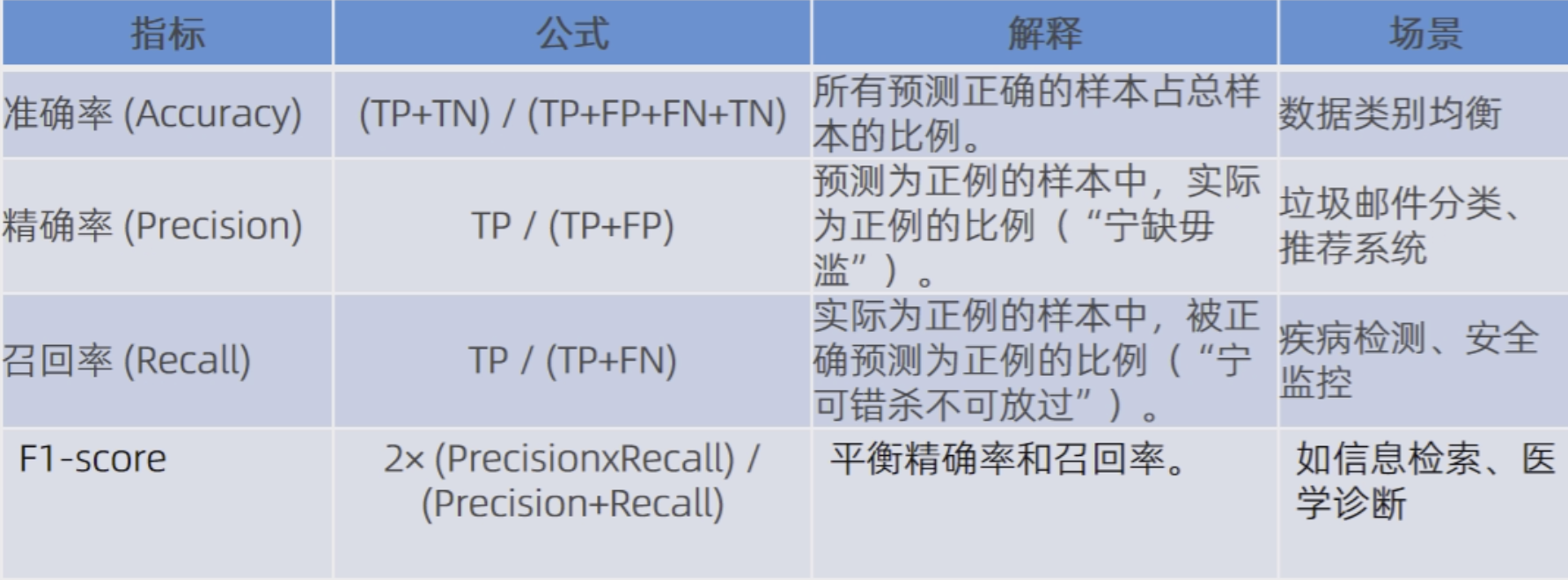
【模型常见评价指标(分类)】
目录
常见指标
其他的评估指标
3.1 BLEU
3.2 ROUGE
3.3 困惑度PPL(perplexity)
常见指标
其他的评估指标
3.1 BLEU
BLEU(Bilingual Evaluation Understudy,双语评估替补)分数是评估一种语言翻译成另一种语言的文本质量的指标。它将“质量”的好坏定义为与人类翻译结果的一致性程度。
BLEU是一种广泛用于评估机器翻译和文本生成任务的自动评价指标,它通过比较生成文本(Candidate)和参考文本(Reference)之间的n-gram重叠程度,量化生成质量。
BLEU算法实际上就是在判断两个句子的相似程度. BLEU 的分数取值范围是 0~1,分数越接近1,说明翻译的质量越高。
BLEU有许多变种,根据n-gram可以划分成多种评价指标,常见的评价指标有BLEU-1、BLEU-2、BLEU-3、BLEU-4四种,其中n-gram指的是连续的单词个数为n,BLEU-1衡量的是单词级别的准确性,更高阶的BLEU可以衡量句子的流畅性.实践中,通常是取N=1~4,然后对进行加权平均。
下面举例说计算过程:
-
基本步骤:
-
分别计算预测文本candidate和目标文本reference的N-gram模型,然后统计其匹配的个数,计算匹配度
-
公式
-
BLEU-N = (Σ Count_match(N-gram)) / (Σ Count(N-gram in candidate))
-
candidate和reference中匹配的 n−gram 的个数 / candidate中 n−gram 的个数.
-
-
-
假设分别给出一个预测文本和目标文本如下:
预测文本: It is a nice day today 目标文本: today is a nice day
-
使用1-gram进行匹配
预测文本: {it, is, a, nice, day, today}
目标文本: {today, is, a, nice, day}
结果:其中{today, is, a, nice, day}匹配,所以匹配度为5/6
-
使用2-gram进行匹配
预测文本: {it is, is a, a nice, nice day, day today}
目标文本: {today is, is a, a nice, nice day}
结果:其中{is a, a nice, nice day}匹配,所以匹配度为3/5
-
使用3-gram进行匹配
预测文本: {it is a, is a nice, a nice day, nice day today}
目标文本: {today is a, is a nice, a nice day}
结果:其中{is a nice, a nice day}匹配,所以匹配度为2/4
-
使用4-gram进行匹配
预测文本: {it is a nice, is a nice day, a nice day today}
目标文本: {today is a nice, is a nice day}
结果:其中{is a nice day}匹配,所以匹配度为1/3
上述例子会出现一种极端情况,请看下面示例:
预测文本: the the the the 目标文本: The cat is standing on the ground 如果按照1-gram的方法进行匹配,则匹配度为1,显然是不合理的,所以计算某个词的出现次数进行改进
-
将计算某个词正确预测次数的方法改为计算某个词在文本中出现的最小次数,如下所示的公式:
-
其中$k$表示在预测文本中出现的第$k$个词语, $c_k$则代表在预测文本中这个词语出现的次数,而$s_k$则代表在目标文本中这个词语出现的次数。
python代码实现:
BLEU计算公式:

BLEU 评分范围
BLEU 分数范围:0 ~ 1(通常用 0 ~ 100 表示)
一般理解:
BLEU 分数 质量 90 - 100 几乎完美 70 - 90 高质量 50 - 70 可接受 30 - 50 勉强可用 0 - 30 低质量
# 第一步安装nltk的包-->pip install nltk
from nltk.translate.bleu_score import sentence_bleudef cumulative_bleu(reference, candidate):# 指标计算:p1^w1*p2^w2 =0.6^0.5*0.25^0.5 = 0.387# math.exp(0.5 * math.log(0.6) + 0.5 * math.log(0.25)) =# math.exp(0.5*math.log(0.15)) = math.exp(math.log(0.15)^0.5) = 0.15^0.5 = 0.387bleu_1_gram = sentence_bleu(reference, candidate, weights=(1, 0, 0, 0))bleu_2_gram = sentence_bleu(reference, candidate, weights=(0.5, 0.5, 0, 0))bleu_3_gram = sentence_bleu(reference, candidate, weights=(0.33, 0.33, 0.33, 0))bleu_4_gram = sentence_bleu(reference, candidate, weights=(0.25, 0.25, 0.25, 0.25))# print('bleu 1-gram: %f' % bleu_1_gram)# print('bleu 2-gram: %f' % bleu_2_gram)# print('bleu 3-gram: %f' % bleu_3_gram)# print('bleu 4-gram: %f' % bleu_4_gram)return bleu_1_gram, bleu_2_gram, bleu_3_gram, bleu_4_gram# 预测文本
candidate_text = ["This", "is", "some", "generated", "text"]# 目标文本列表
reference_texts = [["This", "is", "a", "reference", "text"],["This", "is", "another", "reference", "text"]]# 计算 Bleu 指标
c_bleu = cumulative_bleu(reference_texts, candidate_text)# 打印结果print("The Bleu score is:", c_bleu)
# The Bleu score is: (0.6, 0.387, 1.5949011744633917e-102, 9.283142785759642e-155)3.2 ROUGE
ROUGE(Recall-Oriented Understudy for Gisting Evaluation)指标是在机器翻译、自动摘要、问答生成等领域常见的评估指标。ROUGE通过将模型生成的摘要或者回答与参考答案(一般是人工生成的)进行比较计算,得到对应的得分,专门用于衡量自动生成文本与人工参考文本之间的相似度。
ROUGE指标与BLEU指标非常类似,均可用来衡量生成结果和标准结果的匹配程度,不同的是ROUGE基于召回率,BLEU更看重准确率。
ROUGE分为四种方法:ROUGE-N, ROUGE-L, ROUGE-W, ROUGE-S.
下面举例说计算过程(这里只介绍ROUGE-N):
-
计算公式:ROUGE-N = (Σ Count_match(N-gram)) / (Σ Count(N-gram in reference))
-
基本步骤:Rouge-N实际上是将模型生成的结果和标准结果按N-gram拆分后,计算召回率
-
假设模型预测文本和一个目标文本如下:
预测文本: It is a nice day today 目标文本: Today is a nice day
-
使用ROUGE-1进行匹配
预测文本: {it, is, a, nice, day, today}
目标文本: {today, is, a, nice, day}
结果::其中{today, is, a, nice, day}匹配,所以匹配度为5/5=1,这说明生成的内容完全覆盖了参考文本中的所有单词,质量较高。
-
通过类似的方法,可以计算出其他ROUGE指标(如ROUGE-2、ROUGE-L、ROUGE-S)的评分,从而综合评估系统生成的文本质量。
python代码实现:
# 第一步:安装rouge-->pip install rouge
from rouge import Rouge# 预测文本
generated_text = "This is some generated text."# 目标文本列表
reference_texts = ["This is a reference text.", "This is another generated reference text."]# 计算 ROUGE 指标
rouge = Rouge()
scores = rouge.get_scores(generated_text, reference_texts[1])# 打印结果
print("ROUGE-1 precision:", scores[0]["rouge-1"]["p"])
print("ROUGE-1 recall:", scores[0]["rouge-1"]["r"])
print("ROUGE-1 F1 score:", scores[0]["rouge-1"]["f"])
# ROUGE-1 precision: 0.8
# ROUGE-1 recall: 0.6666666666666666
# ROUGE-1 F1 score: 0.72727272231404963.3 困惑度PPL(perplexity)
PPL用来度量一个概率分布或概率模型预测样本的好坏程度。PPL表示模型在预测下一个词时的“平均不确定性”,可以理解为模型需要“猜测多少次才能正确预测下一个词”。
PPL基本思想:
-
给测试集的句子赋予较高概率值的语言模型较好,当语言模型训练完之后,测试集中的句子都是正常的句子,那么训练好的模型就是在测试集上的概率越高越好.
-
基本公式(两种方式):
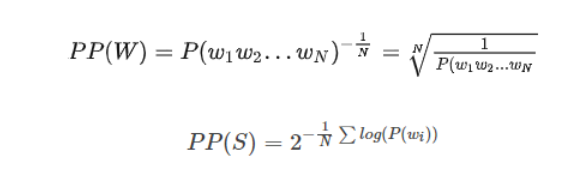
-
由公式可知,句子概率越大,语言模型越好,困惑度越小。
import math# 定义语料库
sentences = [['I', 'have', 'a', 'pen'],['He', 'has', 'a', 'book'],['She', 'has', 'a', 'cat']
]
# 定义语言模型
unigram = {'I': 1 / 12,'have': 1 / 12,'a': 3 / 12,'pen': 1 / 12,'He': 1 / 12,'has': 2 / 12,'book': 1 / 12,'She': 1 / 12,'cat': 1 / 12
}
# 初始化困惑度为0
perplexity = 0
# 循环遍历语料库
for sentence in sentences:# 计算句子的概率, 句子概率等于所有单词的概率相乘sentence_prob = 1# 循环遍历句子中的每个单词for word in sentence:# 计算单词的概率并累乘, 得到句子的概率sentence_prob *= unigram[word]# -1/N * log(P(W1W2...Wn))temp = -math.log(sentence_prob, 2) / len(sentence)# 累加句子的困惑度perplexity += 2 ** temp
# 计算困惑度 2**(-1/N * log(P(W1W2...Wn)))
perplexity = perplexity / len(sentences)
print('困惑度为:', perplexity)
# 困惑度为:8.15相关文章:
】)
【模型常见评价指标(分类)】
目录 常见指标 其他的评估指标 3.1 BLEU 3.2 ROUGE 3.3 困惑度PPL(perplexity) 常见指标 其他的评估指标 3.1 BLEU BLEU(Bilingual Evaluation Understudy,双语评估替补)分数是评估一种语言翻译成另一种语言的文本质量的指标。它将“质…...
)
个人博客系统后端 - 用户信息管理功能实现指南(上)
本文记录了如何实现用获取户信息,用户信息更新,用户头像上传三大基础功能 先上接口实现截图: 一、项目结构概览 先介绍一下 个人博客系统采用了标准的 Spring Boot 项目结构,用户功能相关的文件主要分布在以下几个目录:…...

CyberAgentAILab 开源数字人项目TANGO,heygen的开源版来了~
简介 TANGO 是 CyberAgentAILab 开源的一项前沿研究成果,其初衷在于探索高效生成模型在实际应用场景中的表现。项目诞生于 CyberAgent 在整合创意与人工智能的实践中,旨在为数字内容生成、交互和实时渲染等领域提供一个高性能、模块化、可扩展的解决方案…...

高等数学同步测试卷 同济7版 试卷部分 上 做题记录 上册期中同步测试卷 A 卷
上册期中同步测试卷A卷 一、单项选择题(本大题共5小题,每小题3分,总计15 分) 1. 2. 3. 4. 5. 二、填空题(本大题共5小题,每小题3分,总计15分) 6. 7. 8. 9. 10. 三、求解下列各题(本大题共5小题,每小题6分,总计30分) 11. …...

4.16 AT好题选做
文章目录 前言[ARC103D] Distance Sums(确定树的形态,trick)[AGC062B] Split and Insert(区间 d p dp dp)[AGC012E] Camel and Oases(状压,可行性dp转最优性dp)[ARC094D] Normalization(trick,转化)[ARC125F] Tree Degree Subset Sum(结论,a…...

数据库-day06
一、实验名称和性质 分类查询 验证 综合 设计 二、实验目的 1.掌握数据查询的Group by ; 2. 掌握聚集函数的使用方法。 三、实验的软硬件环境要求 硬件环境要求: PC机(单机) 使用的软件名称、版本号以及模块: …...

基于Flask的漏洞挖掘知识库系统设计与实现
基于Flask的漏洞挖掘知识库系统设计与实现 一、系统架构设计 1.1 整体架构 本系统采用经典的三层Web架构,通过Mermaid图展示的组件交互流程清晰呈现了以下核心模块: 前端展示层:基于Bootstrap5构建响应式界面业务逻辑层:Flask…...

小白从0学习网站搭建的关键事项和避坑指南
以下是针对小白从零学习网站搭建时需要注意的关键事项和避坑指南,帮助你高效学习、少走弯路: 一、学习路径注意事项 不要跳过基础 误区:直接学习框架(如 React、Laravel)而忽视 HTML/CSS/JS 基础。 正确做法ÿ…...

OpenAI 推出一对 AI 推理模型 o3 和 o4-mini
OpenAI 于 2025 年 4 月 16 日(美国东部时间)宣布推出两款全新的 AI 推理模型——o3 与 o4-mini,它们能够在给出最终回答前进行思考与推理。 本文中所有的 ChatGPT 服务,由 ChatShare 镜像站 提供,无需担心网络和地区限…...

知识了解03——怎么解决使用npm包下载慢的问题?
1、为什么使用npm下载包会下载的慢 因为使用npm下载包时,默认使用国外服务器进行下载,此时的网络传输需要经过漫长的海底电缆,因此下载速度会变慢 2、怎么解决?(切换镜像源) (1)方…...

【网络】IP层的重要知识
目录 1.IP层的作用 2.主机和节点 3.网络层和数据链路层的关系 4.路由控制 4.1.路由控制的过程 4.2. IP地址与路由控制 4.3.路由控制表的聚合 4.4.静态路由和动态路由 4.5.动态路由的基础 5.数据链路的抽象化 5.1.数据链路不同,MTU则相异 5.2.路径MTU发…...

【随身WIFI】随身WiFi Debian系统优化教程
0.操作前必看 本教程基于Debian系统进行优化,有些操作对随身WiFi来说可能会带来负优化,根据需要选择。 所有操作需要在root用户环境下运行,否则都要加sudo 随身wifi Debian系统,可以去某安的随声WiFi模块自行搜索刷机 点赞&am…...
)
IPCC指南主要变化(各版本)
1996年IPCC国家温室气体清单指南 背景:是IPCC较早发布的指南之一,为国家温室气体清单编制提供了基础方法。 内容:包括了对温室气体排放源和汇的估算方法,涵盖了能源、工业、农业等多个部门。 2006年IPCC国家温室气体清单指南 背…...

关于Diamond机械手的运动学与动力学的推导
1.关于Diamond机械手 (1)位置模型推导 逆解:机械末端平台的位置与驱动关节之间的关系。 设p点在xy平面的坐标是(x,y)T,此时根据向量求解 OP等于向量r等于e向xy轴的向量主动臂长度向xy轴的向量…...

@JsonSerialize注解自定义序列化方式
JsonSerialize注解自定义序列化方式 文章目录 JsonSerialize注解自定义序列化方式**前言****创建自定义序列化器****应用自定义序列化器****测试序列化结果****高级用法:全局注册序列化器****关键点解析****常见问题解决****问题1:序列化结果不符合预期*…...

第二篇:linux之Xshell使用及相关linux操作
第二篇:linux之Xshell使用及相关linux操作 文章目录 第二篇:linux之Xshell使用及相关linux操作一、Xshell使用1、Xshell安装2、Xshell使用 二、Bash Shell介绍与使用1、什么是Bash Shell(壳)?2、Bash Shell能干什么?3、平时如何使…...

qt中关于思源雅黑字体的使用
首先,需要下载一份思源雅黑字体,我放在了下面位置,https://download.csdn.net/download/Littlehero_121/90631851 2、关于qt中的使用操作,如下: //QString path "绝对路径";QString path QCoreApplicatio…...
)
用 MongoIndexStore 实现对话存档和恢复 实现“多用户、多对话线程”场景(像一个 ChatGPT 对话列表那样)
用LlamaIndex写两个完整实用的案例! 实现如何用 MongoIndexStore 实现对话存档和恢复实现“多用户、多对话线程”场景(像一个 ChatGPT 对话列表那样) ✅ 案例一:使用 MongoIndexStore 实现对话存档 恢复 单用户 单对话线程&am…...

接口测试:实用指南4.0
✨博客主页: https://blog.csdn.net/m0_63815035?typeblog 💗《博客内容》:.NET、Java.测试开发、Python、Android、Go、Node、Android前端小程序等相关领域知识 📢博客专栏: https://blog.csdn.net/m0_63815035/cat…...

2000-2017年各省国有经济煤气生产和供应业固定资产投资数据
2000-2017年各省国有经济煤气生产和供应业固定资产投资数据 1、时间:2000-2017年 2、来源:国家统计局、能源年鉴 3、指标:行政区划代码、城市、年份、国有经济煤气生产和供应业固定资产投资 4、范围:31省 5、指标说明&#x…...

AOP的基本应用案例---统计每个函数的执行时间
1.导入依赖: <dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-aop</artifactId> </dependency> 2.准备好要计算的SpringBoot的项目(本案例以service的实现类为例) 3.编写AOP的代码: package c…...

前端复习遗忘的知识点
这个是我个人平常学习一些博主的东西,如果侵权请联系我或者让我标上博主平台等信息,谢谢! 1:如图涉及知识点jq: 1.获取元素 document.getElementById(""); document.getElementsByClassName(); document.g…...
版本国区下载安装参考)
Unity3d 6(6000.*.*)版本国区下载安装参考
前言 Unity3d 6.是最新的版本,是与来自世界各地的开发者合作构建、测试和优化的成果,现在可以完全投入生产,是我们迄今为止性能最出色、最稳定的 Unity 版本。Unity 6 有许多令人兴奋的新工具和功能:端到端多人游戏工作流程将加速…...

【JavaEE】Maven配置
一、Maven简介 什么是Maven? Maven是一个基于项目对象模型(POM)构建的自动化工具,主要用于Java项目构建、依赖管理和项目信息管理 我理解的Maven:自动下载和管理“代码零件”(比如别人写好的工具包&#x…...

Java排序算法百科全书:原理、实现与实战指南
一、排序算法全景视图 1. 算法分类体系 graph TDA[排序算法] --> B[比较排序]A --> C[非比较排序]B --> B1[基本排序]B1 --> B11[冒泡排序]B1 --> B12[选择排序]B1 --> B13[插入排序]B --> B2[高效排序]B2 --> B21[快速排序]B2 --> B22[归并排序]…...

大模型在教育领域的五大应用
大模型在教育领域的五大应用 随着人工智能技术的迅猛发展,特别是大模型(如GPT-3、BERT等)的出现,教育领域正迎来一场前所未有的变革。大模型不仅能够处理复杂的自然语言任务,还能够通过深度学习算法理解和生成高质量的…...

Lesson 12 Goodbye and good luck
Lesson 12 Goodbye and good luck 词汇 luck n. 运气,幸运 相关:lucky a. 幸运的 luckily ad. 幸运地 unlucky a. 不幸的 搭配:lucky number 幸运数字 lucky color 幸运色 lucky day 幸运日 lucky dog 幸运儿…...

数据结构-前缀树
一、引言 前缀树又叫字典树,可以快速查找字符串或字符串前缀出现的次数,方便进行前缀匹配、词频统计 二、字典树模型 现有一个字典树,里面有money、mother、salary、salary、say五个单词 其中根节点位置还没有字符,相当于空串&am…...

搭建 vue 项目环境详细步骤
在平常的开发工作中,我们经常需要对项目进行打包,后端项目打包及部署在前面总结过。那么,现在前端基本都是 vue 项目,那么应该如何搭建一个 vue 环境呢?下载一个前端项目应该如何启动呢?今天,我…...

【2025最新版】火鸟门户v8.5系统源码+PC、H5、小程序 +数据化大屏插件
一.介绍 火鸟地方门户系统V8.5源码 系统包含4端: PCH5小程序APP 二.搭建环境 系统环境:CentOS、 运行环境:宝塔 Linux 网站环境:Nginx 1.2.22 MySQL 5.6 PHP-7.4 常见插件:fileinfo ; redis 三.测…...

【eNSP实验】OSPF单区域配置
简介 OSPF(开放最短路径优先)是一种基于链路状态算法的内部网关协议(IGP),用于自治系统内部动态路由。其核心机制为:各路由器通过泛洪链路状态通告(LSA)同步网络拓扑,构…...

e实例性能测评:Intel Xeon Platinum处理器,经济型入门级服务器
阿里云服务器ECS经济型e系列是阿里云面向个人开发者、学生、小微企业,在中小型网站建设、开发测试、轻量级应用等场景推出的全新入门级云服务器,阿里云百科分享CPU处理器采用Intel Xeon Platinum架构处理器,支持1:1、1:2、1:4多种处理器内存配…...

uniapp APP端 DOM生成图片保存到相册
<template> <view class"container" style"padding-bottom: 30rpx;"> <view class"hdbg pr w100 " style"height: 150rpx;"> <top-bar content分享 Back"Back"></top-b…...

Leetcode刷题 由浅入深之哈希表——242. 有效的字母异位词
目录 (一)字母异位词的C实现 写法一(辅助数组) (二)复杂度分析 时间复杂度 空间复杂度 (三)总结 【题目链接】242.有效的字母异位词 - 力扣(LeetCode) …...

Opencv函数及练习题
一、函数整理: 1、cv2.adaptiveThreshold() 2、 cv2.split() 3、cv2.merge() 4、cv2.add() 5、cv2.bitwise_and() 6、 cv2.inRange(&…...
-第十六天)
16-算法打卡-哈希表-两个数组的交集-leetcode(349)-第十六天
1 题目地址 349. 两个数组的交集 - 力扣(LeetCode)349. 两个数组的交集 - 给定两个数组 nums1 和 nums2 ,返回 它们的 交集 。输出结果中的每个元素一定是 唯一 的。我们可以 不考虑输出结果的顺序 。 示例 1:输入:nu…...

计算机视觉——JPEG AI 标准发布了图像压缩新突破与数字图像取证的挑战及应对策略
概述 今年2月,经过多年旨在利用机器学习技术开发一种更小、更易于传输和存储且不损失感知质量的图像编解码器的研究后,JPEG AI国际标准正式发布。 来自JPEG AI官方发布流,峰值信噪比(PSNR)与JPEG AI的机器学习增强方法…...

【JavaWeb后端开发01】Maven入门
课程内容: 初始Maven Maven概述 Maven模型 Maven仓库介绍 Maven安装与配置 IDEA集成Maven 依赖管理 单元测试 文章目录 1. 初始Maven1.1 介绍1.2 Maven的作用1.2.1 依赖管理1.2.2 项目构建1.2.3 统一项目结构 2. Maven概述2.1 Maven介绍2.2 Maven模型2.3 Ma…...

【Leetcode】16. 最接近的三数之和
一、题目描述 给你一个长度为 n 的整数数组 nums 和 一个目标值 target。请你从 nums 中选出三个整数,使它们的和与 target 最接近。 返回这三个数的和。 假定每组输入只存在恰好一个解。 示例 1: 输入:nums = [-1,2,1,-4], target = 1 输出:2解释: 与 target 最接近…...

目标检测概述
为什么基于卷积网络的目标检测模型在预测后要使用非极大值抑制 基于卷积网络的目标检测模型可能会在目标的相邻区域生成多个相互重叠框,每个框的预测结果都是同一个目标,引起同一目标的重复检测。造成这一现象的原因主要有两个, 基于卷积网络…...
)
摄影跟拍预定|基于java+vue的摄影跟拍预定管理系统(源码+数据库+文档)
摄影跟拍预定管理系统 目录 基于SprinBootvue的摄影跟拍预定管理系统 一、前言 二、系统设计 三、系统功能设计 1系统功能模块 2管理员功能模块 3摄影师功能模块 4用户功能模块 四、数据库设计 五、核心代码 六、论文参考 七、最新计算机毕设选题推荐 八、源码获…...

--图--
并查集 并查集原理 在一些应用问题中,需要将n个不同的元素划分成一些不相交的集合。开始时,每个元素自成一个单元素集合,然后按一定的规律将归于同一组元素的集合合并。在此过程中要反复用到查询某一个元素归属于那个集合的运算。适合于描述…...
方法)
Python中的count()方法
文章目录 Python中的count()方法基本语法在不同数据类型中的使用1. 列表(List)中的count()2. 元组(Tuple)中的count()3. 字符串(String)中的count() 高级用法1. 指定搜索范围2. 统计复杂元素 注意事项 Python中的count()方法 前言:count()是Python中用于序列类型&a…...

通过gird布局实现div的响应式分布排列
目标:实现对于固定宽度的div盒子在页面中自适应排布,并且最后一行的div盒子可以与前面的盒子对齐。 <!DOCTYPE html> <html lang"en"> <head><meta charset"UTF-8"><meta name"viewport" con…...

Edge 浏览器推出 Copilot Vision:免费实时解析屏幕内容;Aqua Voice:极速 AI 语音输入工具丨日报
开发者朋友们大家好 这里是 「RTE 开发者日报」 ,每天和大家一起看新闻、聊八卦。我们的社区编辑团队会整理分享 RTE(Real-Time Engagement) 领域内「有话题的 技术 」、「有亮点的 产品 」、「有思考的 文章 」、「有态度的 观点 」、「有看…...
)
Linux 防火墙( iptables )
目录 一、 Linux 防火墙基础 1. 防火墙基础概念 (1)防火墙的概述与作用 (2)防火墙的结构与匹配流程 (3)防火墙的类别与各个防火墙的区别 2. iptables 的表、链结构 (1)规则表 …...

Hook插件
hook插件 1.概念 在JavaScript中,hook是一种能够拦截和修改函数或方法行为的技术。通过使用hook,开发者可以在现有的函数执行前、执行后或者替换函数的实现逻辑。hook目的是找到函数入口以及一些参数变化,便于分析js逻辑。 2.hook的作用&a…...

ORA-00600: internal error code, arguments: [kcratr_nab_less_than_odr], [1],
因客户机房断电,2台主机和共享存储全部断电,来电后,集群启动正常,实例无法正常启动,手动启动报错如下 SQL > startup; ORACLE instance started. Total System Global Area 3.9551E10 bytes Fixed Size …...

R4打卡——tensorflow实现火灾预测
🍨 本文为🔗365天深度学习训练营中的学习记录博客 🍖 原作者:K同学啊 1.检查GPU import tensorflow as tf import pandas as pd import numpy as npgpus tf.config.list_physical_devices("GPU") if gpus:…...

基于AI大语言模型的历史文献分析在气候与灾害重建领域中的技术应用
随着人工智能技术的快速发展,大语言模型(如GPT、BERT等)在自然语言处理领域取得了显著进展,特别是在非结构化文本数据的分析方面,极大地拓展了我们的研究视角。这些技术不仅提高了处理和理解文本数据的效率,…...