SpringAI+DeepSeek大模型应用开发——4 对话机器人
目录
项目初始化
pom文件
配置模型
ChatClient
同步调用
流式调用
日志功能
对接前端
解决跨域
会话记忆功能
ChatMemory
添加会话记忆功能
会话历史
管理会话id
保存会话id
查询会话历史
完善会话记忆
定义可序列化的Message
方案一:定期持久化
方案二:自定义ChatMemory
方案三:Cassandra
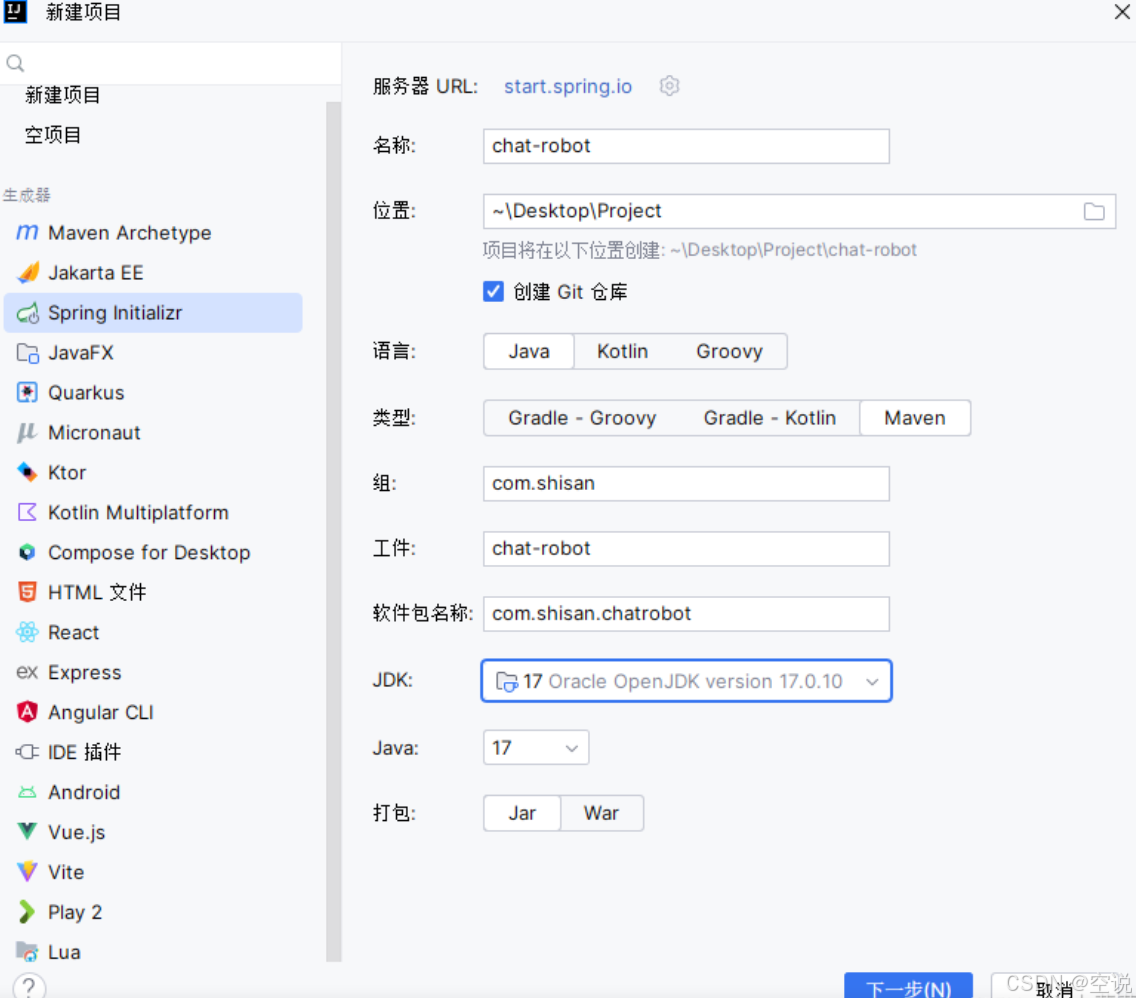
项目初始化
创建一个新的SpringBoot工程,勾选Web、MySQL驱动、Ollama:
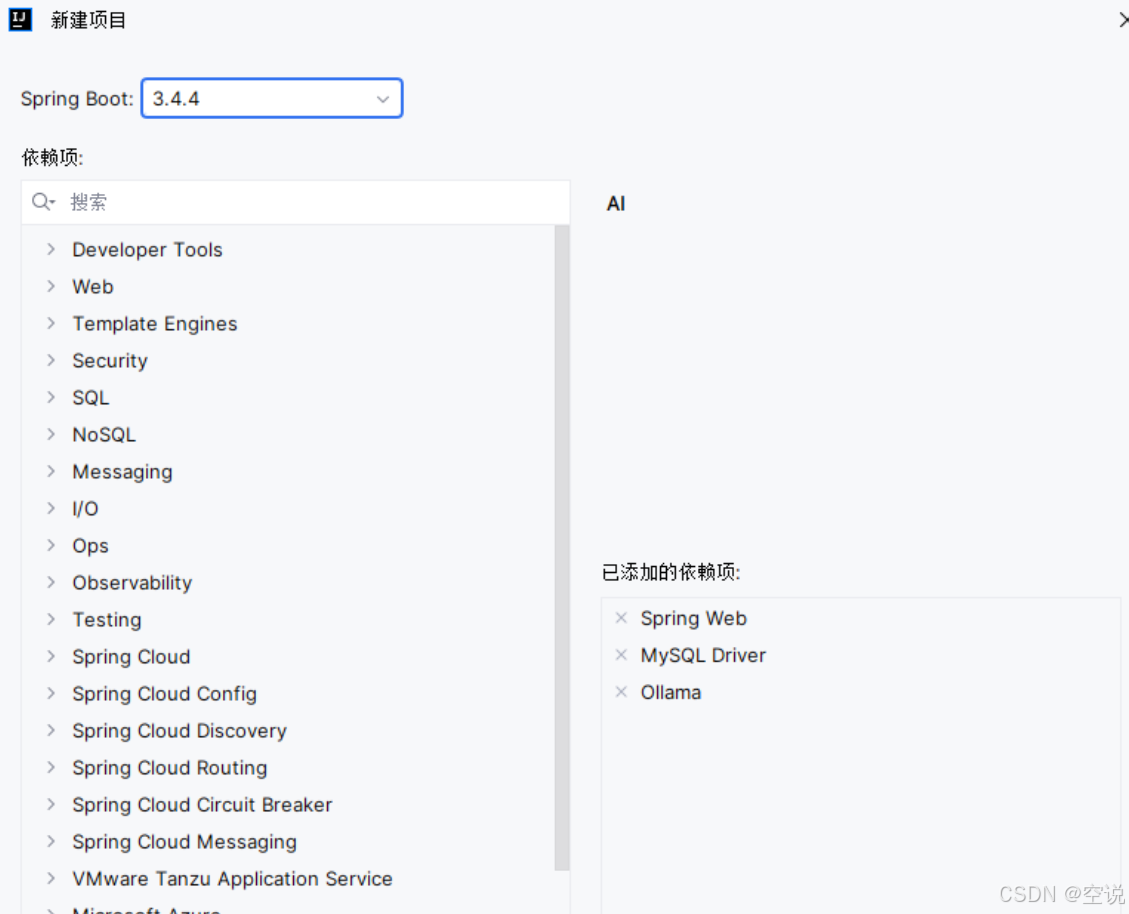
pom文件
主要引入的依赖如下
<properties><java.version>17</java.version><spring-ai.version>1.0.0-M6</spring-ai.version>
</properties>
<dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-web</artifactId>
</dependency>
<dependency><groupId>org.springframework.ai</groupId><artifactId>spring-ai-ollama-spring-boot-starter</artifactId>
</dependency>
<dependency><groupId>org.springframework.ai</groupId><artifactId>spring-ai-openai-spring-boot-starter</artifactId>
</dependency>
<dependency><groupId>com.mysql</groupId><artifactId>mysql-connector-j</artifactId><scope>runtime</scope>
</dependency>
<dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-test</artifactId><scope>test</scope>
</dependency>
<dependency><groupId>org.projectlombok</groupId><artifactId>lombok</artifactId><version>1.18.22</version>
</dependency>
<dependency><groupId>com.baomidou</groupId><artifactId>mybatis-plus-spring-boot3-starter</artifactId><version>3.5.10.1</version>
</dependency>
<dependency><groupId>org.springframework.ai</groupId><artifactId>spring-ai-pdf-document-reader</artifactId>
</dependency>
<dependencyManagement><dependencies><dependency><groupId>org.springframework.ai</groupId><artifactId>spring-ai-bom</artifactId><version>${spring-ai.version}</version><type>pom</type><scope>import</scope></dependency></dependencies>
</dependencyManagement>SpringAI完全适配了SpringBoot的自动装配功能,而且给不同的大模型提供了不同的starter,比如:
<!--Anthropic-->
<dependency><groupId>org.springframework.ai</groupId><artifactId>spring-ai-anthropic-spring-boot-starter</artifactId>
</dependency><!--Azure OpenAI-->
<dependency><groupId>org.springframework.ai</groupId><artifactId>spring-ai-azure-openai-spring-boot-starter</artifactId>
</dependency><!--DeepSeek-->
<dependency><groupId>org.springframework.ai</groupId><artifactId>spring-ai-openai-spring-boot-starter</artifactId>
</dependency><!--Hugging Face-->
<dependency><groupId>org.springframework.ai</groupId><artifactId>spring-ai-huggingface-spring-boot-starter</artifactId>
</dependency><!--Ollama-->
<dependency><groupId>org.springframework.ai</groupId><artifactId>spring-ai-ollama-spring-boot-starter</artifactId>
</dependency><!--OpenAI-->
<dependency><groupId>org.springframework.ai</groupId><artifactId>spring-ai-openai-spring-boot-starter</artifactId>
</dependency>配置模型
在配置文件中配置模型的参数信息,以Ollama为例:
spring:application:name: heima-aiai:ollama:base-url: http://localhost:11434chat:model: deepseek-r1:7bopenai:base-url: https://dashscope.aliyuncs.com/compatible-modeapi-key: 填百炼大模型平台自己的api keychat:options:model: qwen-plusembedding:options:model: text-embedding-v3dimensions: 1024ChatClient
-
ChatClient中封装了与AI大模型对话的各种API,同时支持同步式或响应式交互; -
在使用之前,需要声明一个
ChatClient;在ai.config包下新建一个CommonConfiguration类: -
系统预设:在SpringAI中,设置System信息非常方便,不需要在每次发送时封装到Message,而是创建ChatClient时指定即可;
import org.springframework.ai.chat.client.ChatClient;
import org.springframework.ai.ollama.OllamaChatModel;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;@Configuration
public class CommonConfiguration {// 注意参数中的model就是使用的模型,这里用了Ollama,也可以选择OpenAIChatModel@Beanpublic ChatClient chatClient(OllamaChatModel model) { return ChatClient.builder(model) // 创建ChatClient工厂,利用它可以自由选择模型、添加各种自定义配置.defaultOptions(ChatOptions.builder().model("qwen-omni-turbo").build()).defaultSystem("你是一个热心、可爱的智能助手,你的名字叫小团团,请以小团团的身份和语气回答问题。") //系统预设 .build(); // 构建ChatClient实例}
}同步调用
定义一个Controller,在其中接收用户发送的提示词,然后把提示词发送给大模型,交给大模型处理,拿到结果后返回;
package com.shisan.ai.controller;import lombok.RequiredArgsConstructor;
import org.springframework.ai.chat.client.ChatClient;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RequestParam;
import org.springframework.web.bind.annotation.RestController;@RequiredArgsConstructor
@RestController
@RequestMapping("/ai")
public class ChatController {private final ChatClient chatClient;// 请求方式和路径不要改动,将来要与前端联调@RequestMapping("/chat")public String chat(@RequestParam String prompt) {return chatClient.prompt(prompt) // 传入user提示词.call() // 同步调用请求,会等待AI全部输出完才返回结果.content(); //返回响应内容}
}启动项目,在浏览器中访问:http://localhost:8080/ai/chat?prompt=你好;

流式调用
-
同步调用需要等待很长时间页面才能看到结果,用户体验不好。为了解决这个问题,可以改进调用方式为流式调用;
-
使用了WebFlux技术实现流式调用;修改
ChatController中的chat方法:
// 注意看返回值,是Flux<String>,也就是流式结果,另外需要设定响应类型和编码,不然前端会乱码
@RequestMapping(value = "/chat", produces = "text/html;charset=UTF-8")
public Flux<String> chat(@RequestParam(String prompt) {return chatClient.prompt(prompt).stream() // 流式调用.content();
}日志功能
默认情况下,AI交互时是不记录日志的,我们无法得知SpringAI 组织的提示词到底长什么样,这样不方便我们调试。
SpringAI基于AOP机制实现与大模型对话过程的增强、拦截、修改等功能,所有的增强通知都需要实现Advisor接口;Spring提供了一些Advisor的默认实现,来实现一些基本的增强功能:

-
SimpleLoggerAdvisor:日志记录的Advisor; -
MessageChatMemoryAdvisor:会话记忆的Advisor; -
QuestionAnswerAdvisor:实现RAG的Advisor;
当然,也可以自定义Advisor,具体可以参考:Advisors API
添加日志功能
@Configuration
public class CommonConfiguration {// 注意参数中的model就是使用的模型,这里用了Ollama,也可以选择OpenAIChatModel@Beanpublic ChatClient chatClient(OllamaChatModel model) { return ChatClient.builder(model) // 创建ChatClient工厂,利用它可以自由选择模型、添加各种自定义配置.defaultOptions(ChatOptions.builder().model("qwen-omni-turbo").build()).defaultSystem("你是一个热心、可爱的智能助手,你的名字叫小团团,请以小团团的身份和语气回答问题。") //系统预设.defaultAdvisors(new SimpleLoggerAdvisor(),new MessageChatMemoryAdvisor(chatMemory)).build(); // 构建ChatClient实例}
}日志级别
#配置 application.yaml即可,重启项目,再次聊天就能在IDEA的运行控制台中看到AI对话的日志信息了
logging:level:org.springframework.ai: debugcom.itheima.ai: debug对接前端
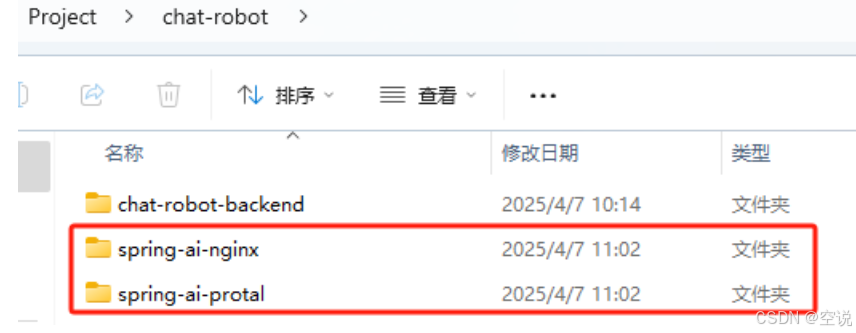
npm运行
进入spring-ai-protal文件夹(该文件夹要放在非中文目录下),然后执行cmd命令:
# 安装依赖
npm install
# 运行程序
npm run dev启动后,访问http://localhost:5173即可看到页面:

nginx运行
若不关心源码,进入spring-ai-nginx文件夹(该文件夹要放在非中文目录下),然后执行cmd命令
# 启动Nginx
start nginx.exe
# 停止
nginx.exe -s stop-
启动后,访问
http://localhost:5173即可看到页面。
解决跨域
前后端在不同端口,存在跨域问题,因此需要在服务端解决cors问题;在ai.config包中添加一个MvcConfiguration类:
@Configuration
public class MvcConfiguration implements WebMvcConfigurer {@Overridepublic void addCorsMappings(CorsRegistry registry) {registry.addMapping("/**").allowedOrigins("*").allowedMethods("GET", "POST", "PUT", "DELETE", "OPTIONS").allowedHeaders("*").exposedHeaders("Content-Disposition");}
}测试

会话记忆功能
前面讲过,让AI有会话记忆的方式就是把每一次历史对话内容拼接到Prompt中,一起发送过去,这种方式比较挺麻烦;
如果使用了SpringAI,并不需要自己拼接,SpringAI自带了会话记忆功能,可以把历史会话保存下来,下一次请求AI时会自动拼接,非常方便。
ChatMemory
会话记忆功能同样是基于AOP实现,Spring提供了一个MessageChatMemoryAdvisor的通知,可以像之前添加日志通知一样添加到ChatClient即可;不过,要注意的是,MessageChatMemoryAdvisor需要指定一个ChatMemory实例,也就是会话历史保存的方式;
ChatMemory接口声明如下:
public interface ChatMemory {// TODO: consider a non-blocking interface for streaming usagesdefault void add(String conversationId, Message message) {this.add(conversationId, List.of(message));}// 添加会话信息到指定conversationId的会话历史中void add(String conversationId, List<Message> messages);// 根据conversationId查询历史会话List<Message> get(String conversationId, int lastN);// 清除指定conversationId的会话历史void clear(String conversationId);
}可以看到,所有的会话记忆都是与conversationId有关联的,也就是会话Id,将来不同会话Id的记忆自然是分开管理的;
目前,在SpringAI中有两个ChatMemory的实现:
-
InMemoryChatMemory:会话历史保存在内存中; -
CassandraChatMemory:会话保存在Cassandra数据库中(需要引入额外依赖,并且绑定了向量数据库,不够灵活);
目前选择用InMemoryChatMemory来实现。
添加会话记忆功能
CommonConfiguration配置类中添加
@Bean
public ChatMemory chatMemory() {return new InMemoryChatMemory();
}@Beanpublic ChatClient chatClient(AlibabaOpenAiChatModel model, ChatMemory chatMemory) {return ChatClient.builder(model).defaultOptions(ChatOptions.builder().model("qwen-omni-turbo").build()).defaultSystem("你是一个热心、可爱的智能助手,你的名字叫小团团,请以小团团的身份和语气回答问题。").defaultAdvisors(new SimpleLoggerAdvisor(), //记录日志new MessageChatMemoryAdvisor(chatMemory) //添加会话记忆功能).build();}现在聊天会话已经有记忆功能了,不过现在的会话记忆还是不完善的,接下来的章节还会继续补充。
会话历史
会话记忆:是指让大模型记住每一轮对话的内容,不至于前一句刚问完,下一句就忘了;
会话历史:是指要记录总共有多少不同的对话;
以DeepSeek为例,页面上的会话历史:

在ChatMemory中,会记录一个会话中的所有消息,记录方式是以conversationId为key,以List<Message>为value,根据这些历史消息,大模型就能继续回答问题,这就是所谓的会话记忆;
而会话历史,其实就是每一个会话的conversationId,用它去查询List<Message>,注意,在接下来业务中,以chatId来代conversationId
管理会话id
由于会话记忆是以conversationId来管理的,也就是会话id(以后简称为chatId)将来要查询会话历史,其实就是查询历史中有哪些chatId;因此,为了实现查询会话历史记录,必须记录所有的chatId。
定义一个ai.repository包,然后新建一个ChatHistoryRepository管理会话历史接口:
public interface ChatHistoryRepository {/*** 保存会话记录* @param type 业务类型,如:chat、service、pdf* @param chatId 会话ID*/void save(String type, String chatId);/*** 获取会话ID列表* @param type 业务类型,如:chat、service、pdf* @return 会话ID列表*/List<String> getChatIds(String type);
}在这个包下继续创建一个实现类InMemoryChatHistoryRepository
import lombok.RequiredArgsConstructor;
import org.springframework.stereotype.Component;
import java.util.ArrayList;
import java.util.List;
import java.util.Map;@Component
@RequiredArgsConstructor
public class InMemoryChatHistoryRepository implements ChatHistoryRepository {private Map<String, List<String>> chatHistory = new HashMap<>(); //存储不同类型的聊天 ID//业务类型,如:chat、service、pdf //按类型存储聊天 ID,避免重复@Overridepublic void save(String type, String chatId) {List<String> chatIds = chatHistory.computeIfAbsent(type, k -> new ArrayList<>());if (chatIds.contains(chatId)) {return;}chatIds.add(chatId);}//根据类型返回对应的聊天 ID 列表@Overridepublic List<String> getChatIds(String type) {return chatHistory.getOrDefault(type, List.of());}
}接下来,修改ChatController中的chat方法,做到以下3点:
-
添加一个请求参数:chatId,每次前端请求AI时都需要传递chatId;
-
每次处理请求时,将chatId存储到ChatRepository;
-
每次发请求到AI大模型时,都传递自定义的chatId;
保存会话id
接下来,修改ChatController中的chat方法,做到以下3点:
-
添加一个请求参数:
chatId,每次前端请求AI时都需要传递chatId; -
每次处理请求时,将chatId存储到ChatRepository;
-
每次发请求到AI大模型时,都传递自定义的chatId;
private final ChatClient chatClient;
private final ChatHistoryRepository chatHistoryRepository;
//流式调用
@RequestMapping(value = "/chat", produces = "text/html;charset=utf-8")
public Flux<String> chat(@RequestParam("prompt") String prompt,@RequestParam("chatId") String chatId,@RequestParam(value = "files", required = false) List<MultipartFile> files) {// 1.保存会话id(如果存在会直接返回)chatHistoryRepository.save("chat", chatId);// 2.请求模型if (files == null || files.isEmpty()) {// 没有附件,纯文本聊天return textChat(prompt, chatId);} else {// 有附件,多模态聊天return multiModalChat(prompt, chatId, files);}
}//纯文本聊天
private Flux<String> textChat(String prompt, String chatId) {return chatClient.prompt() //请求模型.user(prompt) //预设//通过AdvisorContext,也就是以key-value形式存入上下文.advisors(a -> a.param(CHAT_MEMORY_CONVERSATION_ID_KEY, chatId)) .stream().content();
}查询会话历史
定义一个新的Controller,专门实现回话历史的查询。包含两个接口:
-
根据业务类型查询会话历史列表(将来有3个不同业务,需要分别记录历史。可以自己扩展成按userId记录,根据UserId查询)
-
根据chatId查询指定会话的历史消息;
private final ChatHistoryRepository chatHistoryRepository;
private final ChatMemory chatMemory;//根据业务类型查询会话历史列表
@GetMapping("/{type}")
public List<String> getChatIds(@PathVariable("type") String type) {return chatHistoryRepository.getChatIds(type);
}
//根据chatId查询指定会话的历史消息
@GetMapping("/{type}/{chatId}")
public List<MessageVO> getChatHistory(@PathVariable("type") String type, @PathVariable("chatId") String chatId) {List<Message> messages = chatMemory.get(chatId, Integer.MAX_VALUE);if(messages == null) {return List.of();}//由于Message并不符合页面的需要,所以需要自己定义一个VOreturn messages.stream().map(MessageVO::new).toList();
}@NoArgsConstructor
@Data
public class MessageVO {private String role;private String content;public MessageVO(Message message) {switch (message.getMessageType()) {case USER: role = "user"; break;case ASSISTANT:role = "assistant";break;default:role = "";break;}this.content = message.getText();}
}重启服务,现在AI聊天机器人就具备会话记忆和会话历史功能了!
完善会话记忆
目前,会话记忆是基于内存,重启服务就没了;如果要持久化保存,这里提供了3种办法:
-
依然是基于
InMemoryChatMemory,但是在项目停机时,或者使用定时任务实现自动持久化; -
自定义基于Redis的
ChatMemory; -
基于SpringAI官方提供的
CassandraChatMemory,同时会自动启用CassandraVectorStore。
定义可序列化的Message
前面的两种方案,都面临一个问题,SpringAI中的Message类未实现Serializable接口,也没提供public的构造方法,因此无法基于任何形式做序列化。所以必须定义一个可序列化的Message类,方便后续持久化。定义一ai.entity.po包,新建一个Msg类:
@NoArgsConstructor
@AllArgsConstructor
@Data
public class Msg {MessageType messageType;String text;Map<String, Object> metadata;List<AssistantMessage.ToolCall> toolCalls;//将SpringAI的Message转为我们的Msgpublic Msg(Message message) {this.messageType = message.getMessageType();this.text = message.getText();this.metadata = message.getMetadata();if(message instanceof AssistantMessage am) {this.toolCalls = am.getToolCalls();}}//实现将我们的Msg转为SpringAI的Messagepublic Message toMessage() {return switch (messageType) {case SYSTEM -> new SystemMessage(text);case USER -> new UserMessage(text, List.of(), metadata);case ASSISTANT -> new AssistantMessage(text, metadata, toolCalls, List.of());default -> throw new IllegalArgumentException("Unsupported message type: " + messageType);};}
}方案一:定期持久化
接下来,将SpringAI提供的InMemoryChatMemory中的数据持久化到本地磁盘,并且在项目启动时加载;
本方案中,采用Spring的生命周期方法,在项目启动时加载持久化文件,在项目停机时持久化数据;
也可以考虑使用定时任务完成持久化,项目启动加载的方案;
修改ai.repository.InMemoryChatHistoryRepository类,添加持久化功能:
//项目启动时
@PostConstruct
private void init() {// 1.初始化会话历史记录this.chatHistory = new HashMap<>();// 2.加载本地会话历史和会话记忆FileSystemResource historyResource = new FileSystemResource("chat-history.json");FileSystemResource memoryResource = new FileSystemResource("chat-memory.json");if (!historyResource.exists()) {return;}try {// 会话历史Map<String, List<String>> chatIds = this.objectMapper.readValue(historyResource.getInputStream(), new TypeReference<>() {});if (chatIds != null) {this.chatHistory = chatIds;}// 会话记忆Map<String, List<Msg>> memory = this.objectMapper.readValue(memoryResource.getInputStream(), new TypeReference<>() {});if (memory != null) {memory.forEach(this::convertMsgToMessage); //转成message}} catch (IOException ex) {throw new RuntimeException(ex);}
}private void convertMsgToMessage(String chatId, List<Msg> messages) {this.chatMemory.add(chatId, messages.stream().map(Msg::toMessage).toList());
}@PreDestroy
private void persistent() {String history = toJsonString(this.chatHistory);String memory = getMemoryJsonString();FileSystemResource historyResource = new FileSystemResource("chat-history.json");FileSystemResource memoryResource = new FileSystemResource("chat-memory.json");try (PrintWriter historyWriter = new PrintWriter(historyResource.getOutputStream(), true, StandardCharsets.UTF_8);PrintWriter memoryWriter = new PrintWriter(memoryResource.getOutputStream(), true, StandardCharsets.UTF_8)) {historyWriter.write(history);memoryWriter.write(memory);} catch (IOException ex) {log.error("IOException occurred while saving vector store file.", ex);throw new RuntimeException(ex);} catch (SecurityException ex) {log.error("SecurityException occurred while saving vector store file.", ex);throw new RuntimeException(ex);} catch (NullPointerException ex) {log.error("NullPointerException occurred while saving vector store file.", ex);throw new RuntimeException(ex);}
}private String getMemoryJsonString() {Class<InMemoryChatMemory> clazz = InMemoryChatMemory.class;try {Field field = clazz.getDeclaredField("conversationHistory");field.setAccessible(true);Map<String, List<Message>> memory = (Map<String, List<Message>>) field.get(chatMemory);Map<String, List<Msg>> memoryToSave = new HashMap<>();memory.forEach((chatId, messages) -> memoryToSave.put(chatId, messages.stream().map(Msg::new).toList()));return toJsonString(memoryToSave);} catch (NoSuchFieldException | IllegalAccessException e) {throw new RuntimeException(e);}
}private String toJsonString(Object object) {ObjectWriter objectWriter = this.objectMapper.writerWithDefaultPrettyPrinter();try {return objectWriter.writeValueAsString(object);} catch (JsonProcessingException e) {throw new RuntimeException("Error serializing documentMap to JSON.", e);}
}方案二:自定义ChatMemory
基于Redis来实现自定义ChatMemory;
<dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-data-redis</artifactId>
</dependency>ai.repository包中新建一个RedisChatMemory类:由于使用的是Redis的Set结构,无序的,因此要确保chatId是单调递增的。
import com.fasterxml.jackson.core.JsonProcessingException;
import com.fasterxml.jackson.databind.ObjectMapper;
import com.itheima.ai.entity.po.Msg;
import lombok.RequiredArgsConstructor;
import org.springframework.ai.chat.memory.ChatMemory;
import org.springframework.ai.chat.messages.Message;
import org.springframework.data.redis.core.StringRedisTemplate;
import org.springframework.stereotype.Component;
import java.util.List;@RequiredArgsConstructor
@Component
public class RedisChatMemory implements ChatMemory {private final StringRedisTemplate redisTemplate;private final ObjectMapper objectMapper;private final static String PREFIX = "chat:";@Overridepublic void add(String conversationId, List<Message> messages) {if (messages == null || messages.isEmpty()) {return;}List<String> list = messages.stream().map(Msg::new).map(msg -> {try {return objectMapper.writeValueAsString(msg);} catch (JsonProcessingException e) {throw new RuntimeException(e);}}).toList();redisTemplate.opsForList().leftPushAll(PREFIX + conversationId, list);}@Overridepublic List<Message> get(String conversationId, int lastN) {List<String> list = redisTemplate.opsForList().range(PREFIX + conversationId, 0, lastN);if (list == null || list.isEmpty()) {return List.of();}return list.stream().map(s -> {try {return objectMapper.readValue(s, Msg.class);} catch (JsonProcessingException e) {throw new RuntimeException(e);}}).map(Msg::toMessage).toList();}@Overridepublic void clear(String conversationId) {redisTemplate.delete(PREFIX + conversationId);}
}方案三:Cassandra
-
SpringAI官方提供了CassandraChatMemory,但是是跟CassandraVectorStore绑定的,不太灵活;
-
首先,需要安装一个Cassandra访问,使用Docker安装:
docker run -d --name cas -p 9042:9042 cassandra在项目中添加cassandra依赖:
<dependency><groupId>org.springframework.ai</groupId><artifactId>spring-ai-cassandra-store-spring-boot-starter</artifactId>
</dependency>配置Cassandra地址:
spring:cassandra:contact-points: 192.168.150.101:9042local-datacenter: datacenter1-
基于Cassandra的ChatMemory已经实现了,其它不变。
-
注意:多种ChatMemory实现方案不能共存,只能选择其一。
相关文章:

SpringAI+DeepSeek大模型应用开发——4 对话机器人
目录 项目初始化 pom文件 配置模型 ChatClient 同步调用 流式调用 日志功能 对接前端 解决跨域 会话记忆功能 ChatMemory 添加会话记忆功能 会话历史 管理会话id 保存会话id 查询会话历史 完善会话记忆 定义可序列…...

leetcode0058. 最后一个单词的长度-easy
1 题目:最后一个单词的长度 官方标定难度:易 给你一个字符串 s,由若干单词组成,单词前后用一些空格字符隔开。返回字符串中 最后一个 单词的长度。 单词 是指仅由字母组成、不包含任何空格字符的最大子字符串。 示例 1&#x…...

深入理解 Linux top 命令:从字段解读到性能诊断
系统或产品都需要部署到服务器或容器上运行,而服务器的运行效率直接影响到系统的稳定性和用户体验。因此,服务器的性能监控与分析就显得尤为重要。 在实际运维和性能测试过程中,我们可以从以下关键的几个方面入手进行系统监控与分析(网络延迟分析暂时先略过): CPU 使用率…...
原理解析:容器背后的存储技术)
[特殊字符] UnionFS(联合文件系统)原理解析:容器背后的存储技术
🔍 UnionFS(联合文件系统)原理解析:容器背后的存储技术 💡 什么是 UnionFS? UnionFS(联合文件系统) 是一种可以将多个不同来源的文件系统“合并”在一起的技术。它的核心思想是&am…...

部署若依前后端分离
参考部署:https://blog.csdn.net/qq_46073825/article/details/128716794?spm1001.2014.3001.5502 1.连接mysql(windows版本) 2.更新数据库用户为远程可连接 3.redis下载地址 https://github.com/tporadowski/redis/releases 5执行npm init 或者npm install --r…...

用Python Pandas高效操作数据库:从查询到写入的完整指南
一、环境准备与数据库连接 1.1 安装依赖库 pip install pandas sqlalchemy psycopg2 # PostgreSQL # 或 pip install pandas sqlalchemy pymysql # MySQL # 或 pip install pandas sqlalchemy # SQLite 1.2 创建数据库引擎 通过SQLAlchemy创建统一接口:…...

eventBus 事件中心管理组件间的通信
EventBus(事件总线)是Vue中用于实现非父子组件间通信的轻量级方案,通过一个中央Vue实例管理事件的发布与订阅。 一、基本使用步骤 1.创建EventBus实例 推荐单独创建文件(如event-bus.js)导出实例,避免全…...

某客户ORA-600 导致数据库反复重启问题分析
上班期间,收到业务反馈,测试环境数据库连接报错。 查看数据库alert日志,发现从中午的时候就出现了重启。并且在17时20分左右又发生了重启: 同时,在重启前alert日志中出现了ORA-600报错,相关报错在trc文件中…...

LeetCode 2176.统计数组中相等且可以被整除的数对:两层遍历模拟
【LetMeFly】2176.统计数组中相等且可以被整除的数对:两层遍历模拟 力扣题目链接:https://leetcode.cn/problems/count-equal-and-divisible-pairs-in-an-array/ 给你一个下标从 0 开始长度为 n 的整数数组 nums 和一个整数 k ,请你返回满足…...

Vue项目Webpack Loader全解析:从原理到实战配置指南
Vue项目Webpack Loader全解析:从原理到实战配置指南 前言 在Vue项目的开发与构建中,Webpack Loader扮演着资源转换的核心角色。无论是单文件组件(SFC)的解析、样式预处理,还是静态资源的优化,都离不开Loa…...

Vscode --- LinuxPrereqs │远程主机可能不符合 glibc 和 libstdc++ Vs code 服务器的先决条件
打开vscode连接远程linux服务器,发现连接失败,并出现如下报错信息: 原因是: vscode 官网公告如下:2025 年 3 月 (版本 1.99) - VSCode 编辑器 版本1.97 官网公告如下:链接 版本1.98 官网公告如下&am…...
╭)
大数据常见的模型定义及应用场景建议╮(╯▽╰)╭
以下是常见的大数据模型类型及其分析方法: 1. 描述性模型 1.1 定义 描述性模型:用于描述数据的现状和历史趋势,帮助理解数据的特征和模式。 1.2 常见模型 统计摘要:均值、中位数、标准差等。数据可视化:直方图、散…...

红宝书第四十八讲:实时通信双雄:Socket.IO Meteor 的奇妙旅程
红宝书第四十八讲:实时通信双雄:Socket.IO & Meteor 的奇妙旅程 资料取自《JavaScript高级程序设计(第5版)》。 查看总目录:红宝书学习大纲 一、实时通信基础 1. WebSocket与HTTP对比 传统HTTP请求类似送信&…...
)
【数字图像处理】图像分割(1)
图像分割定义 把图像分成若干个特定的、具有独特性质的区域,并提出感兴趣目标的技术和过程 图像分割概述 一幅图像通常是由代表物体的图案与背景组成,简称物体与背景 图像分割的本质:将图像按照区域内的一致性和区域间的不一致性进行分类的过…...

VFlash的自动化和自定义动作
文章目录 一、automation 自动化二、custom actions 自定义动作常用方法如何选择要发送的诊断请求CustomActionValueList 作用Pre Action和Post Action之间交换信息 提示:如何打印软件中变量报错:无法打开源文件 Windows.h stdio.h conio.h报错ÿ…...

pytorch学习02
自动微分 自动微分模块torch.autograd负责自动计算张量操作的梯度,具有自动求导功能。自动微分模块是构成神经网络训练的必要模块,可以实现网络权重参数的更新,使得反向传播算法的实现变得简单而高效。 1. 基础概念 张量 Torch中一切皆为张…...

TV板卡维修技术【四】
【一】热成像松香的结合快速定位短路位置 发现电路短路,但是无法定位到大概位置,可以采用烧机法: 热成像大致定位,松香准确定位: 可以很快找到这种小陶瓷电容短路的故障: 测量电路是否有大短路,…...

Rust生命周期、文件与IO
文章目录 Rust生命周期生命周期注释结构体如何使用字符串静态生命周期 Rust文件与IO接收命令行参数命令行输入文件读取文件写入 Rust生命周期 终于讲到Rust最重要的机制之一了,生命周期机制 我们先复习一下垂悬引用 {let r;{let x 5;r &x;}println!("…...

22、字节与字符的概念以及二者有什么区别?
1、概念 字节(byte) 定义:字节是计算机信息技术中用于计量存储容量和传输容量的一种单位,通常由8个二进制位(bit)组成。 作用:字节是计算机存储和处理信息的基本单位,用于衡量数据…...

APP端测试
一、功能测试 1. 核心测试点 安装/卸载/升级:验证不同安装方式(应用商店/APK/IPA) 注册登录:多种登录方式测试(手机号、第三方账号) 核心业务流程:支付流程、内容发布等关键路径 中断测试&a…...

Langchain-构建向量数据库和检索器
向量数据库安装 pip install langchain-chroma 文档》向量存储》向量数据库。 和0416 提示词工程相同。 初始化 import osfrom langchain_chroma import Chroma from langchain_community.chat_message_histories import ChatMessageHistory from langchain_core.documents im…...

PPT无法编辑怎么办?原因及解决方法全解析
在日常办公中,我们经常会遇到需要编辑PPT的情况。然而,有时我们会发现PPT文件无法编辑,这可能由多种原因引起。今天我们来看看PPT无法编辑的几种常见原因,并提供实用的解决方法,帮助你轻松应对。 原因1:文…...

PH热榜 | 2025-04-17
1. Mailgo 标语:一款利用人工智能的冷邮件平台,能够提升邮件送达率。 介绍:Mailgo将AI线索寻找助手、智能日程安排和预热账户集成到一个直观的平台上——帮助销售团队和创业者高效到达客户邮箱,轻松扩展业务,并加快转…...

maptalks矩形绘制结束后,获取最大经度最大纬度,最小经度最小纬度,从左上角开始依次获取并展示坐标
maptalks矩形绘制结束后,获取最大经度最大纬度,最小经度最小纬度,从左上角开始依次获取并展示坐标 重点 // 获取绘制的矩形图形对象const rectangle param.geometry;// 获取矩形外接矩形范围(西南角/东北角坐标)cons…...

网页图像优化:现代格式与响应式技巧
网页图像优化:现代格式与响应式技巧 网页图像如果处理不好,很容易拖慢加载速度,影响用户体验。这篇文章聊聊怎么用现代图像格式和响应式技巧,让你的网站图片加载更快、效果更好。 推荐的图像格式 选对图像格式,能在保…...

python中参数前**的含义
在Python中,参数前的 ** 表示该参数是一个“关键字参数”或者说是“可变关键字参数”。这种参数允许函数接受任意数量的关键字参数,并将这些参数存储在一个名为**kwargs的字典中。这使得函数可以接收任意数量的键值对参数,这在编写需要处理多…...

内存编码手册:整数与浮点数的二进制世界
1.整数在内存中的存储 之前在学习操作符的博文中,我们就已经学习了整数在内存中存储的一些基本知识,我们来快速回忆一下,并开始学习新的知识。 之前的学习中,我们知道整数的二进制表示方法有三种,即原码,…...

铷元素的市场供需情况如何?
铷元素的市场供需格局呈现出显著的稀缺性与战略价值,其供应高度依赖锂矿开采的副产品,而需求则随着高科技产业的快速发展持续攀升。以下从供应、需求、价格、政策及可持续性五个维度展开分析: 一、供应端:资源稀缺与技术瓶颈并存…...

MATLAB 程序实现了一个层次化光网络的数据传输模拟系统
% 主程序 num_pods = 4; % Pod 数量 num_racks_per_pod = 4; % 每个 Pod 的 Rack 数量 num_nodes_per_rack = 4; % 每个 Rack 的 Node 数量 max_wavelength = 50; % 可用波长数(根据冲突图动态调整) num_packets = 1000; % 模拟的…...

LFI to RCE
LFI不止可以来读取文件,还能用来RCE 在多道CTF题目中都有LFItoRCE的非预期解,下面总结一下LFI的利用姿势 1. /proc/self/environ 利用 条件:目标能读取 /proc/self/environ,并且网页中存在LFI点 利用方式: 修改请…...
:随机数生成器类 QRandomGenerator 的源码阅读)
QT6 源(34):随机数生成器类 QRandomGenerator 的源码阅读
(1)代码来自 qrandom.h ,结合官方的注释: #ifndef QRANDOM_H #define QRANDOM_H#include <QtCore/qalgorithms.h> #include <algorithm> // for std::generate #include <random> // for std::mt1993…...

极狐GitLab GEO 功能介绍
极狐GitLab 是 GitLab 在中国的发行版,关于中文参考文档和资料有: 极狐GitLab 中文文档极狐GitLab 中文论坛极狐GitLab 官网 Geo (PREMIUM SELF) Geo 是广泛分布的开发团队的解决方案,可作为灾难恢复策略的一部分提供热备份。Geo 不是 开箱…...

快速上手,OceanBase + MCP + LLM,搭建 AI 应用
在 AI 技术发展的进程中,大语言模型(LLM)凭借卓越的信息处理与推理能力广受重视。然而,数据孤岛问题仍是 LLM 面临的核心挑战。目前,LLM 的推理主要依赖于预先训练的数据和有限的上下文窗口,既无法动态访问…...

【Python爬虫基础篇】--1.基础概念
目录 1.爬虫--定义 2.爬虫--组成 3.爬虫--URL 1.爬虫--定义 网络爬虫,是一种按照一定规则,自动抓取互联网信息的程序或者脚本。另外一些不常使用的名字还有蚂蚁、自动索引、模拟程序或者蠕虫。随着网络的迅速发展,万维网成为大量信息的载体…...

Linux :进程替换
进程替换 (一)进程程序替换1.替换原理2.替换函数exec函数命名理解 (二)实现简易shell (一)进程程序替换 1.替换原理 用fork创建子进程后执行的是和父进程相同的程序(但有可能执行不同的代码分支),子进程往…...

XC7K410T‑2FFG900I 赛灵思XilinxFPGA Kintex‑7
XC7K410T‑2FFG900I Xilinx 赛灵思FPGA Kintex‑7 系列定位:Kintex‑7 中端,高性价比与高性能平衡 工艺节点:28 nm HPL(High‑Performance, Low‑Power)HKMG(High‑κ Metal Gate) 逻辑资源&…...

list容器介绍及模拟实现和与vector比较
目录 list容器介绍 lisy接口 list迭代器的注意事项 迭代器失效 list的模拟实现 list的节点 list的迭代器实现 list的接口实现 vector和list的优缺点 vector优点: vector缺点: list优点: list缺点: 总结: …...

[图论]Prim
Prim 本质:BFS贪心,对点进行操作。与最短路Dijkstra算法是“孪生兄弟”。存储结构:链式前向星适用对象:可为负权图,可求最大生成树核心思想:最近的邻接点一定在最小生成树(MST)上,对点的最近邻…...
)
【python】pysharm常用快捷键使用-(1)
*1.格式化代码【Ctrl Alt L】 写代码的时候会有很多黄色的波浪号(如图)又叫蚂蚁线,可以点击任意黄色波浪号的代码,然后按下【Ctrl Alt L】进行代码格式化。 2.添加函数功能和参数注释 添加函数文档字符串 docstring 在函数…...

06-DevOps-自动构建Docker镜像
前面已经完成了jar文件的打包和发布,但在实际使用时,可能会遇到外部依赖环境发生改变,为了解决这些问题,更多的做法是把应用程序以docker镜像,生成容器的方式运行,这是一种标准化的方式。 创建Dockerfile文…...

案例驱动的 IT 团队管理:创新与突破之路:第五章 创新管理:从机制设计到文化养成-5.2 技术决策民主化-5.2.2技术选型的量化评估矩阵
👉 点击关注不迷路 👉 点击关注不迷路 👉 点击关注不迷路 文章大纲 案例驱动的 IT 团队管理:创新与突破之路 - 第五章 创新管理:从机制设计到文化养成 - 5.2 技术决策民主化5.2.2 技术选型的量化评估矩阵一、技术选型的…...

力扣面试150题--有效的字母异位词和字母异位词分组
Day 24 题目描述 思路 初次思路:如果两个字符串为异位词,说明它们长度相同并且字母出现的次数相同,于是有以下做法: 定义一个map,来保存s中每个字符的出现次数处理特殊情况,如果长度不同,直接…...

WSL2-Ubuntu22.04安装URSim5.21.3
WSL2-Ubuntu22.04安装URSim5.21.3 准备安装启动 准备 名称版本WSL2Ubuntu22.04URSim5.21.3VcXsrvNaN WSL2安装与可视化请见这篇:WSL2-Ubuntu22.04-配置。 安装 我们是wsl2-ubuntu22.04,所以安装Linux版本的URSim,下载之前需要注册一下,即…...

配合 Spring Bean 注入,把 Function 管理起来?
大家好呀!今天我们来聊聊一个特别有意思的话题 - 如何在Spring中优雅地管理和注入Function对象。就像把各种调料整齐地摆在厨房里一样,我们要把各种函数方法也管理得井井有条!🍳 一、为什么要把Function管起来?&#…...

Wireshark TS | 异常 ACK 数据包处理
问题背景 来自于学习群里群友讨论的一个数据包跟踪文件,在其中涉及到两处数据包异常现象,而产生这些现象的实际原因是数据包乱序。由于这两处数据包异常,都有点特别,本篇也就其中一个异常现象单独展开说明。 问题信息 数据包跟…...

vue3 el-dialog新增弹窗,不希望一进去就校验名称没有填写
就是在进入弹窗时、点击关闭/取消按钮时等情况清空该表单校验,在失去焦点或者点击确定/提交按钮的时候再去校验。这里默认已经写好了在失去焦点或者点击确定/提交按钮的时候的校验逻辑。 解决步骤: 一、定义清空表单校验方法 // 清空表单校验const cle…...

【2-12】CRC循环冗余校验码
前言 前面我们介绍了纠错码——海明码,同时还说明了为什么现代网络常用检错重传而不是纠错,本文介绍CRC循环冗余校验码。 文章目录 前言1. 简单定义2. 生成规则3. 例题3.1 例13.2 例2 后记修改记录 1. 简单定义 CRC(Cyclic Redundancy Chec…...

多 Agent 协作怎么整:从谷歌A2A到多Agent交互方案实现
写在前面:多 Agent 协作模式 大型语言模型(LLM)的浪潮之下,能够自主理解、规划并执行任务的 AI Agent(智能体)正成为人工智能领域最炙手可热的焦点。我们惊叹于单个 Agent 展现出的强大能力,但当面对日益复杂的现实世界任务时,单个 Agent 的局限性也逐渐显现。 正如人…...

内部聊天软件,BeeWorks-安全的企业内部通讯软件
企业在享受数据便利的同时,如何保障企业数据安全已经成为无法回避的重要课题。BeeWorks作为一款专为企业设计的内部通讯软件,通过全链路的安全能力升维,为企业提供了一个安全、高效、便捷的沟通协作平台,全面保障企业数据安全。 …...

健康养生:开启活力生活的密钥
当我们在健身房看到年逾六旬却身形矫健的老人,在公园偶遇精神矍铄、步伐轻快的长者,总会惊叹于他们的健康状态。其实,这些都得益于长期坚持科学的养生之道。健康养生并非遥不可及的玄学,而是融入生活细节的智慧。 在饮食的世界…...