C++镌刻数据密码的树之铭文:二叉搜索树
文章目录
- 1.二叉搜索树的概念
- 2.二叉搜索树的实现
- 2.1 二叉搜索树的结构
- 2.2 二叉搜索树的节点寻找
- 2.2.1 非递归
- 2.2.2 递归
- 2.3 二叉搜索树的插入
- 2.3.1 非递归
- 2.3.2 递归
- 2.4 二叉搜索树的删除
- 2.4.1 非递归
- 2.4.2 递归
- 2.5 二叉搜索树的拷贝
- 3.二叉树的应用
- 希望读者们多多三连支持
- 小编会继续更新
- 你们的鼓励就是我前进的动力!
继数据结构的二叉树学习,本篇进行更进一步的搜索二叉树,是一种更为常见的结构
1.二叉搜索树的概念
二叉搜索树简单来说就是一个排序树
它是具有以下性质的二叉树:
- 若它的
左子树不为空,则左子树上所有节点的值都小于根节点的值 - 若它的
右子树不为空,则右子树上所有节点的值都大于根节点的值 - 它的
左右子树也分别为二叉搜索树
🔥值得注意的是: 每棵子树都满足该性质
2.二叉搜索树的实现
2.1 二叉搜索树的结构
template<class K>
struct BSTreeNode
{BSTreeNode<K>* _left;BSTreeNode<K>* _right;K _key;BSTreeNode(const K& key):_left(nullptr),_right(nullptr),_key(key){ }
};
_left:指向左子节点的指针。_right:指向右子节点的指针。_key:存储节点的键值
2.2 二叉搜索树的节点寻找
2.2.1 非递归
bool Find(const K& key)
{Node* cur = _root;while (cur){if (cur->_key < key){cur = cur->_right;}else if (cur->_key > key){cur = cur->_left;}else{return true;}}return false;
}
借助 cur 指针从根节点开始遍历二叉搜索树:
- 若
cur->_key小于key,则转向右子树继续查找 - 若
cur->_key大于key,则转向左子树继续查找 - 若
cur->_key等于key,说明找到了目标键值,返回true - 若遍历结束
cur为nullptr,表示未找到目标键值,返回false
2.2.2 递归
bool _FindR(Node* root, const K& key)
{if (root == nullptr)return false;if (root->_key < key){return _FindR(root->_right, key);}else if (root->_key > key){return _FindR(root->_left, key);}else{return true;}
}
检查基本情况: 查看当前节点 root 是否为空。若为空,返回 false,递归结束
比较键值: 若当前节点不为空,将当前节点的键值 root->_key 与目标键值 key 进行比较重复,每次递归调用都会将问题规模缩小,直至满足基本情况或者找到目标节点
🔥值得注意的是: 注意这些非递归要放在 private,因为 root 也是 private,由于要控制子树,必须要传入 root,如果是 public 的话,就只能传入自己的 root,而不是二叉搜索树的 root,无法保证 root 的正确性
2.3 二叉搜索树的插入
2.3.1 非递归
bool Insert(const K& key)
{if (_root == nullptr){_root = new Node(key);return true;}Node* parent = nullptr;Node* cur = _root;while (cur){if (cur->_key < key){parent = cur;cur = cur->_right;}else if (cur->_key > key){parent = cur;cur = cur->_left;}else{return false;}}cur = new Node(key);if (parent->_key < key){parent->_right = cur;}else{parent->_left = cur;}return true;
}
当 cur 为空时,说明已经找到了插入位置。创建一个新节点,并根据 parent 的键和要插入的键的大小关系,将新节点插入到 parent 的左子树或右子树中
🔥值得注意的是: 首先检查树是否为空,如果为空,则直接创建一个新节点作为根节点,并返回 true
2.3.2 递归
bool _InsertR(Node*& root, const K& key)
{if (root == nullptr){root = new Node(key);return true;}if (root->_key < key){return _InsertR(root->_right, key);}else if (root->_key > key){return _InsertR(root->_left, key);}else{return false;}
}
这里递归的流程和查找的递归代码几乎一样,唯一不同的是要传入的 root 需要加引用,这是因为这里的代码只执行了节点寻找创建的操作,那么当我们找到空节点并创建的时候,由于 root 是上一个 _InsertR 函数 root->_left 或 root->_right 的别名,创建的时候相当于 root->_left = new Node(key) 或 root->_right = new Node(key),这样才能完成链接
2.4 二叉搜索树的删除
2.4.1 非递归
bool Erase(const K& key)
{Node* parent = nullptr;Node* cur = _root;while (cur){if (cur->_key > key){parent = cur;cur = cur->_left;}else if (cur->_key < key){parent = cur;cur = cur->_right;}else{if (cur->_left == nullptr){// 左为空if (cur == _root){_root = cur->_right;}else{if (parent->_left == cur){parent->_left = cur->_right;}else{parent->_right = cur->_right;}}}// 右为空else if (cur->_right == nullptr){if (cur == _root){_root = cur->_left;}else{if (parent->_right == cur){parent->_right = cur->_left;}else{parent->_left = cur->_left;}}}// 左右都不为空 else{Node* parent = cur;Node* leftMax = cur->_left;while (leftMax->_right){parent = leftMax;leftMax = leftMax->_right;}swap(leftMax->_key, cur->_key);if (parent->_left == leftMax){parent->_left = leftMax->_left;}else{parent->_right = leftMax->_left;}cur = leftMax;}delete cur;return true;}}return false;
}
首先先找到需要删除的节点,接着就需要分了讨论:
- 要删除的结点
无孩子结点 - 要删除的结点
只有左孩子结点 - 要删除的结点
只有右孩子结点 - 要删除的结点
有左、右孩子结点
🔥值得注意的是: 第一点可以直接看成只有一个节点的情况,即链接的是空节点
删除该结点且使被删除节点的双亲结点指向被删除节点的左孩子结点–直接删除
如果待删除节点 cur 的左子树为空,分两种情况处理:
如果 cur 就是根节点,那么将根节点更新为 cur 的右子树;如果 cur 不是根节点,则根据 cur 是其父节点 parent 的左子节点还是右子节点,相应地将 parent 的左指针或右指针指向 cur 的右子树
删除该结点且使被删除节点的双亲结点指向被删除结点的右孩子结点–直接删除
如果待删除节点 cur 的右子树为空,同样分两种情况:
若 cur 是根节点,将根节点更新为 cur 的左子树;若 cur 不是根节点,根据 cur 是 parent 的左子节点还是右子节点,将 parent 的左指针或右指针指向 cur 的左子树
在删除节点的左子树中寻找最大节点或者在它的右子树中寻找最小节点,用它的值填补到被删除节点中,再来处理该节点的删除问题–替换法删除
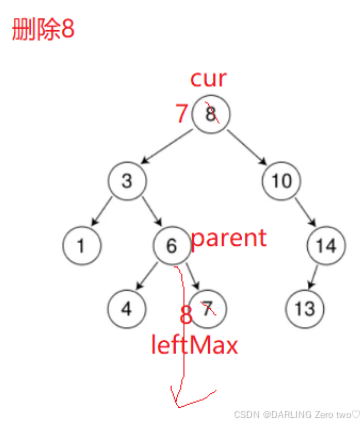
当待删除节点 cur 的左右子树都不为空时,为了保持二叉搜索树的性质,找到 cur 左子树中的最大节点 leftMax(即左子树中最右侧的节点)。通过一个 while 循环找到 leftMax,并记录其父亲节点 parent。然后交换 leftMax 和 cur 的键值,这样就将删除 cur 节点的问题转化为删除 leftMax 节点的问题,leftMax 由于是最大的节点,所以要么没有节点,要么只有左节点
🔥值得注意的是:
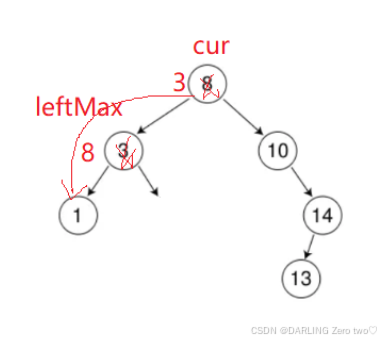
Node* parent = cur 而不是 Node* parent = nullptr,因为如果第一个左子节点就是 leftMax,那么 parent 就不会改变,使用 parent 的时候就会出问题
2.4.2 递归
bool _EraseR(Node*& root, const K& key)
{if (root == nullptr)return false;if (root->_key < key){return _EraseR(root->_right, key);}else if (root->_key > key){return _EraseR(root->_left, key);}else{Node* del = root;// 1、左为空// 2、右为空// 3、左右都不为空if (root->_left == nullptr){root = root->_right;}else if (root->_right == nullptr){root = root->_left;}else{Node* leftMax = root->_left;while (leftMax->_right){leftMax = leftMax->_right;}swap(root->_key, leftMax->_key);return _EraseR(root->_left, key);}delete del;return true;}
}
将即 root 和 leftMax 的键值进行交换,此时原本 leftMax 节点处的键值变为要删除的 key,由于交换后要删除的节点在左子树中,所以递归调用 _EraseR(root->_left, key) 继续在左子树中查找并删除这个键值为 key 的节点。因为在左子树中删除节点时,可能又会遇到不同的情况(如左子树为空、右子树为空或左右子树都不为空),所以递归调用可以继续处理这些情况,直到成功删除节点或者确定节点不存在
🔥值得注意的是:
这里 return _EraseR(root->_left, key) 不能写成 return _EraseR(leftMax, key)
因为 leftMax 只是个局部变量,对其进行操作没法改变 8 与 1 的链接
2.5 二叉搜索树的拷贝
Node* Copy(Node* root)
{if (root == nullptr)return nullptr;Node* copyroot = new Node(root->_key);copyroot->_left = Copy(root->_left);copyroot->_right = Copy(root->_right);return copyroot;
}
- 为当前节点创建一个新的节点
copyroot,新节点的键值和原节点root的键值相同 - 递归调用
Copy函数来拷贝原节点root的左子树,将拷贝结果赋值给新节点copyroot的左子节点指针_left - 同样地,递归调用
Copy函数来拷贝原节点root的右子树,把拷贝结果赋值给新节点copyroot的右子节点指针_right - 最后返回新创建的节点
copyroot,该节点及其子树构成了原节点及其子树的深拷贝
3.二叉树的应用
🚩K模型: 即只有 key 作为关键码,结构中只需要存储 key 即可,关键码即为需要搜索到的值,主要判断在不在的场景
比如: 给一个单词 word,判断该单词是否拼写正确,具体方式如下:
- 以词库中所有单词集合中的每个单词作为
key,构建一棵二叉搜索树 - 在二叉搜索树中检索该单词是否存在,存在则拼写正确,不存在则拼写错误。
🚩KV模型: 每一个关键码 key,都有与之对应的值 value,即 <key, value> 的键值对,通过一个值找另外一个值
- 比如英汉词典就是英文与中文的对应关系,通过英文可以快速找到与其对应的中文,英文单词与其对应的中文
<word, chinese>就构成一种键值对; - 再比如统计单词次数,统计成功后,给定单词就可快速找到其出现的次数,单词与其出现次数就是
<word, count>就构成一种键值对
namespace key_value
{template<class K, class V>struct BSTreeNode{BSTreeNode<K, V>* _left;BSTreeNode<K, V>* _right;K _key;V _value;BSTreeNode(const K& key, const V& value):_left(nullptr), _right(nullptr), _key(key), _value(value){}};template<class K, class V>class BSTree{typedef BSTreeNode<K, V> Node;public:BSTree():_root(nullptr){}void InOrder(){_InOrder(_root);cout << endl;}Node* FindR(const K& key){return _FindR(_root, key);}bool InsertR(const K& key, const V& value){return _InsertR(_root, key, value);}bool EraseR(const K& key){return _EraseR(_root, key);}private:bool _EraseR(Node*& root, const K& key){if (root == nullptr)return false;if (root->_key < key){return _EraseR(root->_right, key);}else if (root->_key > key){return _EraseR(root->_left, key);}else{Node* del = root;// 1、左为空// 2、右为空// 3、左右都不为空if (root->_left == nullptr){root = root->_right;}else if (root->_right == nullptr){root = root->_left;}else{Node* leftMax = root->_left;while (leftMax->_right){leftMax = leftMax->_right;}swap(root->_key, leftMax->_key);return _EraseR(root->_left, key);}delete del;return true;}}bool _InsertR(Node*& root, const K& key, const V& value){if (root == nullptr){root = new Node(key, value);return true;}if (root->_key < key){return _InsertR(root->_right, key, value);}else if (root->_key > key){return _InsertR(root->_left, key, value);}else{return false;}}Node* _FindR(Node* root, const K& key){if (root == nullptr)return nullptr;if (root->_key < key){return _FindR(root->_right, key);}else if (root->_key > key){return _FindR(root->_left, key);}else{return root;}}void _InOrder(Node* root){if (root == NULL){return;}_InOrder(root->_left);cout << root->_key << ":" << root->_value << endl;_InOrder(root->_right);}private:Node* _root;};
key_value 模型主要是通过一个节点里包含两个值:key 和 value 实现的,只要找到了key 就能顺便找到 value,其余的函数逻辑等都与 K 模型几乎一致
🔥值得注意的是: 二叉搜索树的性能是不错的,插入和删除操作都必须先查找,查找效率代表了二叉搜索树中各个操作的性能,
最优情况下,二叉搜索树为完全二叉树(或者接近完全二叉树),其平均比较次数为: l o g 2 N log_2 N log2N最差情况下,二叉搜索树退化为单支树(或者类似单支),其平均比较次数为: N 2 \frac{N}{2} 2N
如果退化成单支树,二叉搜索树的性能就失去了。那能否进行改进,不论按照什么次序插入关键码,二叉搜索树的性能都能达到最优?那么我们涉及到后续章节学习的 AVL树 和 红黑树
希望读者们多多三连支持
小编会继续更新
你们的鼓励就是我前进的动力!

相关文章:

C++镌刻数据密码的树之铭文:二叉搜索树
文章目录 1.二叉搜索树的概念2.二叉搜索树的实现2.1 二叉搜索树的结构2.2 二叉搜索树的节点寻找2.2.1 非递归2.2.2 递归 2.3 二叉搜索树的插入2.3.1 非递归2.3.2 递归 2.4 二叉搜索树的删除2.4.1 非递归2.4.2 递归 2.5 二叉搜索树的拷贝 3.二叉树的应用希望读者们多多三连支持小…...

CAN与CANFD协议说明
在 CAN(Controller Area Network,控制器局域网)协议里,仲裁域波特率和数据域比特率有着不同的含义和作用,下面为你详细介绍并举例说明。 概念解释 仲裁域波特率 含义:仲裁域是 CAN 数据帧中的一部分&…...
)
【C++ Qt】信号和槽(内配思维导图 图文并茂 通俗易懂)
每日激励:“不设限和自我肯定的心态:I can do all things。 — Stephen Curry” 绪论: 本章是Qt中的第三章,也是我们理解Qt中必备的点 信号槽,它本质由信号和槽两个来实现,其中将细致的讲述如何自定义信号…...

【实战】在 Linux 上使用 Nginx 部署 Python Flask 应用
在 Linux 上使用 Nginx 部署 Python Flask 应用 步骤一:准备 Flask 应用 创建 Flask 应用 确保你有一个可以运行的 Flask 应用。例如,创建一个简单的 app.py 文件: from flask import Flask app Flask(__name__)app.route(/) def hello_wor…...

java ai 图像处理
Java AI 图像处理 图像处理是人工智能(AI)领域中非常重要的一个应用方向。通过使用Java编程语言和相应的库,我们可以实现各种图像处理任务,如图像识别、图像分类、图像分割等。本文将介绍一些常见的图像处理算法,并通过…...
 -part7)
【绘制图像轮廓】图像处理(OpenCV) -part7
15 绘制图像轮廓 15.1 什么是轮廓 轮廓是一系列相连的点组成的曲线,代表了物体的基本外形。相对于边缘,轮廓是连续的,边缘不一定连续,如下图所示。轮廓是一个闭合的、封闭的形状。 轮廓的作用: 形状分析 目标识别 …...

Mesh模型孔洞修补算法总汇
关于Mesh 孔洞修补算法(Hole Filling in Meshes),这是计算几何和图形学中的一个重要话题,常用于重建、3D 扫描、建模等领域。下面我会系统总结主流和经典的孔洞修补方法,并按技术路线分类说明每种的原理、优缺点&#…...
)
ARINC818协议(六)
上图中,红色虚线上面为我们常用的simple mode简单模式,下面和上面的结合在一起,就形成了extended mode扩展模式。 ARINC818协议 container header容器头 ancillary data辅助数据 视频流 ADVB帧映射 FHCP传输协议 R_CTRL:路由控制routing ctr…...

RTMP握手流程
RTMP(Real-Time Messaging Protocol) 不支持除H.264/AAC之外的标准。 使用TCP,当到达网络拥塞、宽带上限时,传输质量受到影响。 URL格式: rtmp://host:port/app(名称)/stream(流IDÿ…...

【解决】torch引入过程中的ImportError: __nvJitLinkAddData_12_1, version libnvJitLink.so.12
大纲 本文记录在环境配置好后,在 import torch 过程中报了 异常 ImportError: /home/Coding/Envs/envs/only_test/lib/python3.10/site-packages/torch/lib/../../nvidia/cusparse/lib/libcusparse.so.12: undefined symbol: __nvJitLinkAddData_12_1, version lib…...
)
面试招聘:新能源汽车研发测试人员需求内部研讨会纪要(2025年4月19日草稿流出)
标题:XX汽车技术中心技术管理岗闭门会议纪要完整版:双非招聘策略、面试话术与风控方案(附待定事项) 【内部密级文件】 时间:2025年4月15日 14:00-17:30 地点:某主机厂研发中心会议室(305&#…...

从零开始学习 Lucene.Net:.NET Core 中的全文搜索与索引管理
Lucene.Net 是一个开源的全文搜索引擎库,它是 Apache Lucene 项目的 .NET 移植版本。Lucene.Net 提供了强大的搜索功能,广泛应用于文档搜索、日志分析、数据检索等场景。随着大数据的爆发,开发者越来越依赖高效的搜索引擎来实现复杂的搜索需求…...

opencv--图像处理
图像处理技术 图像处理技术是利用计算机对图像进行计算,分析和处理的技术,包括数字图像处理和计算机视觉两大领域。 对图像的处理包括滤波,缩放,分割,识别(两种信息对比)等。 链接 数字图像处理 1. 数字图像处理(Digital Image Processing) 数字图像处理主要关注图…...

JCST 2025年 区块链论文 录用汇总
Conference:Journal of Computer Science and Technology (JCST) CCF level:CCF B Categories:交叉/综合/新兴 Year:2025(截止4.19) JCST 2024年 区块链论文 录用汇总 1 Title: An Understandable Cro…...

股指期货跨期套利是如何赚取价差利润的?
股指期货跨期套利,简单来说,就是在同一交易所内,针对同一股指期货品种的不同交割月份合约进行的套利交易。投资者会同时买入某一月份的股指期货合约,并卖出另一月份的股指期货合约,待未来某个时间点,再将这…...

【java实现+4种变体完整例子】排序算法中【冒泡排序】的详细解析,包含基础实现、常见变体的完整代码示例,以及各变体的对比表格
以下是冒泡排序的详细解析,包含基础实现、常见变体的完整代码示例,以及各变体的对比表格: 一、冒泡排序基础实现 原理 通过重复遍历数组,比较相邻元素并交换逆序对,逐步将最大值“冒泡”到数组末尾。 代码示例 pu…...

毕业论文超清pdf带标签导出
Word直接导出的pdf不够清晰,使用打印导出的pdf又不带书签以及目录跳转功能这一问题,查阅网上资料使用Adobe DC似乎能够解决但是下载安装比较麻烦,于是写了python程序解决该问题。 解决思路: 使用python脚本对两个pdf文件进行合并…...

STM32单片机入门学习——第43节: [12-3] 读写备份寄存器实时时钟
写这个文章是用来学习的,记录一下我的学习过程。希望我能一直坚持下去,我只是一个小白,只是想好好学习,我知道这会很难,但我还是想去做! 本文写于:2025.04.19 STM32开发板学习——第43节: [12-3] 读写备份寄存器&实时时钟 前言开发板说明…...
C++)
筛选法(埃氏筛法)C++
判断N个数是否质数 输入N个整数M,判断它们是否为质数。如果是输出“YES”,否则输出“NO”。(1<n<10000) 输入格式 第一行为N,第2~n1行每行为一个正整数M。(1<M<1000000)…...

PointCore——利用局部全局特征的高效无监督点云异常检测器论文与算法解读
概述 三维点云异常检测旨在从训练集中检测出异常数据点,是工业检测、自动驾驶等众多应用的基础。然而,现有的点云异常检测方法通常采用多个特征存储库来充分保留局部和全局特征表示,这带来了高昂的计算成本以及特征之间的不匹配问题。为解决…...
)
洛谷P1177【模板】排序:十种排序算法全解(1)
扯谈 之前我已经把十大排序算法全讲了一遍(具体详见专栏C排序算法),今天我们来用一道简单的题目总结实战一下。 算法实现 一、桶排序(Bucket Sort) 适用场景:数据范围已知且较小(需根据测试数据调整…...

Graham Scan算法求解二维凸包
一、凸包及其概念 凸包(Convex Hull)是计算几何中的一个重要概念。在一个实数向量空间中,对于给定的点集,凸包是指包含这些点的最小凸多边形。在二维平面上,凸包可以形象地理解为用一个橡皮圈将所有点紧紧包裹起来&am…...

【java实现+4种变体完整例子】排序算法中【希尔排序】的详细解析,包含基础实现、常见变体的完整代码示例,以及各变体的对比表格
以下是希尔排序的详细解析,包含基础实现、常见变体的完整代码示例,以及各变体的对比表格: 一、希尔排序基础实现 原理 希尔排序是插入排序的改进版本,通过分步缩小增量间隔,将数组分成多个子序列进行插入排序&#…...
)
【文件操作与IO】详细解析文件操作与IO (二)
本篇博客是上一篇文章的续写,重点介绍数据流,还包括三道练习题. 🐎文章专栏: JavaEE初阶 🚀若有问题 评论区见 ❤ 欢迎大家点赞 评论 收藏 分享 如果你不知道分享给谁,那就分享给薯条. 你们的支持是我不断创作的动力 . 王子,公主请阅🚀 要开心…...

【java实现+4种变体完整例子】排序算法中【基数排序】的详细解析,包含基础实现、常见变体的完整代码示例,以及各变体的对比表格
基数排序详解及代码示例 基数排序原理 基数排序通过处理每一位数字进行排序,分为 LSD(最低位优先) 和 MSD(最高位优先) 两种方式。核心步骤: 确定最大值:计算数组中最大数的位数。逐位排序&am…...

Java中的函数式编程详解
Java中的函数式编程是一个在Java 8中引入的特性,它将计算视为数学函数的求值,避免使用可变状态和数据。其核心特性包括Lambda表达式、函数式接口和Stream API。以下将结合代码示例和具体场景详细讲解这些特性。 1. Lambda表达式 Lambda表达式是Java 8引…...

专精特新政策推动,B端UI设计如何赋能中小企业创新发展?
在当前数字化转型浪潮下,专精特新政策为中小企业提供了强大的支持,助力其在细分领域实现专业化、精细化、特色化和创新化发展。B端UI设计作为提升企业数字化产品用户体验和工作效率的重要手段,能够有效赋能中小企业创新发展。本文将探讨专精特…...

从零开始学A2A四:A2A 协议的高级应用与优化
A2A 协议的高级应用与优化 学习目标 掌握 A2A 高级功能 理解多用户支持机制掌握长期任务管理方法学习服务性能优化技巧 理解与 MCP 的差异 分析多智能体场景下的优势掌握不同场景的选择策略 第一部分:多用户支持机制 1. 用户隔离架构 #mermaid-svg-6SCFaVO4oDU…...

海关总署广东:广东外贸一季度进出口2.14万亿元 同期增长4.2%
大湾区经济网湾区财经报道,据海关总署广东分署统计,今年一季度,广东外贸进出口2.14万亿元,较去年同期(下同)增长4.2%,增速高于全国2.9个百分点。其中,出口1.34万亿元,增长…...

C++代码优化
前段时间写了一些代码,但是在运算过程中发现有些代码可以进行改进以提高运行效率,尤其是与PCL相关的部分,可以进行大幅度提高.特意在此进行记录,分享给大家,也供自己查看. pcl::PointCloud< …...

Manim教程:第七章 坐标系统
#什么是坐标系统?特点是什么? 坐标系统是一个用于确定空间中点位置的数学工具。它通过一组数值(坐标)来描述一个点在某个空间中的位置。不同类型的坐标系统可以用于不同的应用场景,最常见的包括: 笛卡尔坐标系:使用直角坐标系,通常用坐标轴(如x轴和y轴)来表示二维空间…...

U盘实现——双盘符实现
文章目录 双盘符实现描述符类特殊命名get max luninquiry上一篇文章中介绍了 U 盘的枚举过程 U盘实现——U 盘枚举过程 双盘符实现 描述符 双盘符的时候中,描述符的实现与上节完全一致,不同的只有类特殊命令 设备描述符配置描述符接口描述符输出端点描述符输入端点描述符上…...

【Linux】【阿里云服务器】【树莓派】学习守护进程编程、gdb调试原理和内网穿透信息
目录 一. 守护进程的含义及编程实现的主要过程 1.1守护进程 1.2编程实现的主要过程 二、在树莓派中通过三种方式创建守护进程 2.1nohup命令创建 2.2fork()函数创建 2.3daemon()函数创建 三、在阿里云中通过三种方式创建守护进程 3.1nohup命令创建 3.2fork()函数创建 …...
等级考试试卷(二级)答案 + 解析)
2025年03月中国电子学会青少年软件编程(Python)等级考试试卷(二级)答案 + 解析
青少年软件编程(Python)等级考试试卷(二级) 分数:100 题数:37 一、单选题(共25题,共50分) 1. 老师要求大家记住四大名著的作者,小明机智地想到了可以用字典进行记录,以下哪个选项的字典格式是正确?( ) A. [‘曹雪芹’:‘红楼梦’, ‘吴承恩’:‘西游记’, ‘罗贯…...

【Linux系统篇】:System V IPC核心技术解析---从共享内存到消息队列与信号量
✨感谢您阅读本篇文章,文章内容是个人学习笔记的整理,如果哪里有误的话还请您指正噢✨ ✨ 个人主页:余辉zmh–CSDN博客 ✨ 文章所属专栏:c篇–CSDN博客 文章目录 一.System V共享内存(重点)1.基本概念和原理…...

关于GPU的涡轮散热与被动散热
显卡涡轮散热与被动散热的深度解析 一、涡轮散热的定义与工作原理 涡轮散热技术是通过高速旋转的涡轮风扇配合封闭式风道设计,将冷空气吸入并强制排出热量的主动散热方案。其核心原理包含以下关键点: 气流动力学设计:涡轮风扇采用精密叶片(如离心式结构),在相同尺寸下能…...

namesapce、cgroup
dd: 制作磁盘镜像:借助 dd 指令能够把整个磁盘或者分区的数据复制到一个文件里,形成磁盘镜像文件。此镜像文件可用于备份数据或者在其他系统中恢复磁盘。 恢复磁盘镜像:可以把之前创建的磁盘镜像文件恢复到磁盘或者分区 磁盘初始…...
)
C++23 新特性:行拼接前去除空白符 (P2223R2)
文章目录 1\. 什么是行拼接前去除空白符2\. 为什么需要这一特性3\. 示例代码输出结果 4\. 编译器支持5\. 优势与应用场景5.1 提高代码可读性5.2 减少潜在错误5.3 适用于多行字符串 6\. 其他相关特性7\. 总结 C 语言一直在不断进化,以满足现代软件开发的需求。C23 标…...

算法思想之链表
欢迎拜访:雾里看山-CSDN博客 本篇主题:算法思想之链表 发布时间:2025.4.18 隶属专栏:算法 目录 算法介绍常用技巧 例题两数相加题目链接题目描述算法思路代码实现 两两交换链表中的节点题目链接题目描述算法思路代码实现 重排链表…...
——测试原则、阶段、测试用例设计、调试)
《软件设计师》复习笔记(11.5)——测试原则、阶段、测试用例设计、调试
目录 1. 测试基础概念 2. 测试方法分类 3. 测试阶段 真题示例: 题目1 题目2 题目3 4. 测试策略 5. 测试用例设计 真题示例: 6. 调试与度量 真题示例: 1. 测试基础概念 定义:系统测试是为发现错误而执行程序的过程&…...
)
工厂方法模式详解及在自动驾驶场景代码示例(c++代码实现)
模式定义 工厂方法模式(Factory Method Pattern)是一种创建型设计模式,通过定义抽象工厂接口将对象创建过程延迟到子类实现,实现对象创建与使用的解耦。该模式特别适合需要动态扩展产品类型的场景。 自动驾驶感知场景分析 自动驾…...

Java 2025:解锁未来5大技术趋势,Kotlin融合AI新篇
各位Java开发者们好!🚀 2025年的Java世界正在经历一场前所未有的技术变革。作为深耕Java领域多年的技术博主,今天我将带大家深入探索Java生态即将迎来的5大技术趋势,特别是Kotlin的深度融合和AI技术的新篇章。准备好了吗ÿ…...

抗辐照设计优化:商业航天高可靠系统设计的关键路径
随着商业航天领域的快速发展,航天器的可靠性和抗辐照能力已成为系统设计的核心需求。在严苛的太空辐射环境中,电子设备面临着单粒子效应、总剂量效应和位移损伤效应等多重挑战。抗辐照设计优化不仅是确保航天器任务成功的关键路径,更是推动商…...

颚式破碎机的设计
一、引言 颚式破碎机作为矿山、建材等行业的重要破碎设备,其性能优劣直接影响物料破碎效率与质量。随着工业生产规模的扩大和对破碎效率要求的提高,设计一款高效、稳定、节能的颚式破碎机具有重要意义。 二、设计需求分析 处理能力:根据目…...
配置和使用)
1panel第三方应用商店(本地商店)配置和使用
文章目录 引言资源网站实战操作说明 引言 1Panel 提供了一个应用提交开发环境,开发者可以通过提交应用的方式将自己的应用推送到 1Panel 的应用商店中,供其他用户使用。由此衍生了一种本地应用商店的概念,用户可以自行编写应用配置并上传到自…...

ObjectOutputStream 深度解析
ObjectOutputStream 深度解析 ObjectOutputStream 是 Java IO 体系中的一个关键类,用于序列化(将对象转换为字节流),通常与 ObjectInputStream 配合使用,实现对象的持久化存储或网络传输。 1.作用:完成对象的序列化过程 2.它可以将JVM当中的Java对象序列化到文件中/网…...

如何学习和研究量子计算与量子计算机:从理论到实践的完整路径
量子计算作为量子力学与计算机科学的交叉领域,正在迅速改变我们对计算能力的认知。无论是破解经典加密算法,还是加速药物分子模拟,量子计算都展现出巨大的潜力。然而,学习这一领域需要系统化的理论知识和实践能力。以下是基于最新…...

数据结构学习笔记 :二叉搜索树与高效查找算法详解
目录 二叉搜索树(BST)实现 1.1 顺序存储实现 1.2 链式存储实现查找算法 2.1 顺序查找 2.2 折半查找 2.3 哈希查找总结与应用场景代码示例与完整实现 一、二叉搜索树(BST)实现 1. 顺序存储实现 BST的顺序存储基于完全二叉树的特…...

广搜bfs-P1443 马的遍历
P1443 马的遍历 题目来源-洛谷 题意 要求马到达棋盘上任意一个点最少要走几步 思路 国际棋盘规则是马的走法是-日字形,也称走马日,即x,y一个是走两步,一个是一步 要求最小步数,所以考虑第一次遍历到的点即为最小步数ÿ…...

Ubuntu22.04安装QT、px4安装环境
Ubuntu22.04安装QGC编译环境、QT、px4编译环境 安装QGC安装Ubuntu安装QT配置px4安装环境出现错误怎么办 安装QGC 我使用的是pixhawk V5飞控,在QGC4.4 Guide里,说 安装Ubuntu 直接去清华源里将Ubuntu镜像下载下来(网址:清华源下…...