食品计算—Coarse-to-fine nutrition prediction
🌟🌟 欢迎来到我的技术小筑,一个专为技术探索者打造的交流空间。在这里,我们不仅分享代码的智慧,还探讨技术的深度与广度。无论您是资深开发者还是技术新手,这里都有一片属于您的天空。让我们在知识的海洋中一起航行,共同成长,探索技术的无限可能。
🚀 探索专栏:学步_技术的首页 —— 持续学习,不断进步,让学习成为我们共同的习惯,让总结成为我们前进的动力。
🔍 技术导航:
- 人工智能:深入探讨人工智能领域核心技术。
- 自动驾驶:分享自动驾驶领域核心技术和实战经验。
- 环境配置:分享Linux环境下相关技术领域环境配置所遇到的问题解决经验。
- 图像生成:分享图像生成领域核心技术和实战经验。
- 虚拟现实技术:分享虚拟现实技术领域核心技术和实战经验。
🌈 非常期待在这个数字世界里与您相遇,一起学习、探讨、成长。不要忘了订阅本专栏,让我们的技术之旅不再孤单!
💖💖💖 ✨✨ 欢迎关注和订阅,一起开启技术探索之旅! ✨✨
文章目录
- 1. 背景介绍
- 2. 相关工作
- 2.1 膳食营养预测:
- 2.2 标签平滑策略:
- 2.3 粗到细的预测范式:
- 3. 方法
- 3.1 粗到细预测(Coarse-to-Fine Prediction)
- 3.2 线性标签平滑(Linear Label Smooth)
- 3.3 结构损失(Structure Loss)
- 3.4 训练与推理(Training and Inference)
- 4. 实验
- 4.1 实验设置
- 4.2 与当前最优方法对比
- 4.3 消融实验
- 4.4 定性分析
- 5. 总结
1. 背景介绍
Wang B, Bu T, Hu Z, et al. Coarse-to-fine nutrition prediction[J]. IEEE Transactions on Multimedia, 2023, 26: 3651-3662.
🚀以上学术论文翻译由ChatGPT辅助。
健康的饮食摄入对生活质量有广泛影响,而营养预测在饮食辅助决策中起着重要作用。
给定一张食物图像,现有的营养预测方法通常直接回归营养成分含量。
然而,由于食物图像中存在诸如拍摄角度和光照条件等复杂变化,直接回归营养含量面临巨大挑战。
食物图像数据的复杂性导致输入空间具有高维且特征丰富的特性,这使得传统回归模型难以高效地进行搜索和优化。
因此,直接回归的范式通常会产生不准确的营养预测结果。
为缓解预测过程中的歧义问题,我们提出通过将直接回归分解为两个步骤来缩小模型预测的搜索空间:
首先粗略选择营养范围,然后精细地回归预测值,从而构建一个粗到细的营养预测范式。
虽然第一步的粗略预测(即从一系列范围区间中选择一个区间)可以被建模为标准的分类问题,但它具有一个显著特征:越接近真实区间,在训练阶段所受的惩罚就越小。
然而,大多数现有方法忽略了这一现象,因此我们在营养预测任务中专门设计了线性平滑标签(linearly smoothed label),以刻画各候选区间到真实区间的相对距离,从而带来显著的性能提升。
此外,我们通过将一维标签扩展到二维空间,对所有区间进行成对比较,提出了一种结构损失(structure loss),以更有效地引导区间选择过程。
得益于缩小后的决策空间,营养预测问题得以有效优化,所提出的方法在 ECUSTFD、VFD 和 Nutrition5K 三个基准数据集上取得了有前景的结果,充分证明了该结合线性平滑结构损失的粗到细预测范式的有效性。
在当代社会,对高质量生活的追求使得保持健康饮食成为人们广泛关注的问题。
然而,碳水化合物和脂肪摄入过量的现象普遍存在,导致超重人群和相关疾病的增加。
此外,追求健美体魄的人也常常高度关注自身的营养摄入 [1]。
因此,准确识别食物的营养成分成为一项紧迫的需求。
本研究聚焦于营养预测任务 [2],并致力于提出一种高效的方法来估算食物图像中的营养含量。
近年来,营养预测任务引起了研究界的广泛关注。
Shroff 等人 [3] 是该领域的先驱之一,提出了识别食物组成并进一步预测卡路里的方法。
后续研究 [4]-[7] 基于这一思路,借助计算机视觉技术来估计食物图像中的热量含量。
部分研究 [8]-[12] 利用 RGB 图像与深度图相结合,预测食物的体积或质量,其中深度图被用于构建几何模型或还原三维参数。
还有一些工作 [13]-[17] 探索了多视角图像,如不同角度拍摄的图像、视频帧以及餐前与餐后图像,以获取互补的食物信息。
尽管深度图和多视角图像在某些基准数据集上能提升营养预测的精度,但收集这类数据在实际中较为不便。
相比之下,仅使用单张 RGB 图像来进行营养成分预测则是一种更加实用的方法。
近期已有研究 [2], [18]-[20] 尝试直接从食物图像中回归营养成分,如图 1 所示。
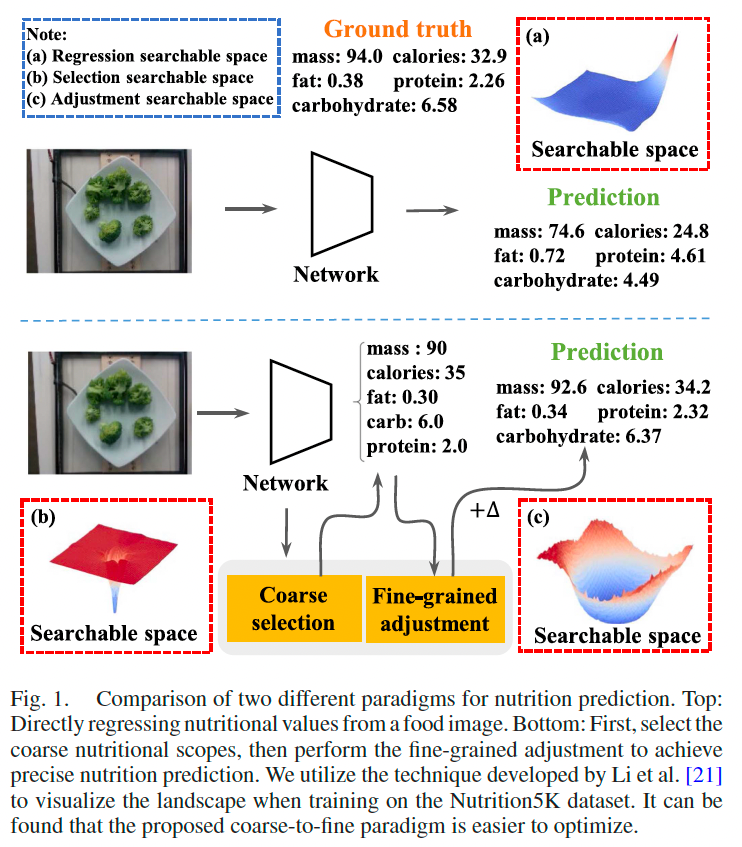
然而,直接回归范式在实际中难以取得良好效果,其核心问题在于“歧义挑战(ambiguity challenge)”。
在机器学习中,歧义可能体现在多种形式,如类别歧义、数据歧义、特征歧义、模型歧义和标签歧义等。
营养预测任务主要受到“数据歧义”的影响。
不同于数据不确定性与模型不确定性 [22]-[24],歧义挑战意味着直接回归往往难以获得精准结果。
食物图像的外观特征可能受到诸多因素影响,如拍摄角度、距离以及食材之间的遮挡,
这会导致两张外观相似的图像实际上可能具有截然不同的营养含量。
我们将模型对图像的可能预测值的集合称为“决策空间(decision space)”。
直接回归任务的难点在于其试图从庞大的决策空间中确定一个具体的数值,
图 1(a) 形象地展示了直接回归法的搜索空间,其过于平坦,不利于模型学习。
为了解决上述问题,已有研究尝试引入多任务学习、迁移学习、带注意力机制的深度架构等方法,
它们在提升营养估计性能方面表现出了一定的前景。
但仍需进一步研究以应对大规模决策空间及图像外观歧义的问题。
本研究提出了一种新颖的“粗到细(coarse-to-fine)”预测范式来引导模型学习过程,从而提高营养成分预测的精度。
该预测范式包括两个阶段:粗略选择(coarse selection)和细粒度调整(fine-grained adjustment)。
第一步通过区间选择过程确定大致的营养范围,第二步则进一步预测偏移量以精细化结果。
这一分解策略有效将原本困难的直接回归问题转化为可求解的两步流程,显著缩小了搜索空间,并提升了预测精度。
这一方法在营养成分预测领域中具有重要意义,有望为长期存在的食物图像营养估计难题提供有效解决方案。
尽管 coarse-to-fine 范式在目标检测 [25]、图像去模糊 [26]、视觉-语言预训练 [27] 等领域已有所应用,
但该范式在应对营养预测中的严重歧义问题方面尚未得到充分探索。
在我们提出的 coarse-to-fine 营养预测范式中,首要挑战是如何准确地选择 coarse scope。
虽然这一步类似于传统的分类问题,但它本质上包含了“结构化信息”:
即预测区间越接近真实区间,其应受到的惩罚应越小。
传统分类方法对所有错误预测一视同仁,忽视了这一结构信息。
为充分利用这一结构信息,我们将标签平滑策略(label smoothing)扩展为线性标签平滑(linear label smooth),
并为每个区间设定专属标签。
此外,我们还提出了结构化线性平滑损失(structural linear smoothing loss),
将一维标签扩展为二维空间,通过成对比较敏锐地捕捉结构信息。
如图 1(b) 所示,所提出结构损失构建的搜索空间包含全局最小点,从而更易于优化。
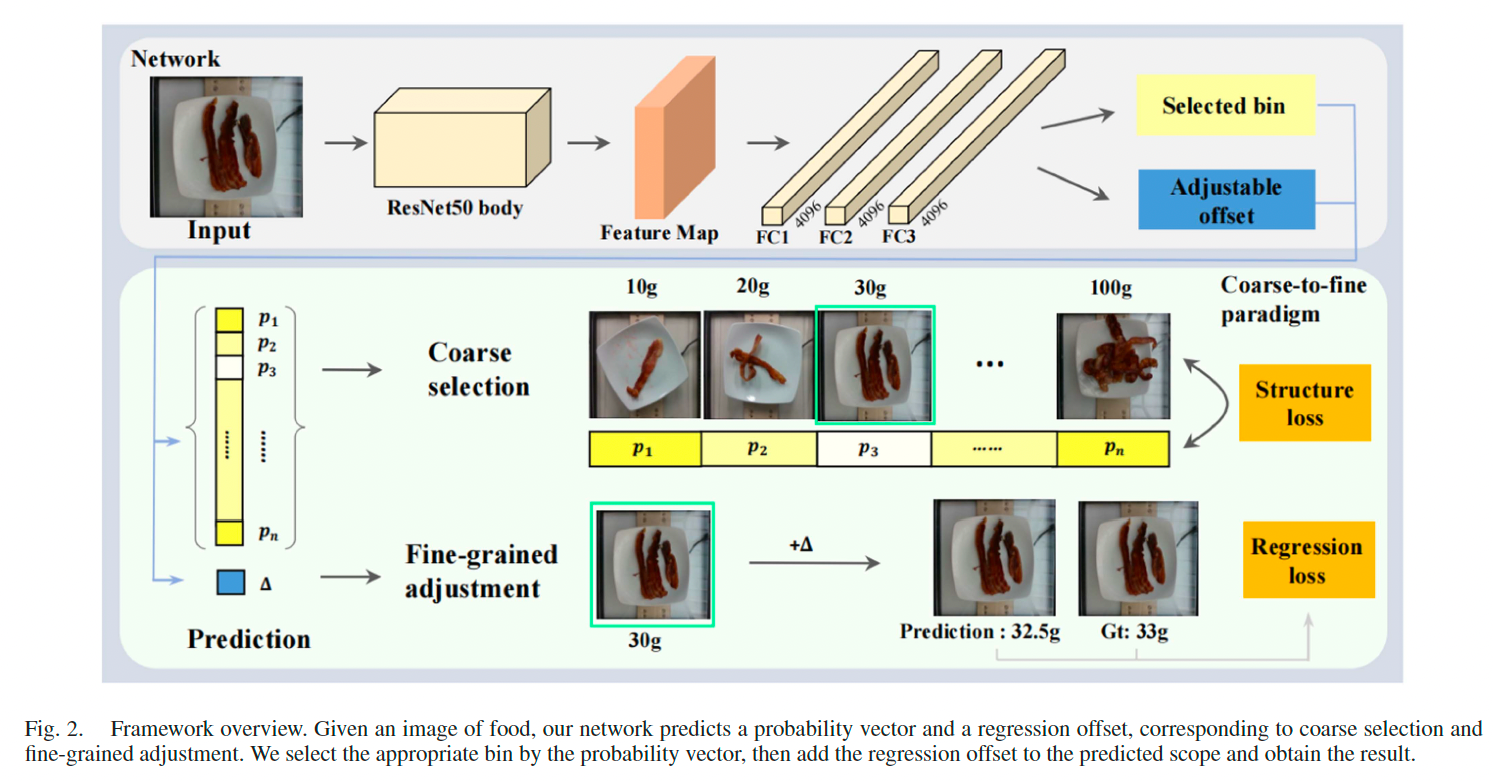
该方法整体流程如图 2 所示,由两步组成:区间选择以确定大致范围,以及偏移量预测以进一步精细估算。
本研究对营养预测领域的主要贡献如下:
- 我们识别出传统直接回归范式在营养预测任务中面临的“歧义挑战”,并提出粗到细预测范式以改进预测流程;
- 在区间选择过程中,我们挖掘出远超传统分类问题的结构信息,并设计结构线性平滑模块引导该阶段的学习;
- 我们的方法在 Nutrition5K [2]、ECUSTFD [4] 和 VFD [28] 三个基准数据集上取得了出色表现;
例如,在 Nutrition5K 上,预测质量的平均误差从 58.5% 降低到 19.7%,验证了该方法在提高营养预测精度方面的有效性,
同时也代表着该领域的重要进步。
2. 相关工作
随着人们对膳食营养认知的提高,越来越多的人希望能够更精准地控制自己的营养摄入。
已有不少前人工作在该领域取得成果,主要在于所使用的图像类型和所预测的食物属性不同。
2.1 膳食营养预测:
-
1)无体积或重量预测的营养估计。
在早期,一些研究无需食物重量或体积信息即可预测营养成分。
Shroff 等人 [3] 最早通过查表的方式实现营养预测。
类似地,Pouladzadeh 等人 [29] 和 Ege 等人 [30] 也采用类比方法进行营养估计。
但在现实生活中,人们通常需要预测任意重量的食物对应的营养成分。 -
2)通过深度图或分布图预测重量或体积。
Chen 等人 [8]、Liao 等人 [31]、He 等人 [9] 和 Fang 等人 [12] 等工作通过生成深度图或能量分布图来估计质量或体积。
例如,Chen 等人 [8] 使用深度摄像头获取深度图并根据距离计算重量;
He 等人 [9] 利用 GAN 网络生成深度图,Fang 等人 [12] 则进一步借助 cGAN 网络获取能量分布图。
但这类图像通常需要额外的设备或处理手段。 -
3)通过多视角图像预测重量或体积 [13], [32], [33], [34], [35], [36]。
Zhu 等人 [32] 描述了多角度的食物分割信息,
Chae 等人 [34] 利用食物特定的形状模板估算体积,
Fang 等人 [13] 则基于估计的三维参数来预测体积。
然而这些方法通常依赖变化较小的数据集,适应性有限。 -
4)多种营养成分的预测。
如 Nutrition5K [2]、GoFood [37]、Ruede 等人 [6]、Chen 等人 [38] 和 Situju 等人 [39],尝试预测多种营养成分。
其中,Thames 等人 [2] 创建了营养多维度的数据集并开展多路径预测;
GoFood [37] 使用三维重建算法进行预测;
Ruede 等人 [6] 引入多任务学习框架实现多营养内容预测。
我们的工作也沿用此思路,从单张 RGB 图像中提取多种营养含量,并获得更高的准确率。 -
5)菜谱预测。
一些研究如 [40], [41], [42] 并不直接输出营养数值,而是通过图像检索对应的菜谱实现间接营养估计。
2.2 标签平滑策略:
标签平滑是深度学习中广泛应用的提升性能的技术 [43]。
与传统的 one-hot 标签相比,标签平滑用一个与均匀分布混合的软标签替代原始标签。
已有大量研究探索标签平滑的原理与应用 [44], [45],覆盖图像分类 [46]、语音识别 [47] 等多个任务。
近年来,其在计算机视觉任务中也变得常见。
例如,Wang 等人 [48] 在车辆重识别中提出了带有跨域适配的标签平滑方法;
Su 等人 [49] 为 anchor-free 目标检测引入了动态标签平滑分配策略;
Zhou 等人 [50] 在头部姿态估计中使用高斯标签平滑以抑制标注噪声。
本研究提出一种新的线性标签平滑(linear label smooth),用于引导模型预测,形式上具有结构性表达的优势。
2.3 粗到细的预测范式:
本研究采用的预测流程可视作一个两阶段过程:先进行粗略选择,再进行精细调整,
这与许多阶段性处理任务的方法类似。
Fleuret 等人 [51] 首先构建了从粗到细的检测树,进行人脸轮廓的粗检,随后被多项研究所改进 [52], [53]。
Zhu 等人 [53] 首先进行形状的粗检,再精确定位关键点。
在识别与定位问题中也经常使用这种分阶段思想 [54], [55]。
例如 Sarlin 等人 [54] 先利用全局特征做粗定位,再用局部特征做配准。
此外,这一思想也被应用于图像超分辨率任务中 [56], [57],如 Zhang 等人 [56] 提出用于超分辨率的 coarse-to-fine 框架。
一些其他工作 [58], [59] 通过多次修正迭代预测,例如 Newell 等人 [58] 多次上下采样以进行人体姿态检测,
Bai 等人 [59] 则利用模型输出来迭代修正标注错误。
在食物营养预测方面,Yang 等人 [28] 使用了两阶段方法进行体积预测,但与我们的方法存在显著差异:
- 首先,他们基于参考类别构建模型,而我们选择真实区间并结合结构线性平滑损失提高精度;
- 其次,他们通过参考体积调整预测值,而我们直接回归偏移量;
- 最后,他们通过两步的乘积得到结果,而我们则在粗预测基础上进行微调。
Hou 等人 [60] 也提出结合粗分支和精分支进行食物分类任务,但其核心是两分支的融合用于细粒度分类,
而我们的研究重点在于通过“分类+回归”的范式来缓解营养预测难题。
3. 方法
营养预测任务的目标是准确地估计给定食物的营养含量。设有一个包含 N N N 个食物图像的数据集 X = { x i } i = 1 N X = \{x_i\}_{i=1}^N X={xi}i=1N,对应的营养标签为 Y = { y i } i = 1 N Y = \{y_i\}_{i=1}^N Y={yi}i=1N,其中每个 y i y_i yi 代表食物的营养属性,如热量、脂肪、蛋白质等。为简洁起见,我们仅考虑单一营养维度。
我们提出一种结合结构化线性平滑损失的粗到细(coarse-to-fine)预测范式。具体地,模型首先进行粗粒度的区间选择,再进行细粒度的值回归。
3.1 粗到细预测(Coarse-to-Fine Prediction)
等量区间划分(Equal-amount scope division):
与直接回归方式不同,我们将可能的营养范围划分为多个子区间(scopes),以缩小决策空间,从而缓解营养预测问题。
假设目标营养值的最小值为 y m i n y_{min} ymin,最大值为 y m a x y_{max} ymax,将其划分为 p p p 个等间距区间,每个区间的宽度为:
d = y m a x − y m i n p d = \frac{y_{max} - y_{min}}{p} d=pymax−ymin
第 s s s 个区间的范围为:
I s = [ y m i n + ( s − 1 ) ⋅ d , y m i n + s ⋅ d ] , s = 1 , 2 , … , p (1) I_s = [y_{min} + (s-1)\cdot d,\; y_{min} + s \cdot d],\quad s=1,2,\dots,p \tag{1} Is=[ymin+(s−1)⋅d,ymin+s⋅d],s=1,2,…,p(1)
由于营养值分布不均,各区间的样本数量可能严重不平衡,训练时容易被样本多的区间主导。为解决这一问题,我们采用等量划分策略:
将所有 N N N 个营养值升序排列为 [ y ^ 1 , y ^ 2 , . . . , y ^ N ] [\hat{y}_1, \hat{y}_2, ..., \hat{y}_N] [y^1,y^2,...,y^N],将其均匀划分为 p p p 份,每份包含 N p \frac{N}{p} pN 个样本,对应第 i i i 个区间:
x ^ i = [ y ^ ( i − 1 ) ⋅ N / p , y ^ i ⋅ N / p ] , i = 1 , 2 , … , p (2) \hat{x}_i = [\hat{y}_{(i-1)\cdot N/p}, \; \hat{y}_{i\cdot N/p}], \quad i = 1,2,\dots,p \tag{2} x^i=[y^(i−1)⋅N/p,y^i⋅N/p],i=1,2,…,p(2)
用划分向量 V = [ x ^ 1 , x ^ 2 , . . . , x ^ p ] V = [\hat{x}_1, \hat{x}_2, ..., \hat{x}_p] V=[x^1,x^2,...,x^p] 表示所有区间。
每张食物图像的营养值 y y y 被转为 one-hot 标签 V n = [ k 1 , k 2 , . . . , k p ] V_n = [k_1, k_2, ..., k_p] Vn=[k1,k2,...,kp],其中 k p ∈ { 0 , 1 } k_p \in \{0, 1\} kp∈{0,1},并记录偏移值 δ \delta δ,即营养值与区间起始值之差。
粗到细范式:
我们将直接回归分解为两个阶段:
- 粗选阶段:从概率向量中选出最大值对应的区间;
- 细调阶段:引入回归函数 f ( δ ) f(\delta) f(δ) 对选中的区间进行精细化修正:
f ( δ ) = ϕ s 2 ⋅ exp ( λ ⋅ δ ) (3) f(\delta) = \frac{\phi_s}{2} \cdot \exp(\lambda \cdot \delta) \tag{3} f(δ)=2ϕs⋅exp(λ⋅δ)(3)
其中 ϕ s \phi_s ϕs 为选中区间宽度, λ \lambda λ 为可学习参数, δ \delta δ 为网络输出。最终预测值为该区间起始值与偏移量之和。
3.2 线性标签平滑(Linear Label Smooth)
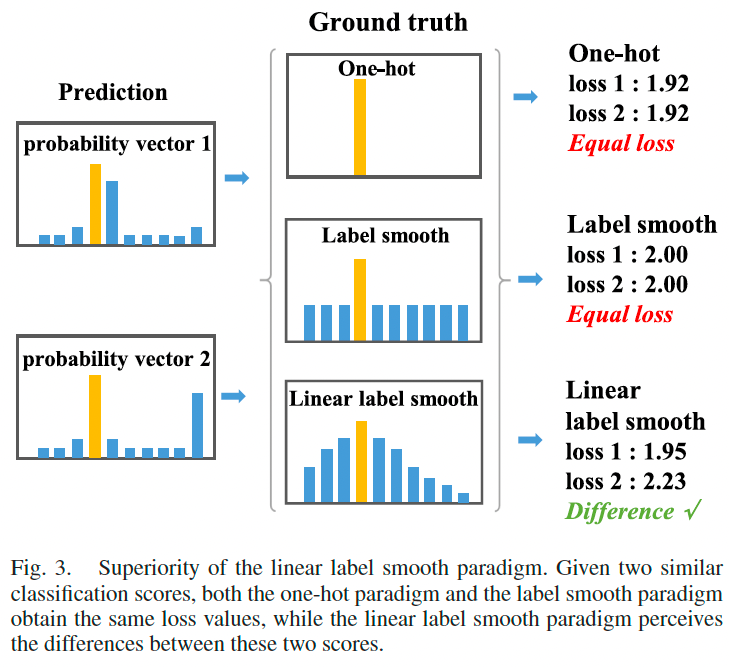
由于距离真实区间越近的预测应受到的惩罚越小,但 one-hot 标签无法体现这一结构信息。即便两个预测向量的方向不同,它们与 one-hot 标签计算出的交叉熵损失仍相同。
为缓解该问题,我们引入标签平滑技术。传统平滑形式如下:
M i = { 1 − τ if i = y τ p − 1 otherwise (4) M_i = \begin{cases} 1 - \tau & \text{if } i = y \\ \frac{\tau}{p - 1} & \text{otherwise} \end{cases} \tag{4} Mi={1−τp−1τif i=yotherwise(4)
其中 τ \tau τ 为超参数, p p p 为区间数。该方法虽能改进效果,但仍未表达结构扩散信息。
于是我们提出线性标签平滑方法,引入变量 ϕ i \phi_i ϕi 表示第 i i i 个位置与真实位置 y y y 的距离关系:
ϕ i = max ( y , p − y ) − ∣ i − y ∣ (5) \phi_i = \max(y, p - y) - |i - y| \tag{5} ϕi=max(y,p−y)−∣i−y∣(5)
得到新的平滑标签:
M i = { 1 − τ if i = y ϕ i ⋅ τ ∑ i = 1 p ϕ i − ϕ y otherwise (6) M_i = \begin{cases} 1 - \tau & \text{if } i = y \\ \phi_i \cdot \frac{\tau}{\sum_{i=1}^p \phi_i - \phi_y} & \text{otherwise} \end{cases} \tag{6} Mi={1−τϕi⋅∑i=1pϕi−ϕyτif i=yotherwise(6)
该向量使结构信息线性扩散,有助于更准确地指导预测方向。
3.3 结构损失(Structure Loss)
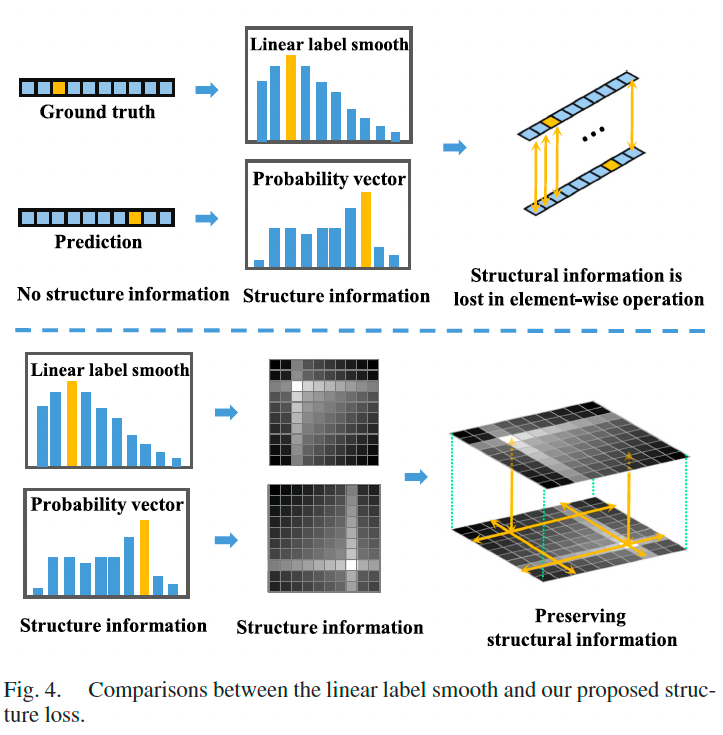
虽然线性标签平滑改善了一维结构信息表达,但它仅进行一对一比较,无法表达向量内部所有元素之间的结构关系。
因此我们将标签空间从 1D 拓展至 2D,引入结构矩阵以实现所有元素之间的一对多比较:
给定预测向量 V m = [ v 1 , . . . , v p ] ∈ R 1 × p V_m = [v_1, ..., v_p] \in \mathbb{R}^{1 \times p} Vm=[v1,...,vp]∈R1×p,定义结构矩阵为:
U i = V m + v i (7) U_i = V_m + v_i \tag{7} Ui=Vm+vi(7)
A = { U i } i = 1 p ∈ R p × p (8) A = \{U_i\}_{i=1}^p \in \mathbb{R}^{p \times p} \tag{8} A={Ui}i=1p∈Rp×p(8)
其中 A A A 为结构矩阵,第 i i i 行 U i U_i Ui 是原向量与第 i i i 个元素的广播和。
最终,结构损失为预测结构矩阵 A p A_p Ap 与真实结构矩阵 A g A_g Ag 的 L 1 L_1 L1 距离:
L s = ∥ A p − A g ∥ 1 (9) L_s = \|A_p - A_g\|_1 \tag{9} Ls=∥Ap−Ag∥1(9)
我们将结构矩阵与线性标签平滑结合,提出结构线性平滑损失,通过径向扩散表达结构信息,解决传统方法中潜在的非线性关系缺失问题。
3.4 训练与推理(Training and Inference)
训练阶段:
- 生成结构矩阵并计算结构损失 L s L_s Ls;
- 使用公式 (3) 计算回归偏移量并构建回归损失:
L r = 1 N ∑ i = 1 N ∣ f ( δ i ) − q i ∣ (10) L_r = \frac{1}{N} \sum_{i=1}^N |f(\delta_i) - q_i| \tag{10} Lr=N1i=1∑N∣f(δi)−qi∣(10)
- 总损失为:
L = α ⋅ L s + β ⋅ L r (11) L = \alpha \cdot L_s + \beta \cdot L_r \tag{11} L=α⋅Ls+β⋅Lr(11)
其中 α \alpha α 和 β \beta β 为损失加权系数。
推理阶段:
- 对输出概率向量 P n P_n Pn 做 softmax;
- 选出最大概率对应的区间;
- 用公式 (3) 计算偏移量;
- 将区间起始值与偏移值相加,得到最终营养预测结果。
最终以平均绝对误差(Mean Average Error)作为评价指标。
4. 实验
4.1 实验设置
数据集: 我们在三个基准数据集上进行了实验评估:Nutrition5K [2]、ECUSTFD [4] 和 VFD [28]。Nutrition5K 数据集包含 5000 道真实菜品,含 3500 张 RGB 图像及配料和菜品的注释,可用于营养预测。ECUSTFD 数据集包括 19 类食物,共计 2978 张图像,并提供食物体积注释。该数据集模拟了多种光照条件下的真实就餐环境。VFD 数据集分为 VFDL-15 和 VFDS-15 两个子集,各包含 15000 张图像,二者在食物体积上有差异。由于 VFD 是通过计算机仿真生成的,未受现实环境干扰,因此我们的方法在该数据集上的精度更高。
评估指标: 在 Nutrition5K 上,我们使用 MAE 和 pMAE 两个指标评估预测性能;在另外两个数据集上,仅使用 pMAE 以保证公平比较。pMAE 的定义如下:
M A E j = 1 N ∑ i = 1 N ∣ y ^ i j − y i j ∣ (12) MAE_j = \frac{1}{N} \sum_{i=1}^{N} |\hat{y}_i^j - y_i^j| \tag{12} MAEj=N1i=1∑N∣y^ij−yij∣(12)
其中 y ^ i j \hat{y}_i^j y^ij 和 y i j y_i^j yij 分别表示第 j j j 个营养成分的预测值与真实值。
实现细节: 实验在单张 NVIDIA 2080Ti GPU 上进行,使用 PyTorch 框架 [61]。采用 ResNet-50 [62] 作为主干编码器,并在其后添加三层 4096 维的全连接层,用于输出 N N N 维的概率向量与偏移值。输入图像裁剪为 256 × 256 256 \times 256 256×256。由于设备限制,batch size 设置为 64,优化器采用 Adam [63],初始学习率为 1 e − 4 1e^{-4} 1e−4。损失函数中 α \alpha α 和 β \beta β 均设为 1。数据划分方面,Nutrition5K 采用最后一次划分方式,其中 10% 用作测试集,其余为训练集;ECUSTFD 和 VFD 则使用其原始划分方式。由于等量划分策略仅基于训练集执行,因此不会发生信息泄露。
4.2 与当前最优方法对比
我们的方法应用于 Nutrition5K 数据集中的全部营养成分或属性预测任务,并在 ECUSTFD 和 VFD 数据集上执行体积预测,以便与现有最优方法进行公平比较。
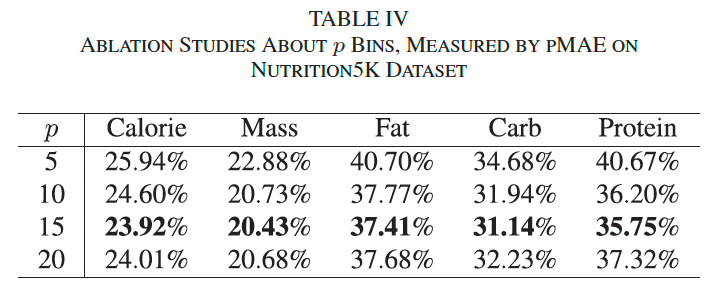
Nutrition5K: 预测了热量、质量、脂肪、碳水化合物和蛋白质五种成分。表 III 显示了我们与 Thames 等人 [2] 的方法的比较。我们与其基础架构进行对比是公平的,因为两者仅使用顶视图图像进行营养预测,而其他设定则依赖旋转视频、体积、深度等额外信息。
表 III 显示我们在所有营养成分上均取得了更高的精度,质量预测方面提升最显著,pMAE 降至 19.7%,在脂肪、碳水化合物和蛋白质上 pMAE 下降超过 25%。此外我们尝试使用旋转视频进行预测,但未获得更优效果,可能因为顶视图提供了更完整的信息。

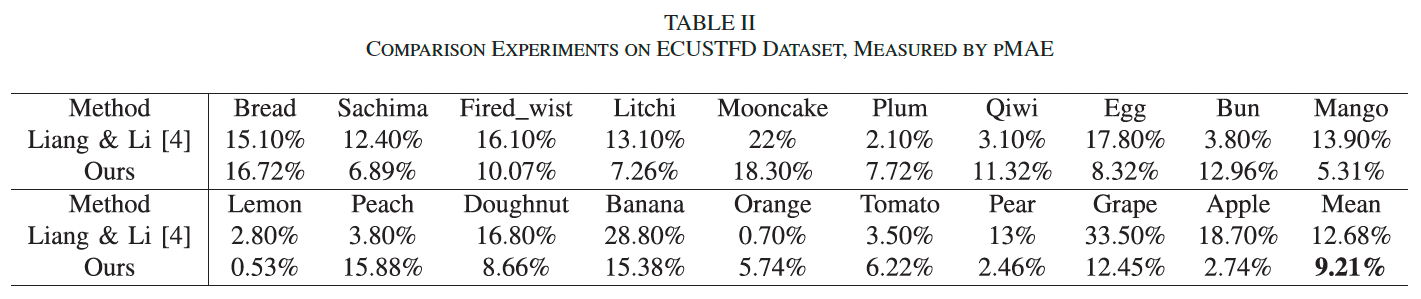
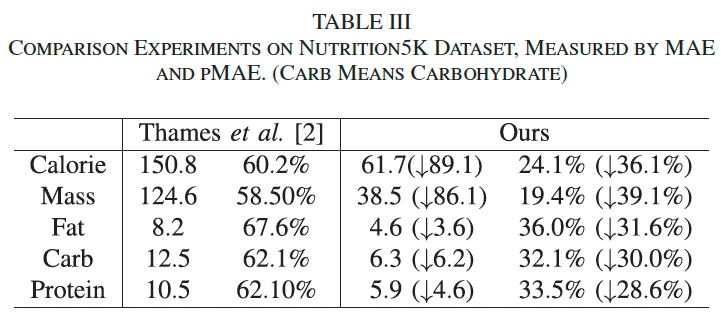
ECUSTFD: 使用其划分方式进行体积预测,并将 Liang & Li [4] 图示结果转为表格进行比较,仅使用 pMAE 评估预测效果。
表 II 显示,我们在大多数食物类别上显著优于对比方法,特别是在苹果、葡萄、梨等类别上 pMAE 下降超过 10%,总平均 pMAE 降至 9.21%。
VFD: 在 VFDL-15 与 VFDS-15 两个子集上进行体积预测。Yang 等人 [28] 将其划分为 15 组,体积从 200ml 到 3400ml 不等。表 I 显示我们在大多数分组中均表现更佳,尤其在第 1、8、11、15 类上提升明显,分别将精度提升至 6.9% 与 6.4%。
4.3 消融实验
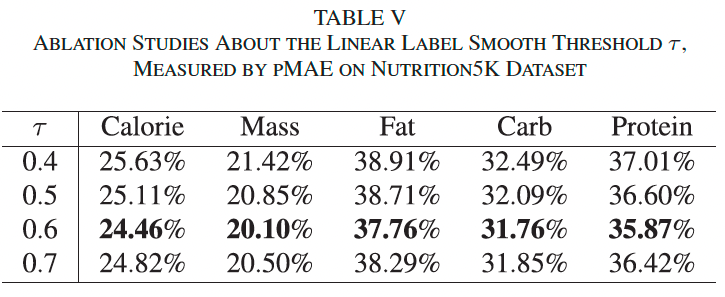
我们在 Nutrition5K 数据集上进行消融实验,以探究分箱数量和线性标签平滑的阈值 τ \tau τ 对 pMAE 的影响,并比较不同损失函数组合的效果。
超参数消融: 表 IV 显示在分箱数为 15 时,各项 pMAE 最小。表 V 显示,当 τ = 0.6 \tau = 0.6 τ=0.6 时效果最佳,过大或过小都会影响结构矩阵的信息表达能力。
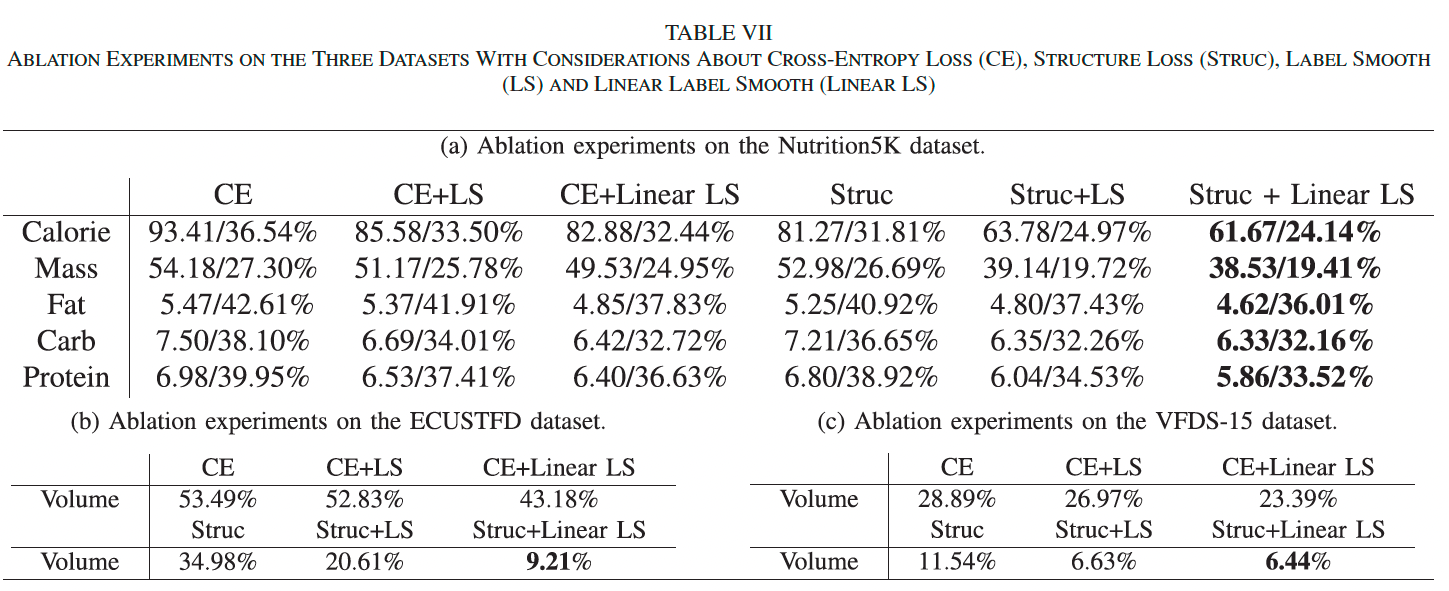
不同损失与组合: 我们在三个数据集上对比了 CE、标签平滑(Ls)、线性标签平滑(Linear Ls)与结构损失(Struc)在交叉熵基础上的效果。表 VII(a)、(b)、© 显示:结构损失与线性标签平滑组合效果最佳,显著优于传统交叉熵或单一平滑方法。
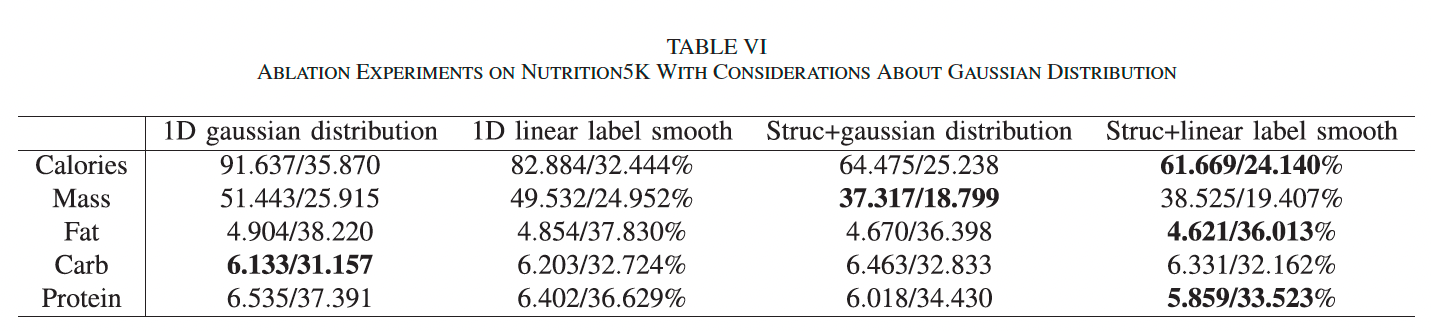
我们进一步与一维高斯标签平滑进行比较(表 VI),发现线性标签平滑与其在 1D 空间表现相当,而结构损失可提升两者性能。由于线性标签平滑实现更简洁,因此选为首选方法。
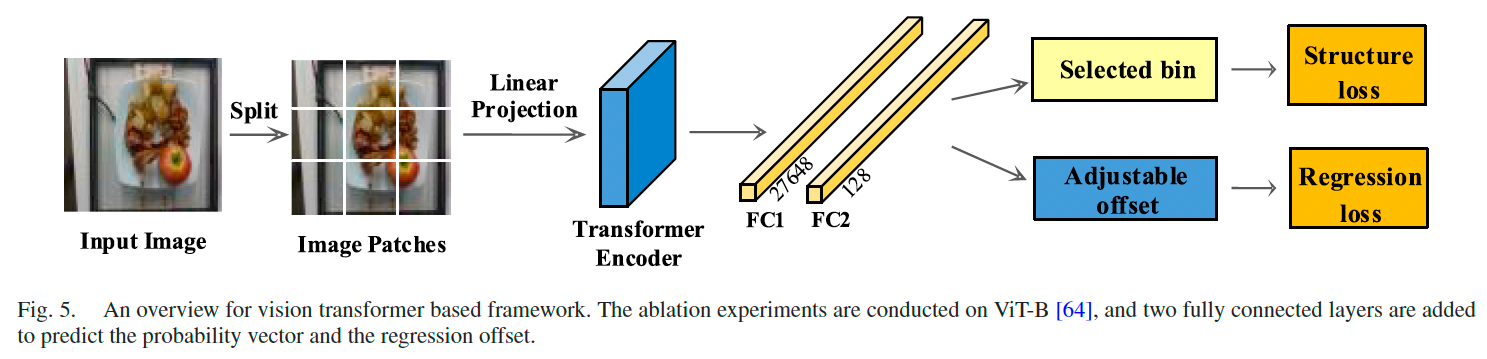
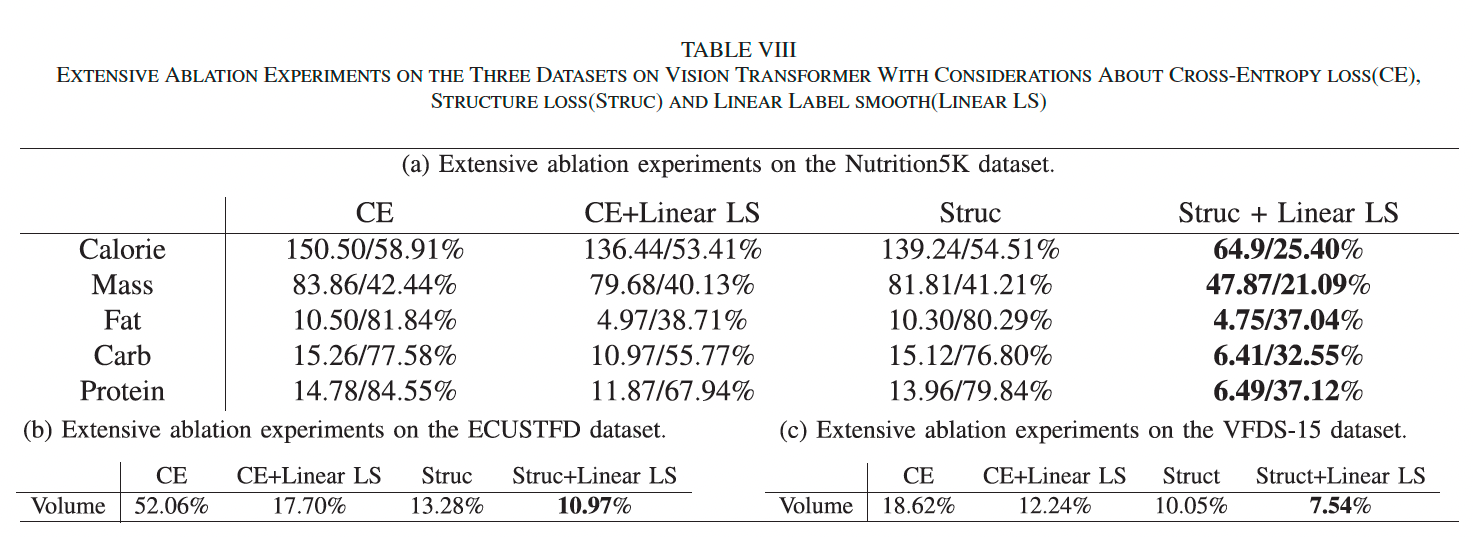
Vision Transformer 消融: 为验证方法的通用性,我们采用 Vision Transformer [64] 作为编码器,在三个数据集上重复实验。结果见表 VIII(a)、(b)、©。在 ViT 架构下,结构损失与线性标签平滑依旧提升显著,五种营养成分预测平均提升 38.4%,验证了方法在不同主干下的适应性与有效性。
分箱策略消融: 最后我们比较了等量划分与等间距划分策略(见表 IX)。虽然等间距划分直观,但造成样本分布极度不平衡,使用过采样进一步恶化效果,可能是因过拟合所致。实验验证了我们提出的等量划分策略在营养预测中的优势,它能保证每个分箱样本数相等,有助于模型学习。
4.4 定性分析
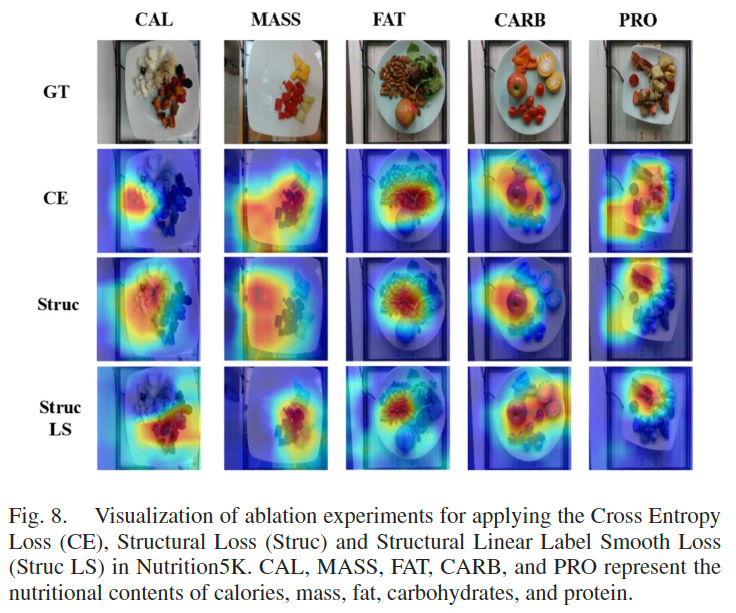
在上述的消融实验中,交叉熵损失函数表现不佳的原因在于,它将寻找正确分箱的过程视为普通的分类任务。虽然普通的标签平滑在一定程度上提高了性能,但仍未解决结构信息无法体现的核心问题。而引入结构线性平滑损失后,可以显式感知空间中的结构信息,从而有效提升预测精度。我们进一步提供定性分析进行说明。
营养预测支持区域的定性结果: 图 6 的第一行展示了披萨、鸡肉和水果类菜肴的图像。可以观察到,热量、质量和蛋白质大多集中在鸡肉和披萨上,而脂肪和碳水化合物在鸡肉中几乎不存在。第二行展示了培根、蛋白和土豆组成的菜肴。几乎所有热量、质量和蛋白质集中在培根和蛋白中,而脂肪主要集中在培根,碳水化合物则集中在土豆。图 6 表明我们的方法能提取到正确的特征区域,其低 pMAE 和激活图结果一致。
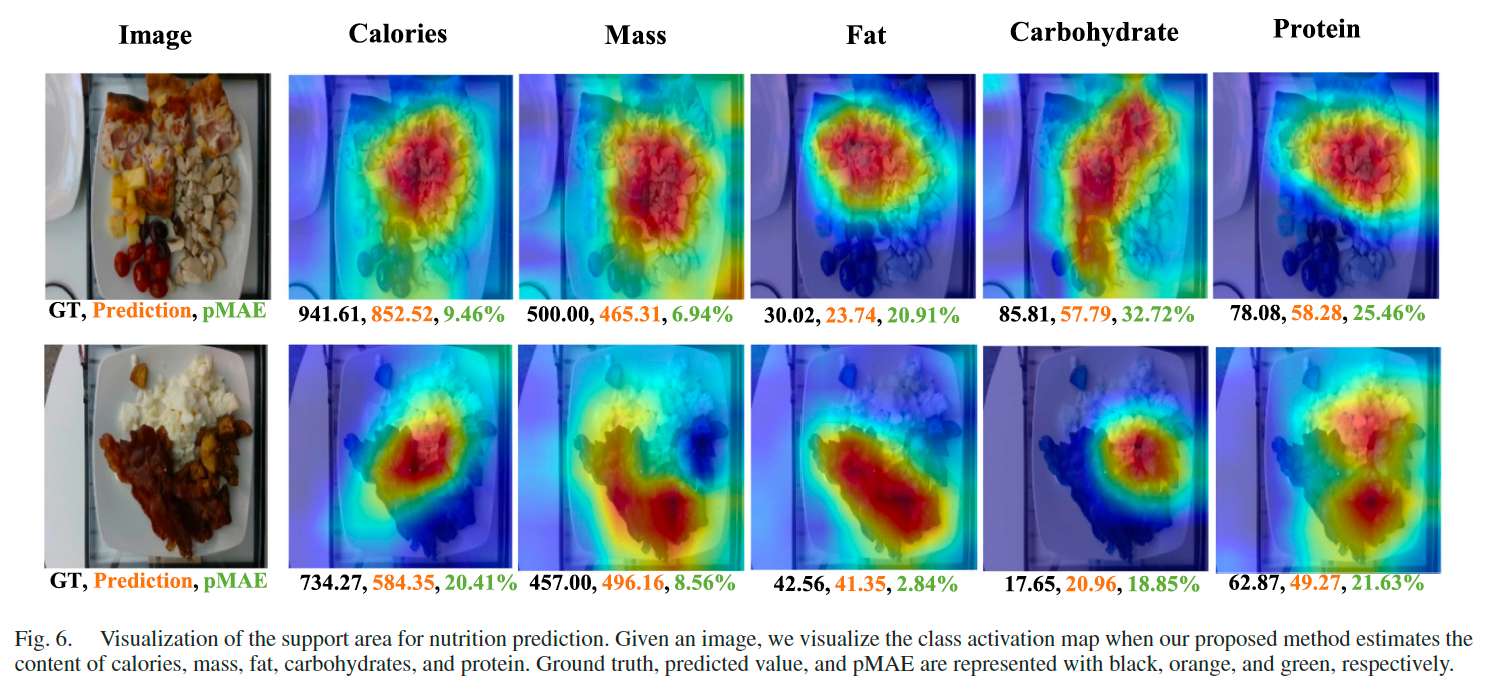
消融实验中的支持区域可视化结果: 图 8 展示了不同消融实验下的可视化结果。可以观察到,在加入结构损失和线性标签平滑后,支持区域的可视化结果更精确。例如在图 8 的第三列中,使用交叉熵的可视化将杏仁与蔬菜和苹果混合,未能准确预测,因为该图像中大多数脂肪来自杏仁。而结构损失和线性标签平滑机制使得模型专注于杏仁区域,预测更为合理。同样,在图 8 的第一列中,热量主要集中在红薯上,交叉熵的可视化无法准确定位红薯区域,而加入结构模块后,结果能准确聚焦于红薯所在区域。上述现象验证了所提出模块的有效性和效率。
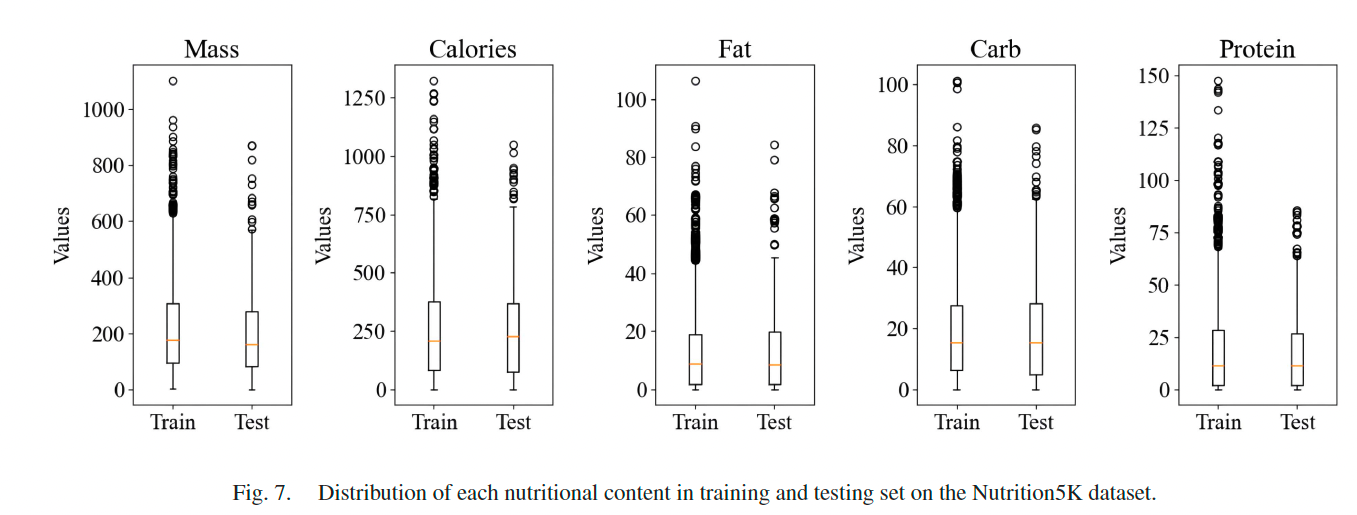
超出范围的预测: 在我们提出的粗到细预测范式中,模型的预测能力受到训练集标签范围的限制。图 7 展示了 Nutrition5K 数据集中各营养成分在训练集与测试集中的分布。可见,二者分布大致一致,因此我们的方法在该基准数据集上表现良好。但当测试样本的营养含量超出训练集范围时,预测精度会下降。为了解决该问题,未来的研究可引入纯回归分支来处理超出范围的预测情况。
5. 总结
本文提出了一种结合“粗到细”范式与结构线性平滑损失的全新方法,能有效提升食物营养预测的准确性。当前的营养预测工作通常基于单张 RGB 图像进行直接回归,导致预测精度较低,尚未充分解决以下两个核心挑战:
- 第一,食物营养值的范围过广,直接回归难以实现精确预测;
- 第二,分箱应体现空间结构信息,即与真实值更接近的分箱应受到更小的惩罚。
针对第一个挑战,我们设计的粗到细预测框架有效缩小了决策空间。粗阶段选择真实值所在的分箱,细阶段对营养值进行偏移修正。针对第二个挑战,我们提出结构线性平滑损失,使模型具备结构信息敏感性,通过径向扩散能力感知真实分箱的位置。在损失函数消融实验中,该方法取得最佳结果,验证了其有效性。
在 Nutrition5K、ECUSTFD 与 VFD 三个基准数据集上的实验证明,我们提出的方法能实现显著性能提升,并具有良好的应用价值。然而,我们仍未完全解决图像分析中的固有难题,如不同拍摄角度和复杂就餐环境等问题。此外,营养控制过度可能导致食物浪费,这也是未来需关注的方向。
未来的工作中,我们计划结合图像增强方法与本文提出的策略,以进一步提升营养成分预测的准确性。
🌟 在这篇博文的旅程中,感谢您的陪伴与阅读。如果内容对您有所启发或帮助,请不要吝啬您的点赞 👍🏻,这是对我最大的鼓励和支持。
📚 本人虽致力于提供准确且深入的技术分享,但学识有限,难免会有疏漏之处。如有不足或错误,恳请各位业界同仁在评论区留下宝贵意见,您的批评指正是我不断进步的动力!😄😄😄
💖💖💖 如果您发现这篇博文对您的研究或工作有所裨益,请不吝点赞、收藏,或分享给更多需要的朋友,让知识的力量传播得更远。
🔥🔥🔥 “Stay Hungry, Stay Foolish” —— 求知的道路永无止境,让我们保持渴望与初心,面对挑战,勇往直前。无论前路多么漫长,只要我们坚持不懈,终将抵达目的地。🌙🌙🌙
👋🏻 在此,我也邀请您加入我的技术交流社区,共同探讨、学习和成长。让我们携手并进,共创辉煌!

相关文章:

食品计算—Coarse-to-fine nutrition prediction
🌟🌟 欢迎来到我的技术小筑,一个专为技术探索者打造的交流空间。在这里,我们不仅分享代码的智慧,还探讨技术的深度与广度。无论您是资深开发者还是技术新手,这里都有一片属于您的天空。让我们在知识的海洋中…...
:ながら 一边。。一边)
日语学习-日语知识点小记-构建基础-JLPT-N4阶段(6):ながら 一边。。一边
日语学习-日语知识点小记-构建基础-JLPT-N4阶段(6):ながら 一边。。一边 1、前言(1)情况说明(2)工程师的信仰 2、知识点(1)ながら1)一边。。一边2࿰…...
 - 机组组合模型以及 Gurobi 求解)
Electricity Market Optimization(VI) - 机组组合模型以及 Gurobi 求解
本文参考链接:link \hspace{1.6em} 机组组合问题在电力系统中非常重要,这个问题也是一个优化问题,研究的就是如何调度现有的机组,调度的对象是以煤炭、石油、天然气为燃料的火力发电机以及水力发电机等可预测处理的发电机组&#…...
和 `LoRA_alpha`(通常简称为 `alpha`))
LoRA个关键超参数:`LoRA_rank`(通常简称为 `rank` 或 `r`)和 `LoRA_alpha`(通常简称为 `alpha`)
LoRA (Low-Rank Adaptation) 中的两个关键超参数:LoRA_rank(通常简称为 rank 或 r)和 LoRA_alpha(通常简称为 alpha)。 LoRA 的核心思想是,在对大型预训练模型(如 LLM 或 Stable Diffusion&…...
)
Sql刷题日志(day3)
一、笔试 1、min(date_time):求最早日期 2、mysql中distinct不能与order by 连用,可以用group by去重 二、面试 1、SQL中如何利用replace函数统计给定重复字段在字符串中的出现次数 (length(all_string)-length(all_string,目标字符串,))/length(ta…...

【AI插件开发】Notepad++ AI插件开发实践:实现对话窗口功能
引言 之前的文章已经介绍实现了AI对话窗口,但只有个空壳,没有实现功能。本次将集中完成对话窗口的功能,主要内容为: 模型动态切换:支持运行时加载配置的AI模型列表交互式输入处理:实现多行文本输入与Ctrl…...

[GESP202409 二级] 小杨的 N 字矩阵 题解
#include<bits/stdc.h> #define int long long using namespace std; int m, a[55][55], sum; signed main(){cin >> m;for(int i 1; i < m; i ){a[i][1] 1;//第一列a[i][m] 1;//第m列sum ;a[i][sum] 1;//斜着的}for(int i 1; i < m; i ){for(int j 1;…...

第八章:探索新兴趋势:Agent 框架、产品与开源力量
引言 在前两章的实战中,我们已经掌握了如何使用 LangChain、LlamaIndex、AutoGen 和 CrewAI 这些主流框架来构建 AI Agent,无论是单个智能体还是协作的多 Agent 系统。然而,AI Agent 领域的发展日新月异,如同奔腾的河流ÿ…...

条款05:了解C++默默编写并调用哪些函数
目录 1.默认生成的函数 2.无法生成的情况 2.1当成员函数有引用 或者 被const修饰 2.2.operator在基类被私有 1.默认生成的函数 class empty {};//相当于class empty { public:empty(){ ... } // 构造函数empty(const empty& rhs) { ... }// 拷贝构造~empty(){ ... } //…...

Vue3 中封装函数实现加载图片加载失败兜底方案。
文章目录 Vue3 中使用动态加载图片并处理加载失败的情况实现思路代码实现代码解析注意事项扩展功能总结 Vue3 中使用动态加载图片并处理加载失败的情况 在开发 Vue3 应用时,我们经常会遇到需要动态加载图片的场景。例如,图片资源可能从后端获取…...

微机控制电液伺服汽车减震器动态试验系统
微机控制电液伺服汽车减震器动态试验系统,用于对汽车筒式减震器、减震器台架、驾驶室减震装置、发动机悬置软垫总成、发动机前置楔形支撑总成等的示功图试验、速度特性试验。 主要的技术参数: 1、最大试验力:5kN; 2、试验力测量精…...

如何简单几步使用 FFmpeg 将任何音频转为 MP3?
在多媒体处理领域,FFmpeg 以其强大的功能和灵活性而闻名。无论是视频编辑、音频转换还是流媒体处理,它都是专业人士和技术爱好者的首选工具之一。在这篇文章中简鹿办公将重点介绍如何使用 FFmpeg 进行音频格式转换,提供一些常用的转换方式&am…...

【软考-系统架构设计师】ATAM方法及效用树
软件架构设计中ATAM方法及效用树深度解析 一、ATAM方法核心框架与流程 ATAM(架构权衡分析方法)是由卡耐基梅隆大学提出的系统性架构评估方法,旨在通过多维度质量属性分析识别架构风险、敏感点与权衡点。其实施流程分为四阶段九步骤…...
文章思路 模型 代码 结果分享)
2025第十七届“华中杯”大学生数学建模挑战赛题目B 题 校园共享单车的调度与维护问题完整成品正文33页(不含附录)文章思路 模型 代码 结果分享
校园共享单车运营优化与调度模型研究 摘 要 本研究聚焦校园共享单车点位布局、供需平衡、运营效率及故障车辆回收四大核心问题,通过构建一系列数学模型,系统分析与优化共享单车的运维体系。 针对问题一,我们建立了基于多时段观测的库存估算…...

React Native 0.79 稳定版发布,更快的工具、更多改进
React Native 0.79 已发布。此版本在多个方面进行了性能改进,并修复了一些漏洞。首先,得益于延迟哈希技术,Metro 的启动速度变快了,并且对包导出提供了稳定支持。由于 JS 包压缩方式的改变等原因,Android 的启动时间也…...

中国AI应用革命开启新纪元:从DeepSeek燎原到全栈生态崛起
当生成式AI的星火点燃华夏大地,一场由DeepSeek引发的智能革命正在重构中国产业版图。在这场算力与智慧的角逐中,全产业链的协同创新正在书写中国式AI进化的新范式。 一、全栈突围:AI基础设施生态全面升维 云端启航:头部云服务商…...

生物系统中的随机性及AI拓展
生物系统远非确定性的机器,而是本质上充满噪声的。这种随机性,或称偶然性,在塑造细胞行为和结果方面起着至关重要的作用。从基因表达到细胞命运决定,波动和不可预测的事件可以显著影响生物过程。理解和建模这种固有的变异性对于全…...

智能交响:EtherCAT转Profinet网关开启汽车自动化通信新纪元
在汽车制造行业,随着自动化程度的不断提升,设备之间的高效通信显得尤为重要。以吉利汽车西安制造基地为例,生产线中广泛应用了西门子PLC与机器人手臂等设备,这些设备分别采用了Profinet和EtherCAT通信协议。为实现不同协议设备之间…...

【2025“华中杯”大学生数学建模挑战赛】选题分析 A题 详细解题思路
目录 2025“华中杯”大学生数学建模挑战赛选题分析A题:晶硅片产销策略优化B题:校园共享单车的调度与维护问题C题:就业状态分析与预测D题:患者院内转运不良事件的分析与预测 A 题 晶硅片产销策略优化问题 1:月利润计算模…...

springboot整合阿里云百炼DeepSeek,实现sse流式打印
1.开通阿里云百炼,获取到key 官方文档地址 https://bailian.console.aliyun.com/?tabapi#/api/?typemodel&urlhttps%3A%2F%2Fhelp.aliyun.com%2Fdocument_detail%2F2868565.html 2.新建SpringBoot项目 <?xml version"1.0" encoding"UTF-8"?&g…...

JMeter中设置HTTPS请求
在JMeter中设置HTTPS请求,你可以按照以下步骤进行操作: 步骤一:添加线程组 打开JMeter后,右键点击“测试计划”,选择“添加” -> “线程(用户)” -> “线程组”。线程组用于定义虚拟用户…...

oracle数据库中,merge into 语句的功能与使用场景
oracle数据库中,merge into 语句的功能与使用场景 一、MERGE INTO 语句的作用 MERGE INTO 是ORACLE数据库 SQL 中的一种数据操作语句,它结合了 INSERT、UPDATE 和 DELETE 操作的功能,通常被称为"upsert"操作(update …...

极狐GitLab 安全文件管理功能介绍
极狐GitLab 是 GitLab 在中国的发行版,关于中文参考文档和资料有: 极狐GitLab 中文文档极狐GitLab 中文论坛极狐GitLab 官网 安全文件管理 (BASIC SELF) 在极狐GitLab 15.6 中 GA,功能标志 ci_secure_files 被移除。 您可以将最多 100 个…...

极狐GitLab CI/CD 流水线计算分钟数如何管理?
极狐GitLab 是 GitLab 在中国的发行版,关于中文参考文档和资料有: 极狐GitLab 中文文档极狐GitLab 中文论坛极狐GitLab 官网 计算分钟管理 (PREMIUM SELF) 在极狐GitLab 16.1 中,从 CI/CD 分钟数重命名为计算配额或计算分钟数。 管理员可…...

XCZU4CG‑2SFVC784I 赛灵思 FPGA XilinxZynq UltraScale+ MPSoC
XCZU4CG‑2SFVC784I 是 AMD Xilinx Zynq UltraScale MPSoC CG 系列中的入门级高性能 SoC FPGA,集成了双核 Arm Cortex‑A53 通用处理器与双核 Arm Cortex‑R5F 实时处理器,以及可编程逻辑(PL)资源。 异构处理系统 (PS) 应用处理…...

软考 中级软件设计师 考点知识点笔记总结 day13 数据库系统基础知识 数据库模式映像 数据模型
文章目录 数据库系统基础知识6.1 基本概念6.1.1 DBMS的特征与分类 6.2 数据库三级模式两级映像6.3 数据库的分析与设计过程6.4 数据模型6.4.1 ER模型6.4.2 关系模型 数据库系统基础知识 基本概念 数据库三级模式两级映像 数据库的分析与设计过程 数据模型 关系代数 数据库完整…...

视频监控EasyCVR视频汇聚平台接入海康监控摄像头如何配置http监听功能?
一、方案概述 本方案主要通过EasyCVR视频管理平台,实现报警信息的高效传输与实时监控。海康监控设备能通过HTTP协议将报警信息发送至指定的目的IP或域名,而EasyCVR平台则可以接收并处理这些报警信息,同时提供丰富的监控与管理功能࿰…...

【八大排序】冒泡、直接选择、直接插入、希尔、堆、归并、快速、计数排序
目录 一、排序的介绍二、排序算法的实现2.1 直接插入排序2.2 希尔排序2.3 直接选择排序2.4 堆排序2.5 冒泡排序2.6 快速排序2.7 归并排序2.8 比较排序算法的性能展示2.9 计数排序 个人主页<— 数据结构专栏<— 一、排序的介绍 我们的生活中有很多排序,比如像…...

AI在市场营销分析中的核心应用及价值,分场景详细说明
以下是 AI在市场营销分析中的核心应用及价值,分场景详细说明: 1. 客户行为分析与细分 AI技术应用: 机器学习:分析用户点击、购买、浏览等行为数据,识别消费模式(如高频购买时段、偏好品类)。聚…...

本地Ubuntu轻松部署高效性能监控平台SigNoz与远程使用教程
目录 ⛳️推荐 前言 1.关于SigNoz 2.本地部署SigNoz 3.SigNoz简单使用 4. 安装内网穿透 5.配置SigNoz公网地址 6. 配置固定公网地址 ⛳️推荐 前些天发现了一个巨牛的人工智能学习网站,通俗易懂,风趣幽默,忍不住分享一下给大家。点击…...
)
解析检验平板:设备还是非设备?深入了解其功能与应用(北重铸铁平台厂家)
检验平板通常被归类为设备,因为它们具有特定的功能,并且被用于测试和评估其他设备或产品的性能和质量。检验平板通常具有平坦的表面,用于放置要进行测试或检验的物品。它们可以用于测量尺寸、形状、平整度、表面光洁度等参数。 检验平板的应…...

【创新实训个人博客】前端实现
一、 目标设定与初步改造 核心目标: 对 visualizer 的前端界面 (index.html, style.css) 进行现代化改造。 基础样式: 初始化页面整体风格,为 body 添加了动态渐变背景;初步调整了页面顶部导航按钮、信息提示块 (Log Visualizer) 及底部任务…...

vue3、原生html交互传值
1、引入原生html 将该文件放到public目录下,在vue项目里面使用iframe 引入该文件,监听load事件(load事件在<iframe>的内容完全加载完成之后触发) <iframeload"onIframeLoad"style"width: 454px; height: 480px"src".…...

于 Jupyter 天地,借 NumPy 之手编织数据锦缎
引言 NumPy是Python科学计算的核心库之一,提供了强大的多维数组对象和丰富的数学函数,是数据科学、机器学习等领域不可或缺的工具。结合Jupyter Notebook的交互式环境,NumPy的使用变得更加直观和高效。本文将介绍如何在Jupyter中充分利用NumP…...

Mac idea WordExcel等文件git modify 一直提示修改状态
CRLF LF CR 换行符自动转换问题 查看状态:git config --global --list Mac需要开启,window下需要关闭 关闭命令:git config --global core.autocrlf false 命令解释: autocrlf true 表示要求git在提交时将crlf转换为lf&a…...
)
代码学习总结(三)
代码学习总结(三) 这个系列的博客是记录下自己学习代码的历程,有来自平台上的,有来自笔试题回忆的,主要基于 C++ 语言,包括题目内容,代码实现,思路,并会注明题目难度,保证代码运行结果 1 判断并构造 eleme 型字符串 简单 eleme 型字符串 判断与构造 小红有一个长…...

Vue的Diff算法原理
Vue中的Diff算法(差异算法)是虚拟DOM的核心优化手段,用于对比新旧虚拟DOM树,找出最小变更,高效更新真实DOM,其设计目标是减少DOM操作次数,提升渲染性能 diff算法: 特点:…...
)
CentOS系统-超详细的Kubernetes集群搭建教程(kubernetes:1.28.2)
小伙伴们,今天给大家带来一份超详细的Kubernetes集群搭建教程,保证让你从环境准备到安装验证,一路畅通无阻!🚀 🌈 一、环境准备 首先,咱们得确保硬件和软件环境都达标哦! &am…...

自动驾驶系列—GLane3D: Detecting Lanes with Graph of 3D Keypoints
🌟🌟 欢迎来到我的技术小筑,一个专为技术探索者打造的交流空间。在这里,我们不仅分享代码的智慧,还探讨技术的深度与广度。无论您是资深开发者还是技术新手,这里都有一片属于您的天空。让我们在知识的海洋中…...

【Amazon 工具】在MacOS本地安装 AWS CLI、kubectl、eksctl工具
文章目录 安装 AWS CLI安装 kubectl安装 eksctl参考链接 安装 AWS CLI 创建访问密钥安装或更新 AWS CLI curl "https://awscli.amazonaws.com/AWSCLIV2.pkg" -o "AWSCLIV2.pkg" sudo installer -pkg AWSCLIV2.pkg -target /要验证 Shell 是否可以在 $PAT…...

基于GTID的主从复制
MySQL主从复制实战指南(基于二进制日志)-CSDN博客 二、基于GTID的主从复制 基于 GTID 方式:全局事务标示符,自mysql5.6版本开启的新型复制方式。 GTID的组成:server_uuid:序列号 UUID:每个m…...
程编程——(8)多进程的冲突问题)
linux多线(进)程编程——(8)多进程的冲突问题
前言 随着时间的推移,共享内存已经在修真界已经沦为禁术。因为使用这种方式沟通的两人往往会陷入到走火入魔的状态,思维扭曲。进程君父子见到这种情况,连忙开始专研起来,终于它们发现了共享内存存在的问题: 进程间冲…...

数据结构——八大排序算法
排序在生活中应用很多,对数据排序有按成绩,商品价格,评论数量等标准来排序。 数据结构中有八大排序,插入、选择、快速、归并四类排序。 目录 插入排序 直接插入排序 希尔排序 选择排序 堆排序 冒泡排序 快速排序 hoare…...

线性代数 | 知识点整理 Ref 1
注:本文为 “线性代数 | 知识点整理” 相关文章合辑。 因 csdn 篇幅合并超限分篇连载,本篇为 Ref 1。 略作重排,未整理去重。 图片清晰度限于引文原状。 如有内容异常,请看原文。 线性代数知识汇总 Arrow 于 2016-11-27 16:27:5…...

Docker 设置镜像源后仍无法拉取镜像问题排查
#记录工作 Windows系统 在使用 Docker 的过程中,许多用户会碰到设置了国内镜像源后,依旧无法拉取镜像的情况。接下来,记录了操作要点以及问题排查方法,帮助我们顺利解决这类问题。 Microsoft Windows [Version 10.0.27823.1000…...
 多项式回归 (Polynomial Regression))
线性回归 (Linear Regression) 多项式回归 (Polynomial Regression)
目录 线性回归 (Linear Regression)单变量线性回归 (Univariate linear regression)代价函数 (Cost function)梯度下降 (gradient descent) 及公式由来梯度下降的变体Quiz多类特征 (Multiple features)多元线性回归 (Multiple linear regression)向量化 (Vectorization)正规方程…...

AI在能源消耗管理及能源效率提升中的核心应用场景及技术实现
以下是 AI在能源消耗管理及能源效率提升中的核心应用场景及技术实现,分领域详细说明: 1. 实时能源监测与异常检测 AI技术应用: 物联网(IoT) 传感器数据采集:实时收集设备、建筑或工厂的能耗数据ÿ…...

dumpsys--音频服务状态信息
Audio相关的信息获取指令: dumpsys media.audio_flinger dumpsys media.audio_policy dumpsys audio media.audio_flinger dumpsys media.audio_flinger 用于获取 AudioFlinger 服务的详细状态信息。 1. 命令作用 该命令输出当前系统的 音频设备状态、活跃音频流…...

JavaScript模块化开发:CommonJS、AMD到ES模块
引言 在Web开发的早期阶段,JavaScript代码通常被编写在一个庞大的文件中或分散在多个脚本标签里,这种方式导致了全局变量污染、依赖关系难以管理、代码复用困难等问题。随着Web应用日益复杂,模块化编程成为了解决这些问题的关键。本文将带您…...

面试情景题:企业内部系统如何做微前端拆分,如何通信?
在前端开发领域,技术的演进总是伴随着业务需求的复杂化与规模化而不断向前推进。近年来,微前端(Micro Frontends)作为一种全新的架构理念,逐渐成为解决大型前端应用复杂性的重要手段。与传统的单体前端应用不同&#x…...