OpenHarmony - 小型系统内核(LiteOS-A)(七)
OpenHarmony - 小型系统内核(LiteOS-A)(七)
八、文件系统
适配新的文件系统
基本概念
所谓对接VFS层,其实就是指实现VFS层定义的若干接口函数,可根据文件系统的特点和需要适配其中部分接口。一般情况下,支持文件读写,最小的文件系统适配看起来是这样的:
struct MountOps g_yourFsMountOps = {.Mount = YourMountMethod,
};struct file_operations_vfs g_yourFsFileOps = {.read = YourReadMethod,.write = YourWriteMethod,
}struct VnodeOps g_yourFsVnodeOps = {.Create = YourCreateMethod;.Lookup = YourLookupMethod;.Reclaim = YourReclaimMethod;
};FSMAP_ENTRY(yourfs_fsmap, "your fs name", g_yourFsMountOps, TRUE, TRUE); // 注册文件系统
说明:
open和close接口不是必须要实现的接口,因为这两个接口是对文件的操作,对下层的文件系统一般是不感知的,只有当要适配的文件系统需要在open和close时做一些特别的操作时,才需要实现。
适配文件系统,对基础知识的要求较高,适配者需要对要适配的文件系统的原理和实现具有深刻的理解,本节中不会事无巨细地介绍相关的基础知识,如果您在适配的过程中遇到疑问,建议参考kernel/liteos_a/fs目录下已经适配好的文件系统的代码,可能就会豁然开朗。

适配Mount接口
Mount是文件系统第一个被调用的接口,该接口一般会读取驱动的参数,根据配置对文件系统的进行初始化,最后生成文件系统的root节点。Mount接口的定义如下:
int (*Mount)(struct Mount *mount, struct Vnode *blkDriver, const void *data);
其中,第一个参数struct Mount *mount是Mount点的信息,适配时需要填写的是下面的变量:
struct Mount {const struct MountOps *ops; /* Mount相关的函数钩子 */struct Vnode *vnodeCovered; /* Mount之后的文件系统root节点 */void *data; /* Mount点的私有数据 */
};
第二个参数struct Vnode *blkDriver是驱动节点,可以通过这个节点访问驱动。
第三个参数const void *data是mount命令传入的数据,可以根据文件系统的需要处理。
下面以JFFS2为例,详细看一下mount接口是如何适配的:
int VfsJffs2Bind(struct Mount *mnt, struct Vnode *blkDriver, const void *data)
{int ret;int partNo;mtd_partition *p = NULL;struct MtdDev *mtd = NULL;struct Vnode *pv = NULL;struct jffs2_inode *rootNode = NULL;LOS_MuxLock(&g_jffs2FsLock, (uint32_t)JFFS2_WAITING_FOREVER);/* 首先是从驱动节点中获取文件系统需要的信息,例如jffs2读取的是分区的编号 */p = (mtd_partition *)((struct drv_data *)blkDriver->data)->priv;mtd = (struct MtdDev *)(p->mtd_info);if (mtd == NULL || mtd->type != MTD_NORFLASH) {LOS_MuxUnlock(&g_jffs2FsLock);return -EINVAL;}partNo = p->patitionnum;/* 然后生成一个文件系统的根Vnode,这里注意不要搞混rootNode和根Vnode,rootNode类型是inode,是jffs2内部维护的私有数据,而Vnode是VFS的概念,是通用的文件节点,这一步实际上就是把文件系统内部的私有信息保存到Vnode中,这样就可以通过Vnode直接找到文件系统中的对应文件。*/ret = jffs2_mount(partNo, &rootNode);if (ret != 0) {LOS_MuxUnlock(&g_jffs2FsLock);return ret;}ret = VnodeAlloc(&g_jffs2Vops, &pv);if (ret != 0) {LOS_MuxUnlock(&g_jffs2FsLock);goto ERROR_WITH_VNODE;}/* 下面这段填写的是关于这个Vnode对应文件的相关信息,uid\gid\mode这部分信息,有的文件系统可能不支持,可以不填 */pv->type = VNODE_TYPE_DIR;pv->data = (void *)rootNode;pv->originMount = mnt;pv->fop = &g_jffs2Fops;mnt->data = p;mnt->vnodeCovered = pv;pv->uid = rootNode->i_uid;pv->gid = rootNode->i_gid;pv->mode = rootNode->i_mode;/* 这里的HashInsert是为了防止重复生成已经生成过的Vnode, 第二个参数一般会选择本文件系统内可以唯一确定某一个文件的信息,例如这里是jffs2内部inode的地址 */(void)VfsHashInsert(pv, rootNode->i_ino);g_jffs2PartList[partNo] = blkDriver;LOS_MuxUnlock(&g_jffs2FsLock);return 0;
ERROR_WITH_VNODE:return ret;
}
// ...
// ...
const struct MountOps jffs_operations = {.Mount = VfsJffs2Bind,// ...// ...
};
总结:
-
首先从驱动节点中获取需要的私有信息。
-
根据私有信息,生成文件系统的根节点。
适配Lookup接口
Lookup是查找文件的接口,它的函数原型是:
int (*Lookup)(struct Vnode *parent, const char *name, int len, struct Vnode **vnode);
很好理解,就是从父节点parent开始,根据文件名name和文件名长度len,查找到对应的vnode返回给上层。
这个接口适配起来思路很清晰,给了父节点的信息和文件名,实现从父目录中查询名字为name的文件这个功能,同样以JFFS2为例:
int VfsJffs2Lookup(struct Vnode *parentVnode, const char *path, int len, struct Vnode **ppVnode)
{int ret;struct Vnode *newVnode = NULL;struct jffs2_inode *node = NULL;struct jffs2_inode *parentNode = NULL;LOS_MuxLock(&g_jffs2FsLock, (uint32_t)JFFS2_WAITING_FOREVER);/* 首先从private data中提取父节点的信息 */parentNode = (struct jffs2_inode *)parentVnode->data;/* 然后查询得到目标节点的信息,注意这里调用的jffs2_lookup是jffs2本身的查询函数 */node = jffs2_lookup(parentNode, (const unsigned char *)path, len);if (!node) {LOS_MuxUnlock(&g_jffs2FsLock);return -ENOENT;}/* 接着先校验一下查找到的目标是否已经有现成的vnode了,这里对应之前提到的VfsHashInsert */(void)VfsHashGet(parentVnode->originMount, node->i_ino, &newVnode, NULL, NULL);LOS_MuxUnlock(&g_jffs2FsLock);if (newVnode) {newVnode->parent = parentVnode;*ppVnode = newVnode;return 0;}/* 如果vnode不存在,就新生成一个vnode,并填写相关信息 */ret = VnodeAlloc(&g_jffs2Vops, &newVnode);if (ret != 0) {PRINT_ERR("%s-%d, ret: %x\n", __FUNCTION__, __LINE__, ret);(void)jffs2_iput(node);LOS_MuxUnlock(&g_jffs2FsLock);return ret;}Jffs2SetVtype(node, newVnode);newVnode->fop = parentVnode->fop;newVnode->data = node;newVnode->parent = parentVnode;newVnode->originMount = parentVnode->originMount;newVnode->uid = node->i_uid;newVnode->gid = node->i_gid;newVnode->mode = node->i_mode;/* 同时不要忘记将新生成的vnode插入hashtable中 */(void)VfsHashInsert(newVnode, node->i_ino);*ppVnode = newVnode;LOS_MuxUnlock(&g_jffs2FsLock);return 0;
}
总结:
-
从父节点获取私有数据;
-
根据私有信息查询到目标文件的私有数据;
-
通过目标文件的私有数据生成目标Vnode。
适配总结和注意事项
通过上面两个接口的适配,其实可以发现一个规律,不管是什么接口,基本都遵循下面的适配步骤:
-
通过入参的vnode获取文件系统所需的私有数据。
-
使用私有数据完成接口的功能。
-
将结果包装成vnode或接口要求的其他返回格式,返回给上层。
核心的逻辑其实在使用私有数据完成接口的功能,这些接口都是些文件系统的通用功能,文件系统在移植前本身应该都有相应实现,所以关键是归纳总结出文件系统所需的私有数据是什么,将其存储在vnode中,供之后使用。一般情况下,私有数据的内容是可以唯一定位到文件在存储介质上位置的信息,大部分文件系统本身都会有类似数据结构可以直接使用,比如JFFS2的inode数据结构。
注意:
访问文件时,不一定会调用文件系统中的Lookup接口,仅在上层的路径缓存失效时才会调用到。
通过VfsHashGet找到了已经存在的Vnode,不要直接将其作为结果返回,其储存的信息可能已经失效,请更新相应字段后再返回。
Vnode会根据内存占用在后台自动释放,需要持久保存的信息,不要只保存在Vnode中。
Reclaim接口在Vnode释放时会自动调用,请在这个接口中释放私有数据中的资源。

九、Plimitsfs文件系统
容器配额(plimits)
简介
面对进程越来越多,应用环境越来越复杂的状况,需要对容器做限制,若不做限制,会发生资源浪费、争夺等。容器配额plimits(Process Limits)是内核提供的一种可以限制单个进程或者多个进程所使用资源的机制,可以对cpu,内存等资源实现精细化控制。plimits的接口通过plimitsfs的伪文件系统提供。通过操作文件对进程及进程资源进行分组管理,通过配置plimits组内限制器Plimiter限制进程组的memory、sched等资源的使用。
基本概念
- plimits:内核的一个特性,用于限制、记录和隔离一组进程的资源使用。
- plimitsfs:plimits文件系统,向用户提供操作接口,实现plimits的创建,删除。向用户展示plimits的层级等。
- plimiter:资源限制器的总称,一个子系统代表一类资源限制器,包含memory限制器、pids限制器、sched限制器。
- sched限制器:限制plimits组内的所有进程,在时间周期内占用的cpu时间。
- memory限制器:限制plimits组内所有进程的内存使用总和。
- pids限制器:限制plimits组内能挂载的最大进程数。
运行机制
plimitsfs文件系统,在系统初始化阶段,初始化plimits目录挂载至proc目录下:
├─proc
│ ├─plimits
│ │ ├─plimits.plimiter_add
│ │ ├─plimits.plimiter_delete
│ │ ├─plimits.procs
│ │ ├─plimits.limiters
│ │ ├─pids.max
│ │ ├─sched.period
│ │ ├─sched.quota
│ │ ├─sched.stat
│ │ ├─memory.failcnt
│ │ ├─memory.limit
│ │ ├─memory.peak
│ │ ├─memory.usage
│ │ ├─memory.oom_ctrl
│ │ └─memory.stat
-
plimits分组:
图1 plimits创建/删除
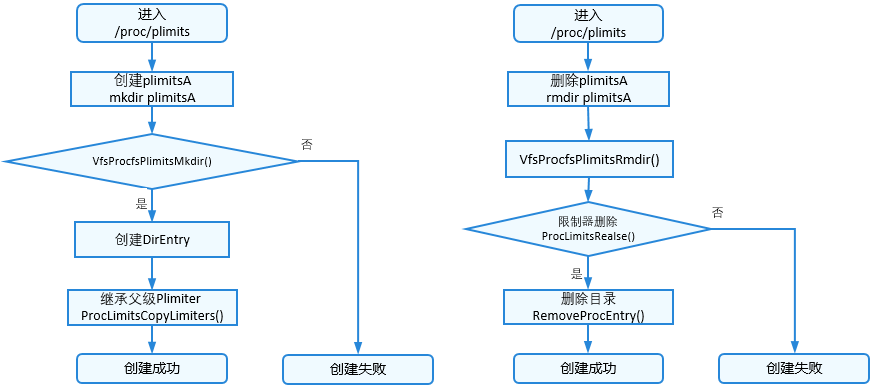
-
sched限制器:
图2 sched限制器配置
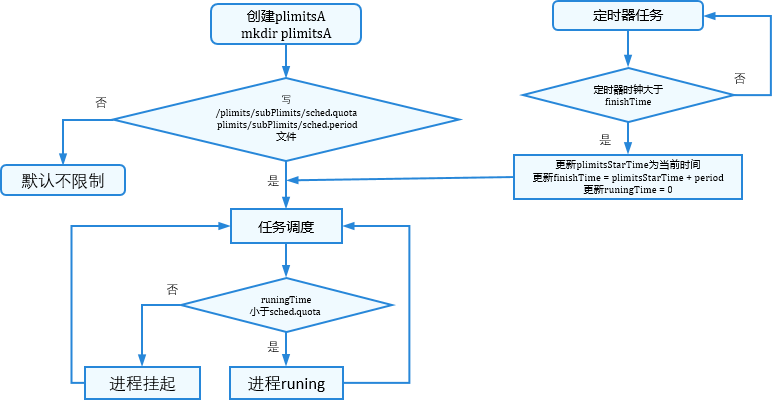
-
memory限制器:
图3 memory限制器配置
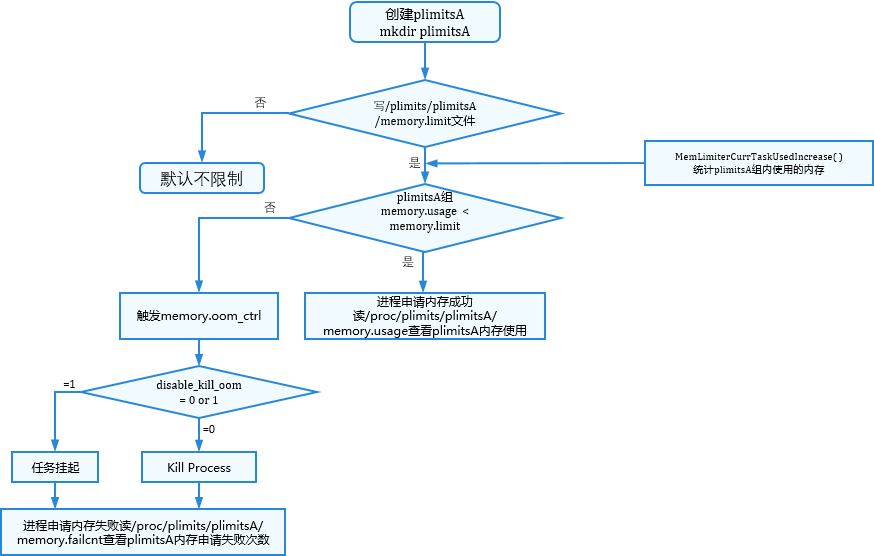
-
pids限制器:
图4 Pids限制器配置
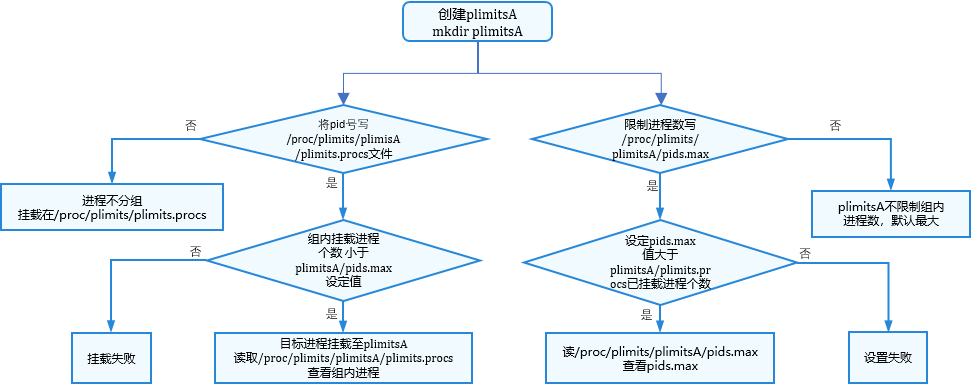
开发指导
接口说明
LiteOS-A的plimits根目录在/proc/plimits下,其下的所有文件只有只读权限,不允许写操作。限制器文件设定值默认为最大值,通过读文件,可查看组内进程资源状态。 通过mkdir创建plimitsA目录完成对进程资源分组,进而操作资源的分配限制。创建的plimitsA目录继承其父plimits目录。
-
plimitsA文件目录见下表:
权限
大小 用户 用户组 文件名 文件描述 -r--r--r-- 0 u:0 g:0 sched.stat 每个线程上周期内使用的时间片信息,方便测试验证使用 -rw-r--r-- 0 u:0 g:0 sched.quota 组内所有进程在周期内使用时间片总和,单位:ns -rw-r--r-- 0 u:0 g:0 sched.period 时间片统计周期,单位:ns -r--r--r-- 0 u:0 g:0 memory.stat 统计内存使用的信息,单位:字节 -r--r--r-- 0 u:0 g:0 memory.usage 已使用内存份额,单位:字节 -r--r--r-- 0 u:0 g:0 memory.peak 内存历史使用峰值,单位:字节 -rw-r--r-- 0 u:0 g:0 memory.limit 内存使用限额,单位:字节 -r--r--r-- 0 u:0 g:0 memory.failcnt 记录超过限额内存分配失败的次数,单位:次 -rw-r--r-- 0 u:0 g:0 pids.max 组内允许挂载进程的最大数,单位:个 -rw-r--r-- 0 u:0 g:0 plimits.procs 组内挂载的所有进程 -rw-r--r-- 0 u:0 g:0 plimits.limiter_delete 根据写入的限制器名称,删除限制器 -rw-r--r-- 0 u:0 g:0 plimits.limiter_add 根据写入的限制器名称,添加限制器 -r--r--r-- 0 u:0 g:0 plimits.limiters 查看组内限制器 在/proc/plimits/下创建的plimitsA目录下文件均可读部分可写,通过write对plimitsA子目录中写入内容,完成对进程资源分配与限制。
- 对文件sched.quota写入时间,单位ns,可限制组内所有进程使用cpu的时间
- 对文件sched.period写入时间,单位ns,可设置组内统计的时间周期
- 对文件memory.limit写入内存,单位字节,可限制组内允许使用的内存制
- 对文件pids.max写入十进制数字,可限制组内允许挂载的进程个数
- 对文件plimits.procs写入Pid,可将进程挂到不同的plimits组
- 通过read读不同的文件,可查看组内资源配置使用状况
-
删除plimitsA组:
首先对/proc/plimits/plimitsA/plimits.limiter_delete文件依次写入字段“sched”、“memory”、“pids”删除限制器,才能使用rmdir删除plimitsA。
权限 大小 用户 用户组 文件名 -rw-r--r-- 0 u:0 g:0 plimits.procs -rw-r--r-- 0 u:0 g:0 plimits.limiter_delete -rw-r--r-- 0 u:0 g:0 plimits.limiter_add -r--r--r-- 0 u:0 g:0 plimits.limiters
开发流程
plimits文件系统的主要开发流程包括创建新的plimitsA,将pid号写入/plimitsA/plimits.procs,对进程资源分组;按照字节大小写文件/plimitsA/memory.limit文件,限制plimitsA组内能使用的最大内存;对文件/plimitsA/pids.max写入十进制数字限制plimitsA组内所能挂载的进程数等;通过配置plimitsA组内限制器文件,对相应的资源进行分配和限制。亦可删除plimitsA,不限制资源的使用。
编程实例
编程示例主要是创建分组plimitsA,通过读写子目录内容,完成进程与进程资源的分组,对Plimits组内进程资源限制。
#include <stdio.h>
#include <unistd.h>
#include <stdlib.h>
#include <string.h>
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>#define LOS_OK 0
#define LOS_NOK -1int main ()
{int ret;ssize_t len;int fd = -1;//get main pidint mainpid = getpid();char plimitsA[128] = "/proc/plimits/plimitsA";char plimitsAPids[128] = "/proc/plimits/plimitsA/pids.max";char plimitsAMemoryLimit[128] = "/proc/plimits/plimitsA/memory.limit";char plimitsAMemoryUsage[128] = "/proc/plimits/plimitsA/memory.usage";char plimitsAProcs[128] = "/proc/plimits/plimitsA/plimits.procs";char plimitsAAdd[128] = "/proc/plimits/plimitsA/plimits.limiter_add";char plimitsADelete[128] = "/proc/plimits/plimitsA/plimits.limiter_delete";char plimitsMem[128] = "/proc/plimits/memory.usage";char plimitsPid[128] = "/proc/plimits/plimits.procs";char *mem = NULL;char writeBuf[128];char readBuf[128];/* 查看根plimits组内进程 */memset(readBuf, 0, sizeof(readBuf));fd = open(plimitsPid, O_RDONLY);len = read(fd, readBuf, sizeof(readBuf));if (len != strlen(readBuf)) {printf("read file failed.\n");return LOS_NOK;}close(fd);printf("/proc/plimits组内进程:%s\n", readBuf);/* 查看根plimits组内内存使用 */memset(readBuf, 0, sizeof(readBuf));fd = open(plimitsMem, O_RDONLY);len = read(fd, readBuf, sizeof(readBuf));if (len != strlen(readBuf)) {printf("read file failed.\n");return LOS_NOK;}close(fd);printf("/proc/plimits组内已使用内存:%s\n", readBuf);/* 创建plimitsA “/proc/plimits/plimitsA” */ret = mkdir(plimitsA, 0777);if (ret != LOS_OK) {printf("mkdir failed.\n");return LOS_NOK;}/* 设置plimitsA组允许挂载进程个数 */memset(writeBuf, 0, sizeof(writeBuf));sprintf(writeBuf, "%d", 3);fd = open(plimitsAPids, O_WRONLY);len = write(fd, writeBuf, strlen(writeBuf));if (len != strlen(writeBuf)) {printf("write file failed.\n");return LOS_NOK;}close(fd);/* 挂载进程至plimitsA组 */memset(writeBuf, 0, sizeof(writeBuf));sprintf(writeBuf, "%d", mainpid);fd = open(plimitsAProcs, O_WRONLY);len = write(fd, writeBuf, strlen(writeBuf));if (len != strlen(writeBuf)) {printf("write file failed.\n");return LOS_NOK;}close(fd);/* 设置plimitsA组内分配内存限额 */memset(writeBuf, 0, sizeof(writeBuf));//limit memorysprintf(writeBuf, "%d", (1024*1024*3));fd = open(plimitsAMemoryLimit, O_WRONLY);len = write(fd, writeBuf, strlen(writeBuf));if (len != strlen(writeBuf)) {printf("write file failed.\n");return LOS_NOK;}close(fd);/* 查看plimitsA组内允许使用的最大内存 */memset(readBuf, 0, sizeof(readBuf));fd = open(plimitsAMemoryLimit, O_RDONLY);len = read(fd, readBuf, sizeof(readBuf));if (len != strlen(readBuf)) {printf("read file failed.\n");return LOS_NOK;}close(fd);printf("/proc/plimits/plimitsA组允许使用的最大内存:%s\n", readBuf);/* 查看plimitsA组内挂载的进程 */memset(readBuf, 0, sizeof(readBuf));fd = open(plimitsAProcs, O_RDONLY);len = read(fd, readBuf, sizeof(readBuf));if (len != strlen(readBuf)) {printf("read file failed.\n");return LOS_NOK;}close(fd);printf("/proc/plimits/plimitsA组内挂载的进程:%s\n", readBuf);/* 查看plimitsA组内存的使用情况 */mem = (char*)malloc(1024*1024);memset(mem, 0, 1024);memset(readBuf, 0, sizeof(readBuf));fd = open(plimitsAMemoryUsage, O_RDONLY);len = read(fd, readBuf, sizeof(readBuf));if (len != strlen(readBuf)) {printf("read file failed.\n");return LOS_NOK;}close(fd);printf("/proc/plimits/plimitsA组已使用内存:%s\n", readBuf);/* 删除plimitsA组内memory限制器 */memset(writeBuf, 0, sizeof(writeBuf));sprintf(writeBuf, "%s", "memory");fd = open(plimitsADelete, O_WRONLY);len = write(fd, writeBuf, strlen(writeBuf));if (len != strlen(writeBuf)) {printf("write file failed.\n");return LOS_NOK;}close(fd);/* 增加plimitsA组内memory限制器 */memset(writeBuf, 0, sizeof(writeBuf));sprintf(writeBuf, "%s", "memory");fd = open(plimitsAAdd, O_WRONLY);len = write(fd, writeBuf, strlen(writeBuf));if (len != strlen(writeBuf)) {printf("write file failed.\n");return LOS_NOK;}close(fd);/* 删除plimitsA组,首先删除memory、pids、sched限制器 */memset(writeBuf, 0, sizeof(writeBuf));sprintf(writeBuf, "%s", "memory");fd = open(plimitsADelete, O_WRONLY);len = write(fd, writeBuf, strlen(writeBuf));if (len != strlen(writeBuf)) {printf("write file failed.\n");return LOS_NOK;}memset(writeBuf, 0, sizeof(writeBuf));sprintf(writeBuf, "%s", "pids");fd = open(plimitsADelete, O_WRONLY);len = write(fd, writeBuf, strlen(writeBuf));memset(writeBuf, 0, sizeof(writeBuf));sprintf(writeBuf, "%s", "sched");fd = open(plimitsADelete, O_WRONLY);len = write(fd, writeBuf, strlen(writeBuf));close(fd);ret = rmdir(plimitsA);if (ret != LOS_OK) {printf("rmdir failed.\n");return LOS_NOK;}return 0;
}
结果验证
编译运行得到的结果为:
/proc/plimits组内进程:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15/proc/plimits组内已使用内存:28016640/proc/plimits/plimitsA组允许使用的最大内存:3145728/proc/plimits/plimitsA组内挂载的进程:
15/proc/plimits/plimitsA组已使用内存:4096
相关文章:
(七))
OpenHarmony - 小型系统内核(LiteOS-A)(七)
OpenHarmony - 小型系统内核(LiteOS-A)(七) 八、文件系统 适配新的文件系统 基本概念 所谓对接VFS层,其实就是指实现VFS层定义的若干接口函数,可根据文件系统的特点和需要适配其中部分接口。一般情况下&…...

四层板的时钟线设计:关键要点与实用策略
在电子电路设计领域,四层板凭借其出色的电气性能和合理的空间布局,广泛应用于各类电子产品中。而时钟线作为系统的 “心跳”,为整个电路提供同步信号,其设计质量直接关系到系统的稳定性、可靠性和性能表现。因此,深入探…...

【TypeScript类型系统解析:一次真实的类型检查修复经历】
TypeScript类型系统解析:一次真实的类型检查修复经历 在最近的管理系统开发过程中,我遇到了一个值得深入探讨的TypeScript类型问题。通过解决这个问题,我更深入地理解了TypeScript的类型系统工作原理,以及如何在Vue项目中正确处理…...

全视通无感护理巡视系统方案及产品,助力医院护士巡视病房到位
传统的护理工作中,护理巡视是一项重要且繁琐的任务。护士们需要根据不同的护理级别,定时对患者进行巡视,并手工填写巡视记录表,登记巡视时间、人员等信息。月末时,还需进行人工数据统计,这一过程不仅效率低…...

初识Redis · 命令、数据结构补充、协议
目录 前言: 数据结构补充 stream geospaital Hyperloglog bitmap bitfield 渐进式遍历命令等 认识Redis客户端及协议 前言: 在前文,我们总览一下,我们已经介绍了什么是Redis,Redis的应用场景是什么ÿ…...

DBA工作常见问题整理
MVCC机制: PostgreSQL的多版本并发控制(MVCC)是其核心特性之一,它允许数据库在高并发环境下保持高性能的同时提供事务隔离。 MVCC通过维护数据的多个版本实现: 读操作不阻塞写操作写操作不阻塞读操作避免使用锁实现并发控制 PostgreSQL的MVCC特点 写时…...
云转型(cloud transformation)——不仅仅是简单的基础设施迁移
李升伟 编译 云转型不仅仅是迁移基础设施,更是重塑企业运营、创新及价值交付的方式。它具有战略性、持续性,并影响着人员、流程和平台。 ☁️ 云转型涉及以下内容: 🔄 应用现代化——从单体架构转向微服务架构。 ⚙️ 运营自动…...

SpringBoot 定时任务
启用定时任务 首先确定需要启用定时任务的SpringBoot类,然后添加注解(EnableScheduling)以启用定时任务 package com.mt.visitorauth.anjian.service;import org.springframework.scheduling.annotation.EnableScheduling;EnableScheduli…...

常见的低代码策略整理
低代码策略通过简化开发流程、降低技术门槛、提升效率,帮助用户快速构建灵活可靠的应用。这些策略的核心优势体现在以下方面: 快速交付与降本增效 减少编码需求:通过可视化配置(如变量替换、表达式函数)替代传统编码…...
学习记录1)
HFSS(李明洋)学习记录1
Hfss操作记录 HFSS—solution type:选择求解类型Modeler—units:设置hfss内部的基本单位可选mm或者in(英寸)设置端口激励—波端口:右键selection model/face 选中对应的表面之后;右键assign excitation/po…...

泛目录站群技术架构演进观察:2025年PHP+Java混合方案实战笔记
https://www.zhanqun.xin/ 在参与某跨国电商平台SEO优化项目时,我们团队对市面上主流站群系统进行了为期半年的技术评估。最终选择部署的2025版无极多功能泛目录站群程序,其技术实现路径与工程化设计思路颇具参考价值,现整理关键发现如下。 …...

sentinel安装部署及测试--实践
一、什么是 Sentinel? Sentinel 是阿里巴巴开源的一款用于微服务流量控制和系统防护的中间件。它的主要功能包括: **流量控制(Flow Control):**限制系统的 QPS 或线程数,防止因流量过大导致系统崩溃。 **…...

Yocto项目实战教程 · 第4章:4.1小节元数据
🔍 B站相应的视频教程: 📌 Yocto项目实战教程-第4章-4.1小节-元数据 记得三连,标为原始粉丝。 在嵌入式Linux系统构建中,Yocto项目凭借其高度模块化、可配置的特性成为主流工具。而其背后的关键支撑之一,便…...

应用镜像是什么?轻量应用服务器的镜像大全
应用镜像是轻量应用服务器专属的,镜像就是轻量应用服务器的装机盘,应用镜像在原有的纯净版操作系统上集成了应用程序,例如WordPress应用镜像、宝塔面板应用镜像、WooCommerce等应用,阿里云服务器网aliyunfuwuqi.com整理什么是轻量…...

关于Java集合中对象字段的不同排序实现方式
📊 关于Java集合中对象字段的不同排序实现方式 #Java集合 #排序算法 #Comparator #性能优化 一、排序基础:两种核心方式对比 方式Comparable接口Comparator接口实现位置目标类内部实现独立类或匿名内部类排序逻辑自然排序(固定规则…...

2000-2017年各省发电量数据
2000-2017年各省发电量数据 1、时间:2000-2017年 2、来源:能源年鉴、国家统计局 3、指标:行政区划代码、城市、年份、发电量 4、范围:31省 5、指标说明:发电量是指在特定时间内,发电设备(如…...

第二十二天 - 安全加固实践 - 漏洞扫描工具开发 - 练习:SSH暴力破解防护
前言 随着网络安全威胁日益严峻,掌握基础防护技能成为开发者必备能力。本文将从零开始,通过安全加固实践、漏洞扫描工具开发、SSH暴力破解防护三个维度,带您快速构建安全防御体系。所有示例均附带完整代码,建议边阅读边实践。 一…...

【AI】React Native中使用Zustand框架及自动生成选择器
引言 随着React Native在移动应用开发领域的广泛应用,高效的状态管理变得尤为重要。Zustand作为一个轻量级的状态管理库,提供了简洁而强大的API,特别适合于React Native应用开发。本报告将详细介绍如何在React Native项目中使用Zustand框架&…...

MySQL GTID集合运算函数总结
MySQL GTID 有一些运算函数可以帮助我们在运维工作中提高运维效率。 1 GTID内置函数 MySQL 包含GTID_SUBSET、GTID_SUBTRACT、WAIT_FOR_EXECUTED_GTID_SET、WAIT_UNTIL_SQL_THREAD_AFTER_GTIDS 4个内置函数,用于GTID集合的基本运算。 1.1 GTID_SUBSET(set1,set2) …...

4.1.2 Redis协议与异步方式
文章目录 4.1.2 Redis协议与异步方式1. redis pipeline2. redis事务1. MULTI2. EXEC3. DISCARD4. WATCH 3. lua脚本1. lua基础语法2. Lua 脚本中访问 Redis 的方式3. Lua 脚本中的 KEYS 和 ARGV4、返回值5、错误处理EVALSHA 来代替 EVAL 4. ACID特性分析5. redis发布订阅1. 工作…...

ecovadis审核有什么原则?什么是ecovadis审核,有什么意义
EcoVadis审核概述 EcoVadis是一家全球知名的企业可持续发展评级机构,成立于2007年,旨在通过评估企业的环境(E)、社会(S)和治理(G)表现,帮助跨国公司管理供应链的可持续性…...

bitnet-b1.58-2B-4T和三进制
最近有个模型挺火啊现在都排进了HF排行榜的第四了 模型叫做microsoft/bitnet-b1.58-2B-4T 其实非常小的一个模型,只有2B,那这东西有多大意义呢? 它主要探索一个打法 也就是这篇论文 The era of 1-bit llms: All large language models ar…...

k8s报错kubelet.go:2461] “Error getting node“ err=“node \“k8s-master\“ not found“
问题 首先最初问题: [rootk8s-master ~]# kubectl get pods -owide --all-namespaces The connection to the server 192.168.2.129:6443 was refused - did you specify the right host or port?检查kubelet状态 查看kubelet status报找不到master节点 [rootk8…...

计算serise数据的唯一值数量
1. Series.unique() 功能:返回 Series 中所有唯一值的 数组(顺序按首次出现排列)。 返回值类型:numpy.ndarray(用户可能误认为是列表,但实际是 NumPy 数组)。 对 NaN 的处理:包含 …...

数组理论基础
什么是数组 在Java中,数组是一种数据结构,用来存储同一类型的多个元素。这些元素可以按照索引访问,方便对数据进行操作和管理。数组在编程中应用广泛,是一种基本且重要的数据结构。 数组的基本概念 1. 元素:数组中的…...

Linux操作系统--静态库和动态库的生成and四种解决加载找不到动态库的四种方法
目录 必要的知识储备: 生成静态库: 生成动态库: 解决加载找不到动态库的四种方法: 第一种:拷贝到系统默认的库路径 /usr/lib64/ 第二种:在系统默认的库路径/usr/lib64/下建立软链接 第三种࿱…...

安科瑞能源管理系统如何解决工业园区能源管理难,运维成本高的问题?
一、行业痛点:高能耗背后的“隐形炸弹 1. 能源管理粗放:水、电、气、冷热等多类型能源分散管理,人工抄表效率低,跑冒滴漏难追踪。 2. 电能质量隐患:变频设备引发谐波干扰,导致设备停机、电容器烧毁&#…...

大模型赋能工业制造革新:10个显效可落地的应用场景
在工业4.0的汹涌浪潮中,制造业正面临着前所未有的转型挑战。传统制造模式在效率、成本、质量等方面逐渐难以满足市场需求,企业急需借助新技术实现数字化转型,以提升自身竞争力。在此背景下,基于先进的数据分析技术、大模型、知识图…...

【android bluetooth 框架分析 02】【Module详解 4】【Btaa 模块介绍】
1. 背景 我们在上一篇文章中介绍 HciHal 模块时,有如下代码 // system/gd/hal/hci_hal_android_hidl.ccvoid ListDependencies(ModuleList* list) const {list->add<SnoopLogger>();if (common::init_flags::btaa_hci_is_enabled()) {list->add<ac…...

gitee新的仓库,Vscode创建新的分支详细步骤
第一步点击创建分支输入新分支的名字 第二步 第三步 第四步...
(五))
OpenHarmony - 小型系统内核(LiteOS-A)(五)
OpenHarmony - 小型系统内核(LiteOS-A)(五) 六、文件系统 虚拟文件系统 基本概念 VFS(Virtual File System)是文件系统的虚拟层,它不是一个实际的文件系统,而是一个异构文件系统之…...
解析)
Unity动态合批(Dynamic Batching)解析
什么是动态合批? 动态合批是Unity引擎的一项核心优化技术,用于减少绘制调用(Draw Calls)数量,提高游戏性能。它通过将多个使用相同材质的小型可移动物体的渲染操作合并为单个绘制调用,减轻CPU向GPU发送命令…...
vs 生成器(Generator))
【Python】迭代器(Iterator)vs 生成器(Generator)
迭代器(Iterator) vs 生成器(Generator) 1.迭代器(Iterator)1.1 是什么?1.2 示例1.3 适用场景 2.生成器(Generator)2.1 是什么?2.2 示例2.3 适用场景 3.迭代器…...

el-input 限制只能输入负数、正数或2位小数的数值
需求 el-input需要指定输入格式,当键盘事件触发时限制只能输入负数、正数或2位小数的数值。 解决方案 自定义校验数字输入的键盘事件方法函数。 具体实现步骤 1、创建验数字输入的键盘事件方法 /*** 校验数字输入的键盘事件* param {Event} event - 键盘事件对…...

对话框类别组件编写
形如如图所示的对话框的编写 一、基本组件的定义 <template><div><el-dialogclass"cust-dialog":title"title":model-value"show":show-close"showClose":top"toppx":width"widthpx":close-on-…...

ICMAN防水触摸芯片 - 复杂环境下精准交互,提升触控体验
▍核心优势 ◆ 超强抗干扰能力 ◆ 工业级设计,一致性和稳定性好 ▍提供场景化解决方案 【智能厨电矩阵】抽油烟机档位调节 | 电磁炉火力触控 | 洗碗机模式切换 【卫浴设备方案】淋浴房雾化玻璃控制 | 智能马桶触控面板 | 浴缸水位感应 【工业控制应用】仪器仪…...

深度剖析:生成式人工智能备案和登记的关键差异
在人工智能技术日新月异的当下,生成式人工智能以前所未有的态势广泛渗透至各个领域,从内容创作到智能客服,从图像生成到数据分析,其应用场景正呈指数级拓展。2024 年,网信部门协同相关部门,依据《生成式人工…...

kotlin + spirngboot3 + spring security6 配置登录与JWT
1. 导包 implementation("com.auth0:java-jwt:3.14.0") implementation("org.springframework.boot:spring-boot-starter-security")配置用户实体类 Entity Table(name "users") data class User(IdGeneratedValue(strategy GenerationType.I…...

d3.js绘制组合PCA边缘分布图
用d3.js研发了个组合PCA边缘分布图; 组合PCA边缘分布图中包括pca散点图、散点图可根据数据自动分为连续型和离散型、还有散点的各种配置、边缘有箱线边缘、密度边缘、柱状边缘一个各个边缘的配置等等,大部分你能想到的配置都是自行传参调整的࿰…...

开源语音合成模型SparkTTS使用
一、环境配置 git clone https://github.com/SparkAudio/Spark-TTS.git pip install -r requirements.txt 二、模型下载 从modelscope进行下载,pip install modelscope 创建一个download.py import torchfrom modelscope import snapshot_downloadsnapshot_dow…...

课程9. 数据降维
课程9. 数据降维 维度灾难奇异值分解SVD 变换SVD 的几何意义 SVD分解应用示例图像压缩文本分析推荐系统中的应用* 主成分分析PCA演示使用 PCA 降低多元数据的维数PCA 说明单词的语义相似性 t-SNE 维度灾难 机器学习和数据科学中的关键问题之一是数据高维性问题。我们已经遇到过…...

24-25【动手学深度学习】AlexNet + Vgg
1. AlexNet 1.1 原理 1.2 代码 import torch from torch import nn from d2l import torch as d2lnet nn.Sequential(nn.Conv2d(1, 96, kernel_size11,stride4, padding1), nn.ReLU(),nn.MaxPool2d(kernel_size3, stride2),nn.Conv2d(96, 256, kernel_size5, padding2), nn.…...

1.Axum 与 Tokio:异步编程的完美结合
摘要 深入解析 Axum 核心架构与 Tokio 异步运行时的集成,掌握关键原理与实践技巧。 一、引言 在当今的软件开发领域,高并发和高性能是衡量一个系统优劣的重要指标。对于 Web 服务器而言,能够高效地处理大量并发请求是至关重要的。Rust 语言…...
、数据湖与数据运河)
快速认识:数据库、数仓(数据仓库)、数据湖与数据运河
数据技术核心概念对比表 概念核心定义核心功能数据特征典型技术/工具核心应用场景数据库结构化数据的「电子档案柜」,按固定 schema 存储和管理数据,支持高效读写和事务处理。实时事务处理(增删改查),确保数据一致性&…...

【Linux】第十章 配置和保护SSH
1. 简单说下ssh如何实现用户的免密登录? (1)生成公钥和私钥:使用 ssh-keygen -t rsa 命令,在客户端(即你登录的机器)上生成一对密钥——公钥(~/.ssh/id_rsa.pub)和私钥&…...

量子计算:开启未来科技之门的钥匙
在当今科技飞速发展的时代,量子计算正逐渐从实验室走向实际应用,成为全球科技领域的焦点之一。它有望为众多行业带来前所未有的变革,从密码学、药物研发到金融风险评估等,量子计算的潜力不可限量。 一、量子计算的原理 量子计算基…...

基础知识 - 结构体
1、结构体类型与结构体变量 1.1 结构体的定义 结构体是一种自定义的数据类型,它把多个不同类型的变量封装在一起,形成一个新的复合数据类型。可以定义该结构体类型的变量,与使用 int 定义变量的方法相同 结构体是一些值的集合,这…...
)
uniapp上传图片时(可选微信头像、相册、拍照)
参考文献:微信小程序登录——头像_onchooseavatar-CSDN博客 <button open-type"chooseAvatar" chooseavatar"onChooseAvatar"> </button>onChooseAvatar(e) {uni.showLoading({title: 上传中...,mask: true});uni.uploadFile({url…...

2025年4月16日华为笔试第二题200分
📌 点击直达笔试专栏 👉《大厂笔试突围》 💻 春秋招笔试突围在线OJ 👉 笔试突围OJ 02. 智慧旅游路线规划 问题描述 LYA正在开发一款智慧旅游APP,该APP需要为游客规划城市景点之间的最佳路线。城市有 N N...

面试题之高频面试题
最近开始面试了,410面试了一家公司 针对自己薄弱的面试题库,深入了解下,也应付下面试。在这里先祝愿大家在现有公司好好沉淀,定位好自己的目标,在自己的领域上发光发热,在自己想要的领域上(技术…...