C语言动规学习
文章目录
- 一、动态规划的基本概念
- 1. 最优子结构
- 2. 重叠子问题
- 二、动态规划的求解步骤
- 三、动态规划与递归的比较
- 四、例题(只讲思维,空间时间复杂度大小不与题目比较)
- 1、斐波那契数列
- 1. 定义状态
- 2. 找出状态转移方程
- 3. 初始化边界条件
- 4. 确定计算顺序
- 2、爬楼梯
- 1. 定义状态
- 2. 找出状态转移方程
- 3. 初始化边界条件
- 4. 确定计算顺序
- 3、使用最小花费爬楼梯
- 1. 定义状态
- 2. 找出状态转移方程
- 3. 初始化边界条件
- 4. 确定计算顺序
- 4、跳跃游戏
- 1. 定义状态
- 2. 找出状态转移方程
- 3. 初始化边界条件
- 4. 确定计算顺序
- 5、不同路径
- 1. 定义状态
- 2. 找出状态转移方程
- 3. 初始化边界条件
- 4. 确定计算顺序
- 6、不同路径2
- 1. 定义状态
- 2. 找出状态转移方程
- 3. 初始化边界条件
- 4. 确定计算顺序
- 5. 定义状态
- 6. 找出状态转移方程
- 7. 初始化边界条件
- 8. 确定计算顺序
- 7、整数拆分
- 1. 定义状态
- 2. 找出状态转移方程
- 3. 初始化边界条件
- 4. 确定计算顺序
- 8、最长回文子串
- 1. 定义状态
- 2. 找出状态转移方程
- 3. 初始化边界条件
- 4. 确定计算顺序
- 9、不同的二叉搜索树
- 1. 定义状态
- 2. 找出状态转移方程
- 3. 初始化边界条件
- 4. 确定计算顺序
- 五、进阶背包理论
- 1、01背包(dp二维数组)
- 1. 问题描述
- 2. 定义状态
- 3. 状态转移方程
- 4. 初始化边界条件
- 5. 计算顺序
- 6. 最终结果
- 7.代码解释
- 8.复杂度分析
- 2、01背包(dp滚动数组)
- 1. 定义状态
- 2. 找出状态转移方程
- 3. 初始化边界条件
- 4. 确定计算顺序
- 5.代码解释
- 6.复杂度分析
- 3.滚动数组!!!
- 1.基本概念
- 2.使用场景
- 3.原理
- 4.优缺点
- 优点
- 缺点
- 4.分割等和子集
- 1. 定义状态
- 2. 找出状态转移方程
- 3. 初始化边界条件
- 4. 确定计算顺序
- 5.最后一块石头的重量 II
- 1. 定义状态
- 2. 找出状态转移方程
- 3. 初始化边界条件
- 4. 确定计算顺序
- 六、总结
动归五部曲!!!:

一、动态规划的基本概念
动态规划(Dynamic Programming,简称 DP)是一种通过把原问题分解为相对简单的子问题,并保存子问题的解来避免重复计算,从而解决复杂问题的算法策略。它通常用于求解具有最优子结构和重叠子问题性质的问题。
1. 最优子结构
最优子结构性质指的是一个问题的最优解包含其子问题的最优解。也就是说,大问题的最优解可以由小问题的最优解组合而成。例如,在求解最短路径问题时,如果从 A 到 C 的最短路径经过 B,那么从 A 到 B 的路径和从 B 到 C 的路径也分别是 A 到 B 和 B 到 C 的最短路径。
2. 重叠子问题
重叠子问题是指在求解过程中,很多子问题会被重复计算。动态规划通过保存子问题的解,避免了这些重复计算,从而提高了算法的效率。比如在计算斐波那契数列时,递归方法会多次重复计算相同的斐波那契数,而动态规划可以通过保存已经计算过的数,避免这些重复计算。
二、动态规划的求解步骤
一般来说,使用动态规划解决问题可以分为以下几个步骤:
- 定义状态:确定问题的状态表示,也就是用什么变量来描述问题的子问题。状态通常是原问题的一个子集,通过状态的定义可以将原问题分解为多个子问题。
- 找出状态转移方程:根据问题的最优子结构性质,找出状态之间的转移关系。状态转移方程描述了如何从已知的子问题的解推导出当前问题的解。
- 初始化边界条件:确定问题的边界情况,也就是最小子问题的解。边界条件是状态转移的起点,没有边界条件,状态转移方程就无法开始递推。
- 计算顺序:根据状态转移方程,确定计算的顺序。通常是从小的子问题开始,逐步计算出大的子问题,直到得到原问题的解。
三、动态规划与递归的比较
递归方法也可以解决斐波那契数列问题,但递归方法会存在大量的重复计算,时间复杂度为 (O(2^n))。而动态规划通过保存子问题的解,避免了重复计算,时间复杂度为 (O(n))。因此,对于具有重叠子问题的问题,动态规划通常比递归方法更高效。
四、例题(只讲思维,空间时间复杂度大小不与题目比较)
1、斐波那契数列
509. 斐波那契数
int fib(int n) {if (n == 0 || n == 1) {return n;}int dp[2];dp[0] = 0;dp[1] = 1;int i;for (i = 2; i <= n; i++) {int sum = dp[0] + dp[1];dp[0] = dp[1];dp[1] = sum;}return dp[1];
}
1. 定义状态
在这个斐波那契数列的实现中,状态定义为存储斐波那契数列中相邻两项的值。代码里使用长度为 2 的数组 dp 来表示状态,具体而言:
dp[0]代表斐波那契数列中当前正在计算的某一项的前一项的值。dp[1]代表斐波那契数列中当前正在计算的某一项的值。
通过不断更新 dp 数组,我们可以逐步计算出斐波那契数列的每一项。
其实最基础的就是可以构建一个dp数组,大小为测试用例上线,或者可以malloc一个动态内存。然后根据状态进行计算。
但其实我们可以发现:对于每个要计算的数,我们只需要维护他的前两个数就行,因此只需要维护两个数据就行。(70.爬楼梯同理)
2. 找出状态转移方程
斐波那契数列的定义是 (F(n)=F(n - 1)+F(n - 2))((n<=2)),(F(0) = 0),(F(1)=1)。在代码中对应的状态转移方程如下:
int sum = dp[0] + dp[1];
dp[0] = dp[1];
dp[1] = sum;
- 首先计算
sum = dp[0] + dp[1],这里的sum就相当于 (F(n)),dp[0]相当于 (F(n - 2)),dp[1]相当于 (F(n - 1))。 - 接着更新
dp[0]为dp[1],也就是让dp[0]变为下一次计算时的 (F(n - 2))。 - 最后将
dp[1]更新为sum,即下一次计算时的 (F(n - 1))。
3. 初始化边界条件
根据斐波那契数列的定义,(F(0) = 0),(F(1)=1)。代码中对边界条件的初始化操作如下:
if (n == 0 || n == 1) {return n;
}
int dp[2];
dp[0] = 0;
dp[1] = 1;
- 当
n为 0 或者 1 时,直接返回n,这是因为 (F(0) = 0),(F(1)=1)。 - 初始化
dp[0]为 0,dp[1]为 1,这是进行后续状态转移计算的起始值。
4. 确定计算顺序
代码中使用 for 循环来确定计算顺序:
for (i = 2; i <= n; i++) {int sum = dp[0] + dp[1];dp[0] = dp[1];dp[1] = sum;
}
从 (n = 2) 开始,按照顺序依次计算斐波那契数列的每一项。每一次循环都会根据当前的 dp[0] 和 dp[1] 计算出下一项的值,并更新 dp 数组,直到计算出第 n 项的值,最终返回 dp[1] 作为结果。
2、爬楼梯
70. 爬楼梯
假设你正在爬楼梯。需要
n阶你才能到达楼顶。每次你可以爬
1或2个台阶。你有多少种不同的方法可以爬到楼顶呢?示例 1:
输入:n = 2 输出:2 解释:有两种方法可以爬到楼顶。 1. 1 阶 + 1 阶 2. 2 阶示例 2:
输入:n = 3 输出:3 解释:有三种方法可以爬到楼顶。 1. 1 阶 + 1 阶 + 1 阶 2. 1 阶 + 2 阶 3. 2 阶 + 1 阶
int climbStairs(int n) {if (n == 1 || n == 2 || n == 3) {return n;}int dp[2];int i;dp[0] = 2;dp[1] = 3;for (i = 4; i <= n; i++) {int sum = dp[0] + dp[1];dp[0] = dp[1];dp[1] = sum;}return dp[1];
}
1. 定义状态
在爬楼梯问题中,我们定义状态 dp[i] 为爬到第 i 阶楼梯的不同方法数。不过在代码里,由于我们发现计算第 i 阶楼梯的方法数只依赖于第 i - 1 阶和第 i - 2 阶楼梯的方法数,所以仅使用长度为 2 的数组 dp 来存储状态:
dp[0]表示爬到第i - 1阶楼梯的不同方法数。dp[1]表示爬到第i阶楼梯的不同方法数。
2. 找出状态转移方程
对于爬楼梯问题,因为每次只能爬 1 个或 2 个台阶,所以要到达第 i 阶楼梯,只能从第 i - 1 阶楼梯爬 1 个台阶上来,或者从第 i - 2 阶楼梯爬 2 个台阶上来。那么到达第 i 阶楼梯的方法数就等于到达第 i - 1 阶楼梯的方法数加上到达第 i - 2 阶楼梯的方法数,即状态转移方程为: (dp[i]=dp[i - 1]+dp[i - 2])。
int sum = dp[0] + dp[1];
dp[0] = dp[1];
dp[1] = sum;
这里 sum 就相当于 (dp[i]),dp[0] 相当于 (dp[i - 2]),dp[1] 相当于 (dp[i - 1])。
3. 初始化边界条件
在代码中,当 n 为 1、2、3 时直接返回 n:
if (n == 1 || n == 2 || n == 3) {return n;
}
并且初始化 dp 数组:
dp[0] = 2;
dp[1] = 3;
这里 dp[0] 初始化为 2,对应 (dp[2]) 的值;dp[1] 初始化为 3,对应 (dp[3]) 的值,为后续从 n = 4 开始的状态转移做准备。
4. 确定计算顺序
由于状态转移方程 (dp[i]=dp[i - 1]+dp[i - 2]) 表明当前状态依赖于前两个状态,所以计算顺序应该是从较小的 i 值逐步计算到较大的 i 值。在代码中,使用 for 循环从 i = 4 开始计算,直到 i = n:
for (i = 4; i <= n; i++) {int sum = dp[0] + dp[1];dp[0] = dp[1];dp[1] = sum;
}
每次循环都会根据当前的 dp[0] 和 dp[1] 计算出下一个状态的值,并更新 dp 数组,保证在计算 dp[i] 时,dp[i - 1] 和 dp[i - 2] 已经被正确计算出来。最终,当循环结束时,dp[1] 中存储的就是爬到第 n 阶楼梯的不同方法数。
通过使用长度为 2 的数组将空间复杂度优化到了 (O(1))。
3、使用最小花费爬楼梯
746. 使用最小花费爬楼梯
给你一个整数数组
cost,其中cost[i]是从楼梯第i个台阶向上爬需要支付的费用。一旦你支付此费用,即可选择向上爬一个或者两个台阶。你可以选择从下标为
0或下标为1的台阶开始爬楼梯。请你计算并返回达到楼梯顶部的最低花费。
示例 1:
输入:cost = [10,15,20] 输出:15 解释:你将从下标为 1 的台阶开始。 - 支付 15 ,向上爬两个台阶,到达楼梯顶部。 总花费为 15 。示例 2:
输入:cost = [1,100,1,1,1,100,1,1,100,1] 输出:6 解释:你将从下标为 0 的台阶开始。 - 支付 1 ,向上爬两个台阶,到达下标为 2 的台阶。 - 支付 1 ,向上爬两个台阶,到达下标为 4 的台阶。 - 支付 1 ,向上爬两个台阶,到达下标为 6 的台阶。 - 支付 1 ,向上爬一个台阶,到达下标为 7 的台阶。 - 支付 1 ,向上爬两个台阶,到达下标为 9 的台阶。 - 支付 1 ,向上爬一个台阶,到达楼梯顶部。 总花费为 6 。
int min(int a, int b) { return a < b ? a : b; }int minCostClimbingStairs(int* cost, int costSize) {int dp[costSize + 1];dp[0] = 0;dp[1] = 0;int i;for (i = 2; i <= costSize; i++) {dp[i] = min(dp[i - 1] + cost[i - 1], dp[i - 2] + cost[i - 2]);}return dp[costSize];
}
1. 定义状态
在这个爬楼梯花费最小成本的问题中,我们定义状态 dp[i] 表示到达第 i 级楼梯所需要的最小花费。这里的第 i 级楼梯是基于 0 索引的,并且最终要到达的楼梯是第 costSize 级(因为 cost 数组长度为 costSize ,表示从第 0 级到第 costSize - 1 级楼梯的花费)。
2. 找出状态转移方程
要到达第 i 级楼梯,有两种方式:
- 从第
i - 1级楼梯爬 1 步到达,此时到达第i级楼梯的总花费是到达第i - 1级楼梯的最小花费dp[i - 1]加上从第i - 1级楼梯爬上来的花费cost[i - 1]。 - 从第
i - 2级楼梯爬 2 步到达,此时到达第i级楼梯的总花费是到达第i - 2级楼梯的最小花费dp[i - 2]加上从第i - 2级楼梯爬上来的花费cost[i - 2]。
我们需要取这两种方式中花费较小的那个, 在代码中对应的实现是:
dp[i] = min(dp[i - 1] + cost[i - 1], dp[i - 2] + cost[i - 2]);
3. 初始化边界条件
对于这个问题,我们可以从第 0 级或者第 1 级楼梯开始爬,且站在第 0 级和第 1 级楼梯上还没有产生额外的向上爬的花费,所以到达第 0 级和第 1 级楼梯的最小花费为 0,即: (dp[0]=0) (dp[1]=0), 在代码中的体现为:
dp[0] = 0;
dp[1] = 0;
4. 确定计算顺序
由于状态转移方程表明,计算 dp[i] 时依赖于 dp[i - 1] 和 dp[i - 2] 的值,所以我们需要按照从低阶楼梯到高阶楼梯的顺序依次计算。
在代码中,使用 for 循环从 i = 2 开始计算,因为 dp[0] 和 dp[1] 已经初始化好了:
for (i = 2; i <= costSize; i++) {dp[i] = min(dp[i - 1] + cost[i - 1], dp[i - 2] + cost[i - 2]);
}
这样能保证在计算 dp[i] 时,所依赖的 dp[i - 1] 和 dp[i - 2] 已经计算完成。最终,当循环结束时,dp[costSize] 就存储了到达第 costSize 级楼梯(也就是楼顶)的最小花费,所以函数返回 dp[costSize]。
| cost | 1 | 100 | 1 | 1 | 1 | 100 | 1 | 1 | 100 | 1 | 楼顶 |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 下标 | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| dp | 0 | 0 | 1 | 2 | 2 | 3 | 3 | 4 | 4 | 5 | 6 |
如图,dp[2]:min(dp[2-1]+cost[2-1],dp[2-2]+cost[2-2]),即求从比它低两阶的楼梯上来的花费和比它低一阶的楼梯上来的花费的较小值。
4、跳跃游戏
55. 跳跃游戏
给你一个非负整数数组
nums,你最初位于数组的 第一个下标 。数组中的每个元素代表你在该位置可以跳跃的最大长度。判断你是否能够到达最后一个下标,如果可以,返回
true;否则,返回false。示例 1:
输入:nums = [2,3,1,1,4] 输出:true 解释:可以先跳 1 步,从下标 0 到达下标 1, 然后再从下标 1 跳 3 步到达最后一个下标。示例 2:
输入:nums = [3,2,1,0,4] 输出:false 解释:无论怎样,总会到达下标为 3 的位置。但该下标的最大跳跃长度是 0 , 所以永远不可能到达最后一个下标。
bool canJump(int* nums, int numsSize) {if (numsSize == 1)return true;bool dp[numsSize];dp[0] = true;for (int i = 1; i < numsSize; i++) {dp[i] = false;for (int j = 0; j < i; j++) {if (dp[j] == true && nums[j] + j >= i) {dp[i] = true;break;}}}return dp[numsSize - 1];
}
1. 定义状态
在这个跳跃游戏问题里,我们定义状态 dp[i] 为一个布尔类型的值,其含义是能否从数组的起始位置(即下标为 0 的位置)跳跃到下标为 i 的位置。若 dp[i] 为 true,表示可以从起始位置跳跃到下标 i;若 dp[i] 为 false,则表示无法从起始位置跳跃到下标 i。
2. 找出状态转移方程
要判断是否能到达下标 i,我们需要考察其前面的所有位置 j(0 <= j < i)。若满足以下两个条件:
- 能够到达位置
j,即dp[j]为true。 - 从位置
j借助该位置元素nums[j]所代表的最大跳跃长度,能够到达位置i,也就是nums[j] + j >= i。
只要存在这样一个位置 j 满足上述两个条件,那么就可以到达位置 i,即 dp[i] 为 true。所以状态转移方程可表示为:
if (dp[j] == true && nums[j] + j >= i) {dp[i] = true;break;
}
3. 初始化边界条件
由于我们最初就位于数组的第一个下标,也就是起始位置,所以肯定可以到达起始位置,因此 dp[0] 初始化为 true。在代码里的体现是:
dp[0] = true;
同时,函数中对数组长度为 1 的情况进行了特殊处理,当 numsSize == 1 时,直接返回 true,因为只有一个元素,自然是可以到达的。
4. 确定计算顺序
根据状态转移方程可知,dp[i] 的值依赖于 dp[j](0 <= j < i),所以我们要按照从左到右的顺序,依次计算 dp[1] 到 dp[numsSize - 1] 的值。在代码中,使用外层的 for 循环来控制 i 从 1 到 numsSize - 1 进行遍历,对于每个 i,再使用内层的 for 循环遍历其前面的所有位置 j 来确定 dp[i] 的值。
| nums | 2 | 3 | 1 | 1 | 4 |
|---|---|---|---|---|---|
| 下标 | 0 | 1 | 2 | 3 | 4 |
| dp | true | true | true | true | true |
但是,时间复杂度是O(n2),空间复杂度是O(n)。最后有一个测试用例没过,显示超时了(作者也不知道有没有更好的dp方法)
这里讲的主要是思路和想法!!!
根据标题,还可以用贪心的方法(作者也顺便附上)
#define MAX(a, b) ((b) > (a) ? (b) : (a))bool canJump(int* nums, int numsSize) {int mx = 0;for (int i = 0; i < numsSize; i++) {if (i > mx) {return false;}mx = MAX(mx, i + nums[i]);}return true;
}
时间复杂度是O(n),空间复杂度是O(1)
5、不同路径
62. 不同路径
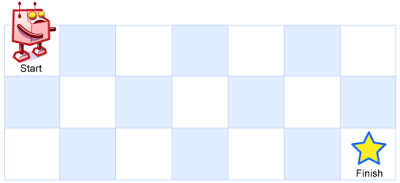
一个机器人位于一个
m x n网格的左上角 (起始点在下图中标记为 “Start” )。机器人每次只能向下或者向右移动一步。机器人试图达到网格的右下角(在下图中标记为 “Finish” )。
问总共有多少条不同的路径?
示例 1:
输入:m = 3, n = 7 输出:28示例 2:
输入:m = 3, n = 2 输出:3 解释: 从左上角开始,总共有 3 条路径可以到达右下角。 1. 向右 -> 向下 -> 向下 2. 向下 -> 向下 -> 向右 3. 向下 -> 向右 -> 向下示例 3:
输入:m = 7, n = 3 输出:28示例 4:
输入:m = 3, n = 3 输出:6
int uniquePaths(int m, int n) {int dp[m][n];for (int i = 0; i < m; i++) {dp[i][0] = 1;}for (int i = 0; i < n; i++) {dp[0][i] = 1;}for (int i = 1; i < m; i++) {for (int j = 1; j < n; j++) {dp[i][j] = dp[i - 1][j] + dp[i][j - 1];}}return dp[m - 1][n - 1];
}
1. 定义状态
本题是在一个 m 行 n 列的网格中,从左上角(坐标 (0, 0))移动到右下角(坐标 (m - 1, n - 1)),每次只能向下或向右移动一步,要求计算不同的路径数量。
我们定义状态 dp[i][j] 表示从网格的左上角 (0, 0) 位置移动到坐标为 (i, j) 位置的不同路径数量。其中 i 表示行索引(范围是 0 到 m - 1),j 表示列索引(范围是 0 到 n - 1)。
2. 找出状态转移方程
由于每次只能向下或向右移动一步,那么要到达坐标 (i, j) 位置,只能从它的上方位置 (i - 1, j) 向下移动一步到达,或者从它的左方位置 (i, j - 1) 向右移动一步到达。
所以到达位置 (i, j) 的不同路径数量等于到达其上方位置 (i - 1, j) 的路径数量加上到达其左方位置 (i, j - 1) 的路径数量,即状态转移方程为:
dp[i][j] = dp[i - 1][j] + dp[i][j - 1];
3. 初始化边界条件
- 第一行:对于网格的第一行(
i = 0),从左上角(0, 0)到第一行的任意位置(0, j)只有一种路径,即一直向右移动。所以dp[0][j]都初始化为1,代码实现为:
for (int i = 0; i < n; i++) {dp[0][i] = 1;
}
- 第一列:对于网格的第一列(
j = 0),从左上角(0, 0)到第一列的任意位置(i, 0)只有一种路径,即一直向下移动。所以dp[i][0]都初始化为1,代码实现为:
for (int i = 0; i < m; i++) {dp[i][0] = 1;
}
4. 确定计算顺序
根据状态转移方程 dp[i][j]=dp[i - 1][j]+dp[i][j - 1] 可知,计算 dp[i][j] 时依赖于 dp[i - 1][j] 和 dp[i][j - 1],也就是需要先计算出上方和左方位置的路径数量。
按照从左到右、从上到下的顺序依次计算每个位置的 dp 值。代码中通过两层嵌套的 for 循环来实现:
for (int i = 1; i < m; i++) {for (int j = 1; j < n; j++) {dp[i][j] = dp[i - 1][j] + dp[i][j - 1];}
}
从第 1 行第 1 列开始,逐行逐列地计算每个位置的 dp 值,直到计算出右下角位置 (m - 1, n - 1) 的 dp 值。
时间复杂度为 O(n*m),空间复杂度也为 O(n*m)。
这个也可以优化空间复杂度,利用滚动数组的方法,详见6
6、不同路径2
63. 不同路径 II
给定一个
m x n的整数数组grid。一个机器人初始位于 左上角(即grid[0][0])。机器人尝试移动到 右下角(即grid[m - 1][n - 1])。机器人每次只能向下或者向右移动一步。网格中的障碍物和空位置分别用
1和0来表示。机器人的移动路径中不能包含 任何 有障碍物的方格。返回机器人能够到达右下角的不同路径数量。
测试用例保证答案小于等于
2 * 109。示例 1:
输入:obstacleGrid = [[0,0,0],[0,1,0],[0,0,0]] 输出:2 解释:3x3 网格的正中间有一个障碍物。 从左上角到右下角一共有 2 条不同的路径: 1. 向右 -> 向右 -> 向下 -> 向下 2. 向下 -> 向下 -> 向右 -> 向右

int uniquePathsWithObstacles(int** obstacleGrid, int obstacleGridSize,int* obstacleGridColSize) {int m = obstacleGridSize, n = obstacleGridColSize[0];if (obstacleGrid[0][0] == 1) {return 0;}int dp[m][n];memset(dp, 0, sizeof(dp));for (int i = 0; i < m; i++) {if (obstacleGrid[i][0] == 1) {break;}dp[i][0] = 1;}for (int i = 0; i < n; i++) {if (obstacleGrid[0][i] == 1) {break;}dp[0][i] = 1;}for (int i = 1; i < m; i++) {for (int j = 1; j < n; j++) {if (obstacleGrid[i][j] == 1) {dp[i][j] = 0;continue;}dp[i][j] = dp[i - 1][j] + dp[i][j - 1];}}return dp[m - 1][n - 1];
}
1. 定义状态
设dp[i][j]表示机器人从网格的左上角(0, 0)出发,到达网格中坐标为(i, j)位置时不同的有效路径数量。
2. 找出状态转移方程
由于机器人每次只能向下或者向右移动一步,所以要到达位置(i, j),它要么是从上方位置(i - 1, j)向下移动一步到达,要么是从左方位置(i, j - 1)向右移动一步到达。 同时,需要考虑网格中是否存在障碍物。如果(i, j)位置有障碍物(即obstacleGrid[i][j] == 1),那么机器人无法到达该位置,dp[i][j]的值为0;如果没有障碍物,则到达该位置的路径数量是到达上方位置的路径数量与到达左方位置的路径数量之和。
if (obstacleGrid[i][j] == 1) {dp[i][j] = 0;continue;
}
dp[i][j] = dp[i - 1][j] + dp[i][j - 1];
3. 初始化边界条件
- 起点情况:如果起点
(0, 0)位置就有障碍物(即obstacleGrid[0][0] == 1),那么机器人无法出发,此时直接返回0。代码体现为:
if (obstacleGrid[0][0] == 1) {return 0;
}
- 第一行:如果在这一行中某个位置
(0, j)之前都没有障碍物,那么到达这些位置的路径数量都为1;一旦遇到障碍物,后续位置的路径数量都为0。代码实现如下:
for (int i = 0; i < n; i++) {if (obstacleGrid[0][i] == 1) {break;}dp[0][i] = 1;
}
- 第一列:同理第一行。
for (int i = 0; i < m; i++) {if (obstacleGrid[i][0] == 1) {break;}dp[i][0] = 1;
}
4. 确定计算顺序
为了确保在计算dp[i][j]时,其依赖的状态已经计算完成,需要按照从左到右、从上到下的顺序依次计算每个位置的dp值。
for (int i = 1; i < m; i++) {for (int j = 1; j < n; j++) {// 根据状态转移方程更新 dp[i][j] 的值if (obstacleGrid[i][j] == 1) {dp[i][j] = 0;continue;}dp[i][j] = dp[i - 1][j] + dp[i][j - 1];}
}
时间空间复杂度为O(n*m) O(n*m)。
但我们还可以使用滚动数组的方法:
int uniquePathsWithObstacles(int** obstacleGrid, int obstacleGridSize,int* obstacleGridColSize) {int m = obstacleGridSize, n = obstacleGridColSize[0];if (obstacleGrid[0][0] == 1) {return 0;}int dp[n];memset(dp, 0, sizeof(dp));dp[0] = 1;for (int i = 0; i < m; i++) {for (int j = 0; j < n; j++) {if (obstacleGrid[i][j] == 1) {dp[j] = 0;continue;}if (j - 1 >= 0) {dp[j] += dp[j - 1];}}}return dp[n - 1];
}
5. 定义状态
这里通过复用 dp 数组,在每次处理新的一行时,dp 数组的值会不断更新,最终 dp[n - 1] 存储的是到达最后一行最后一列(即右下角)位置的不同路径数量。
6. 找出状态转移方程
因为机器人每次只能向下或者向右移动一步,对于位置 (i, j)(i 表示行,j 表示列):
- 如果当前位置
obstacleGrid[i][j]是障碍物(即obstacleGrid[i][j] == 1),那么机器人无法到达该位置,此时dp[j] = 0。 - 如果当前位置不是障碍物(即
obstacleGrid[i][j] == 0),到达该位置的路径数量等于从左边位置(i, j - 1)移动过来的路径数量(前提是j - 1 >= 0,因为不能超出边界)加上当前位置原来的路径数量(在处理新的一行时,当前位置原来的路径数量其实就是上一行对应位置的路径数量)。
if (obstacleGrid[i][j] == 1) {dp[j] = 0;continue;
}
if (j - 1 >= 0) {dp[j] += dp[j - 1];
}
7. 初始化边界条件
- 起点
(0, 0)位置的处理:由于已经判断了obstacleGrid[0][0] != 1(if (obstacleGrid[0][0] == 1) { return 0; }),所以可以从起点出发,将dp[0]初始化为1,表示到达起点的路径数量为1。代码为:dp[0] = 1;。 - 初始化
dp数组的其他元素为0:使用memset(dp, 0, sizeof(dp));将dp数组所有元素初始化为0.
8. 确定计算顺序
外层循环 for (int i = 0; i < m; i++) 遍历每一行,内层循环 for (int j = 0; j < n; j++) 遍历当前行的每一列。从左上角开始,逐行逐列地更新 dp 数组的值,这样可以保证在计算 dp[j] 时,依赖的 dp[j - 1] 已经是正确的(因为是从左到右计算的),并且在处理新的一行时,dp 数组的值会根据上一行的结果和当前行的障碍物情况进行更新。
最后,函数返回 dp[n - 1],即机器人从左上角 (0, 0) 到达右下角 (m - 1, n - 1) 位置的不同路径数量。
这种方法通过一维数组优化了空间复杂度O(n),相比使用二维数组的动态规划方法,减少了空间的占用,时间复杂度仍然是 O(n*m),因为需要遍历整个网格。
7、整数拆分
343. 整数拆分
给定一个正整数
n,将其拆分为k个 正整数 的和(k >= 2),并使这些整数的乘积最大化。返回 你可以获得的最大乘积 。
示例 1:
输入: n = 2 输出: 1 解释: 2 = 1 + 1, 1 × 1 = 1。示例 2:
输入: n = 10 输出: 36 解释: 10 = 3 + 3 + 4, 3 × 3 × 4 = 36。
int integerBreak(int n) {if (n == 2 || n == 3) {return n - 1;}if (n == 4)return n;long long int dp[60];dp[0] = 6;dp[1] = 9;dp[2] = 12;for (int i = 3; i <= n - 5; i++) {dp[i] = dp[i - 3] * 3;}return dp[n-5];
}
1. 定义状态
在整数拆分问题中,定义状态 dp[i] 表示将整数 i + 5 拆分成至少两个正整数的和后,这些正整数的最大乘积。
2. 找出状态转移方程
为了得到将一个整数拆分成若干正整数和后这些正整数的最大乘积,我们可以利用数学性质:尽量多拆出 3,这样得到的乘积最大。
对于大于等于 5 的整数 n,把它拆分成 3 和另一个数的组合能使乘积最大。当 n >= 5 时,我们发现 dp[i] (对应整数 i + 5)可以由 dp[i - 3] (对应整数 (i - 3)+ 5)乘以 3 得到,因为在拆分过程中多拆分出一个 3。所以状态转移方程为:
dp[i] = dp[i - 3] * 3;
3. 初始化边界条件
对于较小的 n 值,我们需要单独处理并作为边界条件进行初始化。
- 当
n = 2时,拆分成1 + 1,乘积为1,即2 - 1,所以if (n == 2 || n == 3) { return n - 1; }。 - 当
n = 4时,拆分成2 + 2,乘积为4,所以if (n == 4) return n;。
对于 dp 数组的初始化,对应 n 从 5 开始:
- 当
n = 5时,拆分为2 + 3,乘积为6,所以dp[0] = 6。 - 当
n = 6时,拆分为3 + 3,乘积为9,所以dp[1] = 9。 - 当
n = 7时,拆分为3 + 4,乘积为12,所以dp[2] = 12。
4. 确定计算顺序
根据状态转移方程 dp[i]=dp[i - 3]\times3 可知,计算 dp[i] 依赖于 dp[i - 3] 的值,所以需要按照从小到大的顺序依次计算 dp 数组的值。
在代码中,使用 for 循环从 i = 3 开始计算,直到 i = n - 5:
for (int i = 3; i <= n - 5; i++) {dp[i] = dp[i - 3] * 3;
}
这样可以保证在计算 dp[i] 时,dp[i - 3] 已经计算完成。
时间复杂度为O(n),空间复杂度也为 O(n)。
我觉得这个其实不是严格意义上的动态规划,更偏向数学规律和贪心算法。力扣的答案有另一种解法,大家可以去看看
本体其实也可以优化空间复杂度,因为只需要维护三个数值即可。
附上代码:
int integerBreak(int n) {if (n == 2 || n == 3) {return n - 1;}if (n == 4)return n;long long int dp[3];dp[0] = 6;dp[1] = 9;dp[2] = 12;int index = 0, count = 0;for (int i = 1; i <= n - 7; i++) {if (index == 0)count++;dp[index++] *= 3;if (index == 3)index = 0;}return dp[n - count * 3 - 5]; }时间复杂度为O(n),空间复杂度也为 O(1)。
不多解释,如上1、2题。
| 下标 | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 |
|---|---|---|---|---|---|---|---|---|---|
| dp | 6 | 9 | 12 | 18 | 27 | 36 | 54 | 81 | 108 |
| 分解数 | 2+3 | 3+3 | 3+4 | 2+3+3 | 3+3+3 | 3+3+4 | 2+3+3+3 | 3+3+3+3 | 3+3+3+4 |
| 数字 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 |
8、最长回文子串
5. 最长回文子串
给你一个字符串
s,找到s中最长的 回文 子串。示例 1:
输入:s = "babad" 输出:"bab" 解释:"aba" 同样是符合题意的答案。示例 2:
输入:s = "cbbd" 输出:"bb"
char* longestPalindrome(char* s) {int n = strlen(s);if (n == 1)return s;bool dp[n][n];int start = 0, maxLen = 1;memset(dp, false, sizeof(dp));for (int i = 0; i < n; i++)dp[i][i] = true;for (int i = 0; i < n - 1; i++) {if (s[i] == s[i + 1]) {dp[i][i + 1] = true;start = i;maxLen = 2;}}for (int l = 3; l <= n; l++) {for (int i = 0; i <= n - l; i++) {int j = i + l - 1;if (dp[i + 1][j - 1] && s[i] == s[j]) {dp[i][j] = true;if (l > maxLen) {start = i;maxLen = l;}}}}s[start + maxLen] = '\0';return s + start;
}1. 定义状态
设 dp[i][j] 表示字符串 s 中从索引 i 到索引 j 的子串(即 s[i...j])是否为回文子串,其中 i 和 j 分别是子串的起始和结束索引,dp[i][j] 为 true 时表示该子串是回文子串,为 false 时则不是。
2. 找出状态转移方程
一个长度大于 2 的子串 s[i...j] 如果是回文子串,需要满足两个条件:
- 子串的首尾字符相等,即
s[i] == s[j]。 - 去掉首尾字符后的子串
s[i + 1...j - 1]也是回文子串,即dp[i + 1][j - 1]为true。
if (dp[i + 1][j - 1] && s[i] == s[j]) {dp[i][j] = true;if (l > maxLen) {start = i;maxLen = l;}
}
3. 初始化边界条件
- 单个字符的子串:对于单个字符的子串
s[i...i],它本身就是回文子串,所以dp[i][i]初始化为true。
for (int i = 0; i < n; i++)dp[i][i] = true;
- 长度为 2 的子串:对于长度为 2 的子串
s[i...i + 1],如果两个字符相等,那么它是回文子串,此时更新dp[i][i + 1]为true,同时记录当前最长回文子串的起始位置和长度。
for (int i = 0; i < n - 1; i++) {if (s[i] == s[i + 1]) {dp[i][i + 1] = true;start = i;maxLen = 2;}
}
4. 确定计算顺序
由于状态转移方程中 dp[i][j] 依赖于 dp[i + 1][j - 1],即当前状态依赖于左下角的状态,所以需要按照子串长度从小到大的顺序进行计算。
先计算长度为 3 的子串,再计算长度为 4 的子串,以此类推,直到计算长度为 n 的子串。对于每个长度 l,遍历所有可能的起始索引 i,计算对应的结束索引 j = i + l - 1,然后根据状态转移方程更新 dp[i][j]。
for (int l = 3; l <= n; l++) {for (int i = 0; i <= n - l; i++) {int j = i + l - 1;if (dp[i + 1][j - 1] && s[i] == s[j]) {dp[i][j] = true;if (l > maxLen) {start = i;maxLen = l;}}}
}
最后,通过 s[start + maxLen] = '\0' 将最长回文子串后面的字符截断,返回 s + start 指向的最长回文子串。
**时间空间复杂度是O(n2),O(n2) **。
| / | b | a | b | a | d |
|---|---|---|---|---|---|
| dp | 0 | 1 | 2 | 3 | 4 |
| 0 | T | / | / | / | / |
| 1 | F | T | / | / | / |
| 2 | T | F | T | / | / |
| 3 | F | T | F | T | / |
| 4 | F | F | F | F | T |
| / | c | b | b | d |
|---|---|---|---|---|
| dp | 0 | 1 | 2 | 3 |
| 0 | T | / | / | / |
| 1 | F | T | / | / |
| 2 | F | T | T | / |
| 3 | F | F | F | T |
这样虽然能通过,但耗时耗地,所以作者最开始还是用双指针的方法写的。
char* longestPalindrome(char* s) {int n = strlen(s);int i, left, right;int curLen = 1, maxLen, pL, pR;for (i = 0; i < n; i++) {left = i - 1;right = i + 1;while (left >= 0 && right < n && s[left] == s[right]) {left--;right++;}curLen = right - left + 1 - 2;if (curLen > maxLen) {maxLen = curLen;pL = left + 1;pR = right - 1;}}for (int j = 0; j < n; j++) {left = j;right = j + 1;while (left >= 0 && right < n && s[left] == s[right]) {left--;right++;}curLen = right - left + 1 - 2;if (curLen > maxLen) {maxLen = curLen;pL = left + 1;pR = right - 1;}}s[pL + maxLen] = '\0';return s + pL; }
9、不同的二叉搜索树
96. 不同的二叉搜索树
给你一个整数
n,求恰由n个节点组成且节点值从1到n互不相同的 二叉搜索树 有多少种?返回满足题意的二叉搜索树的种数。示例 1:
输入:n = 3 输出:5示例 2:
输入:n = 1 输出:1
int numTrees(int n) {if (n == 1) {return 1;}if (n == 2) {return 2;}int dp[n + 1];for (int i = 0; i <= n; i++) {dp[i] = 0;}dp[0] = 1;dp[1] = 1;dp[2] = 2;for (int i = 3; i <= n; i++) {for (int j = 1; j <= i; j++) {dp[i] += dp[j - 1] * dp[i - j];}}return dp[n];
}
1. 定义状态
设 dp[i] 表示节点个数为 i 时,能构成的不同二叉搜索树(Binary Search Tree, BST)的数量。
2. 找出状态转移方程
对于节点个数为 i 的二叉搜索树,我们可以考虑以 1 到 i 中的任意一个数 j 作为根节点。
- 当选择
j作为根节点时,其左子树的节点个数为j - 1,右子树的节点个数为i - j。 - 根据二叉搜索树的性质,左子树的所有节点值小于根节点值,右子树的所有节点值大于根节点值。因此,左子树的不同形态数量为
dp[j - 1],右子树的不同形态数量为dp[i - j]。 - 那么以
j为根节点的二叉搜索树的数量就是左子树的不同形态数量乘以右子树的不同形态数量,即dp[j - 1] * dp[i - j]。 - 由于
j可以从1取到i,所以节点个数为i的二叉搜索树的总数量dp[i]就是以1到i中每个数为根节点的二叉搜索树数量之和。
3. 初始化边界条件
dp[0] = 1:表示空树也是一种二叉搜索树,所以节点个数为0时,不同二叉搜索树的数量为1。dp[1] = 1:当只有一个节点时,显然只能构成一种二叉搜索树,即这个节点本身,所以dp[1]为1。dp[2] = 2:当有两个节点时,有两种不同的二叉搜索树结构,一种是根节点的左子树有一个节点,另一种是根节点的右子树有一个节点,所以dp[2]为2。
4. 确定计算顺序
根据状态转移方程,计算 dp[i] 时需要用到 dp[0] 到 dp[i - 1] 的值,所以我们应该按照从小到大的顺序依次计算 dp[3] 到 dp[n]。
五、进阶背包理论
参考代码随想录:

1、01背包(dp二维数组)
1. 问题描述
有 n 个物品,每个物品有重量 weight[i] 和价值 value[i](i = 0, 1, 2, ..., n - 1),以及一个容量为 W 的背包。每个物品只有一件,要么放入背包,要么不放入背包**(这就是 “01” 的含义,0 表示不选,1 表示选)**。目标是在不超过背包容量的前提下,选择一些物品放入背包,使得放入背包的物品总价值最大。
max=4Kg weight value item0 1 15 item1 2 20 item2 4 30
2. 定义状态
设 dp[i][j] 表示考虑前 i 个物品(i 从 0 到 n - 1),背包容量为 j(j 从 0 到 W)时,能获得的最大价值。
item0放入
dp数组:
/ 0 1 2 3 4 item0 0 15 15 15 15 item1 item2 item1放入
dp数组:
/ 0 1 2 3 4 item0 0 15 15 15 15 item1 0 15 15 20 35 item2
- 背包容量为 0,放不下物品0 或者物品1,此时背包里的价值为0。
- 背包容量为 1,只能放下物品0,背包里的价值为15。
- 背包容量为 2,只能放下物品0,背包里的价值为15。
- 背包容量为 3,上一行同一状态,背包只能放物品0,这次也可以选择物品1了,背包可以放物品1 或者 物品0,物品1价值更大,背包里的价值为20。
- 背包容量为 4,上一行同一状态,背包只能放物品0,这次也可以选择物品1了,背包可以放下物品0 和 物品1,背包价值为35。
3. 状态转移方程
对于每个物品 i 和背包容量 j,有两种情况:
- 不选择物品
i:此时dp[i][j] = dp[i - 1][j],即不选当前物品时,最大价值与考虑前i - 1个物品且背包容量为j时相同。 - 选择物品
i:前提是j >= weight[i](背包容量能装下物品i),此时dp[i][j] = dp[i - 1][j - weight[i]] + value[i],即选了当前物品后,最大价值是考虑前i - 1个物品且背包容量为j - weight[i]时的最大价值加上物品i的价值。
4. 初始化边界条件
- 当
i = 0时,即只考虑第一个物品,若j < weight[0],则dp[0][j] = 0(背包容量装不下第一个物品,价值为 0);若j >= weight[0],则dp[0][j] = value[0](能装下第一个物品,价值就是第一个物品的价值)。 - 当
j = 0时,无论考虑多少个物品,背包容量为 0,能获得的价值都是 0,即dp[i][0] = 0(i = 0, 1, 2, ..., n - 1)。
5. 计算顺序
根据状态转移方程,计算 dp[i][j] 时依赖于 dp[i - 1][j] 和 dp[i - 1][j - weight[i]],所以应该按照 i 从 0 到 n - 1,j 从 0 到 W 的顺序依次计算 dp[i][j] 的值。
6. 最终结果
计算完所有的 dp[i][j] 后,dp[n - 1][W] 就是考虑所有 n 个物品且背包容量为 W 时能获得的最大价值,即 01 背包问题的解。
#include <stdio.h>
#include <stdlib.h>// 函数用于解决 01 背包问题
int knapsack_01(int *weight, int *value, int n, int W) {// 创建二维数组 dp 用于存储中间结果int **dp = (int **)malloc(n * sizeof(int *));for (int i = 0; i < n; i++) {dp[i] = (int *)malloc((W + 1) * sizeof(int));}// 初始化边界条件for(int i = 0; i < n; i++){dp[i][0] = 0;}for (int j = 0; j <= W; j++) {if (j < weight[0]) {dp[0][j] = 0;} else {dp[0][j] = value[0];}}// 动态规划计算for (int i = 1; i < n; i++) {for (int j = 0; j <= W; j++) {if (j < weight[i]) {dp[i][j] = dp[i - 1][j];} else {dp[i][j] = (dp[i - 1][j] > dp[i - 1][j - weight[i]] + value[i]) ? dp[i - 1][j] : dp[i - 1][j - weight[i]] + value[i];}}}// 保存最终结果int result = dp[n - 1][W];// 释放动态分配的内存for (int i = 0; i < n; i++) {free(dp[i]);}free(dp);return result;
}int main() {int weight[] = {2, 3, 4, 5};int value[] = {3, 4, 5, 6};int n = sizeof(weight) / sizeof(weight[0]);int W = 8;int max_value = knapsack_01(weight, value, n, W);printf("能获得的最大价值为: %d\n", max_value);return 0;
}
7.代码解释
- 内存分配:在
knapsack_01函数中,使用malloc函数动态分配一个二维数组dp,用于存储中间结果。 - 边界条件初始化:对于第一个物品(
i = 0),根据背包容量j和物品重量weight[0]的关系初始化dp[0][j]。 - 动态规划计算:使用两层嵌套循环,外层循环遍历物品(
i从 1 到n - 1),内层循环遍历背包容量(j从 0 到W),根据状态转移方程更新dp[i][j]的值。 - 结果保存与内存释放:将最终结果保存到
result变量中,然后使用free函数释放动态分配的内存,避免内存泄漏。 - 主函数:定义物品的重量数组
weight、价值数组value、物品数量n和背包容量W,调用knapsack_01函数计算最大价值并输出结果。
8.复杂度分析
- 时间复杂度:
O(n*W),其中n是物品的数量,W是背包的容量,因为使用了两层嵌套循环。 - 空间复杂度:
O(n*W),主要用于存储二维数组dp。
2、01背包(dp滚动数组)
在 01 背包问题中,我们前面使用二维数组 dp[i][j] 来记录状态,不过可以利用滚动数组把空间复杂度从 O(nW) 优化到 O(W)。这是因为状态转移方程 dp[i][j] 只依赖于 dp[i - 1][j] 和 dp[i - 1][j - weight[i]],也就是当前状态只和上一行的状态有关,所以可以用一维数组来滚动更新状态。
1. 定义状态
在使用滚动数组优化的 01 背包问题中,我们将状态定义为一维数组 dp[j],它表示背包容量为 j 时,能获得的最大价值。
这里的状态其实是对原本二维状态 dp[i][j](表示考虑前 i 个物品,背包容量为 j 时的最大价值)的简化,通过滚动数组的方式,我们在同一数组空间中不断更新状态,使得当前的 dp[j] 实际上记录的是考虑到当前物品时背包容量为 j 的最大价值。
2. 找出状态转移方程
对于每个物品 i 和背包容量 j,同样有两种情况需要考虑:
- 不选择物品
i:此时背包的最大价值不变,即dp[j]保持上一轮(也就是考虑前i - 1个物品时)的值。 - 选择物品
i:前提是背包容量j要大于等于物品i的重量weight[i]。选择该物品后,背包剩余容量为j - weight[i],此时的最大价值为考虑前i - 1个物品且背包容量为j - weight[i]时的最大价值加上物品i的价值value[i]。
3. 初始化边界条件
在代码中,我们使用 calloc 函数创建了一维数组 dp,并将其所有元素初始化为 0,即 dp[j] = 0(j 从 0 到 W)。这是因为当没有考虑任何物品(即初始状态)或者背包容量为 0 时,能获得的最大价值自然为 0。
4. 确定计算顺序
根据状态转移方程,计算 dp[j] 时依赖于 dp[j - weight[i]],而 dp[j - weight[i]] 是上一轮(考虑前 i - 1 个物品时)的状态。为了保证在更新 dp[j] 时,dp[j - weight[i]] 没有被当前轮的更新所覆盖,我们需要从后往前更新 dp 数组。具体的计算顺序如下:
- 外层循环遍历物品,从第一个物品(
i = 0)到第n - 1个物品。 - 对于每个物品
i,内层循环从背包的最大容量W开始,递减到该物品的重量weight[i],依次更新dp[j]的值。
#include <stdio.h>
#include <stdlib.h>
#define max(a, b) (((a) > (b)) ? (a) : (b))// 函数用于解决 01 背包问题,使用滚动数组优化空间
int knapsack_01(int *weight, int *value, int n, int W) {// 创建一维数组 dp 用于滚动更新状态int *dp = (int *)calloc(W + 1, sizeof(int));// 动态规划计算for (int i = 0; i < n; i++) {// 从后往前更新 dp 数组,避免覆盖需要使用的上一轮状态for (int j = W; j >= weight[i]; j--) {// 状态转移方程//代码表示为 `not_choose = dp[j]`//int choose = dp[j - weight[i]] + value[i];//用代码表示为 `choose = dp[j - weight[i]] + value[i]`//int not_choose = dp[j];//dp[j] = (choose > not_choose) ? choose : not_choose;dp[j] = max(dp[j], dp[j - weight[i]] + value[i]);}}// 保存最终结果int result = dp[W];// 释放动态分配的内存free(dp);return result;
}int main() {int weight[] = {2, 3, 4, 5};int value[] = {3, 4, 5, 6};int n = sizeof(weight) / sizeof(weight[0]);int W = 8;int max_value = knapsack_01(weight, value, n, W);printf("能获得的最大价值为: %d\n", max_value);return 0;
}
5.代码解释
- 初始化
dp数组:借助calloc函数创建一个长度为W + 1的一维数组dp,并且把所有元素初始化为 0。此数组用来滚动更新状态。 - 动态规划计算:
- 外层循环遍历每一个物品,从
i = 0到i = n - 1。 - 内层循环从
W到weight[i]倒序更新dp数组。之所以要倒序,是为了保证在更新dp[j]时,dp[j - weight[i]]依旧是上一轮的状态,避免被当前轮的更新覆盖。 - 针对每个
j,计算选择当前物品和不选择当前物品的价值,取二者中的较大值更新dp[j]。
- 外层循环遍历每一个物品,从
- 结果保存与内存释放:把最终结果存于
result变量,接着用free函数释放动态分配的内存,防止内存泄漏。 - 主函数:定义物品的重量数组
weight、价值数组value、物品数量n和背包容量W,调用knapsack_01函数计算最大价值并输出结果。
6.复杂度分析
- 时间复杂度:
O(n*W),这里的n是物品的数量,W是背包的容量,因为使用了两层嵌套循环。 - 空间复杂度:
O(W),主要用于存储一维数组dp。
3.滚动数组!!!
滚动数组是一种在动态规划中常用的优化技巧,主要用于减少空间复杂度。下面从基本概念、使用场景、原理、示例(以 0 - 1 背包问题为例)以及优缺点几个方面详细介绍滚动数组。
1.基本概念
滚动数组本质上是对动态规划中二维或多维状态数组的一种优化手段。在动态规划里,我们通常会定义一个二维或者多维的数组来保存中间状态,然而在某些情况下,当前状态的计算只依赖于前面若干行或者若干层的状态,此时就可以用一个一维数组或者更小维度的数组来滚动更新状态,从而达到节省空间的目的。
2.使用场景
滚动数组适用于满足以下条件的动态规划问题:
- 状态转移依赖局部:当前状态的计算只依赖于前面固定数量的状态。例如在 0 - 1 背包问题中,
dp[i][j]只依赖于dp[i - 1][j]和dp[i - 1][j - weight[i]],即只和上一行的状态有关。 - 状态更新顺序可控制:可以通过合理安排状态更新的顺序,避免新状态覆盖掉后续计算还需要使用的旧状态。
3.原理
滚动数组的核心原理是复用数组空间。以二维数组 dp[i][j] 为例,如果当前状态 dp[i][j] 只依赖于 dp[i - 1][k](k 为某个与 j 相关的值),那么我们可以用一个一维数组 dp[j] 来代替二维数组。在更新 dp[j] 时,我们通过控制更新顺序,使得在更新 dp[j] 时,dp[j - weight[i]] 仍然保存着上一轮(即考虑前 i - 1 个物品时)的状态,这样就可以实现状态的滚动更新。
4.优缺点
优点
- 节省空间:能够显著减少动态规划所需的空间复杂度,尤其在状态数组维度较高或者数据规模较大时,优势更加明显。
- 代码简洁:使用滚动数组后,代码中的数组维度降低,使得代码更加简洁易读。
缺点
- 可读性降低:对于不熟悉滚动数组技巧的人来说,代码的理解难度会增加,因为状态的更新和依赖关系不像二维数组那样直观。
- 适用范围受限:并非所有的动态规划问题都适合使用滚动数组,只有满足状态转移依赖局部和状态更新顺序可控制这两个条件的问题才能使用。
4.分割等和子集
416. 分割等和子集
给你一个 只包含正整数 的 非空 数组
nums。请你判断是否可以将这个数组分割成两个子集,使得两个子集的元素和相等。示例 1:
输入:nums = [1,5,11,5] 输出:true 解释:数组可以分割成 [1, 5, 5] 和 [11] 。示例 2:
输入:nums = [1,2,3,5] 输出:false 解释:数组不能分割成两个元素和相等的子集。
#define max(a, b) (((a) > (b)) ? (a) : (b))int getSum(int* nums, int t) {int sum = 0;for (int i = 0; i < t; i++) {sum += nums[i];}return sum;
}bool canPartition(int* nums, int numsSize) {int sum = getSum(nums, numsSize);if (sum % 2 != 0) {return false;}int tar = sum / 2;int dp[tar + 1];for (int i = 0; i <= tar; i++) {dp[i] = 0;}for (int i = 0; i < numsSize; i++) {for (int j = tar; j >= nums[i]; j--) {dp[j] = max(dp[j], dp[j - nums[i]] + nums[i]);}}return dp[tar] == tar;
}
1. 定义状态
设 dp[j] 表示在当前考虑的数组元素范围内,能否组成和为 j 的子集。这里 j 的范围是从 0 到 sum / 2,其中 sum 是数组 nums 中所有元素的总和。
2. 找出状态转移方程
对于每个元素 nums[i] 和每个可能的和 j(j 从 sum / 2 到 nums[i]),有两种情况需要考虑:
- 不选择当前元素
nums[i]:此时dp[j]保持不变,即dp[j]等于之前考虑过的元素能组成和不超过j的最大子集和,也就是dp[j]本身。 - 选择当前元素
nums[i]:前提是j >= nums[i]。选择该元素后,能组成和不超过j的最大子集和为dp[j - nums[i]] + nums[i],其中dp[j - nums[i]]是之前考虑过的元素能组成和不超过j - nums[i]的最大子集和。
3. 初始化边界条件
由于初始时没有考虑任何元素,所以对于任意的 j(从 0 到 sum / 2),能组成和不超过 j 的最大子集和都为 0,即 dp[j] = 0。
4. 确定计算顺序
根据状态转移方程,计算 dp[j] 时依赖于 dp[j - nums[i]],而 dp[j - nums[i]] 是之前计算得到的状态。为了保证在更新 dp[j] 时,dp[j - nums[i]] 没有被当前轮的更新所覆盖,我们需要从后往前更新 dp 数组。
- 外层循环遍历数组中的每个元素,从
nums[0]到nums[numsSize - 1]。 - 对于每个元素
nums[i],内层循环从sum / 2开始,递减到nums[i],依次更新dp[j]的值。
**时间空间复杂度是O(n*tar),O(tar) **。
5.最后一块石头的重量 II
最后一块石头的重量 II
有一堆石头,用整数数组
stones表示。其中stones[i]表示第i块石头的重量。每一回合,从中选出任意两块石头,然后将它们一起粉碎。假设石头的重量分别为
x和y,且x <= y。那么粉碎的可能结果如下:
- 如果
x == y,那么两块石头都会被完全粉碎;- 如果
x != y,那么重量为x的石头将会完全粉碎,而重量为y的石头新重量为y-x。最后,最多只会剩下一块 石头。返回此石头 最小的可能重量 。如果没有石头剩下,就返回
0。示例 1:
输入:stones = [2,7,4,1,8,1] 输出:1 解释: 组合 2 和 4,得到 2,所以数组转化为 [2,7,1,8,1], 组合 7 和 8,得到 1,所以数组转化为 [2,1,1,1], 组合 2 和 1,得到 1,所以数组转化为 [1,1,1], 组合 1 和 1,得到 0,所以数组转化为 [1],这就是最优值。示例 2:
输入:stones = [31,26,33,21,40] 输出:5
#define max(a, b) (((a) > (b)) ? (a) : (b))int getSum(int* nums, int t) {int sum = 0;for (int i = 0; i < t; i++) {sum += nums[i];}return sum;
}int lastStoneWeightII(int* stones, int stonesSize) {int sum = getSum(stones, stonesSize);int tar = sum / 2;int dp[tar + 1];for (int i = 0; i <= tar; i++) {dp[i] = 0;}for (int i = 0; i < stonesSize; i++) {for (int j = tar; j >= stones[i]; j--) {dp[j] = max(dp[j], dp[j - stones[i]] + stones[i]);}}return sum - dp[tar] - dp[tar];
}1. 定义状态
本题的核心目标是将一堆石头分成两堆,使得这两堆石头重量之差尽可能小。可以将其转化为一个 0 - 1 背包问题,即从所有石头中选取部分石头,使得这部分石头的重量和尽可能接近总重量的一半。
设 dp[j] 表示在考虑前 i 个石头的情况下,能组成的不超过 j 的最大石头重量和。其中 j 的取值范围是从 0 到 sum / 2,sum 是所有石头的总重量。
2. 找出状态转移方程
对于每个石头 stones[i] 和每个可能的重量 j(j 从 sum / 2 到 stones[i]),有两种选择:
- 不选择当前石头
stones[i]:此时能组成的不超过j的最大石头重量和保持不变,即dp[j]维持上一轮的结果。 - 选择当前石头
stones[i]:前提是j >= stones[i]。若选择该石头,那么能组成的不超过j的最大石头重量和为dp[j - stones[i]] + stones[i],其中dp[j - stones[i]]是考虑前i - 1个石头时能组成的不超过j - stones[i]的最大石头重量和。
3. 初始化边界条件
在开始考虑任何石头之前,也就是没有选取任何石头时,对于任意的 j(从 0 到 sum / 2),能组成的不超过 j 的最大石头重量和都为 0。所以需要将 dp 数组初始化为 0。
4. 确定计算顺序
根据状态转移方程,计算 dp[j] 时依赖于 dp[j - stones[i]],而 dp[j - stones[i]] 是之前计算得到的状态。为了保证在更新 dp[j] 时,dp[j - stones[i]] 没有被当前轮的更新所覆盖,需要从后往前更新 dp 数组。具体的计算顺序如下:
- 外层循环:遍历所有石头,从
stones[0]到stones[stonesSize - 1],依次考虑每个石头对dp数组的影响。 - 内层循环:对于每个石头
stones[i],从sum / 2开始递减到stones[i],根据状态转移方程更新dp[j]的值。
**时间空间复杂度是O(n*tar),O(tar) **。
六、总结
动态规划是一种强大的算法策略,适用于解决具有最优子结构和重叠子问题性质的问题。通过合理定义状态、找出状态转移方程、初始化边界条件和确定计算顺序,可以高效地解决复杂问题。
相关文章:

C语言动规学习
文章目录 一、动态规划的基本概念1. 最优子结构2. 重叠子问题 二、动态规划的求解步骤三、动态规划与递归的比较四、例题(只讲思维,空间时间复杂度大小不与题目比较)1、斐波那契数列1. 定义状态2. 找出状态转移方程3. 初始化边界条件4. 确定计…...

Vue3中provide和inject的用法示例
在 Vue3 中,provide 和 inject 用于实现跨层级组件通信。以下是一个简单的示例: 1. 父组件 (祖先组件) - 提供数据 javascript 复制 // ParentComponent.vue import { provide, ref, reactive } from vue;export default {setup() {// 提供静态数据p…...

fastdds:传输层SHM和DATA-SHARING的区别
下图是fastdds官方的图,清晰地展示了dds支持的传输层: 根据通信双方的相对位置(跨机器、同机器跨进程、同进程)的不同选择合适的传输层,是通信中间件必须要考虑的事情。 跨机器:udp、tcp 跨机器通信,只能通过网络, f…...

MQ基础篇
1.初识MQ 1.同步调用 概念: 同步调用是一种程序执行方式,在调用一个函数或服务时,调用方会一直等待被调用方执行完成并返回结果,才会继续执行后续代码 ,期间调用线程处于阻塞状态。 同步调用的优势: 时…...

网络编程2
day2 一、UDP编程 1.编程流程 2.函数接口 3.注意 (1)、对于TCP是先运行服务器,客户端才能运行。(2)、对于UDP来说,服务器和客户端运行顺序没有先后,因为是无连接,所以服务器和客户端谁先开始,没有关系.(3)、一个服务器…...

Python环境中在线训练机器学习模型所遇到的问题及解决方案
我最近开发个智能控制系统,包括实时数据采集、预测、策略优化等功能,最近增加在线学习功能,也就是在线进行模型训练,在线进行模型训练时出现了问题,现象为: 控制台报: cmdstanpy - INFO - Chain [1] start processing所有任务、线程停止,Web服务登录无法访问后台的pyt…...

「仓颉编程语言」Demo
仓颉编程语言」Demo python 1)# 仓颉语言写字楼管理系统示例(虚构语法)# 语法规则:中文关键词 类Python逻辑定义 写字楼管理系统属性:租户库 列表.新建()报修队列 列表.新建()费用单价 5 # 元/平方米方法 添加租户(名称, 楼层, 面积):…...
——处理流程设计、系统设计、人机界面设计)
《软件设计师》复习笔记(11.4)——处理流程设计、系统设计、人机界面设计
目录 一、业务流程建模 二、流程设计工具 三、业务流程重组(BPR) 四、业务流程管理(BPM) 真题示例: 五、系统设计 1. 主要目的 2. 设计方法 3. 主要内容 4. 设计原则 真题示例: 六、人机界面设…...

win11系统截图的几种方式
在 Windows 11 中,系统内置的截图功能已全面升级,不仅支持多种截图模式,还整合了录屏、OCR 文字识别和 AI 增强编辑等功能。以下是从基础操作到高阶技巧的完整指南: 一、快捷键截图(效率首选) 1. Win Sh…...

http://noi.openjudge.cn/——2.5基本算法之搜索——1998:寻找Nemo
文章目录 题目宽搜代码优先队列深搜代码小结 题目 总时间限制: 2000ms 内存限制: 65536kB 描述 Nemo 是个顽皮的小孩. 一天他一个人跑到深海里去玩. 可是他迷路了. 于是他向父亲 Marlin 发送了求救信号.通过查找地图 Marlin 发现那片海像一个有着墙和门的迷宫.所有的墙都是平行…...

win10系统完美配置mamba-ssm全整合方案
好久没瞎写东西了,刚好最近遇到一个逆天需求:要在win10平台上配置可用的mamba-ssm环境。由于这个环境原版以及相关依赖都是仅适配linux的,即使是依赖conda环境直接拿来往windows系统上装也全是bug,网上大量的垃圾教程也都是错的&a…...

MQTTClient.c中的协议解析与报文处理机制
MQTTClient.c中的协议解析与报文处理机制 1. 协议解析的核心逻辑 (1)报文头部解析 MQTT协议报文由固定头(Fixed Header) 可变头(Variable Header) 负载(Payload)三部分组成。在rea…...

LeetCode每日一题4.18
2364.统计坏数对的数目 问题 问题分析 根据题目要求,(i, j) 是一个坏数对的条件是: i < j j - i ! nums[j] - nums[i],即 nums[j] - j ! nums[i] - i 因此,我们可以转换问题:对于每个 j,找到所有 i &l…...

cmd查询占用端口并查杀
查看特定端口的占用情况 netstat -ano | findstr 端口号 netstat -ano | findstr 端口号 结束指定进程 askkill /T /F /PID PID askkill /T /F /PID PID...

ETL数据集成平台在交通运输行业的五大应用场景
在智能交通与数字物流时代,交通运输企业每天产生海量数据——车辆轨迹、货物状态、乘客流量、设备日志……但这些数据往往被困在分散的系统中:GPS定位数据躺在车载终端里,物流订单卡在Excel表中,地铁客流统计锁在本地服务器内。如…...

自定义 el-menu
使用的工具:vue2 element-ui <!DOCTYPE html> <html><head><link rel"stylesheet" href"https://unpkg.com/element-ui/lib/theme-chalk/index.css"><style>.el-menu--horizontal {border-bottom: none !impor…...

创维E900V20C-国科GK6323V100C-rtl8822cs-安卓9.0-短接强刷卡刷固件包
创维E900V20C/创维E900V20D-国科GK6323V100C-安卓9.0-强刷卡刷固件包 创维E900V20C 刷机说明: 1、用个老款4G,2.0的U盘,fat32,2048块单分区格式化, 5个文件复制到根目录,插盒子靠网口U口&…...

DemoGen:用于数据高效视觉运动策略学习的合成演示生成
25年2月来自清华、上海姚期智研究院和上海AI实验室的论文“DemoGen: Synthetic Demonstration Generation for Data-Efficient Visuomotor Policy Learning”。 视觉运动策略在机器人操控中展现出巨大潜力,但通常需要大量人工采集的数据才能有效执行。驱动高数据需…...

影楼精修-高低频磨皮算法解析
注意:本文样例图片为了避免侵权,均使用AIGC生成; 高低频磨皮基础 高低频磨皮是一种常用于人像后期修图的技术,它能在保留皮肤纹理的同时柔化瑕疵,使皮肤看起来更加自然细腻。高低频磨皮的算法原理如下: …...

打造搜索神功:Express 路由中的关键词探查之道
前言 在 Web 开发的江湖,Express 好比一位身怀绝技的武林高手,出手稳准狠,擅长解决各种疑难杂症。今天,我们将与这位高手并肩作战,一探关键词搜索路由的奥义。这不是枯燥的教学,而是一场充满玄机与笑点的江湖奇遇。挥起代码之剑,踏上探索之路,不仅能习得招式,还能在轻…...

kubernetes-使用ceph-csi
kubernetes-使用ceph-csi Kubernetes (简称K8s)和Ceph都是开源的云计算技术,K8s是一个容器编排平台,而Ceph是一个分布式存储系统。将K8s和Ceph集成在一起可以为应用程序提供高可用性和持久性存储。本文主要介绍如何在使用openEul…...

从Shell到域控:内网渗透中定位域控制器的8种核心方法
在内网渗透中,定位域控制器(Domain Controller, DC)是攻防对抗的关键环节。本文结合实战经验与工具技术,总结出8种从Shell快速发现域控主机的方法,涵盖命令探测、网络扫描、日志分析等维度,助你系统…...

FA-YOLO:基于FMDS与AGMF的高效目标检测算法解析
本文《FA-YOLO: Research On Efficient Feature Selection YOLO Improved Algorithm Based On FMDS and AGMF Modules》针对YOLO系列在特征融合与动态调整上的不足,提出两种创新模块:FMDS(细粒度多尺度动态选择模块)和AGMF(自适应门控多分支聚焦融合模块)。论文结构…...

【RK3588 嵌入式图形编程】-SDL2-扫雷游戏-结束和重新开始游戏
结束和重新开始游戏 文章目录 结束和重新开始游戏1、概述2、更新Globals.h3、触发GAME_WON和GAME_LOST事件4、对游戏结束的反应5、重启游戏6、创建新游戏按钮7、完整代码8、总结在本文中,将实现胜负检测并添加重新开始功能以完成游戏循环。 1、概述 在本文中,我们将更新我们…...

OpenAI重返巅峰:o3与o4-mini引领AI推理新时代
引言 2025年4月16日,OpenAI发布了全新的o系列推理模型:o3和o4-mini,这两款模型被官方称为“迎今为止最智能、最强大的大语言模型(LLM)”。它们不仅在AI推理能力上实现了质的飞跃,更首次具备了全面的工具使…...
——质量管理、风险管理)
《软件设计师》复习笔记(12.3)——质量管理、风险管理
目录 一、质量管理 1. 质量定义 2. 质量管理过程 3. 软件质量特性(GB/T 16260-2002) 4. 补充知识 McCall质量模型: 软件评审 软件容错技术 真题示例: 二、风险管理 1. 风险管理的目的: 2. 风险管理流程及内…...

优化自旋锁的实现
在《C11实现一个自旋锁》介绍了分别使用TAS和CAS算法实现自旋锁的方案,以及它们的优缺点。TAS算法虽然实现简单,但是因为每次自旋时都要导致一场内存总线流量风暴,对全局系统影响很大,一般都要对它进行优化,以降低对全…...

项目实战--新闻分类
从antd中拿一个表格 表格 Table - Ant Designhttps://ant-design.antgroup.com/components/table-cn#table-demo-edit-cell使用的是可编辑单元格 实现引入可编辑单元格: import React, { useState, useEffect, useRef, useContext } from react import { Button, …...

人像面部关键点检测
此工作为本人近期做人脸情绪识别,CBAM模块前是否能加人脸关键点检测而做的尝试。由于创新点不是在于检测点的标注,而是CBAM的改进,因此,只是借用了现成库Dilb与cv2进行。 首先,下载人脸关键点预测模型:Index of /file…...

OpenVINO怎么用
目录 OpenVINO 简介 主要组件 安装 OpenVINO 使用 OpenVINO 的基本步骤 OpenVINO 简介 OpenVINO(Open Visual Inference and Neural Network Optimization)是英特尔推出的一个开源工具包,旨在帮助开发者在英特尔硬件平台上高效部署深度学…...

写论文时降AIGC和降重的一些注意事项
‘ 写一些研究成果,英文不是很好,用有道翻译过来句子很简单,句型很单一。那么你会考虑用ai吗? 如果语句太正式,高级,会被误判成aigc ,慎重选择ai润色。 有的话就算没有用ai生成,但…...
、yaml格式配置文件)(读取yml配置文件的3种方式)(详解))
SpringBoot学习(properties、yml(主流)、yaml格式配置文件)(读取yml配置文件的3种方式)(详解)
目录 一、SpringBoot配置文件详解。 1.1配置文件简介。 1.2配置文件分类。(3种配置文件格式) <1>application.properties(properties格式)。 <2>application.yml(yml格式)。 <3>applicat…...

STM32单片机C语言
1、stdint.h简介 stdint.h 是从 C99 中引进的一个标准 C 库的文件 路径:D:\MDK5.34\ARM\ARMCC\include 大家都统一使用一样的标准,这样方便移植 配置MDK支持C99 位操作 如何给寄存器某个值赋值 举个例子:uint32_t temp 0; 宏定义 带参…...

前端为什么需要单元测试?
一. 前言 对于现在的前端工程,一个标准完整的项目,通常情况单元测试是非常必要的。但很多时候我们只是完成了项目而忽略了项目测试。我认为其中一个很大的原因是很多人对单元测试认知不够,因此我写了这篇文章,一方面期望通过这篇…...

QT 文件和文件夹操作
文件操作 1. 文件读写 QFile - 基本文件操作 // 只写模式创建文件(如果文件已存在会清空内容) file.open(QIODevice::WriteOnly);// 读写模式创建文件 file.open(QIODevice::ReadWrite);// 追加模式(如果文件不存在则创建) fil…...

AIP目录
专注于开发灵活API的设计文档。 AIP是总结了谷歌API设计决策的设计文档,它也为其他人提供了用文档记录API设计规则和实践的框架和系统。 基础1AIP目的和指南2AIP编号规则3AIP版本管理200先例8AIP风格与指导9术语表流程100API设计评审常见问题205Beta版本发布前置条…...
)
Function Calling的时序图(含示例)
🧍 用户: 发起请求,输入 prompt(比如:“请告诉我北京的天气”)。 🟪 应用: 将用户输入的 prompt 和函数定义(包括函数名、参数结构等)一起发给 OpenAI。 …...

基于尚硅谷FreeRTOS视频笔记——6—滴答时钟—上下文切换
FreeRTOS滴答 FreeRTOS需要有一个时钟参照,并且这个时钟不会被轻易打断,所以最好选择systick 为什么需要时间参照 就是在高优先级任务进入阻塞态后,也可以理解为进入delay()函数后,需要有一个时间参照&…...

Playwright框架入门
Playwright爬虫框架入门 Playwright介绍 playwright官方文档 Playwright是一个用于自动化浏览器操作的开源工具,由Microsoft开发和维护,支持多种浏览器和多种编程语言,可以用于测试、爬虫、自动化任务等场景。 Playwright是基于WebSocket…...

针对渲染圆柱体出现“麻花“状问题解决
圆柱体渲染结果,在侧面有麻花状条纹,边缘不够硬朗,上下的圆看起来不够平,很明显,是法向量导致的。 原始模型 渲染结果 计算点的法向量采用简单的平均法…...

手撕数据结构算法OJ——栈和队列
文章目录 一、前言二、手撕OJ2.1有效的括号2.2用队列实现栈2.2.1初始化2.2.2入栈2.2.3出栈2.2.4取栈顶2.2.5判空2.2.6销毁2.2.7整体代码 2.3用栈实现队列2.3.1初始化2.3.2入队2.3.3出队2.3.4取队头2.3.5判空2.3.6销毁2.3.7整体代码 四、总结 一、前言 兄弟们,今天的…...

基础知识-指针
1、指针的基本概念 1.1 什么是指针 1.1.1 指针的定义 指针是一种特殊的变量,与普通变量存储具体数据不同,它存储的是内存地址。在计算机程序运行时,数据都被存放在内存中,而指针就像是指向这些数据存放位置的 “路标”。通过指针…...

Thymeleaf简介
在Java中,模板引擎可以帮助生成文本输出。常见的模板引擎包括FreeMarker、Velocity和Thymeleaf等 Thymeleaf是一个适用于Web和独立环境的现代服务器端Java模板引擎。 Thymeleaf 和 JSP比较: Thymeleaf目前所作的工作和JSP有相似之处,Thyme…...

ifconfig -bash: ifconfig: command not found
Ubuntu系统安装完成想查看其ip 报错ifconfig -bash: ifconfig: command not found 解决方法 sudo apt update sudo apt install net-tools ip查找成功...
)
MCP协议量子加密实践:基于QKD的下一代安全通信(2025深度解析版)
一、量子计算威胁的范式转移与MCP协议改造必要性 1.1 传统加密体系的崩塌时间表 根据IBM 2025年量子威胁评估报告,当量子计算机达到4000个逻辑量子比特时(预计2028年实现),现有非对称加密体系将在72小时内被完全破解。工业物联网…...

STM32 基本GPIO控制
目录 GPIO基础知识 编辑IO八种工作模式 固件库实现LED点灯 蜂鸣器 按键基础知识 编辑继电器 震动传感器 433M无线模块 GPIO基础知识 GPIO(General-Purpose input/output,通用输入/输出接口) 用于感知外部信号(输入模式)和控制外部设备&…...
的行列式表示方法)
【天外之物】叉乘(向量积)的行列式表示方法
叉乘(向量积)的行列式表示方法如下: 步骤说明: 构造33矩阵: 将三维向量叉乘转换为行列式的形式,需构造一个包含单位向量 i , j , k \mathbf{i}, \mathbf{j}, \mathbf{k} i,j,k 和原向量分量的矩阵&#x…...

北京SMT贴片厂精密制造关键工艺
内容概要 随着电子设备小型化与功能集成化需求日益提升,北京SMT贴片厂在精密制造领域持续突破工艺瓶颈。本文以高密度PCB板贴片全流程为核心,系统梳理从锡膏印刷、元件贴装到回流焊接的关键技术节点,并结合自动化检测与缺陷预防方案…...

服务器架构:SMP、NUMA、MPP及Docker优化指南
文章目录 引言 一、服务器架构基础1. SMP(对称多处理,Symmetric Multiprocessing)2. NUMA(非统一内存访问,Non-Uniform Memory Access)3. MPP(大规模并行处理,Massively Parallel Pr…...

Datawhale春训营赛题分析和总结
1.Datawhale春训营任务一 借助这个云平台,支持类似于这个anaconda相关的交互式的操作,第一个任务就是跑通这个baseline,然后注册账号之后送了对应的相关算力,跑通这个之后需要进行打卡,跑通其实是没问题不大的&#x…...