Python----机器学习(基于PyTorch框架的逻辑回归)
逻辑回归是一种广泛使用的统计学习方法,主要用于处理二分类问题。它基于线性回归模型,通过Sigmoid函数将输出映射到[0, 1]范围内,表示实例属于正类别的概率。尽管逻辑回归适用于二分类任务,但在多分类问题中常使用Softmax函数,它将多个类别的概率输出为和为1的正值,允许模型进行多类别预测。PyTorch是一个灵活且强大的深度学习框架,以其动态计算图和易用性受到广泛欢迎,适用于研究和生产环境中的各种机器学习任务。
一、sigmoid激活函数
1.1、输入散点
import numpy as npclass1_points = np.array([[1.9, 1.2],[1.5, 2.1],[1.9, 0.5],[1.5, 0.9],[0.9, 1.2],[1.1, 1.7],[1.4, 1.1]])class2_points = np.array([[3.2, 3.2],[3.7, 2.9],[3.2, 2.6],[1.7, 3.3],[3.4, 2.6],[4.1, 2.3],[3.0, 2.9]])
x_train = np.concatenate((class1_points, class2_points))
y_train = np.concatenate((np.zeros(len(class1_points)), np.ones(len(class2_points))))1.2、转换为Tensor张量
import torch
inputs=torch.tensor(x_train,dtype=torch.float32)
labels=torch.tensor(y_train,dtype=torch.float32).unsqueeze(1)1.3、定义模型
import torch
import torch.nn as nn
torch.manual_seed(42)
class LogisticRegreModel(nn.Module):def __init__(self,inputsizes):super().__init__()self.linear=nn.Linear(inputsizes,1)def forward(self,x):return torch.sigmoid(self.linear(x))
model=LogisticRegreModel(x_train.shape[1])1.4、定义损失函数和优化器
from torch.optim import SGD
cri=torch.nn.BCELoss()
optimizer=SGD(model.parameters(),lr=0.05)1.5、开始迭代
for i in range(1,1001):output=model(inputs)loss=cri(output,labels)optimizer.zero_grad()loss.backward()optimizer.step()if i%100==0 or i==1:print(i,loss.item()) 1.6、可视化
from matplotlib import pyplot as plt
fig,(ax1,ax2)=plt.subplots(1,2)
epoch_list=[]
loss_list=[]for i in range(1,1001):inputs=torch.tensor(x_train,dtype=torch.float32)labels=torch.tensor(y_train,dtype=torch.float32).unsqueeze(1)output=model(inputs)loss=cri(output,labels)optimizer.zero_grad()loss.backward()optimizer.step()if i%100==0 or i==1:print(i,loss.item())w1,w2=model.linear.weight.data.flatten()b=model.linear.bias.data[0]slope=-w1/w2intercept=-b/w2x_min,x_max=0,5x=np.array([x_min,x_max])y=slope*x+interceptax1.clear()ax1.scatter(class1_points[:,0],class1_points[:,1])ax1.scatter(class2_points[:,0],class2_points[:,1])ax1.plot(x,y)ax2.clear()epoch_list.append(i)loss_list.append(loss.item())ax2.plot(epoch_list,loss_list)
plt.show()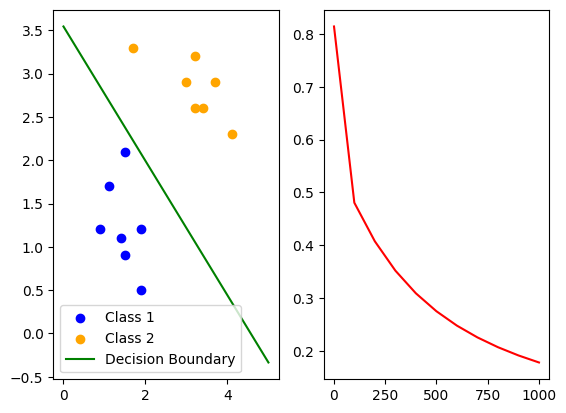
1.7、完整代码
import numpy as np # 导入 NumPy 库以进行数组和数学运算
from matplotlib import pyplot as plt # 导入 Matplotlib 库以绘制图形
import torch # 导入 PyTorch 库
import torch.nn as nn # 导入 PyTorch 的神经网络模块
from torch.optim import SGD # 导入随机梯度下降优化器 # 定义类1的数据点
class1_points = np.array([[1.9, 1.2], [1.5, 2.1], [1.9, 0.5], [1.5, 0.9], [0.9, 1.2], [1.1, 1.7], [1.4, 1.1]]) # 定义类2的数据点
class2_points = np.array([[3.2, 3.2], [3.7, 2.9], [3.2, 2.6], [1.7, 3.3], [3.4, 2.6], [4.1, 2.3], [3.0, 2.9]]) # 合并类1和类2的数据点,作为训练特征
x_train = np.concatenate((class1_points, class2_points))
# 合并类1和类2的标签,类1为 0,类2为 1
y_train = np.concatenate((np.zeros(len(class1_points)), np.ones(len(class2_points)))) # 将训练特征和标签转换为 PyTorch 张量
inputs = torch.tensor(x_train, dtype=torch.float32)
labels = torch.tensor(y_train, dtype=torch.float32).unsqueeze(1) # 设置随机种子以便复现结果
torch.manual_seed(42) # 定义逻辑回归模型类
class LogisticRegreModel(nn.Module): def __init__(self, input_sizes): super().__init__() # 继承父类的初始化方法 self.linear = nn.Linear(input_sizes, 1) # 定义线性层,输入大小为 input_sizes,输出为 1 def forward(self, x): return torch.sigmoid(self.linear(x)) # 前向传播,应用 Sigmoid 函数 # 实例化逻辑回归模型,输入特征的维度为 x_train 的列数
model = LogisticRegreModel(x_train.shape[1]) # 定义二元交叉熵损失函数
cri = torch.nn.BCELoss()
# 使用随机梯度下降算法作为优化器
optimizer = SGD(model.parameters(), lr=0.05) # 创建子图用于展示
fig, (ax1, ax2) = plt.subplots(1, 2)
epoch_list = [] # 存储每次训练的epoch数
loss_list = [] # 存储每次训练的损失值 # 训练模型,进行 1000 次迭代
for i in range(1, 1001): inputs = torch.tensor(x_train, dtype=torch.float32) # 再次定义输入张量 labels = torch.tensor(y_train, dtype=torch.float32).unsqueeze(1) # 再次定义标签张量 output = model(inputs) # 前向传播计算模型输出 loss = cri(output, labels) # 计算损失值 optimizer.zero_grad() # 清空之前的梯度 loss.backward() # 反向传播计算梯度 optimizer.step() # 更新参数 # 每 100 次迭代打印损失并更新图形 if i % 100 == 0 or i == 1: print(i, loss.item()) # 打印当前epoch和损失值 # 获取当前模型参数 w1, w2 = model.linear.weight.data.flatten() # 权重参数 b = model.linear.bias.data[0] # 偏置参数 # 计算决策边界的斜率和截距 slope = -w1 / w2 intercept = -b / w2 x_min, x_max = 0, 5 # 决定x轴的范围 x = np.array([x_min, x_max]) # 创建x值的数组 y = slope * x + intercept # 根据斜率和截# 根据斜率和截距计算决策边界的y值 y = slope * x + intercept ax1.clear() # 清空第一张子图 # 绘制类1和类2的数据点 ax1.scatter(class1_points[:, 0], class1_points[:, 1], color='blue', label='Class 1') ax1.scatter(class2_points[:, 0], class2_points[:, 1], color='orange', label='Class 2') # 绘制当前的决策边界 ax1.plot(x, y, color='green', label='Decision Boundary') ax1.legend() # 显示图例 ax2.clear() # 清空第二张子图 epoch_list.append(i) # 将当前epoch添加到列表 loss_list.append(loss.item()) # 将当前损失值添加到列表 ax2.plot(epoch_list, loss_list, color='red') # 绘制损失变化曲线 # 显示绘制的图形
plt.show() 二、Softmax激活函数
2.1、输入散点
import numpy as npclass1_points = np.array([[1.9, 1.2],[1.5, 2.1],[1.9, 0.5],[1.5, 0.9],[0.9, 1.2],[1.1, 1.7],[1.4, 1.1]])class2_points = np.array([[3.2, 3.2],[3.7, 2.9],[3.2, 2.6],[1.7, 3.3],[3.4, 2.6],[4.1, 2.3],[3.0, 2.9]])
x_train = np.concatenate((class1_points, class2_points))
y_train = np.concatenate((np.zeros(len(class1_points)), np.ones(len(class2_points))))2.2、转换为Tensor张量
import torch
inputs=torch.tensor(x_train,dtype=torch.float32)
labels=torch.tensor(y_train,dtype=torch.long)2.3、定义模型
class LogisticRegreModel(torch.nn.Module):def __init__(self):super(LogisticRegreModel, self).__init__()self.fc = torch.nn.Linear(2, 2)def forward(self, x):x = self.fc(x)# dim 指定了softmax在哪个维度上进行# dim = 1第二个维度上进行,列# example:x (sample, num_classes)# torch.softmax(x, dim=1), pytorch在每个样本上的类别进行softmax,保证每个样本的所有类别的概率和为1。return torch.softmax(x, dim=1)model = LogisticRegreModel()2.4、定义损失函数和优化器
cri = torch.nn.CrossEntropyLoss()
optimizer = torch.optim.SGD(model.parameters(), lr=0.05)2.5、开始迭代
for epoch in range(1, 1001):outputs = model(inputs)loss = cri(outputs, labels)optimizer.zero_grad()loss.backward()optimizer.step()if epoch % 50 == 0 or epoch == 1:print(f"epoch: {epoch}, loss: {loss}")2.6、可视化
plt.figure(figsize=(12, 6))xx, yy = np.meshgrid(np.arange(0, 6, 0.1), np.arange(0, 6, 0.1))
grid_points = np.c_[xx.ravel(), yy.ravel()]epoches = 1000
for epoch in range(1, epoches + 1):outputs = model(inputs)loss = cri(outputs, labels)optimizer.zero_grad()loss.backward()optimizer.step()if epoch % 50 == 0 or epoch == 1:print(f"epoch: {epoch}, loss: {loss}")grid_tensor = torch.tensor(grid_points, dtype=torch.float32)Z = model(grid_tensor).detach().numpy()Z = Z[:, 1]Z = Z.reshape(xx.shape)plt.cla()plt.scatter(class1_points[:, 0], class1_points[:, 1])plt.scatter(class2_points[:, 0], class2_points[:, 1])plt.contour(xx, yy, Z, levels=[0.5])plt.pause(1)plt.show()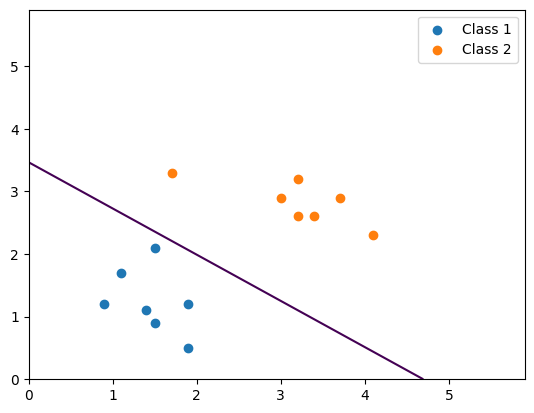
2.7、完整代码
import numpy as np # 导入 NumPy 库进行数组和数学运算
import torch # 导入 PyTorch 库
import matplotlib.pyplot as plt # 导入 Matplotlib 用于绘图 # 定义类1的数据点
class1_points = np.array([[1.9, 1.2], [1.5, 2.1], [1.9, 0.5], [1.5, 0.9], [0.9, 1.2], [1.1, 1.7], [1.4, 1.1]]) # 定义类2的数据点
class2_points = np.array([[3.2, 3.2], [3.7, 2.9], [3.2, 2.6], [1.7, 3.3], [3.4, 2.6], [4.1, 2.3], [3.0, 2.9]]) # 合并类1和类2的数据点,作为训练特征
x_train = np.concatenate((class1_points, class2_points))
# 合并类1和类2的标签,类1为 0,类2为 1
y_train = np.concatenate((np.zeros(len(class1_points)), np.ones(len(class2_points)))) # 将训练特征和标签转换为 PyTorch 张量
inputs = torch.tensor(x_train, dtype=torch.float32) # 输入特征
labels = torch.tensor(y_train, dtype=torch.long) # 标签应为长整型 # 定义逻辑回归模型类
class LogisticRegreModel(torch.nn.Module): def __init__(self): super(LogisticRegreModel, self).__init__() # 继承父类的初始化方法 self.fc = torch.nn.Linear(2, 2) # 定义线性层,输入大小为 2,输出类别数为 2 def forward(self, x): x = self.fc(x) # 进行前向传播,计算线性层输出 # 使用 softmax 函数将输出转换为概率 return torch.softmax(x, dim=1) # dim=1 表示在列上进行 softmax 操作 # 实例化逻辑回归模型
model = LogisticRegreModel() # 定义交叉熵损失函数,适用于多分类问题
cri = torch.nn.CrossEntropyLoss()
# 定义优化器为随机梯度下降
optimizer = torch.optim.SGD(model.parameters(), lr=0.05) # 创建绘图窗口
plt.figure(figsize=(12, 6)) # 创建网格点用于绘制决策边界
xx, yy = np.meshgrid(np.arange(0, 6, 0.1), np.arange(0, 6, 0.1)) # 生成网格坐标
grid_points = np.c_[xx.ravel(), yy.ravel()] # 将网格点展平为 (样本数, 特征数) 的形式 epoches = 1000 # 定义训练的轮数
for epoch in range(1, epoches + 1): outputs = model(inputs) # 前向传播获得模型输出 loss = cri(outputs, labels) # 计算损失 optimizer.zero_grad() # 清空之前的梯度 loss.backward() # 反向传播计算梯度 optimizer.step() # 更新模型参数 # 每 50 个 epoch 更新绘图 if epoch % 50 == 0 or epoch == 1: print(f"epoch: {epoch}, loss: {loss.item()}") # 打印当前 epoch 和损失值 grid_tensor = torch.tensor(grid_points, dtype=torch.float32) # 将网格点转换为张量 Z = model(grid_tensor).detach().numpy() # 前向传播获得每个网格点的输出 Z = Z[:, 1] # 取出第二类的概率,用于绘制决策边界 Z = Z.reshape(xx.shape) # 重塑为网格形状 plt.cla() # 清除当前图形 plt.scatter(class1_points[:, 0], class1_points[:, 1], label='Class 1') # 绘制类1数据点 plt.scatter(class2_points[:, 0], class2_points[:, 1], label='Class 2')plt.contour(xx, yy, Z, levels=[0.5])plt.legend()plt.pause(1)plt.show()相关文章:
)
Python----机器学习(基于PyTorch框架的逻辑回归)
逻辑回归是一种广泛使用的统计学习方法,主要用于处理二分类问题。它基于线性回归模型,通过Sigmoid函数将输出映射到[0, 1]范围内,表示实例属于正类别的概率。尽管逻辑回归适用于二分类任务,但在多分类问题中常使用Softmax函数&…...

工业数据治理范式革新:时序数据库 TDengine虚拟表技术解析
小T导读:在工业数字化过程中,数据如何从设备采集顺利“爬坡”到上层应用,一直是个难题。传统“单列模型”虽贴合设备协议,却让上层分析举步维艰。TDengine 用一种更聪明的方法打通了这条数据通路:不强求建模、不手动转…...

Linux的应用领域,Linux的介绍,VirtualBox和Ubuntu的安装,VMware的安装和打开虚拟机CentOS
目录 Linux的应用领域 Linux的介绍 Linux的介绍 Linux发行版 Unix和Linux的渊源 虚拟机和Linux的安装 VirtualBox和Ubuntu的安装 安装VirtualBox 安装Ubuntu 下载Ubuntu操作系统的镜像文件 创建虚拟机 虚拟机设置 启动虚拟机,安装Ubuntu系统 Ubuntu基…...

使用 Java 8 Stream实现List重复数据判断
import java.util.*; import java.util.stream.Collectors;public class DeduplicateStreamExample {static class ArchiveItem {// 字段定义与Getter/Setter省略(需根据实际补充)private String mATNR;private String lIFNR;private String suppSpecMod…...

GDAL:地理数据的万能瑞士军刀
目录 1. 什么是GDAL?2. 为什么需要GDAL?3. GDAL的主要功能3.1. 数据转换3.2. 数据裁剪和处理3.3. 读取和写入多种格式 4. 实际应用场景4.1 环境监测4.2 城市规划4.3 导航系统 5. 技术原理简单解释6. 如何使用GDAL?6.1 简单命令示例 7. 学习建…...
——Part two)
每日文献(十三)——Part two
今天从第三章节:“实现细节”开始介绍。 目录 三、实现细节 四、实验 五、总结贡献 六、致谢 三、实现细节 我们在多尺度图像上训练和测试区域建议和目标检测网络。这是在KITTI目标检测基准[13]上基于CNN的目标检测的趋势。例如,在[16]中ÿ…...

ArrayList 和 LinkedList 区别
ArrayList 和 LinkedList 是 Java 集合框架中两种常用的列表实现,它们在底层数据结构、性能特点和适用场景上有显著的区别。以下是它们的详细对比以及 ArrayList 的扩容机制。 1. ArrayList 和 LinkedList 的底层区别 (1) 底层数据结构 ArrayList: 基于…...

【iOS】UITableView性能优化
UITableView性能优化 前言优化从何入手优化的本质 CPU层级优化1. Cell的复用2. 尽量少定义Cell,善于使用hidden控制显示视图3. 提前计算并缓存高度UITableView的代理方法执行顺序Cell高度缓存高度数组 4. 异步绘制5. 滑动时按需加载6. 使用异步加载图片,…...
和重排序提升大语言模型(LLM)的准确性)
通过检索增强生成(RAG)和重排序提升大语言模型(LLM)的准确性
探索大语言模型(LLM)结合有效信息检索机制的优势。实现重排序方法,并将其整合到您自己的LLM流程中。 想象一下,一个大语言模型(LLM)不仅能提供相关答案,还能根据您的具体需求进行精细筛选、优先…...

IDEA202403常用快捷键【持续更新】
文章目录 一、全局搜索二、美化格式三、替换四、Git提交五、代码移动六、调试运行 在使用IDEA进行程序开发,快捷键会让这个过程更加酸爽,下面记录各种快捷键的功能。 一、全局搜索 快捷键功能说明Shift Shift全局搜索Ctrl N搜索Java类 二、美化格式 …...

硬件元件三极管:从基础到进阶的电子探秘
一、基础理论 1. PN结(二极管) PN 结是采用不同的掺杂工艺,将 P 型半导体与 N 型半导体紧密接触而形成的一个界面区域。也就是我们常说的二极管。(P型带正电、N型带负电,电流由P流向N) 形成过程࿱…...

4. k8s核心概念 pod deployment service
以下是 Kubernetes 的核心概念详解,涵盖 Pod、Service、Deployment 和 Node,以及它们之间的关系和实际应用场景: 1. Pod 定义与作用 • 最小部署单元:Pod 是 Kubernetes 中可创建和管理的最小计算单元,包含一个或多个…...

12.第二阶段x64游戏实战-远程调试
免责声明:内容仅供学习参考,请合法利用知识,禁止进行违法犯罪活动! 本次游戏没法给 内容参考于:微尘网络安全 上一个内容:11.第二阶段x64游戏实战-框架代码细节优化 本次写的内容是关于调试、排错相关的…...

自然语言处理的进化:BERT模型深度剖析
自然语言处理(NLP)领域近年来取得了跨越式的发展,尤其是随着深度学习技术的应用,不少新兴模型应运而生。其中,BERT(Bidirectional Encoder Representations from Transformers)作为一种革命性的…...
-HTTP请求数据)
鸿蒙学习笔记(5)-HTTP请求数据
一、Http请求数据 http模块是鸿蒙内置的一个模块,提供了网络请求的能力。不需要再写比较原始的AJAS代码。 ps:在项目中如果要访问网络资源,不管是图片文件还是网络请求,必须给项目开放权限。 (1)网络连接方式 HTTP数…...

Golang 的 GMP 协程模型详解
Golang 的 GMP 协程模型详解 Golang 的并发模型基于 GMP(Goroutine-M-Processor) 机制,是其高并发能力的核心支撑。以下从原理、机制、优势、缺点和设计理念展开分析: 一、GMP 的组成与运作原理 Goroutine(Gÿ…...
)
ReportLab 导出 PDF(页面布局)
ReportLab 导出 PDF(文档创建) ReportLab 导出 PDF(页面布局) ReportLab 导出 PDF(图文表格) PLATYPUS - 页面布局和排版 1. 设计目标2. 开始3. Flowables3.1. Flowable.draw()3.2. Flowable.drawOn(canvas,x,y)3.3. F…...

Ubuntu 安装与配置 Docker
Ubuntu 安装与配置 Docker Docker 是一个开源的容器化平台,允许开发者将应用程序及其依赖项打包在一个轻量级、可移植的容器中。它可以帮助开发者和运维人员快速构建、部署和管理应用程序,提升开发和运维效率。本文将介绍如何在 Ubuntu 系统上安装和配置…...

【数据结构与算法】LeetCode每日一题
此题跟27.移除数组中的指定值 类似,都是移除且双指针玩法,只不过判断条件发生了变化...

【HDFS入门】数据存储原理全解,从分块到复制的完整流程剖析
目录 1 HDFS架构概览 2 文件分块机制 2.1 为什么需要分块? 2.2 块大小配置 3 数据写入流程 4 数据复制机制 4.1 副本放置策略 4.2 复制流程 5 数据读取流程 6 一致性模型 7 容错机制 7.1 数据节点故障处理 7.2 校验和验证 8 总结 在大数据时代&#x…...
)
力扣热题100——普通数组(不普通)
普通数组但一点不普通! 最大子数组和合并区间轮转数组除自身以外数组的乘积缺失的第一个正数 最大子数组和 这道题是非常经典的适用动态规划解决题目,但同时这里给出两种解法 动态规划、分治法 那么动态规划方法大家可以在我的另外一篇博客总结中看到&am…...

Ubuntu中snap
通过Snap可以安装众多的软件包。需要注意的是,snap是一种全新的软件包管理方式,它类似一个容器拥有一个应用程序所有的文件和库,各个应用程序之间完全独立。所以使用snap包的好处就是它解决了应用程序之间的依赖问题,使应用程序之…...
开发微信小程序 之 保存图片到本地)
uniapp(Vue)开发微信小程序 之 保存图片到本地
一、保存图片到本地(要拿到图片的 src): 查看隐私条约是否加上相册(仅写入)权限: 微信公众平台 -》 左下角头像 -》账号设置 -》 用户隐私保护指引 -》去完善 -》 相册(仅写入)权限 …...

TailwindCss快速上手
什么是Tailwind Css? 一个实用优先的 CSS 框架,可以直接在标记中组合以构建任何设计。 开始使用Tailwind Css 如何安装 下面是使用vite构建工具的方法 ①安装 Tailwind CSS: tailwindcss通过tailwindcss/vitenpm安装。 npm install tailwindcss tailwindcss…...
)
Gladinet CentreStack Triofox 远程RCE漏洞(CVE-2025-30406)
免责声明 本文档所述漏洞详情及复现方法仅限用于合法授权的安全研究和学术教育用途。任何个人或组织不得利用本文内容从事未经许可的渗透测试、网络攻击或其他违法行为。使用者应确保其行为符合相关法律法规,并取得目标系统的明确授权。 对于因不当使用本文信息而造成的任何直…...

ASP.NET WEB 手动推送 URL 到百度站长工具实例
下面是一个完整的 ASP.NET Web 应用程序示例,演示如何手动推送 URL 到百度站长工具。 1. 创建推送页面 (PushToBaidu.aspx) <%@ Page Language="C#" AutoEventWireup="true" CodeBehind="PushToBaidu.aspx.cs" Inherits="BaiduPushEx…...

【Ragflow】18.更好的推理框架:vLLM的docker部署方式
概述 看到不少人说“Ollama就图一乐,生产环境还得用vLLM”。 本文决定使用docker对vLLM进行部署,并解决模型配置中,IP地址的硬编码问题。 Ollama与vLLM风评比较 查询相关资料,Ollama与vLLM主要特点及对比情况如下[1]: Ollama:轻量级本地大模型部署工具,面向个人用户…...

智能 GitHub Copilot 副驾驶® 更新升级!
智能 GitHub Copilot 副驾驶 迎来重大升级!现在,所有 VS Code 用户都能体验支持 Multi-Context Protocol(MCP)的全新 Agent Mode。此外,微软还推出了智能 GitHub Copilot 副驾驶 Pro 订阅计划,提供更强大的…...

什么是高防服务器
高防服务器是具备高强度防御能力、专门应对网络攻击(如DDoS、 CC攻击)的服务器类 型,通过流量清洗、多层防护等技术保障业务稳定运行。具备高强度防御能力和智能攻击识别技术,可保障业务在极端网络环境下稳定运行。其核心特点及技术原理如下:…...

纷析云开源财务软件:企业财务数字化转型的灵活解决方案
纷析云是一家专注于开源财务软件研发的公司,自2018年成立以来,始终以“开源开放”为核心理念,致力于通过技术创新助力企业实现财务管理的数字化与智能化转型。其开源财务软件凭借高扩展性、灵活部署和全面的功能模块,成为众多企业…...

open webui 介绍 是一个可扩展、功能丰富且用户友好的本地部署 AI 平台,支持完全离线运行。
AI MCP 系列 AgentGPT-01-入门介绍 Browser-use 是连接你的AI代理与浏览器的最简单方式 AI MCP(大模型上下文)-01-入门介绍 AI MCP(大模型上下文)-02-awesome-mcp-servers 精选的 MCP 服务器 AI MCP(大模型上下文)-03-open webui 介绍 是一个可扩展、功能丰富且用户友好的…...

Spring缓存抽象机制
一、核心架构图解 #mermaid-svg-pUShmqsPanYTNVBI {font-family:"trebuchet ms",verdana,arial,sans-serif;font-size:16px;fill:#333;}#mermaid-svg-pUShmqsPanYTNVBI .error-icon{fill:#552222;}#mermaid-svg-pUShmqsPanYTNVBI .error-text{fill:#552222;stroke:#5…...

[Jenkins]pnpm install ‘pnpm‘ 不是内部或外部命令,也不是可运行的程序或批处理文件。
这个错误提示再次说明:你的系统(CMD 或 Jenkins 环境)找不到 pnpm 命令的位置。虽然你可能已经用 npm install -g pnpm 安装过,但系统不知道它装在哪里,也就无法执行 pnpm 命令。 ✅ 快速解决方法:直接用完…...

如何用AI辅助数据分析及工具推荐
以下是针对数据分析的 AI辅助工具推荐,结合国内外主流工具的功能特点、优劣势及适用场景分析,并标注是否为国内软件及付费情况: 一、国内工具推荐 1. WPS AI 特点:集成于WPS Office套件,支持智能数据分析、自动生成可…...

使用KeilAssistant代替keil的UI界面
目录 一、keil Assistant的优势和缺点 二、使用方法 (1)配置keil的路径 (2)导入并使用工程 (3)默认使用keil自带的ARM编译器而非GUN工具链 一、keil Assistant的优势和缺点 在日常学…...

spark-SQL数据加载和保存
数据加载与保存 通用方式: 通过 spark.read.load 和 df.write.save 实现数据加载与保存。可利用 format 指定数据格式,如 csv 、 jdbc 等; option 用于设置特定参数,像 jdbc 格式下的数据库连接信息; load 和 save 则…...

strings.Replace 使用详解
目录 1. 官方包 2. 支持版本 3. 官方说明 4. 作用 5. 实现原理 6. 推荐使用场景和不推荐使用场景 推荐场景 不推荐场景 7. 使用场景示例 示例1:官方示例 示例2:模板变量替换 示例3:敏感信息脱敏(隐藏手机号中间四位&a…...

K8S微服务部署及模拟故障观测
概述 本文介绍了如何在 Kubernetes (K8S) 集群中部署微服务,并模拟常见的故障场景(如 Pod 故障、节点故障、网络故障)以测试系统的容错能力。通过本实验,了解 Kubernetes 的自动恢复机制以及如何通过监控和日志分析快速定位和解决…...

3.k8s是如何工作的
Kubernetes 是一个复杂的分布式系统,其核心设计理念是 声明式管理 和 自动化控制。以下是 Kubernetes 的工作机制详解,从用户提交应用到容器运行的全流程: 1. 核心架构:控制平面(Control Plane)与工作节点&…...

打通任督二脉 - Device Plugin 让 k8s “看见” GPU
打通任督二脉 - Device Plugin 让 k8s “看见” GPU 上一篇咱们聊了为啥要把 GPU 这个“计算猛兽”拉进 Kubernetes (k8s) 这个“智能调度中心”。目标很美好:提高效率、简化管理、弹性伸缩。但现实是,k8s 天生并不认识 GPU 这位“新朋友”。就像你的电脑操作系统,默认只认…...

锚定“体验驱动”,锐捷EDN让园区网络“以人为本”
作者 | 曾响铃 文 | 响铃说 传统的网络升级路径,一如巴别塔的建造思路一般——工程师们按技术蓝图逐层堆砌,却常与地面用户的实际需求渐行渐远,从而带来了诸多体验痛点,如手工配置效率低下、关键业务用网无法保障、网络架构趋于…...

Flutter的自动化测试 python flutter编程
Flutter应用开发入门指南 第一步:创建Flutter应用 创建一个默认的Flutter应用后,将以下代码复制到 lib/main.dart 中: import package:flutter/material.dart;//运行Flutter应用,创建了一个自己实现的Widget对象 void main() > runApp(…...

Day09【基于jieba分词和RNN实现的简单中文分词】
基于jieba分词和RNN实现的中文分词 目标数据准备主程序预测效果 目标 本文基于给定的中文词表,将输入的文本基于jieba分词分割为若干个词,词的末尾对应的标签为1,中间部分对应的标签为0,同时将分词后的单词基于中文词表做初步序列…...

机器学习 | 神经网络介绍 | 概念向
文章目录 📚从生物神经元到人工神经元📚神经网络初识🐇激活函数——让神经元“动起来”🐇权重与偏置——调整信息的重要性🐇训练神经网络——学习的过程🐇过拟合与正则化——避免“死记硬背” 👀…...

使用cursor进行原型图设计
1.下载cursor 2.模式设置: 模型使用claude-3.7-sonnet的think模式 3.引导词模板: 我想要开发一个中高考英语口语考试的模拟考试系统,我需要将上面的这个应用输出成高保真的原型图设计。请考虑以下的规范: 用户体验࿱…...
)
Vue el-from的el-form-item v-for循环表单如何校验rules(二)
在上一篇文章中,通过校验规则写成内联循环去校验from表单项,在之前的代码基础上,进行校验规则的二次封装,使代码更加简洁,灵活高效、 参考上一篇:Vue el-from的el-form-item v-for循环表单如何校验rules&a…...

Spark-SQL3
Spark-SQL 一.Spark-SQL核心编程(四) 1.数据加载与保存: 1)通用方式: SparkSQL 提供了通用的保存数据和数据加载的方式。这里的通用指的是使用相同的API,根据不同的参数读取和保存不同格式的数据&#…...

Redis字符串类型实战:解锁五大高频应用场景
精心整理了最新的面试资料和简历模板,有需要的可以自行获取 点击前往百度网盘获取 点击前往夸克网盘获取 Redis的字符串(String)类型是最基础的数据结构,但其灵活性和原子性操作使其成为解决高并发场景问题的利器。本文通过真实项…...

通信算法之266: 无人机信号带宽计算
pwelch 通常返回功率谱密度(PSD)和对应的频率向量。带宽的计算可能涉及到找到 PSD 的有效频率范围,比如半功率点(-3dB)或者根据信号的能量集中区域。 pwelch 的参数设置,比如窗函数、重叠、FFT 点数&#x…...

【MySQL】前缀索引、索引下推、访问方法,自适应哈希索引
最左前缀原则 对于INDEX(name, age)来说最左前缀可以是联合索引的最左N个字段, 也可以是字符串索引的最左M个字符。 SELECT * FROM t WHERE name LIKE 张%其效果和单独创建一个INDEX(name)的效果是一样的若通过调整索引字段的顺序, 可以少维护一个索引树, 那么这个顺序就是需要…...