pytorch基本操作2
torch.clamp
主要用于对张量中的元素进行截断(clamping),将其限制在一个指定的区间范围内。
函数定义
torch.clamp(input, min=None, max=None) → Tensor参数说明
input
类型:Tensor
需要进行截断操作的输入张量。
min
类型:float 或 None(默认值)
指定张量中元素的最小值。小于 min 的元素会被截断为 min 值。
如果设置为 None,则表示不限制最小值。
max
类型:float 或 None(默认值)
指定张量中元素的最大值。大于 max 的元素会被截断为 max 值。
如果设置为 None,则表示不限制最大值。
返回值
返回一个新的张量,其中元素已经被限制在 ([min, max]) 的范围内。
原张量不会被修改(函数是非原地操作),除非使用 torch.clamp_ 以进行原地操作。
使用场景
torch.clamp 常见的应用场景包括:
- 避免数值溢出:限制张量中的数值在合理范围内,防止出现过大或过小的值导致数值不稳定。
- 归一化操作:将张量值限制在 [0, 1] 或 [-1, 1] 的范围。
- 梯度截断:在训练神经网络时避免梯度爆炸或梯度消失问题。
demo
仅设置最大值或最小值
x = torch.tensor([0.5, 2.0, -1.0, 3.0, -2.0])# 仅限制最大值为 1.0
result_max = torch.clamp(x, max=1.0)# 仅限制最小值为 0.0
result_min = torch.clamp(x, min=0.0)print(result_max) # 输出: tensor([0.5000, 1.0000, -1.0000, 1.0000, -2.0000])
print(result_min) # 输出: tensor([0.5000, 2.0000, 0.0000, 3.0000, 0.0000])
torch.nonzero
返回 input中非零元素的索引下标
无论输入是几维,输出张量都是两维,每行代表输入张量中非零元素的索引位置(在所有维度上面的位置),行数表示非零元素的个数。
import torch
import torch.nn.functional as F
import mathX=torch.tensor([[0, 2, 0, 4],[5, 0, 7, 8]])
index = torch.nonzero(X)
# index = X.nonzero()
print(index)id_t = index.t_()
print(id_t)tensor([[0, 1],
[0, 3],
[1, 0],
[1, 2],
[1, 3]])
tensor([[0, 0, 1, 1, 1],
[1, 3, 0, 2, 3]])
torch.sparse_coo_tensor
torch.sparse_coo_tensor(indices, values, size=None, *, dtype=None, device=None, requires_grad=False, check_invariants=None, is_coalesced=None)
创建一个Coordinate(COO) 格式的稀疏矩阵.
稀疏矩阵指矩阵中的大多数元素的值都为0,由于其中非常多的元素都是0,使用常规方法进行存储非常的浪费空间,所以采用另外的方法存储稀疏矩阵。

使用一个三元组来表示矩阵中的一个非0数,三元组分别表示元素(所在行,所在列,元素值),也就是上图中每一个竖的三元组就是表示了一个非零数,其余值都为0,这样就存储了一个稀疏矩阵.构造这样个矩阵需要知道所有非零数所在的行、所在的列、非零元素的值和矩阵的大小这四个值。
indices:此参数是指定非零元素所在的位置,也就是行和列,所以此参数应该是一个二维的数组,当然它可以是很多格式(ist, tuple, NumPy ndarray, scalar, and other types. )第一维指定了所有非零数所在的行数,第二维指定了所有非零元素所在的列数。例如indices=[[1, 4, 6], [3, 6, 7]]表示我们稀疏矩阵中(1, 3),(4, 6), (6, 7)几个位置是非零的数所在的位置。
values:此参数指定了非零元素的值,所以此矩阵长度应该和上面的indices一样长也可以是很多格式(list, tuple, NumPy ndarray, scalar, and other types.)。例如``values=[1, 4, 5]表示上面的三个位置非零数分别为1, 4, 5。
size:指定了稀疏矩阵的大小,例如size=[10, 10]表示矩阵大小为 10 × 10 10\times 10 10×10,此大小最小应该足以覆盖上面非零元素所在的位置,如果不给定此值,那么默认是生成足以覆盖所有非零值的最小矩阵大小。
dtype:指定返回tensor中数据的类型,如果不指定,那么采取values中数据的类型。
device:指定创建的tensor在cpu还是cuda上。
requires_grad:指定创建的tensor需不需要梯度信息,默认为False
import torchindices = torch.tensor([[4, 2, 1], [2, 0, 2]])
values = torch.tensor([3, 4, 5], dtype=torch.float32)
x = torch.sparse_coo_tensor(indices=indices, values=values, size=[5, 5])
print(x)
print('-----------------------------')
print(x.to_dense())tensor(indices=tensor([[4, 2, 1],
[2, 0, 2]]),
values=tensor([3., 4., 5.]),
size=(5, 5), nnz=3, layout=torch.sparse_coo)
-----------------------------
tensor([[0., 0., 0., 0., 0.],
[0., 0., 5., 0., 0.],
[4., 0., 0., 0., 0.],
[0., 0., 0., 0., 0.],
[0., 0., 3., 0., 0.]])
torch.max
import torch
import torch.nn.functional as F
import math# 创建一个二维张量
x = torch.tensor([[1, 3, 2], [4, 5, 6], [7, 8, 9]])# 返回最大值
value = torch.max(x)
print("value:", value)# 返回最大值及其索引
max_value, max_index = torch.max(x, 0)
print("Max value:", max_value)
print("Max index:", max_index)# 在第一个维度(行)上查找最大值,并保留形状
max_value_row, max_index_row = torch.max(x, 0, keepdim=True)
print("dim=0 keeping shape: ", max_value_row)
print("dim=0 keeping shape: ", max_index_row)value: tensor(9)
Max value: tensor([7, 8, 9])
Max index: tensor([2, 2, 2])
dim=0 keeping shape: tensor([[7, 8, 9]])
dim=0 keeping shape: tensor([[2, 2, 2]])
fastbev:
train
loss function
F.binary_cross_entropy
F.binary_cross_entropy(
input: Tensor, # 预测输入
target: Tensor, # 标签
weight: Optional[Tensor] = None, # 权重可选项
size_average: Optional[bool] = None, # 可选项,快被弃用了
reduce: Optional[bool] = None,
reduction: str = "mean", # 默认均值或求和等形式
) -> Tensor:
input: 形状为(N, *)的张量,表示模型的预测结果,取值范围可以是任意实数。target: 形状为(N, *)的张量,表示真实标签,取值为 0 或 1。

import torch
import torch.nn.functional as F
import mathrow, col = 2, 3
x = torch.randn(row, col)predict = torch.sigmoid(x)index = torch.randint(col, size = (row,), dtype=torch.long)
y = torch.zeros(row, col)
y[range(y.shape[0]), index] = 1
print(range(y.shape[0]))loss1 = F.binary_cross_entropy(predict, y)
print("loss1 ",loss1)def binary_cross_entropy(predict, y):loss = -torch.sum(y * torch.log(predict) + (1 - y) * torch.log(1 - predict)) / torch.numel(y)return lossloss2 = binary_cross_entropy(predict, y)
print("loss2 ", loss2)range(0, 2)
loss1 tensor(1.1794)
loss2 tensor(1.1794)
F.binary_cross_entropy_with_logits
相比F.binary_cross_entropy函数,F.binary_cross_entropy_with_logits函数在内部使用了sigmoid函数.
F.binary_cross_entropy_with_logits = sigmoid + F.binary_cross_entropy。
F.cross_entropy
多分类交叉熵损失函数
F.cross_entropy(input, target, weight=None, size_average=None, ignore_index=-100, reduce=None, reduction='mean')
参数说明:
input:(N, C)形状的张量,其中N为Batch_size,C为类别数。该参数对应于神经网络最后一个全连接层输出的未经Softmax处理的结果。
target:一个大小为(N,)张量,其值是0 <= targets[i] <= C-1的元素,其中C是类别数。该参数包含一组给定的真实标签(ground truth)。
weight:采用类别平衡的加权方式计算损失值。可以传入一个大小为(C,)张量,其中weight[j]是类别j的权重。默认为None。
size_average:弃用,可以忽略。该参数已经被reduce参数取代了。
ignore_index:指定被忽略的目标值的索引。如果目标值等于该索引,则不计算该样本的损失。默认值为-100,即不忽略任何目标值。
reduce:指定返回的损失值的方式。可以是“None”(不返回损失值)、“mean”(返回样本损失值的平均值)和“sum”(返回样本损失值的总和)。默认值为“mean”。
reduction:与reduce参数等价。表示返回的损失值的方式。默认值为“mean”。
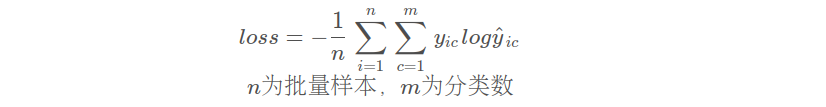
F.cross_entropy函数与nn.CrossEntropyLoss类是相似的,但前者更适合于控制更多的细节。
由于内部已经使用SoftMax函数处理,故两者的输入都不需要使用SoftMax处理。
import torch
import torch.nn.functional as F
import math# redictions:一个2维tensor,表示模型的预测结果。它的形状是(2, 3),其中2是样本数量,3是类别数量。每一行对应一个样本的预测结果,每个元素表示该类别的概率。
# labels:一个1维tensor,表示样本的真实标签。它的形状是(2,),其中2是样本数量。
predictions = torch.tensor([[0.2, 0.3, 0.5], [0.8, 0.1, 0.1]])
labels = torch.tensor([2, 0])# 定义每个类别的权重
weights = torch.tensor([1.0, 2.0, 3.0])# 使用F.cross_entropy计算带权重的交叉熵损失
loss = F.cross_entropy(predictions, labels, weight=weights)
print(loss) # tensor(0.8773)# 测试计算过程
pred = F.softmax(predictions, dim=1)
loss2 = -(weights[2] * math.log(pred[0, 2]) + weights[0]*math.log(pred[1, 0]))/4 # 4 = 1+3 对应权重之和
print(loss2) # 0.8773049571540321# 对于第一个样本,它的预测结果为pred[0],真实标签为2。根据交叉熵损失的定义,我们可以计算出它的损失为:
# -weights[2] * math.log(pred[0, 2])
# 对于第二个样本,它的预测结果为pred[1],真实标签为0。根据交叉熵损失的定义,我们可以计算出它的损失为:
# -weights[0] * math.log(pred[1, 0])torch.nn.BCELoss
torch.nn.BCELoss(
weight=None,
size_average=None,
reduce=None,
reduction='mean' # 默认计算的是批量样本损失的平均值,还可以为'sum'或者'none'
)
torch.nn.BCEWithLogitsLoss
torch.nn.BCEWithLogitsLoss(
weight=None,
size_average=None,
reduce=None,
reduction='mean', # 默认计算的是批量样本损失的平均值,还可以为'sum'或者'none'
pos_weight=None
)
import numpy as np
import torch
from torch import nn
import torch.nn.functional as Fy = torch.tensor([1, 0, 1], dtype=torch.float)
y_hat = torch.tensor([0.8, 0.2, 0.4], dtype=torch.float)bce_loss = nn.BCELoss()# nn.BCELoss()需要先对输入数据进行sigmod
print("官方BCELoss = ", bce_loss(torch.sigmoid(y_hat), y))# nn.BCEWithLogitsLoss()不需要自己sigmod
bcelogits_loss = nn.BCEWithLogitsLoss()
print("官方BCEWithLogitsLoss = ", bcelogits_loss(y_hat, y))# 我们根据二分类交叉熵损失函数实现:
def loss(y_hat, y):y_hat = torch.sigmoid(y_hat)l = -(y * np.log(y_hat) + (1 - y) * np.log(1 - y_hat))l = sum(l) / len(l)return lprint('自己实现Loss = ', loss(y_hat, y))
# 可以看到结果值相同
官方BCELoss = tensor(0.5608)
官方BCEWithLogitsLoss = tensor(0.5608)
自己实现Loss = tensor(0.5608)
BCELoss与BCEWithLogitsLoss的关联:BCEWithLogitsLoss = Sigmoid + BCELoss
import numpy as np
import torch
from torch import nn
import torch.nn.functional as Fy = torch.tensor([1, 0, 1], dtype=torch.float)
y_hat = torch.tensor([0.8, 0.2, 0.4], dtype=torch.float)bce_loss = nn.BCELoss()# nn.BCELoss()需要先对输入数据进行sigmod
print("官方BCELoss = ", bce_loss(torch.sigmoid(y_hat), y))# nn.BCEWithLogitsLoss()不需要自己sigmod
bcelogits_loss = nn.BCEWithLogitsLoss()
print("官方BCEWithLogitsLoss = ", bcelogits_loss(y_hat, y))# 我们根据二分类交叉熵损失函数实现:
def loss(y_hat, y):y_hat = torch.sigmoid(y_hat)l = -(y * np.log(y_hat) + (1 - y) * np.log(1 - y_hat))l = sum(l) / len(l)return lprint('自己实现Loss = ', loss(y_hat, y))
# 可以看到结果值相同
官方BCELoss = tensor(0.5608)
官方BCEWithLogitsLoss = tensor(0.5608)
自己实现Loss = tensor(0.5608)
torch.nn.CrossEntropyLoss()
torch.nn.CrossEntropyLoss(
weight=None,
size_average=None,
ignore_index=-100,
reduce=None,
reduction='mean',
label_smoothing=0.0 # 同样,默认计算的是批量样本损失的平均值,还可以为'sum'或者'none'
)
- 在关于二分类的问题中,输入交叉熵公式的网络预测值必须经过
Sigmoid进行映射 - 而在多分类问题中,需要将
Sigmoid替换成Softmax,这是两者的一个重要区别 - CrossEntropyLoss =
softmax+log+nll_loss的集成
多分类交叉熵损失函数
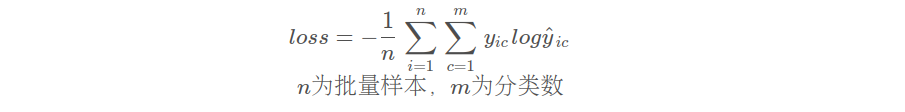


cross_loss = nn.CrossEntropyLoss(reduction="none") # 设置为none,这里输入每个样本的loss值,不计算平均值
target = torch.tensor([0, 1, 2])predict = torch.tensor([[0.9, 0.2, 0.8],[0.5, 0.2, 0.4],[0.4, 0.2, 0.9]]) # 未经过softmax
print('官方实现CrossEntropyLoss: ', cross_loss(predict, target))# 自己实现方便理解版本的CrossEntropyLoss
def cross_loss(predict, target, reduction=None):all_loss = []for index, value in enumerate(target):# 利用多分类简化后的公式,对每一个样本求loss值loss = -predict[index][value] + torch.log(sum(torch.exp(predict[index])))all_loss.append(loss)all_loss = torch.stack(all_loss)if reduction == 'none':return all_losselse:return torch.mean(all_loss)print('实现方便理解的CrossEntropyLoss: ', cross_loss(predict, target, reduction='none'))# 利用F.nll_loss实现的CrossEntropyLoss
def cross_loss2(predict, target, reduction=None):# Softmax的缺点:# 1、如果有得分值特别大的情况,会出现上溢情况;# 2、如果很小的负值很多,会出现下溢情况(超出精度范围会向下取0),分母为0,导致计算错误。# 引入log_softmax可以解决上溢和下溢问题logsoftmax = F.log_softmax(predict)print('target = ', target)print('logsoftmax:\n', logsoftmax)# nll_loss不是将标签值转换为one-hot编码,而是根据target的值,索引到对应元素,然后取相反数。loss = F.nll_loss(logsoftmax, target, reduction=reduction)return lossprint('F.nll_loss实现的CrossEntropyLoss: ', cross_loss2(predict, target, reduction='none'))
官方实现CrossEntropyLoss: tensor([0.8761, 1.2729, 0.7434])
实现方便理解的CrossEntropyLoss: tensor([0.8761, 1.2729, 0.7434])target = tensor([0, 1, 2])
logsoftmax:
tensor([[-0.8761, -1.5761, -0.9761],
[-0.9729, -1.2729, -1.0729],
[-1.2434, -1.4434, -0.7434]])
F.nll_loss实现的CrossEntropyLoss: tensor([0.8761, 1.2729, 0.7434])
相关文章:

pytorch基本操作2
torch.clamp 主要用于对张量中的元素进行截断(clamping),将其限制在一个指定的区间范围内。 函数定义 torch.clamp(input, minNone, maxNone) → Tensor 参数说明 input 类型:Tensor 需要进行截断操作的输入张…...
)
Linux服务器配置Anaconda环境、Pytorch库(图文并茂的教程)
引言:为了方便后续新进组的 师弟/师妹 使用课题组的服务器,特此编文(ps:我导从教至今四年,还未招师妹) ✅ NLP 研 2 选手的学习笔记 笔者简介:Wang Linyong,NPU,2023级&a…...

idea 许可证过期
今天打开IDEA写代码突然提示:Your idea evaluation has expired. Your session will be limited to 30 minutes 评估已过期,您的会话将限制为 30 分钟。也就是说可以使用,但30min就会自动关闭 1 下载 ide-eval-resetter-2.1.6.zip https…...

Git常用命令分类汇总
Git常用命令分类汇总 一、基础操作 初始化仓库git init添加文件到暂存区git add file_name # 添加单个文件 git add . # 添加所有修改提交更改git commit -m "提交描述"查看仓库状态git status二、分支管理 创建/切换分支git branch branch_name …...

归并排序:数据排序的高效之道
🧑 博主简介:CSDN博客专家,历代文学网(PC端可以访问:https://literature.sinhy.com/#/literature?__c1000,移动端可微信小程序搜索“历代文学”)总架构师,15年工作经验,…...
)
分布式训练(记录)
为什么要分布式训练? 单机训练有物理上限: 显存不够(大模型根本放不下) 单机计算慢(数据量一多就耗时太长) 多卡并行性不高 分布式训练的常见方式 Data Parallel(数据并行) 每个G…...

vue3中使用拖拽组件vuedragable@next
vue3中使用拖拽组件vuedragablenext 官网传送门 下载 npm install vuedraggablenext基本使用 <script setup> import draggable from vuedraggable import { ref } from vue const list ref([{ id:1,name:第一个 },{ id:2,name:第二个 },{ id:3,name:第三个 }, ]) <…...

Oracle、MySQL、PostgreSQL三大数据库对比分析
Oracle、MySQL、PostgreSQL 三大数据库的对比分析,结合 Java SpringBoot 项目开发 的实际场景,重点说明分库分表、主从复制的实现难度及案例。 一、数据库核心对比 1. 核心区别与适用场景 维度OracleMySQLPostgreSQL定位企业级商业数据库轻量级开源数据…...

java八股之并发编程
1.java线程和操作系统线程之间的区别? 现在java线程本质上是操作系统线程,java中采用的是一对一的线程模型(一个用户线程对应一个内核进程) 2.什么是进程和线程? 1.进程是操作系统一次执行,资源分配和调度的…...

Qt 入门 5 之其他窗口部件
Qt 入门 5 之其他窗口部件 本文介绍的窗口部件直接或间接继承自 QWidget 类详细介绍其他部件的功能与使用方法 1. QFrame 类 QFrame类是带有边框的部件的基类。它的子类包括最常用的标签部件QLabel另外还有 QLCDNumber、QSplitter,QStackedWidget,QToolBox 和 QAbstractScrol…...

Linux系统之----冯诺依曼结构
1.简要描述 冯诺依曼体系结构是现代计算机的基本设计思想,其核心理念是将计算机的硬件和软件统一为一个整体,通过存储程序的方式实现计算。冯诺依曼体系结构的核心思想是通过存储程序实现自动计算,其五大部件协同工作,奠定了现代…...

C++11新特性
目录 引入 C11新特性 统一的初始化列表 一切皆可{}初始化 std::initializer_list 统一的声明 auto decltype nullptr 范围for STL新增容器 STL新增容器接口 左值引用和右值引用 左值和右值 左值引用和右值引用 右值引用的优势(移动语义) 右值引用的使用场景 …...

492Q 型气缸盖双端面铣削组合铣床总体设计
一、引言 492Q 型气缸盖是发动机的重要组成部分,其双端面的加工精度对发动机的性能和可靠性有着重要影响。设计一款适用于 492Q 型气缸盖双端面铣削的组合铣床,能够提高加工效率和质量,满足发动机生产的需求。 二、总体设计要求 加工精度&…...
——关系代数、函数依赖、范式)
《软件设计师》复习笔记(4.2)——关系代数、函数依赖、范式
目录 一、关系代数 基本运算 笛卡尔积() 投影(π) 选择(σ) 自然连接(⋈) 真题示例: 二、函数依赖 基本概念 Armstrong公理系统 键与约束 三、范式ÿ…...
)
IO流(二)
一、字符流 使用字节流可以读取文件中的字节数据。但是如果文件中有中文使用字节流来读取,就有可能读到半个汉字的情况,这样会导致乱码。虽然使用读取全部字节的方法不会出现乱码,但是如果文件过大又不太合适。 所以Java专门为我们提供了另…...

#Linux动态大小裁剪以及包大小变大排查思路
1 动态库裁剪 库分为动态库和静态库,动态库是在程序运行时才加载,静态库是在编译时就加载到程序中。动态库的大小通常比静态库小,因为动态库只包含了程序需要的函数和数据,而静态库则包含了所有的函数和数据。静态库可以理解为引入…...

天梯赛数据结构合集
1.集合操作:PTA | 程序设计类实验辅助教学平台 主要是注意set的取交集操作,AC代码: #include<bits/stdc.h> using namespace std; int n,m,k; set<int> a[60]; int main(){cin>>n;for(int i1;i<n;i){cin>>m;for…...

pdfjs库使用记录1
import React, { useEffect, useState, useRef } from react; import * as pdfjsLib from pdfjs-dist; // 设置 worker 路径 pdfjsLib.GlobalWorkerOptions.workerSrc /pdf.worker.min.js; const PDFViewer ({ url }) > { const [pdf, setPdf] useState(null); const […...

LIMS引领综合质检中心数字化变革,赋能质量强国战略
在质量强国战略的深入推进下,我国综合质检机构迎来了前所未有的发展机遇,同时也面临着诸多严峻挑战。随着检测领域从传统的食品药品监督向环境监测、新材料检测等新兴领域不断拓展,跨领域协同管理的复杂度呈指数级增长。作为提升产品质量的关…...

MySQL+Redis实战教程:从Docker安装部署到自动化备份与数据恢复20250418
MySQLRedis实战教程:从Docker安装部署到自动化备份与数据恢复 一、前言 在企业应用中,对MySQL和Redis运维的要求越来越高: 不能仅是启动就算部署运行稳定、隔离、访问控制、备份恢复、安全可靠,才是 企业级的基本功能 本文将手…...

嵌入式音视频开发指南:从MPP框架到QT实战全解析
嵌入式音视频开发指南:从MPP框架到QT实战全解析 一、音视频技术全景概述 1.1 技术演进里程碑 2003-2010年:标清时代(H.264/AVC + RTMP)2011-2018年:高清时代(H.265/HEVC + WebRTC)2019-至今:智能时代(AV1 + AI编解码 + 低延迟传输)1.2 现代音视频技术栈 #mermaid-s…...

如何使用Python进行自动化的系统管理?
Python已经成为系统管理员最流行的编程语言之一,因为它简单、灵活,并且广泛支持各种系统管理任务。无论您是自动执行重复性任务,管理文件和目录,还是处理用户权限,Python都提供了一组强大的工具来简化您的工作流程。 …...

拆机装机,通电主板亮灯风扇不转无法开机解决办法
电源开机线 重启线 usb耳机模块 灯线 看来电源没问题 参考https://zhidao.baidu.com/question/83939532/answer/2321171868.html 买了个新主板过几天到看看会不会好...

IntelliSense 已完成初始化,但在尝试加载文档时出错
系列文章目录 文章目录 系列文章目录前言一、原因二、使用步骤 前言 IntelliSense 已完成初始化,但在尝试加载文档时出错 File path: E:\QtExercise\DigitalPlatform\DigitalPlatform\main\propertyWin.ui Frame GUID:96fe523d-6182-49f5-8992-3bea5f7e6ff6 Frame …...

SuperMap iClient3D for WebGL 如何加载WMTS服务
在 SuperMap iClient3D for WebGL 中加载WMTS服务时,参数配置很关键!下面我们详细介绍如何正确填写参数,确保影像服务完美加载。 一、数据制作 对于上述视频中的地图制作,此处不做讲述,如有需要可访问:Onl…...

[密码学实战]基于Python的国密算法与通用密码学工具箱
引言 在当今数字化浪潮中,信息安全已成为个人隐私保护与商业机密守护的核心议题。作为一位在密码学领域深耕多年的技术实践者,我深谙密码学工具在构建数字安全防线中的关键作用。正是基于这份认知与责任,我倾力打造了一款全方位、高性能的密…...

[密码学实战]详解gmssl库与第三方工具兼容性问题及解决方案
[密码学实战]详解gmssl库与第三方工具兼容性问题及解决方案 引言 国密算法(SM2/SM3/SM4)在金融、政务等领域广泛应用,但开发者在集成gmssl库实现SM2签名时,常遇到与第三方工具(如OpenSSL、国密网关)验证不…...
平台通用C/C++扩展库, stream 流操作)
LIB-ZC, 一个跨平台(Linux)平台通用C/C++扩展库, stream 流操作
LIB-ZC, 一个跨平台(Linux)平台通用C/C扩展库, stream 流操作 lib-zc 封装了流操作命名空间 zcc基础类 stream(基类), iostream(io流封装) class stream 介绍 连接相关 // 都是虚函数, 为 iostream 等做准备virtual inline bool connect(const char *destination) { return …...

从零开始解剖Spring Boot启动流程:一个Java小白的奇幻冒险之旅
大家好呀!今天我们要一起探索一个神奇的话题——Spring Boot的启动流程。我知道很多小伙伴一听到"启动流程"四个字就开始头疼,别担心!我会用最通俗易懂的方式,带你从main()方法开始,一步步揭开Spring Boot的…...
:多目标跟踪中的概率软关联与高效跟踪算法解析)
概率多假设跟踪(PMHT):多目标跟踪中的概率软关联与高效跟踪算法解析
一、PMHT 的起源与核心定位 (一)背景 在多目标跟踪中,传统算法面临以下瓶颈: JPDA:单帧局部最优关联,无法处理跨帧长时间断联,且假设目标数固定(如雷达跟踪中预设目标数范围&…...
)
4.信号和槽|存在意义|信号和槽的连接方式|信号和槽断开|lambda表达式|信号和槽优缺点(C++)
信号和槽存在意义 所谓的信号槽,终究要解决的问题,就是响应用户的操作 信号槽,其实在GUI开发的各种框架中,是一个比较有特色的存在 其他的GUI开发框架,搞的方式都要更简洁一些~~ 网页开发 (js dom api) 网…...
)
电脑 BIOS 操作指南(Computer BIOS Operation Guide)
电脑 BIOS 操作指南 电脑的BIOS界面(应为“BIOS”)是一个固件界面,允许用户配置电脑的硬件设置。 进入BIOS后,你可以进行多种设置,具体包括: 1.启动配置 启动顺序:设置从哪个设备启动&#x…...

Scrapeless Scraping Browser: A high-concurrency automation solution for AI
介绍:升级无缝抓取浏览器的并发能力 作为 Scrapeless 的开发者和创始团队,我们对人工智能自动化的未来充满真诚的热情。我们的使命是创建一个真正为 AI 设计的自动化浏览器。在过去的几年中,从 Browserless.io 到众多云服务供应商推出的“浏…...
)
Java项目—— 拼图小游戏(进阶版)
项目需求 在拼图小游戏基础版的基础上,完成下列要求: 一、实现更换拼图图片功能 1,给美女,动物,运动菜单按钮添加单击事件(动作监听) 2,当我们点击了美女之后,就会从13…...

解析:深度优先搜索、广度优先搜索和回溯搜索
一、深度优先搜索(DFS) 1. 原理 思想:从起始节点出发,顺着一条路径不断深入,直到到达目标或无路可走,然后回溯到最近的分支点,继续探索其他分支。 应用场景:路径查找、连通性检测、…...
:循环神经网络的深度解析与实战(RNN、LSTM 与 GRU))
探索大语言模型(LLM):循环神经网络的深度解析与实战(RNN、LSTM 与 GRU)
一、循环神经网络(RNN) 1.1 基本原理 循环神经网络之所以得名,是因为它在处理序列数据时,隐藏层的节点之间存在循环连接。这意味着网络能够记住之前时间步的信息,并利用这些信息来处理当前的输入。 想象一下…...

从零开始开发 MCP Server
作者:张星宇 在大型语言模型(LLM)生态快速演进的今天,Model Context Protocol(MCP)作为连接 AI 能力与真实世界的标准化协议,正逐步成为智能体开发的事实标准。该协议通过定义 Resources&#…...

Oracle日志系统之重做日志和归档日志
Oracle日志系统之重做日志和归档日志 重做日志归档日志 本文讨论Oracle日志系统中对数据恢复非常重要的两个日志:重做日志和归档日志。 重做日志 重做日志,英文名Redo Log,顾名思义,是用来数据重做的,主要使用场景是事…...

嵌入式开发--STM32G4系列硬件CRC支持MODBUS和CRC32
需求 在项目中,需要用到MODBUS CRC16校验,也要用到CRC32的校验,出于效率的考虑,准备用硬件CRC。 CRC 16的参数模型有很多种,我这里用的是MODBUS,对于不同的参数模型,会有不同的参数设置和初值&a…...

基于尚硅谷FreeRTOS视频笔记——4—多任务处理
目录 多任务处理 任务调度 任务的调度策略 优先级不同 优先级相同 多任务处理 通俗来讲就是 能够在同一时间 同时 进行多个任务的处理,这就时多任务处理。 但是,单核处理器一次只能处理一个任务,就是说在while中,任务们只能…...

中小型及初创企业如何实现数字化转型?
在当今动态的商业环境中,财务团队开始肩负起推动企业数字化转型的重任,即从传统的财务规划系统稳步迈向基于商业智能平台和以创新技术为驱动的解决方案领域。这些举措有望提高运营和分析效率,同时依托数据驱动的决策机制,帮助企业…...

java输出、输入语句
先创建一个用于测试的java 编写程序 #java.util使java标准库的一个包,这里拉取Scanner类 import java.util.Scanner;public class VariableTest {public static void main(String[] args) {#创建一个 Scanner 对象Scanner scanner new Scanner(System.in);System.…...
)
Python基础知识语法归纳总结(数据类型-1)
Python基础知识&语法归纳总结(数据类型) 一、Python基本数据类型 尤其注意,Python中的变量不需要特定的去声明,每个变量在使用前都必须对其进行赋值,它没有类型,我们所说的“类型”是变量所指的内存中对…...

Spring数据访问全解析:ORM整合与JDBC高效实践
目录 一、Spring ORM集成深度剖析 🌟 ORM模块架构设计 核心集成特性: 整合MyBatis示例配置: 二、Spring JDBC高效实践指南 🌟 传统JDBC vs Spring JDBC对比 🌟 JdbcTemplate核心操作示例 批量操作优化…...

哪种电脑更稳定?Mac?Windows?还是云电脑? 实测解密
随着科技的发展进步,电脑已成为当下各类群体的必备产品之一,它的妙用有很多,无论是学生党、打工人还是已经退休的人群或都离不开它的存在。然而,电脑虽好却也差异很大、不同品牌、不同系统、不同配置、不同价位的统统都会有区别。…...

【AI模型学习】关于写论文——论文的审美
文章目录 一、“补丁法”(Patching)1.1 介绍1.2 方法论1.3 实例 二、判断工作的价值2.1 介绍2.2 详细思路2.3 科研性vs工程性 三、novelty以及误区3.1 介绍3.2 举例 看了李沐老师的读论文系列后,总结三个老师提到的有关课题研究和论文写作的三…...

【面经】杭州产链数字科技一面
1.介绍一下自己 面试官您好!我叫***,目前是就读于****计算机科学与技术专业的一名学生。我平时在学校也自学了编程相关的知识,比如Java基础、Springboot、SpringCloud,关系型数据库Mysql,非关系型数据库Redisÿ…...

微信小程序调用yolo目标检测模型
目录 后端 前端微信小程序 完整代码 后端 利用Flask,调用目标检测模型,后端代码如下。 # flask_yolo.py from flask import Flask, request, jsonify from ultralytics import YOLO from PIL import Imageapp Flask(__name__) model_path best.p…...

vmware17 虚拟机 ubuntu22.04 桥接模式,虚拟机无法接收组播消息
问题描述: 在一个项目中,宿主机win10中,使用的vmware17pro 虚拟机安装的ubuntu22.04,按照网上的教程使用Qt绑定组播消息,在另外一个Ubuntu工控机上发送用wiresahrk抓包的组播消息 sudo tcpreplay -i enp1s0 --loop0 y…...
)
Kaggle-Bag of Words Meets Bags of Popcorn-(二分类+NLP+Bert模型)
Bag of Words Meets Bags of Popcorn 题意: 有很多条电影评论记录,问你每一条记录是积极性的评论还是消极性的评论。 数据处理: 1.首先这是文件是zip形式,要先解压,注意sep ‘\t’。 2.加载预训练的 BERT 分词器 …...