UNet脑瘤医学影像分割训练实战(PyTorch 完整代码)
UNet是一种基于卷积神经网络(CNN)的医学影像分割模型,由Ronneberger等人于2015年提出。本文我们将简要介绍基于PyTorch框架,使用UNet模型在脑瘤医学影像分割数据集上进行训练,同时通过SwanLab监控训练过程,实现对病灶区域或器官结构的智能定位。
- 代码:完整代码直接看本文第5节 或 Github
- 实验日志过程:Unet-Medical-Segmentation - SwanLab
- 模型:UNet(Pytorch代码直接写)
- 数据集:brain-tumor-image-dataset-semantic-segmentation - Kagggle
- SwanLab:https://swanlab.cn
1. 环境配置
环境配置分为三步:
- 确保你的电脑上至少有一张英伟达显卡,并已安装好了CUDA环境。
- 安装Python(版本>=3.8)以及能够调用CUDA加速的PyTorch。
- 安装UNet微调相关的第三方库,可以使用以下命令:
git clone https://github.com/Zeyi-Lin/UNet-Medical.git
cd UNet-Medical
pip install -r requirements.txt
2. 准备数据集
本节使用的是 脑瘤图像分割 数据集,该数据集主要用于医学影像分割任务。
数据集介绍:Brain Tumor Segmentation Dataset 是专用于医学图像语义分割的数据集,旨在精准识别脑肿瘤区域。该数据集包含两类标注(肿瘤/非肿瘤),通过像素级分类实现肿瘤区域的细粒度分割,适用于训练和评估医学影像分割模型,为脑肿瘤诊断提供自动化分析支持。
在本节的任务中,我们主要是将数据集下载下来并解压,以供后续的训练。
下载数据集并解压:
python download.py
unzip dataset/Brain_Tumor_Image_DataSet.zip -d dataset/
完成上述步骤后,你应该可以根目录下看到这样的文件夹:
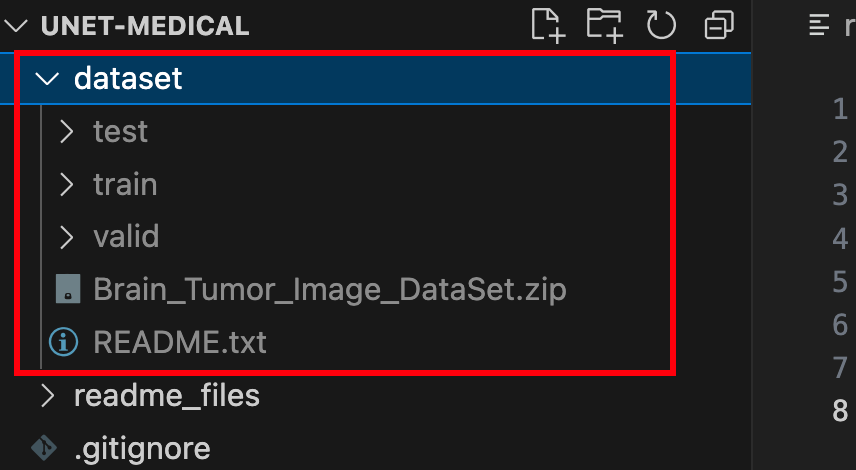
文件夹中包含训练集、验证集和测试集,里面有图像文件(jpg格式)和标注文件(json格式)。至此,我们完成了数据集的准备。
下面是一些细节的代码展示,然后你想马上训练起来,可以直接跳到第五节。
3. 模型代码
这里我们使用PyTorch来写UNet模型(在net.py中)。代码展示如下:
import torch
import torch.nn as nn# 定义U-Net模型的下采样块
class DownBlock(nn.Module):def __init__(self, in_channels, out_channels, dropout_prob=0, max_pooling=True):super(DownBlock, self).__init__()self.conv1 = nn.Conv2d(in_channels, out_channels, 3, padding=1)self.conv2 = nn.Conv2d(out_channels, out_channels, 3, padding=1)self.relu = nn.ReLU(inplace=True)self.maxpool = nn.MaxPool2d(2) if max_pooling else Noneself.dropout = nn.Dropout(dropout_prob) if dropout_prob > 0 else Nonedef forward(self, x):x = self.relu(self.conv1(x))x = self.relu(self.conv2(x))if self.dropout:x = self.dropout(x)skip = xif self.maxpool:x = self.maxpool(x)return x, skip# 定义U-Net模型的上采样块
class UpBlock(nn.Module):def __init__(self, in_channels, out_channels):super(UpBlock, self).__init__()self.up = nn.ConvTranspose2d(in_channels, out_channels, kernel_size=2, stride=2)self.conv1 = nn.Conv2d(out_channels * 2, out_channels, 3, padding=1)self.conv2 = nn.Conv2d(out_channels, out_channels, 3, padding=1)self.relu = nn.ReLU(inplace=True)def forward(self, x, skip):x = self.up(x)x = torch.cat([x, skip], dim=1)x = self.relu(self.conv1(x))x = self.relu(self.conv2(x))return x# 定义完整的U-Net模型
class UNet(nn.Module):def __init__(self, n_channels=3, n_classes=1, n_filters=32):super(UNet, self).__init__()# 编码器路径self.down1 = DownBlock(n_channels, n_filters)self.down2 = DownBlock(n_filters, n_filters * 2)self.down3 = DownBlock(n_filters * 2, n_filters * 4)self.down4 = DownBlock(n_filters * 4, n_filters * 8)self.down5 = DownBlock(n_filters * 8, n_filters * 16)# 瓶颈层 - 移除最后的maxpoolingself.bottleneck = DownBlock(n_filters * 16, n_filters * 32, dropout_prob=0.4, max_pooling=False)# 解码器路径self.up1 = UpBlock(n_filters * 32, n_filters * 16)self.up2 = UpBlock(n_filters * 16, n_filters * 8)self.up3 = UpBlock(n_filters * 8, n_filters * 4)self.up4 = UpBlock(n_filters * 4, n_filters * 2)self.up5 = UpBlock(n_filters * 2, n_filters)# 输出层self.outc = nn.Conv2d(n_filters, n_classes, 1)self.sigmoid = nn.Sigmoid()def forward(self, x):# 编码器路径x1, skip1 = self.down1(x) # 128x2, skip2 = self.down2(x1) # 64x3, skip3 = self.down3(x2) # 32x4, skip4 = self.down4(x3) # 16x5, skip5 = self.down5(x4) # 8# 瓶颈层x6, skip6 = self.bottleneck(x5) # 8 (无下采样)# 解码器路径x = self.up1(x6, skip5) # 16x = self.up2(x, skip4) # 32x = self.up3(x, skip3) # 64x = self.up4(x, skip2) # 128x = self.up5(x, skip1) # 256x = self.outc(x)x = self.sigmoid(x)return x
该模型保存为pth文件,大约需要124MB。
4. 使用SwanLab跟踪实验
SwanLab 是一个开源的模型训练记录工具。SwanLab面向AI研究者,提供了训练可视化、自动日志记录、超参数记录、实验对比、多人协同等功能。在SwanLab上,研究者能基于直观的可视化图表发现训练问题,对比多个实验找到研究灵感,并通过在线链接的分享与基于组织的多人协同训练,打破团队沟通的壁垒。
在本次训练中,我们设置swanlab的项目为Unet-Medical-Segmentation,实验名称为bs32-epoch40,并设置超参数如下:
swanlab.init(project="Unet-Medical-Segmentation",experiment_name="bs32-epoch40",config={"batch_size": 32,"learning_rate": 1e-4,"num_epochs": 40,"device": "cuda" if torch.cuda.is_available() else "cpu",},
)
可以看到,这次训练的batch_size为32,学习率为1e-4,训练40个epoch。
首次使用SwanLab,需要先在官网注册一个账号,然后在用户设置页面复制你的API Key,然后在训练开始提示登录时粘贴即可,后续无需再次登录:

5. 开始训练
查看可视化训练过程:Unet-Medical-Segmentation
本节代码做了以下几件事:
- 加载UNet模型
- 加载数据集,分为训练集、验证集和测试集,数据处理为Resize为 (256, 256)和 Normalization
- 使用SwanLab记录训练过程,包括超参数、指标和最终的模型输出结果
- 训练40个epoch
- 生成最后的预测图像
开始执行代码时的目录结构应该是:
|———— dataset/
|———————— train/
|———————— val/
|———————— test/
|———— readme_files/
|———— train.py
|———— data.py
|———— net.py
|———— download.py
|———— requirements.txt
完整代码如下
train.py:
import torch
import torch.nn as nn
import torch.optim as optim
import matplotlib.pyplot as plt
from pycocotools.coco import COCO
from torch.utils.data import DataLoader
import torchvision.transforms as transforms
import random
import swanlab
from net import UNet
from data import COCOSegmentationDataset# 数据路径设置
train_dir = './dataset/train'
val_dir = './dataset/valid'
test_dir = './dataset/test'train_annotation_file = './dataset/train/_annotations.coco.json'
test_annotation_file = './dataset/test/_annotations.coco.json'
val_annotation_file = './dataset/valid/_annotations.coco.json'# 加载COCO数据集
train_coco = COCO(train_annotation_file)
val_coco = COCO(val_annotation_file)
test_coco = COCO(test_annotation_file)# 定义损失函数
def dice_loss(pred, target, smooth=1e-6):pred_flat = pred.view(-1)target_flat = target.view(-1)intersection = (pred_flat * target_flat).sum()return 1 - ((2. * intersection + smooth) / (pred_flat.sum() + target_flat.sum() + smooth))def combined_loss(pred, target):dice = dice_loss(pred, target)bce = nn.BCELoss()(pred, target)return 0.6 * dice + 0.4 * bce# 训练函数
def train_model(model, train_loader, val_loader, criterion, optimizer, num_epochs, device):best_val_loss = float('inf')patience = 8patience_counter = 0for epoch in range(num_epochs):model.train()train_loss = 0train_acc = 0for images, masks in train_loader:images, masks = images.to(device), masks.to(device)optimizer.zero_grad()outputs = model(images)loss = criterion(outputs, masks)loss.backward()optimizer.step()train_loss += loss.item()train_acc += (outputs.round() == masks).float().mean().item()train_loss /= len(train_loader)train_acc /= len(train_loader)# 验证model.eval()val_loss = 0val_acc = 0with torch.no_grad():for images, masks in val_loader:images, masks = images.to(device), masks.to(device)outputs = model(images)loss = criterion(outputs, masks)val_loss += loss.item()val_acc += (outputs.round() == masks).float().mean().item()val_loss /= len(val_loader)val_acc /= len(val_loader)swanlab.log({"train/loss": train_loss,"train/acc": train_acc,"train/epoch": epoch+1,"val/loss": val_loss,"val/acc": val_acc,},step=epoch+1)print(f'Epoch {epoch+1}/{num_epochs}:')print(f'Train Loss: {train_loss:.4f}, Train Acc: {train_acc:.4f}')print(f'Val Loss: {val_loss:.4f}, Val Acc: {val_acc:.4f}')# 早停if val_loss < best_val_loss:best_val_loss = val_losspatience_counter = 0torch.save(model.state_dict(), 'best_model.pth')else:patience_counter += 1if patience_counter >= patience:print("Early stopping triggered")breakdef main():swanlab.init(project="Unet-Medical-Segmentation",experiment_name="bs32-epoch40",config={"batch_size": 32,"learning_rate": 1e-4,"num_epochs": 40,"device": "cuda" if torch.cuda.is_available() else "cpu",},)# 设置设备device = torch.device(swanlab.config["device"])# 数据预处理transform = transforms.Compose([transforms.ToTensor(),transforms.Resize((256, 256)),transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])])# 创建数据集train_dataset = COCOSegmentationDataset(train_coco, train_dir, transform=transform)val_dataset = COCOSegmentationDataset(val_coco, val_dir, transform=transform)test_dataset = COCOSegmentationDataset(test_coco, test_dir, transform=transform)# 创建数据加载器BATCH_SIZE = swanlab.config["batch_size"]train_loader = DataLoader(train_dataset, batch_size=BATCH_SIZE, shuffle=True)val_loader = DataLoader(val_dataset, batch_size=BATCH_SIZE)test_loader = DataLoader(test_dataset, batch_size=BATCH_SIZE)# 初始化模型model = UNet(n_filters=32).to(device)# 设置优化器和学习率optimizer = optim.Adam(model.parameters(), lr=swanlab.config["learning_rate"])# 训练模型train_model(model=model,train_loader=train_loader,val_loader=val_loader,criterion=combined_loss,optimizer=optimizer,num_epochs=swanlab.config["num_epochs"],device=device,)# 在测试集上评估model.eval()test_loss = 0test_acc = 0with torch.no_grad():for images, masks in test_loader:images, masks = images.to(device), masks.to(device)outputs = model(images)loss = combined_loss(outputs, masks)test_loss += loss.item()test_acc += (outputs.round() == masks).float().mean().item()test_loss /= len(test_loader)test_acc /= len(test_loader)print(f"Test Loss: {test_loss:.4f}, Test Accuracy: {test_acc:.4f}")swanlab.log({"test/loss": test_loss, "test/acc": test_acc})# 可视化预测结果visualize_predictions(model, test_loader, device, num_samples=10)def visualize_predictions(model, test_loader, device, num_samples=5, threshold=0.5):model.eval()with torch.no_grad():# 获取一个批次的数据images, masks = next(iter(test_loader))images, masks = images.to(device), masks.to(device)predictions = model(images)# 将预测结果转换为二值掩码binary_predictions = (predictions > threshold).float()# 选择前3个样本indices = random.sample(range(len(images)), min(num_samples, len(images)))indices = indices[:8]# 创建一个大图plt.figure(figsize=(15, 8)) # 调整图像大小以适应新增的行plt.suptitle(f'Epoch {swanlab.config["num_epochs"]} Predictions (Random 6 samples)')for i, idx in enumerate(indices):# 原始图像plt.subplot(4, 8, i*4 + 1) # 4行而不是3行img = images[idx].cpu().numpy().transpose(1, 2, 0)img = (img * [0.229, 0.224, 0.225] + [0.485, 0.456, 0.406]).clip(0, 1)plt.imshow(img)plt.title('Original Image')plt.axis('off')# 真实掩码plt.subplot(4, 8, i*4 + 2)plt.imshow(masks[idx].cpu().squeeze(), cmap='gray')plt.title('True Mask')plt.axis('off')# 预测掩码plt.subplot(4, 8, i*4 + 3)plt.imshow(binary_predictions[idx].cpu().squeeze(), cmap='gray')plt.title('Predicted Mask')plt.axis('off')# 新增:预测掩码叠加在原图上plt.subplot(4, 8, i*4 + 4)plt.imshow(img) # 先显示原图# 添加红色半透明掩码plt.imshow(binary_predictions[idx].cpu().squeeze(), cmap='Reds', alpha=0.3) # alpha控制透明度plt.title('Overlay')plt.axis('off')# 记录图像到SwanLabswanlab.log({"predictions": swanlab.Image(plt)})if __name__ == '__main__':main()
运行训练
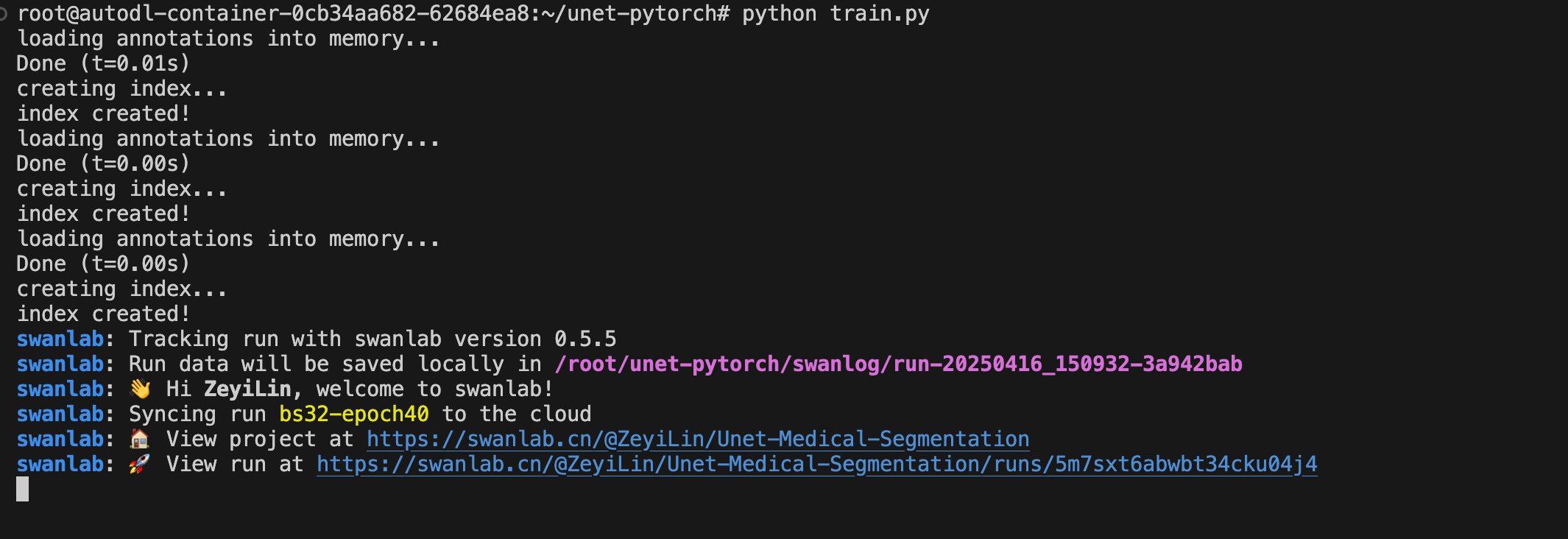
python train.py
看到下面的输出即代表训练开始:
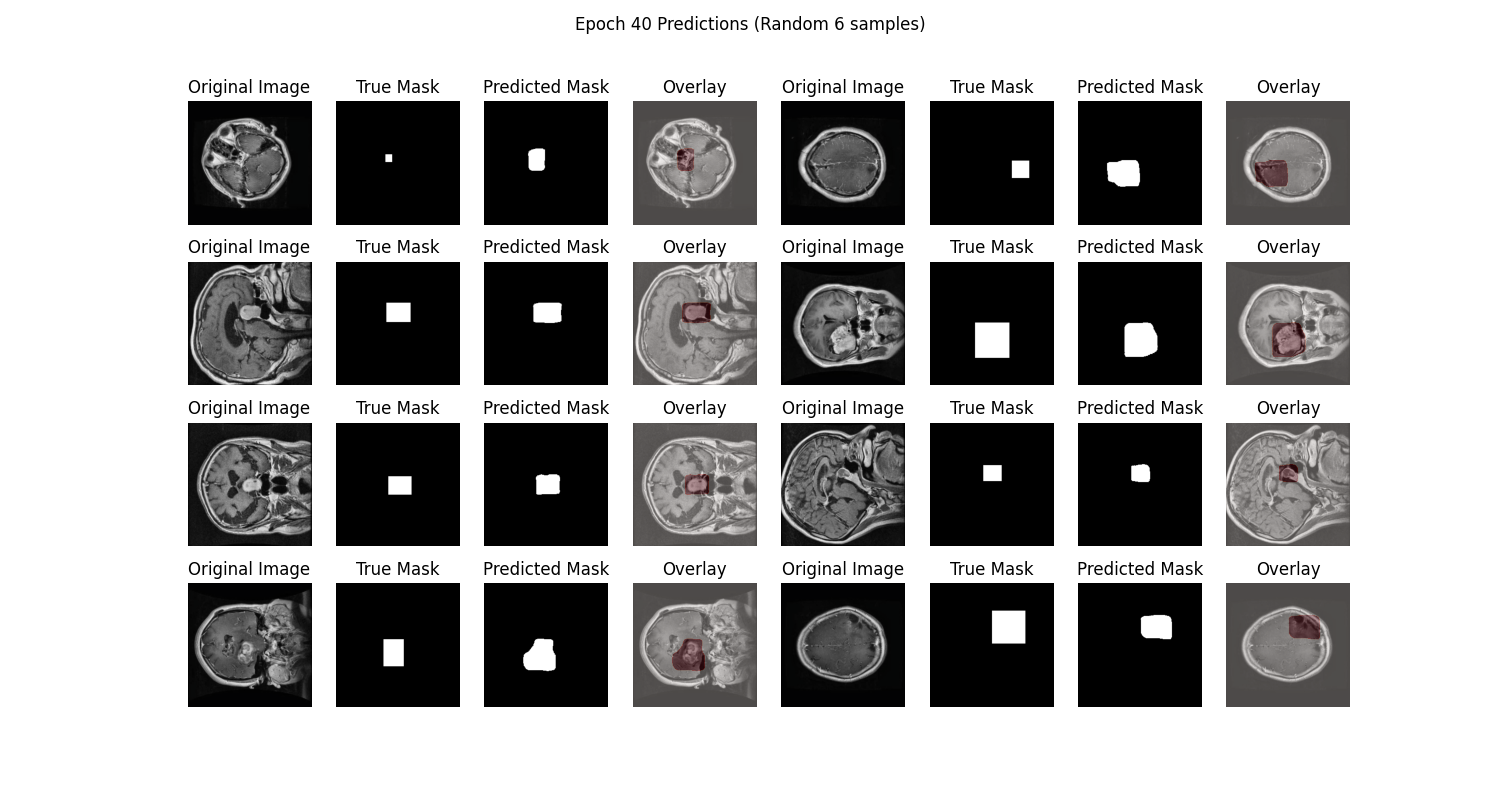
6. 训练结果演示
详细训练过程请看这里:Unet-Medical-Segmentation
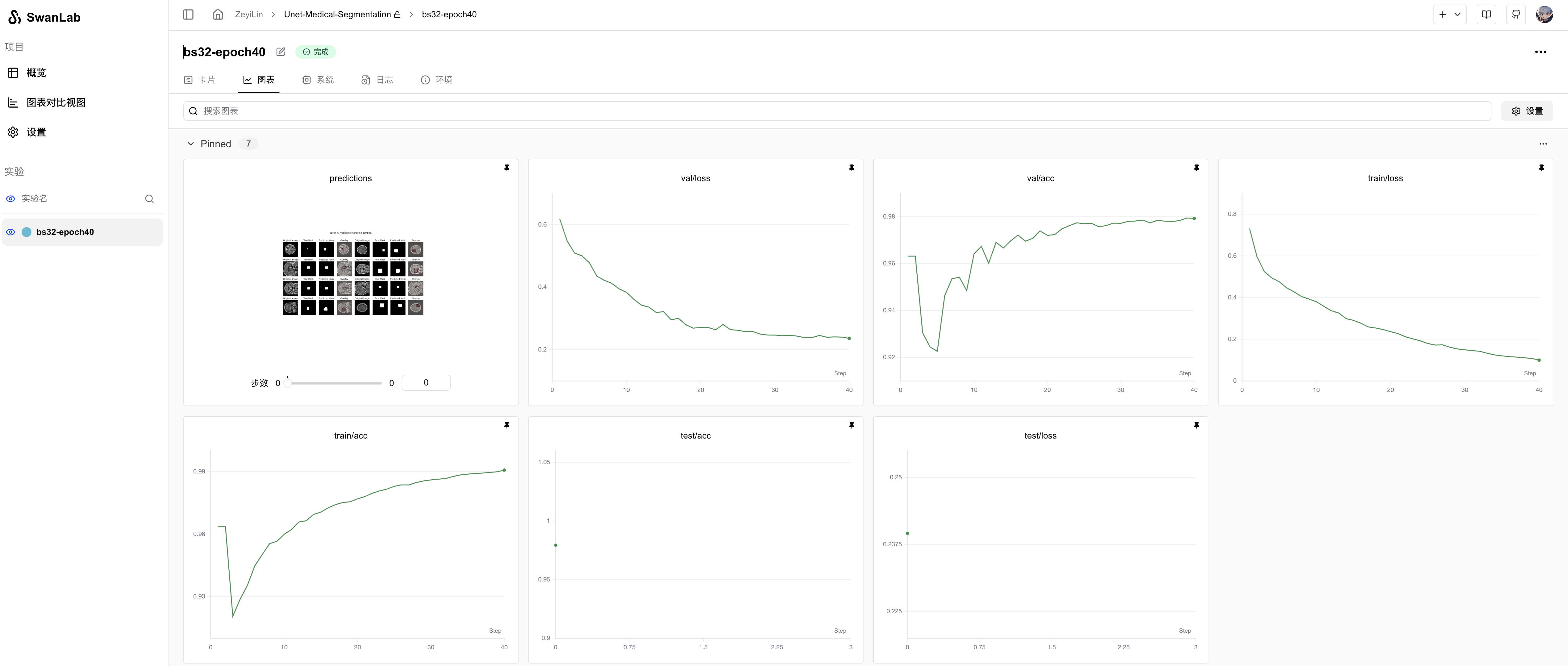
从SwanLab图表中我们可以看到,train loss和val loss随epoch呈现下降趋势,而train acc和val acc随epoch呈现上升趋势。最终的test acc可以达到 97.93%。
在prediction图表中记录着模型最终的测试集图像预测结果,可以看到模型分割的结果还是相对不错的:

当然,这教程主要的目标是帮助大家入门医学影像分割训练,所以没有使用更加复杂的模型结构和数据增强策略,感兴趣的同学可以基于本文的代码进行改变和实验,欢迎在SwanLab基线社区上展示你的结果和过程!

7. 模型推理
加载训练好的模型best_model.pth,并进行推理:
python predict.py
predict.py代码:
import torch
import torchvision.transforms as transforms
from PIL import Image
import matplotlib.pyplot as plt
from net import UNet
import numpy as np
import osdef load_model(model_path='best_model.pth', device='cuda'):"""加载训练好的模型"""try:# 检查文件是否存在if not os.path.exists(model_path):raise FileNotFoundError(f"Model file not found at {model_path}")model = UNet(n_filters=32).to(device)# 添加weights_only=True来避免警告state_dict = torch.load(model_path, map_location=device, weights_only=True)model.load_state_dict(state_dict)model.eval()print(f"Model loaded successfully from {model_path}")return modelexcept Exception as e:print(f"Error loading model: {str(e)}")raisedef preprocess_image(image_path):"""预处理输入图像"""# 读取原始图像image = Image.open(image_path).convert('RGB')# 保存调整大小后的原始图像用于显示display_image = image.resize((256, 256), Image.Resampling.BILINEAR)# 模型输入的预处理transform = transforms.Compose([transforms.ToTensor(),transforms.Resize((256, 256)),transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])])image_tensor = transform(image)return image_tensor.unsqueeze(0), display_imagedef predict_mask(model, image_tensor, device='cuda', threshold=0.5):"""预测分割掩码"""with torch.no_grad():image_tensor = image_tensor.to(device)prediction = model(image_tensor)prediction = (prediction > threshold).float()return predictiondef visualize_result(original_image, predicted_mask):"""可视化预测结果"""plt.figure(figsize=(12, 6))plt.suptitle('Predictions')# 显示原始图像plt.subplot(131)plt.imshow(original_image)plt.title('Original Image')plt.axis('off')# 显示预测掩码plt.subplot(132)plt.imshow(predicted_mask.squeeze(), cmap='gray')plt.title('Predicted Mask')plt.axis('off')# 显示叠加结果plt.subplot(133)plt.imshow(np.array(original_image)) # 转换为numpy数组plt.imshow(predicted_mask.squeeze(), cmap='Reds', alpha=0.3)plt.title('Overlay')plt.axis('off')plt.tight_layout()plt.savefig('./predictions.png')print("Visualization saved as predictions.png")def main():# 设置设备device = torch.device("cuda" if torch.cuda.is_available() else "cpu")print(f"Using device: {device}")try:# 加载模型model_path = "/Users/zeyilin/Desktop/Coding/UNet-Medical/best_model.pth" # 确保这个路径是正确的print(f"Attempting to load model from: {model_path}")model = load_model(model_path, device)# 处理单张图像image_path = "dataset/test/27_jpg.rf.b2a2b9811786cc32a23c46c560f04d07.jpg"if not os.path.exists(image_path):raise FileNotFoundError(f"Image file not found at {image_path}")print(f"Processing image: {image_path}")image_tensor, original_image = preprocess_image(image_path)# 预测predicted_mask = predict_mask(model, image_tensor, device)# 将预测结果转回CPU并转换为numpy数组predicted_mask = predicted_mask.cpu().numpy()# 可视化结果print("Generating visualization...")visualize_result(original_image, predicted_mask)print("Results saved to predictions.png")except Exception as e:print(f"Error during prediction: {str(e)}")raiseif __name__ == '__main__':main()
补充
详细硬件配置和参数说明
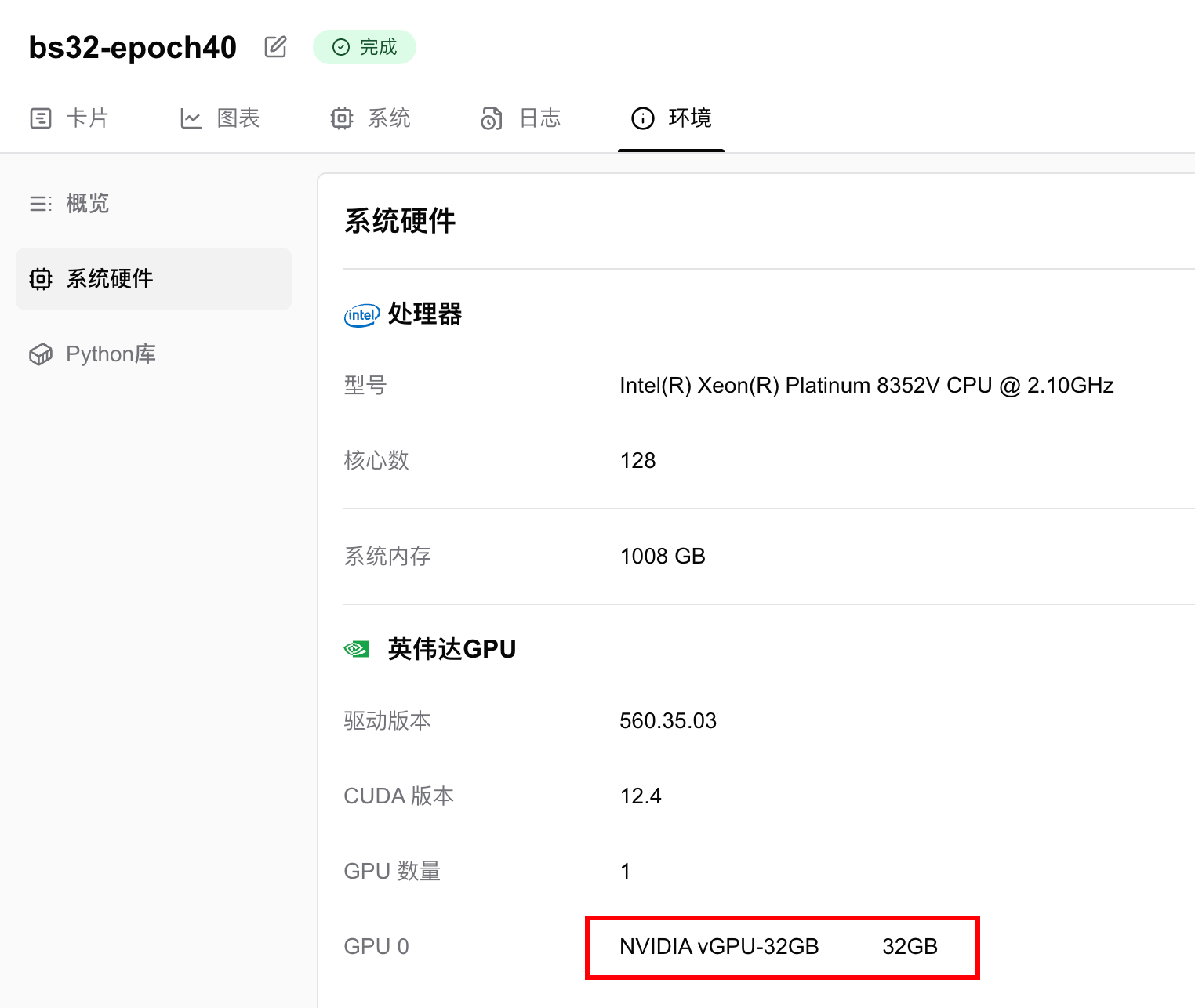
我使用了1张英伟达 vGPU-32GB 显卡,训练40个epoch,用时13分钟22秒。
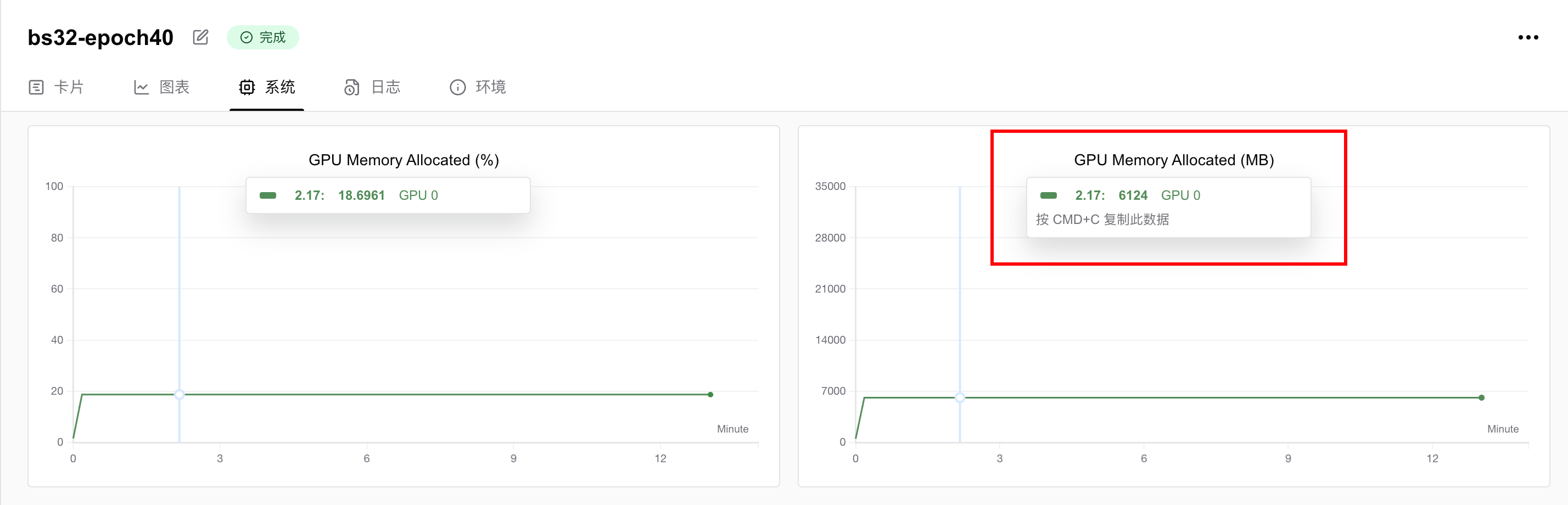
显存占用情况为6.124GB,即只要你的显卡显存大于6GB,就可以跑这个任务。如果想要进一步降低显存要求,可以调低batch size。
参考
- 代码:完整代码直接看本文第5节 或 Github
- 实验日志过程:Unet-Medical-Segmentation - SwanLab
- 模型:UNet(Pytorch代码直接写)
- 数据集:brain-tumor-image-dataset-semantic-segmentation - Kagggle
- SwanLab:https://swanlab.cn
相关文章:
)
UNet脑瘤医学影像分割训练实战(PyTorch 完整代码)
UNet是一种基于卷积神经网络(CNN)的医学影像分割模型,由Ronneberger等人于2015年提出。本文我们将简要介绍基于PyTorch框架,使用UNet模型在脑瘤医学影像分割数据集上进行训练,同时通过SwanLab监控训练过程,…...

MySQL事务隔离级别详解
MySQL事务隔离级别详解 1. 基本概念 1.1 什么是事务隔离级别? 事务隔离级别是数据库管理系统为了保证数据一致性,在多个事务并发访问时提供的不同级别的保护机制。 1.2 事务并发问题 脏读(Dirty Read): 一个事务读…...

2025年K8s最新高频面试题
目录 Kubernetes的核心组件有哪些,各自作用是什么? Pod和Deployment的区别? Service有哪些类型,分别适用于什么场景? ConfigMap和Secret有什么区别? StatefulSet 和 Deployment 的主要区别是什么? 什么是 Ingress,有哪些常用实现方式? 如何限制 Kubernetes 中 Pod …...

CobaltStrike
概述 Cobalt Strike是⼀款基于java的渗透测试神器,常被业界⼈称为CS神器。⾃3.0以后已经不在使用 Metasploit框架⽽作为⼀个独⽴的平台使用,分为客户端与服务端,服务端是⼀个,客户端可以有 多个,⾮常适合团队协同作战…...
)
Web前端 (CSS篇)
什么是CSS? css(Cascading Style Sheets)是层叠样式表或级联样式表,是一组设置规则,用于控制web页面外观。 为什么使用CSS? CSS 用于定义网页的样式,包括针对不同设备和屏幕尺寸的设计和布局。 CSS 实例 body {background-col…...

回归测试中常见的问题:如何避免“越改越错“的陷阱
修复一个Bug,引入三个新Bug "我们只是改了个小功能,为什么整个系统都出问题了?"——这是回归测试失败的典型症状。据IBM研究显示,约40%的线上缺陷源自不充分的回归测试。本文将深入剖析回归测试中的常见陷阱࿰…...

红宝书第四十六讲:Node.js基础与API设计解析
红宝书第四十六讲:Node.js基础与API设计解析 资料取自《JavaScript高级程序设计(第5版)》。 查看总目录:红宝书学习大纲 一、Node.js基础概念 1. 流(Streams)的核心地位 12 Node.js的文件读写和网络通信依…...

IT运维常用的软件工具有哪些
IT运维常用的软件工具主要包括:监控工具、自动化运维工具、日志管理工具、网络管理工具、资产管理工具、服务台工具。这些工具分别用于保障IT系统稳定运行、提升运维效率、快速响应故障。其中,监控工具至关重要,它能实时监测系统运行状态、资…...

eplan许可证迁移到其他计算机
随着电气设计项目的不断扩大和变更,您可能需要将EPLAN许可证从一台计算机迁移到另一台计算机上。然而,在迁移过程中,确保您的软件始终保持最佳状态至关重要。本文将为您提供一份详尽的EPLAN许可证迁移指南,帮助您轻松完成这一操作…...

服务器部署静态页面
前言 需要先下载nginx,然后上传你的静态网页文件,最后设置nginx展示静态页面 安装nginx 第一步:在服务器上下载nginx服务 sudo dnf install nginx 第二步:启动nginx sudo systemctl start nginx 第三步:验证ngin…...

Spring boot 知识整理
一、SpringBoot 背景内容梳理 SpringBoot是一个基于Spring框架的开源框架,用于简化Spring应用程序的初始搭建和开发过程。它通过提供约定优于配置的方式,尽可能减少开发者的工作量,使得开发Spring应用变得更加快速、便捷和高效。 SpringBoot…...

软件测试面试题汇总---实时更新
1. java垃圾回收机制 2. 类为什么不能多继承,而接口可以 参考为什么类之间只能单继承不能多继承,接口之间可以多继承,类与接口之间可以多实现_内部可以多继承而接口可以多实现-CSDN博客 3. java面向对象的三大特性 继承、封装、多态 4. …...

2025海外代理IP测评:Bright Data,ipfoxy,smartproxy,ipipgo,kookeey,ipidea哪个值得推荐?
近年来,随着全球化和跨境业务需求的不断扩大“海外代理IP”逐渐成为企业和个人在多样化场景中的重要工具。无论是进行数据采集、广告验证、社交媒体管理,还是跨境电商平台运营,选择合适的代理IP服务商都显得尤为重要。然而,市场上…...

蓝桥杯 8. 分巧克力
分巧克力 原题目链接 问题描述 儿童节那天有 K 位小朋友到小明家做客。小明拿出了珍藏的巧克力招待小朋友们。 小明一共有 N 块巧克力,其中第 i 块是 Hᵢ Wᵢ 的长方形。为了公平起见,小明需要从这 N 块巧克力中切出 K 块巧克力分给小朋友们。 要求…...

计算机组成原理—————计算机运算方法精讲<3>反码及移码的表示
第一部分:反码表示法 这里我们直接给出整数反码的计算公式 我们实际计算中其实不用死记硬背公式,小编在这里介绍一下求反码的秒杀技 反码秒杀技:定号取反 第一步:确定符号位是0还是1 第二步:符号位不变,…...

关于STM32创建工程文件启动文件选择
注意启动文件只要选择这几个 而不是要把所有都选上...

FC-4 mapping映射协议VI、hippi、fhcp、scma表示啥意思
FC-4 mapping映射协议VI、hippi、fhcp、scma表示啥意思 1.FC-4 Upper layer protocol协议映射层,定义了光纤通道和上层应用,包括FPGA/ARM 或者其他上层应用之间的接口。上层应用协议包括:串行scsi协议,fcp-scsi协议, f…...

15、stack、queue、deque的模拟实现
一、stack 1、stack的使用 请看这篇文章 2、stack的原理 这篇文章的栈原理讲的不错,并且有链式栈和顺序栈的创建,还有栈常使用的场景,没有数据结构基础的可以看,并且实现一下他的2种栈。 3、stack的实现 3.1、成员变量 这里…...

GR00T N1:面向通用类人机器人的开放基础模型
摘要 通用型机器人需要具备多功能的身体和智能的大脑。近年来,类人机器人的发展在构建人类世界中的通用自主性硬件平台方面展现出巨大潜力。一个经过大量多样化数据源训练的机器人基础模型,对于使机器人能够推理新情况、稳健处理现实世界的多变性以及快…...

保姆级教程:RK3588部署yolo目标检测模型
本文用到的板卡设备为鲁班猫4(LubanCat-4),瑞芯微rk3588系列处理器。 官方文档写的挺详细了,但是版本太多不统一,而且涉及了多个代码仓库,稍显杂乱。本着最少代码原则,仅需下载一个代码仓库&am…...

【含文档+PPT+源码】物联网车辆GPS定位管理系统【
项目视频介绍: 毕业作品物联台云平台的设计与实现 课程简介: 本课程演示的是一款物联网车辆GPS定位管理系统,主要针对计算机相关专业的正在做毕设的学生与需要项目实战练习的 Java 学习者。 1.包含:项目源码、项目文档、数据库脚…...

热烈祝贺“中芯机械”选择使用订单日记
感谢潍坊中芯机械制造有限公司选择使用订单日记! 潍坊中芯机械制造有限公司,成立于2023年,位于山东省潍坊市,是一家以从事生产、销售农业机械、汽车配件、机械电气设备等业务为主的企业。 在业务不断壮大的过程中,想…...

2025年保安员考试题库及答案
一、单选题 81、保安员张某和李某在火车站巡逻时,发现一男青年神色慌张,行为诡秘,这两名保安员识别这一可疑情况使用的方法是()。 A.查问法 B.直接观察法 C.判断法 D.视觉判断法 答案:B 82、某天&…...
)
ADB的安装及抓取日志(1)
一、简介 ADB(Android Debug Bridge)是一个通用命令行工具,允许你与 Android 设备进行通信。它主要用于开发和调试目的,但也可用于其他多种功能,如安装应用、运行 shell 命令、查看日志等。ADB 是 Android SDK 的一部…...

用 Iris数据做决策树分析
文章目录 Iris数据的准备1.直接从sklearn.datasets 加载或转化成文件已备本地使用2.可以在https://archive.ics.uci.edu/dataset/53/iris下载 过程示例代码如下生成的决策树如下:生成的分析报告如下: 决策树模型分析报告1. 模型性能2. 特征重要性3. 决策…...
)
【Bluedroid】A2DP Sink播放流程源码分析(三)
AVCTP消息处理 avrc_msg_cback /packages/modules/Bluetooth/system/stack/avrc/avrc_api.cc /******************************************************************************** Function avrc_msg_cback** Description This is the callback function used…...

概念实践极速入门 - 常用的设计模式 - 简单生活例子
概念实践极速入门 - 常用的设计模式 - 简单生活例子 SOLID 五大设计原则的首字母缩写 单一职责原则 和 开闭原则 就省略啦, 这两个概念很简单, 为了写而写反而容易误导人~* 鼓励大家字面理解! // 哎呀还是解释吧 单一(S): 单干一件事; 开闭(O): 拓展开放, 修改关…...

postgres 数据库信息解读 与 sqlshell常用指令介绍
数据库信息: sqlshell Server [localhost]: 192.168.30.101 Database [postgres]: Port [5432]: 5432 Username [postgres]: 用户 postgres 的口令: psql (15.12, 服务器 16.8 (Debian 16.8-1.pgdg1201)) 警告:psql 主版本15,服务器主版本为…...

映射网络路路径和ftp路径原理是什么,如何使用,有什么区别
文章目录 一、原理1. 映射网络路径2. FTP路径 二、使用方法1. 映射网络路径2. FTP路径 三、主要区别1. 协议与功能2. 安全性与权限3. 适用场景 四、如何选择?五、注意事项 映射网络路径(如SMB/CIFS或NFS)和FTP路径(FTP/FTPS/SFTP&…...

微服务3--服务容错
前言:本篇主要介绍服务容错与Sentinel进行限流。 高并发带来的问题 在微服务架构中,我们将业务拆分为一个个的服务,服务与服务之间都可以相互调用,但是由于网络或者说服务器本身的问题,服务不能保证100%可用ÿ…...

4.15redis点评项目下
--->接redis点评项目上 Redis优化秒杀方案 下单流程为:用户请求nginx--->访问tomcat--->查询优惠券--->判断秒杀库存是否足够--->查询订单--->校验是否是一人一单--->扣减库存--->创建订单 以上流程如果要串行执行耗时会很多,…...

Web开发-JavaEE应用原生和FastJson反序列化URLDNS链JDBC链Gadget手搓
知识点: 1、安全开发-JavaEE-原生序列化-URLDNS链分析 2、安全开发-JavaEE-FastJson-JdbcRowSetImpl链分析 利用链也叫"gadget chains",我们通常称为gadget: 1、共同条件:实现Serializable或者Externalizable接口&…...
)
坚持每日Codeforces三题挑战:Day 3 - 题目详解(2024-04-16,难度:900, 1200, 1200)
每天坚持写三道题第三天 (今天写点简单的,剩下去刷力扣了) 今日题目: Problem - B - Codeforces 900 Problem - B - Codeforces 1300 Problem - D - Codeforces 1400 题目一: Problem - B - Codeforces 题目大意: 给你一个数组,每次操…...

MySQL5.7递归查询
向下递归查询 SELECT ID,NAME,PARENT_ID,LEVEL_FROM(SELECT ID AS _IDS,(SELECT ID : GROUP_CONCAT(ID)FROM TREE_TABLE WHERE FIND_IN_SET(PARENT_ID,ID) > 0AND REMOVE N) T1,L : L 1 AS LEVEL_FROM TREE_TABLE,(SELECT ID : start, L: 0) T2WHERE ID IS NOT NULL) T3,…...
之GEM(SEMI 30))
半导体设备通信标准—secsgem v0.3.0版本使用说明文档(2)之GEM(SEMI 30)
文章目录 1、处理器1.1、事件 2、GEM 合规性2.1、状态模型2.2、 设备加工状态2.3、 文档2.4、 控制 (作员启动)2.5、 动态事件报告配置2.6、 跟踪数据收集2.7、 报警管理2.8、 远程控制2.9、 设备常量2.10、 工艺配方管理2.11、 物料移动2.12、 设备终端…...

C++异步编程从入门到精通实战:全面指南与实战案例
C异步编程从入门到精通实战:全面指南与实战案例 在当今多核处理器普及的时代,异步编程成为了提升程序性能和响应能力的关键技术。无论是在高频交易系统、实时游戏引擎,还是网络服务器和大型数据处理平台,异步编程都发挥着至关重要…...

驱动开发硬核特训 · Day 13:从 device_create 到 sysfs,设备文件是如何生成的?
🔍 B站相应的视屏教程: 📌 内核:博文视频 - 备树深度解析:理论 实践全指南(含 of 函数与 i.MX8MP 实例) 敬请关注,记得标为原始粉丝。 🔧 📌 本文目标&#…...
与 “元数据校验异常“(蛋白尿))
肾脏系统触发 “数据包泄漏“ (血尿)与 “元数据校验异常“(蛋白尿)
肾脏系统触发 "数据包泄漏" (血尿)与 "元数据校验异常"(蛋白尿) 用计算机术语来类比。在之前的对话中,肾小球被比作防火墙或过滤器,肾小管则是回收系统。红细胞泄漏通常是因为肾小球的过滤屏障受损,而蛋白尿则可能与肾小…...
流密码)
密码学(二)流密码
2.1流密码的基本概念 流密码的基本思想是利用密钥 k 产生一个密钥流...,并使用如下规则对明文串 ... 加密:。密钥流由密钥流发生器产生: ,这里是加密器中的记忆元件(存储器)在时刻 i 的状态,…...

Python 趣味学习 -数据类型脱口秀速记公式 [特殊字符]
🎤 Python数据类型脱口秀速记公式 🐍 1️⃣ 四大金刚登场 "Set叔(无序洁癖)、Tuple爷(顽固老头)、List姐(百变女王)、Dict哥(万能钥匙)"2️⃣ 特性对比RAP 🎶 内存/作用域: 全局变量 → 函数内修改 → 可变(mutable)会…...

嵌入式Linux设备使用Go语言快速构建Web服务,实现设备参数配置管理方案探究
本文探讨,利用Go语言及gin框架在嵌入式Linux设备上高效搭建Web服务器,以实现设备参数的网页配置。通过gin框架,我们可以在几分钟内创建一个功能完善的管理界面,方便对诸如集中器,集线器等没有界面的嵌入式设备的管理。…...
从算法仿真到工程源码实现-第十二节-总结)
波束形成(BF)从算法仿真到工程源码实现-第十二节-总结
一、总结 (1)基于webrtc的非线性波束形成效果较好,复杂度较低,但是波束形成后引入了非线性,导致噪声估计不准确,降噪效果变差。 (2)MVDR使用噪声协方差矩阵对平稳噪声降噪效果比较…...

【AI】IDEA 集成 AI 工具的背景与意义
一、IDEA 集成 AI 工具的背景与意义 随着人工智能技术的迅猛发展,尤其是大语言模型的不断演进,软件开发行业也迎来了智能化变革的浪潮。对于开发者而言,日常工作中面临着诸多挑战,如代码编写的重复性劳动、复杂逻辑的实现、代码质…...

解释原型链的概念,并说明`Object.prototype.__proto__`的值是什么?
原型链是 JavaScript 中实现继承的核心机制。每个对象都有一个指向其原型对象的私有链接(通过 [[Prototype]] 内部属性),而原型对象自身也可能拥有原型,这种链式结构被称为原型链。当访问对象的属性时,若对象自身不存在…...

prototype`和`__proto__`有什么区别?如何手动修改一个对象的原型?
在 JavaScript 中,prototype 和 __proto__ 都与原型链相关,但它们的角色和用途有本质区别: 1. prototype 和 __proto__ 的区别 特性prototype__proto__归属对象仅函数对象拥有(如构造函数)所有对象默认拥有࿰…...

数据挖掘案例-电力负荷预测
今日课程 时间序列预测介绍 电力负荷预测项目开发(开发一个基于时间以及历史负荷信息,预测未来负荷的模型) 一、时间序列预测简介 1.什么是时序预测 时间序列预测是一种根据历史时间序列数据来预测未来值的方法。 任务比较好理解&#…...

SQL Server中OPENJSON + WITH 来解析JSON
一、概念 OPENJSON 是 SQL Server(2016 及更高版本) 中引入的一个表值函数,它将 JSON 文本转换为行和列的关系型数据结构。通过添加 WITH 子句,可以明确指定返回数据的结构和类型,实现 JSON 数据到表格数据的精确映射…...
)
在 Linux 中判断当前网络类型与网卡类型的实用方法(内外网判断 + 网卡分类)
在日常使用 Linux(例如 Jetson、树莓派、服务器)过程中,我们经常会遇到以下几个问题: 如何知道系统当前是走 有线网络还是无线网络?如何判断是连接了 公网还是内网?169.254.x.x 是什么?为什么我…...

Docker compose入门
目录 Docker Compose简介安装docker compose局限一 适合单机部署,不适合生产环境1. 架构设计目标不同2. 关键功能对比3. 生产环境的核心需求4. 适用场景总结5. 为什么 Compose 不适合生产? Docker Compose 简介 Docker Compose 是一个用于简化多容器Do…...

Docker Search 和 Docker Pull 失效解决
目录 1. Docker Search 1.1 问题描述 1.2 解决方案 1.2.1 方案1 命令行方式 1.2.2 方案2 非命令行方式 2. Docker Pull 2.1 问题描述 2.2 解决方案 2.2.1 替换镜像源 2.2.1.1 编辑镜像源(linux)版 2.2.1.2 编辑镜像源(windows版本…...