hive的基础配置优化与数仓流程
1.HDFS副本数
dfs.replication(HDFS)
文件副本数,通常设为3,不推荐修改。
如果测试环境只有二台虚拟机(2个datanode节点),此值要修改为2。

2.Yarn基础配置
2.1NodeManager配置
2.1.1CPU配置
配置项:yarn.nodemanager.resource.cpu-vcores
表示该节点服务器上yarn可以使用的虚拟CPU个数,默认值是8,推荐将值配置与物理CPU线程数相同,如果节点CPU核心不足8个,要调小这个值,yarn不会智能的去检测物理核心数。

2.1.2内存配置
配置项:yarn.nodemanager.resource.memory-mb
设置该nodemanager节点上可以为容器分配的总内存,默认为8G,如果节点内存资源不足8G,要减少这个值,yarn不会智能的去检测内存资源,一般按照服务器剩余可用内存资源进行配置。生产上根据经验一般要预留15-20%的内存,那么可用内存就是实际内存*0.8,比如实际内存是64G,那么64*0.8=51.2G,我们设置成50G就可以了(固定经验值)。
注意,要同时设置yarn.scheduler.maximum-allocation-mb为一样的值,yarn.app.mapreduce.am.command-opts(JVM内存)的值要同步修改为略小的值(-Xmx1024m)。
也就是:
yarn.nodemanager.resource.memory-mb
yarn.scheduler.maximum-allocation-mb : 与第一个保持一致
yarn.app.mapreduce.am.command-opts : 略小于第一个配置的值(0.9)

2.1.3本地目录
yarn.nodemanager.local-dirs(Yarn)
NodeManager 存储中间数据文件的本地文件系统中的目录列表。
如果单台服务器上有多个磁盘挂载,则配置的值应当是分布在各个磁盘上目录,这样可以充分利用节点的IO读写能力。

3.MapReduce内存配置
当MR内存溢出时,可以根据服务器配置进行调整。
1.mapreduce.map.memory.mb: 在运行MR的时候, 一个mapTask需要占用多大内存
为作业的每个 Map 任务分配的物理内存量(MiB),默认为0,自动判断大小。

2.mapreduce.reduce.memory.mb::在运行MR的时候, 一个reduceTask需要占用多大内存
为作业的每个 Reduce 任务分配的物理内存量(MiB),默认为0,自动判断大小。

3.mapreduce.reduce.java.opts: 在运行MR的时候, 一个reduceTask对应jvm需要占用多大内容
Map和Reduce的JVM配置选项。

注意:
mapreduce.map.java.opts一定要小于mapreduce.map.memory.mb;
mapreduce.reduce.java.opts一定要小于mapreduce.reduce.memory.mb,格式-Xmx4096m。
注意:
此部分所有配置均不能大于Yarn的NodeManager内存配置。
4.Hive基础配置
4.1hiveserver2的内存大小配置
配置项: HiveServer2 的 Java 堆栈大小(字节)
注意:Hiveserver2异常退出,导致连接失败的问题就是因为它
比如:
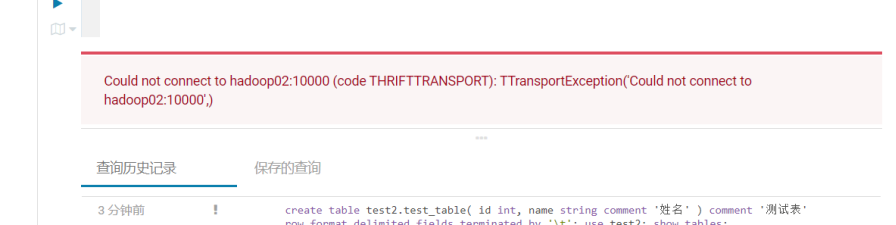
配置:HiveServer2 的 Java 堆栈大小(字节)

4.2动态生成分区的线程数
配置: hive.load.dynamic.partitions.thread
用于加载动态生成的分区的线程数。加载需要将文件重命名为它的最终位置,并更新关于新分区的一些元数据。默认值为 15 。
当有大量动态生成的分区时,增加这个值可以提高性能。根据服务器配置修改。

4.3监听输入文件线程数
hive.exec.input.listing.max.threads
Hive用来监听输入文件的最大线程数。默认值:15。
当需要读取大量分区时,增加这个值可以提高性能。根据服务器配置进行调整。

5.压缩配置
5.1Map输出压缩
除了创建表时指定保存数据时压缩,在查询分析过程中,Map的输出也可以进行压缩。由于map任务的输出需要写到磁盘并通过网络传输到reducer节点,所以通过使用LZO、LZ4或者Snappy这样的快速压缩方式,是可以获得性能提升的,因为需要传输的数据减少了。
MapReduce配置项:
mapreduce.map.output.compress
设置是否启动map输出压缩,默认为false。在需要减少网络传输的时候,可以设置为true。
mapreduce.map.output.compress.codec
设置map输出压缩编码解码器,默认为org.apache.hadoop.io.compress.DefaultCodec,推荐使用SnappyCodec:org.apache.hadoop.io.compress.SnappyCodec。
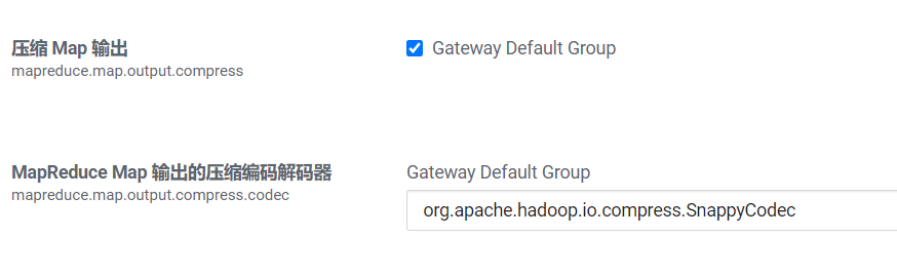
5.2Reduce结果压缩
是否对任务输出结果压缩,默认值false。对传输数据进行压缩,既可以减少文件的存储空间,又可以加快数据在网络不同节点之间的传输速度。
配置项:
mapreduce.output.fileoutputformat.compress
是否启用 MapReduce 作业输出压缩。
mapreduce.output.fileoutputformat.compress.codec
指定要使用的压缩编码解码器,推荐SnappyCodec。
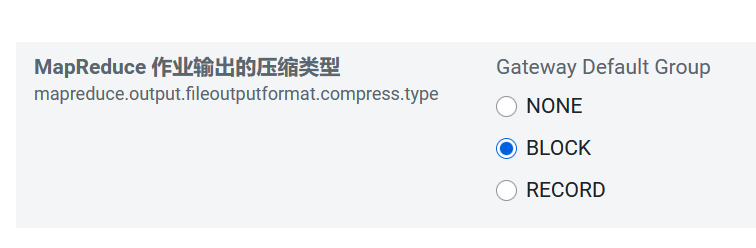
mapreduce.output.fileoutputformat.compress.type
指定MapReduce作业输出的压缩方式,默认值RECORD,可配置值有:NONE、RECORD、BLOCK。推荐使用BLOCK,即针对一组记录进行批量压缩,压缩效率更高。
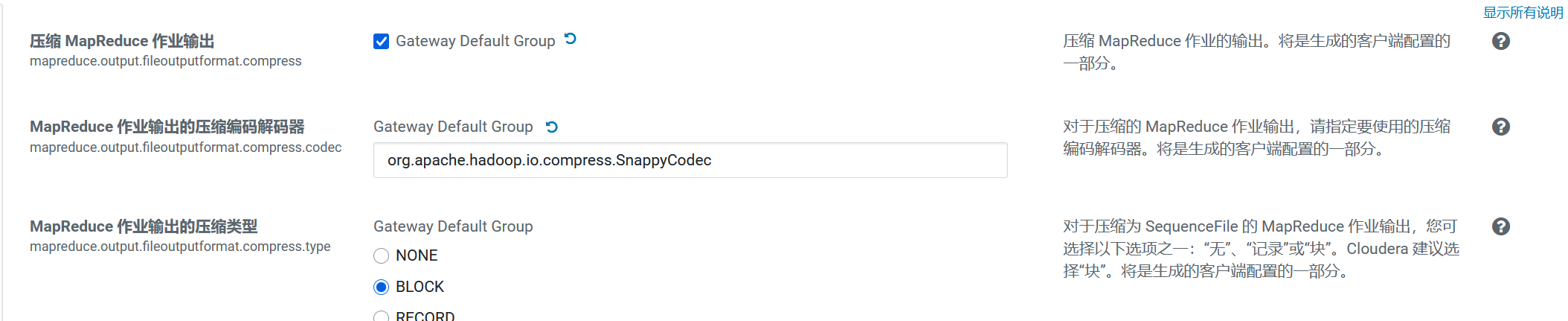
5.3Hive执行过程通用压缩设置
主要包括压缩/解码器设置和压缩方式设置:
mapreduce.output.fileoutputformat.compress.codec(Yarn)
map输出所用的压缩编码解码器,默认为org.apache.hadoop.io.compress.DefaultCodec;
推荐使用SnappyCodec:org.apache.hadoop.io.compress.SnappyCodec

mapreduce.output.fileoutputformat.compress.type
输出产生任务数据的压缩方式,默认值RECORD,可配置值有:NONE、RECORD、BLOCK。推荐使用BLOCK,即针对一组记录进行批量压缩,压缩效率更高。
5.4Hive多个Map-Reduce中间数据压缩
控制 Hive 在多个map-reduce作业之间生成的中间文件是否被压缩。压缩编解码器和其他选项由上面Hive通用压缩mapreduce.output.fileoutputformat.compress.*确定。
set hive.exec.compress.intermediate=true;
5.5Hive最终结果压缩
控制是否压缩查询的最终输出(到 local/hdfs 文件或 Hive table)。压缩编解码器和其他选项由 上面Hive通用压缩mapreduce.output.fileoutputformat.compress.*确定。
set hive.exec.compress.output=true;
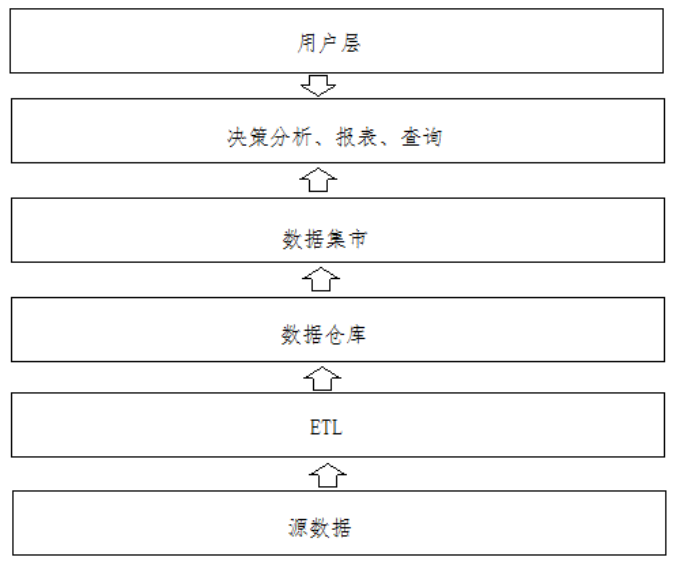
6.全量流程
OLTP原始数据(mysql)——》数据采集(ODS)——》清洗转换(DWD)——》统计分析(DWS)——》导出至OLAP(Mysql)
7.操作
7.1.业务mysql->hive_ODS
code:
--访问咨询主表
sqoop import \
--connect jdbc:mysql://192.168.52.150:3306/nev \
--username root \
--password 123456 \
--query 'SELECT
id,create_date_time,session_id,sid,create_time,seo_source,seo_keywords,ip,
AREA,country,province,city,origin_channel,USER AS user_match,manual_time,begin_time,end_time,
last_customer_msg_time_stamp,last_agent_msg_time_stamp,reply_msg_count,
msg_count,browser_name,os_info, "2021-09-24" AS starts_time
FROM web_chat_ems_2019_07 where 1=1 and $CONDITIONS' \
--hcatalog-database itcast_ods \
--hcatalog-table web_chat_ems \
-m 1--访问咨询附属表
sqoop import \
--connect jdbc:mysql://192.168.52.150:3306/nev \
--username root \
--password 123456 \
--query 'SELECT
*, "2021-09-24" AS start_time
FROM web_chat_text_ems_2019_07 where 1=1 and $CONDITIONS' \
--hcatalog-database itcast_ods \
--hcatalog-table web_chat_text_ems \
-m 1
校验:
查看mysql共计有多少条数据
SELECT COUNT(1) FROM web_chat_ems_2019_07;
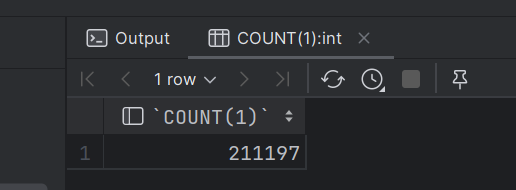
SELECT COUNT(1) FROM web_chat_text_ems_2019_07;
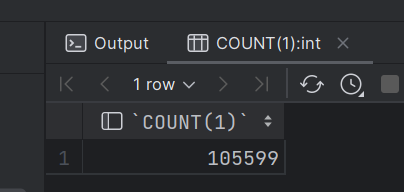
到hive中对表查询一下一共多少条数据
SELECT COUNT(1) FROM itcast_ods.web_chat_ems;
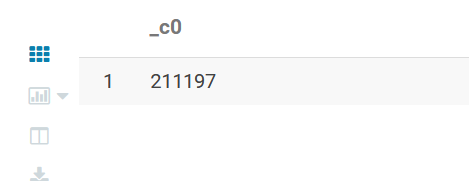
SELECT COUNT(1) FROM itcast_ods.web_chat_text_ems;
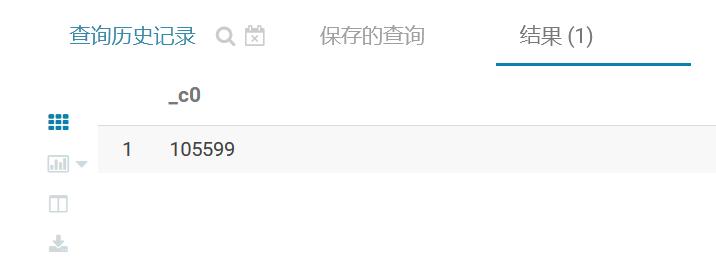
查询其中一部分数据, 观察数据映射是否OK
select * from itcast_ods.web_chat_ems limit 10;
SELECT * FROM itcast_ods.web_chat_text_ems limit 10;
7.2.ODS->DWD
数据清洗与转换,并少量做维度退化
转换: 将create_time转换为 yearinfo,quarterinfo,monthinfo,dayinfo,hourinfo:
方案: 通过 **year() quarter() month() day() hour() quarter() **
select year(‘2019-07-01 23:45:00’) ; – 2019
select month(‘2019-07-01 23:45:00’) ; – 7
select day(‘2019-07-01 23:45:00’) ; – 1
select hour(‘2019-07-01 23:45:00’) ; – 23
select quarter(‘2019-07-01 23:45:00’); – 3
code:
select
wce.session_id,
wce.sid,
unix_timestamp(wce.create_time) as create_time,
wce.seo_source,
wce.ip,
wce.area,
wce.msg_count,
wce.origin_channel,
wcte.referrer,
wcte.from_url,
wcte.landing_page_url,
wcte.url_title,
wcte.platform_description,
wcte.other_params,
wcte.history,
substr(wce.create_time,12,2) as hourinfo,
substr(wce.create_time,1,4) as yearinfo,
quarter(wce.create_time) as quarterinfo,
substr(wce.create_time,6,2) as monthinfo,
substr(wce.create_time,9,2) as dayinfo
from itcast_ods.web_chat_ems wce join itcast_ods.web_chat_text_ems wcte
on wce.id = wcte.id;
报错:Error while processing statement: FAILED: Execution Error, return code 137 from org.apache.hadoop.hive.ql.exec.mr.MapredLocalTask
原因: 在执行转换操作的时候, 由于需要进行二表联查操作, 其中一个表数据量比较少, 此时hive会对其优化, 采用map join的方案进行处理, 而map join需要将小表的数据加载到内存中, 但是内存不足, 导致出现内存溢出错误,
解决:
关闭掉map join 让其采用reduce join即可命令:
set hive.auto.convert.join= false;
执行后:
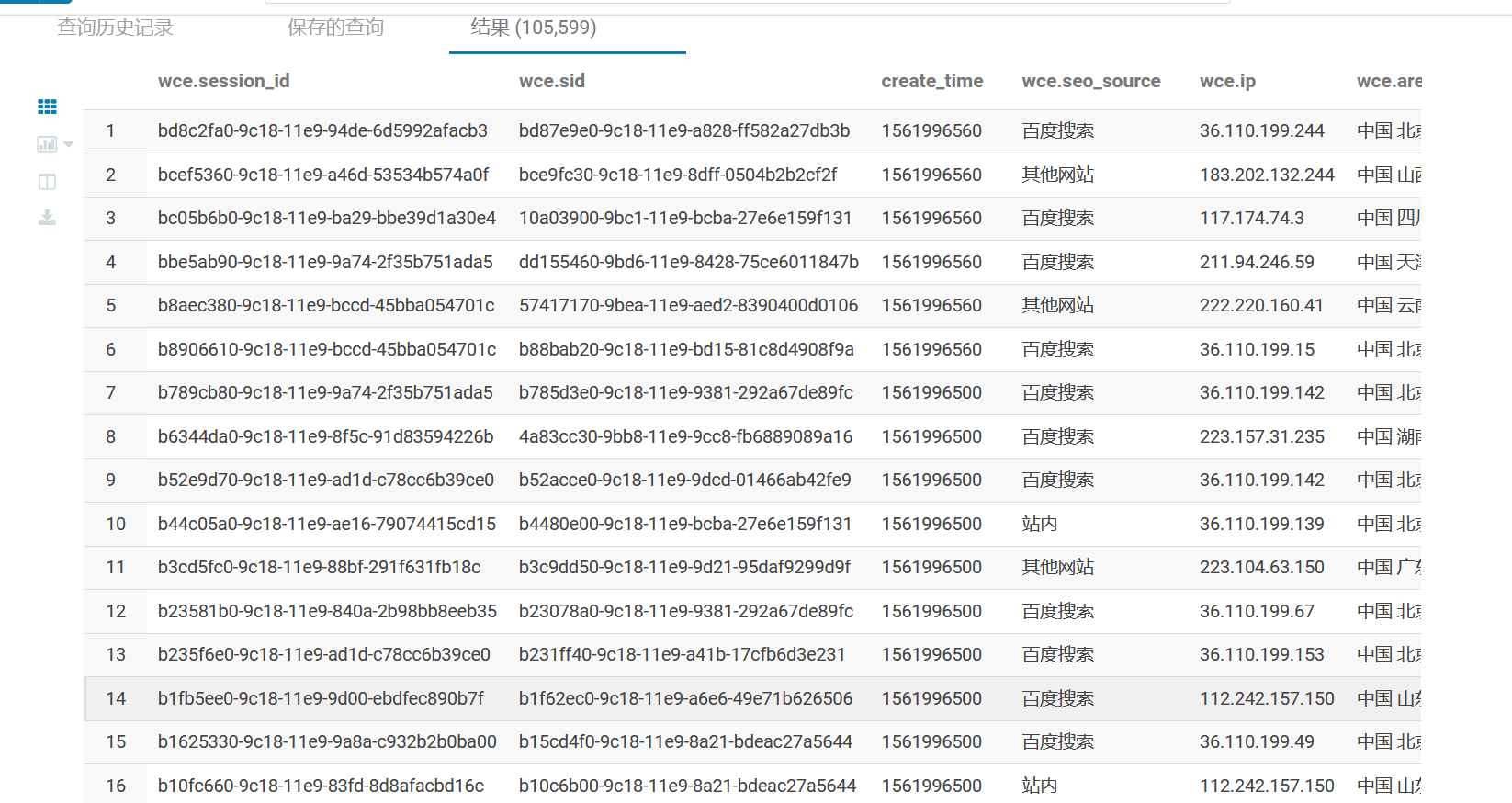
灌入DWD:可能出现分区问题,所以用的动态分区

解决如下:
--动态分区配置
set hive.exec.dynamic.partition=true;
set hive.exec.dynamic.partition.mode=nonstrict;
--hive压缩
set hive.exec.compress.intermediate=true;
set hive.exec.compress.output=true;
--写入时压缩生效
set hive.exec.orc.compression.strategy=COMPRESSION;
insert into table itcast_dwd.visit_consult_dwd partition(yearinfo,quarterinfo,monthinfo,dayinfo)
select
wce.session_id,
wce.sid,
unix_timestamp(wce.create_time) as create_time,
wce.seo_source,
wce.ip,
wce.area,
wce.msg_count,
wce.origin_channel,
wcte.referrer,
wcte.from_url,
wcte.landing_page_url,
wcte.url_title,
wcte.platform_description,
wcte.other_params,
wcte.history,
substr(wce.create_time,12,2) as hourinfo,
substr(wce.create_time,1,4) as yearinfo,
quarter(wce.create_time) as quarterinfo,
substr(wce.create_time,6,2) as monthinfo,
substr(wce.create_time,9,2) as dayinfo
from itcast_ods.web_chat_ems wce join itcast_ods.web_chat_text_ems wcte
on wce.id = wcte.id;
7.3.DWD->DWS
DWS层作用: 细化维度统计操作7.3.1以时间为基准, 统计总访问量
-- 统计每年的总访问量
insert into table itcast_dws.visit_dws partition(yearinfo,quarterinfo,monthinfo,dayinfo)
select
count(distinct sid) as sid_total,
count(distinct session_id) as sessionid_total,
count(distinct ip) as ip_total,
'-1' as area,
'-1' as seo_source,
'-1' as origin_channel,
'-1' as hourinfo,
yearinfo as time_str,
'-1' as from_url,
'5' as grouptype,
'5' as time_type,
yearinfo,
'-1' as quarterinfo,
'-1' as monthinfo,
'-1' as dayinfo
from itcast_dwd.visit_consult_dwd
group by yearinfo;解释:
- Partition: 指定了分区列
yearinfo,quarterinfo,monthinfo,dayinfo。- Select: 选择了需要统计的字段,包括用户ID、会话ID和IP地址的不同数量,以及一些固定的默认值。
- From: 数据来源于
itcast_dwd.visit_consult_dwd表。- Group By: 按
yearinfo进行分组,以便统计每年的总访问量。存放路径:
-- 统计每年每季度的总访问量
insert into table itcast_dws.visit_dws partition(yearinfo,quarterinfo,monthinfo,dayinfo)
select
count(distinct sid) as sid_total,
count(distinct session_id) as sessionid_total,
count(distinct ip) as ip_total,
'-1' as area,
'-1' as seo_source,
'-1' as origin_channel,
'-1' as hourinfo,
concat(yearinfo,'_',quarterinfo) as time_str,
'-1' as from_url,
'5' as grouptype,
'4' as time_type,
yearinfo,
quarterinfo,
'-1' as monthinfo,
'-1' as dayinfo
from itcast_dwd.visit_consult_dwd
group by yearinfo,quarterinfo;
-- 统计每年每季度每月的总访问量
insert into table itcast_dws.visit_dws partition(yearinfo,quarterinfo,monthinfo,dayinfo)
select
count(distinct sid) as sid_total,
count(distinct session_id) as sessionid_total,
count(distinct ip) as ip_total,
'-1' as area,
'-1' as seo_source,
'-1' as origin_channel,
'-1' as hourinfo,
concat(yearinfo,'-',monthinfo) as time_str,
'-1' as from_url,
'5' as grouptype,
'3' as time_type,
yearinfo,
quarterinfo,
monthinfo,
'-1' as dayinfo
from itcast_dwd.visit_consult_dwd
group by yearinfo,quarterinfo,monthinfo;
-- 统计每年每季度每月每天的总访问量
insert into table itcast_dws.visit_dws partition(yearinfo,quarterinfo,monthinfo,dayinfo)
select
count(distinct sid) as sid_total,
count(distinct session_id) as sessionid_total,
count(distinct ip) as ip_total,
'-1' as area,
'-1' as seo_source,
'-1' as origin_channel,
'-1' as hourinfo,
concat(yearinfo,'-',monthinfo,'-',dayinfo) as time_str,
'-1' as from_url,
'5' as grouptype,
'2' as time_type,
yearinfo,
quarterinfo,
monthinfo,
dayinfo
from itcast_dwd.visit_consult_dwd
group by yearinfo,quarterinfo,monthinfo,dayinfo;
-- 统计每年每季度每月每天每小时的总访问量
insert into table itcast_dws.visit_dws partition(yearinfo,quarterinfo,monthinfo,dayinfo)
select
count(distinct sid) as sid_total,
count(distinct session_id) as sessionid_total,
count(distinct ip) as ip_total,
'-1' as area,
'-1' as seo_source,
'-1' as origin_channel,
hourinfo,
concat(yearinfo,'-',monthinfo,'-',dayinfo,' ',hourinfo) as time_str,
'-1' as from_url,
'5' as grouptype,
'1' as time_type,
yearinfo,
quarterinfo,
monthinfo,
dayinfo
from itcast_dwd.visit_consult_dwd
group by yearinfo,quarterinfo,monthinfo,dayinfo,hourinfo;

7.3.2基于时间统计各个受访页面的访问量
-- 统计每年各个受访页面的访问量
insert into table itcast_dws.visit_dws partition(yearinfo,quarterinfo,monthinfo,dayinfo)
select
count(distinct sid) as sid_total,
count(distinct session_id) as sessionid_total,
count(distinct ip) as ip_total,
'-1' as area,
'-1' as seo_source,
'-1' as origin_channel,
'-1' as hourinfo,
yearinfo as time_str,
from_url,
'4' as grouptype,
'5' as time_type,
yearinfo,
'-1' as quarterinfo,
'-1' as monthinfo,
'-1' as dayinfo
from itcast_dwd.visit_consult_dwd
group by yearinfo,from_url;-- 统计每年,每季度各个受访页面的访问量
insert into table itcast_dws.visit_dws partition(yearinfo,quarterinfo,monthinfo,dayinfo)
select
count(distinct sid) as sid_total,
count(distinct session_id) as sessionid_total,
count(distinct ip) as ip_total,
'-1' as area,
'-1' as seo_source,
'-1' as origin_channel,
'-1' as hourinfo,
concat(yearinfo,'_',quarterinfo) as time_str,
from_url,
'4' as grouptype,
'4' as time_type,
yearinfo,
quarterinfo,
'-1' as monthinfo,
'-1' as dayinfo
from itcast_dwd.visit_consult_dwd
group by yearinfo,quarterinfo,from_url;-- 统计每年,每季度,每月各个受访页面的访问量
insert into table itcast_dws.visit_dws partition(yearinfo,quarterinfo,monthinfo,dayinfo)
select
count(distinct sid) as sid_total,
count(distinct session_id) as sessionid_total,
count(distinct ip) as ip_total,
'-1' as area,
'-1' as seo_source,
'-1' as origin_channel,
'-1' as hourinfo,
concat(yearinfo,'-',monthinfo) as time_str,
from_url,
'4' as grouptype,
'3' as time_type,
yearinfo,
quarterinfo,
monthinfo,
'-1' as dayinfo
from itcast_dwd.visit_consult_dwd
group by yearinfo,quarterinfo,monthinfo,from_url;-- 统计每年,每季度,每月.每天各个受访页面的访问量
insert into table itcast_dws.visit_dws partition(yearinfo,quarterinfo,monthinfo,dayinfo)
select
count(distinct sid) as sid_total,
count(distinct session_id) as sessionid_total,
count(distinct ip) as ip_total,
'-1' as area,
'-1' as seo_source,
'-1' as origin_channel,
'-1' as hourinfo,
concat(yearinfo,'-',monthinfo,'-',dayinfo) as time_str,
from_url,
'4' as grouptype,
'2' as time_type,
yearinfo,
quarterinfo,
monthinfo,
dayinfo
from itcast_dwd.visit_consult_dwd
group by yearinfo,quarterinfo,monthinfo,dayinfo,from_url;
-- 统计每年,每季度,每月.每天,每小时各个受访页面的访问量
insert into table itcast_dws.visit_dws partition(yearinfo,quarterinfo,monthinfo,dayinfo)
select
count(distinct sid) as sid_total,
count(distinct session_id) as sessionid_total,
count(distinct ip) as ip_total,
'-1' as area,
'-1' as seo_source,
'-1' as origin_channel,
hourinfo,
concat(yearinfo,'-',monthinfo,'-',dayinfo,' ',hourinfo) as time_str,
from_url,
'4' as grouptype,
'1' as time_type,
yearinfo,
quarterinfo,
monthinfo,
dayinfo
from itcast_dwd.visit_consult_dwd
group by yearinfo,quarterinfo,monthinfo,dayinfo,hourinfo,from_url;
7.3.3基于时间统计总咨询量
-- 统计每年的总咨询量
insert into table itcast_dws.consult_dws partition(yearinfo,quarterinfo,monthinfo,dayinfo)
select
count(distinct sid) as sid_total,
count(distinct session_id) as sessionid_total,
count(distinct ip) as ip_total,
'-1' as area,
'-1' as origin_channel,
'-1' as hourinfo,
yearinfo as time_str,
'3' as grouptype,
'5' as time_type,
yearinfo,
'-1' as quarterinfo,
'-1' as monthinfo,
'-1' as dayinfo
from itcast_dwd.visit_consult_dwd where msg_count >= 1
group by yearinfo;
-- 统计每年每季度的总咨询量
insert into table itcast_dws.consult_dws partition(yearinfo,quarterinfo,monthinfo,dayinfo)
select
count(distinct sid) as sid_total,
count(distinct session_id) as sessionid_total,
count(distinct ip) as ip_total,
'-1' as area,
'-1' as origin_channel,
'-1' as hourinfo,
concat(yearinfo,'_',quarterinfo) as time_str,
'3' as grouptype,
'4' as time_type,
yearinfo,
quarterinfo,
'-1' as monthinfo,
'-1' as dayinfo
from itcast_dwd.visit_consult_dwd where msg_count >= 1
group by yearinfo,quarterinfo;
-- 统计每年每季度每月的总咨询量
insert into table itcast_dws.consult_dws partition(yearinfo,quarterinfo,monthinfo,dayinfo)
select
count(distinct sid) as sid_total,
count(distinct session_id) as sessionid_total,
count(distinct ip) as ip_total,
'-1' as area,
'-1' as origin_channel,
'-1' as hourinfo,
concat(yearinfo,'-',monthinfo) as time_str,
'3' as grouptype,
'3' as time_type,
yearinfo,
quarterinfo,
monthinfo,
'-1' as dayinfo
from itcast_dwd.visit_consult_dwd where msg_count >= 1
group by yearinfo,quarterinfo,monthinfo;
-- 统计每年每季度每月每天的总咨询量
insert into table itcast_dws.consult_dws partition(yearinfo,quarterinfo,monthinfo,dayinfo)
select
count(distinct sid) as sid_total,
count(distinct session_id) as sessionid_total,
count(distinct ip) as ip_total,
'-1' as area,
'-1' as origin_channel,
'-1' as hourinfo,
concat(yearinfo,'-',monthinfo,'-',dayinfo) as time_str,
'3' as grouptype,
'2' as time_type,
yearinfo,
quarterinfo,
monthinfo,
dayinfo
from itcast_dwd.visit_consult_dwd where msg_count >= 1
group by yearinfo,quarterinfo,monthinfo,dayinfo;
-- 统计每年每季度每月每天每小时的总咨询量
insert into table itcast_dws.consult_dws partition(yearinfo,quarterinfo,monthinfo,dayinfo)
select
count(distinct sid) as sid_total,
count(distinct session_id) as sessionid_total,
count(distinct ip) as ip_total,
'-1' as area,
'-1' as origin_channel,
hourinfo,
concat(yearinfo,'-',monthinfo,'-',dayinfo,' ',hourinfo) as time_str,
'3' as grouptype,
'1' as time_type,
yearinfo,
quarterinfo,
monthinfo,
dayinfo
from itcast_dwd.visit_consult_dwd where msg_count >= 1
group by yearinfo,quarterinfo,monthinfo,dayinfo,hourinfo;
7.3.4基于时间,统计各个地区的咨询量
-- 统计每年各个地区的咨询量
insert into table itcast_dws.consult_dws partition(yearinfo,quarterinfo,monthinfo,dayinfo)
select
count(distinct sid) as sid_total,
count(distinct session_id) as sessionid_total,
count(distinct ip) as ip_total,
area,
'-1' as origin_channel,
'-1' as hourinfo,
yearinfo as time_str,
'1' as grouptype,
'5' as time_type,
yearinfo,
'-1' as quarterinfo,
'-1' as monthinfo,
'-1' as dayinfo
from itcast_dwd.visit_consult_dwd where msg_count >= 1
group by yearinfo,area;
-- 统计每年每季度各个地区的咨询量
insert into table itcast_dws.consult_dws partition(yearinfo,quarterinfo,monthinfo,dayinfo)
select
count(distinct sid) as sid_total,
count(distinct session_id) as sessionid_total,
count(distinct ip) as ip_total,
area,
'-1' as origin_channel,
'-1' as hourinfo,
concat(yearinfo,'_',quarterinfo) as time_str,
'1' as grouptype,
'4' as time_type,
yearinfo,
quarterinfo,
'-1' as monthinfo,
'-1' as dayinfo
from itcast_dwd.visit_consult_dwd where msg_count >= 1
group by yearinfo,quarterinfo,area;
-- 统计每年每季度每月各个地区的咨询量
insert into table itcast_dws.consult_dws partition(yearinfo,quarterinfo,monthinfo,dayinfo)
select
count(distinct sid) as sid_total,
count(distinct session_id) as sessionid_total,
count(distinct ip) as ip_total,
area,
'-1' as origin_channel,
'-1' as hourinfo,
concat(yearinfo,'-',monthinfo) as time_str,
'1' as grouptype,
'3' as time_type,
yearinfo,
quarterinfo,
monthinfo,
'-1' as dayinfo
from itcast_dwd.visit_consult_dwd where msg_count >= 1
group by yearinfo,quarterinfo,monthinfo,area;
-- 统计每年每季度每月每天各个地区的咨询量
insert into table itcast_dws.consult_dws partition(yearinfo,quarterinfo,monthinfo,dayinfo)
select
count(distinct sid) as sid_total,
count(distinct session_id) as sessionid_total,
count(distinct ip) as ip_total,
area,
'-1' as origin_channel,
'-1' as hourinfo,
concat(yearinfo,'-',monthinfo,'-',dayinfo) as time_str,
'1' as grouptype,
'2' as time_type,
yearinfo,
quarterinfo,
monthinfo,
dayinfo
from itcast_dwd.visit_consult_dwd where msg_count >= 1
group by yearinfo,quarterinfo,monthinfo,dayinfo,area;
-- 统计每年每季度每月每天每小时各个地区的咨询量
insert into table itcast_dws.consult_dws partition(yearinfo,quarterinfo,monthinfo,dayinfo)
select
count(distinct sid) as sid_total,
count(distinct session_id) as sessionid_total,
count(distinct ip) as ip_total,
area,
'-1' as origin_channel,
hourinfo,
concat(yearinfo,'-',monthinfo,'-',dayinfo,' ',hourinfo) as time_str,
'1' as grouptype,
'1' as time_type,
yearinfo,
quarterinfo,
monthinfo,
dayinfo
from itcast_dwd.visit_consult_dwd where msg_count >= 1
group by yearinfo,quarterinfo,monthinfo,dayinfo,hourinfo,area;
7.4DWS->mysql
7.4.1MySQL中创建目标表
create database scrm_bi default character set utf8mb4 collate utf8mb4_general_ci;
-- 访问量的结果表:
CREATE TABLE IF NOT EXISTS scrm_bi.visit_dws (
sid_total INT COMMENT '根据sid去重求count',
sessionid_total INT COMMENT '根据sessionid去重求count',
ip_total INT COMMENT '根据IP去重求count',
area varchar(32) COMMENT '区域信息',
seo_source varchar(32) COMMENT '搜索来源',
origin_channel varchar(32) COMMENT '来源渠道',
hourinfo varchar(32) COMMENT '创建时间,统计至小时',
time_str varchar(32) COMMENT '时间明细',
from_url varchar(32) comment '会话来源页面',
groupType varchar(32) COMMENT '产品属性类型:1.地区;2.搜索来源;3.来源渠道;4.会话来源页面;5.总访问量',
time_type varchar(32) COMMENT '时间聚合类型:1、按小时聚合;2、按天聚合;3、按月聚合;4、按季度聚合;5、按年聚合;',
yearinfo varchar(32) COMMENT '年' ,
quarterinfo varchar(32) COMMENT '季度',
monthinfo varchar(32) COMMENT '月',
dayinfo varchar(32) COMMENT '天'
)comment 'EMS访客日志dws表';-- 咨询量的结果表:
CREATE TABLE IF NOT EXISTS scrm_bi.consult_dws
(
sid_total INT COMMENT '根据sid去重求count',
sessionid_total INT COMMENT '根据sessionid去重求count',
ip_total INT COMMENT '根据IP去重求count',
area varchar(32) COMMENT '区域信息',
origin_channel varchar(32) COMMENT '来源渠道',
hourinfo varchar(32) COMMENT '创建时间,统计至小时',
time_str varchar(32) COMMENT '时间明细',
groupType varchar(32) COMMENT '产品属性类型:1.地区;2.来源渠道',
time_type varchar(32) COMMENT '时间聚合类型:1、按小时聚合;2、按天聚合;3、按月聚合;4、按季度聚合;5、按年聚合;',
yearinfo varchar(32) COMMENT '年' ,
quarterinfo varchar(32) COMMENT '季度',
monthinfo varchar(32) COMMENT '月',
dayinfo varchar(32) COMMENT '天'
)COMMENT '咨询量DWS宽表';
7.4.2DWS->sqoop->mysql
咨询量数据
sqoop export \
--connect jdbc:mysql://192.168.52.150:3306/scrm_bi \
--username root \
--password 123456 \
--table consult_dws \
--hcatalog-database itcast_dws \
--hcatalog-table consult_dws \
-m 1(指定编码格式)
sqoop export \
--connect "jdbc:mysql://192.168.52.150:3306/scrm_bi?useUnicode=true&characterEncoding=utf-8" \
--username root \
--password 123456 \
--table consult_dws \
--hcatalog-database itcast_dws \
--hcatalog-table consult_dws \
-m 1
访问量数据导出
sqoop export \
--connect "jdbc:mysql://192.168.52.150:3306/scrm_bi?useUnicode=true&characterEncoding=utf-8" \
--username root \
--password 123456 \
--table visit_dws \
--hcatalog-database itcast_dws \
--hcatalog-table visit_dws \
-m 1
相关文章:

hive的基础配置优化与数仓流程
1.HDFS副本数 dfs.replication(HDFS) 文件副本数,通常设为3,不推荐修改。 如果测试环境只有二台虚拟机(2个datanode节点),此值要修改为2。 2.Yarn基础配置 2.1NodeManager配置 2.1.1CPU配置 …...

制作一个简单的操作系统3
打印一个 hello 在 INT 10H 中断中的作用 INT 10H 是 BIOS 提供的中断, 当 AH 寄存器的值被设置为 0x0e 时,INT 10H 中断就会以 TTY 模式工作。 mov ah, 0x0e ;tty模式 mov al, H int 0x10 mov al, e int 0x10 mov al, l int 0x10 int 0x10 ; l is stil…...
 gdb单步调试)
linux ptrace 图文详解(六) gdb单步调试
目录 一、gdb单步调试介绍 二、单步调试原理 三、MDSCR_EL1对单步调试的支持、及起作用时机 四、代码实现 五、总结 (代码:linux 6.3.1,架构:arm64) One look is worth a thousand words. —— Tess Flanders …...

51、项⽬中的权限管理怎么实现的
答:权限管理有三个很重要的模块; (1)⽤⼾模块:可以给⽤⼾分配不同的⻆⾊ (2)⻆⾊模块:可以授于⽤⼾不同的⻆⾊,不同的⻆⾊有不同权限 (3)权限模块:⽤于管理系统中的权限接⼝,为⻆⾊提供对…...

第五章 SQLite数据库:4、SQLite 进阶用法:常见的约束、PRAGMA 配置、数据操作
SQLite PRAGMA PRAGMA 命令用于查询和设置 SQLite 数据库的环境配置,可以帮助管理数据库的行为和性能。 语法 查询 PRAGMA 值: PRAGMA pragma_name;设置 PRAGMA 值: PRAGMA pragma_name value;常见 PRAGMA 示例 1. auto_vacuum Pragma…...

Windows系统安装Boost库
安装Boost库 下载Boost库源码 Boost Downloads 从Boost官方网站下载源码。请访问Boost官网,选择适合您系统的版本进行下载。下载完成后,解压源文件到您选择的目录。 使用Bootstrap脚本准备编译 在Boost源码的根目录下,找到bootstrap.bat文件…...
等级考试试卷(三级)答案 + 解析)
2025年03月中国电子学会青少年软件编程(Python)等级考试试卷(三级)答案 + 解析
青少年软件编程(Python)等级考试试卷(三级) 分数:100 题数:38 一、单选题(共25题,共50分) 1. 学校进行体育跳远期末考试,每人有三次机会,取最远的一次作为最后成绩,1班的成绩如下,CLASS1=[[‘李明’,150,152,147],[‘王红’,146,143,146],[‘刘岩’,148,152,150],[…...

Git 解决“Filename too long”问题
在 Windows 系统中使用 Git 时,遇到 Filename too long 错误通常是由于系统默认的路径长度限制(260 字符)导致的。以下是综合多种场景的解决方案: 一、快速解决方法 启用 Git 长路径支持 通过 Git 配置命令允许处理超长文件名&am…...
,日历_自定义单元格大小示例(CalendarView01_07))
DeepSeek 助力 Vue3 开发:打造丝滑的日历(Calendar),日历_自定义单元格大小示例(CalendarView01_07)
前言:哈喽,大家好,今天给大家分享一篇文章!并提供具体代码帮助大家深入理解,彻底掌握!创作不易,如果能帮助到大家或者给大家一些灵感和启发,欢迎收藏关注哦 💕 目录 Deep…...

麦科信汽车诊断示波器在机车维修领域中的应用实例
麦科信汽车诊断示波器在机车维修领域中的应用实例 “Micsig SATO1004的错误帧统计功能与历史波形存储,让我们在诊断间歇性CAN故障时有了决定性武器。这不仅是工具升级,更是维修理念的革新。” — Ian Coffey, Mototek技术总监(欧洲ECU诊…...

Zookeeper 概述
Zookeeper 概述 Zookeeper 概述与使用指南什么是Zookeeper?Zookeeper的主要作用使用Zookeeper的框架典型使用场景1. 配置管理2. 分布式锁3. 服务注册与发现 Zookeeper的缺陷与其他协调服务的比较实际案例:Kafka使用Zookeeper最佳实践 Zookeeper 概述与使…...

leetcode 188. Best Time to Buy and Sell Stock IV
目录 题目描述 第一步,明确并理解dp数组及下标的含义 第二步,分析明确并理解递推公式 1.求dp[i][j].holding 2.求dp[i][j].sold 第三步,理解dp数组如何初始化 第四步,理解遍历顺序 代码 题目描述 这道题把第123题推广为一…...

Kubernetes》》k8s》》Namespace
Namespace 概述 Namespace(命名空间) 是 Kubernetes 中用于逻辑隔离集群资源的机制,可将同一集群划分为多个虚拟环境,适用于多团队、多项目或多环境(如开发、测试、生产)的场景。 核心作用: 资…...

如何在米尔-STM32MP257开发板上部署环境监测系统
本文将介绍基于米尔电子MYD-LD25X开发板(米尔基于STM35MP257开发板)的环境监测系统方案测试。 摘自优秀创作者-lugl4313820 一、前言 环境监测是当前很多场景需要的项目,刚好我正在论坛参与的一个项目:Thingy:91X 蜂窝物联网原型…...

解决jupyter notebook修改路径下没有c.NotebookApp.notebook_dir【建议收藏】
文章目录 一、检查并解决问题二、重新设置默认路径创作不易,感谢未来首富们的支持与关注! 最近在用jupyter notebook编写代码时,更新了一下Scikit-learn的版本,然后重新打开jupyter notebook的时候,我傻眼了࿰…...

lottie深入玩法
A、json文件和图片资源分开 delete 是json资源名字 /res/lottie/delete_anim_images是图片资源文件夹路径 JSON 中引用的图片名,必须与实际图片文件名一致 B、json文件和图片资源分开,并且图片加载不固定 比如我有7张图片,分别命名1~7&…...

o3和o4-mini的升级有哪些亮点?
ChatGPT是基于OpenAI GPT系列的高性能对话生成AI,经过多代迭代不断提升自然语言理解和生成能力。 在过去的一年中,OpenAI先后发布了GPT-4、GPT‑4.1及多种mini版本,为不同使用场景提供灵活选择。 随着用户需求向更高效、更精准的推理和视觉…...

Spring Boot 3 + SpringDoc:打造接口文档
1、背景公司 新项目使用SpringBoot3.0以上构建,其中需要对外输出接口文档。接口文档一方面给到前端调试,另一方面给到测试使用。 2、SpringDoc 是什么? SpringDoc 是一个基于 Spring Boot 项目的库,能够自动根据项目中的配置、…...

ApiHug 前端解决方案 - M1 内侧
背景 ApiHug UI 解决方案 - ApiHug前后端语义化设计,节约80%以上时间https://apihug.github.io/zhCN-docs/ui 现代前端框架日趋SPA(Single Page Application)化,给前后协同都带来了挑战,ApiHug试图减少多人在前后协同带来的理解难度&#x…...

vue2.6.12 安装babel 以使用 可选链 ?. 和空值合并 ??
package.json文件 {"name": "ruoyi","version": "3.6.4","description": "若依管理系统","author": "若依","license": "MIT","scripts": {"dev":…...

AI数字人如何深度赋能政务场景?魔珐科技政务应用全景解读
在数字中国建设的进程中,政务传播与公共服务正面临效率提升、质量优化与体验改善的多重需求。以魔珐科技所打造的AI数字人为代表,正在逐步融入政务体系,成为推动工作提效和服务创新的重要工具。从国家安全宣讲到政策解读,从反诈防…...

SpringAI+DeepSeek大模型应用开发——5 ChatPDF
ChatPDF 知识库 RAG检索增强 由于训练大模型非常耗时,再加上训练语料本身比较滞后,所以大模型存在知识限制问题: 知识数据比较落后,往往是几个月之前的;不包含太过专业领域或者企业私有的数据; 为了解决…...

音视频之H.265/HEVC变换编码
H.265/HEVC系列文章: 1、音视频之H.265/HEVC编码框架及编码视频格式 2、音视频之H.265码流分析及解析 3、音视频之H.265/HEVC预测编码 4、音视频之H.265/HEVC变换编码 目录 一、离散余弦变换: DCT原理及特点: 一维DCT解析例子࿱…...

网工_FTP协议
2025.04.18:网工老姜&小猿网学习笔记 第27节 FTP协议 7.1 FTP概述7.2 FTP工作原理7.2.1 FTP主动模式7.2.2 FTP被动模式 7.3 FTP客户端常用命令7.4 本章小结 7.1 FTP概述 文件传输协议file transfer protocol 常见用途是从FTP服务器批量下载文件,另一…...

Vue2+Vue3 130~180集学习笔记
Vue2Vue3 130~180集(Vue3)学习笔记 一、create-vue搭建vue3项目 create-vue是vue官方新的脚手架工具,底层切换到了vite 步骤: 查看环境条件 node -v版本需要在16.0及以上创建一个vue应用 npm init vuelatest 这一指令会安装并执…...

前端融合图片mask
之前实现了tif文件的融合,现在实现图片的融合,效果如下 第一张是融合右边两张图的结果 我的思路是: 初始使用canvas加载原图,此时未显示标注点击显示标注后,将原图和mask图传给workerworker接受数据后,转…...

什么是单元测试的“覆盖率”
1. 先搞清楚“覆盖率”是啥? 打个比方,你写完作业(代码),老师(测试)要检查是不是每道题都做对了。覆盖率就是说老师检查了多少题。比如: 行覆盖率:老师看了你作…...

SpringAI入门:对话机器人
SpringAI入门:对话机器人 1.引入依赖 创建一个新的SpringBoot工程,勾选Web、MySQL驱动、Ollama: <?xml version"1.0" encoding"UTF-8"?> <project xmlns"http://maven.apache.org/POM/4.0.0" xm…...

[Java · 初窥门径] Java 语言初识
🌟 想系统化学习 Java 编程?看看这个:[编程基础] Java 学习手册 0x01:Java 编程语言简介 Java 是一种高级计算机编程语言,它是由 Sun Microsystems 公司(已被 Oracle 公司收购)于 1995 年 5 …...

大语言模型智能体:安全挑战与应对之道
在当今科技飞速发展的时代,大语言模型驱动的智能体正逐渐融入我们生活和工作的方方面面,给我们带来了诸多便利。但与此同时,它们的安全问题也引起了广泛的关注。今天,咱们就一起来深入了解一下可信大语言模型智能体所面临的安全挑…...

IHC肿瘤标志物 | 常见乳腺癌诊断——助力守护生命之花
乳腺癌作为一种常见的恶性肿瘤,严重威胁着女性健康。然而,随着医学技术的不断发展,我们有了更为精准和有效的检测方法,为及早发现和治疗乳腺癌提供了强有力的支持。 在这篇文章中,我们将深入了解乳腺癌的IHC检测技术&a…...

利用deepseek+Mermaid画流程图
你是一个产品经理,请绘制一个流程图,要求生成符合Mermaid语法的代码,要求如下: 用户下载文件、上传文件、删除文件的流程过程符合安全规范细节具体到每一步要做什么 graph LRclassDef startend fill:#F5EBFF,stroke:#BE8FED,str…...

Vue3 实战:打造多功能旅游攻略选项卡页面
在旅游类应用开发中,为用户提供全面、直观的信息展示界面至关重要。本文将分享如何基于 Vue3 Axios 技术栈,实现一个包含攻略、游记、问答三大板块的旅游攻略选项卡页面,从样式设计到交互逻辑,带你深入了解整个开发过程。 项目背…...

如何提高单元测试的覆盖率
一、定位未覆盖的代码 利用 IDEA 的覆盖率工具: 右键测试类 → Run with Coverage,或使用 AltShiftF10(Windows)打开运行菜单选择覆盖率。查看高亮标记: 绿色:已覆盖代码行。红色&#x…...
)
水位传感器详解(STM32)
目录 一、介绍 二、传感器原理 1.原理图 2.引脚描述 三、程序设计 main.c文件 water.h文件 water.c文件 四、实验效果 五、资料获取 项目分享 一、介绍 Water Sensor水位传感器是一款简单易用、性价比较高的水位/水滴识别检测传感器,其是通过具有一系列…...

linux服务器命令行获取nvidia显卡SN的方法
机房需要变更机器的GPU显卡配置,入库、出库几块显卡,库管让我去获取显卡序列号。 去现场拆机器的事情毕竟很麻烦,而且也没干过拆装服务器,即使拆下来显卡也不一定找到SN。 于是乎搜索:命令行怎么获取linux服务器上的…...

大模型微服务架构模块实现方案,基于LLaMA Factory和Nebius Cloud实现模型精调的标准流程及代码
以下是基于LLaMA Factory和Nebius Cloud实现模型精调的标准流程及代码示例,结合最新技术动态和行业实践整理: 一、LLaMA Factory本地部署方案 1. 环境配置 # 创建Python环境并安装依赖 conda create -n llama_factory python3.10 conda activate llam…...
:find)
每天学一个 Linux 命令(20):find
可访问网站查看,视觉品味拉满: http://www.616vip.cn/20/index.html find 是 Linux 系统中最强大的文件搜索工具之一,支持按名称、类型、时间、大小、权限等多种条件查找文件,并支持对搜索结果执行操作(如删除、复制、执行命令等)。掌握 find 可大幅提升文件管理效率…...

Kubernetes Pod 调度策略:从基础到进阶
文章目录 环境Kubernetes 部署Kubernetes Pod 调度策略Kubernetes Pod 调度策略对照表调度流程经历阶段案例展示生成yaml文件默认调度节点选择器为节点添加标签编写 Deployment 配置文件应用资源并查看调度结果 Node Affinity(节点亲和性)为节点添加标签…...

4.18学习总结
完成一道算法题 学习了序列化 敲代码卡bug了...

用于数学定理和逻辑推理的符号系统
当前用于数学定理和逻辑推理的前沿符号系统主要基于依赖类型论(Dependent Type Theory),其中Lean 4和**Metamath Zero (MM0)**是最具代表性的新兴系统。以下从技术特性、使用方法和应用实例三个维度展开说明: 一、前沿符号系统解…...

HTTP:九.WEB机器人
概念 Web机器人是能够在无需人类干预的情况下自动进行一系列Web事务处理的软件程序。人们根据这些机器人探查web站点的方式,形象的给它们取了一个饱含特色的名字,比如“爬虫”、“蜘蛛”、“蠕虫”以及“机器人”等!爬虫概述 网络爬虫(英语:web crawler),也叫网络蜘蛛(…...
)
代码学习总结(五)
代码学习总结(五) 这个系列的博客是记录下自己学习代码的历程,有来自平台上的,有来自笔试题回忆的,主要基于 C++ 语言,包括题目内容,代码实现,思路,并会注明题目难度,保证代码运行结果 1 小红的好数 简单 非退化三角形 快速匹配 小红定义一个数对 { x , y } \{x…...

在 Vue 3 项目中引入 js-cookie 库
1. 安装 js-cookie 你可以通过 npm 或者 yarn 来安装 js-cookie: npm install js-cookie # 或者 yarn add js-cookie2. 在组件里引入并使用 js-cookie 以下给出两种使用方式: 全局引入 在 main.js 中全局引入 js-cookie,这样在所有组件里…...

HarmonyOs学习 环境配置后 实验1:创建项目Hello World
HarmonyOS开发入门:环境配置与Hello World实验 实验目标 掌握HarmonyOS开发环境配置,创建首个HarmonyOS应用并实现"Hello World"界面展示 实验准备 已安装DevEco Studio开发环境已配置HarmonyOS开发依赖项熟悉基本TypeScript/ArkTS语法&am…...

Spark on K8s 在 vivo 大数据平台的混部实战与优化
一、Spark on K8s 简介 (一)定义与架构 Spark on K8s 是一种将 Spark 运行在 Kubernetes(K8s)集群上的架构,由 K8s 直接创建 Driver 和 Executor 的 Pod 来运行 Spark 作业。其架构如下。 Driver Pod:相当于 Spark 集群中的 Driver,负责作业的调度和管理,它会根据作业…...
——结构化开发方法)
《软件设计师》复习笔记(13)——结构化开发方法
目录 1. 结构化开发方法 1.1 系统分析过程 1.2 系统设计基本原理 (1)内聚性(模块内部关联程度) (2)耦合性(模块间依赖程度) 真题示例: 1.3 系统总体结构设计&…...

Android创建测试配置和生产配置
Android测试与生产环境配置指南 在Android开发中,创建不同的构建配置来适应测试和生产环境是至关重要的。这样的配置能让我们在不同的开发阶段有效管理代码、资源和环境变量。本文将详细介绍如何在Android中创建和管理测试配置以及生产配置的整个过程。 环境准备 …...

DBeaver连接hive
DBeaver是一个非常好用的数据库管理工具,支持多种不同的数据库类型。 dbeaver 要连接hive时,数据库驱动是无法下载,但在hive 的安装配置包中,有一个目录:jdbc里面有一个专门提供外部程序连接hive的jar。将这个jar下载…...
)
数据结构初阶:二叉树(二)
本篇博客主要讲解二叉树---堆的相关知识。 1.实现顺序结构二叉树 一般堆使用顺序结构的数组来存储数据,堆是一种特殊的二叉树,具有二叉树的特性的同时,还具备其他的特性。 1.1 堆的概念和结构 堆具有以下性质: 堆中某个结点的值…...