深度学习 从入门到精通 day_02
1. 自动微分
自动微分模块torch.autograd负责自动计算张量操作的梯度,具有自动求导功能。自动微分模块是构成神经网络训练的必要模块,可以实现网络权重参数的更新,使得反向传播算法的实现变得简单而高效。
1.1 基础概念
1. 张量 :Torch中一切皆为张量,属性requires_grad决定是否对其进行梯度计算。默认是 False,如需计算梯度则设置为True。
2. 计算图:torch.autograd通过创建一个动态计算图来跟踪张量的操作,每个张量是计算图中的一个节点,节点之间的操作构成图的边。
在 PyTorch 中,当张量的 requires_grad=True 时,PyTorch 会自动跟踪与该张量相关的所有操作,并构建计算图。每个操作都会生成一个新的张量,并记录其依赖关系。当设置为 True 时,表示该张量在计算图中需要参与梯度计算,即在反向传播(Backpropagation)过程中会自动计算其梯度;当设置为 False 时,不会计算梯度。
例如:
在上述代码中,x 和 y 是输入张量,即叶子节点,z 是中间结果,loss 是最终输出。每一步操作都会记录依赖关系:z = x * y:z 依赖于 x 和 y;loss = z.sum():loss 依赖于 z。
这些依赖关系形成了一个动态计算图,如下所示:
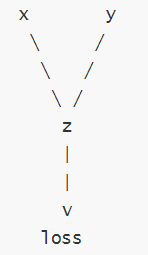
叶子节点:在 PyTorch 的自动微分机制中,叶子节点(leaf node) 是计算图中:
1. 由用户直接创建的张量,并且它的 requires_grad=True;
2. 这些张量是计算图的起始点,通常作为模型参数或输入变量。
特征:
1. 没有由其他张量通过操作生成;
2. 如果参与了计算,其梯度会存储在 leaf_tensor.grad 中;
3. 默认情况下,叶子节点的梯度不会自动清零,需要显式调用 optimizer.zero_grad() 或 x.grad.zero_() 清除。
如何判断一个张量是否是叶子节点?
通过 tensor.is_leaf 属性,可以判断一个张量是否是叶子节点。
x = torch.tensor([1.0, 2.0, 3.0], requires_grad=True) # 叶子节点
y = x ** 2 # 非叶子节点(通过计算生成)
z = y.sum()print(x.is_leaf) # True
print(y.is_leaf) # False
print(z.is_leaf) # False叶子节点与非叶子节点的区别:
| 特性 | 叶子节点 | 非叶子节点 |
|---|---|---|
| 创建方式 | 用户直接创建的张量 | 通过其他张量的运算生成 |
| is_leaf 属性 | True | False |
| 梯度存储 | 梯度存储在 .grad 属性中 | 梯度不会存储在 .grad,只能通过反向传播传递 |
| 是否参与计算图 | 是计算图的起点 | 是计算图的中间或终点 |
| 删除条件 | 默认不会被删除 | 在反向传播后,默认被释放(除非 retain_graph=True) |
detach():张量 x 从计算图中分离出来,返回一个新的张量,与 x 共享数据,但不包含计算图(即不会追踪梯度)。
特点:
1. 返回的张量是一个新的张量,与原始张量共享数据;
2. 对 x.detach() 的操作不会影响原始张量的梯度计算;
3. 推荐使用 detach(),因为它更安全,且在未来版本的 PyTorch 中可能会取代 data。
x = torch.tensor([1.0, 2.0, 3.0], requires_grad=True)
y = x.detach() # y 是一个新张量,不追踪梯度y += 1 # 修改 y 不会影响 x 的梯度计算
print(x) # tensor([1., 2., 3.], requires_grad=True)
print(y) # tensor([2., 3., 4.])3. 反向传播:使用tensor.backward()方法执行反向传播,从而计算张量的梯度。这个过程会自动计算每个张量对损失函数的梯度。例如:调用 loss.backward() 从输出节点 loss 开始,沿着计算图反向传播,计算每个节点的梯度。
4. 梯度:计算得到的梯度通过tensor.grad访问,这些梯度用于优化模型参数,以最小化损失函数。
1.2 计算梯度
使用tensor.backward()方法执行反向传播,从而计算张量的梯度。
1.2.1 标量梯度计算
示例:
import torchdef test001():# 1. 创建张量:必须为浮点类型x = torch.tensor(1.0, requires_grad=True)# 2. 操作张量y = x ** 2# 3. 计算梯度,也就是反向传播y.backward()# 4. 读取梯度值print(x.grad) # 输出: tensor(2.)if __name__ == "__main__":test001()1.2.2 向量梯度计算
示例:
def test003():# 1. 创建张量:必须为浮点类型x = torch.tensor([1.0, 2.0, 3.0], requires_grad=True)# 2. 操作张量y = x ** 2# 3. 计算梯度,也就是反向传播y.backward()# 4. 读取梯度值print(x.grad)if __name__ == "__main__":test003() 错误预警:RuntimeError: grad can be implicitly created only for scalar outputs
由于 y 是一个向量,我们需要提供一个与 y 形状相同的向量作为 backward() 的参数,这个参数通常被称为 梯度张量(gradient tensor),它表示 y 中每个元素的梯度。
示例:
def test003():# 1. 创建张量:必须为浮点类型x = torch.tensor([1.0, 2.0, 3.0], requires_grad=True)# 2. 操作张量y = x ** 2# 3. 计算梯度,也就是反向传播y.backward(torch.tensor([1.0, 1.0, 1.0]))# 4. 读取梯度值print(x.grad)# 输出# tensor([2., 4., 6.])if __name__ == "__main__":test003() 我们也可以将向量 y 通过一个标量损失函数(如 y.mean())转换为一个标量,反向传播时就不需要提供额外的梯度向量参数了。这是因为标量的梯度是明确的,直接调用 .backward() 即可。
示例:
import torchdef test002():# 1. 创建张量:必须为浮点类型x = torch.tensor([1.0, 2.0, 3.0], requires_grad=True)# 2. 操作张量y = x ** 2# 3. 损失函数loss = y.mean()# 4. 计算梯度,也就是反向传播loss.backward()# 5. 读取梯度值print(x.grad)if __name__ == "__main__":test002() 调用 loss.backward() 从输出节点 loss 开始,沿着计算图反向传播,计算每个节点的梯度。
损失函数:,其中 n=3。
对于每个,其梯度为:
;
对于每个,其梯度为:
;
所以,x.grad 的值为:。
2.2.3 多标量梯度计算
示例:
import torchdef test003():# 1. 创建两个标量x1 = torch.tensor(5.0, requires_grad=True, dtype=torch.float64)x2 = torch.tensor(3.0, requires_grad=True, dtype=torch.float64)# 2. 构建运算公式y = x1**2 + 2 * x2 + 7# 3. 计算梯度,也就是反向传播y.backward()# 4. 读取梯度值print(x1.grad, x2.grad)# 输出:# tensor(10., dtype=torch.float64) tensor(2., dtype=torch.float64)if __name__ == "__main__":test003()2.2.4 多向量梯度计算
示例:
import torchdef test004():# 创建两个张量,并设置 requires_grad=Truex = torch.tensor([1.0, 2.0, 3.0], requires_grad=True)y = torch.tensor([4.0, 5.0, 6.0], requires_grad=True)# 前向传播:计算 z = x * yz = x * y# 前向传播:计算 loss = z.sum()loss = z.sum()# 查看前向传播的结果print("z:", z) # 输出: tensor([ 4., 10., 18.], grad_fn=<MulBackward0>)print("loss:", loss) # 输出: tensor(32., grad_fn=<SumBackward0>)# 反向传播:计算梯度loss.backward()# 查看梯度print("x.grad:", x.grad) # 输出: tensor([4., 5., 6.])print("y.grad:", y.grad) # 输出: tensor([1., 2., 3.])if __name__ == "__main__":test004()1.3 梯度上下文控制
梯度计算的上下文控制和设置对于管理计算图、内存消耗、以及计算效率至关重要。下面我们学习下Torch中与梯度计算相关的一些主要设置方式。
1.3.1 控制梯度计算
梯度计算是有性能开销的,有些时候我们只是简单的运算,并不需要梯度。示例:
import torchdef test001():x = torch.tensor(10.5, requires_grad=True)print(x.requires_grad) # True# 1. 默认y的requires_grad=Truey = x**2 + 2 * x + 3print(y.requires_grad) # True# 2. 如果不需要y计算梯度-with进行上下文管理with torch.no_grad():y = x**2 + 2 * x + 3print(y.requires_grad) # False# 3. 如果不需要y计算梯度-使用装饰器@torch.no_grad()def y_fn(x):return x**2 + 2 * x + 3y = y_fn(x)print(y.requires_grad) # False# 4. 如果不需要y计算梯度-全局设置,需要谨慎torch.set_grad_enabled(False)y = x**2 + 2 * x + 3print(y.requires_grad) # Falseif __name__ == "__main__":test001()1.3.2 累计梯度
默认情况下,当我们重复对一个自变量进行梯度计算时,梯度是累加的。示例:
import torchdef test002():# 1. 创建张量:必须为浮点类型x = torch.tensor([1.0, 2.0, 5.3], requires_grad=True)# 2. 累计梯度:每次计算都会累计梯度for i in range(3):y = x**2 + 2 * x + 7z = y.mean()z.backward()print(x.grad)if __name__ == "__main__":test002()1.3.3 梯度清零
大多数情况下是不需要梯度累加的,奇葩的事情还是需要解决的。示例:
import torchdef test002():# 1. 创建张量:必须为浮点类型x = torch.tensor([1.0, 2.0, 5.3], requires_grad=True)# 2. 累计梯度:每次计算都会累计梯度for i in range(3):y = x**2 + 2 * x + 7z = y.mean()# 2.1 反向传播之前先对梯度进行清零if x.grad is not None:x.grad.zero_()z.backward()print(x.grad)if __name__ == "__main__":test002()1.3.4 求函数最小值
代码:
import torch
from matplotlib import pyplot as plt
import numpy as npdef test01():x = np.linspace(-10, 10, 100)y = x ** 2plt.plot(x, y)plt.show()def test02():# 初始化自变量Xx = torch.tensor([3.0], requires_grad=True, dtype=torch.float)# 迭代轮次epochs = 50# 学习率lr = 0.1list = []for i in range(epochs):# 计算函数表达式y = x ** 2# 反向传播y.backward()# 梯度下降,不需要计算梯度,为什么?with torch.no_grad():x -= lr * x.grad# 梯度清零x.grad.zero_()print('epoch:', i, 'x:', x.item(), 'y:', y.item())list.append((x.item(), y.item()))# 散点图,观察收敛效果x_list = [l[0] for l in list]y_list = [l[1] for l in list]plt.scatter(x=x_list, y=y_list)plt.show()if __name__ == "__main__":test01()test02()部分代码解释:
# 梯度下降,不需要计算梯度
with torch.no_grad():x -= lr * x.grad代码中去掉梯度控制会报异常:
RuntimeError: a leaf Variable that requires grad is being used in an in-place operation. 因为代码中x是叶子节点(叶子张量),是计算图的开始节点,并且设置需要梯度。在pytorch中不允许对需要梯度的叶子变量进行原地操作。因为这会破坏计算图,导致梯度计算错误。
在代码中,x 是一个叶子变量(即直接定义的张量,而不是通过其他操作生成的张量),并且设置了 requires_grad=True,因此不能直接通过 -= 进行原地更新。
解决方法:
1. 使用 torch.no_grad() 上下文管理器:在更新参数时,使用 torch.no_grad() 禁用梯度计算,然后通过非原地操作更新参数。
with torch.no_grad():a -= lr * a.grad2. 使用 data 属性或detach():通过 x.data 访问张量的数据部分(不涉及梯度计算),然后进行原地操作。
x.data -= lr * x.gradx.data返回一个与 a 共享数据的张量,但不包含计算图。
特点:
1. 返回的张量与原始张量共享数据;
2. 对 x.data 的操作是原地操作(in-place),可能会影响原始张量的梯度计算;
3. 不推荐使用 data,因为它可能会导致意外的行为(如梯度计算错误)。
能不能将代码修改为:
x = x - lr * x.grad答案是不能,以上代码中=左边的x变量是由右边代码计算得出的,就不是叶子节点了,从计算图中被剥离出来后没有了梯度,执行。
x.grad.zero_() 报错:AttributeError: 'NoneType' object has no attribute 'zero_'。
总结:以上方均不推荐,正确且推荐的做法是使用优化器,优化器后续会讲解。
1.3.5 函数参数求解
代码:
def test02():# 定义数据x = torch.tensor([1, 2, 3, 4, 5], dtype=torch.float)y = torch.tensor([3, 5, 7, 9, 11], dtype=torch.float)# 定义模型参数 a 和 b,并初始化a = torch.tensor([1], dtype=torch.float, requires_grad=True)b = torch.tensor([1], dtype=torch.float, requires_grad=True)# 学习率lr = 0.1# 迭代轮次epochs = 1000for epoch in range(epochs):# 前向传播:计算预测值 y_predy_pred = a * x + b# 定义损失函数loss = ((y_pred - y) ** 2).mean()# 反向传播:计算梯度loss.backward()# 梯度下降with torch.no_grad():a -= lr * a.gradb -= lr * b.grada.grad.zero_()b.grad.zero_()if (epoch + 1) % 10 == 0:print(f'Epoch [{epoch + 1}/{epochs}], Loss: {loss.item():.4f}')print(f'a: {a.item()}, b: {b.item()}') 代码逻辑:在 PyTorch 中,所有的张量操作都会被记录在一个计算图中。
对于代码:
y_pred = a * x + b
loss = ((y_pred - y) ** 2).mean()计算图如下:
a → y_pred → loss
x ↗
b ↗ 1. a 和 b 是需要计算梯度的叶子张量(requires_grad=True);
2. y_pred 是中间结果,依赖于 a 和 b;
3. loss 是最终的标量输出,依赖于 y_pred。
当调用 loss.backward() 时,PyTorch 会从 loss 开始,沿着计算图反向传播,计算 loss 对每个需要梯度的张量(如 a 和 b)的梯度。
计算 loss 对 y_pred 的梯度:
求损失函数关于 y_pred 的梯度(即偏导数组成的向量)。由于 loss 是 y_pred 的函数,我们需要对每个求偏导数,并将它们组合成一个向量。
应用链式法则和常数求导规则,对于每个项,梯度向量的每个分量是:
将结果组合成一个向量,我们得到:
其中n=5,y_pred和y均为向量。
计算 y_pred 对 a 和 b 的梯度:y_pred = a * x + b
对 a 求导:,x为向量;
对 b 求导:。
根据链式法则,loss 对 a 的梯度为:
loss 对 b 的梯度为:
第一次迭代:前向传播
y_pred = a * x + b = [1*1 + 1, 1*2 + 1, 1*3 + 1, 1*4 + 1, 1*5 + 1] = [2, 3, 4, 5, 6]loss = ((y_pred - y) ** 2).mean() = ((2-3)^2 + (3-5)^2 + (4-7)^2 + (5-9)^2 + (6-11)^2) / 5 = (1 + 4 + 9 + 16 + 25) / 5 = 11.0反向传播:
∂loss/∂y_pred = 2/5 * (y_pred - y) = 2/5 * [-1, -2, -3, -4, -5] = [-0.4, -0.8, -1.2, -1.6, -2.0]a.grad = ∂loss/∂a = ∂loss/∂y_pred * x = [-0.4*1, -0.8*2, -1.2*3, -1.6*4, -2.0*5] = [-0.4, -1.6, -3.6, -6.4, -10.0]对 a.grad 求和(因为 a 是标量):a.grad = -0.4 -1.6 -3.6 -6.4 -10.0 = -22.0
b.grad = ∂loss/∂b = ∂loss/∂y_pred * 1 = [-0.4, -0.8, -1.2, -1.6, -2.0]对 b.grad 求和(因为 b 是标量):b.grad = -0.4 -0.8 -1.2 -1.6 -2.0 = -6.0
梯度更新:
a -= lr * a.grad = 1 - 0.1 * (-22.0) = 1 + 2.2 = 3.2
b -= lr * b.grad = 1 - 0.1 * (-6.0) = 1 + 0.6 = 1.6代码运行结果:
Epoch [10/100], Loss: 3020.7896
Epoch [20/100], Loss: 1550043.3750
Epoch [30/100], Loss: 795369408.0000
Epoch [40/100], Loss: 408125767680.0000
Epoch [50/100], Loss: 209420457869312.0000
Epoch [60/100], Loss: 107459239932329984.0000
Epoch [70/100], Loss: 55140217861896667136.0000
Epoch [80/100], Loss: 28293929961149737992192.0000
Epoch [90/100], Loss: 14518387713533614273593344.0000
Epoch [100/100], Loss: 7449779870375595263567855616.0000
a: -33038608105472.0, b: -9151163924480.0 损失函数在训练过程中越来越大,表明模型的学习过程出现了问题。这是因为学习率(Learning Rate)过大,参数更新可能会“跳过”最优值,导致损失函数在最小值附近震荡甚至发散。解决方法:调小学习率,将lr=0.01。
代码运行结果:
Epoch [10/100], Loss: 0.0965
Epoch [20/100], Loss: 0.0110
Epoch [30/100], Loss: 0.0099
Epoch [40/100], Loss: 0.0092
Epoch [50/100], Loss: 0.0086
Epoch [60/100], Loss: 0.0081
Epoch [70/100], Loss: 0.0075
Epoch [80/100], Loss: 0.0071
Epoch [90/100], Loss: 0.0066
Epoch [100/100], Loss: 0.0062
a: 1.9492162466049194, b: 1.18334519863128662. 模型定义组件
模型(神经网络,深度神经网络,深度学习)定义组件帮助我们在 PyTorch 中定义、训练和评估模型等。
在进行模型训练时,有三个基础的概念我们需要颗粒度对齐下:
| 名词 | 定义 |
|---|---|
| Epoch | 使用训练集的全部数据对模型进行一次完整训练,被称为“一代训练” |
| Batch | 使用训练集中的一小部分样本对模型权重进行一次反向传播的参数更新,这一小部分样本被称为“一批数据” |
| Iteration | 使用一个Batch数据对模型进行一次参数更新的过程,被称为“一次训练” |
2.1 基本组件认知
先初步认知,他们用法基本一样的,后续在学习深度神经网络和卷积神经网络的过程中会很自然的学到更多组件。
官方文档:https://pytorch.org/docs/stable/nn.html
2.1.1 损失函数组件
PyTorch已内置多种损失函数,在构建神经网络时随用随取。文档:https://pytorch.org/docs/stable/nn.html#loss-functions
常用损失函数举例:
1. 均方误差损失(MSE Loss)
函数:torch.nn.MSELoss
公式:
适用场景:通常用于回归任务,例如预测连续值。
特点:对异常值敏感,因为误差的平方会放大较大的误差。
2. L1 损失(L1 Loss)(也叫做MAE(Mean Absolute Error,平均绝对误差))
函数:torch.nn.L1Loss
公式:
适用场景:用于回归任务,对异常值的敏感性较低。
特点:比 MSE 更鲁棒,但计算梯度时可能不稳定。
3. 交叉熵损失(Cross-Entropy Loss)
函数:torch.nn.CrossEntropyLoss
参数:reduction:mean-平均值,sum-总和
公式:
适用场景:用于多分类任务,输入是未经 softmax 处理的 logits。
特点:自带 softmax 操作,适合分类任务,能够有效处理类别不平衡问题。
4. 二元交叉熵损失(Binary Cross-Entropy Loss)
函数:torch.nn.BCELoss 或 torch.nn.BCEWithLogitsLoss
参数:reduction:mean-平均值,sum-总和
公式:
适用场景: 用于二分类任务。
特点: BCEWithLogitsLoss 更稳定,因为它结合了 Sigmoid 激活函数和 BCE 损失。
2.1.2 线性层组件
构建一个简单的线性层,后续还有卷积层(Convolution Layers)、池化层(Pooling layers)、激活(Non-linear Activations)、归一化等需要我们去学习和使用...
torch.nn.Linear(in_features, out_features, bias=True)参数说明:
in_features:
-
输入特征的数量(即输入数据的维度)。
-
例如,如果输入是一个长度为 100 的向量,则 in_features=100。
out_features:
-
输出特征的数量(即输出数据的维度)。
-
例如,如果希望输出是一个长度为 50 的向量,则 out_features=50。
bias:
-
是否使用偏置项(默认值为 True)。
-
如果设置为 False,则不会学习偏置项。
nn.Linear 的作用
nn.Linear 执行以下线性变换:output=input⋅W^T+b
其中:
-
input是输入数据,形状为 (batch_size, in_features)。
-
W是权重矩阵,形状为 (out_features, in_features)。
-
b是偏置项,形状为 (out_features,)。
-
output是输出数据,形状为 (batch_size, out_features)。
import torch
import torch.nn as nndef test002():model = nn.Linear(20, 60)# input数据形状为:(batch_size,in_features),其中in_features要和Linear中的数量一致input = torch.randn(128, 20)output = model(input)print(output.size())if __name__ == "__main__":test002()2.1.3 优化器方法
官方文档:https://pytorch.org/docs/stable/optim.html
这里牵涉到的API有:
1. optim.SGD():优化器方法;是 PyTorch 提供的随机梯度下降(Stochastic Gradient Descent, SGD)优化器。
2. model.parameters():模型参数获取;是一个生成器,用于获取模型中所有可训练的参数(权重和偏置)。
3. optimizer.zero_grad():梯度清零;
4. optimizer.step():参数更新;是优化器的核心方法,用于根据计算得到的梯度更新模型参数。优化器会根据梯度和学习率等参数,调整模型的权重和偏置。
import torch
import torch.nn as nn
import torch.optim as optim# 优化方法SGD的学习
def test003():model = nn.Linear(20, 60)criterion = nn.MSELoss()# 优化器:更新模型参数optimizer = optim.SGD(model.parameters(), lr=0.01)input = torch.randn(128, 20)output = model(input)# 计算损失及反向传播loss = criterion(output, torch.randn(128, 60))# 梯度清零optimizer.zero_grad()# 反向传播loss.backward()# 更新模型参数optimizer.step()print(loss.item())if __name__ == "__main__":test003()注意:这里只是组件认识和用法演示,没有具体的模型训练功能实现
2.2 数据加载器
2.2.1 构建数据类
1. Dataset类:
Dataset是一个抽象类,是所有自定义数据集应该继承的基类。它定义了数据集必须实现的方法。
必须实现的方法:1. __len__: 返回数据集的大小;2. __getitem__: 支持整数索引,返回对应的样本。
在 PyTorch 中,构建自定义数据加载类通常需要继承 torch.utils.data.Dataset 并实现以下几个方法:
__init__ 方法:用于初始化数据集对象:通常在这里加载数据,或者定义如何从存储中获取数据的路径和方法。
def __init__(self, data, labels):self.data = dataself.labels = labels__len__ 方法:返回样本数量:需要实现,以便 Dataloader加载器能够知道数据集的大小。
def __len__(self):return len(self.data)__getitem__ 方法:根据索引返回样本:将从数据集中提取一个样本,并可能对样本进行预处理或变换。
def __getitem__(self, index):sample = self.data[index]label = self.labels[index]return sample, label如果你需要进行更多的预处理或数据变换,可以在__getitem__方法中添加额外的逻辑。
示例:
import torch
import torch.nn as nn
from torch.utils.data import Dataset, DataLoader# 定义数据加载类
class CustomDataset(Dataset):def __init__(self, data, labels):"""初始化数据集:data: 样本数据(例如,一个 NumPy 数组或 PyTorch 张量):labels: 样本标签"""self.data = dataself.labels = labelsdef __len__(self):return len(self.data)def __getitem__(self, index):index = min(max(index, 0), len(self.data) - 1)sample = self.data[index]label = self.labels[index]return sample, labeldef test001():# 简单的数据集准备data_x = torch.randn(666, 20, requires_grad=True, dtype=torch.float32)data_y = torch.randn(data_x.shape[0], 1, dtype=torch.float32)dataset = CustomDataset(data_x, data_y)# 随便打印个数据看一下print(dataset[0])if __name__ == "__main__":test001()2. TensorDataset类
TensorDataset是Dataset的一个简单实现,它封装了张量数据,适用于数据已经是张量形式的情况。
特点:
1. 简单快捷:当数据已经是张量形式时,无需自定义Dataset类;
2. 多张量支持:可以接受多个张量作为输入,按顺序返回;
3. 索引一致:所有张量的第一个维度必须相同,表示样本数量。
源码:
class TensorDataset(Dataset):def __init__(self, *tensors):# size(0)在python中同shape[0],获取的是样本数量# 用第一个张量中的样本数量和其他张量对比,如果全部相同则通过断言,否则抛异常assert all(tensors[0].size(0) == tensor.size(0) for tensor in tensors)self.tensors = tensorsdef __getitem__(self, index):return tuple(tensor[index] for tensor in self.tensors)def __len__(self):return self.tensors[0].size(0)示例:
def test03():torch.manual_seed(0)# 创建特征张量和标签张量features = torch.randn(100, 5) # 100个样本,每个样本5个特征labels = torch.randint(0, 2, (100,)) # 100个二进制标签# 创建TensorDatasetdataset = TensorDataset(features, labels)# 使用方式与自定义Dataset相同print(len(dataset)) # 输出: 100print(dataset[0]) # 输出: (tensor([...]), tensor(0))2.2.2 数据加载器
在训练或者验证的时候,需要用到数据加载器批量的加载样本。
DataLoader 是一个迭代器,用于从 Dataset 中批量加载数据。它的主要功能包括:
1. 批量加载:将多个样本组合成一个批次;
2. 打乱数据:在每个 epoch 中随机打乱数据顺序;
3. 多线程加载:使用多线程加速数据加载。
创建DataLoader:
# 创建 DataLoader
dataloader = DataLoader(dataset, # 数据集batch_size=10, # 批量大小shuffle=True, # 是否打乱数据num_workers=2 # 使用 2 个子进程加载数据
)遍历:
# 遍历 DataLoader
# enumerate返回一个枚举对象(iterator),生成由索引和值组成的元组
for batch_idx, (samples, labels) in enumerate(dataloader):print(f"Batch {batch_idx}:")print("Samples:", samples)print("Labels:", labels)示例:
import torch
import torch.nn as nn
from torch.utils.data import Dataset, DataLoader# 定义数据加载类
class CustomDataset(Dataset):#略......def test01():# 简单的数据集准备data_x = torch.randn(666, 20, requires_grad=True, dtype=torch.float32)data_y = torch.randn(data_x.size(0), 1, dtype=torch.float32)dataset = CustomDataset(data_x, data_y)# 构建数据加载器data_loader = DataLoader(dataset, batch_size=8, shuffle=True)for i, (batch_x, batch_y) in enumerate(data_loader):print(batch_x, batch_y)breakif __name__ == "__main__":test01()2.2.3 重构线性回归
示例:
import torch
import torch.optim as optim
import torch.nn as nn
from torch.utils.data import DataLoader, TensorDataset
import random
from sklearn.datasets import make_regression# 定义特征数
n_features = 5"""使用 sklearn 的 make_regression 方法来构建一个模拟的回归数据集。make_regression 方法的参数解释:- n_samples: 生成的样本数量,决定了数据集的规模。- n_features: 生成的特征数量,决定了数据维度。- n_informative: 对目标变量有影响的特征数量(默认 10)。- n_targets: 目标变量的数量(默认 1,单输出回归)。- bias: 目标变量的偏置(截距),默认 0.0。- noise: 添加到目标变量的噪声标准差,用于模拟真实世界数据的不完美。- coef: 如果为 True, 会返回生成数据的真实系数(权重),用于了解特征与目标变量间的真实关系。- random_state: 随机数生成的种子,确保在多次运行中能够复现相同的结果。返回:- X: 生成的特征矩阵。X 的维度是 (n_samples, n_features)- y: 生成的目标变量。y 的维度是(n_samples,) 或 (n_samples, n_targets)- coef: 如果在调用时 coef 参数为 True,则还会返回真实系数(权重)。coef 的维度是 (n_features,)
"""
def build_dataset():noise = random.randint(1, 3)bias = 14.5X, y, coef = make_regression(n_samples=1000,n_features=n_features,bias=bias,noise=noise,coef=True,random_state=0)# 数据转换为张量X = torch.tensor(X, dtype=torch.float32)y = torch.tensor(y, dtype=torch.float32)coef = torch.tensor(coef, dtype=torch.float32)bias = torch.tensor(bias, dtype=torch.float32)return X, y, coef, bias# 训练函数
def train():# 0. 构建模型model = nn.Linear(n_features, 1)# 1. 构建数据集X, y, coef, bias = build_dataset()dataset = TensorDataset(X, y)# 2. 定义训练参数learning_rate = 0.1epochs = 50batch_size = 16# 定义损失函数criterion = nn.MSELoss()# 定义优化器optimizer = optim.SGD(model.parameters(), lr=learning_rate)# 3. 开始训练for epoch in range(epochs):# 4. 构建数据集加载器data_loader = DataLoader(dataset, batch_size=batch_size, shuffle=True)epoch_loss = 0num_batches = 0for train_X, train_y in data_loader:num_batches += 1# 5. 前向传播y_pred = model(train_X)# 6. 计算损失,注意y_pred, train_y的形状保持一致loss = criterion(y_pred, train_y.reshape(-1, 1))# 7. 梯度清零optimizer.zero_grad()# 8. 反向传播:会自动计算梯度loss.backward()# 9. 更新参数optimizer.step()# 10. 训练批次及损失率epoch_loss += loss.item()print(f"Epoch: {epoch}, Loss: {epoch_loss / num_batches}")# 获取训练好的权重和偏置w = model.weight.detach().flatten() # 将 weight 转换为一维张量b = model.bias.detach().item()return coef, bias, w, bif __name__ == "__main__":coef, bias, w, b = train()print(f"真实系数: {coef}")print(f"预测系数: {w}")print(f"真实偏置: {bias}")print(f"预测偏置: {b}")# 训练结果
'''
Epoch: 0, Loss: 515.9365651872423
Epoch: 1, Loss: 17.0213944949801
......
Epoch: 99, Loss: 16.81899456750779
真实系数: tensor([41.2059, 66.4995, 10.7145, 60.1951, 25.9615])
预测系数: tensor([41.2794, 67.1859, 11.3169, 59.5126, 25.6431])
真实偏置: 14.5
预测偏置: 14.348488807678223
'''2.3 数据集加载案例
通过一些数据集的加载案例,真正了解数据类及数据加载器。
2.3.1 加载csv数据集
示例:
import torch
from torch.utils.data import Dataset, DataLoader
import pandas as pdclass MyCsvDataset(Dataset):def __init__(self, filename):df = pd.read_csv(filename)# 删除文字列df = df.drop(["学号", "姓名"], axis=1)# 转换为tensordata = torch.tensor(df.values)# 最后一列以前的为data,最后一列为labelself.data = data[:, :-1]self.label = data[:, -1]self.len = len(self.data)def __len__(self):return self.lendef __getitem__(self, index):idx = min(max(index, 0), self.len - 1)return self.data[idx], self.label[idx]def test001():excel_path = r"./大数据答辩成绩表.csv"dataset = MyCsvDataset(excel_path)dataloader = DataLoader(dataset, batch_size=4, shuffle=True)for i, (data, label) in enumerate(dataloader):print(i, data, label)if __name__ == "__main__":test001()示例:上述示例数据构建器改成TensorDataset
def build_dataset(filepath):df = pd.read_csv(filepath)df.drop(columns=['学号', '姓名'], inplace=True)data = df.iloc[..., :-1]labels = df.iloc[..., -1]x = torch.tensor(data.values, dtype=torch.float)y = torch.tensor(labels.values)dataset = TensorDataset(x, y)return datasetdef test001():filepath = r"./大数据答辩成绩表.csv"dataset = build_dataset(filepath)dataloader = DataLoader(dataset, batch_size=4, shuffle=True)for i, (data, label) in enumerate(dataloader):print(i, data, label)2.3.2 加载图片数据集
参考代码如下:只是用于文件读取测试
import torch
from torch.utils.data import Dataset, DataLoader
import os# 导入opencv
import cv2class MyImageDataset(Dataset):def __init__(self, folder):# 文件存储路径列表self.filepaths = []# 文件对应的目录序号列表self.labels = []# 指定图片大小self.imgsize = (112, 112)# 临时存储文件所在目录名dirnames = []# 递归遍历目录,root:根目录路径,dirs:子目录名称,files:子文件名称for root, dirs, files in os.walk(folder):# 如果dirs和files不同时有值,先遍历dirs,然后再以dirs的目录为路径遍历该dirs下的files# 这里需要在dirs不为空时保存目录名称列表if len(dirs) > 0:dirnames = dirsfor file in files:# 文件路径filepath = os.path.join(root, file)self.filepaths.append(filepath)# 分割root中的dir目录名classname = os.path.split(root)[-1]# 根据目录名到临时目录列表中获取下标self.labels.append(dirnames.index(classname))self.len = len(self.filepaths)def __len__(self):return self.lendef __getitem__(self, index):# 获取下标idx = min(max(index, 0), self.len - 1)# 根据下标获取文件路径filepath = self.filepaths[idx]# opencv读取图片img = cv2.imread(filepath)# 图片缩放,图片加载器要求同一批次的图片大小一致img = cv2.resize(img, self.imgsize)# 转换为tensorimg_tensor = torch.tensor(img)# 将图片HWC调整为CHWimg_tensor = torch.permute(img_tensor, (2, 0, 1))# 获取目录标签label = self.labels[idx]return img_tensor, labeldef test02():path = os.path.join(os.path.dirname(__file__), 'dataset')# 转换为相对路径path = os.path.relpath(path)dataset = MyImageDataset(path)dataloader = DataLoader(dataset, batch_size=8, shuffle=True)for img, label in dataloader:print(img.shape)print(label)if __name__ == "__main__":test02()1.重写上述代码,如果不对图片进行缩放会产生什么结果?2.在遍历图片的代码中打印图片查看图片效果(打印一批次即可)
# 导入opencv
import cv2class MyDataset(Dataset):def __init__(self, folder):dirnames = []self.filepaths = []self.labels = []for root, dirs, files in os.walk(folder):if len(dirs) > 0:dirnames = dirsfor file in files:filepath = os.path.join(root, file)self.filepaths.append(filepath)classname = os.path.split(root)[-1]if classname in dirnames:self.labels.append(dirnames.index(classname))else:print(f'{classname} not in {dirnames}')self.len = len(self.filepaths)def __len__(self):return self.lendef __getitem__(self, index):idx = min(max(index, 0), self.len - 1)filepath = self.filepaths[idx]img = cv2.imread(filepath)print(img.shape)# 不做图片缩放,报:RuntimeError: stack expects each tensor to be equal size, but got [3, 1333, 2000] at entry 0 and [3, 335, 600] at entry 1img = cv2.resize(img, (112, 112))t_img = torch.tensor(img)t_img = torch.permute(t_img, (2, 0, 1))label = self.labels[idx]return t_img, labeldef test02():path = os.path.join(os.path.dirname(__file__), 'dataset')dataset = MyDataset(path)dataloader = DataLoader(dataset, batch_size=4, shuffle=True)for img, label in dataloader:print(img.shape, label)for i in range(img.shape[0]):im = torch.permute(img[i], (1, 2, 0))plt.imshow(im)plt.show()breakif __name__ == "__main__":test02()ImageFolder会根据文件夹的结构来加载图像数据。它假设每个子文件夹对应一个类别,文件夹名称即为类别名称。例如,一个典型的文件夹结构如下:
root/class1/img1.jpgimg2.jpg...class2/img1.jpgimg2.jpg......在这个结构中:
-
root是根目录。 -
class1、class2等是类别名称。 -
每个类别文件夹中的图像文件会被加载为一个样本。
ImageFolder构造函数如下:
torchvision.datasets.ImageFolder(root, transform=None, target_transform=None, is_valid_file=None)参数解释:
-
root:字符串,指定图像数据集的根目录。 -
transform:可选参数,用于对图像进行预处理。通常是一个torchvision.transforms的组合。 -
target_transform:可选参数,用于对目标(标签)进行转换。 -
is_valid_file:可选参数,用于过滤无效文件。如果提供,只有返回True的文件才会被加载。
示例:
import torch
from torchvision import datasets, transforms
import os
from torch.utils.data import DataLoader
from matplotlib import pyplot as plttorch.manual_seed(42)def load():path = os.path.join(os.path.dirname(__file__), 'dataset')print(path)transform = transforms.Compose([transforms.Resize((112, 112)),transforms.ToTensor()])dataset = datasets.ImageFolder(path, transform=transform)dataloader = DataLoader(dataset, batch_size=1, shuffle=True)for x,y in dataloader:x = x.squeeze(0).permute(1, 2, 0).numpy()plt.imshow(x)plt.show()print(y[0])breakif __name__ == '__main__':load()2.3.3 加载官方数据集
在 PyTorch 中官方提供了一些经典的数据集,如 CIFAR-10、MNIST、ImageNet 等,可以直接使用这些数据集进行训练和测试。
数据集:https://pytorch.org/vision/stable/datasets.html
常见数据集:
1. MNIST:手写数字数据集,包含 60,000 张训练图像和 10,000 张测试图像;
2. CIFAR10:包含 10 个类别的 60,000 张 32x32 彩色图像,每个类别 6,000 张图像;
3. CIFAR100:包含 100 个类别的 60,000 张 32x32 彩色图像,每个类别 600 张图像;
4. COCO:通用对象识别数据集,包含超过 330,000 张图像,涵盖 80 个对象类别。
torchvision.transforms 和 torchvision.datasets 是 PyTorch 中处理计算机视觉任务的两个核心模块,它们为图像数据的预处理和标准数据集的加载提供了强大支持。
transforms模块提供了一系列用于图像预处理的工具,可以将多个变换组合成处理流水线。
datasets模块提供了多种常用计算机视觉数据集的接口,可以方便地下载和加载。
示例:
import torch
from torch.utils.data import Dataset, DataLoader
import torchvision
from torchvision import transforms, datasetsdef test():transform = transforms.Compose([transforms.ToTensor(),])# 训练数据集data_train = datasets.MNIST(root="./data",train=True,download=True,transform=transform,)trainloader = DataLoader(data_train, batch_size=8, shuffle=True)for x, y in trainloader:print(x.shape)print(y)break# 测试数据集data_test = datasets.MNIST(root="./data",train=False,download=True,transform=transform,)testloader = DataLoader(data_test, batch_size=8, shuffle=True)for x, y in testloader:print(x.shape)print(y)breakdef test006():transform = transforms.Compose([transforms.ToTensor(),])# 训练数据集data_train = datasets.CIFAR10(root="./data",train=True,download=True,transform=transform,)trainloader = DataLoader(data_train, batch_size=4, shuffle=True, num_workers=2)for x, y in trainloader:print(x.shape)print(y)break# 测试数据集data_test = datasets.CIFAR10(root="./data",train=False,download=True,transform=transform,)testloader = DataLoader(data_test, batch_size=4, shuffle=False, num_workers=2)for x, y in testloader:print(x.shape)print(y)breakif __name__ == "__main__":test()test006()相关文章:

深度学习 从入门到精通 day_02
1. 自动微分 自动微分模块torch.autograd负责自动计算张量操作的梯度,具有自动求导功能。自动微分模块是构成神经网络训练的必要模块,可以实现网络权重参数的更新,使得反向传播算法的实现变得简单而高效。 1.1 基础概念 1. 张量 :…...

Selenium 实现自动化分页处理与信息提取
Selenium 实现自动化分页处理与信息提取 在 Web 自动化测试或数据抓取场景中,分页处理是一个常见的需求。通过 Selenium,我们可以实现对多页面内容的自动遍历,并从中提取所需的信息。本文将详细介绍如何利用 Selenium 进行自动化分页处理和信…...

【系统搭建】DPDK实现两虚拟机基于testpmd和l2fwd的收发包
testpmd与l2fwd的配合构建一个高性能的虚拟网络测试环境。l2fwd服务工作在数据链路层,使用MAC地址寻址,很多基于DPDK的策略实现可以基于l2fwd进行开发。 一、拓扑结构示意 ------------------- 虚拟化层网络 ------------------- | 虚拟机1 …...
)
简单接口工具(ApiCraft-Web)
ApiCraft-Web 项目介绍 ApiCraft-Web 是一个轻量级的 API 测试工具,提供了简洁直观的界面,帮助开发者快速测试和调试 HTTP 接口。 功能特点 支持多种 HTTP 请求方法(GET、POST、PUT、DELETE)可配置请求参数(Query …...

C语言数据类型取值范围
32位C语言整型数据类型取值范围 64位C语言整型数据类型取值范围 C语言标准数据类型保证的取值范围 在编写程序时如果要方便移植,我们应该关注的是图2-11的取值范围。 摘录自《CSAPP》。...

【机器学习】大数据时代,模型训练慢如牛?解锁Spark MLlib与分布式策略
Langchain系列文章目录 01-玩转LangChain:从模型调用到Prompt模板与输出解析的完整指南 02-玩转 LangChain Memory 模块:四种记忆类型详解及应用场景全覆盖 03-全面掌握 LangChain:从核心链条构建到动态任务分配的实战指南 04-玩转 LangChai…...

合成数据赋能AI:从生成到闭环的全景图谱
目录 合成数据赋能AI:从生成到闭环的全景图谱 🎯 项目目标 📄 白皮书 / PPT 大纲结构 一、合成数据概述(What & Why) 二、合成数据的核心生成技术(How) 三、合成数据适配任务…...

CS144 Lab0实战记录:搭建网络编程基础
文章目录 1 实验概述与背景2 ByteStream的设计与实现2.1 字节流抽象概述2.2 实现思路2.3 核心数据结构2.4 Writer实现细节2.5 Reader实现细节 3 WebGet应用实现 1 实验概述与背景 Stanford大学的CS144课程是计算机网络领域最著名的课程之一,其实验设计巧妙地引导学…...

杂记-LeetCode中部分题思路详解与笔记-HOT100篇-其三
时光荏苒啊,没想到这么快就到了四月份... 这个坑好久没写了,现在我们重启一下。 我看了一下之前的笔记,似乎是停留在了链表部分且HOT100中可以说最重要的链表题之一:LRU缓存居然没有写,真是岂有此理,让我…...

【python画图】:从入门到精通绘制完美柱状图
目录 Python数据可视化:从入门到精通绘制完美柱状图一、基础篇:快速绘制柱状图1.1 使用Matplotlib基础绘制1.2 使用Pandas快速绘图 二、进阶篇:专业级柱状图定制2.1 多系列柱状图2.2 堆叠柱状图2.3 水平柱状图 三、专业参数速查表Matplotlib …...

医疗设备预测性维护的合规性挑战与标准化路径研究
摘要 本研究从医疗设备全生命周期管理视角,探讨预测性维护技术面临的特殊合规性挑战及其标准化解决方案。通过分析全球12个主要医疗市场的监管差异,提出基于ISO 23510的通用合规框架,并验证其在三类典型医疗设备(生命支持类、影像…...

使用 XWPFDocument 生成表格时固定列宽度
一、XWPFDocument XWPFTable个性化属性 1.初始默认写法 XWPFTable table document.createTable(n, m); //在文档中创建一个n行m列的表格 table.setWidth("100%"); // 表格占页面100%宽度// 通过getRow获取行进行自定义设置 XWPFTableRow row table.getRow(0); XW…...

抽象的https原理简介
前言 小明和小美是一对好朋友,他们分隔两地,平时经常写信沟通,但是偶然被小明发现他回给小美的信好像被人拆开看过,甚至偷偷被篡改过。 对称加密算法 开头的通信过程比较像HTTP服务器与客户端的通信过程,全明文传输…...

Chakra UI框架中响应式断点
默认的断点:base是默认样式,不带任何媒体查询,适用于所有屏幕。 sm是30em(约480px) md是48em(768px) lg是62em(992px) xl是80em(1280px) 2xl是96e…...

【cocos creator 3.x】cocos creator2.x项目升级3.x项目改动点
1、基本改动 基本改动:去掉了cc.,改成在顶部添加导入 项目升级时候直接将cc.去掉,根据提示添加引用 node只保留position,scale,rotation,layer 其余属性如opacity,如果需要使用需要在节点手动添加UIOpacity组件 3d层和ui层分开…...

【android telecom 框架分析 01】【基本介绍 2】【BluetoothPhoneService为何没有源码实现】
1. 背景 我们会在很多资料上看到 BluetoothPhoneService 类,但是我们在实际 aosp 中确找不到具体的实现, 这是为何? 这是一个很好的问题!虽然在车载蓝牙电话场景中我们经常提到类似 BluetoothPhoneService 的概念,但…...

Linux:进程:进程调度
进程在CPU上运行具有以下特性: 竞争、独⽴、并⾏、并发 竞争性:系统进程数⽬众多,⽽CPU资源很少甚至只有一个,所以进程之间是具有竞争属性的。为 了⾼效完成任务,更合理竞争相关资源,便具有了优先级 独⽴性: 为了避…...

2025年探秘特种设备安全管理 A 证:守护安全的关键凭证
在现代工业与生活中,特种设备如锅炉、压力容器、电梯、起重机械等广泛应用,它们给我们带来便利的同时,也伴随着较高的安全风险。为了确保这些设备的安全运行,保障人民生命财产安全,特种设备安全管理显得尤为重要&#…...

WebSocket 实现数据实时推送原理
WebSocket 实现数据实时推送的核心机制在于其全双工通信能力和持久的连接特性。以下是其工作原理的详细步骤: 1. 握手阶段(HTTP 升级协议) 客户端发起请求:通过发送一个带有特殊头部的 HTTP 请求,请求协议升级。 GET …...
)
快速迭代收缩-阈值算法(FISTA)
文章目录 1. 数学与优化基础2. FISTA 算法的原理、推导与机制3. Matlab 实现4. FISTA 在图像处理与压缩感知中的应用4.1. 基于小波稀疏先验的图像去噪4.2 压缩感知图像重建 1. 数学与优化基础 在许多信号处理与机器学习问题中,我们希望获得稀疏解,即解向…...

XC6SLX100T-2FGG484I 赛灵思 XilinxFPGA Spartan-6
XC6SLX100T-2FGG484I 是Xilinx 推出的Spartan-6 LXT 系列FPGA芯片,采用45nm工艺设计,以高性价比和低功耗为核心 系列定位:Spartan‑6 LXT,中端逻辑与 DSP 加速 逻辑资源:101 261 个逻辑单元(LE࿰…...

DP 32bit位宽数据扰码实现和仿真
关于DisplayPort 1.4协议中扰码用的16-bit LFSR的移位8个时钟周期后的输出表达式我们已经用迭代的方法推导过,那么移位32个时钟周期的输出表达式同样可以迭代32次推导出,或者将移位8个时钟的输出表达式迭代3次也可以得到。以下就是移位32个时钟周期的输出…...
)
Electricity Market Optimization 探索系列(V)
本文参考链接link \hspace{1.6em} 众所周知, 社会福利是指消费者剩余和生产者剩余的和,也等价于产品的市值减去产品的成本,在电力市场中也非常关注社会福利这一概念,基于电力商品的同质性的特点,我们引入反价格需求函数来形象地刻…...

vue3 element-plus el-time-picker控制只显示时 分,并且控制可选的开始结束时间
只显示时分 控制只显示时分 HH:mm 控制只显示时分秒 HH:mm:ss 全部代码: <template><el-time-pickerstyle"width: 220px !important;"v-model"timeValue"format"HH:mm"value-format"HH:mm"/> </template&…...

从技术本质到未来演进:全方位解读Web的过去、现在与未来
一、Web的本质定义 Web(万维网)是一种基于**超文本传输协议(HTTP)和统一资源标识符(URI)**构建的分布式信息系统。它的核心在于通过超链接将全球范围内的信息资源连接成网状结构,使任何接入互联网的设备都能访问这些资源。Web的本质特征体现在三个方面: 跨平台性:无论…...

C++十进制与十六进制
在C中,可以使用不同的方式来表示十进制和十六进制数值。下面是一个简单的示例代码,展示了如何在C中表示和输出十进制和十六进制数值: #include <iostream> #include <iomanip>int main() {int decimalValue 255; // 十进制数值…...

MySQL基本语法
本地登录:mysql -u 用户名 -p 查看数据库:show databeases 创建库:create database 名字; 删除库:drop database 名字; 选择库:use 名字; 创建表:create table 表名 在…...

机器学习有多少种算法?当下入门需要全部学习吗?
机器学习算法如同工具箱中的器械——种类繁多却各有专攻。面对数百种公开算法,新手常陷入"学不完"的焦虑。本文将拆解算法体系,为初学者指明高效学习路径。 一、算法森林的全景地图 机器学习算法可按四大维度分类: 监督学习&#…...

【c语言】深入理解指针2
文章目录 一、指针数组指针数组模拟二维数组 二、数组指针二维数组传参的本质 三、字符指针变量四、函数指针变量4.1. 函数指针的应用4.2 两端有趣的代码4.3. typedef关键字4.3.1 typedef 的使用4.3.2. typedef与#define对比 五、函数指针数组函数指针数组的应用 一、指针数组 …...

Nacos
Nacos是阿里巴巴的产品, 现在是SpringCloud中的一个组件。相比Eureka功能更加丰富,在国内受欢迎程度较高。 官网地址:Redirecting to: https://nacos.io/ GitHub: https://github.com/alibaba/nacos 1.Nacos快入门 Nacos可以直…...

Linux,redis群集模式,主从复制,读写分离
redis的群集模式 主从模式 (单项复制,主复制到从) 一主两从 一台主机上的一主两从 需要修改三个配置文件 主要端口不一样 redis-8001.conf redis-8002.conf redis-8003.conf 哨兵模式 分布式集群模式 redis 安装部署 1,下载…...

《手环表带保养全攻略:材质、清洁与化学品避坑指南》
系列文章目录 文章目录 系列文章目录前言一、表带材质特性与专属养护方案二、清洁剂使用红黑榜三、家庭清洁实验:化学反应警示录四、保养实践方法论总结 前言 手环作为现代生活的智能伴侣,表带材质选择丰富多样。从柔软亲肤的皮质到耐用耐磨的金属&…...

【Leetcode 每日一题 - 补卡】1534. 统计好三元组
问题背景 给你一个整数数组 a r r arr arr,以及 a 、 b 、 c a、b 、c a、b、c 三个整数。请你统计其中好三元组的数量。 如果三元组 ( a r r [ i ] , a r r [ j ] , a r r [ k ] ) (arr[i], arr[j], arr[k]) (arr[i],arr[j],arr[k]) 满足下列全部条件ÿ…...

医疗设备预测性维护合规架构:从法规遵循到技术实现的深度解析
在医疗行业数字化转型加速推进的当下,医疗设备预测性维护已成为提升设备可用性、保障医疗安全的核心技术。然而,该技术的有效落地必须建立在严格的合规框架之上。医疗设备直接关乎患者生命健康,其维护过程涉及医疗法规、数据安全、质量管控等…...

如何在 IntelliJ IDEA 中安装 FindBugs-IDEA 1.0.1
以下是 FindBugs-IDEA 1.0.1 插件在 IntelliJ IDEA 中的安装步骤(适用于较旧版本的 IDEA,新版本可能需使用替代插件如 SpotBugs): 方法一:手动下载安装(适用于无法通过市场安装的情况) 下载插件…...

小车正常但是加载不出地图 找不到mapserver
Request for map failed; trying again... 找不到mapserver 原因: bash [ERROR] [1744895448.714854952]: failed to open image file "/home/liyb/catkin_ws/src/nav_demo/map/crossing.pgm": Couldnt open /home/xxx/catkin_ws/src/nav_demo/map/cr…...

无头开发模式
“无头”开发模式(Headless Development Mode)是指在没有直接连接物理显示器(monitor)、键盘或鼠标等输入输出设备的情况下,通过远程工具(如 SSH、SCP、rsync、VNC 或 Web 界面)对设备进行开发、…...

DAY 47 leetcode 232--栈与队列.用栈实现队列
题号232 请你仅使用两个栈实现先入先出队列。队列应当支持一般队列支持的所有操作(push、pop、peek、empty): class MyQueue {Stack<Integer> stackIn;Stack<Integer> stackOut;/** Initialize your data structure here. */pu…...

SpringAI+DeepSeek大模型应用开发——4 对话机器人
目录 项目初始化 pom文件 配置模型 ChatClient 同步调用 流式调用 日志功能 对接前端 解决跨域 会话记忆功能 ChatMemory 添加会话记忆功能 会话历史 管理会话id 保存会话id 查询会话历史 完善会话记忆 定义可序列…...

leetcode0058. 最后一个单词的长度-easy
1 题目:最后一个单词的长度 官方标定难度:易 给你一个字符串 s,由若干单词组成,单词前后用一些空格字符隔开。返回字符串中 最后一个 单词的长度。 单词 是指仅由字母组成、不包含任何空格字符的最大子字符串。 示例 1&#x…...

深入理解 Linux top 命令:从字段解读到性能诊断
系统或产品都需要部署到服务器或容器上运行,而服务器的运行效率直接影响到系统的稳定性和用户体验。因此,服务器的性能监控与分析就显得尤为重要。 在实际运维和性能测试过程中,我们可以从以下关键的几个方面入手进行系统监控与分析(网络延迟分析暂时先略过): CPU 使用率…...
原理解析:容器背后的存储技术)
[特殊字符] UnionFS(联合文件系统)原理解析:容器背后的存储技术
🔍 UnionFS(联合文件系统)原理解析:容器背后的存储技术 💡 什么是 UnionFS? UnionFS(联合文件系统) 是一种可以将多个不同来源的文件系统“合并”在一起的技术。它的核心思想是&am…...

部署若依前后端分离
参考部署:https://blog.csdn.net/qq_46073825/article/details/128716794?spm1001.2014.3001.5502 1.连接mysql(windows版本) 2.更新数据库用户为远程可连接 3.redis下载地址 https://github.com/tporadowski/redis/releases 5执行npm init 或者npm install --r…...

用Python Pandas高效操作数据库:从查询到写入的完整指南
一、环境准备与数据库连接 1.1 安装依赖库 pip install pandas sqlalchemy psycopg2 # PostgreSQL # 或 pip install pandas sqlalchemy pymysql # MySQL # 或 pip install pandas sqlalchemy # SQLite 1.2 创建数据库引擎 通过SQLAlchemy创建统一接口:…...

eventBus 事件中心管理组件间的通信
EventBus(事件总线)是Vue中用于实现非父子组件间通信的轻量级方案,通过一个中央Vue实例管理事件的发布与订阅。 一、基本使用步骤 1.创建EventBus实例 推荐单独创建文件(如event-bus.js)导出实例,避免全…...

某客户ORA-600 导致数据库反复重启问题分析
上班期间,收到业务反馈,测试环境数据库连接报错。 查看数据库alert日志,发现从中午的时候就出现了重启。并且在17时20分左右又发生了重启: 同时,在重启前alert日志中出现了ORA-600报错,相关报错在trc文件中…...

LeetCode 2176.统计数组中相等且可以被整除的数对:两层遍历模拟
【LetMeFly】2176.统计数组中相等且可以被整除的数对:两层遍历模拟 力扣题目链接:https://leetcode.cn/problems/count-equal-and-divisible-pairs-in-an-array/ 给你一个下标从 0 开始长度为 n 的整数数组 nums 和一个整数 k ,请你返回满足…...

Vue项目Webpack Loader全解析:从原理到实战配置指南
Vue项目Webpack Loader全解析:从原理到实战配置指南 前言 在Vue项目的开发与构建中,Webpack Loader扮演着资源转换的核心角色。无论是单文件组件(SFC)的解析、样式预处理,还是静态资源的优化,都离不开Loa…...

Vscode --- LinuxPrereqs │远程主机可能不符合 glibc 和 libstdc++ Vs code 服务器的先决条件
打开vscode连接远程linux服务器,发现连接失败,并出现如下报错信息: 原因是: vscode 官网公告如下:2025 年 3 月 (版本 1.99) - VSCode 编辑器 版本1.97 官网公告如下:链接 版本1.98 官网公告如下&am…...
╭)
大数据常见的模型定义及应用场景建议╮(╯▽╰)╭
以下是常见的大数据模型类型及其分析方法: 1. 描述性模型 1.1 定义 描述性模型:用于描述数据的现状和历史趋势,帮助理解数据的特征和模式。 1.2 常见模型 统计摘要:均值、中位数、标准差等。数据可视化:直方图、散…...