SpringAI+DeepSeek大模型应用开发——5 ChatPDF
ChatPDF 知识库
RAG检索增强
由于训练大模型非常耗时,再加上训练语料本身比较滞后,所以大模型存在知识限制问题:
-
知识数据比较落后,往往是几个月之前的;不包含太过专业领域或者企业私有的数据;
-
为了解决这些问题,就需要用到RAG了。
RAG原理
RAG 的核心原理是将检索技术与生成模型相结合,结合外部知识库来检索相关信息来增强模型的输出,其实就是给大模型挂一个知识库
其核心工作流程分为三个阶段:
- 接收请求: 首先,系统接收到用户的请求(例如提出一个问题)
- 信息检索®: 系统从一个大型文档库中检索出与查询最相关的文档片段。这一步的目标是找到那些可能包含答案或相关信息的文档。这里不一定是从向量数据库中检索,但是向量数据库能反应相似度最高的几个文档(比如说法不同,意思相同),而不是精确查找
- 生成增强(A): 将检索到的文档片段与原始查询一起输入到大模型(如chatGPT)中,注意使用合适的提示词,比如原始的问题是XXX,检索到的信息是YY,给大模型的输入应该类似于: 请基于YYY回答XXXX。
- 输出生成(G): 大模型LLM 基于输入的査询和检索到的文档片段生成最终的文本答案,并返回给用户
注意:知识库不能写在提示词中,因为通常知识库数据量都是非常大的,而大模型的上下文是有大小限制的,那怎么办呢?
只要想办法从庞大的知识库中找到与用户问题相关的一小部分,组装成提示词,发送给大模型就可以了;那么该如何从知识库中找到与用户问题相关的内容呢?
- 全文检索?但在这里是不合适的,因为全文检索是文字匹配,而这里要求的是内容上的相似度;
- 而要从内容相似度来判断,这就不得不提到向量模型的知识了。
向量模型
向量是空间中有方向和长度的量,空间可以是二维,也可以是多维;向量既然是在空间中,那么两个向量之间就一定能计算距离;
向量之间的距离一般有两种计算方法:
欧几里得距离
在n维空间中,两点间的直线距离。它是两点间最直接的距离测量方式。很适合用于RGB色彩空间中衡量两种颜色之间的差异
颜色可以用 RGB 值表示,然后通过计算两种颜色 RGB 值之间的欧几里得距离来判断它们的相似度。
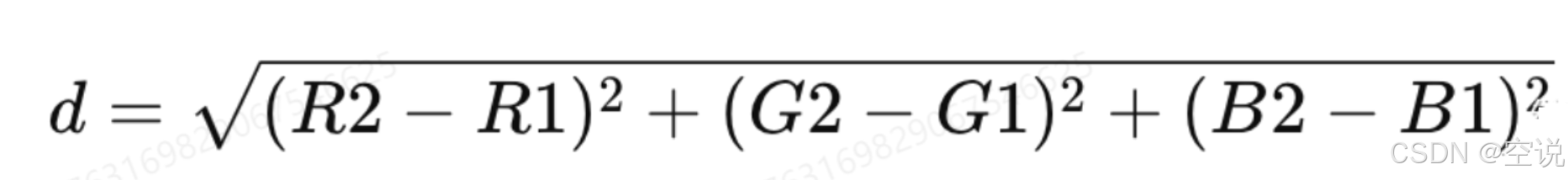
- R G B: 两个颜色的 RGB 分量(红色、绿色、蓝色)
- d: 两个颜色之间的欧几里得距离。
- 距离越小,表示颜色越相似; 距离越大,表示颜色越不同
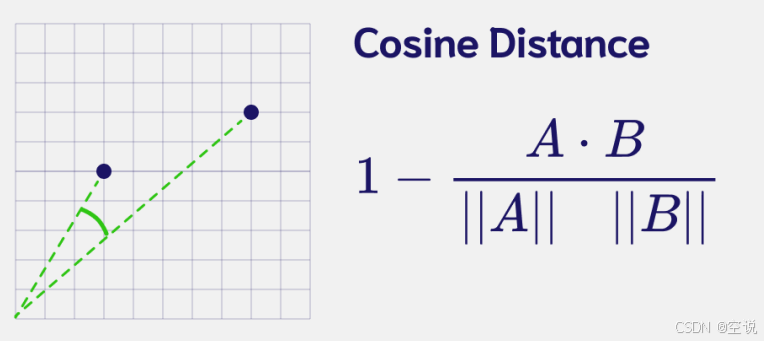
余弦相似度
通过比较两个向量之间的夹角余弦值来衡量它们的方向是否相似,如果夹角余弦值越小,说明它们越相似,但这种方法不能考虑到向量的大小。
在颜色分析中,它可以用来比较颜色 色调的相似性,但是它对于亮度和饱和度的变化不敏感。
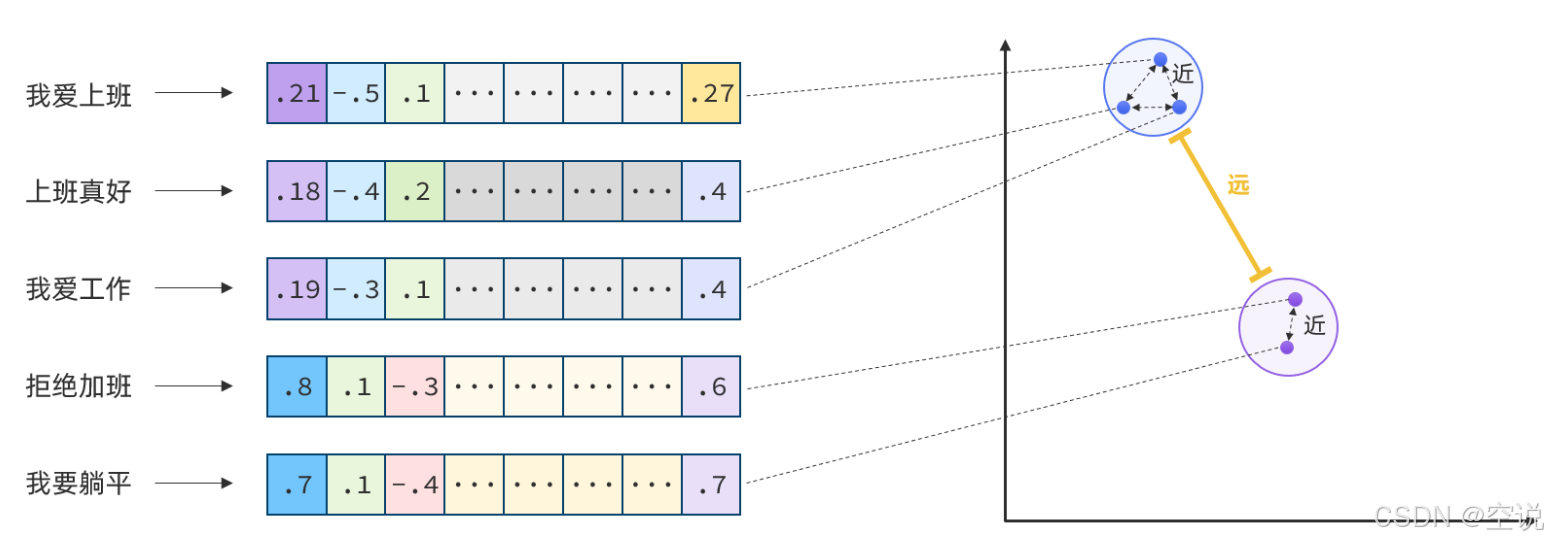
综上,如果能把文本转为向量,就可以通过向量距离来判断文本的相似度了;
现在有不少的专门的向量模型,就可以实现将文本向量化。一个好的向量模型,就是要尽可能让文本含义相似的向量,在空间中距离更近:
阿里云百炼平台就提供了这样的模型,用于将文本向量化:
这里选择通用文本向量-v3,这个模型兼容OpenAI,所以我们依然采用OpenAI的配置;修改yml配置
spring:application:name: chart-robotai:ollama:# Ollama服务地址base-url: http://localhost:11434chat:# 模型名称,可更改model: deepseek-r1:14boptions:# 模型温度,值越大,输出结果越随机temperature: 0.8openai:base-url: https://dashscope.aliyuncs.com/compatible-modeapi-key: ${OPENAI_API_KEY} #API keychat:options:# 可选择的模型列表 https://help.aliyun.com/zh/model-studio/getting-started/modelsmodel: qwen-plusembedding:options:model: text-embedding-v3 #通用文本向量-v3dimensions: 1024
向量模型测试
文本向量化以后,就可以通过向量之间的距离来判断文本相似度;接下来,我们来测试下阿里百炼提供的向量大模型;
在项目中写一个工具类,用以计算向量之间的欧氏距离和**余弦距离。**新建一个ai.util包,在其中新建一个VectorDistanceUtils类:
public class VectorDistanceUtils {// 私有构造函数:防止该工具类被实例化。private VectorDistanceUtils() {}// 浮点数计算精度阈值,用于判断浮点数是否接近零。private static final double EPSILON = 1e-12;/*** 计算欧氏距离(Euclidean Distance)* 欧氏距离是两个向量之间的直线距离,常用于衡量多维空间中两点的距离。* @param vectorA 向量A(非空且与B等长)* @param vectorB 向量B(非空且与A等长)*/public static double euclideanDistance(float[] vectorA, float[] vectorB) {// 校验输入向量的合法性validateVectors(vectorA, vectorB);double sum = 0.0; // 用于累加差值平方for (int i = 0; i < vectorA.length; i++) {double diff = vectorA[i] - vectorB[i]; // 计算对应维度上的差值sum += diff * diff; // 累加差值的平方}return Math.sqrt(sum); // 返回平方和的平方根,即欧氏距离}/*** 计算余弦距离(Cosine Distance)* 余弦距离基于余弦相似度计算,表示两个向量在方向上的差异。距离范围为[0, 2],* 其中0表示完全相同,2表示完全相反。*/public static double cosineDistance(float[] vectorA, float[] vectorB) {// 校验输入向量的合法性validateVectors(vectorA, vectorB);double dotProduct = 0.0; // 点积double normA = 0.0; // 向量A的模double normB = 0.0; // 向量B的模// 遍历向量的每个维度,计算点积和模的平方for (int i = 0; i < vectorA.length; i++) {dotProduct += vectorA[i] * vectorB[i]; // 点积累加normA += vectorA[i] * vectorA[i]; // A模的平方累加normB += vectorB[i] * vectorB[i]; // B模的平方累加}// 计算向量的模normA = Math.sqrt(normA);normB = Math.sqrt(normB);// 如果任意一个向量为零向量,则无法计算余弦距离,抛出异常if (normA < EPSILON || normB < EPSILON) {throw new IllegalArgumentException("Vectors cannot be zero vectors");}// 计算余弦相似度,确保结果在[-1, 1]范围内(处理浮点误差)double similarity = dotProduct / (normA * normB);similarity = Math.max(Math.min(similarity, 1.0), -1.0);// 余弦距离 = 1 - 相似度,范围为[0, 2]return 1.0 - similarity;}/*** 参数校验统一方法* 确保输入向量满足以下条件:* 1. 不为空(null);* 2. 长度相等;* 3. 非空数组。*/private static void validateVectors(float[] a, float[] b) {if (a == null || b == null) {throw new IllegalArgumentException("Vectors cannot be null");}if (a.length != b.length) {throw new IllegalArgumentException("Vectors must have same dimension");}if (a.length == 0) {throw new IllegalArgumentException("Vectors cannot be empty");}}
}
由于SpringBoot的自动装配能力,刚才配置的向量模型可以直接使用;
@SpringBootTest
...
// 自动注入向量模型
@Autowired
private OpenAiEmbeddingModel embeddingModel;
@Test
void contextLoads() {// 1.测试数据// 1.1.用来查询的文本,国际冲突String query = "global conflicts";// 1.2.用来做比较的文本String[] texts = new String[]{"哈马斯称加沙下阶段停火谈判仍在进行 以方尚未做出承诺","土耳其、芬兰、瑞典与北约代表将继续就瑞典“入约”问题进行谈判","日本航空基地水井中检测出有机氟化物超标","国家游泳中心(水立方):恢复游泳、嬉水乐园等水上项目运营","我国首次在空间站开展舱外辐射生物学暴露实验",};// 2.向量化// 2.1.先将查询文本向量化float[] queryVector = embeddingModel.embed(query);// 2.2.再将比较文本向量化,放到一个数组List<float[]> textVectors = embeddingModel.embed(Arrays.asList(texts));// 3.比较欧氏距离// 3.1.把查询文本自己与自己比较,肯定是相似度最高的System.out.println(VectorDistanceUtils.euclideanDistance(queryVector, queryVector));// 3.2.把查询文本与其它文本比较for (float[] textVector : textVectors) {System.out.println(VectorDistanceUtils.euclideanDistance(queryVector, textVector));}System.out.println("------------------");// 4.比较余弦距离// 4.1.把查询文本自己与自己比较,肯定是相似度最高的System.out.println(VectorDistanceUtils.cosineDistance(queryVector, queryVector));// 4.2.把查询文本与其它文本比较for (float[] textVector : textVectors) {System.out.println(VectorDistanceUtils.cosineDistance(queryVector, textVector));}
}
运行结果:
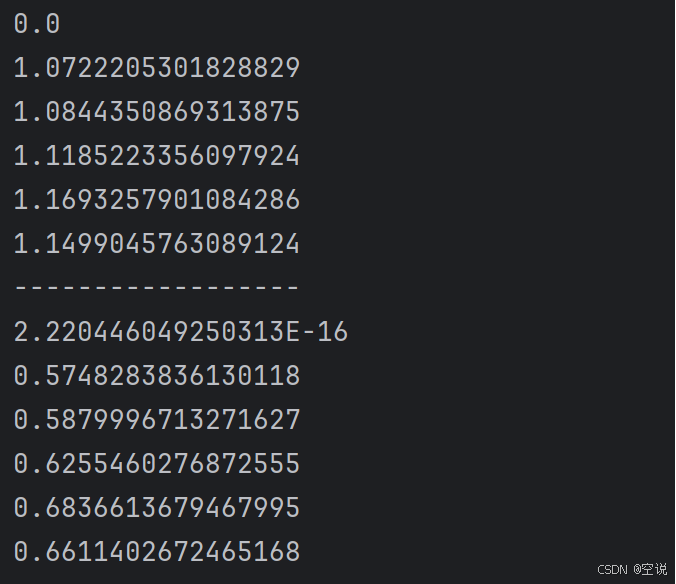
可以看到,向量相似度确实符合我们的预期。有了比较文本相似度的办法,知识库的问题就可以解决了;前面说了,知识库数据量很大,无法全部写入提示词,而且庞大的知识库中与用户问题相关的其实并不多;
所以,我们需要想办法从庞大的知识库中找到与用户问题相关的一小部分,组装成提示词,发送给大模型就可以了;
现但是新的问题来了:向量模型是生成向量的,如此庞大的知识库,谁来从中比较和检索数据呢? 这就需要用到向量数据库了
向量数据库
文本向量化
由于需要将已拆分的知识片段文本存储向量库,以便后续可以进行检索,而向量库存储的数据是向量不是文本
因此需要将文本进行向量化,即将一个字符串转换为一个N维数组,这个过程在自然语言处理(NLP)领域称为文本嵌入
不同的LLM对于文本嵌入的实现是不同的,ChatGPT的实现是基于transformer架构的,相关实现存储在服务端,每次嵌入都需要访问OpenAI的HTTP接口。
通过下面的例子可以看到OpenAi使用的模型是:text-embedding-ada-002,向量的维度是:1536
OpenAiEmbeddingModel embeddingModel = new OpenAiEmbeddingModel.OpenAiEmbeddingModelBuilder().apiKey(API_KEY).baseUrl(BASE_URL).build();
log.info("当前的模型是: {}", embeddingModel.modelName());
String text = "两只眼睛";
Embedding embedding = embeddingModel.embed(text).content();
log.info("文本:{}的嵌入结果是:\n{}", text, embedding.vectorAsList());
log.info("它是{}维的向量", embedding.dimension());
向量库存储
向量数据库,也称为向量存储或向量搜索引擎,是一种专门设计用于存储和管理向量(固定长度的数字列表)及其他数据项的数据库。
这些向量是数据点在高维空间中的数学表示,其中每个维度对应数据的一个特征。向量数据库的主要目的是通过近似最近邻(ANN)算法实现高效的相似性搜索。
向量数据库的主要作用有两个:
- 存储向量数据;
- 基于相似度检索数据;
SpringAI支持很多向量数据库,并且都进行了封装,可以用统一的API去访问:
- Azure Vector Search - The Azure vector store
- Apache Cassandra - The Apache Cassandra vector store
- Chroma Vector Store - The Chroma vector store
- Elasticsearch Vector Store - The Elasticsearch vector store
- GemFire Vector Store - The GemFire vector store
- MariaDB Vector Store - The MariaDB vector store
- Milvus Vector Store - The Milvus vector store
- MongoDB Atlas Vector Store - The MongoDB Atlas vector store
- Neo4j Vector Store - The Neo4j vector store
- OpenSearch Vector Store - The OpenSearch vector store
- Oracle Vector Store - The Oracle Database vector store
- PgVector Store - The PostgreSQL/PGVector vector store
- Pinecone Vector Store - PineCone vector store
- Qdrant Vector Store - Qdrant vector store
- Redis Vector Store - The Redis vector store
- SAP Hana Vector Store - The SAP HANA vector store
- Typesense Vector Store - The Typesense vector store
- Weaviate Vector Store - The Weaviate vector store
- SimpleVectorStore - A simple implementation of persistent vector storage, good for educational purposes
这些库都实现了统一的接口:VectorStore,因此操作方式一模一样,只要学会任意一个,其它就都不是问题;
注意:除了最后一个库,其它所有向量数据库都是需要安装部署的,而且每个企业用的向量库都不一样。
SimpleVectorStore
- 最后一个
SimpleVectorStore向量库是基于内存实现,是一个专门用来测试、教学用的库,非常适合此处案例的使用; - 修改
CommonConfiguration,添加一个VectorStore的Bean
@Bean
public VectorStore vectorStore(OpenAiEmbeddingModel embeddingModel) {return SimpleVectorStore.builder(embeddingModel).build();
}
VectorStore接口
- 接下来就可以使用
VectorStore接口中的各种功能了,可以参考SpringAI官方文档:Vector Databases :: Spring AI Reference; - 这是
VectorStore接口中声明的方法:
public interface VectorStore extends DocumentWriter {default String getName() {return this.getClass().getSimpleName();}// 保存文档到向量库void add(List<Document> documents);// 根据文档id删除文档void delete(List<String> idList);void delete(Filter.Expression filterExpression);default void delete(String filterExpression) {SearchRequest searchRequest = SearchRequest.builder().filterExpression(filterExpression).build();Filter.Expression textExpression = searchRequest.getFilterExpression();Assert.notNull(textExpression, "Filter expression must not be null");this.delete(textExpression);}// 根据条件检索文档@NullableList<Document> similaritySearch(String query);// 根据条件检索文档@NullableList<Document> similaritySearch(SearchRequest request);default <T> Optional<T> getNativeClient() {return Optional.empty();}
}
注意,VectorStore操作向量化的基本单位是Document,在使用时需要将自己的知识库分割转换为一个个的Document,然后写入VectorStore;
那么问题来了,该如何把各种不同的知识库文件转为Document呢?
文件读取和转换
由于知识库太大,所以要将知识库拆分成文档片段,然后再做向量化。而且SpringAI中向量库接收的是Document类型的文档,即我们处理文档还要转成Document格式
不过,文档读取、拆分、转换的动作并不需要我们亲自完成。在SpringAI中提供了各种文档读取的工具,可以参考官网:Spring AI Reference
比如PDF文档读取和拆分,SpringAI提供了两种默认的拆分原则:
PagePdfDocumentReader:按页拆分,推荐使用;ParagraphPdfDocumentReader:按pdf的目录拆分,不推荐,因为很多PDF不规范,没有章节标签;
此处选择使用PagePdfDocumentReader。首先,在pom.xml中引入依赖:
<dependency><groupId>org.springframework.ai</groupId><artifactId>spring-ai-pdf-document-reader</artifactId>
</dependency>
然后就可以利用工具把PDF文件读取并处理成Document了;
编写一个单元测试
@Test
public void testVectorStore(){Resource resource = new FileSystemResource("中二知识笔记.pdf");// 1.创建PDF的读取器PagePdfDocumentReader reader = new PagePdfDocumentReader(resource, // 文件源PdfDocumentReaderConfig.builder().withPageExtractedTextFormatter(ExtractedTextFormatter.defaults()).withPagesPerDocument(1) // 每1页PDF作为一个Document.build());// 2.读取PDF文档,拆分为DocumentList<Document> documents = reader.read();// 3.写入向量库vectorStore.add(documents);// 4.构建一个搜索请求SearchRequest request = SearchRequest.builder().query("论语中教育的目的是什么").topK(1) //返回最相关的前 1 个结果.similarityThreshold(0.6) //只有相似度大于等于 0.6 的结果才会被返回.filterExpression("file_name == '中二知识笔记.pdf'").build();List<Document> docs = vectorStore.similaritySearch(request); //搜索if (docs == null) {System.out.println("没有搜索到任何内容");return;}//遍历搜索结果,打印每个文档的相关信息for (Document doc : docs) {System.out.println(doc.getId());System.out.println(doc.getScore());System.out.println(doc.getText());}
}
注意:启动测试之前,要将中二知识笔记.pdf文件放到工程目录结构下;结果如下

RAG原理总结
目前已经有了以下这些工具
PDFReader:读取文档并拆分为片段;- 向量大模型:将文本片段向量化;
- 向量数据库:存储向量,检索向量;
接下来梳理一下要解决的问题和解决思路:
- 要解决大模型的知识限制问题,需要外挂知识库;
- 受到大模型上下文限制,知识库不能直接拼接在提示词中;
- 需要从庞大的外挂知识库中找到与用户问题相关的一小部分,再组装成提示词;
- 这些可以利用文档读取器、向量大模型、向量数据库来解决;
- RAG要做的事情就是将知识库分割==>利用向量模型做向量化==>存入向量数据库==>查询的时候去检索;
- 每当用户询问AI时,将用户问题向量化==>拿着问题向量==>去向量数据库检索最相关的片段
- 对话大模型:将检索到的片段、用户的问题一起拼接为提示词==> 发送提示词给大模型,得到响应。
目标
接下来就来实现一个非常火爆的个人知识库AI应用——ChatPDF,原网站如下:
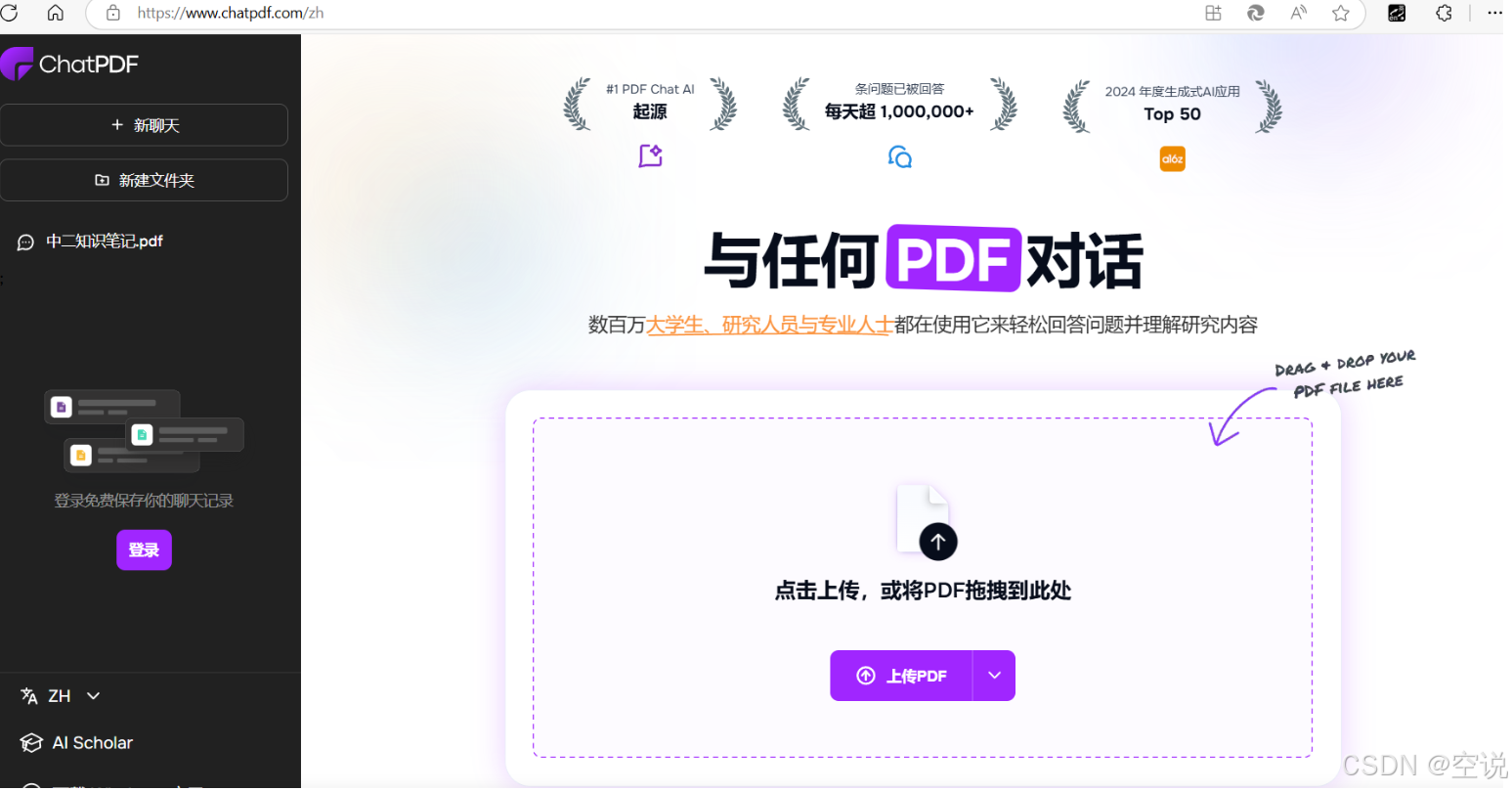
这个网站其实就是把个人的PDF文件作为知识库,让AI基于PDF内容来回答问题,对于大学生、研究人员、专业人士来说,非常方便。
PDF上传下载向量化
既然是ChatPDF,即所有知识库都是PDF形式的,由用户提交给服务器。所以,需要先实现一个上传PDF的接口,在接口中实现下列功能:
- 校验文件格式是否为PDF;
- 保存文件信息;
- 保存文件(可以是oss或本地保存);
- 保存会话ID和文件路径的映射关系(方便查询会话历史的时候再次读取文件);
- 文档拆分和向量化(文档太大,需要拆分为一个个片段,分别向量化);
另外,将来用户查询会话历史,还需要返回pdf文件给前端用于预览,所以需要实现一个下载PDF接口,包含下面功能:
- 读取文件
- 返回文件给前端
PDF文件管理
由于将来要实现PDF下载功能,就需要记住每一个chatId对应的PDF文件名称;
所以定义一个类,记录chatId与pdf文件的映射关系,同时实现基本的文件保存功能。在repository包中定义FileRepository接口
public interface FileRepository {/*** 保存文件,还要记录chatId与文件的映射关系* @param chatId 会话id* @param resource 文件* @return 上传成功,返回true; 否则返回false*/boolean save(String chatId, Resource resource);/*** 根据chatId获取文件* @param chatId 会话id* @return 找到的文件*/Resource getFile(String chatId);
}
@Slf4j
@Component
@RequiredArgsConstructor
public class LocalPdfFileRepository implements FileRepository {private final VectorStore vectorStore; // 向量存储组件// 会话id 与 文件名的对应关系,方便查询会话历史时重新加载文件private final Properties chatFiles = new Properties();/*** 保存资源到本地磁盘,并记录会话 ID 与文件名的映射关系。*/@Overridepublic boolean save(String chatId, Resource resource) {// 1. 获取文件名并检查是否已存在String filename = resource.getFilename();File target = new File(Objects.requireNonNull(filename));if (!target.exists()) {try {// 将资源内容复制到目标文件Files.copy(resource.getInputStream(), target.toPath());} catch (IOException e) {log.error("Failed to save PDF resource.", e);return false;}}// 2. 保存会话 ID 与文件名的映射关系chatFiles.put(chatId, filename);return true;}/*** 根据会话 ID 获取对应的文件资源。*/@Overridepublic Resource getFile(String chatId) {// 根据会话 ID 查找文件名String filename = chatFiles.getProperty(chatId);if (filename == null) {log.warn("No file found for chatId: {}", chatId);return null;}return new FileSystemResource(filename);}/*** 初始化方法,在 Spring 容器启动时执行。* 加载 `chat-pdf.properties` 文件中的会话 ID 映射关系,* 并加载 `chat-pdf.json` 中的向量数据。*/@PostConstructprivate void init() {// 加载会话 ID 映射关系FileSystemResource pdfResource = new FileSystemResource("chat-pdf.properties");if (pdfResource.exists()) { //如果文件存在try (BufferedReader reader = new BufferedReader(new InputStreamReader(pdfResource.getInputStream(), StandardCharsets.UTF_8))) {chatFiles.load(reader); //加载chatFiles到本地文件} catch (IOException e) {throw new RuntimeException("Failed to load chat-pdf.properties", e);}}// 加载向量存储数据FileSystemResource vectorResource = new FileSystemResource("chat-pdf.json");if (vectorResource.exists()) {SimpleVectorStore simpleVectorStore = (SimpleVectorStore) vectorStore;try {simpleVectorStore.load(vectorResource);} catch (Exception e) {throw new RuntimeException("Failed to load chat-pdf.json", e);}}}/*** 销毁方法,在 Spring 容器关闭时执行。* 持久化会话 ID 映射关系和向量存储数据到磁盘。*/@PreDestroyprivate void persistent() {try {// 持久化会话 ID 映射关系try (FileWriter writer = new FileWriter("chat-pdf.properties")) {chatFiles.store(writer, "Persisted at " + LocalDateTime.now());}// 持久化向量存储数据SimpleVectorStore simpleVectorStore = (SimpleVectorStore) vectorStore;simpleVectorStore.save(new File("chat-pdf.json"));} catch (IOException e) {throw new RuntimeException("Failed to persist data", e);}}
}
此处选择了基于内存的SimpleVectorStore,重启就会丢失向量数据。所以这里是将pdf文件与chatId的对应关系、VectorStore都持久化到了磁盘;
实际开发中,如果选择了RedisVectorStore,或者CassandraVectorStore,则无需自己持久化。但是chatId和PDF文件之间的对应关系,还是需要自己维护的。
上传文件相应结果
由于前端文件上传给后端后,后端需要返回响应结果,在ai.entity.vo中定义一个Result类:
import lombok.Data;
import lombok.NoArgsConstructor;
@Data
@NoArgsConstructor
public class Result {private Integer ok;private String msg;private Result(Integer ok, String msg) {this.ok = ok;this.msg = msg;}public static Result ok() {return new Result(1, "ok");}public static Result fail(String msg) {return new Result(0, msg);}
}
文件上传下载
在ai.controller中创建一个PdfController:
@Slf4j
@RequiredArgsConstructor //配合final实现自动注入
@RestController
@RequestMapping("/ai/pdf")
public class PdfController {private final FileRepository fileRepository; //文件存储组件private final VectorStore vectorStore; //向量存储组件private final ChatClient pdfChatClient; //问答模型客户端private final ChatHistoryRepository chatHistoryRepository; //会话历史记录/*** 对话*/@RequestMapping(value = "/chat", produces = "text/html;charset=utf-8")public Flux<String> chat(String prompt, String chatId) {// 1.找到会话文件Resource file = fileRepository.getFile(chatId);if (!file.exists()) {// 文件不存在,不回答throw new RuntimeException("会话文件不存在!");}// 2.保存会话idchatHistoryRepository.save("pdf", chatId);// 3.请求模型return pdfChatClient.prompt().user(prompt).advisors(a -> a.param(CHAT_MEMORY_CONVERSATION_ID_KEY, chatId)).advisors(a -> a.param(FILTER_EXPRESSION, "file_name == '" + file.getFilename() + "'")).stream().content();}/*** 文件上传*/@RequestMapping("/upload/{chatId}")public Result uploadPdf(@PathVariable String chatId, @RequestParam("file") MultipartFile file) {try {// 1. 校验文件是否为PDF格式if (!Objects.equals(file.getContentType(), "application/pdf")) {return Result.fail("只能上传PDF文件!");}// 2.保存文件boolean success = fileRepository.save(chatId, file.getResource());if (!success) {return Result.fail("保存文件失败!");}// 3.写入向量库this.writeToVectorStore(file.getResource());return Result.ok();} catch (Exception e) {log.error("Failed to upload PDF.", e);return Result.fail("上传文件失败!");}}/*** 文件下载*/@GetMapping("/file/{chatId}")public ResponseEntity<Resource> download(@PathVariable("chatId") String chatId) throws IOException {// 1.读取文件Resource resource = fileRepository.getFile(chatId);if (!resource.exists()) {return ResponseEntity.notFound().build();}// 2.文件名编码,写入响应头String filename = URLEncoder.encode(Objects.requireNonNull(resource.getFilename()), StandardCharsets.UTF_8);// 3.返回文件return ResponseEntity.ok().contentType(MediaType.APPLICATION_OCTET_STREAM).header("Content-Disposition", "attachment; filename=\"" + filename + "\"").body(resource);}/*** 写入向量库*/private void writeToVectorStore(Resource resource) {// 1.创建PDF的读取器PagePdfDocumentReader reader = new PagePdfDocumentReader(resource, // 文件源PdfDocumentReaderConfig.builder().withPageExtractedTextFormatter(ExtractedTextFormatter.defaults()).withPagesPerDocument(1) // 每1页PDF作为一个Document.build());// 2.读取PDF文档,拆分为DocumentList<Document> documents = reader.read();// 3.写入向量库vectorStore.add(documents);}
}
上传大小限制
SpringMVC有默认的文件大小限制,只有10M,很多知识库文件都会超过这个值,所以我们需要修改配置,增加文件上传允许的上限;
修改application.yaml文件,添加配置:
spring:servlet:multipart:# 单个文件的最大大小为100MBmax-file-size: 104857600# 整个请求的最大大小为100MBmax-request-size: 104857600
配置ChatClient
理论上来说,每次与AI对话的完整流程是这样的:
- 将用户的问题利用向量大模型做向量化
OpenAiEmbeddingModel; - 去向量数据库检索相关的文档
VectorStore; - 拼接提示词,发送给大模型;
- 解析响应结果;
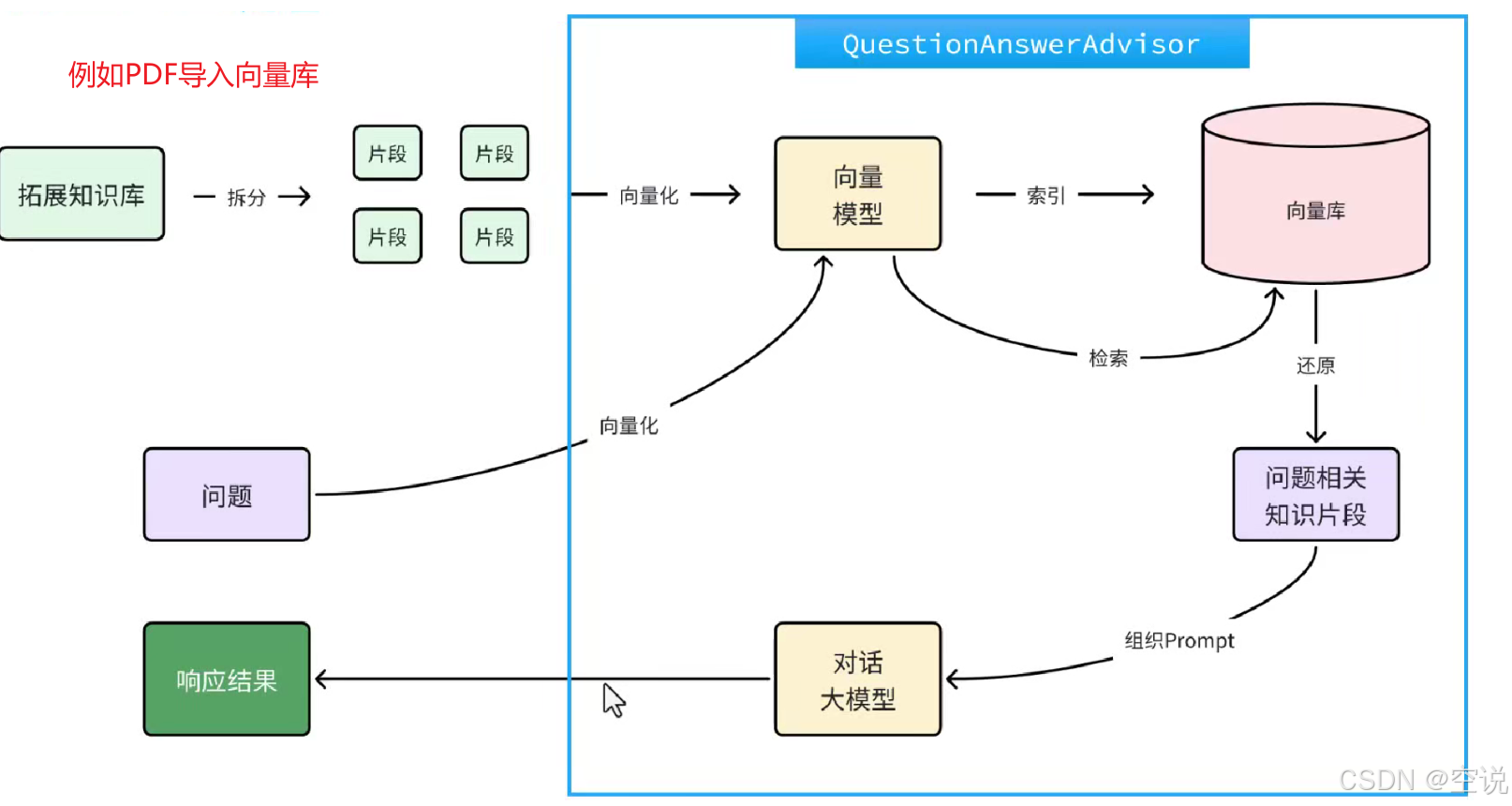
不过,SpringAI同样基于AOP技术帮我们完成了全部流程,用的是一个名为QuestionAnswerAdvisor的Advisor。我们只需要把VectorStore配置到Advisor即可。在CommonConfiguration类中给ChatPDF也单独定义一个ChatClient:
@Bean
public ChatClient pdfChatClient(OpenAiChatModel model, ChatMemory chatMemory, VectorStore vectorStore) {return ChatClient.builder(model).defaultSystem("请根据上下文回答问题,遇到上下文没有的问题,不要随意编造。").defaultAdvisors(new SimpleLoggerAdvisor(),new MessageChatMemoryAdvisor(chatMemory), // 会话记忆new QuestionAnswerAdvisor( vectorStore, // 向量库SearchRequest.builder() // 向量检索的请求参数.similarityThreshold(0.6) // 相似度阈值.topK(2) // 返回的文档片段数量.build())).build();
}
也可以自己自定义RAG查询的流程,不使用Advisor,具体可参考官网
对话接口
最后,对接前端与大模型对话。修改PdfController,添加一个接口:
/*** 对话
*/
@RequestMapping(value = "/chat", produces = "text/html;charset=utf-8")
public Flux<String> chat(String prompt, String chatId) {// 1.找到会话文件Resource file = fileRepository.getFile(chatId);if (!file.exists()) {// 文件不存在,不回答throw new RuntimeException("会话文件不存在!");}// 2.保存会话idchatHistoryRepository.save("pdf", chatId);// 3.请求模型return pdfChatClient.prompt().user(prompt).advisors(a -> a.param(CHAT_MEMORY_CONVERSATION_ID_KEY, chatId)).advisors(a -> a.param(FILTER_EXPRESSION, "file_name == '" + file.getFilename() + "'")).stream().content();
}
测试
持久化VectorStore
SpringAI提供了很多持久化的VectorStore,下面以其中两个为例来介绍:
- RedisVectorStore : 目前测试metafiled过滤有异常;
- CassandraVectorStore。
RedisVectorStore
- 需要安装一个Redis Stack,这是Redis官方提供的拓展版本,其中有向量库的功能;
- 可以使用Docker安装:
docker run -d --name redis-stack -p 6379:6379 -p 8001:8001 redis/redis-stack:latest
#通过命令行访问
docker exec -it redis-stack redis-cli
#也可以通过浏览器访问控制台:http://localhost:8001 ip换成自己配置的
在项目中引入RedisVectorStore的依赖:
<dependency><groupId>org.springframework.ai</groupId><artifactId>spring-ai-redis-store-spring-boot-starter</artifactId>
</dependency>
在application.yml配置Redis:
spring:ai:vectorstore:redis:index: spring_ai_index # 向量库索引名initialize-schema: true # 是否初始化向量库索引结构prefix: "doc:" # 向量库key前缀data:redis:host: XXX # redis地址
接下来,无需声明bean,直接就可以直接使用VectorStore了。
CassandraVectorStore
首先,需要安装一个Cassandra访问,使用Docker安装:
docker run -d --name cas -p 9042:9042 cassandra
在项目中添加cassandra依赖:
<dependency><groupId>org.springframework.ai</groupId><artifactId>spring-ai-cassandra-store-spring-boot-starter</artifactId>
</dependency>
配置Cassandra地址:
spring:cassandra:contact-points: xxx:9042local-datacenter: datacenter1
配置VectorStore:
public CassandraVectorStore vectorStore(OpenAiEmbeddingModel embeddingModel, CqlSession cqlSession) {return CassandraVectorStore.builder(embeddingModel).session(cqlSession).addMetadataColumn(new CassandraVectorStore.SchemaColumn("file_name", DataTypes.TEXT, CassandraVectorStore.SchemaColumnTags.INDEXED)).build();
}
相关文章:

SpringAI+DeepSeek大模型应用开发——5 ChatPDF
ChatPDF 知识库 RAG检索增强 由于训练大模型非常耗时,再加上训练语料本身比较滞后,所以大模型存在知识限制问题: 知识数据比较落后,往往是几个月之前的;不包含太过专业领域或者企业私有的数据; 为了解决…...

音视频之H.265/HEVC变换编码
H.265/HEVC系列文章: 1、音视频之H.265/HEVC编码框架及编码视频格式 2、音视频之H.265码流分析及解析 3、音视频之H.265/HEVC预测编码 4、音视频之H.265/HEVC变换编码 目录 一、离散余弦变换: DCT原理及特点: 一维DCT解析例子࿱…...

网工_FTP协议
2025.04.18:网工老姜&小猿网学习笔记 第27节 FTP协议 7.1 FTP概述7.2 FTP工作原理7.2.1 FTP主动模式7.2.2 FTP被动模式 7.3 FTP客户端常用命令7.4 本章小结 7.1 FTP概述 文件传输协议file transfer protocol 常见用途是从FTP服务器批量下载文件,另一…...

Vue2+Vue3 130~180集学习笔记
Vue2Vue3 130~180集(Vue3)学习笔记 一、create-vue搭建vue3项目 create-vue是vue官方新的脚手架工具,底层切换到了vite 步骤: 查看环境条件 node -v版本需要在16.0及以上创建一个vue应用 npm init vuelatest 这一指令会安装并执…...

前端融合图片mask
之前实现了tif文件的融合,现在实现图片的融合,效果如下 第一张是融合右边两张图的结果 我的思路是: 初始使用canvas加载原图,此时未显示标注点击显示标注后,将原图和mask图传给workerworker接受数据后,转…...

什么是单元测试的“覆盖率”
1. 先搞清楚“覆盖率”是啥? 打个比方,你写完作业(代码),老师(测试)要检查是不是每道题都做对了。覆盖率就是说老师检查了多少题。比如: 行覆盖率:老师看了你作…...

SpringAI入门:对话机器人
SpringAI入门:对话机器人 1.引入依赖 创建一个新的SpringBoot工程,勾选Web、MySQL驱动、Ollama: <?xml version"1.0" encoding"UTF-8"?> <project xmlns"http://maven.apache.org/POM/4.0.0" xm…...

[Java · 初窥门径] Java 语言初识
🌟 想系统化学习 Java 编程?看看这个:[编程基础] Java 学习手册 0x01:Java 编程语言简介 Java 是一种高级计算机编程语言,它是由 Sun Microsystems 公司(已被 Oracle 公司收购)于 1995 年 5 …...

大语言模型智能体:安全挑战与应对之道
在当今科技飞速发展的时代,大语言模型驱动的智能体正逐渐融入我们生活和工作的方方面面,给我们带来了诸多便利。但与此同时,它们的安全问题也引起了广泛的关注。今天,咱们就一起来深入了解一下可信大语言模型智能体所面临的安全挑…...

IHC肿瘤标志物 | 常见乳腺癌诊断——助力守护生命之花
乳腺癌作为一种常见的恶性肿瘤,严重威胁着女性健康。然而,随着医学技术的不断发展,我们有了更为精准和有效的检测方法,为及早发现和治疗乳腺癌提供了强有力的支持。 在这篇文章中,我们将深入了解乳腺癌的IHC检测技术&a…...

利用deepseek+Mermaid画流程图
你是一个产品经理,请绘制一个流程图,要求生成符合Mermaid语法的代码,要求如下: 用户下载文件、上传文件、删除文件的流程过程符合安全规范细节具体到每一步要做什么 graph LRclassDef startend fill:#F5EBFF,stroke:#BE8FED,str…...

Vue3 实战:打造多功能旅游攻略选项卡页面
在旅游类应用开发中,为用户提供全面、直观的信息展示界面至关重要。本文将分享如何基于 Vue3 Axios 技术栈,实现一个包含攻略、游记、问答三大板块的旅游攻略选项卡页面,从样式设计到交互逻辑,带你深入了解整个开发过程。 项目背…...

如何提高单元测试的覆盖率
一、定位未覆盖的代码 利用 IDEA 的覆盖率工具: 右键测试类 → Run with Coverage,或使用 AltShiftF10(Windows)打开运行菜单选择覆盖率。查看高亮标记: 绿色:已覆盖代码行。红色&#x…...
)
水位传感器详解(STM32)
目录 一、介绍 二、传感器原理 1.原理图 2.引脚描述 三、程序设计 main.c文件 water.h文件 water.c文件 四、实验效果 五、资料获取 项目分享 一、介绍 Water Sensor水位传感器是一款简单易用、性价比较高的水位/水滴识别检测传感器,其是通过具有一系列…...

linux服务器命令行获取nvidia显卡SN的方法
机房需要变更机器的GPU显卡配置,入库、出库几块显卡,库管让我去获取显卡序列号。 去现场拆机器的事情毕竟很麻烦,而且也没干过拆装服务器,即使拆下来显卡也不一定找到SN。 于是乎搜索:命令行怎么获取linux服务器上的…...

大模型微服务架构模块实现方案,基于LLaMA Factory和Nebius Cloud实现模型精调的标准流程及代码
以下是基于LLaMA Factory和Nebius Cloud实现模型精调的标准流程及代码示例,结合最新技术动态和行业实践整理: 一、LLaMA Factory本地部署方案 1. 环境配置 # 创建Python环境并安装依赖 conda create -n llama_factory python3.10 conda activate llam…...
:find)
每天学一个 Linux 命令(20):find
可访问网站查看,视觉品味拉满: http://www.616vip.cn/20/index.html find 是 Linux 系统中最强大的文件搜索工具之一,支持按名称、类型、时间、大小、权限等多种条件查找文件,并支持对搜索结果执行操作(如删除、复制、执行命令等)。掌握 find 可大幅提升文件管理效率…...

Kubernetes Pod 调度策略:从基础到进阶
文章目录 环境Kubernetes 部署Kubernetes Pod 调度策略Kubernetes Pod 调度策略对照表调度流程经历阶段案例展示生成yaml文件默认调度节点选择器为节点添加标签编写 Deployment 配置文件应用资源并查看调度结果 Node Affinity(节点亲和性)为节点添加标签…...

4.18学习总结
完成一道算法题 学习了序列化 敲代码卡bug了...

用于数学定理和逻辑推理的符号系统
当前用于数学定理和逻辑推理的前沿符号系统主要基于依赖类型论(Dependent Type Theory),其中Lean 4和**Metamath Zero (MM0)**是最具代表性的新兴系统。以下从技术特性、使用方法和应用实例三个维度展开说明: 一、前沿符号系统解…...

HTTP:九.WEB机器人
概念 Web机器人是能够在无需人类干预的情况下自动进行一系列Web事务处理的软件程序。人们根据这些机器人探查web站点的方式,形象的给它们取了一个饱含特色的名字,比如“爬虫”、“蜘蛛”、“蠕虫”以及“机器人”等!爬虫概述 网络爬虫(英语:web crawler),也叫网络蜘蛛(…...
)
代码学习总结(五)
代码学习总结(五) 这个系列的博客是记录下自己学习代码的历程,有来自平台上的,有来自笔试题回忆的,主要基于 C++ 语言,包括题目内容,代码实现,思路,并会注明题目难度,保证代码运行结果 1 小红的好数 简单 非退化三角形 快速匹配 小红定义一个数对 { x , y } \{x…...

在 Vue 3 项目中引入 js-cookie 库
1. 安装 js-cookie 你可以通过 npm 或者 yarn 来安装 js-cookie: npm install js-cookie # 或者 yarn add js-cookie2. 在组件里引入并使用 js-cookie 以下给出两种使用方式: 全局引入 在 main.js 中全局引入 js-cookie,这样在所有组件里…...

HarmonyOs学习 环境配置后 实验1:创建项目Hello World
HarmonyOS开发入门:环境配置与Hello World实验 实验目标 掌握HarmonyOS开发环境配置,创建首个HarmonyOS应用并实现"Hello World"界面展示 实验准备 已安装DevEco Studio开发环境已配置HarmonyOS开发依赖项熟悉基本TypeScript/ArkTS语法&am…...

Spark on K8s 在 vivo 大数据平台的混部实战与优化
一、Spark on K8s 简介 (一)定义与架构 Spark on K8s 是一种将 Spark 运行在 Kubernetes(K8s)集群上的架构,由 K8s 直接创建 Driver 和 Executor 的 Pod 来运行 Spark 作业。其架构如下。 Driver Pod:相当于 Spark 集群中的 Driver,负责作业的调度和管理,它会根据作业…...
——结构化开发方法)
《软件设计师》复习笔记(13)——结构化开发方法
目录 1. 结构化开发方法 1.1 系统分析过程 1.2 系统设计基本原理 (1)内聚性(模块内部关联程度) (2)耦合性(模块间依赖程度) 真题示例: 1.3 系统总体结构设计&…...

Android创建测试配置和生产配置
Android测试与生产环境配置指南 在Android开发中,创建不同的构建配置来适应测试和生产环境是至关重要的。这样的配置能让我们在不同的开发阶段有效管理代码、资源和环境变量。本文将详细介绍如何在Android中创建和管理测试配置以及生产配置的整个过程。 环境准备 …...

DBeaver连接hive
DBeaver是一个非常好用的数据库管理工具,支持多种不同的数据库类型。 dbeaver 要连接hive时,数据库驱动是无法下载,但在hive 的安装配置包中,有一个目录:jdbc里面有一个专门提供外部程序连接hive的jar。将这个jar下载…...
)
数据结构初阶:二叉树(二)
本篇博客主要讲解二叉树---堆的相关知识。 1.实现顺序结构二叉树 一般堆使用顺序结构的数组来存储数据,堆是一种特殊的二叉树,具有二叉树的特性的同时,还具备其他的特性。 1.1 堆的概念和结构 堆具有以下性质: 堆中某个结点的值…...

React 列表渲染基础示例
React 中最常见的一个需求就是「把一组数据渲染成一组 DOM 元素」,比如一个列表。下面是我写的一个最小示例,目的是搞清楚它到底是怎么工作的。 示例代码 // 定义一个静态数组,模拟后续要渲染的数据源 // 每个对象代表一个前端框架…...

android PackageName ClassName
目录 系统应用: 设置 蓝牙 时钟 计算机 录音机 图库 视频 文件管理 FM 日历 谷歌浏览器 谷歌商店 热门商店 国外应用: amazon spotify deezer pandora audible applemusic omnia mxtech youtubemusic facebook familylink tidal tiktok kindle 系统应用: 设置 …...

万物对接大模型:【爆火】MCP原理与使用指南
###原文链接 OpenAI、谷歌、微软、阿里云、腾讯云、百度等国内外各大厂商都陆续宣布支持MCP服务。MCP是什么,为什么能获得高度的关注? MCP(Model Context Protocol,模型上下文协议)是由Anthropic公司(核心产品是Claude大模型)推出的一种开源协议…...

SAP系统中MD01与MD02区别
知识点普及-MD01与MD02区别 1、从日常业务中,我们都容易知道MD01是运行全部物料,MD02是运行单个物料 2、在做配置测试中,也出现过MD02可以跑出物料,但是MD01跑不出的情况。 3、MD01与MD02的差异: 3.1、只要在物料主数…...

python——字符串使用
目录 1、字符串表示 2、转义字符 (1)将一些具有特殊含义的字符,标识成普通的字符(\) (2)特殊的控制符 (3)(\)还可以表示python中续行符 3、…...

嵌入式ARM RISCV toolchain工具 梳理arm-none-eabi-gcc
嵌入式TOOLchain工具 梳理 简介 本文总结和梳理一下一些toolchain的规则和原理,方便后续跨平台的时候,给大家使用toolchain做一个参考。 解释如何理解arm-none-eabi-gcc等含义,以及如何一看就知道该用什么编译器。 当然如果有哪里写的不是…...

团体程序设计天梯赛PTA-SHU冲刺赛4. L22-L32
这是4.18 SHU备赛天梯赛的最后一场冲刺赛 10.病毒溯源 1.本题PTA中拓栈后会MTL,不拓栈会报非零返回 所以本题最好用栈模拟递归过程 2.源头得是入度为0的,也就是没有节点指向它 所以得设置inn是否有指向该节点 3.这题用dfs(用bfs的话不同…...

【数据结构与算法】——插入排序
概要 本文将介绍插入排序方法——直接插入、希尔排序 想了解数据结构其他内容,本人主页 恋风诗 获取源码,gitte仓库:mozhengy 正文 1.排序的分类 目前将主要介绍下面几种排序: 后续学习更多内容后会及时更新 2、插入排序 2…...

手撕STL——vector
目录 引言 1,了解 STL 中的 vector 2,先来一个简易版跑起来 2_1,构造函数 2_2,扩容reserve() 2_3,push_back() 2_4,pop_back() …...

新书速览|DeepSeek移动端AI应用开发:基于Android与iOS
《DeepSeek移动端AI应用开发:基于Android与iOS》 1 本书内容 《DeepSeek移动端AI应用开发:基于Android与iOS》深入剖析了DeepSeek平台的架构原理、API调用及开发实践等核心内容,助力读者在Android与iOS移动端高效集成DeepSeek API,打造出契…...

详解STM32时基单元中参数 TIM_ClockDivision 的含义
在 STM32 定时器时基单元配置中,TIM_TimeBaseInitStruct->TIM_ClockDivision 用于设置 定时器时钟的分频系数,主要影响 输入捕获滤波器 和 输出比较同步信号 的时钟分割。以下是其核心作用、参数含义及应用场景的详细解析: 一、核心作用&…...

黑马V11版 最新Java高级软件工程师课程-JavaEE精英进阶课
课程大小:60.2G 课程下载:https://download.csdn.net/download/m0_66047725/90615581 更多资源下载:关注我 阶段一 中台战略与组件化开发专题课程 阶段二 【物流行业】品达物流TMS 阶段三 智牛股 阶段四 千亿级电商秒杀解决方案专题 …...

【Win】 cmd 执行curl命令时,输出 ‘命令管道位置 1 的 cmdlet Invoke-WebRequest 请为以下参数提供值: Uri: ’ ?
1.原因: 有一个名为 Invoke-WebRequest 的 CmdLet,其别名为 curl。因此,当您执行此命令时,它会尝试使用 Invoke-WebRequest,而不是使用 curl。 2.解决办法 在cmd中输入如下命令删除这个curl别名: Remov…...

【k8s系列4】工具介绍
1、虚拟机软件 vmware workstation 2、shell 软件 MobaXterm 3、centos7.9 下载地址 (https://mirrors.aliyun.com/centos/7.9.2009/isos/x86_64/?spma2c6h.25603864.0.0.374bf5adOaiFPW) 4、上网软件...

设计模式 --- 装饰器模式
装饰模式是一种结构型设计模式,它允许向一个现有的对象添加新的功能,同时又不改变其结构。这种模式创建了一个装饰类,用来包装原有的类,并在保持类方法签名完整性的前提下,提供了额外的功能。 优点: 1.灵…...

docker.desktop下安装普罗米修斯prometheus、grafana并看服务器信息
目标 在docker.desktop下先安装这三种组件,然后显示当前服务的CPU等指标。各种坑已踩,用的是当前时间最新的镜像 核心关系概述 组件角色依赖关系Prometheus开源监控系统,负责 数据采集、存储、查询及告警。依赖 Node-Exporter 提供的指标数据。Node-Exporter专用的 数据采集…...

学习设计模式《二》——外观模式
一、基础概念 1.1、外观模式的简介 外观模式的本质是【封装交互、简化调用】; 外观模式的说明:就是通过引入一个外观类,在这个类里面定义客户端想要的简单方法,然后在这些方法里面实现;由外观类再去分别调用内部的多个…...

python中,处理多分类时,模型之间的参数设置
在Python的机器学习库中,处理多分类问题时,不同的模型可能会有不同的参数设置来适应多分类场景。这里列举几个常见模型及相关的多分类参数: 1. Logistic Regression (逻辑回归) 在Scikit-Learn库中,逻辑回归模型可以通过设置mul…...
等级考试试卷(四级)真题)
2025年03月中国电子学会青少年软件编程(Python)等级考试试卷(四级)真题
青少年软件编程(Python)等级考试试卷(四级) 分数:100 题数:38 答案解析:https://blog.csdn.net/qq_33897084/article/details/147341407 一、单选题(共25题,共50分) 1. 下列程序段…...

蓝桥杯12. 日期问题
日期问题 原题目链接 题目描述 小明正在整理一批历史文献。这些历史文献中出现了很多日期。 小明知道这些日期都在 1960 年 1 月 1 日 至 2059 年 12 月 31 日 之间。 令小明头疼的是,这些日期采用的格式非常不统一: 有的采用 年/月/日有的采用 月…...

【MATLAB代码例程】AOA与TOA结合的高精度平面地位,适用于四个基站的情况,附完整的代码
本代码实现了一种基于到达角(AOA) 和到达时间(TOA) 的混合定位算法,适用于二维平面内移动或静止目标的定位。通过4个基站的协同测量,结合最小二乘法和几何解算,能够有效估计目标位置,并支持噪声模拟、误差分析和可视化输出。适用于室内定位、无人机导航、工业监测等场景…...