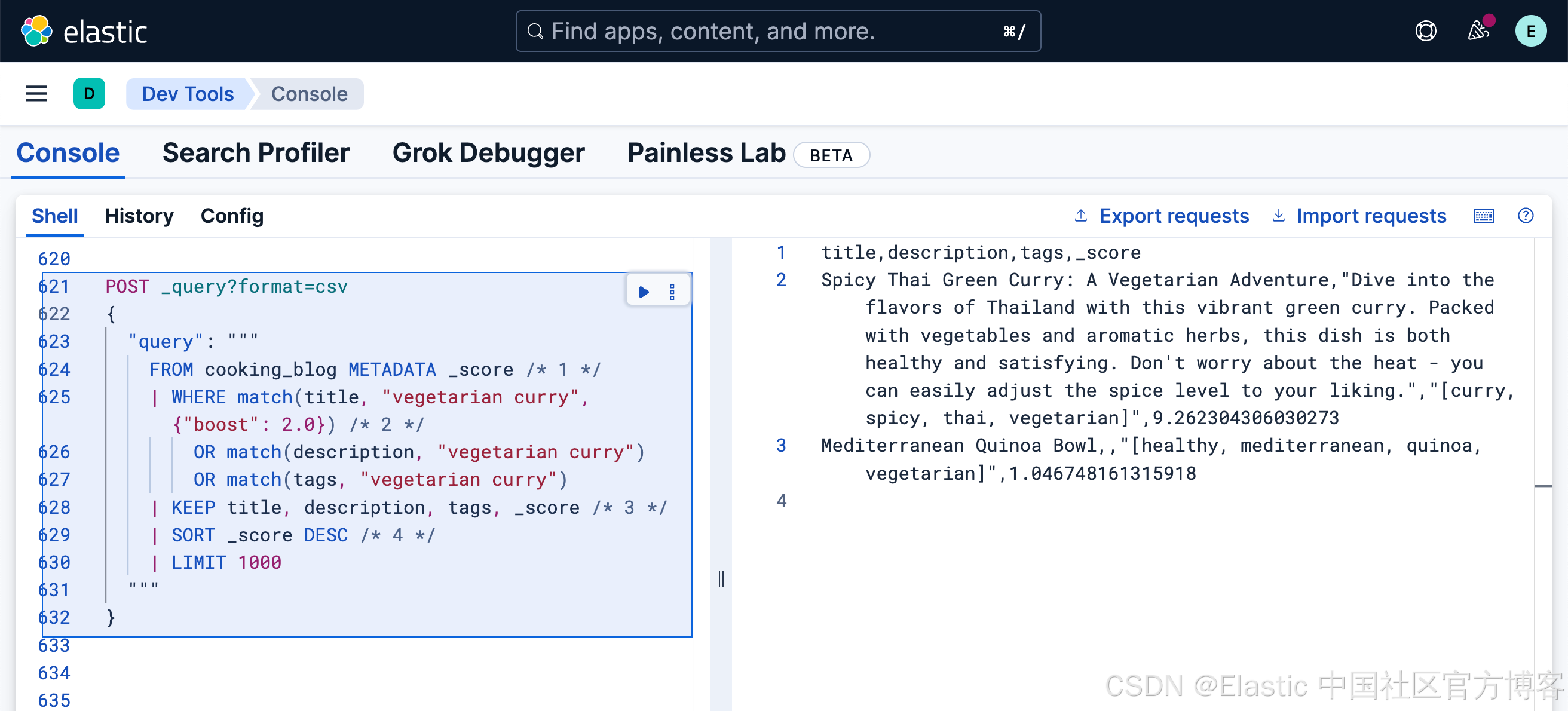
FROM cooking_blog METADATA _score /* 1 */
| WHERE match(title, "vegetarian curry", {"boost": 2.0}) /* 2 */OR match(description, "vegetarian curry") OR match(tags, "vegetarian curry")
| KEEP title, description, tags, _score /* 3 */
| SORT _score DESC /* 4 */
| LIMIT 1000- 请求 _score 元数据以获取基于相关性的结果
- 标题匹配的重要性是其他字段的两倍
- 在结果中包含相关性评分
- 必须明确按 _score 排序才能查看基于相关性的结果
提示:在 ES|QL 中使用相关性评分时,理解 _score 非常重要。如果你在查询中不包含 METADATA _score,你将无法在结果中看到相关性评分。这意味着你将无法根据相关性进行排序或基于相关性评分进行过滤。
当你包含 METADATA _score 时,WHERE 条件中的搜索功能会贡献相关性评分。过滤操作(如范围条件和精确匹配)不会影响评分。
如果你想要最相关的结果排在前面,必须通过显式使用 SORT _score DESC 或 SORT _score ASC 来按 _score 排序。
步骤 6:过滤和查找精确匹配
过滤允许你根据精确标准缩小搜索结果的范围。与全文搜索不同,过滤是二元的(是/否),并且不会影响相关性评分。过滤执行比查询更快,因为排除的结果不需要进行评分。
FROM cooking_blog
| WHERE category.keyword == "Breakfast"
| KEEP title, author, rating, tags
| SORT rating DESC
| LIMIT 1000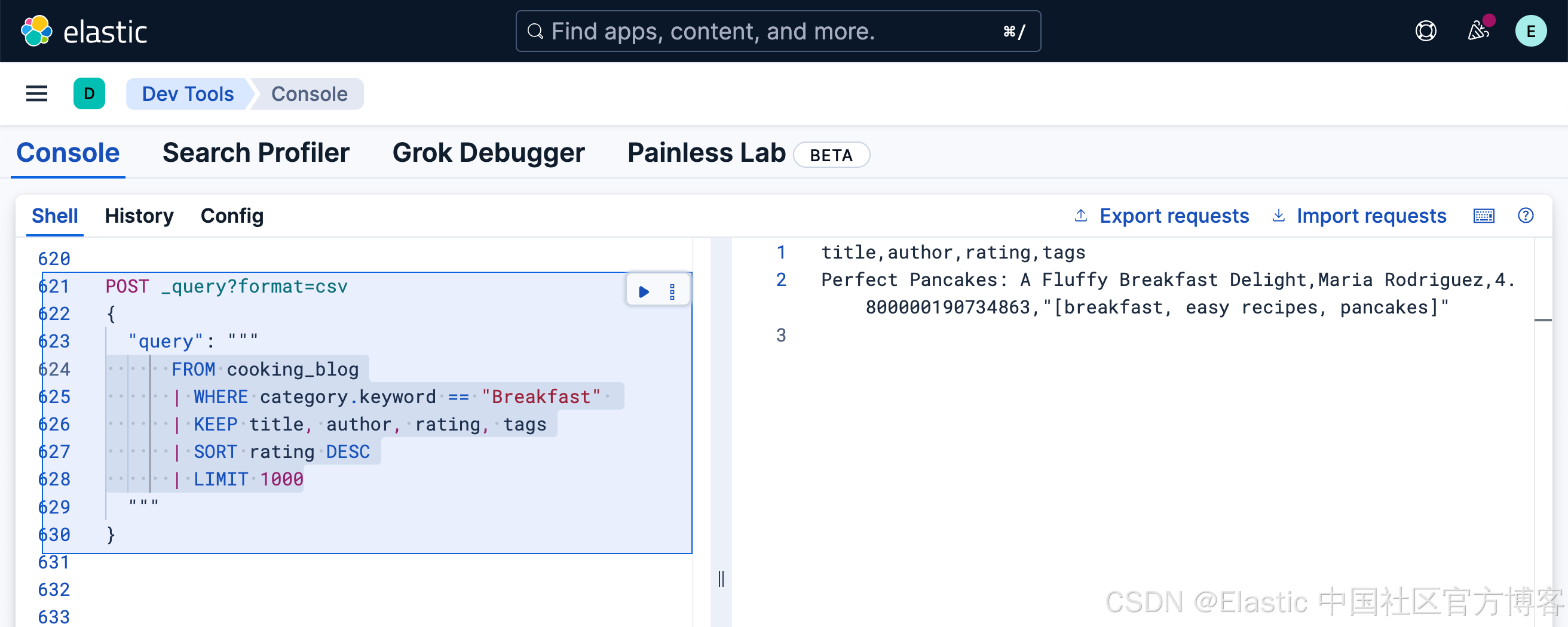
使用 keyword 字段进行精确匹配(区分大小写)。
注意:这里使用了 category.keyword。它指的是 category 字段的 keyword 多字段,确保进行精确的、区分大小写的匹配。
在日期范围内搜索帖子
通常,用户希望找到在特定时间范围内发布的内容:
FROM cooking_blog
| WHERE date >= "2023-05-01" AND date <= "2023-05-31"
| KEEP title, author, date, rating
| LIMIT 1000包含日期范围过滤器。
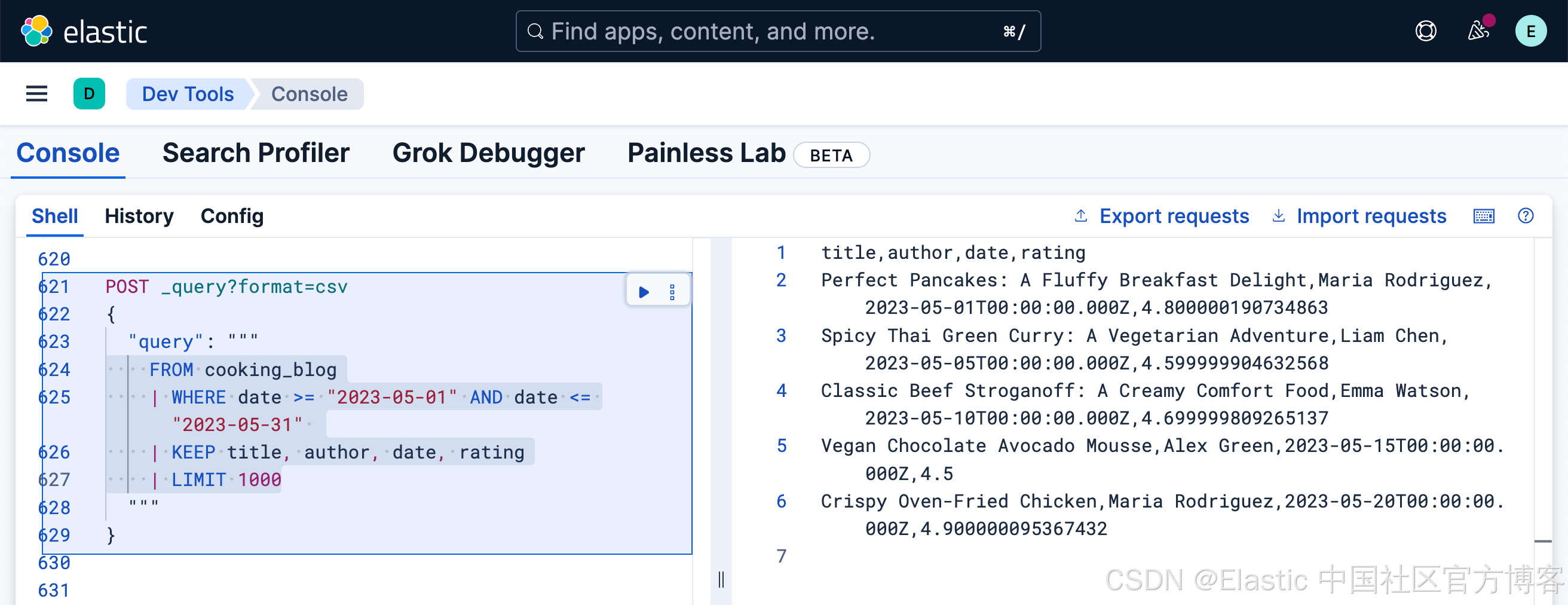
查找精确匹配
有时,用户希望搜索精确的术语,以消除搜索结果中的歧义:
FROM cooking_blog
| WHERE author.keyword == "Maria Rodriguez"
| KEEP title, author, rating, tags
| SORT rating DESC
| LIMIT 1000在 author 字段上进行精确匹配。
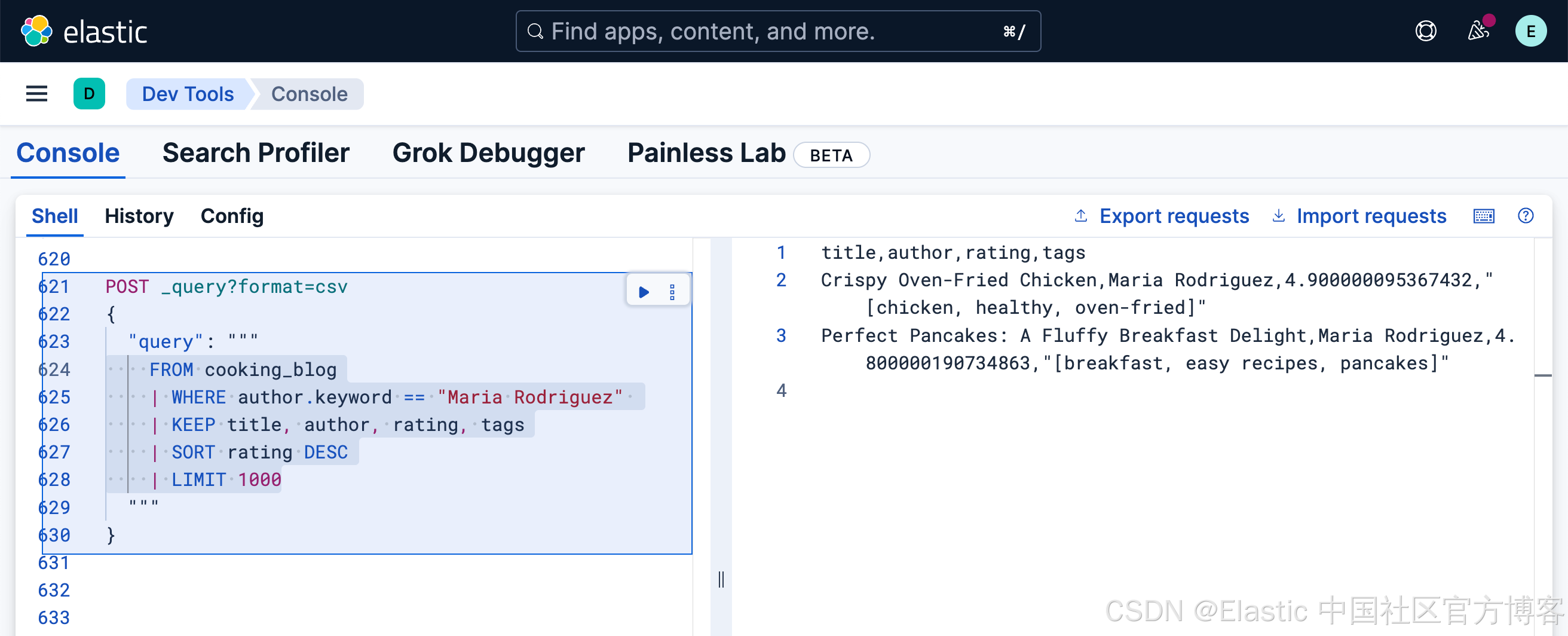
与 Query DSL 中的 term 查询类似,这种查询没有灵活性,并且区分大小写。
步骤 7:组合多个搜索条件
复杂的搜索通常需要组合多个搜索条件:
FROM cooking_blog METADATA _score
| WHERE rating >= 4.5 AND NOT category.keyword == "Dessert" AND (title:"curry spicy" OR description:"curry spicy")
| SORT _score DESC
| KEEP title, author, rating, tags, description
| LIMIT 1000将相关性评分与自定义条件结合
对于更复杂的相关性评分和组合条件,你可以使用 EVAL 命令来计算自定义评分:
FROM cooking_blog METADATA _score
| WHERE NOT category.keyword == "Dessert"
| EVAL tags_concat = MV_CONCAT(tags.keyword, ",") /* 1 */
| WHERE tags_concat LIKE "*vegetarian*" AND rating >= 4.5 /* 2 */
| WHERE match(title, "curry spicy", {"boost": 2.0}) OR match(description, "curry spicy") /* 3 */
| EVAL category_boost = CASE(category.keyword == "Main Course", 1.0, 0.0) /* 4 */
| EVAL date_boost = CASE(DATE_DIFF("month", date, NOW()) <= 1, 0.5, 0.0) /* 5 */
| EVAL custom_score = _score + category_boost + date_boost /* 6 */
| WHERE custom_score > 0 /* 7 */
| SORT custom_score DESC
| LIMIT 1000- 将多值字段转换为字符串
- 通配符模式匹配
- 使用全文本功能,将更新 _score 元数据字段
- 条件加权
- 加权最近内容
- 组合评分
- 基于自定义评分进行过滤
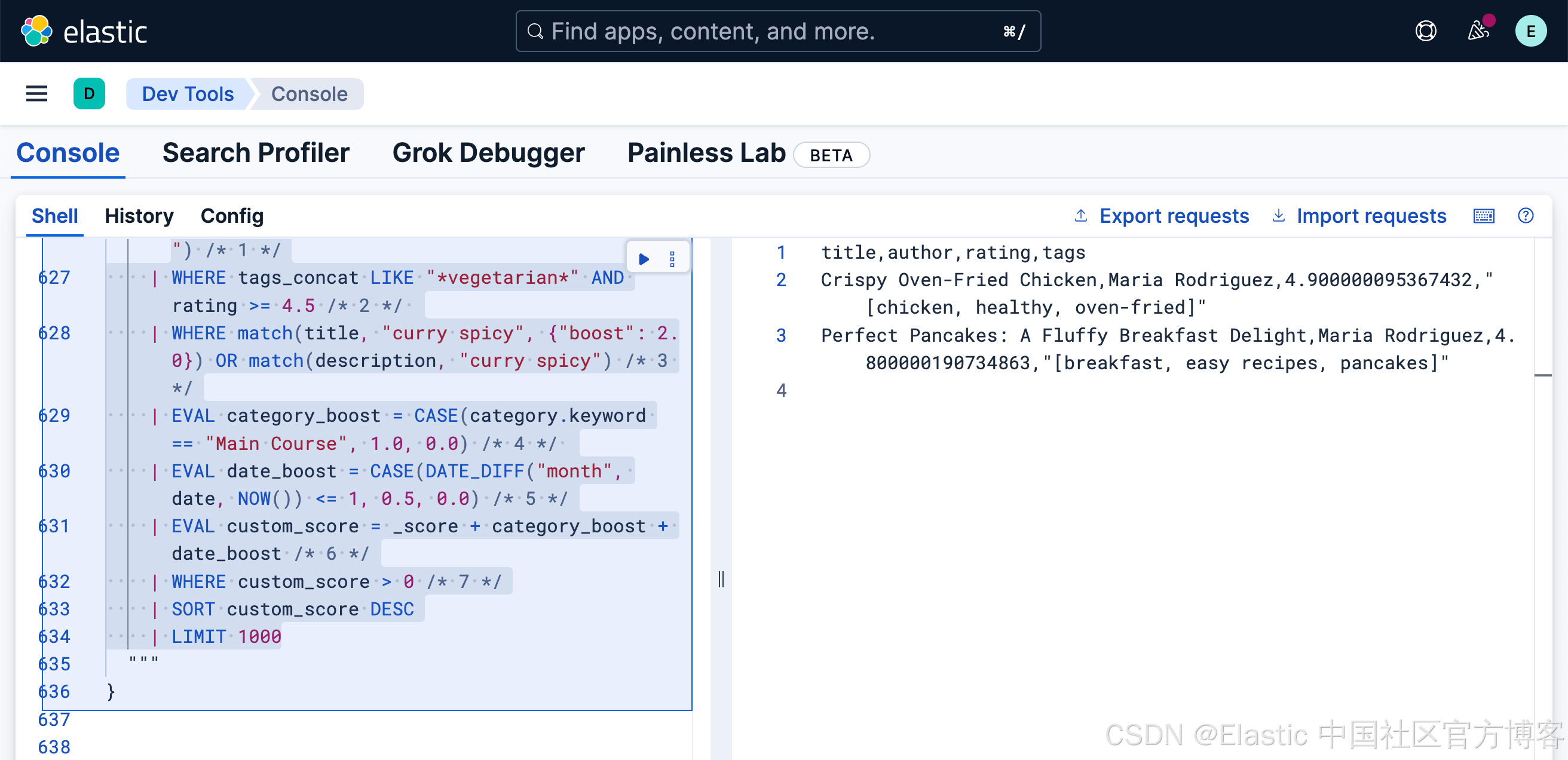
相关文章:

Elasticsearch:使用 ES|QL 进行搜索和过滤
本教程展示了 ES|QL 语法的示例。请参考 Query DSL 版本,以获得等效的 Query DSL 语法示例。 这是一个使用 ES|QL 进行全文搜索和语义搜索基础知识的实践介绍。 有关 ES|QL 中所有搜索功能的概述,请参考《使用 ES|QL 进行搜索》。 在这个场景中&#x…...
应用的物联网框架)
面向新一代扩展现实(XR)应用的物联网框架
中文标题: 面向新一代扩展现实(XR)应用的物联网框架 英文标题: Towards an IoT Framework for the New Generation of XR Applications 作者信息 Joo A. Dias,UNIDCOM - IADE,欧洲大学,里斯本&…...
)
Docker Overlay 网络的核心工作(以跨节点容器通信为例)
Docker 的 overlay 网络是一种基于 VXLAN(Virtual Extensible LAN)的多主机网络模式,专为 Docker Swarm 集群设计,用于实现跨节点的容器通信。它通过虚拟二层网络,允许容器在不同主机上像在同一局域网内一样通信。Dock…...

开发基于python的商品推荐系统,前端框架和后端框架的选择比较
开发一个基于Python的商品推荐系统时,前端和后端框架的选择需要综合考虑项目需求、开发效率、团队熟悉度以及系统的可扩展性等因素。 以下是一些推荐的框架和建议: 后端框架 Flask 优点: 轻量级:Flask的核心非常简洁,…...

CSRF 请求伪造Referer 同源置空配合 XSSToken 值校验复用删除
#CSRF- 无检测防护 - 检测 & 生成 & 利用(那数据包怎么整 找相似源码自己搭建整) 检测:黑盒手工利用测试,白盒看代码检验(有无 token ,来源检验等) 生成: BurpSuite->Engagement t…...
Task1)
Datawhale AI春训营】AI + 新能源(发电功率预测)Task1
赛题链接 官网 新能源发电功率预测赛题进阶方案 下面是ai给的一些建议 新能源发电功率预测赛题进阶方案 一、时序特性深度挖掘 1. 多尺度周期特征 # 分钟级周期编码 train[15min_index] (train[hour]*4 train[minute]//15)# 周周期特征 train[weekday] pd.to_datetime…...

@EnableAsync+@Async源码学习笔记之二
从本文开始,就正式进入源码追踪阶段了,上一篇的最后我们提到了 EnableAsync 注解上的 Import(AsyncConfigurationSelector.class)了,本文就来看下它,源码如下: package org.springframework.scheduling.annotation;im…...

C++ STL 环形队列模拟实现
C STL 环形队列模拟实现 下面是一个使用C STL实现的环形队列(Circular Queue)的完整示例: #include <iostream> #include <vector> #include <stdexcept>template <typename T> class CircularQueue { private:std…...

每天五分钟深度学习PyTorch:0填充函数在搭建神经网络中的应用
本文重点 在深度学习中,神经网络的搭建涉及对输入数据、权重矩阵以及中间计算结果的处理。masked_fill 是 PyTorch 等深度学习框架中常用的张量操作函数,它通过布尔掩码(mask)对张量中的指定元素进行填充。当将矩阵元素填充为 0 时,masked_fill 在神经网络中发挥着重要作…...

pycharm中怎么解决系统cuda版本高于pytorch可以支持的版本的问题?
在PyCharm中安装与系统CUDA版本不一致的PyTorch是可行的。以下是解决方案的步骤: 1. 确认系统驱动兼容性 检查NVIDIA驱动支持的CUDA版本:运行 nvidia-smi,右上角显示的CUDA版本是驱动支持的最高版本。只要该版本不低于PyTorch所需的CUDA版本…...

【概率论】条件期望
在高等概率论中,给定一个概率空间 ( Ω , F , P ) (\Omega, \mathcal{F}, P) (Ω,F,P) 和其子 σ \sigma σ-代数 G ⊆ F \mathcal{G} \subseteq \mathcal{F} G⊆F,随机变量 X X X 关于 G \mathcal{G} G 的 条件期望 E [ X ∣ G ] E[X|\mathcal{G}…...

【java实现+4种变体完整例子】排序算法中【计数排序】的详细解析,包含基础实现、常见变体的完整代码示例,以及各变体的对比表格
以下是计数排序的详细解析,包含基础实现、常见变体的完整代码示例,以及各变体的对比表格: 一、计数排序基础实现 原理 通过统计每个元素的出现次数,按顺序累加得到每个元素的最终位置,并填充到结果数组中。 代码示…...

Qt C++ 解析和处理 XML 文件示例
使用 Qt C 解析和处理 XML 文件 以下是使用 Qt C 实现 XML 文件处理的几种方法,包括解析、创建和修改 XML 文件。 1. 使用 QXmlStreamReader (推荐方式) #include <QFile> #include <QXmlStreamReader> #include <QDebug>void parseXmlWithStr…...

在服务器上部署MinIO Server
MinIO的优势 高性能:MinIO号称是目前速度最快的对象存储服务器,据称在标准硬件上,对象存储的读/写速度最高可以高达183 GB/s和171 GB/s,可惜我的磁盘跟不上 兼容性:MinIO基于Amazon S3协议,并提供了与S3兼…...

第二十七讲:AI+农学导论
关键词:人工智能、农业、作物识别、遥感、机器学习、案例实战 目录 📌 一、为什么农业需要人工智能? 📈 二、AI在农学中的典型应用场景 🧪 三、实战案例:AI识别作物类型(以随机森林为例) ✅ 数据集:iris(模拟作物种类识别) 📦 所需包: 🚀 数据准备: …...

医院科研科AI智能科研支撑平台系统设计架构方案探析
一、系统设计概述 1.1 系统定位 本系统是基于MCP(Model Context Protocol,模型上下文协议)协议构建的智能科研支撑平台,旨在为医院科研科室提供全流程AI辅助能力,覆盖课题立项、数据采集、分析建模到成果转化的完整科研生命周期。系统通过MCP协议实现与医院信息系统的深…...
之条件语句)
Python基础总结(七)之条件语句
文章目录 条件语句if一、Python中的真假二、条件语句格式2.1 if语句格式2.2 if-else语句2.3 if-elif-else语句 三、if语句嵌套 条件语句if 条件语句其实就是if语句,在讲解if语句之前需要知道Python中对于真假的判断。 一、Python中的真假 在Python中非0的都为真&…...

Day10【基于encoder- decoder架构实现新闻文本摘要的提取】
实现新闻文本摘要的提取 1. 概述与背景2.参数配置3.数据准备4.数据加载5.主程序6.预测评估7.生成效果8.总结 1. 概述与背景 新闻摘要生成是自然语言处理(NLP)中的一个重要任务,其目标是自动从长篇的新闻文章中提取出简洁、准确的摘要。近年来…...
)
深度解析算法之二分查找(2)
17.二分查找 题目链接 给定一个 n 个元素有序的(升序)整型数组 nums 和一个目标值 target ,写一个函数搜索 nums 中的 target,如果目标值存在返回下标,否则返回 -1。 示例 1: 输入: nums [-1,0,3,5,9,12], target…...

前端工程化之自动化测试
自动化测试 自动化测试为什么需要测试?什么时候需要考虑测试测试类型前端测试框架单元测试Jest 重点掌握项目示例package.jsonsrc/utils/math.tssrc/utils/math.test.ts进行测试jest.config.js覆盖率直观看覆盖率coverage/lcov-report/index.html src/main.test.tst…...

CANFD技术在新能源汽车通信网络中的应用与可靠性分析
一、引言 新能源汽车产业正处于快速发展阶段,其电子系统复杂度不断攀升,涵盖众多传感器、控制器与执行器。高效通信网络成为确保新能源汽车安全运行与智能功能实现的核心要素。传统CAN总线因带宽限制,难以满足高级驾驶辅助系统(A…...

【机器学习】朴素贝叶斯算法:原理剖析与实战应用
引言 朴素贝叶斯算法就像是一位善于从经验中学习的侦探,根据已有的线索来推断未知事件的概率。这是一种基于概率论的分类算法,以贝叶斯定理为基础,却做了一个"朴素"的假设:认为所有特征彼此独立。虽然这个假设在现实中…...

【更新完毕】2025妈妈杯C题 mathercup数学建模挑战赛C题数学建模思路代码文章教学:音频文件的高质量读写与去噪优化
完整内容请看文章最下面的推广群 我将先给出文章、代码、结果的完整展示, 再给出四个问题详细的模型 面向音频质量优化与存储效率提升的自适应编码与去噪模型研究 摘 要 随着数字媒体技术的迅速发展,音频处理技术在信息时代的应用愈加广泛,特别是在存储…...

UI键盘操作
1、Selenium中send_keys除了可以模拟键盘输入之外,还有些时候需要操作键盘上的按键,甚至是组合键,比如CTRLA,CTRLC等, 所以我们需要代码操作键盘。使用的是send_keys里的Keys的类。 from selenium.webdriver.common.keys import …...

【正则表达式】正则表达式使用总结
正则表达式除了匹配普通字符外,还可以匹配特殊字符,这些特殊字符被称为“元字符”。 特殊字符(元字符) 限定符:用于指定正则表达式中某个组件的出现次数。常见的限定符包括: *:0次或多次 +:1次或多次 ?:0次或1次 {n}:恰好n次…...

Qt编写推流程序/支持webrtc265/从此不用再转码/打开新世界的大门
一、前言 在推流领域,尤其是监控行业,现在主流设备基本上都是265格式的视频流,想要在网页上直接显示监控流,之前的方案是,要么转成hls,要么魔改支持265格式的flv,要么265转成264,如…...
推送机制实践)
Spring Boot 中基于 Reactor 的服务器端事件(SSE)推送机制实践
Spring Boot 3.0 中基于 Reactor 的服务器端事件(SSE)推送机制实践 在现代 Web 应用开发中,实时数据交互越来越成为刚需,从股票行情的实时更新到社交平台的消息即时推送,服务器端事件(Server-Sent Events,简称 SSE)作为一种高效的单向数据传输技术,正发挥着重要作用。…...

CRC实战宝典:从原理到代码,全面攻克循环冗余校验
CRC实战宝典:从原理到代码,全面攻克循环冗余校验 github开源:CRC软硬件协同测试项目 CRC 简介 CRC(循环冗余校验)是一种强大的错误检测技术,广泛应用于数字网络和存储系统。它是确保数据完整性的重要方法…...
)
【愚公系列】《Python网络爬虫从入门到精通》056-Scrapy_Redis分布式爬虫(Scrapy-Redis 模块)
🌟【技术大咖愚公搬代码:全栈专家的成长之路,你关注的宝藏博主在这里!】🌟 📣开发者圈持续输出高质量干货的"愚公精神"践行者——全网百万开发者都在追更的顶级技术博主! …...

ZLMediaKit 和 SRS的区别,哪个更好用?
ZLMediaKit 和 SRS(Simple RTMP Server)是两个主流的开源流媒体服务器框架,各自在功能、性能、适用场景等方面存在显著差异。以下是两者的对比分析及选择建议: 一、核心差异对比 协议支持 ZLMediaKit:支持更广泛的流媒…...
数据集是 CIFAR10)
【PyTorch】colab上跑VGG(深度学习)数据集是 CIFAR10
跑得结果是测试准确率10%,欠拟合。 import torch import torchvision.datasets from torch import nn from torch.utils.data import DataLoader from torch.utils.tensorboard import SummaryWriter from torchvision import datasets, transformstransform tran…...

pytorch 51 GroundingDINO模型导出tensorrt并使用c++进行部署,53ms一张图
本专栏博客第49篇文章分享了将 GroundingDINO模型导出onnx并使用c++进行部署,并尝试将onnx模型转换为trt模型,fp16进行推理,可以发现推理速度提升了一倍。为此对GroundingDINO的trt推理进行调研,发现 在GroundingDINO-TensorRT-and-ONNX-Inference项目中分享了模型导出onnx…...

编程语言基础 - C++ 面试题
C++ 面试题 tags: c++ 文章目录 C++ 面试题关键字1. const2. static3. this 指针4. inline 内联函数5. volatile6. struct, class7. enum关键字 1. const 修饰变量:该变量不能被改变 修饰指针: 指针常量: 指针本身是常量 TYPE* const pContent;指向常量的指针:指针所指向…...

JVM笔记【一】java和Tomcat类加载机制
JVM笔记一java和Tomcat类加载机制 java和Tomcat类加载机制 Java类加载 * loadClass加载步骤类加载机制类加载器初始化过程双亲委派机制全盘负责委托机制类关系图自定义类加载器打破双亲委派机制 Tomcat类加载器 * 为了解决以上问题,tomcat是如何实现类加载机制的…...
)
Python----深度学习(全连接与链式求导法则)
一、机器学习和深度学习的区别 机器学习:利用计算机、概率论、统计学等知识,输入数据,让计算机学会新知 识。机器学习的过程,就是训练数据去优化目标函数。 深度学习:是一种特殊的机器学习,具有强大的能力和…...

基于SpringBoot的网上找律师管理系统
博主介绍:java高级开发,从事互联网行业六年,熟悉各种主流语言,精通java、python、php、爬虫、web开发,已经做了六年的毕业设计程序开发,开发过上千套毕业设计程序,没有什么华丽的语言࿰…...

《目标检测双雄:YOLO与Faster R-CNN,谁主沉浮?》
在计算机视觉的广阔天地里,目标检测技术宛如一颗璀璨的明星,照亮了无数应用场景。从安防监控中对行人与车辆的精准识别,到自动驾驶领域对道路障碍物的快速判断,再到工业生产里对产品缺陷的严格检测,目标检测无处不在&a…...

CUDA编程中影响性能的小细节总结
一、内存访问优化 合并内存访问:确保相邻线程访问连续内存地址(全局内存对齐访问)。优先使用共享内存(Shared Memory)减少全局内存访问。避免共享内存的Bank Conflict(例如,使用padding或调整访…...

C#学习第17天:序列化和反序列化
什么是序列化? 定义:序列化是指把对象转换为一种可以轻松存储或传输的格式,如JSON、XML或二进制格式。这个过程需要捕获对象的类型信息和数据内容。用途:使得对象可以持久化到文件、发送至网络、或存储在数据库中。 什么是反序列…...

kafka的零拷贝技术
在 Kafka 中,高性能数据传输依赖于操作系统提供的 零拷贝(Zero-Copy) 技术,主要包括 sendfile 和 mmap 两种实现方式。它们的核心目标是减少数据在用户态和内核态之间的拷贝次数,从而提升 I/O 效率。下面详细解析它们的…...

从 0~1 保姆级 详细版 PostgreSQL 数据库安装教程
PostgreSQL数据库安装 PostgreSQL官网 【PostgreSQL官网】 | 【PostgreSQL安装官网_Windows】 安装步骤 step1: 选择与电脑相对应的PostgreSQL版本进行下载。 step2: 双击打开刚才下载好的文件。 step3: 在弹出的setup窗口中点击 …...

MySQL中常用函数的分类及示例
概述 以下是 MySQL 中常用函数的分类及示例,涵盖字符串处理、数值计算、日期操作、条件判断等常见场景: 一、字符串函数 1. CONCAT(str1, str2, ...) 拼接字符串。 SELECT CONCAT(Hello, , World); -- 输出: Hello World2. SUBSTRING(str, start,…...
)
【论文阅读21】-PSOSVM-CNN-GRU-Attention-滑坡预测(2024-12)
这篇论文主要提出并验证了一种新型的混合智能模型(PSOSVM-CNN-GRU-Attention),用于准确预测滑坡的点位移,并构建可靠的位移预测区间。通过对Baishuihe滑坡和Shuping滑坡的案例分析,展示了该模型的出色性能。 [1] Zai D…...

Shiro-550 动调分析与密钥正确性判断
一、Shiro 简介 Apache Shiro是一个开源安全框架,用于构建 Java 应用程序,提供身份验证、授权、加密和会话管理等功能。 二、Shiro-550(CVE-2016-4437) 1、漏洞原理 Shiro 在用户登陆时提供可选项 RememberMe,若勾选…...

Codeforces Educational Round 177 Div. 2 【B题,C待补
B 二分 题意 样例 5 3 10 3 4 2 1 512 找最右边的L下标即可 思路 二分最靠右的L端点,R端点取最右端(n*k处),找到后,答案就是L的位置(pos),(因为如果pos满足,则pos左边的所有下标都满足 代码 const in…...

【Lua语言】Lua语言快速入门
初始Lua Lua是一种轻量小巧的脚本语言,他使用标准C语言编写并以源代码形式开放。这意味着Lua虚拟机可以很方便的嵌入别的程序中,从而为应用程序提供灵活的扩展和定制功能。同时,在目前脚本引擎中,Lua的运行速度占有绝对优势。 变…...

Matlab画海洋与大气变量的时间序列并带标记面的三维折线图--来源粉丝
Matlab画带标记面的三维折线图–来源粉丝 图片 目标图: 图片 复现: 图片 细节可在代码中更改: 数据构造 clear;clc;close all; % 数据构造 X1 1:8;Y1ones(length(X1),1); X2 X1;Y22*ones(length(X1),1); X3 X1;Y33*ones(length(X1),1); …...
)
NestJS——多环境配置方案(dotenv、config、@nestjs/config、joi配置校验)
个人简介 👀个人主页: 前端杂货铺 🙋♂️学习方向: 主攻前端方向,正逐渐往全干发展 📃个人状态: 研发工程师,现效力于中国工业软件事业 🚀人生格言: 积跬步…...

RAGFlow在Docker中运行Ollama直接运行于主机的基础URL的地址
基础Url http://host.docker.internal:11434...

python 库 下载 ,整合在一个小程序 UIUIUI
上图 import os import time import threading import requests import subprocess import importlib import tkinter as tk from tkinter import ttk, messagebox, scrolledtext from concurrent.futures import ThreadPoolExecutor, as_completed from urllib.parse import…...