PyTorch - Tensor 学习笔记
上层链接:PyTorch 学习笔记-CSDN博客
Tensor
初始化Tensor
import torch
import numpy as np# 1、直接从数据创建张量。数据类型是自动推断的
data = [[1, 2],[3, 4]]
x_data = torch.tensor(data)torch.tensor([[2, 1, 4, 3], [1, 2, 3, 4], [4, 3, 2, 1]])
''' 输出:
tensor([[2, 1, 4, 3],[1, 2, 3, 4],[4, 3, 2, 1]])
'''# 2、从 NumPy 数组创建张量(反之亦然)
np_array = np.array(data)
x_np = torch.from_numpy(np_array)3、从另一个张量创建:
# 从另一个张量创建张量,新张量保留参数张量的属性(形状、数据类型),除非显式覆盖
x_ones = torch.ones_like(x_data) # retains the properties of x_data 保留原有属性
print(f"Ones Tensor: \n {x_ones} \n")x_rand = torch.rand_like(x_data, dtype=torch.float) # overrides the datatype of x_data 覆盖原有类型
print(f"Random Tensor: \n {x_rand} \n") 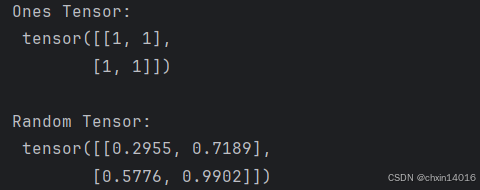
4、使用随机值或常量值:(三个皆是数据类型默认为浮点型(torch.float32))
# 使用随机值或常量值创建张量:
shape = (2,3,) # shape是张量维度的元组,确定输出张量的维数
rand_tensor = torch.rand(shape) # 元素为 [0, 1) 中的随机浮点型,
ones_tensor = torch.ones(shape) # 元素为全 1
zeros_tensor = torch.zeros(shape) # 元素为全 0print(f"Random Tensor: \n {rand_tensor} \n")
print(f"Ones Tensor: \n {ones_tensor} \n")
print(f"Zeros Tensor: \n {zeros_tensor}")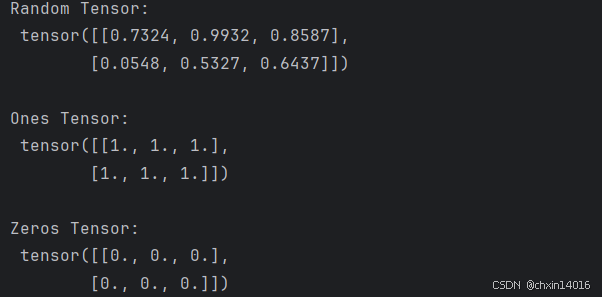
torch.zeros((2, 3, 4))
''' 输出:
tensor([[[0., 0., 0., 0.],[0., 0., 0., 0.],[0., 0., 0., 0.]],[[0., 0., 0., 0.],[0., 0., 0., 0.],[0., 0., 0., 0.]]])
'''torch.ones((2, 3, 4))
''' 输出:
tensor([[[1., 1., 1., 1.],[1., 1., 1., 1.],[1., 1., 1., 1.]],[[1., 1., 1., 1.],[1., 1., 1., 1.],[1., 1., 1., 1.]]])
'''若想指定生成其他数据类型的张量,可以通过
dtype参数显式指定。例如:# 整数类型 rand_tensor_int = torch.rand((2, 3), dtype=torch.int32) print(rand_tensor_int.dtype) # 输出: torch.int32# 双精度浮点型 ones_tensor_double = torch.ones((2, 3), dtype=torch.float64) print(ones_tensor_double.dtype) # 输出: torch.float64
动手学深度学习的内容
x = torch.arange(12) # 创建行向量 x,其包含以0开始的前12个整数,默认创建为整数
# 除非额外指定,新的张量将存储在内存中,并采用基于CPU的计算。
# 输出:tensor([ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11])x.shape # 访问张量(沿每个轴的长度)的形状
# 输出:torch.Size([12])x.numel() # 张量中元素的总数,即形状的所有元素乘积,可以检查它的大小(size)。因为这里在处理的是一个向量,所以它的shape与它的size相同
# 输出:12X = x.reshape(3, 4) # 改变张量的形状,而不改变其元素数量和元素值。
'''
把张量x从形状为(12,)的行向量转换为形状为(3,4)的矩阵。
这个新的张量包含与转换前相同的值,但是它被看成一个3行4列的矩阵。
重点说明:虽然张量的形状发生了改变,但其元素值并没有变。
注意,通过改变张量的形状,张量的大小不会改变。
输出:
tensor([[ 0, 1, 2, 3],[ 4, 5, 6, 7],[ 8, 9, 10, 11]])
'''属性
Tensor 属性描述其形状、数据类型和存储它们的设备
tensor = torch.rand(3,4)
print(f"Shape of tensor: {tensor.shape}") # 形状
print(f"Datatype of tensor: {tensor.dtype}") # 数据类型
print(f"Device tensor is stored on: {tensor.device}") # 存储其的设备
操作(形状相同的两个矩阵)
索引和切片:(类似 numpy )
tensor = torch.ones(4, 4)
# tensor = torch.tensor([[1, 2, 3, 4],
# [5, 6, 7, 8],
# [9, 10, 11, 12],
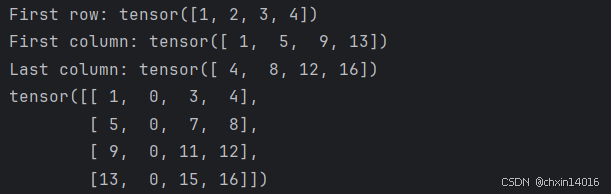
# [13, 14, 15, 16]])print(f"First row: {tensor[0]}")
print(f"First column: {tensor[:, 0]}")
print(f"Last column: {tensor[..., -1]}")
tensor[:,1] = 0
print(tensor)
torch.cat() 拼接张量 (沿给定维度连接一系列张量)。
另请参见 torch.stack, 另一个与 . 略有不同的 Tensor Joining 运算符。torch.cattorch.cat
'''
dim=1 :沿着第 1 维(通常是列)进行拼接
如果 tensor 的形状是 (a, b),
则沿着第 1 维拼接三次后,结果张量 t1 的形状将是 (a, b * 3)。
'''
t1 = torch.cat([tensor, tensor, tensor], dim=1) # 沿着第 1 维拼接三次
print(t1)

- 沿行连结(轴-0,形状的第一个元素)
- 按列连结(轴-1,形状的第二个元素)
X = torch.arange(12, dtype=torch.float32).reshape((3,4))
Y = torch.tensor([[2.0, 1, 4, 3], [1, 2, 3, 4], [4, 3, 2, 1]])
torch.cat((X, Y), dim=0), torch.cat((X, Y), dim=1)
''' 输出:
(tensor([[ 0., 1., 2., 3.],[ 4., 5., 6., 7.],[ 8., 9., 10., 11.],[ 2., 1., 4., 3.],[ 1., 2., 3., 4.],[ 4., 3., 2., 1.]]),tensor([[ 0., 1., 2., 3., 2., 1., 4., 3.],[ 4., 5., 6., 7., 1., 2., 3., 4.],[ 8., 9., 10., 11., 4., 3., 2., 1.]]))
'''单个张量 (tensor.sum()求和 & 转int/float)
.sum() 聚合所有 值转换为一个值;.item() 将其转换为 Python 数值使用。
agg = tensor.sum() # 所有元素求和,返回新的张量(标量张量)
agg_item = agg.item() # 将标量张量agg转成Python的基本数据类型(如float或int,具体取决于张量中数据的类型)
print(agg_item, type(agg_item))# 输出 agg的值为 tensor(12.)![]()
In-place 操作
add_是一个 in-place 操作,会直接修改原张量tensor的值,而不会创建新的张量。- 若不想修改原张量,可使用非 in-place 操作
tensor + 5,这样会返回一个新的张量,而原张量保持不变。
# 使用 in-place 操作对张量中的每个元素加 5
print(f"{tensor} \n")
tensor.add_(5) # add_ 是 in-place 操作,会直接修改原张量
print(tensor)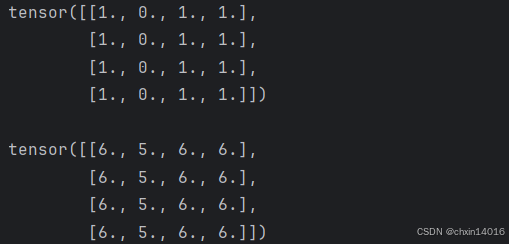
in-place 的优缺点
优点:节省内存。(直接在原张量上操作,避免额外分配内存)
缺点:因为是直接修改原数据,会丢失历史记录,因此不鼓励使用。
算术运算
矩阵乘法 和 元素积(逐元素乘积)
计算两张量间的 矩阵乘法 和 元素积(逐元素乘积)
# 计算两个张量间的矩阵乘法
# This computes the matrix multiplication between two tensors. y1, y2, y3 will have the same value
# ``tensor.T`` 返回张量的转置 returns the transpose of a tensor
y1 = tensor @ tensor.T # “@”是矩阵乘法的简写,用于张量之间的矩阵乘法; tensor.T 返回 tensor 的转置
y2 = tensor.matmul(tensor.T) # matmul用于矩阵乘法,与 @ 功能等价y3 = torch.rand_like(y1) # 创建与 y1 形状相同的新张量,元素为随机值
torch.matmul(tensor, tensor.T, out=y3) # 进行矩阵乘法,并将结果存储在 y3 中print("Matrix Multiplication Results:") # y1, y2, y3 三者相等
print("y1:\n", y1)
print("y2:\n", y2)
print("y3:\n", y3)# 计算元素积
# This computes the element-wise product. z1, z2, z3 will have the same value
z1 = tensor * tensor # 对 tensor 进行逐元素相乘
z2 = tensor.mul(tensor) # 与 * 相同的逐元素相乘z3 = torch.rand_like(tensor)
torch.mul(tensor, tensor, out=z3) # 使用 torch.mul 函数对 tensor 进行逐元素相乘,并将结果存储在 z3 中print("\nElement-wise Product Results:") # z1, z2, z3 三者相等
print("z1:\n", z1)
print("z2:\n", z2)
print("z3:\n", z3)
按元素操作 (加减乘除 **幂 等)
对于任意具有相同形状的张量, 常见的标准算术运算符(+、-、*、/和**)都可以被升级为按元素运算。 我们可以在同一形状的任意两个张量上调用按元素操作。
在下面的例子中,使用逗号来表示一个具有5个元素的元组,其中每个元素都是按元素操作的结果。
x = torch.tensor([1.0, 2, 4, 8])
y = torch.tensor([2, 2, 2, 2])
x + y, x - y, x * y, x / y, x ** y # **运算符是求幂运算
''' 输出:
(tensor([ 3., 4., 6., 10.]),tensor([-1., 0., 2., 6.]),tensor([ 2., 4., 8., 16.]),tensor([0.5000, 1.0000, 2.0000, 4.0000]),tensor([ 1., 4., 16., 64.]))
'''逻辑运算符构建二元张量
以X == Y为例: 对于每个位置,如果X和Y在该位置相等,则新张量中相应项的值为1。 这意味着逻辑语句X == Y在该位置处为真,否则该位置为0。
X = torch.arange(12, dtype=torch.float32).reshape((3,4))
Y = torch.tensor([[2.0, 1, 4, 3], [1, 2, 3, 4], [4, 3, 2, 1]])
X == Y
''' 输出:
tensor([[False, True, False, True],[False, False, False, False],[False, False, False, False]])
'''torch.exp() 对张量中每个元素计算自然指数
“按元素”方式可以应用更多的计算,包括像求幂这样的一元运算符:
用于对张量中每个元素计算自然指数函数 的函数,常用于 实现 softmax、log-normalization、指数增长建模 等场景:
对输入张量中的每个元素 执行:
其中
import torch
x = torch.tensor([1.0, 2, 4, 8])
torch.exp(x)
''' 输出:
tensor([2.7183e+00, 7.3891e+00, 5.4598e+01, 2.9810e+03])
'''x = torch.tensor([0.0, 1.0, 2.0])
y = torch.exp(x)
print(y) # 输出:tensor([1.0000, 2.7183, 7.3891])x = torch.tensor([[0.0, -1.0], [1.0, -2.0]])
print(torch.exp(x))
''' 输出:
tensor([[1.0000, 0.3679],[2.7183, 0.1353]])
'''常见应用:Softmax 的实现
x = torch.tensor([1.0, 2.0, 3.0]) softmax = torch.exp(x) / torch.sum(torch.exp(x)) print(softmax)常见应用:概率建模中的对数概率反变换
log_probs = torch.tensor([-1.0, -2.0]) probs = torch.exp(log_probs)常见应用:正态化、注意力机制等。
注意:
- 输入为负数时,输出仍为正数(因为
对任意实数
成立)。
- 大数值可能导致数值溢出(输出为
inf),因此常配合数值稳定性处理(如在 softmax 前减去最大值)使用。
使用NumPy桥接
- 共享内存:Tensor 和 NumPy 数组在
.numpy()和torch.from_numpy()转换时,会 共享底层内存(共享底层数据存储),因此对一方的修改会直接影响另一方。 - 潜在风险:如果对共享内存的张量或数组进行了非原地安全的操作(如直接赋值),可能导致数据竞争或意外覆盖。
以下例子中 t 和 n 的值始终同步,因为它们共享相同的内存。这种特性在需要高效数据传递时非常有用,但需要谨慎操作以避免数据竞争。
Tensor 转 NumPy 数组
t = torch.ones(5) # 创建一个包含 5 个 1.0 的张量
print(f"t: {t}")# 将张量 t 转换为 NumPy 数组
n = t.numpy() # .numpy() 方法将 PyTorch 张量转换为 NumPy 数组
print(f"n: {n}")![]()
张量的变化反映在 NumPy 数组中:
t.add_(1) # 使用 add_ 进行原地加法
print(f"t: {t}")
print(f"n: {n}") # n 的值也会改变,因为 t 和 n 共享内存![]()
NumPy 数组 转 Tensor
n = np.ones(5) # 创建一个包含 5 个 1.0 的 NumPy 数组
t = torch.from_numpy(n) # 将 NumPy 数组转换为 PyTorch 张量NumPy 数组中的更改反映在张量中:
np.add(n, 5, out=n) # 对 NumPy 数组,使用 out 参数 进行原地加法操作
print(f"t: {t}") # 由于 t 和 n 底层共享内存,t 的值也会随之改变
print(f"n: {n}")
广播机制(形状不同的两个矩阵)
在上面的部分中,我们看到了如何在相同形状的两个张量上执行按元素操作。 在某些情况下,即使形状不同,我们仍然可以通过调用 广播机制(broadcasting mechanism)来执行按元素操作。 这种机制的工作方式如下:
-
通过适当复制元素来扩展一个或两个数组,以便在转换之后,两个张量具有相同的形状;
-
对生成的数组执行按元素操作。
在大多数情况下,我们将沿着数组中长度为1的轴进行广播,如下例子:
a = torch.arange(3).reshape((3, 1))
b = torch.arange(2).reshape((1, 2))
a, b
''' 输出
(tensor([[0],[1],[2]]),tensor([[0, 1]]))
'''由于a和b分别是形状不同的 3*3 和 1*2 矩阵,若让它们相加,它们的形状不匹配。 我们将两个矩阵广播为一个更大的3*2 矩阵,如下所示:
# 矩阵a将复制列, 矩阵b将复制行,然后再按元素相加。
a + b
''' 输出
tensor([[0, 1],[1, 2],[2, 3]])
'''索引和切片
与任何Python数组一样:第一个元素的索引是0,最后一个元素索引是-1; 可以指定范围以包含第一个元素和最后一个之前的元素,即。
x = torch.arange(12) # 创建行向量 x,其包含以0开始的前12个整数,默认创建为整数
# 除非额外指定,新的张量将存储在内存中,并采用基于CPU的计算。
# 输出:tensor([ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11])X = x.reshape(3, 4) # 改变张量的形状,而不改变其元素数量和元素值。
'''
把张量x从形状为(12,)的行向量转换为形状为(3,4)的矩阵。
这个新的张量包含与转换前相同的值,但是它被看成一个3行4列的矩阵。
重点说明:虽然张量的形状发生了改变,但其元素值并没有变。
注意,通过改变张量的形状,张量的大小不会改变。
输出:
tensor([[ 0, 1, 2, 3],[ 4, 5, 6, 7],[ 8, 9, 10, 11]])
'''X[-1], X[1:3]
'''
(tensor([ 8., 9., 10., 11.]),tensor([[ 4., 5., 6., 7.],[ 8., 9., 10., 11.]]))
'''相关文章:

PyTorch - Tensor 学习笔记
上层链接:PyTorch 学习笔记-CSDN博客 Tensor 初始化Tensor import torch import numpy as np# 1、直接从数据创建张量。数据类型是自动推断的 data [[1, 2],[3, 4]] x_data torch.tensor(data)torch.tensor([[2, 1, 4, 3], [1, 2, 3, 4], [4, 3, 2, 1]])输出&am…...

《协议栈的骨架:从Web请求到比特流——详解四层架构的可靠传输与流量控制》
前言 本篇博客将详细介绍网络原理(细~~~) 💖 个人主页:熬夜写代码的小蔡 🖥 文章专栏 若有问题 评论区见 🎉欢迎大家点赞👍收藏⭐文章 一.应用层 这里的应用层只是个开头&a…...

软考 系统架构设计师系列知识点 —— 设计模式之创建者模式
本文内容参考: 软考 系统架构设计师系列知识点之设计模式(2)_系统架构设计师中考设计模式吗-CSDN博客 创建者模式_百度百科 建造者模式_百度百科 https://zhuanlan.zhihu.com/p/551870461 特此致谢! Builder Pattern…...

oracle判断同表同条件查出两条数据,根据长短判断差异
目标:同一个物料,账套不同,排查同料号有差异的规格名称 在Oracle数据库中,如果你想查询同一张表中两条数据某个字段的长度不同的情况,你可以使用JOIN语句或者窗口函数(如ROW_NUMBER()、RANK()、DENSE_RANK…...

咋用fliki的AI生成各类视频?AI生成视频教程
最近想制作视频,多方考查了决定用fliki,于是订阅了一年试试,这个AI生成的视频效果来看真是不错,感兴趣的自己官网注册个账号体验一下就知道了。 fliki官网 Fliki生成视频教程 创建账户并登录 首先,访问fliki官网并注…...

【STM32-代码】
STM32-代码 ■ printf() 输出到uart1■■■ ■ printf() 输出到uart1 static UART_HandleTypeDef * g_HDebugUART &huart1;int fputc(int c, FILE *f) {(void)f;HAL_UART_Transmit(g_HDebugUART, (const uint8_t *)&c, 1, DEBUG_UART_TIMEOUT);return c; }int fgetc…...

用cursor三个小时复刻高德地图的足迹地图
用cursor三个小时复刻了高德地图的足迹地图,当然,是“低配”版的。 1、首先要初始化,提出一个需求,让它自由发挥 运行之后发现它报错了,原因出在这行代码,“https://cdn.jsdelivr.net/npm/echarts5,4.3/…...

Git分支管理与工作流实践
Git分支管理与工作流实践 一、Git分支规范与核心原则 主分支(master/main) 核心作用:存储生产环境代码,永远保持稳定且可直接发布。禁止直接在此分支开发。操作规范:仅通过合并release或hotfix分支更新,合…...

python面试总结
目录 Python基础 1、python及其特点 2、动态类型和静态类型? 3、变量命名规则是什么? 4、基本数据类型有哪些? 5、Python 中字典? 6、集合set是什么?有什么特点? 7、python的字符串格式化 函数 1…...

基于骨骼识别的危险动作报警系统设计与实现
基于骨骼识别的危险动作报警系统设计与实现 基于骨骼识别的危险动作报警分析系统 【包含内容】 【一】项目提供完整源代码及详细注释 【二】系统设计思路与实现说明 【三】基于骨骼识别算法的实时危险行为预警方案 【技术栈】 ①:系统环境:Windows 10…...
开发)
HarmonyOS 5.0应用开发——五子棋游戏(鸿蒙版)开发
【高心星出品】 文章目录 五子棋游戏(鸿蒙版)开发运行效果开发步骤项目结构核心代码棋盘组件:游戏逻辑处理:主页面: 五子棋游戏(鸿蒙版)开发 五子棋是一款传统的两人策略型棋类游戏࿰…...

避坑,app 播放器media:MediaElement paly报错
System.Runtime.InteropServices.COMException HResult=0x8001010E Message= Source=WinRT.Runtime StackTrace: 在 WinRT.ExceptionHelpers.<ThrowExceptionForHR>g__Throw|38_0(Int32 hr) 在 ABI.Microsoft.UI.Xaml.Controls.IMediaPlayerElementMethods.get_MediaPlay…...

STM32单片机入门学习——第38节: [11-3] 软件SPI读写W25Q64
写这个文章是用来学习的,记录一下我的学习过程。希望我能一直坚持下去,我只是一个小白,只是想好好学习,我知道这会很难,但我还是想去做! 本文写于:2025.04.16 STM32开发板学习——第一节: [1-1]课程简介 前言开发板说明引用解答和…...
)
使用阿里云创建公司官网(使用wordpress)
安装 LNMP 不通的lnmp版本 https://lnmp.org/download.html wget http://soft.vpser.net/lnmp/lnmp2.1.tar.gz -cO lnmp2.1.tar.gztar zxf lnmp2.1.tar.gz && cd lnmp2.1 && ./install.sh lnmp数据库选5.7 选好数据库,会让你设置数据库 root 用户…...

Python程序结构深度解析:顺序结构与对象布尔值的底层逻辑与应用
一、程序结构的三大基石 在计算机科学领域,任何复杂的算法都可以分解为顺序结构、选择结构和循环结构这三种基本结构的组合。这种结构化编程思想由计算机科学家Bhm和Jacopini在1966年首次提出,至今仍是现代编程语言设计的核心原则。 1.1 顺序结构的本质…...

【系统搭建】Ubuntu系统两节点间SSH免密配置
SSH免密配置是MPI分布式、DPDK通信等集群节点间通信的基础配置 1. 安装SSH服务端(所有节点执行) Ubuntu 默认只安装 SSH 客户端(openssh-client),未安装服务端(openssh-server),需要手动安装并…...

美信监控易:揭秘高效数据采集和数据分析双引擎
在当今复杂多变的运维环境中,一款强大的运维管理软件对于保障企业的IT系统稳定运行至关重要。北京美信时代的美信监控易运维管理软件,凭借其卓越的数据分析双引擎,成为了众多运维团队的首选。 首先,美信监控易的数据采集引擎展现出…...

基于STM32+FPGA的地震数据采集器软件设计,支持RK3568+FPGA平台
0 引言 地震观测是地球物理观测的重点,是地震学和 地球物理学发展的基础 [1] 。地震数据采集器主要功 能是将地震计采集的地震波模拟信号转换为数字信 号并进行记录或传输 [2] ,为地震学提供大量的基础 数据。本文将介绍基FPGAARM的地震数据采集器软…...
)
NO.95十六届蓝桥杯备战|图论基础-单源最短路|负环|BF判断负环|SPFA判断负环|邮递员送信|采购特价产品|拉近距离|最短路计数(C++)
P3385 【模板】负环 - 洛谷 如果图中存在负环,那么有可能不存在最短路。 BF算法判断负环 执⾏n轮松弛操作,如果第n轮还存在松弛操作,那么就有负环。 #include <bits/stdc.h> using namespace std;const int N 2e3 10, M 3e3 1…...

Linux 网络管理深度指南:从基础到高阶的网卡、端口与路由实战
一、网卡管理:构建网络连接的基石 1.1 现代网络工具链解析 在当代Linux系统中,iproute2套件已全面取代传统的net-tools,其优势体现在: 推荐组合命令: ip -c addr show | grep "inet " # 彩色显示有效IP…...

《重构全球贸易体系用户指南》解读
文章目录 背景核心矛盾与理论框架美元的“特里芬难题”核心矛盾目标理论框架 政策工具箱的协同运作机制关税体系的精准打击汇率政策的混合干预安全工具的复合运用 实施路径与全球秩序重构阶段性目标 风险传导与反制效应内部失衡加剧外部反制升级系统性风险 范式突破与理论再思考…...

stateflow中的函数
最近开始使用STATEFLOW,感觉功能比较强大,在嵌入式的应用中应该缺少不了,先将用到的仔细总结一下。还有一点,积极拥抱ai,学会使用AI的强大功能来学习。 在 Stateflow 中,不同类型的函数和状态适用于不同的建模需求。以下是 图形函数(Graphical Function)、Simulink 函…...

41.[前端开发-JavaScript高级]Day06-原型关系图-ES6类的使用-ES6转ES5
JavaScript ES6实现继承 1 原型继承关系图 原型继承关系 创建对象的内存表现 2 class方式定义类 认识class定义类 <!DOCTYPE html> <html lang"en"> <head><meta charset"UTF-8"><meta http-equiv"X-UA-Compatible&qu…...
Widget)
Flutter学习四:Flutter开发基础(一)Widget
Widget 简介 0 引言 本文是对 Flutter Widget 相关知识的学习和总结。 1 Widget 概念 1.1 Widget 基础 Widget 字面意思:控件、组件、部件、微件、插件、小工具widget 的功能是"描述一个UI元素的配置信息",所谓的配置信息就是 Widget 接收…...
 - 优化知识库pdf文档的识别)
Dify智能体平台源码二次开发笔记(6) - 优化知识库pdf文档的识别
目录 前言 新增PdfNewExtractor类 替换ExtractProcessor类 最终结果 前言 dify的1.1.3版本知识库pdf解析实现使用pypdfium2提取文本,主要存在以下问题: 1. 文本提取能力有限,对表格和图片支持不足 2. 缺乏专门的中文处理优化 3. 没有文档结…...

【LaTeX】公式图表进阶操作
公式 解决不认识的符号 查资料:1)知道符号样子;2)知道符号含义 放大版括号 用来括住存在分式的式子,或者用来括住内部由有很多括号的式子。用法是在左右括号[]分别加上\left和\right \[ J_r\dfrac{i \hbar}{2m} \l…...

第二阶段:数据结构与函数
模块4:常用数据结构 (Organizing Lots of Data) 在前面的模块中,我们学习了如何使用变量来存储单个数据,比如一个数字、一个名字或一个布尔值。但很多时候,我们需要处理一组相关的数据,比如班级里所有学生的名字、一本…...

matlab中simulink的快捷使用方法
连接系统模块还有如下更有效的方式:单击起始模块。 按下 Ctrl键,并单击目标块。 图示为已经连接好的系统模块 旋转模块:选中模块后按图示点击即可...

Redux部分
在src文件夹下 的store文件夹下创建modules/user.js和index.js module/ user.js // 存储用户相关const { createSlice } require("reduxjs/toolkit");const userStore createSlice({name:"user",// 数据状态initialState:{token:},// 同步修改方法red…...

基于STM32F103C8T6的温湿度检测装置
一、系统方案设计 1、系统功能分析 本项目设计的是一款基于STM32F103C8T6的温室大棚检测系统低配版。由 STM32F103C8T6最小系统板,OLED显示屏,DHT11温湿度检测传感器,光敏电阻传感器组成, 可以实现如下功能: 使用D…...

设计模式 - 单例模式
一个类不管创建多少次对象,永远只能得到该类型一个对象的实力 常用到的,比如日志模块,数据库模块 饿汉式单例模式:还没有获取实例对象,实例对象就已经产生了 懒汉式单例模式:唯一的实例对象,…...

Linux驱动开发1 - Platform设备
背景 所有驱动开发都是基于全志T507(Android 10)进行开发,用于记录驱动开发过程。 简介 什么是platform驱动自己上网搜索了解。 在driver/linux/platform_device.h中定义了platform_driver结构体。 struct platform_driver {int (*probe…...
)
力扣-hot100(盛最多水的容器)
11. 盛最多水的容器 中等 给定一个长度为 n 的整数数组 height 。有 n 条垂线,第 i 条线的两个端点是 (i, 0) 和 (i, height[i]) 。 找出其中的两条线,使得它们与 x 轴共同构成的容器可以容纳最多的水。 返回容器可以储存的最大水量。 说明…...

使用 PyTorch 构建 UNet 图像去噪模型:从数据加载到模型训练的完整流程
图像去噪是计算机视觉中的一个基础问题,在医学图像、遥感、夜间视觉等领域有广泛应用。本文将手把手带你用 PyTorch 构建一个 UNet 架构的图像去噪模型,包括数据预处理、网络搭建、PSNR 评估与模型保存的完整流程。 本项目已支持将数据增强版本保存为独立…...

从信号处理角度理解图像处理的滤波函数
目录 1、预备知识 1.1 什么是LTI系统? 1.1.1 首先来看什么是线性系统,前提我们要了解什么是齐次性和叠加性。...

集合框架--List集合详解
List集合 List 接口直接继承 Collection 接口,它定义为可以存储重复元素的集合,并且元素按照插入顺序有序排列,且可以通过索引访问指定位置的元素。常见的实现有:ArrayList、LinkedList。 Arraylist:有序、可重复、有索引 Linke…...

需求分析---软件架构师武器库中的天眼系统
在软件架构中,需求分析决定了系统的核心设计方向。 然而,现实中的需求往往存在以下问题: 需求被二次加工:产品经理或业务方可能直接提供“解决方案”(如“我们需要一个聊天功能”),而非原始需…...

Spring Cloud Gateway 的执行链路详解
Spring Cloud Gateway 的执行链路详解 🎯 核心目标 明确 Spring Cloud Gateway 的请求处理全过程(从接收到请求 → 到转发 → 到返回响应),方便你在合适的生命周期节点插入你的逻辑。 🧱 核心执行链路图(执…...
)
Python----机器学习(基于PyTorch框架的逻辑回归)
逻辑回归是一种广泛使用的统计学习方法,主要用于处理二分类问题。它基于线性回归模型,通过Sigmoid函数将输出映射到[0, 1]范围内,表示实例属于正类别的概率。尽管逻辑回归适用于二分类任务,但在多分类问题中常使用Softmax函数&…...

工业数据治理范式革新:时序数据库 TDengine虚拟表技术解析
小T导读:在工业数字化过程中,数据如何从设备采集顺利“爬坡”到上层应用,一直是个难题。传统“单列模型”虽贴合设备协议,却让上层分析举步维艰。TDengine 用一种更聪明的方法打通了这条数据通路:不强求建模、不手动转…...

Linux的应用领域,Linux的介绍,VirtualBox和Ubuntu的安装,VMware的安装和打开虚拟机CentOS
目录 Linux的应用领域 Linux的介绍 Linux的介绍 Linux发行版 Unix和Linux的渊源 虚拟机和Linux的安装 VirtualBox和Ubuntu的安装 安装VirtualBox 安装Ubuntu 下载Ubuntu操作系统的镜像文件 创建虚拟机 虚拟机设置 启动虚拟机,安装Ubuntu系统 Ubuntu基…...

使用 Java 8 Stream实现List重复数据判断
import java.util.*; import java.util.stream.Collectors;public class DeduplicateStreamExample {static class ArchiveItem {// 字段定义与Getter/Setter省略(需根据实际补充)private String mATNR;private String lIFNR;private String suppSpecMod…...

GDAL:地理数据的万能瑞士军刀
目录 1. 什么是GDAL?2. 为什么需要GDAL?3. GDAL的主要功能3.1. 数据转换3.2. 数据裁剪和处理3.3. 读取和写入多种格式 4. 实际应用场景4.1 环境监测4.2 城市规划4.3 导航系统 5. 技术原理简单解释6. 如何使用GDAL?6.1 简单命令示例 7. 学习建…...
——Part two)
每日文献(十三)——Part two
今天从第三章节:“实现细节”开始介绍。 目录 三、实现细节 四、实验 五、总结贡献 六、致谢 三、实现细节 我们在多尺度图像上训练和测试区域建议和目标检测网络。这是在KITTI目标检测基准[13]上基于CNN的目标检测的趋势。例如,在[16]中ÿ…...

ArrayList 和 LinkedList 区别
ArrayList 和 LinkedList 是 Java 集合框架中两种常用的列表实现,它们在底层数据结构、性能特点和适用场景上有显著的区别。以下是它们的详细对比以及 ArrayList 的扩容机制。 1. ArrayList 和 LinkedList 的底层区别 (1) 底层数据结构 ArrayList: 基于…...

【iOS】UITableView性能优化
UITableView性能优化 前言优化从何入手优化的本质 CPU层级优化1. Cell的复用2. 尽量少定义Cell,善于使用hidden控制显示视图3. 提前计算并缓存高度UITableView的代理方法执行顺序Cell高度缓存高度数组 4. 异步绘制5. 滑动时按需加载6. 使用异步加载图片,…...
和重排序提升大语言模型(LLM)的准确性)
通过检索增强生成(RAG)和重排序提升大语言模型(LLM)的准确性
探索大语言模型(LLM)结合有效信息检索机制的优势。实现重排序方法,并将其整合到您自己的LLM流程中。 想象一下,一个大语言模型(LLM)不仅能提供相关答案,还能根据您的具体需求进行精细筛选、优先…...

IDEA202403常用快捷键【持续更新】
文章目录 一、全局搜索二、美化格式三、替换四、Git提交五、代码移动六、调试运行 在使用IDEA进行程序开发,快捷键会让这个过程更加酸爽,下面记录各种快捷键的功能。 一、全局搜索 快捷键功能说明Shift Shift全局搜索Ctrl N搜索Java类 二、美化格式 …...

硬件元件三极管:从基础到进阶的电子探秘
一、基础理论 1. PN结(二极管) PN 结是采用不同的掺杂工艺,将 P 型半导体与 N 型半导体紧密接触而形成的一个界面区域。也就是我们常说的二极管。(P型带正电、N型带负电,电流由P流向N) 形成过程࿱…...

4. k8s核心概念 pod deployment service
以下是 Kubernetes 的核心概念详解,涵盖 Pod、Service、Deployment 和 Node,以及它们之间的关系和实际应用场景: 1. Pod 定义与作用 • 最小部署单元:Pod 是 Kubernetes 中可创建和管理的最小计算单元,包含一个或多个…...