《What Are Step-Level Reward Models Rewarding?》全文翻译
《What Are Step-Level Reward Models Rewarding?Counterintuitive Findings from MCTS-Boosted Mathematical Reasoning》
Step-Level奖励模型到底奖励了什么?来自基于MCTS提升的数学推理的反直觉发现
摘要
Step-level奖励模型(SRMs)通过过程监督或基于强化学习的步级偏好对齐,可以显著提升数学推理性能。SRMs的表现至关重要,因为它们作为关键指引,确保推理过程中的每一步都与期望的结果保持一致。近年来,类似AlphaZero的方法中,利用蒙特卡洛树搜索(MCTS)进行自动的步级偏好标注,证明了其特别有效。然而,SRMs成功背后的具体机制尚未得到充分探究。为弥补这一空白,本研究深入分析了SRMs的反直觉特征,尤其聚焦于基于MCTS的方法。我们的发现显示,移除对思维过程的自然语言描述对SRMs的效果影响甚微。此外,我们证明SRMs擅长评估数学语言中复杂的逻辑一致性,但在自然语言上的表现较差。这些见解为理解驱动有效步级奖励建模的核心要素提供了细致入微的认知。通过阐明这些机制,本研究为开发更高效且简化的SRMs提供了宝贵指导,表明聚焦数学推理关键部分即可实现目标。
引言
大规模语言模型(LLMs)已展示其在广泛任务上的卓越能力,如信息抽取、自然语言理解等(Zhao等,2023),彻底革新了深度学习领域。在这些能力中,推理尤为关键,尤其是数学推理,由于其复杂性,亟需进一步提升。众多研究表明,多步推理,通常借助Chain-of-Thought(CoT)提示,能够显著改善模型在推理任务上的表现(Zhou等,2023;Besta等,2024;Ding等,2023;Yao等,2024;Wang等,2022;Wei等,2022;Zheng等,2024;Li等,2024;Zhan等,2024)。
近来,受导向的树搜索方法进一步提升了推理能力,通过在线模拟探索多条推理路径,以找出最优解路径(Hao等,2023,2024;Feng等,2023)。尽管更优的推理路径带来更好表现,但推理链长导致搜索空间呈指数级增长,计算成本大幅提升。鉴于LLM推理本身代价高昂,对每道推理问题进行在线树搜索会带来重复且不必要的开销。
为解决该问题,提出了步级奖励模型(SRM)。Lightman等(2023)引入了过程奖励模型(PRM),采用人工注解的步级评分进行奖励建模;而Ma等(2023)进一步证实SRMs在数学推理和编程任务中的有效性。随后,Math-Shepherd(Wang等,2024)通过穷举推理过程遍历,系统地生成步级偏好数据以训练奖励模型,加强模型能力。更近期地,受AlphaZero启发,蒙特卡洛树搜索(MCTS)(Xie等,2024;Chen等,2024a,b)被用来更高效地收集偏好,利用其平衡探索与利用的能力。这些训练出来的SRMs能通过训练阶段的近端策略优化(PPO)协助步级偏好对齐,或者在推理阶段作为步骤验证器,有效提升推理表现。
尽管基于MCTS的方法构建的SRMs在数学推理上取得显著成就,它们的具体工作原理及究竟奖励了什么,仍未清晰。认知科学家和脑科学家指出,丰富的思考与推理过程不必然依赖自然语言(Fedorenko, Piantadosi, 和 Gibson,2024)。例如,一名熟练的数学家能判断数学表达式的逻辑一致及数值正确性,而不依赖自然语言。借此思想,我们提出针对LLM的类似假设:自然语言对数学推理而言非必需。我们推测,LLMs可直接对数学语言中的推理步骤学习偏好,而非依赖自然语言描述。这意味着LLMs或能通过数学语言的内在结构理解与处理数学推理,有望带来更高效、更加聚焦的训练方法,跳过自然语言解释的需求。此外,错误解答往往源于错误的数学计算或逻辑失误(Zhang等,2024),后者更具挑战性(Chen等,2024a)。因此,我们进一步探索SRMs在评估纯数学语言逻辑一致性方面的效力,表明改进并非仅是鼓励单步中计算正确。更令人意外的是,SRMs在学习评估自然语言中逻辑一致性时遇到困难,这进一步支持自然语言对步级奖励建模的非必要性。
为探究自然语言与数学语言在步级奖励建模中的不同作用,我们将推理路径的每一步拆分为两部分:思考过程的自然语言描述和数学表达式(见图1)。通过选择性地从SRM输入中剔除不同部分进行消融分析。此拆分模拟了人类数学问题解决中的典型流程,通常包含先思考策略,继而执行相关计算。思考过程包括该步应采用的策略,而计算则执行该思路。换言之,我们的拆分旨在将构成“思考”的自然语言与包含“思考”执行的数学表达式区分开,以期深入理解自然语言在步级奖励建模中的作用。
总而言之,实验结果支持SRMs对数学表达式有内在亲和力,而非自然语言。具体而言,我们总结如下关键见解:
-
思考过程的自然语言描述对成功进行步级奖励建模并非必须。
-
SRMs不仅推动单步计算准确,还能有效评估数学语言中具挑战性的逻辑一致性。
-
评估自然语言中的逻辑一致性较困难,SRMs往往难以胜任。
预备知识
马尔科夫决策过程
定义:马尔科夫决策过程(MDP)是一种用来建模决策问题的数学框架,广泛应用于强化学习(RL)领域,处理部分随机且部分可控的环境。MDP由五元组 ( S , A , P , R , γ ) (S, A, P, R, \gamma) (S,A,P,R,γ)定义,其中:
-
S S S为状态集合。
-
A A A为动作集合。
-
P P P为状态转移概率函数, P ( s t + 1 ∣ s t , a t ) P(s_{t+1} | s_t, a_t) P(st+1∣st,at),定义在状态 s t s_t st采取动作 a t a_t at后转移到状态 s t + 1 s_{t+1} st+1的概率。
-
R R R为奖励函数, R ( s t , a t , s t + 1 ) R(s_t, a_t, s_{t+1}) R(st,at,st+1),定义从状态 s t s_t st通过动作 a t a_t at转移到状态 s t + 1 s_{t+1} st+1后获得的即时奖励。
-
γ \gamma γ为折扣因子,决定未来奖励的重要性。
贝尔曼期望方程:
状态价值函数 V ( s ) V(s) V(s)的贝尔曼期望方程为: V π ( s ) = E a ∼ π ( ⋅ ∣ s ) [ E s ′ ∼ P ( ⋅ ∣ s , a ) [ R ( s , a , s ′ ) + V π ( s ′ ) ] ] V^{\pi}(s) = \mathbb{E}_{a \sim \pi(\cdot|s)} \left[ \mathbb{E}_{s' \sim P(\cdot|s,a)} \left[ R(s,a,s') + V^{\pi}(s') \right] \right] Vπ(s)=Ea∼π(⋅∣s)[Es′∼P(⋅∣s,a)[R(s,a,s′)+Vπ(s′)]]状态-动作价值函数 Q ( s , a ) Q(s,a) Q(s,a)的贝尔曼期望方程为: Q π ( s , a ) = E s ′ ∼ P ( ⋅ ∣ s , a ) [ R ( s , a , s ′ ) + E a ′ ∼ π ( ⋅ ∣ s ′ ) [ Q π ( s ′ , a ′ ) ] ] Q^{\pi}(s,a) = \mathbb{E}_{s' \sim P(\cdot|s,a)} \left[ R(s,a,s') + \mathbb{E}_{a' \sim \pi(\cdot|s')} \left[ Q^{\pi}(s',a') \right] \right] Qπ(s,a)=Es′∼P(⋅∣s,a)[R(s,a,s′)+Ea′∼π(⋅∣s′)[Qπ(s′,a′)]]最优价值函数定义为:
KaTeX parse error: Undefined control sequence: \* at position 13: \begin{align\̲*̲} V^{\*}(s) & =…
最优价值函数与最优贝尔曼方程的关系为:
V ∗ ( s ) = max a Q ∗ ( s , a ) (2) V^{*}(s) = \max_{a} Q^{*}(s,a) \tag{2} V∗(s)=amaxQ∗(s,a)(2)
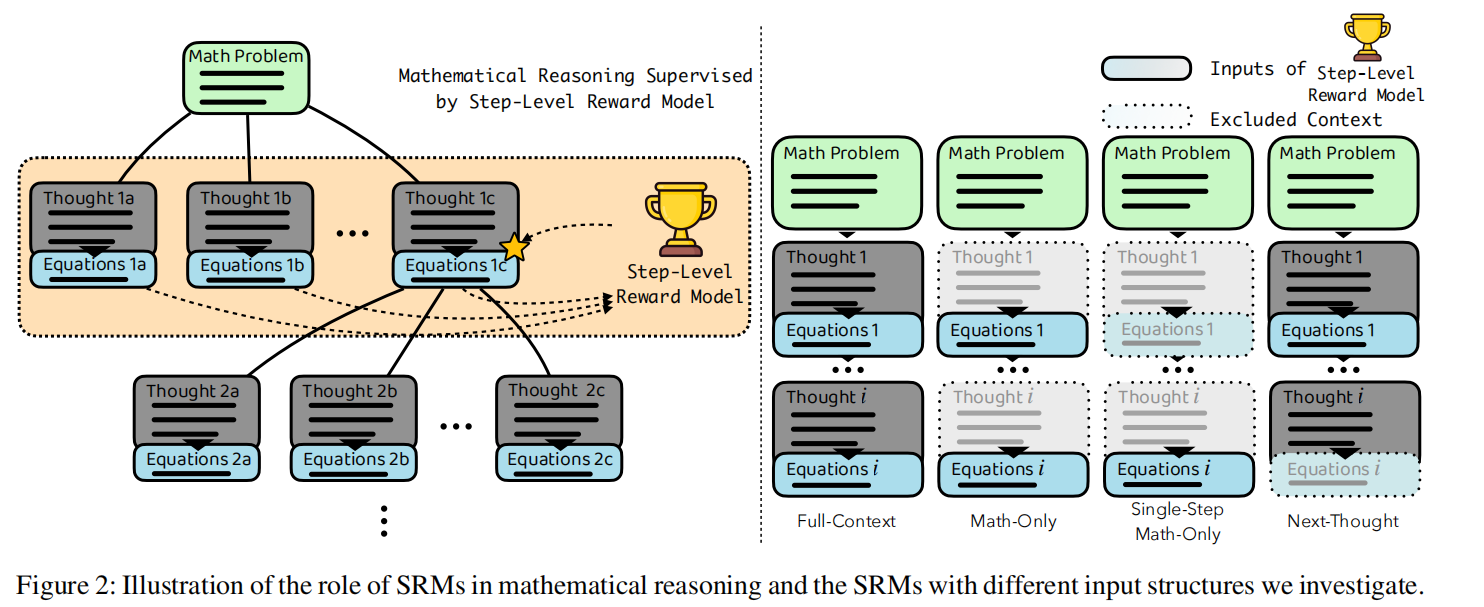
图2:数学推理中SRMs的作用示意及我们调查的不同输入结构的SRMs示意。
方法论
将LLM的数学推理视为MDP:我们的定义}
图2展示了数学推理过程,每步拆分为思考和数学表达式两部分。具体的MDP定义如下: M D P = ( S , A , P , R ) \mathrm{MDP} = (S, A, P, R) MDP=(S,A,P,R)其中:
-
状态空间 S S S由状态 s i = ( T k , E k ) k = 0 i s_i = \left(T_k, E_k\right)_{k=0}^i si=(Tk,Ek)k=0i组成,代表截至步骤 i i i的思考序列 T k T_k Tk与数学表达式序列 E k E_k Ek。
-
动作空间 A A A由动作 a i = T i + 1 a_i = T_{i+1} ai=Ti+1组成,表示LLM生成的下一步思考的自然语言描述。
-
状态转移函数 P ( s i + 1 ∣ s i , a i ) P(s_{i+1} | s_i, a_i) P(si+1∣si,ai)定义了在状态 s i s_i si采取动作 a i a_i ai后转移至 s i + 1 s_{i+1} si+1的概率。该函数由LLM实现,即基于下一思考 a i = T i + 1 a_i = T_{i+1} ai=Ti+1和现有状态 s i = ( T k , E k ) k = 0 i s_i = (T_k, E_k)_{k=0}^i si=(Tk,Ek)k=0i,生成对应数学表达式 E i + 1 E_{i+1} Ei+1。
-
奖励函数 R ( s i , a i , s i + 1 ) R(s_i, a_i, s_{i+1}) R(si,ai,si+1)定义了从状态 s i s_i si经过动作 a i a_i ai转移至 s i + 1 s_{i+1} si+1获得的即时奖励。我们根据最终答案是否正确,定义奖励为:
R ( s i , a i , s i + 1 ) = { 1 , 最终答案正确 0 , 最终答案错误 (3) R(s_i, a_i, s_{i+1}) = \begin{cases} 1, & \text{最终答案正确} \\ 0, & \text{最终答案错误} \end{cases} \tag{3} R(si,ai,si+1)={1,0,最终答案正确最终答案错误(3)
此外,策略 π ( a i ∣ s i ) \pi(a_i| s_i) π(ai∣si)由LLM实现,即根据当前状态 s i = ( T k , E k ) k = 0 i s_i = (T_k, E_k)_{k=0}^i si=(Tk,Ek)k=0i生成下一步思考 a i = T i + 1 a_i = T_{i+1} ai=Ti+1。基于式(1),智能体的目标是在每一步生成正确思考 T T T以最大化 V π ( s i ) V_\pi (s_i) Vπ(si)或 Q π ( s i , a ) Q_\pi (s_i, a) Qπ(si,a)。
总结:
语言模型在MDP框架中承担双重角色:
-
作为智能体(Agent):LLM依据策略 π ( a i ∣ s i ) \pi(a_i|s_i) π(ai∣si)在每个状态选择合适动作(下一步思考 T i + 1 T_{i+1} Ti+1)。
-
作为世界模型(World Model):LLM也充当状态转移函数 P ( s i + 1 ∣ s i , a i ) P(s_{i+1} | s_i, a_i) P(si+1∣si,ai),根据内在知识和训练数据预测动作结果,模拟数学推理环境,通过执行思考 T i + 1 T_{i+1} Ti+1及对应计算,输出新状态 s i + 1 s_{i+1} si+1。
基于MCTS的步级偏好采集}
数学推理与MDP的天然对应关系使我们可利用蒙特卡洛树搜索(MCTS)高效采集步级偏好。MCTS从根节点 s 0 s_0 s0(数学问题)开始,每个新节点代表状态更新。MCTS的每次迭代包含四个阶段:选择、扩展、模拟和回传。
- 选择。自根节点 s 0 s_0 s0起,沿树遍历至叶节点,利用上置信界(UCT)策略平衡探索与利用。在节点 s i s_i si,按式:
s i + 1 ∗ = arg max s i + 1 [ c ( s i + 1 ) N ( s i + 1 ) + w exp ⋅ log N ( s i ) N ( s i + 1 ) ] (4) s_{i+1}^* = \arg\max_{s_{i+1}} \left[ \frac{c(s_{i+1})}{N(s_{i+1})} + w_{\exp} \cdot \sqrt{\frac{\log N(s_i)}{N(s_{i+1})}} \right] \tag{4} si+1∗=argsi+1max[N(si+1)c(si+1)+wexp⋅N(si+1)logN(si)](4)
其中 c ( s i + 1 ) c(s_{i+1}) c(si+1)为正确计数, N ( s i ) N(s_i) N(si)与 N ( s i + 1 ) N(s_{i+1}) N(si+1)是访问计数, w exp w_{\exp} wexp平衡探索与利用。重复此过程至发现未扩展节点。
2. 扩展。到达叶节点后,代理生成 n n n个候选动作(思考) { a i j ∣ j = 1 , . . . , n } \{a_i^j| j=1,...,n\} {aij∣j=1,...,n},世界模型基于这些动作执行对应数学计算,构建新候选状态 { s i j ∣ j = 1 , . . . , n } \{s_i^j | j=1,...,n\} {sij∣j=1,...,n}。这些节点作为子节点加入树,拓宽搜索空间。
3. 模拟。模拟阶段从新扩展节点模拟推理至终止状态或设定深度,依据式(3)计算节点得分。此步骤用于估计新节点性能,为回传阶段提供依据。
4. 回传。从最终状态开始,将模拟结果沿路径向上回传,更新节点价值和访问次数,通过提升选择策略质量促进后续迭代。
MCTS完成后,可在树内通过节点值比较采集步级偏好对。
步级奖励建模
在完成偏好对的采集后,即可通过对比学习构造步级奖励模型。依据我们的MDP定义,SRM被视作动作价值函数 Q ( s , a ) Q(s,a) Q(s,a)或状态价值函数 V ( s ) V(s) V(s)。本研究调查四种不同输入格式的SRM进行消融,具体定义见图2右:
- \textbf{全上下文步级奖励模型(FC-SRM)}:输入当前状态的思考和数学表达式组合。
V 1 ( s i ) = V 1 ( ( T k , E k ) k = 0 i ) (5) V_1(s_i) = V_1 \left( (T_k, E_k)_{k=0}^i \right) \tag{5} V1(si)=V1((Tk,Ek)k=0i)(5)
- \textbf{纯数学步级奖励模型(MO-SRM)}:仅输入当前状态的数学表达式序列,不包含自然语言思考描述。
V 2 ( s i ) = V 2 ( ( E k ) k = 0 i ) (6) V_2(s_i) = V_2 \left( (E_k)_{k=0}^i \right) \tag{6} V2(si)=V2((Ek)k=0i)(6)
- \textbf{单步纯数学步级奖励模型(SSMO-SRM)}:仅输入当前步骤最新的数学表达式,不含自然语言也不含先前步骤表达式。
V 3 ( s i ) = V 3 ( E i ) (7) V_3(s_i) = V_3(E_i) \tag{7} V3(si)=V3(Ei)(7)
- \textbf{下一步思考步级奖励模型(NT-SRM)}:输入当前状态的思考和数学表达式,评估下一步思考。根据我们的定义,下一思考即为智能体的动作,故该模型即为动作价值函数。
Q ( s i , a i ) = Q ( ( T k , E k ) k = 0 i , T i + 1 ) (8) Q(s_i, a_i) = Q \left( (T_k, E_k)_{k=0}^i, T_{i+1} \right) \tag{8} Q(si,ai)=Q((Tk,Ek)k=0i,Ti+1)(8)
基于步级奖励模型的束搜索}
训练好SRMs后,常用它们进行步级偏好对齐以更新策略,旨在生成最优动作,减少在线MCTS引入的开销。亦可利用这些偏好数据提升世界模型 P P P的准确度,进而提高数学表现。
\begin{verbatim}
算法1:束搜索算法
输入:初始状态 s 0 s_0 s0,束宽 B B B,候选动作数 c c c
初始化束 B ← { s 0 } \mathcal{B} \leftarrow \{ s_0 \} B←{s0}
当 B \mathcal{B} B非空时循环:
初始化空列表$\mathcal{B}_{next} \leftarrow \emptyset$对每个状态$s_i \in \mathcal{B}$:生成动作候选集$\{ a_i^1, a_i^2, ..., a_i^c \}$对每个动作$a_i^j$:计算后续状态$s_{i+1}^j \leftarrow P(s_{i+1}| s_i, a_i^j)$评估$s_{i+1}^j$得分将$s_{i+1}^j$加入$\mathcal{B}_{next}$按分数对$\mathcal{B}_{next}$排序,保留前$B$个状态更新束$\mathcal{B} \leftarrow$ 前$B$状态
返回最终束中最佳状态
\end{verbatim}
鉴于本研究聚焦于SRMs,实验未包含偏好对齐过程,直接视SRMs为束搜索的打分函数,简化流程。该简化避免偏好对齐潜在不确定性,更清晰地展现SRMs的效力。特别是,当 B = 1 B=1 B=1时,束搜索退化为贪婪搜索(GS)。
贪婪搜索可理解为在SRM监督下的推理过程(图2左)。理论上,若样本无限,策略 π \pi π和世界模型 P P P在动作或状态选取上,将渐近于最优策略KaTeX parse error: Undefined control sequence: \* at position 5: \pi^\̲*̲,满足:
lim n → ∞ P ( arg max { a t } t = 0 n Q ( s , a t ) = arg max a ∈ A π ( s ) Q ( s , a ) ) = 1 (9) \lim_{n \to \infty} P \left( \arg\max_{\{a_t\}_{t=0}^n} Q(s,a_t) = \arg\max_{a \in A_\pi(s)} Q(s,a) \right) = 1 \tag{9} n→∞limP(arg{at}t=0nmaxQ(s,at)=arga∈Aπ(s)maxQ(s,a))=1(9)
其中 a t ∼ π ( a ∣ s ) a_t \sim \pi(a|s) at∼π(a∣s), A π ( s ) A_\pi(s) Aπ(s)为策略 π \pi π在状态 s s s下可选动作集合。状态空间同理:
lim n → ∞ P ( arg max { s t ′ } t = 0 n V ( s t ′ ) = arg max s ′ ∈ S ( s , a ) V ( s ′ ) ) = 1 (10) \lim_{n \to \infty} P \left( \arg\max_{\{s_t'\}_{t=0}^n} V(s_t') = \arg\max_{s' \in S(s,a)} V(s') \right) = 1 \tag{10} n→∞limP(arg{st′}t=0nmaxV(st′)=args′∈S(s,a)maxV(s′))=1(10)
其中 s t ∼ E a t − 1 ∈ π ( a ∣ s t − 1 ) P ( s ∣ s t − 1 , a t − 1 ) s_t \sim \mathbb{E}_{a_{t-1} \in \pi(a|s_{t-1})} P(s | s_{t-1}, a_{t-1}) st∼Eat−1∈π(a∣st−1)P(s∣st−1,at−1)。
实验}
实现细节}
数据集 为通过MCTS构造步级偏好对,使用GSM8K(Cobbe等,2021)和MATH(Hendrycks等,2021)训练数据中的数学题及对应答案。准确率在测试集上评估。
模型 推理过程由两个LLM协作实现,采用Llama-3-8B-Instruct(Dubey等,2024)作为MCTS中的代理与世界模型,因其指令遵循优良。
提示 一台LLM(代理)负责生成自然语言思考描述,另一台(世界模型)依据思考执行计算。具体提示见附录。
基线 使用Llama-3-8B-Instruct构建Pass@1基线,采用3-shot示例。
MCTS步级偏好采集 代理在扩展阶段采样 n = 6 n=6 n=6候选动作,针对每道题进行500次迭代评估节点质量。为避免答案格式差异影响,采用基于DeepSeek-Math-7B-Base的有监督微调模型判定模拟后的答案正确性,该模型也用于评测。为强化偏好,仅保留值差大于0.7的偏好对。详细超参见附录。
奖励训练 DeepSeek-Math-7B-Base(Shao等,2024)与Qwen2-7B(Yang等,2024)作为SRM训练基础模型。每个SRM训练两个实例,每实例配备8张A800 GPU。超参数详见附录。
主要结果}
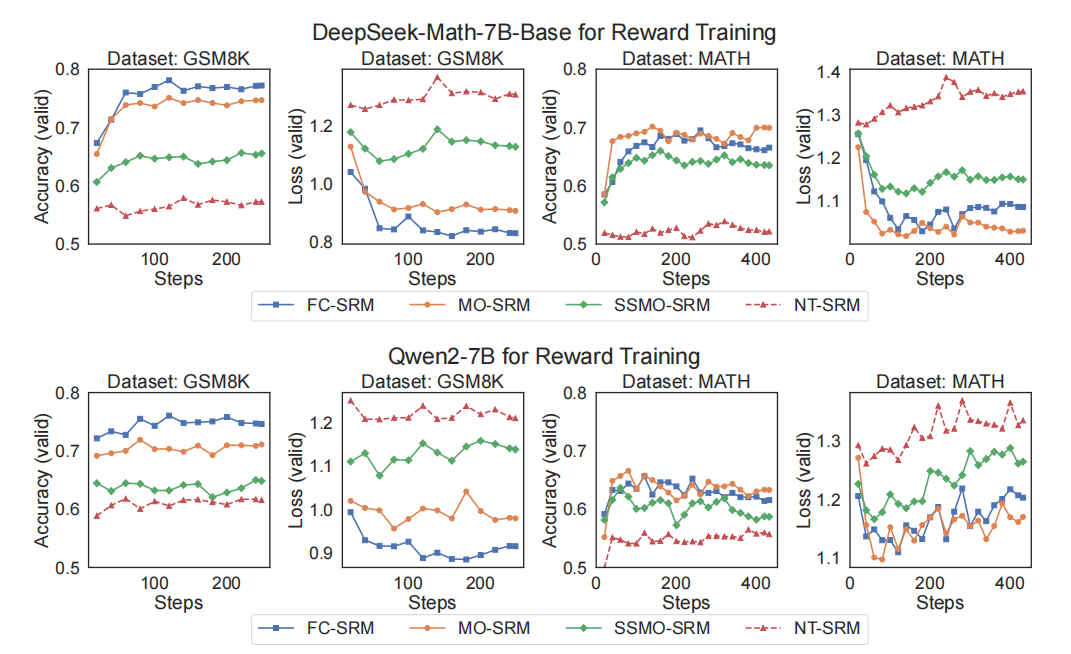
通过MCTS采集所有步级偏好对后,针对FC-SRM、MO-SRM、SSMO-SRM和NT-SRM提取相应数据训练奖励模型,训练曲线见图3。训练完成的SRMs作为贪婪搜索打分函数使用,结果及相对于基线的绝对提升见表1。后续章节进行深入分析。
我们真的需要自然语言吗?}
直觉上,自然语言描述应提供关键上下文,有助于SRMs“理解”。为验证,训练全上下文(FC)及纯数学(MO)输入格式的SRMs。
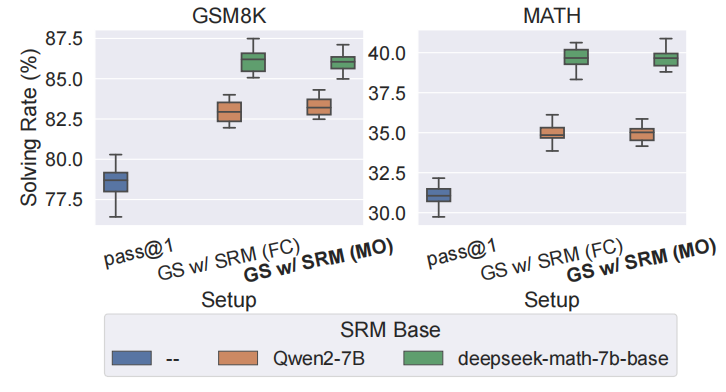
图4:仅输入数学表达式的SRMs在贪婪搜索时表现与全上下文输入的SRMs近似。图中箱线图基于20次运行统计。
结果显示,移除自然语言对步级奖励建模影响甚微。FC-SRMs与MO-SRMs在偏好预测准确率和贪婪搜索性能上表现极为接近,表明成功的步级奖励建模并不依赖自然语言描述,反常理。即使缺失每步的自然语言思考描述,MO-SRMs依然能成功训练(见图3)。表1和图4展示其作为贪婪搜索评分函数时表现;例如在MATH数据集上,基于DeepSeek-Math-7B-Base的MO-SRM( 39.64 % 39.64\% 39.64%)甚至优于FC-SRM( 38.58 % 38.58\% 38.58%)。我们进一步用t检验比较多个数据集及基础模型下FC-SRM与MO-SRM表现:GSM8K的 t = − 0.18 , p = 0.86 t=-0.18, p=0.86 t=−0.18,p=0.86(Qwen2-7B)、 t = − 0.14 , p = 0.89 t=-0.14, p=0.89 t=−0.14,p=0.89(DeepSeek-Math-7B-Base);MATH的 t = 0.79 , p = 0.44 t=0.79, p=0.44 t=0.79,p=0.44(Qwen2-7B)、 t = 0.77 , p = 0.45 t=0.77, p=0.45 t=0.77,p=0.45(DeepSeek-Math-7B-Base)。四组检验均 p > 0.05 p>0.05 p>0.05,差异无统计学意义。结果支持去除自然语言对SRMs效用无显著影响的结论。
SRMs能评估数学语言中的逻辑一致性吗?
MCTS方法的成功归因于避免逻辑和数值错误。常认为逻辑错误更难评估,MCTS被视为有效解决方案,通过收集偏好解决这难题。本节比较SSMO-SRM、MO-SRM和NT-SRM,探讨自然语言与数学语言在评估纯数学逻辑一致性中的作用。
若输入中上下文信息有用,含多步信息的SRM表现应优于仅依赖当前步的SSMO-SRM。此能力即模型对逻辑一致性的评估能力,意味着识别后续步骤是否逻辑上衔接前文及结论。结果见表1。
LLMs可被训练以评估纯数学语言的逻辑一致性。以DeepSeek-Math-7BBase为例,MO-SRM在GSM8K和MATH上分别获得 + 7.35 % +7.35\% +7.35%和 + 8.48 % +8.48\% +8.48%的提升,高于SSMO-SRM的 + 3.64 % +3.64\% +3.64%和 + 6.30 % +6.30\% +6.30%。Qwen2-7B基础模型下,MO-SRM在GSM8K和MATH分别提升 + 5.31 % +5.31\% +5.31%和 + 3.94 % +3.94\% +3.94%,亦超过SSMO-SRM的 + 3.18 % +3.18\% +3.18%和 + 1.92 % +1.92\% +1.92%。显著差距表明考虑全部数学表达式序列的MO-SRM更能捕获逻辑一致性,而非单步计算,从而SRMs可评估数学语言中的逻辑一致性。
相反,SRMs训练以评估自然语言中逻辑一致性则困难重重。依据我们的MDP定义,即使剥离当前步骤中的数学表达式,思考的自然语言描述仍包含了要执行动作的细节。理论上SRMs应能从构造的偏好对中学习判定有助解题的动作。然而,图3中虚线曲线显示在多数据集和基础模型下,NT-SRMs训练均表现出识别困难。表1也显示NT-SRMs作为评分函数表现欠佳。这暗示LLMs难以有效捕获并评估自然语言隐含的逻辑结构。
附加分析
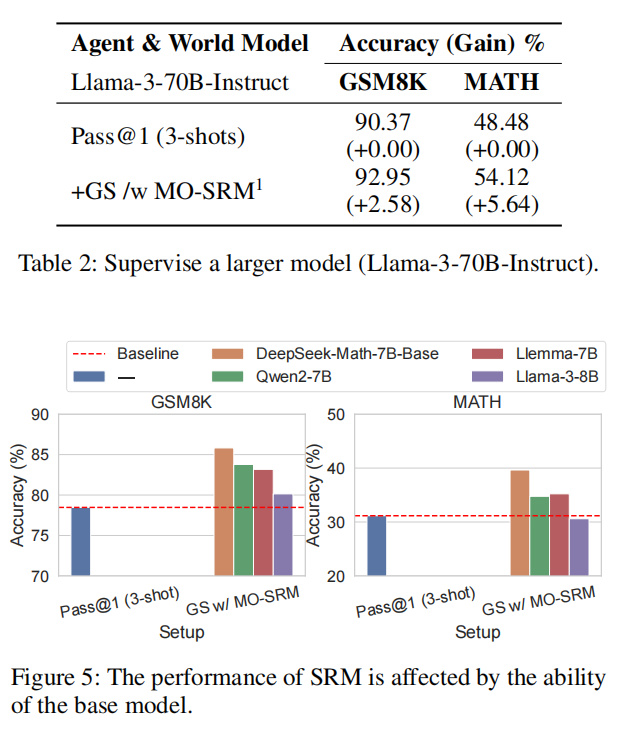
表2:利用大模型(Llama-3-70B-Instruct)进行监督。
图5:SRM性能受基础模型能力影响。
监督更大模型:尽管MO-SRM的偏好数据由较小模型产生,依然能有效指导更大模型推理,带来显著提升(GSM8K+ 2.58 % 2.58\% 2.58%,MATH+ 5.64 % 5.64\% 5.64%)(表2)。这进一步表明SRM可专注数学语言。
基础模型对MO-SRM的影响:MO-SRM基础模型不同影响表现(图5)。该影响不完全与基础模型的数学能力成正比。Llama-3-8B虽数学能力优异,却表现不及Llama-7B(Azerbayev等,2023)、Qwen2-7B及DeepSeek-Math-7B-Base,可能因自我评估难度或其他尚未探明因素所致。
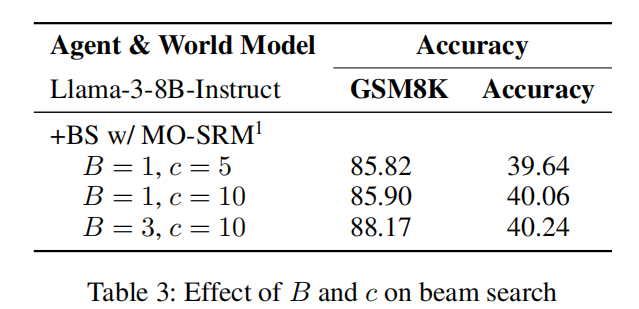
表3:束宽 B B B与候选动作数 c c c对束搜索的影响。
束宽和候选动作数的影响:增加 B B B和 c c c会带来小幅准确率提升,但提升将在一定程度后趋于饱和(详见表3)。
结论
本文探究自然语言与数学表达式在步级奖励建模中的作用,发现自然语言描述非成功的必要条件。大量实验表明,仅基于数学表达式的奖励模型能实现与包含自然语言同等的性能。同时,训练模型评估自然语言逻辑一致性较为困难,突显LLMs捕获隐性逻辑结构的挑战。相较之下,数学表达式内在逻辑结构的逻辑一致性可被训练基于LLM的SRMs有效评定。鉴于获取步级奖励的高昂成本,这些发现为构建更为高效、聚焦的奖励模型指明了方向,即通过聚焦数学推理步骤的关键要素,减少不必要的自然语言信息干扰。
\end{document}
相关文章:

《What Are Step-Level Reward Models Rewarding?》全文翻译
《What Are Step-Level Reward Models Rewarding?Counterintuitive Findings from MCTS-Boosted Mathematical Reasoning》 Step-Level奖励模型到底奖励了什么?来自基于MCTS提升的数学推理的反直觉发现 摘要 Step-level奖励模型(SRMs)通过…...

windows使用docker-desktop安装milvus和可视化工具attu
这里写目录标题 docker-desktop安装docker安装milvusdocker安装milvus可视化工具attu注意点 docker-desktop安装 参考:Windows Docker 安装 docker安装milvus 参考:添加链接描述在 Docker 中运行 Milvus(Windows) docker安装m…...
?)
如何通过原型链实现方法的“重写”(Override)?
在 JavaScript 中,通过原型链实现方法的 “重写”(Override) 的核心思路是:在子类(或子对象)的原型链上定义同名方法,覆盖父类(或父对象)的方法。以下是具体实现步骤和代…...

PyTorch - Tensor 学习笔记
上层链接:PyTorch 学习笔记-CSDN博客 Tensor 初始化Tensor import torch import numpy as np# 1、直接从数据创建张量。数据类型是自动推断的 data [[1, 2],[3, 4]] x_data torch.tensor(data)torch.tensor([[2, 1, 4, 3], [1, 2, 3, 4], [4, 3, 2, 1]])输出&am…...

《协议栈的骨架:从Web请求到比特流——详解四层架构的可靠传输与流量控制》
前言 本篇博客将详细介绍网络原理(细~~~) 💖 个人主页:熬夜写代码的小蔡 🖥 文章专栏 若有问题 评论区见 🎉欢迎大家点赞👍收藏⭐文章 一.应用层 这里的应用层只是个开头&a…...

软考 系统架构设计师系列知识点 —— 设计模式之创建者模式
本文内容参考: 软考 系统架构设计师系列知识点之设计模式(2)_系统架构设计师中考设计模式吗-CSDN博客 创建者模式_百度百科 建造者模式_百度百科 https://zhuanlan.zhihu.com/p/551870461 特此致谢! Builder Pattern…...

oracle判断同表同条件查出两条数据,根据长短判断差异
目标:同一个物料,账套不同,排查同料号有差异的规格名称 在Oracle数据库中,如果你想查询同一张表中两条数据某个字段的长度不同的情况,你可以使用JOIN语句或者窗口函数(如ROW_NUMBER()、RANK()、DENSE_RANK…...

咋用fliki的AI生成各类视频?AI生成视频教程
最近想制作视频,多方考查了决定用fliki,于是订阅了一年试试,这个AI生成的视频效果来看真是不错,感兴趣的自己官网注册个账号体验一下就知道了。 fliki官网 Fliki生成视频教程 创建账户并登录 首先,访问fliki官网并注…...

【STM32-代码】
STM32-代码 ■ printf() 输出到uart1■■■ ■ printf() 输出到uart1 static UART_HandleTypeDef * g_HDebugUART &huart1;int fputc(int c, FILE *f) {(void)f;HAL_UART_Transmit(g_HDebugUART, (const uint8_t *)&c, 1, DEBUG_UART_TIMEOUT);return c; }int fgetc…...

用cursor三个小时复刻高德地图的足迹地图
用cursor三个小时复刻了高德地图的足迹地图,当然,是“低配”版的。 1、首先要初始化,提出一个需求,让它自由发挥 运行之后发现它报错了,原因出在这行代码,“https://cdn.jsdelivr.net/npm/echarts5,4.3/…...

Git分支管理与工作流实践
Git分支管理与工作流实践 一、Git分支规范与核心原则 主分支(master/main) 核心作用:存储生产环境代码,永远保持稳定且可直接发布。禁止直接在此分支开发。操作规范:仅通过合并release或hotfix分支更新,合…...

python面试总结
目录 Python基础 1、python及其特点 2、动态类型和静态类型? 3、变量命名规则是什么? 4、基本数据类型有哪些? 5、Python 中字典? 6、集合set是什么?有什么特点? 7、python的字符串格式化 函数 1…...

基于骨骼识别的危险动作报警系统设计与实现
基于骨骼识别的危险动作报警系统设计与实现 基于骨骼识别的危险动作报警分析系统 【包含内容】 【一】项目提供完整源代码及详细注释 【二】系统设计思路与实现说明 【三】基于骨骼识别算法的实时危险行为预警方案 【技术栈】 ①:系统环境:Windows 10…...
开发)
HarmonyOS 5.0应用开发——五子棋游戏(鸿蒙版)开发
【高心星出品】 文章目录 五子棋游戏(鸿蒙版)开发运行效果开发步骤项目结构核心代码棋盘组件:游戏逻辑处理:主页面: 五子棋游戏(鸿蒙版)开发 五子棋是一款传统的两人策略型棋类游戏࿰…...

避坑,app 播放器media:MediaElement paly报错
System.Runtime.InteropServices.COMException HResult=0x8001010E Message= Source=WinRT.Runtime StackTrace: 在 WinRT.ExceptionHelpers.<ThrowExceptionForHR>g__Throw|38_0(Int32 hr) 在 ABI.Microsoft.UI.Xaml.Controls.IMediaPlayerElementMethods.get_MediaPlay…...

STM32单片机入门学习——第38节: [11-3] 软件SPI读写W25Q64
写这个文章是用来学习的,记录一下我的学习过程。希望我能一直坚持下去,我只是一个小白,只是想好好学习,我知道这会很难,但我还是想去做! 本文写于:2025.04.16 STM32开发板学习——第一节: [1-1]课程简介 前言开发板说明引用解答和…...
)
使用阿里云创建公司官网(使用wordpress)
安装 LNMP 不通的lnmp版本 https://lnmp.org/download.html wget http://soft.vpser.net/lnmp/lnmp2.1.tar.gz -cO lnmp2.1.tar.gztar zxf lnmp2.1.tar.gz && cd lnmp2.1 && ./install.sh lnmp数据库选5.7 选好数据库,会让你设置数据库 root 用户…...

Python程序结构深度解析:顺序结构与对象布尔值的底层逻辑与应用
一、程序结构的三大基石 在计算机科学领域,任何复杂的算法都可以分解为顺序结构、选择结构和循环结构这三种基本结构的组合。这种结构化编程思想由计算机科学家Bhm和Jacopini在1966年首次提出,至今仍是现代编程语言设计的核心原则。 1.1 顺序结构的本质…...

【系统搭建】Ubuntu系统两节点间SSH免密配置
SSH免密配置是MPI分布式、DPDK通信等集群节点间通信的基础配置 1. 安装SSH服务端(所有节点执行) Ubuntu 默认只安装 SSH 客户端(openssh-client),未安装服务端(openssh-server),需要手动安装并…...

美信监控易:揭秘高效数据采集和数据分析双引擎
在当今复杂多变的运维环境中,一款强大的运维管理软件对于保障企业的IT系统稳定运行至关重要。北京美信时代的美信监控易运维管理软件,凭借其卓越的数据分析双引擎,成为了众多运维团队的首选。 首先,美信监控易的数据采集引擎展现出…...

基于STM32+FPGA的地震数据采集器软件设计,支持RK3568+FPGA平台
0 引言 地震观测是地球物理观测的重点,是地震学和 地球物理学发展的基础 [1] 。地震数据采集器主要功 能是将地震计采集的地震波模拟信号转换为数字信 号并进行记录或传输 [2] ,为地震学提供大量的基础 数据。本文将介绍基FPGAARM的地震数据采集器软…...
)
NO.95十六届蓝桥杯备战|图论基础-单源最短路|负环|BF判断负环|SPFA判断负环|邮递员送信|采购特价产品|拉近距离|最短路计数(C++)
P3385 【模板】负环 - 洛谷 如果图中存在负环,那么有可能不存在最短路。 BF算法判断负环 执⾏n轮松弛操作,如果第n轮还存在松弛操作,那么就有负环。 #include <bits/stdc.h> using namespace std;const int N 2e3 10, M 3e3 1…...

Linux 网络管理深度指南:从基础到高阶的网卡、端口与路由实战
一、网卡管理:构建网络连接的基石 1.1 现代网络工具链解析 在当代Linux系统中,iproute2套件已全面取代传统的net-tools,其优势体现在: 推荐组合命令: ip -c addr show | grep "inet " # 彩色显示有效IP…...

《重构全球贸易体系用户指南》解读
文章目录 背景核心矛盾与理论框架美元的“特里芬难题”核心矛盾目标理论框架 政策工具箱的协同运作机制关税体系的精准打击汇率政策的混合干预安全工具的复合运用 实施路径与全球秩序重构阶段性目标 风险传导与反制效应内部失衡加剧外部反制升级系统性风险 范式突破与理论再思考…...

stateflow中的函数
最近开始使用STATEFLOW,感觉功能比较强大,在嵌入式的应用中应该缺少不了,先将用到的仔细总结一下。还有一点,积极拥抱ai,学会使用AI的强大功能来学习。 在 Stateflow 中,不同类型的函数和状态适用于不同的建模需求。以下是 图形函数(Graphical Function)、Simulink 函…...

41.[前端开发-JavaScript高级]Day06-原型关系图-ES6类的使用-ES6转ES5
JavaScript ES6实现继承 1 原型继承关系图 原型继承关系 创建对象的内存表现 2 class方式定义类 认识class定义类 <!DOCTYPE html> <html lang"en"> <head><meta charset"UTF-8"><meta http-equiv"X-UA-Compatible&qu…...
Widget)
Flutter学习四:Flutter开发基础(一)Widget
Widget 简介 0 引言 本文是对 Flutter Widget 相关知识的学习和总结。 1 Widget 概念 1.1 Widget 基础 Widget 字面意思:控件、组件、部件、微件、插件、小工具widget 的功能是"描述一个UI元素的配置信息",所谓的配置信息就是 Widget 接收…...
 - 优化知识库pdf文档的识别)
Dify智能体平台源码二次开发笔记(6) - 优化知识库pdf文档的识别
目录 前言 新增PdfNewExtractor类 替换ExtractProcessor类 最终结果 前言 dify的1.1.3版本知识库pdf解析实现使用pypdfium2提取文本,主要存在以下问题: 1. 文本提取能力有限,对表格和图片支持不足 2. 缺乏专门的中文处理优化 3. 没有文档结…...

【LaTeX】公式图表进阶操作
公式 解决不认识的符号 查资料:1)知道符号样子;2)知道符号含义 放大版括号 用来括住存在分式的式子,或者用来括住内部由有很多括号的式子。用法是在左右括号[]分别加上\left和\right \[ J_r\dfrac{i \hbar}{2m} \l…...

第二阶段:数据结构与函数
模块4:常用数据结构 (Organizing Lots of Data) 在前面的模块中,我们学习了如何使用变量来存储单个数据,比如一个数字、一个名字或一个布尔值。但很多时候,我们需要处理一组相关的数据,比如班级里所有学生的名字、一本…...

matlab中simulink的快捷使用方法
连接系统模块还有如下更有效的方式:单击起始模块。 按下 Ctrl键,并单击目标块。 图示为已经连接好的系统模块 旋转模块:选中模块后按图示点击即可...

Redux部分
在src文件夹下 的store文件夹下创建modules/user.js和index.js module/ user.js // 存储用户相关const { createSlice } require("reduxjs/toolkit");const userStore createSlice({name:"user",// 数据状态initialState:{token:},// 同步修改方法red…...

基于STM32F103C8T6的温湿度检测装置
一、系统方案设计 1、系统功能分析 本项目设计的是一款基于STM32F103C8T6的温室大棚检测系统低配版。由 STM32F103C8T6最小系统板,OLED显示屏,DHT11温湿度检测传感器,光敏电阻传感器组成, 可以实现如下功能: 使用D…...

设计模式 - 单例模式
一个类不管创建多少次对象,永远只能得到该类型一个对象的实力 常用到的,比如日志模块,数据库模块 饿汉式单例模式:还没有获取实例对象,实例对象就已经产生了 懒汉式单例模式:唯一的实例对象,…...

Linux驱动开发1 - Platform设备
背景 所有驱动开发都是基于全志T507(Android 10)进行开发,用于记录驱动开发过程。 简介 什么是platform驱动自己上网搜索了解。 在driver/linux/platform_device.h中定义了platform_driver结构体。 struct platform_driver {int (*probe…...
)
力扣-hot100(盛最多水的容器)
11. 盛最多水的容器 中等 给定一个长度为 n 的整数数组 height 。有 n 条垂线,第 i 条线的两个端点是 (i, 0) 和 (i, height[i]) 。 找出其中的两条线,使得它们与 x 轴共同构成的容器可以容纳最多的水。 返回容器可以储存的最大水量。 说明…...

使用 PyTorch 构建 UNet 图像去噪模型:从数据加载到模型训练的完整流程
图像去噪是计算机视觉中的一个基础问题,在医学图像、遥感、夜间视觉等领域有广泛应用。本文将手把手带你用 PyTorch 构建一个 UNet 架构的图像去噪模型,包括数据预处理、网络搭建、PSNR 评估与模型保存的完整流程。 本项目已支持将数据增强版本保存为独立…...

从信号处理角度理解图像处理的滤波函数
目录 1、预备知识 1.1 什么是LTI系统? 1.1.1 首先来看什么是线性系统,前提我们要了解什么是齐次性和叠加性。...

集合框架--List集合详解
List集合 List 接口直接继承 Collection 接口,它定义为可以存储重复元素的集合,并且元素按照插入顺序有序排列,且可以通过索引访问指定位置的元素。常见的实现有:ArrayList、LinkedList。 Arraylist:有序、可重复、有索引 Linke…...

需求分析---软件架构师武器库中的天眼系统
在软件架构中,需求分析决定了系统的核心设计方向。 然而,现实中的需求往往存在以下问题: 需求被二次加工:产品经理或业务方可能直接提供“解决方案”(如“我们需要一个聊天功能”),而非原始需…...

Spring Cloud Gateway 的执行链路详解
Spring Cloud Gateway 的执行链路详解 🎯 核心目标 明确 Spring Cloud Gateway 的请求处理全过程(从接收到请求 → 到转发 → 到返回响应),方便你在合适的生命周期节点插入你的逻辑。 🧱 核心执行链路图(执…...
)
Python----机器学习(基于PyTorch框架的逻辑回归)
逻辑回归是一种广泛使用的统计学习方法,主要用于处理二分类问题。它基于线性回归模型,通过Sigmoid函数将输出映射到[0, 1]范围内,表示实例属于正类别的概率。尽管逻辑回归适用于二分类任务,但在多分类问题中常使用Softmax函数&…...

工业数据治理范式革新:时序数据库 TDengine虚拟表技术解析
小T导读:在工业数字化过程中,数据如何从设备采集顺利“爬坡”到上层应用,一直是个难题。传统“单列模型”虽贴合设备协议,却让上层分析举步维艰。TDengine 用一种更聪明的方法打通了这条数据通路:不强求建模、不手动转…...

Linux的应用领域,Linux的介绍,VirtualBox和Ubuntu的安装,VMware的安装和打开虚拟机CentOS
目录 Linux的应用领域 Linux的介绍 Linux的介绍 Linux发行版 Unix和Linux的渊源 虚拟机和Linux的安装 VirtualBox和Ubuntu的安装 安装VirtualBox 安装Ubuntu 下载Ubuntu操作系统的镜像文件 创建虚拟机 虚拟机设置 启动虚拟机,安装Ubuntu系统 Ubuntu基…...

使用 Java 8 Stream实现List重复数据判断
import java.util.*; import java.util.stream.Collectors;public class DeduplicateStreamExample {static class ArchiveItem {// 字段定义与Getter/Setter省略(需根据实际补充)private String mATNR;private String lIFNR;private String suppSpecMod…...

GDAL:地理数据的万能瑞士军刀
目录 1. 什么是GDAL?2. 为什么需要GDAL?3. GDAL的主要功能3.1. 数据转换3.2. 数据裁剪和处理3.3. 读取和写入多种格式 4. 实际应用场景4.1 环境监测4.2 城市规划4.3 导航系统 5. 技术原理简单解释6. 如何使用GDAL?6.1 简单命令示例 7. 学习建…...
——Part two)
每日文献(十三)——Part two
今天从第三章节:“实现细节”开始介绍。 目录 三、实现细节 四、实验 五、总结贡献 六、致谢 三、实现细节 我们在多尺度图像上训练和测试区域建议和目标检测网络。这是在KITTI目标检测基准[13]上基于CNN的目标检测的趋势。例如,在[16]中ÿ…...

ArrayList 和 LinkedList 区别
ArrayList 和 LinkedList 是 Java 集合框架中两种常用的列表实现,它们在底层数据结构、性能特点和适用场景上有显著的区别。以下是它们的详细对比以及 ArrayList 的扩容机制。 1. ArrayList 和 LinkedList 的底层区别 (1) 底层数据结构 ArrayList: 基于…...

【iOS】UITableView性能优化
UITableView性能优化 前言优化从何入手优化的本质 CPU层级优化1. Cell的复用2. 尽量少定义Cell,善于使用hidden控制显示视图3. 提前计算并缓存高度UITableView的代理方法执行顺序Cell高度缓存高度数组 4. 异步绘制5. 滑动时按需加载6. 使用异步加载图片,…...
和重排序提升大语言模型(LLM)的准确性)
通过检索增强生成(RAG)和重排序提升大语言模型(LLM)的准确性
探索大语言模型(LLM)结合有效信息检索机制的优势。实现重排序方法,并将其整合到您自己的LLM流程中。 想象一下,一个大语言模型(LLM)不仅能提供相关答案,还能根据您的具体需求进行精细筛选、优先…...