基于深度学习并利用时间信息在X射线血管造影中进行冠状动脉血管分割|文献速递-深度学习医疗AI最新文献
Title
题目
Deep learning based coronary vessels segmentation in X-ray angiographyusing temporal information
基于深度学习并利用时间信息在X射线血管造影中进行冠状动脉血管分割
01
文献速递介绍
有创冠状动脉造影(ICA)在冠状动脉疾病(CAD)的诊断和介入治疗的临床实践中被广泛应用(拉什加里等人,2024年)。它是诊断冠状动脉狭窄的金标准,同时为治疗提供定性和定量的指导(科奇卡,2015年)。冠状动脉血管的分割能够实现清晰的可视化,并可计算诸如血流储备分数等定量临床指标(屠等人,2014年)。在有创冠状动脉造影中,获取的血管结构总是与背景结构重叠。图像还会受到身体运动和造影剂分布不均的影响,从而导致分割伪影,如边界错位和血管不连续(布隆代尔等人,2006年)。 在这项工作中,我们应对了这些挑战,并开发出一种完全自动化的方法,以准确有效地从连续的有创冠状动脉造影图像序列中勾勒出冠状动脉血管。 血管分割在文献中受到了大量关注。传统方法包括血管增强和血管跟踪技术(弗兰吉等人,1998年;法兹拉利等人,2015年;耶尔曼等人,2016年),这些方法在存在大规模和对比度变化的情况下常常失效,并且会将有创冠状动脉造影中的其他结构(如导管或肋骨)错误标记。跟踪算法更常用于利用拓扑信息和先验信息对血管中心线进行处理,并且对有创冠状动脉造影的伪影很敏感(邹等人,2009年;安布罗西尼等人,2015年)。 申等人(2016年)和夏等人(2020年)提出了涉及优化和矩阵分解的复杂非机器学习方法。尽管他们的结果可与当前最先进水平(SOTA)相媲美,但诸如测试期间标准差较大以及由于血管不连续导致拓扑结构不完整等问题仍未得到解决。 机器学习方法,尤其是神经网络,已成为包括分割在内的大多数医学图像分析应用中的最先进技术。它们通常涉及U-Net(龙内贝格尔等人,2015年)或全卷积网络(FCN)(朗等人,2015年)的变体。血管分割受到最多关注的领域是视网膜成像(卡姆兰等人,2021年;谭等人,2022年)。马尼尼斯等人(2016年)表明,自动化方法可以实现与人类专家标注相当的视网膜血管勾勒。然而,由于有创冠状动脉造影存在独特的挑战,如灰度成像、不规则的血管结构、血管直径的显著变化以及运动伪影,视网膜血管分割算法不能直接应用于有创冠状动脉造影。此外,对整个血管树,尤其是细小血管进行手动标注既耗时又困难,这是由于人为错误、时间限制以及准确勾勒细小且低对比度血管的固有难度所致。这些因素常常导致标注较为粗略,并使数据集的规模和质量成为提高有创冠状动脉造影分割性能的关键挑战。第二个主要挑战是有创冠状动脉造影图像的质量问题,不一致的对比度常常使血管难以与背景区分开来。诸如造影剂注射时间、血流速度、患者运动以及冠状动脉内造影剂弥散的变化等因素导致了这种不一致性,使准确分割变得更加复杂。最后一个挑战与维持生成的血管树的结构完整性有关,其中尽量减少不连续的血管并避免血管边界的过度或欠分割对于降低狭窄误判的风险至关重要。因此,需要设计特定的解决方案。 1.1 相关工作 纳斯尔 - 伊斯法哈尼等人(2018年)提出了一种冠状动脉血管分割流程,其中包括一个图像增强模块、一个用于上下文特征提取的网络以及一个用于概率特征提取的网络。蒋等人(2021年)开发了一种多尺度、多分辨率的方法,以处理有创冠状动脉造影中冠状动脉血管的对比度分布和尺寸的较大变化。这些带有专门组件以提升性能的方法在主要血管上效果显著,但常常无法区分细小血管,并且无法获得准确的血管边界,这严重影响了狭窄的识别。因此,奥等人(2018年)和杨等人(2019年)开发了仅专注于准确分割单个主要血管(右冠状动脉(RCA)或左前降支(LAD)动脉)或进行狭窄分类的方法。这些方法的一个优点是每张图像仅需要对一个分支进行手动标注,这在相对较大的数据集里是可行的,因为可用的标注有创冠状动脉造影数据集的规模常常限制了冠状动脉血管分割的性能。例如,在纳斯尔 - 伊斯法哈尼等人(2018年)的方法中,金标准仅包含44个有创冠状动脉造影图像。在最近的一项研究中,郝等人(2020年)提出了一种用于冠状动脉血管分割的深度通道注意力网络,使用了一个包含300多个有创冠状动脉造影图像的数据集。一种潜在的策略是使用诸如均值教师模型等方法进行半监督学习,该方法可以从未标注的图像中提取有意义的信息(何等人,2022年)。 运动伪影,尤其是来自心脏和呼吸运动的伪影,会对有创冠状动脉造影的质量产生不利影响。伴随着造影剂的冲洗效应,即使是人类专家也难以识别血管。对运动物体分割的早期尝试可以追溯到计算机视觉领域。弗拉基阿达基等人(2015年)提出了一种双通路神经网络,该网络采用RGB视频及其光流来检测视频序列中的物体。弗隆佐斯和米科拉伊奇克(2018年)采用了类似的方法,在低级二进制分割和光流上使用了一个多阶段U-Net架构。郝等人(2020年)采用了带有时间融合卷积和通道注意力的传统U-Net,但并未旨在维持血管树的结构完整性。梁等人(2021年)设计了半三维U-Net,该网络结合了时间特征提取,用于从血管造影视频中分割冠状动脉血管,重点是通过利用空间和时间特征来提高分割质量。他们的方法只能考虑以目标帧为中心的奇数个时间帧。万等人(2021年)将全卷积网络应用于三帧有创冠状动脉造影分割,使用三通路全卷积网络和影响矩阵来解码时间信息。这些方法常常面临局限性,例如在更密集的网络中缺乏对有效推断局部和全局信息的分析。 类似的方法已被用于数字减影血管造影(DSA)中的脑血管分割。苏等人(2024年)采用了一种时空U-Net,通过时间学习模块同时集成空间和时间特征,从而能够对时空动态进行连贯的解码和学习。相比之下,谢等人(2024年)提出了DSANet,该网络将空间和时间特征提取过程解耦。该模型利用时间变换器模块来捕获时间关系,并使用时空融合模块来合并空间和时间信息,从而产生了一种级联解码方法。然而,与有创冠状动脉造影图像相比,脑血管的数字减影血管造影在背景结构的复杂性和运动伪影方面都有所降低。 解决血管不连续的挑战有助于直接应对有创冠状动脉造影图像质量的挑战,从而提高分割效果。已经有一些针对视网膜图像分割提出的尝试解决血管不连续问题的方法。林等人(2022年)创建了一个类似于生成对抗网络(GAN)的模型,带有一个判别网络来指导分割网络。李等人(2020年)提出了IterNet,该网络通过权重共享和模型内跳跃连接多次迭代一个小型U-Net。这些都是隐式方法,对于改善血管连通性的机制没有明确的解释。兰等人(2020年)设计了一个损失函数,通过将不连续的部分融合在一起来缩小预测的血管边界与金标准边界之间的差距。希特等人(2021年)提出将ClDice损失与Dice损失一起使用,重点是保留分割的管状结构的骨架并确保拓扑准确性,特别是保持连接组件和分支的连续性。然而,它对精确的边界勾勒不太敏感,这可能会影响在诸如狭窄区域等具有临床意义区域的性能。奥纳等人(2022年)和克拉夫等人(2022年)引入了连接优化损失函数,旨在保留特定的结构特征,包括线性连续性、背景区域的分离和全局连接性。虽然这些方法在保持类似网络结构的这些方面有效,但它们优先考虑连接性而非边界精度,这可能限制了它们在具有精细细节和复杂分支模式的冠状动脉血管中的适用性。 最近的研究工作主要集中在自适应或先进的架构上。伊森塞等人(2020年)提出的nnUNet框架已成为医学图像分割任务中广泛采用的基线,这是因为它具有在不同数据集上进行泛化的自适应功能。赵等人(2023年)使用图注意力网络进行基于图的节点相似性比较,用于骨架分割。这种方法侧重于利用节点关系来提高分割准确性。何等人(2024年)融合了图注意力网络和卷积神经网络,以在冠状动脉血管分割过程中学习全局几何信息。此外,阮和向(2024年)引入了视觉曼巴U-Net(VM-UNet),该网络利用状态空间模型(SSMs)以线性计算复杂度捕获广泛的上下文信息和长距离交互。这些方法在各种情况下都非常有效,尽管并非专门为应对有创冠状动脉造影序列的独特挑战而设计。 1.2 贡献 对文献的分析以及我们对郝等人(2020年)中使用的公开的323个有创冠状动脉造影短序列样本的研究结果表明,第二个挑战中的运动伪影是有创冠状动脉造影中冠状动脉血管分割准确性有限的主要原因。身体运动可能会将早期帧中清晰勾勒的血管或部分血管移动到目标帧中的低对比度区域,从而导致血管边界不准确和潜在的不连续性。这种结构完整性的破坏最终加剧了与血管不连续相关的问题。人类标注员通常通过可视化有创冠状动脉造影序列,利用连续帧之间的关系来解决重叠血管的问题,从而减轻这一问题。这表明机器学习方法也可以从观察多个有创冠状动脉造影帧中受益,模仿人类标注员的行为。因此,我们假设引入时间信息是在无需复杂运动建模的情况下解决与运动相关挑战的基础。 我们引入了一种新颖的架构,即时间血管分割网络(TVS-Net),在该模型中,时间被视为第三维,能够有效地提取时空特征以应对运动伪影。我们的主要贡献可以总结为四个方面: - 我们开发了一个新的三维(二维+时间)框架,该框架可以同时从多个连续的有创冠状动脉造影帧中提取特征,以分割目标帧。我们的框架结合了一种新颖的密集嵌套三维编码器,该编码器通过其中间层中的额外卷积节点进行扩展,以及一个高度连接的二维解码器。这种双通路设计以UNet++为骨干,确保了强大的时空特征提取和精确的空间识别,从而实现了高保真的分割。 - 我们纳入了一个保持连接性的损失函数(兰等人,2020年),以维持血管结构的完整性,并采用特定的骨架化指标来评估结构准确性。这种方法对于生成用于三维重建的精确血管骨架至关重要。 - 我们的TVS-Net在各种不同的数据源和标注协议下均优于可比方法,在一个公开数据集上实现了83.4%的Dice系数和84.3%的召回率。在一个经过精细标注的精炼子集上,它实现了更高的86.3%的召回率,显著超过了原始数据集的手动标注结果。 - TVS-Net在一个由60个有创冠状动脉造影图像组成的外部数据集上达到了78.5%的Dice系数和82.4%的召回率,超过了所有当前最先进的方法。这些结果突出了我们方法的鲁棒性和泛化性。
Aastract
摘要
Invasive coronary angiography (ICA) is the gold standard imaging modality during cardiac interventions.Accurate segmentation of coronary vessels in ICA is required for aiding diagnosis and creating treatment plans.Current automated algorithms for vessel segmentation face task-specific challenges, including motion artifactsand unevenly distributed contrast, as well as the general challenge inherent to X-ray imaging, which is thepresence of shadows from overlapping organs in the background. To address these issues, we present TemporalVessel Segmentation Network (TVS-Net) model that fuses sequential ICA information into a novel denselyconnected 3D encoder-2D decoder structure with a loss function based on elastic interaction. We develop ourmodel using an ICA dataset comprising 323 samples, split into 173 for training, 82 for validation, and 68for testing, with a relatively relaxed annotation protocol that produced coarse-grained samples, and achieve83.4% Dice and 84.3% recall on the test dataset. We additionally perform an external evaluation over 60images from a local hospital, achieving 78.5% Dice and 82.4% recall and outperforming the state-of-the-artapproaches. We also conduct a detailed manual re-segmentation for evaluation only on a subset of the firstdataset under strict annotation protocol, achieving a Dice score of 86.2% and recall of 86.3% and surpassingeven the coarse-grained gold standard used in training. The results indicate our TVS-Net is effective for multiframe ICA segmentation, highlights the network’s generalizability and robustness across diverse settings, andshowcases the feasibility of weak supervision in ICA segmentation
有创冠状动脉造影(ICA)是心脏介入治疗过程中的金标准成像方式。在有创冠状动脉造影中,准确分割冠状动脉血管对于辅助诊断和制定治疗方案是必要的。目前,用于血管分割的自动算法面临着特定任务的挑战,包括运动伪影和造影剂分布不均匀,以及X射线成像所固有的一般性挑战,即背景中存在来自重叠器官的阴影。 为了解决这些问题,我们提出了时间血管分割网络(TVS-Net)模型,该模型将连续的有创冠状动脉造影信息融合到一种新颖的密集连接的三维编码器-二维解码器结构中,并采用基于弹性相互作用的损失函数。我们使用一个包含323个样本的有创冠状动脉造影数据集来开发我们的模型,将其分为173个用于训练、82个用于验证和68个用于测试,采用了相对宽松的注释协议,生成了粗粒度的样本,并在测试数据集上达到了83.4%的Dice系数和84.3%的召回率。 此外,我们对来自当地一家医院的60张图像进行了外部评估,实现了78.5%的Dice系数和82.4%的召回率,优于当前最先进的方法。我们还在严格的注释协议下仅对第一个数据集中的一个子集进行了详细的手动重新分割以用于评估,获得了86.2%的Dice系数和86.3%的召回率,甚至超过了训练中使用的粗粒度金标准。 结果表明,我们的TVS-Net对于多帧有创冠状动脉造影分割是有效的,突出了该网络在不同场景下的泛化性和鲁棒性,并展示了在有创冠状动脉造影分割中弱监督的可行性。
Method
方法
This section introduces the input data, describes in detail the neuralnetwork architecture and loss function, and explains post-processing,evaluation methods, evaluation metrics, as well as the experimentalsettings and comparison methods. We denote 𝑋 as the ICA sequence,with 𝑇 being the total number of frames. 𝑥𝑡 is frame number 𝑡, 𝑥𝑡=0is the selected ICA frame for manual labeling, and 𝑦 is gold standardsegmentation, where 𝑋 ∈ [0, 255]𝑇×𝐻×𝑊 and 𝑦 ∈ {0, 1}𝐻×𝑊 with 𝐶, 𝑇 ,𝐻, and 𝑊 representing the number of channels, number of temporalframes, and height and width of the frame, respectively. A full datasetis 𝐷 = {(𝑋𝑛 , 𝑦𝑛 )}𝑁 𝑛=1 with 𝑁 being the total number of cases. Thesegmentation output of the network is 𝑓𝑠 (⋅).
本节介绍了输入数据,详细描述了神经网络架构和损失函数,并解释了后处理、评估方法、评估指标,以及实验设置和对比方法。我们将(X)表示为有创冠状动脉造影(ICA)序列,其中(T)为总帧数。(x_t)是第(t)帧,(x{t = 0})是选定用于手动标注的ICA帧,(y)是金标准分割结果,其中(X\in[0,255]^{T\times H\times W}),(y\in{0,1}^{H\times W}),(C)、(T)、(H)和(W)分别表示通道数、时间帧数以及帧的高度和宽度。完整的数据集为(D = {(X_n, y_n)}{n = 1}^{N}),其中(N)是病例总数。网络的分割输出为(f_s(\cdot))。
Conclusion
结论
In this paper, we develop a novel deep learning framework witha densely connected 3D encoder-2D decoder, named TVS-Net, that utilizes multiple frames of ICA sequences for generating accurate coronaryvessels segmentation. The architecture integrates temporal convolution blocks for fusing the image sequence information and a uniqueenergy loss for enhancing topology preservation onto a dense framework featuring deep supervision. This framework can be combinedwith vascular post-processing techniques, such as the method proposedby Qiu et al. (2023), to further enhance segmentation quality. To enabledirect comparison between our method and the closest SOTA temporalsegmentation (Hao et al., 2020) and other SOTA methods, we trainour framework on the same public dataset using the same data split.The experimental analysis not only demonstrates the advantages of amulti-frame approach but also illustrates the problem of incomplete annotations of vascular trees. The significant performance improvementsobserved by the TVS-Net over UNet++ underscore the effectivenessof integrating densely connected 3D–2D temporal blocks. We proposethe use of skeletonization metrics and demonstrate the ability of ourmethod to preserve thin vascular structures accurately. The combineduse of spatio-temporal encoding, connectivity-preserving loss function,and deep supervision enables our proposed TVS-Net to capture a widerange of vessel appearances and motion patterns. This generalizabilityis further highlighted in our evaluation using data collected from a localhospital, where our method achieves the highest Dice, recall, precision,and AUPRC of 78.49%, 82.41%, 75.79% and 0.8437, respectively,despite the fact that our hyperparameters were optimized for the publicdataset alone and no retraining was performed. The smaller size of theprivate dataset and the random selection of cases may contribute togreater variance and performance variability. Due to the OOD nature ofthe private data, all models show less confident predictions. However,the fact that our method excels in this context demonstrates its abilityto adapt to different annotation protocols and data characteristics andhighlights its strong potential for real-world deployment. Additionally,we proposed a variant of TVS-Net, named TVS-Net+, with the sameideology after expanding the 3D encoder. However, due to the largersize of TVS-Net and available GPU resources, its batch size is limited to4, which impacts the network’s ability to generalize effectively, therebylimiting the observed performance gains of TVS-Net+.We re-segment 10 cases with a strict annotation protocol, includingall visible vessels, and use it as the new (fine-grained) gold standardfor the same evaluation pipeline. Trained by the original (coarsegrained) gold standard, our proposed TVS-Net achieves a recall of86.26%, which is 0.96% higher than the original gold standard and16% higher than the current SOTA method SVS-Net (Hao et al., 2020).The performance in accurately preserving vascular skeletons achieves84.00% in 𝐶**𝑟 , improving on the original gold standard by 9.36% andSVS-Net by 26.54%. The qualitative evaluation illustrates the improvements, including the reduction in over-segmented vascular boundaries.Most interestingly, our extensive analyses demonstrate the feasibility ofweak supervision with coarse-grained annotations for coronary vesselssegmentation. This is evidenced by the superior delineation achievedby the TVS-Net model compared to its training gold standard — thecoarse-grained annotations when evaluated against fine-grained annotations. It is important to note that the ICA datasets were created byselecting high-quality frames, limiting our ability to fully demonstratethe network’s performance across low-quality frames, where manualsegmentation is more challenging and often results in coarser gold standards. Consequently, by modulating the completeness level of manualannotations in the dataset, this framework can also facilitate the exploration of a time-performance trade-off between manual and automaticsegmentations in annotation protocols, as well as elucidate the impactof partially segmented ground truth on final trained segmentationquality
在本文中,我们开发了一种新颖的深度学习框架,即具有密集连接的三维编码器-二维解码器的时间血管分割网络(TVS-Net),它利用有创冠状动脉造影(ICA)序列的多个帧来实现准确的冠状动脉血管分割。该架构集成了时间卷积模块以融合图像序列信息,以及一种独特的能量损失函数,用于在具有深度监督的密集框架上增强拓扑结构的保留。这个框架可以与血管后处理技术相结合,比如邱等人(2023年)提出的方法,以进一步提高分割质量。 为了使我们的方法能够与最相近的当前最先进的时间分割方法(郝等人,2020年)以及其他当前最先进的方法进行直接比较,我们在相同的公开数据集上使用相同的数据划分来训练我们的框架。实验分析不仅展示了多帧方法的优势,还说明了血管树标注不完整的问题。TVS-Net相对于UNet++在性能上的显著提升强调了集成密集连接的三维-二维时间模块的有效性。我们提出使用骨架化指标,并证明了我们的方法能够准确保留细小血管结构的能力。时空编码、保持连接性的损失函数以及深度监督的综合运用,使我们提出的TVS-Net能够捕捉到广泛的血管外观和运动模式。 在我们使用从当地一家医院收集的数据进行的评估中,这种泛化能力得到了进一步凸显。尽管我们的超参数仅针对公开数据集进行了优化且未进行重新训练,但我们的方法在该评估中分别实现了最高的Dice系数(78.49%)、召回率(82.41%)、精确率(75.79%)和曲线下面积(AUPRC,0.8437)。私有数据集规模较小以及病例的随机选择可能导致更大的方差和性能差异。由于私有数据具有分布外(OOD)的性质,所有模型的预测结果都显得信心不足。然而,我们的方法在这种情况下表现出色,这证明了它适应不同标注协议和数据特征的能力,并凸显了其在实际应用中强大的潜力。 此外,我们提出了TVS-Net的一个变体,称为TVS-Net+,它在扩展了三维编码器后采用了相同的理念。然而,由于TVS-Net+的规模较大以及可用的GPU资源限制,其批量大小被限制为4,这影响了网络的有效泛化能力,从而限制了TVS-Net+所观察到的性能提升。 我们按照严格的标注协议对10个病例进行了重新分割,包括所有可见的血管,并将其作为新的(细粒度的)金标准用于相同的评估流程。在原始(粗粒度的)金标准的训练下,我们提出的TVS-Net实现了86.26%的召回率,比原始金标准高0.96%,比当前最先进的方法SVS-Net(郝等人,2020年)高16%。在准确保留血管骨架方面的性能在(C_r)指标上达到了84.00%,比原始金标准提高了9.36%,比SVS-Net提高了26.54%。定性评估展示了这些改进,包括过度分割的血管边界的减少。 最有趣的是,我们广泛的分析证明了对于冠状动脉血管分割而言,使用粗粒度标注进行弱监督的可行性。TVS-Net模型与训练时的金标准(粗粒度标注)相比,在与细粒度标注进行评估时实现了更优的勾勒效果,这就证明了这一点。需要注意的是,有创冠状动脉造影数据集是通过选择高质量的帧创建的,这限制了我们全面展示网络在低质量帧上性能的能力,在低质量帧上手动分割更具挑战性,并且常常会产生更粗糙的金标准。因此,通过调节数据集中手动标注的完整程度,这个框架还可以促进在标注协议中探索手动分割和自动分割之间的时间-性能权衡,以及阐明部分分割的真实标注对最终训练的分割质量的影响。
Results
结果
In this section, we present extensive quantitative and qualitativecomparisons. First, we compare the performance of TVS-Net againstits variant, TVS-Net+, to evaluate architectural effectiveness. Next, webenchmark TVS-Net against SOTA methods, highlighting its superiorperformance. Following this, we assess its generalizability on an outof-distribution (OOD) dataset. Additionally, we evaluate the impact ofour loss function and deep supervision setting on segmentation performance. Finally, we conduct a comprehensive study on the re-segmentedgold standard.
在本节中,我们进行了大量的定量和定性比较。首先,我们将TVS-Net与其变体TVS-Net+的性能进行比较,以评估架构的有效性。接下来,我们将TVS-Net与最先进的(SOTA)方法进行基准测试,突出其优越的性能。在此之后,我们在一个分布外(OOD)数据集上评估其泛化能力。此外,我们还评估了我们的损失函数和深度监督设置对分割性能的影响。最后,我们对重新分割的金标准进行了一项全面的研究。
Figure
图

Fig. 1. The proposed TVS-Net model (left) and TVS-Net+ (right) for vessels segmentation from ICA sequences using temporal information. 3D and 2D blocks are represented inpurple and orange, respectively, with all kernel sizes and strides shown in the boxes. The gray output paths at the top indicate deep supervision.
图1:所提出的用于利用时间信息从有创冠状动脉造影(ICA)序列中进行血管分割的时间血管分割网络(TVS-Net)模型(左)和增强版时间血管分割网络(TVS-Net+)(右)。三维(3D)模块和二维(2D)模块分别用紫色和橙色表示,所有的卷积核大小和步长都标注在方框内。顶部的灰色输出路径表示深度监督。
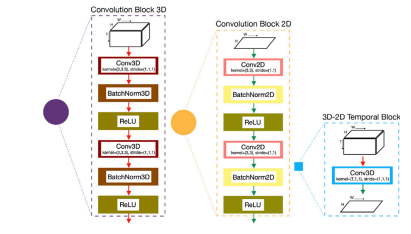
Fig. 2. Details of the convolution blocks and temporal block with the same legend forcolored path in Fig. 1
图2:卷积模块和时间模块的详细信息,其彩色路径的图例与图1中的一致。

Fig. 3. Skeletonization metrics for vessel centerline with 1-pixel width. True Positives(TP) are green, whereas False Positives (FP) and False Negatives (FN) are blue and red,respectively
图3:宽度为1像素的血管中心线的骨架化指标。真正例(TP)为绿色,而假正例(FP)和假负例(FN)分别为蓝色和红色。
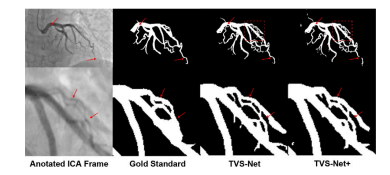
Fig. 4. Qualitative evaluation of segmentation performance using TVS-Net and TVSNet+. The bottom row is a zoomed-in version of the red square in the top row
图4:使用时间血管分割网络(TVS-Net)和增强版时间血管分割网络(TVS-Net+)对分割性能进行的定性评估。底行是顶行中红色方框区域的放大图。
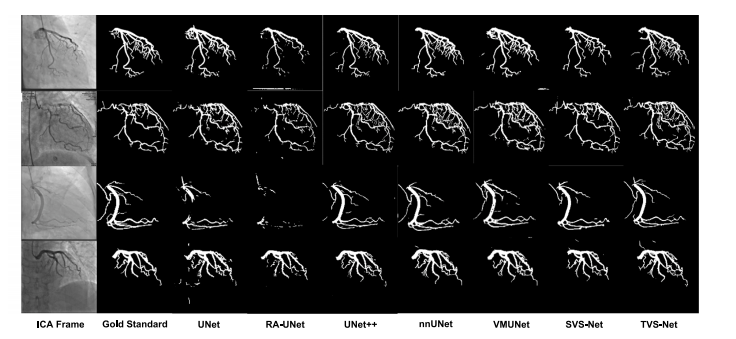
Fig. 5. Qualitative evaluation of segmentation performance of SOTA methods and TVS-Net on dataset 𝐷1 .
图5:在数据集(D_1)上,对当前最先进(SOTA)方法和时间血管分割网络(TVS-Net)的分割性能进行的定性评估。
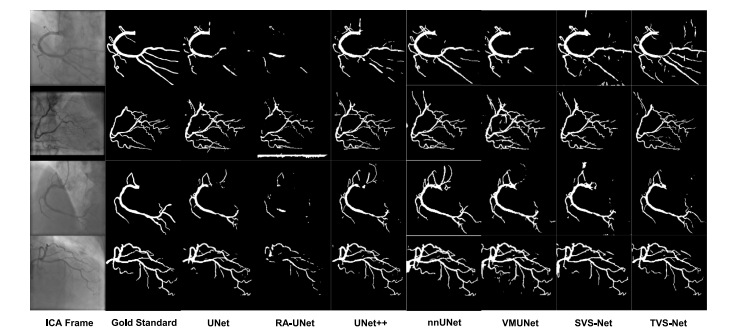
Fig. 6. Qualitative evaluation of segmentation performance of SOTA methods and TVS-Net on OOD dataset 𝐷2
图6:在分布外(OOD)数据集(D_2)上,对当前最先进(SOTA)方法和时间血管分割网络(TVS-Net)的分割性能进行的定性评估。
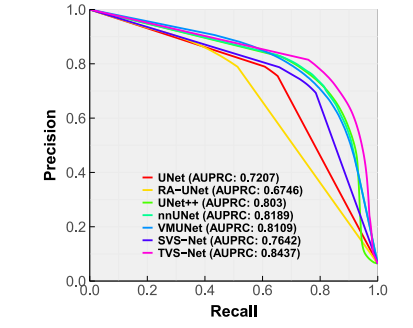
Fig. 7. Precision–Recall curve for evaluation on OOD dataset 𝐷2 .
图7:在分布外(OOD)数据集(D_2)上进行评估的精确率-召回率曲线。

Fig. 8. Qualitative evaluation of segmentation and skeletonization performance of TVS-Net with Dice loss and energy loss, without deep supervision. The color codes for TP, FP,and FN are the same as in Fig. 3.
图8:在无深度监督的情况下,对使用Dice损失函数和能量损失函数的时间血管分割网络(TVS-Net)的分割和骨架化性能进行的定性评估。真正例(TP)、假正例(FP)和假负例(FN)的颜色编码与图3中的相同。

Fig. 9. Vessel segmentation and skeletonization performance of TVS-Net without andwith deep supervision. Color codes are the same
图9:有无深度监督情况下,时间血管分割网络(TVS-Net)的血管分割和骨架化性能。颜色编码相同。
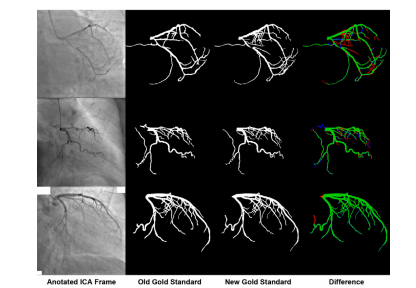
Fig. 10. Three re-segmented samples with minimum (81.61%), median (84.69%), andmaximum (94.76%) Dice scores (top to bottom). Color codes are the same.
图10:三个重新分割的样本,其Dice系数分别为最小值(81.61%)、中位数(84.69%)和最大值(94.76%)(从上至下排列)。颜色编码保持一致。

Fig. 11. Qualitative evaluation of segmentation and skeletonization on the new gold standard. The same color code is used here
图11:基于新金标准对分割和骨架化处理的定性评估。此处使用了相同的颜色编码。
Table
表
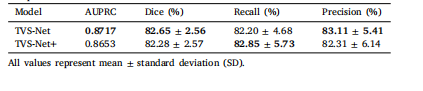
Table 1Comparison of different architecture variants.
表1:不同架构变体的比较。
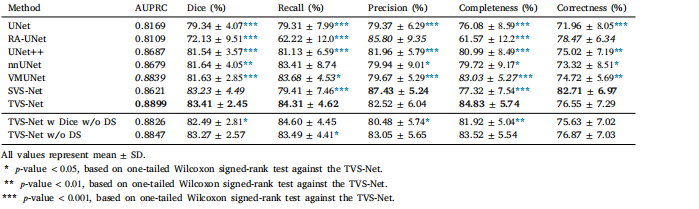
Table 2Comparison of TVS-Net with SOTA methods on test dataset of 𝐷1 .
表2:在数据集(D_1)的测试集上,时间血管分割网络(TVS-Net)与当前最先进(SOTA)方法的比较。
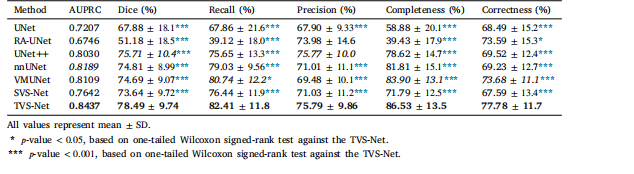
Table 3Comparison of TVS-Net with SOTA methods on OOD dataset 𝐷2 .
表3:在分布外(OOD)数据集(D_2)上,时间血管分割网络(TVS-Net)与当前最先进(SOTA)方法的比较。
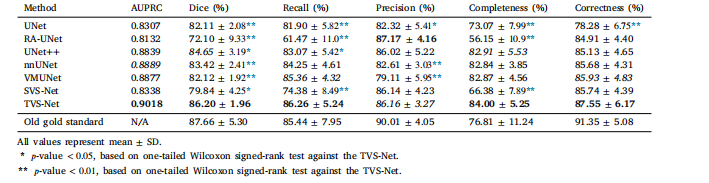
Table 4Performance evaluation on the new gold standard with 10 re-segmented samples.
表4:基于重新分割的10个样本所构成的新金标准进行的性能评估。
相关文章:

基于深度学习并利用时间信息在X射线血管造影中进行冠状动脉血管分割|文献速递-深度学习医疗AI最新文献
Title 题目 Deep learning based coronary vessels segmentation in X-ray angiographyusing temporal information 基于深度学习并利用时间信息在X射线血管造影中进行冠状动脉血管分割 01 文献速递介绍 有创冠状动脉造影(ICA)在冠状动脉疾病&#…...
)
JVM详解(曼波脑图版)
(✪ω✪)ノ 好哒!曼波会用最可爱的比喻给小白同学讲解JVM,准备好开启奇妙旅程了吗?(๑˃̵ᴗ˂̵)و 📌 思维导图 ━━━━━━━━━━━━━━━━━━━ 🍎 JVM是什么?(苹果式比…...

深度理解指针之例题
文章目录 前言题目分析与讲解涉及知识点 前言 对指针有一定了解后,讲一下一道初学者的易错题 题目分析与讲解 先定义一个数组跟一个指针变量 然后把数组名赋值给指针变量————也就是把首地址传到pulPtr中 重点是分析这一句: *(pulPtr…...
 - 机组组合问题的 GAMS 求解)
Electricity Market Optimization(VI) - 机组组合问题的 GAMS 求解
根据之前的博客,我们考虑机组的启动成本只讨论考虑以下几种约束的机组组合问题: 功率平衡约束火电机组启停约束和爬坡约束备用容量约束 min ∑ t 1 T ( C t g e n C t u c C t curt ) s.t. C t g e n ∑ i ∈ [ G ] c i ( p i , t c ) C t u c …...

【Leetcode 每日一题】2176. 统计数组中相等且可以被整除的数对
问题背景 给你一个下标从 0 0 0 开始长度为 n n n 的整数数组 n u m s nums nums 和一个整数 k k k,请你返回满足 0 ≤ i < j < n 0 \le i < j < n 0≤i<j<n, n u m s [ i ] n u m s [ j ] nums[i] nums[j] nums[i]nums[j] 且…...

赛灵思 XCVU3P‑2FFVC1517I XilinxFPGA Virtex UltraScale+
XCVU3P‑2FFVC1517I AMD Xilinx Virtex UltraScale 系列中的高端 FPGA,基于 TSMC 16 nm FinFET 工艺及第三代 3D IC 堆栈互连技术(SSI),旨在为数据中心互连、高性能计算、网络加速和信号处理等苛刻应用提供领先的性能‑功耗比。…...

Rust 与 JavaScript 的 WebAssembly 互操作指南
1. Rust 中导入和导出 JS 函数 导入 JS 函数 Rust 代码中可以通过 extern 块导入 JavaScript 函数: #[link(wasm_import_module "mod")] // 指定 JS 模块名 extern { fn foo(); // 声明导入的 JS 函数 }如果没有指定 wasm_import_module,默…...

2025年特种设备安全管理 A 证考试全解析
对于想要获取特种设备安全管理 A 证的人员来说,了解考试的具体内容与形式是备考的关键。下面将为大家全面解析特种设备安全管理 A 证考试,助力大家顺利备考,成功取证。 特种设备安全管理 A 证考试内容丰富,涵盖多个重要领域。特种…...

TOA与AOA联合定位的高精度算法,三维、4个基站的情况,MATLAB例程,附完整代码
本代码实现了三维空间内目标的高精度定位,结合到达角(AOA) 和到达时间(TOA) 两种测量方法,通过4个基站的协同观测,利用最小二乘法解算目标位置。代码支持噪声模拟、误差分析及三维可视化,适用于无人机导航、室内定位等场景。订阅专栏后可获得完整代码 文章目录 运行结果…...

java 设计模式之策略模式
简介 策略模式:策略模式可以定制目标对象的行为,它尅通过传入不同的策略实现,来配置目标对象的行为。使用策略模式,就是为了定制目标对象在某个关键点的行为。 策略模式中的角色: 上下文类:持有一个策略…...

BH1750光照传感器---附代码
目录 BH1750简介BH1750指令集BH1750工作流程 BH1750简介 VCC-->电源正; ADDR-->地址端口; GND-->电源负; PA5-->SDA-->I2C数据线; PA3-->SCL-->I2C时钟线; DVI-->I2C端口参考电压;…...

docker harbor私有仓库登录报错
docker harbor私有仓库登录报错如下: [rootsrv-1 ~]# docker login -u user1 -p pwd1 harbor.chinacloudapi.cn WARNING! Using --password via the CLI is insecure. Use --password-stdin. Error response from daemon: Get "https://harbor.chinacloudapi.…...

浔川AI翻译v7.0更新预告
亲爱的浔川AI翻译用户: 感谢您一直以来的支持!浔川AI翻译自推出以来,已迭代6个版本,其中**v2.0和v4.0因技术问题(翻译结果显示异常、注册失败、密码找回功能失效等)**被迫下架。我们深知这些问题影响了您…...

Linux网络编程实战:从字节序到UDP协议栈的深度解析与开发指南
网路通信的三大要素:协议,端口和IP 知识点1【字节序】 多字节在主机中的存放数据 把多字节看成一个整体存储的顺序。 为什么我们在文件中没有这个概念呢? 因为文件是字节流(流指针),流是以一个字节为操…...
)
Java基础知识面试题(已整理Java面试宝典pdf版)
什么是Java Java是一门面向对象编程语言,不仅吸收了C语言的各种优点,还摒弃了C里难以理解的多继承、指针等概念,因此Java语言具有功能强大和简单易用两个特征。Java语言作为静态面向对象编程语言的代表,极好地实现了面向对象理论…...

速盾:高防CDN访问多了会影响源站吗?
在当今数字化时代,内容分发网络(CDN)已经成为保障网站性能和用户体验的重要工具。特别是高防CDN,它不仅能够加速内容传输,还能有效抵御各种类型的网络攻击,确保业务的连续性和稳定性。然而,一些…...
Python并发编程:深入解析多线程与多进程的差异及锁机制实战)
Python(19)Python并发编程:深入解析多线程与多进程的差异及锁机制实战
目录 一、背景:Python并发编程的必要性二、核心概念对比2.1 技术特性对比表2.2 性能测试对比(4核CPU) 三、线程与进程的创建实战3.1 多线程基础模板3.2 多进程进阶模板 四、锁机制深度解析4.1 资源竞争问题重现4.2 线程锁解决方案4.3 进程锁的…...

赛灵思 XCVU440-2FLGA2892E XilinxFPGA Virtex UltraScale
XCVU440-2FLGA2892E 属于 Xilinx Virtex UltraScale 系列,是面向高端应用的旗舰 FPGA 器件。该系列产品以出色的高并行处理能力、丰富的逻辑资源和高速互联能力闻名,广泛用于 高性能计算、数字信号处理等对计算能力和带宽要求极高的场景。采用先进的 20n…...

UE5 相机裁剪面
UE5无法单独修改相机的裁剪面,不论是场景相机还是游戏相机都不可以 只能在配置里统一修改 项目设置里直接搜clip...

uniapp自定义底部导航栏,解决下拉时候顶部空白的问题
一、背景 最近使用uniapp开发微信小程序,因为使用了自定义的顶部导航栏,所以在ios平台上(Android未测试)测试的时候,下拉的时候会出现整个页面下拉并且顶部留下大片空白的问题 二、任务:解决这个问题 经…...

vue2 element-ui 中 el-radio 单选框点击事件失效问题
前情提要 点进这篇文章的小伙伴,应该和博主一样,都是遇到了这种单选框可点击取消的需求。也就只有这种不同寻常的需求,才能让我们发现element框架的缺陷点,话不多说,下面博主来提供一个解决思路。 click为什么无法触发…...

yolov8复现
Yolov8的复现流程主要包含环境配置、下载源码和验证环境三大步骤: 环境配置 查看电脑状况:通过任务管理器查看电脑是否有独立显卡(NVIDIA卡)。若有,后续可安装GPU版本的pytorch以加速训练;若没有࿰…...

提高Qt工作线程的运行速度
1. 使用线程池(QThreadPool)替代单一线程 做过,但是当时没想到。。。 目的:减少线程创建和销毁的开销,复用线程资源。 实现步骤: 创建自定义任务类:继承QRunnable,实现run()方法。…...

ZStack文档DevOps平台建设实践
(一)前言 对于软件产品而言,文档是不可或缺的一环。文档能帮助用户快速了解并使用软件,包括不限于特性概览、用户手册、API手册、安装部署以及场景实践教程等。由于软件与文档紧密耦合,面对业务的瞬息万变以及软件的飞…...

网络规划设计之广域网结构设计,6种架构模式对比
在数字化转型的浪潮中,网络基础设施的设计理念正在发生深刻变革。传统的基于点线拓扑的研究方法已无法满足现代复杂网络的需求,取而代之的是更具系统性的网络结构设计理念。本文将深入解析网络结构的定义特征,并重点剖析六种主流广域网架构的…...

FortiAI 重塑Fortinet Security Fabric全面智能化进阶
专注推动网络与安全融合的全球性综合网络安全解决方案供应商 Fortinet(NASDAQ:FTNT),近日宣布,旗下 Fortinet Security Fabric 安全平台成功嵌入了 FortiAI 关键创新功能。这一举措将有效增强用户对各类新兴威胁的防护…...

uniapp h5接入地图选点组件
uniapp h5接入地图选点组件 1、申请腾讯地图key2、代码接入2.1入口页面 (pages/map/map)templatescript 2.2选点页面(pages/map/mapselect/mapselect)templatescript 该内容只针对uniapp 打包h5接入地图选点组件做详细说明&#x…...
)
Openfein实现远程调用的方法(实操)
文章目录 环境准备一、URL中接收参数二、接收一个参数三、接收多个参数四、传递对象五、传递JSON格式数据 环境准备 下面的配置,服务调用方加入即可。 依赖导入: <!-- openfeign依赖--><dependency><groupId>org.springframe…...

Matter如何终结智能家居生态割据,重构你的居住体验?
现阶段,Zigbee、Z-Wave、Thread、Wi-Fi与蓝牙等多种通信协议在智能家居行业中已得到广泛应用,但协议间互不兼容的通信问题仍在凸显。由于各协议自成体系、彼此割据,智能家居市场被迫催生出大量桥接器、集线器及兼容性软件以在不同生态的设备间…...
概述)
Thin-Agent服务(TAS)概述
### **Thin-Agent服务(TAS)概述** **Thin-Agent服务(TAS)** 是一种轻量级监控服务,通过 **BMC/IPMI**(基板管理控制器/智能平台管理接口)收集**硬件和操作系统特定数据**,为系统管…...

2025.4.17学习日记 初识JavaScript 以及Java和JavaScript有什么区别
Java 和 JavaScript 虽然名字相似,但实际上是两种不同的编程语言。 1. 语言背景和设计目的 Java:由 Sun Microsystems(现被 Oracle 收购)在 1995 年推出。设计初衷是为了实现 “一次编写,到处运行(Write O…...

python学习—合并多个word文档
系列文章目录 python学习—合并TXT文本文件 python学习—统计嵌套文件夹内的文件数量并建立索引表格 python学习—查找指定目录下的指定类型文件 python学习—年会不能停,游戏抽签抽奖 python学习—循环语句-控制流 python学习—合并多个Excel工作簿表格文件 pytho…...

01、单片机简介
单片机简介 1、什么是单片机2、STM32F103ZET6介绍2.1、参数的含义2.2、存储器映射 3、外设寄存器介绍 1、什么是单片机 单片机(Single-Chip Microcomputer)是一种微型计算机,是一种集成电路芯片。把具有数据处理能力的中央处理器CPU、随机存储器RAM、闪存flash、多…...

常用UI设计工具及平台概览
在当今快速发展的数字世界中,UI设计平台成为设计师和开发者创建用户界面不可或缺的利器。这些平台不仅支持从简单原型到复杂交互设计的各种需求,而且许多还提供将设计直接转换为代码的功能,极大地提高了开发效率。下面将为您介绍几个主流的UI设计工具及其特点,帮助您根据项…...

考研单词笔记 2025.04.17
associate v联系,联想n同事,伙伴,朋友a副的,准的,非正式的 association n联系,联想,协会,社团,关系,交往 associative a联想的 bond n纽带,联系…...

MySQL常用SQL语句的示例
概述 MySQL 常用 SQL 语句的示例,涵盖数据定义、操作、查询等常见场景 一、数据库操作 创建数据库 CREATE DATABASE mydb;选择数据库 USE mydb;删除数据库 DROP DATABASE mydb;二、表操作 创建表 CREATE TABLE users (id INT PRIMARY KEY AUTO_INCREMENT,name VAR…...
)
java 多线程之Worker Thread模式(Thread Pool模式)
Worker Thread模式 Worker的意思是工作的人,在Worker Thread模式中,工人线程Worker thread会逐个取回工作并进行处理,当所有工作全部完成后,工人线程会等待新的工作到来。 Worker Thread模式也被成为Background Threadÿ…...

4月17日星期四今日早报简报微语报早读
4月17日星期四,农历三月二十,早报#微语早读。 1、国家统计局:一季度国内生产总值同比增长5.4%; 2、我国博士后已超40万人,2024年招收人数再创新高; 3、神舟二十号计划近日择机实施发射,船箭组…...

【最新版】芸众商城独立版源码 425+插件 全新后台框架
一.系统介绍 芸众商城系统最新版 已经更新425全插件版,一套系统支持各种新零售、商城、模式,天天美丽链动商城。不要相信那些外面的旧版本。旧版本等于是废品,无法小程序运营的,框架还是旧的! 芸众系统最新版 服务器可…...

android liveData observeForever 与 observe对比
LiveData 是一个非常有用的组件,用于在数据变化时通知观察者。LiveData 提供了两种主要的观察方法:observe 和 observeForever。这两种方法在使用场景、生命周期感知以及内存管理等方面有所不同。 一、observe 方法 1. 基本介绍 生命周期感知:observe…...

定制化 Docsify 文档框架实战分享
🌟 定制化 Docsify 文档框架实战分享 在构建前端文档平台时,我们希望拥有更友好的用户界面、便捷的搜索、清晰的目录导航以及实用的代码复制功能。借助 Docsify,我实现了以下几个方面的定制优化,分享给大家 🙌。 &…...

蓝桥杯题目:二维前缀和
首先分析一下二维数组的差分。s[x2][y2]-s[x1][y1]s[x2][y2]-s[x2][y1-1]-s[x1-1][y2]s[x1-1][y1-1] 因为对于二维数组x2y2-x1y1范围内的值需要通过x2y2减去从x1,y2-1的这段存储的前缀和以及减去x2-1,y1这两部分的前缀和,但是还有一个x1-1&a…...
(附下载))
数字孪生城市技术应用典型实践案例汇编(22个典型案例)(附下载)
近年来,数字孪生技术在我国从战略框架逐步向系统性落地推进,成为推动数字中国建设的重要技术引擎。随着《数字中国建设整体布局规划》《"十四五"数字经济发展规划》《深化智慧城市发展推进城市全域数字化转型的指导意见》等政策的实施…...
信号的产生)
Linux——信号(1)信号的产生
我们在讲进程的多种状态时提到过,一个进程的退出有三种情况:正常退出,结果出错退出(代码也执行完了),异常终止退出(代码未执行完),其中最后一种退出相当于进程在运行时&a…...
】)
【模型常见评价指标(分类)】
目录 常见指标 其他的评估指标 3.1 BLEU 3.2 ROUGE 3.3 困惑度PPL(perplexity) 常见指标 其他的评估指标 3.1 BLEU BLEU(Bilingual Evaluation Understudy,双语评估替补)分数是评估一种语言翻译成另一种语言的文本质量的指标。它将“质…...
)
个人博客系统后端 - 用户信息管理功能实现指南(上)
本文记录了如何实现用获取户信息,用户信息更新,用户头像上传三大基础功能 先上接口实现截图: 一、项目结构概览 先介绍一下 个人博客系统采用了标准的 Spring Boot 项目结构,用户功能相关的文件主要分布在以下几个目录:…...

CyberAgentAILab 开源数字人项目TANGO,heygen的开源版来了~
简介 TANGO 是 CyberAgentAILab 开源的一项前沿研究成果,其初衷在于探索高效生成模型在实际应用场景中的表现。项目诞生于 CyberAgent 在整合创意与人工智能的实践中,旨在为数字内容生成、交互和实时渲染等领域提供一个高性能、模块化、可扩展的解决方案…...

高等数学同步测试卷 同济7版 试卷部分 上 做题记录 上册期中同步测试卷 A 卷
上册期中同步测试卷A卷 一、单项选择题(本大题共5小题,每小题3分,总计15 分) 1. 2. 3. 4. 5. 二、填空题(本大题共5小题,每小题3分,总计15分) 6. 7. 8. 9. 10. 三、求解下列各题(本大题共5小题,每小题6分,总计30分) 11. …...

4.16 AT好题选做
文章目录 前言[ARC103D] Distance Sums(确定树的形态,trick)[AGC062B] Split and Insert(区间 d p dp dp)[AGC012E] Camel and Oases(状压,可行性dp转最优性dp)[ARC094D] Normalization(trick,转化)[ARC125F] Tree Degree Subset Sum(结论,a…...

数据库-day06
一、实验名称和性质 分类查询 验证 综合 设计 二、实验目的 1.掌握数据查询的Group by ; 2. 掌握聚集函数的使用方法。 三、实验的软硬件环境要求 硬件环境要求: PC机(单机) 使用的软件名称、版本号以及模块: …...