Kubernetes Pod 调度策略:从基础到进阶
文章目录
- 环境
- Kubernetes 部署
- Kubernetes Pod 调度策略
- Kubernetes Pod 调度策略对照表
- 调度流程经历阶段
- 案例展示
- 生成yaml文件
- 默认调度
- 节点选择器
- 为节点添加标签
- 编写 Deployment 配置文件
- 应用资源并查看调度结果
- Node Affinity(节点亲和性)
- 为节点添加标签
- 硬约束(Required)
- 软约束(Preferred)
- 先不设置标签
- 设置标签
- 运算符支持的类型
- 污点与容忍(Taints & Tolerations)
- 污点(Taint)
- 添加污点的命令:
- 容忍(Toleration)
- 示例 YAML:
- 三种 Effect 类型(效果)
- 案例演示
- 给所有节点打上污点
- 没有容忍的 Pod(会调度失败)
- 有容忍的 Pod(调度成功)
- Pod Affinity(Pod 亲和性)与 Pod Anti-Affinity(反亲和性)
- Pod Affinity(亲和性)
- 示例:调度到和标签为 app=nginx 的 Pod 相同节点的 Pod 上(硬约束)
- Pod Anti-Affinity(反亲和性)
- 示例:调度到与标签为 app=nginx 的 Pod 不同节点上(软约束)
- 拓扑域 TopologyKey 说明
- 总结
- ✅ 默认调度策略
- ✅ NodeSelector
- ✅ Node Affinity(节点亲和性)
- ✅ Pod Affinity / Anti-Affinity(Pod 间亲和/反亲和)
- ✅ Taints and Tolerations(污点与容忍)
- ✅ 自定义调度器(Custom Scheduler)
- 📌 建议使用场景总结
环境
[root@10-255-101-217 ~]# kubectl get nodes -o wide
NAME STATUS ROLES AGE VERSION INTERNAL-IP EXTERNAL-IP OS-IMAGE KERNEL-VERSION CONTAINER-RUNTIME
10-255-101-152 Ready <none> 24h v1.22.0 10.255.101.152 <none> CentOS Linux 7 (Core) 4.18.9-1.el7.elrepo.x86_64 containerd://1.4.3
10-255-101-216 Ready <none> 24h v1.22.0 10.255.101.216 <none> CentOS Linux 7 (Core) 4.18.9-1.el7.elrepo.x86_64 containerd://1.4.3
10-255-101-217 Ready control-plane,master 24h v1.22.0 10.255.101.217 <none> CentOS Linux 7 (Core) 4.18.9-1.el7.elrepo.x86_64 containerd://1.4.3
10-255-101-82 Ready <none> 24h v1.22.0 10.255.101.82 <none> CentOS Linux 7 (Core) 4.18.9-1.el7.elrepo.x86_64 containerd://1.4.3
[root@10-255-101-217 ~]#
Kubernetes 部署
一台 Master 多节点玩转 Kubernetes:sealos 一键部署实践
下边的案例基于这个部署方式以及环境进行演示
Kubernetes Pod 调度策略
-
默认调度(Default Scheduling)
在没有额外配置的情况下,kube-scheduler会根据 Pod 的资源请求(requests)和节点的可用资源(allocatable)进行自动调度。这是大多数常规应用场景的默认策略,适合无需精细控制资源分配的情况。 -
节点选择器(NodeSelector)
通过在 Pod 规格中设置nodeSelector: { key: value },可以强制 Pod 仅被调度到具有指定标签的节点。这是一种硬性匹配策略,适用于将 Pod 部署到具有特定硬件、特定配置或专用节点的场景。 -
节点亲和性(Node Affinity)
节点亲和性允许用户基于节点的标签进行更复杂的软/硬约束。它包含两种类型:requiredDuringSchedulingIgnoredDuringExecution(硬性约束):要求 Pod 只能被调度到满足条件的节点上。preferredDuringSchedulingIgnoredDuringExecution(软性偏好):Pod 会尝试被调度到满足条件的节点上,但若无法满足条件,仍会被调度到其他节点。
这种方法可以让调度策略更加灵活,特别是在需要对节点进行复杂匹配或按优先级排序时。
-
污点与容忍(Taints & Tolerations)
通过在节点上添加污点,防止不容忍的 Pod 被调度到该节点。Pod 需要配置tolerations,以接受特定污点。这是一种细粒度的控制机制,广泛应用于专用节点的隔离、故障剔除、热点节点流量控制等场景。 -
Pod 亲和性与反亲和性(Pod Affinity & Anti-Affinity)
- Pod Affinity:确保相关 Pod 部署在同一节点或拓扑域内,以提升性能或数据本地性。
- Pod Anti-Affinity:确保相关 Pod 不部署在同一节点,适用于高可用性要求,避免单点故障。
使用 Pod 亲和性和反亲和性可以精确控制 Pod 的分布策略,增强系统的弹性和容错性。
-
自定义调度器与调度扩展(Custom Scheduler & Scheduler Extenders)
如果 Kubernetes 的默认调度器无法满足特定需求,可以通过自定义调度器或扩展插件来实现个性化调度。例如,可以指定schedulerName: <your-scheduler>,或使用调度扩展与外部系统进行集成,适用于特殊资源(如 GPU、Spot 实例)或复杂调度逻辑的场景。
Kubernetes Pod 调度策略对照表
| 策略中文名称 | 策略英文术语 | 简要描述 | 适用场景 | 配置方式(简化) |
|---|---|---|---|---|
| 默认调度 | Default Scheduling | kube-scheduler 根据资源需求和节点可用性自动分配 Pod | 无特殊调度需求的常规应用 | 无需配置 |
| 节点选择器 | NodeSelector | 通过节点标签(Label)进行硬性匹配,Pod 只会被调度到指定标签的节点上 | 将 Pod 部署到具备特定硬件或配置的节点 | nodeSelector: { key: value } |
| 节点亲和性 | Node Affinity | 基于节点标签的软/硬约束,支持更灵活的偏好与必选规则 | 对节点标签有复杂匹配需求,需在节点间进行偏好排序 | 使用 affinity.nodeAffinity 配置 |
| 污点与容忍 | Taints & Tolerations | 节点通过污点阻止不容忍的 Pod 被调度,Pod 通过容忍接受污点 | 专用节点隔离、故障节点剔除、热点节点流控等 | 节点 taint + Pod tolerations |
| Pod 亲和性 | Pod Affinity | 控制 Pod 之间的协同部署,确保相关 Pod 被调度到同一节点或拓扑域中 | 提高性能或数据本地性,相关服务部署在一起 | 使用 affinity.podAffinity 配置 |
| Pod 反亲和性 | Pod Anti-Affinity | 控制 Pod 之间的分散部署,避免相关 Pod 被调度到同一节点 | 高可用场景下避免单点故障,确保 Pod 分布在不同节点上 | 使用 affinity.podAntiAffinity 配置 |
自定义调度器(未进行实践,博文无案例) | Custom Scheduler / Extenders | 使用插件或替换方案,支持 GPU、Spot 实例等特殊资源的定制调度逻辑 | 企业级集群,需自定义调度算法或集成外部调度系统 | schedulerName: 自定义调度器名称 |
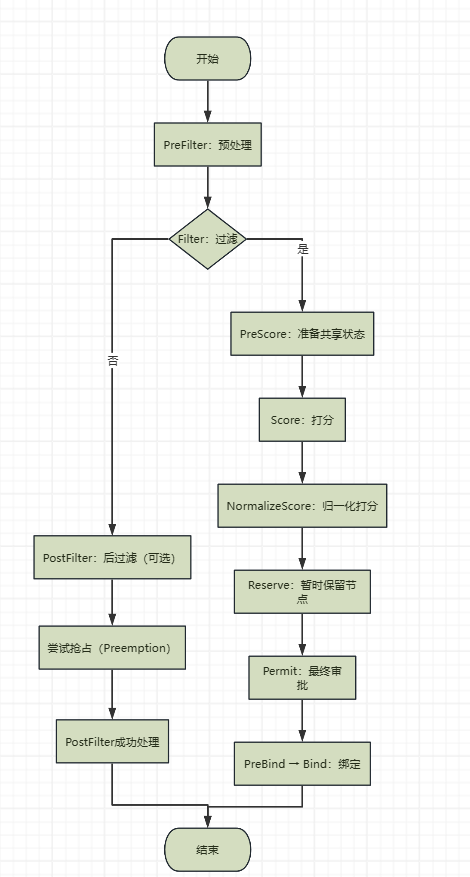
调度流程经历阶段
- PreFilter(预处理):收集 Pod 相关信息,检查必须满足的前置条件。
- Filter(过滤):通过各类 Filter 插件 排除不符合条件的节点,例如资源不足、NodeSelector、Node Affinity、Taints 等规则。
- PostFilter(后过滤,可选):当没有可行节点时触发,如抢占(Preemption)机制,尝试腾出资源。
- PreScore:为 Score 插件 准备共享状态。
- Score(打分):对剩余节点执行各类 Score 插件,根据算法(如资源均衡、拓扑感知等)对节点进行打分。
- NormalizeScore:将各插件打分归一化到 0–100。
- Reserve:暂时保留选中的节点,防止并发 Pod 冲突。
- Permit:最终审批,可用于等待或速率限制等场景。
- PreBind → Bind(绑定):将 Pod.spec.nodeName 设置为选定节点,完成调度。
- PostBind(绑定后,可选):信息收集或清理工作。
仅供参考
案例展示
生成yaml文件
kubectl create deployment test-nginx \--image=nginx \--replicas=2 \--port=80 \-n default\--dry-run=client \-o yaml \> nginx-deploy.yaml
各参数含义
| 参数 | 作用说明 |
|---|---|
kubectl create deployment | 创建一个 Deployment 资源 |
test-nginx | Deployment 的名称 |
--image=nginx | 指定容器镜像为 nginx |
--replicas=2 | 设置副本数为 2 个 Pod |
--port=80 | 指定容器对外暴露的端口(虽然这个参数不一定反映在 YAML 中) |
-n default | 指定命名空间为 default |
--dry-run=client | 客户端验证,不真正创建资源 |
-o yaml | 以 YAML 格式输出资源清单 |
> nginx-deploy.yaml | 将输出重定向到文件 nginx-deploy.yaml 中 |
生成的yaml文件
apiVersion: apps/v1
kind: Deployment
metadata:creationTimestamp: nulllabels:app: test-nginxname: test-nginxnamespace: default
spec:replicas: 2selector:matchLabels:app: test-nginxstrategy: {}template:metadata:creationTimestamp: nulllabels:app: test-nginxspec:containers:- image: nginxname: nginxports:- containerPort: 80resources: {}
status: {}
YAML 关键字段说明
| 字段路径 | 含义说明 |
|---|---|
spec.replicas: 2 | 定义 Deployment 期望运行 2 个 Pod 实例 |
spec.selector.matchLabels | 用于匹配 Pod 标签,Deployment 用于关联控制的 Pod |
spec.template.metadata.labels | Pod 模板的标签,与 selector 匹配 |
spec.template.spec.containers | 定义容器镜像、端口、资源等关键参数 |
ports.containerPort: 80 | 定义容器对外开放的端口 |
默认调度
[root@10-255-101-217 ~]# kubectl get pods
No resources found in default namespace.
[root@10-255-101-217 ~]# kubectl apply -f nginx-deploy.yaml
deployment.apps/test-nginx created
[root@10-255-101-217 ~]# kubectl get pods -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
test-nginx-6f5d5f6564-gbgc6 1/1 Running 0 13s 192.168.154.1 10-255-101-82 <none> <none>
test-nginx-6f5d5f6564-jpbhl 1/1 Running 0 13s 192.168.154.65 10-255-101-152 <none> <none>
[root@10-255-101-217 ~]#
kube-scheduler默认调度器会根据集群中各节点的资源使用情况(如 CPU、内存等),自动选择最合适的节点部署 Pod。上例中,两个 Pod 被均衡地调度到不同节点上,体现了默认调度的负载均衡策略。
节点选择器
使用 NodeSelector 指定节点调度
为节点添加标签
我们可以通过 kubectl label 命令给某个节点添加标签,方便后续在 Pod 调度时进行筛选。
kubectl label nodes 10-255-101-82 disktype=ssd
此命令为节点
10-255-101-82添加了一个标签:disktype=ssd
编写 Deployment 配置文件
创建名为 ssd.yaml 的 Deployment 文件,指定 nodeSelector 字段:
apiVersion: apps/v1
kind: Deployment
metadata:name: test-nginx-nodeselectornamespace: defaultlabels:app: test-nginx
spec:replicas: 2selector:matchLabels:app: test-nginxtemplate:metadata:labels:app: test-nginxspec:nodeSelector:disktype: ssdcontainers:- name: nginximage: nginxports:- containerPort: 80
status: {}
在
spec.template.spec.nodeSelector中声明节点标签disktype: ssd,表示仅在拥有该标签的节点上运行 Pod。
应用资源并查看调度结果
kubectl apply -f ssd.yaml
查看 Pod 分布情况:
kubectl get pods -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
test-nginx-6f5d5f6564-gbgc6 1/1 Running 0 18m 192.168.154.1 10-255-101-82 <none> <none>
test-nginx-6f5d5f6564-jpbhl 1/1 Running 0 18m 192.168.154.65 10-255-101-152 <none> <none>
test-nginx-nodeselector-7cfb54fc6b-9grcj 1/1 Running 0 5s 192.168.154.3 10-255-101-82 <none> <none>
test-nginx-nodeselector-7cfb54fc6b-q5m72 1/1 Running 0 5s 192.168.154.2 10-255-101-82 <none> <none>
从结果可以看到,test-nginx-nodeselector 这两个 Pod 均调度到了节点 10-255-101-82 上,符合我们通过 NodeSelector 限定的调度条件。
Node Affinity(节点亲和性)
为节点添加标签
我们可以通过 kubectl label 命令给某个节点添加标签,方便后续在 Pod 调度时进行筛选。
kubectl label nodes 10-255-101-152 10-255-101-216 nodeaffinity=test
此命令为节点
10-255-101-152 10-255-101-216添加了一个标签:nodeaffinity=test
在 Kubernetes 中,Node Affinity(节点亲和性) 是一种调度策略,用于控制 Pod 应该调度到哪些具有特定标签的节点上。它是对传统 nodeSelector 的增强版,提供了更灵活、更强大的表达能力。
Node Affinity 分为两种:
- 硬约束:
requiredDuringSchedulingIgnoredDuringExecution
→ 必须匹配,否则无法调度。 - 软约束:
preferredDuringSchedulingIgnoredDuringExecution
→ 尽量匹配,不匹配也能调度。
硬约束(Required)
apiVersion: apps/v1
kind: Deployment
metadata:name: nginx-hard-affinitynamespace: default
spec:replicas: 2selector:matchLabels:app: nginxtemplate:metadata:labels:app: nginxspec:affinity:nodeAffinity:requiredDuringSchedulingIgnoredDuringExecution:nodeSelectorTerms:- matchExpressions:- key: nodeaffinityoperator: Invalues:- testcontainers:- name: nginximage: nginxports:- containerPort: 80
含义
- Pod 只能被调度到那些带有
nodeaffinity=test标签的节点上。 - 如果没有满足条件的节点,Pod 不会被创建,调度器也不会“妥协”。
- 用于强制性约束,适用于:必须部署到某类节点,例如有 GPU、有 SSD 的节点。
字段说明
| 字段 | 说明 |
|---|---|
requiredDuringSchedulingIgnoredDuringExecution | 硬约束:调度时必须满足,执行时不再检查 |
nodeSelectorTerms | 多个条件之间是“或”(OR)关系 |
matchExpressions | 条件表达式数组,内部是“与”(AND)关系 |
key | 节点的标签键,例如 disktype |
operator | 条件运算符,如 In、NotIn、Exists 等 |
values | 标签值列表 |

软约束(Preferred)
只是多了 weight
先不设置标签
apiVersion: apps/v1
kind: Deployment
metadata:name: nginx-soft-affinitynamespace: default
spec:replicas: 2selector:matchLabels:app: nginxtemplate:metadata:labels:app: nginxspec:affinity:nodeAffinity:preferredDuringSchedulingIgnoredDuringExecution:- weight: 100preference:matchExpressions:- key: kkkoperator: Invalues:- vvvcontainers:- name: nginximage: nginxports:- containerPort: 80
含义
- Pod 优先调度到带有
kkk=vvv标签的节点上,如果没有这样的节点,也可以调度到别的节点。 - 属于“加分项”或者“倾向性偏好”。
- 可以设置多个条件,调度器会根据
weight评估权重。
字段说明
| 字段 | 说明 |
|---|---|
preferredDuringSchedulingIgnoredDuringExecution | 软约束,调度时尽量满足,执行时不检查 |
weight | 权重值(1-100),用于排序优先级 |
preference | 匹配条件,与 required 内部结构相同 |

截屏查看都到216了
设置标签
kubectl label nodes 10-255-101-152 kkk=vvv
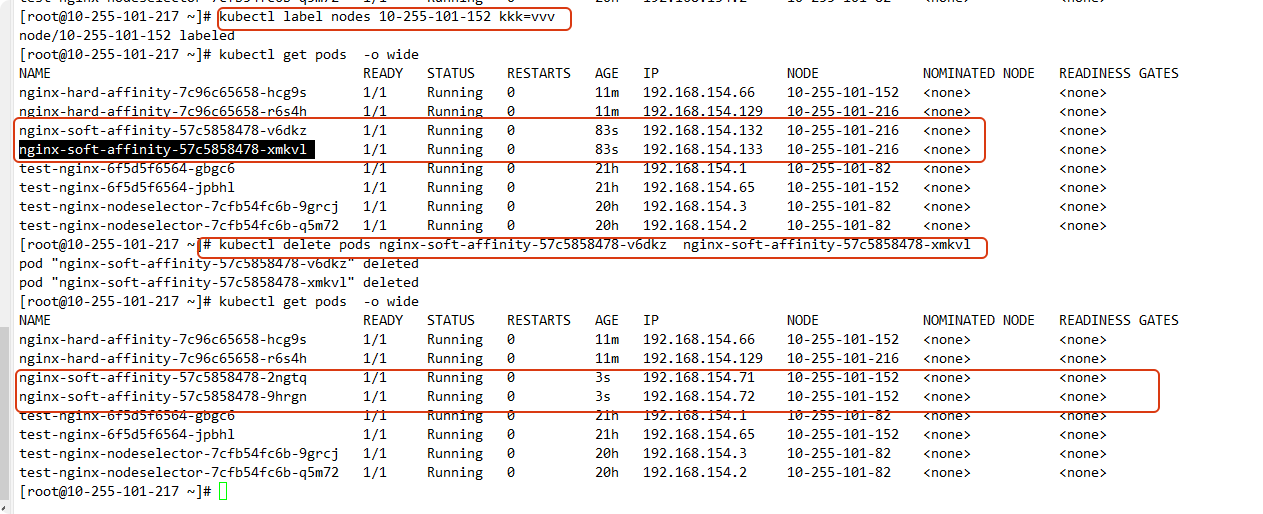
运算符支持的类型
| 运算符 | 含义 |
|---|---|
In | 键的值必须在列表中 |
NotIn | 键的值不能在列表中 |
Exists | 键存在即可,不关心值 |
DoesNotExist | 键不存在 |
Gt | 键的值大于指定值(整数) |
Lt | 键的值小于指定值(整数) |
污点与容忍(Taints & Tolerations)
在 Kubernetes 中,污点(Taint) 是给节点“贴标签”,表示这个节点不希望被调度 Pod;而 容忍(Toleration) 是对 Pod 设置“通行证”,告诉调度器:我可以接受这个污点,允许调度到这个节点。
🚧 说白了,就是节点用 Taint 拒绝普通 Pod,而 Pod 用 Toleration 表示“我不怕”,可以进去。
污点(Taint)
添加污点的命令:
kubectl taint nodes <节点名> key=value:effect
例子:
kubectl taint nodes node1 disktype=ssd:NoSchedule
这表示 node1 节点上有个污点,键为 disktype,值为 ssd,调度器将不再把普通 Pod 安排到这个节点上。
容忍(Toleration)
Pod 通过 tolerations 字段声明可以容忍哪些污点。
示例 YAML:
apiVersion: v1
kind: Pod
metadata:name: toleration-pod
spec:tolerations:- key: "disktype"operator: "Equal"value: "ssd"effect: "NoSchedule"containers:- name: nginximage: nginx
📌 含义:
- 这个 Pod 可以调度到被
disktype=ssd:NoSchedule污染的节点。 - 如果节点没有这个污点,Pod 也能正常调度。
三种 Effect 类型(效果)
| Effect 类型 | 含义说明 |
|---|---|
NoSchedule | 不允许没有容忍的 Pod 被调度 |
PreferNoSchedule | 尽量不调度,没有强制性 |
NoExecute | 不仅不调度,还会驱逐正在运行但不容忍的 Pod |
案例演示
给所有节点打上污点
kubectl taint nodes 10-255-101-152 10-255-101-216 10-255-101-82 key1=value1:NoSchedule
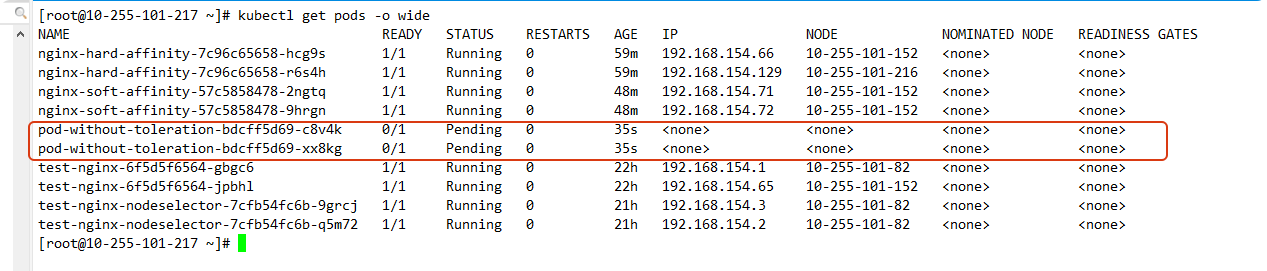
没有容忍的 Pod(会调度失败)
apiVersion: apps/v1
kind: Deployment
metadata:name: pod-without-tolerationnamespace: default
spec:replicas: 2selector:matchLabels:app: nginxtemplate:metadata:labels:app: nginxspec:containers:- name: nginximage: nginxports:- containerPort: 80
这个 Pod 不会调度成功,因为它无法容忍污点。
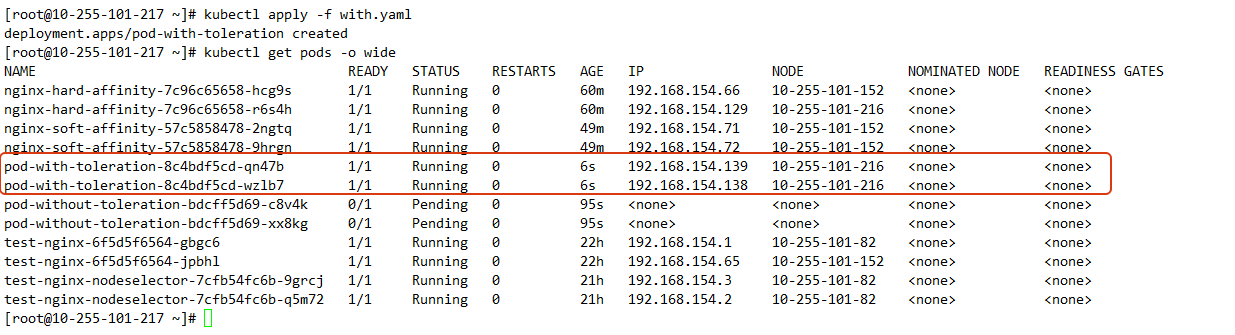
有容忍的 Pod(调度成功)
apiVersion: apps/v1
kind: Deployment
metadata:name: pod-with-tolerationnamespace: default
spec:replicas: 2selector:matchLabels:app: nginxtemplate:metadata:labels:app: nginxspec:tolerations:- key: "key1"operator: "Equal"value: "value1"effect: "NoSchedule"containers:- name: nginximage: nginxports:- containerPort: 80
字段解析
| 字段 | 说明 |
|---|---|
key | 与节点上污点的键匹配。这个例子中是 key1 |
operator | 表示比较方式,这里是 Equal,意思是 key=key1 且 value=value1 |
value | 必须与节点污点的值相同。 |
effect | 表示容忍哪种类型的污点效果,这里是 NoSchedule,表示可以调度到原本不允许的节点上。 |
Pod Affinity(Pod 亲和性)与 Pod Anti-Affinity(反亲和性)
Pod 亲和性用于指定一个 Pod 应该调度到和哪些 Pod 同节点或同拓扑域的节点上;而反亲和性则用于指定 不应该调度到和某些 Pod 同节点上的节点上。这在某些实际场景中非常有用,比如将应用组件部署在一起或故意分散部署。
Pod Affinity 和 Node Affinity 类似,也分为:
- 硬约束:
requiredDuringSchedulingIgnoredDuringExecution- 软约束:
preferredDuringSchedulingIgnoredDuringExecution
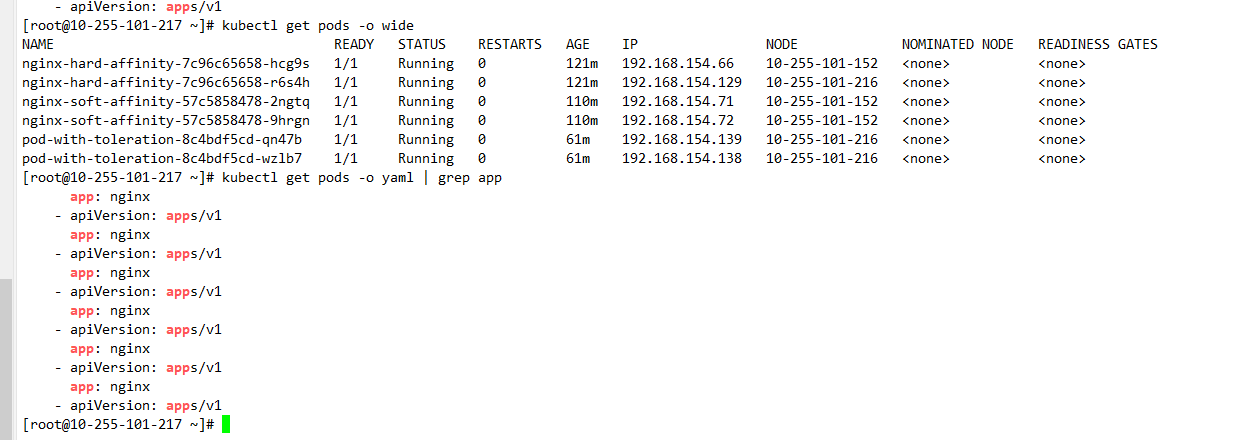
Pod Affinity(亲和性)
示例:调度到和标签为 app=nginx 的 Pod 相同节点的 Pod 上(硬约束)
apiVersion: apps/v1
kind: Deployment
metadata:name: nginx-pod-affinitynamespace: default
spec:replicas: 2selector:matchLabels:app: nginx-affinitytemplate:metadata:labels:app: nginx-affinityspec:affinity:podAffinity:requiredDuringSchedulingIgnoredDuringExecution:- labelSelector:matchExpressions:- key: appoperator: Invalues:- nginxtopologyKey: kubernetes.io/hostnamecontainers:- name: nginximage: nginxports:- containerPort: 80
说明:
labelSelector:匹配目标 Pod 的标签topologyKey:指定拓扑域,一般用kubernetes.io/hostname表示同一节点

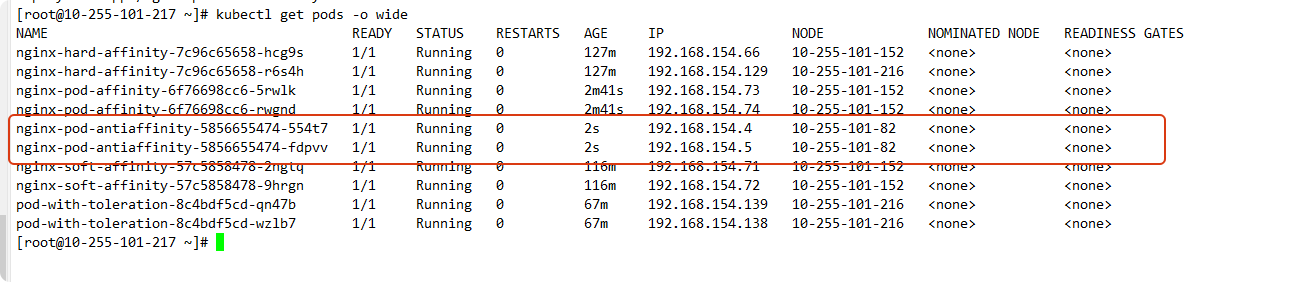
Pod Anti-Affinity(反亲和性)
示例:调度到与标签为 app=nginx 的 Pod 不同节点上(软约束)
apiVersion: apps/v1
kind: Deployment
metadata:name: nginx-pod-antiaffinitynamespace: default
spec:replicas: 2selector:matchLabels:app: nginx-antiaffinitytemplate:metadata:labels:app: nginx-antiaffinityspec:affinity:podAntiAffinity:preferredDuringSchedulingIgnoredDuringExecution:- weight: 100podAffinityTerm:labelSelector:matchExpressions:- key: appoperator: Invalues:- nginxtopologyKey: kubernetes.io/hostnamecontainers:- name: nginximage: nginxports:- containerPort: 80
这个配置表示:“尽量避免和已有的 nginx Pod 被调度到同一节点”。
拓扑域 TopologyKey 说明
| 拓扑键 | 含义说明 |
|---|---|
kubernetes.io/hostname | 节点级别,同一 Node |
topology.kubernetes.io/zone | 同一可用区(适用于云平台) |
topology.kubernetes.io/region | 同一区域(适用于云平台) |
总结
在 Kubernetes 中,Pod 的调度策略直接关系到集群资源的利用率和业务运行的稳定性。通过本篇博文,我们从多个维度深入了解了 Pod 的调度机制:
✅ 默认调度策略
Kubernetes 默认调度器会基于资源可用性、亲和性、污点容忍等信息,为 Pod 自动选择最合适的节点。这种方式适合大多数通用业务场景。
✅ NodeSelector
最简单的调度约束方式,通过指定 nodeSelector 键值对,将 Pod 调度到拥有对应标签的节点上,配置简单,逻辑清晰。
✅ Node Affinity(节点亲和性)
提供了更强大、灵活的调度表达能力,支持软约束(preferred)和硬约束(required)两种模式,并支持多种匹配运算符如 In、Exists、Gt 等,更适合复杂调度场景。
✅ Pod Affinity / Anti-Affinity(Pod 间亲和/反亲和)
允许调度决策考虑其他 Pod 的位置关系。例如可以将某些 Pod 调度到相同或不同节点,以实现高可用、节点隔离、业务分层部署等目的,是构建微服务间拓扑结构的重要手段。
✅ Taints and Tolerations(污点与容忍)
用于限制某些节点只接受特定 Pod,反向实现“节点选择”的效果,常用于控制特殊硬件资源节点的使用,例如 GPU 节点、安全节点等。
✅ 自定义调度器(Custom Scheduler)
当内置调度逻辑无法满足需求时,可通过编写并部署自定义调度器,灵活实现业务定制的调度策略,具备最高的自由度和扩展性。
📌 建议使用场景总结
| 需求类型 | 推荐策略 |
|---|---|
| 简单节点筛选 | nodeSelector |
| 灵活的节点规则匹配 | nodeAffinity |
| 根据其他 Pod 的位置调度 | podAffinity / podAntiAffinity |
| 限制 Pod 访问某些节点 | taints and tolerations |
| 实现复杂定制调度逻辑 | 自定义调度器(Custom Scheduler) |
Kubernetes 的调度机制具有极高的可扩展性和可编程性,在实际生产中,合理地选择调度策略不仅能提高资源利用效率,更能保障服务的高可用性与运行稳定性。
如果你掌握了这些策略,也就掌握了 Kubernetes 调度的灵魂。
相关文章:

Kubernetes Pod 调度策略:从基础到进阶
文章目录 环境Kubernetes 部署Kubernetes Pod 调度策略Kubernetes Pod 调度策略对照表调度流程经历阶段案例展示生成yaml文件默认调度节点选择器为节点添加标签编写 Deployment 配置文件应用资源并查看调度结果 Node Affinity(节点亲和性)为节点添加标签…...

4.18学习总结
完成一道算法题 学习了序列化 敲代码卡bug了...

用于数学定理和逻辑推理的符号系统
当前用于数学定理和逻辑推理的前沿符号系统主要基于依赖类型论(Dependent Type Theory),其中Lean 4和**Metamath Zero (MM0)**是最具代表性的新兴系统。以下从技术特性、使用方法和应用实例三个维度展开说明: 一、前沿符号系统解…...

HTTP:九.WEB机器人
概念 Web机器人是能够在无需人类干预的情况下自动进行一系列Web事务处理的软件程序。人们根据这些机器人探查web站点的方式,形象的给它们取了一个饱含特色的名字,比如“爬虫”、“蜘蛛”、“蠕虫”以及“机器人”等!爬虫概述 网络爬虫(英语:web crawler),也叫网络蜘蛛(…...
)
代码学习总结(五)
代码学习总结(五) 这个系列的博客是记录下自己学习代码的历程,有来自平台上的,有来自笔试题回忆的,主要基于 C++ 语言,包括题目内容,代码实现,思路,并会注明题目难度,保证代码运行结果 1 小红的好数 简单 非退化三角形 快速匹配 小红定义一个数对 { x , y } \{x…...

在 Vue 3 项目中引入 js-cookie 库
1. 安装 js-cookie 你可以通过 npm 或者 yarn 来安装 js-cookie: npm install js-cookie # 或者 yarn add js-cookie2. 在组件里引入并使用 js-cookie 以下给出两种使用方式: 全局引入 在 main.js 中全局引入 js-cookie,这样在所有组件里…...

HarmonyOs学习 环境配置后 实验1:创建项目Hello World
HarmonyOS开发入门:环境配置与Hello World实验 实验目标 掌握HarmonyOS开发环境配置,创建首个HarmonyOS应用并实现"Hello World"界面展示 实验准备 已安装DevEco Studio开发环境已配置HarmonyOS开发依赖项熟悉基本TypeScript/ArkTS语法&am…...

Spark on K8s 在 vivo 大数据平台的混部实战与优化
一、Spark on K8s 简介 (一)定义与架构 Spark on K8s 是一种将 Spark 运行在 Kubernetes(K8s)集群上的架构,由 K8s 直接创建 Driver 和 Executor 的 Pod 来运行 Spark 作业。其架构如下。 Driver Pod:相当于 Spark 集群中的 Driver,负责作业的调度和管理,它会根据作业…...
——结构化开发方法)
《软件设计师》复习笔记(13)——结构化开发方法
目录 1. 结构化开发方法 1.1 系统分析过程 1.2 系统设计基本原理 (1)内聚性(模块内部关联程度) (2)耦合性(模块间依赖程度) 真题示例: 1.3 系统总体结构设计&…...

Android创建测试配置和生产配置
Android测试与生产环境配置指南 在Android开发中,创建不同的构建配置来适应测试和生产环境是至关重要的。这样的配置能让我们在不同的开发阶段有效管理代码、资源和环境变量。本文将详细介绍如何在Android中创建和管理测试配置以及生产配置的整个过程。 环境准备 …...

DBeaver连接hive
DBeaver是一个非常好用的数据库管理工具,支持多种不同的数据库类型。 dbeaver 要连接hive时,数据库驱动是无法下载,但在hive 的安装配置包中,有一个目录:jdbc里面有一个专门提供外部程序连接hive的jar。将这个jar下载…...
)
数据结构初阶:二叉树(二)
本篇博客主要讲解二叉树---堆的相关知识。 1.实现顺序结构二叉树 一般堆使用顺序结构的数组来存储数据,堆是一种特殊的二叉树,具有二叉树的特性的同时,还具备其他的特性。 1.1 堆的概念和结构 堆具有以下性质: 堆中某个结点的值…...

React 列表渲染基础示例
React 中最常见的一个需求就是「把一组数据渲染成一组 DOM 元素」,比如一个列表。下面是我写的一个最小示例,目的是搞清楚它到底是怎么工作的。 示例代码 // 定义一个静态数组,模拟后续要渲染的数据源 // 每个对象代表一个前端框架…...

android PackageName ClassName
目录 系统应用: 设置 蓝牙 时钟 计算机 录音机 图库 视频 文件管理 FM 日历 谷歌浏览器 谷歌商店 热门商店 国外应用: amazon spotify deezer pandora audible applemusic omnia mxtech youtubemusic facebook familylink tidal tiktok kindle 系统应用: 设置 …...

万物对接大模型:【爆火】MCP原理与使用指南
###原文链接 OpenAI、谷歌、微软、阿里云、腾讯云、百度等国内外各大厂商都陆续宣布支持MCP服务。MCP是什么,为什么能获得高度的关注? MCP(Model Context Protocol,模型上下文协议)是由Anthropic公司(核心产品是Claude大模型)推出的一种开源协议…...

SAP系统中MD01与MD02区别
知识点普及-MD01与MD02区别 1、从日常业务中,我们都容易知道MD01是运行全部物料,MD02是运行单个物料 2、在做配置测试中,也出现过MD02可以跑出物料,但是MD01跑不出的情况。 3、MD01与MD02的差异: 3.1、只要在物料主数…...

python——字符串使用
目录 1、字符串表示 2、转义字符 (1)将一些具有特殊含义的字符,标识成普通的字符(\) (2)特殊的控制符 (3)(\)还可以表示python中续行符 3、…...

嵌入式ARM RISCV toolchain工具 梳理arm-none-eabi-gcc
嵌入式TOOLchain工具 梳理 简介 本文总结和梳理一下一些toolchain的规则和原理,方便后续跨平台的时候,给大家使用toolchain做一个参考。 解释如何理解arm-none-eabi-gcc等含义,以及如何一看就知道该用什么编译器。 当然如果有哪里写的不是…...

团体程序设计天梯赛PTA-SHU冲刺赛4. L22-L32
这是4.18 SHU备赛天梯赛的最后一场冲刺赛 10.病毒溯源 1.本题PTA中拓栈后会MTL,不拓栈会报非零返回 所以本题最好用栈模拟递归过程 2.源头得是入度为0的,也就是没有节点指向它 所以得设置inn是否有指向该节点 3.这题用dfs(用bfs的话不同…...

【数据结构与算法】——插入排序
概要 本文将介绍插入排序方法——直接插入、希尔排序 想了解数据结构其他内容,本人主页 恋风诗 获取源码,gitte仓库:mozhengy 正文 1.排序的分类 目前将主要介绍下面几种排序: 后续学习更多内容后会及时更新 2、插入排序 2…...

手撕STL——vector
目录 引言 1,了解 STL 中的 vector 2,先来一个简易版跑起来 2_1,构造函数 2_2,扩容reserve() 2_3,push_back() 2_4,pop_back() …...

新书速览|DeepSeek移动端AI应用开发:基于Android与iOS
《DeepSeek移动端AI应用开发:基于Android与iOS》 1 本书内容 《DeepSeek移动端AI应用开发:基于Android与iOS》深入剖析了DeepSeek平台的架构原理、API调用及开发实践等核心内容,助力读者在Android与iOS移动端高效集成DeepSeek API,打造出契…...

详解STM32时基单元中参数 TIM_ClockDivision 的含义
在 STM32 定时器时基单元配置中,TIM_TimeBaseInitStruct->TIM_ClockDivision 用于设置 定时器时钟的分频系数,主要影响 输入捕获滤波器 和 输出比较同步信号 的时钟分割。以下是其核心作用、参数含义及应用场景的详细解析: 一、核心作用&…...

黑马V11版 最新Java高级软件工程师课程-JavaEE精英进阶课
课程大小:60.2G 课程下载:https://download.csdn.net/download/m0_66047725/90615581 更多资源下载:关注我 阶段一 中台战略与组件化开发专题课程 阶段二 【物流行业】品达物流TMS 阶段三 智牛股 阶段四 千亿级电商秒杀解决方案专题 …...

【Win】 cmd 执行curl命令时,输出 ‘命令管道位置 1 的 cmdlet Invoke-WebRequest 请为以下参数提供值: Uri: ’ ?
1.原因: 有一个名为 Invoke-WebRequest 的 CmdLet,其别名为 curl。因此,当您执行此命令时,它会尝试使用 Invoke-WebRequest,而不是使用 curl。 2.解决办法 在cmd中输入如下命令删除这个curl别名: Remov…...

【k8s系列4】工具介绍
1、虚拟机软件 vmware workstation 2、shell 软件 MobaXterm 3、centos7.9 下载地址 (https://mirrors.aliyun.com/centos/7.9.2009/isos/x86_64/?spma2c6h.25603864.0.0.374bf5adOaiFPW) 4、上网软件...

设计模式 --- 装饰器模式
装饰模式是一种结构型设计模式,它允许向一个现有的对象添加新的功能,同时又不改变其结构。这种模式创建了一个装饰类,用来包装原有的类,并在保持类方法签名完整性的前提下,提供了额外的功能。 优点: 1.灵…...

docker.desktop下安装普罗米修斯prometheus、grafana并看服务器信息
目标 在docker.desktop下先安装这三种组件,然后显示当前服务的CPU等指标。各种坑已踩,用的是当前时间最新的镜像 核心关系概述 组件角色依赖关系Prometheus开源监控系统,负责 数据采集、存储、查询及告警。依赖 Node-Exporter 提供的指标数据。Node-Exporter专用的 数据采集…...

学习设计模式《二》——外观模式
一、基础概念 1.1、外观模式的简介 外观模式的本质是【封装交互、简化调用】; 外观模式的说明:就是通过引入一个外观类,在这个类里面定义客户端想要的简单方法,然后在这些方法里面实现;由外观类再去分别调用内部的多个…...

python中,处理多分类时,模型之间的参数设置
在Python的机器学习库中,处理多分类问题时,不同的模型可能会有不同的参数设置来适应多分类场景。这里列举几个常见模型及相关的多分类参数: 1. Logistic Regression (逻辑回归) 在Scikit-Learn库中,逻辑回归模型可以通过设置mul…...
等级考试试卷(四级)真题)
2025年03月中国电子学会青少年软件编程(Python)等级考试试卷(四级)真题
青少年软件编程(Python)等级考试试卷(四级) 分数:100 题数:38 答案解析:https://blog.csdn.net/qq_33897084/article/details/147341407 一、单选题(共25题,共50分) 1. 下列程序段…...

蓝桥杯12. 日期问题
日期问题 原题目链接 题目描述 小明正在整理一批历史文献。这些历史文献中出现了很多日期。 小明知道这些日期都在 1960 年 1 月 1 日 至 2059 年 12 月 31 日 之间。 令小明头疼的是,这些日期采用的格式非常不统一: 有的采用 年/月/日有的采用 月…...

【MATLAB代码例程】AOA与TOA结合的高精度平面地位,适用于四个基站的情况,附完整的代码
本代码实现了一种基于到达角(AOA) 和到达时间(TOA) 的混合定位算法,适用于二维平面内移动或静止目标的定位。通过4个基站的协同测量,结合最小二乘法和几何解算,能够有效估计目标位置,并支持噪声模拟、误差分析和可视化输出。适用于室内定位、无人机导航、工业监测等场景…...
)
ARINC818协议(五)
1.R_CTL,设置固定的0x44即可 2.Dest_ID:目的地D_ID,如果不需要目的地址,就设置为0;ADVB协议支持 多个视频目的地址,广播通信; 3.cs_ctl在FC-AV上不用 4.source_ID:S_ID [23:0]包含源实体的端口的地址标识;不用就设置为0. ADVB允许…...

国产品牌芯洲科技100V降压芯片系列
SCT2A25采用带集成环路补偿的恒导通时间(COT)模式控制,大大简化了转换器的片外配置。SCT2A25具有典型的140uA低静态电流,采用脉冲频率调制(PFM)模式,它使转换器在轻载或空载条件下实现高转换效率。 芯洲科技100V降压芯片系列提供丰富的48V系…...

遨游科普:三防平板除了三防特性?还能实现什么功能?
在工业4.0浪潮席卷全球的今天,电子设备的功能边界正经历着革命性突破。三防平板电脑作为"危、急、特"场景的智能终端代表,其价值早已超越防水、防尘、防摔的基础防护属性。遨游通讯通过系统级技术创新,将三防平板打造为集通信中枢、…...

边缘计算网关组态功能的定义
边缘计算网关组态功能的定义 边缘计算网关组态是指根据特定的应用场景和需求,对边缘计算网关进行配置和定制的过程。它涵盖了硬件接口的选择、软件功能的设定、通信协议的配置以及数据处理流程的设计等多个方面,旨在使网关设备更加贴合实际应用场景&…...

数据可视化笔记:柱状图
数据可视化笔记:柱状图与饼图 1.1 一、基础配置 在进行数据可视化之前,需要对Matplotlib进行一些基础配置,以确保图表能够正确显示中文以及设置合适的分辨率和大小。 from matplotlib import pyplot as plt import numpy as np# 设置中文字…...

珈和科技:无人机技术赋能智慧农业,精准施肥与病虫害监控全面升级
无人机技术在农业领域的兴起,是现代技术发展为传统农业带来的重要变革。目前, 无人机已成为农业生产中不可或缺的关键工具,在提高粮食产量、改善土壤健康和保护生态环境等方面提供了新的解决方案。珈和科技从无人机的类型、特点和监测系统入手…...

UR5e机器人动力学
机器人动力学研究力与运动之间的关系,核心目标是建立关节力矩与关节位置、速度、加速度的数学关系。动力学模型通常分为: 正向动力学:已知关节力矩,计算末端执行器的运动(加速度)。 逆向动力学:已知期望的运动(位置、速度、加速度),计算所需的关节力矩。 https://www…...

【go】什么是Go语言的GPM模型?工作流程?为什么Go语言中的GMP模型需要有P?
Go语言GMP调度模型详解 一、GMP模型核心概念 Go语言的GMP模型是一种高效的轻量级线程管理调度系统,由三个核心组件构成: G (Goroutine): 轻量级协程,初始栈仅2KB(可动态扩容)用户态调度,创建成…...

X-AnyLabeling开源程序借助 Segment Anything 和其他出色模型的 AI 支持轻松进行数据标记。
一、软件介绍 文末提供源码和程序下载学习 使用 X-AnyLabeling开源程序可以 导入、管理和保存数据。用户可以通过多种方式导入图像和视频文件,包括快捷方式或菜单选项。此外,它还涵盖数据删除、图像切换以及标签和图像数据的保存,以确保高效…...

简易 Python 爬虫实现,10min可完成带效果源码
目录 准备工作 编写爬虫代码 运行爬虫 查看结果 遇到的问题及解决 总结 前言和效果 本文记录了使用 Python 实现一个简单网页爬虫的过程,目标是爬取 quotes.toscrape.com 的名言和作者,并将结果保存到文本文件。以下是完整步骤,包含环境…...

全志H5,NanopiKP1lus移植QT5.12记录
移植步骤 机器环境下载QT5.12.0源码安装交叉编译器修改qmake.conf文件配置编译选项qt5的configure选项说明基本配置选项编译器和链接器选项功能模块配置第三方库集成注意事项 配置过程报错解决配置完成编译过程报错解决编译完成将arm-qt文件夹传送到开发板配置板子环境变量运行…...

Spring Boot 依赖注入与Bean管理:JavaConfig如何取代XML?
大家好呀!今天我们来聊一个超级实用的技术话题 —— Spring Boot 中的依赖注入和Bean管理,特别是JavaConfig是如何一步步取代XML配置的。我知道很多小伙伴一听到"依赖注入"、"Bean管理"这些词就头大,别担心!我…...
AUTOSAR图解==>AUTOSAR_SWS_E2ETransformer
AUTOSAR E2E Transformer详解 基于AUTOSAR标准的端到端通信保护变换器技术解析 目录 1. E2E Transformer概述 1.1 E2E Transformer的作用1.2 功能特点1.3 应用场景限制 2. 模块架构 2.1 架构设计2.2 与其他模块的关系 3. 初始化与状态机 3.1 模块状态流转3.2 初始化与去初始化…...

从Archery到NineData:积加科技驱动数据库研发效能与数据安全双升级
积加科技作为国内领先的企业级数字化解决方案服务商,依托自研的 A4X 数字化平台(https://a4x.io/),专注于为全球范围内的视觉物联网(IoT)设备提供 PaaS/SaaS 服务。致力于运用 AI 技术赋能物联网世界的各类…...

hadoop和Yarn的基本介绍
Hadoop的三大结构及各自作用? Hadoop是一个由Apache基金会开发的分布式系统基础架构,主要用于处理大规模数据集的分布式存储和计算。Hadoop的三大核心结构是HDFS(Hadoop Distributed File System)、MapReduce和YARN(Y…...

神经接口安全攻防:从技术漏洞到伦理挑战
随着脑机接口(BCI)技术的快速发展,神经接口设备已从实验室走向消费市场。然而,2025年曝光的某品牌脑机接口设备漏洞(CVE-2025-3278)引发了行业对神经数据安全的深度反思。本文围绕神经接口安全的核心矛盾&a…...

云轴科技ZStack入选中国人工智能产业发展联盟《大模型应用交付供应商名录》
2025年4月8日至9日,中国人工智能产业发展联盟(以下简称AIIA)第十四次全体会议暨人工智能赋能新型工业化深度行(南京站)在南京召开。工业和信息化部科技司副司长杜广达,中国信息通信研究院院长、中国人工智能…...